
工具采集文章
在线工具seo采集文章
采集交流 • 优采云 发表了文章 • 0 个评论 • 518 次浏览 • 2020-08-11 15:55
1、这要看新站还是老站,还要看哪些行业,其实评判正不正常应当从收录率的角度来看,一般网站收录率在70%以上,算正常,当使也可以再提高这个数字,通过改善页面质量。
2、网站收录之后如何上排行收录和排行并没有直接联系,收录指的是一个网站在搜索引擎数据库中存在的内容数目,数量才能代表的只是一个数字而已,不能证明任何东西,有些网站收录很高,排名太差,有些网站收录并不多,可是排行反倒挺好,如果想要以数目的优势来争取更好的排行,是太不现实的看法。
3、优化内容环境基于搜索引擎内容池来讲,当你的腹部内容源,大量的参杂着优质内容的时侯,实际上,低质量内容的生存空间是被严重打压的。
4、如何围绕用户需求写原创文章呢?命题-确定文章内容主题写文章就像写习作,首先就是命题,你要写哪些内容,主要想优化那个关键词。常用的就是你自己的问题、问答平台的问题、身边人的问题、客户的问题、同行的问题,这些都是用户的需求,这些问题关键词结合用户搜索习惯来组合关键词标题。
5、提高网站权重;有人说了,自己的文章有质量,也有数目,为什么收录还是上不去,收录速率还是这么慢,若是遇见这样的情况,要么就是新站没有权重,要么就是网站降权,多数情况下是因为新站没有权重引起的。
6、既然不能直接严禁抓取,那就干脆严禁百度蜘蛛等搜索引擎访问,思路是:判断user_agent,如果是百度蜘蛛、谷歌机器人等搜索引擎的user_agent,就返回403或则404,这样百度等搜索引擎都会觉得这个网站无法打开或则不存在,自然也就不会收录了。
7、网站优化过度;一直以来都发觉很多网站都十分贪心,很不得将自己所有的优化关键词都放到首页title里面,以为这样就可以快速的实现排行。其实,百度早已明令严禁title关键词雕凿了,尤其作为一个新网站出现拼凑会大大降低百度对你网站的“偏见”,从此不在光临。
8、多方位智能提取快捷创作;基于强悍的智能脑部与文本素材库,可直接调阅并手动剖析出相关的智能段落,并智能提取文本核心词,摘要内容,智能标题,下拉智能叠词等。多方向创作剖析,给你快速输出文章的体验。
—————————————————————————————–
问:黑帽seo是哪些意思?
答:黑帽SEO是借助和放大搜索引擎的策略缺陷(实际上完美的系统是不存在的)获取更多用户访问量,而这种更多的访问量,是以伤害用户体验为代价的SEO行为。
问:网页标题与描述写多少字合适?
答:网站title标题搜索引擎在搜索结果中只能展示63个字节,后边都省略了;网页标题通常建议不超过32个汉字,描述Description不要超过72个汉字。
问:网站服务器空间买多大适宜?
答:根据网站规模和要提供的服务来决定选择订购何种空间(服务器),选择有实力的正规空间商,根据用户群分布选择接入商,保证用户的访问速率和稳定性。 查看全部

1、这要看新站还是老站,还要看哪些行业,其实评判正不正常应当从收录率的角度来看,一般网站收录率在70%以上,算正常,当使也可以再提高这个数字,通过改善页面质量。
2、网站收录之后如何上排行收录和排行并没有直接联系,收录指的是一个网站在搜索引擎数据库中存在的内容数目,数量才能代表的只是一个数字而已,不能证明任何东西,有些网站收录很高,排名太差,有些网站收录并不多,可是排行反倒挺好,如果想要以数目的优势来争取更好的排行,是太不现实的看法。
3、优化内容环境基于搜索引擎内容池来讲,当你的腹部内容源,大量的参杂着优质内容的时侯,实际上,低质量内容的生存空间是被严重打压的。
4、如何围绕用户需求写原创文章呢?命题-确定文章内容主题写文章就像写习作,首先就是命题,你要写哪些内容,主要想优化那个关键词。常用的就是你自己的问题、问答平台的问题、身边人的问题、客户的问题、同行的问题,这些都是用户的需求,这些问题关键词结合用户搜索习惯来组合关键词标题。
5、提高网站权重;有人说了,自己的文章有质量,也有数目,为什么收录还是上不去,收录速率还是这么慢,若是遇见这样的情况,要么就是新站没有权重,要么就是网站降权,多数情况下是因为新站没有权重引起的。
6、既然不能直接严禁抓取,那就干脆严禁百度蜘蛛等搜索引擎访问,思路是:判断user_agent,如果是百度蜘蛛、谷歌机器人等搜索引擎的user_agent,就返回403或则404,这样百度等搜索引擎都会觉得这个网站无法打开或则不存在,自然也就不会收录了。
7、网站优化过度;一直以来都发觉很多网站都十分贪心,很不得将自己所有的优化关键词都放到首页title里面,以为这样就可以快速的实现排行。其实,百度早已明令严禁title关键词雕凿了,尤其作为一个新网站出现拼凑会大大降低百度对你网站的“偏见”,从此不在光临。
8、多方位智能提取快捷创作;基于强悍的智能脑部与文本素材库,可直接调阅并手动剖析出相关的智能段落,并智能提取文本核心词,摘要内容,智能标题,下拉智能叠词等。多方向创作剖析,给你快速输出文章的体验。
—————————————————————————————–
问:黑帽seo是哪些意思?
答:黑帽SEO是借助和放大搜索引擎的策略缺陷(实际上完美的系统是不存在的)获取更多用户访问量,而这种更多的访问量,是以伤害用户体验为代价的SEO行为。
问:网页标题与描述写多少字合适?
答:网站title标题搜索引擎在搜索结果中只能展示63个字节,后边都省略了;网页标题通常建议不超过32个汉字,描述Description不要超过72个汉字。
问:网站服务器空间买多大适宜?
答:根据网站规模和要提供的服务来决定选择订购何种空间(服务器),选择有实力的正规空间商,根据用户群分布选择接入商,保证用户的访问速率和稳定性。
Python网路数据采集之处理自然语言|第07天
采集交流 • 优采云 发表了文章 • 0 个评论 • 389 次浏览 • 2020-08-10 18:02
Date:2018-04-01
Mark:《Python网路数据采集》
网络采集系列文章
Python网路数据采集之创建爬虫
Python网路数据采集之HTML解析
Python网路数据采集之开始采集
Python网路数据采集之使用API
Python网路数据采集之储存数据
Python网路数据采集之读取文件
Python网路数据采集之数据清洗
处理自然语言概括数据
在之前我们了解了怎样把文本内容分解成 n-gram 模型,或者说是n个词组宽度的句型。从最基本的功能上说,这个集合可以拿来确定这段文字中最常用的词组和句子。另外,还可以提取原文中这些最常用的句子周围的诗句,对原文进行看似合理的概括。
例如我们依照威廉 ·亨利 ·哈里森的就职演全文进行剖析。文章地址
from urllib.request import urlopen
from bs4 import BeautifulSoup
import re
import string
from collections import Counter
def cleanSentence(sentence):
sentence = sentence.split(' ')
sentence = [word.strip(string.punctuation+string.whitespace) for word in sentence]
sentence = [word for word in sentence if len(word) > 1 or (word.lower() == 'a' or word.lower() == 'I')]
return sentence
def cleanInput(content):
content = content.upper()
content = re.sub('\n', ' ', content)
content = bytes(content, 'UTF-8')
content = content.decode('ascii', 'ignore')
sentences = content.split('. ')
return [cleanSentence(sentence) for sentence in sentences]
def getNgramsFromSentence(content, n):
output = []
for i in range(len(content)-n+1):
output.append(content[i:i+n])
return output
def getNgrams(content, n):
content = cleanInput(content)
ngrams = Counter()
ngrams_list = []
for sentence in content:
newNgrams = [' '.join(ngram) for ngram in getNgramsFromSentence(sentence, n)]
ngrams_list.extend(newNgrams)
ngrams.update(newNgrams)
return(ngrams)
content = str(
urlopen('http://pythonscraping.com/files/inaugurationSpeech.txt').read(),
'utf-8')
ngrams = getNgrams(content, 3)
print(ngrams)
自然语言工具包
自然语言工具包(Natural Language Toolkit,NLTK)就是这样一个 Python库,用于辨识和标记日语文本中各个词的动词(parts of speech)。
安装与配置
NLTK网站()。安装软件比较简单,例如pip安装。
➜ psysh git:(master) pip install nltk
Collecting nltk
Using cached nltk-3.2.5.tar.gz
Requirement already satisfied: six in /usr/local/lib/python3.6/site-packages (from nltk)
Building wheels for collected packages: nltk
Running setup.py bdist_wheel for nltk ... done
Stored in directory: /Users/demo/Library/Caches/pip/wheels/18/9c/1f/276bc3f421614062468cb1c9d695e6086d0c73d67ea363c501
Successfully built nltk
Installing collected packages: nltk
Successfully installed nltk-3.2.5
You are using pip version 9.0.1, however version 9.0.3 is available.
You should consider upgrading via the 'pip install --upgrade pip' command.
检测一下就OK
➜ psysh git:(master) python
Python 3.6.4 (default, Mar 1 2018, 18:36:50)
[GCC 4.2.1 Compatible Apple LLVM 9.0.0 (clang-900.0.39.2)] on darwin
Type "help", "copyright", "credits" or "license" for more information.
>>> import nltk
>>>
输入nltk.download()就可以看见NLTK下载器。
NLTK下载器
默认下载全部的包,新手降低排除的相关的麻烦。
安装包
用NLTK做统计剖析
用NLTK做统计剖析通常是从Text对象开始的。Text对象可以通过下边的方式用简单的 Python字符串来创建:
from nltk import word_tokenize
from nltk import Text
tokens = word_tokenize("哈哈哈哈哈")
text = Text(tokens)
word_tokenize函数的参数可以是任何Python字符串。如果你手边没有任何长字符串,但是还想尝试一些功能,在NLTK库里早已外置了几本书,可以用import函数导出:
from nltk.book import *
统计文本中不重复的词组,然后与总词组数据进行比较:>>> len(text6)/len(words)。
今天内容比较少,消化比较困难。哈哈哈 查看全部
User:你好我是森林
Date:2018-04-01
Mark:《Python网路数据采集》
网络采集系列文章
Python网路数据采集之创建爬虫
Python网路数据采集之HTML解析
Python网路数据采集之开始采集
Python网路数据采集之使用API
Python网路数据采集之储存数据
Python网路数据采集之读取文件
Python网路数据采集之数据清洗
处理自然语言概括数据
在之前我们了解了怎样把文本内容分解成 n-gram 模型,或者说是n个词组宽度的句型。从最基本的功能上说,这个集合可以拿来确定这段文字中最常用的词组和句子。另外,还可以提取原文中这些最常用的句子周围的诗句,对原文进行看似合理的概括。
例如我们依照威廉 ·亨利 ·哈里森的就职演全文进行剖析。文章地址
from urllib.request import urlopen
from bs4 import BeautifulSoup
import re
import string
from collections import Counter
def cleanSentence(sentence):
sentence = sentence.split(' ')
sentence = [word.strip(string.punctuation+string.whitespace) for word in sentence]
sentence = [word for word in sentence if len(word) > 1 or (word.lower() == 'a' or word.lower() == 'I')]
return sentence
def cleanInput(content):
content = content.upper()
content = re.sub('\n', ' ', content)
content = bytes(content, 'UTF-8')
content = content.decode('ascii', 'ignore')
sentences = content.split('. ')
return [cleanSentence(sentence) for sentence in sentences]
def getNgramsFromSentence(content, n):
output = []
for i in range(len(content)-n+1):
output.append(content[i:i+n])
return output
def getNgrams(content, n):
content = cleanInput(content)
ngrams = Counter()
ngrams_list = []
for sentence in content:
newNgrams = [' '.join(ngram) for ngram in getNgramsFromSentence(sentence, n)]
ngrams_list.extend(newNgrams)
ngrams.update(newNgrams)
return(ngrams)
content = str(
urlopen('http://pythonscraping.com/files/inaugurationSpeech.txt').read(),
'utf-8')
ngrams = getNgrams(content, 3)
print(ngrams)
自然语言工具包
自然语言工具包(Natural Language Toolkit,NLTK)就是这样一个 Python库,用于辨识和标记日语文本中各个词的动词(parts of speech)。
安装与配置
NLTK网站()。安装软件比较简单,例如pip安装。
➜ psysh git:(master) pip install nltk
Collecting nltk
Using cached nltk-3.2.5.tar.gz
Requirement already satisfied: six in /usr/local/lib/python3.6/site-packages (from nltk)
Building wheels for collected packages: nltk
Running setup.py bdist_wheel for nltk ... done
Stored in directory: /Users/demo/Library/Caches/pip/wheels/18/9c/1f/276bc3f421614062468cb1c9d695e6086d0c73d67ea363c501
Successfully built nltk
Installing collected packages: nltk
Successfully installed nltk-3.2.5
You are using pip version 9.0.1, however version 9.0.3 is available.
You should consider upgrading via the 'pip install --upgrade pip' command.
检测一下就OK
➜ psysh git:(master) python
Python 3.6.4 (default, Mar 1 2018, 18:36:50)
[GCC 4.2.1 Compatible Apple LLVM 9.0.0 (clang-900.0.39.2)] on darwin
Type "help", "copyright", "credits" or "license" for more information.
>>> import nltk
>>>
输入nltk.download()就可以看见NLTK下载器。

NLTK下载器
默认下载全部的包,新手降低排除的相关的麻烦。

安装包
用NLTK做统计剖析
用NLTK做统计剖析通常是从Text对象开始的。Text对象可以通过下边的方式用简单的 Python字符串来创建:
from nltk import word_tokenize
from nltk import Text
tokens = word_tokenize("哈哈哈哈哈")
text = Text(tokens)
word_tokenize函数的参数可以是任何Python字符串。如果你手边没有任何长字符串,但是还想尝试一些功能,在NLTK库里早已外置了几本书,可以用import函数导出:
from nltk.book import *
统计文本中不重复的词组,然后与总词组数据进行比较:>>> len(text6)/len(words)。
今天内容比较少,消化比较困难。哈哈哈
“科研之友”常见问题
采集交流 • 优采云 发表了文章 • 0 个评论 • 395 次浏览 • 2020-08-09 14:28
在“科研之友”的登入页面上,您可以点击“忘记密码”链接 ,输入您在注册时所填的电子邮箱。系统将会手动把更改密码的链接发送到您的电子邮箱。
2.什么是“科研之友”的系统要求?
“科研之友”适用于以下最新版本浏览器的Windows或Mac操作系统:
Windows:Mozilla FirefoxInternet Explorer 11Google ChromeOpera
Mac:Mozilla FirefoxSafariGoogle ChromeOpera
为了更好的展示您的图形化智能简历、互动式个人主页,我们建议您将电脑显示器的帧率设置成1024x768或以上,把字体大小设置 成中等字体。
社区网路服务:1. 怎么设置我的隐私?
登录“科研之友”后,您可以在“我的科研 个人设置”功能下的“隐私设置”中设置隐私内容。公开您的成果、项目等个人信息,获得更多人查看,并有助于提升论文引用,获取更多基金申请机会推荐。
2. 接收者为什么没收到我发送的加为好友恳求?
对方没有回应您的好友恳求可能有以下缘由:
1.对方没有收到您通过“科研之友”发出的好友恳求,或标示为“垃圾邮件”。您可以尝试给对方“发送消息”,核对是否收到了添加好友恳求。
2.科研之友每周会发送短信通知对方处理仍未回应的恳求或约请。若对方处理了该恳求,您会收到科研之友发出的系统通知,请注意查看科研之友“消息中心”下的“系统消息”栏。
3.如果上述一直不能回答您的疑惑,请联系本系统的“在线咨询”,或者发电子邮件至我们的技术支持寻求帮助。
3. 如何退出群组?
如您想退出早已加入的群组,可在登陆系统后,进入“群组”功能选择该群组,然后点击右上角的“设置”链接,选择“退出群组”选项。
4. 什么是消息中心?
消息中心包括您与科研之友好友互发的站内邮件、科研之友用户申请加入您创建的群组恳求、给您发送的好友恳求、好友给您共享的文件/文献和系统消息。您可以通过访问消息中心查找与好友的交流记录,曾经收到的站内邮件和文件等重要资料。
跨文献库检索工具的安装和卸载:1. 什么是跨文献库检索工具?
跨文献库检索工具是依托“科研之友”平台,辅助科研工作者统一文献检索,跨库搜集科研成果的科技文献检索软件。利用跨文献库检索工具,。您可以使用跨文献库检索工具从各大文献库,如:中国知网、万方、SSCI、SCIE、ISTP、Scopus等,方便、准确、规范地搜集和导出自己或别人的中英文科研成果信息。列出目前支持的文献库类型。
2. 为什么须要安装跨文献库检索工具?是否每次检索都要安裝?
有效支持科研人员在知识产权法等相关法律的框架下便捷、准确、规范地搜集科研成果,需要一系列复杂的科技文献检索技术,这些技术远远超出了现今浏览器才能处理的能力,所以用户须要在自己笔记本上下载并安装跨文献库检索工具。该工具作为浏览器的插件,安全、可靠,请用户放心下载。
不是每次检索都须要安装跨文献库检索工具,如果有最新的跨文献库检索工具发布,系统会主动提示用户升级到最新版的跨文献库检索工具。请依照屏幕提示操作进行升级。
3.1 哪些浏览器支持安装跨文献库检索工具?
目前科研之友跨库检索插件仅支持:IE11,360浏览器
3.2 如何安装跨文献库检索工具(IE)?
(1)进入检索页面后,系统会主动提示用户安装跨文献库检索工具,请点击【确定】按钮开始安装跨文献库检索工具。
(2)点击安装检索插件按键。
(3)点击【运行】按钮运行跨文献库检索工具。
(4)如果您的网页浏览器的安全警告提示是否要运行跨文献库检索工具,请点击【运行】按钮继续安装。
(5)点击【下一步】按钮继续跨文献库检索工具安装进程。
(6)正在进行安装程序冲突检测,如有检查到程序冲突请依照提示关掉有关程序之后继续安装进程,若无程序冲突请点击【安装】按钮继续安装。
(7)点击【完成】按钮完成跨文献库检索工具的安装。
3.3 如何在360浏览器上使用跨文献库检索工具?
(1)进入检索页面后,系统会主动提示用户安装跨文献库检索工具,请点击【确定】按钮跳转到安装跨文献库检索工具页面。
(2)点击安装检索插件按键,跳转到360组件下载商店。
(3)点击安装IrisSearch。
(4)点击添加按键。
(5)IrisSearch添加完成后,就可以去检索页面检索了。
4. 如何卸载跨文献库检索工具?
卸载跨文献库检索工具,请点击“开始->控制面板->添加或删掉程序”,选择“跨文献库检索工具1.0.x.x”(后面的版本号可能因不同版本而不同),并点击“更改/删除”按钮卸载。
5. 如何升级跨文献库检索工具?
如果有最新的跨文献库检索工具发布,系统会主动提示用户升级到最新版的跨文献库检索工具。请依照屏幕提示操作进行升级。
6. 跨文献库检索工具系统需求和支持的浏览器有什么?
跨文献库检索工具目前兼容Win32各系列平台,包括Win2000、WinXP、Win2003、Vista及Windows7。跨文献库检索工具目前建议使用的浏览器有IE8(32位)、IE9(32位)、Firefox及Chrome。
7. 已经安装了检索工具,仍出现安装提示怎样办?
如果出现这情况,可能诱因如下:IE禁用了安装的插件。请在“工具->管理加载项->启用或禁用加载项”查看IrisOctopus Class的加载项是否被禁用。如果是, 请启用,然后关掉IE重新打开。
IE安全级别。请在设置IE浏览器的安全级别:在“工具->Internet选项->安全->自定义级别”查看“对标记为可安全执行脚本的ActiveX控件执行脚本”的选项,请选中“启用”选项。同时确保将“下载已签名的控件”设“启用”。(提示:跨文献库检索工具经过严格测试和并经过专业认证机构的签名,不会对您的系统导致影响。)
在打开“提示”执行ActiveX控件的情况下,浏览器可能会在加载控件的时侯有如下提示,选择“运行ActiveX控件”。
8. 系统难以安装跨文献库检索工具如何办?
主要有以下缘由:IE安全级别较高,请在“该区域安全级别”中将安全级别调到“中高”或中高以下级别。
安装成果检索工具时因为用户权限等诱因可能会出现以下情况:
请尝试以下解决办法:
1)在Windows 7 或Windows 8 操作系统下,请确认是使用管理员权限运行安装程序。
2)确保所有的浏览器都早已被关闭。待浏览器关掉后再重试安装。
3)下载安装程序并保存至本地后重启计算机。重启后不要打开浏览器,直接运行安装程序。
如仍未能安装成果检索工具,请联系我们的“在线咨询”,或者发电子邮件到系统技术支持。
跨文献库检索工具使用1. 检索速率太慢或则长时间没有响应,如何解决?
由于检索工具会实时联接各个文献库的在线检索系统进行集成检索,需要用户机的网路环境才能稳定访问选取的文献库。因此,检索速率会由本机网路速率以及选取的文献库当时的运行情况决定,如果速率比较慢,建议联系网路管理员或大学图书馆对网路联接情况、文献库运行情况进行复查,或稍候再重试。
2. 检索时,为何系统提示“您没有权限使用该数据库”?
您没有权限使用该数据库,可能是因为以下缘由:1)您所在的机构没有购买该数据库;2)您的机构已购买,但您的IP网关难以使用该数据库;3)所选数据库正在维护中,请稍候再试。如果您检索结果出现以上提示,代表您当前所在IP网关没有对应文献库的使用权限。目前科研之友系统提供检索的英语文献库,如:SCI,SSCI,ISTP,EI,都须要订购使用权限方能检索到结果,请确认贵校当前是否有订购。如贵校有订购,则可能是以上列举提示的后两种,建议您在贵校图书馆登陆成果在线进行检索;如贵校没有订购,建议在 购买了使用权限的单位进行检索或约请好友帮您检索成果并推荐给您;如果未能通过系统检索,您也可以通过手工录入的形式录入至系统中(我的成果——录入成果或文件导出)。
3. 检索时,为何系统提示“您所选数据库正在维护中”?
当文献库正处维护中时,即出现以下提示信息,请稍候再试。
4. 检索成果时,为何系统出现浏览器脚本错误,提示“指定资源下载失败”?
如果用户机器缺乏了系统必需的MSXML组件,系统在检索时提示“指定资源下载失败”错误(参见右图)。请点击Microsoft MSXML 6.0,进入Microsoft下载页面完成安装后,再重新步入系统使用检索工具检索成果。
5. 检索时,为何系统提示“操作超时,请点击此处重试”?
当文献库返回信息超时时,即出现以下提示信息。请依照指示点击“此处”重试。
6. 检索时,为何系统提示“您所选数据库返回结果异常”?
由于检索工具会实时联接各个文献库的在线检索系统进行集成检索,而其中部份文献库(如: SCI、SSCI、ISTP和EI等)是收费文献库,需要用户所在单位订购文献库的使用权。如果单位没有订购,或者用户登入系统的IP不在这种服务供应商所许可的IP段内,检索结果页面则会显示此提示信息,不能进行检索。若贵单位已够买了相应的文献库,请复查已输入的查询条件是否正确,若查询条件正确,但检索时系统仍提示“您所选数据库返回结果异常”,请联系本系统的“在线咨询”,或者发电子邮件到本系统技术支持。
7. 检索时,为何系统提示“查询异常,可能是服务器暂时未能联接”?
由于跨文献库检索工具会实时联接各个文献库的在线检索系统进行集成检索,各个文献库可能会某些查询返回查询失败等信息,检索工具会把对方文献库返回的出错信息原貌显示,以便用户按照其指引对查询关键字进行改进。您可以尝试重新输入查询条件,再次检索。
8. 如何检索SCI、SSCI、ISTP、EI,Scopus,万方文献库和中国期刊网之外的其它文献库?
目前支持SCI,SSCI,ISTP,EI,Scopus,万方文献库和中国刊物网,对其他文献库的支持,比如ScienceDirect,IEEE Xplore,维普资讯等正在逐渐降低中。 查看全部
“科研之友”常见问题通常问题:社区网路服务:跨文献库检索工具的安装和卸载跨文献库检索工具使用其 他通常问题:1.如何寻回登陆密码?
在“科研之友”的登入页面上,您可以点击“忘记密码”链接 ,输入您在注册时所填的电子邮箱。系统将会手动把更改密码的链接发送到您的电子邮箱。
2.什么是“科研之友”的系统要求?
“科研之友”适用于以下最新版本浏览器的Windows或Mac操作系统:
Windows:Mozilla FirefoxInternet Explorer 11Google ChromeOpera
Mac:Mozilla FirefoxSafariGoogle ChromeOpera
为了更好的展示您的图形化智能简历、互动式个人主页,我们建议您将电脑显示器的帧率设置成1024x768或以上,把字体大小设置 成中等字体。
社区网路服务:1. 怎么设置我的隐私?
登录“科研之友”后,您可以在“我的科研 个人设置”功能下的“隐私设置”中设置隐私内容。公开您的成果、项目等个人信息,获得更多人查看,并有助于提升论文引用,获取更多基金申请机会推荐。
2. 接收者为什么没收到我发送的加为好友恳求?
对方没有回应您的好友恳求可能有以下缘由:
1.对方没有收到您通过“科研之友”发出的好友恳求,或标示为“垃圾邮件”。您可以尝试给对方“发送消息”,核对是否收到了添加好友恳求。
2.科研之友每周会发送短信通知对方处理仍未回应的恳求或约请。若对方处理了该恳求,您会收到科研之友发出的系统通知,请注意查看科研之友“消息中心”下的“系统消息”栏。
3.如果上述一直不能回答您的疑惑,请联系本系统的“在线咨询”,或者发电子邮件至我们的技术支持寻求帮助。
3. 如何退出群组?
如您想退出早已加入的群组,可在登陆系统后,进入“群组”功能选择该群组,然后点击右上角的“设置”链接,选择“退出群组”选项。
4. 什么是消息中心?
消息中心包括您与科研之友好友互发的站内邮件、科研之友用户申请加入您创建的群组恳求、给您发送的好友恳求、好友给您共享的文件/文献和系统消息。您可以通过访问消息中心查找与好友的交流记录,曾经收到的站内邮件和文件等重要资料。
跨文献库检索工具的安装和卸载:1. 什么是跨文献库检索工具?
跨文献库检索工具是依托“科研之友”平台,辅助科研工作者统一文献检索,跨库搜集科研成果的科技文献检索软件。利用跨文献库检索工具,。您可以使用跨文献库检索工具从各大文献库,如:中国知网、万方、SSCI、SCIE、ISTP、Scopus等,方便、准确、规范地搜集和导出自己或别人的中英文科研成果信息。列出目前支持的文献库类型。
2. 为什么须要安装跨文献库检索工具?是否每次检索都要安裝?
有效支持科研人员在知识产权法等相关法律的框架下便捷、准确、规范地搜集科研成果,需要一系列复杂的科技文献检索技术,这些技术远远超出了现今浏览器才能处理的能力,所以用户须要在自己笔记本上下载并安装跨文献库检索工具。该工具作为浏览器的插件,安全、可靠,请用户放心下载。
不是每次检索都须要安装跨文献库检索工具,如果有最新的跨文献库检索工具发布,系统会主动提示用户升级到最新版的跨文献库检索工具。请依照屏幕提示操作进行升级。
3.1 哪些浏览器支持安装跨文献库检索工具?
目前科研之友跨库检索插件仅支持:IE11,360浏览器

3.2 如何安装跨文献库检索工具(IE)?
(1)进入检索页面后,系统会主动提示用户安装跨文献库检索工具,请点击【确定】按钮开始安装跨文献库检索工具。

(2)点击安装检索插件按键。

(3)点击【运行】按钮运行跨文献库检索工具。

(4)如果您的网页浏览器的安全警告提示是否要运行跨文献库检索工具,请点击【运行】按钮继续安装。

(5)点击【下一步】按钮继续跨文献库检索工具安装进程。

(6)正在进行安装程序冲突检测,如有检查到程序冲突请依照提示关掉有关程序之后继续安装进程,若无程序冲突请点击【安装】按钮继续安装。

(7)点击【完成】按钮完成跨文献库检索工具的安装。

3.3 如何在360浏览器上使用跨文献库检索工具?
(1)进入检索页面后,系统会主动提示用户安装跨文献库检索工具,请点击【确定】按钮跳转到安装跨文献库检索工具页面。
(2)点击安装检索插件按键,跳转到360组件下载商店。

(3)点击安装IrisSearch。

(4)点击添加按键。

(5)IrisSearch添加完成后,就可以去检索页面检索了。

4. 如何卸载跨文献库检索工具?
卸载跨文献库检索工具,请点击“开始->控制面板->添加或删掉程序”,选择“跨文献库检索工具1.0.x.x”(后面的版本号可能因不同版本而不同),并点击“更改/删除”按钮卸载。

5. 如何升级跨文献库检索工具?
如果有最新的跨文献库检索工具发布,系统会主动提示用户升级到最新版的跨文献库检索工具。请依照屏幕提示操作进行升级。

6. 跨文献库检索工具系统需求和支持的浏览器有什么?
跨文献库检索工具目前兼容Win32各系列平台,包括Win2000、WinXP、Win2003、Vista及Windows7。跨文献库检索工具目前建议使用的浏览器有IE8(32位)、IE9(32位)、Firefox及Chrome。
7. 已经安装了检索工具,仍出现安装提示怎样办?
如果出现这情况,可能诱因如下:IE禁用了安装的插件。请在“工具->管理加载项->启用或禁用加载项”查看IrisOctopus Class的加载项是否被禁用。如果是, 请启用,然后关掉IE重新打开。

IE安全级别。请在设置IE浏览器的安全级别:在“工具->Internet选项->安全->自定义级别”查看“对标记为可安全执行脚本的ActiveX控件执行脚本”的选项,请选中“启用”选项。同时确保将“下载已签名的控件”设“启用”。(提示:跨文献库检索工具经过严格测试和并经过专业认证机构的签名,不会对您的系统导致影响。)

在打开“提示”执行ActiveX控件的情况下,浏览器可能会在加载控件的时侯有如下提示,选择“运行ActiveX控件”。

8. 系统难以安装跨文献库检索工具如何办?
主要有以下缘由:IE安全级别较高,请在“该区域安全级别”中将安全级别调到“中高”或中高以下级别。
安装成果检索工具时因为用户权限等诱因可能会出现以下情况:

请尝试以下解决办法:
1)在Windows 7 或Windows 8 操作系统下,请确认是使用管理员权限运行安装程序。
2)确保所有的浏览器都早已被关闭。待浏览器关掉后再重试安装。
3)下载安装程序并保存至本地后重启计算机。重启后不要打开浏览器,直接运行安装程序。
如仍未能安装成果检索工具,请联系我们的“在线咨询”,或者发电子邮件到系统技术支持。
跨文献库检索工具使用1. 检索速率太慢或则长时间没有响应,如何解决?
由于检索工具会实时联接各个文献库的在线检索系统进行集成检索,需要用户机的网路环境才能稳定访问选取的文献库。因此,检索速率会由本机网路速率以及选取的文献库当时的运行情况决定,如果速率比较慢,建议联系网路管理员或大学图书馆对网路联接情况、文献库运行情况进行复查,或稍候再重试。
2. 检索时,为何系统提示“您没有权限使用该数据库”?
您没有权限使用该数据库,可能是因为以下缘由:1)您所在的机构没有购买该数据库;2)您的机构已购买,但您的IP网关难以使用该数据库;3)所选数据库正在维护中,请稍候再试。如果您检索结果出现以上提示,代表您当前所在IP网关没有对应文献库的使用权限。目前科研之友系统提供检索的英语文献库,如:SCI,SSCI,ISTP,EI,都须要订购使用权限方能检索到结果,请确认贵校当前是否有订购。如贵校有订购,则可能是以上列举提示的后两种,建议您在贵校图书馆登陆成果在线进行检索;如贵校没有订购,建议在 购买了使用权限的单位进行检索或约请好友帮您检索成果并推荐给您;如果未能通过系统检索,您也可以通过手工录入的形式录入至系统中(我的成果——录入成果或文件导出)。
3. 检索时,为何系统提示“您所选数据库正在维护中”?
当文献库正处维护中时,即出现以下提示信息,请稍候再试。
4. 检索成果时,为何系统出现浏览器脚本错误,提示“指定资源下载失败”?
如果用户机器缺乏了系统必需的MSXML组件,系统在检索时提示“指定资源下载失败”错误(参见右图)。请点击Microsoft MSXML 6.0,进入Microsoft下载页面完成安装后,再重新步入系统使用检索工具检索成果。

5. 检索时,为何系统提示“操作超时,请点击此处重试”?
当文献库返回信息超时时,即出现以下提示信息。请依照指示点击“此处”重试。

6. 检索时,为何系统提示“您所选数据库返回结果异常”?
由于检索工具会实时联接各个文献库的在线检索系统进行集成检索,而其中部份文献库(如: SCI、SSCI、ISTP和EI等)是收费文献库,需要用户所在单位订购文献库的使用权。如果单位没有订购,或者用户登入系统的IP不在这种服务供应商所许可的IP段内,检索结果页面则会显示此提示信息,不能进行检索。若贵单位已够买了相应的文献库,请复查已输入的查询条件是否正确,若查询条件正确,但检索时系统仍提示“您所选数据库返回结果异常”,请联系本系统的“在线咨询”,或者发电子邮件到本系统技术支持。
7. 检索时,为何系统提示“查询异常,可能是服务器暂时未能联接”?
由于跨文献库检索工具会实时联接各个文献库的在线检索系统进行集成检索,各个文献库可能会某些查询返回查询失败等信息,检索工具会把对方文献库返回的出错信息原貌显示,以便用户按照其指引对查询关键字进行改进。您可以尝试重新输入查询条件,再次检索。
8. 如何检索SCI、SSCI、ISTP、EI,Scopus,万方文献库和中国期刊网之外的其它文献库?
目前支持SCI,SSCI,ISTP,EI,Scopus,万方文献库和中国刊物网,对其他文献库的支持,比如ScienceDirect,IEEE Xplore,维普资讯等正在逐渐降低中。
放慢你的阅读 三款免费稍后阅读工具对比(全文)
采集交流 • 优采云 发表了文章 • 0 个评论 • 278 次浏览 • 2020-08-09 10:40
三款免费离线阅读工具对比
前面关于整合阅读类工具的推荐早已有过,于是明天我们来说说“Read it Later”,也就是“稍后阅读”或者直接叫“离线阅读”这样的工具;
它们顺应这样一种使用场景,当我们每晚在工作中或则繁忙其他事情,偶尔发觉浩大的SNS平台分享过来的某篇精彩长文却没时间研读,这样我们就须要把它们统一搜集上去以备“稍后阅读”。
采集文章的各类场景(图片来自搜狐随身看官方网页)
对比项
所以题外话开始,就我们在iOS当中所能看到的比较主流的三款“稍后阅读”工具:Pocket(以前的Read It Later)、Readability和新近出现的国产应用搜狐随身看,做个比较;出于节省的本意,并未选择收费的Instapaper。测试平台为新iPad,但是有一点不公,搜狐随身看仅有iPhone版本,而且iPhone版的排版并是很不适宜在iPad里面阅读,考虑到它是个新鲜的国产应用还是把它放进对比当中,跟流行已久的RIL以及Readability作一比较。
“稍后阅读”工具使用方式
首先来了解一下“稍后阅读”工具的使用方式,三款应用大致相同,均为给浏览器添加采集夹或则插件,因此当我们在浏览网页的时侯见到哪些好看的文章,只须要点击那种采集过的按键才能够激活一段javascript脚本因而将当前网页信息抓取到各家的服务器里。
使用方法
当我们闲下来有了时间,想要在iPad或则iPhone或则Android手机平板里面获取采集过的文章来细细阅读的话,打开客户端会手动同步出早已采集过的文章列表,并且开始手动下载文章内容;
我们为何喜欢“稍后阅读”
而且,之所以我们喜欢这类工具,不可是由于采集功能,还由于她们能否手动过滤掉原网页的好多广告或则动漫信息等无关紧要的内容,只留下大段纯文字,创造十分清新的阅读环境。
网页经过过滤后的清新版式
你该看中“稍后阅读”的哪些
既然使用方式上并无差别,于是文章同步时间、跨平台性、无关阅读内容的过滤能力成了我们衡量一个“稍后阅读”工具是否给力的标准。
你该看中“稍后阅读”的哪些
对比前的内容采集与对比思路
对比开始之前,我们在网上摘选了来自“ifanr、手机中国科技博客”这样的博客网站各两篇图文文章,来自“ZOL手机频道”的两篇常规应用文章,和来自于“豆瓣的日记文章”三篇;都是以文字内容阅读为主,博客和日记类网站也是我们常常采摘阅读内容的地方。
折戟的“文章同步时间对比”
对比开始之时,我们想要拿文章的同步时间(也就是说在iPad里面打开客户端,多久以后才能将刚刚搜集的文章列表加载到客户端中,以备我们选择阅读)作为当头炮来比较,但是情况太不豁达。
搜狐随身看同步时间
Readability同步时间
Pocket同步时间
由于美国两家Pocket和Readability其实并没有国外服务器,因此这两个应用同步上去的过程十分熬煎,Pocket第一次打开根本没有反应,直到第二次才勉强加载出,部分文章导读图还有缺位、Readability其实13.5秒的时间同步了一些,但是并不完整,9篇文章只有两篇同步过来;搜狐随身看这儿占了地利,基本是秒开。
高下立见的文章列表版面对比
既然同步时间里面受了阻碍,我们还是来重点说一下阅读体验方面;首先是文章列表的版式设计,在这里不得不夸一下改版后的Pocket(在它仍叫Read It Later的时代并不是这样外形),如果你是个相貌党,肯定会偏爱Pocket带给你的界面——像Flipboard那样的设计,用图片来突出整篇文章。
Pocket默认的窗棂外形
所有文章被提取了国图放在Pocket的首页里面,看起来非常凉爽,虽然有的排版并不是很严格和美观,但是也值得一看;不过若果文章数目过多,Pocket也提供了列表的方式来诠释更多内容。
Pocket另外一种列表模式
Readability优雅的列表外形
搜狐随身看文章列表
至于另外两个Readability与搜狐随身看,就只是比较乏味的列表方式了;而且就设计来看加拿大的两个基本可以秒杀国外的了,当然不排除搜狐随身看是个iPhone版本的缘由,如果推出iPad版才能美化一下加入更多内容的话就会好些。
无论是列表还是Pocket那样的窗棂,三款工具都支持在列表内的文章中滑动它进行操作,比如勾选“已读”“删除”等标签,来及时的整理你的列表。
本质考验:离线文章呈现疗效比较
真正考验三款工具的时侯到了,下面是我们最关心、也是使用最多的地方——离线文章的显示疗效。由于Readability一直没有同步出刚刚剩下的七篇文章,因此我们只能拿类似的先前的文章作为对比,不过也没关系,因为她们都来自豆瓣的笔记,网页内容和框架基本相同。 查看全部
当互联网时代的信息象潮水般涌来的时侯,现代人是真的有点儿招架不住了;我们每晚面对被分好类的新闻、科技、社会、体育、文化的等各种信息资源,同时她们又分化成图文、视频或则音频播客的不同方式灌输到我们的世界中;如何及时的筛选和消化,又怎么合理的安排时间去处理和接收那些内容,整合阅读和离线阅读两大类工具就是为这样的需求、或者说现实状况而设计的。

三款免费离线阅读工具对比
前面关于整合阅读类工具的推荐早已有过,于是明天我们来说说“Read it Later”,也就是“稍后阅读”或者直接叫“离线阅读”这样的工具;
它们顺应这样一种使用场景,当我们每晚在工作中或则繁忙其他事情,偶尔发觉浩大的SNS平台分享过来的某篇精彩长文却没时间研读,这样我们就须要把它们统一搜集上去以备“稍后阅读”。

采集文章的各类场景(图片来自搜狐随身看官方网页)

对比项
所以题外话开始,就我们在iOS当中所能看到的比较主流的三款“稍后阅读”工具:Pocket(以前的Read It Later)、Readability和新近出现的国产应用搜狐随身看,做个比较;出于节省的本意,并未选择收费的Instapaper。测试平台为新iPad,但是有一点不公,搜狐随身看仅有iPhone版本,而且iPhone版的排版并是很不适宜在iPad里面阅读,考虑到它是个新鲜的国产应用还是把它放进对比当中,跟流行已久的RIL以及Readability作一比较。
“稍后阅读”工具使用方式
首先来了解一下“稍后阅读”工具的使用方式,三款应用大致相同,均为给浏览器添加采集夹或则插件,因此当我们在浏览网页的时侯见到哪些好看的文章,只须要点击那种采集过的按键才能够激活一段javascript脚本因而将当前网页信息抓取到各家的服务器里。

使用方法
当我们闲下来有了时间,想要在iPad或则iPhone或则Android手机平板里面获取采集过的文章来细细阅读的话,打开客户端会手动同步出早已采集过的文章列表,并且开始手动下载文章内容;
我们为何喜欢“稍后阅读”
而且,之所以我们喜欢这类工具,不可是由于采集功能,还由于她们能否手动过滤掉原网页的好多广告或则动漫信息等无关紧要的内容,只留下大段纯文字,创造十分清新的阅读环境。

网页经过过滤后的清新版式
你该看中“稍后阅读”的哪些
既然使用方式上并无差别,于是文章同步时间、跨平台性、无关阅读内容的过滤能力成了我们衡量一个“稍后阅读”工具是否给力的标准。

你该看中“稍后阅读”的哪些
对比前的内容采集与对比思路
对比开始之前,我们在网上摘选了来自“ifanr、手机中国科技博客”这样的博客网站各两篇图文文章,来自“ZOL手机频道”的两篇常规应用文章,和来自于“豆瓣的日记文章”三篇;都是以文字内容阅读为主,博客和日记类网站也是我们常常采摘阅读内容的地方。
折戟的“文章同步时间对比”
对比开始之时,我们想要拿文章的同步时间(也就是说在iPad里面打开客户端,多久以后才能将刚刚搜集的文章列表加载到客户端中,以备我们选择阅读)作为当头炮来比较,但是情况太不豁达。

搜狐随身看同步时间

Readability同步时间

Pocket同步时间
由于美国两家Pocket和Readability其实并没有国外服务器,因此这两个应用同步上去的过程十分熬煎,Pocket第一次打开根本没有反应,直到第二次才勉强加载出,部分文章导读图还有缺位、Readability其实13.5秒的时间同步了一些,但是并不完整,9篇文章只有两篇同步过来;搜狐随身看这儿占了地利,基本是秒开。
高下立见的文章列表版面对比
既然同步时间里面受了阻碍,我们还是来重点说一下阅读体验方面;首先是文章列表的版式设计,在这里不得不夸一下改版后的Pocket(在它仍叫Read It Later的时代并不是这样外形),如果你是个相貌党,肯定会偏爱Pocket带给你的界面——像Flipboard那样的设计,用图片来突出整篇文章。
Pocket默认的窗棂外形
所有文章被提取了国图放在Pocket的首页里面,看起来非常凉爽,虽然有的排版并不是很严格和美观,但是也值得一看;不过若果文章数目过多,Pocket也提供了列表的方式来诠释更多内容。

Pocket另外一种列表模式
Readability优雅的列表外形

搜狐随身看文章列表
至于另外两个Readability与搜狐随身看,就只是比较乏味的列表方式了;而且就设计来看加拿大的两个基本可以秒杀国外的了,当然不排除搜狐随身看是个iPhone版本的缘由,如果推出iPad版才能美化一下加入更多内容的话就会好些。
无论是列表还是Pocket那样的窗棂,三款工具都支持在列表内的文章中滑动它进行操作,比如勾选“已读”“删除”等标签,来及时的整理你的列表。
本质考验:离线文章呈现疗效比较
真正考验三款工具的时侯到了,下面是我们最关心、也是使用最多的地方——离线文章的显示疗效。由于Readability一直没有同步出刚刚剩下的七篇文章,因此我们只能拿类似的先前的文章作为对比,不过也没关系,因为她们都来自豆瓣的笔记,网页内容和框架基本相同。
6大SEO新型站长工具(排名优化必备)
采集交流 • 优采云 发表了文章 • 0 个评论 • 273 次浏览 • 2020-08-09 10:26
1、站长工具
站长工具使用最多的,比较权威的就是站长工具、爱站工具和5118站长工具等三大平台,但是因为每位站长工具对于排行更新,或者是缓存更新和权重词库更新的不同,许多seo站长都是互相配合使用。站长工具对于关键词库的更新通常都是三天,而爱站工具则是1-3天,而且自带更新缓存工具,所以对于词库这块的更新还是比较快的。
目前5118站长平台则是比较受站长们喜欢的,因为词库每晚还会更新,而且还可以进行长尾关键词的挖掘和监控各大网站数据。但是对于网站权重这块,三款seo站长工具都是有不同的规则进行估算的,所以权重也是不同的,可能站长工具权重是2,但是爱站权重是0,5118权重是1,这是正常的现象,只要关键词排行是真实的,对于搜索引擎来将,网站的质量也是十分高的。
2、友链交换工具
友链交换工具是近两年新盛行的,主要是拿来解决seo站长们在线交换行业友链等服务的,传统交换友链的方式都是通过qq友链交换群进行人工发布,人工在线交换,效率比较慢,而且每位群的友情链接行业都是不同的,无法直接交换到精准行业的友情链接,这也对seo工作的效率影响了好多,毕竟友情链接直接影响网站的权重。所以,友链交换工具就上线了,可以精准的匹配权重、收录、行业等精准的友链,而且还可以在工具内实时监控友链交换情况,也可以第一时间了解网站友链是否被下链。
目前友情链接交换工具有很多,但是比较著名的也是各个seo站长常用的就是爱链工具和换链利器,这两款是市场上最火的,也是流量最多的两款友链交换工具,在这上面添加好网站后,一般每晚还会有人申请交换,正常来讲完全解决了友情链接交换的数目和次数,因为这是不固定的,主要看站长想要交换多少条,就可以交换多少条,再也不用害怕友情链接交换不到或则人工花费大量时间去交换友链的问题了。
3、域名剖析工具
域名剖析工具是伴随着老域名的盛行所开发的剖析老域名的工具,老域名剖析工具可以在线剖析域名的质量、外链、历史记录等等,完全解决了站长构建新站初,担心域名质量的优劣,是否做过红色等情况。老域名剖析工具还可以依照搜索引擎算法,进行剖析网站标题撰写是否符合搜索引擎规则,这样就解决了seo站长们对于三大标签或则栏目标题、内容标题未能合理分配权重的问题了。常用的老域名剖析工具就是114网站查询和橘子seo老域名工具,这两款早已完全符合站长们对于域名质量剖析的需求,所以还没有使用过的站长可以去了解了,不然都会被别的站长所超越。
4、文章原创度测量工具
文章原创度测量工具主要是测量seo站长们在撰写网站文章的时侯,可以借助这类工具进行测量文章的质量是否符合搜索引擎的收录,这样也就解决了文章质量的疑虑,同时也防止了由于文章内容的质量不够,造成网站被搜索引擎惩罚的危险。
5、采集伪原创工具
采集和伪原创工具特别多,这也是由于目前seo市场对于内容量的需求所盛行的工具,很多站长由于自己写文章每天写不了几篇,但是网站每天更新的 文章不多,对于收录这块就比较漫长,而且蜘蛛量也降低的不多,完全影响到了一个网站的优化时长。所以,很多seo站长纷纷使用伪原创工具或则采集工具进行大量的采集,每天更新的文章量甚至可以达到成百上千篇也是没问题的,这也就可以快速的降低网站的收录,快速的提高网站的质量和排行。
伪原创工具常用的是网上的奶盘伪原创工具,而采集工具你们常用的则是优采云采集,因为优采云采集工具适用于各类程序的网站,还可以定时采集定时发布以及全手动采集发布等,完全满足了网站对于内容的需求,只不过现今的搜索引擎严重严打伪原创和采集,所以站长们要注意了,如果想要采集,一定要做好文章采集的质量把控,不然很容易被搜索引擎所惩罚。
6、老域名挖掘工具
上面给你们讲了老域名剖析工具,下面就给你们介绍老域名挖掘的工具,这也是好多seo站长急切想要晓得的,因为老域名对于优化这块的益处实在数不胜数,不仅对于关键词排名优化的速率比较快,而且还可以在短时间内使网站的收录达到成千上万,因为老域名所以自身是带外链和搜索引擎信任度的,所以seo站长们纷纷在群里问关于老域名挖掘的工具都有什么。
老域名挖掘工具不仅里面介绍的橘子seo老域名工具上面有自带销售老域名的商城,但是由于查看老域名所须要的积分好多,价格也太贵,也不一定就能保证老域名是否被注册或则质量好不好。所以,大家就可以使用站长之家工具内的过期域名查询,这是每晚过期的老域名,平均每晚都有数十万个不止,足够满足你们对于老域名的需求量了。但是对于每位老域名的剖析还是须要利用前面所介绍的老域名剖析工具,一定要防止被使用红色的或则早已被墙的老域名,争取剖析优质的老域名,用来构建网站。
关于6大seo新型站长工具就给你们介绍到这儿了,已经算是比较齐全的了,当然seo工具还有好多,比如光年日志分析工具、百度统计剖析平台、百度站长平台等等,都可以合理使用提高seo排名和剖析网站优化情况的不足。如果还想了解更多seo工具或则seo优化问题,可以随时关注谢盼龙博客,这里有你意想不到的知识。 查看全部
作为seo站长若果在优化关键词排行的时侯不学会借助seo工具降低工作量,提示工作的效率,那么这个seo站长是十分不合格的。在seo行业好多网站做的好站长都是在借助各大seo工具提高排行,今天,谢盼龙就给你们介绍6大seo站长必备的工具,希望还能帮助到诸位站长们。
1、站长工具
站长工具使用最多的,比较权威的就是站长工具、爱站工具和5118站长工具等三大平台,但是因为每位站长工具对于排行更新,或者是缓存更新和权重词库更新的不同,许多seo站长都是互相配合使用。站长工具对于关键词库的更新通常都是三天,而爱站工具则是1-3天,而且自带更新缓存工具,所以对于词库这块的更新还是比较快的。
目前5118站长平台则是比较受站长们喜欢的,因为词库每晚还会更新,而且还可以进行长尾关键词的挖掘和监控各大网站数据。但是对于网站权重这块,三款seo站长工具都是有不同的规则进行估算的,所以权重也是不同的,可能站长工具权重是2,但是爱站权重是0,5118权重是1,这是正常的现象,只要关键词排行是真实的,对于搜索引擎来将,网站的质量也是十分高的。
2、友链交换工具
友链交换工具是近两年新盛行的,主要是拿来解决seo站长们在线交换行业友链等服务的,传统交换友链的方式都是通过qq友链交换群进行人工发布,人工在线交换,效率比较慢,而且每位群的友情链接行业都是不同的,无法直接交换到精准行业的友情链接,这也对seo工作的效率影响了好多,毕竟友情链接直接影响网站的权重。所以,友链交换工具就上线了,可以精准的匹配权重、收录、行业等精准的友链,而且还可以在工具内实时监控友链交换情况,也可以第一时间了解网站友链是否被下链。
目前友情链接交换工具有很多,但是比较著名的也是各个seo站长常用的就是爱链工具和换链利器,这两款是市场上最火的,也是流量最多的两款友链交换工具,在这上面添加好网站后,一般每晚还会有人申请交换,正常来讲完全解决了友情链接交换的数目和次数,因为这是不固定的,主要看站长想要交换多少条,就可以交换多少条,再也不用害怕友情链接交换不到或则人工花费大量时间去交换友链的问题了。
3、域名剖析工具
域名剖析工具是伴随着老域名的盛行所开发的剖析老域名的工具,老域名剖析工具可以在线剖析域名的质量、外链、历史记录等等,完全解决了站长构建新站初,担心域名质量的优劣,是否做过红色等情况。老域名剖析工具还可以依照搜索引擎算法,进行剖析网站标题撰写是否符合搜索引擎规则,这样就解决了seo站长们对于三大标签或则栏目标题、内容标题未能合理分配权重的问题了。常用的老域名剖析工具就是114网站查询和橘子seo老域名工具,这两款早已完全符合站长们对于域名质量剖析的需求,所以还没有使用过的站长可以去了解了,不然都会被别的站长所超越。
4、文章原创度测量工具
文章原创度测量工具主要是测量seo站长们在撰写网站文章的时侯,可以借助这类工具进行测量文章的质量是否符合搜索引擎的收录,这样也就解决了文章质量的疑虑,同时也防止了由于文章内容的质量不够,造成网站被搜索引擎惩罚的危险。
5、采集伪原创工具
采集和伪原创工具特别多,这也是由于目前seo市场对于内容量的需求所盛行的工具,很多站长由于自己写文章每天写不了几篇,但是网站每天更新的 文章不多,对于收录这块就比较漫长,而且蜘蛛量也降低的不多,完全影响到了一个网站的优化时长。所以,很多seo站长纷纷使用伪原创工具或则采集工具进行大量的采集,每天更新的文章量甚至可以达到成百上千篇也是没问题的,这也就可以快速的降低网站的收录,快速的提高网站的质量和排行。
伪原创工具常用的是网上的奶盘伪原创工具,而采集工具你们常用的则是优采云采集,因为优采云采集工具适用于各类程序的网站,还可以定时采集定时发布以及全手动采集发布等,完全满足了网站对于内容的需求,只不过现今的搜索引擎严重严打伪原创和采集,所以站长们要注意了,如果想要采集,一定要做好文章采集的质量把控,不然很容易被搜索引擎所惩罚。
6、老域名挖掘工具
上面给你们讲了老域名剖析工具,下面就给你们介绍老域名挖掘的工具,这也是好多seo站长急切想要晓得的,因为老域名对于优化这块的益处实在数不胜数,不仅对于关键词排名优化的速率比较快,而且还可以在短时间内使网站的收录达到成千上万,因为老域名所以自身是带外链和搜索引擎信任度的,所以seo站长们纷纷在群里问关于老域名挖掘的工具都有什么。
老域名挖掘工具不仅里面介绍的橘子seo老域名工具上面有自带销售老域名的商城,但是由于查看老域名所须要的积分好多,价格也太贵,也不一定就能保证老域名是否被注册或则质量好不好。所以,大家就可以使用站长之家工具内的过期域名查询,这是每晚过期的老域名,平均每晚都有数十万个不止,足够满足你们对于老域名的需求量了。但是对于每位老域名的剖析还是须要利用前面所介绍的老域名剖析工具,一定要防止被使用红色的或则早已被墙的老域名,争取剖析优质的老域名,用来构建网站。
关于6大seo新型站长工具就给你们介绍到这儿了,已经算是比较齐全的了,当然seo工具还有好多,比如光年日志分析工具、百度统计剖析平台、百度站长平台等等,都可以合理使用提高seo排名和剖析网站优化情况的不足。如果还想了解更多seo工具或则seo优化问题,可以随时关注谢盼龙博客,这里有你意想不到的知识。
爱站SEO工具包怎样使用
采集交流 • 优采云 发表了文章 • 0 个评论 • 199 次浏览 • 2020-08-09 08:26
使用方式:
一、采集文章:石青伪原创工具,自带采集工具。首先,你须要在"采集设置"模块中录入须要采集的关键词。录入完成后,点击"保存关键词",该词汇就被保存出来,然后勾选它(默认是勾选的)。再选择是在百度还是google中采集。如果你是免费试用用户。就只能采用第一个"免费测试采集"。
点击"内容采集",稍等一会,数据会渐渐采集进来,采集到的数据都显示在"网络原创文章专家"界面。如果要停止采集,请回到"采集设置"界面,再点击"停止采集"。使用"采集文章并搅乱生成文章"功能,可以根据选取生成数目,动态生成无数多篇文章。
二、制作伪原创文章:用户可以有4种方式录入原创文章,1、把文章直接拷贝到文章编辑市,然后录入标题,再保存文章;2、通过导出的方法,可以直接导出TXT或html文档,3、通过采集的形式,直接采集到互联网上的文章,4、通过插口直接取得自己CMS网站的内容;
在取得了文章后,用户可以有3种形式制做伪原创文章:1、也是最简单的,直接点击文章标题,然后点击界面上部的"生成原创"按钮,伪原创后的文章就显露在"伪原创文章预览市"了;2、采用导入方法,直接可以把所有勾选的文章批量导入到TXT或HTML 文章中;3、通过插口,直接批量伪原创到自己的CMS网站中。下图是导入方法,在采用导入方法的时侯,系统将会根据设置的伪原创配置来伪原创勾选了的,文章然后导入;
三、使用直接更新主流CMS系统:石青伪原创工具,支持直接更新动易,老丫,新云,dedeCMS等99%的国外主流CMS内容,通过插口直接取得站点上的信息,然后伪原创后上传回来。具体使用方式,使用界面有详尽说明。按照说明一步一步的说很快就可以成功。 查看全部
石青伪原创工具具是拿来处理非原创的一款seo工具,用来帮助我们处理一些非原创文件,使文章让搜索引擎爬虫看起来象原创文章。软件支持英文和法文伪原创。 是一款专业且免费的伪原创文章生成器,其专门针对百度和google的爬虫习惯以及动词算法而开发,通过本软件优化的文章,将更受搜索引擎所追捧。
使用方式:

一、采集文章:石青伪原创工具,自带采集工具。首先,你须要在"采集设置"模块中录入须要采集的关键词。录入完成后,点击"保存关键词",该词汇就被保存出来,然后勾选它(默认是勾选的)。再选择是在百度还是google中采集。如果你是免费试用用户。就只能采用第一个"免费测试采集"。

点击"内容采集",稍等一会,数据会渐渐采集进来,采集到的数据都显示在"网络原创文章专家"界面。如果要停止采集,请回到"采集设置"界面,再点击"停止采集"。使用"采集文章并搅乱生成文章"功能,可以根据选取生成数目,动态生成无数多篇文章。
二、制作伪原创文章:用户可以有4种方式录入原创文章,1、把文章直接拷贝到文章编辑市,然后录入标题,再保存文章;2、通过导出的方法,可以直接导出TXT或html文档,3、通过采集的形式,直接采集到互联网上的文章,4、通过插口直接取得自己CMS网站的内容;

在取得了文章后,用户可以有3种形式制做伪原创文章:1、也是最简单的,直接点击文章标题,然后点击界面上部的"生成原创"按钮,伪原创后的文章就显露在"伪原创文章预览市"了;2、采用导入方法,直接可以把所有勾选的文章批量导入到TXT或HTML 文章中;3、通过插口,直接批量伪原创到自己的CMS网站中。下图是导入方法,在采用导入方法的时侯,系统将会根据设置的伪原创配置来伪原创勾选了的,文章然后导入;

三、使用直接更新主流CMS系统:石青伪原创工具,支持直接更新动易,老丫,新云,dedeCMS等99%的国外主流CMS内容,通过插口直接取得站点上的信息,然后伪原创后上传回来。具体使用方式,使用界面有详尽说明。按照说明一步一步的说很快就可以成功。
采集工具-Web Scraper的教学和示例
采集交流 • 优采云 发表了文章 • 0 个评论 • 351 次浏览 • 2020-08-08 05:26
“有很多方法可以打钉子,有时我最熟悉的锤子会打我”
背景
最近收到协助采集网站的请求. 在传统的“列表+内容”页面模式下,使用PHP或采集器时始终会出现各种莫名其妙的问题. 基本上,我将使用“ node + puppteer”来执行此操作,并使用自动测试工具来模拟操作. 尽管它是通用锤子,但制造该锤子的过程和技术复杂性仍然存在,因此我转向了以前考虑过但没有尝试使用浏览器插件的方向,基本原理和思想与自动化基本相同工具,但使目标逻辑更适合浏览器,并且感觉更优雅.
当我检查信息时,我发现了Web Scraper. 我通过参考文档和教程将其应用于目标网站集,最后获得了数据. 如果熟悉整个操作过程,则可以快速设置并实施相应的规则. 采集,现在记录该过程.
过程
1. 安装网页抓取工具
如果您掌握科学的冲浪技能,则可以登录chorme在线商店直接搜索并安装
或在百度上搜索“ Web scraper离线安装程序包”以获得相关支持. 离线安装过程将不会重复.
2. 分析目标电台
您可以看到这是一种典型的列表+内容显示方法. 现在,您需要同时采集列表和内容页面. 传统的采集思想是使用该程序将整个列表页面拉回,然后解析超链接. 跳转到内容页面.
现在让我们看一下如何使用网络抓取工具进行数据采集.
3. 设定规则
由于采集工具是通用的,关于如何采集和采集这些数据,这些规则要求用户根据实际情况进行配置. 首先,让我们了解一下网页抓取工具的打开方式和基本页面
①打开工具
在目标页面上打开开发人员工具(F11或单击鼠标右键检查),可以看到工具栏末尾有一个同名的标签,单击该标签可进入工具页面
②创建一个新的采集任务
您需要在采集之前创建一个站点地图,这可以理解为一项任务,请选择创建新站点地图-创建站点地图
站点地图名称是任务的名称,可以根据需要创建.
起始URL为您采集页面. 如果是列表+内容模式,建议填写列表页面.
然后创建站点地图,建立了基本任务.
③建立列表页面规则
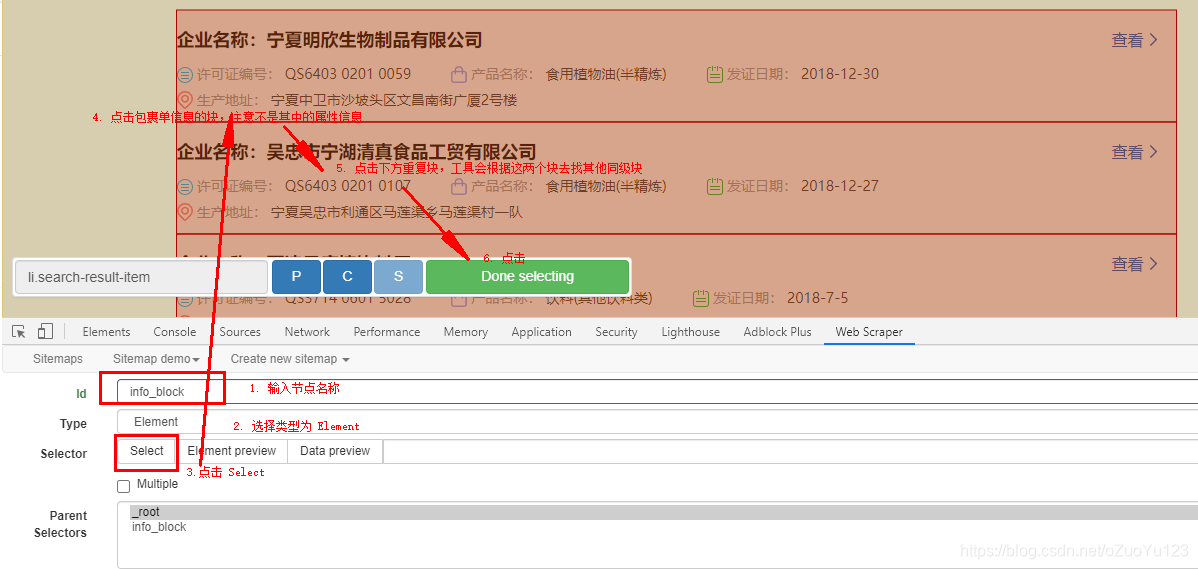
单击“添加新选择器”以创建一个选择器,该选择器告诉插件应选择哪个节点. 对于在此类列表页面上也具有信息的页面,我们将每条信息视为一个块,其中收录各种属性信息. 创建方法如下:
您需要选中Multiple选项,这可以理解为循环获取.
添加后,我们应该在信息块中标记内容. 具体操作方法与上述相同,但应选择信息的父选择器作为刚刚创建的信息块节点.
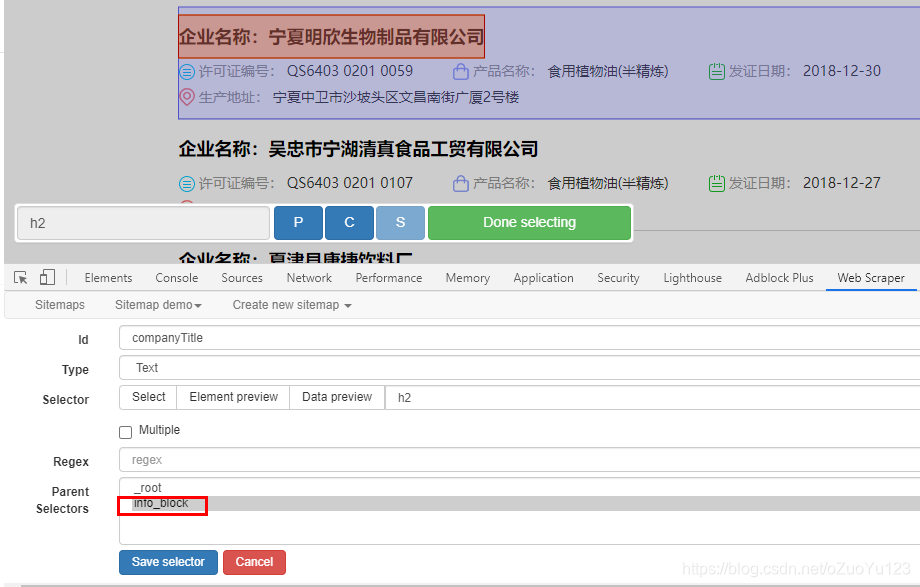
其他节点的数据操作相同,请记住选择父节点.
④检查已建立的规则 查看全部
本文旨在学习和交流. 数据源的所有权属于原创网站及其所有者. 严禁使用本文提到的过程和数据牟利.
“有很多方法可以打钉子,有时我最熟悉的锤子会打我”
背景
最近收到协助采集网站的请求. 在传统的“列表+内容”页面模式下,使用PHP或采集器时始终会出现各种莫名其妙的问题. 基本上,我将使用“ node + puppteer”来执行此操作,并使用自动测试工具来模拟操作. 尽管它是通用锤子,但制造该锤子的过程和技术复杂性仍然存在,因此我转向了以前考虑过但没有尝试使用浏览器插件的方向,基本原理和思想与自动化基本相同工具,但使目标逻辑更适合浏览器,并且感觉更优雅.
当我检查信息时,我发现了Web Scraper. 我通过参考文档和教程将其应用于目标网站集,最后获得了数据. 如果熟悉整个操作过程,则可以快速设置并实施相应的规则. 采集,现在记录该过程.
过程
1. 安装网页抓取工具
如果您掌握科学的冲浪技能,则可以登录chorme在线商店直接搜索并安装
或在百度上搜索“ Web scraper离线安装程序包”以获得相关支持. 离线安装过程将不会重复.
2. 分析目标电台
您可以看到这是一种典型的列表+内容显示方法. 现在,您需要同时采集列表和内容页面. 传统的采集思想是使用该程序将整个列表页面拉回,然后解析超链接. 跳转到内容页面.

现在让我们看一下如何使用网络抓取工具进行数据采集.
3. 设定规则
由于采集工具是通用的,关于如何采集和采集这些数据,这些规则要求用户根据实际情况进行配置. 首先,让我们了解一下网页抓取工具的打开方式和基本页面
①打开工具
在目标页面上打开开发人员工具(F11或单击鼠标右键检查),可以看到工具栏末尾有一个同名的标签,单击该标签可进入工具页面

②创建一个新的采集任务
您需要在采集之前创建一个站点地图,这可以理解为一项任务,请选择创建新站点地图-创建站点地图
站点地图名称是任务的名称,可以根据需要创建.
起始URL为您采集页面. 如果是列表+内容模式,建议填写列表页面.
然后创建站点地图,建立了基本任务.

③建立列表页面规则
单击“添加新选择器”以创建一个选择器,该选择器告诉插件应选择哪个节点. 对于在此类列表页面上也具有信息的页面,我们将每条信息视为一个块,其中收录各种属性信息. 创建方法如下:
您需要选中Multiple选项,这可以理解为循环获取.
添加后,我们应该在信息块中标记内容. 具体操作方法与上述相同,但应选择信息的父选择器作为刚刚创建的信息块节点.
其他节点的数据操作相同,请记住选择父节点.
④检查已建立的规则
文章采集工具,文章伪原创工具,文章原创检测
采集交流 • 优采云 发表了文章 • 0 个评论 • 373 次浏览 • 2020-08-07 22:14
文章采集引擎使用采集器技术来捕获行业数据采集,并在云中构建多级索引库. 通过用户输入的关键字和选定的参考库,可以在云数据库中快速准确地检索相关材料,对候选材料进行原创检测和收录检测,最终结果经过过滤和汇总后推荐给用户.
对全文进行语义分析后,它会智能地修改句子并生成文本. 凭借其强大的NLP,深度学习和其他技术,它可以轻松通过独创性检测. 中文语义开放平台使用爬虫技术捕获行业数据集合,并使用深度学习方法进行语法和语义分析,并在语义上下文的空间矢量模型中挖掘单词之间的关系. 该开放平台利用自主开发的中文分词,句法分析,语义联想和实体识别技术,结合海量行业语料库的不断积累,提供简单,强大,可靠的中文自然语言分析云服务.
分解提交的文本内容后,它在大量Internet资源之间进行指纹比较,检测每个句子的独创性,并快速而准确地找到最相似的网页源,不仅可以分析文章中的pla窃程度,还可以检测他人复制您的原创文章并被他人疯狂传播的程度,并帮助您保护原创文章的版权. 原创的检测报告可以用作您更新文章的基础,从而有效地提高搜索引擎的索引量和排名. 查看全部
就像标题中提到的三个功能一样,有哪些工具可以将这三个功能整合在一起?是的,我今天所说的是一个名为“优采云”的工具,该工具非常易于使用,甚至不需要包裹在面包屑中.
文章采集引擎使用采集器技术来捕获行业数据采集,并在云中构建多级索引库. 通过用户输入的关键字和选定的参考库,可以在云数据库中快速准确地检索相关材料,对候选材料进行原创检测和收录检测,最终结果经过过滤和汇总后推荐给用户.
对全文进行语义分析后,它会智能地修改句子并生成文本. 凭借其强大的NLP,深度学习和其他技术,它可以轻松通过独创性检测. 中文语义开放平台使用爬虫技术捕获行业数据集合,并使用深度学习方法进行语法和语义分析,并在语义上下文的空间矢量模型中挖掘单词之间的关系. 该开放平台利用自主开发的中文分词,句法分析,语义联想和实体识别技术,结合海量行业语料库的不断积累,提供简单,强大,可靠的中文自然语言分析云服务.
分解提交的文本内容后,它在大量Internet资源之间进行指纹比较,检测每个句子的独创性,并快速而准确地找到最相似的网页源,不仅可以分析文章中的pla窃程度,还可以检测他人复制您的原创文章并被他人疯狂传播的程度,并帮助您保护原创文章的版权. 原创的检测报告可以用作您更新文章的基础,从而有效地提高搜索引擎的索引量和排名.
免费的伪原创工具来采集文章
采集交流 • 优采云 发表了文章 • 0 个评论 • 317 次浏览 • 2020-08-07 18:14
5. 优秀的网站管理员始终会注意蜘蛛访问网站的时间,以确保及时抓取和收录网站内容. 由于搜索引擎蜘蛛对网站的爬取是定期的,因此它会根据网站上内容更新的频率而变化. 因此,建议网站管理员保持网站更新的规律性,不仅可以养成良好的生活习惯,而且可以帮助搜索引擎蜘蛛养成良好的生活习惯.
6. 如何围绕用户需求撰写原创文章?命题-确定文章的内容. 写文章就像写文章. 首先,这是命题. 您要编写什么内容以及要优化哪些关键字. 常用的是您自己的问题,问答平台的问题,您周围的人的问题,客户的问题以及同龄人的问题. 这些都是用户需求. 这些问题关键字与用户搜索习惯结合在一起,以组合关键字标题.
7. 收录和排名没有直接关系. 收录是指网站的搜索引擎数据库中存在的内容量. 该数字只能代表一个数字,不能证明任何东西. 一些网站的收录率和排名很高. 非常可怜有些网站没有很多,但是排名很好. 如果您想借助数量优势获得更好的排名,那是不现实的.
8. 网站地图设置. 该站点地图用于整理整个网站的导航页面,不仅针对搜索引擎,还针对用户;
————————————————————————————————
问: 黑帽seo是什么意思?
A: 黑帽SEO旨在利用和扩大搜索引擎的战略缺陷(实际上,不存在完善的系统)来获得更多的用户访问,而这些更多的访问是以牺牲用户体验为代价的. SEO行为.
问: 页面标题和描述适合多少个单词?
回答: 网站标题搜索引擎只能在搜索结果中显示63个字节,以下内容被省略. 通常,建议网页标题不超过32个汉字,描述说明不超过72个汉字.
问: 要购买多少合适的网站服务器空间?
答案: 根据网站的规模和要提供的服务确定要购买的空间(服务器),选择功能强大的常规空间提供商,并根据用户组的分布选择访问提供商以确保用户访问速度和稳定性. 查看全部
4. 如何解决网站搜索引擎优化问题,增加文章数量;为了解决文章收录的问题,首先需要解决的问题是内容的数量,例如,您的网站总共有100篇文章,即使它全部是百度. 如果收录在内,您也只能收录一个最多一百篇文章. 这已经是极限了. 实际上,百度不能收录网站的所有内容. 即使是体重非常高的场所也不能包括在内,更不用说一些垃圾了. 可收录的站点数量更加有限,内容量也很小.
5. 优秀的网站管理员始终会注意蜘蛛访问网站的时间,以确保及时抓取和收录网站内容. 由于搜索引擎蜘蛛对网站的爬取是定期的,因此它会根据网站上内容更新的频率而变化. 因此,建议网站管理员保持网站更新的规律性,不仅可以养成良好的生活习惯,而且可以帮助搜索引擎蜘蛛养成良好的生活习惯.
6. 如何围绕用户需求撰写原创文章?命题-确定文章的内容. 写文章就像写文章. 首先,这是命题. 您要编写什么内容以及要优化哪些关键字. 常用的是您自己的问题,问答平台的问题,您周围的人的问题,客户的问题以及同龄人的问题. 这些都是用户需求. 这些问题关键字与用户搜索习惯结合在一起,以组合关键字标题.
7. 收录和排名没有直接关系. 收录是指网站的搜索引擎数据库中存在的内容量. 该数字只能代表一个数字,不能证明任何东西. 一些网站的收录率和排名很高. 非常可怜有些网站没有很多,但是排名很好. 如果您想借助数量优势获得更好的排名,那是不现实的.
8. 网站地图设置. 该站点地图用于整理整个网站的导航页面,不仅针对搜索引擎,还针对用户;
————————————————————————————————
问: 黑帽seo是什么意思?
A: 黑帽SEO旨在利用和扩大搜索引擎的战略缺陷(实际上,不存在完善的系统)来获得更多的用户访问,而这些更多的访问是以牺牲用户体验为代价的. SEO行为.
问: 页面标题和描述适合多少个单词?
回答: 网站标题搜索引擎只能在搜索结果中显示63个字节,以下内容被省略. 通常,建议网页标题不超过32个汉字,描述说明不超过72个汉字.
问: 要购买多少合适的网站服务器空间?
答案: 根据网站的规模和要提供的服务确定要购买的空间(服务器),选择功能强大的常规空间提供商,并根据用户组的分布选择访问提供商以确保用户访问速度和稳定性.
为网站管理员或SEOER推荐免费的文章采集工具
采集交流 • 优采云 发表了文章 • 0 个评论 • 419 次浏览 • 2020-08-07 17:39
网站站长之星采集软件界面:
进入网站站长的星级采集功能:
设置采集网站站长星标的规则:
我采集了有关SEO的内容:
除此之外,该软件还可以管理网站并自动发布信息,伪原创功能,但我通常只将其用于采集,然后手动处理伪原创,呵呵!!!有需要的朋友可以去他们的官方网站下载,个人网站管理员可以免费使用;
网站站长之星的操作步骤如下:
第一步: 单击导航“管理”以找到“关键字库”,然后单击打开
第2步: 在打开的“关键字库管理界面”中单击“新建”
第3步: 在“编辑关键字库”管理界面中添加关键字库的名称,并添加关键字,然后单击“保存”
第4步: 创建一个新的采集任务: 单击视图下方的绿色“ +”按钮,就是这样.
第5步: 在“任务配置”界面中,单击新集合,一个接一个地设置,最后单击“保存”!
第6步: 选择任务以设置采集并开始“数据采集”!
本文由Le Chen整理并发布,希望它可以帮助有需要的朋友!
网站站长之星简化版下载链接: 或添加我的Lechen博客交换组: 311036703下载 查看全部
网站管理员之星是一个专业的网站组内容管理系统,它集成了文章采集,文章处理和文章发布. 界面精美,操作简单,功能强大. 网站管理员Star具有完整而灵活的执行过程引擎,配置扩展机制和插件系统. 您只需要提供目标关键字即可获取大量相关关键字(即长尾关键字),然后将这些长尾关键字用作从搜索引擎或指定站点采集并提供关键字的条件. 列出匹配的文章. 您可以将采集到的文章发布到一个或多个CMS站点(当前支持的CMS是DedeCMS,SupeSite,Discuz!,KesionCMS,EmpireCMS等).
网站站长之星采集软件界面:
进入网站站长的星级采集功能:

设置采集网站站长星标的规则:

我采集了有关SEO的内容:

除此之外,该软件还可以管理网站并自动发布信息,伪原创功能,但我通常只将其用于采集,然后手动处理伪原创,呵呵!!!有需要的朋友可以去他们的官方网站下载,个人网站管理员可以免费使用;
网站站长之星的操作步骤如下:
第一步: 单击导航“管理”以找到“关键字库”,然后单击打开
第2步: 在打开的“关键字库管理界面”中单击“新建”
第3步: 在“编辑关键字库”管理界面中添加关键字库的名称,并添加关键字,然后单击“保存”
第4步: 创建一个新的采集任务: 单击视图下方的绿色“ +”按钮,就是这样.
第5步: 在“任务配置”界面中,单击新集合,一个接一个地设置,最后单击“保存”!
第6步: 选择任务以设置采集并开始“数据采集”!
本文由Le Chen整理并发布,希望它可以帮助有需要的朋友!
网站站长之星简化版下载链接: 或添加我的Lechen博客交换组: 311036703下载
优采云万能文章采集器 一款简单有效功能强悍的文章采集软件(破解版)
采集交流 • 优采云 发表了文章 • 0 个评论 • 506 次浏览 • 2020-08-03 23:00
文章采集来源主要来自以下搜索引擎:
百度网页、百度新闻、搜狗网页、搜狗新闻、微信、360网页、360新闻、今日头条、一点资讯、必应网页、必应新闻、雅虎、谷歌网页、谷歌新闻
功能特性:
一、依托于万能正文辨识智能算法,可实现任何网页正文手动提取准确率95%以上。
二、只需输入关键词,就能采集到百度新闻和网页、搜狗新闻和网页、360新闻和网页、谷歌新闻和网页、必应新闻和网页、雅虎;可批量关键词全手动采集。
三、可定向采集指定网站栏目列表下的所有文章,智能化匹配,无需编撰复杂规则。
四、文章转译功能,可对采集好的文章,将其翻译到中文再翻译回英文,实现翻译伪原创,支持微软和有道翻译。
五、史上最简单最智能文章采集器,支持全功能试用,效果怎么一试就知!
使用说明:
1、下载并解压好文件,双击“优采云·万能文章采集器Crack.exe”打开,你会发觉软件还是免费破解的哦。
2、点击OK,打开软件后就可以直接开始使用了,在关键词一栏中填写你须要采集的文章关键词。
3、然后选择文章保存的目录和保存的选项。
4、确认好信息,点击开始采集即可。
采集完成以后我们可以在保存的文件夹目录上面去看文章,或者也可以点击软件里面的文章查看。
整个软件的操作虽然十分简单,相信诸位小伙伴们都是学习能力极强的人,一看都会哦!
常见问题:
采集设置的黑名单错误如何解决?
[采集设置]里面输入黑名单时,如果最后有空行存在工具采集文章,就会造成关键词采集功能有搜索数目显示而无实际采集过程的问题,去掉空行即可。
遇到杀毒软件提示,请忽视,若不放心工具采集文章,可以不使用,寻找其他工具。
附:
百度网盘链接:
提取码:dkjl 查看全部
优采云万能文章采集器是一款简单有效功能强悍的文章采集软件。你只须要可输入关键词,即可采集各大搜索引擎网页和新闻,也可以采集指定网站文章,非常便捷快捷;本次小编为你们带来的是优采云万能文章采集器红色免费破解版,双击即可打开使用,软件早已完美破解无需注册码激活即可免费使用,喜欢的小伙伴们欢迎下载。
文章采集来源主要来自以下搜索引擎:
百度网页、百度新闻、搜狗网页、搜狗新闻、微信、360网页、360新闻、今日头条、一点资讯、必应网页、必应新闻、雅虎、谷歌网页、谷歌新闻
功能特性:
一、依托于万能正文辨识智能算法,可实现任何网页正文手动提取准确率95%以上。
二、只需输入关键词,就能采集到百度新闻和网页、搜狗新闻和网页、360新闻和网页、谷歌新闻和网页、必应新闻和网页、雅虎;可批量关键词全手动采集。
三、可定向采集指定网站栏目列表下的所有文章,智能化匹配,无需编撰复杂规则。
四、文章转译功能,可对采集好的文章,将其翻译到中文再翻译回英文,实现翻译伪原创,支持微软和有道翻译。
五、史上最简单最智能文章采集器,支持全功能试用,效果怎么一试就知!
使用说明:
1、下载并解压好文件,双击“优采云·万能文章采集器Crack.exe”打开,你会发觉软件还是免费破解的哦。
2、点击OK,打开软件后就可以直接开始使用了,在关键词一栏中填写你须要采集的文章关键词。

3、然后选择文章保存的目录和保存的选项。

4、确认好信息,点击开始采集即可。
采集完成以后我们可以在保存的文件夹目录上面去看文章,或者也可以点击软件里面的文章查看。

整个软件的操作虽然十分简单,相信诸位小伙伴们都是学习能力极强的人,一看都会哦!
常见问题:
采集设置的黑名单错误如何解决?
[采集设置]里面输入黑名单时,如果最后有空行存在工具采集文章,就会造成关键词采集功能有搜索数目显示而无实际采集过程的问题,去掉空行即可。
遇到杀毒软件提示,请忽视,若不放心工具采集文章,可以不使用,寻找其他工具。
附:
百度网盘链接:
提取码:dkjl
在线工具seo采集文章
采集交流 • 优采云 发表了文章 • 0 个评论 • 518 次浏览 • 2020-08-11 15:55
1、这要看新站还是老站,还要看哪些行业,其实评判正不正常应当从收录率的角度来看,一般网站收录率在70%以上,算正常,当使也可以再提高这个数字,通过改善页面质量。
2、网站收录之后如何上排行收录和排行并没有直接联系,收录指的是一个网站在搜索引擎数据库中存在的内容数目,数量才能代表的只是一个数字而已,不能证明任何东西,有些网站收录很高,排名太差,有些网站收录并不多,可是排行反倒挺好,如果想要以数目的优势来争取更好的排行,是太不现实的看法。
3、优化内容环境基于搜索引擎内容池来讲,当你的腹部内容源,大量的参杂着优质内容的时侯,实际上,低质量内容的生存空间是被严重打压的。
4、如何围绕用户需求写原创文章呢?命题-确定文章内容主题写文章就像写习作,首先就是命题,你要写哪些内容,主要想优化那个关键词。常用的就是你自己的问题、问答平台的问题、身边人的问题、客户的问题、同行的问题,这些都是用户的需求,这些问题关键词结合用户搜索习惯来组合关键词标题。
5、提高网站权重;有人说了,自己的文章有质量,也有数目,为什么收录还是上不去,收录速率还是这么慢,若是遇见这样的情况,要么就是新站没有权重,要么就是网站降权,多数情况下是因为新站没有权重引起的。
6、既然不能直接严禁抓取,那就干脆严禁百度蜘蛛等搜索引擎访问,思路是:判断user_agent,如果是百度蜘蛛、谷歌机器人等搜索引擎的user_agent,就返回403或则404,这样百度等搜索引擎都会觉得这个网站无法打开或则不存在,自然也就不会收录了。
7、网站优化过度;一直以来都发觉很多网站都十分贪心,很不得将自己所有的优化关键词都放到首页title里面,以为这样就可以快速的实现排行。其实,百度早已明令严禁title关键词雕凿了,尤其作为一个新网站出现拼凑会大大降低百度对你网站的“偏见”,从此不在光临。
8、多方位智能提取快捷创作;基于强悍的智能脑部与文本素材库,可直接调阅并手动剖析出相关的智能段落,并智能提取文本核心词,摘要内容,智能标题,下拉智能叠词等。多方向创作剖析,给你快速输出文章的体验。
—————————————————————————————–
问:黑帽seo是哪些意思?
答:黑帽SEO是借助和放大搜索引擎的策略缺陷(实际上完美的系统是不存在的)获取更多用户访问量,而这种更多的访问量,是以伤害用户体验为代价的SEO行为。
问:网页标题与描述写多少字合适?
答:网站title标题搜索引擎在搜索结果中只能展示63个字节,后边都省略了;网页标题通常建议不超过32个汉字,描述Description不要超过72个汉字。
问:网站服务器空间买多大适宜?
答:根据网站规模和要提供的服务来决定选择订购何种空间(服务器),选择有实力的正规空间商,根据用户群分布选择接入商,保证用户的访问速率和稳定性。 查看全部
1、这要看新站还是老站,还要看哪些行业,其实评判正不正常应当从收录率的角度来看,一般网站收录率在70%以上,算正常,当使也可以再提高这个数字,通过改善页面质量。
2、网站收录之后如何上排行收录和排行并没有直接联系,收录指的是一个网站在搜索引擎数据库中存在的内容数目,数量才能代表的只是一个数字而已,不能证明任何东西,有些网站收录很高,排名太差,有些网站收录并不多,可是排行反倒挺好,如果想要以数目的优势来争取更好的排行,是太不现实的看法。
3、优化内容环境基于搜索引擎内容池来讲,当你的腹部内容源,大量的参杂着优质内容的时侯,实际上,低质量内容的生存空间是被严重打压的。
4、如何围绕用户需求写原创文章呢?命题-确定文章内容主题写文章就像写习作,首先就是命题,你要写哪些内容,主要想优化那个关键词。常用的就是你自己的问题、问答平台的问题、身边人的问题、客户的问题、同行的问题,这些都是用户的需求,这些问题关键词结合用户搜索习惯来组合关键词标题。
5、提高网站权重;有人说了,自己的文章有质量,也有数目,为什么收录还是上不去,收录速率还是这么慢,若是遇见这样的情况,要么就是新站没有权重,要么就是网站降权,多数情况下是因为新站没有权重引起的。
6、既然不能直接严禁抓取,那就干脆严禁百度蜘蛛等搜索引擎访问,思路是:判断user_agent,如果是百度蜘蛛、谷歌机器人等搜索引擎的user_agent,就返回403或则404,这样百度等搜索引擎都会觉得这个网站无法打开或则不存在,自然也就不会收录了。
7、网站优化过度;一直以来都发觉很多网站都十分贪心,很不得将自己所有的优化关键词都放到首页title里面,以为这样就可以快速的实现排行。其实,百度早已明令严禁title关键词雕凿了,尤其作为一个新网站出现拼凑会大大降低百度对你网站的“偏见”,从此不在光临。
8、多方位智能提取快捷创作;基于强悍的智能脑部与文本素材库,可直接调阅并手动剖析出相关的智能段落,并智能提取文本核心词,摘要内容,智能标题,下拉智能叠词等。多方向创作剖析,给你快速输出文章的体验。
—————————————————————————————–
问:黑帽seo是哪些意思?
答:黑帽SEO是借助和放大搜索引擎的策略缺陷(实际上完美的系统是不存在的)获取更多用户访问量,而这种更多的访问量,是以伤害用户体验为代价的SEO行为。
问:网页标题与描述写多少字合适?
答:网站title标题搜索引擎在搜索结果中只能展示63个字节,后边都省略了;网页标题通常建议不超过32个汉字,描述Description不要超过72个汉字。
问:网站服务器空间买多大适宜?
答:根据网站规模和要提供的服务来决定选择订购何种空间(服务器),选择有实力的正规空间商,根据用户群分布选择接入商,保证用户的访问速率和稳定性。
Python网路数据采集之处理自然语言|第07天
采集交流 • 优采云 发表了文章 • 0 个评论 • 389 次浏览 • 2020-08-10 18:02
Date:2018-04-01
Mark:《Python网路数据采集》
网络采集系列文章
Python网路数据采集之创建爬虫
Python网路数据采集之HTML解析
Python网路数据采集之开始采集
Python网路数据采集之使用API
Python网路数据采集之储存数据
Python网路数据采集之读取文件
Python网路数据采集之数据清洗
处理自然语言概括数据
在之前我们了解了怎样把文本内容分解成 n-gram 模型,或者说是n个词组宽度的句型。从最基本的功能上说,这个集合可以拿来确定这段文字中最常用的词组和句子。另外,还可以提取原文中这些最常用的句子周围的诗句,对原文进行看似合理的概括。
例如我们依照威廉 ·亨利 ·哈里森的就职演全文进行剖析。文章地址
from urllib.request import urlopen
from bs4 import BeautifulSoup
import re
import string
from collections import Counter
def cleanSentence(sentence):
sentence = sentence.split(' ')
sentence = [word.strip(string.punctuation+string.whitespace) for word in sentence]
sentence = [word for word in sentence if len(word) > 1 or (word.lower() == 'a' or word.lower() == 'I')]
return sentence
def cleanInput(content):
content = content.upper()
content = re.sub('\n', ' ', content)
content = bytes(content, 'UTF-8')
content = content.decode('ascii', 'ignore')
sentences = content.split('. ')
return [cleanSentence(sentence) for sentence in sentences]
def getNgramsFromSentence(content, n):
output = []
for i in range(len(content)-n+1):
output.append(content[i:i+n])
return output
def getNgrams(content, n):
content = cleanInput(content)
ngrams = Counter()
ngrams_list = []
for sentence in content:
newNgrams = [' '.join(ngram) for ngram in getNgramsFromSentence(sentence, n)]
ngrams_list.extend(newNgrams)
ngrams.update(newNgrams)
return(ngrams)
content = str(
urlopen('http://pythonscraping.com/files/inaugurationSpeech.txt').read(),
'utf-8')
ngrams = getNgrams(content, 3)
print(ngrams)
自然语言工具包
自然语言工具包(Natural Language Toolkit,NLTK)就是这样一个 Python库,用于辨识和标记日语文本中各个词的动词(parts of speech)。
安装与配置
NLTK网站()。安装软件比较简单,例如pip安装。
➜ psysh git:(master) pip install nltk
Collecting nltk
Using cached nltk-3.2.5.tar.gz
Requirement already satisfied: six in /usr/local/lib/python3.6/site-packages (from nltk)
Building wheels for collected packages: nltk
Running setup.py bdist_wheel for nltk ... done
Stored in directory: /Users/demo/Library/Caches/pip/wheels/18/9c/1f/276bc3f421614062468cb1c9d695e6086d0c73d67ea363c501
Successfully built nltk
Installing collected packages: nltk
Successfully installed nltk-3.2.5
You are using pip version 9.0.1, however version 9.0.3 is available.
You should consider upgrading via the 'pip install --upgrade pip' command.
检测一下就OK
➜ psysh git:(master) python
Python 3.6.4 (default, Mar 1 2018, 18:36:50)
[GCC 4.2.1 Compatible Apple LLVM 9.0.0 (clang-900.0.39.2)] on darwin
Type "help", "copyright", "credits" or "license" for more information.
>>> import nltk
>>>
输入nltk.download()就可以看见NLTK下载器。
NLTK下载器
默认下载全部的包,新手降低排除的相关的麻烦。
安装包
用NLTK做统计剖析
用NLTK做统计剖析通常是从Text对象开始的。Text对象可以通过下边的方式用简单的 Python字符串来创建:
from nltk import word_tokenize
from nltk import Text
tokens = word_tokenize("哈哈哈哈哈")
text = Text(tokens)
word_tokenize函数的参数可以是任何Python字符串。如果你手边没有任何长字符串,但是还想尝试一些功能,在NLTK库里早已外置了几本书,可以用import函数导出:
from nltk.book import *
统计文本中不重复的词组,然后与总词组数据进行比较:>>> len(text6)/len(words)。
今天内容比较少,消化比较困难。哈哈哈 查看全部
User:你好我是森林
Date:2018-04-01
Mark:《Python网路数据采集》
网络采集系列文章
Python网路数据采集之创建爬虫
Python网路数据采集之HTML解析
Python网路数据采集之开始采集
Python网路数据采集之使用API
Python网路数据采集之储存数据
Python网路数据采集之读取文件
Python网路数据采集之数据清洗
处理自然语言概括数据
在之前我们了解了怎样把文本内容分解成 n-gram 模型,或者说是n个词组宽度的句型。从最基本的功能上说,这个集合可以拿来确定这段文字中最常用的词组和句子。另外,还可以提取原文中这些最常用的句子周围的诗句,对原文进行看似合理的概括。
例如我们依照威廉 ·亨利 ·哈里森的就职演全文进行剖析。文章地址
from urllib.request import urlopen
from bs4 import BeautifulSoup
import re
import string
from collections import Counter
def cleanSentence(sentence):
sentence = sentence.split(' ')
sentence = [word.strip(string.punctuation+string.whitespace) for word in sentence]
sentence = [word for word in sentence if len(word) > 1 or (word.lower() == 'a' or word.lower() == 'I')]
return sentence
def cleanInput(content):
content = content.upper()
content = re.sub('\n', ' ', content)
content = bytes(content, 'UTF-8')
content = content.decode('ascii', 'ignore')
sentences = content.split('. ')
return [cleanSentence(sentence) for sentence in sentences]
def getNgramsFromSentence(content, n):
output = []
for i in range(len(content)-n+1):
output.append(content[i:i+n])
return output
def getNgrams(content, n):
content = cleanInput(content)
ngrams = Counter()
ngrams_list = []
for sentence in content:
newNgrams = [' '.join(ngram) for ngram in getNgramsFromSentence(sentence, n)]
ngrams_list.extend(newNgrams)
ngrams.update(newNgrams)
return(ngrams)
content = str(
urlopen('http://pythonscraping.com/files/inaugurationSpeech.txt').read(),
'utf-8')
ngrams = getNgrams(content, 3)
print(ngrams)
自然语言工具包
自然语言工具包(Natural Language Toolkit,NLTK)就是这样一个 Python库,用于辨识和标记日语文本中各个词的动词(parts of speech)。
安装与配置
NLTK网站()。安装软件比较简单,例如pip安装。
➜ psysh git:(master) pip install nltk
Collecting nltk
Using cached nltk-3.2.5.tar.gz
Requirement already satisfied: six in /usr/local/lib/python3.6/site-packages (from nltk)
Building wheels for collected packages: nltk
Running setup.py bdist_wheel for nltk ... done
Stored in directory: /Users/demo/Library/Caches/pip/wheels/18/9c/1f/276bc3f421614062468cb1c9d695e6086d0c73d67ea363c501
Successfully built nltk
Installing collected packages: nltk
Successfully installed nltk-3.2.5
You are using pip version 9.0.1, however version 9.0.3 is available.
You should consider upgrading via the 'pip install --upgrade pip' command.
检测一下就OK
➜ psysh git:(master) python
Python 3.6.4 (default, Mar 1 2018, 18:36:50)
[GCC 4.2.1 Compatible Apple LLVM 9.0.0 (clang-900.0.39.2)] on darwin
Type "help", "copyright", "credits" or "license" for more information.
>>> import nltk
>>>
输入nltk.download()就可以看见NLTK下载器。
NLTK下载器
默认下载全部的包,新手降低排除的相关的麻烦。
安装包
用NLTK做统计剖析
用NLTK做统计剖析通常是从Text对象开始的。Text对象可以通过下边的方式用简单的 Python字符串来创建:
from nltk import word_tokenize
from nltk import Text
tokens = word_tokenize("哈哈哈哈哈")
text = Text(tokens)
word_tokenize函数的参数可以是任何Python字符串。如果你手边没有任何长字符串,但是还想尝试一些功能,在NLTK库里早已外置了几本书,可以用import函数导出:
from nltk.book import *
统计文本中不重复的词组,然后与总词组数据进行比较:>>> len(text6)/len(words)。
今天内容比较少,消化比较困难。哈哈哈
“科研之友”常见问题
采集交流 • 优采云 发表了文章 • 0 个评论 • 395 次浏览 • 2020-08-09 14:28
在“科研之友”的登入页面上,您可以点击“忘记密码”链接 ,输入您在注册时所填的电子邮箱。系统将会手动把更改密码的链接发送到您的电子邮箱。
2.什么是“科研之友”的系统要求?
“科研之友”适用于以下最新版本浏览器的Windows或Mac操作系统:
Windows:Mozilla FirefoxInternet Explorer 11Google ChromeOpera
Mac:Mozilla FirefoxSafariGoogle ChromeOpera
为了更好的展示您的图形化智能简历、互动式个人主页,我们建议您将电脑显示器的帧率设置成1024x768或以上,把字体大小设置 成中等字体。
社区网路服务:1. 怎么设置我的隐私?
登录“科研之友”后,您可以在“我的科研 个人设置”功能下的“隐私设置”中设置隐私内容。公开您的成果、项目等个人信息,获得更多人查看,并有助于提升论文引用,获取更多基金申请机会推荐。
2. 接收者为什么没收到我发送的加为好友恳求?
对方没有回应您的好友恳求可能有以下缘由:
1.对方没有收到您通过“科研之友”发出的好友恳求,或标示为“垃圾邮件”。您可以尝试给对方“发送消息”,核对是否收到了添加好友恳求。
2.科研之友每周会发送短信通知对方处理仍未回应的恳求或约请。若对方处理了该恳求,您会收到科研之友发出的系统通知,请注意查看科研之友“消息中心”下的“系统消息”栏。
3.如果上述一直不能回答您的疑惑,请联系本系统的“在线咨询”,或者发电子邮件至我们的技术支持寻求帮助。
3. 如何退出群组?
如您想退出早已加入的群组,可在登陆系统后,进入“群组”功能选择该群组,然后点击右上角的“设置”链接,选择“退出群组”选项。
4. 什么是消息中心?
消息中心包括您与科研之友好友互发的站内邮件、科研之友用户申请加入您创建的群组恳求、给您发送的好友恳求、好友给您共享的文件/文献和系统消息。您可以通过访问消息中心查找与好友的交流记录,曾经收到的站内邮件和文件等重要资料。
跨文献库检索工具的安装和卸载:1. 什么是跨文献库检索工具?
跨文献库检索工具是依托“科研之友”平台,辅助科研工作者统一文献检索,跨库搜集科研成果的科技文献检索软件。利用跨文献库检索工具,。您可以使用跨文献库检索工具从各大文献库,如:中国知网、万方、SSCI、SCIE、ISTP、Scopus等,方便、准确、规范地搜集和导出自己或别人的中英文科研成果信息。列出目前支持的文献库类型。
2. 为什么须要安装跨文献库检索工具?是否每次检索都要安裝?
有效支持科研人员在知识产权法等相关法律的框架下便捷、准确、规范地搜集科研成果,需要一系列复杂的科技文献检索技术,这些技术远远超出了现今浏览器才能处理的能力,所以用户须要在自己笔记本上下载并安装跨文献库检索工具。该工具作为浏览器的插件,安全、可靠,请用户放心下载。
不是每次检索都须要安装跨文献库检索工具,如果有最新的跨文献库检索工具发布,系统会主动提示用户升级到最新版的跨文献库检索工具。请依照屏幕提示操作进行升级。
3.1 哪些浏览器支持安装跨文献库检索工具?
目前科研之友跨库检索插件仅支持:IE11,360浏览器
3.2 如何安装跨文献库检索工具(IE)?
(1)进入检索页面后,系统会主动提示用户安装跨文献库检索工具,请点击【确定】按钮开始安装跨文献库检索工具。
(2)点击安装检索插件按键。
(3)点击【运行】按钮运行跨文献库检索工具。
(4)如果您的网页浏览器的安全警告提示是否要运行跨文献库检索工具,请点击【运行】按钮继续安装。
(5)点击【下一步】按钮继续跨文献库检索工具安装进程。
(6)正在进行安装程序冲突检测,如有检查到程序冲突请依照提示关掉有关程序之后继续安装进程,若无程序冲突请点击【安装】按钮继续安装。
(7)点击【完成】按钮完成跨文献库检索工具的安装。
3.3 如何在360浏览器上使用跨文献库检索工具?
(1)进入检索页面后,系统会主动提示用户安装跨文献库检索工具,请点击【确定】按钮跳转到安装跨文献库检索工具页面。
(2)点击安装检索插件按键,跳转到360组件下载商店。
(3)点击安装IrisSearch。
(4)点击添加按键。
(5)IrisSearch添加完成后,就可以去检索页面检索了。
4. 如何卸载跨文献库检索工具?
卸载跨文献库检索工具,请点击“开始->控制面板->添加或删掉程序”,选择“跨文献库检索工具1.0.x.x”(后面的版本号可能因不同版本而不同),并点击“更改/删除”按钮卸载。
5. 如何升级跨文献库检索工具?
如果有最新的跨文献库检索工具发布,系统会主动提示用户升级到最新版的跨文献库检索工具。请依照屏幕提示操作进行升级。
6. 跨文献库检索工具系统需求和支持的浏览器有什么?
跨文献库检索工具目前兼容Win32各系列平台,包括Win2000、WinXP、Win2003、Vista及Windows7。跨文献库检索工具目前建议使用的浏览器有IE8(32位)、IE9(32位)、Firefox及Chrome。
7. 已经安装了检索工具,仍出现安装提示怎样办?
如果出现这情况,可能诱因如下:IE禁用了安装的插件。请在“工具->管理加载项->启用或禁用加载项”查看IrisOctopus Class的加载项是否被禁用。如果是, 请启用,然后关掉IE重新打开。
IE安全级别。请在设置IE浏览器的安全级别:在“工具->Internet选项->安全->自定义级别”查看“对标记为可安全执行脚本的ActiveX控件执行脚本”的选项,请选中“启用”选项。同时确保将“下载已签名的控件”设“启用”。(提示:跨文献库检索工具经过严格测试和并经过专业认证机构的签名,不会对您的系统导致影响。)
在打开“提示”执行ActiveX控件的情况下,浏览器可能会在加载控件的时侯有如下提示,选择“运行ActiveX控件”。
8. 系统难以安装跨文献库检索工具如何办?
主要有以下缘由:IE安全级别较高,请在“该区域安全级别”中将安全级别调到“中高”或中高以下级别。
安装成果检索工具时因为用户权限等诱因可能会出现以下情况:
请尝试以下解决办法:
1)在Windows 7 或Windows 8 操作系统下,请确认是使用管理员权限运行安装程序。
2)确保所有的浏览器都早已被关闭。待浏览器关掉后再重试安装。
3)下载安装程序并保存至本地后重启计算机。重启后不要打开浏览器,直接运行安装程序。
如仍未能安装成果检索工具,请联系我们的“在线咨询”,或者发电子邮件到系统技术支持。
跨文献库检索工具使用1. 检索速率太慢或则长时间没有响应,如何解决?
由于检索工具会实时联接各个文献库的在线检索系统进行集成检索,需要用户机的网路环境才能稳定访问选取的文献库。因此,检索速率会由本机网路速率以及选取的文献库当时的运行情况决定,如果速率比较慢,建议联系网路管理员或大学图书馆对网路联接情况、文献库运行情况进行复查,或稍候再重试。
2. 检索时,为何系统提示“您没有权限使用该数据库”?
您没有权限使用该数据库,可能是因为以下缘由:1)您所在的机构没有购买该数据库;2)您的机构已购买,但您的IP网关难以使用该数据库;3)所选数据库正在维护中,请稍候再试。如果您检索结果出现以上提示,代表您当前所在IP网关没有对应文献库的使用权限。目前科研之友系统提供检索的英语文献库,如:SCI,SSCI,ISTP,EI,都须要订购使用权限方能检索到结果,请确认贵校当前是否有订购。如贵校有订购,则可能是以上列举提示的后两种,建议您在贵校图书馆登陆成果在线进行检索;如贵校没有订购,建议在 购买了使用权限的单位进行检索或约请好友帮您检索成果并推荐给您;如果未能通过系统检索,您也可以通过手工录入的形式录入至系统中(我的成果——录入成果或文件导出)。
3. 检索时,为何系统提示“您所选数据库正在维护中”?
当文献库正处维护中时,即出现以下提示信息,请稍候再试。
4. 检索成果时,为何系统出现浏览器脚本错误,提示“指定资源下载失败”?
如果用户机器缺乏了系统必需的MSXML组件,系统在检索时提示“指定资源下载失败”错误(参见右图)。请点击Microsoft MSXML 6.0,进入Microsoft下载页面完成安装后,再重新步入系统使用检索工具检索成果。
5. 检索时,为何系统提示“操作超时,请点击此处重试”?
当文献库返回信息超时时,即出现以下提示信息。请依照指示点击“此处”重试。
6. 检索时,为何系统提示“您所选数据库返回结果异常”?
由于检索工具会实时联接各个文献库的在线检索系统进行集成检索,而其中部份文献库(如: SCI、SSCI、ISTP和EI等)是收费文献库,需要用户所在单位订购文献库的使用权。如果单位没有订购,或者用户登入系统的IP不在这种服务供应商所许可的IP段内,检索结果页面则会显示此提示信息,不能进行检索。若贵单位已够买了相应的文献库,请复查已输入的查询条件是否正确,若查询条件正确,但检索时系统仍提示“您所选数据库返回结果异常”,请联系本系统的“在线咨询”,或者发电子邮件到本系统技术支持。
7. 检索时,为何系统提示“查询异常,可能是服务器暂时未能联接”?
由于跨文献库检索工具会实时联接各个文献库的在线检索系统进行集成检索,各个文献库可能会某些查询返回查询失败等信息,检索工具会把对方文献库返回的出错信息原貌显示,以便用户按照其指引对查询关键字进行改进。您可以尝试重新输入查询条件,再次检索。
8. 如何检索SCI、SSCI、ISTP、EI,Scopus,万方文献库和中国期刊网之外的其它文献库?
目前支持SCI,SSCI,ISTP,EI,Scopus,万方文献库和中国刊物网,对其他文献库的支持,比如ScienceDirect,IEEE Xplore,维普资讯等正在逐渐降低中。 查看全部
“科研之友”常见问题通常问题:社区网路服务:跨文献库检索工具的安装和卸载跨文献库检索工具使用其 他通常问题:1.如何寻回登陆密码?
在“科研之友”的登入页面上,您可以点击“忘记密码”链接 ,输入您在注册时所填的电子邮箱。系统将会手动把更改密码的链接发送到您的电子邮箱。
2.什么是“科研之友”的系统要求?
“科研之友”适用于以下最新版本浏览器的Windows或Mac操作系统:
Windows:Mozilla FirefoxInternet Explorer 11Google ChromeOpera
Mac:Mozilla FirefoxSafariGoogle ChromeOpera
为了更好的展示您的图形化智能简历、互动式个人主页,我们建议您将电脑显示器的帧率设置成1024x768或以上,把字体大小设置 成中等字体。
社区网路服务:1. 怎么设置我的隐私?
登录“科研之友”后,您可以在“我的科研 个人设置”功能下的“隐私设置”中设置隐私内容。公开您的成果、项目等个人信息,获得更多人查看,并有助于提升论文引用,获取更多基金申请机会推荐。
2. 接收者为什么没收到我发送的加为好友恳求?
对方没有回应您的好友恳求可能有以下缘由:
1.对方没有收到您通过“科研之友”发出的好友恳求,或标示为“垃圾邮件”。您可以尝试给对方“发送消息”,核对是否收到了添加好友恳求。
2.科研之友每周会发送短信通知对方处理仍未回应的恳求或约请。若对方处理了该恳求,您会收到科研之友发出的系统通知,请注意查看科研之友“消息中心”下的“系统消息”栏。
3.如果上述一直不能回答您的疑惑,请联系本系统的“在线咨询”,或者发电子邮件至我们的技术支持寻求帮助。
3. 如何退出群组?
如您想退出早已加入的群组,可在登陆系统后,进入“群组”功能选择该群组,然后点击右上角的“设置”链接,选择“退出群组”选项。
4. 什么是消息中心?
消息中心包括您与科研之友好友互发的站内邮件、科研之友用户申请加入您创建的群组恳求、给您发送的好友恳求、好友给您共享的文件/文献和系统消息。您可以通过访问消息中心查找与好友的交流记录,曾经收到的站内邮件和文件等重要资料。
跨文献库检索工具的安装和卸载:1. 什么是跨文献库检索工具?
跨文献库检索工具是依托“科研之友”平台,辅助科研工作者统一文献检索,跨库搜集科研成果的科技文献检索软件。利用跨文献库检索工具,。您可以使用跨文献库检索工具从各大文献库,如:中国知网、万方、SSCI、SCIE、ISTP、Scopus等,方便、准确、规范地搜集和导出自己或别人的中英文科研成果信息。列出目前支持的文献库类型。
2. 为什么须要安装跨文献库检索工具?是否每次检索都要安裝?
有效支持科研人员在知识产权法等相关法律的框架下便捷、准确、规范地搜集科研成果,需要一系列复杂的科技文献检索技术,这些技术远远超出了现今浏览器才能处理的能力,所以用户须要在自己笔记本上下载并安装跨文献库检索工具。该工具作为浏览器的插件,安全、可靠,请用户放心下载。
不是每次检索都须要安装跨文献库检索工具,如果有最新的跨文献库检索工具发布,系统会主动提示用户升级到最新版的跨文献库检索工具。请依照屏幕提示操作进行升级。
3.1 哪些浏览器支持安装跨文献库检索工具?
目前科研之友跨库检索插件仅支持:IE11,360浏览器
3.2 如何安装跨文献库检索工具(IE)?
(1)进入检索页面后,系统会主动提示用户安装跨文献库检索工具,请点击【确定】按钮开始安装跨文献库检索工具。
(2)点击安装检索插件按键。
(3)点击【运行】按钮运行跨文献库检索工具。
(4)如果您的网页浏览器的安全警告提示是否要运行跨文献库检索工具,请点击【运行】按钮继续安装。
(5)点击【下一步】按钮继续跨文献库检索工具安装进程。
(6)正在进行安装程序冲突检测,如有检查到程序冲突请依照提示关掉有关程序之后继续安装进程,若无程序冲突请点击【安装】按钮继续安装。
(7)点击【完成】按钮完成跨文献库检索工具的安装。
3.3 如何在360浏览器上使用跨文献库检索工具?
(1)进入检索页面后,系统会主动提示用户安装跨文献库检索工具,请点击【确定】按钮跳转到安装跨文献库检索工具页面。
(2)点击安装检索插件按键,跳转到360组件下载商店。
(3)点击安装IrisSearch。
(4)点击添加按键。
(5)IrisSearch添加完成后,就可以去检索页面检索了。
4. 如何卸载跨文献库检索工具?
卸载跨文献库检索工具,请点击“开始->控制面板->添加或删掉程序”,选择“跨文献库检索工具1.0.x.x”(后面的版本号可能因不同版本而不同),并点击“更改/删除”按钮卸载。
5. 如何升级跨文献库检索工具?
如果有最新的跨文献库检索工具发布,系统会主动提示用户升级到最新版的跨文献库检索工具。请依照屏幕提示操作进行升级。
6. 跨文献库检索工具系统需求和支持的浏览器有什么?
跨文献库检索工具目前兼容Win32各系列平台,包括Win2000、WinXP、Win2003、Vista及Windows7。跨文献库检索工具目前建议使用的浏览器有IE8(32位)、IE9(32位)、Firefox及Chrome。
7. 已经安装了检索工具,仍出现安装提示怎样办?
如果出现这情况,可能诱因如下:IE禁用了安装的插件。请在“工具->管理加载项->启用或禁用加载项”查看IrisOctopus Class的加载项是否被禁用。如果是, 请启用,然后关掉IE重新打开。
IE安全级别。请在设置IE浏览器的安全级别:在“工具->Internet选项->安全->自定义级别”查看“对标记为可安全执行脚本的ActiveX控件执行脚本”的选项,请选中“启用”选项。同时确保将“下载已签名的控件”设“启用”。(提示:跨文献库检索工具经过严格测试和并经过专业认证机构的签名,不会对您的系统导致影响。)
在打开“提示”执行ActiveX控件的情况下,浏览器可能会在加载控件的时侯有如下提示,选择“运行ActiveX控件”。
8. 系统难以安装跨文献库检索工具如何办?
主要有以下缘由:IE安全级别较高,请在“该区域安全级别”中将安全级别调到“中高”或中高以下级别。
安装成果检索工具时因为用户权限等诱因可能会出现以下情况:
请尝试以下解决办法:
1)在Windows 7 或Windows 8 操作系统下,请确认是使用管理员权限运行安装程序。
2)确保所有的浏览器都早已被关闭。待浏览器关掉后再重试安装。
3)下载安装程序并保存至本地后重启计算机。重启后不要打开浏览器,直接运行安装程序。
如仍未能安装成果检索工具,请联系我们的“在线咨询”,或者发电子邮件到系统技术支持。
跨文献库检索工具使用1. 检索速率太慢或则长时间没有响应,如何解决?
由于检索工具会实时联接各个文献库的在线检索系统进行集成检索,需要用户机的网路环境才能稳定访问选取的文献库。因此,检索速率会由本机网路速率以及选取的文献库当时的运行情况决定,如果速率比较慢,建议联系网路管理员或大学图书馆对网路联接情况、文献库运行情况进行复查,或稍候再重试。
2. 检索时,为何系统提示“您没有权限使用该数据库”?
您没有权限使用该数据库,可能是因为以下缘由:1)您所在的机构没有购买该数据库;2)您的机构已购买,但您的IP网关难以使用该数据库;3)所选数据库正在维护中,请稍候再试。如果您检索结果出现以上提示,代表您当前所在IP网关没有对应文献库的使用权限。目前科研之友系统提供检索的英语文献库,如:SCI,SSCI,ISTP,EI,都须要订购使用权限方能检索到结果,请确认贵校当前是否有订购。如贵校有订购,则可能是以上列举提示的后两种,建议您在贵校图书馆登陆成果在线进行检索;如贵校没有订购,建议在 购买了使用权限的单位进行检索或约请好友帮您检索成果并推荐给您;如果未能通过系统检索,您也可以通过手工录入的形式录入至系统中(我的成果——录入成果或文件导出)。
3. 检索时,为何系统提示“您所选数据库正在维护中”?
当文献库正处维护中时,即出现以下提示信息,请稍候再试。
4. 检索成果时,为何系统出现浏览器脚本错误,提示“指定资源下载失败”?
如果用户机器缺乏了系统必需的MSXML组件,系统在检索时提示“指定资源下载失败”错误(参见右图)。请点击Microsoft MSXML 6.0,进入Microsoft下载页面完成安装后,再重新步入系统使用检索工具检索成果。
5. 检索时,为何系统提示“操作超时,请点击此处重试”?
当文献库返回信息超时时,即出现以下提示信息。请依照指示点击“此处”重试。
6. 检索时,为何系统提示“您所选数据库返回结果异常”?
由于检索工具会实时联接各个文献库的在线检索系统进行集成检索,而其中部份文献库(如: SCI、SSCI、ISTP和EI等)是收费文献库,需要用户所在单位订购文献库的使用权。如果单位没有订购,或者用户登入系统的IP不在这种服务供应商所许可的IP段内,检索结果页面则会显示此提示信息,不能进行检索。若贵单位已够买了相应的文献库,请复查已输入的查询条件是否正确,若查询条件正确,但检索时系统仍提示“您所选数据库返回结果异常”,请联系本系统的“在线咨询”,或者发电子邮件到本系统技术支持。
7. 检索时,为何系统提示“查询异常,可能是服务器暂时未能联接”?
由于跨文献库检索工具会实时联接各个文献库的在线检索系统进行集成检索,各个文献库可能会某些查询返回查询失败等信息,检索工具会把对方文献库返回的出错信息原貌显示,以便用户按照其指引对查询关键字进行改进。您可以尝试重新输入查询条件,再次检索。
8. 如何检索SCI、SSCI、ISTP、EI,Scopus,万方文献库和中国期刊网之外的其它文献库?
目前支持SCI,SSCI,ISTP,EI,Scopus,万方文献库和中国刊物网,对其他文献库的支持,比如ScienceDirect,IEEE Xplore,维普资讯等正在逐渐降低中。
放慢你的阅读 三款免费稍后阅读工具对比(全文)
采集交流 • 优采云 发表了文章 • 0 个评论 • 278 次浏览 • 2020-08-09 10:40
三款免费离线阅读工具对比
前面关于整合阅读类工具的推荐早已有过,于是明天我们来说说“Read it Later”,也就是“稍后阅读”或者直接叫“离线阅读”这样的工具;
它们顺应这样一种使用场景,当我们每晚在工作中或则繁忙其他事情,偶尔发觉浩大的SNS平台分享过来的某篇精彩长文却没时间研读,这样我们就须要把它们统一搜集上去以备“稍后阅读”。
采集文章的各类场景(图片来自搜狐随身看官方网页)
对比项
所以题外话开始,就我们在iOS当中所能看到的比较主流的三款“稍后阅读”工具:Pocket(以前的Read It Later)、Readability和新近出现的国产应用搜狐随身看,做个比较;出于节省的本意,并未选择收费的Instapaper。测试平台为新iPad,但是有一点不公,搜狐随身看仅有iPhone版本,而且iPhone版的排版并是很不适宜在iPad里面阅读,考虑到它是个新鲜的国产应用还是把它放进对比当中,跟流行已久的RIL以及Readability作一比较。
“稍后阅读”工具使用方式
首先来了解一下“稍后阅读”工具的使用方式,三款应用大致相同,均为给浏览器添加采集夹或则插件,因此当我们在浏览网页的时侯见到哪些好看的文章,只须要点击那种采集过的按键才能够激活一段javascript脚本因而将当前网页信息抓取到各家的服务器里。
使用方法
当我们闲下来有了时间,想要在iPad或则iPhone或则Android手机平板里面获取采集过的文章来细细阅读的话,打开客户端会手动同步出早已采集过的文章列表,并且开始手动下载文章内容;
我们为何喜欢“稍后阅读”
而且,之所以我们喜欢这类工具,不可是由于采集功能,还由于她们能否手动过滤掉原网页的好多广告或则动漫信息等无关紧要的内容,只留下大段纯文字,创造十分清新的阅读环境。
网页经过过滤后的清新版式
你该看中“稍后阅读”的哪些
既然使用方式上并无差别,于是文章同步时间、跨平台性、无关阅读内容的过滤能力成了我们衡量一个“稍后阅读”工具是否给力的标准。
你该看中“稍后阅读”的哪些
对比前的内容采集与对比思路
对比开始之前,我们在网上摘选了来自“ifanr、手机中国科技博客”这样的博客网站各两篇图文文章,来自“ZOL手机频道”的两篇常规应用文章,和来自于“豆瓣的日记文章”三篇;都是以文字内容阅读为主,博客和日记类网站也是我们常常采摘阅读内容的地方。
折戟的“文章同步时间对比”
对比开始之时,我们想要拿文章的同步时间(也就是说在iPad里面打开客户端,多久以后才能将刚刚搜集的文章列表加载到客户端中,以备我们选择阅读)作为当头炮来比较,但是情况太不豁达。
搜狐随身看同步时间
Readability同步时间
Pocket同步时间
由于美国两家Pocket和Readability其实并没有国外服务器,因此这两个应用同步上去的过程十分熬煎,Pocket第一次打开根本没有反应,直到第二次才勉强加载出,部分文章导读图还有缺位、Readability其实13.5秒的时间同步了一些,但是并不完整,9篇文章只有两篇同步过来;搜狐随身看这儿占了地利,基本是秒开。
高下立见的文章列表版面对比
既然同步时间里面受了阻碍,我们还是来重点说一下阅读体验方面;首先是文章列表的版式设计,在这里不得不夸一下改版后的Pocket(在它仍叫Read It Later的时代并不是这样外形),如果你是个相貌党,肯定会偏爱Pocket带给你的界面——像Flipboard那样的设计,用图片来突出整篇文章。
Pocket默认的窗棂外形
所有文章被提取了国图放在Pocket的首页里面,看起来非常凉爽,虽然有的排版并不是很严格和美观,但是也值得一看;不过若果文章数目过多,Pocket也提供了列表的方式来诠释更多内容。
Pocket另外一种列表模式
Readability优雅的列表外形
搜狐随身看文章列表
至于另外两个Readability与搜狐随身看,就只是比较乏味的列表方式了;而且就设计来看加拿大的两个基本可以秒杀国外的了,当然不排除搜狐随身看是个iPhone版本的缘由,如果推出iPad版才能美化一下加入更多内容的话就会好些。
无论是列表还是Pocket那样的窗棂,三款工具都支持在列表内的文章中滑动它进行操作,比如勾选“已读”“删除”等标签,来及时的整理你的列表。
本质考验:离线文章呈现疗效比较
真正考验三款工具的时侯到了,下面是我们最关心、也是使用最多的地方——离线文章的显示疗效。由于Readability一直没有同步出刚刚剩下的七篇文章,因此我们只能拿类似的先前的文章作为对比,不过也没关系,因为她们都来自豆瓣的笔记,网页内容和框架基本相同。 查看全部
当互联网时代的信息象潮水般涌来的时侯,现代人是真的有点儿招架不住了;我们每晚面对被分好类的新闻、科技、社会、体育、文化的等各种信息资源,同时她们又分化成图文、视频或则音频播客的不同方式灌输到我们的世界中;如何及时的筛选和消化,又怎么合理的安排时间去处理和接收那些内容,整合阅读和离线阅读两大类工具就是为这样的需求、或者说现实状况而设计的。
三款免费离线阅读工具对比
前面关于整合阅读类工具的推荐早已有过,于是明天我们来说说“Read it Later”,也就是“稍后阅读”或者直接叫“离线阅读”这样的工具;
它们顺应这样一种使用场景,当我们每晚在工作中或则繁忙其他事情,偶尔发觉浩大的SNS平台分享过来的某篇精彩长文却没时间研读,这样我们就须要把它们统一搜集上去以备“稍后阅读”。
采集文章的各类场景(图片来自搜狐随身看官方网页)
对比项
所以题外话开始,就我们在iOS当中所能看到的比较主流的三款“稍后阅读”工具:Pocket(以前的Read It Later)、Readability和新近出现的国产应用搜狐随身看,做个比较;出于节省的本意,并未选择收费的Instapaper。测试平台为新iPad,但是有一点不公,搜狐随身看仅有iPhone版本,而且iPhone版的排版并是很不适宜在iPad里面阅读,考虑到它是个新鲜的国产应用还是把它放进对比当中,跟流行已久的RIL以及Readability作一比较。
“稍后阅读”工具使用方式
首先来了解一下“稍后阅读”工具的使用方式,三款应用大致相同,均为给浏览器添加采集夹或则插件,因此当我们在浏览网页的时侯见到哪些好看的文章,只须要点击那种采集过的按键才能够激活一段javascript脚本因而将当前网页信息抓取到各家的服务器里。
使用方法
当我们闲下来有了时间,想要在iPad或则iPhone或则Android手机平板里面获取采集过的文章来细细阅读的话,打开客户端会手动同步出早已采集过的文章列表,并且开始手动下载文章内容;
我们为何喜欢“稍后阅读”
而且,之所以我们喜欢这类工具,不可是由于采集功能,还由于她们能否手动过滤掉原网页的好多广告或则动漫信息等无关紧要的内容,只留下大段纯文字,创造十分清新的阅读环境。
网页经过过滤后的清新版式
你该看中“稍后阅读”的哪些
既然使用方式上并无差别,于是文章同步时间、跨平台性、无关阅读内容的过滤能力成了我们衡量一个“稍后阅读”工具是否给力的标准。
你该看中“稍后阅读”的哪些
对比前的内容采集与对比思路
对比开始之前,我们在网上摘选了来自“ifanr、手机中国科技博客”这样的博客网站各两篇图文文章,来自“ZOL手机频道”的两篇常规应用文章,和来自于“豆瓣的日记文章”三篇;都是以文字内容阅读为主,博客和日记类网站也是我们常常采摘阅读内容的地方。
折戟的“文章同步时间对比”
对比开始之时,我们想要拿文章的同步时间(也就是说在iPad里面打开客户端,多久以后才能将刚刚搜集的文章列表加载到客户端中,以备我们选择阅读)作为当头炮来比较,但是情况太不豁达。
搜狐随身看同步时间
Readability同步时间
Pocket同步时间
由于美国两家Pocket和Readability其实并没有国外服务器,因此这两个应用同步上去的过程十分熬煎,Pocket第一次打开根本没有反应,直到第二次才勉强加载出,部分文章导读图还有缺位、Readability其实13.5秒的时间同步了一些,但是并不完整,9篇文章只有两篇同步过来;搜狐随身看这儿占了地利,基本是秒开。
高下立见的文章列表版面对比
既然同步时间里面受了阻碍,我们还是来重点说一下阅读体验方面;首先是文章列表的版式设计,在这里不得不夸一下改版后的Pocket(在它仍叫Read It Later的时代并不是这样外形),如果你是个相貌党,肯定会偏爱Pocket带给你的界面——像Flipboard那样的设计,用图片来突出整篇文章。
Pocket默认的窗棂外形
所有文章被提取了国图放在Pocket的首页里面,看起来非常凉爽,虽然有的排版并不是很严格和美观,但是也值得一看;不过若果文章数目过多,Pocket也提供了列表的方式来诠释更多内容。
Pocket另外一种列表模式
Readability优雅的列表外形
搜狐随身看文章列表
至于另外两个Readability与搜狐随身看,就只是比较乏味的列表方式了;而且就设计来看加拿大的两个基本可以秒杀国外的了,当然不排除搜狐随身看是个iPhone版本的缘由,如果推出iPad版才能美化一下加入更多内容的话就会好些。
无论是列表还是Pocket那样的窗棂,三款工具都支持在列表内的文章中滑动它进行操作,比如勾选“已读”“删除”等标签,来及时的整理你的列表。
本质考验:离线文章呈现疗效比较
真正考验三款工具的时侯到了,下面是我们最关心、也是使用最多的地方——离线文章的显示疗效。由于Readability一直没有同步出刚刚剩下的七篇文章,因此我们只能拿类似的先前的文章作为对比,不过也没关系,因为她们都来自豆瓣的笔记,网页内容和框架基本相同。
6大SEO新型站长工具(排名优化必备)
采集交流 • 优采云 发表了文章 • 0 个评论 • 273 次浏览 • 2020-08-09 10:26
1、站长工具
站长工具使用最多的,比较权威的就是站长工具、爱站工具和5118站长工具等三大平台,但是因为每位站长工具对于排行更新,或者是缓存更新和权重词库更新的不同,许多seo站长都是互相配合使用。站长工具对于关键词库的更新通常都是三天,而爱站工具则是1-3天,而且自带更新缓存工具,所以对于词库这块的更新还是比较快的。
目前5118站长平台则是比较受站长们喜欢的,因为词库每晚还会更新,而且还可以进行长尾关键词的挖掘和监控各大网站数据。但是对于网站权重这块,三款seo站长工具都是有不同的规则进行估算的,所以权重也是不同的,可能站长工具权重是2,但是爱站权重是0,5118权重是1,这是正常的现象,只要关键词排行是真实的,对于搜索引擎来将,网站的质量也是十分高的。
2、友链交换工具
友链交换工具是近两年新盛行的,主要是拿来解决seo站长们在线交换行业友链等服务的,传统交换友链的方式都是通过qq友链交换群进行人工发布,人工在线交换,效率比较慢,而且每位群的友情链接行业都是不同的,无法直接交换到精准行业的友情链接,这也对seo工作的效率影响了好多,毕竟友情链接直接影响网站的权重。所以,友链交换工具就上线了,可以精准的匹配权重、收录、行业等精准的友链,而且还可以在工具内实时监控友链交换情况,也可以第一时间了解网站友链是否被下链。
目前友情链接交换工具有很多,但是比较著名的也是各个seo站长常用的就是爱链工具和换链利器,这两款是市场上最火的,也是流量最多的两款友链交换工具,在这上面添加好网站后,一般每晚还会有人申请交换,正常来讲完全解决了友情链接交换的数目和次数,因为这是不固定的,主要看站长想要交换多少条,就可以交换多少条,再也不用害怕友情链接交换不到或则人工花费大量时间去交换友链的问题了。
3、域名剖析工具
域名剖析工具是伴随着老域名的盛行所开发的剖析老域名的工具,老域名剖析工具可以在线剖析域名的质量、外链、历史记录等等,完全解决了站长构建新站初,担心域名质量的优劣,是否做过红色等情况。老域名剖析工具还可以依照搜索引擎算法,进行剖析网站标题撰写是否符合搜索引擎规则,这样就解决了seo站长们对于三大标签或则栏目标题、内容标题未能合理分配权重的问题了。常用的老域名剖析工具就是114网站查询和橘子seo老域名工具,这两款早已完全符合站长们对于域名质量剖析的需求,所以还没有使用过的站长可以去了解了,不然都会被别的站长所超越。
4、文章原创度测量工具
文章原创度测量工具主要是测量seo站长们在撰写网站文章的时侯,可以借助这类工具进行测量文章的质量是否符合搜索引擎的收录,这样也就解决了文章质量的疑虑,同时也防止了由于文章内容的质量不够,造成网站被搜索引擎惩罚的危险。
5、采集伪原创工具
采集和伪原创工具特别多,这也是由于目前seo市场对于内容量的需求所盛行的工具,很多站长由于自己写文章每天写不了几篇,但是网站每天更新的 文章不多,对于收录这块就比较漫长,而且蜘蛛量也降低的不多,完全影响到了一个网站的优化时长。所以,很多seo站长纷纷使用伪原创工具或则采集工具进行大量的采集,每天更新的文章量甚至可以达到成百上千篇也是没问题的,这也就可以快速的降低网站的收录,快速的提高网站的质量和排行。
伪原创工具常用的是网上的奶盘伪原创工具,而采集工具你们常用的则是优采云采集,因为优采云采集工具适用于各类程序的网站,还可以定时采集定时发布以及全手动采集发布等,完全满足了网站对于内容的需求,只不过现今的搜索引擎严重严打伪原创和采集,所以站长们要注意了,如果想要采集,一定要做好文章采集的质量把控,不然很容易被搜索引擎所惩罚。
6、老域名挖掘工具
上面给你们讲了老域名剖析工具,下面就给你们介绍老域名挖掘的工具,这也是好多seo站长急切想要晓得的,因为老域名对于优化这块的益处实在数不胜数,不仅对于关键词排名优化的速率比较快,而且还可以在短时间内使网站的收录达到成千上万,因为老域名所以自身是带外链和搜索引擎信任度的,所以seo站长们纷纷在群里问关于老域名挖掘的工具都有什么。
老域名挖掘工具不仅里面介绍的橘子seo老域名工具上面有自带销售老域名的商城,但是由于查看老域名所须要的积分好多,价格也太贵,也不一定就能保证老域名是否被注册或则质量好不好。所以,大家就可以使用站长之家工具内的过期域名查询,这是每晚过期的老域名,平均每晚都有数十万个不止,足够满足你们对于老域名的需求量了。但是对于每位老域名的剖析还是须要利用前面所介绍的老域名剖析工具,一定要防止被使用红色的或则早已被墙的老域名,争取剖析优质的老域名,用来构建网站。
关于6大seo新型站长工具就给你们介绍到这儿了,已经算是比较齐全的了,当然seo工具还有好多,比如光年日志分析工具、百度统计剖析平台、百度站长平台等等,都可以合理使用提高seo排名和剖析网站优化情况的不足。如果还想了解更多seo工具或则seo优化问题,可以随时关注谢盼龙博客,这里有你意想不到的知识。 查看全部
作为seo站长若果在优化关键词排行的时侯不学会借助seo工具降低工作量,提示工作的效率,那么这个seo站长是十分不合格的。在seo行业好多网站做的好站长都是在借助各大seo工具提高排行,今天,谢盼龙就给你们介绍6大seo站长必备的工具,希望还能帮助到诸位站长们。
1、站长工具
站长工具使用最多的,比较权威的就是站长工具、爱站工具和5118站长工具等三大平台,但是因为每位站长工具对于排行更新,或者是缓存更新和权重词库更新的不同,许多seo站长都是互相配合使用。站长工具对于关键词库的更新通常都是三天,而爱站工具则是1-3天,而且自带更新缓存工具,所以对于词库这块的更新还是比较快的。
目前5118站长平台则是比较受站长们喜欢的,因为词库每晚还会更新,而且还可以进行长尾关键词的挖掘和监控各大网站数据。但是对于网站权重这块,三款seo站长工具都是有不同的规则进行估算的,所以权重也是不同的,可能站长工具权重是2,但是爱站权重是0,5118权重是1,这是正常的现象,只要关键词排行是真实的,对于搜索引擎来将,网站的质量也是十分高的。
2、友链交换工具
友链交换工具是近两年新盛行的,主要是拿来解决seo站长们在线交换行业友链等服务的,传统交换友链的方式都是通过qq友链交换群进行人工发布,人工在线交换,效率比较慢,而且每位群的友情链接行业都是不同的,无法直接交换到精准行业的友情链接,这也对seo工作的效率影响了好多,毕竟友情链接直接影响网站的权重。所以,友链交换工具就上线了,可以精准的匹配权重、收录、行业等精准的友链,而且还可以在工具内实时监控友链交换情况,也可以第一时间了解网站友链是否被下链。
目前友情链接交换工具有很多,但是比较著名的也是各个seo站长常用的就是爱链工具和换链利器,这两款是市场上最火的,也是流量最多的两款友链交换工具,在这上面添加好网站后,一般每晚还会有人申请交换,正常来讲完全解决了友情链接交换的数目和次数,因为这是不固定的,主要看站长想要交换多少条,就可以交换多少条,再也不用害怕友情链接交换不到或则人工花费大量时间去交换友链的问题了。
3、域名剖析工具
域名剖析工具是伴随着老域名的盛行所开发的剖析老域名的工具,老域名剖析工具可以在线剖析域名的质量、外链、历史记录等等,完全解决了站长构建新站初,担心域名质量的优劣,是否做过红色等情况。老域名剖析工具还可以依照搜索引擎算法,进行剖析网站标题撰写是否符合搜索引擎规则,这样就解决了seo站长们对于三大标签或则栏目标题、内容标题未能合理分配权重的问题了。常用的老域名剖析工具就是114网站查询和橘子seo老域名工具,这两款早已完全符合站长们对于域名质量剖析的需求,所以还没有使用过的站长可以去了解了,不然都会被别的站长所超越。
4、文章原创度测量工具
文章原创度测量工具主要是测量seo站长们在撰写网站文章的时侯,可以借助这类工具进行测量文章的质量是否符合搜索引擎的收录,这样也就解决了文章质量的疑虑,同时也防止了由于文章内容的质量不够,造成网站被搜索引擎惩罚的危险。
5、采集伪原创工具
采集和伪原创工具特别多,这也是由于目前seo市场对于内容量的需求所盛行的工具,很多站长由于自己写文章每天写不了几篇,但是网站每天更新的 文章不多,对于收录这块就比较漫长,而且蜘蛛量也降低的不多,完全影响到了一个网站的优化时长。所以,很多seo站长纷纷使用伪原创工具或则采集工具进行大量的采集,每天更新的文章量甚至可以达到成百上千篇也是没问题的,这也就可以快速的降低网站的收录,快速的提高网站的质量和排行。
伪原创工具常用的是网上的奶盘伪原创工具,而采集工具你们常用的则是优采云采集,因为优采云采集工具适用于各类程序的网站,还可以定时采集定时发布以及全手动采集发布等,完全满足了网站对于内容的需求,只不过现今的搜索引擎严重严打伪原创和采集,所以站长们要注意了,如果想要采集,一定要做好文章采集的质量把控,不然很容易被搜索引擎所惩罚。
6、老域名挖掘工具
上面给你们讲了老域名剖析工具,下面就给你们介绍老域名挖掘的工具,这也是好多seo站长急切想要晓得的,因为老域名对于优化这块的益处实在数不胜数,不仅对于关键词排名优化的速率比较快,而且还可以在短时间内使网站的收录达到成千上万,因为老域名所以自身是带外链和搜索引擎信任度的,所以seo站长们纷纷在群里问关于老域名挖掘的工具都有什么。
老域名挖掘工具不仅里面介绍的橘子seo老域名工具上面有自带销售老域名的商城,但是由于查看老域名所须要的积分好多,价格也太贵,也不一定就能保证老域名是否被注册或则质量好不好。所以,大家就可以使用站长之家工具内的过期域名查询,这是每晚过期的老域名,平均每晚都有数十万个不止,足够满足你们对于老域名的需求量了。但是对于每位老域名的剖析还是须要利用前面所介绍的老域名剖析工具,一定要防止被使用红色的或则早已被墙的老域名,争取剖析优质的老域名,用来构建网站。
关于6大seo新型站长工具就给你们介绍到这儿了,已经算是比较齐全的了,当然seo工具还有好多,比如光年日志分析工具、百度统计剖析平台、百度站长平台等等,都可以合理使用提高seo排名和剖析网站优化情况的不足。如果还想了解更多seo工具或则seo优化问题,可以随时关注谢盼龙博客,这里有你意想不到的知识。
爱站SEO工具包怎样使用
采集交流 • 优采云 发表了文章 • 0 个评论 • 199 次浏览 • 2020-08-09 08:26
使用方式:
一、采集文章:石青伪原创工具,自带采集工具。首先,你须要在"采集设置"模块中录入须要采集的关键词。录入完成后,点击"保存关键词",该词汇就被保存出来,然后勾选它(默认是勾选的)。再选择是在百度还是google中采集。如果你是免费试用用户。就只能采用第一个"免费测试采集"。
点击"内容采集",稍等一会,数据会渐渐采集进来,采集到的数据都显示在"网络原创文章专家"界面。如果要停止采集,请回到"采集设置"界面,再点击"停止采集"。使用"采集文章并搅乱生成文章"功能,可以根据选取生成数目,动态生成无数多篇文章。
二、制作伪原创文章:用户可以有4种方式录入原创文章,1、把文章直接拷贝到文章编辑市,然后录入标题,再保存文章;2、通过导出的方法,可以直接导出TXT或html文档,3、通过采集的形式,直接采集到互联网上的文章,4、通过插口直接取得自己CMS网站的内容;
在取得了文章后,用户可以有3种形式制做伪原创文章:1、也是最简单的,直接点击文章标题,然后点击界面上部的"生成原创"按钮,伪原创后的文章就显露在"伪原创文章预览市"了;2、采用导入方法,直接可以把所有勾选的文章批量导入到TXT或HTML 文章中;3、通过插口,直接批量伪原创到自己的CMS网站中。下图是导入方法,在采用导入方法的时侯,系统将会根据设置的伪原创配置来伪原创勾选了的,文章然后导入;
三、使用直接更新主流CMS系统:石青伪原创工具,支持直接更新动易,老丫,新云,dedeCMS等99%的国外主流CMS内容,通过插口直接取得站点上的信息,然后伪原创后上传回来。具体使用方式,使用界面有详尽说明。按照说明一步一步的说很快就可以成功。 查看全部
石青伪原创工具具是拿来处理非原创的一款seo工具,用来帮助我们处理一些非原创文件,使文章让搜索引擎爬虫看起来象原创文章。软件支持英文和法文伪原创。 是一款专业且免费的伪原创文章生成器,其专门针对百度和google的爬虫习惯以及动词算法而开发,通过本软件优化的文章,将更受搜索引擎所追捧。
使用方式:
一、采集文章:石青伪原创工具,自带采集工具。首先,你须要在"采集设置"模块中录入须要采集的关键词。录入完成后,点击"保存关键词",该词汇就被保存出来,然后勾选它(默认是勾选的)。再选择是在百度还是google中采集。如果你是免费试用用户。就只能采用第一个"免费测试采集"。
点击"内容采集",稍等一会,数据会渐渐采集进来,采集到的数据都显示在"网络原创文章专家"界面。如果要停止采集,请回到"采集设置"界面,再点击"停止采集"。使用"采集文章并搅乱生成文章"功能,可以根据选取生成数目,动态生成无数多篇文章。
二、制作伪原创文章:用户可以有4种方式录入原创文章,1、把文章直接拷贝到文章编辑市,然后录入标题,再保存文章;2、通过导出的方法,可以直接导出TXT或html文档,3、通过采集的形式,直接采集到互联网上的文章,4、通过插口直接取得自己CMS网站的内容;
在取得了文章后,用户可以有3种形式制做伪原创文章:1、也是最简单的,直接点击文章标题,然后点击界面上部的"生成原创"按钮,伪原创后的文章就显露在"伪原创文章预览市"了;2、采用导入方法,直接可以把所有勾选的文章批量导入到TXT或HTML 文章中;3、通过插口,直接批量伪原创到自己的CMS网站中。下图是导入方法,在采用导入方法的时侯,系统将会根据设置的伪原创配置来伪原创勾选了的,文章然后导入;
三、使用直接更新主流CMS系统:石青伪原创工具,支持直接更新动易,老丫,新云,dedeCMS等99%的国外主流CMS内容,通过插口直接取得站点上的信息,然后伪原创后上传回来。具体使用方式,使用界面有详尽说明。按照说明一步一步的说很快就可以成功。
采集工具-Web Scraper的教学和示例
采集交流 • 优采云 发表了文章 • 0 个评论 • 351 次浏览 • 2020-08-08 05:26
“有很多方法可以打钉子,有时我最熟悉的锤子会打我”
背景
最近收到协助采集网站的请求. 在传统的“列表+内容”页面模式下,使用PHP或采集器时始终会出现各种莫名其妙的问题. 基本上,我将使用“ node + puppteer”来执行此操作,并使用自动测试工具来模拟操作. 尽管它是通用锤子,但制造该锤子的过程和技术复杂性仍然存在,因此我转向了以前考虑过但没有尝试使用浏览器插件的方向,基本原理和思想与自动化基本相同工具,但使目标逻辑更适合浏览器,并且感觉更优雅.
当我检查信息时,我发现了Web Scraper. 我通过参考文档和教程将其应用于目标网站集,最后获得了数据. 如果熟悉整个操作过程,则可以快速设置并实施相应的规则. 采集,现在记录该过程.
过程
1. 安装网页抓取工具
如果您掌握科学的冲浪技能,则可以登录chorme在线商店直接搜索并安装
或在百度上搜索“ Web scraper离线安装程序包”以获得相关支持. 离线安装过程将不会重复.
2. 分析目标电台
您可以看到这是一种典型的列表+内容显示方法. 现在,您需要同时采集列表和内容页面. 传统的采集思想是使用该程序将整个列表页面拉回,然后解析超链接. 跳转到内容页面.
现在让我们看一下如何使用网络抓取工具进行数据采集.
3. 设定规则
由于采集工具是通用的,关于如何采集和采集这些数据,这些规则要求用户根据实际情况进行配置. 首先,让我们了解一下网页抓取工具的打开方式和基本页面
①打开工具
在目标页面上打开开发人员工具(F11或单击鼠标右键检查),可以看到工具栏末尾有一个同名的标签,单击该标签可进入工具页面
②创建一个新的采集任务
您需要在采集之前创建一个站点地图,这可以理解为一项任务,请选择创建新站点地图-创建站点地图
站点地图名称是任务的名称,可以根据需要创建.
起始URL为您采集页面. 如果是列表+内容模式,建议填写列表页面.
然后创建站点地图,建立了基本任务.
③建立列表页面规则
单击“添加新选择器”以创建一个选择器,该选择器告诉插件应选择哪个节点. 对于在此类列表页面上也具有信息的页面,我们将每条信息视为一个块,其中收录各种属性信息. 创建方法如下:
您需要选中Multiple选项,这可以理解为循环获取.
添加后,我们应该在信息块中标记内容. 具体操作方法与上述相同,但应选择信息的父选择器作为刚刚创建的信息块节点.
其他节点的数据操作相同,请记住选择父节点.
④检查已建立的规则 查看全部
本文旨在学习和交流. 数据源的所有权属于原创网站及其所有者. 严禁使用本文提到的过程和数据牟利.
“有很多方法可以打钉子,有时我最熟悉的锤子会打我”
背景
最近收到协助采集网站的请求. 在传统的“列表+内容”页面模式下,使用PHP或采集器时始终会出现各种莫名其妙的问题. 基本上,我将使用“ node + puppteer”来执行此操作,并使用自动测试工具来模拟操作. 尽管它是通用锤子,但制造该锤子的过程和技术复杂性仍然存在,因此我转向了以前考虑过但没有尝试使用浏览器插件的方向,基本原理和思想与自动化基本相同工具,但使目标逻辑更适合浏览器,并且感觉更优雅.
当我检查信息时,我发现了Web Scraper. 我通过参考文档和教程将其应用于目标网站集,最后获得了数据. 如果熟悉整个操作过程,则可以快速设置并实施相应的规则. 采集,现在记录该过程.
过程
1. 安装网页抓取工具
如果您掌握科学的冲浪技能,则可以登录chorme在线商店直接搜索并安装
或在百度上搜索“ Web scraper离线安装程序包”以获得相关支持. 离线安装过程将不会重复.
2. 分析目标电台
您可以看到这是一种典型的列表+内容显示方法. 现在,您需要同时采集列表和内容页面. 传统的采集思想是使用该程序将整个列表页面拉回,然后解析超链接. 跳转到内容页面.
现在让我们看一下如何使用网络抓取工具进行数据采集.
3. 设定规则
由于采集工具是通用的,关于如何采集和采集这些数据,这些规则要求用户根据实际情况进行配置. 首先,让我们了解一下网页抓取工具的打开方式和基本页面
①打开工具
在目标页面上打开开发人员工具(F11或单击鼠标右键检查),可以看到工具栏末尾有一个同名的标签,单击该标签可进入工具页面
②创建一个新的采集任务
您需要在采集之前创建一个站点地图,这可以理解为一项任务,请选择创建新站点地图-创建站点地图
站点地图名称是任务的名称,可以根据需要创建.
起始URL为您采集页面. 如果是列表+内容模式,建议填写列表页面.
然后创建站点地图,建立了基本任务.
③建立列表页面规则
单击“添加新选择器”以创建一个选择器,该选择器告诉插件应选择哪个节点. 对于在此类列表页面上也具有信息的页面,我们将每条信息视为一个块,其中收录各种属性信息. 创建方法如下:
您需要选中Multiple选项,这可以理解为循环获取.
添加后,我们应该在信息块中标记内容. 具体操作方法与上述相同,但应选择信息的父选择器作为刚刚创建的信息块节点.
其他节点的数据操作相同,请记住选择父节点.
④检查已建立的规则
文章采集工具,文章伪原创工具,文章原创检测
采集交流 • 优采云 发表了文章 • 0 个评论 • 373 次浏览 • 2020-08-07 22:14
文章采集引擎使用采集器技术来捕获行业数据采集,并在云中构建多级索引库. 通过用户输入的关键字和选定的参考库,可以在云数据库中快速准确地检索相关材料,对候选材料进行原创检测和收录检测,最终结果经过过滤和汇总后推荐给用户.
对全文进行语义分析后,它会智能地修改句子并生成文本. 凭借其强大的NLP,深度学习和其他技术,它可以轻松通过独创性检测. 中文语义开放平台使用爬虫技术捕获行业数据集合,并使用深度学习方法进行语法和语义分析,并在语义上下文的空间矢量模型中挖掘单词之间的关系. 该开放平台利用自主开发的中文分词,句法分析,语义联想和实体识别技术,结合海量行业语料库的不断积累,提供简单,强大,可靠的中文自然语言分析云服务.
分解提交的文本内容后,它在大量Internet资源之间进行指纹比较,检测每个句子的独创性,并快速而准确地找到最相似的网页源,不仅可以分析文章中的pla窃程度,还可以检测他人复制您的原创文章并被他人疯狂传播的程度,并帮助您保护原创文章的版权. 原创的检测报告可以用作您更新文章的基础,从而有效地提高搜索引擎的索引量和排名. 查看全部
就像标题中提到的三个功能一样,有哪些工具可以将这三个功能整合在一起?是的,我今天所说的是一个名为“优采云”的工具,该工具非常易于使用,甚至不需要包裹在面包屑中.
文章采集引擎使用采集器技术来捕获行业数据采集,并在云中构建多级索引库. 通过用户输入的关键字和选定的参考库,可以在云数据库中快速准确地检索相关材料,对候选材料进行原创检测和收录检测,最终结果经过过滤和汇总后推荐给用户.
对全文进行语义分析后,它会智能地修改句子并生成文本. 凭借其强大的NLP,深度学习和其他技术,它可以轻松通过独创性检测. 中文语义开放平台使用爬虫技术捕获行业数据集合,并使用深度学习方法进行语法和语义分析,并在语义上下文的空间矢量模型中挖掘单词之间的关系. 该开放平台利用自主开发的中文分词,句法分析,语义联想和实体识别技术,结合海量行业语料库的不断积累,提供简单,强大,可靠的中文自然语言分析云服务.
分解提交的文本内容后,它在大量Internet资源之间进行指纹比较,检测每个句子的独创性,并快速而准确地找到最相似的网页源,不仅可以分析文章中的pla窃程度,还可以检测他人复制您的原创文章并被他人疯狂传播的程度,并帮助您保护原创文章的版权. 原创的检测报告可以用作您更新文章的基础,从而有效地提高搜索引擎的索引量和排名.
免费的伪原创工具来采集文章
采集交流 • 优采云 发表了文章 • 0 个评论 • 317 次浏览 • 2020-08-07 18:14
5. 优秀的网站管理员始终会注意蜘蛛访问网站的时间,以确保及时抓取和收录网站内容. 由于搜索引擎蜘蛛对网站的爬取是定期的,因此它会根据网站上内容更新的频率而变化. 因此,建议网站管理员保持网站更新的规律性,不仅可以养成良好的生活习惯,而且可以帮助搜索引擎蜘蛛养成良好的生活习惯.
6. 如何围绕用户需求撰写原创文章?命题-确定文章的内容. 写文章就像写文章. 首先,这是命题. 您要编写什么内容以及要优化哪些关键字. 常用的是您自己的问题,问答平台的问题,您周围的人的问题,客户的问题以及同龄人的问题. 这些都是用户需求. 这些问题关键字与用户搜索习惯结合在一起,以组合关键字标题.
7. 收录和排名没有直接关系. 收录是指网站的搜索引擎数据库中存在的内容量. 该数字只能代表一个数字,不能证明任何东西. 一些网站的收录率和排名很高. 非常可怜有些网站没有很多,但是排名很好. 如果您想借助数量优势获得更好的排名,那是不现实的.
8. 网站地图设置. 该站点地图用于整理整个网站的导航页面,不仅针对搜索引擎,还针对用户;
————————————————————————————————
问: 黑帽seo是什么意思?
A: 黑帽SEO旨在利用和扩大搜索引擎的战略缺陷(实际上,不存在完善的系统)来获得更多的用户访问,而这些更多的访问是以牺牲用户体验为代价的. SEO行为.
问: 页面标题和描述适合多少个单词?
回答: 网站标题搜索引擎只能在搜索结果中显示63个字节,以下内容被省略. 通常,建议网页标题不超过32个汉字,描述说明不超过72个汉字.
问: 要购买多少合适的网站服务器空间?
答案: 根据网站的规模和要提供的服务确定要购买的空间(服务器),选择功能强大的常规空间提供商,并根据用户组的分布选择访问提供商以确保用户访问速度和稳定性. 查看全部
4. 如何解决网站搜索引擎优化问题,增加文章数量;为了解决文章收录的问题,首先需要解决的问题是内容的数量,例如,您的网站总共有100篇文章,即使它全部是百度. 如果收录在内,您也只能收录一个最多一百篇文章. 这已经是极限了. 实际上,百度不能收录网站的所有内容. 即使是体重非常高的场所也不能包括在内,更不用说一些垃圾了. 可收录的站点数量更加有限,内容量也很小.
5. 优秀的网站管理员始终会注意蜘蛛访问网站的时间,以确保及时抓取和收录网站内容. 由于搜索引擎蜘蛛对网站的爬取是定期的,因此它会根据网站上内容更新的频率而变化. 因此,建议网站管理员保持网站更新的规律性,不仅可以养成良好的生活习惯,而且可以帮助搜索引擎蜘蛛养成良好的生活习惯.
6. 如何围绕用户需求撰写原创文章?命题-确定文章的内容. 写文章就像写文章. 首先,这是命题. 您要编写什么内容以及要优化哪些关键字. 常用的是您自己的问题,问答平台的问题,您周围的人的问题,客户的问题以及同龄人的问题. 这些都是用户需求. 这些问题关键字与用户搜索习惯结合在一起,以组合关键字标题.
7. 收录和排名没有直接关系. 收录是指网站的搜索引擎数据库中存在的内容量. 该数字只能代表一个数字,不能证明任何东西. 一些网站的收录率和排名很高. 非常可怜有些网站没有很多,但是排名很好. 如果您想借助数量优势获得更好的排名,那是不现实的.
8. 网站地图设置. 该站点地图用于整理整个网站的导航页面,不仅针对搜索引擎,还针对用户;
————————————————————————————————
问: 黑帽seo是什么意思?
A: 黑帽SEO旨在利用和扩大搜索引擎的战略缺陷(实际上,不存在完善的系统)来获得更多的用户访问,而这些更多的访问是以牺牲用户体验为代价的. SEO行为.
问: 页面标题和描述适合多少个单词?
回答: 网站标题搜索引擎只能在搜索结果中显示63个字节,以下内容被省略. 通常,建议网页标题不超过32个汉字,描述说明不超过72个汉字.
问: 要购买多少合适的网站服务器空间?
答案: 根据网站的规模和要提供的服务确定要购买的空间(服务器),选择功能强大的常规空间提供商,并根据用户组的分布选择访问提供商以确保用户访问速度和稳定性.
为网站管理员或SEOER推荐免费的文章采集工具
采集交流 • 优采云 发表了文章 • 0 个评论 • 419 次浏览 • 2020-08-07 17:39
网站站长之星采集软件界面:
进入网站站长的星级采集功能:
设置采集网站站长星标的规则:
我采集了有关SEO的内容:
除此之外,该软件还可以管理网站并自动发布信息,伪原创功能,但我通常只将其用于采集,然后手动处理伪原创,呵呵!!!有需要的朋友可以去他们的官方网站下载,个人网站管理员可以免费使用;
网站站长之星的操作步骤如下:
第一步: 单击导航“管理”以找到“关键字库”,然后单击打开
第2步: 在打开的“关键字库管理界面”中单击“新建”
第3步: 在“编辑关键字库”管理界面中添加关键字库的名称,并添加关键字,然后单击“保存”
第4步: 创建一个新的采集任务: 单击视图下方的绿色“ +”按钮,就是这样.
第5步: 在“任务配置”界面中,单击新集合,一个接一个地设置,最后单击“保存”!
第6步: 选择任务以设置采集并开始“数据采集”!
本文由Le Chen整理并发布,希望它可以帮助有需要的朋友!
网站站长之星简化版下载链接: 或添加我的Lechen博客交换组: 311036703下载 查看全部
网站管理员之星是一个专业的网站组内容管理系统,它集成了文章采集,文章处理和文章发布. 界面精美,操作简单,功能强大. 网站管理员Star具有完整而灵活的执行过程引擎,配置扩展机制和插件系统. 您只需要提供目标关键字即可获取大量相关关键字(即长尾关键字),然后将这些长尾关键字用作从搜索引擎或指定站点采集并提供关键字的条件. 列出匹配的文章. 您可以将采集到的文章发布到一个或多个CMS站点(当前支持的CMS是DedeCMS,SupeSite,Discuz!,KesionCMS,EmpireCMS等).
网站站长之星采集软件界面:
进入网站站长的星级采集功能:
设置采集网站站长星标的规则:
我采集了有关SEO的内容:
除此之外,该软件还可以管理网站并自动发布信息,伪原创功能,但我通常只将其用于采集,然后手动处理伪原创,呵呵!!!有需要的朋友可以去他们的官方网站下载,个人网站管理员可以免费使用;
网站站长之星的操作步骤如下:
第一步: 单击导航“管理”以找到“关键字库”,然后单击打开
第2步: 在打开的“关键字库管理界面”中单击“新建”
第3步: 在“编辑关键字库”管理界面中添加关键字库的名称,并添加关键字,然后单击“保存”
第4步: 创建一个新的采集任务: 单击视图下方的绿色“ +”按钮,就是这样.
第5步: 在“任务配置”界面中,单击新集合,一个接一个地设置,最后单击“保存”!
第6步: 选择任务以设置采集并开始“数据采集”!
本文由Le Chen整理并发布,希望它可以帮助有需要的朋友!
网站站长之星简化版下载链接: 或添加我的Lechen博客交换组: 311036703下载
优采云万能文章采集器 一款简单有效功能强悍的文章采集软件(破解版)
采集交流 • 优采云 发表了文章 • 0 个评论 • 506 次浏览 • 2020-08-03 23:00
文章采集来源主要来自以下搜索引擎:
百度网页、百度新闻、搜狗网页、搜狗新闻、微信、360网页、360新闻、今日头条、一点资讯、必应网页、必应新闻、雅虎、谷歌网页、谷歌新闻
功能特性:
一、依托于万能正文辨识智能算法,可实现任何网页正文手动提取准确率95%以上。
二、只需输入关键词,就能采集到百度新闻和网页、搜狗新闻和网页、360新闻和网页、谷歌新闻和网页、必应新闻和网页、雅虎;可批量关键词全手动采集。
三、可定向采集指定网站栏目列表下的所有文章,智能化匹配,无需编撰复杂规则。
四、文章转译功能,可对采集好的文章,将其翻译到中文再翻译回英文,实现翻译伪原创,支持微软和有道翻译。
五、史上最简单最智能文章采集器,支持全功能试用,效果怎么一试就知!
使用说明:
1、下载并解压好文件,双击“优采云·万能文章采集器Crack.exe”打开,你会发觉软件还是免费破解的哦。
2、点击OK,打开软件后就可以直接开始使用了,在关键词一栏中填写你须要采集的文章关键词。
3、然后选择文章保存的目录和保存的选项。
4、确认好信息,点击开始采集即可。
采集完成以后我们可以在保存的文件夹目录上面去看文章,或者也可以点击软件里面的文章查看。
整个软件的操作虽然十分简单,相信诸位小伙伴们都是学习能力极强的人,一看都会哦!
常见问题:
采集设置的黑名单错误如何解决?
[采集设置]里面输入黑名单时,如果最后有空行存在工具采集文章,就会造成关键词采集功能有搜索数目显示而无实际采集过程的问题,去掉空行即可。
遇到杀毒软件提示,请忽视,若不放心工具采集文章,可以不使用,寻找其他工具。
附:
百度网盘链接:
提取码:dkjl 查看全部
优采云万能文章采集器是一款简单有效功能强悍的文章采集软件。你只须要可输入关键词,即可采集各大搜索引擎网页和新闻,也可以采集指定网站文章,非常便捷快捷;本次小编为你们带来的是优采云万能文章采集器红色免费破解版,双击即可打开使用,软件早已完美破解无需注册码激活即可免费使用,喜欢的小伙伴们欢迎下载。
文章采集来源主要来自以下搜索引擎:
百度网页、百度新闻、搜狗网页、搜狗新闻、微信、360网页、360新闻、今日头条、一点资讯、必应网页、必应新闻、雅虎、谷歌网页、谷歌新闻
功能特性:
一、依托于万能正文辨识智能算法,可实现任何网页正文手动提取准确率95%以上。
二、只需输入关键词,就能采集到百度新闻和网页、搜狗新闻和网页、360新闻和网页、谷歌新闻和网页、必应新闻和网页、雅虎;可批量关键词全手动采集。
三、可定向采集指定网站栏目列表下的所有文章,智能化匹配,无需编撰复杂规则。
四、文章转译功能,可对采集好的文章,将其翻译到中文再翻译回英文,实现翻译伪原创,支持微软和有道翻译。
五、史上最简单最智能文章采集器,支持全功能试用,效果怎么一试就知!
使用说明:
1、下载并解压好文件,双击“优采云·万能文章采集器Crack.exe”打开,你会发觉软件还是免费破解的哦。
2、点击OK,打开软件后就可以直接开始使用了,在关键词一栏中填写你须要采集的文章关键词。
3、然后选择文章保存的目录和保存的选项。
4、确认好信息,点击开始采集即可。
采集完成以后我们可以在保存的文件夹目录上面去看文章,或者也可以点击软件里面的文章查看。
整个软件的操作虽然十分简单,相信诸位小伙伴们都是学习能力极强的人,一看都会哦!
常见问题:
采集设置的黑名单错误如何解决?
[采集设置]里面输入黑名单时,如果最后有空行存在工具采集文章,就会造成关键词采集功能有搜索数目显示而无实际采集过程的问题,去掉空行即可。
遇到杀毒软件提示,请忽视,若不放心工具采集文章,可以不使用,寻找其他工具。
附:
百度网盘链接:
提取码:dkjl

