
字符
Ipidea丨网络爬虫正则表达式的使用
采集交流 • 优采云 发表了文章 • 0 个评论 • 394 次浏览 • 2020-06-17 08:00
## 网络爬虫正则表达式的使用
---
我们在处理网页文本内容时有时会碰到一些特殊的情况网络爬虫 正则表达式,或者须要匹配某类字符串方式,通常都会用到正则表达式。许多程序语言都支持使用正则表达式,python中正则表达式可以实现字符串的匹配、检索和替换等功能,是一个比较强悍的工具。
### 1.正则表达式句型
Python中实现正则表达式功能一般使用re模块,可以实现对文本字符串的匹配,检索和替换,但不仅引入正则模块网络爬虫 正则表达式,还须要把握正则表达式字符和基本句型,才能正确使用python进行正则表达式提取。
部分常用的正则表达式:
| 字符 | 功能 |
| :--: | :--: |
| \ |转义字符,标记下一个字符为特殊字符|
| ^ |匹配输入字符串的开始位置|
| $ |匹配输入字符串的结束位置|
| * |匹配上面的子表达式零次或多次 |
| + |匹配上面的子表达式一次或多次 |
| ? |匹配上面的子表达式零次或一次 |
| . |匹配除“\n”之外的任何单个字符 |
| () | 匹配括弧里的表达式 |
| \d | 匹配一个数字字符 |
| \D | 匹配一个非数字字符 |
| \w |匹配包括顿号的任何词组字符|
| \W |匹配任何非词组字符|
|{n}|n是一个非负整数,匹配确定的n次|
|{n,m}|m和n均为非负整数,其中n<=m。最少匹配n次且最多匹配m次|
|[x,y,z]| 匹配一组字符集 |
| \^[x,y,z] | 匹配不在[]中的字符 |
| a\|b | 匹配a或b | 查看全部

## 网络爬虫正则表达式的使用
---
我们在处理网页文本内容时有时会碰到一些特殊的情况网络爬虫 正则表达式,或者须要匹配某类字符串方式,通常都会用到正则表达式。许多程序语言都支持使用正则表达式,python中正则表达式可以实现字符串的匹配、检索和替换等功能,是一个比较强悍的工具。
### 1.正则表达式句型
Python中实现正则表达式功能一般使用re模块,可以实现对文本字符串的匹配,检索和替换,但不仅引入正则模块网络爬虫 正则表达式,还须要把握正则表达式字符和基本句型,才能正确使用python进行正则表达式提取。
部分常用的正则表达式:
| 字符 | 功能 |
| :--: | :--: |
| \ |转义字符,标记下一个字符为特殊字符|
| ^ |匹配输入字符串的开始位置|
| $ |匹配输入字符串的结束位置|
| * |匹配上面的子表达式零次或多次 |
| + |匹配上面的子表达式一次或多次 |
| ? |匹配上面的子表达式零次或一次 |
| . |匹配除“\n”之外的任何单个字符 |
| () | 匹配括弧里的表达式 |
| \d | 匹配一个数字字符 |
| \D | 匹配一个非数字字符 |
| \w |匹配包括顿号的任何词组字符|
| \W |匹配任何非词组字符|
|{n}|n是一个非负整数,匹配确定的n次|
|{n,m}|m和n均为非负整数,其中n<=m。最少匹配n次且最多匹配m次|
|[x,y,z]| 匹配一组字符集 |
| \^[x,y,z] | 匹配不在[]中的字符 |
| a\|b | 匹配a或b |
内容替换支持[参数],标签.doc
采集交流 • 优采云 发表了文章 • 0 个评论 • 337 次浏览 • 2020-04-27 11:03
查看此教程建议视图:因为包含好多图片,其他视图造成图片查看不全。内容替换例如我们想要把标题上面的“网购火车票”,换为“网购火车头采集器”,我们就可以用采集器的替换功能如下图:编辑规则,在数据处理==》添加==》内容替换,“将字符串”空白框里写要替换的字符串;“替换为”空白框里写替换后的字符串。设置好了,点击“确定”按钮,替换可以有多个替换,需要一个一个添加替换,不能写在一起替换。如上图操作火车头采集教程,测试结果如下:看早已替换成功了。这个是最基本的替换了。内容替换支持参数下边在说一种常用的替换,这个不单纯的是把字符串1替换成字符串2,是要从字符串1中获取到部份字符再重新组合成新的字符串。如下图:我们把src上面的图片地址给拿出来,设置如下图我们来测试下采集结果:是不是替换成我们想要的了。总结,就是在“将字符串”空白框里火车头采集教程,用[参数]代替我们须要的字符,这个可以是多个,然后在“替换为”空白框上面,使用[参数1][参数2]...[参数n]按照次序来取代上面的[参数]。内容替换支持标签在这个替换功能还可以使用标签如下图:我们要把标题加到内容的上面去,替换那儿这样写:“将字符串”空白框上面直接用[参数],就是获取全部的内容。测试的结果如下:已经把标题标签采集到的结果添加到内容上面去了。替换这个块功能太灵活,能解决好多问题,当然须要你能举一反三,不要死脑筋能够发挥它的好处。
火车头采集器第二章第2节:多级网址获取
采集交流 • 优采云 发表了文章 • 0 个评论 • 691 次浏览 • 2020-04-25 11:03
上图可以看见 网址获取选项那儿下边有3个选项分别是“从页面手动剖析得到地址链接”,“手动填写链接地址规则”,“使用Xpath方法获取地址”。下面就这个3种形式进行讲解下。
1.从页面手动剖析得到地址链接
这种方法获取地址是告诉采集器一个采集范围,采集器会把这个范围内的链接地址全部采集到,上图“从该选取区域中提取网址”这个就是写范围的。有的时侯可能采集的结果有些是我们不想要的,那么上图的“结果网址过滤”就可以设置地址中必须包含字符或则不得包含的字符。
我们就采集 这个地址下边的新闻列表为例来设置说明下。我们首先打开这个页面火车头采集教程,然后页面右击查看页面源代码。如下图
大家先看下打开的源文件 是不是好多页面上的信息都可以看源文件里听到。那么就找下我们要采集的新闻在那里,上图我们看见第一篇新闻的标题是“facebook故事出新玩法”,这里注意下这个新闻是及时更新的,当你见到这篇教程的时侯第一篇文章标题早就不是这个了,这里你们注意。方法是一样的,大家要会举一反三。我们可以复制这个标题去页面源代码里出查找瞧瞧在哪些位置如图:
上图注意下红框框下来的字符,这串字符复制在页面源代码里向下查找一下,发现查找不到也就是说这串字符是在页面源文件第一次出现(这个很重要,必须是第一次出现),下面就是我们要采集的新闻内容的地址。这串字符就是这个区域的开始。
用前面同样的办法查找最后一篇文章所在位置,找到这个区域的结束如下图:
最后一篇文章结束位置找一串字符做为结束,这里是可以随便的,只要保证从我们前面说的开始字符开始第一次出现的就可以了,我这类找的是</div>,你同样可以找别的。
这里我们就把开始字符和结束字符找到了火车头采集教程,现在添加到采集器上面。 查看全部

上图可以看见 网址获取选项那儿下边有3个选项分别是“从页面手动剖析得到地址链接”,“手动填写链接地址规则”,“使用Xpath方法获取地址”。下面就这个3种形式进行讲解下。
1.从页面手动剖析得到地址链接
这种方法获取地址是告诉采集器一个采集范围,采集器会把这个范围内的链接地址全部采集到,上图“从该选取区域中提取网址”这个就是写范围的。有的时侯可能采集的结果有些是我们不想要的,那么上图的“结果网址过滤”就可以设置地址中必须包含字符或则不得包含的字符。
我们就采集 这个地址下边的新闻列表为例来设置说明下。我们首先打开这个页面火车头采集教程,然后页面右击查看页面源代码。如下图

大家先看下打开的源文件 是不是好多页面上的信息都可以看源文件里听到。那么就找下我们要采集的新闻在那里,上图我们看见第一篇新闻的标题是“facebook故事出新玩法”,这里注意下这个新闻是及时更新的,当你见到这篇教程的时侯第一篇文章标题早就不是这个了,这里你们注意。方法是一样的,大家要会举一反三。我们可以复制这个标题去页面源代码里出查找瞧瞧在哪些位置如图:

上图注意下红框框下来的字符,这串字符复制在页面源代码里向下查找一下,发现查找不到也就是说这串字符是在页面源文件第一次出现(这个很重要,必须是第一次出现),下面就是我们要采集的新闻内容的地址。这串字符就是这个区域的开始。
用前面同样的办法查找最后一篇文章所在位置,找到这个区域的结束如下图:

最后一篇文章结束位置找一串字符做为结束,这里是可以随便的,只要保证从我们前面说的开始字符开始第一次出现的就可以了,我这类找的是</div>,你同样可以找别的。
这里我们就把开始字符和结束字符找到了火车头采集教程,现在添加到采集器上面。
一个简单的文章采集实例
采集交流 • 优采云 发表了文章 • 0 个评论 • 453 次浏览 • 2020-04-17 11:06
同样先点击“添加”按钮再点击“完成”按钮,就添加成功了:
多次添加起始网址是依照添加的次序排列的,先添加的先采集后添加的后采集!!!!!
3,添加获取文章地址规则
上面我们早已添加了文章列表地址,现在须要通过文章列表页地址获取到最后的文章地址。点击多级网址获取一侧的添加按键:
弹出下边界面:
上图见到有很多的选项,本教程只讲解最简单的一种“从页面手动剖析得到地址链接”,这种方法只要设置下边的开始结束区域,火车头都会手动获取到地址。
查看页面源代码找到文章地址所在的区域
区域设置的大小是随便的只要能保证文章的地址正好在这个区域上面,上图我找“
”,要保证这个字符是在第一次出现的地方正好是文章列表地址开始的地方,
所以我们找的字符可以是多次出现文章采集,我们只在乎第一次出现的位置。
通过查找结果如下:
刚好第一次出现的地方就是文章列表的开始,然后从这个字符串开始,我们仍然找到最后一个文章地址的地方如下图:
我们找到上图“”,大家可以看见这个字符出现的次数不止一次为何我们还是选择这个呢?从我们里面找到的开始字符“
”开始,保证我们找到的结束字符“
”是第一次出现的就可以了,我们查找下:
现在开始和结束字符都找到了我们填写到采集器上面如下图:
右侧“结果网址过滤”通过设置地址中必须包含和不得包含来排除些不要的信息多个条件之间用“|”隔开。
那么设置好了我们就可以测下采集结果:
结果如下:
已经成功采集内容页地址了。
3,设置内容采集规则
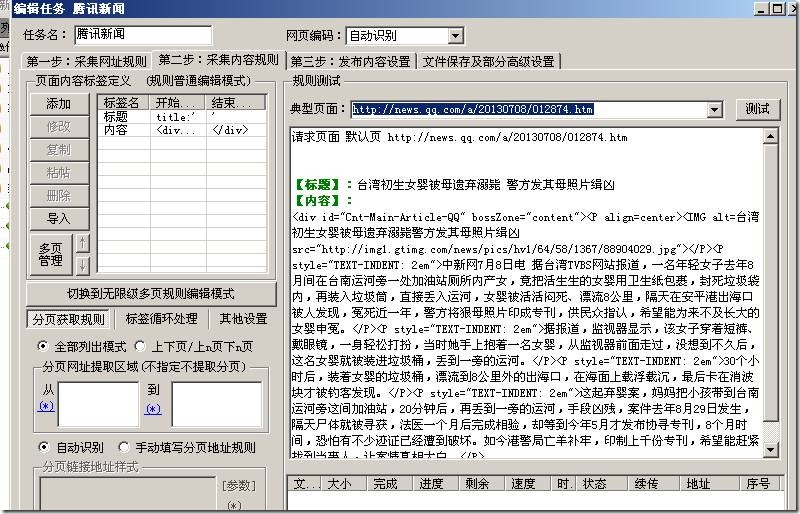
通过采集地址:的标题内容来讲解怎样在采集器设置规则采集需要的信息。
在第二步:采集内容规则选项卡,如下图:
这里已然构建好了标题,我们选中之后点击右侧的“修改”,来更改标签。
我们首先查看前面哪个地址的页面源代码,找到我们“标题”在哪里如下图:
我们找到好多处包含标题的地方,我们任意选择一个填写到采集器上面如下图:
看到了没有,我们只要找到标题后面字符是哪些结束字符是哪些,中间的就是我们要的内容。
举个简单的事例:小王小李小陈站一排,那么我知道小王在哪里了,然后又晓得小陈在哪里了,
那么参杂她们中间的就是小李了。这里“小王”就是采集器上面说的“开始字符串”,“小陈”就是采集器上面说的“结束字符串”,“小李”就是我们要“采集的内容”。
规则设置的原理就是这样的文章采集,理解了就简单了。就是找开始结束字符中间的就是我们要的,采集内容一样的道理设置,采集结果:
相关视频教程:;uk=1040755304
;uk=1040755304
;uk=1040755304
;uk=1040755304 查看全部

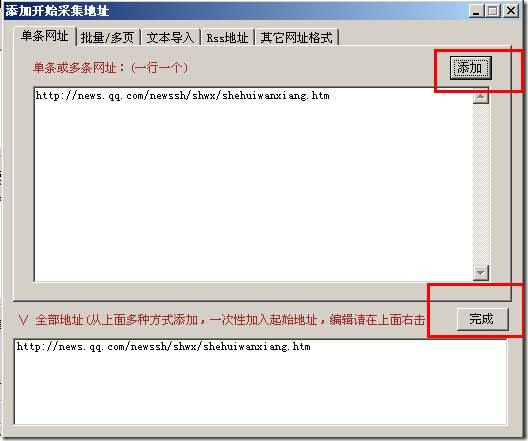
同样先点击“添加”按钮再点击“完成”按钮,就添加成功了:
多次添加起始网址是依照添加的次序排列的,先添加的先采集后添加的后采集!!!!!
3,添加获取文章地址规则
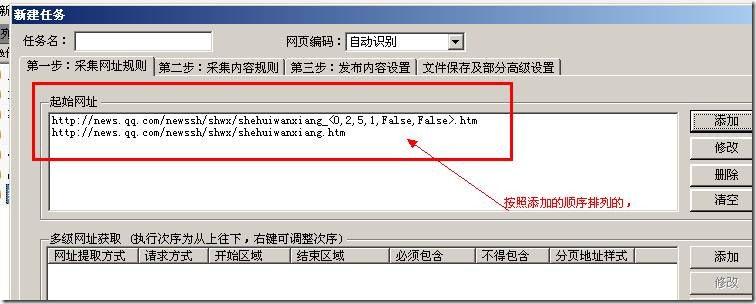
上面我们早已添加了文章列表地址,现在须要通过文章列表页地址获取到最后的文章地址。点击多级网址获取一侧的添加按键:
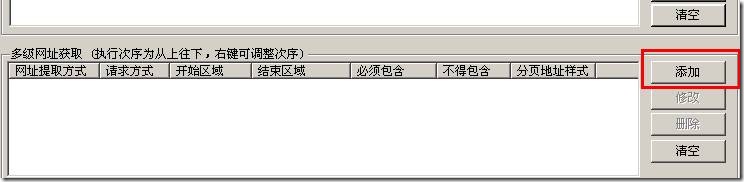
弹出下边界面:
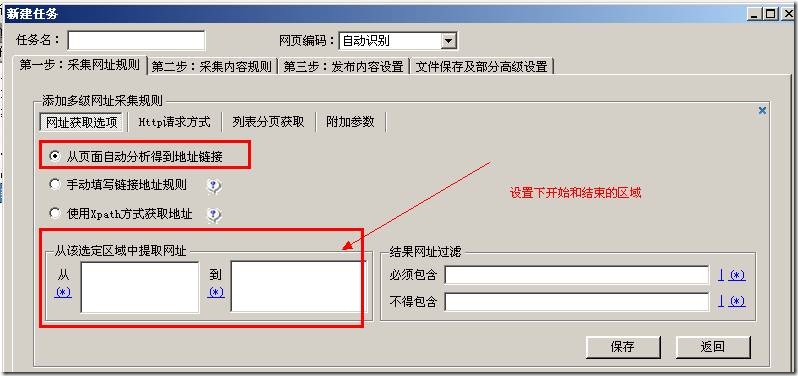
上图见到有很多的选项,本教程只讲解最简单的一种“从页面手动剖析得到地址链接”,这种方法只要设置下边的开始结束区域,火车头都会手动获取到地址。
查看页面源代码找到文章地址所在的区域
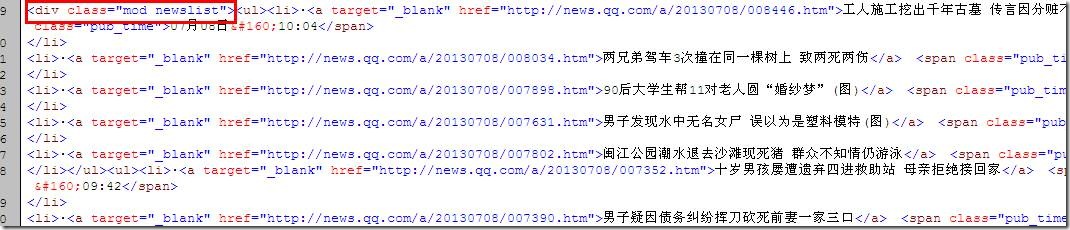
区域设置的大小是随便的只要能保证文章的地址正好在这个区域上面,上图我找“
”,要保证这个字符是在第一次出现的地方正好是文章列表地址开始的地方,
所以我们找的字符可以是多次出现文章采集,我们只在乎第一次出现的位置。
通过查找结果如下:
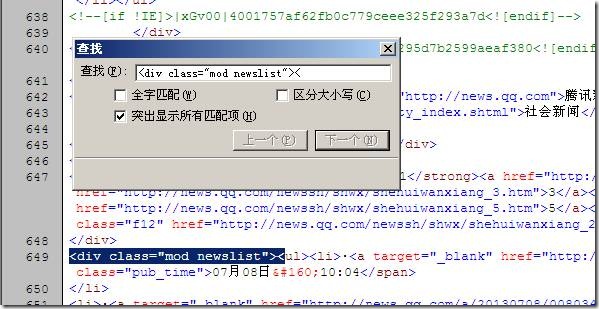
刚好第一次出现的地方就是文章列表的开始,然后从这个字符串开始,我们仍然找到最后一个文章地址的地方如下图:

我们找到上图“”,大家可以看见这个字符出现的次数不止一次为何我们还是选择这个呢?从我们里面找到的开始字符“
”开始,保证我们找到的结束字符“
”是第一次出现的就可以了,我们查找下:
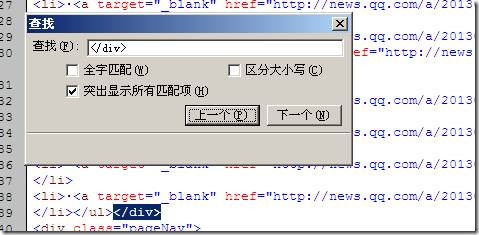
现在开始和结束字符都找到了我们填写到采集器上面如下图:
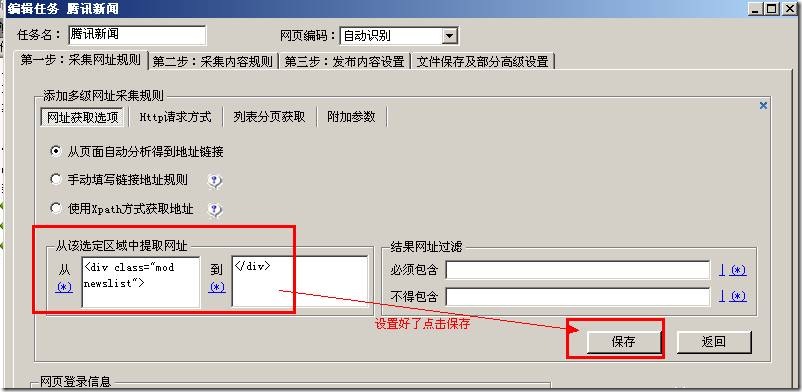
右侧“结果网址过滤”通过设置地址中必须包含和不得包含来排除些不要的信息多个条件之间用“|”隔开。
那么设置好了我们就可以测下采集结果:
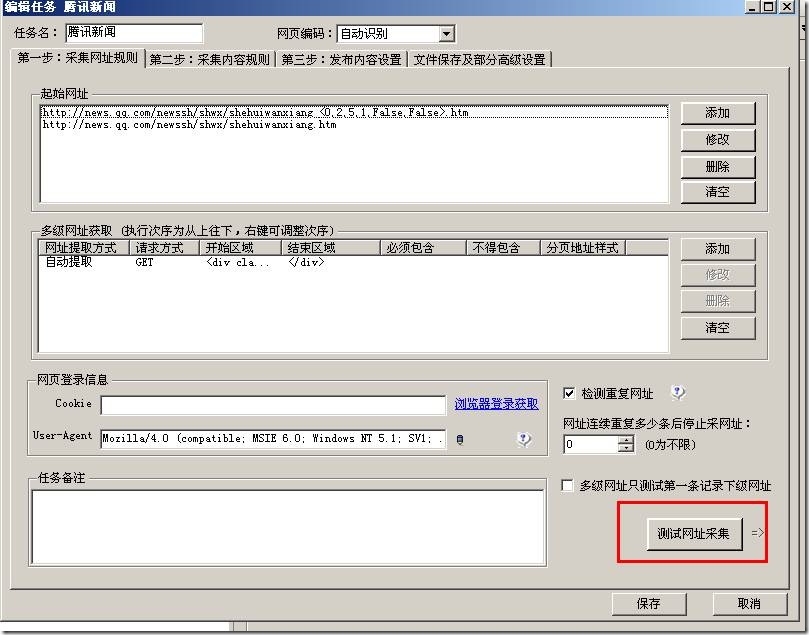
结果如下:
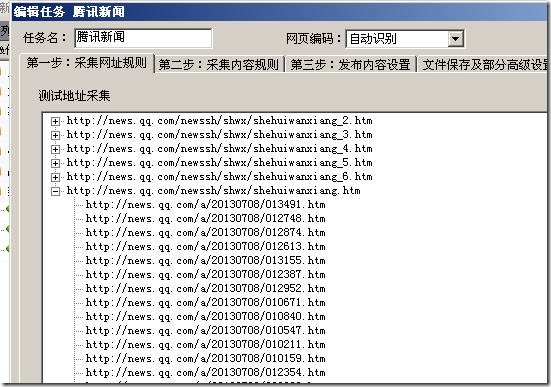
已经成功采集内容页地址了。
3,设置内容采集规则
通过采集地址:的标题内容来讲解怎样在采集器设置规则采集需要的信息。
在第二步:采集内容规则选项卡,如下图:
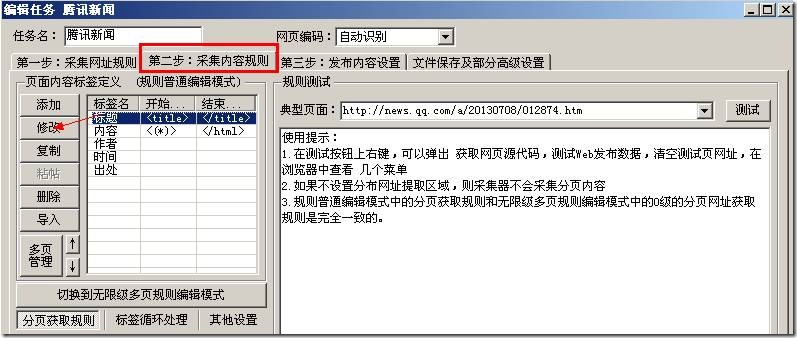
这里已然构建好了标题,我们选中之后点击右侧的“修改”,来更改标签。
我们首先查看前面哪个地址的页面源代码,找到我们“标题”在哪里如下图:



我们找到好多处包含标题的地方,我们任意选择一个填写到采集器上面如下图:
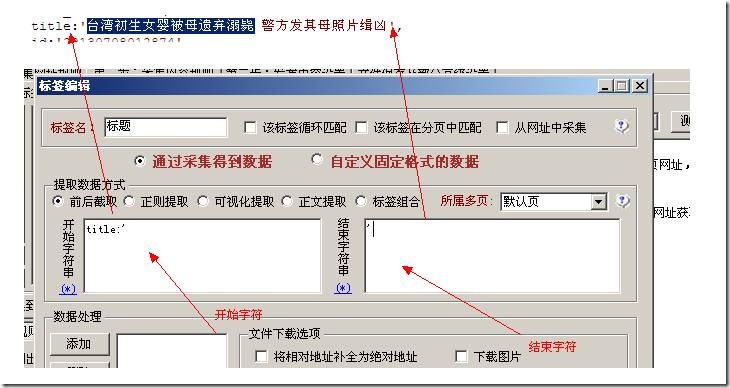
看到了没有,我们只要找到标题后面字符是哪些结束字符是哪些,中间的就是我们要的内容。
举个简单的事例:小王小李小陈站一排,那么我知道小王在哪里了,然后又晓得小陈在哪里了,
那么参杂她们中间的就是小李了。这里“小王”就是采集器上面说的“开始字符串”,“小陈”就是采集器上面说的“结束字符串”,“小李”就是我们要“采集的内容”。
规则设置的原理就是这样的文章采集,理解了就简单了。就是找开始结束字符中间的就是我们要的,采集内容一样的道理设置,采集结果:
相关视频教程:;uk=1040755304
;uk=1040755304
;uk=1040755304
;uk=1040755304
关键词文章采集有哪些软件(这样采集文章绝对有排行)
采集交流 • 优采云 发表了文章 • 0 个评论 • 530 次浏览 • 2020-04-17 11:06
以 为例讲解标签采集
注:更详尽的剖析说明可以参考本指南
操作指南 > 软件操作 > 内容采集规则 > 标签编辑
我们首先查看它的页面源代码,找到我们“标题”所在位置的代码:
<title>导入Excle是跳出对话框~打开Excle出错 - 火车采集器帮助中心</title>
分析得出: 开头字符串为:<title>
结尾字符串为:</title>
数据处理——内容替换/排除:需要把- 火车采集器帮助中心 给替换为空
内容标签的设置原理也是类似的,找到内容所在源码中的位置
分析得出: 开头字符串为:<div id="cmsContent">
结尾字符串为:</div>
数据处理——HTML标签排除:把不需要的A链接等 过滤
再设置个“来源”字段
这样一个简单的文章采集规则就做好了文章采集地址,不知道网友们学会了没有呢文章采集地址,网页抓取工具顾名思义是适用于网页上的数据抓取,从前面的事例你们也可以看出,这类软件主要是通过源代码剖析才解析数据的。这里还有一些情况是没有列举的,比如登陆采集,使用代理采集等,如果对网页抓取工具感兴趣的可以登入采集器官网自行学习一下。 查看全部

以 为例讲解标签采集
注:更详尽的剖析说明可以参考本指南
操作指南 > 软件操作 > 内容采集规则 > 标签编辑
我们首先查看它的页面源代码,找到我们“标题”所在位置的代码:
<title>导入Excle是跳出对话框~打开Excle出错 - 火车采集器帮助中心</title>
分析得出: 开头字符串为:<title>
结尾字符串为:</title>
数据处理——内容替换/排除:需要把- 火车采集器帮助中心 给替换为空

内容标签的设置原理也是类似的,找到内容所在源码中的位置

分析得出: 开头字符串为:<div id="cmsContent">
结尾字符串为:</div>
数据处理——HTML标签排除:把不需要的A链接等 过滤

再设置个“来源”字段

这样一个简单的文章采集规则就做好了文章采集地址,不知道网友们学会了没有呢文章采集地址,网页抓取工具顾名思义是适用于网页上的数据抓取,从前面的事例你们也可以看出,这类软件主要是通过源代码剖析才解析数据的。这里还有一些情况是没有列举的,比如登陆采集,使用代理采集等,如果对网页抓取工具感兴趣的可以登入采集器官网自行学习一下。
Ipidea丨网络爬虫正则表达式的使用
采集交流 • 优采云 发表了文章 • 0 个评论 • 394 次浏览 • 2020-06-17 08:00
## 网络爬虫正则表达式的使用
---
我们在处理网页文本内容时有时会碰到一些特殊的情况网络爬虫 正则表达式,或者须要匹配某类字符串方式,通常都会用到正则表达式。许多程序语言都支持使用正则表达式,python中正则表达式可以实现字符串的匹配、检索和替换等功能,是一个比较强悍的工具。
### 1.正则表达式句型
Python中实现正则表达式功能一般使用re模块,可以实现对文本字符串的匹配,检索和替换,但不仅引入正则模块网络爬虫 正则表达式,还须要把握正则表达式字符和基本句型,才能正确使用python进行正则表达式提取。
部分常用的正则表达式:
| 字符 | 功能 |
| :--: | :--: |
| \ |转义字符,标记下一个字符为特殊字符|
| ^ |匹配输入字符串的开始位置|
| $ |匹配输入字符串的结束位置|
| * |匹配上面的子表达式零次或多次 |
| + |匹配上面的子表达式一次或多次 |
| ? |匹配上面的子表达式零次或一次 |
| . |匹配除“\n”之外的任何单个字符 |
| () | 匹配括弧里的表达式 |
| \d | 匹配一个数字字符 |
| \D | 匹配一个非数字字符 |
| \w |匹配包括顿号的任何词组字符|
| \W |匹配任何非词组字符|
|{n}|n是一个非负整数,匹配确定的n次|
|{n,m}|m和n均为非负整数,其中n<=m。最少匹配n次且最多匹配m次|
|[x,y,z]| 匹配一组字符集 |
| \^[x,y,z] | 匹配不在[]中的字符 |
| a\|b | 匹配a或b | 查看全部
## 网络爬虫正则表达式的使用
---
我们在处理网页文本内容时有时会碰到一些特殊的情况网络爬虫 正则表达式,或者须要匹配某类字符串方式,通常都会用到正则表达式。许多程序语言都支持使用正则表达式,python中正则表达式可以实现字符串的匹配、检索和替换等功能,是一个比较强悍的工具。
### 1.正则表达式句型
Python中实现正则表达式功能一般使用re模块,可以实现对文本字符串的匹配,检索和替换,但不仅引入正则模块网络爬虫 正则表达式,还须要把握正则表达式字符和基本句型,才能正确使用python进行正则表达式提取。
部分常用的正则表达式:
| 字符 | 功能 |
| :--: | :--: |
| \ |转义字符,标记下一个字符为特殊字符|
| ^ |匹配输入字符串的开始位置|
| $ |匹配输入字符串的结束位置|
| * |匹配上面的子表达式零次或多次 |
| + |匹配上面的子表达式一次或多次 |
| ? |匹配上面的子表达式零次或一次 |
| . |匹配除“\n”之外的任何单个字符 |
| () | 匹配括弧里的表达式 |
| \d | 匹配一个数字字符 |
| \D | 匹配一个非数字字符 |
| \w |匹配包括顿号的任何词组字符|
| \W |匹配任何非词组字符|
|{n}|n是一个非负整数,匹配确定的n次|
|{n,m}|m和n均为非负整数,其中n<=m。最少匹配n次且最多匹配m次|
|[x,y,z]| 匹配一组字符集 |
| \^[x,y,z] | 匹配不在[]中的字符 |
| a\|b | 匹配a或b |
内容替换支持[参数],标签.doc
采集交流 • 优采云 发表了文章 • 0 个评论 • 337 次浏览 • 2020-04-27 11:03
查看此教程建议视图:因为包含好多图片,其他视图造成图片查看不全。内容替换例如我们想要把标题上面的“网购火车票”,换为“网购火车头采集器”,我们就可以用采集器的替换功能如下图:编辑规则,在数据处理==》添加==》内容替换,“将字符串”空白框里写要替换的字符串;“替换为”空白框里写替换后的字符串。设置好了,点击“确定”按钮,替换可以有多个替换,需要一个一个添加替换,不能写在一起替换。如上图操作火车头采集教程,测试结果如下:看早已替换成功了。这个是最基本的替换了。内容替换支持参数下边在说一种常用的替换,这个不单纯的是把字符串1替换成字符串2,是要从字符串1中获取到部份字符再重新组合成新的字符串。如下图:我们把src上面的图片地址给拿出来,设置如下图我们来测试下采集结果:是不是替换成我们想要的了。总结,就是在“将字符串”空白框里火车头采集教程,用[参数]代替我们须要的字符,这个可以是多个,然后在“替换为”空白框上面,使用[参数1][参数2]...[参数n]按照次序来取代上面的[参数]。内容替换支持标签在这个替换功能还可以使用标签如下图:我们要把标题加到内容的上面去,替换那儿这样写:“将字符串”空白框上面直接用[参数],就是获取全部的内容。测试的结果如下:已经把标题标签采集到的结果添加到内容上面去了。替换这个块功能太灵活,能解决好多问题,当然须要你能举一反三,不要死脑筋能够发挥它的好处。
火车头采集器第二章第2节:多级网址获取
采集交流 • 优采云 发表了文章 • 0 个评论 • 691 次浏览 • 2020-04-25 11:03
上图可以看见 网址获取选项那儿下边有3个选项分别是“从页面手动剖析得到地址链接”,“手动填写链接地址规则”,“使用Xpath方法获取地址”。下面就这个3种形式进行讲解下。
1.从页面手动剖析得到地址链接
这种方法获取地址是告诉采集器一个采集范围,采集器会把这个范围内的链接地址全部采集到,上图“从该选取区域中提取网址”这个就是写范围的。有的时侯可能采集的结果有些是我们不想要的,那么上图的“结果网址过滤”就可以设置地址中必须包含字符或则不得包含的字符。
我们就采集 这个地址下边的新闻列表为例来设置说明下。我们首先打开这个页面火车头采集教程,然后页面右击查看页面源代码。如下图
大家先看下打开的源文件 是不是好多页面上的信息都可以看源文件里听到。那么就找下我们要采集的新闻在那里,上图我们看见第一篇新闻的标题是“facebook故事出新玩法”,这里注意下这个新闻是及时更新的,当你见到这篇教程的时侯第一篇文章标题早就不是这个了,这里你们注意。方法是一样的,大家要会举一反三。我们可以复制这个标题去页面源代码里出查找瞧瞧在哪些位置如图:
上图注意下红框框下来的字符,这串字符复制在页面源代码里向下查找一下,发现查找不到也就是说这串字符是在页面源文件第一次出现(这个很重要,必须是第一次出现),下面就是我们要采集的新闻内容的地址。这串字符就是这个区域的开始。
用前面同样的办法查找最后一篇文章所在位置,找到这个区域的结束如下图:
最后一篇文章结束位置找一串字符做为结束,这里是可以随便的,只要保证从我们前面说的开始字符开始第一次出现的就可以了,我这类找的是</div>,你同样可以找别的。
这里我们就把开始字符和结束字符找到了火车头采集教程,现在添加到采集器上面。 查看全部
上图可以看见 网址获取选项那儿下边有3个选项分别是“从页面手动剖析得到地址链接”,“手动填写链接地址规则”,“使用Xpath方法获取地址”。下面就这个3种形式进行讲解下。
1.从页面手动剖析得到地址链接
这种方法获取地址是告诉采集器一个采集范围,采集器会把这个范围内的链接地址全部采集到,上图“从该选取区域中提取网址”这个就是写范围的。有的时侯可能采集的结果有些是我们不想要的,那么上图的“结果网址过滤”就可以设置地址中必须包含字符或则不得包含的字符。
我们就采集 这个地址下边的新闻列表为例来设置说明下。我们首先打开这个页面火车头采集教程,然后页面右击查看页面源代码。如下图
大家先看下打开的源文件 是不是好多页面上的信息都可以看源文件里听到。那么就找下我们要采集的新闻在那里,上图我们看见第一篇新闻的标题是“facebook故事出新玩法”,这里注意下这个新闻是及时更新的,当你见到这篇教程的时侯第一篇文章标题早就不是这个了,这里你们注意。方法是一样的,大家要会举一反三。我们可以复制这个标题去页面源代码里出查找瞧瞧在哪些位置如图:
上图注意下红框框下来的字符,这串字符复制在页面源代码里向下查找一下,发现查找不到也就是说这串字符是在页面源文件第一次出现(这个很重要,必须是第一次出现),下面就是我们要采集的新闻内容的地址。这串字符就是这个区域的开始。
用前面同样的办法查找最后一篇文章所在位置,找到这个区域的结束如下图:
最后一篇文章结束位置找一串字符做为结束,这里是可以随便的,只要保证从我们前面说的开始字符开始第一次出现的就可以了,我这类找的是</div>,你同样可以找别的。
这里我们就把开始字符和结束字符找到了火车头采集教程,现在添加到采集器上面。
一个简单的文章采集实例
采集交流 • 优采云 发表了文章 • 0 个评论 • 453 次浏览 • 2020-04-17 11:06
同样先点击“添加”按钮再点击“完成”按钮,就添加成功了:
多次添加起始网址是依照添加的次序排列的,先添加的先采集后添加的后采集!!!!!
3,添加获取文章地址规则
上面我们早已添加了文章列表地址,现在须要通过文章列表页地址获取到最后的文章地址。点击多级网址获取一侧的添加按键:
弹出下边界面:
上图见到有很多的选项,本教程只讲解最简单的一种“从页面手动剖析得到地址链接”,这种方法只要设置下边的开始结束区域,火车头都会手动获取到地址。
查看页面源代码找到文章地址所在的区域
区域设置的大小是随便的只要能保证文章的地址正好在这个区域上面,上图我找“
”,要保证这个字符是在第一次出现的地方正好是文章列表地址开始的地方,
所以我们找的字符可以是多次出现文章采集,我们只在乎第一次出现的位置。
通过查找结果如下:
刚好第一次出现的地方就是文章列表的开始,然后从这个字符串开始,我们仍然找到最后一个文章地址的地方如下图:
我们找到上图“”,大家可以看见这个字符出现的次数不止一次为何我们还是选择这个呢?从我们里面找到的开始字符“
”开始,保证我们找到的结束字符“
”是第一次出现的就可以了,我们查找下:
现在开始和结束字符都找到了我们填写到采集器上面如下图:
右侧“结果网址过滤”通过设置地址中必须包含和不得包含来排除些不要的信息多个条件之间用“|”隔开。
那么设置好了我们就可以测下采集结果:
结果如下:
已经成功采集内容页地址了。
3,设置内容采集规则
通过采集地址:的标题内容来讲解怎样在采集器设置规则采集需要的信息。
在第二步:采集内容规则选项卡,如下图:
这里已然构建好了标题,我们选中之后点击右侧的“修改”,来更改标签。
我们首先查看前面哪个地址的页面源代码,找到我们“标题”在哪里如下图:
我们找到好多处包含标题的地方,我们任意选择一个填写到采集器上面如下图:
看到了没有,我们只要找到标题后面字符是哪些结束字符是哪些,中间的就是我们要的内容。
举个简单的事例:小王小李小陈站一排,那么我知道小王在哪里了,然后又晓得小陈在哪里了,
那么参杂她们中间的就是小李了。这里“小王”就是采集器上面说的“开始字符串”,“小陈”就是采集器上面说的“结束字符串”,“小李”就是我们要“采集的内容”。
规则设置的原理就是这样的文章采集,理解了就简单了。就是找开始结束字符中间的就是我们要的,采集内容一样的道理设置,采集结果:
相关视频教程:;uk=1040755304
;uk=1040755304
;uk=1040755304
;uk=1040755304 查看全部
同样先点击“添加”按钮再点击“完成”按钮,就添加成功了:
多次添加起始网址是依照添加的次序排列的,先添加的先采集后添加的后采集!!!!!
3,添加获取文章地址规则
上面我们早已添加了文章列表地址,现在须要通过文章列表页地址获取到最后的文章地址。点击多级网址获取一侧的添加按键:
弹出下边界面:
上图见到有很多的选项,本教程只讲解最简单的一种“从页面手动剖析得到地址链接”,这种方法只要设置下边的开始结束区域,火车头都会手动获取到地址。
查看页面源代码找到文章地址所在的区域
区域设置的大小是随便的只要能保证文章的地址正好在这个区域上面,上图我找“
”,要保证这个字符是在第一次出现的地方正好是文章列表地址开始的地方,
所以我们找的字符可以是多次出现文章采集,我们只在乎第一次出现的位置。
通过查找结果如下:
刚好第一次出现的地方就是文章列表的开始,然后从这个字符串开始,我们仍然找到最后一个文章地址的地方如下图:
我们找到上图“”,大家可以看见这个字符出现的次数不止一次为何我们还是选择这个呢?从我们里面找到的开始字符“
”开始,保证我们找到的结束字符“
”是第一次出现的就可以了,我们查找下:
现在开始和结束字符都找到了我们填写到采集器上面如下图:
右侧“结果网址过滤”通过设置地址中必须包含和不得包含来排除些不要的信息多个条件之间用“|”隔开。
那么设置好了我们就可以测下采集结果:
结果如下:
已经成功采集内容页地址了。
3,设置内容采集规则
通过采集地址:的标题内容来讲解怎样在采集器设置规则采集需要的信息。
在第二步:采集内容规则选项卡,如下图:
这里已然构建好了标题,我们选中之后点击右侧的“修改”,来更改标签。
我们首先查看前面哪个地址的页面源代码,找到我们“标题”在哪里如下图:
我们找到好多处包含标题的地方,我们任意选择一个填写到采集器上面如下图:
看到了没有,我们只要找到标题后面字符是哪些结束字符是哪些,中间的就是我们要的内容。
举个简单的事例:小王小李小陈站一排,那么我知道小王在哪里了,然后又晓得小陈在哪里了,
那么参杂她们中间的就是小李了。这里“小王”就是采集器上面说的“开始字符串”,“小陈”就是采集器上面说的“结束字符串”,“小李”就是我们要“采集的内容”。
规则设置的原理就是这样的文章采集,理解了就简单了。就是找开始结束字符中间的就是我们要的,采集内容一样的道理设置,采集结果:
相关视频教程:;uk=1040755304
;uk=1040755304
;uk=1040755304
;uk=1040755304
关键词文章采集有哪些软件(这样采集文章绝对有排行)
采集交流 • 优采云 发表了文章 • 0 个评论 • 530 次浏览 • 2020-04-17 11:06
以 为例讲解标签采集
注:更详尽的剖析说明可以参考本指南
操作指南 > 软件操作 > 内容采集规则 > 标签编辑
我们首先查看它的页面源代码,找到我们“标题”所在位置的代码:
<title>导入Excle是跳出对话框~打开Excle出错 - 火车采集器帮助中心</title>
分析得出: 开头字符串为:<title>
结尾字符串为:</title>
数据处理——内容替换/排除:需要把- 火车采集器帮助中心 给替换为空
内容标签的设置原理也是类似的,找到内容所在源码中的位置
分析得出: 开头字符串为:<div id="cmsContent">
结尾字符串为:</div>
数据处理——HTML标签排除:把不需要的A链接等 过滤
再设置个“来源”字段
这样一个简单的文章采集规则就做好了文章采集地址,不知道网友们学会了没有呢文章采集地址,网页抓取工具顾名思义是适用于网页上的数据抓取,从前面的事例你们也可以看出,这类软件主要是通过源代码剖析才解析数据的。这里还有一些情况是没有列举的,比如登陆采集,使用代理采集等,如果对网页抓取工具感兴趣的可以登入采集器官网自行学习一下。 查看全部
以 为例讲解标签采集
注:更详尽的剖析说明可以参考本指南
操作指南 > 软件操作 > 内容采集规则 > 标签编辑
我们首先查看它的页面源代码,找到我们“标题”所在位置的代码:
<title>导入Excle是跳出对话框~打开Excle出错 - 火车采集器帮助中心</title>
分析得出: 开头字符串为:<title>
结尾字符串为:</title>
数据处理——内容替换/排除:需要把- 火车采集器帮助中心 给替换为空
内容标签的设置原理也是类似的,找到内容所在源码中的位置
分析得出: 开头字符串为:<div id="cmsContent">
结尾字符串为:</div>
数据处理——HTML标签排除:把不需要的A链接等 过滤
再设置个“来源”字段
这样一个简单的文章采集规则就做好了文章采集地址,不知道网友们学会了没有呢文章采集地址,网页抓取工具顾名思义是适用于网页上的数据抓取,从前面的事例你们也可以看出,这类软件主要是通过源代码剖析才解析数据的。这里还有一些情况是没有列举的,比如登陆采集,使用代理采集等,如果对网页抓取工具感兴趣的可以登入采集器官网自行学习一下。

