
实时抓取网页数据
实时抓取网页数据(一个就买了一个阿里云服务器把个人网站迁移上去)
网站优化 • 优采云 发表了文章 • 0 个评论 • 130 次浏览 • 2021-11-02 11:17
前言
前段时间github崩溃了,差点毁了心态,于是干脆买了个阿里云服务器来迁移我的个人网站。
服务器镜像选择nodejs应用,预装nginx。nginx的其他配置我就不多说了。
本文主要介绍如何通过GoAccess分析nginx日志数据。
最终运行效果图:
1、GoAccess 介绍和安装 GoAccess 是一个开源的实时网络日志分析器和交互式查看器,可以在 *nix 系统中运行,也可以通过浏览器终端运行。它为需要动态可视化服务器报告的系统管理员提供快速且有价值的 HTTP 统计信息。
Goaccess用于分析服务器日志数据,主要可以通过两种方式输出数据分析报告:终端或HTML(分为静态和动态)
安装
可以通过官网或者包管理工具下载源码安装,这里使用yum安装
yum install goaccess
验证是否正确安装了 goaccess:
goaccess --v
2、GoAccess 配置
安装完成后,/etc目录下会有一个goaccess.conf配置文件。将以下代码添加到最后一行:
log-format %h %^[%d:%t %^] "%r" %s %b "%R" "%u"
date-format %d/%b/%Y
time-format %H:%M:%S
real-time-html true
port 618
output /usr/local/nginx/html/stat/index.html
上面配置了goaccess的日志格式、日期格式和时间格式,
设置实时HTML分析为true,因为通过WebSocket连接服务器时需要设置端口请求数据。默认端口是7890,这里设置的是618。记得在阿里云后台打开端口,不然数据不可用。最后设置输出HTML地址,该地址放置在nginx服务器静态资源的HTML目录下,可以自行配置。
3、最终输出实时数据分析HTML
在服务器端输入:
goaccess -f /usr/local/nginx/logs/access.log -a > /usr/local/nginx/html/stat/index.html
前者是需要分析的日志文件的地址,后者是输出HTML的地址
打开你的 网站stat 目录,查看实时数据分析。
例如:我的网站可以看到结果 查看全部
实时抓取网页数据(一个就买了一个阿里云服务器把个人网站迁移上去)
前言
前段时间github崩溃了,差点毁了心态,于是干脆买了个阿里云服务器来迁移我的个人网站。
服务器镜像选择nodejs应用,预装nginx。nginx的其他配置我就不多说了。
本文主要介绍如何通过GoAccess分析nginx日志数据。
最终运行效果图:

1、GoAccess 介绍和安装 GoAccess 是一个开源的实时网络日志分析器和交互式查看器,可以在 *nix 系统中运行,也可以通过浏览器终端运行。它为需要动态可视化服务器报告的系统管理员提供快速且有价值的 HTTP 统计信息。
Goaccess用于分析服务器日志数据,主要可以通过两种方式输出数据分析报告:终端或HTML(分为静态和动态)
安装
可以通过官网或者包管理工具下载源码安装,这里使用yum安装
yum install goaccess
验证是否正确安装了 goaccess:
goaccess --v
2、GoAccess 配置
安装完成后,/etc目录下会有一个goaccess.conf配置文件。将以下代码添加到最后一行:
log-format %h %^[%d:%t %^] "%r" %s %b "%R" "%u"
date-format %d/%b/%Y
time-format %H:%M:%S
real-time-html true
port 618
output /usr/local/nginx/html/stat/index.html
上面配置了goaccess的日志格式、日期格式和时间格式,
设置实时HTML分析为true,因为通过WebSocket连接服务器时需要设置端口请求数据。默认端口是7890,这里设置的是618。记得在阿里云后台打开端口,不然数据不可用。最后设置输出HTML地址,该地址放置在nginx服务器静态资源的HTML目录下,可以自行配置。
3、最终输出实时数据分析HTML
在服务器端输入:
goaccess -f /usr/local/nginx/logs/access.log -a > /usr/local/nginx/html/stat/index.html

前者是需要分析的日志文件的地址,后者是输出HTML的地址
打开你的 网站stat 目录,查看实时数据分析。
例如:我的网站可以看到结果
实时抓取网页数据(本文实例讲述php+ajax实时刷新简单实现方法,分享)
网站优化 • 优采云 发表了文章 • 0 个评论 • 58 次浏览 • 2021-11-02 11:16
本文介绍了php+ajax实时刷新的简单实现方法,分享给大家,供大家参考。详情如下:
Ajax 自动刷新似乎是一个很常见的问题。在做网络聊天室程序之前,我被困在它上面。经过这一段时间的学习,终于做出了一个可以自动刷新网页的代码框架。我希望你感到困惑。不要像我一样走那么多弯路
代码不多废话:
html部分:
function loadxmldoc()//ajax发送请求并显示
{
var xmlhttp;
if (window.xmlhttprequest)
{// code for ie7+, firefox, chrome, opera, safari
xmlhttp=new xmlhttprequest();
}
else
{// code for ie6, ie5
xmlhttp=new activexobject("microsoft.xmlhttp");
}
xmlhttp.onreadystatechange=function()
{
if (xmlhttp.readystate==4 && xmlhttp.status==200)
{
document.getelementbyid("mydiv").innerhtml=xmlhttp.responsetext;
}
}
xmlhttp.open("post","/chat.php",true);
xmlhttp.send();
settimeout("loadxmldoc()",1000);//递归调用
}
loadxmldoc();//先执行一次
手动刷新
php部分(只是一个实时刷新的测试网页)
这样,只要修改data.dat,就可以实时显示在网页上。
希望这篇文章对你的php程序设计有所帮助。 查看全部
实时抓取网页数据(本文实例讲述php+ajax实时刷新简单实现方法,分享)
本文介绍了php+ajax实时刷新的简单实现方法,分享给大家,供大家参考。详情如下:
Ajax 自动刷新似乎是一个很常见的问题。在做网络聊天室程序之前,我被困在它上面。经过这一段时间的学习,终于做出了一个可以自动刷新网页的代码框架。我希望你感到困惑。不要像我一样走那么多弯路
代码不多废话:
html部分:
function loadxmldoc()//ajax发送请求并显示
{
var xmlhttp;
if (window.xmlhttprequest)
{// code for ie7+, firefox, chrome, opera, safari
xmlhttp=new xmlhttprequest();
}
else
{// code for ie6, ie5
xmlhttp=new activexobject("microsoft.xmlhttp");
}
xmlhttp.onreadystatechange=function()
{
if (xmlhttp.readystate==4 && xmlhttp.status==200)
{
document.getelementbyid("mydiv").innerhtml=xmlhttp.responsetext;
}
}
xmlhttp.open("post","/chat.php",true);
xmlhttp.send();
settimeout("loadxmldoc()",1000);//递归调用
}
loadxmldoc();//先执行一次
手动刷新
php部分(只是一个实时刷新的测试网页)
这样,只要修改data.dat,就可以实时显示在网页上。
希望这篇文章对你的php程序设计有所帮助。
实时抓取网页数据(js+wcf实现进度条实时监测数据加载量的方法(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 131 次浏览 • 2021-10-31 03:16
本文以js+wcf如何实现进度条实时监控数据加载为例。分享给大家,供大家参考,如下:
背景
因为项目需要导入很多数据到memcache
您需要使用wcf 检索110,000 条数据。因为那里多级联检查排序,比较慢(1分钟左右)
同时这里需要对数据进行处理,合并成20000条数据,然后存储,需要一定的时间(也是1分钟左右)
总之,完成数据导入大约需要1分30秒
这时候就需要一个进度条来实时监控完成的数据量
(之前用动态图,无法知道程序当前的完成量,或者就算卡住了,也只能等)
功能
1.开启线程加载数据和处理数据
2.前台实时读取后台数据并显示
代码
视图-html
@* 数据准备进度条 *@
数据准备
完成量3%
<p>数据准备完成!
</p>
视图-js
$(function () {
$('#initialization').click(function () {
$.messager.confirm('提示', '是否要进行数据初始化?', function (r) {
if (!r) {
return;
}
else {
$('#container').show();
var t1 = window.setinterval(process_bar, 1500);
}
});
});
});
function process_bar() {
$.ajax({
type: "post",
async: true,
url: "/paper/loaddata",
success: function (result) {
$('#progress_bar .ui-progress').animateprogress(result);
if (result =="100") {
$('#main_content').slidedown();
$('#fork_me').fadein();
settimeout(function () { $('#container').hide();; }, 1500);
window.clearinterval(t1);
}
}
})
}
控制器
static bool flag = true;
public int loaddata()
{
int result = ipaperbll.loaddataamount();
if (flag)
{
thread thread = new thread(new threadstart(threadloaddata));
thread.start();
flag = false;
}
return result;
}
private void threadloaddata()
{
ipaperbll.initializedata();
}
后台
static int load_data_amount;//当前数据准备量
public bool initializedata()
{
bool flag = false; //定义返回值
//获得数据
//code....code ....code....
load_data_amount = 5;//完成工作量
int page = 0;
int amount = 50000;//一次获取数据量不能超过10万
while (page * amount == list.count)
{
//code....code ....code....
load_data_amount = load_data_amount + 5;
}
load_data_amount = 50;//读取数据默认的工作量
double totalamount = list.count();
foreach (var item in list)
{
//code....code ....code....
load_data_amount = convert.toint32((1 - (totalamount--) / double.parse(list.count().tostring())) * 50) + 50;//根据数据改变的完成工作量
}
load_data_amount = 100;//完成工作量
flag = true;
return flag;
}
//返回当前准备数据量
public int loaddataamount() {
return load_data_amount;
}
问题解决了
1.进度条生成
解决方法:使用在线demo,css+js可以动态生成,只需改变数据
2.线程问题
解决方法:开始监控线程的使用,后来改用线程进行数据处理
3.问题实时监控
解决方法:使用线程自动运行数据处理,前台使用ajax在后台不断查询一个变量load_data_amount
4.ajax 错误报告
注意返回值的类型,无论是result还是result.d,在不同的情况下是不同的
5.数据类型问题
解:读取数据的百分比是用完成量/全部量得到的。这里的数字总是不正确的,因为int类型经不起110,000及后续小数的运算。可以使用 double 和 float。
概括
本来想开个线程,加个变量,返回前台,加个进度条,读取变量就ok了。
但是中间的mvc,这个spring,这个接口,之前的方法都不好用,下面的计算,ajax……一一解决,终于解决了。
分而治之,一一解决,测试即可
另外,框架和合作带来便利的同时,中间的限制和bug也会降低你的效率。
对javascript相关内容感兴趣的读者可以查看本站专题:《JavaScript时间日期操作技巧总结》、《JavaScript搜索算法技巧总结》、《JavaScript错误与调试技巧总结》、《JavaScript数据结构与算法技巧》《总结》《JavaScript遍历算法与技巧总结》《JavaScript数学运算使用总结》
我希望这篇文章能帮助你进行 JavaScript 编程。 查看全部
实时抓取网页数据(js+wcf实现进度条实时监测数据加载量的方法(组图))
本文以js+wcf如何实现进度条实时监控数据加载为例。分享给大家,供大家参考,如下:
背景
因为项目需要导入很多数据到memcache
您需要使用wcf 检索110,000 条数据。因为那里多级联检查排序,比较慢(1分钟左右)
同时这里需要对数据进行处理,合并成20000条数据,然后存储,需要一定的时间(也是1分钟左右)
总之,完成数据导入大约需要1分30秒
这时候就需要一个进度条来实时监控完成的数据量
(之前用动态图,无法知道程序当前的完成量,或者就算卡住了,也只能等)
功能
1.开启线程加载数据和处理数据
2.前台实时读取后台数据并显示
代码
视图-html
@* 数据准备进度条 *@
数据准备
完成量3%
<p>数据准备完成!
</p>
视图-js
$(function () {
$('#initialization').click(function () {
$.messager.confirm('提示', '是否要进行数据初始化?', function (r) {
if (!r) {
return;
}
else {
$('#container').show();
var t1 = window.setinterval(process_bar, 1500);
}
});
});
});
function process_bar() {
$.ajax({
type: "post",
async: true,
url: "/paper/loaddata",
success: function (result) {
$('#progress_bar .ui-progress').animateprogress(result);
if (result =="100") {
$('#main_content').slidedown();
$('#fork_me').fadein();
settimeout(function () { $('#container').hide();; }, 1500);
window.clearinterval(t1);
}
}
})
}
控制器
static bool flag = true;
public int loaddata()
{
int result = ipaperbll.loaddataamount();
if (flag)
{
thread thread = new thread(new threadstart(threadloaddata));
thread.start();
flag = false;
}
return result;
}
private void threadloaddata()
{
ipaperbll.initializedata();
}
后台
static int load_data_amount;//当前数据准备量
public bool initializedata()
{
bool flag = false; //定义返回值
//获得数据
//code....code ....code....
load_data_amount = 5;//完成工作量
int page = 0;
int amount = 50000;//一次获取数据量不能超过10万
while (page * amount == list.count)
{
//code....code ....code....
load_data_amount = load_data_amount + 5;
}
load_data_amount = 50;//读取数据默认的工作量
double totalamount = list.count();
foreach (var item in list)
{
//code....code ....code....
load_data_amount = convert.toint32((1 - (totalamount--) / double.parse(list.count().tostring())) * 50) + 50;//根据数据改变的完成工作量
}
load_data_amount = 100;//完成工作量
flag = true;
return flag;
}
//返回当前准备数据量
public int loaddataamount() {
return load_data_amount;
}
问题解决了
1.进度条生成
解决方法:使用在线demo,css+js可以动态生成,只需改变数据
2.线程问题
解决方法:开始监控线程的使用,后来改用线程进行数据处理
3.问题实时监控
解决方法:使用线程自动运行数据处理,前台使用ajax在后台不断查询一个变量load_data_amount
4.ajax 错误报告
注意返回值的类型,无论是result还是result.d,在不同的情况下是不同的
5.数据类型问题
解:读取数据的百分比是用完成量/全部量得到的。这里的数字总是不正确的,因为int类型经不起110,000及后续小数的运算。可以使用 double 和 float。
概括
本来想开个线程,加个变量,返回前台,加个进度条,读取变量就ok了。
但是中间的mvc,这个spring,这个接口,之前的方法都不好用,下面的计算,ajax……一一解决,终于解决了。
分而治之,一一解决,测试即可
另外,框架和合作带来便利的同时,中间的限制和bug也会降低你的效率。
对javascript相关内容感兴趣的读者可以查看本站专题:《JavaScript时间日期操作技巧总结》、《JavaScript搜索算法技巧总结》、《JavaScript错误与调试技巧总结》、《JavaScript数据结构与算法技巧》《总结》《JavaScript遍历算法与技巧总结》《JavaScript数学运算使用总结》
我希望这篇文章能帮助你进行 JavaScript 编程。
实时抓取网页数据( 1.1.5使用json数据解析网址1.2模拟浏览器请求提取关注的信息 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 68 次浏览 • 2021-10-31 03:14
1.1.5使用json数据解析网址1.2模拟浏览器请求提取关注的信息
)
1.1.5 使用json数据解析URL
1.2 模拟浏览器请求
2.提取相关信息2.1 遇到的问题
(1)使用post方法得到的数据总是带着下图所示的字符串,这里纠结了很久...
结果是我得到了错误的请求方法。
(2) 响应数据虽然是json格式,但是没有像往常一样播放,是一维的,耽误了很久,之前没注意,一直在尝试访问按照往常的方式查字典,再仔细看。看下面数据中的引号(“”),真的是未来的另一个村庄。
(3) 访问data的值后,数据为str类型,但文本内容仍为字典格式,因此该函数用于将文本转换为字典格式
2.2 提取全国、湖南等地的疫情信息。
由于返回的数据是排序后的数据,所以需要找到需要的数据
for i in range(len(dict_data["areaTree"][0]["children"])):
if dict_data["areaTree"][0]["children"][i]["name"]=="湖南":
for j in range(len(dict_data["areaTree"][0]["children"][i]["children"])):
if dict_data["areaTree"][0]["children"][i]["children"][j]["name"]=="衡阳":
index1=i
index2=j
break
3.使用服务器酱接收微信消息3.1 推荐一款好用的微信提醒工具
3.2 使用服务器酱服务效果图
4.阿里云服务器部署py脚本4.1 阿里云服务器操作
我以前从未接触过 Linux。为了补充知识,买了阿里云的学生专用服务器,想用这个来练习。所以百度了解了很多关于py脚本在Ubuntu服务器后台是如何运行的。Ubuntu最初安装了python2.7和python3.5版本,方便我们程序的运行。Linux学习中~~请指教
(1)使用Xshell上传py文件
(2)Linux 命令在后台运行脚本
查看全部
实时抓取网页数据(
1.1.5使用json数据解析网址1.2模拟浏览器请求提取关注的信息
)

1.1.5 使用json数据解析URL
1.2 模拟浏览器请求

2.提取相关信息2.1 遇到的问题
(1)使用post方法得到的数据总是带着下图所示的字符串,这里纠结了很久...
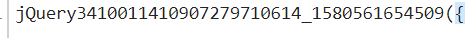
结果是我得到了错误的请求方法。
(2) 响应数据虽然是json格式,但是没有像往常一样播放,是一维的,耽误了很久,之前没注意,一直在尝试访问按照往常的方式查字典,再仔细看。看下面数据中的引号(“”),真的是未来的另一个村庄。
(3) 访问data的值后,数据为str类型,但文本内容仍为字典格式,因此该函数用于将文本转换为字典格式

2.2 提取全国、湖南等地的疫情信息。
由于返回的数据是排序后的数据,所以需要找到需要的数据
for i in range(len(dict_data["areaTree"][0]["children"])):
if dict_data["areaTree"][0]["children"][i]["name"]=="湖南":
for j in range(len(dict_data["areaTree"][0]["children"][i]["children"])):
if dict_data["areaTree"][0]["children"][i]["children"][j]["name"]=="衡阳":
index1=i
index2=j
break
3.使用服务器酱接收微信消息3.1 推荐一款好用的微信提醒工具
3.2 使用服务器酱服务效果图

4.阿里云服务器部署py脚本4.1 阿里云服务器操作
我以前从未接触过 Linux。为了补充知识,买了阿里云的学生专用服务器,想用这个来练习。所以百度了解了很多关于py脚本在Ubuntu服务器后台是如何运行的。Ubuntu最初安装了python2.7和python3.5版本,方便我们程序的运行。Linux学习中~~请指教
(1)使用Xshell上传py文件
(2)Linux 命令在后台运行脚本

实时抓取网页数据( 小编来一起示例代码介绍-2019年07月01日)
网站优化 • 优采云 发表了文章 • 0 个评论 • 68 次浏览 • 2021-10-29 16:00
小编来一起示例代码介绍-2019年07月01日)
详解python websocket获取实时数据的几种常用链接方法
更新时间:2019-07-01 09:24:16 作者:Jerry_JD
本文文章主要详细介绍几种常用的从python websocket获取实时数据的链接方式。文章中介绍的示例代码非常详细,对大家的学习或工作有一定的参考学习价值。有需要的朋友在下面和小编一起学习吧
第一种是使用create_connection链接,需要pip install websocket-client(不推荐这种方法,链接不稳定,容易断,连接耗时)
import time
from websocket import create_connection
url = 'wss://i.cg.net/wi/ws'
while True: # 一直链接,直到连接上就退出循环
time.sleep(2)
try:
ws = create_connection(url)
print(ws)
break
except Exception as e:
print('连接异常:', e)
continue
while True: # 连接上,退出第一个循环之后,此循环用于一直获取数据
ws.send('{"event":"subscribe", "channel":"btc_usdt.ticker"}')
response = ws.recv()
print(response)
第二种,运行效果很好,连接方便,获取数据的速度也很快
import json
from ws4py.client.threadedclient import WebSocketClient
class CG_Client(WebSocketClient):
def opened(self):
req = '{"event":"subscribe", "channel":"eth_usdt.deep"}'
self.send(req)
def closed(self, code, reason=None):
print("Closed down:", code, reason)
def received_message(self, resp):
resp = json.loads(str(resp))
data = resp['data']
if type(data) is dict:
ask = data['asks'][0]
print('Ask:', ask)
bid = data['bids'][0]
print('Bid:', bid)
if __name__ == '__main__':
ws = None
try:
ws = CG_Client('wss://i.cg.net/wi/ws')
ws.connect()
ws.run_forever()
except KeyboardInterrupt:
ws.close()
第三种其实和第一种类似,只是写法不同,运行效果不理想,连接耗时,容易断线
import websocket
while True:
ws = websocket.WebSocket()
try:
ws.connect("wss://i.cg.net/wi/ws")
print(ws)
break
except Exception as e:
print('异常:', e)
continue
print('OK')
while True:
req = '{"event":"subscribe", "channel":"btc_usdt.deep"}'
ws.send(req)
resp = ws.recv()
print(resp)
第四,运行效果也是可以的,run_forever里面的参数很多,需要自己设置
import websocket
def on_message(ws, message): # 服务器有数据更新时,主动推送过来的数据
print(message)
def on_error(ws, error): # 程序报错时,就会触发on_error事件
print(error)
def on_close(ws):
print("Connection closed ……")
def on_open(ws): # 连接到服务器之后就会触发on_open事件,这里用于send数据
req = '{"event":"subscribe", "channel":"btc_usdt.deep"}'
print(req)
ws.send(req)
if __name__ == "__main__":
websocket.enableTrace(True)
ws = websocket.WebSocketApp("wss://i.cg.net/wi/ws",
on_message=on_message,
on_error=on_error,
on_close=on_close)
ws.on_open = on_open
ws.run_forever(ping_timeout=30)
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持脚本之家。 查看全部
实时抓取网页数据(
小编来一起示例代码介绍-2019年07月01日)
详解python websocket获取实时数据的几种常用链接方法
更新时间:2019-07-01 09:24:16 作者:Jerry_JD
本文文章主要详细介绍几种常用的从python websocket获取实时数据的链接方式。文章中介绍的示例代码非常详细,对大家的学习或工作有一定的参考学习价值。有需要的朋友在下面和小编一起学习吧
第一种是使用create_connection链接,需要pip install websocket-client(不推荐这种方法,链接不稳定,容易断,连接耗时)
import time
from websocket import create_connection
url = 'wss://i.cg.net/wi/ws'
while True: # 一直链接,直到连接上就退出循环
time.sleep(2)
try:
ws = create_connection(url)
print(ws)
break
except Exception as e:
print('连接异常:', e)
continue
while True: # 连接上,退出第一个循环之后,此循环用于一直获取数据
ws.send('{"event":"subscribe", "channel":"btc_usdt.ticker"}')
response = ws.recv()
print(response)
第二种,运行效果很好,连接方便,获取数据的速度也很快
import json
from ws4py.client.threadedclient import WebSocketClient
class CG_Client(WebSocketClient):
def opened(self):
req = '{"event":"subscribe", "channel":"eth_usdt.deep"}'
self.send(req)
def closed(self, code, reason=None):
print("Closed down:", code, reason)
def received_message(self, resp):
resp = json.loads(str(resp))
data = resp['data']
if type(data) is dict:
ask = data['asks'][0]
print('Ask:', ask)
bid = data['bids'][0]
print('Bid:', bid)
if __name__ == '__main__':
ws = None
try:
ws = CG_Client('wss://i.cg.net/wi/ws')
ws.connect()
ws.run_forever()
except KeyboardInterrupt:
ws.close()
第三种其实和第一种类似,只是写法不同,运行效果不理想,连接耗时,容易断线
import websocket
while True:
ws = websocket.WebSocket()
try:
ws.connect("wss://i.cg.net/wi/ws")
print(ws)
break
except Exception as e:
print('异常:', e)
continue
print('OK')
while True:
req = '{"event":"subscribe", "channel":"btc_usdt.deep"}'
ws.send(req)
resp = ws.recv()
print(resp)
第四,运行效果也是可以的,run_forever里面的参数很多,需要自己设置
import websocket
def on_message(ws, message): # 服务器有数据更新时,主动推送过来的数据
print(message)
def on_error(ws, error): # 程序报错时,就会触发on_error事件
print(error)
def on_close(ws):
print("Connection closed ……")
def on_open(ws): # 连接到服务器之后就会触发on_open事件,这里用于send数据
req = '{"event":"subscribe", "channel":"btc_usdt.deep"}'
print(req)
ws.send(req)
if __name__ == "__main__":
websocket.enableTrace(True)
ws = websocket.WebSocketApp("wss://i.cg.net/wi/ws",
on_message=on_message,
on_error=on_error,
on_close=on_close)
ws.on_open = on_open
ws.run_forever(ping_timeout=30)
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持脚本之家。
实时抓取网页数据(统计COVID-19疫情数据可视化分析考核要点及使用方法 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 92 次浏览 • 2021-10-27 04:00
)
一、实验目的
通过本次实验,掌握数据采集、数据清洗与存储、数据可视化工具的基本使用方法。
二、 实验平台
操作系统:window10
Python 版本:3.8
IDE:pycharm
可视化工具:echarts
三、新冠疫情数据采集实验内容及要求
评估要点:尽可能全面的获取疫情数据,包括国内外流行的历史数据,尽可能的获取新的信息,同时也尽可能的获取疫苗接种次数等信息。老师会根据资料的综合程度打分。推荐使用爬虫方式获取数据。如果有困难,可以使用网上其他人整理的数据。关于数据来源,可以从世界卫生组织、定香园、腾讯新闻等渠道获取。网上有很多资料可以参考。
数据来源1:json格式网页抓取腾讯疫情数据
数据来源2:来自约翰霍普金斯大学的GitHub流行病数据
新冠疫情数据采集
评估要点:对获取的疫情相关数据进行清理,去除冗余数据。关于数据存储,可以使用csv文件,但欢迎大家尝试将数据存储在关系型数据库(如MySQL、SQLite等轻量级数据库)或NoSQL数据库(如MongoDB)中。
获取中美两国现有确诊人数、累计死亡人数、累计治愈人数,并存入字典
获取中国所有省份累计确诊病例数
获取中国及美国各省州累计确诊病例和累计死亡人数列表
读取疫情数据的csv文件,得到中国各省7个时间节点累计确诊COVID-19人数
获取并处理中国、美国、印度、意大利7个时间节点累计确诊病例、累计死亡、累计治愈数
COVID-19 数据的可视化分析
评估要点:基于获取的疫情数据,多角度可视化COVID-19疫情的发展过程。计算 COVID-19 流行的地理分布,包括国际和国内。关于可视化工具,可以使用Python或R。有很多强大的包。网上也有很多资料供大家参考。
使用五张echarts图表
效果图
查看全部
实时抓取网页数据(统计COVID-19疫情数据可视化分析考核要点及使用方法
)
一、实验目的
通过本次实验,掌握数据采集、数据清洗与存储、数据可视化工具的基本使用方法。
二、 实验平台
操作系统:window10
Python 版本:3.8
IDE:pycharm
可视化工具:echarts
三、新冠疫情数据采集实验内容及要求
评估要点:尽可能全面的获取疫情数据,包括国内外流行的历史数据,尽可能的获取新的信息,同时也尽可能的获取疫苗接种次数等信息。老师会根据资料的综合程度打分。推荐使用爬虫方式获取数据。如果有困难,可以使用网上其他人整理的数据。关于数据来源,可以从世界卫生组织、定香园、腾讯新闻等渠道获取。网上有很多资料可以参考。
数据来源1:json格式网页抓取腾讯疫情数据

数据来源2:来自约翰霍普金斯大学的GitHub流行病数据

新冠疫情数据采集
评估要点:对获取的疫情相关数据进行清理,去除冗余数据。关于数据存储,可以使用csv文件,但欢迎大家尝试将数据存储在关系型数据库(如MySQL、SQLite等轻量级数据库)或NoSQL数据库(如MongoDB)中。
获取中美两国现有确诊人数、累计死亡人数、累计治愈人数,并存入字典

获取中国所有省份累计确诊病例数

获取中国及美国各省州累计确诊病例和累计死亡人数列表

读取疫情数据的csv文件,得到中国各省7个时间节点累计确诊COVID-19人数

获取并处理中国、美国、印度、意大利7个时间节点累计确诊病例、累计死亡、累计治愈数


COVID-19 数据的可视化分析
评估要点:基于获取的疫情数据,多角度可视化COVID-19疫情的发展过程。计算 COVID-19 流行的地理分布,包括国际和国内。关于可视化工具,可以使用Python或R。有很多强大的包。网上也有很多资料供大家参考。
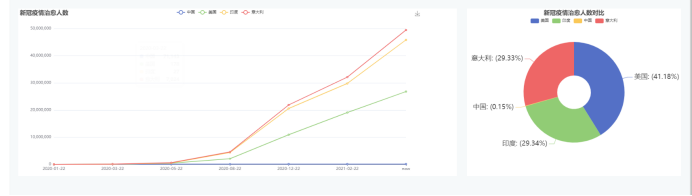
使用五张echarts图表




效果图





实时抓取网页数据( 宅家“疫情数据信息实时监控项目”演示如何获取腾讯数据接口的地址)
网站优化 • 优采云 发表了文章 • 0 个评论 • 97 次浏览 • 2021-10-27 02:16
宅家“疫情数据信息实时监控项目”演示如何获取腾讯数据接口的地址)
房子很无聊,所以最好学习一些技能!
1.前言
在近期新冠病毒引发的肺炎疫情中,很多人不得不宅在家里。为了让自己不那么无聊,给自己找点事情做,做一个“疫情数据信息实时监测项目”。我去年开始学习 Qt/C++。让我们用这个小项目来练习。代码是开源的。下载地址在文末。当然,如果你和我一样,我建议你用熟悉的编程语言自己实现,也就是学了知识,打发时间。在做之前,我在Github上搜索了一下,看看有没有相关的资料。好像很多人已经在做了:
不过大部分都是基于JavaScript或Python的项目,没有一个是使用Qt/C++平台开发的。
2.主要功能
界面也很简单,主要包括实时数据和历史数据的展示,实时疫情信息的展示,谣言信息的展示。数据来自腾讯新闻。
基于Qt的疫情实时监测平台主界面
一共使用了两个数据接口。一个是收录实时数据、历史数据、疫情动态的界面,一个是收录辟谣信息的界面。
功能也很简单:
3.获取数据接口
现在各大网站都发布了自己的实时疫情展示平台,如定香园、腾讯、新浪、百度、知乎、网易等,包括个别开发者也开发了一些接口、数据均来自国家或地方卫生健康委员会发布的信息。
我使用的是腾讯数据源,数据为JSON格式,解析方便。下面以Chrome浏览器为例,演示如何获取腾讯数据接口的地址。
打开链接后,按F12切换到开发者模式。再次刷新网页,切换到Network,按Ctrl+F搜索当前全国确诊人数:44765,然后回车,可以看到这个数据收录在一个JSON字符串中,这个字符串就是返回的数据某个请求地址,而这个地址就是数据的接口地址。
为了验证这个接口是否正确,我们复制这个地址,然后在地址栏中输入回车,可以看到返回了很多字符串:
这意味着我们找到了正确的地址。完整地址:
在:
时间戳是指格林威治标准时间1970年1月1日00:00:00(北京时间1970年1月1日08:00)到现在的总毫秒数。
因此,如果要获取最新的数据,可以省略以上两个参数:
如果要获取历史数据,只需要修改时间戳即可,其他网站接口地址获取方式类似。
这里我们只使用腾讯新闻的界面。保存 JSON 文件并对其进行格式化。您可以看到收录的信息:
关于腾讯的数据,我还要说一件事。腾讯的JSON数据这几天更新了好几次:
JSON 数据文件的大小也从最初的 80KB 变成了现在的 160KB。
对于辟谣信息,腾讯还放了两个接口,一是查询最新的辟谣信息,二是获取辟谣信息的详细内容。同理,我们可以通过上面获取数据接口地址的方法来获取这两个地址。
查看最新反谣言信息地址:
参数与数据接口相同,函数名和时间戳可以省略:
在这个界面中,有最新的10条辟谣消息。每条辟谣消息包括标题、发布者、发布时间、图片地址、辟谣类型、辟谣id等,通过另一个界面可以查询到某个辟谣新闻的详细信息。
比如这个传闻:
我们访问这样一个地址:
8be33c500e00257c97419ac24ab59d8f
您将获得该谣言新闻的 JSON 格式详细信息如下:
我们实际开发中没有用到这个接口,而是直接调用浏览器打开这个地址的网页地址:
8be33c500e00257c97419ac24ab59d8f
不过这个界面是针对移动端的,在电脑端浏览效果不好:
移动端:
4.Qt 实现
涉及的主要Qt知识如下:
QCustomplot绘图:
驳斥信息显示:
5.主要难点
整个开发过程就是一个解决一个问题的过程。许多控件都是第一次使用。幸运的是,有很多材料。主要困难如下:
历史数据折线图显示:
实时疫情新闻显示:
实时谣言信息显示:
6.包发布
为了让没有安装Qt环境的用户可以使用我们开发的Qt程序,我们需要将生成的程序文件打包发布。首先,使用 Qt 自带的 windeploy filename.exe 命令添加运行该程序所需的所有内容。然后用程序打包软件把这个文件打包成setup.exe安装文件安装在其他电脑上,或者打包成绿色版软件,直接双击运行,我用下面两个软件打包。
7.开源地址
我已经开源了这个项目的Qt项目的所有代码和安装包下载地址,如下: 查看全部
实时抓取网页数据(
宅家“疫情数据信息实时监控项目”演示如何获取腾讯数据接口的地址)
房子很无聊,所以最好学习一些技能!
1.前言
在近期新冠病毒引发的肺炎疫情中,很多人不得不宅在家里。为了让自己不那么无聊,给自己找点事情做,做一个“疫情数据信息实时监测项目”。我去年开始学习 Qt/C++。让我们用这个小项目来练习。代码是开源的。下载地址在文末。当然,如果你和我一样,我建议你用熟悉的编程语言自己实现,也就是学了知识,打发时间。在做之前,我在Github上搜索了一下,看看有没有相关的资料。好像很多人已经在做了:
不过大部分都是基于JavaScript或Python的项目,没有一个是使用Qt/C++平台开发的。
2.主要功能
界面也很简单,主要包括实时数据和历史数据的展示,实时疫情信息的展示,谣言信息的展示。数据来自腾讯新闻。
基于Qt的疫情实时监测平台主界面
一共使用了两个数据接口。一个是收录实时数据、历史数据、疫情动态的界面,一个是收录辟谣信息的界面。
功能也很简单:
3.获取数据接口
现在各大网站都发布了自己的实时疫情展示平台,如定香园、腾讯、新浪、百度、知乎、网易等,包括个别开发者也开发了一些接口、数据均来自国家或地方卫生健康委员会发布的信息。
我使用的是腾讯数据源,数据为JSON格式,解析方便。下面以Chrome浏览器为例,演示如何获取腾讯数据接口的地址。
打开链接后,按F12切换到开发者模式。再次刷新网页,切换到Network,按Ctrl+F搜索当前全国确诊人数:44765,然后回车,可以看到这个数据收录在一个JSON字符串中,这个字符串就是返回的数据某个请求地址,而这个地址就是数据的接口地址。
为了验证这个接口是否正确,我们复制这个地址,然后在地址栏中输入回车,可以看到返回了很多字符串:
这意味着我们找到了正确的地址。完整地址:
在:
时间戳是指格林威治标准时间1970年1月1日00:00:00(北京时间1970年1月1日08:00)到现在的总毫秒数。
因此,如果要获取最新的数据,可以省略以上两个参数:
如果要获取历史数据,只需要修改时间戳即可,其他网站接口地址获取方式类似。
这里我们只使用腾讯新闻的界面。保存 JSON 文件并对其进行格式化。您可以看到收录的信息:
关于腾讯的数据,我还要说一件事。腾讯的JSON数据这几天更新了好几次:
JSON 数据文件的大小也从最初的 80KB 变成了现在的 160KB。
对于辟谣信息,腾讯还放了两个接口,一是查询最新的辟谣信息,二是获取辟谣信息的详细内容。同理,我们可以通过上面获取数据接口地址的方法来获取这两个地址。
查看最新反谣言信息地址:
参数与数据接口相同,函数名和时间戳可以省略:
在这个界面中,有最新的10条辟谣消息。每条辟谣消息包括标题、发布者、发布时间、图片地址、辟谣类型、辟谣id等,通过另一个界面可以查询到某个辟谣新闻的详细信息。
比如这个传闻:
我们访问这样一个地址:
8be33c500e00257c97419ac24ab59d8f
您将获得该谣言新闻的 JSON 格式详细信息如下:
我们实际开发中没有用到这个接口,而是直接调用浏览器打开这个地址的网页地址:
8be33c500e00257c97419ac24ab59d8f
不过这个界面是针对移动端的,在电脑端浏览效果不好:
移动端:
4.Qt 实现
涉及的主要Qt知识如下:
QCustomplot绘图:
驳斥信息显示:
5.主要难点
整个开发过程就是一个解决一个问题的过程。许多控件都是第一次使用。幸运的是,有很多材料。主要困难如下:
历史数据折线图显示:
实时疫情新闻显示:
实时谣言信息显示:
6.包发布
为了让没有安装Qt环境的用户可以使用我们开发的Qt程序,我们需要将生成的程序文件打包发布。首先,使用 Qt 自带的 windeploy filename.exe 命令添加运行该程序所需的所有内容。然后用程序打包软件把这个文件打包成setup.exe安装文件安装在其他电脑上,或者打包成绿色版软件,直接双击运行,我用下面两个软件打包。
7.开源地址
我已经开源了这个项目的Qt项目的所有代码和安装包下载地址,如下:
实时抓取网页数据( soup解析器的惯用方法及修改解析树的使用方法介绍 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 122 次浏览 • 2021-10-25 02:02
soup解析器的惯用方法及修改解析树的使用方法介绍
)
<a id="_0"></a>数据抓取操作步骤
创建用于发送HTTP请求时将用到的所有值发出HTTP请求并下载所有数据解析这些数据文件中需要的数据,
<a id="_4"></a>具体操作步骤
<p>首先需要弄清需要访问哪个URL以及需要哪种HTTP方法。HTTP方法类似于:
method="post"
</p>
该网址类似于:
action="Data_Elements.aspx?Data=2"
美汤
Beautiful Soup 是一个 Python 库,用于从 HTML 和 XML 文件中提取数据。它使用您最喜欢的解析器来提供用于导航、搜索和修改解析树的惯用方法。它通常可以为程序员节省数小时或数天。
以下是中文帮助文档的链接
这是不同美汤解析器的对比
使用 Beautiful Soup 提取隐藏字段
任务:使用 BeautifulSoup 处理 HTML 并提取
“__EVENTVALIDATION”和“__VIEWSTATE”的隐藏表字段值,并在数据字典中设置相应的值。
代码:
def extract_data(page):
# 同之前的方法一样,定义字典,方便对键赋值
data = {"eventvalidation": "",
"viewstate": ""}
with open(page, "r") as html:
# 这里用lxml解析器,后文会做简要介绍
soup = BeautifulSoup(html, "lxml")
ev = soup.find(id="__EVENTVALIDATION")
# 把ev中value的值取出来给data的键
data["eventvalidation"] = ev["value"]
vs = soup.find(id="__VIEWSTATE")
data["viewstate"] = vs["value"]
return data
解析器图像
建议使用 lxml 作为解析器,因为它更高效。Python32.7.3之前的版本和3.2.2之前的版本,必须安装lxml或者html5lib,因为标准内置的HTML解析方法这些 Python 版本的库不够稳定。
提示:如果 HTML 或 XML 文档的格式不正确,不同的解析器返回的结果可能不同
find() 方法
查找(名称,属性,递归,文本,**kwargs)
find_all() 方法会返回文档中所有符合条件的标签,尽管有时我们只想得到一个结果。比如文档中只有一个标签,那么就不宜使用find_all()方法查找标签,使用find_all方法并设置limit=1参数不如使用find()方法直接。下面两行代码是等价的:
soup.find_all('title', limit=1)
# [The Dormouse's story]
soup.find('title')
# The Dormouse's story
唯一的区别是 find_all() 方法的返回结果是一个值收录一个元素的列表,而 find() 方法直接返回结果。
find_all() 方法没有找到目标是返回一个空列表,当find() 方法找不到目标时,它返回None。
print(soup.find("nosuchtag"))
# None
Soup.head.title 是标签名称方法的简写。这个速记的原理是多次调用当前标签的find()方法:
soup.head.title
# The Dormouse's story
soup.find("head").find("title")
# The Dormouse's story
练习:获取运算符列表
任务
获取所有航空公司的列表。删除您返回的数据中的所有组合,例如“所有美国运营商”。最终,您应该返回操作员代码列表。
部分处理代码:
All U.S. and Foreign Carriers
All U.S. Carriers
All Foreign Carriers
AirTran Airways
Alaska Airlines
American Airlines
American Eagle Airlines
Atlas Air
Delta Air Lines
ExpressJet Airlines
Frontier Airlines
Hawaiian Airlines
JetBlue Airways
SkyWest Airlines
Southwest Airlines
Spirit Air Lines
US Airways
United Air Lines
Virgin America
All
All Major Airports
- Atlanta, GA: Hartsfield-Jackson Atlanta International
- Baltimore, MD: Baltimore/Washington International Thurgood Marshall
- Boston, MA: Logan International
- Charlotte, NC: Charlotte Douglas International
- Chicago, IL: Chicago Midway International
- Chicago, IL: Chicago O'Hare International
- Dallas/Fort Worth, TX: Dallas/Fort Worth International
- Denver, CO: Denver International
- Detroit, MI: Detroit Metro Wayne County
- Fort Lauderdale, FL: Fort Lauderdale-Hollywood International
- Houston, TX: George Bush Intercontinental/Houston
- Las Vegas, NV: McCarran International
- Los Angeles, CA: Los Angeles International
All Other Airports
- Aberdeen, SD: Aberdeen Regional
- Abilene, TX: Abilene Regional
解决方案:
def extract_carriers(page):
data = []
with open(page, "r") as html:
soup = BeautifulSoup(html, 'lxml')
# find方法里为什么必须要用id定位:问题一
carrier_list=soup.find(id='CarrierList')
options=carrier_list.find_all('option')
for tag in options:
# 取出标签value所对应的值,添加到列表中。不要标签值中带有All的
if 'All' not in tag['value']:
data.append(tag['value'])
return data
一问一答
注意 find() 方法格式:find( name, attrs, recursive, text, **kwargs)。
虽然名称标签也是唯一的,但是因为find函数已经使用了名称参数name来接收标签类型信息,下面两条语句其实是等价的:
carrier_tag = soup.find(name='CarrierList')
carrier_tag = soup.find('CarrierList')
相当于搜索了这种标签:,那么在目前的情况下肯定是搜索不到的~
如果要使用 name 属性进行搜索,可以使用以下语法:
carrier_list = soup.find('select', {'name': 'CarrierList'})
练习:处理所有数据 练习:专利数据库
在处理 XML 部分文件时,通常会遇到这样的错误:Error parsing XML: waste after document element。这是因为通常有效的 XML 文件只有一个主根节点,例如:
如果出现 Error parsing XML: waste after document element 之类的错误,你的想法可能是只要主根有多个节点
实际上,这种文件通常是由多个相互连接的 XML 文档组成的。一种解决方案是将文件拆分为多个文档,然后将这些文档处理为有效的 XML 文档。
任务:根据分割,将不合格的XML文件分割成合格的XML文件。实现代码如下:
<p>def split_file(filename):
with open(filename) as infile:
n = -1 # 由于第一次遇到 ' 查看全部
实时抓取网页数据(
soup解析器的惯用方法及修改解析树的使用方法介绍
)
<a id="_0"></a>数据抓取操作步骤
创建用于发送HTTP请求时将用到的所有值发出HTTP请求并下载所有数据解析这些数据文件中需要的数据,
<a id="_4"></a>具体操作步骤
<p>首先需要弄清需要访问哪个URL以及需要哪种HTTP方法。HTTP方法类似于:
method="post"
</p>
该网址类似于:
action="Data_Elements.aspx?Data=2"
美汤
Beautiful Soup 是一个 Python 库,用于从 HTML 和 XML 文件中提取数据。它使用您最喜欢的解析器来提供用于导航、搜索和修改解析树的惯用方法。它通常可以为程序员节省数小时或数天。
以下是中文帮助文档的链接
这是不同美汤解析器的对比

使用 Beautiful Soup 提取隐藏字段
任务:使用 BeautifulSoup 处理 HTML 并提取
“__EVENTVALIDATION”和“__VIEWSTATE”的隐藏表字段值,并在数据字典中设置相应的值。
代码:
def extract_data(page):
# 同之前的方法一样,定义字典,方便对键赋值
data = {"eventvalidation": "",
"viewstate": ""}
with open(page, "r") as html:
# 这里用lxml解析器,后文会做简要介绍
soup = BeautifulSoup(html, "lxml")
ev = soup.find(id="__EVENTVALIDATION")
# 把ev中value的值取出来给data的键
data["eventvalidation"] = ev["value"]
vs = soup.find(id="__VIEWSTATE")
data["viewstate"] = vs["value"]
return data
解析器图像
建议使用 lxml 作为解析器,因为它更高效。Python32.7.3之前的版本和3.2.2之前的版本,必须安装lxml或者html5lib,因为标准内置的HTML解析方法这些 Python 版本的库不够稳定。
提示:如果 HTML 或 XML 文档的格式不正确,不同的解析器返回的结果可能不同
find() 方法
查找(名称,属性,递归,文本,**kwargs)
find_all() 方法会返回文档中所有符合条件的标签,尽管有时我们只想得到一个结果。比如文档中只有一个标签,那么就不宜使用find_all()方法查找标签,使用find_all方法并设置limit=1参数不如使用find()方法直接。下面两行代码是等价的:
soup.find_all('title', limit=1)
# [The Dormouse's story]
soup.find('title')
# The Dormouse's story
唯一的区别是 find_all() 方法的返回结果是一个值收录一个元素的列表,而 find() 方法直接返回结果。
find_all() 方法没有找到目标是返回一个空列表,当find() 方法找不到目标时,它返回None。
print(soup.find("nosuchtag"))
# None
Soup.head.title 是标签名称方法的简写。这个速记的原理是多次调用当前标签的find()方法:
soup.head.title
# The Dormouse's story
soup.find("head").find("title")
# The Dormouse's story
练习:获取运算符列表
任务
获取所有航空公司的列表。删除您返回的数据中的所有组合,例如“所有美国运营商”。最终,您应该返回操作员代码列表。
部分处理代码:
All U.S. and Foreign Carriers
All U.S. Carriers
All Foreign Carriers
AirTran Airways
Alaska Airlines
American Airlines
American Eagle Airlines
Atlas Air
Delta Air Lines
ExpressJet Airlines
Frontier Airlines
Hawaiian Airlines
JetBlue Airways
SkyWest Airlines
Southwest Airlines
Spirit Air Lines
US Airways
United Air Lines
Virgin America
All
All Major Airports
- Atlanta, GA: Hartsfield-Jackson Atlanta International
- Baltimore, MD: Baltimore/Washington International Thurgood Marshall
- Boston, MA: Logan International
- Charlotte, NC: Charlotte Douglas International
- Chicago, IL: Chicago Midway International
- Chicago, IL: Chicago O'Hare International
- Dallas/Fort Worth, TX: Dallas/Fort Worth International
- Denver, CO: Denver International
- Detroit, MI: Detroit Metro Wayne County
- Fort Lauderdale, FL: Fort Lauderdale-Hollywood International
- Houston, TX: George Bush Intercontinental/Houston
- Las Vegas, NV: McCarran International
- Los Angeles, CA: Los Angeles International
All Other Airports
- Aberdeen, SD: Aberdeen Regional
- Abilene, TX: Abilene Regional
解决方案:
def extract_carriers(page):
data = []
with open(page, "r") as html:
soup = BeautifulSoup(html, 'lxml')
# find方法里为什么必须要用id定位:问题一
carrier_list=soup.find(id='CarrierList')
options=carrier_list.find_all('option')
for tag in options:
# 取出标签value所对应的值,添加到列表中。不要标签值中带有All的
if 'All' not in tag['value']:
data.append(tag['value'])
return data
一问一答
注意 find() 方法格式:find( name, attrs, recursive, text, **kwargs)。
虽然名称标签也是唯一的,但是因为find函数已经使用了名称参数name来接收标签类型信息,下面两条语句其实是等价的:
carrier_tag = soup.find(name='CarrierList')
carrier_tag = soup.find('CarrierList')
相当于搜索了这种标签:,那么在目前的情况下肯定是搜索不到的~
如果要使用 name 属性进行搜索,可以使用以下语法:
carrier_list = soup.find('select', {'name': 'CarrierList'})
练习:处理所有数据 练习:专利数据库
在处理 XML 部分文件时,通常会遇到这样的错误:Error parsing XML: waste after document element。这是因为通常有效的 XML 文件只有一个主根节点,例如:
如果出现 Error parsing XML: waste after document element 之类的错误,你的想法可能是只要主根有多个节点
实际上,这种文件通常是由多个相互连接的 XML 文档组成的。一种解决方案是将文件拆分为多个文档,然后将这些文档处理为有效的 XML 文档。
任务:根据分割,将不合格的XML文件分割成合格的XML文件。实现代码如下:
<p>def split_file(filename):
with open(filename) as infile:
n = -1 # 由于第一次遇到 '
实时抓取网页数据(优采云原创的自动提取正文算法能适应网页的主体正文)
网站优化 • 优采云 发表了文章 • 0 个评论 • 111 次浏览 • 2021-10-23 20:11
当监听到最新网页时,该软件会列在列表框的最上方,并有提示音。
然后你点击列表中的一个标题,网页的文字就会自动显示在“快速阅读窗口”中。
优采云原创的自动文本提取算法,该算法可以适应大部分网页,自动提取网页的主体部分,单独阅读。
当然,你也可能会遇到提取错误,比如一些没有大正文的网页,比如视频播放页面等,这时候可以点击“打开原创网页”链接查看原创网页页。
指示
1、 一般网速为4M,同一程序监控的关键词数量不建议超过20个。即使你的网速很快,也不建议设置太多多个关键词同时监控,也可以尝试打开多个程序进行监控(将多个程序拷贝到不同文件夹,独立添加监控配置操作)。
2、 刷新列表显示数量,软件会动态保持在1500以内,超出的会自动去除
3、刷新列表的URL已经保存在【软件目录-刷新列表】目录下,关键词HTML和TXT格式文件各有两份。如果长时间运行后文件过大,可以自行删除或移动文件到新位置(先关闭监控程序)。
4、右键刷新列表中的标题,直接在浏览器中打开原网页,无需提取文字。
5、【关键词出现在标题中】只是在搜索引擎爬取中添加了[intitle:]参数,即使在搜索论坛或微信时使用该参数,返回的标题也可能不收录关键词(通常网页正文收录关键词),然后可以勾选[Fully Appear]强制关键词出现在标题中。
6、 刷新列表时间栏,[]方括号括起来是当地时间,网页时间不括起来。 查看全部
实时抓取网页数据(优采云原创的自动提取正文算法能适应网页的主体正文)
当监听到最新网页时,该软件会列在列表框的最上方,并有提示音。
然后你点击列表中的一个标题,网页的文字就会自动显示在“快速阅读窗口”中。
优采云原创的自动文本提取算法,该算法可以适应大部分网页,自动提取网页的主体部分,单独阅读。
当然,你也可能会遇到提取错误,比如一些没有大正文的网页,比如视频播放页面等,这时候可以点击“打开原创网页”链接查看原创网页页。
指示
1、 一般网速为4M,同一程序监控的关键词数量不建议超过20个。即使你的网速很快,也不建议设置太多多个关键词同时监控,也可以尝试打开多个程序进行监控(将多个程序拷贝到不同文件夹,独立添加监控配置操作)。
2、 刷新列表显示数量,软件会动态保持在1500以内,超出的会自动去除
3、刷新列表的URL已经保存在【软件目录-刷新列表】目录下,关键词HTML和TXT格式文件各有两份。如果长时间运行后文件过大,可以自行删除或移动文件到新位置(先关闭监控程序)。
4、右键刷新列表中的标题,直接在浏览器中打开原网页,无需提取文字。
5、【关键词出现在标题中】只是在搜索引擎爬取中添加了[intitle:]参数,即使在搜索论坛或微信时使用该参数,返回的标题也可能不收录关键词(通常网页正文收录关键词),然后可以勾选[Fully Appear]强制关键词出现在标题中。
6、 刷新列表时间栏,[]方括号括起来是当地时间,网页时间不括起来。
实时抓取网页数据(PM2.5监测站点的数据前台)
网站优化 • 优采云 发表了文章 • 0 个评论 • 147 次浏览 • 2021-10-23 04:10
用wpf做一个表单,类似Silverlight开发环境,将前端设计与后端开发逻辑分离,抓取9个PM2.南京5个监控站点的数据
前台代码:
背景代码:
<p> class MonitorInfo
{
public string Name{get;set;}
public string Density{get;set;}
};
List myListString=new List();
private string GetWebContent(string Url)
{
string strResult = "";
try
{
HttpWebRequest request = (HttpWebRequest)WebRequest.Create(Url);
//声明一个HttpWebRequest请求
request.Timeout = 30000;
//设置连接超时时间
request.Headers.Set("Pragma", "no-cache");
HttpWebResponse response = (HttpWebResponse)request.GetResponse();
Stream streamReceive = response.GetResponseStream();
Encoding encoding = Encoding.GetEncoding("GB2312");
StreamReader streamReader = new StreamReader(streamReceive, encoding);
strResult = streamReader.ReadToEnd();
}
catch
{
System.Windows.Forms.MessageBox.Show("出错");
}
return strResult;
}
private void button1_Click(object sender, RoutedEventArgs e)
{
textBox1.Text="http://www.pm2d5.com/city/nanjing.html";
String Url = textBox1.Text;
string strWebContent = GetWebContent(Url);
int divIndex = strWebContent.IndexOf("weilai");
int tableStartIndex = strWebContent.IndexOf(" 查看全部
实时抓取网页数据(PM2.5监测站点的数据前台)
用wpf做一个表单,类似Silverlight开发环境,将前端设计与后端开发逻辑分离,抓取9个PM2.南京5个监控站点的数据

前台代码:
背景代码:
<p> class MonitorInfo
{
public string Name{get;set;}
public string Density{get;set;}
};
List myListString=new List();
private string GetWebContent(string Url)
{
string strResult = "";
try
{
HttpWebRequest request = (HttpWebRequest)WebRequest.Create(Url);
//声明一个HttpWebRequest请求
request.Timeout = 30000;
//设置连接超时时间
request.Headers.Set("Pragma", "no-cache");
HttpWebResponse response = (HttpWebResponse)request.GetResponse();
Stream streamReceive = response.GetResponseStream();
Encoding encoding = Encoding.GetEncoding("GB2312");
StreamReader streamReader = new StreamReader(streamReceive, encoding);
strResult = streamReader.ReadToEnd();
}
catch
{
System.Windows.Forms.MessageBox.Show("出错");
}
return strResult;
}
private void button1_Click(object sender, RoutedEventArgs e)
{
textBox1.Text="http://www.pm2d5.com/city/nanjing.html";
String Url = textBox1.Text;
string strWebContent = GetWebContent(Url);
int divIndex = strWebContent.IndexOf("weilai");
int tableStartIndex = strWebContent.IndexOf("
实时抓取网页数据(网页监控管理-添加你的第一个监控(py3.7))
网站优化 • 优采云 发表了文章 • 0 个评论 • 163 次浏览 • 2021-10-22 20:13
3) 然后就可以自己部署docker-compose up -d了:
docker-compose up -d
4)打开你的就可以访问如下界面,说明一切正常:(如果不能访问,让8000端口安全~)
注:默认账号密码:admin、password
4、手动部署
1)很多人不喜欢docker的方式,所以我们可以手动部署。但最好的前提是安装下面的测试代码。独立运行环境(py3.7)
curl -sSO http://download.bt.cn/install/install_panel.sh && bash install_panel.sh
2)下载WebMonitor的源代码
git clone https://github.com/LogicJake/WebMonitor.git
cd WebMonitor
3)下载后安装依赖
pip install -r requirements.txt
4) 第一次运行需要迁移数据库并设置管理账号。假设账号为admin,密码为password,运行端口为8000。
python manage.py migrate
python manage.py initadmin --username admin --password password
python manage.py runserver 0.0.0.0:8000 --noreload
5)不是第一次运行,只是指定端口
python manage.py runserver 0.0.0.0:8000 --noreload
注:默认账号密码:admin、password
5、设置网络监控
1) 登录后,我们首先需要设置通知方式,这里我们使用Server酱的微信通知~
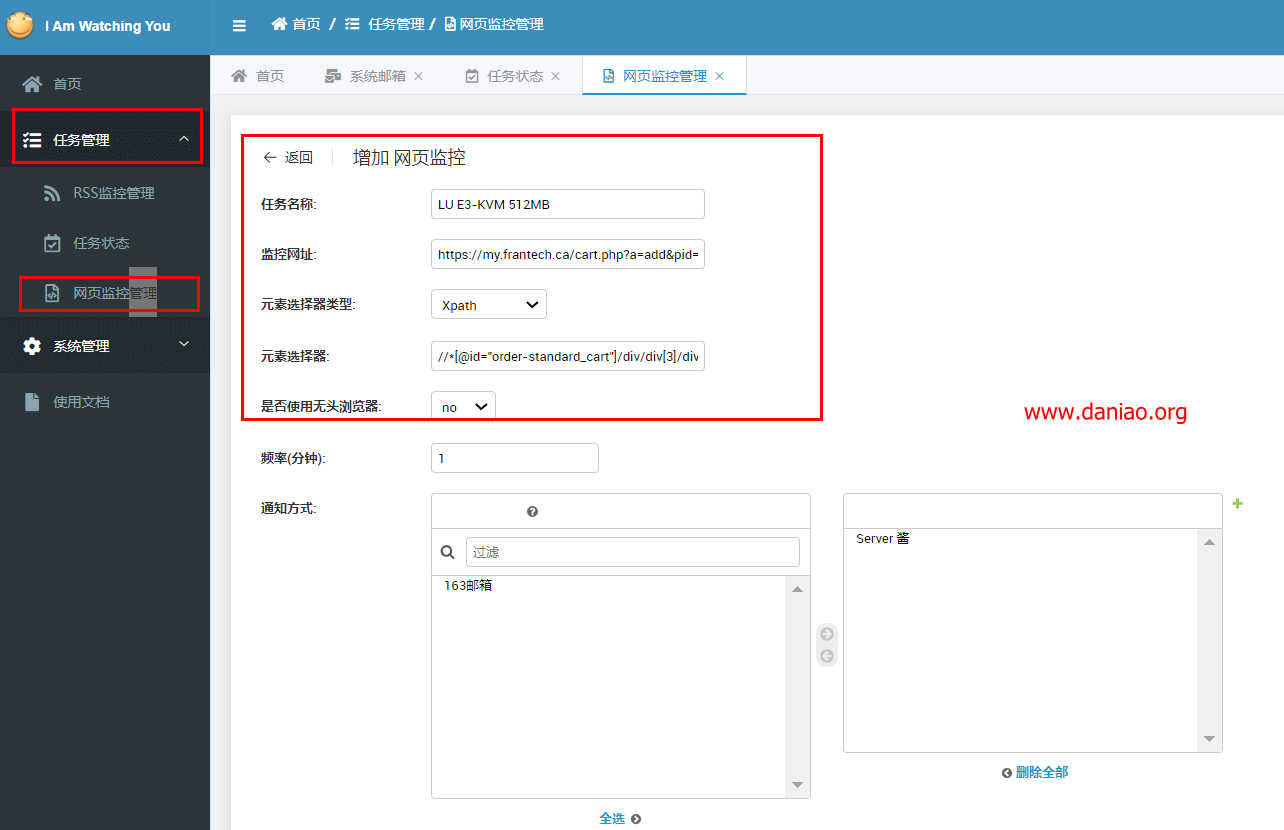
2)添加监控项,在任务管理-Web监控管理-添加你的第一个监控。
例子:我想监控BUYVM的VPS是否有货。元素选择器类型使用 XPath:
注意:
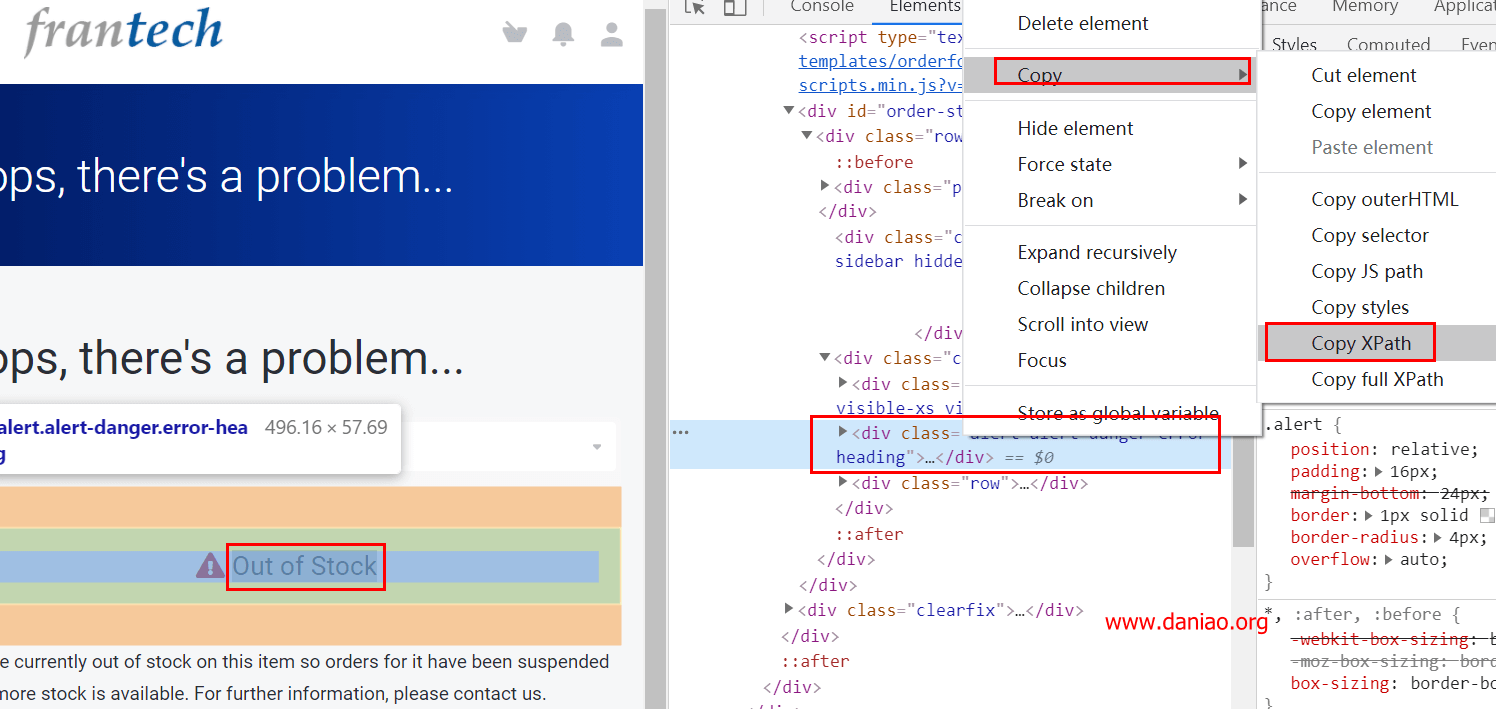
3)元素选择器的内容可以通过Chrome浏览器F12获取:
4) 保存以上即可完成监控项目的创建。在下面找到任务状态,看看你添加的监控项目是否可以正常工作:
5) 第一次添加的监控项,如果正常的话,你的微信应该也能收到服务器酱的消息:
设置RSS监控
设置方法和网页监控类似,这里截图展示一下。
7、设置域名访问
直接看图:
8、终于
监控网页内容变化非常好用,安装方法也非常简单。有这个要求的童鞋可以用。具体特点如下:
内容 查看全部
实时抓取网页数据(网页监控管理-添加你的第一个监控(py3.7))
3) 然后就可以自己部署docker-compose up -d了:
docker-compose up -d
4)打开你的就可以访问如下界面,说明一切正常:(如果不能访问,让8000端口安全~)
注:默认账号密码:admin、password
4、手动部署
1)很多人不喜欢docker的方式,所以我们可以手动部署。但最好的前提是安装下面的测试代码。独立运行环境(py3.7)
curl -sSO http://download.bt.cn/install/install_panel.sh && bash install_panel.sh
2)下载WebMonitor的源代码
git clone https://github.com/LogicJake/WebMonitor.git
cd WebMonitor
3)下载后安装依赖
pip install -r requirements.txt
4) 第一次运行需要迁移数据库并设置管理账号。假设账号为admin,密码为password,运行端口为8000。
python manage.py migrate
python manage.py initadmin --username admin --password password
python manage.py runserver 0.0.0.0:8000 --noreload
5)不是第一次运行,只是指定端口
python manage.py runserver 0.0.0.0:8000 --noreload
注:默认账号密码:admin、password
5、设置网络监控
1) 登录后,我们首先需要设置通知方式,这里我们使用Server酱的微信通知~
2)添加监控项,在任务管理-Web监控管理-添加你的第一个监控。
例子:我想监控BUYVM的VPS是否有货。元素选择器类型使用 XPath:
注意:
3)元素选择器的内容可以通过Chrome浏览器F12获取:
4) 保存以上即可完成监控项目的创建。在下面找到任务状态,看看你添加的监控项目是否可以正常工作:

5) 第一次添加的监控项,如果正常的话,你的微信应该也能收到服务器酱的消息:


设置RSS监控
设置方法和网页监控类似,这里截图展示一下。
7、设置域名访问
直接看图:
8、终于
监控网页内容变化非常好用,安装方法也非常简单。有这个要求的童鞋可以用。具体特点如下:
内容
实时抓取网页数据(Python爬虫入门教程!手把手教会你爬取网页数据(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 88 次浏览 • 2021-10-21 08:17
链接提交工具是网站主动推送数据到百度搜索的工具。该工具可以缩短爬虫发现网站链接的时间,网站时间敏感的内容推荐使用链接提交工具实时推送搜索数据。这个工具可以加快爬虫的爬行速度,但是不能解决网站。
网页内容智能抓取的实现和实例详解完全基于java。核心技术核心技术XML解析、HTML解析、开源组件应用。该应用程序的开源组件包括: DOM4J:解析 XMLjericho-。
Python爬虫入门教程!手把手教你爬取网页数据。
它可以帮助我们快速采集互联网的海量内容,进行深入的数据分析和挖掘。比如抓取各大网站的排名,抓取各大购物的价格信息网站等等。而我们每天常用的搜索引擎都是“网络爬虫”。但毕竟要学习。
爬取网页内容的一个例子来自于通过程序自动读取其他网站网页上显示的信息,类似于爬虫程序。例如,我们有一个。
优采云网页数据采集器,是一款简单易用、功能强大的网络爬虫工具,完全可视化操作,无需编写代码,内置海量模板,支持任意网页数据抓取,连续五年.
网页内容提取器可以帮助我们快速提取输入的URL链接中的所有图片、链接和网页文本内容。
优采云·云采集服务平台网站如何使用内容爬取工具网络每天都在产生海量的图文数据。如何为你我使用这些数据,让数据给我们工作带来真正的价值? 查看全部
实时抓取网页数据(Python爬虫入门教程!手把手教会你爬取网页数据(组图))
链接提交工具是网站主动推送数据到百度搜索的工具。该工具可以缩短爬虫发现网站链接的时间,网站时间敏感的内容推荐使用链接提交工具实时推送搜索数据。这个工具可以加快爬虫的爬行速度,但是不能解决网站。
网页内容智能抓取的实现和实例详解完全基于java。核心技术核心技术XML解析、HTML解析、开源组件应用。该应用程序的开源组件包括: DOM4J:解析 XMLjericho-。
Python爬虫入门教程!手把手教你爬取网页数据。
它可以帮助我们快速采集互联网的海量内容,进行深入的数据分析和挖掘。比如抓取各大网站的排名,抓取各大购物的价格信息网站等等。而我们每天常用的搜索引擎都是“网络爬虫”。但毕竟要学习。
爬取网页内容的一个例子来自于通过程序自动读取其他网站网页上显示的信息,类似于爬虫程序。例如,我们有一个。

优采云网页数据采集器,是一款简单易用、功能强大的网络爬虫工具,完全可视化操作,无需编写代码,内置海量模板,支持任意网页数据抓取,连续五年.
网页内容提取器可以帮助我们快速提取输入的URL链接中的所有图片、链接和网页文本内容。

优采云·云采集服务平台网站如何使用内容爬取工具网络每天都在产生海量的图文数据。如何为你我使用这些数据,让数据给我们工作带来真正的价值?
实时抓取网页数据(运营商大数据,全行业精准平台大平台)
网站优化 • 优采云 发表了文章 • 0 个评论 • 160 次浏览 • 2021-10-17 03:14
运营商大数据,全行业精准大数据获客平台
在大数据时代的今天,我们可以利用大数据,通过算法,在app或者网站中精准推送用户兴趣偏好的产品和内容。运营商大数据具有互联网公司无法比拟的用户数据、实时性和准确性。运营商对大数据的应用,不像互联网公司,只能应用到自己的业务上,而是可以帮助各个行业和企业拓展获客、营销等应用,可以根据不同的行业领域帮助不同的行业领域。到他们的收购。对客户需求进行建模以获得准确的客户数据。
如何帮助企业解决获客难题?
运营商大数据拥有海量数据资源,运营商大数据强大的建模能力,可实时分析捕捉实时访客数据,如:网站、网站、网页、URL;手机APP的每日活跃用户/新注册用户数据;400/固话主叫、被叫、出线、来电和去电记录;短信接收群;关键词搜索群等多维度、多平台的用户数据信息,并通过建立用户画像,准确分析用户所在地区、年龄、性别、访问次数、通话时长等用户信息,和短信互动。还可以分析同行业、垂直领域、竞品线索(如URL、APP、400/固话等)。
网站、网页、网址、URL:如搜索引擎排名靠前的推广网页、网站、出价网站、网页等将被屏蔽。
手机APP:例如装修行业的垂直领域APP:土巴兔装修;金融行业垂直APP:平安普惠、平安银行等,用于活跃用户和新注册用户的获取。
400/固话:如竞品、对等400/固话、座机,捕捉来电和被叫、来电和去电记录。
SMS/关键词:如果短信接收者拥挤,关键词 搜索人群以捕获。
移动、联通运营商大数据可以帮助全行业、中小微企业精准获客、精准营销、精准触达目标客户。可以帮助不同行业的多领域、多维度,企业可以获得精准的目标客户群。对获取的实时数据进行脱敏处理,从而规避法律风险。企业可以使用专业的CRM客户管理外呼系统进行实时管理,精准触达客户,确定客户意向,进行转化和交易。 查看全部
实时抓取网页数据(运营商大数据,全行业精准平台大平台)
运营商大数据,全行业精准大数据获客平台
在大数据时代的今天,我们可以利用大数据,通过算法,在app或者网站中精准推送用户兴趣偏好的产品和内容。运营商大数据具有互联网公司无法比拟的用户数据、实时性和准确性。运营商对大数据的应用,不像互联网公司,只能应用到自己的业务上,而是可以帮助各个行业和企业拓展获客、营销等应用,可以根据不同的行业领域帮助不同的行业领域。到他们的收购。对客户需求进行建模以获得准确的客户数据。

如何帮助企业解决获客难题?
运营商大数据拥有海量数据资源,运营商大数据强大的建模能力,可实时分析捕捉实时访客数据,如:网站、网站、网页、URL;手机APP的每日活跃用户/新注册用户数据;400/固话主叫、被叫、出线、来电和去电记录;短信接收群;关键词搜索群等多维度、多平台的用户数据信息,并通过建立用户画像,准确分析用户所在地区、年龄、性别、访问次数、通话时长等用户信息,和短信互动。还可以分析同行业、垂直领域、竞品线索(如URL、APP、400/固话等)。

网站、网页、网址、URL:如搜索引擎排名靠前的推广网页、网站、出价网站、网页等将被屏蔽。
手机APP:例如装修行业的垂直领域APP:土巴兔装修;金融行业垂直APP:平安普惠、平安银行等,用于活跃用户和新注册用户的获取。
400/固话:如竞品、对等400/固话、座机,捕捉来电和被叫、来电和去电记录。
SMS/关键词:如果短信接收者拥挤,关键词 搜索人群以捕获。
移动、联通运营商大数据可以帮助全行业、中小微企业精准获客、精准营销、精准触达目标客户。可以帮助不同行业的多领域、多维度,企业可以获得精准的目标客户群。对获取的实时数据进行脱敏处理,从而规避法律风险。企业可以使用专业的CRM客户管理外呼系统进行实时管理,精准触达客户,确定客户意向,进行转化和交易。
实时抓取网页数据(天天自动抓取更新系统全智能抓取,行业分类卡布奇诺)
网站优化 • 优采云 发表了文章 • 0 个评论 • 179 次浏览 • 2021-10-17 03:09
每天自动爬取更新。系统全智能抓取,多网页、多站点抓取,数据智能分析。模仿搜索引擎抓取网页,成功率超过90。实时通知,数据更新实时邮件/微信通知。无需人工操作,启动后会持续推送。模仿搜索引擎抓取网页,成功率很高。无需一直坐在电脑前刷新网页,数据自动获取。经过近一年的实际生产环境测试和应用,该软件正式上市。
支持新闻列表、论坛帖子、竞价信息、新品、股市财经资讯、微博更新等网站平台爬取监控,通用网页列表监控软件。
监控网站信息列表,有更新或满足关键字条件时立即提醒记录。帮助您从海量的网络信息中获取有用的信息,第一时间获取最准确的信息。最适合广大投资者或记者。
每日自动爬取更新系统特点:
1、软件具有更新监控和关键链接过滤功能。
2、更新监控是指当出现新的信息链接网站时,会被捕获并放入数据库,不会重复提醒。
3、软件支持同时监控多个网站,获取更全面的信息。
4、 抓取数据存入数据库,随时打开参考。
5、支持常用的提醒方式,包括邮件/微信等。
6、一般网站使用源码监控的方式,速度快又节省资源。
免责声明:源代码仅供研究和学习代码使用,严禁用于非法和商业用途!不提供任何技术支持,不包括安装。商用请购买官方源码!
类别
ㄣ卡布奇诺╰☆ぷ普通 查看全部
实时抓取网页数据(天天自动抓取更新系统全智能抓取,行业分类卡布奇诺)
每天自动爬取更新。系统全智能抓取,多网页、多站点抓取,数据智能分析。模仿搜索引擎抓取网页,成功率超过90。实时通知,数据更新实时邮件/微信通知。无需人工操作,启动后会持续推送。模仿搜索引擎抓取网页,成功率很高。无需一直坐在电脑前刷新网页,数据自动获取。经过近一年的实际生产环境测试和应用,该软件正式上市。
支持新闻列表、论坛帖子、竞价信息、新品、股市财经资讯、微博更新等网站平台爬取监控,通用网页列表监控软件。
监控网站信息列表,有更新或满足关键字条件时立即提醒记录。帮助您从海量的网络信息中获取有用的信息,第一时间获取最准确的信息。最适合广大投资者或记者。
每日自动爬取更新系统特点:
1、软件具有更新监控和关键链接过滤功能。
2、更新监控是指当出现新的信息链接网站时,会被捕获并放入数据库,不会重复提醒。
3、软件支持同时监控多个网站,获取更全面的信息。
4、 抓取数据存入数据库,随时打开参考。
5、支持常用的提醒方式,包括邮件/微信等。
6、一般网站使用源码监控的方式,速度快又节省资源。


免责声明:源代码仅供研究和学习代码使用,严禁用于非法和商业用途!不提供任何技术支持,不包括安装。商用请购买官方源码!
类别
ㄣ卡布奇诺╰☆ぷ普通
实时抓取网页数据( 如何利用Python爬取模块获取查看器的html内容(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 95 次浏览 • 2021-10-16 07:41
如何利用Python爬取模块获取查看器的html内容(图))
1. 文章 目的
我们在使用Python抓取网页数据时,经常会用到urllib模块,通过调用urllib模块的urlopen(url)方法返回网页。
页面对象,使用read()方法获取url的html内容,然后使用BeautifulSoup抓取某个标签的内容,结合正则表
亲爱的过滤器。然而,你用 urllib.urlopen(url).read() 得到的只是网页的静态 html 内容,还有很多动态数据(比如 网站
访问量、当前在线人数、微博点赞数等)不收录在静态html中,比如我要抢这个bbs网
当前点击打开站点内各版块链接的在线人数不收录在静态html页面中(不信你去查一下页面源码,
只有一条简单的线)。像这样的动态数据更多是由 JavaScript、JQuery、PHP 等语言动态生成的。因此,
不宜使用爬取静态html内容的方法。
2. 解决方案
我试过网上提到的浏览器自带的开发者工具(一般是F12弹出对应网页的开发者工具),上网查了一下
动态数据的趋势是可以得到的,但是这需要从众多的URL中寻找线索,我个人觉得太麻烦了。另外,使用查看器
查看的html内容也收录动态数据,但是有几个问题:如何实时获取查看器的html内容?如何查看
html变成python程序?因此,使用查看器的html内容的方法也不符合爬虫的要求。
偶然发现了selenium模块,发现这个模块可以很方便的根据url加载页面获取session,并找到当前se
ssion 对应的标签。本文将使用 selenium webdriver 模块来获取这些动态生成的内容,尤其是一个
一些重要的动态数据。其实selenium模块的功能不仅限于抓取网页,它是网络自动化测试的常用模块
,在Ruby和Java中被广泛使用。Python虽然使用的比较少,但它也是一个非常简洁、高效、易用的工具。
手的自动化测试模块。通过使用selenium的子模块webdriver解决动态数据的捕获问题,还可以
可以对selenium有一个基本的了解,为进一步学习自动化测试打下基础。
3. 实施过程
3.1 运行环境
我在windows 7系统上安装了Python2.7版本,使用的是Python(X,Y)的IDE,安装的Python库没有self
用selenium,如果直接在Python程序中导入selenium,会提示没有这个模块。联网状态下,cmd直接进入pip i
安装selenium,系统会找到Python安装目录直接下载、解压安装这个模块。等到终端提示完成
我们看看C:\Python27\Lib\site-packages目录下有没有selenium模块。这个目录取决于你安装的 Python
的路径。如果有两个文件夹,selenium和selenium-2.47.3.dist-info,可以在Python程序中添加模块
已加载。
使用 webdriver 捕获动态数据
先导入webdriver子模块
从硒导入网络驱动程序
获取浏览器会话,可以使用火狐、Chrome、IE等浏览器,这里以火狐为例
浏览器 = webdriver.Firefox()
加载页面,在 url 本身中指定一个合法的字符串
browser.get(url)
获取到session对象后,为了定位元素,webdriver提供了一系列的元素定位方法。常用的方法有以下几种:
ID
姓名
班级名称
关联
文本
部分的
关联
文本
标签
姓名
路径
css选择器
比如通过id定位,返回一个所有元素组成的列表,lis=borwser.find_elements_by_id_name('kw'')
按类名定位,lis=find_elements_by_class_name('title_1')
更详细的定位方法请参考selenium webdriver(python)教程第三章-定位方法(第一版可百度
学位图书馆阅读)
结合正则表达式过滤相关信息
定位后的一些元素是不可取的,只需使用常规过滤即可。比如我想只提取英文字符(包括0-9),创建如下
常规的
pa=堆(r'\w+')
对于 lis 中的你:
en=pa.findall(u.lis)
印刷英文
关闭会话
执行fetch操作后必须关闭session,否则让它一直占用内存会影响机器上其他进程的操作
Browser.close() 或 browser.quit() 可以关闭会话,前者只是关闭当前会话,浏览器的webdrive
r 未关闭,后者已关闭,包括 webdriver 等所有内容
添加异常处理
这个是必须的,因为有时候会获取session失败,所以把上面的语句块放到try里面,然后用exception处理
除了 NoSuchElementException:
断言 0,“找不到元素”
4. 代码实现
我通过点击打开链接抓取了指定分区每个板块的在线用户数,并指定了分区id号(0-9),可以得到板块名称和
在线用户数应该打印在一个列表中,代码如下
[python] 查看平原
# -*- 编码:utf-8 -*-
从硒导入网络驱动程序
从 mon.exceptions 导入 NoSuchElementException
导入时间
进口重新
def find_sec(secid):
pa=堆(r'\w+')
browser = webdriver.Firefox() # 获取firefox的本地会话
browser.get("!section/%s "%secid) # 加载页面
time.sleep(1) # 让页面加载
结果=[]
尝试:
#获取页面名称和在线号码组成列表
board=browser.find_elements_by_class_name('title_1')
ol_num=browser.find_elements_by_class_name('title_4')
max_bindex=len(板)
max_oindex=len(ol_num)
assert max_bindex==max_oindex,'索引不等价!'
#页面名称为中英文,所以常规过滤后只剩下英文
对于范围内的 i(1,max_oindex):
board_en=pa.findall(board.text)
result.append([str(board_en[-1]),int(ol_num.text)])
浏览器关闭()
返回结果
除了 NoSuchElementException:
断言 0,“找不到元素”
print find_sec('5')#打印第5分区下所有版块的当前在线用户列表
操作结果如下:
终端打印效果
4. 总结
Selenium 在代码简洁性和执行效率方面非常出色。使用 selenium webdriver 捕获动态数据不是
它通常简单而有效。也可以进一步利用这个实现数据挖掘、机器学习等深入研究,所以selenium+pyth
就值得深入研究!如果觉得每次都用selenium打开浏览器不方便,可以用phantomjs模拟一个虚拟的
浏览器出来了,这里就不赘述了。 查看全部
实时抓取网页数据(
如何利用Python爬取模块获取查看器的html内容(图))

1. 文章 目的
我们在使用Python抓取网页数据时,经常会用到urllib模块,通过调用urllib模块的urlopen(url)方法返回网页。
页面对象,使用read()方法获取url的html内容,然后使用BeautifulSoup抓取某个标签的内容,结合正则表
亲爱的过滤器。然而,你用 urllib.urlopen(url).read() 得到的只是网页的静态 html 内容,还有很多动态数据(比如 网站
访问量、当前在线人数、微博点赞数等)不收录在静态html中,比如我要抢这个bbs网
当前点击打开站点内各版块链接的在线人数不收录在静态html页面中(不信你去查一下页面源码,
只有一条简单的线)。像这样的动态数据更多是由 JavaScript、JQuery、PHP 等语言动态生成的。因此,
不宜使用爬取静态html内容的方法。
2. 解决方案
我试过网上提到的浏览器自带的开发者工具(一般是F12弹出对应网页的开发者工具),上网查了一下
动态数据的趋势是可以得到的,但是这需要从众多的URL中寻找线索,我个人觉得太麻烦了。另外,使用查看器
查看的html内容也收录动态数据,但是有几个问题:如何实时获取查看器的html内容?如何查看
html变成python程序?因此,使用查看器的html内容的方法也不符合爬虫的要求。
偶然发现了selenium模块,发现这个模块可以很方便的根据url加载页面获取session,并找到当前se
ssion 对应的标签。本文将使用 selenium webdriver 模块来获取这些动态生成的内容,尤其是一个
一些重要的动态数据。其实selenium模块的功能不仅限于抓取网页,它是网络自动化测试的常用模块
,在Ruby和Java中被广泛使用。Python虽然使用的比较少,但它也是一个非常简洁、高效、易用的工具。
手的自动化测试模块。通过使用selenium的子模块webdriver解决动态数据的捕获问题,还可以
可以对selenium有一个基本的了解,为进一步学习自动化测试打下基础。
3. 实施过程
3.1 运行环境
我在windows 7系统上安装了Python2.7版本,使用的是Python(X,Y)的IDE,安装的Python库没有self
用selenium,如果直接在Python程序中导入selenium,会提示没有这个模块。联网状态下,cmd直接进入pip i
安装selenium,系统会找到Python安装目录直接下载、解压安装这个模块。等到终端提示完成
我们看看C:\Python27\Lib\site-packages目录下有没有selenium模块。这个目录取决于你安装的 Python
的路径。如果有两个文件夹,selenium和selenium-2.47.3.dist-info,可以在Python程序中添加模块
已加载。
使用 webdriver 捕获动态数据
先导入webdriver子模块
从硒导入网络驱动程序
获取浏览器会话,可以使用火狐、Chrome、IE等浏览器,这里以火狐为例
浏览器 = webdriver.Firefox()
加载页面,在 url 本身中指定一个合法的字符串
browser.get(url)
获取到session对象后,为了定位元素,webdriver提供了一系列的元素定位方法。常用的方法有以下几种:
ID
姓名
班级名称
关联
文本
部分的
关联
文本
标签
姓名
路径
css选择器
比如通过id定位,返回一个所有元素组成的列表,lis=borwser.find_elements_by_id_name('kw'')
按类名定位,lis=find_elements_by_class_name('title_1')
更详细的定位方法请参考selenium webdriver(python)教程第三章-定位方法(第一版可百度
学位图书馆阅读)
结合正则表达式过滤相关信息
定位后的一些元素是不可取的,只需使用常规过滤即可。比如我想只提取英文字符(包括0-9),创建如下
常规的
pa=堆(r'\w+')
对于 lis 中的你:
en=pa.findall(u.lis)
印刷英文
关闭会话
执行fetch操作后必须关闭session,否则让它一直占用内存会影响机器上其他进程的操作
Browser.close() 或 browser.quit() 可以关闭会话,前者只是关闭当前会话,浏览器的webdrive
r 未关闭,后者已关闭,包括 webdriver 等所有内容
添加异常处理
这个是必须的,因为有时候会获取session失败,所以把上面的语句块放到try里面,然后用exception处理
除了 NoSuchElementException:
断言 0,“找不到元素”
4. 代码实现
我通过点击打开链接抓取了指定分区每个板块的在线用户数,并指定了分区id号(0-9),可以得到板块名称和
在线用户数应该打印在一个列表中,代码如下
[python] 查看平原
# -*- 编码:utf-8 -*-
从硒导入网络驱动程序
从 mon.exceptions 导入 NoSuchElementException
导入时间
进口重新
def find_sec(secid):
pa=堆(r'\w+')
browser = webdriver.Firefox() # 获取firefox的本地会话
browser.get("!section/%s "%secid) # 加载页面
time.sleep(1) # 让页面加载
结果=[]
尝试:
#获取页面名称和在线号码组成列表
board=browser.find_elements_by_class_name('title_1')
ol_num=browser.find_elements_by_class_name('title_4')
max_bindex=len(板)
max_oindex=len(ol_num)
assert max_bindex==max_oindex,'索引不等价!'
#页面名称为中英文,所以常规过滤后只剩下英文
对于范围内的 i(1,max_oindex):
board_en=pa.findall(board.text)
result.append([str(board_en[-1]),int(ol_num.text)])
浏览器关闭()
返回结果
除了 NoSuchElementException:
断言 0,“找不到元素”
print find_sec('5')#打印第5分区下所有版块的当前在线用户列表
操作结果如下:
终端打印效果
4. 总结
Selenium 在代码简洁性和执行效率方面非常出色。使用 selenium webdriver 捕获动态数据不是
它通常简单而有效。也可以进一步利用这个实现数据挖掘、机器学习等深入研究,所以selenium+pyth
就值得深入研究!如果觉得每次都用selenium打开浏览器不方便,可以用phantomjs模拟一个虚拟的
浏览器出来了,这里就不赘述了。
实时抓取网页数据(下有模拟浏览器本文几种网站示例详解方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 294 次浏览 • 2021-10-16 07:37
使用python爬取网站数据非常方便,效率也很高,但是常用的BeautifSoup和requests的组合一般用于爬取静态页面(即网页上显示的数据)可以在html源码中找到,不是网站通过js或者ajax异步加载的),这种网站数据比较容易爬取。但是网站上的一些数据是通过执行js代码更新的。这时候,传统的方法就不那么适用了。这种情况下有几种方法:
一、准备
模拟浏览器需要两个工具:
Selenium,可以直接通过pip install selenium安装PhantomJS。这是一个无界面、脚本可编程的 WebKit 浏览器引擎。百度在其官方网站上搜索并下载。下载后,您无需安装。把它放在指定的路径中。使用时只需要指定文件所在的路径即可。二、使用selenium模拟浏览器
本文爬取网站的例子是:8099/ths-report/report!list.action?xmlname=46(最新测试发现网站打不开,2021年5月25日)
学习示例时请不要抓取太多页面,只需通过过程了解如何抓取它。
打开网站后可以看到要爬取的数据是一个普通的表,但是页面很多。
在这个网站中,点击下一页的页面的url没有变化,通过执行一段js代码来更新页面。所以本文的思路是用selenium模拟浏览器点击,点击“下一步”更新页面数据,得到更新后的页面数据。这是完整的代码:
# -*- coding:utf-8 -*-
import requests
from bs4 import BeautifulSoup
import json
import time
from selenium import webdriver
import sys
reload(sys)
sys.setdefaultencoding( "utf-8" )
curpath=sys.path[0]
print curpath
def getData(url):
# 使用下载好的phantomjs,网上也有人用firefox,chrome,但是我没有成功,用这个也挺方便
driver =webdriver.PhantomJS(executable_path="C:/phantomjs.exe")
driver.set_page_load_timeout(30)
time.sleep(3)
html=driver.get(url[0]) # 使用get方法请求url,因为是模拟浏览器,所以不需要headers信息
for page in range(3):
html=driver.page_source # 获取网页的html数据
soup=BeautifulSoup(html,'lxml') # 对html进行解析,如果提示lxml未安装,直接pip install lxml即可
table=soup.find('table',class_="report-table")
name=[]
for th in table.find_all('tr')[0].find_all('th'):
name.append(th.get_text()) # 获取表格的字段名称作为字典的键
flag=0 # 标记,当爬取字段数据是为0,否则为1
for tr in table.find_all('tr'):
# 第一行为表格字段数据,因此跳过第一行
if flag==1:
dic={}
i=0
for td in tr.find_all('td'):
dic[name[i]]=td.get_text()
i+=1
jsonDump(dic,url[1])#保存数据
flag=1
# 利用find_element_by_link_text方法得到下一页所在的位置并点击,点击后页面会自动更新,只需要重新获取driver.page_source即可
driver.find_element_by_link_text(u"下一页").click()
def jsonDump(_json,name):
"""store json data"""
with open(curpath+'/'+name+'.json','a') as outfile:
json.dump(_json,outfile,ensure_ascii=False)
with open(curpath+'/'+name+'.json','a') as outfile:
outfile.write(',\n')
if __name__ == '__main__':
url=['http://datacenter.mep.gov.cn:8 ... 39%3B,'yzc'] # yzc为文件名,此处输入中文会报错,前面加u也不行,只好保存后手动改文件名……
getData(url) # 调用函数
本文通过driver.find_element_by_link_text方法获取下一页的位置。这是因为在这个页面中,这个标签没有唯一可识别的 id,也没有类。如果是通过xpath定位,第一页和其他页面的xpath路径不完全一样,需要加一个if来判断。所以直接通过链接的text参数定位。click() 函数模拟浏览器中的点击操作。如何定位页面中的元素位置,可以参考下面的博客。
Selenuim+Python 元素定位总结及示例说明
硒非常强大。可以解决很多普通爬虫无法解决的问题。可以模拟点击、鼠标移动、提交表单(应用如:登录邮箱账号、登录wifi等,网上有很多例子,我暂时还没试过),当你遇到一些非常规网站 数据爬取难度很大,不妨试试selenium+phantomjs。
以上,欢迎交流。 查看全部
实时抓取网页数据(下有模拟浏览器本文几种网站示例详解方法)
使用python爬取网站数据非常方便,效率也很高,但是常用的BeautifSoup和requests的组合一般用于爬取静态页面(即网页上显示的数据)可以在html源码中找到,不是网站通过js或者ajax异步加载的),这种网站数据比较容易爬取。但是网站上的一些数据是通过执行js代码更新的。这时候,传统的方法就不那么适用了。这种情况下有几种方法:
一、准备
模拟浏览器需要两个工具:
Selenium,可以直接通过pip install selenium安装PhantomJS。这是一个无界面、脚本可编程的 WebKit 浏览器引擎。百度在其官方网站上搜索并下载。下载后,您无需安装。把它放在指定的路径中。使用时只需要指定文件所在的路径即可。二、使用selenium模拟浏览器
本文爬取网站的例子是:8099/ths-report/report!list.action?xmlname=46(最新测试发现网站打不开,2021年5月25日)
学习示例时请不要抓取太多页面,只需通过过程了解如何抓取它。
打开网站后可以看到要爬取的数据是一个普通的表,但是页面很多。

在这个网站中,点击下一页的页面的url没有变化,通过执行一段js代码来更新页面。所以本文的思路是用selenium模拟浏览器点击,点击“下一步”更新页面数据,得到更新后的页面数据。这是完整的代码:
# -*- coding:utf-8 -*-
import requests
from bs4 import BeautifulSoup
import json
import time
from selenium import webdriver
import sys
reload(sys)
sys.setdefaultencoding( "utf-8" )
curpath=sys.path[0]
print curpath
def getData(url):
# 使用下载好的phantomjs,网上也有人用firefox,chrome,但是我没有成功,用这个也挺方便
driver =webdriver.PhantomJS(executable_path="C:/phantomjs.exe")
driver.set_page_load_timeout(30)
time.sleep(3)
html=driver.get(url[0]) # 使用get方法请求url,因为是模拟浏览器,所以不需要headers信息
for page in range(3):
html=driver.page_source # 获取网页的html数据
soup=BeautifulSoup(html,'lxml') # 对html进行解析,如果提示lxml未安装,直接pip install lxml即可
table=soup.find('table',class_="report-table")
name=[]
for th in table.find_all('tr')[0].find_all('th'):
name.append(th.get_text()) # 获取表格的字段名称作为字典的键
flag=0 # 标记,当爬取字段数据是为0,否则为1
for tr in table.find_all('tr'):
# 第一行为表格字段数据,因此跳过第一行
if flag==1:
dic={}
i=0
for td in tr.find_all('td'):
dic[name[i]]=td.get_text()
i+=1
jsonDump(dic,url[1])#保存数据
flag=1
# 利用find_element_by_link_text方法得到下一页所在的位置并点击,点击后页面会自动更新,只需要重新获取driver.page_source即可
driver.find_element_by_link_text(u"下一页").click()
def jsonDump(_json,name):
"""store json data"""
with open(curpath+'/'+name+'.json','a') as outfile:
json.dump(_json,outfile,ensure_ascii=False)
with open(curpath+'/'+name+'.json','a') as outfile:
outfile.write(',\n')
if __name__ == '__main__':
url=['http://datacenter.mep.gov.cn:8 ... 39%3B,'yzc'] # yzc为文件名,此处输入中文会报错,前面加u也不行,只好保存后手动改文件名……
getData(url) # 调用函数
本文通过driver.find_element_by_link_text方法获取下一页的位置。这是因为在这个页面中,这个标签没有唯一可识别的 id,也没有类。如果是通过xpath定位,第一页和其他页面的xpath路径不完全一样,需要加一个if来判断。所以直接通过链接的text参数定位。click() 函数模拟浏览器中的点击操作。如何定位页面中的元素位置,可以参考下面的博客。
Selenuim+Python 元素定位总结及示例说明
硒非常强大。可以解决很多普通爬虫无法解决的问题。可以模拟点击、鼠标移动、提交表单(应用如:登录邮箱账号、登录wifi等,网上有很多例子,我暂时还没试过),当你遇到一些非常规网站 数据爬取难度很大,不妨试试selenium+phantomjs。
以上,欢迎交流。
实时抓取网页数据( 网页数据如下图:#找到要数据的网址(rvest))
网站优化 • 优采云 发表了文章 • 0 个评论 • 163 次浏览 • 2021-10-11 13:28
网页数据如下图:#找到要数据的网址(rvest))
写论文,没有数据?R语言爬取网络大数据
放眼国内外,大数据市场发展迅猛,政府支持力度空前,甚至将大数据纳入发展战略。这样的形势给社会各界提供了许多机遇和挑战,作为卫生(医疗)统计领域的一员,我们更要抓住机遇。放眼全球,大数据的应用规模不断扩大,几乎每个行业都将目光投向了大数据背后的巨大价值。未来五到十年将是我国推动大数据发展的关键时期,亟需打造高效的大数据应用机制和产业链。
根据对当前大数据行业发展的分析,我们可能会从“视觉数据捕捉”开始思考大数据。这里所说的可视化数据抓取主要是指对互联网网页数据的抓取,可以实现大数据应用的普及。目前,我们已经可以使用一个简单的网页数据爬取工具来爬取它所需要的网页数据,比如知名的网页数据爬取工具“**采集器”(收费)。现有的互联网数据采集、处理、分析、挖掘软件可以灵活、快速地捕捉网络上分散的数据信息,并通过一系列的分析处理,准确地挖掘出所需的数据。由此带来的效率、便利和文明化不言而喻。
作为大数据行业的一员,今天小编就基于流行的R软件,为大家介绍如何实现网页数据采集技术。是的,是R!除了强大的统计分析功能外,它对网页的抓取能力也不容小觑,尤其是Hadley写的R包rvest,把复杂的事情简单化了。使用R语言抓取网页数据的最大优势在于获得数据后强大的数据处理、分析和可视化功能。
R语言示例
下面以rvest包捕获的广州空气质量数据为例进行说明。
网页数据如下:
#加载包
图书馆(rvest)
#找到获取数据的URL 查看全部
实时抓取网页数据(
网页数据如下图:#找到要数据的网址(rvest))
写论文,没有数据?R语言爬取网络大数据
放眼国内外,大数据市场发展迅猛,政府支持力度空前,甚至将大数据纳入发展战略。这样的形势给社会各界提供了许多机遇和挑战,作为卫生(医疗)统计领域的一员,我们更要抓住机遇。放眼全球,大数据的应用规模不断扩大,几乎每个行业都将目光投向了大数据背后的巨大价值。未来五到十年将是我国推动大数据发展的关键时期,亟需打造高效的大数据应用机制和产业链。
根据对当前大数据行业发展的分析,我们可能会从“视觉数据捕捉”开始思考大数据。这里所说的可视化数据抓取主要是指对互联网网页数据的抓取,可以实现大数据应用的普及。目前,我们已经可以使用一个简单的网页数据爬取工具来爬取它所需要的网页数据,比如知名的网页数据爬取工具“**采集器”(收费)。现有的互联网数据采集、处理、分析、挖掘软件可以灵活、快速地捕捉网络上分散的数据信息,并通过一系列的分析处理,准确地挖掘出所需的数据。由此带来的效率、便利和文明化不言而喻。
作为大数据行业的一员,今天小编就基于流行的R软件,为大家介绍如何实现网页数据采集技术。是的,是R!除了强大的统计分析功能外,它对网页的抓取能力也不容小觑,尤其是Hadley写的R包rvest,把复杂的事情简单化了。使用R语言抓取网页数据的最大优势在于获得数据后强大的数据处理、分析和可视化功能。
R语言示例
下面以rvest包捕获的广州空气质量数据为例进行说明。
网页数据如下:

#加载包
图书馆(rvest)
#找到获取数据的URL
实时抓取网页数据(我正在尝试从这个网页中获取实时商品价值它有一个iframe)
网站优化 • 优采云 发表了文章 • 0 个评论 • 124 次浏览 • 2021-10-11 13:27
我正在尝试从此网页获取实时产品价值。它有一个 iframe 地址::8000/
这是我用 BeautifulSoup 尝试过的:
from bs4 import BeautifulSoup
#import time
import urllib
data = []
url=urllib.urlopen("http://213.136.84.136:8000/")
html=url.read()
url.close()
soup = BeautifulSoup(html,"html.parser")
span=soup.find('table', attrs={'class':'table2'})
table_body = span.find('tbody')
rows = table_body.find_all('tr')
for row in rows:
cols = row.find_all('td')
cols = [ele.text.strip() for ele in cols]
data.append([ele for ele in cols if ele]) # Get rid of empty values
print([data])
这是我得到的输出:
[[[], [u'INTERNATIONAL MARKET'], [u'SPOT Gold'], [u'SPOT Silver'], [u'CrudeOil'], [u'Copper'], [u'NaturalGas'], [u'Dow Jones'], [u'Bank Nifty'], [u'INDIAN MARKET'], [u'MCXGold'], [u'MCXSilver'], [u'MCXCrudeOil'], [u'MCXCopper'], [u'MCXLead'], [u'MCXNickel'], [u'MCXZinc'], [u'MCXNaturalGas'], [u'MCXAluminium'], [u'MCXMenthaOil'], [u'USDINR'], [], [u"Disclaimer: We can't assure any guarantee about the accuaracy of the data."]]]
它不返回任何引号。你知道吗?
以下是HTML代码:
SYMBOL
LTP
HIGH
LOW
INTERNATIONAL MARKET
SPOT Gold
SPOT Silver
CrudeOil
Copper
NaturalGas
Dow Jones
Bank Nifty
INDIAN MARKET
MCXGold
MCXSilver
MCXCrudeOil
MCXCopper
MCXLead
MCXNickel
MCXZinc
MCXNaturalGas
MCXAluminium
MCXMenthaOil
USDINR
Disclaimer: We can't assure any guarantee about the accuaracy of the data.
有没有人知道其他方式来获得这个实时报价?你知道吗? 查看全部
实时抓取网页数据(我正在尝试从这个网页中获取实时商品价值它有一个iframe)
我正在尝试从此网页获取实时产品价值。它有一个 iframe 地址::8000/
这是我用 BeautifulSoup 尝试过的:
from bs4 import BeautifulSoup
#import time
import urllib
data = []
url=urllib.urlopen("http://213.136.84.136:8000/";)
html=url.read()
url.close()
soup = BeautifulSoup(html,"html.parser")
span=soup.find('table', attrs={'class':'table2'})
table_body = span.find('tbody')
rows = table_body.find_all('tr')
for row in rows:
cols = row.find_all('td')
cols = [ele.text.strip() for ele in cols]
data.append([ele for ele in cols if ele]) # Get rid of empty values
print([data])
这是我得到的输出:
[[[], [u'INTERNATIONAL MARKET'], [u'SPOT Gold'], [u'SPOT Silver'], [u'CrudeOil'], [u'Copper'], [u'NaturalGas'], [u'Dow Jones'], [u'Bank Nifty'], [u'INDIAN MARKET'], [u'MCXGold'], [u'MCXSilver'], [u'MCXCrudeOil'], [u'MCXCopper'], [u'MCXLead'], [u'MCXNickel'], [u'MCXZinc'], [u'MCXNaturalGas'], [u'MCXAluminium'], [u'MCXMenthaOil'], [u'USDINR'], [], [u"Disclaimer: We can't assure any guarantee about the accuaracy of the data."]]]
它不返回任何引号。你知道吗?
以下是HTML代码:
SYMBOL
LTP
HIGH
LOW
INTERNATIONAL MARKET
SPOT Gold
SPOT Silver
CrudeOil
Copper
NaturalGas
Dow Jones
Bank Nifty
INDIAN MARKET
MCXGold
MCXSilver
MCXCrudeOil
MCXCopper
MCXLead
MCXNickel
MCXZinc
MCXNaturalGas
MCXAluminium
MCXMenthaOil
USDINR
Disclaimer: We can't assure any guarantee about the accuaracy of the data.
有没有人知道其他方式来获得这个实时报价?你知道吗?
实时抓取网页数据(网探网页数据监控软件现在各行各业都在应用互联网技术,晚了可能价值已经归零)
网站优化 • 优采云 发表了文章 • 0 个评论 • 103 次浏览 • 2021-10-11 10:27
Netexplorer网络数据监控软件现在各行各业都在使用互联网技术,互联网上的数据也越来越丰富。一些数据的价值与时间有关。早点知道是有用的,晚点值可能为零。Netexploration软件就是来解决这类问题的,让您“永远领先一步”是我们的目标。
特征:
☆基于IE浏览器
没有任何反爬虫技术手段的感觉,只要能在IE浏览器中正常浏览网页,就可以监控里面的所有数据。
☆网页数据抓取
“文本匹配”和“文档结构分析”可以单独使用,也可以结合使用来采集数据,让数据采集更简单、更准确。
☆数据对比验证
自动判断最近更新的数据,支持自定义数据对比验证公式,筛选出用户最感兴趣的数据内容。
☆及时通知用户
用户注册后,可以将验证后的数据发送到用户邮箱,也可以推送到用户指定的界面重新处理数据。
☆多任务同时运行
程序支持多个监控任务同时运行,用户可以同时监控多个网页中感兴趣的数据。
☆任务间互相调用
可以将监控任务A得到的结果(必须是URL)转交给监控任务B执行,从而获得更丰富的数据结果。
☆开放通知界面
直接与您的服务器后台对接,后续流程自定义,实时高效接入数据自动化处理流程。
☆在线分享爬取公式
“人人为我,我为人”分享任意网页的爬取公式,免去编辑公式的烦恼。
☆无人值守长期运行
资源消耗低,内置内存管理模块,自动清除运行过程中产生的内存垃圾,守护进程长时间无人值守运行
更新内容
改进安装和卸载程序,添加皮肤 查看全部
实时抓取网页数据(网探网页数据监控软件现在各行各业都在应用互联网技术,晚了可能价值已经归零)
Netexplorer网络数据监控软件现在各行各业都在使用互联网技术,互联网上的数据也越来越丰富。一些数据的价值与时间有关。早点知道是有用的,晚点值可能为零。Netexploration软件就是来解决这类问题的,让您“永远领先一步”是我们的目标。
特征:
☆基于IE浏览器
没有任何反爬虫技术手段的感觉,只要能在IE浏览器中正常浏览网页,就可以监控里面的所有数据。
☆网页数据抓取
“文本匹配”和“文档结构分析”可以单独使用,也可以结合使用来采集数据,让数据采集更简单、更准确。
☆数据对比验证
自动判断最近更新的数据,支持自定义数据对比验证公式,筛选出用户最感兴趣的数据内容。
☆及时通知用户
用户注册后,可以将验证后的数据发送到用户邮箱,也可以推送到用户指定的界面重新处理数据。
☆多任务同时运行
程序支持多个监控任务同时运行,用户可以同时监控多个网页中感兴趣的数据。
☆任务间互相调用
可以将监控任务A得到的结果(必须是URL)转交给监控任务B执行,从而获得更丰富的数据结果。
☆开放通知界面
直接与您的服务器后台对接,后续流程自定义,实时高效接入数据自动化处理流程。
☆在线分享爬取公式
“人人为我,我为人”分享任意网页的爬取公式,免去编辑公式的烦恼。
☆无人值守长期运行
资源消耗低,内置内存管理模块,自动清除运行过程中产生的内存垃圾,守护进程长时间无人值守运行
更新内容
改进安装和卸载程序,添加皮肤
实时抓取网页数据(如何让数据处理后仍可以留在当前页?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 89 次浏览 • 2021-10-07 01:17
BootstrapTable 组件在最近的项目中用于开发。在开发过程中,我们遇到了这样一个需求:javascript
表格分页后,处理完一页中的一条数据后,刷新表格。为了保证表的实时正确性,先销毁表,再获取新表,获取数据java
$('#bootstrapTableId').bootstrapTable('destroy');
$('#bootstrapTableId').bootstrapTable({
...
pageNumber:1,
...
});
在接下来的开发过程中,如果对某条数据进行操作后需要刷新表格数据,但刷新表格后,pageNumber会被重置为1,即跳转回首页。处理后如何保持当前页面的数据,有两种方式:ajax
1、refresh:刷新表数据,可以加参数url指定请求发送到的url(可以是新的),silent:true 静默更新时,query:{}可以指出一些新的ajax请求参数。引导程序
$('#bootStrapTableId').bootStrapTable('refresh');
2、获取当前表格显示的页码,即当前表格页面显示的页数。处理完表格数据后,在回调函数中加入表格当晚的页码,这样表格在销毁后显示给定的页码 Render data: function
$('#bootStrapTableId').bootStrapTable('getOptions').pageNumber;
注意:getOptions:获取表的一些基本属性,并返回一个对象。键有许多属性,如 conlumns、data、sortOrder、class。如果不知道属性是什么,可以通过控制台查看url。
pageNumber:这是你之前的bootstraptable的属性spa
总结:最后使用2中的方法解决问题,既可以保证表销毁后新发起的请求渲染出来的数据的及时性,也可以保证数据的正确性。至于刷新方式,就是刷新表,可以理解为我对ajax的局部请求效果没有深入理解,但是能够实现需求。代码 查看全部
实时抓取网页数据(如何让数据处理后仍可以留在当前页?)
BootstrapTable 组件在最近的项目中用于开发。在开发过程中,我们遇到了这样一个需求:javascript
表格分页后,处理完一页中的一条数据后,刷新表格。为了保证表的实时正确性,先销毁表,再获取新表,获取数据java
$('#bootstrapTableId').bootstrapTable('destroy');
$('#bootstrapTableId').bootstrapTable({
...
pageNumber:1,
...
});
在接下来的开发过程中,如果对某条数据进行操作后需要刷新表格数据,但刷新表格后,pageNumber会被重置为1,即跳转回首页。处理后如何保持当前页面的数据,有两种方式:ajax
1、refresh:刷新表数据,可以加参数url指定请求发送到的url(可以是新的),silent:true 静默更新时,query:{}可以指出一些新的ajax请求参数。引导程序
$('#bootStrapTableId').bootStrapTable('refresh');
2、获取当前表格显示的页码,即当前表格页面显示的页数。处理完表格数据后,在回调函数中加入表格当晚的页码,这样表格在销毁后显示给定的页码 Render data: function
$('#bootStrapTableId').bootStrapTable('getOptions').pageNumber;
注意:getOptions:获取表的一些基本属性,并返回一个对象。键有许多属性,如 conlumns、data、sortOrder、class。如果不知道属性是什么,可以通过控制台查看url。
pageNumber:这是你之前的bootstraptable的属性spa
总结:最后使用2中的方法解决问题,既可以保证表销毁后新发起的请求渲染出来的数据的及时性,也可以保证数据的正确性。至于刷新方式,就是刷新表,可以理解为我对ajax的局部请求效果没有深入理解,但是能够实现需求。代码
实时抓取网页数据(一个就买了一个阿里云服务器把个人网站迁移上去)
网站优化 • 优采云 发表了文章 • 0 个评论 • 130 次浏览 • 2021-11-02 11:17
前言
前段时间github崩溃了,差点毁了心态,于是干脆买了个阿里云服务器来迁移我的个人网站。
服务器镜像选择nodejs应用,预装nginx。nginx的其他配置我就不多说了。
本文主要介绍如何通过GoAccess分析nginx日志数据。
最终运行效果图:
1、GoAccess 介绍和安装 GoAccess 是一个开源的实时网络日志分析器和交互式查看器,可以在 *nix 系统中运行,也可以通过浏览器终端运行。它为需要动态可视化服务器报告的系统管理员提供快速且有价值的 HTTP 统计信息。
Goaccess用于分析服务器日志数据,主要可以通过两种方式输出数据分析报告:终端或HTML(分为静态和动态)
安装
可以通过官网或者包管理工具下载源码安装,这里使用yum安装
yum install goaccess
验证是否正确安装了 goaccess:
goaccess --v
2、GoAccess 配置
安装完成后,/etc目录下会有一个goaccess.conf配置文件。将以下代码添加到最后一行:
log-format %h %^[%d:%t %^] "%r" %s %b "%R" "%u"
date-format %d/%b/%Y
time-format %H:%M:%S
real-time-html true
port 618
output /usr/local/nginx/html/stat/index.html
上面配置了goaccess的日志格式、日期格式和时间格式,
设置实时HTML分析为true,因为通过WebSocket连接服务器时需要设置端口请求数据。默认端口是7890,这里设置的是618。记得在阿里云后台打开端口,不然数据不可用。最后设置输出HTML地址,该地址放置在nginx服务器静态资源的HTML目录下,可以自行配置。
3、最终输出实时数据分析HTML
在服务器端输入:
goaccess -f /usr/local/nginx/logs/access.log -a > /usr/local/nginx/html/stat/index.html
前者是需要分析的日志文件的地址,后者是输出HTML的地址
打开你的 网站stat 目录,查看实时数据分析。
例如:我的网站可以看到结果 查看全部
实时抓取网页数据(一个就买了一个阿里云服务器把个人网站迁移上去)
前言
前段时间github崩溃了,差点毁了心态,于是干脆买了个阿里云服务器来迁移我的个人网站。
服务器镜像选择nodejs应用,预装nginx。nginx的其他配置我就不多说了。
本文主要介绍如何通过GoAccess分析nginx日志数据。
最终运行效果图:
1、GoAccess 介绍和安装 GoAccess 是一个开源的实时网络日志分析器和交互式查看器,可以在 *nix 系统中运行,也可以通过浏览器终端运行。它为需要动态可视化服务器报告的系统管理员提供快速且有价值的 HTTP 统计信息。
Goaccess用于分析服务器日志数据,主要可以通过两种方式输出数据分析报告:终端或HTML(分为静态和动态)
安装
可以通过官网或者包管理工具下载源码安装,这里使用yum安装
yum install goaccess
验证是否正确安装了 goaccess:
goaccess --v
2、GoAccess 配置
安装完成后,/etc目录下会有一个goaccess.conf配置文件。将以下代码添加到最后一行:
log-format %h %^[%d:%t %^] "%r" %s %b "%R" "%u"
date-format %d/%b/%Y
time-format %H:%M:%S
real-time-html true
port 618
output /usr/local/nginx/html/stat/index.html
上面配置了goaccess的日志格式、日期格式和时间格式,
设置实时HTML分析为true,因为通过WebSocket连接服务器时需要设置端口请求数据。默认端口是7890,这里设置的是618。记得在阿里云后台打开端口,不然数据不可用。最后设置输出HTML地址,该地址放置在nginx服务器静态资源的HTML目录下,可以自行配置。
3、最终输出实时数据分析HTML
在服务器端输入:
goaccess -f /usr/local/nginx/logs/access.log -a > /usr/local/nginx/html/stat/index.html
前者是需要分析的日志文件的地址,后者是输出HTML的地址
打开你的 网站stat 目录,查看实时数据分析。
例如:我的网站可以看到结果
实时抓取网页数据(本文实例讲述php+ajax实时刷新简单实现方法,分享)
网站优化 • 优采云 发表了文章 • 0 个评论 • 58 次浏览 • 2021-11-02 11:16
本文介绍了php+ajax实时刷新的简单实现方法,分享给大家,供大家参考。详情如下:
Ajax 自动刷新似乎是一个很常见的问题。在做网络聊天室程序之前,我被困在它上面。经过这一段时间的学习,终于做出了一个可以自动刷新网页的代码框架。我希望你感到困惑。不要像我一样走那么多弯路
代码不多废话:
html部分:
function loadxmldoc()//ajax发送请求并显示
{
var xmlhttp;
if (window.xmlhttprequest)
{// code for ie7+, firefox, chrome, opera, safari
xmlhttp=new xmlhttprequest();
}
else
{// code for ie6, ie5
xmlhttp=new activexobject("microsoft.xmlhttp");
}
xmlhttp.onreadystatechange=function()
{
if (xmlhttp.readystate==4 && xmlhttp.status==200)
{
document.getelementbyid("mydiv").innerhtml=xmlhttp.responsetext;
}
}
xmlhttp.open("post","/chat.php",true);
xmlhttp.send();
settimeout("loadxmldoc()",1000);//递归调用
}
loadxmldoc();//先执行一次
手动刷新
php部分(只是一个实时刷新的测试网页)
这样,只要修改data.dat,就可以实时显示在网页上。
希望这篇文章对你的php程序设计有所帮助。 查看全部
实时抓取网页数据(本文实例讲述php+ajax实时刷新简单实现方法,分享)
本文介绍了php+ajax实时刷新的简单实现方法,分享给大家,供大家参考。详情如下:
Ajax 自动刷新似乎是一个很常见的问题。在做网络聊天室程序之前,我被困在它上面。经过这一段时间的学习,终于做出了一个可以自动刷新网页的代码框架。我希望你感到困惑。不要像我一样走那么多弯路
代码不多废话:
html部分:
function loadxmldoc()//ajax发送请求并显示
{
var xmlhttp;
if (window.xmlhttprequest)
{// code for ie7+, firefox, chrome, opera, safari
xmlhttp=new xmlhttprequest();
}
else
{// code for ie6, ie5
xmlhttp=new activexobject("microsoft.xmlhttp");
}
xmlhttp.onreadystatechange=function()
{
if (xmlhttp.readystate==4 && xmlhttp.status==200)
{
document.getelementbyid("mydiv").innerhtml=xmlhttp.responsetext;
}
}
xmlhttp.open("post","/chat.php",true);
xmlhttp.send();
settimeout("loadxmldoc()",1000);//递归调用
}
loadxmldoc();//先执行一次
手动刷新
php部分(只是一个实时刷新的测试网页)
这样,只要修改data.dat,就可以实时显示在网页上。
希望这篇文章对你的php程序设计有所帮助。
实时抓取网页数据(js+wcf实现进度条实时监测数据加载量的方法(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 131 次浏览 • 2021-10-31 03:16
本文以js+wcf如何实现进度条实时监控数据加载为例。分享给大家,供大家参考,如下:
背景
因为项目需要导入很多数据到memcache
您需要使用wcf 检索110,000 条数据。因为那里多级联检查排序,比较慢(1分钟左右)
同时这里需要对数据进行处理,合并成20000条数据,然后存储,需要一定的时间(也是1分钟左右)
总之,完成数据导入大约需要1分30秒
这时候就需要一个进度条来实时监控完成的数据量
(之前用动态图,无法知道程序当前的完成量,或者就算卡住了,也只能等)
功能
1.开启线程加载数据和处理数据
2.前台实时读取后台数据并显示
代码
视图-html
@* 数据准备进度条 *@
数据准备
完成量3%
<p>数据准备完成!
</p>
视图-js
$(function () {
$('#initialization').click(function () {
$.messager.confirm('提示', '是否要进行数据初始化?', function (r) {
if (!r) {
return;
}
else {
$('#container').show();
var t1 = window.setinterval(process_bar, 1500);
}
});
});
});
function process_bar() {
$.ajax({
type: "post",
async: true,
url: "/paper/loaddata",
success: function (result) {
$('#progress_bar .ui-progress').animateprogress(result);
if (result =="100") {
$('#main_content').slidedown();
$('#fork_me').fadein();
settimeout(function () { $('#container').hide();; }, 1500);
window.clearinterval(t1);
}
}
})
}
控制器
static bool flag = true;
public int loaddata()
{
int result = ipaperbll.loaddataamount();
if (flag)
{
thread thread = new thread(new threadstart(threadloaddata));
thread.start();
flag = false;
}
return result;
}
private void threadloaddata()
{
ipaperbll.initializedata();
}
后台
static int load_data_amount;//当前数据准备量
public bool initializedata()
{
bool flag = false; //定义返回值
//获得数据
//code....code ....code....
load_data_amount = 5;//完成工作量
int page = 0;
int amount = 50000;//一次获取数据量不能超过10万
while (page * amount == list.count)
{
//code....code ....code....
load_data_amount = load_data_amount + 5;
}
load_data_amount = 50;//读取数据默认的工作量
double totalamount = list.count();
foreach (var item in list)
{
//code....code ....code....
load_data_amount = convert.toint32((1 - (totalamount--) / double.parse(list.count().tostring())) * 50) + 50;//根据数据改变的完成工作量
}
load_data_amount = 100;//完成工作量
flag = true;
return flag;
}
//返回当前准备数据量
public int loaddataamount() {
return load_data_amount;
}
问题解决了
1.进度条生成
解决方法:使用在线demo,css+js可以动态生成,只需改变数据
2.线程问题
解决方法:开始监控线程的使用,后来改用线程进行数据处理
3.问题实时监控
解决方法:使用线程自动运行数据处理,前台使用ajax在后台不断查询一个变量load_data_amount
4.ajax 错误报告
注意返回值的类型,无论是result还是result.d,在不同的情况下是不同的
5.数据类型问题
解:读取数据的百分比是用完成量/全部量得到的。这里的数字总是不正确的,因为int类型经不起110,000及后续小数的运算。可以使用 double 和 float。
概括
本来想开个线程,加个变量,返回前台,加个进度条,读取变量就ok了。
但是中间的mvc,这个spring,这个接口,之前的方法都不好用,下面的计算,ajax……一一解决,终于解决了。
分而治之,一一解决,测试即可
另外,框架和合作带来便利的同时,中间的限制和bug也会降低你的效率。
对javascript相关内容感兴趣的读者可以查看本站专题:《JavaScript时间日期操作技巧总结》、《JavaScript搜索算法技巧总结》、《JavaScript错误与调试技巧总结》、《JavaScript数据结构与算法技巧》《总结》《JavaScript遍历算法与技巧总结》《JavaScript数学运算使用总结》
我希望这篇文章能帮助你进行 JavaScript 编程。 查看全部
实时抓取网页数据(js+wcf实现进度条实时监测数据加载量的方法(组图))
本文以js+wcf如何实现进度条实时监控数据加载为例。分享给大家,供大家参考,如下:
背景
因为项目需要导入很多数据到memcache
您需要使用wcf 检索110,000 条数据。因为那里多级联检查排序,比较慢(1分钟左右)
同时这里需要对数据进行处理,合并成20000条数据,然后存储,需要一定的时间(也是1分钟左右)
总之,完成数据导入大约需要1分30秒
这时候就需要一个进度条来实时监控完成的数据量
(之前用动态图,无法知道程序当前的完成量,或者就算卡住了,也只能等)
功能
1.开启线程加载数据和处理数据
2.前台实时读取后台数据并显示
代码
视图-html
@* 数据准备进度条 *@
数据准备
完成量3%
<p>数据准备完成!
</p>
视图-js
$(function () {
$('#initialization').click(function () {
$.messager.confirm('提示', '是否要进行数据初始化?', function (r) {
if (!r) {
return;
}
else {
$('#container').show();
var t1 = window.setinterval(process_bar, 1500);
}
});
});
});
function process_bar() {
$.ajax({
type: "post",
async: true,
url: "/paper/loaddata",
success: function (result) {
$('#progress_bar .ui-progress').animateprogress(result);
if (result =="100") {
$('#main_content').slidedown();
$('#fork_me').fadein();
settimeout(function () { $('#container').hide();; }, 1500);
window.clearinterval(t1);
}
}
})
}
控制器
static bool flag = true;
public int loaddata()
{
int result = ipaperbll.loaddataamount();
if (flag)
{
thread thread = new thread(new threadstart(threadloaddata));
thread.start();
flag = false;
}
return result;
}
private void threadloaddata()
{
ipaperbll.initializedata();
}
后台
static int load_data_amount;//当前数据准备量
public bool initializedata()
{
bool flag = false; //定义返回值
//获得数据
//code....code ....code....
load_data_amount = 5;//完成工作量
int page = 0;
int amount = 50000;//一次获取数据量不能超过10万
while (page * amount == list.count)
{
//code....code ....code....
load_data_amount = load_data_amount + 5;
}
load_data_amount = 50;//读取数据默认的工作量
double totalamount = list.count();
foreach (var item in list)
{
//code....code ....code....
load_data_amount = convert.toint32((1 - (totalamount--) / double.parse(list.count().tostring())) * 50) + 50;//根据数据改变的完成工作量
}
load_data_amount = 100;//完成工作量
flag = true;
return flag;
}
//返回当前准备数据量
public int loaddataamount() {
return load_data_amount;
}
问题解决了
1.进度条生成
解决方法:使用在线demo,css+js可以动态生成,只需改变数据
2.线程问题
解决方法:开始监控线程的使用,后来改用线程进行数据处理
3.问题实时监控
解决方法:使用线程自动运行数据处理,前台使用ajax在后台不断查询一个变量load_data_amount
4.ajax 错误报告
注意返回值的类型,无论是result还是result.d,在不同的情况下是不同的
5.数据类型问题
解:读取数据的百分比是用完成量/全部量得到的。这里的数字总是不正确的,因为int类型经不起110,000及后续小数的运算。可以使用 double 和 float。
概括
本来想开个线程,加个变量,返回前台,加个进度条,读取变量就ok了。
但是中间的mvc,这个spring,这个接口,之前的方法都不好用,下面的计算,ajax……一一解决,终于解决了。
分而治之,一一解决,测试即可
另外,框架和合作带来便利的同时,中间的限制和bug也会降低你的效率。
对javascript相关内容感兴趣的读者可以查看本站专题:《JavaScript时间日期操作技巧总结》、《JavaScript搜索算法技巧总结》、《JavaScript错误与调试技巧总结》、《JavaScript数据结构与算法技巧》《总结》《JavaScript遍历算法与技巧总结》《JavaScript数学运算使用总结》
我希望这篇文章能帮助你进行 JavaScript 编程。
实时抓取网页数据( 1.1.5使用json数据解析网址1.2模拟浏览器请求提取关注的信息 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 68 次浏览 • 2021-10-31 03:14
1.1.5使用json数据解析网址1.2模拟浏览器请求提取关注的信息
)
1.1.5 使用json数据解析URL
1.2 模拟浏览器请求
2.提取相关信息2.1 遇到的问题
(1)使用post方法得到的数据总是带着下图所示的字符串,这里纠结了很久...
结果是我得到了错误的请求方法。
(2) 响应数据虽然是json格式,但是没有像往常一样播放,是一维的,耽误了很久,之前没注意,一直在尝试访问按照往常的方式查字典,再仔细看。看下面数据中的引号(“”),真的是未来的另一个村庄。
(3) 访问data的值后,数据为str类型,但文本内容仍为字典格式,因此该函数用于将文本转换为字典格式
2.2 提取全国、湖南等地的疫情信息。
由于返回的数据是排序后的数据,所以需要找到需要的数据
for i in range(len(dict_data["areaTree"][0]["children"])):
if dict_data["areaTree"][0]["children"][i]["name"]=="湖南":
for j in range(len(dict_data["areaTree"][0]["children"][i]["children"])):
if dict_data["areaTree"][0]["children"][i]["children"][j]["name"]=="衡阳":
index1=i
index2=j
break
3.使用服务器酱接收微信消息3.1 推荐一款好用的微信提醒工具
3.2 使用服务器酱服务效果图
4.阿里云服务器部署py脚本4.1 阿里云服务器操作
我以前从未接触过 Linux。为了补充知识,买了阿里云的学生专用服务器,想用这个来练习。所以百度了解了很多关于py脚本在Ubuntu服务器后台是如何运行的。Ubuntu最初安装了python2.7和python3.5版本,方便我们程序的运行。Linux学习中~~请指教
(1)使用Xshell上传py文件
(2)Linux 命令在后台运行脚本
查看全部
实时抓取网页数据(
1.1.5使用json数据解析网址1.2模拟浏览器请求提取关注的信息
)
1.1.5 使用json数据解析URL
1.2 模拟浏览器请求
2.提取相关信息2.1 遇到的问题
(1)使用post方法得到的数据总是带着下图所示的字符串,这里纠结了很久...
结果是我得到了错误的请求方法。
(2) 响应数据虽然是json格式,但是没有像往常一样播放,是一维的,耽误了很久,之前没注意,一直在尝试访问按照往常的方式查字典,再仔细看。看下面数据中的引号(“”),真的是未来的另一个村庄。
(3) 访问data的值后,数据为str类型,但文本内容仍为字典格式,因此该函数用于将文本转换为字典格式
2.2 提取全国、湖南等地的疫情信息。
由于返回的数据是排序后的数据,所以需要找到需要的数据
for i in range(len(dict_data["areaTree"][0]["children"])):
if dict_data["areaTree"][0]["children"][i]["name"]=="湖南":
for j in range(len(dict_data["areaTree"][0]["children"][i]["children"])):
if dict_data["areaTree"][0]["children"][i]["children"][j]["name"]=="衡阳":
index1=i
index2=j
break
3.使用服务器酱接收微信消息3.1 推荐一款好用的微信提醒工具
3.2 使用服务器酱服务效果图
4.阿里云服务器部署py脚本4.1 阿里云服务器操作
我以前从未接触过 Linux。为了补充知识,买了阿里云的学生专用服务器,想用这个来练习。所以百度了解了很多关于py脚本在Ubuntu服务器后台是如何运行的。Ubuntu最初安装了python2.7和python3.5版本,方便我们程序的运行。Linux学习中~~请指教
(1)使用Xshell上传py文件
(2)Linux 命令在后台运行脚本
实时抓取网页数据( 小编来一起示例代码介绍-2019年07月01日)
网站优化 • 优采云 发表了文章 • 0 个评论 • 68 次浏览 • 2021-10-29 16:00
小编来一起示例代码介绍-2019年07月01日)
详解python websocket获取实时数据的几种常用链接方法
更新时间:2019-07-01 09:24:16 作者:Jerry_JD
本文文章主要详细介绍几种常用的从python websocket获取实时数据的链接方式。文章中介绍的示例代码非常详细,对大家的学习或工作有一定的参考学习价值。有需要的朋友在下面和小编一起学习吧
第一种是使用create_connection链接,需要pip install websocket-client(不推荐这种方法,链接不稳定,容易断,连接耗时)
import time
from websocket import create_connection
url = 'wss://i.cg.net/wi/ws'
while True: # 一直链接,直到连接上就退出循环
time.sleep(2)
try:
ws = create_connection(url)
print(ws)
break
except Exception as e:
print('连接异常:', e)
continue
while True: # 连接上,退出第一个循环之后,此循环用于一直获取数据
ws.send('{"event":"subscribe", "channel":"btc_usdt.ticker"}')
response = ws.recv()
print(response)
第二种,运行效果很好,连接方便,获取数据的速度也很快
import json
from ws4py.client.threadedclient import WebSocketClient
class CG_Client(WebSocketClient):
def opened(self):
req = '{"event":"subscribe", "channel":"eth_usdt.deep"}'
self.send(req)
def closed(self, code, reason=None):
print("Closed down:", code, reason)
def received_message(self, resp):
resp = json.loads(str(resp))
data = resp['data']
if type(data) is dict:
ask = data['asks'][0]
print('Ask:', ask)
bid = data['bids'][0]
print('Bid:', bid)
if __name__ == '__main__':
ws = None
try:
ws = CG_Client('wss://i.cg.net/wi/ws')
ws.connect()
ws.run_forever()
except KeyboardInterrupt:
ws.close()
第三种其实和第一种类似,只是写法不同,运行效果不理想,连接耗时,容易断线
import websocket
while True:
ws = websocket.WebSocket()
try:
ws.connect("wss://i.cg.net/wi/ws")
print(ws)
break
except Exception as e:
print('异常:', e)
continue
print('OK')
while True:
req = '{"event":"subscribe", "channel":"btc_usdt.deep"}'
ws.send(req)
resp = ws.recv()
print(resp)
第四,运行效果也是可以的,run_forever里面的参数很多,需要自己设置
import websocket
def on_message(ws, message): # 服务器有数据更新时,主动推送过来的数据
print(message)
def on_error(ws, error): # 程序报错时,就会触发on_error事件
print(error)
def on_close(ws):
print("Connection closed ……")
def on_open(ws): # 连接到服务器之后就会触发on_open事件,这里用于send数据
req = '{"event":"subscribe", "channel":"btc_usdt.deep"}'
print(req)
ws.send(req)
if __name__ == "__main__":
websocket.enableTrace(True)
ws = websocket.WebSocketApp("wss://i.cg.net/wi/ws",
on_message=on_message,
on_error=on_error,
on_close=on_close)
ws.on_open = on_open
ws.run_forever(ping_timeout=30)
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持脚本之家。 查看全部
实时抓取网页数据(
小编来一起示例代码介绍-2019年07月01日)
详解python websocket获取实时数据的几种常用链接方法
更新时间:2019-07-01 09:24:16 作者:Jerry_JD
本文文章主要详细介绍几种常用的从python websocket获取实时数据的链接方式。文章中介绍的示例代码非常详细,对大家的学习或工作有一定的参考学习价值。有需要的朋友在下面和小编一起学习吧
第一种是使用create_connection链接,需要pip install websocket-client(不推荐这种方法,链接不稳定,容易断,连接耗时)
import time
from websocket import create_connection
url = 'wss://i.cg.net/wi/ws'
while True: # 一直链接,直到连接上就退出循环
time.sleep(2)
try:
ws = create_connection(url)
print(ws)
break
except Exception as e:
print('连接异常:', e)
continue
while True: # 连接上,退出第一个循环之后,此循环用于一直获取数据
ws.send('{"event":"subscribe", "channel":"btc_usdt.ticker"}')
response = ws.recv()
print(response)
第二种,运行效果很好,连接方便,获取数据的速度也很快
import json
from ws4py.client.threadedclient import WebSocketClient
class CG_Client(WebSocketClient):
def opened(self):
req = '{"event":"subscribe", "channel":"eth_usdt.deep"}'
self.send(req)
def closed(self, code, reason=None):
print("Closed down:", code, reason)
def received_message(self, resp):
resp = json.loads(str(resp))
data = resp['data']
if type(data) is dict:
ask = data['asks'][0]
print('Ask:', ask)
bid = data['bids'][0]
print('Bid:', bid)
if __name__ == '__main__':
ws = None
try:
ws = CG_Client('wss://i.cg.net/wi/ws')
ws.connect()
ws.run_forever()
except KeyboardInterrupt:
ws.close()
第三种其实和第一种类似,只是写法不同,运行效果不理想,连接耗时,容易断线
import websocket
while True:
ws = websocket.WebSocket()
try:
ws.connect("wss://i.cg.net/wi/ws")
print(ws)
break
except Exception as e:
print('异常:', e)
continue
print('OK')
while True:
req = '{"event":"subscribe", "channel":"btc_usdt.deep"}'
ws.send(req)
resp = ws.recv()
print(resp)
第四,运行效果也是可以的,run_forever里面的参数很多,需要自己设置
import websocket
def on_message(ws, message): # 服务器有数据更新时,主动推送过来的数据
print(message)
def on_error(ws, error): # 程序报错时,就会触发on_error事件
print(error)
def on_close(ws):
print("Connection closed ……")
def on_open(ws): # 连接到服务器之后就会触发on_open事件,这里用于send数据
req = '{"event":"subscribe", "channel":"btc_usdt.deep"}'
print(req)
ws.send(req)
if __name__ == "__main__":
websocket.enableTrace(True)
ws = websocket.WebSocketApp("wss://i.cg.net/wi/ws",
on_message=on_message,
on_error=on_error,
on_close=on_close)
ws.on_open = on_open
ws.run_forever(ping_timeout=30)
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持脚本之家。
实时抓取网页数据(统计COVID-19疫情数据可视化分析考核要点及使用方法 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 92 次浏览 • 2021-10-27 04:00
)
一、实验目的
通过本次实验,掌握数据采集、数据清洗与存储、数据可视化工具的基本使用方法。
二、 实验平台
操作系统:window10
Python 版本:3.8
IDE:pycharm
可视化工具:echarts
三、新冠疫情数据采集实验内容及要求
评估要点:尽可能全面的获取疫情数据,包括国内外流行的历史数据,尽可能的获取新的信息,同时也尽可能的获取疫苗接种次数等信息。老师会根据资料的综合程度打分。推荐使用爬虫方式获取数据。如果有困难,可以使用网上其他人整理的数据。关于数据来源,可以从世界卫生组织、定香园、腾讯新闻等渠道获取。网上有很多资料可以参考。
数据来源1:json格式网页抓取腾讯疫情数据
数据来源2:来自约翰霍普金斯大学的GitHub流行病数据
新冠疫情数据采集
评估要点:对获取的疫情相关数据进行清理,去除冗余数据。关于数据存储,可以使用csv文件,但欢迎大家尝试将数据存储在关系型数据库(如MySQL、SQLite等轻量级数据库)或NoSQL数据库(如MongoDB)中。
获取中美两国现有确诊人数、累计死亡人数、累计治愈人数,并存入字典
获取中国所有省份累计确诊病例数
获取中国及美国各省州累计确诊病例和累计死亡人数列表
读取疫情数据的csv文件,得到中国各省7个时间节点累计确诊COVID-19人数
获取并处理中国、美国、印度、意大利7个时间节点累计确诊病例、累计死亡、累计治愈数
COVID-19 数据的可视化分析
评估要点:基于获取的疫情数据,多角度可视化COVID-19疫情的发展过程。计算 COVID-19 流行的地理分布,包括国际和国内。关于可视化工具,可以使用Python或R。有很多强大的包。网上也有很多资料供大家参考。
使用五张echarts图表
效果图
查看全部
实时抓取网页数据(统计COVID-19疫情数据可视化分析考核要点及使用方法
)
一、实验目的
通过本次实验,掌握数据采集、数据清洗与存储、数据可视化工具的基本使用方法。
二、 实验平台
操作系统:window10
Python 版本:3.8
IDE:pycharm
可视化工具:echarts
三、新冠疫情数据采集实验内容及要求
评估要点:尽可能全面的获取疫情数据,包括国内外流行的历史数据,尽可能的获取新的信息,同时也尽可能的获取疫苗接种次数等信息。老师会根据资料的综合程度打分。推荐使用爬虫方式获取数据。如果有困难,可以使用网上其他人整理的数据。关于数据来源,可以从世界卫生组织、定香园、腾讯新闻等渠道获取。网上有很多资料可以参考。
数据来源1:json格式网页抓取腾讯疫情数据
数据来源2:来自约翰霍普金斯大学的GitHub流行病数据
新冠疫情数据采集
评估要点:对获取的疫情相关数据进行清理,去除冗余数据。关于数据存储,可以使用csv文件,但欢迎大家尝试将数据存储在关系型数据库(如MySQL、SQLite等轻量级数据库)或NoSQL数据库(如MongoDB)中。
获取中美两国现有确诊人数、累计死亡人数、累计治愈人数,并存入字典
获取中国所有省份累计确诊病例数
获取中国及美国各省州累计确诊病例和累计死亡人数列表
读取疫情数据的csv文件,得到中国各省7个时间节点累计确诊COVID-19人数
获取并处理中国、美国、印度、意大利7个时间节点累计确诊病例、累计死亡、累计治愈数
COVID-19 数据的可视化分析
评估要点:基于获取的疫情数据,多角度可视化COVID-19疫情的发展过程。计算 COVID-19 流行的地理分布,包括国际和国内。关于可视化工具,可以使用Python或R。有很多强大的包。网上也有很多资料供大家参考。
使用五张echarts图表
效果图
实时抓取网页数据( 宅家“疫情数据信息实时监控项目”演示如何获取腾讯数据接口的地址)
网站优化 • 优采云 发表了文章 • 0 个评论 • 97 次浏览 • 2021-10-27 02:16
宅家“疫情数据信息实时监控项目”演示如何获取腾讯数据接口的地址)
房子很无聊,所以最好学习一些技能!
1.前言
在近期新冠病毒引发的肺炎疫情中,很多人不得不宅在家里。为了让自己不那么无聊,给自己找点事情做,做一个“疫情数据信息实时监测项目”。我去年开始学习 Qt/C++。让我们用这个小项目来练习。代码是开源的。下载地址在文末。当然,如果你和我一样,我建议你用熟悉的编程语言自己实现,也就是学了知识,打发时间。在做之前,我在Github上搜索了一下,看看有没有相关的资料。好像很多人已经在做了:
不过大部分都是基于JavaScript或Python的项目,没有一个是使用Qt/C++平台开发的。
2.主要功能
界面也很简单,主要包括实时数据和历史数据的展示,实时疫情信息的展示,谣言信息的展示。数据来自腾讯新闻。
基于Qt的疫情实时监测平台主界面
一共使用了两个数据接口。一个是收录实时数据、历史数据、疫情动态的界面,一个是收录辟谣信息的界面。
功能也很简单:
3.获取数据接口
现在各大网站都发布了自己的实时疫情展示平台,如定香园、腾讯、新浪、百度、知乎、网易等,包括个别开发者也开发了一些接口、数据均来自国家或地方卫生健康委员会发布的信息。
我使用的是腾讯数据源,数据为JSON格式,解析方便。下面以Chrome浏览器为例,演示如何获取腾讯数据接口的地址。
打开链接后,按F12切换到开发者模式。再次刷新网页,切换到Network,按Ctrl+F搜索当前全国确诊人数:44765,然后回车,可以看到这个数据收录在一个JSON字符串中,这个字符串就是返回的数据某个请求地址,而这个地址就是数据的接口地址。
为了验证这个接口是否正确,我们复制这个地址,然后在地址栏中输入回车,可以看到返回了很多字符串:
这意味着我们找到了正确的地址。完整地址:
在:
时间戳是指格林威治标准时间1970年1月1日00:00:00(北京时间1970年1月1日08:00)到现在的总毫秒数。
因此,如果要获取最新的数据,可以省略以上两个参数:
如果要获取历史数据,只需要修改时间戳即可,其他网站接口地址获取方式类似。
这里我们只使用腾讯新闻的界面。保存 JSON 文件并对其进行格式化。您可以看到收录的信息:
关于腾讯的数据,我还要说一件事。腾讯的JSON数据这几天更新了好几次:
JSON 数据文件的大小也从最初的 80KB 变成了现在的 160KB。
对于辟谣信息,腾讯还放了两个接口,一是查询最新的辟谣信息,二是获取辟谣信息的详细内容。同理,我们可以通过上面获取数据接口地址的方法来获取这两个地址。
查看最新反谣言信息地址:
参数与数据接口相同,函数名和时间戳可以省略:
在这个界面中,有最新的10条辟谣消息。每条辟谣消息包括标题、发布者、发布时间、图片地址、辟谣类型、辟谣id等,通过另一个界面可以查询到某个辟谣新闻的详细信息。
比如这个传闻:
我们访问这样一个地址:
8be33c500e00257c97419ac24ab59d8f
您将获得该谣言新闻的 JSON 格式详细信息如下:
我们实际开发中没有用到这个接口,而是直接调用浏览器打开这个地址的网页地址:
8be33c500e00257c97419ac24ab59d8f
不过这个界面是针对移动端的,在电脑端浏览效果不好:
移动端:
4.Qt 实现
涉及的主要Qt知识如下:
QCustomplot绘图:
驳斥信息显示:
5.主要难点
整个开发过程就是一个解决一个问题的过程。许多控件都是第一次使用。幸运的是,有很多材料。主要困难如下:
历史数据折线图显示:
实时疫情新闻显示:
实时谣言信息显示:
6.包发布
为了让没有安装Qt环境的用户可以使用我们开发的Qt程序,我们需要将生成的程序文件打包发布。首先,使用 Qt 自带的 windeploy filename.exe 命令添加运行该程序所需的所有内容。然后用程序打包软件把这个文件打包成setup.exe安装文件安装在其他电脑上,或者打包成绿色版软件,直接双击运行,我用下面两个软件打包。
7.开源地址
我已经开源了这个项目的Qt项目的所有代码和安装包下载地址,如下: 查看全部
实时抓取网页数据(
宅家“疫情数据信息实时监控项目”演示如何获取腾讯数据接口的地址)
房子很无聊,所以最好学习一些技能!
1.前言
在近期新冠病毒引发的肺炎疫情中,很多人不得不宅在家里。为了让自己不那么无聊,给自己找点事情做,做一个“疫情数据信息实时监测项目”。我去年开始学习 Qt/C++。让我们用这个小项目来练习。代码是开源的。下载地址在文末。当然,如果你和我一样,我建议你用熟悉的编程语言自己实现,也就是学了知识,打发时间。在做之前,我在Github上搜索了一下,看看有没有相关的资料。好像很多人已经在做了:
不过大部分都是基于JavaScript或Python的项目,没有一个是使用Qt/C++平台开发的。
2.主要功能
界面也很简单,主要包括实时数据和历史数据的展示,实时疫情信息的展示,谣言信息的展示。数据来自腾讯新闻。
基于Qt的疫情实时监测平台主界面
一共使用了两个数据接口。一个是收录实时数据、历史数据、疫情动态的界面,一个是收录辟谣信息的界面。
功能也很简单:
3.获取数据接口
现在各大网站都发布了自己的实时疫情展示平台,如定香园、腾讯、新浪、百度、知乎、网易等,包括个别开发者也开发了一些接口、数据均来自国家或地方卫生健康委员会发布的信息。
我使用的是腾讯数据源,数据为JSON格式,解析方便。下面以Chrome浏览器为例,演示如何获取腾讯数据接口的地址。
打开链接后,按F12切换到开发者模式。再次刷新网页,切换到Network,按Ctrl+F搜索当前全国确诊人数:44765,然后回车,可以看到这个数据收录在一个JSON字符串中,这个字符串就是返回的数据某个请求地址,而这个地址就是数据的接口地址。
为了验证这个接口是否正确,我们复制这个地址,然后在地址栏中输入回车,可以看到返回了很多字符串:
这意味着我们找到了正确的地址。完整地址:
在:
时间戳是指格林威治标准时间1970年1月1日00:00:00(北京时间1970年1月1日08:00)到现在的总毫秒数。
因此,如果要获取最新的数据,可以省略以上两个参数:
如果要获取历史数据,只需要修改时间戳即可,其他网站接口地址获取方式类似。
这里我们只使用腾讯新闻的界面。保存 JSON 文件并对其进行格式化。您可以看到收录的信息:
关于腾讯的数据,我还要说一件事。腾讯的JSON数据这几天更新了好几次:
JSON 数据文件的大小也从最初的 80KB 变成了现在的 160KB。
对于辟谣信息,腾讯还放了两个接口,一是查询最新的辟谣信息,二是获取辟谣信息的详细内容。同理,我们可以通过上面获取数据接口地址的方法来获取这两个地址。
查看最新反谣言信息地址:
参数与数据接口相同,函数名和时间戳可以省略:
在这个界面中,有最新的10条辟谣消息。每条辟谣消息包括标题、发布者、发布时间、图片地址、辟谣类型、辟谣id等,通过另一个界面可以查询到某个辟谣新闻的详细信息。
比如这个传闻:
我们访问这样一个地址:
8be33c500e00257c97419ac24ab59d8f
您将获得该谣言新闻的 JSON 格式详细信息如下:
我们实际开发中没有用到这个接口,而是直接调用浏览器打开这个地址的网页地址:
8be33c500e00257c97419ac24ab59d8f
不过这个界面是针对移动端的,在电脑端浏览效果不好:
移动端:
4.Qt 实现
涉及的主要Qt知识如下:
QCustomplot绘图:
驳斥信息显示:
5.主要难点
整个开发过程就是一个解决一个问题的过程。许多控件都是第一次使用。幸运的是,有很多材料。主要困难如下:
历史数据折线图显示:
实时疫情新闻显示:
实时谣言信息显示:
6.包发布
为了让没有安装Qt环境的用户可以使用我们开发的Qt程序,我们需要将生成的程序文件打包发布。首先,使用 Qt 自带的 windeploy filename.exe 命令添加运行该程序所需的所有内容。然后用程序打包软件把这个文件打包成setup.exe安装文件安装在其他电脑上,或者打包成绿色版软件,直接双击运行,我用下面两个软件打包。
7.开源地址
我已经开源了这个项目的Qt项目的所有代码和安装包下载地址,如下:
实时抓取网页数据( soup解析器的惯用方法及修改解析树的使用方法介绍 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 122 次浏览 • 2021-10-25 02:02
soup解析器的惯用方法及修改解析树的使用方法介绍
)
<a id="_0"></a>数据抓取操作步骤
创建用于发送HTTP请求时将用到的所有值发出HTTP请求并下载所有数据解析这些数据文件中需要的数据,
<a id="_4"></a>具体操作步骤
<p>首先需要弄清需要访问哪个URL以及需要哪种HTTP方法。HTTP方法类似于:
method="post"
</p>
该网址类似于:
action="Data_Elements.aspx?Data=2"
美汤
Beautiful Soup 是一个 Python 库,用于从 HTML 和 XML 文件中提取数据。它使用您最喜欢的解析器来提供用于导航、搜索和修改解析树的惯用方法。它通常可以为程序员节省数小时或数天。
以下是中文帮助文档的链接
这是不同美汤解析器的对比
使用 Beautiful Soup 提取隐藏字段
任务:使用 BeautifulSoup 处理 HTML 并提取
“__EVENTVALIDATION”和“__VIEWSTATE”的隐藏表字段值,并在数据字典中设置相应的值。
代码:
def extract_data(page):
# 同之前的方法一样,定义字典,方便对键赋值
data = {"eventvalidation": "",
"viewstate": ""}
with open(page, "r") as html:
# 这里用lxml解析器,后文会做简要介绍
soup = BeautifulSoup(html, "lxml")
ev = soup.find(id="__EVENTVALIDATION")
# 把ev中value的值取出来给data的键
data["eventvalidation"] = ev["value"]
vs = soup.find(id="__VIEWSTATE")
data["viewstate"] = vs["value"]
return data
解析器图像
建议使用 lxml 作为解析器,因为它更高效。Python32.7.3之前的版本和3.2.2之前的版本,必须安装lxml或者html5lib,因为标准内置的HTML解析方法这些 Python 版本的库不够稳定。
提示:如果 HTML 或 XML 文档的格式不正确,不同的解析器返回的结果可能不同
find() 方法
查找(名称,属性,递归,文本,**kwargs)
find_all() 方法会返回文档中所有符合条件的标签,尽管有时我们只想得到一个结果。比如文档中只有一个标签,那么就不宜使用find_all()方法查找标签,使用find_all方法并设置limit=1参数不如使用find()方法直接。下面两行代码是等价的:
soup.find_all('title', limit=1)
# [The Dormouse's story]
soup.find('title')
# The Dormouse's story
唯一的区别是 find_all() 方法的返回结果是一个值收录一个元素的列表,而 find() 方法直接返回结果。
find_all() 方法没有找到目标是返回一个空列表,当find() 方法找不到目标时,它返回None。
print(soup.find("nosuchtag"))
# None
Soup.head.title 是标签名称方法的简写。这个速记的原理是多次调用当前标签的find()方法:
soup.head.title
# The Dormouse's story
soup.find("head").find("title")
# The Dormouse's story
练习:获取运算符列表
任务
获取所有航空公司的列表。删除您返回的数据中的所有组合,例如“所有美国运营商”。最终,您应该返回操作员代码列表。
部分处理代码:
All U.S. and Foreign Carriers
All U.S. Carriers
All Foreign Carriers
AirTran Airways
Alaska Airlines
American Airlines
American Eagle Airlines
Atlas Air
Delta Air Lines
ExpressJet Airlines
Frontier Airlines
Hawaiian Airlines
JetBlue Airways
SkyWest Airlines
Southwest Airlines
Spirit Air Lines
US Airways
United Air Lines
Virgin America
All
All Major Airports
- Atlanta, GA: Hartsfield-Jackson Atlanta International
- Baltimore, MD: Baltimore/Washington International Thurgood Marshall
- Boston, MA: Logan International
- Charlotte, NC: Charlotte Douglas International
- Chicago, IL: Chicago Midway International
- Chicago, IL: Chicago O'Hare International
- Dallas/Fort Worth, TX: Dallas/Fort Worth International
- Denver, CO: Denver International
- Detroit, MI: Detroit Metro Wayne County
- Fort Lauderdale, FL: Fort Lauderdale-Hollywood International
- Houston, TX: George Bush Intercontinental/Houston
- Las Vegas, NV: McCarran International
- Los Angeles, CA: Los Angeles International
All Other Airports
- Aberdeen, SD: Aberdeen Regional
- Abilene, TX: Abilene Regional
解决方案:
def extract_carriers(page):
data = []
with open(page, "r") as html:
soup = BeautifulSoup(html, 'lxml')
# find方法里为什么必须要用id定位:问题一
carrier_list=soup.find(id='CarrierList')
options=carrier_list.find_all('option')
for tag in options:
# 取出标签value所对应的值,添加到列表中。不要标签值中带有All的
if 'All' not in tag['value']:
data.append(tag['value'])
return data
一问一答
注意 find() 方法格式:find( name, attrs, recursive, text, **kwargs)。
虽然名称标签也是唯一的,但是因为find函数已经使用了名称参数name来接收标签类型信息,下面两条语句其实是等价的:
carrier_tag = soup.find(name='CarrierList')
carrier_tag = soup.find('CarrierList')
相当于搜索了这种标签:,那么在目前的情况下肯定是搜索不到的~
如果要使用 name 属性进行搜索,可以使用以下语法:
carrier_list = soup.find('select', {'name': 'CarrierList'})
练习:处理所有数据 练习:专利数据库
在处理 XML 部分文件时,通常会遇到这样的错误:Error parsing XML: waste after document element。这是因为通常有效的 XML 文件只有一个主根节点,例如:
如果出现 Error parsing XML: waste after document element 之类的错误,你的想法可能是只要主根有多个节点
实际上,这种文件通常是由多个相互连接的 XML 文档组成的。一种解决方案是将文件拆分为多个文档,然后将这些文档处理为有效的 XML 文档。
任务:根据分割,将不合格的XML文件分割成合格的XML文件。实现代码如下:
<p>def split_file(filename):
with open(filename) as infile:
n = -1 # 由于第一次遇到 ' 查看全部
实时抓取网页数据(
soup解析器的惯用方法及修改解析树的使用方法介绍
)
<a id="_0"></a>数据抓取操作步骤
创建用于发送HTTP请求时将用到的所有值发出HTTP请求并下载所有数据解析这些数据文件中需要的数据,
<a id="_4"></a>具体操作步骤
<p>首先需要弄清需要访问哪个URL以及需要哪种HTTP方法。HTTP方法类似于:
method="post"
</p>
该网址类似于:
action="Data_Elements.aspx?Data=2"
美汤
Beautiful Soup 是一个 Python 库,用于从 HTML 和 XML 文件中提取数据。它使用您最喜欢的解析器来提供用于导航、搜索和修改解析树的惯用方法。它通常可以为程序员节省数小时或数天。
以下是中文帮助文档的链接
这是不同美汤解析器的对比
使用 Beautiful Soup 提取隐藏字段
任务:使用 BeautifulSoup 处理 HTML 并提取
“__EVENTVALIDATION”和“__VIEWSTATE”的隐藏表字段值,并在数据字典中设置相应的值。
代码:
def extract_data(page):
# 同之前的方法一样,定义字典,方便对键赋值
data = {"eventvalidation": "",
"viewstate": ""}
with open(page, "r") as html:
# 这里用lxml解析器,后文会做简要介绍
soup = BeautifulSoup(html, "lxml")
ev = soup.find(id="__EVENTVALIDATION")
# 把ev中value的值取出来给data的键
data["eventvalidation"] = ev["value"]
vs = soup.find(id="__VIEWSTATE")
data["viewstate"] = vs["value"]
return data
解析器图像
建议使用 lxml 作为解析器,因为它更高效。Python32.7.3之前的版本和3.2.2之前的版本,必须安装lxml或者html5lib,因为标准内置的HTML解析方法这些 Python 版本的库不够稳定。
提示:如果 HTML 或 XML 文档的格式不正确,不同的解析器返回的结果可能不同
find() 方法
查找(名称,属性,递归,文本,**kwargs)
find_all() 方法会返回文档中所有符合条件的标签,尽管有时我们只想得到一个结果。比如文档中只有一个标签,那么就不宜使用find_all()方法查找标签,使用find_all方法并设置limit=1参数不如使用find()方法直接。下面两行代码是等价的:
soup.find_all('title', limit=1)
# [The Dormouse's story]
soup.find('title')
# The Dormouse's story
唯一的区别是 find_all() 方法的返回结果是一个值收录一个元素的列表,而 find() 方法直接返回结果。
find_all() 方法没有找到目标是返回一个空列表,当find() 方法找不到目标时,它返回None。
print(soup.find("nosuchtag"))
# None
Soup.head.title 是标签名称方法的简写。这个速记的原理是多次调用当前标签的find()方法:
soup.head.title
# The Dormouse's story
soup.find("head").find("title")
# The Dormouse's story
练习:获取运算符列表
任务
获取所有航空公司的列表。删除您返回的数据中的所有组合,例如“所有美国运营商”。最终,您应该返回操作员代码列表。
部分处理代码:
All U.S. and Foreign Carriers
All U.S. Carriers
All Foreign Carriers
AirTran Airways
Alaska Airlines
American Airlines
American Eagle Airlines
Atlas Air
Delta Air Lines
ExpressJet Airlines
Frontier Airlines
Hawaiian Airlines
JetBlue Airways
SkyWest Airlines
Southwest Airlines
Spirit Air Lines
US Airways
United Air Lines
Virgin America
All
All Major Airports
- Atlanta, GA: Hartsfield-Jackson Atlanta International
- Baltimore, MD: Baltimore/Washington International Thurgood Marshall
- Boston, MA: Logan International
- Charlotte, NC: Charlotte Douglas International
- Chicago, IL: Chicago Midway International
- Chicago, IL: Chicago O'Hare International
- Dallas/Fort Worth, TX: Dallas/Fort Worth International
- Denver, CO: Denver International
- Detroit, MI: Detroit Metro Wayne County
- Fort Lauderdale, FL: Fort Lauderdale-Hollywood International
- Houston, TX: George Bush Intercontinental/Houston
- Las Vegas, NV: McCarran International
- Los Angeles, CA: Los Angeles International
All Other Airports
- Aberdeen, SD: Aberdeen Regional
- Abilene, TX: Abilene Regional
解决方案:
def extract_carriers(page):
data = []
with open(page, "r") as html:
soup = BeautifulSoup(html, 'lxml')
# find方法里为什么必须要用id定位:问题一
carrier_list=soup.find(id='CarrierList')
options=carrier_list.find_all('option')
for tag in options:
# 取出标签value所对应的值,添加到列表中。不要标签值中带有All的
if 'All' not in tag['value']:
data.append(tag['value'])
return data
一问一答
注意 find() 方法格式:find( name, attrs, recursive, text, **kwargs)。
虽然名称标签也是唯一的,但是因为find函数已经使用了名称参数name来接收标签类型信息,下面两条语句其实是等价的:
carrier_tag = soup.find(name='CarrierList')
carrier_tag = soup.find('CarrierList')
相当于搜索了这种标签:,那么在目前的情况下肯定是搜索不到的~
如果要使用 name 属性进行搜索,可以使用以下语法:
carrier_list = soup.find('select', {'name': 'CarrierList'})
练习:处理所有数据 练习:专利数据库
在处理 XML 部分文件时,通常会遇到这样的错误:Error parsing XML: waste after document element。这是因为通常有效的 XML 文件只有一个主根节点,例如:
如果出现 Error parsing XML: waste after document element 之类的错误,你的想法可能是只要主根有多个节点
实际上,这种文件通常是由多个相互连接的 XML 文档组成的。一种解决方案是将文件拆分为多个文档,然后将这些文档处理为有效的 XML 文档。
任务:根据分割,将不合格的XML文件分割成合格的XML文件。实现代码如下:
<p>def split_file(filename):
with open(filename) as infile:
n = -1 # 由于第一次遇到 '
实时抓取网页数据(优采云原创的自动提取正文算法能适应网页的主体正文)
网站优化 • 优采云 发表了文章 • 0 个评论 • 111 次浏览 • 2021-10-23 20:11
当监听到最新网页时,该软件会列在列表框的最上方,并有提示音。
然后你点击列表中的一个标题,网页的文字就会自动显示在“快速阅读窗口”中。
优采云原创的自动文本提取算法,该算法可以适应大部分网页,自动提取网页的主体部分,单独阅读。
当然,你也可能会遇到提取错误,比如一些没有大正文的网页,比如视频播放页面等,这时候可以点击“打开原创网页”链接查看原创网页页。
指示
1、 一般网速为4M,同一程序监控的关键词数量不建议超过20个。即使你的网速很快,也不建议设置太多多个关键词同时监控,也可以尝试打开多个程序进行监控(将多个程序拷贝到不同文件夹,独立添加监控配置操作)。
2、 刷新列表显示数量,软件会动态保持在1500以内,超出的会自动去除
3、刷新列表的URL已经保存在【软件目录-刷新列表】目录下,关键词HTML和TXT格式文件各有两份。如果长时间运行后文件过大,可以自行删除或移动文件到新位置(先关闭监控程序)。
4、右键刷新列表中的标题,直接在浏览器中打开原网页,无需提取文字。
5、【关键词出现在标题中】只是在搜索引擎爬取中添加了[intitle:]参数,即使在搜索论坛或微信时使用该参数,返回的标题也可能不收录关键词(通常网页正文收录关键词),然后可以勾选[Fully Appear]强制关键词出现在标题中。
6、 刷新列表时间栏,[]方括号括起来是当地时间,网页时间不括起来。 查看全部
实时抓取网页数据(优采云原创的自动提取正文算法能适应网页的主体正文)
当监听到最新网页时,该软件会列在列表框的最上方,并有提示音。
然后你点击列表中的一个标题,网页的文字就会自动显示在“快速阅读窗口”中。
优采云原创的自动文本提取算法,该算法可以适应大部分网页,自动提取网页的主体部分,单独阅读。
当然,你也可能会遇到提取错误,比如一些没有大正文的网页,比如视频播放页面等,这时候可以点击“打开原创网页”链接查看原创网页页。
指示
1、 一般网速为4M,同一程序监控的关键词数量不建议超过20个。即使你的网速很快,也不建议设置太多多个关键词同时监控,也可以尝试打开多个程序进行监控(将多个程序拷贝到不同文件夹,独立添加监控配置操作)。
2、 刷新列表显示数量,软件会动态保持在1500以内,超出的会自动去除
3、刷新列表的URL已经保存在【软件目录-刷新列表】目录下,关键词HTML和TXT格式文件各有两份。如果长时间运行后文件过大,可以自行删除或移动文件到新位置(先关闭监控程序)。
4、右键刷新列表中的标题,直接在浏览器中打开原网页,无需提取文字。
5、【关键词出现在标题中】只是在搜索引擎爬取中添加了[intitle:]参数,即使在搜索论坛或微信时使用该参数,返回的标题也可能不收录关键词(通常网页正文收录关键词),然后可以勾选[Fully Appear]强制关键词出现在标题中。
6、 刷新列表时间栏,[]方括号括起来是当地时间,网页时间不括起来。
实时抓取网页数据(PM2.5监测站点的数据前台)
网站优化 • 优采云 发表了文章 • 0 个评论 • 147 次浏览 • 2021-10-23 04:10
用wpf做一个表单,类似Silverlight开发环境,将前端设计与后端开发逻辑分离,抓取9个PM2.南京5个监控站点的数据
前台代码:
背景代码:
<p> class MonitorInfo
{
public string Name{get;set;}
public string Density{get;set;}
};
List myListString=new List();
private string GetWebContent(string Url)
{
string strResult = "";
try
{
HttpWebRequest request = (HttpWebRequest)WebRequest.Create(Url);
//声明一个HttpWebRequest请求
request.Timeout = 30000;
//设置连接超时时间
request.Headers.Set("Pragma", "no-cache");
HttpWebResponse response = (HttpWebResponse)request.GetResponse();
Stream streamReceive = response.GetResponseStream();
Encoding encoding = Encoding.GetEncoding("GB2312");
StreamReader streamReader = new StreamReader(streamReceive, encoding);
strResult = streamReader.ReadToEnd();
}
catch
{
System.Windows.Forms.MessageBox.Show("出错");
}
return strResult;
}
private void button1_Click(object sender, RoutedEventArgs e)
{
textBox1.Text="http://www.pm2d5.com/city/nanjing.html";
String Url = textBox1.Text;
string strWebContent = GetWebContent(Url);
int divIndex = strWebContent.IndexOf("weilai");
int tableStartIndex = strWebContent.IndexOf(" 查看全部
实时抓取网页数据(PM2.5监测站点的数据前台)
用wpf做一个表单,类似Silverlight开发环境,将前端设计与后端开发逻辑分离,抓取9个PM2.南京5个监控站点的数据
前台代码:
背景代码:
<p> class MonitorInfo
{
public string Name{get;set;}
public string Density{get;set;}
};
List myListString=new List();
private string GetWebContent(string Url)
{
string strResult = "";
try
{
HttpWebRequest request = (HttpWebRequest)WebRequest.Create(Url);
//声明一个HttpWebRequest请求
request.Timeout = 30000;
//设置连接超时时间
request.Headers.Set("Pragma", "no-cache");
HttpWebResponse response = (HttpWebResponse)request.GetResponse();
Stream streamReceive = response.GetResponseStream();
Encoding encoding = Encoding.GetEncoding("GB2312");
StreamReader streamReader = new StreamReader(streamReceive, encoding);
strResult = streamReader.ReadToEnd();
}
catch
{
System.Windows.Forms.MessageBox.Show("出错");
}
return strResult;
}
private void button1_Click(object sender, RoutedEventArgs e)
{
textBox1.Text="http://www.pm2d5.com/city/nanjing.html";
String Url = textBox1.Text;
string strWebContent = GetWebContent(Url);
int divIndex = strWebContent.IndexOf("weilai");
int tableStartIndex = strWebContent.IndexOf("
实时抓取网页数据(网页监控管理-添加你的第一个监控(py3.7))
网站优化 • 优采云 发表了文章 • 0 个评论 • 163 次浏览 • 2021-10-22 20:13
3) 然后就可以自己部署docker-compose up -d了:
docker-compose up -d
4)打开你的就可以访问如下界面,说明一切正常:(如果不能访问,让8000端口安全~)
注:默认账号密码:admin、password
4、手动部署
1)很多人不喜欢docker的方式,所以我们可以手动部署。但最好的前提是安装下面的测试代码。独立运行环境(py3.7)
curl -sSO http://download.bt.cn/install/install_panel.sh && bash install_panel.sh
2)下载WebMonitor的源代码
git clone https://github.com/LogicJake/WebMonitor.git
cd WebMonitor
3)下载后安装依赖
pip install -r requirements.txt
4) 第一次运行需要迁移数据库并设置管理账号。假设账号为admin,密码为password,运行端口为8000。
python manage.py migrate
python manage.py initadmin --username admin --password password
python manage.py runserver 0.0.0.0:8000 --noreload
5)不是第一次运行,只是指定端口
python manage.py runserver 0.0.0.0:8000 --noreload
注:默认账号密码:admin、password
5、设置网络监控
1) 登录后,我们首先需要设置通知方式,这里我们使用Server酱的微信通知~
2)添加监控项,在任务管理-Web监控管理-添加你的第一个监控。
例子:我想监控BUYVM的VPS是否有货。元素选择器类型使用 XPath:
注意:
3)元素选择器的内容可以通过Chrome浏览器F12获取:
4) 保存以上即可完成监控项目的创建。在下面找到任务状态,看看你添加的监控项目是否可以正常工作:
5) 第一次添加的监控项,如果正常的话,你的微信应该也能收到服务器酱的消息:
设置RSS监控
设置方法和网页监控类似,这里截图展示一下。
7、设置域名访问
直接看图:
8、终于
监控网页内容变化非常好用,安装方法也非常简单。有这个要求的童鞋可以用。具体特点如下:
内容 查看全部
实时抓取网页数据(网页监控管理-添加你的第一个监控(py3.7))
3) 然后就可以自己部署docker-compose up -d了:
docker-compose up -d
4)打开你的就可以访问如下界面,说明一切正常:(如果不能访问,让8000端口安全~)
注:默认账号密码:admin、password
4、手动部署
1)很多人不喜欢docker的方式,所以我们可以手动部署。但最好的前提是安装下面的测试代码。独立运行环境(py3.7)
curl -sSO http://download.bt.cn/install/install_panel.sh && bash install_panel.sh
2)下载WebMonitor的源代码
git clone https://github.com/LogicJake/WebMonitor.git
cd WebMonitor
3)下载后安装依赖
pip install -r requirements.txt
4) 第一次运行需要迁移数据库并设置管理账号。假设账号为admin,密码为password,运行端口为8000。
python manage.py migrate
python manage.py initadmin --username admin --password password
python manage.py runserver 0.0.0.0:8000 --noreload
5)不是第一次运行,只是指定端口
python manage.py runserver 0.0.0.0:8000 --noreload
注:默认账号密码:admin、password
5、设置网络监控
1) 登录后,我们首先需要设置通知方式,这里我们使用Server酱的微信通知~
2)添加监控项,在任务管理-Web监控管理-添加你的第一个监控。
例子:我想监控BUYVM的VPS是否有货。元素选择器类型使用 XPath:
注意:
3)元素选择器的内容可以通过Chrome浏览器F12获取:
4) 保存以上即可完成监控项目的创建。在下面找到任务状态,看看你添加的监控项目是否可以正常工作:
5) 第一次添加的监控项,如果正常的话,你的微信应该也能收到服务器酱的消息:
设置RSS监控
设置方法和网页监控类似,这里截图展示一下。
7、设置域名访问
直接看图:
8、终于
监控网页内容变化非常好用,安装方法也非常简单。有这个要求的童鞋可以用。具体特点如下:
内容
实时抓取网页数据(Python爬虫入门教程!手把手教会你爬取网页数据(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 88 次浏览 • 2021-10-21 08:17
链接提交工具是网站主动推送数据到百度搜索的工具。该工具可以缩短爬虫发现网站链接的时间,网站时间敏感的内容推荐使用链接提交工具实时推送搜索数据。这个工具可以加快爬虫的爬行速度,但是不能解决网站。
网页内容智能抓取的实现和实例详解完全基于java。核心技术核心技术XML解析、HTML解析、开源组件应用。该应用程序的开源组件包括: DOM4J:解析 XMLjericho-。
Python爬虫入门教程!手把手教你爬取网页数据。
它可以帮助我们快速采集互联网的海量内容,进行深入的数据分析和挖掘。比如抓取各大网站的排名,抓取各大购物的价格信息网站等等。而我们每天常用的搜索引擎都是“网络爬虫”。但毕竟要学习。
爬取网页内容的一个例子来自于通过程序自动读取其他网站网页上显示的信息,类似于爬虫程序。例如,我们有一个。
优采云网页数据采集器,是一款简单易用、功能强大的网络爬虫工具,完全可视化操作,无需编写代码,内置海量模板,支持任意网页数据抓取,连续五年.
网页内容提取器可以帮助我们快速提取输入的URL链接中的所有图片、链接和网页文本内容。
优采云·云采集服务平台网站如何使用内容爬取工具网络每天都在产生海量的图文数据。如何为你我使用这些数据,让数据给我们工作带来真正的价值? 查看全部
实时抓取网页数据(Python爬虫入门教程!手把手教会你爬取网页数据(组图))
链接提交工具是网站主动推送数据到百度搜索的工具。该工具可以缩短爬虫发现网站链接的时间,网站时间敏感的内容推荐使用链接提交工具实时推送搜索数据。这个工具可以加快爬虫的爬行速度,但是不能解决网站。
网页内容智能抓取的实现和实例详解完全基于java。核心技术核心技术XML解析、HTML解析、开源组件应用。该应用程序的开源组件包括: DOM4J:解析 XMLjericho-。
Python爬虫入门教程!手把手教你爬取网页数据。
它可以帮助我们快速采集互联网的海量内容,进行深入的数据分析和挖掘。比如抓取各大网站的排名,抓取各大购物的价格信息网站等等。而我们每天常用的搜索引擎都是“网络爬虫”。但毕竟要学习。
爬取网页内容的一个例子来自于通过程序自动读取其他网站网页上显示的信息,类似于爬虫程序。例如,我们有一个。
优采云网页数据采集器,是一款简单易用、功能强大的网络爬虫工具,完全可视化操作,无需编写代码,内置海量模板,支持任意网页数据抓取,连续五年.
网页内容提取器可以帮助我们快速提取输入的URL链接中的所有图片、链接和网页文本内容。
优采云·云采集服务平台网站如何使用内容爬取工具网络每天都在产生海量的图文数据。如何为你我使用这些数据,让数据给我们工作带来真正的价值?
实时抓取网页数据(运营商大数据,全行业精准平台大平台)
网站优化 • 优采云 发表了文章 • 0 个评论 • 160 次浏览 • 2021-10-17 03:14
运营商大数据,全行业精准大数据获客平台
在大数据时代的今天,我们可以利用大数据,通过算法,在app或者网站中精准推送用户兴趣偏好的产品和内容。运营商大数据具有互联网公司无法比拟的用户数据、实时性和准确性。运营商对大数据的应用,不像互联网公司,只能应用到自己的业务上,而是可以帮助各个行业和企业拓展获客、营销等应用,可以根据不同的行业领域帮助不同的行业领域。到他们的收购。对客户需求进行建模以获得准确的客户数据。
如何帮助企业解决获客难题?
运营商大数据拥有海量数据资源,运营商大数据强大的建模能力,可实时分析捕捉实时访客数据,如:网站、网站、网页、URL;手机APP的每日活跃用户/新注册用户数据;400/固话主叫、被叫、出线、来电和去电记录;短信接收群;关键词搜索群等多维度、多平台的用户数据信息,并通过建立用户画像,准确分析用户所在地区、年龄、性别、访问次数、通话时长等用户信息,和短信互动。还可以分析同行业、垂直领域、竞品线索(如URL、APP、400/固话等)。
网站、网页、网址、URL:如搜索引擎排名靠前的推广网页、网站、出价网站、网页等将被屏蔽。
手机APP:例如装修行业的垂直领域APP:土巴兔装修;金融行业垂直APP:平安普惠、平安银行等,用于活跃用户和新注册用户的获取。
400/固话:如竞品、对等400/固话、座机,捕捉来电和被叫、来电和去电记录。
SMS/关键词:如果短信接收者拥挤,关键词 搜索人群以捕获。
移动、联通运营商大数据可以帮助全行业、中小微企业精准获客、精准营销、精准触达目标客户。可以帮助不同行业的多领域、多维度,企业可以获得精准的目标客户群。对获取的实时数据进行脱敏处理,从而规避法律风险。企业可以使用专业的CRM客户管理外呼系统进行实时管理,精准触达客户,确定客户意向,进行转化和交易。 查看全部
实时抓取网页数据(运营商大数据,全行业精准平台大平台)
运营商大数据,全行业精准大数据获客平台
在大数据时代的今天,我们可以利用大数据,通过算法,在app或者网站中精准推送用户兴趣偏好的产品和内容。运营商大数据具有互联网公司无法比拟的用户数据、实时性和准确性。运营商对大数据的应用,不像互联网公司,只能应用到自己的业务上,而是可以帮助各个行业和企业拓展获客、营销等应用,可以根据不同的行业领域帮助不同的行业领域。到他们的收购。对客户需求进行建模以获得准确的客户数据。
如何帮助企业解决获客难题?
运营商大数据拥有海量数据资源,运营商大数据强大的建模能力,可实时分析捕捉实时访客数据,如:网站、网站、网页、URL;手机APP的每日活跃用户/新注册用户数据;400/固话主叫、被叫、出线、来电和去电记录;短信接收群;关键词搜索群等多维度、多平台的用户数据信息,并通过建立用户画像,准确分析用户所在地区、年龄、性别、访问次数、通话时长等用户信息,和短信互动。还可以分析同行业、垂直领域、竞品线索(如URL、APP、400/固话等)。
网站、网页、网址、URL:如搜索引擎排名靠前的推广网页、网站、出价网站、网页等将被屏蔽。
手机APP:例如装修行业的垂直领域APP:土巴兔装修;金融行业垂直APP:平安普惠、平安银行等,用于活跃用户和新注册用户的获取。
400/固话:如竞品、对等400/固话、座机,捕捉来电和被叫、来电和去电记录。
SMS/关键词:如果短信接收者拥挤,关键词 搜索人群以捕获。
移动、联通运营商大数据可以帮助全行业、中小微企业精准获客、精准营销、精准触达目标客户。可以帮助不同行业的多领域、多维度,企业可以获得精准的目标客户群。对获取的实时数据进行脱敏处理,从而规避法律风险。企业可以使用专业的CRM客户管理外呼系统进行实时管理,精准触达客户,确定客户意向,进行转化和交易。
实时抓取网页数据(天天自动抓取更新系统全智能抓取,行业分类卡布奇诺)
网站优化 • 优采云 发表了文章 • 0 个评论 • 179 次浏览 • 2021-10-17 03:09
每天自动爬取更新。系统全智能抓取,多网页、多站点抓取,数据智能分析。模仿搜索引擎抓取网页,成功率超过90。实时通知,数据更新实时邮件/微信通知。无需人工操作,启动后会持续推送。模仿搜索引擎抓取网页,成功率很高。无需一直坐在电脑前刷新网页,数据自动获取。经过近一年的实际生产环境测试和应用,该软件正式上市。
支持新闻列表、论坛帖子、竞价信息、新品、股市财经资讯、微博更新等网站平台爬取监控,通用网页列表监控软件。
监控网站信息列表,有更新或满足关键字条件时立即提醒记录。帮助您从海量的网络信息中获取有用的信息,第一时间获取最准确的信息。最适合广大投资者或记者。
每日自动爬取更新系统特点:
1、软件具有更新监控和关键链接过滤功能。
2、更新监控是指当出现新的信息链接网站时,会被捕获并放入数据库,不会重复提醒。
3、软件支持同时监控多个网站,获取更全面的信息。
4、 抓取数据存入数据库,随时打开参考。
5、支持常用的提醒方式,包括邮件/微信等。
6、一般网站使用源码监控的方式,速度快又节省资源。
免责声明:源代码仅供研究和学习代码使用,严禁用于非法和商业用途!不提供任何技术支持,不包括安装。商用请购买官方源码!
类别
ㄣ卡布奇诺╰☆ぷ普通 查看全部
实时抓取网页数据(天天自动抓取更新系统全智能抓取,行业分类卡布奇诺)
每天自动爬取更新。系统全智能抓取,多网页、多站点抓取,数据智能分析。模仿搜索引擎抓取网页,成功率超过90。实时通知,数据更新实时邮件/微信通知。无需人工操作,启动后会持续推送。模仿搜索引擎抓取网页,成功率很高。无需一直坐在电脑前刷新网页,数据自动获取。经过近一年的实际生产环境测试和应用,该软件正式上市。
支持新闻列表、论坛帖子、竞价信息、新品、股市财经资讯、微博更新等网站平台爬取监控,通用网页列表监控软件。
监控网站信息列表,有更新或满足关键字条件时立即提醒记录。帮助您从海量的网络信息中获取有用的信息,第一时间获取最准确的信息。最适合广大投资者或记者。
每日自动爬取更新系统特点:
1、软件具有更新监控和关键链接过滤功能。
2、更新监控是指当出现新的信息链接网站时,会被捕获并放入数据库,不会重复提醒。
3、软件支持同时监控多个网站,获取更全面的信息。
4、 抓取数据存入数据库,随时打开参考。
5、支持常用的提醒方式,包括邮件/微信等。
6、一般网站使用源码监控的方式,速度快又节省资源。
免责声明:源代码仅供研究和学习代码使用,严禁用于非法和商业用途!不提供任何技术支持,不包括安装。商用请购买官方源码!
类别
ㄣ卡布奇诺╰☆ぷ普通
实时抓取网页数据( 如何利用Python爬取模块获取查看器的html内容(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 95 次浏览 • 2021-10-16 07:41
如何利用Python爬取模块获取查看器的html内容(图))
1. 文章 目的
我们在使用Python抓取网页数据时,经常会用到urllib模块,通过调用urllib模块的urlopen(url)方法返回网页。
页面对象,使用read()方法获取url的html内容,然后使用BeautifulSoup抓取某个标签的内容,结合正则表
亲爱的过滤器。然而,你用 urllib.urlopen(url).read() 得到的只是网页的静态 html 内容,还有很多动态数据(比如 网站
访问量、当前在线人数、微博点赞数等)不收录在静态html中,比如我要抢这个bbs网
当前点击打开站点内各版块链接的在线人数不收录在静态html页面中(不信你去查一下页面源码,
只有一条简单的线)。像这样的动态数据更多是由 JavaScript、JQuery、PHP 等语言动态生成的。因此,
不宜使用爬取静态html内容的方法。
2. 解决方案
我试过网上提到的浏览器自带的开发者工具(一般是F12弹出对应网页的开发者工具),上网查了一下
动态数据的趋势是可以得到的,但是这需要从众多的URL中寻找线索,我个人觉得太麻烦了。另外,使用查看器
查看的html内容也收录动态数据,但是有几个问题:如何实时获取查看器的html内容?如何查看
html变成python程序?因此,使用查看器的html内容的方法也不符合爬虫的要求。
偶然发现了selenium模块,发现这个模块可以很方便的根据url加载页面获取session,并找到当前se
ssion 对应的标签。本文将使用 selenium webdriver 模块来获取这些动态生成的内容,尤其是一个
一些重要的动态数据。其实selenium模块的功能不仅限于抓取网页,它是网络自动化测试的常用模块
,在Ruby和Java中被广泛使用。Python虽然使用的比较少,但它也是一个非常简洁、高效、易用的工具。
手的自动化测试模块。通过使用selenium的子模块webdriver解决动态数据的捕获问题,还可以
可以对selenium有一个基本的了解,为进一步学习自动化测试打下基础。
3. 实施过程
3.1 运行环境
我在windows 7系统上安装了Python2.7版本,使用的是Python(X,Y)的IDE,安装的Python库没有self
用selenium,如果直接在Python程序中导入selenium,会提示没有这个模块。联网状态下,cmd直接进入pip i
安装selenium,系统会找到Python安装目录直接下载、解压安装这个模块。等到终端提示完成
我们看看C:\Python27\Lib\site-packages目录下有没有selenium模块。这个目录取决于你安装的 Python
的路径。如果有两个文件夹,selenium和selenium-2.47.3.dist-info,可以在Python程序中添加模块
已加载。
使用 webdriver 捕获动态数据
先导入webdriver子模块
从硒导入网络驱动程序
获取浏览器会话,可以使用火狐、Chrome、IE等浏览器,这里以火狐为例
浏览器 = webdriver.Firefox()
加载页面,在 url 本身中指定一个合法的字符串
browser.get(url)
获取到session对象后,为了定位元素,webdriver提供了一系列的元素定位方法。常用的方法有以下几种:
ID
姓名
班级名称
关联
文本
部分的
关联
文本
标签
姓名
路径
css选择器
比如通过id定位,返回一个所有元素组成的列表,lis=borwser.find_elements_by_id_name('kw'')
按类名定位,lis=find_elements_by_class_name('title_1')
更详细的定位方法请参考selenium webdriver(python)教程第三章-定位方法(第一版可百度
学位图书馆阅读)
结合正则表达式过滤相关信息
定位后的一些元素是不可取的,只需使用常规过滤即可。比如我想只提取英文字符(包括0-9),创建如下
常规的
pa=堆(r'\w+')
对于 lis 中的你:
en=pa.findall(u.lis)
印刷英文
关闭会话
执行fetch操作后必须关闭session,否则让它一直占用内存会影响机器上其他进程的操作
Browser.close() 或 browser.quit() 可以关闭会话,前者只是关闭当前会话,浏览器的webdrive
r 未关闭,后者已关闭,包括 webdriver 等所有内容
添加异常处理
这个是必须的,因为有时候会获取session失败,所以把上面的语句块放到try里面,然后用exception处理
除了 NoSuchElementException:
断言 0,“找不到元素”
4. 代码实现
我通过点击打开链接抓取了指定分区每个板块的在线用户数,并指定了分区id号(0-9),可以得到板块名称和
在线用户数应该打印在一个列表中,代码如下
[python] 查看平原
# -*- 编码:utf-8 -*-
从硒导入网络驱动程序
从 mon.exceptions 导入 NoSuchElementException
导入时间
进口重新
def find_sec(secid):
pa=堆(r'\w+')
browser = webdriver.Firefox() # 获取firefox的本地会话
browser.get("!section/%s "%secid) # 加载页面
time.sleep(1) # 让页面加载
结果=[]
尝试:
#获取页面名称和在线号码组成列表
board=browser.find_elements_by_class_name('title_1')
ol_num=browser.find_elements_by_class_name('title_4')
max_bindex=len(板)
max_oindex=len(ol_num)
assert max_bindex==max_oindex,'索引不等价!'
#页面名称为中英文,所以常规过滤后只剩下英文
对于范围内的 i(1,max_oindex):
board_en=pa.findall(board.text)
result.append([str(board_en[-1]),int(ol_num.text)])
浏览器关闭()
返回结果
除了 NoSuchElementException:
断言 0,“找不到元素”
print find_sec('5')#打印第5分区下所有版块的当前在线用户列表
操作结果如下:
终端打印效果
4. 总结
Selenium 在代码简洁性和执行效率方面非常出色。使用 selenium webdriver 捕获动态数据不是
它通常简单而有效。也可以进一步利用这个实现数据挖掘、机器学习等深入研究,所以selenium+pyth
就值得深入研究!如果觉得每次都用selenium打开浏览器不方便,可以用phantomjs模拟一个虚拟的
浏览器出来了,这里就不赘述了。 查看全部
实时抓取网页数据(
如何利用Python爬取模块获取查看器的html内容(图))
1. 文章 目的
我们在使用Python抓取网页数据时,经常会用到urllib模块,通过调用urllib模块的urlopen(url)方法返回网页。
页面对象,使用read()方法获取url的html内容,然后使用BeautifulSoup抓取某个标签的内容,结合正则表
亲爱的过滤器。然而,你用 urllib.urlopen(url).read() 得到的只是网页的静态 html 内容,还有很多动态数据(比如 网站
访问量、当前在线人数、微博点赞数等)不收录在静态html中,比如我要抢这个bbs网
当前点击打开站点内各版块链接的在线人数不收录在静态html页面中(不信你去查一下页面源码,
只有一条简单的线)。像这样的动态数据更多是由 JavaScript、JQuery、PHP 等语言动态生成的。因此,
不宜使用爬取静态html内容的方法。
2. 解决方案
我试过网上提到的浏览器自带的开发者工具(一般是F12弹出对应网页的开发者工具),上网查了一下
动态数据的趋势是可以得到的,但是这需要从众多的URL中寻找线索,我个人觉得太麻烦了。另外,使用查看器
查看的html内容也收录动态数据,但是有几个问题:如何实时获取查看器的html内容?如何查看
html变成python程序?因此,使用查看器的html内容的方法也不符合爬虫的要求。
偶然发现了selenium模块,发现这个模块可以很方便的根据url加载页面获取session,并找到当前se
ssion 对应的标签。本文将使用 selenium webdriver 模块来获取这些动态生成的内容,尤其是一个
一些重要的动态数据。其实selenium模块的功能不仅限于抓取网页,它是网络自动化测试的常用模块
,在Ruby和Java中被广泛使用。Python虽然使用的比较少,但它也是一个非常简洁、高效、易用的工具。
手的自动化测试模块。通过使用selenium的子模块webdriver解决动态数据的捕获问题,还可以
可以对selenium有一个基本的了解,为进一步学习自动化测试打下基础。
3. 实施过程
3.1 运行环境
我在windows 7系统上安装了Python2.7版本,使用的是Python(X,Y)的IDE,安装的Python库没有self
用selenium,如果直接在Python程序中导入selenium,会提示没有这个模块。联网状态下,cmd直接进入pip i
安装selenium,系统会找到Python安装目录直接下载、解压安装这个模块。等到终端提示完成
我们看看C:\Python27\Lib\site-packages目录下有没有selenium模块。这个目录取决于你安装的 Python
的路径。如果有两个文件夹,selenium和selenium-2.47.3.dist-info,可以在Python程序中添加模块
已加载。
使用 webdriver 捕获动态数据
先导入webdriver子模块
从硒导入网络驱动程序
获取浏览器会话,可以使用火狐、Chrome、IE等浏览器,这里以火狐为例
浏览器 = webdriver.Firefox()
加载页面,在 url 本身中指定一个合法的字符串
browser.get(url)
获取到session对象后,为了定位元素,webdriver提供了一系列的元素定位方法。常用的方法有以下几种:
ID
姓名
班级名称
关联
文本
部分的
关联
文本
标签
姓名
路径
css选择器
比如通过id定位,返回一个所有元素组成的列表,lis=borwser.find_elements_by_id_name('kw'')
按类名定位,lis=find_elements_by_class_name('title_1')
更详细的定位方法请参考selenium webdriver(python)教程第三章-定位方法(第一版可百度
学位图书馆阅读)
结合正则表达式过滤相关信息
定位后的一些元素是不可取的,只需使用常规过滤即可。比如我想只提取英文字符(包括0-9),创建如下
常规的
pa=堆(r'\w+')
对于 lis 中的你:
en=pa.findall(u.lis)
印刷英文
关闭会话
执行fetch操作后必须关闭session,否则让它一直占用内存会影响机器上其他进程的操作
Browser.close() 或 browser.quit() 可以关闭会话,前者只是关闭当前会话,浏览器的webdrive
r 未关闭,后者已关闭,包括 webdriver 等所有内容
添加异常处理
这个是必须的,因为有时候会获取session失败,所以把上面的语句块放到try里面,然后用exception处理
除了 NoSuchElementException:
断言 0,“找不到元素”
4. 代码实现
我通过点击打开链接抓取了指定分区每个板块的在线用户数,并指定了分区id号(0-9),可以得到板块名称和
在线用户数应该打印在一个列表中,代码如下
[python] 查看平原
# -*- 编码:utf-8 -*-
从硒导入网络驱动程序
从 mon.exceptions 导入 NoSuchElementException
导入时间
进口重新
def find_sec(secid):
pa=堆(r'\w+')
browser = webdriver.Firefox() # 获取firefox的本地会话
browser.get("!section/%s "%secid) # 加载页面
time.sleep(1) # 让页面加载
结果=[]
尝试:
#获取页面名称和在线号码组成列表
board=browser.find_elements_by_class_name('title_1')
ol_num=browser.find_elements_by_class_name('title_4')
max_bindex=len(板)
max_oindex=len(ol_num)
assert max_bindex==max_oindex,'索引不等价!'
#页面名称为中英文,所以常规过滤后只剩下英文
对于范围内的 i(1,max_oindex):
board_en=pa.findall(board.text)
result.append([str(board_en[-1]),int(ol_num.text)])
浏览器关闭()
返回结果
除了 NoSuchElementException:
断言 0,“找不到元素”
print find_sec('5')#打印第5分区下所有版块的当前在线用户列表
操作结果如下:
终端打印效果
4. 总结
Selenium 在代码简洁性和执行效率方面非常出色。使用 selenium webdriver 捕获动态数据不是
它通常简单而有效。也可以进一步利用这个实现数据挖掘、机器学习等深入研究,所以selenium+pyth
就值得深入研究!如果觉得每次都用selenium打开浏览器不方便,可以用phantomjs模拟一个虚拟的
浏览器出来了,这里就不赘述了。
实时抓取网页数据(下有模拟浏览器本文几种网站示例详解方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 294 次浏览 • 2021-10-16 07:37
使用python爬取网站数据非常方便,效率也很高,但是常用的BeautifSoup和requests的组合一般用于爬取静态页面(即网页上显示的数据)可以在html源码中找到,不是网站通过js或者ajax异步加载的),这种网站数据比较容易爬取。但是网站上的一些数据是通过执行js代码更新的。这时候,传统的方法就不那么适用了。这种情况下有几种方法:
一、准备
模拟浏览器需要两个工具:
Selenium,可以直接通过pip install selenium安装PhantomJS。这是一个无界面、脚本可编程的 WebKit 浏览器引擎。百度在其官方网站上搜索并下载。下载后,您无需安装。把它放在指定的路径中。使用时只需要指定文件所在的路径即可。二、使用selenium模拟浏览器
本文爬取网站的例子是:8099/ths-report/report!list.action?xmlname=46(最新测试发现网站打不开,2021年5月25日)
学习示例时请不要抓取太多页面,只需通过过程了解如何抓取它。
打开网站后可以看到要爬取的数据是一个普通的表,但是页面很多。
在这个网站中,点击下一页的页面的url没有变化,通过执行一段js代码来更新页面。所以本文的思路是用selenium模拟浏览器点击,点击“下一步”更新页面数据,得到更新后的页面数据。这是完整的代码:
# -*- coding:utf-8 -*-
import requests
from bs4 import BeautifulSoup
import json
import time
from selenium import webdriver
import sys
reload(sys)
sys.setdefaultencoding( "utf-8" )
curpath=sys.path[0]
print curpath
def getData(url):
# 使用下载好的phantomjs,网上也有人用firefox,chrome,但是我没有成功,用这个也挺方便
driver =webdriver.PhantomJS(executable_path="C:/phantomjs.exe")
driver.set_page_load_timeout(30)
time.sleep(3)
html=driver.get(url[0]) # 使用get方法请求url,因为是模拟浏览器,所以不需要headers信息
for page in range(3):
html=driver.page_source # 获取网页的html数据
soup=BeautifulSoup(html,'lxml') # 对html进行解析,如果提示lxml未安装,直接pip install lxml即可
table=soup.find('table',class_="report-table")
name=[]
for th in table.find_all('tr')[0].find_all('th'):
name.append(th.get_text()) # 获取表格的字段名称作为字典的键
flag=0 # 标记,当爬取字段数据是为0,否则为1
for tr in table.find_all('tr'):
# 第一行为表格字段数据,因此跳过第一行
if flag==1:
dic={}
i=0
for td in tr.find_all('td'):
dic[name[i]]=td.get_text()
i+=1
jsonDump(dic,url[1])#保存数据
flag=1
# 利用find_element_by_link_text方法得到下一页所在的位置并点击,点击后页面会自动更新,只需要重新获取driver.page_source即可
driver.find_element_by_link_text(u"下一页").click()
def jsonDump(_json,name):
"""store json data"""
with open(curpath+'/'+name+'.json','a') as outfile:
json.dump(_json,outfile,ensure_ascii=False)
with open(curpath+'/'+name+'.json','a') as outfile:
outfile.write(',\n')
if __name__ == '__main__':
url=['http://datacenter.mep.gov.cn:8 ... 39%3B,'yzc'] # yzc为文件名,此处输入中文会报错,前面加u也不行,只好保存后手动改文件名……
getData(url) # 调用函数
本文通过driver.find_element_by_link_text方法获取下一页的位置。这是因为在这个页面中,这个标签没有唯一可识别的 id,也没有类。如果是通过xpath定位,第一页和其他页面的xpath路径不完全一样,需要加一个if来判断。所以直接通过链接的text参数定位。click() 函数模拟浏览器中的点击操作。如何定位页面中的元素位置,可以参考下面的博客。
Selenuim+Python 元素定位总结及示例说明
硒非常强大。可以解决很多普通爬虫无法解决的问题。可以模拟点击、鼠标移动、提交表单(应用如:登录邮箱账号、登录wifi等,网上有很多例子,我暂时还没试过),当你遇到一些非常规网站 数据爬取难度很大,不妨试试selenium+phantomjs。
以上,欢迎交流。 查看全部
实时抓取网页数据(下有模拟浏览器本文几种网站示例详解方法)
使用python爬取网站数据非常方便,效率也很高,但是常用的BeautifSoup和requests的组合一般用于爬取静态页面(即网页上显示的数据)可以在html源码中找到,不是网站通过js或者ajax异步加载的),这种网站数据比较容易爬取。但是网站上的一些数据是通过执行js代码更新的。这时候,传统的方法就不那么适用了。这种情况下有几种方法:
一、准备
模拟浏览器需要两个工具:
Selenium,可以直接通过pip install selenium安装PhantomJS。这是一个无界面、脚本可编程的 WebKit 浏览器引擎。百度在其官方网站上搜索并下载。下载后,您无需安装。把它放在指定的路径中。使用时只需要指定文件所在的路径即可。二、使用selenium模拟浏览器
本文爬取网站的例子是:8099/ths-report/report!list.action?xmlname=46(最新测试发现网站打不开,2021年5月25日)
学习示例时请不要抓取太多页面,只需通过过程了解如何抓取它。
打开网站后可以看到要爬取的数据是一个普通的表,但是页面很多。
在这个网站中,点击下一页的页面的url没有变化,通过执行一段js代码来更新页面。所以本文的思路是用selenium模拟浏览器点击,点击“下一步”更新页面数据,得到更新后的页面数据。这是完整的代码:
# -*- coding:utf-8 -*-
import requests
from bs4 import BeautifulSoup
import json
import time
from selenium import webdriver
import sys
reload(sys)
sys.setdefaultencoding( "utf-8" )
curpath=sys.path[0]
print curpath
def getData(url):
# 使用下载好的phantomjs,网上也有人用firefox,chrome,但是我没有成功,用这个也挺方便
driver =webdriver.PhantomJS(executable_path="C:/phantomjs.exe")
driver.set_page_load_timeout(30)
time.sleep(3)
html=driver.get(url[0]) # 使用get方法请求url,因为是模拟浏览器,所以不需要headers信息
for page in range(3):
html=driver.page_source # 获取网页的html数据
soup=BeautifulSoup(html,'lxml') # 对html进行解析,如果提示lxml未安装,直接pip install lxml即可
table=soup.find('table',class_="report-table")
name=[]
for th in table.find_all('tr')[0].find_all('th'):
name.append(th.get_text()) # 获取表格的字段名称作为字典的键
flag=0 # 标记,当爬取字段数据是为0,否则为1
for tr in table.find_all('tr'):
# 第一行为表格字段数据,因此跳过第一行
if flag==1:
dic={}
i=0
for td in tr.find_all('td'):
dic[name[i]]=td.get_text()
i+=1
jsonDump(dic,url[1])#保存数据
flag=1
# 利用find_element_by_link_text方法得到下一页所在的位置并点击,点击后页面会自动更新,只需要重新获取driver.page_source即可
driver.find_element_by_link_text(u"下一页").click()
def jsonDump(_json,name):
"""store json data"""
with open(curpath+'/'+name+'.json','a') as outfile:
json.dump(_json,outfile,ensure_ascii=False)
with open(curpath+'/'+name+'.json','a') as outfile:
outfile.write(',\n')
if __name__ == '__main__':
url=['http://datacenter.mep.gov.cn:8 ... 39%3B,'yzc'] # yzc为文件名,此处输入中文会报错,前面加u也不行,只好保存后手动改文件名……
getData(url) # 调用函数
本文通过driver.find_element_by_link_text方法获取下一页的位置。这是因为在这个页面中,这个标签没有唯一可识别的 id,也没有类。如果是通过xpath定位,第一页和其他页面的xpath路径不完全一样,需要加一个if来判断。所以直接通过链接的text参数定位。click() 函数模拟浏览器中的点击操作。如何定位页面中的元素位置,可以参考下面的博客。
Selenuim+Python 元素定位总结及示例说明
硒非常强大。可以解决很多普通爬虫无法解决的问题。可以模拟点击、鼠标移动、提交表单(应用如:登录邮箱账号、登录wifi等,网上有很多例子,我暂时还没试过),当你遇到一些非常规网站 数据爬取难度很大,不妨试试selenium+phantomjs。
以上,欢迎交流。
实时抓取网页数据( 网页数据如下图:#找到要数据的网址(rvest))
网站优化 • 优采云 发表了文章 • 0 个评论 • 163 次浏览 • 2021-10-11 13:28
网页数据如下图:#找到要数据的网址(rvest))
写论文,没有数据?R语言爬取网络大数据
放眼国内外,大数据市场发展迅猛,政府支持力度空前,甚至将大数据纳入发展战略。这样的形势给社会各界提供了许多机遇和挑战,作为卫生(医疗)统计领域的一员,我们更要抓住机遇。放眼全球,大数据的应用规模不断扩大,几乎每个行业都将目光投向了大数据背后的巨大价值。未来五到十年将是我国推动大数据发展的关键时期,亟需打造高效的大数据应用机制和产业链。
根据对当前大数据行业发展的分析,我们可能会从“视觉数据捕捉”开始思考大数据。这里所说的可视化数据抓取主要是指对互联网网页数据的抓取,可以实现大数据应用的普及。目前,我们已经可以使用一个简单的网页数据爬取工具来爬取它所需要的网页数据,比如知名的网页数据爬取工具“**采集器”(收费)。现有的互联网数据采集、处理、分析、挖掘软件可以灵活、快速地捕捉网络上分散的数据信息,并通过一系列的分析处理,准确地挖掘出所需的数据。由此带来的效率、便利和文明化不言而喻。
作为大数据行业的一员,今天小编就基于流行的R软件,为大家介绍如何实现网页数据采集技术。是的,是R!除了强大的统计分析功能外,它对网页的抓取能力也不容小觑,尤其是Hadley写的R包rvest,把复杂的事情简单化了。使用R语言抓取网页数据的最大优势在于获得数据后强大的数据处理、分析和可视化功能。
R语言示例
下面以rvest包捕获的广州空气质量数据为例进行说明。
网页数据如下:
#加载包
图书馆(rvest)
#找到获取数据的URL 查看全部
实时抓取网页数据(
网页数据如下图:#找到要数据的网址(rvest))
写论文,没有数据?R语言爬取网络大数据
放眼国内外,大数据市场发展迅猛,政府支持力度空前,甚至将大数据纳入发展战略。这样的形势给社会各界提供了许多机遇和挑战,作为卫生(医疗)统计领域的一员,我们更要抓住机遇。放眼全球,大数据的应用规模不断扩大,几乎每个行业都将目光投向了大数据背后的巨大价值。未来五到十年将是我国推动大数据发展的关键时期,亟需打造高效的大数据应用机制和产业链。
根据对当前大数据行业发展的分析,我们可能会从“视觉数据捕捉”开始思考大数据。这里所说的可视化数据抓取主要是指对互联网网页数据的抓取,可以实现大数据应用的普及。目前,我们已经可以使用一个简单的网页数据爬取工具来爬取它所需要的网页数据,比如知名的网页数据爬取工具“**采集器”(收费)。现有的互联网数据采集、处理、分析、挖掘软件可以灵活、快速地捕捉网络上分散的数据信息,并通过一系列的分析处理,准确地挖掘出所需的数据。由此带来的效率、便利和文明化不言而喻。
作为大数据行业的一员,今天小编就基于流行的R软件,为大家介绍如何实现网页数据采集技术。是的,是R!除了强大的统计分析功能外,它对网页的抓取能力也不容小觑,尤其是Hadley写的R包rvest,把复杂的事情简单化了。使用R语言抓取网页数据的最大优势在于获得数据后强大的数据处理、分析和可视化功能。
R语言示例
下面以rvest包捕获的广州空气质量数据为例进行说明。
网页数据如下:
#加载包
图书馆(rvest)
#找到获取数据的URL
实时抓取网页数据(我正在尝试从这个网页中获取实时商品价值它有一个iframe)
网站优化 • 优采云 发表了文章 • 0 个评论 • 124 次浏览 • 2021-10-11 13:27
我正在尝试从此网页获取实时产品价值。它有一个 iframe 地址::8000/
这是我用 BeautifulSoup 尝试过的:
from bs4 import BeautifulSoup
#import time
import urllib
data = []
url=urllib.urlopen("http://213.136.84.136:8000/")
html=url.read()
url.close()
soup = BeautifulSoup(html,"html.parser")
span=soup.find('table', attrs={'class':'table2'})
table_body = span.find('tbody')
rows = table_body.find_all('tr')
for row in rows:
cols = row.find_all('td')
cols = [ele.text.strip() for ele in cols]
data.append([ele for ele in cols if ele]) # Get rid of empty values
print([data])
这是我得到的输出:
[[[], [u'INTERNATIONAL MARKET'], [u'SPOT Gold'], [u'SPOT Silver'], [u'CrudeOil'], [u'Copper'], [u'NaturalGas'], [u'Dow Jones'], [u'Bank Nifty'], [u'INDIAN MARKET'], [u'MCXGold'], [u'MCXSilver'], [u'MCXCrudeOil'], [u'MCXCopper'], [u'MCXLead'], [u'MCXNickel'], [u'MCXZinc'], [u'MCXNaturalGas'], [u'MCXAluminium'], [u'MCXMenthaOil'], [u'USDINR'], [], [u"Disclaimer: We can't assure any guarantee about the accuaracy of the data."]]]
它不返回任何引号。你知道吗?
以下是HTML代码:
SYMBOL
LTP
HIGH
LOW
INTERNATIONAL MARKET
SPOT Gold
SPOT Silver
CrudeOil
Copper
NaturalGas
Dow Jones
Bank Nifty
INDIAN MARKET
MCXGold
MCXSilver
MCXCrudeOil
MCXCopper
MCXLead
MCXNickel
MCXZinc
MCXNaturalGas
MCXAluminium
MCXMenthaOil
USDINR
Disclaimer: We can't assure any guarantee about the accuaracy of the data.
有没有人知道其他方式来获得这个实时报价?你知道吗? 查看全部
实时抓取网页数据(我正在尝试从这个网页中获取实时商品价值它有一个iframe)
我正在尝试从此网页获取实时产品价值。它有一个 iframe 地址::8000/
这是我用 BeautifulSoup 尝试过的:
from bs4 import BeautifulSoup
#import time
import urllib
data = []
url=urllib.urlopen("http://213.136.84.136:8000/";)
html=url.read()
url.close()
soup = BeautifulSoup(html,"html.parser")
span=soup.find('table', attrs={'class':'table2'})
table_body = span.find('tbody')
rows = table_body.find_all('tr')
for row in rows:
cols = row.find_all('td')
cols = [ele.text.strip() for ele in cols]
data.append([ele for ele in cols if ele]) # Get rid of empty values
print([data])
这是我得到的输出:
[[[], [u'INTERNATIONAL MARKET'], [u'SPOT Gold'], [u'SPOT Silver'], [u'CrudeOil'], [u'Copper'], [u'NaturalGas'], [u'Dow Jones'], [u'Bank Nifty'], [u'INDIAN MARKET'], [u'MCXGold'], [u'MCXSilver'], [u'MCXCrudeOil'], [u'MCXCopper'], [u'MCXLead'], [u'MCXNickel'], [u'MCXZinc'], [u'MCXNaturalGas'], [u'MCXAluminium'], [u'MCXMenthaOil'], [u'USDINR'], [], [u"Disclaimer: We can't assure any guarantee about the accuaracy of the data."]]]
它不返回任何引号。你知道吗?
以下是HTML代码:
SYMBOL
LTP
HIGH
LOW
INTERNATIONAL MARKET
SPOT Gold
SPOT Silver
CrudeOil
Copper
NaturalGas
Dow Jones
Bank Nifty
INDIAN MARKET
MCXGold
MCXSilver
MCXCrudeOil
MCXCopper
MCXLead
MCXNickel
MCXZinc
MCXNaturalGas
MCXAluminium
MCXMenthaOil
USDINR
Disclaimer: We can't assure any guarantee about the accuaracy of the data.
有没有人知道其他方式来获得这个实时报价?你知道吗?
实时抓取网页数据(网探网页数据监控软件现在各行各业都在应用互联网技术,晚了可能价值已经归零)
网站优化 • 优采云 发表了文章 • 0 个评论 • 103 次浏览 • 2021-10-11 10:27
Netexplorer网络数据监控软件现在各行各业都在使用互联网技术,互联网上的数据也越来越丰富。一些数据的价值与时间有关。早点知道是有用的,晚点值可能为零。Netexploration软件就是来解决这类问题的,让您“永远领先一步”是我们的目标。
特征:
☆基于IE浏览器
没有任何反爬虫技术手段的感觉,只要能在IE浏览器中正常浏览网页,就可以监控里面的所有数据。
☆网页数据抓取
“文本匹配”和“文档结构分析”可以单独使用,也可以结合使用来采集数据,让数据采集更简单、更准确。
☆数据对比验证
自动判断最近更新的数据,支持自定义数据对比验证公式,筛选出用户最感兴趣的数据内容。
☆及时通知用户
用户注册后,可以将验证后的数据发送到用户邮箱,也可以推送到用户指定的界面重新处理数据。
☆多任务同时运行
程序支持多个监控任务同时运行,用户可以同时监控多个网页中感兴趣的数据。
☆任务间互相调用
可以将监控任务A得到的结果(必须是URL)转交给监控任务B执行,从而获得更丰富的数据结果。
☆开放通知界面
直接与您的服务器后台对接,后续流程自定义,实时高效接入数据自动化处理流程。
☆在线分享爬取公式
“人人为我,我为人”分享任意网页的爬取公式,免去编辑公式的烦恼。
☆无人值守长期运行
资源消耗低,内置内存管理模块,自动清除运行过程中产生的内存垃圾,守护进程长时间无人值守运行
更新内容
改进安装和卸载程序,添加皮肤 查看全部
实时抓取网页数据(网探网页数据监控软件现在各行各业都在应用互联网技术,晚了可能价值已经归零)
Netexplorer网络数据监控软件现在各行各业都在使用互联网技术,互联网上的数据也越来越丰富。一些数据的价值与时间有关。早点知道是有用的,晚点值可能为零。Netexploration软件就是来解决这类问题的,让您“永远领先一步”是我们的目标。
特征:
☆基于IE浏览器
没有任何反爬虫技术手段的感觉,只要能在IE浏览器中正常浏览网页,就可以监控里面的所有数据。
☆网页数据抓取
“文本匹配”和“文档结构分析”可以单独使用,也可以结合使用来采集数据,让数据采集更简单、更准确。
☆数据对比验证
自动判断最近更新的数据,支持自定义数据对比验证公式,筛选出用户最感兴趣的数据内容。
☆及时通知用户
用户注册后,可以将验证后的数据发送到用户邮箱,也可以推送到用户指定的界面重新处理数据。
☆多任务同时运行
程序支持多个监控任务同时运行,用户可以同时监控多个网页中感兴趣的数据。
☆任务间互相调用
可以将监控任务A得到的结果(必须是URL)转交给监控任务B执行,从而获得更丰富的数据结果。
☆开放通知界面
直接与您的服务器后台对接,后续流程自定义,实时高效接入数据自动化处理流程。
☆在线分享爬取公式
“人人为我,我为人”分享任意网页的爬取公式,免去编辑公式的烦恼。
☆无人值守长期运行
资源消耗低,内置内存管理模块,自动清除运行过程中产生的内存垃圾,守护进程长时间无人值守运行
更新内容
改进安装和卸载程序,添加皮肤
实时抓取网页数据(如何让数据处理后仍可以留在当前页?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 89 次浏览 • 2021-10-07 01:17
BootstrapTable 组件在最近的项目中用于开发。在开发过程中,我们遇到了这样一个需求:javascript
表格分页后,处理完一页中的一条数据后,刷新表格。为了保证表的实时正确性,先销毁表,再获取新表,获取数据java
$('#bootstrapTableId').bootstrapTable('destroy');
$('#bootstrapTableId').bootstrapTable({
...
pageNumber:1,
...
});
在接下来的开发过程中,如果对某条数据进行操作后需要刷新表格数据,但刷新表格后,pageNumber会被重置为1,即跳转回首页。处理后如何保持当前页面的数据,有两种方式:ajax
1、refresh:刷新表数据,可以加参数url指定请求发送到的url(可以是新的),silent:true 静默更新时,query:{}可以指出一些新的ajax请求参数。引导程序
$('#bootStrapTableId').bootStrapTable('refresh');
2、获取当前表格显示的页码,即当前表格页面显示的页数。处理完表格数据后,在回调函数中加入表格当晚的页码,这样表格在销毁后显示给定的页码 Render data: function
$('#bootStrapTableId').bootStrapTable('getOptions').pageNumber;
注意:getOptions:获取表的一些基本属性,并返回一个对象。键有许多属性,如 conlumns、data、sortOrder、class。如果不知道属性是什么,可以通过控制台查看url。
pageNumber:这是你之前的bootstraptable的属性spa
总结:最后使用2中的方法解决问题,既可以保证表销毁后新发起的请求渲染出来的数据的及时性,也可以保证数据的正确性。至于刷新方式,就是刷新表,可以理解为我对ajax的局部请求效果没有深入理解,但是能够实现需求。代码 查看全部
实时抓取网页数据(如何让数据处理后仍可以留在当前页?)
BootstrapTable 组件在最近的项目中用于开发。在开发过程中,我们遇到了这样一个需求:javascript
表格分页后,处理完一页中的一条数据后,刷新表格。为了保证表的实时正确性,先销毁表,再获取新表,获取数据java
$('#bootstrapTableId').bootstrapTable('destroy');
$('#bootstrapTableId').bootstrapTable({
...
pageNumber:1,
...
});
在接下来的开发过程中,如果对某条数据进行操作后需要刷新表格数据,但刷新表格后,pageNumber会被重置为1,即跳转回首页。处理后如何保持当前页面的数据,有两种方式:ajax
1、refresh:刷新表数据,可以加参数url指定请求发送到的url(可以是新的),silent:true 静默更新时,query:{}可以指出一些新的ajax请求参数。引导程序
$('#bootStrapTableId').bootStrapTable('refresh');
2、获取当前表格显示的页码,即当前表格页面显示的页数。处理完表格数据后,在回调函数中加入表格当晚的页码,这样表格在销毁后显示给定的页码 Render data: function
$('#bootStrapTableId').bootStrapTable('getOptions').pageNumber;
注意:getOptions:获取表的一些基本属性,并返回一个对象。键有许多属性,如 conlumns、data、sortOrder、class。如果不知道属性是什么,可以通过控制台查看url。
pageNumber:这是你之前的bootstraptable的属性spa
总结:最后使用2中的方法解决问题,既可以保证表销毁后新发起的请求渲染出来的数据的及时性,也可以保证数据的正确性。至于刷新方式,就是刷新表,可以理解为我对ajax的局部请求效果没有深入理解,但是能够实现需求。代码

