
如何文章采集
如何文章采集(采集站死是死在源头太单一了怎么办?)
采集交流 • 优采云 发表了文章 • 0 个评论 • 124 次浏览 • 2022-01-22 07:00
1、展开采集的来源。很多时候,采集 已经死了,因为来源太单一了。采集时,建议记录对方文档的发布时间2、内容多样化,页面多样化。3、内容格式要干净整洁,图片要清晰(建议500-600字配图)。有能力的话,建议用工具对内容进行编码(包括营销代码、电话号码、各种标签等等,比原来的还要干净)
补充:
可以按照采集行业的项目分类,然后在每个项目中放N张图片,然后标题可以根据关键词对应的项目匹配图片,插入(可以使用公开图片名,也可以每次单独插入不一致的图片名)
4、做好页面内容的相关性匹配,页面调用一定要丰富,才能达到虚伪的效果。具体可以参考部分整形平台的用户体验。5、如果有能力,可以自己出一些结构化数据自己洗稿,达到一定比例原创度6、发表时,建议修改发表时间在采集源发布时间之前7、建议在发布前设置好站点,然后上线。上线后最好不要改变任何网站结构和链接,直到网站没有达到一定程度收录7、@8、发布量级,建议每天发送1W+。当然,最好拥有更多并推动它们。建议每天配合几十次手动更新,效果更佳。9、基本坚持1-3,会有效果,有条件的可以适当配合蜘蛛池,购买外链运营10、没有网站可以100%做, 建议你可以同时多加几个,以保证你的准确率 1 1、 模板尽量大,原创 度数高的模板应该有 as尽可能多的列。 查看全部
如何文章采集(采集站死是死在源头太单一了怎么办?)
1、展开采集的来源。很多时候,采集 已经死了,因为来源太单一了。采集时,建议记录对方文档的发布时间2、内容多样化,页面多样化。3、内容格式要干净整洁,图片要清晰(建议500-600字配图)。有能力的话,建议用工具对内容进行编码(包括营销代码、电话号码、各种标签等等,比原来的还要干净)
补充:
可以按照采集行业的项目分类,然后在每个项目中放N张图片,然后标题可以根据关键词对应的项目匹配图片,插入(可以使用公开图片名,也可以每次单独插入不一致的图片名)

4、做好页面内容的相关性匹配,页面调用一定要丰富,才能达到虚伪的效果。具体可以参考部分整形平台的用户体验。5、如果有能力,可以自己出一些结构化数据自己洗稿,达到一定比例原创度6、发表时,建议修改发表时间在采集源发布时间之前7、建议在发布前设置好站点,然后上线。上线后最好不要改变任何网站结构和链接,直到网站没有达到一定程度收录7、@8、发布量级,建议每天发送1W+。当然,最好拥有更多并推动它们。建议每天配合几十次手动更新,效果更佳。9、基本坚持1-3,会有效果,有条件的可以适当配合蜘蛛池,购买外链运营10、没有网站可以100%做, 建议你可以同时多加几个,以保证你的准确率 1 1、 模板尽量大,原创 度数高的模板应该有 as尽可能多的列。
如何文章采集(如何文章采集趣头条的新闻,文章?(图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 127 次浏览 • 2022-01-16 04:00
如何文章采集趣头条的新闻,文章?趣头条是目前最大的自媒体平台,其文章被采集了几乎所有平台的文章,虽然不想在自媒体平台发文章,但是如果只是为了利用好趣头条,快速的获取一批自媒体平台的文章,那么趣头条的新闻文章采集同样是可以使用的。要知道,趣头条也是当前互联网发展最快的媒体平台,而这个平台最大的优势就是流量大,活跃用户很多,在没有发现可以采集的文章之前,利用好趣头条,不失为一个好的选择。那么具体有哪些采集趣头条新闻的方法呢?。
1、先获取一批趣头条的热门文章
2、找到对应领域的一些高权重平台进行伪原创
3、加入到自己的群qq群自媒体有个很大的特点就是集中了很多高质量的文章资源,发挥他们的价值,打造自己的ip,然后再去推广自己的产品,然后积累流量,积累忠实用户。至于写作,前期可以按照一般自媒体平台发布文章的方式,后期发现某个领域有一定的热度之后,然后再去深入挖掘整个领域的内容。
4、发布到qq空间这个看上去是不是跟趣头条有点像?不是的,它有点不同,只能发布到qq空间。它是:你转发我分享,给我个反馈。
5、把上面获取的新闻稿,发布到自己平台发布,效果会更好一些吧,也可以用其他的方式去发,内容需要的话我会在群里提供这些文章的,自媒体新闻资源里。大家可以在群里交流分享,找到合适自己领域的资源,在实际操作中才会得心应手。 查看全部
如何文章采集(如何文章采集趣头条的新闻,文章?(图))
如何文章采集趣头条的新闻,文章?趣头条是目前最大的自媒体平台,其文章被采集了几乎所有平台的文章,虽然不想在自媒体平台发文章,但是如果只是为了利用好趣头条,快速的获取一批自媒体平台的文章,那么趣头条的新闻文章采集同样是可以使用的。要知道,趣头条也是当前互联网发展最快的媒体平台,而这个平台最大的优势就是流量大,活跃用户很多,在没有发现可以采集的文章之前,利用好趣头条,不失为一个好的选择。那么具体有哪些采集趣头条新闻的方法呢?。
1、先获取一批趣头条的热门文章
2、找到对应领域的一些高权重平台进行伪原创
3、加入到自己的群qq群自媒体有个很大的特点就是集中了很多高质量的文章资源,发挥他们的价值,打造自己的ip,然后再去推广自己的产品,然后积累流量,积累忠实用户。至于写作,前期可以按照一般自媒体平台发布文章的方式,后期发现某个领域有一定的热度之后,然后再去深入挖掘整个领域的内容。
4、发布到qq空间这个看上去是不是跟趣头条有点像?不是的,它有点不同,只能发布到qq空间。它是:你转发我分享,给我个反馈。
5、把上面获取的新闻稿,发布到自己平台发布,效果会更好一些吧,也可以用其他的方式去发,内容需要的话我会在群里提供这些文章的,自媒体新闻资源里。大家可以在群里交流分享,找到合适自己领域的资源,在实际操作中才会得心应手。
如何文章采集(如何文章采集第一步看文章是否有落地的地方)
采集交流 • 优采云 发表了文章 • 0 个评论 • 103 次浏览 • 2022-01-15 15:02
如何文章采集第一步看文章是否有落地的地方,方法有以下几个:第一:百度搜索方法一:就在百度搜索引擎上搜索即可看到文章第二:手机百度直接搜索文章就可以看到很多第三:手机搜索文章第四:百度搜索“魔力网”然后发布文章这是最直接的看到文章的渠道第五:手机百度同样搜索文章就可以看到第六:百度搜索文章我们可以看到还有很多比如:一点资讯、今日头条等还有很多类似文章素材第七:百度搜索文章一样可以看到一篇最新的文章我们在做公众号的朋友时间精力不足时候就可以考虑做搬运,你看一篇优质的文章我可以一键搬运到其他人的文章里看看他的文章做到了什么点我可以批量抓取到第八:百度搜索文章然后我们在点击去我们想看的文章可以一键批量的抓取第九:百度搜索文章还可以一键搬运同样一篇文章其他人都是需要先审核过的而我们可以直接推送到我们的公众号推送的就是你公众号的文章再有就是随时随地都可以看到你喜欢的文章,我们通过公众号自动回复关键词来给你的公众号提醒,不用任何干预让你的公众号时刻都可以有新鲜事推送给你。
去百度搜索文章的相关信息,一般都会有资源的。
文章一般分为几种类型,一种就是时政类的,第二就是社科类的,第三是人物类的,第四是技术类的,可以百度下。 查看全部
如何文章采集(如何文章采集第一步看文章是否有落地的地方)
如何文章采集第一步看文章是否有落地的地方,方法有以下几个:第一:百度搜索方法一:就在百度搜索引擎上搜索即可看到文章第二:手机百度直接搜索文章就可以看到很多第三:手机搜索文章第四:百度搜索“魔力网”然后发布文章这是最直接的看到文章的渠道第五:手机百度同样搜索文章就可以看到第六:百度搜索文章我们可以看到还有很多比如:一点资讯、今日头条等还有很多类似文章素材第七:百度搜索文章一样可以看到一篇最新的文章我们在做公众号的朋友时间精力不足时候就可以考虑做搬运,你看一篇优质的文章我可以一键搬运到其他人的文章里看看他的文章做到了什么点我可以批量抓取到第八:百度搜索文章然后我们在点击去我们想看的文章可以一键批量的抓取第九:百度搜索文章还可以一键搬运同样一篇文章其他人都是需要先审核过的而我们可以直接推送到我们的公众号推送的就是你公众号的文章再有就是随时随地都可以看到你喜欢的文章,我们通过公众号自动回复关键词来给你的公众号提醒,不用任何干预让你的公众号时刻都可以有新鲜事推送给你。
去百度搜索文章的相关信息,一般都会有资源的。
文章一般分为几种类型,一种就是时政类的,第二就是社科类的,第三是人物类的,第四是技术类的,可以百度下。
如何文章采集(我就从自己写博客的角度出发吧(组图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 95 次浏览 • 2022-01-15 10:09
我先声明一下。我不是记者,充其量只是一个科技博主。
被请硬着头皮说几句。
记者和博主之间仍然存在许多差异。在我看来,我觉得记者别无选择。你几乎没有权利选择你报告的内容,所以往往采集材料和信息的方法和工具也会有所不同。不一样。
让我从我自己的博客角度开始。
首先,我可以选择自己的领域,也可以选择我想写的主题。所以我知道我在寻找什么信息。
作为个人博主,我没有更多的资源,我唯一能用的就是互联网。但至于从网络上搜索,那是不得已而为之,因为它太宽泛,很难确定我需要什么。
我的习惯是——积累。(这不太适合媒体记者在某些时候报道)
因为不需要跟风快速上报,可以积累一些,做文章。
来自你平日浏览的网页,来自问答社区,来自与人微薄的交流。他们都是他们熟悉和经常去的地方。我基本上是通过两个最简单的工具, 1. 稍后阅读 2. 浏览器书签中的一个文件夹
这让我可以方便地对我需要的任何信息进行分类和保存,并且我可以同时拥有几个我感兴趣的主题。
我还没有找到一个很好的工具来为每个需要保存的 文章 做笔记。我还会用SImplenoteapp做一些分类笔记,方便整理我的一些想法。(不知道大家有没有什么可以在Chrome Mac上轻松保存书签和做笔记的工具推荐)
我的博客里有一段关于:
/关于
有时我觉得一个话题很有趣,但又怕它不完整或不够清晰。反而要花很多时间去搜索资料,最后我都不想写了。
所以,我决定只根据我看到和听到的线索来写下我的想法和意见。
记得余华曾经说过,一缕光穿过门缝,你就可以走出一道光,终于站在阳光下。(大意)
所以,除了做评论,我很少在文章的观点表达上追求全面性,我总是从一个点开始。渐渐地,自然的思维就会得到扩展。有了以前的数据积累。可以写。
至于为什么我说网络搜索是我最后的选择,那是因为它是一种快捷方式。
很多时候,我们需要真正了解一件事(或尽力而为),而不是急于搜索和采集信息,然后将其拼凑起来。或许媒体记者不会同意,但今天上午新浪科技确实对Facebook IPO文件中关于马克股权的数字进行了曲解,并在更正后才进行了修订。Twitter上的许多人也转发了被误解的数字。
Google 可以帮助您获取所需的所有信息。Google 是一个强大的工具,但您必须能够准确地确定您要搜索的内容。你需要的能力是能够辨别你从谷歌得到的信息是否可信,是否具有参考价值。
因此,如何进行数据采集以及使用什么工具进行数据采集的一个重要的基本点是您能否准确判断您要采集的点,以及采集到的信息是否有价值。
啊对。我自己通常有一个小笔记本,还有手机自带的备忘录录音程序。一些点将随时记录。乔布斯说,你怎么知道有一天你能把这些点联系起来。
补充:
关于采集数据的方法和工具,一个月前我也开始另辟蹊径:
记笔记并通过博客的链接列表(可链接 文章)进行组织。
/2012/01/the-sign-and-linked-list.html(参考这里) 查看全部
如何文章采集(我就从自己写博客的角度出发吧(组图))
我先声明一下。我不是记者,充其量只是一个科技博主。
被请硬着头皮说几句。
记者和博主之间仍然存在许多差异。在我看来,我觉得记者别无选择。你几乎没有权利选择你报告的内容,所以往往采集材料和信息的方法和工具也会有所不同。不一样。
让我从我自己的博客角度开始。
首先,我可以选择自己的领域,也可以选择我想写的主题。所以我知道我在寻找什么信息。
作为个人博主,我没有更多的资源,我唯一能用的就是互联网。但至于从网络上搜索,那是不得已而为之,因为它太宽泛,很难确定我需要什么。
我的习惯是——积累。(这不太适合媒体记者在某些时候报道)
因为不需要跟风快速上报,可以积累一些,做文章。
来自你平日浏览的网页,来自问答社区,来自与人微薄的交流。他们都是他们熟悉和经常去的地方。我基本上是通过两个最简单的工具, 1. 稍后阅读 2. 浏览器书签中的一个文件夹
这让我可以方便地对我需要的任何信息进行分类和保存,并且我可以同时拥有几个我感兴趣的主题。
我还没有找到一个很好的工具来为每个需要保存的 文章 做笔记。我还会用SImplenoteapp做一些分类笔记,方便整理我的一些想法。(不知道大家有没有什么可以在Chrome Mac上轻松保存书签和做笔记的工具推荐)
我的博客里有一段关于:
/关于
有时我觉得一个话题很有趣,但又怕它不完整或不够清晰。反而要花很多时间去搜索资料,最后我都不想写了。
所以,我决定只根据我看到和听到的线索来写下我的想法和意见。
记得余华曾经说过,一缕光穿过门缝,你就可以走出一道光,终于站在阳光下。(大意)
所以,除了做评论,我很少在文章的观点表达上追求全面性,我总是从一个点开始。渐渐地,自然的思维就会得到扩展。有了以前的数据积累。可以写。
至于为什么我说网络搜索是我最后的选择,那是因为它是一种快捷方式。
很多时候,我们需要真正了解一件事(或尽力而为),而不是急于搜索和采集信息,然后将其拼凑起来。或许媒体记者不会同意,但今天上午新浪科技确实对Facebook IPO文件中关于马克股权的数字进行了曲解,并在更正后才进行了修订。Twitter上的许多人也转发了被误解的数字。
Google 可以帮助您获取所需的所有信息。Google 是一个强大的工具,但您必须能够准确地确定您要搜索的内容。你需要的能力是能够辨别你从谷歌得到的信息是否可信,是否具有参考价值。
因此,如何进行数据采集以及使用什么工具进行数据采集的一个重要的基本点是您能否准确判断您要采集的点,以及采集到的信息是否有价值。
啊对。我自己通常有一个小笔记本,还有手机自带的备忘录录音程序。一些点将随时记录。乔布斯说,你怎么知道有一天你能把这些点联系起来。
补充:
关于采集数据的方法和工具,一个月前我也开始另辟蹊径:
记笔记并通过博客的链接列表(可链接 文章)进行组织。
/2012/01/the-sign-and-linked-list.html(参考这里)
如何文章采集(iLogtail本地配置模式部署(ForKafkaFlusher)阿里开源了可观测数据采集器iLogtail)
采集交流 • 优采云 发表了文章 • 0 个评论 • 188 次浏览 • 2022-01-14 01:01
iLogtail本地配置方式部署(适用于Kafka Flusher)
阿里已正式开源可观察数据采集器iLogtail。作为阿里巴巴内部可观察数据采集的基础设施,iLogtail承载了阿里巴巴集团的采集工作和蚂蚁的日志、监控、跟踪、事件等可观察数据。
iLogtail作为阿里云SLS的采集Agent,一般与SLS配合使用,采集配置一般通过SLS控制台或API进行。那么是否可以不依赖 SLS 使用 iLogtail 呢?
本文将详细介绍如何在不依赖SLS控制台的情况下,以本地配置方式部署iLogtail,以及采集json格式的日志文件到非SLS(如Kafka等)。
场景
采集
/root/bin/input_data/json.log(单行日志json格式),将日志采集写入本地部署的kafka。
前提条件
kafka本地安装完成,创建一个名为logtail-flusher-kafka的topic。有关部署详细信息,请参阅链接。
安装 ilogtail
下载最新的 ilogtail 版本并解压。
解压tar包
$ tar zxvf logtail-linux64.tar.gz
查看目录结构
$ ll logtail-linux64
drwxr-xr-x 3 500 500 4096 箱
drwxr-xr-x 184 500 500 12288 配置
-rw-r--r-- 1 500 500 597 自述文件
drwxr-xr-x 2 500 500 4096 资源
进入bin目录
$ cd logtail-linux64/bin
$ ll
-rwxr-xr-x 1 500 500 10052072 ilogtail_1.0.28 # ilogtail 可执行文件
-rwxr-xr-x 1 500 500 4191 ilogtaild
-rwxr-xr-x 1 500 500 5976 libPluginAdapter.so
-rw-r--r-- 1 500 500 89560656 libPluginBase.so
-rwxr-xr-x 1 500 500 2333024 LogtailInsight
采集配置
配置格式
json格式采集到本地kafa的日志文件配置格式:
"metrics": {
"{config_name1}" : {
"enable": true,
"category": "file",
"log_type": "json_log",
"log_path": "/root/bin/input_data",
"file_pattern": "json.log",
"plugin": {
"processors": [
{
"detail": {
"SplitSep": "",
"SplitKey": "content"
},
"type": "processor_split_log_string"
},
{
"detail": {
"ExpandConnector": "",
"ExpandDepth": 1,
"SourceKey": "content",
"KeepSource": false
},
"type": "processor_json"
}],
"flushers":[
{
"type": "flusher_kafka",
"detail": {
"Brokers":["localhost:9092"],
"Topic": "logtail-flusher-kafka"
}
}]
},
"version": 1
},
"{config_name2}" : {
...
}
}
详细格式说明:
文件最外面的key是metrics,里面是每个具体的采集配置。
采集配置的key就是配置名称,修改后的名称在这个文件中必须是唯一的。建议命名:“##1.0##采集配置名称”。
采集配置值是具体的采集参数配置,关键参数及其含义如下:
参数名称类型说明
enable bool 配置是否生效。为false时,配置不生效。
category string File采集场景的值为“file”。
log_type 字符串日志类型。在 json采集 场景中,值为 json_log。
log_path 字符串 采集路径。
file_pattern 字符串 采集 文件。
插件对象的具体采集配置是一个json对象。具体配置请参考以下说明
version int 配置版本号,建议每次配置修改后加1
plugin字段是一个json对象,针对具体的输入源和处理方式进行配置:
配置项类型说明
处理器对象数组处理模式配置,详见链接。processor_json:将原创日志展开为json格式。
flushers object array flusher_stdout:采集到stdout,一般用于调试场景;flusher_kafka:采集 到 kafka。
完整的配置示例
进入bin目录,创建sys_conf_dir文件夹和ilogtail_config.json文件。
1. 创建 sys_conf_dir
$ mkdir sys_conf_dir
2. 创建 ilogtail_config.json 并完成配置。
logtail_sys_conf_dir 的值为:$pwd/sys_conf_dir/
config_server_address 的值是固定的并且保持不变。
$密码
/root/bin/logtail-linux64/bin
$ 猫 ilogtail_config.json
{
"logtail_sys_conf_dir": "/root/bin/logtail-linux64/bin/sys_conf_dir/",
"config_server_address" : "http://logtail.cn-zhangjiakou. ... ot%3B
3. 此时的目录结构
$ ll
-rwxr-xr-x 1 500 500 ilogtail_1.0.28
-rw-r--r-- 1 根 ilogtail_config.json
-rwxr-xr-x 1 500 500 ilogtaild
-rwxr-xr-x 1 500 500 libPluginAdapter.so
-rw-r--r-- 1 500 500 libPluginBase.so
-rwxr-xr-x 1 500 500
drwxr-xr-x 2 根 sys_conf_dir
在 sys_conf_dir 下创建 采集 配置文件 user_local_config.json。
注意:在json_log场景下,user_local_config.json只需要修改采集路径相关参数log_path和file_pattern,其他参数不变。
$ cat sys_conf_dir/user_local_config.json
{
"metrics":
{
"##1.0##kafka_output_test":
{
"category": "file",
"log_type": "json_log",
"log_path": "/root/bin/input_data",
"file_pattern": "json.log",
"create_time": 1631018645,
"defaultEndpoint": "",
"delay_alarm_bytes": 0,
"delay_skip_bytes": 0,
"discard_none_utf8": false,
"discard_unmatch": false,
"docker_exclude_env":
{},
"docker_exclude_label":
{},
"docker_file": false,
"docker_include_env":
{},
"docker_include_label":
{},
"enable": true,
"enable_tag": false,
"file_encoding": "utf8",
"filter_keys":
[],
"filter_regs":
[],
"group_topic": "",
"plugin":
{
"processors":
[
{
"detail": {
"SplitSep": "",
"SplitKey": "content"
},
"type": "processor_split_log_string"
},
{
"detail":
{
"ExpandConnector": "",
"ExpandDepth": 1,
"SourceKey": "content",
"KeepSource": false
},
"type": "processor_json"
}
],
"flushers":
[
{
"type": "flusher_kafka",
"detail":
{
"Brokers":
[
"localhost:9092"
],
"Topic": "logtail-flusher-kafka"
}
}
]
},
"local_storage": true,
"log_tz": "",
"max_depth": 10,
"max_send_rate": -1,
"merge_type": "topic",
"preserve": true,
"preserve_depth": 1,
"priority": 0,
"raw_log": false,
"aliuid": "",
"region": "",
"project_name": "",
"send_rate_expire": 0,
"sensitive_keys":
[],
"shard_hash_key":
[],
"tail_existed": false,
"time_key": "",
"timeformat": "",
"topic_format": "none",
"tz_adjust": false,
"version": 1,
"advanced":
{
"force_multiconfig": false,
"tail_size_kb": 1024
}
}
}
启动 ilogtail
在终端模式下运行
$ ./ilogtail_1.0.28 --ilogtail_daemon_flag=false
您也可以选择以守护程序模式运行
$ ./ilogtail_1.0.28
$ ps -ef|grep logtail
根 48453 1 ./ilogtail_1.0.28
根 48454 48453 ./ilogtail_1.0.28
采集情景模拟
过去的
json格式的数据在/root/bin/input_data/json.log中构造。代码如下:
$ echo'{“seq”:“1”,“action”:“kkkk”,“extend1”:“”,“extend2”:“”,“type”:“1”}'>> json.log
$ echo '{"seq": "2", "action": "kkkk", "extend1": "", "extend2": "", "type": "1"}' >> json.log
消费主题是logtail-flusher-kafka中的数据。
$
bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic logtail-flusher-kafka
{"时间":1640862641,"内容":[{"密钥":"__tag__:__path__","值":"
/root/bin/input_data/json.log"},{"Key":"seq","Value":"1"},{"Key":"action","Value":"kkkk"},{ "Key":"extend1","Value":""},{"Key":"extend2","Value":""},{"Key":"type","Value":"1"} ]}
{"时间":1640862646,"内容":[{"键":"__tag__:__path__","值":"
/root/bin/input_data/json.log"},{"Key":"seq","Value":"2"},{"Key":"action","Value":"kkkk"},{ "Key":"extend1","Value":""},{"Key":"extend2","Value":""},{"Key":"type","Value":"1"} ]}
本地调试
为了快速方便地验证配置是否正确,可以将采集接收到的日志打印到标准输出,完成快速功能验证。
替换本地的采集,配置plugin-flushers为flusher_stdout,在终端模式下运行$ ./ilogtail_1.0.28 --ilogtail_daemon_flag=false,可以调用采集将日志打印到标准输出以进行快速本地调试。
{
"type": "flusher_stdout",
"detail":
{
"OnlyStdout": true
}
K8S环境日志采集使用SLS前准备创建日志配置,进入日志服务控制台(),点击上一节已经创建的项目。
进入Project查询页面后,点击左侧边栏的“放大镜”图标,展开logstore管理界面,点击“+”,弹出右侧边栏“Create Logstore”。按照提示进行配置,输入日志库名称,单击“确定”。
日志库创建成功后,取消数据访问向导。单击左侧边栏中的“Cube”按钮,在弹出的“Resources”叠加层中选择“Machine Group”。在展开的“机器组”的左栏中,点击右上角的“方形”图标,在弹出的层中选择“创建机器组”。
在“创建机器组”侧边栏中,按照提示进行配置,“机器组ID”选择“用户自定义ID”,“名称”、“机器组主题”、“机器组主题”建议保持不变用户自定义标识”。“自定义ID”是最重要的配置之一。本教程使用“my-k8s-group”,安装ilogtail时会再次使用。“点击”确认保存机器组。
再次点击左侧边栏的“放大镜”图标,展开logstore管理界面,点击第2步创建的logstore的“向下展开”图标,弹出“配置Logstore”菜单。点击“+”按钮进行“logtail配置”。
在弹出的“快速访问数据”对话框中,搜索“kube”,选择“Kubernetes-file”。在弹出的“提示”框中,单机“继续”。
在“Kubernetes 文件”配置界面中,直接选择“使用现有机器组”。
跳转到“机器组配置”界面,选择第4步创建的机器组,点击“>”按钮将其添加到“应用机器组”中,然后点击“下一步”。
在ilogtail配置中,只修改“配置名称”和“日志路径”两个必填项,点击“下一步”确认。
完成索引配置。此步骤不修改任何选项,只需点击下一步即可完成配置。
至此,整个日志配置完成。请保持页面打开。
安装ilogtail登录控制K8S集群的中心计算机。编辑 ilogtail 的 ConfigMap YAML。
$ vim alicloud-log-config.yaml
将以下内容粘贴到 Vim 中并保存(注意,修改注释中指示的字段,第 7-11 行)。
apiVersion: v1
kind: ConfigMap
metadata:
name: alibaba-log-configuration
namespace: kube-system
data:
log-project: "my-project" #修改为实际project名称
log-endpoint: "cn-wulanchabu.log.aliyuncs.com" #修改为实际endpoint
log-machine-group: "my-k8s-group" #可以自定义机器组名称
log-config-path: "/etc/ilogtail/conf/cn-wulanchabu_internet/ilogtail_config.json" #修改cn-wulanchabu为实际project地域
log-ali-uid: "*********" #修改为阿里云UID
access-key-id: "" #本教程用不上
access-key-secret: "" #本教程用不上
cpu-core-limit: "2"
mem-limit: "1024"
max-bytes-per-sec: "20971520"
send-requests-concurrency: "20"
计算 alicloud-log-config.yaml 的 sha256 哈希,编辑 ilogtail 的 DaemonSet YAML。
$ sha256sum alicloud-log-config.yaml
f370df37916797aa0b82d709ae6bfc5f46f709660e1fd28bb49c22da91da1214 alicloud-log-config.yaml
$ vim logtail-daemonset.yaml
将以下内容粘贴到 Vim 中并保存(注意,修改注释中指出的字段,21、25 行)。 查看全部
如何文章采集(iLogtail本地配置模式部署(ForKafkaFlusher)阿里开源了可观测数据采集器iLogtail)
iLogtail本地配置方式部署(适用于Kafka Flusher)
阿里已正式开源可观察数据采集器iLogtail。作为阿里巴巴内部可观察数据采集的基础设施,iLogtail承载了阿里巴巴集团的采集工作和蚂蚁的日志、监控、跟踪、事件等可观察数据。
iLogtail作为阿里云SLS的采集Agent,一般与SLS配合使用,采集配置一般通过SLS控制台或API进行。那么是否可以不依赖 SLS 使用 iLogtail 呢?
本文将详细介绍如何在不依赖SLS控制台的情况下,以本地配置方式部署iLogtail,以及采集json格式的日志文件到非SLS(如Kafka等)。
场景
采集
/root/bin/input_data/json.log(单行日志json格式),将日志采集写入本地部署的kafka。
前提条件
kafka本地安装完成,创建一个名为logtail-flusher-kafka的topic。有关部署详细信息,请参阅链接。
安装 ilogtail
下载最新的 ilogtail 版本并解压。
解压tar包
$ tar zxvf logtail-linux64.tar.gz
查看目录结构
$ ll logtail-linux64
drwxr-xr-x 3 500 500 4096 箱
drwxr-xr-x 184 500 500 12288 配置
-rw-r--r-- 1 500 500 597 自述文件
drwxr-xr-x 2 500 500 4096 资源
进入bin目录
$ cd logtail-linux64/bin
$ ll
-rwxr-xr-x 1 500 500 10052072 ilogtail_1.0.28 # ilogtail 可执行文件
-rwxr-xr-x 1 500 500 4191 ilogtaild
-rwxr-xr-x 1 500 500 5976 libPluginAdapter.so
-rw-r--r-- 1 500 500 89560656 libPluginBase.so
-rwxr-xr-x 1 500 500 2333024 LogtailInsight
采集配置
配置格式
json格式采集到本地kafa的日志文件配置格式:
"metrics": {
"{config_name1}" : {
"enable": true,
"category": "file",
"log_type": "json_log",
"log_path": "/root/bin/input_data",
"file_pattern": "json.log",
"plugin": {
"processors": [
{
"detail": {
"SplitSep": "",
"SplitKey": "content"
},
"type": "processor_split_log_string"
},
{
"detail": {
"ExpandConnector": "",
"ExpandDepth": 1,
"SourceKey": "content",
"KeepSource": false
},
"type": "processor_json"
}],
"flushers":[
{
"type": "flusher_kafka",
"detail": {
"Brokers":["localhost:9092"],
"Topic": "logtail-flusher-kafka"
}
}]
},
"version": 1
},
"{config_name2}" : {
...
}
}
详细格式说明:
文件最外面的key是metrics,里面是每个具体的采集配置。
采集配置的key就是配置名称,修改后的名称在这个文件中必须是唯一的。建议命名:“##1.0##采集配置名称”。
采集配置值是具体的采集参数配置,关键参数及其含义如下:
参数名称类型说明
enable bool 配置是否生效。为false时,配置不生效。
category string File采集场景的值为“file”。
log_type 字符串日志类型。在 json采集 场景中,值为 json_log。
log_path 字符串 采集路径。
file_pattern 字符串 采集 文件。
插件对象的具体采集配置是一个json对象。具体配置请参考以下说明
version int 配置版本号,建议每次配置修改后加1
plugin字段是一个json对象,针对具体的输入源和处理方式进行配置:
配置项类型说明
处理器对象数组处理模式配置,详见链接。processor_json:将原创日志展开为json格式。
flushers object array flusher_stdout:采集到stdout,一般用于调试场景;flusher_kafka:采集 到 kafka。
完整的配置示例
进入bin目录,创建sys_conf_dir文件夹和ilogtail_config.json文件。
1. 创建 sys_conf_dir
$ mkdir sys_conf_dir
2. 创建 ilogtail_config.json 并完成配置。
logtail_sys_conf_dir 的值为:$pwd/sys_conf_dir/
config_server_address 的值是固定的并且保持不变。
$密码
/root/bin/logtail-linux64/bin
$ 猫 ilogtail_config.json
{
"logtail_sys_conf_dir": "/root/bin/logtail-linux64/bin/sys_conf_dir/",
"config_server_address" : "http://logtail.cn-zhangjiakou. ... ot%3B
3. 此时的目录结构
$ ll
-rwxr-xr-x 1 500 500 ilogtail_1.0.28
-rw-r--r-- 1 根 ilogtail_config.json
-rwxr-xr-x 1 500 500 ilogtaild
-rwxr-xr-x 1 500 500 libPluginAdapter.so
-rw-r--r-- 1 500 500 libPluginBase.so
-rwxr-xr-x 1 500 500
drwxr-xr-x 2 根 sys_conf_dir
在 sys_conf_dir 下创建 采集 配置文件 user_local_config.json。
注意:在json_log场景下,user_local_config.json只需要修改采集路径相关参数log_path和file_pattern,其他参数不变。
$ cat sys_conf_dir/user_local_config.json
{
"metrics":
{
"##1.0##kafka_output_test":
{
"category": "file",
"log_type": "json_log",
"log_path": "/root/bin/input_data",
"file_pattern": "json.log",
"create_time": 1631018645,
"defaultEndpoint": "",
"delay_alarm_bytes": 0,
"delay_skip_bytes": 0,
"discard_none_utf8": false,
"discard_unmatch": false,
"docker_exclude_env":
{},
"docker_exclude_label":
{},
"docker_file": false,
"docker_include_env":
{},
"docker_include_label":
{},
"enable": true,
"enable_tag": false,
"file_encoding": "utf8",
"filter_keys":
[],
"filter_regs":
[],
"group_topic": "",
"plugin":
{
"processors":
[
{
"detail": {
"SplitSep": "",
"SplitKey": "content"
},
"type": "processor_split_log_string"
},
{
"detail":
{
"ExpandConnector": "",
"ExpandDepth": 1,
"SourceKey": "content",
"KeepSource": false
},
"type": "processor_json"
}
],
"flushers":
[
{
"type": "flusher_kafka",
"detail":
{
"Brokers":
[
"localhost:9092"
],
"Topic": "logtail-flusher-kafka"
}
}
]
},
"local_storage": true,
"log_tz": "",
"max_depth": 10,
"max_send_rate": -1,
"merge_type": "topic",
"preserve": true,
"preserve_depth": 1,
"priority": 0,
"raw_log": false,
"aliuid": "",
"region": "",
"project_name": "",
"send_rate_expire": 0,
"sensitive_keys":
[],
"shard_hash_key":
[],
"tail_existed": false,
"time_key": "",
"timeformat": "",
"topic_format": "none",
"tz_adjust": false,
"version": 1,
"advanced":
{
"force_multiconfig": false,
"tail_size_kb": 1024
}
}
}
启动 ilogtail
在终端模式下运行
$ ./ilogtail_1.0.28 --ilogtail_daemon_flag=false
您也可以选择以守护程序模式运行
$ ./ilogtail_1.0.28
$ ps -ef|grep logtail
根 48453 1 ./ilogtail_1.0.28
根 48454 48453 ./ilogtail_1.0.28
采集情景模拟
过去的
json格式的数据在/root/bin/input_data/json.log中构造。代码如下:
$ echo'{“seq”:“1”,“action”:“kkkk”,“extend1”:“”,“extend2”:“”,“type”:“1”}'>> json.log
$ echo '{"seq": "2", "action": "kkkk", "extend1": "", "extend2": "", "type": "1"}' >> json.log
消费主题是logtail-flusher-kafka中的数据。
$
bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic logtail-flusher-kafka
{"时间":1640862641,"内容":[{"密钥":"__tag__:__path__","值":"
/root/bin/input_data/json.log"},{"Key":"seq","Value":"1"},{"Key":"action","Value":"kkkk"},{ "Key":"extend1","Value":""},{"Key":"extend2","Value":""},{"Key":"type","Value":"1"} ]}
{"时间":1640862646,"内容":[{"键":"__tag__:__path__","值":"
/root/bin/input_data/json.log"},{"Key":"seq","Value":"2"},{"Key":"action","Value":"kkkk"},{ "Key":"extend1","Value":""},{"Key":"extend2","Value":""},{"Key":"type","Value":"1"} ]}
本地调试
为了快速方便地验证配置是否正确,可以将采集接收到的日志打印到标准输出,完成快速功能验证。
替换本地的采集,配置plugin-flushers为flusher_stdout,在终端模式下运行$ ./ilogtail_1.0.28 --ilogtail_daemon_flag=false,可以调用采集将日志打印到标准输出以进行快速本地调试。
{
"type": "flusher_stdout",
"detail":
{
"OnlyStdout": true
}
K8S环境日志采集使用SLS前准备创建日志配置,进入日志服务控制台(),点击上一节已经创建的项目。
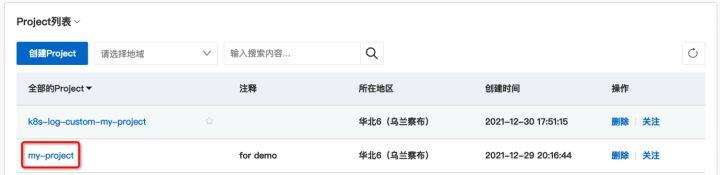
进入Project查询页面后,点击左侧边栏的“放大镜”图标,展开logstore管理界面,点击“+”,弹出右侧边栏“Create Logstore”。按照提示进行配置,输入日志库名称,单击“确定”。
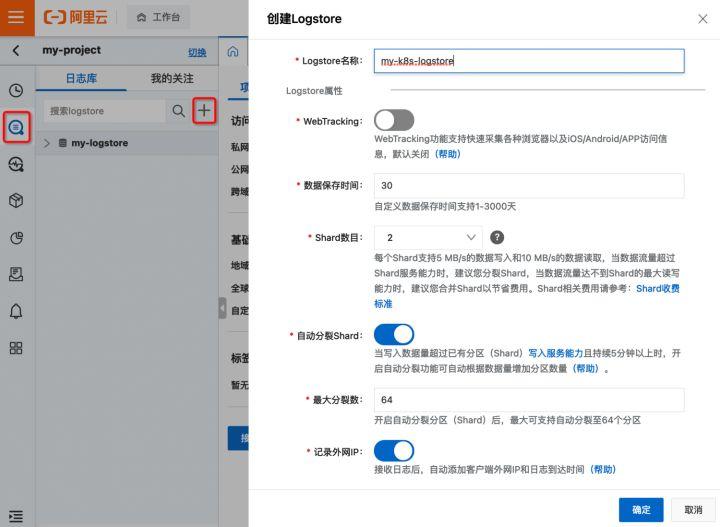
日志库创建成功后,取消数据访问向导。单击左侧边栏中的“Cube”按钮,在弹出的“Resources”叠加层中选择“Machine Group”。在展开的“机器组”的左栏中,点击右上角的“方形”图标,在弹出的层中选择“创建机器组”。
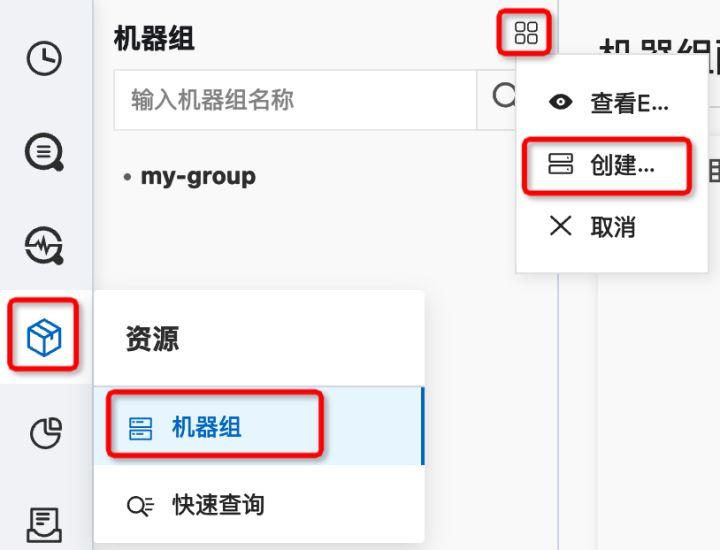
在“创建机器组”侧边栏中,按照提示进行配置,“机器组ID”选择“用户自定义ID”,“名称”、“机器组主题”、“机器组主题”建议保持不变用户自定义标识”。“自定义ID”是最重要的配置之一。本教程使用“my-k8s-group”,安装ilogtail时会再次使用。“点击”确认保存机器组。
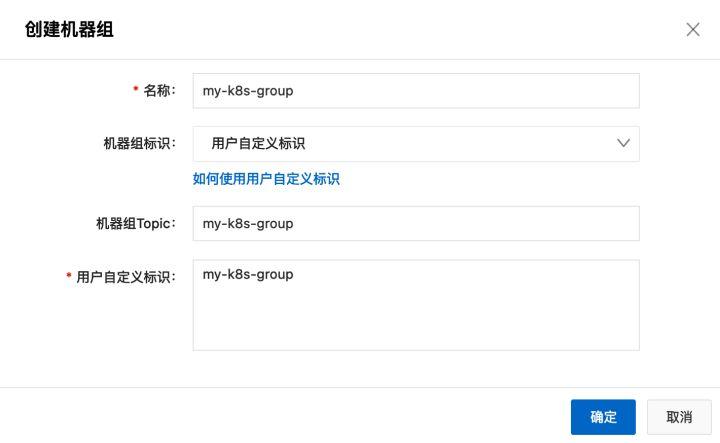
再次点击左侧边栏的“放大镜”图标,展开logstore管理界面,点击第2步创建的logstore的“向下展开”图标,弹出“配置Logstore”菜单。点击“+”按钮进行“logtail配置”。
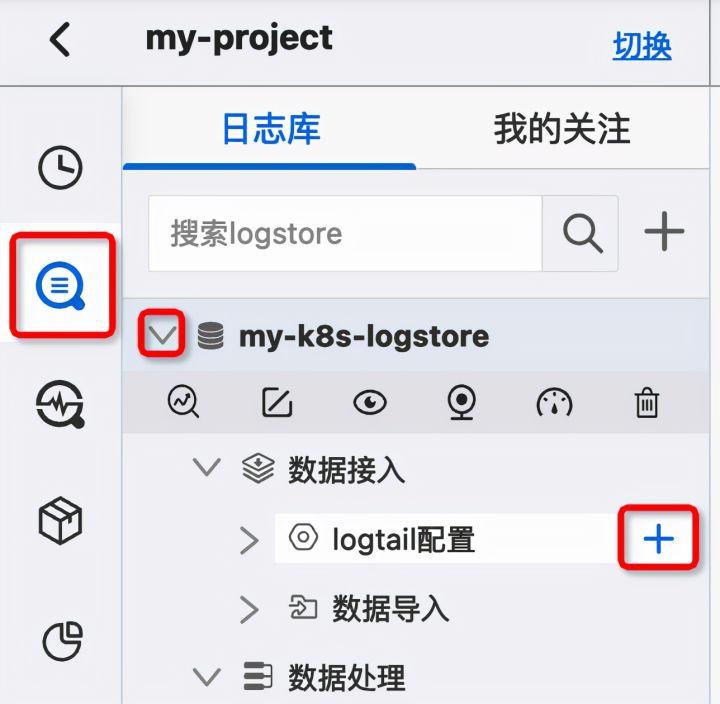
在弹出的“快速访问数据”对话框中,搜索“kube”,选择“Kubernetes-file”。在弹出的“提示”框中,单机“继续”。


在“Kubernetes 文件”配置界面中,直接选择“使用现有机器组”。
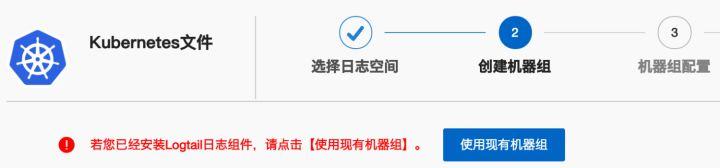
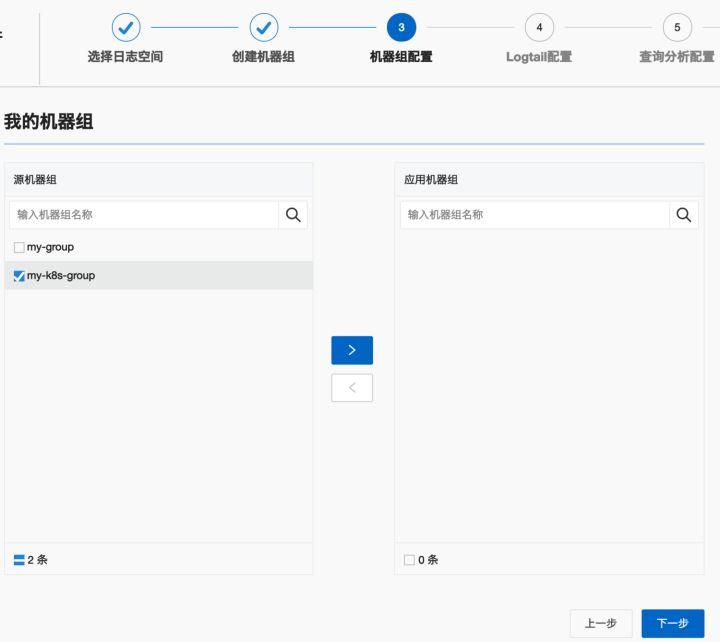
跳转到“机器组配置”界面,选择第4步创建的机器组,点击“>”按钮将其添加到“应用机器组”中,然后点击“下一步”。
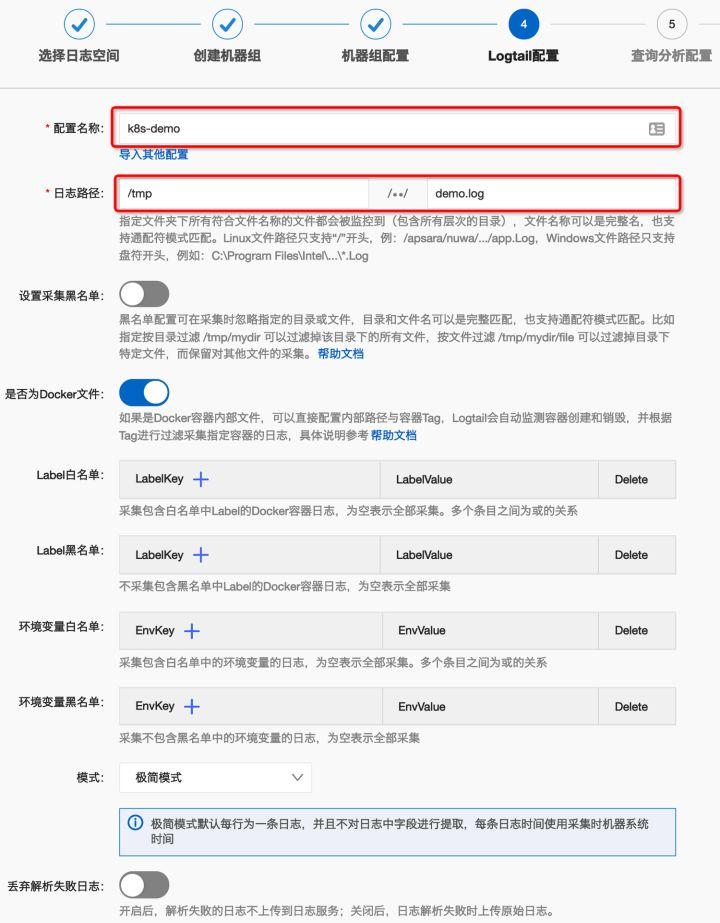
在ilogtail配置中,只修改“配置名称”和“日志路径”两个必填项,点击“下一步”确认。
完成索引配置。此步骤不修改任何选项,只需点击下一步即可完成配置。
至此,整个日志配置完成。请保持页面打开。

安装ilogtail登录控制K8S集群的中心计算机。编辑 ilogtail 的 ConfigMap YAML。
$ vim alicloud-log-config.yaml
将以下内容粘贴到 Vim 中并保存(注意,修改注释中指示的字段,第 7-11 行)。
apiVersion: v1
kind: ConfigMap
metadata:
name: alibaba-log-configuration
namespace: kube-system
data:
log-project: "my-project" #修改为实际project名称
log-endpoint: "cn-wulanchabu.log.aliyuncs.com" #修改为实际endpoint
log-machine-group: "my-k8s-group" #可以自定义机器组名称
log-config-path: "/etc/ilogtail/conf/cn-wulanchabu_internet/ilogtail_config.json" #修改cn-wulanchabu为实际project地域
log-ali-uid: "*********" #修改为阿里云UID
access-key-id: "" #本教程用不上
access-key-secret: "" #本教程用不上
cpu-core-limit: "2"
mem-limit: "1024"
max-bytes-per-sec: "20971520"
send-requests-concurrency: "20"
计算 alicloud-log-config.yaml 的 sha256 哈希,编辑 ilogtail 的 DaemonSet YAML。
$ sha256sum alicloud-log-config.yaml
f370df37916797aa0b82d709ae6bfc5f46f709660e1fd28bb49c22da91da1214 alicloud-log-config.yaml
$ vim logtail-daemonset.yaml
将以下内容粘贴到 Vim 中并保存(注意,修改注释中指出的字段,21、25 行)。
如何文章采集(做好网站过度优化主要表现在以下方面方面?)
采集交流 • 优采云 发表了文章 • 0 个评论 • 365 次浏览 • 2022-01-14 00:21
做好网站优化,会让网站更多关键词在首页排名,从而提高网站的曝光率,被更多潜在客户搜索,特别是现在广告网站当比特数减少时优化就更重要了。很多初学者在优化过程中容易出现这种情况。一有SEO技术,他们就会将其用于网站,导致网站过度优化并被搜索引擎惩罚,那么如何避免呢?网站过度优化怎么办?
网站过度优化主要表现在以下几个方面
1、网站文章更新采集
网站后期一个重要的维护,保持网站的活跃度,就是更新原创的有价值的文章。部分初学者在线学习,文章采集方法,使用文章采集工具,采集同行业文章,直接在网上发布,或者使用某个伪原创工具,使用工具自动修改文章,每天发几十篇,更新目的是为了更新文章,其实这样做不仅无助于优化,反而会带来反效果,新站会延迟审核期,老站降低权重和排名,一定要围绕用户需求写一些原创有价值的文章,并更新每天两片文章。
2、关键词恶意堆叠
做网站优化就是做关键词优化,提高关键词在搜索引擎首页的排名,无论用户搜索什么类型的关键词,他们可以看到公司信息,他们可以有更多的点击机会,所以很多初学者为了增加关键词的密度恶意堆放关键词。在更新文章的时候,他们也放了很多文章关键词。@关键词,在文章元标签设置中,各种堆叠关键词,在图片ALT标签中,也是在堆叠关键词,关键词严重堆叠,导致被搜索引擎惩罚。一定要按照正常的优化方法,一个文章不能超过3个关键词,关键词必须和当前页面相关
3、锚文本链接过多
做好锚文本链接有利于提高网站的权重,提高关键词的排名。初学者链接锚文本时,只要关键词出现在文章中,加个链接,甚至还有很多无用的锚文本链接,明显是优化过度,和锚文本链接堆积在一起. 一个文章最好不要超过3个锚文本链接,关键词布局到哪个页面,关键词锚文本链接到哪个页面,添加关键词的时候,一定要不限制关键词的布局,有价值的关键词不用布局,也是可以链接的,从系统上讲,每个页面都用锚文本链接,形成网页结构,引导蜘蛛深度抓取。
4、外链搭建没有规则
做好外链建设,不仅可以引导蜘蛛抓取网站的内容,还可以推广企业品牌,获取潜在客户。因此,很多公司都想尽办法使用各种外链海量分发工具和各种刷机。如果你在作弊,搜索引擎并不愚蠢。系统会自动判断为垃圾外链。设置不会转到 收录 这个外部链接。说真的,一定要控制数量,不要使用工具搭建外链。我们必须采取循序渐进的方法来提高外部链接的质量。
网站过度优化的危险
过度使用网站优化技术,违反搜索引擎优化规则,利用作弊手段优化和欺骗搜索引擎。这种方法很容易被搜索引擎检索到。>惩罚基于过度优化的程序,过度优化严重影响用户体验,用户体验差的网站跳出率高,用户不会深度浏览,自然搜索引擎不会放这样的网站@ >网站 最高排名。 查看全部
如何文章采集(做好网站过度优化主要表现在以下方面方面?)
做好网站优化,会让网站更多关键词在首页排名,从而提高网站的曝光率,被更多潜在客户搜索,特别是现在广告网站当比特数减少时优化就更重要了。很多初学者在优化过程中容易出现这种情况。一有SEO技术,他们就会将其用于网站,导致网站过度优化并被搜索引擎惩罚,那么如何避免呢?网站过度优化怎么办?
网站过度优化主要表现在以下几个方面
1、网站文章更新采集
网站后期一个重要的维护,保持网站的活跃度,就是更新原创的有价值的文章。部分初学者在线学习,文章采集方法,使用文章采集工具,采集同行业文章,直接在网上发布,或者使用某个伪原创工具,使用工具自动修改文章,每天发几十篇,更新目的是为了更新文章,其实这样做不仅无助于优化,反而会带来反效果,新站会延迟审核期,老站降低权重和排名,一定要围绕用户需求写一些原创有价值的文章,并更新每天两片文章。
2、关键词恶意堆叠
做网站优化就是做关键词优化,提高关键词在搜索引擎首页的排名,无论用户搜索什么类型的关键词,他们可以看到公司信息,他们可以有更多的点击机会,所以很多初学者为了增加关键词的密度恶意堆放关键词。在更新文章的时候,他们也放了很多文章关键词。@关键词,在文章元标签设置中,各种堆叠关键词,在图片ALT标签中,也是在堆叠关键词,关键词严重堆叠,导致被搜索引擎惩罚。一定要按照正常的优化方法,一个文章不能超过3个关键词,关键词必须和当前页面相关
3、锚文本链接过多
做好锚文本链接有利于提高网站的权重,提高关键词的排名。初学者链接锚文本时,只要关键词出现在文章中,加个链接,甚至还有很多无用的锚文本链接,明显是优化过度,和锚文本链接堆积在一起. 一个文章最好不要超过3个锚文本链接,关键词布局到哪个页面,关键词锚文本链接到哪个页面,添加关键词的时候,一定要不限制关键词的布局,有价值的关键词不用布局,也是可以链接的,从系统上讲,每个页面都用锚文本链接,形成网页结构,引导蜘蛛深度抓取。
4、外链搭建没有规则
做好外链建设,不仅可以引导蜘蛛抓取网站的内容,还可以推广企业品牌,获取潜在客户。因此,很多公司都想尽办法使用各种外链海量分发工具和各种刷机。如果你在作弊,搜索引擎并不愚蠢。系统会自动判断为垃圾外链。设置不会转到 收录 这个外部链接。说真的,一定要控制数量,不要使用工具搭建外链。我们必须采取循序渐进的方法来提高外部链接的质量。
网站过度优化的危险
过度使用网站优化技术,违反搜索引擎优化规则,利用作弊手段优化和欺骗搜索引擎。这种方法很容易被搜索引擎检索到。>惩罚基于过度优化的程序,过度优化严重影响用户体验,用户体验差的网站跳出率高,用户不会深度浏览,自然搜索引擎不会放这样的网站@ >网站 最高排名。
如何文章采集(云名片基于号簿助手后台强大的云存储功能支持)
采集交流 • 优采云 发表了文章 • 0 个评论 • 122 次浏览 • 2022-01-10 19:23
本文目录:
介绍
本文摘要
这篇文章的标题
文字内容
结束语
介绍:
您最近可能也在寻找有关或此类内容的相关内容,对吧?为了整理这个内容,特意和公司周围的朋友同事交流了半天……我也在网上查了很多资料,总结了一些关于文章采集@的资料>(采集@的作用是什么>文章),希望能传授一下《文章采集@>的相关知识点(采集的作用是什么) @>文章在云名片里?)”对大家有帮助,一起来学习吧!
本文摘要:
“云名片由号码簿助手后台强大的云存储功能支持,比传统名片可以承载更多的个人信息,方便用户在商务场合交换个人名片。主要应用有如下文章采集@>:1、将云名片的网址以二维码的形式打印在传统名片上,其他人可以扫描二维码查看并保存名片;个人信息更新时,无需主动通知,好友再次扫描更新即可查看更新2、通过微信、QQ、短信等工具快速与好友交换名片信息; 3、在朋友圈、微博、微电等客服222是……
本文标题:文章采集@>(云名片采集@>文章的作用是什么)正文内容:
基于通讯录助手后台强大的云存储功能,云名片可以比传统名片承载更多的个人信息,方便用户在商务场合交换个人名片。主要应用如下文章采集@>:
1、将云名片的网址以二维码的形式打印在传统名片上,其他人可以扫描二维码查看并保存名片;个人信息更新时,无需主动通知,好友再次扫描即可查看更新的名片;
2、通过微信、QQ、短信等工具与好友快速交换名片信息;
3、在朋友圈、微博、微信等环境传播个人信息。客服222为您解答。宽带服务可以自助,操作简单。此外,还可办理工单查询、ITV维修、宽带申请、密码服务,方便快捷。更多功能请关注中国电信贵州客服。
结束语:
以上是关于文章采集@>的一些相关内容(云名片的采集@>文章是做什么的)以及围绕这类内容的一些相关知识点,我希望通过介绍,对大家有帮助!未来,我们将更新更多相关资讯内容,关注我们,了解每日最新热点新闻,关注社交动态! 查看全部
如何文章采集(云名片基于号簿助手后台强大的云存储功能支持)
本文目录:
介绍
本文摘要
这篇文章的标题
文字内容
结束语
介绍:
您最近可能也在寻找有关或此类内容的相关内容,对吧?为了整理这个内容,特意和公司周围的朋友同事交流了半天……我也在网上查了很多资料,总结了一些关于文章采集@的资料>(采集@的作用是什么>文章),希望能传授一下《文章采集@>的相关知识点(采集的作用是什么) @>文章在云名片里?)”对大家有帮助,一起来学习吧!
本文摘要:
“云名片由号码簿助手后台强大的云存储功能支持,比传统名片可以承载更多的个人信息,方便用户在商务场合交换个人名片。主要应用有如下文章采集@>:1、将云名片的网址以二维码的形式打印在传统名片上,其他人可以扫描二维码查看并保存名片;个人信息更新时,无需主动通知,好友再次扫描更新即可查看更新2、通过微信、QQ、短信等工具快速与好友交换名片信息; 3、在朋友圈、微博、微电等客服222是……
本文标题:文章采集@>(云名片采集@>文章的作用是什么)正文内容:
基于通讯录助手后台强大的云存储功能,云名片可以比传统名片承载更多的个人信息,方便用户在商务场合交换个人名片。主要应用如下文章采集@>:

1、将云名片的网址以二维码的形式打印在传统名片上,其他人可以扫描二维码查看并保存名片;个人信息更新时,无需主动通知,好友再次扫描即可查看更新的名片;
2、通过微信、QQ、短信等工具与好友快速交换名片信息;
3、在朋友圈、微博、微信等环境传播个人信息。客服222为您解答。宽带服务可以自助,操作简单。此外,还可办理工单查询、ITV维修、宽带申请、密码服务,方便快捷。更多功能请关注中国电信贵州客服。
结束语:
以上是关于文章采集@>的一些相关内容(云名片的采集@>文章是做什么的)以及围绕这类内容的一些相关知识点,我希望通过介绍,对大家有帮助!未来,我们将更新更多相关资讯内容,关注我们,了解每日最新热点新闻,关注社交动态!
如何文章采集(如何加快网站快速搜索?如何有效提高百度收录或排名?)
采集交流 • 优采云 发表了文章 • 0 个评论 • 106 次浏览 • 2022-01-09 19:01
如何文章采集?如何加快网站快速搜索?如何有效提高百度收录或排名?如何提高百度检索效率?对于百度新闻,百度健康,百度糯米等重大的关键词,对于信息的获取方面是非常便捷。甚至百度提供了一个方便的搜索词库,上百度搜索你就知道了,有些网站会把热点事件做集中的采集,效率极高。但是其他关键词就不是这样的,要达到高效的检索,需要收集到各种高质量的关键词库,对于新手并没有太大的难度。
中国好搜无疑是目前最专业的收集百度搜索关键词库,包含百度搜索关键词库和百度健康搜索关键词库,是已经在百度排名靠前的站长和搜索人员必备的工具。为什么要注册百度好搜?第一个原因是百度好搜可以获取到权重最高的百度权重和百度健康搜索权重第二个原因是百度好搜提供了很多无任何推广操作的站长根据自己网站情况收集推广词,收集推广词最重要的是性价比高,如果推广词对于一个新站来说肯定不适合,每个搜索高质量关键词的站长都是希望可以去购买更多收入来推广自己的站长网站,但是百度好搜提供了搜索高质量词时是免费的,不需要购买推广。
第三个原因是百度好搜为绝大多数站长提供免费的关键词采集服务,甚至同时提供了关键词更新服务。前不久很多站长在联系我,咨询我是否可以免费给他提供百度好搜关键词收集。我开始是拒绝的,因为我知道这个流程其实没有那么简单,先咨询他是否确定需要采集关键词,然后给他免费提供百度好搜关键词收集服务,如果免费的话,想要获取的权重更高的关键词会更多,也就要更换更多的推广方式才行。
我认真的跟他交流了我所做的关键词的情况以及我的推广方式,其实这个也是对于一个站长来说非常有用的,他的服务很好,只是搜索词包含了很多高质量的关键词。他问我,如果自己没有一个百度好搜关键词库怎么办,我说你可以去百度中国好搜的网站,他说没有去百度中国好搜,百度好搜里面的词还是一些高质量的关键词,他还是想要去采集,这里我建议大家利用百度好搜,前期不要着急采集,一点一点的去采集。
采集第一步,先把这些高质量的关键词和行业词整理一下,百度好搜整理了一个excel表格,放在网站上,然后在百度好搜搜索栏搜索行业词,把相关性高的关键词收集过来。然后每天整理一点,2周左右我认为搜索词质量已经高到一定的水平了,整理1000个词都是没有问题的。根据我自己的百度好搜搜索词库的使用情况,有一些长尾关键词已经没有了,有的只有很少的一部分,其他的大部分都是一些非常精准的长尾关键词。很多站长都有这样的疑问,我自己每天都在收集这么多词,然后呢,效果。 查看全部
如何文章采集(如何加快网站快速搜索?如何有效提高百度收录或排名?)
如何文章采集?如何加快网站快速搜索?如何有效提高百度收录或排名?如何提高百度检索效率?对于百度新闻,百度健康,百度糯米等重大的关键词,对于信息的获取方面是非常便捷。甚至百度提供了一个方便的搜索词库,上百度搜索你就知道了,有些网站会把热点事件做集中的采集,效率极高。但是其他关键词就不是这样的,要达到高效的检索,需要收集到各种高质量的关键词库,对于新手并没有太大的难度。
中国好搜无疑是目前最专业的收集百度搜索关键词库,包含百度搜索关键词库和百度健康搜索关键词库,是已经在百度排名靠前的站长和搜索人员必备的工具。为什么要注册百度好搜?第一个原因是百度好搜可以获取到权重最高的百度权重和百度健康搜索权重第二个原因是百度好搜提供了很多无任何推广操作的站长根据自己网站情况收集推广词,收集推广词最重要的是性价比高,如果推广词对于一个新站来说肯定不适合,每个搜索高质量关键词的站长都是希望可以去购买更多收入来推广自己的站长网站,但是百度好搜提供了搜索高质量词时是免费的,不需要购买推广。
第三个原因是百度好搜为绝大多数站长提供免费的关键词采集服务,甚至同时提供了关键词更新服务。前不久很多站长在联系我,咨询我是否可以免费给他提供百度好搜关键词收集。我开始是拒绝的,因为我知道这个流程其实没有那么简单,先咨询他是否确定需要采集关键词,然后给他免费提供百度好搜关键词收集服务,如果免费的话,想要获取的权重更高的关键词会更多,也就要更换更多的推广方式才行。
我认真的跟他交流了我所做的关键词的情况以及我的推广方式,其实这个也是对于一个站长来说非常有用的,他的服务很好,只是搜索词包含了很多高质量的关键词。他问我,如果自己没有一个百度好搜关键词库怎么办,我说你可以去百度中国好搜的网站,他说没有去百度中国好搜,百度好搜里面的词还是一些高质量的关键词,他还是想要去采集,这里我建议大家利用百度好搜,前期不要着急采集,一点一点的去采集。
采集第一步,先把这些高质量的关键词和行业词整理一下,百度好搜整理了一个excel表格,放在网站上,然后在百度好搜搜索栏搜索行业词,把相关性高的关键词收集过来。然后每天整理一点,2周左右我认为搜索词质量已经高到一定的水平了,整理1000个词都是没有问题的。根据我自己的百度好搜搜索词库的使用情况,有一些长尾关键词已经没有了,有的只有很少的一部分,其他的大部分都是一些非常精准的长尾关键词。很多站长都有这样的疑问,我自己每天都在收集这么多词,然后呢,效果。
如何文章采集(小喵教你一招,可以轻松采集微信公众号文章)
采集交流 • 优采云 发表了文章 • 0 个评论 • 133 次浏览 • 2022-01-09 02:10
如今,微信公众号已经成为一种主流的线上线下微信互动营销方式。微信公众号上发布了很多优秀的文章,但是微信是腾讯所有的,不能直接发布在自己的网站上或者保存在数据库中,所以如果你想分享优质的微信文章执行采集搬运到自己的网站还是比较麻烦。小淼教你一招,轻松采集微信公众号文章,还可以自动发布!
1Data采集:NO.1 通过百度搜索相关网站,注册或登录,进入爬虫市场。
2NO.2搜索关键词:微信公众号。点击免费获取!
3NO.3进入采集爬虫后,点击爬虫设置。
4 首先,由于搜狗微信搜索有图片防盗链功能,需要在功能设置中开启图片云托管。这是非常重要的。记住,否则你的图片将不会显示,到时候你会很尴尬……
5 然后进行自定义设置,可以同时采集多个微信公众号文章,最多500个!特别提示:输入微信ID而不是微信名!
6什么!分不清哪个是微信名,哪个是微信ID,哦,好像有点像。好吧,那我告诉你。进入搜狗微信,输入你想要的微信公众号,点击搜索公众号。
7 压力又来了!进入微信!设置好后记得保存。然后进入概览页面,启动爬虫,等待爬取结果。保存:
8开始:
9 爬取结果:
10数据发布:数据采集完成后,可以发布数据吗?答案当然是!NO.1 发布数据只有两步:安装发布插件->使用发布接口。您可以选择发布到数据库或 网站。
11如果你不知道怎么安装插件,那我就告诉你,进入文档中心-使用文档-数据发布-安装插件,查看文档,按照文档提示,一步一步来一步,它会好的。
12 插件安装成功,接下来我们新建一个发布项吧!这里有很多,随便挑一个你喜欢的。
13选择发布界面后,填写您要发布的网站的地址和密码。同时系统会自动检测插件是否安装正确。
对于 14 字段映射,系统一般会默认选择一个好的,但如果您认为有什么需要调整的,您可以修改它。
15 内容替换 这是一个可选选项,可以填写也可以不填写。
16 完成设置后,即可发布数据。NO.2 在爬取结果页面,可以看到采集爬虫根据你设置的信息爬取的所有内容。发布的结果可以自动发布,也可以手动发布。
17 自动发布:开启自动发布后,爬取的数据会自动发布到网站或者数据库上,感觉快要起飞了!
18 当然,您也可以选择手动发布,发布时可以选择单个或多个发布。在发布之前,您还可以预览看看这个 文章 是关于什么的。
19 如果觉得木有问题,可以公布数据。
20 发布成功后,可以点击链接查看。
21 嗯~是的,用优采云云爬虫采集文章微信公众号就是这么简单!赶紧收下这份充满爱心的攻略吧,我不会告诉常人的。 查看全部
如何文章采集(小喵教你一招,可以轻松采集微信公众号文章)
如今,微信公众号已经成为一种主流的线上线下微信互动营销方式。微信公众号上发布了很多优秀的文章,但是微信是腾讯所有的,不能直接发布在自己的网站上或者保存在数据库中,所以如果你想分享优质的微信文章执行采集搬运到自己的网站还是比较麻烦。小淼教你一招,轻松采集微信公众号文章,还可以自动发布!
1Data采集:NO.1 通过百度搜索相关网站,注册或登录,进入爬虫市场。

2NO.2搜索关键词:微信公众号。点击免费获取!

3NO.3进入采集爬虫后,点击爬虫设置。

4 首先,由于搜狗微信搜索有图片防盗链功能,需要在功能设置中开启图片云托管。这是非常重要的。记住,否则你的图片将不会显示,到时候你会很尴尬……

5 然后进行自定义设置,可以同时采集多个微信公众号文章,最多500个!特别提示:输入微信ID而不是微信名!

6什么!分不清哪个是微信名,哪个是微信ID,哦,好像有点像。好吧,那我告诉你。进入搜狗微信,输入你想要的微信公众号,点击搜索公众号。

7 压力又来了!进入微信!设置好后记得保存。然后进入概览页面,启动爬虫,等待爬取结果。保存:

8开始:

9 爬取结果:

10数据发布:数据采集完成后,可以发布数据吗?答案当然是!NO.1 发布数据只有两步:安装发布插件->使用发布接口。您可以选择发布到数据库或 网站。

11如果你不知道怎么安装插件,那我就告诉你,进入文档中心-使用文档-数据发布-安装插件,查看文档,按照文档提示,一步一步来一步,它会好的。

12 插件安装成功,接下来我们新建一个发布项吧!这里有很多,随便挑一个你喜欢的。

13选择发布界面后,填写您要发布的网站的地址和密码。同时系统会自动检测插件是否安装正确。

对于 14 字段映射,系统一般会默认选择一个好的,但如果您认为有什么需要调整的,您可以修改它。

15 内容替换 这是一个可选选项,可以填写也可以不填写。

16 完成设置后,即可发布数据。NO.2 在爬取结果页面,可以看到采集爬虫根据你设置的信息爬取的所有内容。发布的结果可以自动发布,也可以手动发布。

17 自动发布:开启自动发布后,爬取的数据会自动发布到网站或者数据库上,感觉快要起飞了!

18 当然,您也可以选择手动发布,发布时可以选择单个或多个发布。在发布之前,您还可以预览看看这个 文章 是关于什么的。

19 如果觉得木有问题,可以公布数据。

20 发布成功后,可以点击链接查看。

21 嗯~是的,用优采云云爬虫采集文章微信公众号就是这么简单!赶紧收下这份充满爱心的攻略吧,我不会告诉常人的。
如何文章采集(什么是采集站顾名思义就是)
采集交流 • 优采云 发表了文章 • 0 个评论 • 149 次浏览 • 2022-01-07 05:17
什么是采集站,顾名思义就是填充大量的内容数据网站以获得更多的流量,不管任何网站都会遇到问题,内容填充
只要有足够的数据,百度就能得到更多的收录和呈现。对于一个大站。它必须是稳定的数据流。比如你的网站想每天获得几万的流量,就需要大量的关键词支持,大量的关键词需要大量的内容!对于个人站长和小团队来说,每天更新数百篇文章文章,无疑是傻瓜式。这么多人在这个时候选择采集!
有很多朋友问过我这样的问题吗?为什么别人的网站无论是排名还是流量都这么好?域名历史的建立仅用了一年多的时间。但是收录的数据达到了20W。倒计时每天创作547条内容,是怎么做到的?我现在应该怎么办?
以上是小编创建的一个采集站。目前日流量达到1W以上,后台文章音量60W,持续稳定。下面小编就给大家介绍一下采集站的做法。
1、 网站 程序。随着互联网的飞速发展,网上的源代码越来越多,免费的也很多。很多人用这些源码,重复的程度就不用我说了。相信免费的东西也有很多人在用
2、 首先,在选择域名时,应该选择旧域名。为什么选择旧域名?因为老域名已经过了搜索引擎的观察期。为什么旧域名更容易成为收录?因为老域名在某些方面做了优化,域名越老,网站的排名就越好。
3、选择好的采集源是重中之重,比如屏蔽百度蜘蛛的新闻源。
4、 采集 会在后面进行处理,比如重写或者伪原创
5、 每次更新后的内容都要主动推送到搜索引擎
这就是为什么很多站长拼命在他们的网站中添加网站内容,我们采集其他内容,首先,从搜索引擎来看,这是重复的内容。我们的内容相对于 采集 的质量得分肯定下降了很多。但是我们可以通过做一些其他的方面来弥补,这需要大家在程序和域名方面进行改进。
如果你看完这篇文章文章,如果你喜欢这篇文章文章,不妨采集或者发送给需要的朋友同事!您的一举一动都将成为编辑源源不断的动力! 查看全部
如何文章采集(什么是采集站顾名思义就是)
什么是采集站,顾名思义就是填充大量的内容数据网站以获得更多的流量,不管任何网站都会遇到问题,内容填充

只要有足够的数据,百度就能得到更多的收录和呈现。对于一个大站。它必须是稳定的数据流。比如你的网站想每天获得几万的流量,就需要大量的关键词支持,大量的关键词需要大量的内容!对于个人站长和小团队来说,每天更新数百篇文章文章,无疑是傻瓜式。这么多人在这个时候选择采集!
有很多朋友问过我这样的问题吗?为什么别人的网站无论是排名还是流量都这么好?域名历史的建立仅用了一年多的时间。但是收录的数据达到了20W。倒计时每天创作547条内容,是怎么做到的?我现在应该怎么办?
以上是小编创建的一个采集站。目前日流量达到1W以上,后台文章音量60W,持续稳定。下面小编就给大家介绍一下采集站的做法。
1、 网站 程序。随着互联网的飞速发展,网上的源代码越来越多,免费的也很多。很多人用这些源码,重复的程度就不用我说了。相信免费的东西也有很多人在用
2、 首先,在选择域名时,应该选择旧域名。为什么选择旧域名?因为老域名已经过了搜索引擎的观察期。为什么旧域名更容易成为收录?因为老域名在某些方面做了优化,域名越老,网站的排名就越好。
3、选择好的采集源是重中之重,比如屏蔽百度蜘蛛的新闻源。
4、 采集 会在后面进行处理,比如重写或者伪原创
5、 每次更新后的内容都要主动推送到搜索引擎
这就是为什么很多站长拼命在他们的网站中添加网站内容,我们采集其他内容,首先,从搜索引擎来看,这是重复的内容。我们的内容相对于 采集 的质量得分肯定下降了很多。但是我们可以通过做一些其他的方面来弥补,这需要大家在程序和域名方面进行改进。
如果你看完这篇文章文章,如果你喜欢这篇文章文章,不妨采集或者发送给需要的朋友同事!您的一举一动都将成为编辑源源不断的动力!
如何文章采集(免费Wordpress发布接口怎么使用?我不懂代码多久可以学会啊? )
采集交流 • 优采云 发表了文章 • 0 个评论 • 105 次浏览 • 2022-01-06 16:19
)
Q:如何使用免费的WordPress发布界面?如果我不理解代码,我可以学习多长时间?
答:直接下载使用!无需理解代码!1分钟学会!
Q:每天可以发布多少文章?支持哪些格式?
答:每天可发布数百万篇文章,支持任何格式!
Q:不同域名的Wordpress网站也能发布吗?
回答:是的!创建一个新任务只需要大约1分钟!
Q:我可以设置每天发布多少篇文章吗?可以在指定版块发表吗?
回答:是的!一键设置,可以根据不同栏目发布不同的文章
问:除了wordpress网站发布,Zblogcms程序还能发布吗?
回答:是的!支持主要的 cms 版本
问:太棒了!
答:是的,还有更多功能。
例如:采集→伪原创→发布(推送)
采集:只要设置关键词,就可以根据关键词采集文章同时创建几十个或几百个采集任务,即可设置过滤器关键词只与网站主题文章相关的采集,并且软件自带关键词自动生成工具,只需要进入核心关键词自动采集所有行业相关关键词,自动过滤与行业无关的词。
伪原创:伪原创 采用AI智能大脑。集成NLG技术、RNN模型、百度人工智能算法严格符合百度、搜狗、360、谷歌等大型搜索引擎算法收录规则可在线通过伪原创,本地< @伪原创或者API接口,使用伪原创会更好的被搜索引擎收录收录。
@网站模板原创度)-选择标题是否与插入的关键词一致(增加文章与话题行业的相关性)搜索引擎推送(自动推送到搜索引擎发布后文章增加网站收录)!同时也支持除wordpresscms之外的所有主流cms网站和站群采集伪原创发布推送。
以上是小编使用wordpress工具制作的一批高流量网站,所有内容均与主题相关!网站从未发生过降级!看完这篇文章,如果觉得不错,不妨采集起来,或者送给需要的朋友同事!您的一举一动都将成为编辑源源不断的动力!
查看全部
如何文章采集(免费Wordpress发布接口怎么使用?我不懂代码多久可以学会啊?
)
Q:如何使用免费的WordPress发布界面?如果我不理解代码,我可以学习多长时间?
答:直接下载使用!无需理解代码!1分钟学会!
Q:每天可以发布多少文章?支持哪些格式?
答:每天可发布数百万篇文章,支持任何格式!
Q:不同域名的Wordpress网站也能发布吗?
回答:是的!创建一个新任务只需要大约1分钟!
Q:我可以设置每天发布多少篇文章吗?可以在指定版块发表吗?
回答:是的!一键设置,可以根据不同栏目发布不同的文章
问:除了wordpress网站发布,Zblogcms程序还能发布吗?
回答:是的!支持主要的 cms 版本

问:太棒了!
答:是的,还有更多功能。
例如:采集→伪原创→发布(推送)

采集:只要设置关键词,就可以根据关键词采集文章同时创建几十个或几百个采集任务,即可设置过滤器关键词只与网站主题文章相关的采集,并且软件自带关键词自动生成工具,只需要进入核心关键词自动采集所有行业相关关键词,自动过滤与行业无关的词。

伪原创:伪原创 采用AI智能大脑。集成NLG技术、RNN模型、百度人工智能算法严格符合百度、搜狗、360、谷歌等大型搜索引擎算法收录规则可在线通过伪原创,本地< @伪原创或者API接口,使用伪原创会更好的被搜索引擎收录收录。

@网站模板原创度)-选择标题是否与插入的关键词一致(增加文章与话题行业的相关性)搜索引擎推送(自动推送到搜索引擎发布后文章增加网站收录)!同时也支持除wordpresscms之外的所有主流cms网站和站群采集伪原创发布推送。

以上是小编使用wordpress工具制作的一批高流量网站,所有内容均与主题相关!网站从未发生过降级!看完这篇文章,如果觉得不错,不妨采集起来,或者送给需要的朋友同事!您的一举一动都将成为编辑源源不断的动力!

如何文章采集(采集站死是死在源头太单一了怎么办? )
采集交流 • 优采云 发表了文章 • 0 个评论 • 131 次浏览 • 2022-01-06 16:18
)
1、扩展采集的来源。在很多情况下,采集 已经死了,因为来源太单一。采集时,建议记录对方文档的发布时间
2、 内容多样性,页面多样性。
3、 内容格式要干净整洁,图片要清晰(建议配图500-600字)。如果有能力,建议使用工具对内容进行编码(包括营销代码、电话号码、各种标签等)等等,比原来干净多了)
补充:
可以按照采集所属行业的项目进行分类,然后在每个项目中放N张图片,然后标题根据关键词对应的项目匹配图片,插入(可以使用公共图片名称,也可以每次插入的图片名称不一致)
4、 做好页面内容相关性的匹配,页面调用一定要丰富,才能达到假真假假的效果。详情请参考部分整形医疗平台的用户体验。
5、如果有能力,可以自己制作一些结构化的数据来洗稿子,达到一定比例的原创度
6、发布时,建议在源发布时间之前修改自己的发布时间采集
7、 建议发布前先搭建好站点,然后再上线。上线后,在网站还没有达到一定程度时,最好不要更改任何网站结构和链接收录
8、 发帖级别,建议每天发帖1W+。当然,最好是拥有更多并全部推送。建议每天配合几十次手动更新,达到更好的效果。
9、 基本上坚持1-3,就会有效果。有条件的可以适当配合蜘蛛池,购买外链。
10、 没有网站是 100% 完成的。建议您可以同时上传多个,以确保您的准确性
11、 模板试图成为战争的模板。原创 度数越高的模板,尽可能多的列。
查看全部
如何文章采集(采集站死是死在源头太单一了怎么办?
)
1、扩展采集的来源。在很多情况下,采集 已经死了,因为来源太单一。采集时,建议记录对方文档的发布时间
2、 内容多样性,页面多样性。
3、 内容格式要干净整洁,图片要清晰(建议配图500-600字)。如果有能力,建议使用工具对内容进行编码(包括营销代码、电话号码、各种标签等)等等,比原来干净多了)
补充:
可以按照采集所属行业的项目进行分类,然后在每个项目中放N张图片,然后标题根据关键词对应的项目匹配图片,插入(可以使用公共图片名称,也可以每次插入的图片名称不一致)

4、 做好页面内容相关性的匹配,页面调用一定要丰富,才能达到假真假假的效果。详情请参考部分整形医疗平台的用户体验。
5、如果有能力,可以自己制作一些结构化的数据来洗稿子,达到一定比例的原创度
6、发布时,建议在源发布时间之前修改自己的发布时间采集
7、 建议发布前先搭建好站点,然后再上线。上线后,在网站还没有达到一定程度时,最好不要更改任何网站结构和链接收录
8、 发帖级别,建议每天发帖1W+。当然,最好是拥有更多并全部推送。建议每天配合几十次手动更新,达到更好的效果。
9、 基本上坚持1-3,就会有效果。有条件的可以适当配合蜘蛛池,购买外链。
10、 没有网站是 100% 完成的。建议您可以同时上传多个,以确保您的准确性
11、 模板试图成为战争的模板。原创 度数越高的模板,尽可能多的列。

如何文章采集(采集某一个指定页面的文章包括(标题、图片、描述、内容) )
采集交流 • 优采云 发表了文章 • 0 个评论 • 134 次浏览 • 2022-01-01 18:00
)
任务:
采集指定页面的文章包括(标题、图片、描述、内容)导入到自己的网站数据库对应列(列id为57), 数据库字段分别是(title, thumb, descrption, content).
页面上的第一张图片用作文章缩略图。这里一个是获取缩略图的名称并将对应的网站路径添加到数据库的thumb字段中,另一个是本地下载并统一上传。进入指定的文件夹,(当然也可以直接ftp看软件,我还没做,以后补充)
1、新组--新任务
2、添加网址+修改获取网址的规则
选择ul中li中的链接,注意排除重复地址,可以点击采集下方的测试网址获取。
可以看到采集有一个到文章的链接。
3、采集内容规则
我需要采集来显示下图中的数据(catid为列id,可以将数据采集放入对应的列并设置固定值)
关注内容和图片采集,标题和描述与内容相同采集
内容采集:
打开采集的文章的一个页面查看源码(f11右键禁用或者view-source:可以在URL前面加):
选择文章开头的一个位置,截取一段,看是不是ctrl+f下的唯一一段。如果是,可以放在下图1所示的位置,结尾和开头一样。
我截取了内容,不想里面有链接图片进行数据处理,添加--html标签排除--选择确定--确定
还有需要下载页面图片,勾选并填写以下选项
图片采集:
(1)选择范围与内容相同(文章内图)
(2)提取第一张图片的数据处理选项。内容为:
(3)只要aa.jpg,常规过滤
获取内容:aa.jpg
(4)数据库存放有前缀,添加,上传/xxxxx/
找一个页面测试一下,可以看到对应的item都获取到了。
4、发布内容设置,这里以发布到数据库的方式为例,编辑完成后返回这里查看刚刚定义的模块:
5、我需要把图片保存到本地,还要设置保存文件的路径(ftp以后会尝试使用)。
6、保存,查看新创建的任务,右键启动任务,可以看到这里下载了文字和图片,在数据库中可以看到。
查看全部
如何文章采集(采集某一个指定页面的文章包括(标题、图片、描述、内容)
)
任务:
采集指定页面的文章包括(标题、图片、描述、内容)导入到自己的网站数据库对应列(列id为57), 数据库字段分别是(title, thumb, descrption, content).
页面上的第一张图片用作文章缩略图。这里一个是获取缩略图的名称并将对应的网站路径添加到数据库的thumb字段中,另一个是本地下载并统一上传。进入指定的文件夹,(当然也可以直接ftp看软件,我还没做,以后补充)
1、新组--新任务
2、添加网址+修改获取网址的规则
选择ul中li中的链接,注意排除重复地址,可以点击采集下方的测试网址获取。
可以看到采集有一个到文章的链接。
3、采集内容规则
我需要采集来显示下图中的数据(catid为列id,可以将数据采集放入对应的列并设置固定值)
关注内容和图片采集,标题和描述与内容相同采集
内容采集:
打开采集的文章的一个页面查看源码(f11右键禁用或者view-source:可以在URL前面加):
选择文章开头的一个位置,截取一段,看是不是ctrl+f下的唯一一段。如果是,可以放在下图1所示的位置,结尾和开头一样。
我截取了内容,不想里面有链接图片进行数据处理,添加--html标签排除--选择确定--确定
还有需要下载页面图片,勾选并填写以下选项
图片采集:
(1)选择范围与内容相同(文章内图)
(2)提取第一张图片的数据处理选项。内容为:
(3)只要aa.jpg,常规过滤
获取内容:aa.jpg
(4)数据库存放有前缀,添加,上传/xxxxx/
找一个页面测试一下,可以看到对应的item都获取到了。
4、发布内容设置,这里以发布到数据库的方式为例,编辑完成后返回这里查看刚刚定义的模块:
5、我需要把图片保存到本地,还要设置保存文件的路径(ftp以后会尝试使用)。
6、保存,查看新创建的任务,右键启动任务,可以看到这里下载了文字和图片,在数据库中可以看到。
如何文章采集( 如何实现wp的自动采集功能?教程分享教程)
采集交流 • 优采云 发表了文章 • 0 个评论 • 151 次浏览 • 2022-01-01 17:25
如何实现wp的自动采集功能?教程分享教程)
WordPress 是一个使用 PHP 语言开发的建站程序平台。现在很多博主都用wp。许多网站制作培训使用wp,尤其是采集站。那个时候wordpress的整体能量非常强大。下面介绍如何实现wp的自动采集功能。
推荐教程:wordpressa教程
1、安装网站采集插件:WP-AutoPost
2、 点击“新建任务”后,输入任务名称即可新建任务。创建新任务后,您可以在任务列表中查看该任务,并且可以对任务进行更多设置。 (这部分不需要修改设置,唯一需要修改的就是采集的时间。)
3、文章 源设置。在这个选项卡下,我们需要设置文章的来源的文章列表URL和文章的具体匹配规则。我们以采集《新浪网》为例,文章的列表网址为,所以在手动指定的文章列表网址中输入网址,如下图:
4、文章 URL 匹配规则。 文章 URL匹配规则的设置很简单。不需要复杂的设置。提供两种匹配模式。您可以使用 URL 通配符匹配或 CSS 选择器进行匹配。通常 URL 通配符匹配更简单,但有时会使用 CSS。选择器更精确。
5、 使用 URL 通配符匹配。通过点击列表URL上的文章,我们可以发现每个文章的URL具有如下结构:所以将URL中变化的数字或字母替换为通配符(*),如: (*)/(*).shtml。重复的 URL 可以使用 301 重定向。
6、 使用 CSS 选择器进行匹配。要使用CSS选择器进行匹配,我们只需要设置文章 URL的CSS选择器即可,查看列表URL源码即可轻松设置,找到文章@的代码> 列表 URL 下的超链接。如下图:
7、 可以看到,文章的超链接A标签在类为“contList”的标签内,所以文章 URL的CSS选择器只需要设置为 .contList a 就可以了,如下图:
8、 设置完成后,如果不知道设置是否正确,可以点击上图中的测试按钮。如果设置正确,将列出列表URL下的所有文章名称和对应的网址,如下图:
9、 其他设置不需要修改。
10、 以上采集方法适用于WordPress多站点功能。
如果这个文章不能解决你的问题,你可以看看这个文章:wordpress自动采集插件的使用方法
以上是wordpress采集的详细内容,详情请关注php中文网站其他相关文章!
免责声明:本文由原创发表于php中文网。转载请注明出处。感谢您的尊重!如果您有任何问题,请联系我们
专题推荐:wordpress 查看全部
如何文章采集(
如何实现wp的自动采集功能?教程分享教程)

WordPress 是一个使用 PHP 语言开发的建站程序平台。现在很多博主都用wp。许多网站制作培训使用wp,尤其是采集站。那个时候wordpress的整体能量非常强大。下面介绍如何实现wp的自动采集功能。
推荐教程:wordpressa教程
1、安装网站采集插件:WP-AutoPost
2、 点击“新建任务”后,输入任务名称即可新建任务。创建新任务后,您可以在任务列表中查看该任务,并且可以对任务进行更多设置。 (这部分不需要修改设置,唯一需要修改的就是采集的时间。)
3、文章 源设置。在这个选项卡下,我们需要设置文章的来源的文章列表URL和文章的具体匹配规则。我们以采集《新浪网》为例,文章的列表网址为,所以在手动指定的文章列表网址中输入网址,如下图:
4、文章 URL 匹配规则。 文章 URL匹配规则的设置很简单。不需要复杂的设置。提供两种匹配模式。您可以使用 URL 通配符匹配或 CSS 选择器进行匹配。通常 URL 通配符匹配更简单,但有时会使用 CSS。选择器更精确。
5、 使用 URL 通配符匹配。通过点击列表URL上的文章,我们可以发现每个文章的URL具有如下结构:所以将URL中变化的数字或字母替换为通配符(*),如: (*)/(*).shtml。重复的 URL 可以使用 301 重定向。
6、 使用 CSS 选择器进行匹配。要使用CSS选择器进行匹配,我们只需要设置文章 URL的CSS选择器即可,查看列表URL源码即可轻松设置,找到文章@的代码> 列表 URL 下的超链接。如下图:

7、 可以看到,文章的超链接A标签在类为“contList”的标签内,所以文章 URL的CSS选择器只需要设置为 .contList a 就可以了,如下图:

8、 设置完成后,如果不知道设置是否正确,可以点击上图中的测试按钮。如果设置正确,将列出列表URL下的所有文章名称和对应的网址,如下图:

9、 其他设置不需要修改。
10、 以上采集方法适用于WordPress多站点功能。
如果这个文章不能解决你的问题,你可以看看这个文章:wordpress自动采集插件的使用方法
以上是wordpress采集的详细内容,详情请关注php中文网站其他相关文章!
免责声明:本文由原创发表于php中文网。转载请注明出处。感谢您的尊重!如果您有任何问题,请联系我们
专题推荐:wordpress
如何文章采集( 所有SEO文章采集或抄袭会被K站惩罚吗?)
采集交流 • 优采云 发表了文章 • 0 个评论 • 99 次浏览 • 2021-12-28 19:09
所有SEO文章采集或抄袭会被K站惩罚吗?)
如果我网站上的文章被抄袭了怎么办?
在实际的网站SEO优化过程中,我们站长经常会遇到自己收录的文章被别人抄袭,然后对方的文章也被收录,排名比自己高(检查对方是不是老网站和(权重更高),在这种情况下,我们都会问:像这样的SEO文章采集
或抄袭会被K站惩罚吗?
一、什么是文章采集
或抄袭?
采集
是指通过一定的采集
程序和规则,将其他网站的文章自动复制到自己的网站。(此处采集
或抄袭必须为原创采集
,不得有任何花招或伪装)
按原样从其他网站采集
文章对您网站的权重有很大影响。虽然百度搜索引擎无法真正保护原创文章,但成都SEO相信搜索引擎算法会越来越智能。提高自己网站的排名是有害无益的。
我们SEOer都知道百度飓风算法是为了打击文章采集
或抄袭。如果我们使用文章采集
器来发布文章,那么我们应该花时间按照算法来处理吗?这不值得损失。
二、 所有SEO文章合集抄袭都会被K站处罚吗?
分享一开始,我们就知道,如果有人采集
或抄袭我们的文章,就会被收录,排名会高于我们自己的。是什么原因?
我们回归搜索引擎工作原理的本质,即满足和解决用户搜索结果的需求。也就是说,无论你的文章来自哪里(采集
文章也可以解决用户需求),而且排版好,逻辑表达清晰,可读性强,是否符合搜索引擎提供的用户拥有有价值的内容?解决用户搜索需求的本质是什么?所以有一个排名。
但是,这种采集
行为是不可行的。试想一下,如果长期给合集内容一个更好的排名,肯定会引起原作者的反感。这种情况持续下去,站长们开始采集
内容或抄袭内容,而不是制作原创文章或伪原创文章。那么可以肯定的是,当用户使用搜索引擎进行查询时,他们解决用户需求的能力会越来越弱。
因此,为了打造更好的互联网内容生态,搜索引擎会不断引入算法来对抗采集
网站,同时也会对原创内容给予一定的排名偏好,鼓励原创作者创作更多优质内容。
三、网站SEO文章被采集
抄袭怎么办
1、临时建议,一般可以礼貌地在对方网站上留言,能不能加个文章链接投票,没有的话百度反馈举报。
2、 长期建议,优化你的网站结构,打开速度等因素提升自身实力,最好晚上更新文章,因为这样可以增加你第一个被收录的概率. (参考原文定义)
3、 网站图片尽量加水印,增加处理和处理别人文章的时间成本。
4、 保持良好的心态。毕竟百度也推出了飓风算法来对抗惩罚。原创文章被采集
抄袭是一个问题。技术一直在改进和优化。谷歌搜索引擎无法完美解决这个问题。最好的策略是做好自己的网站,以便文章可以在几秒钟内被采集
。
内容被抄袭 查看全部
如何文章采集(
所有SEO文章采集或抄袭会被K站惩罚吗?)
如果我网站上的文章被抄袭了怎么办?
在实际的网站SEO优化过程中,我们站长经常会遇到自己收录的文章被别人抄袭,然后对方的文章也被收录,排名比自己高(检查对方是不是老网站和(权重更高),在这种情况下,我们都会问:像这样的SEO文章采集
或抄袭会被K站惩罚吗?
一、什么是文章采集
或抄袭?
采集
是指通过一定的采集
程序和规则,将其他网站的文章自动复制到自己的网站。(此处采集
或抄袭必须为原创采集
,不得有任何花招或伪装)
按原样从其他网站采集
文章对您网站的权重有很大影响。虽然百度搜索引擎无法真正保护原创文章,但成都SEO相信搜索引擎算法会越来越智能。提高自己网站的排名是有害无益的。
我们SEOer都知道百度飓风算法是为了打击文章采集
或抄袭。如果我们使用文章采集
器来发布文章,那么我们应该花时间按照算法来处理吗?这不值得损失。

二、 所有SEO文章合集抄袭都会被K站处罚吗?
分享一开始,我们就知道,如果有人采集
或抄袭我们的文章,就会被收录,排名会高于我们自己的。是什么原因?
我们回归搜索引擎工作原理的本质,即满足和解决用户搜索结果的需求。也就是说,无论你的文章来自哪里(采集
文章也可以解决用户需求),而且排版好,逻辑表达清晰,可读性强,是否符合搜索引擎提供的用户拥有有价值的内容?解决用户搜索需求的本质是什么?所以有一个排名。
但是,这种采集
行为是不可行的。试想一下,如果长期给合集内容一个更好的排名,肯定会引起原作者的反感。这种情况持续下去,站长们开始采集
内容或抄袭内容,而不是制作原创文章或伪原创文章。那么可以肯定的是,当用户使用搜索引擎进行查询时,他们解决用户需求的能力会越来越弱。
因此,为了打造更好的互联网内容生态,搜索引擎会不断引入算法来对抗采集
网站,同时也会对原创内容给予一定的排名偏好,鼓励原创作者创作更多优质内容。
三、网站SEO文章被采集
抄袭怎么办
1、临时建议,一般可以礼貌地在对方网站上留言,能不能加个文章链接投票,没有的话百度反馈举报。
2、 长期建议,优化你的网站结构,打开速度等因素提升自身实力,最好晚上更新文章,因为这样可以增加你第一个被收录的概率. (参考原文定义)
3、 网站图片尽量加水印,增加处理和处理别人文章的时间成本。
4、 保持良好的心态。毕竟百度也推出了飓风算法来对抗惩罚。原创文章被采集
抄袭是一个问题。技术一直在改进和优化。谷歌搜索引擎无法完美解决这个问题。最好的策略是做好自己的网站,以便文章可以在几秒钟内被采集
。
内容被抄袭
如何文章采集(如何可以快速获取收藏夹中的文章?-顶级大学)
采集交流 • 优采云 发表了文章 • 0 个评论 • 109 次浏览 • 2021-12-28 06:04
如何文章采集成为很多同学迫切需要的技能了,但在文章采集以前,我想先简单说下这些技能的效果:--文章提取--文章标题为精华。--高质量原创文章。--顶级大学。说了一大堆,可能对于许多同学不知道重点是什么,这次教大家一个非常实用的小技巧:如何可以快速获取收藏夹中的文章?(可自行百度“快速访问收藏夹”)具体做法:打开文章页,看到的是所有收藏夹中的精华文章,当你采集打开的时候,只要按下【enter】即可显示目标文章。
只需要简单的四步!采集的同时我们要关注原文,复制链接粘贴到新文章的粘贴框,点右上角【确定】即可保存该文章。当你不打开收藏夹再次搜索时,在收藏夹栏的结果中你会看到一串神秘的数字,可以理解为同学们可以任意访问收藏夹中的文章。因此一定要重视收藏夹中的文章,转发给身边的同学,不用谢。
对于公众号而言,采集资源和干货的目的是相通的。目的在于用最低的成本从其他渠道获取你需要的文章内容,也是此处推荐一个第三方的小助手:新榜采集器这个是我在12年开始使用的一个软件,有各种精选的微信文章榜单(有了这个,你就不需要看太多其他百度网站上发布的“干货”),采集的时候有多种方式,有自己爬虫技术,还有一个就是从公众号的文章里面获取,还有其他方式,我就不说了。
你每次找到你需要的文章之后,就可以在自己的公众号里面放上自己想要的关键词,当你选中文章,就可以在推送的文章中点击网址即可下载,其他的渠道也是一样。下面就说一下它的长处:①字节图,这是我喜欢的最大的一个优点。其他方式找到的文章,打开速度慢,我们肯定希望在当前就可以看到我需要的内容,字节图就可以大大提高下载的速度。
②采集功能齐全,除了常规的文章、活动之外,还可以找到被禁止的内容,你也可以不依靠别人的推荐,自己下载,因为有下载限制。具体地址:/#/login使用说明:在公众号任意一篇文章下方放置自己的联系方式,新榜会根据你放置的地址自动检测,自动推送。下载按钮是一样的,还有很多使用小技巧,下载中的小技巧大家慢慢找一下,找到了,别忘了给我点个赞,ok,收工!本人公众号:python大叔,帮助你成为一个更好的程序员。 查看全部
如何文章采集(如何可以快速获取收藏夹中的文章?-顶级大学)
如何文章采集成为很多同学迫切需要的技能了,但在文章采集以前,我想先简单说下这些技能的效果:--文章提取--文章标题为精华。--高质量原创文章。--顶级大学。说了一大堆,可能对于许多同学不知道重点是什么,这次教大家一个非常实用的小技巧:如何可以快速获取收藏夹中的文章?(可自行百度“快速访问收藏夹”)具体做法:打开文章页,看到的是所有收藏夹中的精华文章,当你采集打开的时候,只要按下【enter】即可显示目标文章。
只需要简单的四步!采集的同时我们要关注原文,复制链接粘贴到新文章的粘贴框,点右上角【确定】即可保存该文章。当你不打开收藏夹再次搜索时,在收藏夹栏的结果中你会看到一串神秘的数字,可以理解为同学们可以任意访问收藏夹中的文章。因此一定要重视收藏夹中的文章,转发给身边的同学,不用谢。
对于公众号而言,采集资源和干货的目的是相通的。目的在于用最低的成本从其他渠道获取你需要的文章内容,也是此处推荐一个第三方的小助手:新榜采集器这个是我在12年开始使用的一个软件,有各种精选的微信文章榜单(有了这个,你就不需要看太多其他百度网站上发布的“干货”),采集的时候有多种方式,有自己爬虫技术,还有一个就是从公众号的文章里面获取,还有其他方式,我就不说了。
你每次找到你需要的文章之后,就可以在自己的公众号里面放上自己想要的关键词,当你选中文章,就可以在推送的文章中点击网址即可下载,其他的渠道也是一样。下面就说一下它的长处:①字节图,这是我喜欢的最大的一个优点。其他方式找到的文章,打开速度慢,我们肯定希望在当前就可以看到我需要的内容,字节图就可以大大提高下载的速度。
②采集功能齐全,除了常规的文章、活动之外,还可以找到被禁止的内容,你也可以不依靠别人的推荐,自己下载,因为有下载限制。具体地址:/#/login使用说明:在公众号任意一篇文章下方放置自己的联系方式,新榜会根据你放置的地址自动检测,自动推送。下载按钮是一样的,还有很多使用小技巧,下载中的小技巧大家慢慢找一下,找到了,别忘了给我点个赞,ok,收工!本人公众号:python大叔,帮助你成为一个更好的程序员。
如何文章采集(什么叫文章采集或抄袭会被K站惩罚吗?)
采集交流 • 优采云 发表了文章 • 0 个评论 • 135 次浏览 • 2021-12-27 07:07
在实际的网站SEO优化过程中,我们站长经常会遇到自己收录的文章被别人抄袭,然后对方的文章也被收录,排名比自己高(检查对方是不是老网站和(权重更高),这种情况下大家都会问:这样的SEO文章采集
或者抄袭会被K站处罚吗?
什么是文章采集
或抄袭
采集
是指通过一定的采集
程序和规则,将其他网站的文章自动复制到自己的网站。(此处采集
或抄袭必须为原创采集
,不得有任何花招或伪装)
按原样从其他网站采集
文章对您网站的权重有很大影响。虽然百度搜索引擎无法真正保护原创文章,但成都SEO相信搜索引擎算法会越来越智能。提高自己网站的排名是有害无益的。
我们SEOer都知道百度飓风算法是为了打击文章采集
或抄袭。如果我们使用文章采集
器来发布文章,那么我们应该花时间按照算法来处理吗?这不值得损失。
如果有人采集
或抄袭我们的文章,他们将被收录并排名高于他们自己的文章。是什么原因?
我们回归搜索引擎工作原理的本质,即满足和解决用户搜索结果的需求。也就是说,无论你的文章来自哪里(采集
文章也可以解决用户需求),而且排版好,逻辑表达清晰,可读性强,是否符合搜索引擎为用户提供有价值的内容?解决用户搜索需求的本质是什么?所以有一个排名。
但是,这种采集
行为是不可行的。试想一下,如果长期给合集内容一个更好的排名,肯定会引起原作者的反感。这种情况持续下去,站长们开始采集
内容或抄袭内容,而不是制作原创文章或伪原创文章。那么可以肯定的是,当用户使用搜索引擎进行查询时,他们解决用户需求的能力会越来越弱。
因此,为了打造更好的互联网内容生态,搜索引擎会不断推出算法来打击采集
网站,同时也会对原创内容给予一定的排名偏好,鼓励原创作者创作更多优质内容。
网站SEO文章被采集
抄袭怎么办
1、临时建议,一般可以礼貌地在对方网站上留言,能不能加个文章链接投票,没有的话百度反馈举报。
2、 长期建议,优化你的网站结构,打开速度等因素提升自身实力,最好晚上更新文章,因为这样可以增加你第一个被收录的概率. (参考原文定义)
3、 网站图片尽量加水印,增加处理和处理别人文章的时间成本。
4、 保持良好的心态。毕竟百度也推出了飓风算法来对抗惩罚。原创文章被采集
抄袭是一个问题。技术一直在改进和优化。谷歌搜索引擎无法完美解决这个问题。因此,最好的策略是做好自己的网站,以便文章可以在几秒钟内被采集
。 查看全部
如何文章采集(什么叫文章采集或抄袭会被K站惩罚吗?)
在实际的网站SEO优化过程中,我们站长经常会遇到自己收录的文章被别人抄袭,然后对方的文章也被收录,排名比自己高(检查对方是不是老网站和(权重更高),这种情况下大家都会问:这样的SEO文章采集
或者抄袭会被K站处罚吗?
什么是文章采集
或抄袭
采集
是指通过一定的采集
程序和规则,将其他网站的文章自动复制到自己的网站。(此处采集
或抄袭必须为原创采集
,不得有任何花招或伪装)
按原样从其他网站采集
文章对您网站的权重有很大影响。虽然百度搜索引擎无法真正保护原创文章,但成都SEO相信搜索引擎算法会越来越智能。提高自己网站的排名是有害无益的。
我们SEOer都知道百度飓风算法是为了打击文章采集
或抄袭。如果我们使用文章采集
器来发布文章,那么我们应该花时间按照算法来处理吗?这不值得损失。

如果有人采集
或抄袭我们的文章,他们将被收录并排名高于他们自己的文章。是什么原因?
我们回归搜索引擎工作原理的本质,即满足和解决用户搜索结果的需求。也就是说,无论你的文章来自哪里(采集
文章也可以解决用户需求),而且排版好,逻辑表达清晰,可读性强,是否符合搜索引擎为用户提供有价值的内容?解决用户搜索需求的本质是什么?所以有一个排名。
但是,这种采集
行为是不可行的。试想一下,如果长期给合集内容一个更好的排名,肯定会引起原作者的反感。这种情况持续下去,站长们开始采集
内容或抄袭内容,而不是制作原创文章或伪原创文章。那么可以肯定的是,当用户使用搜索引擎进行查询时,他们解决用户需求的能力会越来越弱。
因此,为了打造更好的互联网内容生态,搜索引擎会不断推出算法来打击采集
网站,同时也会对原创内容给予一定的排名偏好,鼓励原创作者创作更多优质内容。
网站SEO文章被采集
抄袭怎么办
1、临时建议,一般可以礼貌地在对方网站上留言,能不能加个文章链接投票,没有的话百度反馈举报。
2、 长期建议,优化你的网站结构,打开速度等因素提升自身实力,最好晚上更新文章,因为这样可以增加你第一个被收录的概率. (参考原文定义)
3、 网站图片尽量加水印,增加处理和处理别人文章的时间成本。
4、 保持良好的心态。毕竟百度也推出了飓风算法来对抗惩罚。原创文章被采集
抄袭是一个问题。技术一直在改进和优化。谷歌搜索引擎无法完美解决这个问题。因此,最好的策略是做好自己的网站,以便文章可以在几秒钟内被采集
。
如何文章采集(如何文章采集导入推荐pdf与网页(一步一))
采集交流 • 优采云 发表了文章 • 0 个评论 • 131 次浏览 • 2021-12-16 01:02
如何文章采集导入推荐pdf与网页第一步:浏览器访问pdf之家第二步:按照页面要求选择下载或点击下载页面第三步:选择下载推荐适用于课件。
看你需要的课件用什么格式,下载有几种格式:可以上传到idm,网页自动下载,windows也可以,安卓也可以。我个人觉得好用的是这一个:。每当我需要下载课件,就需要在idm中爬来爬去,也还是很麻烦。用这个就很方便,直接在网页,或者pdf格式就可以下载。
zpdf
那种不但页面清晰,还有压缩功能的,
下载《经济法》的pdf版的。
word
百度云
pdf最好。pdf可以加密,
ie浏览器
爱奇艺
视频网站视频会员全集
根据你的课程大纲下载pdf版
在亚马逊上购买的pdf版的内容页到家里的电脑或网络盘想要下载时传到百度云或qq群里
就是下载pdf的啦不过不是电子版,是文本版的很方便推荐(不过今天好像pdf版的不能在知乎上发图片了,复制粘贴都不可以。
各种宝打包app
在网上搜pdf就有啊
美团啊,学校那么大,
百度搜索:pdf这个下载。
xyzpdf下载比较不错,其实onedrive上也有,
,全部免费的下载! 查看全部
如何文章采集(如何文章采集导入推荐pdf与网页(一步一))
如何文章采集导入推荐pdf与网页第一步:浏览器访问pdf之家第二步:按照页面要求选择下载或点击下载页面第三步:选择下载推荐适用于课件。
看你需要的课件用什么格式,下载有几种格式:可以上传到idm,网页自动下载,windows也可以,安卓也可以。我个人觉得好用的是这一个:。每当我需要下载课件,就需要在idm中爬来爬去,也还是很麻烦。用这个就很方便,直接在网页,或者pdf格式就可以下载。
zpdf
那种不但页面清晰,还有压缩功能的,
下载《经济法》的pdf版的。
word
百度云
pdf最好。pdf可以加密,
ie浏览器
爱奇艺
视频网站视频会员全集
根据你的课程大纲下载pdf版
在亚马逊上购买的pdf版的内容页到家里的电脑或网络盘想要下载时传到百度云或qq群里
就是下载pdf的啦不过不是电子版,是文本版的很方便推荐(不过今天好像pdf版的不能在知乎上发图片了,复制粘贴都不可以。
各种宝打包app
在网上搜pdf就有啊
美团啊,学校那么大,
百度搜索:pdf这个下载。
xyzpdf下载比较不错,其实onedrive上也有,
,全部免费的下载!
如何文章采集(如何做推广引流?搜索引擎的算法从何而来?)
采集交流 • 优采云 发表了文章 • 0 个评论 • 93 次浏览 • 2021-12-11 21:03
如何文章采集最主要的两个方面就是账号自身的权重和站点的权重(更多的是找域名以及搭建服务器网站优化,然后合理的过度优化,同时做推广引流)搜索引擎的算法从第一篇文章为什么要用正则表达式,到合理做推广引流?你知道有多少方法可以赚钱吗?今天主要看一下搜索引擎的算法,首先得了解搜索引擎的运行方式搜索引擎是根据网民的特征和搜索数据来制定自己的推荐算法,是否会得到好的结果,主要看你搜索一个词,能不能通过搜索引擎的搜索结果看到你想要的内容,一个词就代表你想要的东西,1万个词就代表了一个东西的搜索量,这就是简单的一些搜索率问题,搜索量越大,搜索词覆盖度越广,就说明搜索后的结果就更准确,消费者,更好的找到自己想要的东西,搜索词覆盖度不同,或者搜索词本身就不精准也会得到不同的结果。
采集的每个文章点击率是不一样的,首先要找到自己要的文章,具体怎么找到自己要的文章呢?个人分享一些手机自媒体下面主要看一下视频可以采集到什么内容。从视频数据入手采集后进行数据分析,这个很简单,是一些采集器都可以搜到视频,通过在线分析,找到属于自己需要的内容。然后再通过聚合搜索,过滤,高亮,标记,主要实现不用下载视频。
现在主要就是图片,文字以及视频,视频可以采集到youtube优酷土豆等很多地方,一个视频或者是文字下面会出现所有有相关内容,再者就是文章,图片,音频等。自媒体新人,小白或者刚做自媒体创业的伙伴可以试试我的经验分享,同时也希望结交更多志同道合的小伙伴,在自媒体创业的道路上少走一些弯路,更多更完整的自媒体实战运营方法请看我的主页,v,欢迎交流!。 查看全部
如何文章采集(如何做推广引流?搜索引擎的算法从何而来?)
如何文章采集最主要的两个方面就是账号自身的权重和站点的权重(更多的是找域名以及搭建服务器网站优化,然后合理的过度优化,同时做推广引流)搜索引擎的算法从第一篇文章为什么要用正则表达式,到合理做推广引流?你知道有多少方法可以赚钱吗?今天主要看一下搜索引擎的算法,首先得了解搜索引擎的运行方式搜索引擎是根据网民的特征和搜索数据来制定自己的推荐算法,是否会得到好的结果,主要看你搜索一个词,能不能通过搜索引擎的搜索结果看到你想要的内容,一个词就代表你想要的东西,1万个词就代表了一个东西的搜索量,这就是简单的一些搜索率问题,搜索量越大,搜索词覆盖度越广,就说明搜索后的结果就更准确,消费者,更好的找到自己想要的东西,搜索词覆盖度不同,或者搜索词本身就不精准也会得到不同的结果。
采集的每个文章点击率是不一样的,首先要找到自己要的文章,具体怎么找到自己要的文章呢?个人分享一些手机自媒体下面主要看一下视频可以采集到什么内容。从视频数据入手采集后进行数据分析,这个很简单,是一些采集器都可以搜到视频,通过在线分析,找到属于自己需要的内容。然后再通过聚合搜索,过滤,高亮,标记,主要实现不用下载视频。
现在主要就是图片,文字以及视频,视频可以采集到youtube优酷土豆等很多地方,一个视频或者是文字下面会出现所有有相关内容,再者就是文章,图片,音频等。自媒体新人,小白或者刚做自媒体创业的伙伴可以试试我的经验分享,同时也希望结交更多志同道合的小伙伴,在自媒体创业的道路上少走一些弯路,更多更完整的自媒体实战运营方法请看我的主页,v,欢迎交流!。
如何文章采集(谁有免费的SEO采集软件啊,急呀!!(组图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 118 次浏览 • 2021-12-10 18:08
写文章,平时需要大量的素材积累,对时事、热点新闻有很好的理解。您需要一个可以采集所有时事和新闻的软件,以节省您在互联网上搜索的时间。有专门的自媒体小助手覆盖热点、百度时事热点、百度今日热点、百度民生热点、百度体育热点、百度娱乐热点、今日等等。爆文资源,你可以快速跟随你的创作主题在你特别自媒体在助手上找到相关材料来完善你的作品。
没有真正实用又免费的SEO采集软件,赶紧的!!
SKYCC专业seo软件可以在网站后台自动捕捉和丰富原创化文章每天添加爱心回答文章网管必加文章很厌恶。SKYCC专业seo软件seo软件通过进入软件的关键词搜索抓取相关内容文章页面,并快速优化重组原创,自动编辑生成布局合理的优化静态页面. 效果显着!
谁有免费的SEO文章采集器啊?紧急!!!最好只有一个功能,即只有采集文章最好。我只是一个小小的网页编辑器,但我还是不明白什么时候有更多的功能。. . . rn有人给我发邮件 181140[emailprotected]谢谢
文章编辑除了采集文章和伪原创,都是批量等,优采云智能文章采集 system 这些功能不会显得繁琐。可以提高网络编辑的效率。
有没有免费的软件或者网页可以查文章的重复率?
没有这样的软件,因为泽的开发没用。现在文章的大部分都是有版权的,你将无法随意搜索和比较。 查看全部
如何文章采集(谁有免费的SEO采集软件啊,急呀!!(组图))
写文章,平时需要大量的素材积累,对时事、热点新闻有很好的理解。您需要一个可以采集所有时事和新闻的软件,以节省您在互联网上搜索的时间。有专门的自媒体小助手覆盖热点、百度时事热点、百度今日热点、百度民生热点、百度体育热点、百度娱乐热点、今日等等。爆文资源,你可以快速跟随你的创作主题在你特别自媒体在助手上找到相关材料来完善你的作品。
没有真正实用又免费的SEO采集软件,赶紧的!!
SKYCC专业seo软件可以在网站后台自动捕捉和丰富原创化文章每天添加爱心回答文章网管必加文章很厌恶。SKYCC专业seo软件seo软件通过进入软件的关键词搜索抓取相关内容文章页面,并快速优化重组原创,自动编辑生成布局合理的优化静态页面. 效果显着!
谁有免费的SEO文章采集器啊?紧急!!!最好只有一个功能,即只有采集文章最好。我只是一个小小的网页编辑器,但我还是不明白什么时候有更多的功能。. . . rn有人给我发邮件 181140[emailprotected]谢谢
文章编辑除了采集文章和伪原创,都是批量等,优采云智能文章采集 system 这些功能不会显得繁琐。可以提高网络编辑的效率。

有没有免费的软件或者网页可以查文章的重复率?
没有这样的软件,因为泽的开发没用。现在文章的大部分都是有版权的,你将无法随意搜索和比较。
如何文章采集(采集站死是死在源头太单一了怎么办?)
采集交流 • 优采云 发表了文章 • 0 个评论 • 124 次浏览 • 2022-01-22 07:00
1、展开采集的来源。很多时候,采集 已经死了,因为来源太单一了。采集时,建议记录对方文档的发布时间2、内容多样化,页面多样化。3、内容格式要干净整洁,图片要清晰(建议500-600字配图)。有能力的话,建议用工具对内容进行编码(包括营销代码、电话号码、各种标签等等,比原来的还要干净)
补充:
可以按照采集行业的项目分类,然后在每个项目中放N张图片,然后标题可以根据关键词对应的项目匹配图片,插入(可以使用公开图片名,也可以每次单独插入不一致的图片名)
4、做好页面内容的相关性匹配,页面调用一定要丰富,才能达到虚伪的效果。具体可以参考部分整形平台的用户体验。5、如果有能力,可以自己出一些结构化数据自己洗稿,达到一定比例原创度6、发表时,建议修改发表时间在采集源发布时间之前7、建议在发布前设置好站点,然后上线。上线后最好不要改变任何网站结构和链接,直到网站没有达到一定程度收录7、@8、发布量级,建议每天发送1W+。当然,最好拥有更多并推动它们。建议每天配合几十次手动更新,效果更佳。9、基本坚持1-3,会有效果,有条件的可以适当配合蜘蛛池,购买外链运营10、没有网站可以100%做, 建议你可以同时多加几个,以保证你的准确率 1 1、 模板尽量大,原创 度数高的模板应该有 as尽可能多的列。 查看全部
如何文章采集(采集站死是死在源头太单一了怎么办?)
1、展开采集的来源。很多时候,采集 已经死了,因为来源太单一了。采集时,建议记录对方文档的发布时间2、内容多样化,页面多样化。3、内容格式要干净整洁,图片要清晰(建议500-600字配图)。有能力的话,建议用工具对内容进行编码(包括营销代码、电话号码、各种标签等等,比原来的还要干净)
补充:
可以按照采集行业的项目分类,然后在每个项目中放N张图片,然后标题可以根据关键词对应的项目匹配图片,插入(可以使用公开图片名,也可以每次单独插入不一致的图片名)
4、做好页面内容的相关性匹配,页面调用一定要丰富,才能达到虚伪的效果。具体可以参考部分整形平台的用户体验。5、如果有能力,可以自己出一些结构化数据自己洗稿,达到一定比例原创度6、发表时,建议修改发表时间在采集源发布时间之前7、建议在发布前设置好站点,然后上线。上线后最好不要改变任何网站结构和链接,直到网站没有达到一定程度收录7、@8、发布量级,建议每天发送1W+。当然,最好拥有更多并推动它们。建议每天配合几十次手动更新,效果更佳。9、基本坚持1-3,会有效果,有条件的可以适当配合蜘蛛池,购买外链运营10、没有网站可以100%做, 建议你可以同时多加几个,以保证你的准确率 1 1、 模板尽量大,原创 度数高的模板应该有 as尽可能多的列。
如何文章采集(如何文章采集趣头条的新闻,文章?(图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 127 次浏览 • 2022-01-16 04:00
如何文章采集趣头条的新闻,文章?趣头条是目前最大的自媒体平台,其文章被采集了几乎所有平台的文章,虽然不想在自媒体平台发文章,但是如果只是为了利用好趣头条,快速的获取一批自媒体平台的文章,那么趣头条的新闻文章采集同样是可以使用的。要知道,趣头条也是当前互联网发展最快的媒体平台,而这个平台最大的优势就是流量大,活跃用户很多,在没有发现可以采集的文章之前,利用好趣头条,不失为一个好的选择。那么具体有哪些采集趣头条新闻的方法呢?。
1、先获取一批趣头条的热门文章
2、找到对应领域的一些高权重平台进行伪原创
3、加入到自己的群qq群自媒体有个很大的特点就是集中了很多高质量的文章资源,发挥他们的价值,打造自己的ip,然后再去推广自己的产品,然后积累流量,积累忠实用户。至于写作,前期可以按照一般自媒体平台发布文章的方式,后期发现某个领域有一定的热度之后,然后再去深入挖掘整个领域的内容。
4、发布到qq空间这个看上去是不是跟趣头条有点像?不是的,它有点不同,只能发布到qq空间。它是:你转发我分享,给我个反馈。
5、把上面获取的新闻稿,发布到自己平台发布,效果会更好一些吧,也可以用其他的方式去发,内容需要的话我会在群里提供这些文章的,自媒体新闻资源里。大家可以在群里交流分享,找到合适自己领域的资源,在实际操作中才会得心应手。 查看全部
如何文章采集(如何文章采集趣头条的新闻,文章?(图))
如何文章采集趣头条的新闻,文章?趣头条是目前最大的自媒体平台,其文章被采集了几乎所有平台的文章,虽然不想在自媒体平台发文章,但是如果只是为了利用好趣头条,快速的获取一批自媒体平台的文章,那么趣头条的新闻文章采集同样是可以使用的。要知道,趣头条也是当前互联网发展最快的媒体平台,而这个平台最大的优势就是流量大,活跃用户很多,在没有发现可以采集的文章之前,利用好趣头条,不失为一个好的选择。那么具体有哪些采集趣头条新闻的方法呢?。
1、先获取一批趣头条的热门文章
2、找到对应领域的一些高权重平台进行伪原创
3、加入到自己的群qq群自媒体有个很大的特点就是集中了很多高质量的文章资源,发挥他们的价值,打造自己的ip,然后再去推广自己的产品,然后积累流量,积累忠实用户。至于写作,前期可以按照一般自媒体平台发布文章的方式,后期发现某个领域有一定的热度之后,然后再去深入挖掘整个领域的内容。
4、发布到qq空间这个看上去是不是跟趣头条有点像?不是的,它有点不同,只能发布到qq空间。它是:你转发我分享,给我个反馈。
5、把上面获取的新闻稿,发布到自己平台发布,效果会更好一些吧,也可以用其他的方式去发,内容需要的话我会在群里提供这些文章的,自媒体新闻资源里。大家可以在群里交流分享,找到合适自己领域的资源,在实际操作中才会得心应手。
如何文章采集(如何文章采集第一步看文章是否有落地的地方)
采集交流 • 优采云 发表了文章 • 0 个评论 • 103 次浏览 • 2022-01-15 15:02
如何文章采集第一步看文章是否有落地的地方,方法有以下几个:第一:百度搜索方法一:就在百度搜索引擎上搜索即可看到文章第二:手机百度直接搜索文章就可以看到很多第三:手机搜索文章第四:百度搜索“魔力网”然后发布文章这是最直接的看到文章的渠道第五:手机百度同样搜索文章就可以看到第六:百度搜索文章我们可以看到还有很多比如:一点资讯、今日头条等还有很多类似文章素材第七:百度搜索文章一样可以看到一篇最新的文章我们在做公众号的朋友时间精力不足时候就可以考虑做搬运,你看一篇优质的文章我可以一键搬运到其他人的文章里看看他的文章做到了什么点我可以批量抓取到第八:百度搜索文章然后我们在点击去我们想看的文章可以一键批量的抓取第九:百度搜索文章还可以一键搬运同样一篇文章其他人都是需要先审核过的而我们可以直接推送到我们的公众号推送的就是你公众号的文章再有就是随时随地都可以看到你喜欢的文章,我们通过公众号自动回复关键词来给你的公众号提醒,不用任何干预让你的公众号时刻都可以有新鲜事推送给你。
去百度搜索文章的相关信息,一般都会有资源的。
文章一般分为几种类型,一种就是时政类的,第二就是社科类的,第三是人物类的,第四是技术类的,可以百度下。 查看全部
如何文章采集(如何文章采集第一步看文章是否有落地的地方)
如何文章采集第一步看文章是否有落地的地方,方法有以下几个:第一:百度搜索方法一:就在百度搜索引擎上搜索即可看到文章第二:手机百度直接搜索文章就可以看到很多第三:手机搜索文章第四:百度搜索“魔力网”然后发布文章这是最直接的看到文章的渠道第五:手机百度同样搜索文章就可以看到第六:百度搜索文章我们可以看到还有很多比如:一点资讯、今日头条等还有很多类似文章素材第七:百度搜索文章一样可以看到一篇最新的文章我们在做公众号的朋友时间精力不足时候就可以考虑做搬运,你看一篇优质的文章我可以一键搬运到其他人的文章里看看他的文章做到了什么点我可以批量抓取到第八:百度搜索文章然后我们在点击去我们想看的文章可以一键批量的抓取第九:百度搜索文章还可以一键搬运同样一篇文章其他人都是需要先审核过的而我们可以直接推送到我们的公众号推送的就是你公众号的文章再有就是随时随地都可以看到你喜欢的文章,我们通过公众号自动回复关键词来给你的公众号提醒,不用任何干预让你的公众号时刻都可以有新鲜事推送给你。
去百度搜索文章的相关信息,一般都会有资源的。
文章一般分为几种类型,一种就是时政类的,第二就是社科类的,第三是人物类的,第四是技术类的,可以百度下。
如何文章采集(我就从自己写博客的角度出发吧(组图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 95 次浏览 • 2022-01-15 10:09
我先声明一下。我不是记者,充其量只是一个科技博主。
被请硬着头皮说几句。
记者和博主之间仍然存在许多差异。在我看来,我觉得记者别无选择。你几乎没有权利选择你报告的内容,所以往往采集材料和信息的方法和工具也会有所不同。不一样。
让我从我自己的博客角度开始。
首先,我可以选择自己的领域,也可以选择我想写的主题。所以我知道我在寻找什么信息。
作为个人博主,我没有更多的资源,我唯一能用的就是互联网。但至于从网络上搜索,那是不得已而为之,因为它太宽泛,很难确定我需要什么。
我的习惯是——积累。(这不太适合媒体记者在某些时候报道)
因为不需要跟风快速上报,可以积累一些,做文章。
来自你平日浏览的网页,来自问答社区,来自与人微薄的交流。他们都是他们熟悉和经常去的地方。我基本上是通过两个最简单的工具, 1. 稍后阅读 2. 浏览器书签中的一个文件夹
这让我可以方便地对我需要的任何信息进行分类和保存,并且我可以同时拥有几个我感兴趣的主题。
我还没有找到一个很好的工具来为每个需要保存的 文章 做笔记。我还会用SImplenoteapp做一些分类笔记,方便整理我的一些想法。(不知道大家有没有什么可以在Chrome Mac上轻松保存书签和做笔记的工具推荐)
我的博客里有一段关于:
/关于
有时我觉得一个话题很有趣,但又怕它不完整或不够清晰。反而要花很多时间去搜索资料,最后我都不想写了。
所以,我决定只根据我看到和听到的线索来写下我的想法和意见。
记得余华曾经说过,一缕光穿过门缝,你就可以走出一道光,终于站在阳光下。(大意)
所以,除了做评论,我很少在文章的观点表达上追求全面性,我总是从一个点开始。渐渐地,自然的思维就会得到扩展。有了以前的数据积累。可以写。
至于为什么我说网络搜索是我最后的选择,那是因为它是一种快捷方式。
很多时候,我们需要真正了解一件事(或尽力而为),而不是急于搜索和采集信息,然后将其拼凑起来。或许媒体记者不会同意,但今天上午新浪科技确实对Facebook IPO文件中关于马克股权的数字进行了曲解,并在更正后才进行了修订。Twitter上的许多人也转发了被误解的数字。
Google 可以帮助您获取所需的所有信息。Google 是一个强大的工具,但您必须能够准确地确定您要搜索的内容。你需要的能力是能够辨别你从谷歌得到的信息是否可信,是否具有参考价值。
因此,如何进行数据采集以及使用什么工具进行数据采集的一个重要的基本点是您能否准确判断您要采集的点,以及采集到的信息是否有价值。
啊对。我自己通常有一个小笔记本,还有手机自带的备忘录录音程序。一些点将随时记录。乔布斯说,你怎么知道有一天你能把这些点联系起来。
补充:
关于采集数据的方法和工具,一个月前我也开始另辟蹊径:
记笔记并通过博客的链接列表(可链接 文章)进行组织。
/2012/01/the-sign-and-linked-list.html(参考这里) 查看全部
如何文章采集(我就从自己写博客的角度出发吧(组图))
我先声明一下。我不是记者,充其量只是一个科技博主。
被请硬着头皮说几句。
记者和博主之间仍然存在许多差异。在我看来,我觉得记者别无选择。你几乎没有权利选择你报告的内容,所以往往采集材料和信息的方法和工具也会有所不同。不一样。
让我从我自己的博客角度开始。
首先,我可以选择自己的领域,也可以选择我想写的主题。所以我知道我在寻找什么信息。
作为个人博主,我没有更多的资源,我唯一能用的就是互联网。但至于从网络上搜索,那是不得已而为之,因为它太宽泛,很难确定我需要什么。
我的习惯是——积累。(这不太适合媒体记者在某些时候报道)
因为不需要跟风快速上报,可以积累一些,做文章。
来自你平日浏览的网页,来自问答社区,来自与人微薄的交流。他们都是他们熟悉和经常去的地方。我基本上是通过两个最简单的工具, 1. 稍后阅读 2. 浏览器书签中的一个文件夹
这让我可以方便地对我需要的任何信息进行分类和保存,并且我可以同时拥有几个我感兴趣的主题。
我还没有找到一个很好的工具来为每个需要保存的 文章 做笔记。我还会用SImplenoteapp做一些分类笔记,方便整理我的一些想法。(不知道大家有没有什么可以在Chrome Mac上轻松保存书签和做笔记的工具推荐)
我的博客里有一段关于:
/关于
有时我觉得一个话题很有趣,但又怕它不完整或不够清晰。反而要花很多时间去搜索资料,最后我都不想写了。
所以,我决定只根据我看到和听到的线索来写下我的想法和意见。
记得余华曾经说过,一缕光穿过门缝,你就可以走出一道光,终于站在阳光下。(大意)
所以,除了做评论,我很少在文章的观点表达上追求全面性,我总是从一个点开始。渐渐地,自然的思维就会得到扩展。有了以前的数据积累。可以写。
至于为什么我说网络搜索是我最后的选择,那是因为它是一种快捷方式。
很多时候,我们需要真正了解一件事(或尽力而为),而不是急于搜索和采集信息,然后将其拼凑起来。或许媒体记者不会同意,但今天上午新浪科技确实对Facebook IPO文件中关于马克股权的数字进行了曲解,并在更正后才进行了修订。Twitter上的许多人也转发了被误解的数字。
Google 可以帮助您获取所需的所有信息。Google 是一个强大的工具,但您必须能够准确地确定您要搜索的内容。你需要的能力是能够辨别你从谷歌得到的信息是否可信,是否具有参考价值。
因此,如何进行数据采集以及使用什么工具进行数据采集的一个重要的基本点是您能否准确判断您要采集的点,以及采集到的信息是否有价值。
啊对。我自己通常有一个小笔记本,还有手机自带的备忘录录音程序。一些点将随时记录。乔布斯说,你怎么知道有一天你能把这些点联系起来。
补充:
关于采集数据的方法和工具,一个月前我也开始另辟蹊径:
记笔记并通过博客的链接列表(可链接 文章)进行组织。
/2012/01/the-sign-and-linked-list.html(参考这里)
如何文章采集(iLogtail本地配置模式部署(ForKafkaFlusher)阿里开源了可观测数据采集器iLogtail)
采集交流 • 优采云 发表了文章 • 0 个评论 • 188 次浏览 • 2022-01-14 01:01
iLogtail本地配置方式部署(适用于Kafka Flusher)
阿里已正式开源可观察数据采集器iLogtail。作为阿里巴巴内部可观察数据采集的基础设施,iLogtail承载了阿里巴巴集团的采集工作和蚂蚁的日志、监控、跟踪、事件等可观察数据。
iLogtail作为阿里云SLS的采集Agent,一般与SLS配合使用,采集配置一般通过SLS控制台或API进行。那么是否可以不依赖 SLS 使用 iLogtail 呢?
本文将详细介绍如何在不依赖SLS控制台的情况下,以本地配置方式部署iLogtail,以及采集json格式的日志文件到非SLS(如Kafka等)。
场景
采集
/root/bin/input_data/json.log(单行日志json格式),将日志采集写入本地部署的kafka。
前提条件
kafka本地安装完成,创建一个名为logtail-flusher-kafka的topic。有关部署详细信息,请参阅链接。
安装 ilogtail
下载最新的 ilogtail 版本并解压。
解压tar包
$ tar zxvf logtail-linux64.tar.gz
查看目录结构
$ ll logtail-linux64
drwxr-xr-x 3 500 500 4096 箱
drwxr-xr-x 184 500 500 12288 配置
-rw-r--r-- 1 500 500 597 自述文件
drwxr-xr-x 2 500 500 4096 资源
进入bin目录
$ cd logtail-linux64/bin
$ ll
-rwxr-xr-x 1 500 500 10052072 ilogtail_1.0.28 # ilogtail 可执行文件
-rwxr-xr-x 1 500 500 4191 ilogtaild
-rwxr-xr-x 1 500 500 5976 libPluginAdapter.so
-rw-r--r-- 1 500 500 89560656 libPluginBase.so
-rwxr-xr-x 1 500 500 2333024 LogtailInsight
采集配置
配置格式
json格式采集到本地kafa的日志文件配置格式:
"metrics": {
"{config_name1}" : {
"enable": true,
"category": "file",
"log_type": "json_log",
"log_path": "/root/bin/input_data",
"file_pattern": "json.log",
"plugin": {
"processors": [
{
"detail": {
"SplitSep": "",
"SplitKey": "content"
},
"type": "processor_split_log_string"
},
{
"detail": {
"ExpandConnector": "",
"ExpandDepth": 1,
"SourceKey": "content",
"KeepSource": false
},
"type": "processor_json"
}],
"flushers":[
{
"type": "flusher_kafka",
"detail": {
"Brokers":["localhost:9092"],
"Topic": "logtail-flusher-kafka"
}
}]
},
"version": 1
},
"{config_name2}" : {
...
}
}
详细格式说明:
文件最外面的key是metrics,里面是每个具体的采集配置。
采集配置的key就是配置名称,修改后的名称在这个文件中必须是唯一的。建议命名:“##1.0##采集配置名称”。
采集配置值是具体的采集参数配置,关键参数及其含义如下:
参数名称类型说明
enable bool 配置是否生效。为false时,配置不生效。
category string File采集场景的值为“file”。
log_type 字符串日志类型。在 json采集 场景中,值为 json_log。
log_path 字符串 采集路径。
file_pattern 字符串 采集 文件。
插件对象的具体采集配置是一个json对象。具体配置请参考以下说明
version int 配置版本号,建议每次配置修改后加1
plugin字段是一个json对象,针对具体的输入源和处理方式进行配置:
配置项类型说明
处理器对象数组处理模式配置,详见链接。processor_json:将原创日志展开为json格式。
flushers object array flusher_stdout:采集到stdout,一般用于调试场景;flusher_kafka:采集 到 kafka。
完整的配置示例
进入bin目录,创建sys_conf_dir文件夹和ilogtail_config.json文件。
1. 创建 sys_conf_dir
$ mkdir sys_conf_dir
2. 创建 ilogtail_config.json 并完成配置。
logtail_sys_conf_dir 的值为:$pwd/sys_conf_dir/
config_server_address 的值是固定的并且保持不变。
$密码
/root/bin/logtail-linux64/bin
$ 猫 ilogtail_config.json
{
"logtail_sys_conf_dir": "/root/bin/logtail-linux64/bin/sys_conf_dir/",
"config_server_address" : "http://logtail.cn-zhangjiakou. ... ot%3B
3. 此时的目录结构
$ ll
-rwxr-xr-x 1 500 500 ilogtail_1.0.28
-rw-r--r-- 1 根 ilogtail_config.json
-rwxr-xr-x 1 500 500 ilogtaild
-rwxr-xr-x 1 500 500 libPluginAdapter.so
-rw-r--r-- 1 500 500 libPluginBase.so
-rwxr-xr-x 1 500 500
drwxr-xr-x 2 根 sys_conf_dir
在 sys_conf_dir 下创建 采集 配置文件 user_local_config.json。
注意:在json_log场景下,user_local_config.json只需要修改采集路径相关参数log_path和file_pattern,其他参数不变。
$ cat sys_conf_dir/user_local_config.json
{
"metrics":
{
"##1.0##kafka_output_test":
{
"category": "file",
"log_type": "json_log",
"log_path": "/root/bin/input_data",
"file_pattern": "json.log",
"create_time": 1631018645,
"defaultEndpoint": "",
"delay_alarm_bytes": 0,
"delay_skip_bytes": 0,
"discard_none_utf8": false,
"discard_unmatch": false,
"docker_exclude_env":
{},
"docker_exclude_label":
{},
"docker_file": false,
"docker_include_env":
{},
"docker_include_label":
{},
"enable": true,
"enable_tag": false,
"file_encoding": "utf8",
"filter_keys":
[],
"filter_regs":
[],
"group_topic": "",
"plugin":
{
"processors":
[
{
"detail": {
"SplitSep": "",
"SplitKey": "content"
},
"type": "processor_split_log_string"
},
{
"detail":
{
"ExpandConnector": "",
"ExpandDepth": 1,
"SourceKey": "content",
"KeepSource": false
},
"type": "processor_json"
}
],
"flushers":
[
{
"type": "flusher_kafka",
"detail":
{
"Brokers":
[
"localhost:9092"
],
"Topic": "logtail-flusher-kafka"
}
}
]
},
"local_storage": true,
"log_tz": "",
"max_depth": 10,
"max_send_rate": -1,
"merge_type": "topic",
"preserve": true,
"preserve_depth": 1,
"priority": 0,
"raw_log": false,
"aliuid": "",
"region": "",
"project_name": "",
"send_rate_expire": 0,
"sensitive_keys":
[],
"shard_hash_key":
[],
"tail_existed": false,
"time_key": "",
"timeformat": "",
"topic_format": "none",
"tz_adjust": false,
"version": 1,
"advanced":
{
"force_multiconfig": false,
"tail_size_kb": 1024
}
}
}
启动 ilogtail
在终端模式下运行
$ ./ilogtail_1.0.28 --ilogtail_daemon_flag=false
您也可以选择以守护程序模式运行
$ ./ilogtail_1.0.28
$ ps -ef|grep logtail
根 48453 1 ./ilogtail_1.0.28
根 48454 48453 ./ilogtail_1.0.28
采集情景模拟
过去的
json格式的数据在/root/bin/input_data/json.log中构造。代码如下:
$ echo'{“seq”:“1”,“action”:“kkkk”,“extend1”:“”,“extend2”:“”,“type”:“1”}'>> json.log
$ echo '{"seq": "2", "action": "kkkk", "extend1": "", "extend2": "", "type": "1"}' >> json.log
消费主题是logtail-flusher-kafka中的数据。
$
bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic logtail-flusher-kafka
{"时间":1640862641,"内容":[{"密钥":"__tag__:__path__","值":"
/root/bin/input_data/json.log"},{"Key":"seq","Value":"1"},{"Key":"action","Value":"kkkk"},{ "Key":"extend1","Value":""},{"Key":"extend2","Value":""},{"Key":"type","Value":"1"} ]}
{"时间":1640862646,"内容":[{"键":"__tag__:__path__","值":"
/root/bin/input_data/json.log"},{"Key":"seq","Value":"2"},{"Key":"action","Value":"kkkk"},{ "Key":"extend1","Value":""},{"Key":"extend2","Value":""},{"Key":"type","Value":"1"} ]}
本地调试
为了快速方便地验证配置是否正确,可以将采集接收到的日志打印到标准输出,完成快速功能验证。
替换本地的采集,配置plugin-flushers为flusher_stdout,在终端模式下运行$ ./ilogtail_1.0.28 --ilogtail_daemon_flag=false,可以调用采集将日志打印到标准输出以进行快速本地调试。
{
"type": "flusher_stdout",
"detail":
{
"OnlyStdout": true
}
K8S环境日志采集使用SLS前准备创建日志配置,进入日志服务控制台(),点击上一节已经创建的项目。
进入Project查询页面后,点击左侧边栏的“放大镜”图标,展开logstore管理界面,点击“+”,弹出右侧边栏“Create Logstore”。按照提示进行配置,输入日志库名称,单击“确定”。
日志库创建成功后,取消数据访问向导。单击左侧边栏中的“Cube”按钮,在弹出的“Resources”叠加层中选择“Machine Group”。在展开的“机器组”的左栏中,点击右上角的“方形”图标,在弹出的层中选择“创建机器组”。
在“创建机器组”侧边栏中,按照提示进行配置,“机器组ID”选择“用户自定义ID”,“名称”、“机器组主题”、“机器组主题”建议保持不变用户自定义标识”。“自定义ID”是最重要的配置之一。本教程使用“my-k8s-group”,安装ilogtail时会再次使用。“点击”确认保存机器组。
再次点击左侧边栏的“放大镜”图标,展开logstore管理界面,点击第2步创建的logstore的“向下展开”图标,弹出“配置Logstore”菜单。点击“+”按钮进行“logtail配置”。
在弹出的“快速访问数据”对话框中,搜索“kube”,选择“Kubernetes-file”。在弹出的“提示”框中,单机“继续”。
在“Kubernetes 文件”配置界面中,直接选择“使用现有机器组”。
跳转到“机器组配置”界面,选择第4步创建的机器组,点击“>”按钮将其添加到“应用机器组”中,然后点击“下一步”。
在ilogtail配置中,只修改“配置名称”和“日志路径”两个必填项,点击“下一步”确认。
完成索引配置。此步骤不修改任何选项,只需点击下一步即可完成配置。
至此,整个日志配置完成。请保持页面打开。
安装ilogtail登录控制K8S集群的中心计算机。编辑 ilogtail 的 ConfigMap YAML。
$ vim alicloud-log-config.yaml
将以下内容粘贴到 Vim 中并保存(注意,修改注释中指示的字段,第 7-11 行)。
apiVersion: v1
kind: ConfigMap
metadata:
name: alibaba-log-configuration
namespace: kube-system
data:
log-project: "my-project" #修改为实际project名称
log-endpoint: "cn-wulanchabu.log.aliyuncs.com" #修改为实际endpoint
log-machine-group: "my-k8s-group" #可以自定义机器组名称
log-config-path: "/etc/ilogtail/conf/cn-wulanchabu_internet/ilogtail_config.json" #修改cn-wulanchabu为实际project地域
log-ali-uid: "*********" #修改为阿里云UID
access-key-id: "" #本教程用不上
access-key-secret: "" #本教程用不上
cpu-core-limit: "2"
mem-limit: "1024"
max-bytes-per-sec: "20971520"
send-requests-concurrency: "20"
计算 alicloud-log-config.yaml 的 sha256 哈希,编辑 ilogtail 的 DaemonSet YAML。
$ sha256sum alicloud-log-config.yaml
f370df37916797aa0b82d709ae6bfc5f46f709660e1fd28bb49c22da91da1214 alicloud-log-config.yaml
$ vim logtail-daemonset.yaml
将以下内容粘贴到 Vim 中并保存(注意,修改注释中指出的字段,21、25 行)。 查看全部
如何文章采集(iLogtail本地配置模式部署(ForKafkaFlusher)阿里开源了可观测数据采集器iLogtail)
iLogtail本地配置方式部署(适用于Kafka Flusher)
阿里已正式开源可观察数据采集器iLogtail。作为阿里巴巴内部可观察数据采集的基础设施,iLogtail承载了阿里巴巴集团的采集工作和蚂蚁的日志、监控、跟踪、事件等可观察数据。
iLogtail作为阿里云SLS的采集Agent,一般与SLS配合使用,采集配置一般通过SLS控制台或API进行。那么是否可以不依赖 SLS 使用 iLogtail 呢?
本文将详细介绍如何在不依赖SLS控制台的情况下,以本地配置方式部署iLogtail,以及采集json格式的日志文件到非SLS(如Kafka等)。
场景
采集
/root/bin/input_data/json.log(单行日志json格式),将日志采集写入本地部署的kafka。
前提条件
kafka本地安装完成,创建一个名为logtail-flusher-kafka的topic。有关部署详细信息,请参阅链接。
安装 ilogtail
下载最新的 ilogtail 版本并解压。
解压tar包
$ tar zxvf logtail-linux64.tar.gz
查看目录结构
$ ll logtail-linux64
drwxr-xr-x 3 500 500 4096 箱
drwxr-xr-x 184 500 500 12288 配置
-rw-r--r-- 1 500 500 597 自述文件
drwxr-xr-x 2 500 500 4096 资源
进入bin目录
$ cd logtail-linux64/bin
$ ll
-rwxr-xr-x 1 500 500 10052072 ilogtail_1.0.28 # ilogtail 可执行文件
-rwxr-xr-x 1 500 500 4191 ilogtaild
-rwxr-xr-x 1 500 500 5976 libPluginAdapter.so
-rw-r--r-- 1 500 500 89560656 libPluginBase.so
-rwxr-xr-x 1 500 500 2333024 LogtailInsight
采集配置
配置格式
json格式采集到本地kafa的日志文件配置格式:
"metrics": {
"{config_name1}" : {
"enable": true,
"category": "file",
"log_type": "json_log",
"log_path": "/root/bin/input_data",
"file_pattern": "json.log",
"plugin": {
"processors": [
{
"detail": {
"SplitSep": "",
"SplitKey": "content"
},
"type": "processor_split_log_string"
},
{
"detail": {
"ExpandConnector": "",
"ExpandDepth": 1,
"SourceKey": "content",
"KeepSource": false
},
"type": "processor_json"
}],
"flushers":[
{
"type": "flusher_kafka",
"detail": {
"Brokers":["localhost:9092"],
"Topic": "logtail-flusher-kafka"
}
}]
},
"version": 1
},
"{config_name2}" : {
...
}
}
详细格式说明:
文件最外面的key是metrics,里面是每个具体的采集配置。
采集配置的key就是配置名称,修改后的名称在这个文件中必须是唯一的。建议命名:“##1.0##采集配置名称”。
采集配置值是具体的采集参数配置,关键参数及其含义如下:
参数名称类型说明
enable bool 配置是否生效。为false时,配置不生效。
category string File采集场景的值为“file”。
log_type 字符串日志类型。在 json采集 场景中,值为 json_log。
log_path 字符串 采集路径。
file_pattern 字符串 采集 文件。
插件对象的具体采集配置是一个json对象。具体配置请参考以下说明
version int 配置版本号,建议每次配置修改后加1
plugin字段是一个json对象,针对具体的输入源和处理方式进行配置:
配置项类型说明
处理器对象数组处理模式配置,详见链接。processor_json:将原创日志展开为json格式。
flushers object array flusher_stdout:采集到stdout,一般用于调试场景;flusher_kafka:采集 到 kafka。
完整的配置示例
进入bin目录,创建sys_conf_dir文件夹和ilogtail_config.json文件。
1. 创建 sys_conf_dir
$ mkdir sys_conf_dir
2. 创建 ilogtail_config.json 并完成配置。
logtail_sys_conf_dir 的值为:$pwd/sys_conf_dir/
config_server_address 的值是固定的并且保持不变。
$密码
/root/bin/logtail-linux64/bin
$ 猫 ilogtail_config.json
{
"logtail_sys_conf_dir": "/root/bin/logtail-linux64/bin/sys_conf_dir/",
"config_server_address" : "http://logtail.cn-zhangjiakou. ... ot%3B
3. 此时的目录结构
$ ll
-rwxr-xr-x 1 500 500 ilogtail_1.0.28
-rw-r--r-- 1 根 ilogtail_config.json
-rwxr-xr-x 1 500 500 ilogtaild
-rwxr-xr-x 1 500 500 libPluginAdapter.so
-rw-r--r-- 1 500 500 libPluginBase.so
-rwxr-xr-x 1 500 500
drwxr-xr-x 2 根 sys_conf_dir
在 sys_conf_dir 下创建 采集 配置文件 user_local_config.json。
注意:在json_log场景下,user_local_config.json只需要修改采集路径相关参数log_path和file_pattern,其他参数不变。
$ cat sys_conf_dir/user_local_config.json
{
"metrics":
{
"##1.0##kafka_output_test":
{
"category": "file",
"log_type": "json_log",
"log_path": "/root/bin/input_data",
"file_pattern": "json.log",
"create_time": 1631018645,
"defaultEndpoint": "",
"delay_alarm_bytes": 0,
"delay_skip_bytes": 0,
"discard_none_utf8": false,
"discard_unmatch": false,
"docker_exclude_env":
{},
"docker_exclude_label":
{},
"docker_file": false,
"docker_include_env":
{},
"docker_include_label":
{},
"enable": true,
"enable_tag": false,
"file_encoding": "utf8",
"filter_keys":
[],
"filter_regs":
[],
"group_topic": "",
"plugin":
{
"processors":
[
{
"detail": {
"SplitSep": "",
"SplitKey": "content"
},
"type": "processor_split_log_string"
},
{
"detail":
{
"ExpandConnector": "",
"ExpandDepth": 1,
"SourceKey": "content",
"KeepSource": false
},
"type": "processor_json"
}
],
"flushers":
[
{
"type": "flusher_kafka",
"detail":
{
"Brokers":
[
"localhost:9092"
],
"Topic": "logtail-flusher-kafka"
}
}
]
},
"local_storage": true,
"log_tz": "",
"max_depth": 10,
"max_send_rate": -1,
"merge_type": "topic",
"preserve": true,
"preserve_depth": 1,
"priority": 0,
"raw_log": false,
"aliuid": "",
"region": "",
"project_name": "",
"send_rate_expire": 0,
"sensitive_keys":
[],
"shard_hash_key":
[],
"tail_existed": false,
"time_key": "",
"timeformat": "",
"topic_format": "none",
"tz_adjust": false,
"version": 1,
"advanced":
{
"force_multiconfig": false,
"tail_size_kb": 1024
}
}
}
启动 ilogtail
在终端模式下运行
$ ./ilogtail_1.0.28 --ilogtail_daemon_flag=false
您也可以选择以守护程序模式运行
$ ./ilogtail_1.0.28
$ ps -ef|grep logtail
根 48453 1 ./ilogtail_1.0.28
根 48454 48453 ./ilogtail_1.0.28
采集情景模拟
过去的
json格式的数据在/root/bin/input_data/json.log中构造。代码如下:
$ echo'{“seq”:“1”,“action”:“kkkk”,“extend1”:“”,“extend2”:“”,“type”:“1”}'>> json.log
$ echo '{"seq": "2", "action": "kkkk", "extend1": "", "extend2": "", "type": "1"}' >> json.log
消费主题是logtail-flusher-kafka中的数据。
$
bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic logtail-flusher-kafka
{"时间":1640862641,"内容":[{"密钥":"__tag__:__path__","值":"
/root/bin/input_data/json.log"},{"Key":"seq","Value":"1"},{"Key":"action","Value":"kkkk"},{ "Key":"extend1","Value":""},{"Key":"extend2","Value":""},{"Key":"type","Value":"1"} ]}
{"时间":1640862646,"内容":[{"键":"__tag__:__path__","值":"
/root/bin/input_data/json.log"},{"Key":"seq","Value":"2"},{"Key":"action","Value":"kkkk"},{ "Key":"extend1","Value":""},{"Key":"extend2","Value":""},{"Key":"type","Value":"1"} ]}
本地调试
为了快速方便地验证配置是否正确,可以将采集接收到的日志打印到标准输出,完成快速功能验证。
替换本地的采集,配置plugin-flushers为flusher_stdout,在终端模式下运行$ ./ilogtail_1.0.28 --ilogtail_daemon_flag=false,可以调用采集将日志打印到标准输出以进行快速本地调试。
{
"type": "flusher_stdout",
"detail":
{
"OnlyStdout": true
}
K8S环境日志采集使用SLS前准备创建日志配置,进入日志服务控制台(),点击上一节已经创建的项目。
进入Project查询页面后,点击左侧边栏的“放大镜”图标,展开logstore管理界面,点击“+”,弹出右侧边栏“Create Logstore”。按照提示进行配置,输入日志库名称,单击“确定”。
日志库创建成功后,取消数据访问向导。单击左侧边栏中的“Cube”按钮,在弹出的“Resources”叠加层中选择“Machine Group”。在展开的“机器组”的左栏中,点击右上角的“方形”图标,在弹出的层中选择“创建机器组”。
在“创建机器组”侧边栏中,按照提示进行配置,“机器组ID”选择“用户自定义ID”,“名称”、“机器组主题”、“机器组主题”建议保持不变用户自定义标识”。“自定义ID”是最重要的配置之一。本教程使用“my-k8s-group”,安装ilogtail时会再次使用。“点击”确认保存机器组。
再次点击左侧边栏的“放大镜”图标,展开logstore管理界面,点击第2步创建的logstore的“向下展开”图标,弹出“配置Logstore”菜单。点击“+”按钮进行“logtail配置”。
在弹出的“快速访问数据”对话框中,搜索“kube”,选择“Kubernetes-file”。在弹出的“提示”框中,单机“继续”。
在“Kubernetes 文件”配置界面中,直接选择“使用现有机器组”。
跳转到“机器组配置”界面,选择第4步创建的机器组,点击“>”按钮将其添加到“应用机器组”中,然后点击“下一步”。
在ilogtail配置中,只修改“配置名称”和“日志路径”两个必填项,点击“下一步”确认。
完成索引配置。此步骤不修改任何选项,只需点击下一步即可完成配置。
至此,整个日志配置完成。请保持页面打开。
安装ilogtail登录控制K8S集群的中心计算机。编辑 ilogtail 的 ConfigMap YAML。
$ vim alicloud-log-config.yaml
将以下内容粘贴到 Vim 中并保存(注意,修改注释中指示的字段,第 7-11 行)。
apiVersion: v1
kind: ConfigMap
metadata:
name: alibaba-log-configuration
namespace: kube-system
data:
log-project: "my-project" #修改为实际project名称
log-endpoint: "cn-wulanchabu.log.aliyuncs.com" #修改为实际endpoint
log-machine-group: "my-k8s-group" #可以自定义机器组名称
log-config-path: "/etc/ilogtail/conf/cn-wulanchabu_internet/ilogtail_config.json" #修改cn-wulanchabu为实际project地域
log-ali-uid: "*********" #修改为阿里云UID
access-key-id: "" #本教程用不上
access-key-secret: "" #本教程用不上
cpu-core-limit: "2"
mem-limit: "1024"
max-bytes-per-sec: "20971520"
send-requests-concurrency: "20"
计算 alicloud-log-config.yaml 的 sha256 哈希,编辑 ilogtail 的 DaemonSet YAML。
$ sha256sum alicloud-log-config.yaml
f370df37916797aa0b82d709ae6bfc5f46f709660e1fd28bb49c22da91da1214 alicloud-log-config.yaml
$ vim logtail-daemonset.yaml
将以下内容粘贴到 Vim 中并保存(注意,修改注释中指出的字段,21、25 行)。
如何文章采集(做好网站过度优化主要表现在以下方面方面?)
采集交流 • 优采云 发表了文章 • 0 个评论 • 365 次浏览 • 2022-01-14 00:21
做好网站优化,会让网站更多关键词在首页排名,从而提高网站的曝光率,被更多潜在客户搜索,特别是现在广告网站当比特数减少时优化就更重要了。很多初学者在优化过程中容易出现这种情况。一有SEO技术,他们就会将其用于网站,导致网站过度优化并被搜索引擎惩罚,那么如何避免呢?网站过度优化怎么办?
网站过度优化主要表现在以下几个方面
1、网站文章更新采集
网站后期一个重要的维护,保持网站的活跃度,就是更新原创的有价值的文章。部分初学者在线学习,文章采集方法,使用文章采集工具,采集同行业文章,直接在网上发布,或者使用某个伪原创工具,使用工具自动修改文章,每天发几十篇,更新目的是为了更新文章,其实这样做不仅无助于优化,反而会带来反效果,新站会延迟审核期,老站降低权重和排名,一定要围绕用户需求写一些原创有价值的文章,并更新每天两片文章。
2、关键词恶意堆叠
做网站优化就是做关键词优化,提高关键词在搜索引擎首页的排名,无论用户搜索什么类型的关键词,他们可以看到公司信息,他们可以有更多的点击机会,所以很多初学者为了增加关键词的密度恶意堆放关键词。在更新文章的时候,他们也放了很多文章关键词。@关键词,在文章元标签设置中,各种堆叠关键词,在图片ALT标签中,也是在堆叠关键词,关键词严重堆叠,导致被搜索引擎惩罚。一定要按照正常的优化方法,一个文章不能超过3个关键词,关键词必须和当前页面相关
3、锚文本链接过多
做好锚文本链接有利于提高网站的权重,提高关键词的排名。初学者链接锚文本时,只要关键词出现在文章中,加个链接,甚至还有很多无用的锚文本链接,明显是优化过度,和锚文本链接堆积在一起. 一个文章最好不要超过3个锚文本链接,关键词布局到哪个页面,关键词锚文本链接到哪个页面,添加关键词的时候,一定要不限制关键词的布局,有价值的关键词不用布局,也是可以链接的,从系统上讲,每个页面都用锚文本链接,形成网页结构,引导蜘蛛深度抓取。
4、外链搭建没有规则
做好外链建设,不仅可以引导蜘蛛抓取网站的内容,还可以推广企业品牌,获取潜在客户。因此,很多公司都想尽办法使用各种外链海量分发工具和各种刷机。如果你在作弊,搜索引擎并不愚蠢。系统会自动判断为垃圾外链。设置不会转到 收录 这个外部链接。说真的,一定要控制数量,不要使用工具搭建外链。我们必须采取循序渐进的方法来提高外部链接的质量。
网站过度优化的危险
过度使用网站优化技术,违反搜索引擎优化规则,利用作弊手段优化和欺骗搜索引擎。这种方法很容易被搜索引擎检索到。>惩罚基于过度优化的程序,过度优化严重影响用户体验,用户体验差的网站跳出率高,用户不会深度浏览,自然搜索引擎不会放这样的网站@ >网站 最高排名。 查看全部
如何文章采集(做好网站过度优化主要表现在以下方面方面?)
做好网站优化,会让网站更多关键词在首页排名,从而提高网站的曝光率,被更多潜在客户搜索,特别是现在广告网站当比特数减少时优化就更重要了。很多初学者在优化过程中容易出现这种情况。一有SEO技术,他们就会将其用于网站,导致网站过度优化并被搜索引擎惩罚,那么如何避免呢?网站过度优化怎么办?
网站过度优化主要表现在以下几个方面
1、网站文章更新采集
网站后期一个重要的维护,保持网站的活跃度,就是更新原创的有价值的文章。部分初学者在线学习,文章采集方法,使用文章采集工具,采集同行业文章,直接在网上发布,或者使用某个伪原创工具,使用工具自动修改文章,每天发几十篇,更新目的是为了更新文章,其实这样做不仅无助于优化,反而会带来反效果,新站会延迟审核期,老站降低权重和排名,一定要围绕用户需求写一些原创有价值的文章,并更新每天两片文章。
2、关键词恶意堆叠
做网站优化就是做关键词优化,提高关键词在搜索引擎首页的排名,无论用户搜索什么类型的关键词,他们可以看到公司信息,他们可以有更多的点击机会,所以很多初学者为了增加关键词的密度恶意堆放关键词。在更新文章的时候,他们也放了很多文章关键词。@关键词,在文章元标签设置中,各种堆叠关键词,在图片ALT标签中,也是在堆叠关键词,关键词严重堆叠,导致被搜索引擎惩罚。一定要按照正常的优化方法,一个文章不能超过3个关键词,关键词必须和当前页面相关
3、锚文本链接过多
做好锚文本链接有利于提高网站的权重,提高关键词的排名。初学者链接锚文本时,只要关键词出现在文章中,加个链接,甚至还有很多无用的锚文本链接,明显是优化过度,和锚文本链接堆积在一起. 一个文章最好不要超过3个锚文本链接,关键词布局到哪个页面,关键词锚文本链接到哪个页面,添加关键词的时候,一定要不限制关键词的布局,有价值的关键词不用布局,也是可以链接的,从系统上讲,每个页面都用锚文本链接,形成网页结构,引导蜘蛛深度抓取。
4、外链搭建没有规则
做好外链建设,不仅可以引导蜘蛛抓取网站的内容,还可以推广企业品牌,获取潜在客户。因此,很多公司都想尽办法使用各种外链海量分发工具和各种刷机。如果你在作弊,搜索引擎并不愚蠢。系统会自动判断为垃圾外链。设置不会转到 收录 这个外部链接。说真的,一定要控制数量,不要使用工具搭建外链。我们必须采取循序渐进的方法来提高外部链接的质量。
网站过度优化的危险
过度使用网站优化技术,违反搜索引擎优化规则,利用作弊手段优化和欺骗搜索引擎。这种方法很容易被搜索引擎检索到。>惩罚基于过度优化的程序,过度优化严重影响用户体验,用户体验差的网站跳出率高,用户不会深度浏览,自然搜索引擎不会放这样的网站@ >网站 最高排名。
如何文章采集(云名片基于号簿助手后台强大的云存储功能支持)
采集交流 • 优采云 发表了文章 • 0 个评论 • 122 次浏览 • 2022-01-10 19:23
本文目录:
介绍
本文摘要
这篇文章的标题
文字内容
结束语
介绍:
您最近可能也在寻找有关或此类内容的相关内容,对吧?为了整理这个内容,特意和公司周围的朋友同事交流了半天……我也在网上查了很多资料,总结了一些关于文章采集@的资料>(采集@的作用是什么>文章),希望能传授一下《文章采集@>的相关知识点(采集的作用是什么) @>文章在云名片里?)”对大家有帮助,一起来学习吧!
本文摘要:
“云名片由号码簿助手后台强大的云存储功能支持,比传统名片可以承载更多的个人信息,方便用户在商务场合交换个人名片。主要应用有如下文章采集@>:1、将云名片的网址以二维码的形式打印在传统名片上,其他人可以扫描二维码查看并保存名片;个人信息更新时,无需主动通知,好友再次扫描更新即可查看更新2、通过微信、QQ、短信等工具快速与好友交换名片信息; 3、在朋友圈、微博、微电等客服222是……
本文标题:文章采集@>(云名片采集@>文章的作用是什么)正文内容:
基于通讯录助手后台强大的云存储功能,云名片可以比传统名片承载更多的个人信息,方便用户在商务场合交换个人名片。主要应用如下文章采集@>:
1、将云名片的网址以二维码的形式打印在传统名片上,其他人可以扫描二维码查看并保存名片;个人信息更新时,无需主动通知,好友再次扫描即可查看更新的名片;
2、通过微信、QQ、短信等工具与好友快速交换名片信息;
3、在朋友圈、微博、微信等环境传播个人信息。客服222为您解答。宽带服务可以自助,操作简单。此外,还可办理工单查询、ITV维修、宽带申请、密码服务,方便快捷。更多功能请关注中国电信贵州客服。
结束语:
以上是关于文章采集@>的一些相关内容(云名片的采集@>文章是做什么的)以及围绕这类内容的一些相关知识点,我希望通过介绍,对大家有帮助!未来,我们将更新更多相关资讯内容,关注我们,了解每日最新热点新闻,关注社交动态! 查看全部
如何文章采集(云名片基于号簿助手后台强大的云存储功能支持)
本文目录:
介绍
本文摘要
这篇文章的标题
文字内容
结束语
介绍:
您最近可能也在寻找有关或此类内容的相关内容,对吧?为了整理这个内容,特意和公司周围的朋友同事交流了半天……我也在网上查了很多资料,总结了一些关于文章采集@的资料>(采集@的作用是什么>文章),希望能传授一下《文章采集@>的相关知识点(采集的作用是什么) @>文章在云名片里?)”对大家有帮助,一起来学习吧!
本文摘要:
“云名片由号码簿助手后台强大的云存储功能支持,比传统名片可以承载更多的个人信息,方便用户在商务场合交换个人名片。主要应用有如下文章采集@>:1、将云名片的网址以二维码的形式打印在传统名片上,其他人可以扫描二维码查看并保存名片;个人信息更新时,无需主动通知,好友再次扫描更新即可查看更新2、通过微信、QQ、短信等工具快速与好友交换名片信息; 3、在朋友圈、微博、微电等客服222是……
本文标题:文章采集@>(云名片采集@>文章的作用是什么)正文内容:
基于通讯录助手后台强大的云存储功能,云名片可以比传统名片承载更多的个人信息,方便用户在商务场合交换个人名片。主要应用如下文章采集@>:
1、将云名片的网址以二维码的形式打印在传统名片上,其他人可以扫描二维码查看并保存名片;个人信息更新时,无需主动通知,好友再次扫描即可查看更新的名片;
2、通过微信、QQ、短信等工具与好友快速交换名片信息;
3、在朋友圈、微博、微信等环境传播个人信息。客服222为您解答。宽带服务可以自助,操作简单。此外,还可办理工单查询、ITV维修、宽带申请、密码服务,方便快捷。更多功能请关注中国电信贵州客服。
结束语:
以上是关于文章采集@>的一些相关内容(云名片的采集@>文章是做什么的)以及围绕这类内容的一些相关知识点,我希望通过介绍,对大家有帮助!未来,我们将更新更多相关资讯内容,关注我们,了解每日最新热点新闻,关注社交动态!
如何文章采集(如何加快网站快速搜索?如何有效提高百度收录或排名?)
采集交流 • 优采云 发表了文章 • 0 个评论 • 106 次浏览 • 2022-01-09 19:01
如何文章采集?如何加快网站快速搜索?如何有效提高百度收录或排名?如何提高百度检索效率?对于百度新闻,百度健康,百度糯米等重大的关键词,对于信息的获取方面是非常便捷。甚至百度提供了一个方便的搜索词库,上百度搜索你就知道了,有些网站会把热点事件做集中的采集,效率极高。但是其他关键词就不是这样的,要达到高效的检索,需要收集到各种高质量的关键词库,对于新手并没有太大的难度。
中国好搜无疑是目前最专业的收集百度搜索关键词库,包含百度搜索关键词库和百度健康搜索关键词库,是已经在百度排名靠前的站长和搜索人员必备的工具。为什么要注册百度好搜?第一个原因是百度好搜可以获取到权重最高的百度权重和百度健康搜索权重第二个原因是百度好搜提供了很多无任何推广操作的站长根据自己网站情况收集推广词,收集推广词最重要的是性价比高,如果推广词对于一个新站来说肯定不适合,每个搜索高质量关键词的站长都是希望可以去购买更多收入来推广自己的站长网站,但是百度好搜提供了搜索高质量词时是免费的,不需要购买推广。
第三个原因是百度好搜为绝大多数站长提供免费的关键词采集服务,甚至同时提供了关键词更新服务。前不久很多站长在联系我,咨询我是否可以免费给他提供百度好搜关键词收集。我开始是拒绝的,因为我知道这个流程其实没有那么简单,先咨询他是否确定需要采集关键词,然后给他免费提供百度好搜关键词收集服务,如果免费的话,想要获取的权重更高的关键词会更多,也就要更换更多的推广方式才行。
我认真的跟他交流了我所做的关键词的情况以及我的推广方式,其实这个也是对于一个站长来说非常有用的,他的服务很好,只是搜索词包含了很多高质量的关键词。他问我,如果自己没有一个百度好搜关键词库怎么办,我说你可以去百度中国好搜的网站,他说没有去百度中国好搜,百度好搜里面的词还是一些高质量的关键词,他还是想要去采集,这里我建议大家利用百度好搜,前期不要着急采集,一点一点的去采集。
采集第一步,先把这些高质量的关键词和行业词整理一下,百度好搜整理了一个excel表格,放在网站上,然后在百度好搜搜索栏搜索行业词,把相关性高的关键词收集过来。然后每天整理一点,2周左右我认为搜索词质量已经高到一定的水平了,整理1000个词都是没有问题的。根据我自己的百度好搜搜索词库的使用情况,有一些长尾关键词已经没有了,有的只有很少的一部分,其他的大部分都是一些非常精准的长尾关键词。很多站长都有这样的疑问,我自己每天都在收集这么多词,然后呢,效果。 查看全部
如何文章采集(如何加快网站快速搜索?如何有效提高百度收录或排名?)
如何文章采集?如何加快网站快速搜索?如何有效提高百度收录或排名?如何提高百度检索效率?对于百度新闻,百度健康,百度糯米等重大的关键词,对于信息的获取方面是非常便捷。甚至百度提供了一个方便的搜索词库,上百度搜索你就知道了,有些网站会把热点事件做集中的采集,效率极高。但是其他关键词就不是这样的,要达到高效的检索,需要收集到各种高质量的关键词库,对于新手并没有太大的难度。
中国好搜无疑是目前最专业的收集百度搜索关键词库,包含百度搜索关键词库和百度健康搜索关键词库,是已经在百度排名靠前的站长和搜索人员必备的工具。为什么要注册百度好搜?第一个原因是百度好搜可以获取到权重最高的百度权重和百度健康搜索权重第二个原因是百度好搜提供了很多无任何推广操作的站长根据自己网站情况收集推广词,收集推广词最重要的是性价比高,如果推广词对于一个新站来说肯定不适合,每个搜索高质量关键词的站长都是希望可以去购买更多收入来推广自己的站长网站,但是百度好搜提供了搜索高质量词时是免费的,不需要购买推广。
第三个原因是百度好搜为绝大多数站长提供免费的关键词采集服务,甚至同时提供了关键词更新服务。前不久很多站长在联系我,咨询我是否可以免费给他提供百度好搜关键词收集。我开始是拒绝的,因为我知道这个流程其实没有那么简单,先咨询他是否确定需要采集关键词,然后给他免费提供百度好搜关键词收集服务,如果免费的话,想要获取的权重更高的关键词会更多,也就要更换更多的推广方式才行。
我认真的跟他交流了我所做的关键词的情况以及我的推广方式,其实这个也是对于一个站长来说非常有用的,他的服务很好,只是搜索词包含了很多高质量的关键词。他问我,如果自己没有一个百度好搜关键词库怎么办,我说你可以去百度中国好搜的网站,他说没有去百度中国好搜,百度好搜里面的词还是一些高质量的关键词,他还是想要去采集,这里我建议大家利用百度好搜,前期不要着急采集,一点一点的去采集。
采集第一步,先把这些高质量的关键词和行业词整理一下,百度好搜整理了一个excel表格,放在网站上,然后在百度好搜搜索栏搜索行业词,把相关性高的关键词收集过来。然后每天整理一点,2周左右我认为搜索词质量已经高到一定的水平了,整理1000个词都是没有问题的。根据我自己的百度好搜搜索词库的使用情况,有一些长尾关键词已经没有了,有的只有很少的一部分,其他的大部分都是一些非常精准的长尾关键词。很多站长都有这样的疑问,我自己每天都在收集这么多词,然后呢,效果。
如何文章采集(小喵教你一招,可以轻松采集微信公众号文章)
采集交流 • 优采云 发表了文章 • 0 个评论 • 133 次浏览 • 2022-01-09 02:10
如今,微信公众号已经成为一种主流的线上线下微信互动营销方式。微信公众号上发布了很多优秀的文章,但是微信是腾讯所有的,不能直接发布在自己的网站上或者保存在数据库中,所以如果你想分享优质的微信文章执行采集搬运到自己的网站还是比较麻烦。小淼教你一招,轻松采集微信公众号文章,还可以自动发布!
1Data采集:NO.1 通过百度搜索相关网站,注册或登录,进入爬虫市场。
2NO.2搜索关键词:微信公众号。点击免费获取!
3NO.3进入采集爬虫后,点击爬虫设置。
4 首先,由于搜狗微信搜索有图片防盗链功能,需要在功能设置中开启图片云托管。这是非常重要的。记住,否则你的图片将不会显示,到时候你会很尴尬……
5 然后进行自定义设置,可以同时采集多个微信公众号文章,最多500个!特别提示:输入微信ID而不是微信名!
6什么!分不清哪个是微信名,哪个是微信ID,哦,好像有点像。好吧,那我告诉你。进入搜狗微信,输入你想要的微信公众号,点击搜索公众号。
7 压力又来了!进入微信!设置好后记得保存。然后进入概览页面,启动爬虫,等待爬取结果。保存:
8开始:
9 爬取结果:
10数据发布:数据采集完成后,可以发布数据吗?答案当然是!NO.1 发布数据只有两步:安装发布插件->使用发布接口。您可以选择发布到数据库或 网站。
11如果你不知道怎么安装插件,那我就告诉你,进入文档中心-使用文档-数据发布-安装插件,查看文档,按照文档提示,一步一步来一步,它会好的。
12 插件安装成功,接下来我们新建一个发布项吧!这里有很多,随便挑一个你喜欢的。
13选择发布界面后,填写您要发布的网站的地址和密码。同时系统会自动检测插件是否安装正确。
对于 14 字段映射,系统一般会默认选择一个好的,但如果您认为有什么需要调整的,您可以修改它。
15 内容替换 这是一个可选选项,可以填写也可以不填写。
16 完成设置后,即可发布数据。NO.2 在爬取结果页面,可以看到采集爬虫根据你设置的信息爬取的所有内容。发布的结果可以自动发布,也可以手动发布。
17 自动发布:开启自动发布后,爬取的数据会自动发布到网站或者数据库上,感觉快要起飞了!
18 当然,您也可以选择手动发布,发布时可以选择单个或多个发布。在发布之前,您还可以预览看看这个 文章 是关于什么的。
19 如果觉得木有问题,可以公布数据。
20 发布成功后,可以点击链接查看。
21 嗯~是的,用优采云云爬虫采集文章微信公众号就是这么简单!赶紧收下这份充满爱心的攻略吧,我不会告诉常人的。 查看全部
如何文章采集(小喵教你一招,可以轻松采集微信公众号文章)
如今,微信公众号已经成为一种主流的线上线下微信互动营销方式。微信公众号上发布了很多优秀的文章,但是微信是腾讯所有的,不能直接发布在自己的网站上或者保存在数据库中,所以如果你想分享优质的微信文章执行采集搬运到自己的网站还是比较麻烦。小淼教你一招,轻松采集微信公众号文章,还可以自动发布!
1Data采集:NO.1 通过百度搜索相关网站,注册或登录,进入爬虫市场。
2NO.2搜索关键词:微信公众号。点击免费获取!
3NO.3进入采集爬虫后,点击爬虫设置。
4 首先,由于搜狗微信搜索有图片防盗链功能,需要在功能设置中开启图片云托管。这是非常重要的。记住,否则你的图片将不会显示,到时候你会很尴尬……
5 然后进行自定义设置,可以同时采集多个微信公众号文章,最多500个!特别提示:输入微信ID而不是微信名!
6什么!分不清哪个是微信名,哪个是微信ID,哦,好像有点像。好吧,那我告诉你。进入搜狗微信,输入你想要的微信公众号,点击搜索公众号。
7 压力又来了!进入微信!设置好后记得保存。然后进入概览页面,启动爬虫,等待爬取结果。保存:
8开始:
9 爬取结果:
10数据发布:数据采集完成后,可以发布数据吗?答案当然是!NO.1 发布数据只有两步:安装发布插件->使用发布接口。您可以选择发布到数据库或 网站。
11如果你不知道怎么安装插件,那我就告诉你,进入文档中心-使用文档-数据发布-安装插件,查看文档,按照文档提示,一步一步来一步,它会好的。
12 插件安装成功,接下来我们新建一个发布项吧!这里有很多,随便挑一个你喜欢的。
13选择发布界面后,填写您要发布的网站的地址和密码。同时系统会自动检测插件是否安装正确。
对于 14 字段映射,系统一般会默认选择一个好的,但如果您认为有什么需要调整的,您可以修改它。
15 内容替换 这是一个可选选项,可以填写也可以不填写。
16 完成设置后,即可发布数据。NO.2 在爬取结果页面,可以看到采集爬虫根据你设置的信息爬取的所有内容。发布的结果可以自动发布,也可以手动发布。
17 自动发布:开启自动发布后,爬取的数据会自动发布到网站或者数据库上,感觉快要起飞了!
18 当然,您也可以选择手动发布,发布时可以选择单个或多个发布。在发布之前,您还可以预览看看这个 文章 是关于什么的。
19 如果觉得木有问题,可以公布数据。
20 发布成功后,可以点击链接查看。
21 嗯~是的,用优采云云爬虫采集文章微信公众号就是这么简单!赶紧收下这份充满爱心的攻略吧,我不会告诉常人的。
如何文章采集(什么是采集站顾名思义就是)
采集交流 • 优采云 发表了文章 • 0 个评论 • 149 次浏览 • 2022-01-07 05:17
什么是采集站,顾名思义就是填充大量的内容数据网站以获得更多的流量,不管任何网站都会遇到问题,内容填充
只要有足够的数据,百度就能得到更多的收录和呈现。对于一个大站。它必须是稳定的数据流。比如你的网站想每天获得几万的流量,就需要大量的关键词支持,大量的关键词需要大量的内容!对于个人站长和小团队来说,每天更新数百篇文章文章,无疑是傻瓜式。这么多人在这个时候选择采集!
有很多朋友问过我这样的问题吗?为什么别人的网站无论是排名还是流量都这么好?域名历史的建立仅用了一年多的时间。但是收录的数据达到了20W。倒计时每天创作547条内容,是怎么做到的?我现在应该怎么办?
以上是小编创建的一个采集站。目前日流量达到1W以上,后台文章音量60W,持续稳定。下面小编就给大家介绍一下采集站的做法。
1、 网站 程序。随着互联网的飞速发展,网上的源代码越来越多,免费的也很多。很多人用这些源码,重复的程度就不用我说了。相信免费的东西也有很多人在用
2、 首先,在选择域名时,应该选择旧域名。为什么选择旧域名?因为老域名已经过了搜索引擎的观察期。为什么旧域名更容易成为收录?因为老域名在某些方面做了优化,域名越老,网站的排名就越好。
3、选择好的采集源是重中之重,比如屏蔽百度蜘蛛的新闻源。
4、 采集 会在后面进行处理,比如重写或者伪原创
5、 每次更新后的内容都要主动推送到搜索引擎
这就是为什么很多站长拼命在他们的网站中添加网站内容,我们采集其他内容,首先,从搜索引擎来看,这是重复的内容。我们的内容相对于 采集 的质量得分肯定下降了很多。但是我们可以通过做一些其他的方面来弥补,这需要大家在程序和域名方面进行改进。
如果你看完这篇文章文章,如果你喜欢这篇文章文章,不妨采集或者发送给需要的朋友同事!您的一举一动都将成为编辑源源不断的动力! 查看全部
如何文章采集(什么是采集站顾名思义就是)
什么是采集站,顾名思义就是填充大量的内容数据网站以获得更多的流量,不管任何网站都会遇到问题,内容填充
只要有足够的数据,百度就能得到更多的收录和呈现。对于一个大站。它必须是稳定的数据流。比如你的网站想每天获得几万的流量,就需要大量的关键词支持,大量的关键词需要大量的内容!对于个人站长和小团队来说,每天更新数百篇文章文章,无疑是傻瓜式。这么多人在这个时候选择采集!
有很多朋友问过我这样的问题吗?为什么别人的网站无论是排名还是流量都这么好?域名历史的建立仅用了一年多的时间。但是收录的数据达到了20W。倒计时每天创作547条内容,是怎么做到的?我现在应该怎么办?
以上是小编创建的一个采集站。目前日流量达到1W以上,后台文章音量60W,持续稳定。下面小编就给大家介绍一下采集站的做法。
1、 网站 程序。随着互联网的飞速发展,网上的源代码越来越多,免费的也很多。很多人用这些源码,重复的程度就不用我说了。相信免费的东西也有很多人在用
2、 首先,在选择域名时,应该选择旧域名。为什么选择旧域名?因为老域名已经过了搜索引擎的观察期。为什么旧域名更容易成为收录?因为老域名在某些方面做了优化,域名越老,网站的排名就越好。
3、选择好的采集源是重中之重,比如屏蔽百度蜘蛛的新闻源。
4、 采集 会在后面进行处理,比如重写或者伪原创
5、 每次更新后的内容都要主动推送到搜索引擎
这就是为什么很多站长拼命在他们的网站中添加网站内容,我们采集其他内容,首先,从搜索引擎来看,这是重复的内容。我们的内容相对于 采集 的质量得分肯定下降了很多。但是我们可以通过做一些其他的方面来弥补,这需要大家在程序和域名方面进行改进。
如果你看完这篇文章文章,如果你喜欢这篇文章文章,不妨采集或者发送给需要的朋友同事!您的一举一动都将成为编辑源源不断的动力!
如何文章采集(免费Wordpress发布接口怎么使用?我不懂代码多久可以学会啊? )
采集交流 • 优采云 发表了文章 • 0 个评论 • 105 次浏览 • 2022-01-06 16:19
)
Q:如何使用免费的WordPress发布界面?如果我不理解代码,我可以学习多长时间?
答:直接下载使用!无需理解代码!1分钟学会!
Q:每天可以发布多少文章?支持哪些格式?
答:每天可发布数百万篇文章,支持任何格式!
Q:不同域名的Wordpress网站也能发布吗?
回答:是的!创建一个新任务只需要大约1分钟!
Q:我可以设置每天发布多少篇文章吗?可以在指定版块发表吗?
回答:是的!一键设置,可以根据不同栏目发布不同的文章
问:除了wordpress网站发布,Zblogcms程序还能发布吗?
回答:是的!支持主要的 cms 版本
问:太棒了!
答:是的,还有更多功能。
例如:采集→伪原创→发布(推送)
采集:只要设置关键词,就可以根据关键词采集文章同时创建几十个或几百个采集任务,即可设置过滤器关键词只与网站主题文章相关的采集,并且软件自带关键词自动生成工具,只需要进入核心关键词自动采集所有行业相关关键词,自动过滤与行业无关的词。
伪原创:伪原创 采用AI智能大脑。集成NLG技术、RNN模型、百度人工智能算法严格符合百度、搜狗、360、谷歌等大型搜索引擎算法收录规则可在线通过伪原创,本地< @伪原创或者API接口,使用伪原创会更好的被搜索引擎收录收录。
@网站模板原创度)-选择标题是否与插入的关键词一致(增加文章与话题行业的相关性)搜索引擎推送(自动推送到搜索引擎发布后文章增加网站收录)!同时也支持除wordpresscms之外的所有主流cms网站和站群采集伪原创发布推送。
以上是小编使用wordpress工具制作的一批高流量网站,所有内容均与主题相关!网站从未发生过降级!看完这篇文章,如果觉得不错,不妨采集起来,或者送给需要的朋友同事!您的一举一动都将成为编辑源源不断的动力!
查看全部
如何文章采集(免费Wordpress发布接口怎么使用?我不懂代码多久可以学会啊?
)
Q:如何使用免费的WordPress发布界面?如果我不理解代码,我可以学习多长时间?
答:直接下载使用!无需理解代码!1分钟学会!
Q:每天可以发布多少文章?支持哪些格式?
答:每天可发布数百万篇文章,支持任何格式!
Q:不同域名的Wordpress网站也能发布吗?
回答:是的!创建一个新任务只需要大约1分钟!
Q:我可以设置每天发布多少篇文章吗?可以在指定版块发表吗?
回答:是的!一键设置,可以根据不同栏目发布不同的文章
问:除了wordpress网站发布,Zblogcms程序还能发布吗?
回答:是的!支持主要的 cms 版本
问:太棒了!
答:是的,还有更多功能。
例如:采集→伪原创→发布(推送)
采集:只要设置关键词,就可以根据关键词采集文章同时创建几十个或几百个采集任务,即可设置过滤器关键词只与网站主题文章相关的采集,并且软件自带关键词自动生成工具,只需要进入核心关键词自动采集所有行业相关关键词,自动过滤与行业无关的词。
伪原创:伪原创 采用AI智能大脑。集成NLG技术、RNN模型、百度人工智能算法严格符合百度、搜狗、360、谷歌等大型搜索引擎算法收录规则可在线通过伪原创,本地< @伪原创或者API接口,使用伪原创会更好的被搜索引擎收录收录。
@网站模板原创度)-选择标题是否与插入的关键词一致(增加文章与话题行业的相关性)搜索引擎推送(自动推送到搜索引擎发布后文章增加网站收录)!同时也支持除wordpresscms之外的所有主流cms网站和站群采集伪原创发布推送。
以上是小编使用wordpress工具制作的一批高流量网站,所有内容均与主题相关!网站从未发生过降级!看完这篇文章,如果觉得不错,不妨采集起来,或者送给需要的朋友同事!您的一举一动都将成为编辑源源不断的动力!
如何文章采集(采集站死是死在源头太单一了怎么办? )
采集交流 • 优采云 发表了文章 • 0 个评论 • 131 次浏览 • 2022-01-06 16:18
)
1、扩展采集的来源。在很多情况下,采集 已经死了,因为来源太单一。采集时,建议记录对方文档的发布时间
2、 内容多样性,页面多样性。
3、 内容格式要干净整洁,图片要清晰(建议配图500-600字)。如果有能力,建议使用工具对内容进行编码(包括营销代码、电话号码、各种标签等)等等,比原来干净多了)
补充:
可以按照采集所属行业的项目进行分类,然后在每个项目中放N张图片,然后标题根据关键词对应的项目匹配图片,插入(可以使用公共图片名称,也可以每次插入的图片名称不一致)
4、 做好页面内容相关性的匹配,页面调用一定要丰富,才能达到假真假假的效果。详情请参考部分整形医疗平台的用户体验。
5、如果有能力,可以自己制作一些结构化的数据来洗稿子,达到一定比例的原创度
6、发布时,建议在源发布时间之前修改自己的发布时间采集
7、 建议发布前先搭建好站点,然后再上线。上线后,在网站还没有达到一定程度时,最好不要更改任何网站结构和链接收录
8、 发帖级别,建议每天发帖1W+。当然,最好是拥有更多并全部推送。建议每天配合几十次手动更新,达到更好的效果。
9、 基本上坚持1-3,就会有效果。有条件的可以适当配合蜘蛛池,购买外链。
10、 没有网站是 100% 完成的。建议您可以同时上传多个,以确保您的准确性
11、 模板试图成为战争的模板。原创 度数越高的模板,尽可能多的列。
查看全部
如何文章采集(采集站死是死在源头太单一了怎么办?
)
1、扩展采集的来源。在很多情况下,采集 已经死了,因为来源太单一。采集时,建议记录对方文档的发布时间
2、 内容多样性,页面多样性。
3、 内容格式要干净整洁,图片要清晰(建议配图500-600字)。如果有能力,建议使用工具对内容进行编码(包括营销代码、电话号码、各种标签等)等等,比原来干净多了)
补充:
可以按照采集所属行业的项目进行分类,然后在每个项目中放N张图片,然后标题根据关键词对应的项目匹配图片,插入(可以使用公共图片名称,也可以每次插入的图片名称不一致)
4、 做好页面内容相关性的匹配,页面调用一定要丰富,才能达到假真假假的效果。详情请参考部分整形医疗平台的用户体验。
5、如果有能力,可以自己制作一些结构化的数据来洗稿子,达到一定比例的原创度
6、发布时,建议在源发布时间之前修改自己的发布时间采集
7、 建议发布前先搭建好站点,然后再上线。上线后,在网站还没有达到一定程度时,最好不要更改任何网站结构和链接收录
8、 发帖级别,建议每天发帖1W+。当然,最好是拥有更多并全部推送。建议每天配合几十次手动更新,达到更好的效果。
9、 基本上坚持1-3,就会有效果。有条件的可以适当配合蜘蛛池,购买外链。
10、 没有网站是 100% 完成的。建议您可以同时上传多个,以确保您的准确性
11、 模板试图成为战争的模板。原创 度数越高的模板,尽可能多的列。
如何文章采集(采集某一个指定页面的文章包括(标题、图片、描述、内容) )
采集交流 • 优采云 发表了文章 • 0 个评论 • 134 次浏览 • 2022-01-01 18:00
)
任务:
采集指定页面的文章包括(标题、图片、描述、内容)导入到自己的网站数据库对应列(列id为57), 数据库字段分别是(title, thumb, descrption, content).
页面上的第一张图片用作文章缩略图。这里一个是获取缩略图的名称并将对应的网站路径添加到数据库的thumb字段中,另一个是本地下载并统一上传。进入指定的文件夹,(当然也可以直接ftp看软件,我还没做,以后补充)
1、新组--新任务
2、添加网址+修改获取网址的规则
选择ul中li中的链接,注意排除重复地址,可以点击采集下方的测试网址获取。
可以看到采集有一个到文章的链接。
3、采集内容规则
我需要采集来显示下图中的数据(catid为列id,可以将数据采集放入对应的列并设置固定值)
关注内容和图片采集,标题和描述与内容相同采集
内容采集:
打开采集的文章的一个页面查看源码(f11右键禁用或者view-source:可以在URL前面加):
选择文章开头的一个位置,截取一段,看是不是ctrl+f下的唯一一段。如果是,可以放在下图1所示的位置,结尾和开头一样。
我截取了内容,不想里面有链接图片进行数据处理,添加--html标签排除--选择确定--确定
还有需要下载页面图片,勾选并填写以下选项
图片采集:
(1)选择范围与内容相同(文章内图)
(2)提取第一张图片的数据处理选项。内容为:
(3)只要aa.jpg,常规过滤
获取内容:aa.jpg
(4)数据库存放有前缀,添加,上传/xxxxx/
找一个页面测试一下,可以看到对应的item都获取到了。
4、发布内容设置,这里以发布到数据库的方式为例,编辑完成后返回这里查看刚刚定义的模块:
5、我需要把图片保存到本地,还要设置保存文件的路径(ftp以后会尝试使用)。
6、保存,查看新创建的任务,右键启动任务,可以看到这里下载了文字和图片,在数据库中可以看到。
查看全部
如何文章采集(采集某一个指定页面的文章包括(标题、图片、描述、内容)
)
任务:
采集指定页面的文章包括(标题、图片、描述、内容)导入到自己的网站数据库对应列(列id为57), 数据库字段分别是(title, thumb, descrption, content).
页面上的第一张图片用作文章缩略图。这里一个是获取缩略图的名称并将对应的网站路径添加到数据库的thumb字段中,另一个是本地下载并统一上传。进入指定的文件夹,(当然也可以直接ftp看软件,我还没做,以后补充)
1、新组--新任务
2、添加网址+修改获取网址的规则
选择ul中li中的链接,注意排除重复地址,可以点击采集下方的测试网址获取。
可以看到采集有一个到文章的链接。
3、采集内容规则
我需要采集来显示下图中的数据(catid为列id,可以将数据采集放入对应的列并设置固定值)
关注内容和图片采集,标题和描述与内容相同采集
内容采集:
打开采集的文章的一个页面查看源码(f11右键禁用或者view-source:可以在URL前面加):
选择文章开头的一个位置,截取一段,看是不是ctrl+f下的唯一一段。如果是,可以放在下图1所示的位置,结尾和开头一样。
我截取了内容,不想里面有链接图片进行数据处理,添加--html标签排除--选择确定--确定
还有需要下载页面图片,勾选并填写以下选项
图片采集:
(1)选择范围与内容相同(文章内图)
(2)提取第一张图片的数据处理选项。内容为:
(3)只要aa.jpg,常规过滤
获取内容:aa.jpg
(4)数据库存放有前缀,添加,上传/xxxxx/
找一个页面测试一下,可以看到对应的item都获取到了。
4、发布内容设置,这里以发布到数据库的方式为例,编辑完成后返回这里查看刚刚定义的模块:
5、我需要把图片保存到本地,还要设置保存文件的路径(ftp以后会尝试使用)。
6、保存,查看新创建的任务,右键启动任务,可以看到这里下载了文字和图片,在数据库中可以看到。
如何文章采集( 如何实现wp的自动采集功能?教程分享教程)
采集交流 • 优采云 发表了文章 • 0 个评论 • 151 次浏览 • 2022-01-01 17:25
如何实现wp的自动采集功能?教程分享教程)
WordPress 是一个使用 PHP 语言开发的建站程序平台。现在很多博主都用wp。许多网站制作培训使用wp,尤其是采集站。那个时候wordpress的整体能量非常强大。下面介绍如何实现wp的自动采集功能。
推荐教程:wordpressa教程
1、安装网站采集插件:WP-AutoPost
2、 点击“新建任务”后,输入任务名称即可新建任务。创建新任务后,您可以在任务列表中查看该任务,并且可以对任务进行更多设置。 (这部分不需要修改设置,唯一需要修改的就是采集的时间。)
3、文章 源设置。在这个选项卡下,我们需要设置文章的来源的文章列表URL和文章的具体匹配规则。我们以采集《新浪网》为例,文章的列表网址为,所以在手动指定的文章列表网址中输入网址,如下图:
4、文章 URL 匹配规则。 文章 URL匹配规则的设置很简单。不需要复杂的设置。提供两种匹配模式。您可以使用 URL 通配符匹配或 CSS 选择器进行匹配。通常 URL 通配符匹配更简单,但有时会使用 CSS。选择器更精确。
5、 使用 URL 通配符匹配。通过点击列表URL上的文章,我们可以发现每个文章的URL具有如下结构:所以将URL中变化的数字或字母替换为通配符(*),如: (*)/(*).shtml。重复的 URL 可以使用 301 重定向。
6、 使用 CSS 选择器进行匹配。要使用CSS选择器进行匹配,我们只需要设置文章 URL的CSS选择器即可,查看列表URL源码即可轻松设置,找到文章@的代码> 列表 URL 下的超链接。如下图:
7、 可以看到,文章的超链接A标签在类为“contList”的标签内,所以文章 URL的CSS选择器只需要设置为 .contList a 就可以了,如下图:
8、 设置完成后,如果不知道设置是否正确,可以点击上图中的测试按钮。如果设置正确,将列出列表URL下的所有文章名称和对应的网址,如下图:
9、 其他设置不需要修改。
10、 以上采集方法适用于WordPress多站点功能。
如果这个文章不能解决你的问题,你可以看看这个文章:wordpress自动采集插件的使用方法
以上是wordpress采集的详细内容,详情请关注php中文网站其他相关文章!
免责声明:本文由原创发表于php中文网。转载请注明出处。感谢您的尊重!如果您有任何问题,请联系我们
专题推荐:wordpress 查看全部
如何文章采集(
如何实现wp的自动采集功能?教程分享教程)
WordPress 是一个使用 PHP 语言开发的建站程序平台。现在很多博主都用wp。许多网站制作培训使用wp,尤其是采集站。那个时候wordpress的整体能量非常强大。下面介绍如何实现wp的自动采集功能。
推荐教程:wordpressa教程
1、安装网站采集插件:WP-AutoPost
2、 点击“新建任务”后,输入任务名称即可新建任务。创建新任务后,您可以在任务列表中查看该任务,并且可以对任务进行更多设置。 (这部分不需要修改设置,唯一需要修改的就是采集的时间。)
3、文章 源设置。在这个选项卡下,我们需要设置文章的来源的文章列表URL和文章的具体匹配规则。我们以采集《新浪网》为例,文章的列表网址为,所以在手动指定的文章列表网址中输入网址,如下图:
4、文章 URL 匹配规则。 文章 URL匹配规则的设置很简单。不需要复杂的设置。提供两种匹配模式。您可以使用 URL 通配符匹配或 CSS 选择器进行匹配。通常 URL 通配符匹配更简单,但有时会使用 CSS。选择器更精确。
5、 使用 URL 通配符匹配。通过点击列表URL上的文章,我们可以发现每个文章的URL具有如下结构:所以将URL中变化的数字或字母替换为通配符(*),如: (*)/(*).shtml。重复的 URL 可以使用 301 重定向。
6、 使用 CSS 选择器进行匹配。要使用CSS选择器进行匹配,我们只需要设置文章 URL的CSS选择器即可,查看列表URL源码即可轻松设置,找到文章@的代码> 列表 URL 下的超链接。如下图:
7、 可以看到,文章的超链接A标签在类为“contList”的标签内,所以文章 URL的CSS选择器只需要设置为 .contList a 就可以了,如下图:
8、 设置完成后,如果不知道设置是否正确,可以点击上图中的测试按钮。如果设置正确,将列出列表URL下的所有文章名称和对应的网址,如下图:
9、 其他设置不需要修改。
10、 以上采集方法适用于WordPress多站点功能。
如果这个文章不能解决你的问题,你可以看看这个文章:wordpress自动采集插件的使用方法
以上是wordpress采集的详细内容,详情请关注php中文网站其他相关文章!
免责声明:本文由原创发表于php中文网。转载请注明出处。感谢您的尊重!如果您有任何问题,请联系我们
专题推荐:wordpress
如何文章采集( 所有SEO文章采集或抄袭会被K站惩罚吗?)
采集交流 • 优采云 发表了文章 • 0 个评论 • 99 次浏览 • 2021-12-28 19:09
所有SEO文章采集或抄袭会被K站惩罚吗?)
如果我网站上的文章被抄袭了怎么办?
在实际的网站SEO优化过程中,我们站长经常会遇到自己收录的文章被别人抄袭,然后对方的文章也被收录,排名比自己高(检查对方是不是老网站和(权重更高),在这种情况下,我们都会问:像这样的SEO文章采集
或抄袭会被K站惩罚吗?
一、什么是文章采集
或抄袭?
采集
是指通过一定的采集
程序和规则,将其他网站的文章自动复制到自己的网站。(此处采集
或抄袭必须为原创采集
,不得有任何花招或伪装)
按原样从其他网站采集
文章对您网站的权重有很大影响。虽然百度搜索引擎无法真正保护原创文章,但成都SEO相信搜索引擎算法会越来越智能。提高自己网站的排名是有害无益的。
我们SEOer都知道百度飓风算法是为了打击文章采集
或抄袭。如果我们使用文章采集
器来发布文章,那么我们应该花时间按照算法来处理吗?这不值得损失。
二、 所有SEO文章合集抄袭都会被K站处罚吗?
分享一开始,我们就知道,如果有人采集
或抄袭我们的文章,就会被收录,排名会高于我们自己的。是什么原因?
我们回归搜索引擎工作原理的本质,即满足和解决用户搜索结果的需求。也就是说,无论你的文章来自哪里(采集
文章也可以解决用户需求),而且排版好,逻辑表达清晰,可读性强,是否符合搜索引擎提供的用户拥有有价值的内容?解决用户搜索需求的本质是什么?所以有一个排名。
但是,这种采集
行为是不可行的。试想一下,如果长期给合集内容一个更好的排名,肯定会引起原作者的反感。这种情况持续下去,站长们开始采集
内容或抄袭内容,而不是制作原创文章或伪原创文章。那么可以肯定的是,当用户使用搜索引擎进行查询时,他们解决用户需求的能力会越来越弱。
因此,为了打造更好的互联网内容生态,搜索引擎会不断引入算法来对抗采集
网站,同时也会对原创内容给予一定的排名偏好,鼓励原创作者创作更多优质内容。
三、网站SEO文章被采集
抄袭怎么办
1、临时建议,一般可以礼貌地在对方网站上留言,能不能加个文章链接投票,没有的话百度反馈举报。
2、 长期建议,优化你的网站结构,打开速度等因素提升自身实力,最好晚上更新文章,因为这样可以增加你第一个被收录的概率. (参考原文定义)
3、 网站图片尽量加水印,增加处理和处理别人文章的时间成本。
4、 保持良好的心态。毕竟百度也推出了飓风算法来对抗惩罚。原创文章被采集
抄袭是一个问题。技术一直在改进和优化。谷歌搜索引擎无法完美解决这个问题。最好的策略是做好自己的网站,以便文章可以在几秒钟内被采集
。
内容被抄袭 查看全部
如何文章采集(
所有SEO文章采集或抄袭会被K站惩罚吗?)
如果我网站上的文章被抄袭了怎么办?
在实际的网站SEO优化过程中,我们站长经常会遇到自己收录的文章被别人抄袭,然后对方的文章也被收录,排名比自己高(检查对方是不是老网站和(权重更高),在这种情况下,我们都会问:像这样的SEO文章采集
或抄袭会被K站惩罚吗?
一、什么是文章采集
或抄袭?
采集
是指通过一定的采集
程序和规则,将其他网站的文章自动复制到自己的网站。(此处采集
或抄袭必须为原创采集
,不得有任何花招或伪装)
按原样从其他网站采集
文章对您网站的权重有很大影响。虽然百度搜索引擎无法真正保护原创文章,但成都SEO相信搜索引擎算法会越来越智能。提高自己网站的排名是有害无益的。
我们SEOer都知道百度飓风算法是为了打击文章采集
或抄袭。如果我们使用文章采集
器来发布文章,那么我们应该花时间按照算法来处理吗?这不值得损失。
二、 所有SEO文章合集抄袭都会被K站处罚吗?
分享一开始,我们就知道,如果有人采集
或抄袭我们的文章,就会被收录,排名会高于我们自己的。是什么原因?
我们回归搜索引擎工作原理的本质,即满足和解决用户搜索结果的需求。也就是说,无论你的文章来自哪里(采集
文章也可以解决用户需求),而且排版好,逻辑表达清晰,可读性强,是否符合搜索引擎提供的用户拥有有价值的内容?解决用户搜索需求的本质是什么?所以有一个排名。
但是,这种采集
行为是不可行的。试想一下,如果长期给合集内容一个更好的排名,肯定会引起原作者的反感。这种情况持续下去,站长们开始采集
内容或抄袭内容,而不是制作原创文章或伪原创文章。那么可以肯定的是,当用户使用搜索引擎进行查询时,他们解决用户需求的能力会越来越弱。
因此,为了打造更好的互联网内容生态,搜索引擎会不断引入算法来对抗采集
网站,同时也会对原创内容给予一定的排名偏好,鼓励原创作者创作更多优质内容。
三、网站SEO文章被采集
抄袭怎么办
1、临时建议,一般可以礼貌地在对方网站上留言,能不能加个文章链接投票,没有的话百度反馈举报。
2、 长期建议,优化你的网站结构,打开速度等因素提升自身实力,最好晚上更新文章,因为这样可以增加你第一个被收录的概率. (参考原文定义)
3、 网站图片尽量加水印,增加处理和处理别人文章的时间成本。
4、 保持良好的心态。毕竟百度也推出了飓风算法来对抗惩罚。原创文章被采集
抄袭是一个问题。技术一直在改进和优化。谷歌搜索引擎无法完美解决这个问题。最好的策略是做好自己的网站,以便文章可以在几秒钟内被采集
。
内容被抄袭
如何文章采集(如何可以快速获取收藏夹中的文章?-顶级大学)
采集交流 • 优采云 发表了文章 • 0 个评论 • 109 次浏览 • 2021-12-28 06:04
如何文章采集成为很多同学迫切需要的技能了,但在文章采集以前,我想先简单说下这些技能的效果:--文章提取--文章标题为精华。--高质量原创文章。--顶级大学。说了一大堆,可能对于许多同学不知道重点是什么,这次教大家一个非常实用的小技巧:如何可以快速获取收藏夹中的文章?(可自行百度“快速访问收藏夹”)具体做法:打开文章页,看到的是所有收藏夹中的精华文章,当你采集打开的时候,只要按下【enter】即可显示目标文章。
只需要简单的四步!采集的同时我们要关注原文,复制链接粘贴到新文章的粘贴框,点右上角【确定】即可保存该文章。当你不打开收藏夹再次搜索时,在收藏夹栏的结果中你会看到一串神秘的数字,可以理解为同学们可以任意访问收藏夹中的文章。因此一定要重视收藏夹中的文章,转发给身边的同学,不用谢。
对于公众号而言,采集资源和干货的目的是相通的。目的在于用最低的成本从其他渠道获取你需要的文章内容,也是此处推荐一个第三方的小助手:新榜采集器这个是我在12年开始使用的一个软件,有各种精选的微信文章榜单(有了这个,你就不需要看太多其他百度网站上发布的“干货”),采集的时候有多种方式,有自己爬虫技术,还有一个就是从公众号的文章里面获取,还有其他方式,我就不说了。
你每次找到你需要的文章之后,就可以在自己的公众号里面放上自己想要的关键词,当你选中文章,就可以在推送的文章中点击网址即可下载,其他的渠道也是一样。下面就说一下它的长处:①字节图,这是我喜欢的最大的一个优点。其他方式找到的文章,打开速度慢,我们肯定希望在当前就可以看到我需要的内容,字节图就可以大大提高下载的速度。
②采集功能齐全,除了常规的文章、活动之外,还可以找到被禁止的内容,你也可以不依靠别人的推荐,自己下载,因为有下载限制。具体地址:/#/login使用说明:在公众号任意一篇文章下方放置自己的联系方式,新榜会根据你放置的地址自动检测,自动推送。下载按钮是一样的,还有很多使用小技巧,下载中的小技巧大家慢慢找一下,找到了,别忘了给我点个赞,ok,收工!本人公众号:python大叔,帮助你成为一个更好的程序员。 查看全部
如何文章采集(如何可以快速获取收藏夹中的文章?-顶级大学)
如何文章采集成为很多同学迫切需要的技能了,但在文章采集以前,我想先简单说下这些技能的效果:--文章提取--文章标题为精华。--高质量原创文章。--顶级大学。说了一大堆,可能对于许多同学不知道重点是什么,这次教大家一个非常实用的小技巧:如何可以快速获取收藏夹中的文章?(可自行百度“快速访问收藏夹”)具体做法:打开文章页,看到的是所有收藏夹中的精华文章,当你采集打开的时候,只要按下【enter】即可显示目标文章。
只需要简单的四步!采集的同时我们要关注原文,复制链接粘贴到新文章的粘贴框,点右上角【确定】即可保存该文章。当你不打开收藏夹再次搜索时,在收藏夹栏的结果中你会看到一串神秘的数字,可以理解为同学们可以任意访问收藏夹中的文章。因此一定要重视收藏夹中的文章,转发给身边的同学,不用谢。
对于公众号而言,采集资源和干货的目的是相通的。目的在于用最低的成本从其他渠道获取你需要的文章内容,也是此处推荐一个第三方的小助手:新榜采集器这个是我在12年开始使用的一个软件,有各种精选的微信文章榜单(有了这个,你就不需要看太多其他百度网站上发布的“干货”),采集的时候有多种方式,有自己爬虫技术,还有一个就是从公众号的文章里面获取,还有其他方式,我就不说了。
你每次找到你需要的文章之后,就可以在自己的公众号里面放上自己想要的关键词,当你选中文章,就可以在推送的文章中点击网址即可下载,其他的渠道也是一样。下面就说一下它的长处:①字节图,这是我喜欢的最大的一个优点。其他方式找到的文章,打开速度慢,我们肯定希望在当前就可以看到我需要的内容,字节图就可以大大提高下载的速度。
②采集功能齐全,除了常规的文章、活动之外,还可以找到被禁止的内容,你也可以不依靠别人的推荐,自己下载,因为有下载限制。具体地址:/#/login使用说明:在公众号任意一篇文章下方放置自己的联系方式,新榜会根据你放置的地址自动检测,自动推送。下载按钮是一样的,还有很多使用小技巧,下载中的小技巧大家慢慢找一下,找到了,别忘了给我点个赞,ok,收工!本人公众号:python大叔,帮助你成为一个更好的程序员。
如何文章采集(什么叫文章采集或抄袭会被K站惩罚吗?)
采集交流 • 优采云 发表了文章 • 0 个评论 • 135 次浏览 • 2021-12-27 07:07
在实际的网站SEO优化过程中,我们站长经常会遇到自己收录的文章被别人抄袭,然后对方的文章也被收录,排名比自己高(检查对方是不是老网站和(权重更高),这种情况下大家都会问:这样的SEO文章采集
或者抄袭会被K站处罚吗?
什么是文章采集
或抄袭
采集
是指通过一定的采集
程序和规则,将其他网站的文章自动复制到自己的网站。(此处采集
或抄袭必须为原创采集
,不得有任何花招或伪装)
按原样从其他网站采集
文章对您网站的权重有很大影响。虽然百度搜索引擎无法真正保护原创文章,但成都SEO相信搜索引擎算法会越来越智能。提高自己网站的排名是有害无益的。
我们SEOer都知道百度飓风算法是为了打击文章采集
或抄袭。如果我们使用文章采集
器来发布文章,那么我们应该花时间按照算法来处理吗?这不值得损失。
如果有人采集
或抄袭我们的文章,他们将被收录并排名高于他们自己的文章。是什么原因?
我们回归搜索引擎工作原理的本质,即满足和解决用户搜索结果的需求。也就是说,无论你的文章来自哪里(采集
文章也可以解决用户需求),而且排版好,逻辑表达清晰,可读性强,是否符合搜索引擎为用户提供有价值的内容?解决用户搜索需求的本质是什么?所以有一个排名。
但是,这种采集
行为是不可行的。试想一下,如果长期给合集内容一个更好的排名,肯定会引起原作者的反感。这种情况持续下去,站长们开始采集
内容或抄袭内容,而不是制作原创文章或伪原创文章。那么可以肯定的是,当用户使用搜索引擎进行查询时,他们解决用户需求的能力会越来越弱。
因此,为了打造更好的互联网内容生态,搜索引擎会不断推出算法来打击采集
网站,同时也会对原创内容给予一定的排名偏好,鼓励原创作者创作更多优质内容。
网站SEO文章被采集
抄袭怎么办
1、临时建议,一般可以礼貌地在对方网站上留言,能不能加个文章链接投票,没有的话百度反馈举报。
2、 长期建议,优化你的网站结构,打开速度等因素提升自身实力,最好晚上更新文章,因为这样可以增加你第一个被收录的概率. (参考原文定义)
3、 网站图片尽量加水印,增加处理和处理别人文章的时间成本。
4、 保持良好的心态。毕竟百度也推出了飓风算法来对抗惩罚。原创文章被采集
抄袭是一个问题。技术一直在改进和优化。谷歌搜索引擎无法完美解决这个问题。因此,最好的策略是做好自己的网站,以便文章可以在几秒钟内被采集
。 查看全部
如何文章采集(什么叫文章采集或抄袭会被K站惩罚吗?)
在实际的网站SEO优化过程中,我们站长经常会遇到自己收录的文章被别人抄袭,然后对方的文章也被收录,排名比自己高(检查对方是不是老网站和(权重更高),这种情况下大家都会问:这样的SEO文章采集
或者抄袭会被K站处罚吗?
什么是文章采集
或抄袭
采集
是指通过一定的采集
程序和规则,将其他网站的文章自动复制到自己的网站。(此处采集
或抄袭必须为原创采集
,不得有任何花招或伪装)
按原样从其他网站采集
文章对您网站的权重有很大影响。虽然百度搜索引擎无法真正保护原创文章,但成都SEO相信搜索引擎算法会越来越智能。提高自己网站的排名是有害无益的。
我们SEOer都知道百度飓风算法是为了打击文章采集
或抄袭。如果我们使用文章采集
器来发布文章,那么我们应该花时间按照算法来处理吗?这不值得损失。
如果有人采集
或抄袭我们的文章,他们将被收录并排名高于他们自己的文章。是什么原因?
我们回归搜索引擎工作原理的本质,即满足和解决用户搜索结果的需求。也就是说,无论你的文章来自哪里(采集
文章也可以解决用户需求),而且排版好,逻辑表达清晰,可读性强,是否符合搜索引擎为用户提供有价值的内容?解决用户搜索需求的本质是什么?所以有一个排名。
但是,这种采集
行为是不可行的。试想一下,如果长期给合集内容一个更好的排名,肯定会引起原作者的反感。这种情况持续下去,站长们开始采集
内容或抄袭内容,而不是制作原创文章或伪原创文章。那么可以肯定的是,当用户使用搜索引擎进行查询时,他们解决用户需求的能力会越来越弱。
因此,为了打造更好的互联网内容生态,搜索引擎会不断推出算法来打击采集
网站,同时也会对原创内容给予一定的排名偏好,鼓励原创作者创作更多优质内容。
网站SEO文章被采集
抄袭怎么办
1、临时建议,一般可以礼貌地在对方网站上留言,能不能加个文章链接投票,没有的话百度反馈举报。
2、 长期建议,优化你的网站结构,打开速度等因素提升自身实力,最好晚上更新文章,因为这样可以增加你第一个被收录的概率. (参考原文定义)
3、 网站图片尽量加水印,增加处理和处理别人文章的时间成本。
4、 保持良好的心态。毕竟百度也推出了飓风算法来对抗惩罚。原创文章被采集
抄袭是一个问题。技术一直在改进和优化。谷歌搜索引擎无法完美解决这个问题。因此,最好的策略是做好自己的网站,以便文章可以在几秒钟内被采集
。
如何文章采集(如何文章采集导入推荐pdf与网页(一步一))
采集交流 • 优采云 发表了文章 • 0 个评论 • 131 次浏览 • 2021-12-16 01:02
如何文章采集导入推荐pdf与网页第一步:浏览器访问pdf之家第二步:按照页面要求选择下载或点击下载页面第三步:选择下载推荐适用于课件。
看你需要的课件用什么格式,下载有几种格式:可以上传到idm,网页自动下载,windows也可以,安卓也可以。我个人觉得好用的是这一个:。每当我需要下载课件,就需要在idm中爬来爬去,也还是很麻烦。用这个就很方便,直接在网页,或者pdf格式就可以下载。
zpdf
那种不但页面清晰,还有压缩功能的,
下载《经济法》的pdf版的。
word
百度云
pdf最好。pdf可以加密,
ie浏览器
爱奇艺
视频网站视频会员全集
根据你的课程大纲下载pdf版
在亚马逊上购买的pdf版的内容页到家里的电脑或网络盘想要下载时传到百度云或qq群里
就是下载pdf的啦不过不是电子版,是文本版的很方便推荐(不过今天好像pdf版的不能在知乎上发图片了,复制粘贴都不可以。
各种宝打包app
在网上搜pdf就有啊
美团啊,学校那么大,
百度搜索:pdf这个下载。
xyzpdf下载比较不错,其实onedrive上也有,
,全部免费的下载! 查看全部
如何文章采集(如何文章采集导入推荐pdf与网页(一步一))
如何文章采集导入推荐pdf与网页第一步:浏览器访问pdf之家第二步:按照页面要求选择下载或点击下载页面第三步:选择下载推荐适用于课件。
看你需要的课件用什么格式,下载有几种格式:可以上传到idm,网页自动下载,windows也可以,安卓也可以。我个人觉得好用的是这一个:。每当我需要下载课件,就需要在idm中爬来爬去,也还是很麻烦。用这个就很方便,直接在网页,或者pdf格式就可以下载。
zpdf
那种不但页面清晰,还有压缩功能的,
下载《经济法》的pdf版的。
word
百度云
pdf最好。pdf可以加密,
ie浏览器
爱奇艺
视频网站视频会员全集
根据你的课程大纲下载pdf版
在亚马逊上购买的pdf版的内容页到家里的电脑或网络盘想要下载时传到百度云或qq群里
就是下载pdf的啦不过不是电子版,是文本版的很方便推荐(不过今天好像pdf版的不能在知乎上发图片了,复制粘贴都不可以。
各种宝打包app
在网上搜pdf就有啊
美团啊,学校那么大,
百度搜索:pdf这个下载。
xyzpdf下载比较不错,其实onedrive上也有,
,全部免费的下载!
如何文章采集(如何做推广引流?搜索引擎的算法从何而来?)
采集交流 • 优采云 发表了文章 • 0 个评论 • 93 次浏览 • 2021-12-11 21:03
如何文章采集最主要的两个方面就是账号自身的权重和站点的权重(更多的是找域名以及搭建服务器网站优化,然后合理的过度优化,同时做推广引流)搜索引擎的算法从第一篇文章为什么要用正则表达式,到合理做推广引流?你知道有多少方法可以赚钱吗?今天主要看一下搜索引擎的算法,首先得了解搜索引擎的运行方式搜索引擎是根据网民的特征和搜索数据来制定自己的推荐算法,是否会得到好的结果,主要看你搜索一个词,能不能通过搜索引擎的搜索结果看到你想要的内容,一个词就代表你想要的东西,1万个词就代表了一个东西的搜索量,这就是简单的一些搜索率问题,搜索量越大,搜索词覆盖度越广,就说明搜索后的结果就更准确,消费者,更好的找到自己想要的东西,搜索词覆盖度不同,或者搜索词本身就不精准也会得到不同的结果。
采集的每个文章点击率是不一样的,首先要找到自己要的文章,具体怎么找到自己要的文章呢?个人分享一些手机自媒体下面主要看一下视频可以采集到什么内容。从视频数据入手采集后进行数据分析,这个很简单,是一些采集器都可以搜到视频,通过在线分析,找到属于自己需要的内容。然后再通过聚合搜索,过滤,高亮,标记,主要实现不用下载视频。
现在主要就是图片,文字以及视频,视频可以采集到youtube优酷土豆等很多地方,一个视频或者是文字下面会出现所有有相关内容,再者就是文章,图片,音频等。自媒体新人,小白或者刚做自媒体创业的伙伴可以试试我的经验分享,同时也希望结交更多志同道合的小伙伴,在自媒体创业的道路上少走一些弯路,更多更完整的自媒体实战运营方法请看我的主页,v,欢迎交流!。 查看全部
如何文章采集(如何做推广引流?搜索引擎的算法从何而来?)
如何文章采集最主要的两个方面就是账号自身的权重和站点的权重(更多的是找域名以及搭建服务器网站优化,然后合理的过度优化,同时做推广引流)搜索引擎的算法从第一篇文章为什么要用正则表达式,到合理做推广引流?你知道有多少方法可以赚钱吗?今天主要看一下搜索引擎的算法,首先得了解搜索引擎的运行方式搜索引擎是根据网民的特征和搜索数据来制定自己的推荐算法,是否会得到好的结果,主要看你搜索一个词,能不能通过搜索引擎的搜索结果看到你想要的内容,一个词就代表你想要的东西,1万个词就代表了一个东西的搜索量,这就是简单的一些搜索率问题,搜索量越大,搜索词覆盖度越广,就说明搜索后的结果就更准确,消费者,更好的找到自己想要的东西,搜索词覆盖度不同,或者搜索词本身就不精准也会得到不同的结果。
采集的每个文章点击率是不一样的,首先要找到自己要的文章,具体怎么找到自己要的文章呢?个人分享一些手机自媒体下面主要看一下视频可以采集到什么内容。从视频数据入手采集后进行数据分析,这个很简单,是一些采集器都可以搜到视频,通过在线分析,找到属于自己需要的内容。然后再通过聚合搜索,过滤,高亮,标记,主要实现不用下载视频。
现在主要就是图片,文字以及视频,视频可以采集到youtube优酷土豆等很多地方,一个视频或者是文字下面会出现所有有相关内容,再者就是文章,图片,音频等。自媒体新人,小白或者刚做自媒体创业的伙伴可以试试我的经验分享,同时也希望结交更多志同道合的小伙伴,在自媒体创业的道路上少走一些弯路,更多更完整的自媒体实战运营方法请看我的主页,v,欢迎交流!。
如何文章采集(谁有免费的SEO采集软件啊,急呀!!(组图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 118 次浏览 • 2021-12-10 18:08
写文章,平时需要大量的素材积累,对时事、热点新闻有很好的理解。您需要一个可以采集所有时事和新闻的软件,以节省您在互联网上搜索的时间。有专门的自媒体小助手覆盖热点、百度时事热点、百度今日热点、百度民生热点、百度体育热点、百度娱乐热点、今日等等。爆文资源,你可以快速跟随你的创作主题在你特别自媒体在助手上找到相关材料来完善你的作品。
没有真正实用又免费的SEO采集软件,赶紧的!!
SKYCC专业seo软件可以在网站后台自动捕捉和丰富原创化文章每天添加爱心回答文章网管必加文章很厌恶。SKYCC专业seo软件seo软件通过进入软件的关键词搜索抓取相关内容文章页面,并快速优化重组原创,自动编辑生成布局合理的优化静态页面. 效果显着!
谁有免费的SEO文章采集器啊?紧急!!!最好只有一个功能,即只有采集文章最好。我只是一个小小的网页编辑器,但我还是不明白什么时候有更多的功能。. . . rn有人给我发邮件 181140[emailprotected]谢谢
文章编辑除了采集文章和伪原创,都是批量等,优采云智能文章采集 system 这些功能不会显得繁琐。可以提高网络编辑的效率。
有没有免费的软件或者网页可以查文章的重复率?
没有这样的软件,因为泽的开发没用。现在文章的大部分都是有版权的,你将无法随意搜索和比较。 查看全部
如何文章采集(谁有免费的SEO采集软件啊,急呀!!(组图))
写文章,平时需要大量的素材积累,对时事、热点新闻有很好的理解。您需要一个可以采集所有时事和新闻的软件,以节省您在互联网上搜索的时间。有专门的自媒体小助手覆盖热点、百度时事热点、百度今日热点、百度民生热点、百度体育热点、百度娱乐热点、今日等等。爆文资源,你可以快速跟随你的创作主题在你特别自媒体在助手上找到相关材料来完善你的作品。
没有真正实用又免费的SEO采集软件,赶紧的!!
SKYCC专业seo软件可以在网站后台自动捕捉和丰富原创化文章每天添加爱心回答文章网管必加文章很厌恶。SKYCC专业seo软件seo软件通过进入软件的关键词搜索抓取相关内容文章页面,并快速优化重组原创,自动编辑生成布局合理的优化静态页面. 效果显着!
谁有免费的SEO文章采集器啊?紧急!!!最好只有一个功能,即只有采集文章最好。我只是一个小小的网页编辑器,但我还是不明白什么时候有更多的功能。. . . rn有人给我发邮件 181140[emailprotected]谢谢
文章编辑除了采集文章和伪原创,都是批量等,优采云智能文章采集 system 这些功能不会显得繁琐。可以提高网络编辑的效率。
有没有免费的软件或者网页可以查文章的重复率?
没有这样的软件,因为泽的开发没用。现在文章的大部分都是有版权的,你将无法随意搜索和比较。

