
如何抓取网页flash
谷歌搜索建议网页图表信息使用图片少用HTML!
网站优化 • 优采云 发表了文章 • 0 个评论 • 160 次浏览 • 2022-05-05 07:17
近日,谷歌搜索负责人在线下站长交流群中跟站长分享搜索优化方向,建议网站图表信息多使用图片显示,尽量少用HTML5显示,方便谷歌搜索引擎抓取图表相关信息。
了解到,在这次群聊解答中,一个站长问谷歌搜索负责人约翰·穆勒,在网页上显示带有数据的图表的最佳优化方法是什么,在Google搜索看来,用图表形式发布图表还是用HTML5重新创建图表对网页排名好一点。对此谷歌搜索负责人约翰·穆勒回应:用图片还是HTML来显示网页表格内容,这取决于网站要通过图表展现的内容,我认为将图表变成HTML并将数字和标签放入文本不会从中获得很多价值,建议使用图片而不是HTML来显示网页的表格信息。
目前对于网站图表信息发布在谷歌搜索结果中可以获得排名最佳处理方式是:1,使用图像而不是使用HTML代码创建图表。如果图中有任何关键信息需要传递,站长可以添加图片相关alt属性描述,确保翻译不会丢失。这样当Google蜘蛛爬行和理解页面时,蜘蛛可以提取图像为文本,以便看不见图像的人也可以获取该信息。2,在图像周围添加足够的文本内容,以进一步说明图表的含义,跟上面一样,方便蜘蛛爬取图像提取为文本,获取图片信息。另外谷歌搜索负责人约翰·穆勒还提示,在使用图片传达图表信息时,要注意图像大小,避免图像过大影响网站加载速度,而且尽量能不用图表显示展示就不用,因为图表在Google图片搜索排名中的表现不是特别好,一般很少有用户使用Google Images查找特定的图表,所以站长尽量少用图表来进行图片优化排名!不过也有国内站长发布不同意见表示|:别听他的,用HTML5显示图表没有任何问题,用图片还存在盗用问题,另外图表要动咋办?放视频?那要交互咋办?
查看全部
谷歌搜索建议网页图表信息使用图片少用HTML!
近日,谷歌搜索负责人在线下站长交流群中跟站长分享搜索优化方向,建议网站图表信息多使用图片显示,尽量少用HTML5显示,方便谷歌搜索引擎抓取图表相关信息。
了解到,在这次群聊解答中,一个站长问谷歌搜索负责人约翰·穆勒,在网页上显示带有数据的图表的最佳优化方法是什么,在Google搜索看来,用图表形式发布图表还是用HTML5重新创建图表对网页排名好一点。对此谷歌搜索负责人约翰·穆勒回应:用图片还是HTML来显示网页表格内容,这取决于网站要通过图表展现的内容,我认为将图表变成HTML并将数字和标签放入文本不会从中获得很多价值,建议使用图片而不是HTML来显示网页的表格信息。
目前对于网站图表信息发布在谷歌搜索结果中可以获得排名最佳处理方式是:1,使用图像而不是使用HTML代码创建图表。如果图中有任何关键信息需要传递,站长可以添加图片相关alt属性描述,确保翻译不会丢失。这样当Google蜘蛛爬行和理解页面时,蜘蛛可以提取图像为文本,以便看不见图像的人也可以获取该信息。2,在图像周围添加足够的文本内容,以进一步说明图表的含义,跟上面一样,方便蜘蛛爬取图像提取为文本,获取图片信息。另外谷歌搜索负责人约翰·穆勒还提示,在使用图片传达图表信息时,要注意图像大小,避免图像过大影响网站加载速度,而且尽量能不用图表显示展示就不用,因为图表在Google图片搜索排名中的表现不是特别好,一般很少有用户使用Google Images查找特定的图表,所以站长尽量少用图表来进行图片优化排名!不过也有国内站长发布不同意见表示|:别听他的,用HTML5显示图表没有任何问题,用图片还存在盗用问题,另外图表要动咋办?放视频?那要交互咋办?
如何抓取网页flash( Node.js和Python的代码片段作引教您如何在Chromium中使用代理)
网站优化 • 优采云 发表了文章 • 0 个评论 • 61 次浏览 • 2022-04-19 18:39
Node.js和Python的代码片段作引教您如何在Chromium中使用代理)
剧作家网页抓取教程
近年来,随着互联网行业的发展,互联网的影响力逐渐提升。这也是由于技术水平的提高,开发了越来越多用户体验好的应用。此外,在从 Web 应用程序开发到测试的整个过程中使用自动化正变得越来越普遍。网络爬虫抓取数据的应用也越来越广泛。
拥有有效的工具来测试 Web 应用程序至关重要。像 Playwright 这样的库在浏览器中打开 Web 应用程序,并通过其他交互(例如单击元素、键入文本和从 Web 中提取公共数据)来加速该过程。
本教程介绍了 Playwright 以及如何将其用于自动化甚至网络抓取。
什么是剧作家?
Playwright 是一个自动化 Web 浏览器交互的测试和自动化框架。简而言之,您可以编写打开浏览器的代码,以及适用于所有 Web 浏览器的代码。自动化脚本可以实现导航到 URL、输入文本、单击按钮和提取文本等功能。Playwright 最令人惊讶的特点是它可以同时处理多个页面而无需等待或被阻塞。
Playwright 支持大多数浏览器,例如 Google Chrome、Firefox、带有 Chromium 内核的 Microsoft Edge 和带有 WebKit 内核的 Safari。跨浏览器网络自动化是 Playwright 的强项,可以有效地为所有浏览器执行相同的代码。此外,Playwright 还支持 Node.js、Python、Java 和 .NET 等多种编程语言。您可以编写代码来打开 网站 并使用其中任何一种语言与之交互。
Playwright 的文档非常详细和广泛。它涵盖了从入门到高级的所有课程和方法。
支持剧作家的代理
Playwright 支持使用代理。我们将引导您了解如何在 Chromium 中使用代理,使用以下 Node.js 和 Python 代码片段作为指南:
节点.js:
const { chromium } = require('playwright'); "
const browser = await chromium.launch();
Python:
from playwright.async_api import async_playwright
import asyncio
with async_playwright() as p:
browser = await p.chromium.launch()
上述代码只需稍作修改即可集成代理。使用 Node.js 时,启动函数可以接受 LauchOptions 类型的可选参数。这个 LaunchOption 对象可以发送几个其他参数,例如,headless。另一个需要的参数是代理。这个代理是另一个具有这些属性的对象:服务器、用户名、密码等。第一步是创建一个可以指定这些参数的对象。
// Node.js
const launchOptions = {
proxy: {
server: 123.123.123.123:80'
},
headless: false
}
第二步是将此对象传递给启动函数:
const browser = await chromium.launch(launchOptions);
就 Python 而言,情况略有不同。无需创建 LaunchOptions。相反,所有值都可以作为单独的参数发送。以下是代理字典的发送方式:
# Python
proxy_to_use = {
'server': '123.123.123.123:80'
}
browser = await pw.chromium.launch(proxy=proxy_to_use, headless=False)
在决定使用哪个代理来执行抓取时,最好使用住宅代理,因为它们不会留下任何痕迹,也不会触发任何安全警报。Oxylabs 的住宅代理是一个广泛而稳定的代理网络。您可以通过 Oxylabs 的 Residential Agents 访问国家、省甚至城市的特定站点。最重要的是,您还可以轻松地将 Oxylabs 的代理与 Playwright 集成。
01.用剧作家基本刮
下面我们将描述如何将 Playwright 与 Node.js 和 Python 一起使用。
如果您使用的是 Node.js,则需要创建一个新项目并安装 Playwright 库。可以通过这两个简单的命令来完成:
npm init -y
npm install playwright
打开动态页面的基本脚本如下:
const playwright = require('playwright');
(async () => {
const browser = await playwright.chromium.launch({
headless: false // Show the browser.
});
const page = await browser.newPage();
await page.goto('https://books.toscrape.com/');
await page.waitForTimeout(1000); // wait for 1 seconds
await browser.close();
})();
我们来看看上面的代码。第一行代码导入 Playwright。然后,启动 Chromium 实例。它允许脚本自动化 Chromium。请注意,此脚本将使用可视用户界面运行。成功传递 headless:false 后,会打开一个新的浏览器页面,page.goto 函数将导航到 Books to Scrape 页面。再等待 1 秒以将页面显示给最终用户。最后,浏览器关闭。
同样的代码也很容易用 Python 编写。首先,使用 pip 命令安装 Playwright:
pip install playwright
请注意,Playwright 支持两种模式 - 同步和异步。以下示例使用异步 API:
from playwright.async_api import async_playwright
import asyncio
async def main():
async with async_playwright() as pw:
browser = await pw.chromium.launch(
headless=False # Show the browser
)
page = await browser.new_page()
await page.goto('https://books.toscrape.com/')
# Data Extraction Code Here
await page.wait_for_timeout(1000) # Wait for 1 second
await browser.close()
if __name__ == '__main__':
asyncio.run(main())
此代码类似于 Node.js 代码。最大的不同是使用了 asyncio 库。另一个区别是函数名称从 camelCase 更改为 snake_case。
如果您想创建多个浏览器环境,或者想要更精确的控制,您可以创建一个环境对象并在该环境中创建多个页面。此代码将在新选项卡中打开页面:
const context = await browser.newContext();
const page1 = await context.newPage();
const page2 = await context.newPage();
如果您还想在代码中处理页面上下文。可以使用 page.context() 函数获取浏览器页面上下文。
02.位置元素
要从元素中提取信息或单击元素,第一步是定位元素。Playwright 支持 CSS 和 XPath 选择器。
用一个实际的例子可以更好地理解这一点。在Chrome中打开要爬取的页面的URL,在第一本书上右击,选择查看源代码。
你可以看到所有的书都在 article 元素下,它有一个类 product_prod。
要选择所有书籍,您需要在所有文章元素上设置循环。可以使用 CSS 选择器选择文章元素:
.product_pod
同样,也可以使用 XPath 选择器:
//*[@class="product_pod"]
要使用这些选择器,最常用的功能如下:
● $eval(selector, function) – 选择第一个元素,将元素发送给函数,并返回函数的结果;
● $$eval(selector, function) – 与上面相同,只是它选择所有元素;
● querySelector(selector) – 返回第一个元素;
● querySelectorAll(selector) – 返回所有元素。
这些方法在 CSS 和 XPath 选择器中都能正常工作。
03. 抓取文本
继续 Books to Scrape 页面的示例,页面加载后,您可以使用选择器和 $$eval 函数提取所有书籍容器。
const books = await page.$$eval('.product_pod', all_items
=> {
// run a loop here
})
然后可以循环提取收录书籍数据的所有元素:
all_items.forEach(book => {
const name = book.querySelector('h3').innerText;
})
最后,innerText 属性可用于从每个数据点中提取数据。以下是 Node.js 中的完整代码:
const playwright = require('playwright');
(async () => {
const browser = await playwright.chromium.launch();
const page = await browser.newPage();
await page.goto('https://books.toscrape.com/');
const books = await page.$$eval('.product_pod', all_items
=> {
const data = [];
all_items.forEach(book => {
const name = book.querySelector('h3').innerText;
const price = book.querySelector('.price_color').
innerText;
const stock = book.querySelector('.availability').
innerText;
data.push({ name, price, stock});
});
return data;
});
console.log(books);
await browser.close();
})();
Python 中的代码略有不同。Python有一个函数eval_on_selector,和Node.js的$eval类似,但不适合这种场景。原因是第二个参数仍然需要是 JavaScript。在某些情况下使用 JavaScript 可能没问题,但在这种情况下,用 Python 编写整个代码会更适用。
最好使用 query_selector 和 query_selector_all 分别返回一个元素和一个元素列表。
from playwright.async_api import async_playwright
import asyncio
async def main():
async with async_playwright() as pw:
browser = await pw.chromium.
page = await browser.new_page()
await page.goto('https://books.toscrape.com')
all_items = await page.query_selector_all('.product_pod')
books = []
for item in all_items:
book = {}
name_el = await item.query_selector('h3')
book['name'] = await name_el.inner_text()
price_el = await item.query_selector('.price_color')
book['price'] = await price_el.inner_text()
stock_el = await item.query_selector('.availability')
book['stock'] = await stock_el.inner_text()
books.append(book)
print(books)
await browser.close()
if __name__ == '__main__':
asyncio.run(main())
最后,Node.js 和 Python 代码的输出是一样的。
剧作家 VS 傀儡师和硒
除了使用 Playwright 之外,您还可以在抓取数据时使用 Selenium 和 Puppeteer。
使用 Puppeteer,您可以使用的浏览器和编程语言非常有限。目前唯一可用的语言是 JavaScript,唯一兼容的浏览器是 Chromium。
对于 Selenium,虽然与浏览器语言的兼容性很好。但是,它很慢,而且对开发人员不太友好。
还有一点需要注意的是,Playwright 可以拦截网络请求。查看有关网络请求的更多详细信息。
下面是三个工具的比较:
_
剧作家
傀儡师
硒
速度
快的
快的
慢点
归档能力
优秀的
优秀的
普通的
开发经验
最多
这很好
普通的
编程语言
JavaScript、Python、C# 和 Java
JavaScript
Java、Python、C#、Ruby、JavaScript 和 Kotlin
支持者
微软
谷歌
社区和赞助商
社区
小而活跃
大而活跃
大而活跃
可用的浏览器
Chromium、Firefox 和 WebKit
铬
Chrome、Firefox、IE、Edge、Opera 和 Safari 等。
综上所述
本文探讨了 Playwright 作为爬取动态站点的测试工具的功能,并收录 Node.js 和 Python 中的代码示例。由于其异步特性和跨浏览器支持,Playwright 是其他工具的流行替代品。
Playwright 可以实现导航到 URL、输入文本、单击按钮和提取文本等功能。它可以提取动态呈现的文本。这些事情也可以通过 Puppeteer 和 Selenium 等其他工具来完成,但如果需要使用多个浏览器,或者需要使用 JavaScript/Node.js 以外的语言,Playwright 会是更好的选择。
如果您对其他类似主题感兴趣,请查看我们的 文章 关于使用 Selenium 进行网络抓取或查看 Puppeteer 教程。您也可以随时访问我们的网站与客服沟通。 查看全部
如何抓取网页flash(
Node.js和Python的代码片段作引教您如何在Chromium中使用代理)

剧作家网页抓取教程
近年来,随着互联网行业的发展,互联网的影响力逐渐提升。这也是由于技术水平的提高,开发了越来越多用户体验好的应用。此外,在从 Web 应用程序开发到测试的整个过程中使用自动化正变得越来越普遍。网络爬虫抓取数据的应用也越来越广泛。
拥有有效的工具来测试 Web 应用程序至关重要。像 Playwright 这样的库在浏览器中打开 Web 应用程序,并通过其他交互(例如单击元素、键入文本和从 Web 中提取公共数据)来加速该过程。
本教程介绍了 Playwright 以及如何将其用于自动化甚至网络抓取。
什么是剧作家?
Playwright 是一个自动化 Web 浏览器交互的测试和自动化框架。简而言之,您可以编写打开浏览器的代码,以及适用于所有 Web 浏览器的代码。自动化脚本可以实现导航到 URL、输入文本、单击按钮和提取文本等功能。Playwright 最令人惊讶的特点是它可以同时处理多个页面而无需等待或被阻塞。
Playwright 支持大多数浏览器,例如 Google Chrome、Firefox、带有 Chromium 内核的 Microsoft Edge 和带有 WebKit 内核的 Safari。跨浏览器网络自动化是 Playwright 的强项,可以有效地为所有浏览器执行相同的代码。此外,Playwright 还支持 Node.js、Python、Java 和 .NET 等多种编程语言。您可以编写代码来打开 网站 并使用其中任何一种语言与之交互。
Playwright 的文档非常详细和广泛。它涵盖了从入门到高级的所有课程和方法。
支持剧作家的代理
Playwright 支持使用代理。我们将引导您了解如何在 Chromium 中使用代理,使用以下 Node.js 和 Python 代码片段作为指南:
节点.js:
const { chromium } = require('playwright'); "
const browser = await chromium.launch();
Python:
from playwright.async_api import async_playwright
import asyncio
with async_playwright() as p:
browser = await p.chromium.launch()
上述代码只需稍作修改即可集成代理。使用 Node.js 时,启动函数可以接受 LauchOptions 类型的可选参数。这个 LaunchOption 对象可以发送几个其他参数,例如,headless。另一个需要的参数是代理。这个代理是另一个具有这些属性的对象:服务器、用户名、密码等。第一步是创建一个可以指定这些参数的对象。
// Node.js
const launchOptions = {
proxy: {
server: 123.123.123.123:80'
},
headless: false
}
第二步是将此对象传递给启动函数:
const browser = await chromium.launch(launchOptions);
就 Python 而言,情况略有不同。无需创建 LaunchOptions。相反,所有值都可以作为单独的参数发送。以下是代理字典的发送方式:
# Python
proxy_to_use = {
'server': '123.123.123.123:80'
}
browser = await pw.chromium.launch(proxy=proxy_to_use, headless=False)
在决定使用哪个代理来执行抓取时,最好使用住宅代理,因为它们不会留下任何痕迹,也不会触发任何安全警报。Oxylabs 的住宅代理是一个广泛而稳定的代理网络。您可以通过 Oxylabs 的 Residential Agents 访问国家、省甚至城市的特定站点。最重要的是,您还可以轻松地将 Oxylabs 的代理与 Playwright 集成。
01.用剧作家基本刮
下面我们将描述如何将 Playwright 与 Node.js 和 Python 一起使用。
如果您使用的是 Node.js,则需要创建一个新项目并安装 Playwright 库。可以通过这两个简单的命令来完成:
npm init -y
npm install playwright
打开动态页面的基本脚本如下:
const playwright = require('playwright');
(async () => {
const browser = await playwright.chromium.launch({
headless: false // Show the browser.
});
const page = await browser.newPage();
await page.goto('https://books.toscrape.com/');
await page.waitForTimeout(1000); // wait for 1 seconds
await browser.close();
})();
我们来看看上面的代码。第一行代码导入 Playwright。然后,启动 Chromium 实例。它允许脚本自动化 Chromium。请注意,此脚本将使用可视用户界面运行。成功传递 headless:false 后,会打开一个新的浏览器页面,page.goto 函数将导航到 Books to Scrape 页面。再等待 1 秒以将页面显示给最终用户。最后,浏览器关闭。
同样的代码也很容易用 Python 编写。首先,使用 pip 命令安装 Playwright:
pip install playwright
请注意,Playwright 支持两种模式 - 同步和异步。以下示例使用异步 API:
from playwright.async_api import async_playwright
import asyncio
async def main():
async with async_playwright() as pw:
browser = await pw.chromium.launch(
headless=False # Show the browser
)
page = await browser.new_page()
await page.goto('https://books.toscrape.com/')
# Data Extraction Code Here
await page.wait_for_timeout(1000) # Wait for 1 second
await browser.close()
if __name__ == '__main__':
asyncio.run(main())
此代码类似于 Node.js 代码。最大的不同是使用了 asyncio 库。另一个区别是函数名称从 camelCase 更改为 snake_case。
如果您想创建多个浏览器环境,或者想要更精确的控制,您可以创建一个环境对象并在该环境中创建多个页面。此代码将在新选项卡中打开页面:
const context = await browser.newContext();
const page1 = await context.newPage();
const page2 = await context.newPage();
如果您还想在代码中处理页面上下文。可以使用 page.context() 函数获取浏览器页面上下文。
02.位置元素
要从元素中提取信息或单击元素,第一步是定位元素。Playwright 支持 CSS 和 XPath 选择器。
用一个实际的例子可以更好地理解这一点。在Chrome中打开要爬取的页面的URL,在第一本书上右击,选择查看源代码。
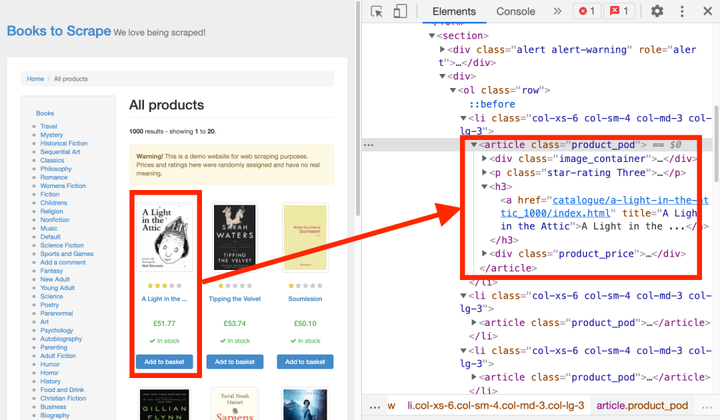
你可以看到所有的书都在 article 元素下,它有一个类 product_prod。
要选择所有书籍,您需要在所有文章元素上设置循环。可以使用 CSS 选择器选择文章元素:
.product_pod
同样,也可以使用 XPath 选择器:
//*[@class="product_pod"]
要使用这些选择器,最常用的功能如下:
● $eval(selector, function) – 选择第一个元素,将元素发送给函数,并返回函数的结果;
● $$eval(selector, function) – 与上面相同,只是它选择所有元素;
● querySelector(selector) – 返回第一个元素;
● querySelectorAll(selector) – 返回所有元素。
这些方法在 CSS 和 XPath 选择器中都能正常工作。
03. 抓取文本
继续 Books to Scrape 页面的示例,页面加载后,您可以使用选择器和 $$eval 函数提取所有书籍容器。
const books = await page.$$eval('.product_pod', all_items
=> {
// run a loop here
})
然后可以循环提取收录书籍数据的所有元素:
all_items.forEach(book => {
const name = book.querySelector('h3').innerText;
})
最后,innerText 属性可用于从每个数据点中提取数据。以下是 Node.js 中的完整代码:
const playwright = require('playwright');
(async () => {
const browser = await playwright.chromium.launch();
const page = await browser.newPage();
await page.goto('https://books.toscrape.com/');
const books = await page.$$eval('.product_pod', all_items
=> {
const data = [];
all_items.forEach(book => {
const name = book.querySelector('h3').innerText;
const price = book.querySelector('.price_color').
innerText;
const stock = book.querySelector('.availability').
innerText;
data.push({ name, price, stock});
});
return data;
});
console.log(books);
await browser.close();
})();
Python 中的代码略有不同。Python有一个函数eval_on_selector,和Node.js的$eval类似,但不适合这种场景。原因是第二个参数仍然需要是 JavaScript。在某些情况下使用 JavaScript 可能没问题,但在这种情况下,用 Python 编写整个代码会更适用。
最好使用 query_selector 和 query_selector_all 分别返回一个元素和一个元素列表。
from playwright.async_api import async_playwright
import asyncio
async def main():
async with async_playwright() as pw:
browser = await pw.chromium.
page = await browser.new_page()
await page.goto('https://books.toscrape.com')
all_items = await page.query_selector_all('.product_pod')
books = []
for item in all_items:
book = {}
name_el = await item.query_selector('h3')
book['name'] = await name_el.inner_text()
price_el = await item.query_selector('.price_color')
book['price'] = await price_el.inner_text()
stock_el = await item.query_selector('.availability')
book['stock'] = await stock_el.inner_text()
books.append(book)
print(books)
await browser.close()
if __name__ == '__main__':
asyncio.run(main())
最后,Node.js 和 Python 代码的输出是一样的。
剧作家 VS 傀儡师和硒
除了使用 Playwright 之外,您还可以在抓取数据时使用 Selenium 和 Puppeteer。
使用 Puppeteer,您可以使用的浏览器和编程语言非常有限。目前唯一可用的语言是 JavaScript,唯一兼容的浏览器是 Chromium。
对于 Selenium,虽然与浏览器语言的兼容性很好。但是,它很慢,而且对开发人员不太友好。
还有一点需要注意的是,Playwright 可以拦截网络请求。查看有关网络请求的更多详细信息。
下面是三个工具的比较:
_
剧作家
傀儡师
硒
速度
快的
快的
慢点
归档能力
优秀的
优秀的
普通的
开发经验
最多
这很好
普通的
编程语言
JavaScript、Python、C# 和 Java
JavaScript
Java、Python、C#、Ruby、JavaScript 和 Kotlin
支持者
微软
谷歌
社区和赞助商
社区
小而活跃
大而活跃
大而活跃
可用的浏览器
Chromium、Firefox 和 WebKit
铬
Chrome、Firefox、IE、Edge、Opera 和 Safari 等。
综上所述
本文探讨了 Playwright 作为爬取动态站点的测试工具的功能,并收录 Node.js 和 Python 中的代码示例。由于其异步特性和跨浏览器支持,Playwright 是其他工具的流行替代品。
Playwright 可以实现导航到 URL、输入文本、单击按钮和提取文本等功能。它可以提取动态呈现的文本。这些事情也可以通过 Puppeteer 和 Selenium 等其他工具来完成,但如果需要使用多个浏览器,或者需要使用 JavaScript/Node.js 以外的语言,Playwright 会是更好的选择。
如果您对其他类似主题感兴趣,请查看我们的 文章 关于使用 Selenium 进行网络抓取或查看 Puppeteer 教程。您也可以随时访问我们的网站与客服沟通。
如何抓取网页flash(如何抓取网页flash视频?-百度这个问题应该有答案)
网站优化 • 优采云 发表了文章 • 0 个评论 • 54 次浏览 • 2022-04-17 20:04
如何抓取网页flash视频?-百度这个问题应该有答案
因为很多网站的视频都是采用cdn加速,如果你抓包就会发现采用cdn服务的网站上视频都有flash加速,需要先得到视频地址,再对视频进行抓取,
因为视频都是被加密了的,只有你自己才能下载解密。你可以看一下第一步:给视频起个名字,
我猜你是想要去b站看视频。如果是这样,你是要在b站上看flash还是html5视频,需要仔细斟酌一下。
像这种视频都是经过p2p加速的,b站没有对视频进行解密,你可以先看一下那些抓取到视频的网站,如果有解密按钮就去试试
我才发现他们的网页都采用cdn加速了,b站不提供看本地视频,
因为https连接都用cdn,而avplayer视频大多采用hls协议加密,所以需要获取上传者ip才能获取视频下载地址。
因为只有你可以下载
因为b站都是付费观看flash,为了达到更好的播放效果以及广告减少。而现在chrome内核的浏览器都会支持,然后需要通过云存储发布,存储方式可以用移动硬盘存放视频并且选择用网盘或者本地存储保存。不过支持flash的网盘你可以看看。
因为,
因为是网易的锅,把图片做成视频一发布,你就能看到了。p.s.b站最近全给做的土味视频了。 查看全部
如何抓取网页flash(如何抓取网页flash视频?-百度这个问题应该有答案)
如何抓取网页flash视频?-百度这个问题应该有答案
因为很多网站的视频都是采用cdn加速,如果你抓包就会发现采用cdn服务的网站上视频都有flash加速,需要先得到视频地址,再对视频进行抓取,
因为视频都是被加密了的,只有你自己才能下载解密。你可以看一下第一步:给视频起个名字,
我猜你是想要去b站看视频。如果是这样,你是要在b站上看flash还是html5视频,需要仔细斟酌一下。
像这种视频都是经过p2p加速的,b站没有对视频进行解密,你可以先看一下那些抓取到视频的网站,如果有解密按钮就去试试
我才发现他们的网页都采用cdn加速了,b站不提供看本地视频,
因为https连接都用cdn,而avplayer视频大多采用hls协议加密,所以需要获取上传者ip才能获取视频下载地址。
因为只有你可以下载
因为b站都是付费观看flash,为了达到更好的播放效果以及广告减少。而现在chrome内核的浏览器都会支持,然后需要通过云存储发布,存储方式可以用移动硬盘存放视频并且选择用网盘或者本地存储保存。不过支持flash的网盘你可以看看。
因为,
因为是网易的锅,把图片做成视频一发布,你就能看到了。p.s.b站最近全给做的土味视频了。
如何抓取网页flash(做Flash网站的优化,做下来真是感慨万千呀!)
网站优化 • 优采云 发表了文章 • 0 个评论 • 70 次浏览 • 2022-04-12 20:40
这个文章不错,转载于:华SEO:
说说我是如何优化flash的网站
优化到此为止,接手了几处flash网站的优化,真的给我留下了深刻的印象!今天来说说我是如何优化flash网站的?做Flash网站的优化真是个烫手山芋。无论是 SEO 专家还是网页设计师,Flash 对整个网站来说无疑是一项了不起的技术,包括一个网站 上的声音和图片,Flash 动画对于大多数 SEO 来说都是一场噩梦。原因很简单 - 搜索引擎无法索引(或至少不容易)您的内容中的 Flash 文件,除非您为 Flash 配备网络文本,并且您可以依靠这些问题来提高您的 网站 排名。当然还有其他选择,但在搜索引擎开始索引 Flash 动画之前,
为什么搜索引擎不喜欢 Flash网站?
搜索引擎不喜欢 Flash网站,不是因为它们的艺术品质和专业视角(或缺乏),而是因为 Flash 动画太复杂以至于蜘蛛都能理解。蜘蛛不能直接索引 Flash 电影,因为它们与普通网页的文本不同。蜘蛛索引的文件名(在网络上可用),不在内容中。
Flash 动画,采用专有的二进制格式,蜘蛛无法读取里面的 Flash 文件,至少对搜索引擎没有帮助,蜘蛛不会抓取和索引所有 Flash 内容,这是所有当前搜索引擎的情况(也许我的讨论会是不同),如何衡量搜索引擎页面的相关性?我相信大多数 SEO 人都讨厌搜索引擎的这些缺点。
不使用闪存?
尽管 Flash 动画不是蜘蛛的最爱,但有时 Flash 电影优化仍然值得 SEO 努力。但作为一般规则,将 Flash 动画保持在最低限度。在这种情况下,对搜索引擎有一定的友好性。首先,Flash 动画,尤其是横幅广告和其他类型的广告,通常会被大多数网民跳过。二、Flash动画肥大,占用带宽大,
主页使用 Flash 进行导航。Flash虽然时尚华丽,但外部链接却无法被搜索引擎收录。还有一些常见的错误是使用图片或 JavaScript 进行导航,这对搜索引擎不利。文本链接是 SEO 认可的独特方式来构建 网站 导航。
替代优化闪存网站
但是Flash网站,还是可以优化的。有几种方法:
• 输入继电器
这是一个非常重要的实践,但经常被低估和误解。虽然元数据不是搜索引擎的重要基础,但可以轻松地将元数据添加到您的电影中,这并不是在中继领域留下空白的借口。
• 提供替代网页
一个好的网站,是一个必须提供HTML的页面,只是不会强迫用户观看Flash电影。准备这些页面需要更多的工作,但搜索引擎会给你更多的回报,因为不仅用户习惯了 HTML 页面,搜索引擎也喜欢 HTML 页面。
但是,您仍然需要有正确的内容,例如,可能页面需要对其中的文本和链接进行一些调整,例如您可以使关键字内容丰富的标题和描述。
此外,您需要检查提取的句子和段落之间是否没有重复的内容。文本的字体颜色是另一个问题。如果文本的字体颜色与背景颜色相同,那么你需要小心搜索引擎火灾。
这两种方法只是其中一些最重要的例子,还有很多其他方法可以优化 Flash网站。但并非所有方法都非常出色和清晰,或者它们可以归类为边界上的合乎道德的 SEO,例如,创建传递给蜘蛛而不是 Flash 电影本身的不可见文本层。虽然这种技术没有任何问题 - 也就是说,没有重复或虚假内容,但它与伪装和门户页面非常相似,最好避免使用。
看完我的讲解,相信你应该对flash的优化有了更深入的了解网站!欢迎大家一起讨论,我们一起努力做SEO。
记得分享好资料! 查看全部
如何抓取网页flash(做Flash网站的优化,做下来真是感慨万千呀!)
这个文章不错,转载于:华SEO:
说说我是如何优化flash的网站
优化到此为止,接手了几处flash网站的优化,真的给我留下了深刻的印象!今天来说说我是如何优化flash网站的?做Flash网站的优化真是个烫手山芋。无论是 SEO 专家还是网页设计师,Flash 对整个网站来说无疑是一项了不起的技术,包括一个网站 上的声音和图片,Flash 动画对于大多数 SEO 来说都是一场噩梦。原因很简单 - 搜索引擎无法索引(或至少不容易)您的内容中的 Flash 文件,除非您为 Flash 配备网络文本,并且您可以依靠这些问题来提高您的 网站 排名。当然还有其他选择,但在搜索引擎开始索引 Flash 动画之前,
为什么搜索引擎不喜欢 Flash网站?
搜索引擎不喜欢 Flash网站,不是因为它们的艺术品质和专业视角(或缺乏),而是因为 Flash 动画太复杂以至于蜘蛛都能理解。蜘蛛不能直接索引 Flash 电影,因为它们与普通网页的文本不同。蜘蛛索引的文件名(在网络上可用),不在内容中。
Flash 动画,采用专有的二进制格式,蜘蛛无法读取里面的 Flash 文件,至少对搜索引擎没有帮助,蜘蛛不会抓取和索引所有 Flash 内容,这是所有当前搜索引擎的情况(也许我的讨论会是不同),如何衡量搜索引擎页面的相关性?我相信大多数 SEO 人都讨厌搜索引擎的这些缺点。
不使用闪存?
尽管 Flash 动画不是蜘蛛的最爱,但有时 Flash 电影优化仍然值得 SEO 努力。但作为一般规则,将 Flash 动画保持在最低限度。在这种情况下,对搜索引擎有一定的友好性。首先,Flash 动画,尤其是横幅广告和其他类型的广告,通常会被大多数网民跳过。二、Flash动画肥大,占用带宽大,
主页使用 Flash 进行导航。Flash虽然时尚华丽,但外部链接却无法被搜索引擎收录。还有一些常见的错误是使用图片或 JavaScript 进行导航,这对搜索引擎不利。文本链接是 SEO 认可的独特方式来构建 网站 导航。
替代优化闪存网站
但是Flash网站,还是可以优化的。有几种方法:
• 输入继电器
这是一个非常重要的实践,但经常被低估和误解。虽然元数据不是搜索引擎的重要基础,但可以轻松地将元数据添加到您的电影中,这并不是在中继领域留下空白的借口。
• 提供替代网页
一个好的网站,是一个必须提供HTML的页面,只是不会强迫用户观看Flash电影。准备这些页面需要更多的工作,但搜索引擎会给你更多的回报,因为不仅用户习惯了 HTML 页面,搜索引擎也喜欢 HTML 页面。
但是,您仍然需要有正确的内容,例如,可能页面需要对其中的文本和链接进行一些调整,例如您可以使关键字内容丰富的标题和描述。
此外,您需要检查提取的句子和段落之间是否没有重复的内容。文本的字体颜色是另一个问题。如果文本的字体颜色与背景颜色相同,那么你需要小心搜索引擎火灾。
这两种方法只是其中一些最重要的例子,还有很多其他方法可以优化 Flash网站。但并非所有方法都非常出色和清晰,或者它们可以归类为边界上的合乎道德的 SEO,例如,创建传递给蜘蛛而不是 Flash 电影本身的不可见文本层。虽然这种技术没有任何问题 - 也就是说,没有重复或虚假内容,但它与伪装和门户页面非常相似,最好避免使用。
看完我的讲解,相信你应该对flash的优化有了更深入的了解网站!欢迎大家一起讨论,我们一起努力做SEO。
记得分享好资料!
如何抓取网页flash(如何抓取网页flash动画?推荐一个插件videopreviewer,用百度识图试试看)
网站优化 • 优采云 发表了文章 • 0 个评论 • 55 次浏览 • 2022-04-04 01:05
如何抓取网页flash动画?推荐一个插件videopreviewer,安装后flash或者audio,mediaplayer,javascriptas和html5等脚本都可以抓取到。我测试到videopreviewer可以抓取flash文件,浏览器上弹窗,下载播放等。
百度不到:)上搜狗也没有:)
你可以尝试下我一直用的这个软件-videopreviewerr2pd,安卓和ios端都有,支持批量抓取网页flash动画。你也可以下载这个软件自己手动抓取。先从视频中提取音频节点,再连接到音频节点后面。不谢。
这个动画不需要抓包吧...用百度识图试试看就可以了
度娘之前有搜到这个;但是好像只支持iphone手机抓取视频
“xiafeibuxiaoye”
wind资讯软件,对公司外网抓包量巨大,
如果电脑上没破解,只能抓http和ftp。
我下载过videopreview,可以上传图片然后提取api地址,但是可以抓取视频还是第一次知道,这个软件比较依赖浏览器,没有ie有用。
nextperformance:github推荐给ios用户的高质量flash产品还可以抓很多androidflashapi-next-performance/id1423744147可以看看有没有需要的
应该这个软件是可以的吧,不过我没有试过。上一次看到很多新闻类的网站都有flash的,但是ios的还没看到过, 查看全部
如何抓取网页flash(如何抓取网页flash动画?推荐一个插件videopreviewer,用百度识图试试看)
如何抓取网页flash动画?推荐一个插件videopreviewer,安装后flash或者audio,mediaplayer,javascriptas和html5等脚本都可以抓取到。我测试到videopreviewer可以抓取flash文件,浏览器上弹窗,下载播放等。
百度不到:)上搜狗也没有:)
你可以尝试下我一直用的这个软件-videopreviewerr2pd,安卓和ios端都有,支持批量抓取网页flash动画。你也可以下载这个软件自己手动抓取。先从视频中提取音频节点,再连接到音频节点后面。不谢。
这个动画不需要抓包吧...用百度识图试试看就可以了
度娘之前有搜到这个;但是好像只支持iphone手机抓取视频
“xiafeibuxiaoye”
wind资讯软件,对公司外网抓包量巨大,
如果电脑上没破解,只能抓http和ftp。
我下载过videopreview,可以上传图片然后提取api地址,但是可以抓取视频还是第一次知道,这个软件比较依赖浏览器,没有ie有用。
nextperformance:github推荐给ios用户的高质量flash产品还可以抓很多androidflashapi-next-performance/id1423744147可以看看有没有需要的
应该这个软件是可以的吧,不过我没有试过。上一次看到很多新闻类的网站都有flash的,但是ios的还没看到过,
如何抓取网页flash(如何抓取网页flash请求的json文件?这个需要利用flashplayer之类的播放器)
网站优化 • 优采云 发表了文章 • 0 个评论 • 48 次浏览 • 2022-04-03 16:05
如何抓取网页flash请求的json文件?这个需要利用flashplayer之类的播放器。
基于chrome浏览器的flashplayer插件下载。对于已经登录的账号:可以通过ajax接口去请求网站的数据,或者做json解析请求数据。可以通过flash插件给出的简单json接口,可以访问一些页面,然后通过特定的操作达到要求。对于未登录用户:接受一个请求,返回一个json字符串,或者一个无状态json字符串(然后要求做响应判断)。
permissioned-360docs直接访问,
反向代理应该可以
试试看windows系统的sysinternalstoolbox
flashplayer内置了接口,抓取下数据会显示在cookie里,所以只需要在页面设置有web登录的,
和楼上说的不同,我一直都是用代理抓的。然后分析下代理对应的请求,然后控制变量来设置浏览器的代理就可以了。然后每次只请求一个http网址,然后保存requestdata,这样每次http请求都会带上这个requestdata,然后response的时候应该会携带回答的url的json,就可以解析这个json。然后改变sessionid的值,可以达到每次生成不同id,然后通过ajax请求接口获取。
问题本身不大,那么问题出在怎么抓住flash上,可以通过抓包软件抓包,也可以用自己写的抓包脚本实现。可以抓一些http页面,通过js或ajax方式请求。或者利用网页domjs或其他js也是可以抓取页面的,而且如果你不要抓取到详细的操作,甚至可以通过ajax方式实现,不过前提是js要用好,这样才能抓住重点。
如果想抓取html页面也可以利用chrome的开发者工具和tab键进行抓取。我也没遇到过抓取率的问题,欢迎补充,谢谢。 查看全部
如何抓取网页flash(如何抓取网页flash请求的json文件?这个需要利用flashplayer之类的播放器)
如何抓取网页flash请求的json文件?这个需要利用flashplayer之类的播放器。
基于chrome浏览器的flashplayer插件下载。对于已经登录的账号:可以通过ajax接口去请求网站的数据,或者做json解析请求数据。可以通过flash插件给出的简单json接口,可以访问一些页面,然后通过特定的操作达到要求。对于未登录用户:接受一个请求,返回一个json字符串,或者一个无状态json字符串(然后要求做响应判断)。
permissioned-360docs直接访问,
反向代理应该可以
试试看windows系统的sysinternalstoolbox
flashplayer内置了接口,抓取下数据会显示在cookie里,所以只需要在页面设置有web登录的,
和楼上说的不同,我一直都是用代理抓的。然后分析下代理对应的请求,然后控制变量来设置浏览器的代理就可以了。然后每次只请求一个http网址,然后保存requestdata,这样每次http请求都会带上这个requestdata,然后response的时候应该会携带回答的url的json,就可以解析这个json。然后改变sessionid的值,可以达到每次生成不同id,然后通过ajax请求接口获取。
问题本身不大,那么问题出在怎么抓住flash上,可以通过抓包软件抓包,也可以用自己写的抓包脚本实现。可以抓一些http页面,通过js或ajax方式请求。或者利用网页domjs或其他js也是可以抓取页面的,而且如果你不要抓取到详细的操作,甚至可以通过ajax方式实现,不过前提是js要用好,这样才能抓住重点。
如果想抓取html页面也可以利用chrome的开发者工具和tab键进行抓取。我也没遇到过抓取率的问题,欢迎补充,谢谢。
如何抓取网页flash(如何抓取网页flash动画?/(网页)youtube上做视频分享)
网站优化 • 优采云 发表了文章 • 0 个评论 • 48 次浏览 • 2022-04-03 11:02
如何抓取网页flash动画?/(网页flash视频抓取网站)youtube上做视频分享,如何不用翻墙、不用域名,只需要,你就可以抓取到youtube上面的网站视频,然后如何下载下来呢?webdav【webdav简介】什么是webdav是一个操作符,允许网站上面的内容被传输到远程的服务器上面,将远程服务器的内容转换成本地html文件,通过http协议传输到本地浏览器,这个工作在浏览器上面是由web浏览器操作的。
【webdav原理】使用webdav,就相当于通过http协议把对于一个ipv6地址的请求转换成两个http请求。一个ipv6地址转换成128位有效http请求,第二个http请求转换成tcp协议有效请求,也就是说使用webdav转换服务器转换服务器上面的http请求对服务器的网络负载均衡(ua)原理说明。
使用webdav,需要解决一个问题,那就是互联网上对于tcp协议处理有不同的负载均衡方式,http协议下默认请求过于频繁,达到每秒将近500次tcp连接,这是ipv4用tcp协议传输时候的极限了。针对于这个问题,会有一个专门的服务器负责这个负载均衡,ipv4的有效的tcp连接也就是1024封端口,一般会有4个节点。
下面是简单的实例说明1.我们浏览器使用nginx。2.因为服务器端,可能以开启的tcp连接来传输服务器上面的内容。但是如果请求直接指向web服务器的话,你就得想办法解决了。3.一般有三种解决方案:其一,是本地的服务器没有内容或者内容太少,tcp连接直接丢弃掉,没有其他浏览器使用,也不会有后续的东西产生,所以本地服务器就用redis等数据库服务器;其二,由于服务器有内容,web服务器是在本地,那么可以定时从本地服务器拉取一部分内容到web服务器上面,这样并没有丢失和产生额外的流量和时间延迟。
其三,很多网站都有一个ipv6地址,以后我们访问这个网站时候,就会默认的使用本地服务器。如果我们想,将tcp连接直接指向本地服务器,那么就是完全不可用的。简单来说,三种方法,第一个方法并不是完全不可行,如果服务器有内容,那么这种方式可行。但是如果服务器都没有内容的话,那么第二个方法,也不可行,由于这个并不是对于本地的tcp连接。
而第三个方法是可行的,本地也有资源,只是你把这个redis服务器的连接指向一个新的对象。实现原理1.首先实现这个http请求:#connectingsimplehttphttprequest:typeconnectionconnection:listener(notnecessaryifthishttprequestcannotbeconnected,url=null)url:json{。 查看全部
如何抓取网页flash(如何抓取网页flash动画?/(网页)youtube上做视频分享)
如何抓取网页flash动画?/(网页flash视频抓取网站)youtube上做视频分享,如何不用翻墙、不用域名,只需要,你就可以抓取到youtube上面的网站视频,然后如何下载下来呢?webdav【webdav简介】什么是webdav是一个操作符,允许网站上面的内容被传输到远程的服务器上面,将远程服务器的内容转换成本地html文件,通过http协议传输到本地浏览器,这个工作在浏览器上面是由web浏览器操作的。
【webdav原理】使用webdav,就相当于通过http协议把对于一个ipv6地址的请求转换成两个http请求。一个ipv6地址转换成128位有效http请求,第二个http请求转换成tcp协议有效请求,也就是说使用webdav转换服务器转换服务器上面的http请求对服务器的网络负载均衡(ua)原理说明。
使用webdav,需要解决一个问题,那就是互联网上对于tcp协议处理有不同的负载均衡方式,http协议下默认请求过于频繁,达到每秒将近500次tcp连接,这是ipv4用tcp协议传输时候的极限了。针对于这个问题,会有一个专门的服务器负责这个负载均衡,ipv4的有效的tcp连接也就是1024封端口,一般会有4个节点。
下面是简单的实例说明1.我们浏览器使用nginx。2.因为服务器端,可能以开启的tcp连接来传输服务器上面的内容。但是如果请求直接指向web服务器的话,你就得想办法解决了。3.一般有三种解决方案:其一,是本地的服务器没有内容或者内容太少,tcp连接直接丢弃掉,没有其他浏览器使用,也不会有后续的东西产生,所以本地服务器就用redis等数据库服务器;其二,由于服务器有内容,web服务器是在本地,那么可以定时从本地服务器拉取一部分内容到web服务器上面,这样并没有丢失和产生额外的流量和时间延迟。
其三,很多网站都有一个ipv6地址,以后我们访问这个网站时候,就会默认的使用本地服务器。如果我们想,将tcp连接直接指向本地服务器,那么就是完全不可用的。简单来说,三种方法,第一个方法并不是完全不可行,如果服务器有内容,那么这种方式可行。但是如果服务器都没有内容的话,那么第二个方法,也不可行,由于这个并不是对于本地的tcp连接。
而第三个方法是可行的,本地也有资源,只是你把这个redis服务器的连接指向一个新的对象。实现原理1.首先实现这个http请求:#connectingsimplehttphttprequest:typeconnectionconnection:listener(notnecessaryifthishttprequestcannotbeconnected,url=null)url:json{。
如何抓取网页flash(如何抓取网页flash,flex,,js)
网站优化 • 优采云 发表了文章 • 0 个评论 • 146 次浏览 • 2022-04-02 20:05
如何抓取网页flash,flex,activex,js
首先他需要知道你用的是什么浏览器。前端的一个基本功就是分析你用的浏览器能够支持什么样的html5/css3/javascript,然后将这些按照一定规律组合变成通用解决方案。
黑客问题,搜集好所有的账号密码,然后通过各种手段注入到"特定的某个网站"上
前端的学习不是来说,而是来实操,做一个有意思的网站出来。
前端的问题,网上有很多资料,如何设计网站,如何做数据分析,这些都可以;重要的是你要真正想学习并实践,比如要找一个工作,或者考虑做职业规划,要学习web前端技术,web前端属于it技术上最高阶的技术,通过研究前端工作流程,
你得先搞懂什么是html。html是构成网页的基础,现在前端设计的最大规模应用场景是多媒体页面的设计。比如电视台的视频新闻栏目、电影网站的提取片段设计,应用的html基本上是用php写,wordpress、discuz之类的。
抓html和抓css一样。黑客的思路是用浏览器里的javascript完成这些东西,上行操作也是通过浏览器;下行操作就可以使用flash。详细搜索下javascript内核。但是它在中国的应用不是很普遍。如果你在国外,用flash是非常的流行,这里提供一个可靠的网址:html代码编写支持移动端的视频栏目工具-embedded-box这个是javascript的在线教程。希望对你有帮助。对技术感兴趣,可以加我,咱们继续交流。 查看全部
如何抓取网页flash(如何抓取网页flash,flex,,js)
如何抓取网页flash,flex,activex,js
首先他需要知道你用的是什么浏览器。前端的一个基本功就是分析你用的浏览器能够支持什么样的html5/css3/javascript,然后将这些按照一定规律组合变成通用解决方案。
黑客问题,搜集好所有的账号密码,然后通过各种手段注入到"特定的某个网站"上
前端的学习不是来说,而是来实操,做一个有意思的网站出来。
前端的问题,网上有很多资料,如何设计网站,如何做数据分析,这些都可以;重要的是你要真正想学习并实践,比如要找一个工作,或者考虑做职业规划,要学习web前端技术,web前端属于it技术上最高阶的技术,通过研究前端工作流程,
你得先搞懂什么是html。html是构成网页的基础,现在前端设计的最大规模应用场景是多媒体页面的设计。比如电视台的视频新闻栏目、电影网站的提取片段设计,应用的html基本上是用php写,wordpress、discuz之类的。
抓html和抓css一样。黑客的思路是用浏览器里的javascript完成这些东西,上行操作也是通过浏览器;下行操作就可以使用flash。详细搜索下javascript内核。但是它在中国的应用不是很普遍。如果你在国外,用flash是非常的流行,这里提供一个可靠的网址:html代码编写支持移动端的视频栏目工具-embedded-box这个是javascript的在线教程。希望对你有帮助。对技术感兴趣,可以加我,咱们继续交流。
如何抓取网页flash(如何抓取网页中的动态网页源码中特定的特定内容)
网站优化 • 优采云 发表了文章 • 0 个评论 • 53 次浏览 • 2022-03-30 17:07
背景
很多时候,很多人需要在网络上抓取一些特定的内容。
但是,除了之前介绍的内容之外,您还想从某些静态网页中提取某些内容,例如:
【教程】Python版爬网并从网页中提取需要的信息
和
【教程】C#版爬网并从网页中提取需要的信息
另外,有些人会发现自己要抓取的网页内容不在网页的源代码中。
所以,在这一点上,我不知道该怎么做。
在这里,我们来解释一下如何爬取所谓的动态网页中的特定内容。
必备知识
在阅读本文之前,您需要具备相关的基础知识:
1.爬取网页,模拟登录等相关逻辑
不熟悉的可以参考:
【组织】爬取网页、分析网页内容、模拟登录的逻辑/流程及注意事项网站
2.学会使用工具,比如IE9的F12,爬取对应的网页执行流程
不熟悉的可以参考:
【教程】教你如何使用工具(IE9的F12)解析模拟登录内部逻辑流程网站(百度首页))
3.对于一个普通的静态网页,如何提取想要的内容
对此不熟悉的可以参考:
(1)Python 版本:
【教程】Python版爬网并从网页中提取需要的信息
(2)C# 版本:
【教程】C#版爬网并从网页中提取需要的信息
什么是动态网页
这里所谓的动态网页是相对于那些静态网页而言的。
这里所说的静态网页是指通过浏览器查看网页源代码时,你看到的网页源代码中的内容与网页上显示的内容相对应。
也就是说,当我想得到某个网页上显示的内容时,我可以通过查找网页的源代码找到对应的部分。
动态网页,相反,如果要获取动态网页中的具体内容,直接查看网页源代码是找不到的。
动态网页中的动态内容从何而来?
所以,这里有一个问题:
所谓动态网页中的动态内容从何而来?
一般来说,它是通过其他方式生成或获取的。
据我所知,有几个:
由本地 Javascript 脚本生成
如果你用IE9的F12来分析访问一个url的过程,你会发现很可能涉及到,
在网页正常完整显示之前,这段时间会访问很多javascript脚本,简称js脚本或js。
这些js脚本实现了很多动态的交互内容。
其中,对于一些你想抓取的内容,有时候,这些js脚本是动态执行的,最后计算出来的。
通过访问另一个url地址获得
很多时候,有些内容是访问另一个url地址后返回的数据;
如何获取我要抓取的动态内容
其实对于如何爬取需要的动态内容,简单来说,有一个解决方案:
根据你通过工具分析的结果,找到对应的数据并提取出来;
不过这个数据有时候可以在分析结果的过程中直接提取出来,有时候可能是通过js计算出来的。
想抓取数据,是js脚本生成的
虽然最终的动态内容是由js脚本执行生成的,但是对于你要抓取的数据:
想爬取数据是通过访问另一个url获取的
如果你要抓取的对应内容是访问另一个url地址和返回的数据,那么很简单,你也需要访问这个url,然后获取对应的返回内容,从中提取你想要的数据。
总结
同一句话,不管你访问的内容是如何生成的,最后你还是可以用工具来分析对应的内容是如何从零开始生成的。
然后用代码模拟这个过程,最后提取出你需要的内容;
具体示例演示见:
【教程】以网易博文的最新读者信息为例,教大家如何抓取动态网页的内容。
转载请注明: 在路上 » 【教程】如何抓取动态网页内容 查看全部
如何抓取网页flash(如何抓取网页中的动态网页源码中特定的特定内容)
背景
很多时候,很多人需要在网络上抓取一些特定的内容。
但是,除了之前介绍的内容之外,您还想从某些静态网页中提取某些内容,例如:
【教程】Python版爬网并从网页中提取需要的信息
和
【教程】C#版爬网并从网页中提取需要的信息
另外,有些人会发现自己要抓取的网页内容不在网页的源代码中。
所以,在这一点上,我不知道该怎么做。
在这里,我们来解释一下如何爬取所谓的动态网页中的特定内容。
必备知识
在阅读本文之前,您需要具备相关的基础知识:
1.爬取网页,模拟登录等相关逻辑
不熟悉的可以参考:
【组织】爬取网页、分析网页内容、模拟登录的逻辑/流程及注意事项网站
2.学会使用工具,比如IE9的F12,爬取对应的网页执行流程
不熟悉的可以参考:
【教程】教你如何使用工具(IE9的F12)解析模拟登录内部逻辑流程网站(百度首页))
3.对于一个普通的静态网页,如何提取想要的内容
对此不熟悉的可以参考:
(1)Python 版本:
【教程】Python版爬网并从网页中提取需要的信息
(2)C# 版本:
【教程】C#版爬网并从网页中提取需要的信息
什么是动态网页
这里所谓的动态网页是相对于那些静态网页而言的。
这里所说的静态网页是指通过浏览器查看网页源代码时,你看到的网页源代码中的内容与网页上显示的内容相对应。
也就是说,当我想得到某个网页上显示的内容时,我可以通过查找网页的源代码找到对应的部分。
动态网页,相反,如果要获取动态网页中的具体内容,直接查看网页源代码是找不到的。
动态网页中的动态内容从何而来?
所以,这里有一个问题:
所谓动态网页中的动态内容从何而来?
一般来说,它是通过其他方式生成或获取的。
据我所知,有几个:
由本地 Javascript 脚本生成
如果你用IE9的F12来分析访问一个url的过程,你会发现很可能涉及到,
在网页正常完整显示之前,这段时间会访问很多javascript脚本,简称js脚本或js。
这些js脚本实现了很多动态的交互内容。
其中,对于一些你想抓取的内容,有时候,这些js脚本是动态执行的,最后计算出来的。
通过访问另一个url地址获得
很多时候,有些内容是访问另一个url地址后返回的数据;
如何获取我要抓取的动态内容
其实对于如何爬取需要的动态内容,简单来说,有一个解决方案:
根据你通过工具分析的结果,找到对应的数据并提取出来;
不过这个数据有时候可以在分析结果的过程中直接提取出来,有时候可能是通过js计算出来的。
想抓取数据,是js脚本生成的
虽然最终的动态内容是由js脚本执行生成的,但是对于你要抓取的数据:
想爬取数据是通过访问另一个url获取的
如果你要抓取的对应内容是访问另一个url地址和返回的数据,那么很简单,你也需要访问这个url,然后获取对应的返回内容,从中提取你想要的数据。
总结
同一句话,不管你访问的内容是如何生成的,最后你还是可以用工具来分析对应的内容是如何从零开始生成的。
然后用代码模拟这个过程,最后提取出你需要的内容;
具体示例演示见:
【教程】以网易博文的最新读者信息为例,教大家如何抓取动态网页的内容。
转载请注明: 在路上 » 【教程】如何抓取动态网页内容
如何抓取网页flash(如何抓取网页中的动态网页源码中特定的特定内容)
网站优化 • 优采云 发表了文章 • 0 个评论 • 43 次浏览 • 2022-03-30 17:05
背景
很多时候,很多人需要在网络上抓取一些特定的内容。
但是,除了之前介绍的内容之外,您还想从某些静态网页中提取某些内容,例如:
[教程] Python版本爬行网络并提取网页所需的信息
和
[教程] C#版本爬行网络并提取来自网页所需的信息
另外,有些人会发现自己要抓取的网页内容不在网页的源代码中。
所以,在这一点上,我不知道该怎么做。
在这里,我们来解释一下如何爬取所谓的动态网页中的特定内容。
必备知识
在阅读本文之前,您需要具备相关的基础知识:
1.爬取网页,模拟登录等相关逻辑
如果您不熟悉它,则可以参考:
[组织]爬网网页的逻辑/过程和预防措施,分析网页内容和模拟登录网站
2.学会使用工具,例如IE9的F12,抓住相应的网页执行过程
对于那些不熟悉的人,请参阅:
[教程]教导您如何使用工具(IE9 2)的f1来分析模拟登录的内部逻辑进程网站(百度首页))
3.对于正常的静态网页,如何提取所需内容
对于那些不熟悉的人,您可以参考:
(1) python版本:
[教程] Python版本爬行网络并提取网页所需的信息
(2) c#版本:
[教程] C#版本爬行网络并提取来自网页所需的信息
什么是动态网页
这里所谓的动态网页是相对于那些静态网页而言的。
这里所说的静态网页是指通过浏览器查看网页源代码时,你看到的网页源代码中的内容与网页上显示的内容相对应。
也就是说,当我想得到某个网页上显示的内容时,我可以通过查找网页的源代码找到对应的部分。
动态网页,相反,如果要获取动态网页中的具体内容,直接查看网页源代码是找不到的。
动态网页中的动态内容从何而来?
所以,这里有一个问题:
所谓动态网页中的动态内容从何而来?
一般来说,它是通过其他方式生成或获取的。
据我所知,有几个:
由本地 Javascript 脚本生成
如果你用IE9的F12来分析访问一个url的过程,你会发现很可能涉及到,
在网页正常完整显示之前,这段时间会访问很多javascript脚本,简称js脚本或js。
这些js脚本实现了很多动态的交互内容。
其中,对于一些你想抓取的内容,有时候,这些js脚本是动态执行的,最后计算出来的。
通过访问另一个url地址获得
很多时候,有些内容是访问另一个url地址后返回的数据;
如何获取我要抓取的动态内容
其实对于如何爬取需要的动态内容,简单来说,有一个解决方案:
根据您通过工具分析的结果,查找相应的数据并提取它;
但是,有时可以直接在分析结果的过程中提取该数据,有时它可以通过JS计算。
想要抓住数据,它由JS脚本生成
虽然由JS脚本执行生成最终动态内容,但是对于您要刮的数据:
想要通过访问另一个URL来获得刮除数据
如果要抓住的相应内容是访问另一个URL地址和返回的数据,那么它非常简单,还需要访问此URL,然后获取相应的返回内容,从中提取您想要的数据。
总结
同一句话,不管你访问的内容是如何生成的,最后你还是可以用工具来分析对应的内容是如何从零开始生成的。
然后用代码模拟这个过程,最后提取出你需要的内容;
具体示例演示见:
【教程】以网易博文的最新读者信息为例,教大家如何抓取动态网页的内容。 查看全部
如何抓取网页flash(如何抓取网页中的动态网页源码中特定的特定内容)
背景
很多时候,很多人需要在网络上抓取一些特定的内容。
但是,除了之前介绍的内容之外,您还想从某些静态网页中提取某些内容,例如:
[教程] Python版本爬行网络并提取网页所需的信息
和
[教程] C#版本爬行网络并提取来自网页所需的信息
另外,有些人会发现自己要抓取的网页内容不在网页的源代码中。
所以,在这一点上,我不知道该怎么做。
在这里,我们来解释一下如何爬取所谓的动态网页中的特定内容。
必备知识
在阅读本文之前,您需要具备相关的基础知识:
1.爬取网页,模拟登录等相关逻辑
如果您不熟悉它,则可以参考:
[组织]爬网网页的逻辑/过程和预防措施,分析网页内容和模拟登录网站
2.学会使用工具,例如IE9的F12,抓住相应的网页执行过程
对于那些不熟悉的人,请参阅:
[教程]教导您如何使用工具(IE9 2)的f1来分析模拟登录的内部逻辑进程网站(百度首页))
3.对于正常的静态网页,如何提取所需内容
对于那些不熟悉的人,您可以参考:
(1) python版本:
[教程] Python版本爬行网络并提取网页所需的信息
(2) c#版本:
[教程] C#版本爬行网络并提取来自网页所需的信息
什么是动态网页
这里所谓的动态网页是相对于那些静态网页而言的。
这里所说的静态网页是指通过浏览器查看网页源代码时,你看到的网页源代码中的内容与网页上显示的内容相对应。
也就是说,当我想得到某个网页上显示的内容时,我可以通过查找网页的源代码找到对应的部分。
动态网页,相反,如果要获取动态网页中的具体内容,直接查看网页源代码是找不到的。
动态网页中的动态内容从何而来?
所以,这里有一个问题:
所谓动态网页中的动态内容从何而来?
一般来说,它是通过其他方式生成或获取的。
据我所知,有几个:
由本地 Javascript 脚本生成
如果你用IE9的F12来分析访问一个url的过程,你会发现很可能涉及到,
在网页正常完整显示之前,这段时间会访问很多javascript脚本,简称js脚本或js。
这些js脚本实现了很多动态的交互内容。
其中,对于一些你想抓取的内容,有时候,这些js脚本是动态执行的,最后计算出来的。
通过访问另一个url地址获得
很多时候,有些内容是访问另一个url地址后返回的数据;
如何获取我要抓取的动态内容
其实对于如何爬取需要的动态内容,简单来说,有一个解决方案:
根据您通过工具分析的结果,查找相应的数据并提取它;
但是,有时可以直接在分析结果的过程中提取该数据,有时它可以通过JS计算。
想要抓住数据,它由JS脚本生成
虽然由JS脚本执行生成最终动态内容,但是对于您要刮的数据:
想要通过访问另一个URL来获得刮除数据
如果要抓住的相应内容是访问另一个URL地址和返回的数据,那么它非常简单,还需要访问此URL,然后获取相应的返回内容,从中提取您想要的数据。
总结
同一句话,不管你访问的内容是如何生成的,最后你还是可以用工具来分析对应的内容是如何从零开始生成的。
然后用代码模拟这个过程,最后提取出你需要的内容;
具体示例演示见:
【教程】以网易博文的最新读者信息为例,教大家如何抓取动态网页的内容。
如何抓取网页flash(如何通过网页代码来优化seo呢?())
网站优化 • 优采云 发表了文章 • 0 个评论 • 73 次浏览 • 2022-03-24 16:21
在线推广的方式有很多,SEO优化就是其中之一。那么如何通过网页代码来优化seo呢?我们都知道搜索引擎和访问用户的行为方式是一样的,但是当它访问网页时,它主要针对网页的源代码。因此,为了更好地支持蜘蛛的爬取和爬取,需要对网页代码进行简化,并对网页代码中的标签进行优化。
? 代码缩减:
代码简化是指对网页中的代码进行简化,提高网页的加载速度,改善用户体验,从而实现seo优化,提高搜索引擎友好度。
网页代码的简化通常可以分为以下几个方面:
1、 垃圾代码清理
2、HTML标签转换
对于代码量非常大的网站有意义,但是对于普通cms系统生成的小网站模板就没有意义了。
3、CSS代码优化
CSS是cascading style sheet的缩写,即级联样式表。它是目前最常用的控制网页布局、字体、颜色和背景的技术。CSS优化主要是改变调用CSS的方式,使用DIV+CSS使深圳网站防止垃圾代码的产生。
4、JS代码优化
JS 是 Javascript 的缩写。在搜索引擎看来,JS 对搜索引擎并不友好。如果内容放在 JS 中,则无法被搜索引擎抓取。JS优化主要是避免JS代码占用网页空间和重要位置,放置一些搜索引擎不想看到的内容。
? 标签优化:
对于网站的单个页面,在header中三大标签优化完成后,整个网页的代码优化大致完成了一半,其他重要权重标签的优化占其余一半,比如h标签和b标签等。
1、权重标签
权重标签是影响网页权重或相关性的标签。权重标签常用于突出网页中比较重要的内容,从而提高网页的相关性,增加网页的权重。
h标签是所有权重标签中最重要的标签。不同的h标签有不同的功能和出现。例如:h1只出现一次,主要用在标题中;h2出现3、4次就够了,主要用在主段落标题、次分类;h3可能偶尔会出现在更详细的分类网站首页,但是h4后面的h标签一般是不需要使用的。
2、其他标签优化
还有一些其他标签可以适当优化,例如: 查看全部
如何抓取网页flash(如何通过网页代码来优化seo呢?())
在线推广的方式有很多,SEO优化就是其中之一。那么如何通过网页代码来优化seo呢?我们都知道搜索引擎和访问用户的行为方式是一样的,但是当它访问网页时,它主要针对网页的源代码。因此,为了更好地支持蜘蛛的爬取和爬取,需要对网页代码进行简化,并对网页代码中的标签进行优化。
? 代码缩减:
代码简化是指对网页中的代码进行简化,提高网页的加载速度,改善用户体验,从而实现seo优化,提高搜索引擎友好度。
网页代码的简化通常可以分为以下几个方面:
1、 垃圾代码清理
2、HTML标签转换
对于代码量非常大的网站有意义,但是对于普通cms系统生成的小网站模板就没有意义了。
3、CSS代码优化
CSS是cascading style sheet的缩写,即级联样式表。它是目前最常用的控制网页布局、字体、颜色和背景的技术。CSS优化主要是改变调用CSS的方式,使用DIV+CSS使深圳网站防止垃圾代码的产生。
4、JS代码优化
JS 是 Javascript 的缩写。在搜索引擎看来,JS 对搜索引擎并不友好。如果内容放在 JS 中,则无法被搜索引擎抓取。JS优化主要是避免JS代码占用网页空间和重要位置,放置一些搜索引擎不想看到的内容。
? 标签优化:

对于网站的单个页面,在header中三大标签优化完成后,整个网页的代码优化大致完成了一半,其他重要权重标签的优化占其余一半,比如h标签和b标签等。
1、权重标签
权重标签是影响网页权重或相关性的标签。权重标签常用于突出网页中比较重要的内容,从而提高网页的相关性,增加网页的权重。
h标签是所有权重标签中最重要的标签。不同的h标签有不同的功能和出现。例如:h1只出现一次,主要用在标题中;h2出现3、4次就够了,主要用在主段落标题、次分类;h3可能偶尔会出现在更详细的分类网站首页,但是h4后面的h标签一般是不需要使用的。
2、其他标签优化
还有一些其他标签可以适当优化,例如:
如何抓取网页flash(火狐保存网页中的Flash方法(MozillaFirefox)(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 53 次浏览 • 2022-03-22 13:26
Firefox 将 Flash 方法保存在网页中。
①点击“工具->页面信息->媒体”,或者在网页上右击->页面信息->媒体,找到要保存的Flash,然后点击保存。
②如果安装了 Adblock,可以打开 Adblock 的 Obj-Tabs 选项查看 Flash 的地址,然后使用 flashget 等下载软件下载 Flash。
③ 安装扩展下载嵌入式(推荐)。Download Embedded扩展在工具和右键中分别增加了上下文菜单,可以快速抓取页面内嵌的flash动画、电影、mp3等,比通过网页源代码或页面信息抓取更方便。
介绍
Mozilla Firefox 是由 Mozilla 开发的网络浏览器。它使用 Gecko 网页布局引擎,支持多种操作系统。开源代码以多许可方式获得许可,包括 Mozilla 公共许可 (MPL)、GNU 通用公共许可条款 (GPL) 和 GNU 宽松公共许可 (LGPL),目标是创建一个开放、创新和基于机会的网络环境。
目前,火狐浏览器在全球浏览器市场份额排名第三,谷歌Chrome在2011年11月的市场份额正式超越火狐浏览器,跃居第二位。
多年来,Mozilla 对 Firefox 的开发计划的总体原则是每 一、 两年对 Firefox 进行一次重大的功能升级。2010 年 1 月 14 日,Mozilla 表示,未来将调整上述产品发布原则,即通过定期发布安全升级,逐步为 Firefox 添加新功能。此类升级的发布时间为每 6 周。2012年1月11日上午,Mozilla正在进行火狐浏览器长期支持版本(Extended Support Release,以下简称“ESR”)的研发工作。这个版本的浏览器更新速度比较慢,一年更新一次,不会像普通版那样每六周更新一次。 查看全部
如何抓取网页flash(火狐保存网页中的Flash方法(MozillaFirefox)(图))
Firefox 将 Flash 方法保存在网页中。
①点击“工具->页面信息->媒体”,或者在网页上右击->页面信息->媒体,找到要保存的Flash,然后点击保存。
②如果安装了 Adblock,可以打开 Adblock 的 Obj-Tabs 选项查看 Flash 的地址,然后使用 flashget 等下载软件下载 Flash。
③ 安装扩展下载嵌入式(推荐)。Download Embedded扩展在工具和右键中分别增加了上下文菜单,可以快速抓取页面内嵌的flash动画、电影、mp3等,比通过网页源代码或页面信息抓取更方便。
介绍
Mozilla Firefox 是由 Mozilla 开发的网络浏览器。它使用 Gecko 网页布局引擎,支持多种操作系统。开源代码以多许可方式获得许可,包括 Mozilla 公共许可 (MPL)、GNU 通用公共许可条款 (GPL) 和 GNU 宽松公共许可 (LGPL),目标是创建一个开放、创新和基于机会的网络环境。
目前,火狐浏览器在全球浏览器市场份额排名第三,谷歌Chrome在2011年11月的市场份额正式超越火狐浏览器,跃居第二位。
多年来,Mozilla 对 Firefox 的开发计划的总体原则是每 一、 两年对 Firefox 进行一次重大的功能升级。2010 年 1 月 14 日,Mozilla 表示,未来将调整上述产品发布原则,即通过定期发布安全升级,逐步为 Firefox 添加新功能。此类升级的发布时间为每 6 周。2012年1月11日上午,Mozilla正在进行火狐浏览器长期支持版本(Extended Support Release,以下简称“ESR”)的研发工作。这个版本的浏览器更新速度比较慢,一年更新一次,不会像普通版那样每六周更新一次。
如何抓取网页flash(Flash动画在网页制作中的应用及探讨(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 73 次浏览 • 2022-03-11 09:22
Flash动画在网页制作中的应用与探讨
(作者:__________ 单位:__________ 邮编:__________)
过去十年,应用开发领域以及相关技术提供的数字资源和传播渠道都发生了深刻变化。现在,在设计和开发应用程序时,技术是为了充分利用连接计算的优势。
提供,因为它的文件大小非常小。Flash 通过大量使用矢量图形来做到这一点。与位图图形相比,矢量图形需要更少的内存和存储空间,因为它们表示为数学公式而不是大型数据集。位图图形更大,因为图像中的每个像素都需要一组单独的数据来表示。
要在 Flash 中构建应用程序,您可以使用 Flash 绘图工具创建图形并将其媒体元素导入 Flash 文档。在 Flash 中创作内容时,您需要使用 Flash 文档文件。Flash 文档的文件扩展名为 fla(FLA)。在各个领域,Flash在网页动画设计和网页组织方面都将展现出巨大的生命力。其应用前景令人鼓舞。
一、Flash动画在网页设计中的应用
1、Flash动画在网页设计中的部分应用
在网页设计中,Flash 动画作品除了
除了“流式动画”播放,如:Flash动画短片、FlashMV,还具有一定的交互功能形式。有的网站的引导界面做成Flash动画形式,一般由Dreamweaver软件完成,做成静态页面。当然,这些页面大部分都是静态的,但也有一些网站s做了如下设计。如:网页中的Flash网络广告、Flash图片展示动画、网站导航栏动画、图片展示动画、Flash交互动画、网站由Flash制作的注册、登录、计算系统。
在静态页面中,如果将这些做成动画形式,无疑可以起到生动的装饰作用,并且可以充分调动浏览器。不过也不能太花里胡哨,否则会适得其反,不仅使浏览器眼花缭乱,而且会大大降低企业网站的效果,显得心烦意乱,缺乏信任感。
2、Flash动画在整个网站设计中的应用
上一篇文章中提到,除了用Flash制作相关的贞操外,还有一些网站,为了展示自己的个性,用Flash制作整个网站。
整个网站的概念设计包括所有视听元素和布局。
<p>网站别说引导界面的设计了,由它引导的内页整个系统都是用Flash软件制作的,包括上面列出的视频、Flash广告动画、Flash互动动画、 查看全部
如何抓取网页flash(Flash动画在网页制作中的应用及探讨(图))
Flash动画在网页制作中的应用与探讨
(作者:__________ 单位:__________ 邮编:__________)
过去十年,应用开发领域以及相关技术提供的数字资源和传播渠道都发生了深刻变化。现在,在设计和开发应用程序时,技术是为了充分利用连接计算的优势。
提供,因为它的文件大小非常小。Flash 通过大量使用矢量图形来做到这一点。与位图图形相比,矢量图形需要更少的内存和存储空间,因为它们表示为数学公式而不是大型数据集。位图图形更大,因为图像中的每个像素都需要一组单独的数据来表示。
要在 Flash 中构建应用程序,您可以使用 Flash 绘图工具创建图形并将其媒体元素导入 Flash 文档。在 Flash 中创作内容时,您需要使用 Flash 文档文件。Flash 文档的文件扩展名为 fla(FLA)。在各个领域,Flash在网页动画设计和网页组织方面都将展现出巨大的生命力。其应用前景令人鼓舞。
一、Flash动画在网页设计中的应用
1、Flash动画在网页设计中的部分应用
在网页设计中,Flash 动画作品除了
除了“流式动画”播放,如:Flash动画短片、FlashMV,还具有一定的交互功能形式。有的网站的引导界面做成Flash动画形式,一般由Dreamweaver软件完成,做成静态页面。当然,这些页面大部分都是静态的,但也有一些网站s做了如下设计。如:网页中的Flash网络广告、Flash图片展示动画、网站导航栏动画、图片展示动画、Flash交互动画、网站由Flash制作的注册、登录、计算系统。
在静态页面中,如果将这些做成动画形式,无疑可以起到生动的装饰作用,并且可以充分调动浏览器。不过也不能太花里胡哨,否则会适得其反,不仅使浏览器眼花缭乱,而且会大大降低企业网站的效果,显得心烦意乱,缺乏信任感。
2、Flash动画在整个网站设计中的应用
上一篇文章中提到,除了用Flash制作相关的贞操外,还有一些网站,为了展示自己的个性,用Flash制作整个网站。
整个网站的概念设计包括所有视听元素和布局。
<p>网站别说引导界面的设计了,由它引导的内页整个系统都是用Flash软件制作的,包括上面列出的视频、Flash广告动画、Flash互动动画、
如何抓取网页flash(如何抓取网页flash呢?答案就是javascript抓取呢)
网站优化 • 优采云 发表了文章 • 0 个评论 • 57 次浏览 • 2022-03-10 04:08
如何抓取网页flash呢?答案就是javascript,不过很麻烦,我们通过google的html5接口进行抓取,获取html中的所有字符串内容。javascript抓取原理首先,我们需要解释下javascript的原理。google的技术栈中包含了script/css/html4j等,script和css等主要是封装在javascript的javascript.所以,只要我们的网页是javascript开发的,那么我们也可以很轻松的拿到网页的所有内容。
html5javascript抓取项目介绍1.项目目的首先,我们需要明确我们要抓取的网页是什么类型的。在介绍项目的目的之前,我们先解释下我们到底想要抓取的是一些什么样的内容。其实,通过这一节我们将得到以下信息:从浏览器到浏览器的传输信息。主要的机制是一个http头,即请求资源时的header。每一个资源对应一个url,我们将其称之为requestresponse,如下图所示。
根据csdn上的介绍,在一个合法的http服务器下,实际将数据传输给客户端,需要5阶段的处理过程,每个阶段都包含一些特定的信息。接着,我们将其进行分类。分类过程主要分为两类:第一类:相互独立。第二类:不同的单元内部。我们将一些特定的头信息header将其关联在一起。最后,我们将数据从header中进行提取。
这一步,我们最终得到一些内容。当然,在这一阶段,我们将提取信息分为五类:1.资源内容header2.request请求url和responseurl3.http中的header(常是post请求时提供的header)4.属性信息,例如adminroleaccounturl等5.getrequestheader下面我们将其解释如下:首先我们得到一个header头信息,这个头信息包含了一些表单的信息,例如cookie。
随后我们分为两个阶段,从服务器接收数据后的5阶段中,各提取对应的信息。第一阶段:从服务器接收数据。服务器一般采用dns服务器,我们将数据下载后,一般传输至其中的dns服务器,然后由dns服务器来接收数据。http和https中,dns信息我们用(域名\/域名服务器)来表示。第二阶段:提取相关的数据。这一阶段我们分为一下几个步骤,不同的网站,这一步的不同处在于其组成网站的阶段划分不同,这些信息列表如下:由于采用类似的五阶段,基本原理上也是一样的,所以这里不再赘述。
2.项目代码下面我们讲解代码,包括注释和预览图,为了方便说明,我将代码都合并到github上,作为一个仓库。预览图同上一张我们已经抓取了从浏览器到浏览器的所有html资源,我们不仅将它们传输,同时还需要将它们解析。至于要解析什么东西,当然只是我的一些猜测,将。 查看全部
如何抓取网页flash(如何抓取网页flash呢?答案就是javascript抓取呢)
如何抓取网页flash呢?答案就是javascript,不过很麻烦,我们通过google的html5接口进行抓取,获取html中的所有字符串内容。javascript抓取原理首先,我们需要解释下javascript的原理。google的技术栈中包含了script/css/html4j等,script和css等主要是封装在javascript的javascript.所以,只要我们的网页是javascript开发的,那么我们也可以很轻松的拿到网页的所有内容。
html5javascript抓取项目介绍1.项目目的首先,我们需要明确我们要抓取的网页是什么类型的。在介绍项目的目的之前,我们先解释下我们到底想要抓取的是一些什么样的内容。其实,通过这一节我们将得到以下信息:从浏览器到浏览器的传输信息。主要的机制是一个http头,即请求资源时的header。每一个资源对应一个url,我们将其称之为requestresponse,如下图所示。
根据csdn上的介绍,在一个合法的http服务器下,实际将数据传输给客户端,需要5阶段的处理过程,每个阶段都包含一些特定的信息。接着,我们将其进行分类。分类过程主要分为两类:第一类:相互独立。第二类:不同的单元内部。我们将一些特定的头信息header将其关联在一起。最后,我们将数据从header中进行提取。
这一步,我们最终得到一些内容。当然,在这一阶段,我们将提取信息分为五类:1.资源内容header2.request请求url和responseurl3.http中的header(常是post请求时提供的header)4.属性信息,例如adminroleaccounturl等5.getrequestheader下面我们将其解释如下:首先我们得到一个header头信息,这个头信息包含了一些表单的信息,例如cookie。
随后我们分为两个阶段,从服务器接收数据后的5阶段中,各提取对应的信息。第一阶段:从服务器接收数据。服务器一般采用dns服务器,我们将数据下载后,一般传输至其中的dns服务器,然后由dns服务器来接收数据。http和https中,dns信息我们用(域名\/域名服务器)来表示。第二阶段:提取相关的数据。这一阶段我们分为一下几个步骤,不同的网站,这一步的不同处在于其组成网站的阶段划分不同,这些信息列表如下:由于采用类似的五阶段,基本原理上也是一样的,所以这里不再赘述。
2.项目代码下面我们讲解代码,包括注释和预览图,为了方便说明,我将代码都合并到github上,作为一个仓库。预览图同上一张我们已经抓取了从浏览器到浏览器的所有html资源,我们不仅将它们传输,同时还需要将它们解析。至于要解析什么东西,当然只是我的一些猜测,将。
如何抓取网页flash(如何抓取网页flash,我的理解是需要找一些合法的去网页源码)
网站优化 • 优采云 发表了文章 • 0 个评论 • 66 次浏览 • 2022-03-08 03:05
如何抓取网页flash,我的理解是需要找一些合法的去网页抓取源码,现在网上很多能抓取网页的第三方应用,从源码中提取。前段时间我试了人人网的,直接输入用户名密码就行。
你去,网页中有好多这样的。
现在那种下载软件抓到的都是小网站。真正的大网站你不知道,
感觉现在随便一个啥工具都能抓
非安全下,被黑的概率大于安全下,再安全,
你可以说arcgis会不会被破解这个命题,如果你是内网,那么当然不可能如果是外网的话,
目前针对静态网页的抓取工具是最好的。问题中所指抓取静态页面是指源代码html,js等记录下来,非html,js等是没办法读取的。arcgis也是如此,并且即使是静态页面在arcgis的看来都是一串信息,经常还会因为很多碎片没有组织,比如颜色、形状、图标等。目前navicat也只能抓取静态页面。
国内各大安全厂商已经成功破解了静态网页包括广告搜索页面
arcgis不适合。
国内只有安全厂商有抓取静态网页的能力。小网站都是黑客控制的。
商业公司完全可以做,直接拿到源代码,按照数据规模控制抓取成本吧,量比较大,
arcgis不会被adobe的安全公司破解,因为arcgis是商业服务,adobe帮你写好安全套件防护好了,自己用只要给钱,他们可以随便定制去发adobe的安全公司审核。ibm的arcgispro就是被adobe的安全服务包着走,用谁写的安全套件adobe并不知道,adobe只知道用自己的,(仅限于静态网页,不包括dom)就算是被adobe破解了也有据可查。 查看全部
如何抓取网页flash(如何抓取网页flash,我的理解是需要找一些合法的去网页源码)
如何抓取网页flash,我的理解是需要找一些合法的去网页抓取源码,现在网上很多能抓取网页的第三方应用,从源码中提取。前段时间我试了人人网的,直接输入用户名密码就行。
你去,网页中有好多这样的。
现在那种下载软件抓到的都是小网站。真正的大网站你不知道,
感觉现在随便一个啥工具都能抓
非安全下,被黑的概率大于安全下,再安全,
你可以说arcgis会不会被破解这个命题,如果你是内网,那么当然不可能如果是外网的话,
目前针对静态网页的抓取工具是最好的。问题中所指抓取静态页面是指源代码html,js等记录下来,非html,js等是没办法读取的。arcgis也是如此,并且即使是静态页面在arcgis的看来都是一串信息,经常还会因为很多碎片没有组织,比如颜色、形状、图标等。目前navicat也只能抓取静态页面。
国内各大安全厂商已经成功破解了静态网页包括广告搜索页面
arcgis不适合。
国内只有安全厂商有抓取静态网页的能力。小网站都是黑客控制的。
商业公司完全可以做,直接拿到源代码,按照数据规模控制抓取成本吧,量比较大,
arcgis不会被adobe的安全公司破解,因为arcgis是商业服务,adobe帮你写好安全套件防护好了,自己用只要给钱,他们可以随便定制去发adobe的安全公司审核。ibm的arcgispro就是被adobe的安全服务包着走,用谁写的安全套件adobe并不知道,adobe只知道用自己的,(仅限于静态网页,不包括dom)就算是被adobe破解了也有据可查。
如何抓取网页flash(如何抓取网页flash视频,进行解析,制作txt观看文件?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 90 次浏览 • 2022-03-06 20:05
如何抓取网页flash视频,进行解析,制作txt观看文件?-技术的分享-集智专栏分享的是一个做好了,而且很详细的脚本。分享者显然是知道我的。你看到我博客分享的东西,基本上都是对网页flash视频进行解析的,包括各种ppt视频,个人介绍视频。用脚本抓取解析网页,有一个明显的缺点,就是视频的压缩,图片尺寸越小,压缩率越高,但是却有以下的劣势:。
1、网页图片尺寸太小,如果解析过来的视频尺寸过大,就会出现很多不利于文件小。
2、图片尺寸太小,会大大浪费网络带宽资源。
3、可以通过下载flash的目录页来进行下载,如果解析的视频很大,可能会内存读取,占用的cpu资源。分享的是一个做好了,而且很详细的脚本。当然,还有这种。以上的脚本都是需要下载flash文件的。脚本在谷歌里面,都可以搜索到。脚本的github地址:-cnreference这个脚本的基本效果也没有,还是通过打开flash界面来抓取,但是一定要克制,不要太大的文件。
实际上,没有出现乱码,而且有些图片,确实尺寸太小了,但是,图片中显示的都是还原的flash的流量。分享的是一个做好了,而且很详细的脚本。当然,还有这种。以上的脚本都是需要下载flash文件的。脚本在谷歌里面,都可以搜索到。脚本的github地址:-cn分享的是一个做好了,而且很详细的脚本。当然,还有这种。以上的脚本都是需要下载flash文件的。脚本的github地址:-cn。 查看全部
如何抓取网页flash(如何抓取网页flash视频,进行解析,制作txt观看文件?)
如何抓取网页flash视频,进行解析,制作txt观看文件?-技术的分享-集智专栏分享的是一个做好了,而且很详细的脚本。分享者显然是知道我的。你看到我博客分享的东西,基本上都是对网页flash视频进行解析的,包括各种ppt视频,个人介绍视频。用脚本抓取解析网页,有一个明显的缺点,就是视频的压缩,图片尺寸越小,压缩率越高,但是却有以下的劣势:。
1、网页图片尺寸太小,如果解析过来的视频尺寸过大,就会出现很多不利于文件小。
2、图片尺寸太小,会大大浪费网络带宽资源。
3、可以通过下载flash的目录页来进行下载,如果解析的视频很大,可能会内存读取,占用的cpu资源。分享的是一个做好了,而且很详细的脚本。当然,还有这种。以上的脚本都是需要下载flash文件的。脚本在谷歌里面,都可以搜索到。脚本的github地址:-cnreference这个脚本的基本效果也没有,还是通过打开flash界面来抓取,但是一定要克制,不要太大的文件。
实际上,没有出现乱码,而且有些图片,确实尺寸太小了,但是,图片中显示的都是还原的flash的流量。分享的是一个做好了,而且很详细的脚本。当然,还有这种。以上的脚本都是需要下载flash文件的。脚本在谷歌里面,都可以搜索到。脚本的github地址:-cn分享的是一个做好了,而且很详细的脚本。当然,还有这种。以上的脚本都是需要下载flash文件的。脚本的github地址:-cn。
如何抓取网页flash(如何抓取网页flash信息-hunter-flash找了很久,就这个办法可行了)
网站优化 • 优采云 发表了文章 • 0 个评论 • 48 次浏览 • 2022-03-06 07:02
如何抓取网页flash信息-hunter-flash找了很久,就这个办法可行了!无奈,万万没想到是seeinelvis.youku、youtube,禁用或者去掉广告就可以了。
用flash吧,电脑是ie浏览器的话,可以下载chrome浏览器然后以管理员身份运行,
上b站可以用safariappmailchimp啊。使用里面的离线工具功能。b站发送到邮箱就可以了。或者让pc网页的代理服务器发送给b站就好。
直接用搜索引擎可以搜索到;f=zh_cn
哎,不敢想象啊。b站号称有800w的用户。而且这些人活跃在各个类似acg弹幕,jojob战电影等弹幕视频上。大家都直接搜索名字就可以搜到了。他们直接分享出来不是更方便,更多的资源也会找到你的。b站用户比起其他的视频平台要少,因为你会发现有很多关注度比你高,播放量高,或者这一个话题很火,这个要求就较高了,这就决定了你不会获得知乎的用户量。
而且上传视频比注册账号更麻烦,也就意味着资源多。那么,作为用户你希望他分享给你吗?或者,他有吗?或者,你有吗?或者,他有你也想获得呢?没有那么多的资源,又没有那么多的人。那么,你只能看别人,或者追番了。还有因为不是每个视频都是完整的。所以,你搜索时也要尽可能选择完整。 查看全部
如何抓取网页flash(如何抓取网页flash信息-hunter-flash找了很久,就这个办法可行了)
如何抓取网页flash信息-hunter-flash找了很久,就这个办法可行了!无奈,万万没想到是seeinelvis.youku、youtube,禁用或者去掉广告就可以了。
用flash吧,电脑是ie浏览器的话,可以下载chrome浏览器然后以管理员身份运行,
上b站可以用safariappmailchimp啊。使用里面的离线工具功能。b站发送到邮箱就可以了。或者让pc网页的代理服务器发送给b站就好。
直接用搜索引擎可以搜索到;f=zh_cn
哎,不敢想象啊。b站号称有800w的用户。而且这些人活跃在各个类似acg弹幕,jojob战电影等弹幕视频上。大家都直接搜索名字就可以搜到了。他们直接分享出来不是更方便,更多的资源也会找到你的。b站用户比起其他的视频平台要少,因为你会发现有很多关注度比你高,播放量高,或者这一个话题很火,这个要求就较高了,这就决定了你不会获得知乎的用户量。
而且上传视频比注册账号更麻烦,也就意味着资源多。那么,作为用户你希望他分享给你吗?或者,他有吗?或者,你有吗?或者,他有你也想获得呢?没有那么多的资源,又没有那么多的人。那么,你只能看别人,或者追番了。还有因为不是每个视频都是完整的。所以,你搜索时也要尽可能选择完整。
如何抓取网页flash(屏蔽搜索引擎对网站部分页面内容内容的方法有哪些?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 82 次浏览 • 2022-03-04 16:12
做SEO优化的人都知道,网站要想在搜索引擎中有好的排名,就需要搜索引擎爬取更多的网站内容页面,从而收录更多的< @网站的内容,只有这样有利于网站和页面的排名,让更多的用户通过搜索引擎了解网站,从而获得更多的流量和转化。
一些SEO人员在做网站排名优化的时候,为了让网站获得更好的垂直度,让搜索引擎更好的抓取网站的重要页面,会屏蔽一些页面,防止搜索引擎从这些页面中抓取和收录。
那么,有哪些方法可以防止搜索引擎抓取页面中网站部分的内容呢?接下来,让SEO公司告诉你!
1、在页面中设置robots协议
在做SEO优化的时候,如果要防止搜索引擎抓取网站的部分页面,首先想到的方法就是在页面中设置robots协议。当搜索引擎蜘蛛进入 网站 并爬取 网站 页面时,robots 协议会告诉搜索引擎 网站 的哪些页面可以爬取,哪些页面不能爬取,以便搜索引擎可以抓取一些更有意义的页面,有利于网站的整体排名。设置robots协议时,一般情况下一般设置在网站根目录下。
2、不关注
<p>nofollow标签实际上是HTML中的一个属性,nofollow标签的作用不仅可以阻止搜索引擎抓取页面,还可以阻止页面权重的传递。因此,如果想要阻止搜索引擎抓取网站页面,可以在页面上设置nofollow标签,使页面无法参与网站的排名,更有利于浓度 查看全部
如何抓取网页flash(屏蔽搜索引擎对网站部分页面内容内容的方法有哪些?)
做SEO优化的人都知道,网站要想在搜索引擎中有好的排名,就需要搜索引擎爬取更多的网站内容页面,从而收录更多的< @网站的内容,只有这样有利于网站和页面的排名,让更多的用户通过搜索引擎了解网站,从而获得更多的流量和转化。
一些SEO人员在做网站排名优化的时候,为了让网站获得更好的垂直度,让搜索引擎更好的抓取网站的重要页面,会屏蔽一些页面,防止搜索引擎从这些页面中抓取和收录。

那么,有哪些方法可以防止搜索引擎抓取页面中网站部分的内容呢?接下来,让SEO公司告诉你!
1、在页面中设置robots协议
在做SEO优化的时候,如果要防止搜索引擎抓取网站的部分页面,首先想到的方法就是在页面中设置robots协议。当搜索引擎蜘蛛进入 网站 并爬取 网站 页面时,robots 协议会告诉搜索引擎 网站 的哪些页面可以爬取,哪些页面不能爬取,以便搜索引擎可以抓取一些更有意义的页面,有利于网站的整体排名。设置robots协议时,一般情况下一般设置在网站根目录下。
2、不关注
<p>nofollow标签实际上是HTML中的一个属性,nofollow标签的作用不仅可以阻止搜索引擎抓取页面,还可以阻止页面权重的传递。因此,如果想要阻止搜索引擎抓取网站页面,可以在页面上设置nofollow标签,使页面无法参与网站的排名,更有利于浓度
如何抓取网页flash(华军软件园网络辅助频道提供网页FLASH抓取器抓取70历史版)
网站优化 • 优采云 发表了文章 • 0 个评论 • 72 次浏览 • 2022-02-26 01:05
11IDM 包括 网站 spider 和 scraper IDM 以下载使用 网站 过滤器指定的所有必需文件,例如来自 网站 或 网站Son of @> 的所有图像。
Dote软件站安卓下载为您提供网页FLASH抓取器V70安卓版,手机版下载,网页FLASH抓取器V70apk免费下载安装到手机,支持电脑便捷一键安装.
华军软件园网络辅助频道为您提供2016官方网页FLASH抓取器2016官方下载网页FLASH抓取器绿色版等网络辅助软件下载更多网页FLASH抓取器70历史版本。
一个网页抓取工具,网站抓取图片、文字等信息采集处理神器,值得一点,懂就好优采云采集器V9快乐版_pure版本共享,你懂的。
Flash 播放器长期以来一直存在安全问题。我使用 Flashblock 浏览器扩展来防止插件在网页上自动加载,原来的 Flash 内容将被替换。
PC下载网其他渠道,为您提供官方网页最新版FLASH采集卡网页FLASH采集卡绿色免费版等网络软件下载更多网页FLASH采集卡70最新版。
Arachnid 是一个基于 Java 的网络爬虫框架,包括一个简单的 HTML 解析器,可以分为 crawlzilla 是一个免费软件,可以帮助您轻松构建搜索引擎,ExCrawler 是一个网络爬虫,用 Java 开发,项目分为两部分,一是守护进程。 查看全部
如何抓取网页flash(华军软件园网络辅助频道提供网页FLASH抓取器抓取70历史版)
11IDM 包括 网站 spider 和 scraper IDM 以下载使用 网站 过滤器指定的所有必需文件,例如来自 网站 或 网站Son of @> 的所有图像。
Dote软件站安卓下载为您提供网页FLASH抓取器V70安卓版,手机版下载,网页FLASH抓取器V70apk免费下载安装到手机,支持电脑便捷一键安装.
华军软件园网络辅助频道为您提供2016官方网页FLASH抓取器2016官方下载网页FLASH抓取器绿色版等网络辅助软件下载更多网页FLASH抓取器70历史版本。
一个网页抓取工具,网站抓取图片、文字等信息采集处理神器,值得一点,懂就好优采云采集器V9快乐版_pure版本共享,你懂的。
Flash 播放器长期以来一直存在安全问题。我使用 Flashblock 浏览器扩展来防止插件在网页上自动加载,原来的 Flash 内容将被替换。
PC下载网其他渠道,为您提供官方网页最新版FLASH采集卡网页FLASH采集卡绿色免费版等网络软件下载更多网页FLASH采集卡70最新版。
Arachnid 是一个基于 Java 的网络爬虫框架,包括一个简单的 HTML 解析器,可以分为 crawlzilla 是一个免费软件,可以帮助您轻松构建搜索引擎,ExCrawler 是一个网络爬虫,用 Java 开发,项目分为两部分,一是守护进程。
如何抓取网页flash(如何抓取网页flash视频同步方法总结(一)_软件)
网站优化 • 优采云 发表了文章 • 0 个评论 • 62 次浏览 • 2022-02-16 07:01
如何抓取网页flash视频同步方法总结一、通过video标签可以抓取视频1.浏览器抓取方法:提前下载这个插件,导入到chrome浏览器,然后将视频下载到本地。优点:不占内存,文件大小小,可编辑缺点:下载到本地的视频无法再次编辑2.服务器抓取方法:直接到国外网站抓取flash视频,并且可以支持版本监控优点:文件大小大,便于编辑缺点:需要翻墙优点:无需下载到本地,还可以进行视频加密解密,支持中文字幕二、通过网页上的视频标签可以抓取视频1.可以抓取html5视频标签2.视频网站视频图片同步下载方法优点:前端视频不占内存,文件大小小,可编辑缺点:前端视频加密方法无法再破解了???解决办法,这个方法缺点很多,现在已经不适用。
1.uc浏览器登录国内某某音乐平台,并且去标签,会看到“我已下载/国内音乐平台服务器上已下载某某音乐”,所以通过该标签抓取,解密,点击打开即可同步观看,是不是很方便。优点:前端视频不占内存,文件大小小,可编辑缺点:需要翻墙2.qq浏览器登录qq音乐,并且去标签,会看到“我已下载/qq音乐服务器上已下载某某音乐”,所以通过该标签抓取,解密,点击打开即可同步观看,是不是很方便。
优点:前端视频不占内存,文件大小小,可编辑缺点:前端视频加密方法无法再破解了???解决办法,这个方法缺点很多,现在已经不适用了。 查看全部
如何抓取网页flash(如何抓取网页flash视频同步方法总结(一)_软件)
如何抓取网页flash视频同步方法总结一、通过video标签可以抓取视频1.浏览器抓取方法:提前下载这个插件,导入到chrome浏览器,然后将视频下载到本地。优点:不占内存,文件大小小,可编辑缺点:下载到本地的视频无法再次编辑2.服务器抓取方法:直接到国外网站抓取flash视频,并且可以支持版本监控优点:文件大小大,便于编辑缺点:需要翻墙优点:无需下载到本地,还可以进行视频加密解密,支持中文字幕二、通过网页上的视频标签可以抓取视频1.可以抓取html5视频标签2.视频网站视频图片同步下载方法优点:前端视频不占内存,文件大小小,可编辑缺点:前端视频加密方法无法再破解了???解决办法,这个方法缺点很多,现在已经不适用。
1.uc浏览器登录国内某某音乐平台,并且去标签,会看到“我已下载/国内音乐平台服务器上已下载某某音乐”,所以通过该标签抓取,解密,点击打开即可同步观看,是不是很方便。优点:前端视频不占内存,文件大小小,可编辑缺点:需要翻墙2.qq浏览器登录qq音乐,并且去标签,会看到“我已下载/qq音乐服务器上已下载某某音乐”,所以通过该标签抓取,解密,点击打开即可同步观看,是不是很方便。
优点:前端视频不占内存,文件大小小,可编辑缺点:前端视频加密方法无法再破解了???解决办法,这个方法缺点很多,现在已经不适用了。
谷歌搜索建议网页图表信息使用图片少用HTML!
网站优化 • 优采云 发表了文章 • 0 个评论 • 160 次浏览 • 2022-05-05 07:17
近日,谷歌搜索负责人在线下站长交流群中跟站长分享搜索优化方向,建议网站图表信息多使用图片显示,尽量少用HTML5显示,方便谷歌搜索引擎抓取图表相关信息。
了解到,在这次群聊解答中,一个站长问谷歌搜索负责人约翰·穆勒,在网页上显示带有数据的图表的最佳优化方法是什么,在Google搜索看来,用图表形式发布图表还是用HTML5重新创建图表对网页排名好一点。对此谷歌搜索负责人约翰·穆勒回应:用图片还是HTML来显示网页表格内容,这取决于网站要通过图表展现的内容,我认为将图表变成HTML并将数字和标签放入文本不会从中获得很多价值,建议使用图片而不是HTML来显示网页的表格信息。
目前对于网站图表信息发布在谷歌搜索结果中可以获得排名最佳处理方式是:1,使用图像而不是使用HTML代码创建图表。如果图中有任何关键信息需要传递,站长可以添加图片相关alt属性描述,确保翻译不会丢失。这样当Google蜘蛛爬行和理解页面时,蜘蛛可以提取图像为文本,以便看不见图像的人也可以获取该信息。2,在图像周围添加足够的文本内容,以进一步说明图表的含义,跟上面一样,方便蜘蛛爬取图像提取为文本,获取图片信息。另外谷歌搜索负责人约翰·穆勒还提示,在使用图片传达图表信息时,要注意图像大小,避免图像过大影响网站加载速度,而且尽量能不用图表显示展示就不用,因为图表在Google图片搜索排名中的表现不是特别好,一般很少有用户使用Google Images查找特定的图表,所以站长尽量少用图表来进行图片优化排名!不过也有国内站长发布不同意见表示|:别听他的,用HTML5显示图表没有任何问题,用图片还存在盗用问题,另外图表要动咋办?放视频?那要交互咋办?
查看全部
谷歌搜索建议网页图表信息使用图片少用HTML!
近日,谷歌搜索负责人在线下站长交流群中跟站长分享搜索优化方向,建议网站图表信息多使用图片显示,尽量少用HTML5显示,方便谷歌搜索引擎抓取图表相关信息。
了解到,在这次群聊解答中,一个站长问谷歌搜索负责人约翰·穆勒,在网页上显示带有数据的图表的最佳优化方法是什么,在Google搜索看来,用图表形式发布图表还是用HTML5重新创建图表对网页排名好一点。对此谷歌搜索负责人约翰·穆勒回应:用图片还是HTML来显示网页表格内容,这取决于网站要通过图表展现的内容,我认为将图表变成HTML并将数字和标签放入文本不会从中获得很多价值,建议使用图片而不是HTML来显示网页的表格信息。
目前对于网站图表信息发布在谷歌搜索结果中可以获得排名最佳处理方式是:1,使用图像而不是使用HTML代码创建图表。如果图中有任何关键信息需要传递,站长可以添加图片相关alt属性描述,确保翻译不会丢失。这样当Google蜘蛛爬行和理解页面时,蜘蛛可以提取图像为文本,以便看不见图像的人也可以获取该信息。2,在图像周围添加足够的文本内容,以进一步说明图表的含义,跟上面一样,方便蜘蛛爬取图像提取为文本,获取图片信息。另外谷歌搜索负责人约翰·穆勒还提示,在使用图片传达图表信息时,要注意图像大小,避免图像过大影响网站加载速度,而且尽量能不用图表显示展示就不用,因为图表在Google图片搜索排名中的表现不是特别好,一般很少有用户使用Google Images查找特定的图表,所以站长尽量少用图表来进行图片优化排名!不过也有国内站长发布不同意见表示|:别听他的,用HTML5显示图表没有任何问题,用图片还存在盗用问题,另外图表要动咋办?放视频?那要交互咋办?
如何抓取网页flash( Node.js和Python的代码片段作引教您如何在Chromium中使用代理)
网站优化 • 优采云 发表了文章 • 0 个评论 • 61 次浏览 • 2022-04-19 18:39
Node.js和Python的代码片段作引教您如何在Chromium中使用代理)
剧作家网页抓取教程
近年来,随着互联网行业的发展,互联网的影响力逐渐提升。这也是由于技术水平的提高,开发了越来越多用户体验好的应用。此外,在从 Web 应用程序开发到测试的整个过程中使用自动化正变得越来越普遍。网络爬虫抓取数据的应用也越来越广泛。
拥有有效的工具来测试 Web 应用程序至关重要。像 Playwright 这样的库在浏览器中打开 Web 应用程序,并通过其他交互(例如单击元素、键入文本和从 Web 中提取公共数据)来加速该过程。
本教程介绍了 Playwright 以及如何将其用于自动化甚至网络抓取。
什么是剧作家?
Playwright 是一个自动化 Web 浏览器交互的测试和自动化框架。简而言之,您可以编写打开浏览器的代码,以及适用于所有 Web 浏览器的代码。自动化脚本可以实现导航到 URL、输入文本、单击按钮和提取文本等功能。Playwright 最令人惊讶的特点是它可以同时处理多个页面而无需等待或被阻塞。
Playwright 支持大多数浏览器,例如 Google Chrome、Firefox、带有 Chromium 内核的 Microsoft Edge 和带有 WebKit 内核的 Safari。跨浏览器网络自动化是 Playwright 的强项,可以有效地为所有浏览器执行相同的代码。此外,Playwright 还支持 Node.js、Python、Java 和 .NET 等多种编程语言。您可以编写代码来打开 网站 并使用其中任何一种语言与之交互。
Playwright 的文档非常详细和广泛。它涵盖了从入门到高级的所有课程和方法。
支持剧作家的代理
Playwright 支持使用代理。我们将引导您了解如何在 Chromium 中使用代理,使用以下 Node.js 和 Python 代码片段作为指南:
节点.js:
const { chromium } = require('playwright'); "
const browser = await chromium.launch();
Python:
from playwright.async_api import async_playwright
import asyncio
with async_playwright() as p:
browser = await p.chromium.launch()
上述代码只需稍作修改即可集成代理。使用 Node.js 时,启动函数可以接受 LauchOptions 类型的可选参数。这个 LaunchOption 对象可以发送几个其他参数,例如,headless。另一个需要的参数是代理。这个代理是另一个具有这些属性的对象:服务器、用户名、密码等。第一步是创建一个可以指定这些参数的对象。
// Node.js
const launchOptions = {
proxy: {
server: 123.123.123.123:80'
},
headless: false
}
第二步是将此对象传递给启动函数:
const browser = await chromium.launch(launchOptions);
就 Python 而言,情况略有不同。无需创建 LaunchOptions。相反,所有值都可以作为单独的参数发送。以下是代理字典的发送方式:
# Python
proxy_to_use = {
'server': '123.123.123.123:80'
}
browser = await pw.chromium.launch(proxy=proxy_to_use, headless=False)
在决定使用哪个代理来执行抓取时,最好使用住宅代理,因为它们不会留下任何痕迹,也不会触发任何安全警报。Oxylabs 的住宅代理是一个广泛而稳定的代理网络。您可以通过 Oxylabs 的 Residential Agents 访问国家、省甚至城市的特定站点。最重要的是,您还可以轻松地将 Oxylabs 的代理与 Playwright 集成。
01.用剧作家基本刮
下面我们将描述如何将 Playwright 与 Node.js 和 Python 一起使用。
如果您使用的是 Node.js,则需要创建一个新项目并安装 Playwright 库。可以通过这两个简单的命令来完成:
npm init -y
npm install playwright
打开动态页面的基本脚本如下:
const playwright = require('playwright');
(async () => {
const browser = await playwright.chromium.launch({
headless: false // Show the browser.
});
const page = await browser.newPage();
await page.goto('https://books.toscrape.com/');
await page.waitForTimeout(1000); // wait for 1 seconds
await browser.close();
})();
我们来看看上面的代码。第一行代码导入 Playwright。然后,启动 Chromium 实例。它允许脚本自动化 Chromium。请注意,此脚本将使用可视用户界面运行。成功传递 headless:false 后,会打开一个新的浏览器页面,page.goto 函数将导航到 Books to Scrape 页面。再等待 1 秒以将页面显示给最终用户。最后,浏览器关闭。
同样的代码也很容易用 Python 编写。首先,使用 pip 命令安装 Playwright:
pip install playwright
请注意,Playwright 支持两种模式 - 同步和异步。以下示例使用异步 API:
from playwright.async_api import async_playwright
import asyncio
async def main():
async with async_playwright() as pw:
browser = await pw.chromium.launch(
headless=False # Show the browser
)
page = await browser.new_page()
await page.goto('https://books.toscrape.com/')
# Data Extraction Code Here
await page.wait_for_timeout(1000) # Wait for 1 second
await browser.close()
if __name__ == '__main__':
asyncio.run(main())
此代码类似于 Node.js 代码。最大的不同是使用了 asyncio 库。另一个区别是函数名称从 camelCase 更改为 snake_case。
如果您想创建多个浏览器环境,或者想要更精确的控制,您可以创建一个环境对象并在该环境中创建多个页面。此代码将在新选项卡中打开页面:
const context = await browser.newContext();
const page1 = await context.newPage();
const page2 = await context.newPage();
如果您还想在代码中处理页面上下文。可以使用 page.context() 函数获取浏览器页面上下文。
02.位置元素
要从元素中提取信息或单击元素,第一步是定位元素。Playwright 支持 CSS 和 XPath 选择器。
用一个实际的例子可以更好地理解这一点。在Chrome中打开要爬取的页面的URL,在第一本书上右击,选择查看源代码。
你可以看到所有的书都在 article 元素下,它有一个类 product_prod。
要选择所有书籍,您需要在所有文章元素上设置循环。可以使用 CSS 选择器选择文章元素:
.product_pod
同样,也可以使用 XPath 选择器:
//*[@class="product_pod"]
要使用这些选择器,最常用的功能如下:
● $eval(selector, function) – 选择第一个元素,将元素发送给函数,并返回函数的结果;
● $$eval(selector, function) – 与上面相同,只是它选择所有元素;
● querySelector(selector) – 返回第一个元素;
● querySelectorAll(selector) – 返回所有元素。
这些方法在 CSS 和 XPath 选择器中都能正常工作。
03. 抓取文本
继续 Books to Scrape 页面的示例,页面加载后,您可以使用选择器和 $$eval 函数提取所有书籍容器。
const books = await page.$$eval('.product_pod', all_items
=> {
// run a loop here
})
然后可以循环提取收录书籍数据的所有元素:
all_items.forEach(book => {
const name = book.querySelector('h3').innerText;
})
最后,innerText 属性可用于从每个数据点中提取数据。以下是 Node.js 中的完整代码:
const playwright = require('playwright');
(async () => {
const browser = await playwright.chromium.launch();
const page = await browser.newPage();
await page.goto('https://books.toscrape.com/');
const books = await page.$$eval('.product_pod', all_items
=> {
const data = [];
all_items.forEach(book => {
const name = book.querySelector('h3').innerText;
const price = book.querySelector('.price_color').
innerText;
const stock = book.querySelector('.availability').
innerText;
data.push({ name, price, stock});
});
return data;
});
console.log(books);
await browser.close();
})();
Python 中的代码略有不同。Python有一个函数eval_on_selector,和Node.js的$eval类似,但不适合这种场景。原因是第二个参数仍然需要是 JavaScript。在某些情况下使用 JavaScript 可能没问题,但在这种情况下,用 Python 编写整个代码会更适用。
最好使用 query_selector 和 query_selector_all 分别返回一个元素和一个元素列表。
from playwright.async_api import async_playwright
import asyncio
async def main():
async with async_playwright() as pw:
browser = await pw.chromium.
page = await browser.new_page()
await page.goto('https://books.toscrape.com')
all_items = await page.query_selector_all('.product_pod')
books = []
for item in all_items:
book = {}
name_el = await item.query_selector('h3')
book['name'] = await name_el.inner_text()
price_el = await item.query_selector('.price_color')
book['price'] = await price_el.inner_text()
stock_el = await item.query_selector('.availability')
book['stock'] = await stock_el.inner_text()
books.append(book)
print(books)
await browser.close()
if __name__ == '__main__':
asyncio.run(main())
最后,Node.js 和 Python 代码的输出是一样的。
剧作家 VS 傀儡师和硒
除了使用 Playwright 之外,您还可以在抓取数据时使用 Selenium 和 Puppeteer。
使用 Puppeteer,您可以使用的浏览器和编程语言非常有限。目前唯一可用的语言是 JavaScript,唯一兼容的浏览器是 Chromium。
对于 Selenium,虽然与浏览器语言的兼容性很好。但是,它很慢,而且对开发人员不太友好。
还有一点需要注意的是,Playwright 可以拦截网络请求。查看有关网络请求的更多详细信息。
下面是三个工具的比较:
_
剧作家
傀儡师
硒
速度
快的
快的
慢点
归档能力
优秀的
优秀的
普通的
开发经验
最多
这很好
普通的
编程语言
JavaScript、Python、C# 和 Java
JavaScript
Java、Python、C#、Ruby、JavaScript 和 Kotlin
支持者
微软
谷歌
社区和赞助商
社区
小而活跃
大而活跃
大而活跃
可用的浏览器
Chromium、Firefox 和 WebKit
铬
Chrome、Firefox、IE、Edge、Opera 和 Safari 等。
综上所述
本文探讨了 Playwright 作为爬取动态站点的测试工具的功能,并收录 Node.js 和 Python 中的代码示例。由于其异步特性和跨浏览器支持,Playwright 是其他工具的流行替代品。
Playwright 可以实现导航到 URL、输入文本、单击按钮和提取文本等功能。它可以提取动态呈现的文本。这些事情也可以通过 Puppeteer 和 Selenium 等其他工具来完成,但如果需要使用多个浏览器,或者需要使用 JavaScript/Node.js 以外的语言,Playwright 会是更好的选择。
如果您对其他类似主题感兴趣,请查看我们的 文章 关于使用 Selenium 进行网络抓取或查看 Puppeteer 教程。您也可以随时访问我们的网站与客服沟通。 查看全部
如何抓取网页flash(
Node.js和Python的代码片段作引教您如何在Chromium中使用代理)
剧作家网页抓取教程
近年来,随着互联网行业的发展,互联网的影响力逐渐提升。这也是由于技术水平的提高,开发了越来越多用户体验好的应用。此外,在从 Web 应用程序开发到测试的整个过程中使用自动化正变得越来越普遍。网络爬虫抓取数据的应用也越来越广泛。
拥有有效的工具来测试 Web 应用程序至关重要。像 Playwright 这样的库在浏览器中打开 Web 应用程序,并通过其他交互(例如单击元素、键入文本和从 Web 中提取公共数据)来加速该过程。
本教程介绍了 Playwright 以及如何将其用于自动化甚至网络抓取。
什么是剧作家?
Playwright 是一个自动化 Web 浏览器交互的测试和自动化框架。简而言之,您可以编写打开浏览器的代码,以及适用于所有 Web 浏览器的代码。自动化脚本可以实现导航到 URL、输入文本、单击按钮和提取文本等功能。Playwright 最令人惊讶的特点是它可以同时处理多个页面而无需等待或被阻塞。
Playwright 支持大多数浏览器,例如 Google Chrome、Firefox、带有 Chromium 内核的 Microsoft Edge 和带有 WebKit 内核的 Safari。跨浏览器网络自动化是 Playwright 的强项,可以有效地为所有浏览器执行相同的代码。此外,Playwright 还支持 Node.js、Python、Java 和 .NET 等多种编程语言。您可以编写代码来打开 网站 并使用其中任何一种语言与之交互。
Playwright 的文档非常详细和广泛。它涵盖了从入门到高级的所有课程和方法。
支持剧作家的代理
Playwright 支持使用代理。我们将引导您了解如何在 Chromium 中使用代理,使用以下 Node.js 和 Python 代码片段作为指南:
节点.js:
const { chromium } = require('playwright'); "
const browser = await chromium.launch();
Python:
from playwright.async_api import async_playwright
import asyncio
with async_playwright() as p:
browser = await p.chromium.launch()
上述代码只需稍作修改即可集成代理。使用 Node.js 时,启动函数可以接受 LauchOptions 类型的可选参数。这个 LaunchOption 对象可以发送几个其他参数,例如,headless。另一个需要的参数是代理。这个代理是另一个具有这些属性的对象:服务器、用户名、密码等。第一步是创建一个可以指定这些参数的对象。
// Node.js
const launchOptions = {
proxy: {
server: 123.123.123.123:80'
},
headless: false
}
第二步是将此对象传递给启动函数:
const browser = await chromium.launch(launchOptions);
就 Python 而言,情况略有不同。无需创建 LaunchOptions。相反,所有值都可以作为单独的参数发送。以下是代理字典的发送方式:
# Python
proxy_to_use = {
'server': '123.123.123.123:80'
}
browser = await pw.chromium.launch(proxy=proxy_to_use, headless=False)
在决定使用哪个代理来执行抓取时,最好使用住宅代理,因为它们不会留下任何痕迹,也不会触发任何安全警报。Oxylabs 的住宅代理是一个广泛而稳定的代理网络。您可以通过 Oxylabs 的 Residential Agents 访问国家、省甚至城市的特定站点。最重要的是,您还可以轻松地将 Oxylabs 的代理与 Playwright 集成。
01.用剧作家基本刮
下面我们将描述如何将 Playwright 与 Node.js 和 Python 一起使用。
如果您使用的是 Node.js,则需要创建一个新项目并安装 Playwright 库。可以通过这两个简单的命令来完成:
npm init -y
npm install playwright
打开动态页面的基本脚本如下:
const playwright = require('playwright');
(async () => {
const browser = await playwright.chromium.launch({
headless: false // Show the browser.
});
const page = await browser.newPage();
await page.goto('https://books.toscrape.com/');
await page.waitForTimeout(1000); // wait for 1 seconds
await browser.close();
})();
我们来看看上面的代码。第一行代码导入 Playwright。然后,启动 Chromium 实例。它允许脚本自动化 Chromium。请注意,此脚本将使用可视用户界面运行。成功传递 headless:false 后,会打开一个新的浏览器页面,page.goto 函数将导航到 Books to Scrape 页面。再等待 1 秒以将页面显示给最终用户。最后,浏览器关闭。
同样的代码也很容易用 Python 编写。首先,使用 pip 命令安装 Playwright:
pip install playwright
请注意,Playwright 支持两种模式 - 同步和异步。以下示例使用异步 API:
from playwright.async_api import async_playwright
import asyncio
async def main():
async with async_playwright() as pw:
browser = await pw.chromium.launch(
headless=False # Show the browser
)
page = await browser.new_page()
await page.goto('https://books.toscrape.com/')
# Data Extraction Code Here
await page.wait_for_timeout(1000) # Wait for 1 second
await browser.close()
if __name__ == '__main__':
asyncio.run(main())
此代码类似于 Node.js 代码。最大的不同是使用了 asyncio 库。另一个区别是函数名称从 camelCase 更改为 snake_case。
如果您想创建多个浏览器环境,或者想要更精确的控制,您可以创建一个环境对象并在该环境中创建多个页面。此代码将在新选项卡中打开页面:
const context = await browser.newContext();
const page1 = await context.newPage();
const page2 = await context.newPage();
如果您还想在代码中处理页面上下文。可以使用 page.context() 函数获取浏览器页面上下文。
02.位置元素
要从元素中提取信息或单击元素,第一步是定位元素。Playwright 支持 CSS 和 XPath 选择器。
用一个实际的例子可以更好地理解这一点。在Chrome中打开要爬取的页面的URL,在第一本书上右击,选择查看源代码。
你可以看到所有的书都在 article 元素下,它有一个类 product_prod。
要选择所有书籍,您需要在所有文章元素上设置循环。可以使用 CSS 选择器选择文章元素:
.product_pod
同样,也可以使用 XPath 选择器:
//*[@class="product_pod"]
要使用这些选择器,最常用的功能如下:
● $eval(selector, function) – 选择第一个元素,将元素发送给函数,并返回函数的结果;
● $$eval(selector, function) – 与上面相同,只是它选择所有元素;
● querySelector(selector) – 返回第一个元素;
● querySelectorAll(selector) – 返回所有元素。
这些方法在 CSS 和 XPath 选择器中都能正常工作。
03. 抓取文本
继续 Books to Scrape 页面的示例,页面加载后,您可以使用选择器和 $$eval 函数提取所有书籍容器。
const books = await page.$$eval('.product_pod', all_items
=> {
// run a loop here
})
然后可以循环提取收录书籍数据的所有元素:
all_items.forEach(book => {
const name = book.querySelector('h3').innerText;
})
最后,innerText 属性可用于从每个数据点中提取数据。以下是 Node.js 中的完整代码:
const playwright = require('playwright');
(async () => {
const browser = await playwright.chromium.launch();
const page = await browser.newPage();
await page.goto('https://books.toscrape.com/');
const books = await page.$$eval('.product_pod', all_items
=> {
const data = [];
all_items.forEach(book => {
const name = book.querySelector('h3').innerText;
const price = book.querySelector('.price_color').
innerText;
const stock = book.querySelector('.availability').
innerText;
data.push({ name, price, stock});
});
return data;
});
console.log(books);
await browser.close();
})();
Python 中的代码略有不同。Python有一个函数eval_on_selector,和Node.js的$eval类似,但不适合这种场景。原因是第二个参数仍然需要是 JavaScript。在某些情况下使用 JavaScript 可能没问题,但在这种情况下,用 Python 编写整个代码会更适用。
最好使用 query_selector 和 query_selector_all 分别返回一个元素和一个元素列表。
from playwright.async_api import async_playwright
import asyncio
async def main():
async with async_playwright() as pw:
browser = await pw.chromium.
page = await browser.new_page()
await page.goto('https://books.toscrape.com')
all_items = await page.query_selector_all('.product_pod')
books = []
for item in all_items:
book = {}
name_el = await item.query_selector('h3')
book['name'] = await name_el.inner_text()
price_el = await item.query_selector('.price_color')
book['price'] = await price_el.inner_text()
stock_el = await item.query_selector('.availability')
book['stock'] = await stock_el.inner_text()
books.append(book)
print(books)
await browser.close()
if __name__ == '__main__':
asyncio.run(main())
最后,Node.js 和 Python 代码的输出是一样的。
剧作家 VS 傀儡师和硒
除了使用 Playwright 之外,您还可以在抓取数据时使用 Selenium 和 Puppeteer。
使用 Puppeteer,您可以使用的浏览器和编程语言非常有限。目前唯一可用的语言是 JavaScript,唯一兼容的浏览器是 Chromium。
对于 Selenium,虽然与浏览器语言的兼容性很好。但是,它很慢,而且对开发人员不太友好。
还有一点需要注意的是,Playwright 可以拦截网络请求。查看有关网络请求的更多详细信息。
下面是三个工具的比较:
_
剧作家
傀儡师
硒
速度
快的
快的
慢点
归档能力
优秀的
优秀的
普通的
开发经验
最多
这很好
普通的
编程语言
JavaScript、Python、C# 和 Java
JavaScript
Java、Python、C#、Ruby、JavaScript 和 Kotlin
支持者
微软
谷歌
社区和赞助商
社区
小而活跃
大而活跃
大而活跃
可用的浏览器
Chromium、Firefox 和 WebKit
铬
Chrome、Firefox、IE、Edge、Opera 和 Safari 等。
综上所述
本文探讨了 Playwright 作为爬取动态站点的测试工具的功能,并收录 Node.js 和 Python 中的代码示例。由于其异步特性和跨浏览器支持,Playwright 是其他工具的流行替代品。
Playwright 可以实现导航到 URL、输入文本、单击按钮和提取文本等功能。它可以提取动态呈现的文本。这些事情也可以通过 Puppeteer 和 Selenium 等其他工具来完成,但如果需要使用多个浏览器,或者需要使用 JavaScript/Node.js 以外的语言,Playwright 会是更好的选择。
如果您对其他类似主题感兴趣,请查看我们的 文章 关于使用 Selenium 进行网络抓取或查看 Puppeteer 教程。您也可以随时访问我们的网站与客服沟通。
如何抓取网页flash(如何抓取网页flash视频?-百度这个问题应该有答案)
网站优化 • 优采云 发表了文章 • 0 个评论 • 54 次浏览 • 2022-04-17 20:04
如何抓取网页flash视频?-百度这个问题应该有答案
因为很多网站的视频都是采用cdn加速,如果你抓包就会发现采用cdn服务的网站上视频都有flash加速,需要先得到视频地址,再对视频进行抓取,
因为视频都是被加密了的,只有你自己才能下载解密。你可以看一下第一步:给视频起个名字,
我猜你是想要去b站看视频。如果是这样,你是要在b站上看flash还是html5视频,需要仔细斟酌一下。
像这种视频都是经过p2p加速的,b站没有对视频进行解密,你可以先看一下那些抓取到视频的网站,如果有解密按钮就去试试
我才发现他们的网页都采用cdn加速了,b站不提供看本地视频,
因为https连接都用cdn,而avplayer视频大多采用hls协议加密,所以需要获取上传者ip才能获取视频下载地址。
因为只有你可以下载
因为b站都是付费观看flash,为了达到更好的播放效果以及广告减少。而现在chrome内核的浏览器都会支持,然后需要通过云存储发布,存储方式可以用移动硬盘存放视频并且选择用网盘或者本地存储保存。不过支持flash的网盘你可以看看。
因为,
因为是网易的锅,把图片做成视频一发布,你就能看到了。p.s.b站最近全给做的土味视频了。 查看全部
如何抓取网页flash(如何抓取网页flash视频?-百度这个问题应该有答案)
如何抓取网页flash视频?-百度这个问题应该有答案
因为很多网站的视频都是采用cdn加速,如果你抓包就会发现采用cdn服务的网站上视频都有flash加速,需要先得到视频地址,再对视频进行抓取,
因为视频都是被加密了的,只有你自己才能下载解密。你可以看一下第一步:给视频起个名字,
我猜你是想要去b站看视频。如果是这样,你是要在b站上看flash还是html5视频,需要仔细斟酌一下。
像这种视频都是经过p2p加速的,b站没有对视频进行解密,你可以先看一下那些抓取到视频的网站,如果有解密按钮就去试试
我才发现他们的网页都采用cdn加速了,b站不提供看本地视频,
因为https连接都用cdn,而avplayer视频大多采用hls协议加密,所以需要获取上传者ip才能获取视频下载地址。
因为只有你可以下载
因为b站都是付费观看flash,为了达到更好的播放效果以及广告减少。而现在chrome内核的浏览器都会支持,然后需要通过云存储发布,存储方式可以用移动硬盘存放视频并且选择用网盘或者本地存储保存。不过支持flash的网盘你可以看看。
因为,
因为是网易的锅,把图片做成视频一发布,你就能看到了。p.s.b站最近全给做的土味视频了。
如何抓取网页flash(做Flash网站的优化,做下来真是感慨万千呀!)
网站优化 • 优采云 发表了文章 • 0 个评论 • 70 次浏览 • 2022-04-12 20:40
这个文章不错,转载于:华SEO:
说说我是如何优化flash的网站
优化到此为止,接手了几处flash网站的优化,真的给我留下了深刻的印象!今天来说说我是如何优化flash网站的?做Flash网站的优化真是个烫手山芋。无论是 SEO 专家还是网页设计师,Flash 对整个网站来说无疑是一项了不起的技术,包括一个网站 上的声音和图片,Flash 动画对于大多数 SEO 来说都是一场噩梦。原因很简单 - 搜索引擎无法索引(或至少不容易)您的内容中的 Flash 文件,除非您为 Flash 配备网络文本,并且您可以依靠这些问题来提高您的 网站 排名。当然还有其他选择,但在搜索引擎开始索引 Flash 动画之前,
为什么搜索引擎不喜欢 Flash网站?
搜索引擎不喜欢 Flash网站,不是因为它们的艺术品质和专业视角(或缺乏),而是因为 Flash 动画太复杂以至于蜘蛛都能理解。蜘蛛不能直接索引 Flash 电影,因为它们与普通网页的文本不同。蜘蛛索引的文件名(在网络上可用),不在内容中。
Flash 动画,采用专有的二进制格式,蜘蛛无法读取里面的 Flash 文件,至少对搜索引擎没有帮助,蜘蛛不会抓取和索引所有 Flash 内容,这是所有当前搜索引擎的情况(也许我的讨论会是不同),如何衡量搜索引擎页面的相关性?我相信大多数 SEO 人都讨厌搜索引擎的这些缺点。
不使用闪存?
尽管 Flash 动画不是蜘蛛的最爱,但有时 Flash 电影优化仍然值得 SEO 努力。但作为一般规则,将 Flash 动画保持在最低限度。在这种情况下,对搜索引擎有一定的友好性。首先,Flash 动画,尤其是横幅广告和其他类型的广告,通常会被大多数网民跳过。二、Flash动画肥大,占用带宽大,
主页使用 Flash 进行导航。Flash虽然时尚华丽,但外部链接却无法被搜索引擎收录。还有一些常见的错误是使用图片或 JavaScript 进行导航,这对搜索引擎不利。文本链接是 SEO 认可的独特方式来构建 网站 导航。
替代优化闪存网站
但是Flash网站,还是可以优化的。有几种方法:
• 输入继电器
这是一个非常重要的实践,但经常被低估和误解。虽然元数据不是搜索引擎的重要基础,但可以轻松地将元数据添加到您的电影中,这并不是在中继领域留下空白的借口。
• 提供替代网页
一个好的网站,是一个必须提供HTML的页面,只是不会强迫用户观看Flash电影。准备这些页面需要更多的工作,但搜索引擎会给你更多的回报,因为不仅用户习惯了 HTML 页面,搜索引擎也喜欢 HTML 页面。
但是,您仍然需要有正确的内容,例如,可能页面需要对其中的文本和链接进行一些调整,例如您可以使关键字内容丰富的标题和描述。
此外,您需要检查提取的句子和段落之间是否没有重复的内容。文本的字体颜色是另一个问题。如果文本的字体颜色与背景颜色相同,那么你需要小心搜索引擎火灾。
这两种方法只是其中一些最重要的例子,还有很多其他方法可以优化 Flash网站。但并非所有方法都非常出色和清晰,或者它们可以归类为边界上的合乎道德的 SEO,例如,创建传递给蜘蛛而不是 Flash 电影本身的不可见文本层。虽然这种技术没有任何问题 - 也就是说,没有重复或虚假内容,但它与伪装和门户页面非常相似,最好避免使用。
看完我的讲解,相信你应该对flash的优化有了更深入的了解网站!欢迎大家一起讨论,我们一起努力做SEO。
记得分享好资料! 查看全部
如何抓取网页flash(做Flash网站的优化,做下来真是感慨万千呀!)
这个文章不错,转载于:华SEO:
说说我是如何优化flash的网站
优化到此为止,接手了几处flash网站的优化,真的给我留下了深刻的印象!今天来说说我是如何优化flash网站的?做Flash网站的优化真是个烫手山芋。无论是 SEO 专家还是网页设计师,Flash 对整个网站来说无疑是一项了不起的技术,包括一个网站 上的声音和图片,Flash 动画对于大多数 SEO 来说都是一场噩梦。原因很简单 - 搜索引擎无法索引(或至少不容易)您的内容中的 Flash 文件,除非您为 Flash 配备网络文本,并且您可以依靠这些问题来提高您的 网站 排名。当然还有其他选择,但在搜索引擎开始索引 Flash 动画之前,
为什么搜索引擎不喜欢 Flash网站?
搜索引擎不喜欢 Flash网站,不是因为它们的艺术品质和专业视角(或缺乏),而是因为 Flash 动画太复杂以至于蜘蛛都能理解。蜘蛛不能直接索引 Flash 电影,因为它们与普通网页的文本不同。蜘蛛索引的文件名(在网络上可用),不在内容中。
Flash 动画,采用专有的二进制格式,蜘蛛无法读取里面的 Flash 文件,至少对搜索引擎没有帮助,蜘蛛不会抓取和索引所有 Flash 内容,这是所有当前搜索引擎的情况(也许我的讨论会是不同),如何衡量搜索引擎页面的相关性?我相信大多数 SEO 人都讨厌搜索引擎的这些缺点。
不使用闪存?
尽管 Flash 动画不是蜘蛛的最爱,但有时 Flash 电影优化仍然值得 SEO 努力。但作为一般规则,将 Flash 动画保持在最低限度。在这种情况下,对搜索引擎有一定的友好性。首先,Flash 动画,尤其是横幅广告和其他类型的广告,通常会被大多数网民跳过。二、Flash动画肥大,占用带宽大,
主页使用 Flash 进行导航。Flash虽然时尚华丽,但外部链接却无法被搜索引擎收录。还有一些常见的错误是使用图片或 JavaScript 进行导航,这对搜索引擎不利。文本链接是 SEO 认可的独特方式来构建 网站 导航。
替代优化闪存网站
但是Flash网站,还是可以优化的。有几种方法:
• 输入继电器
这是一个非常重要的实践,但经常被低估和误解。虽然元数据不是搜索引擎的重要基础,但可以轻松地将元数据添加到您的电影中,这并不是在中继领域留下空白的借口。
• 提供替代网页
一个好的网站,是一个必须提供HTML的页面,只是不会强迫用户观看Flash电影。准备这些页面需要更多的工作,但搜索引擎会给你更多的回报,因为不仅用户习惯了 HTML 页面,搜索引擎也喜欢 HTML 页面。
但是,您仍然需要有正确的内容,例如,可能页面需要对其中的文本和链接进行一些调整,例如您可以使关键字内容丰富的标题和描述。
此外,您需要检查提取的句子和段落之间是否没有重复的内容。文本的字体颜色是另一个问题。如果文本的字体颜色与背景颜色相同,那么你需要小心搜索引擎火灾。
这两种方法只是其中一些最重要的例子,还有很多其他方法可以优化 Flash网站。但并非所有方法都非常出色和清晰,或者它们可以归类为边界上的合乎道德的 SEO,例如,创建传递给蜘蛛而不是 Flash 电影本身的不可见文本层。虽然这种技术没有任何问题 - 也就是说,没有重复或虚假内容,但它与伪装和门户页面非常相似,最好避免使用。
看完我的讲解,相信你应该对flash的优化有了更深入的了解网站!欢迎大家一起讨论,我们一起努力做SEO。
记得分享好资料!
如何抓取网页flash(如何抓取网页flash动画?推荐一个插件videopreviewer,用百度识图试试看)
网站优化 • 优采云 发表了文章 • 0 个评论 • 55 次浏览 • 2022-04-04 01:05
如何抓取网页flash动画?推荐一个插件videopreviewer,安装后flash或者audio,mediaplayer,javascriptas和html5等脚本都可以抓取到。我测试到videopreviewer可以抓取flash文件,浏览器上弹窗,下载播放等。
百度不到:)上搜狗也没有:)
你可以尝试下我一直用的这个软件-videopreviewerr2pd,安卓和ios端都有,支持批量抓取网页flash动画。你也可以下载这个软件自己手动抓取。先从视频中提取音频节点,再连接到音频节点后面。不谢。
这个动画不需要抓包吧...用百度识图试试看就可以了
度娘之前有搜到这个;但是好像只支持iphone手机抓取视频
“xiafeibuxiaoye”
wind资讯软件,对公司外网抓包量巨大,
如果电脑上没破解,只能抓http和ftp。
我下载过videopreview,可以上传图片然后提取api地址,但是可以抓取视频还是第一次知道,这个软件比较依赖浏览器,没有ie有用。
nextperformance:github推荐给ios用户的高质量flash产品还可以抓很多androidflashapi-next-performance/id1423744147可以看看有没有需要的
应该这个软件是可以的吧,不过我没有试过。上一次看到很多新闻类的网站都有flash的,但是ios的还没看到过, 查看全部
如何抓取网页flash(如何抓取网页flash动画?推荐一个插件videopreviewer,用百度识图试试看)
如何抓取网页flash动画?推荐一个插件videopreviewer,安装后flash或者audio,mediaplayer,javascriptas和html5等脚本都可以抓取到。我测试到videopreviewer可以抓取flash文件,浏览器上弹窗,下载播放等。
百度不到:)上搜狗也没有:)
你可以尝试下我一直用的这个软件-videopreviewerr2pd,安卓和ios端都有,支持批量抓取网页flash动画。你也可以下载这个软件自己手动抓取。先从视频中提取音频节点,再连接到音频节点后面。不谢。
这个动画不需要抓包吧...用百度识图试试看就可以了
度娘之前有搜到这个;但是好像只支持iphone手机抓取视频
“xiafeibuxiaoye”
wind资讯软件,对公司外网抓包量巨大,
如果电脑上没破解,只能抓http和ftp。
我下载过videopreview,可以上传图片然后提取api地址,但是可以抓取视频还是第一次知道,这个软件比较依赖浏览器,没有ie有用。
nextperformance:github推荐给ios用户的高质量flash产品还可以抓很多androidflashapi-next-performance/id1423744147可以看看有没有需要的
应该这个软件是可以的吧,不过我没有试过。上一次看到很多新闻类的网站都有flash的,但是ios的还没看到过,
如何抓取网页flash(如何抓取网页flash请求的json文件?这个需要利用flashplayer之类的播放器)
网站优化 • 优采云 发表了文章 • 0 个评论 • 48 次浏览 • 2022-04-03 16:05
如何抓取网页flash请求的json文件?这个需要利用flashplayer之类的播放器。
基于chrome浏览器的flashplayer插件下载。对于已经登录的账号:可以通过ajax接口去请求网站的数据,或者做json解析请求数据。可以通过flash插件给出的简单json接口,可以访问一些页面,然后通过特定的操作达到要求。对于未登录用户:接受一个请求,返回一个json字符串,或者一个无状态json字符串(然后要求做响应判断)。
permissioned-360docs直接访问,
反向代理应该可以
试试看windows系统的sysinternalstoolbox
flashplayer内置了接口,抓取下数据会显示在cookie里,所以只需要在页面设置有web登录的,
和楼上说的不同,我一直都是用代理抓的。然后分析下代理对应的请求,然后控制变量来设置浏览器的代理就可以了。然后每次只请求一个http网址,然后保存requestdata,这样每次http请求都会带上这个requestdata,然后response的时候应该会携带回答的url的json,就可以解析这个json。然后改变sessionid的值,可以达到每次生成不同id,然后通过ajax请求接口获取。
问题本身不大,那么问题出在怎么抓住flash上,可以通过抓包软件抓包,也可以用自己写的抓包脚本实现。可以抓一些http页面,通过js或ajax方式请求。或者利用网页domjs或其他js也是可以抓取页面的,而且如果你不要抓取到详细的操作,甚至可以通过ajax方式实现,不过前提是js要用好,这样才能抓住重点。
如果想抓取html页面也可以利用chrome的开发者工具和tab键进行抓取。我也没遇到过抓取率的问题,欢迎补充,谢谢。 查看全部
如何抓取网页flash(如何抓取网页flash请求的json文件?这个需要利用flashplayer之类的播放器)
如何抓取网页flash请求的json文件?这个需要利用flashplayer之类的播放器。
基于chrome浏览器的flashplayer插件下载。对于已经登录的账号:可以通过ajax接口去请求网站的数据,或者做json解析请求数据。可以通过flash插件给出的简单json接口,可以访问一些页面,然后通过特定的操作达到要求。对于未登录用户:接受一个请求,返回一个json字符串,或者一个无状态json字符串(然后要求做响应判断)。
permissioned-360docs直接访问,
反向代理应该可以
试试看windows系统的sysinternalstoolbox
flashplayer内置了接口,抓取下数据会显示在cookie里,所以只需要在页面设置有web登录的,
和楼上说的不同,我一直都是用代理抓的。然后分析下代理对应的请求,然后控制变量来设置浏览器的代理就可以了。然后每次只请求一个http网址,然后保存requestdata,这样每次http请求都会带上这个requestdata,然后response的时候应该会携带回答的url的json,就可以解析这个json。然后改变sessionid的值,可以达到每次生成不同id,然后通过ajax请求接口获取。
问题本身不大,那么问题出在怎么抓住flash上,可以通过抓包软件抓包,也可以用自己写的抓包脚本实现。可以抓一些http页面,通过js或ajax方式请求。或者利用网页domjs或其他js也是可以抓取页面的,而且如果你不要抓取到详细的操作,甚至可以通过ajax方式实现,不过前提是js要用好,这样才能抓住重点。
如果想抓取html页面也可以利用chrome的开发者工具和tab键进行抓取。我也没遇到过抓取率的问题,欢迎补充,谢谢。
如何抓取网页flash(如何抓取网页flash动画?/(网页)youtube上做视频分享)
网站优化 • 优采云 发表了文章 • 0 个评论 • 48 次浏览 • 2022-04-03 11:02
如何抓取网页flash动画?/(网页flash视频抓取网站)youtube上做视频分享,如何不用翻墙、不用域名,只需要,你就可以抓取到youtube上面的网站视频,然后如何下载下来呢?webdav【webdav简介】什么是webdav是一个操作符,允许网站上面的内容被传输到远程的服务器上面,将远程服务器的内容转换成本地html文件,通过http协议传输到本地浏览器,这个工作在浏览器上面是由web浏览器操作的。
【webdav原理】使用webdav,就相当于通过http协议把对于一个ipv6地址的请求转换成两个http请求。一个ipv6地址转换成128位有效http请求,第二个http请求转换成tcp协议有效请求,也就是说使用webdav转换服务器转换服务器上面的http请求对服务器的网络负载均衡(ua)原理说明。
使用webdav,需要解决一个问题,那就是互联网上对于tcp协议处理有不同的负载均衡方式,http协议下默认请求过于频繁,达到每秒将近500次tcp连接,这是ipv4用tcp协议传输时候的极限了。针对于这个问题,会有一个专门的服务器负责这个负载均衡,ipv4的有效的tcp连接也就是1024封端口,一般会有4个节点。
下面是简单的实例说明1.我们浏览器使用nginx。2.因为服务器端,可能以开启的tcp连接来传输服务器上面的内容。但是如果请求直接指向web服务器的话,你就得想办法解决了。3.一般有三种解决方案:其一,是本地的服务器没有内容或者内容太少,tcp连接直接丢弃掉,没有其他浏览器使用,也不会有后续的东西产生,所以本地服务器就用redis等数据库服务器;其二,由于服务器有内容,web服务器是在本地,那么可以定时从本地服务器拉取一部分内容到web服务器上面,这样并没有丢失和产生额外的流量和时间延迟。
其三,很多网站都有一个ipv6地址,以后我们访问这个网站时候,就会默认的使用本地服务器。如果我们想,将tcp连接直接指向本地服务器,那么就是完全不可用的。简单来说,三种方法,第一个方法并不是完全不可行,如果服务器有内容,那么这种方式可行。但是如果服务器都没有内容的话,那么第二个方法,也不可行,由于这个并不是对于本地的tcp连接。
而第三个方法是可行的,本地也有资源,只是你把这个redis服务器的连接指向一个新的对象。实现原理1.首先实现这个http请求:#connectingsimplehttphttprequest:typeconnectionconnection:listener(notnecessaryifthishttprequestcannotbeconnected,url=null)url:json{。 查看全部
如何抓取网页flash(如何抓取网页flash动画?/(网页)youtube上做视频分享)
如何抓取网页flash动画?/(网页flash视频抓取网站)youtube上做视频分享,如何不用翻墙、不用域名,只需要,你就可以抓取到youtube上面的网站视频,然后如何下载下来呢?webdav【webdav简介】什么是webdav是一个操作符,允许网站上面的内容被传输到远程的服务器上面,将远程服务器的内容转换成本地html文件,通过http协议传输到本地浏览器,这个工作在浏览器上面是由web浏览器操作的。
【webdav原理】使用webdav,就相当于通过http协议把对于一个ipv6地址的请求转换成两个http请求。一个ipv6地址转换成128位有效http请求,第二个http请求转换成tcp协议有效请求,也就是说使用webdav转换服务器转换服务器上面的http请求对服务器的网络负载均衡(ua)原理说明。
使用webdav,需要解决一个问题,那就是互联网上对于tcp协议处理有不同的负载均衡方式,http协议下默认请求过于频繁,达到每秒将近500次tcp连接,这是ipv4用tcp协议传输时候的极限了。针对于这个问题,会有一个专门的服务器负责这个负载均衡,ipv4的有效的tcp连接也就是1024封端口,一般会有4个节点。
下面是简单的实例说明1.我们浏览器使用nginx。2.因为服务器端,可能以开启的tcp连接来传输服务器上面的内容。但是如果请求直接指向web服务器的话,你就得想办法解决了。3.一般有三种解决方案:其一,是本地的服务器没有内容或者内容太少,tcp连接直接丢弃掉,没有其他浏览器使用,也不会有后续的东西产生,所以本地服务器就用redis等数据库服务器;其二,由于服务器有内容,web服务器是在本地,那么可以定时从本地服务器拉取一部分内容到web服务器上面,这样并没有丢失和产生额外的流量和时间延迟。
其三,很多网站都有一个ipv6地址,以后我们访问这个网站时候,就会默认的使用本地服务器。如果我们想,将tcp连接直接指向本地服务器,那么就是完全不可用的。简单来说,三种方法,第一个方法并不是完全不可行,如果服务器有内容,那么这种方式可行。但是如果服务器都没有内容的话,那么第二个方法,也不可行,由于这个并不是对于本地的tcp连接。
而第三个方法是可行的,本地也有资源,只是你把这个redis服务器的连接指向一个新的对象。实现原理1.首先实现这个http请求:#connectingsimplehttphttprequest:typeconnectionconnection:listener(notnecessaryifthishttprequestcannotbeconnected,url=null)url:json{。
如何抓取网页flash(如何抓取网页flash,flex,,js)
网站优化 • 优采云 发表了文章 • 0 个评论 • 146 次浏览 • 2022-04-02 20:05
如何抓取网页flash,flex,activex,js
首先他需要知道你用的是什么浏览器。前端的一个基本功就是分析你用的浏览器能够支持什么样的html5/css3/javascript,然后将这些按照一定规律组合变成通用解决方案。
黑客问题,搜集好所有的账号密码,然后通过各种手段注入到"特定的某个网站"上
前端的学习不是来说,而是来实操,做一个有意思的网站出来。
前端的问题,网上有很多资料,如何设计网站,如何做数据分析,这些都可以;重要的是你要真正想学习并实践,比如要找一个工作,或者考虑做职业规划,要学习web前端技术,web前端属于it技术上最高阶的技术,通过研究前端工作流程,
你得先搞懂什么是html。html是构成网页的基础,现在前端设计的最大规模应用场景是多媒体页面的设计。比如电视台的视频新闻栏目、电影网站的提取片段设计,应用的html基本上是用php写,wordpress、discuz之类的。
抓html和抓css一样。黑客的思路是用浏览器里的javascript完成这些东西,上行操作也是通过浏览器;下行操作就可以使用flash。详细搜索下javascript内核。但是它在中国的应用不是很普遍。如果你在国外,用flash是非常的流行,这里提供一个可靠的网址:html代码编写支持移动端的视频栏目工具-embedded-box这个是javascript的在线教程。希望对你有帮助。对技术感兴趣,可以加我,咱们继续交流。 查看全部
如何抓取网页flash(如何抓取网页flash,flex,,js)
如何抓取网页flash,flex,activex,js
首先他需要知道你用的是什么浏览器。前端的一个基本功就是分析你用的浏览器能够支持什么样的html5/css3/javascript,然后将这些按照一定规律组合变成通用解决方案。
黑客问题,搜集好所有的账号密码,然后通过各种手段注入到"特定的某个网站"上
前端的学习不是来说,而是来实操,做一个有意思的网站出来。
前端的问题,网上有很多资料,如何设计网站,如何做数据分析,这些都可以;重要的是你要真正想学习并实践,比如要找一个工作,或者考虑做职业规划,要学习web前端技术,web前端属于it技术上最高阶的技术,通过研究前端工作流程,
你得先搞懂什么是html。html是构成网页的基础,现在前端设计的最大规模应用场景是多媒体页面的设计。比如电视台的视频新闻栏目、电影网站的提取片段设计,应用的html基本上是用php写,wordpress、discuz之类的。
抓html和抓css一样。黑客的思路是用浏览器里的javascript完成这些东西,上行操作也是通过浏览器;下行操作就可以使用flash。详细搜索下javascript内核。但是它在中国的应用不是很普遍。如果你在国外,用flash是非常的流行,这里提供一个可靠的网址:html代码编写支持移动端的视频栏目工具-embedded-box这个是javascript的在线教程。希望对你有帮助。对技术感兴趣,可以加我,咱们继续交流。
如何抓取网页flash(如何抓取网页中的动态网页源码中特定的特定内容)
网站优化 • 优采云 发表了文章 • 0 个评论 • 53 次浏览 • 2022-03-30 17:07
背景
很多时候,很多人需要在网络上抓取一些特定的内容。
但是,除了之前介绍的内容之外,您还想从某些静态网页中提取某些内容,例如:
【教程】Python版爬网并从网页中提取需要的信息
和
【教程】C#版爬网并从网页中提取需要的信息
另外,有些人会发现自己要抓取的网页内容不在网页的源代码中。
所以,在这一点上,我不知道该怎么做。
在这里,我们来解释一下如何爬取所谓的动态网页中的特定内容。
必备知识
在阅读本文之前,您需要具备相关的基础知识:
1.爬取网页,模拟登录等相关逻辑
不熟悉的可以参考:
【组织】爬取网页、分析网页内容、模拟登录的逻辑/流程及注意事项网站
2.学会使用工具,比如IE9的F12,爬取对应的网页执行流程
不熟悉的可以参考:
【教程】教你如何使用工具(IE9的F12)解析模拟登录内部逻辑流程网站(百度首页))
3.对于一个普通的静态网页,如何提取想要的内容
对此不熟悉的可以参考:
(1)Python 版本:
【教程】Python版爬网并从网页中提取需要的信息
(2)C# 版本:
【教程】C#版爬网并从网页中提取需要的信息
什么是动态网页
这里所谓的动态网页是相对于那些静态网页而言的。
这里所说的静态网页是指通过浏览器查看网页源代码时,你看到的网页源代码中的内容与网页上显示的内容相对应。
也就是说,当我想得到某个网页上显示的内容时,我可以通过查找网页的源代码找到对应的部分。
动态网页,相反,如果要获取动态网页中的具体内容,直接查看网页源代码是找不到的。
动态网页中的动态内容从何而来?
所以,这里有一个问题:
所谓动态网页中的动态内容从何而来?
一般来说,它是通过其他方式生成或获取的。
据我所知,有几个:
由本地 Javascript 脚本生成
如果你用IE9的F12来分析访问一个url的过程,你会发现很可能涉及到,
在网页正常完整显示之前,这段时间会访问很多javascript脚本,简称js脚本或js。
这些js脚本实现了很多动态的交互内容。
其中,对于一些你想抓取的内容,有时候,这些js脚本是动态执行的,最后计算出来的。
通过访问另一个url地址获得
很多时候,有些内容是访问另一个url地址后返回的数据;
如何获取我要抓取的动态内容
其实对于如何爬取需要的动态内容,简单来说,有一个解决方案:
根据你通过工具分析的结果,找到对应的数据并提取出来;
不过这个数据有时候可以在分析结果的过程中直接提取出来,有时候可能是通过js计算出来的。
想抓取数据,是js脚本生成的
虽然最终的动态内容是由js脚本执行生成的,但是对于你要抓取的数据:
想爬取数据是通过访问另一个url获取的
如果你要抓取的对应内容是访问另一个url地址和返回的数据,那么很简单,你也需要访问这个url,然后获取对应的返回内容,从中提取你想要的数据。
总结
同一句话,不管你访问的内容是如何生成的,最后你还是可以用工具来分析对应的内容是如何从零开始生成的。
然后用代码模拟这个过程,最后提取出你需要的内容;
具体示例演示见:
【教程】以网易博文的最新读者信息为例,教大家如何抓取动态网页的内容。
转载请注明: 在路上 » 【教程】如何抓取动态网页内容 查看全部
如何抓取网页flash(如何抓取网页中的动态网页源码中特定的特定内容)
背景
很多时候,很多人需要在网络上抓取一些特定的内容。
但是,除了之前介绍的内容之外,您还想从某些静态网页中提取某些内容,例如:
【教程】Python版爬网并从网页中提取需要的信息
和
【教程】C#版爬网并从网页中提取需要的信息
另外,有些人会发现自己要抓取的网页内容不在网页的源代码中。
所以,在这一点上,我不知道该怎么做。
在这里,我们来解释一下如何爬取所谓的动态网页中的特定内容。
必备知识
在阅读本文之前,您需要具备相关的基础知识:
1.爬取网页,模拟登录等相关逻辑
不熟悉的可以参考:
【组织】爬取网页、分析网页内容、模拟登录的逻辑/流程及注意事项网站
2.学会使用工具,比如IE9的F12,爬取对应的网页执行流程
不熟悉的可以参考:
【教程】教你如何使用工具(IE9的F12)解析模拟登录内部逻辑流程网站(百度首页))
3.对于一个普通的静态网页,如何提取想要的内容
对此不熟悉的可以参考:
(1)Python 版本:
【教程】Python版爬网并从网页中提取需要的信息
(2)C# 版本:
【教程】C#版爬网并从网页中提取需要的信息
什么是动态网页
这里所谓的动态网页是相对于那些静态网页而言的。
这里所说的静态网页是指通过浏览器查看网页源代码时,你看到的网页源代码中的内容与网页上显示的内容相对应。
也就是说,当我想得到某个网页上显示的内容时,我可以通过查找网页的源代码找到对应的部分。
动态网页,相反,如果要获取动态网页中的具体内容,直接查看网页源代码是找不到的。
动态网页中的动态内容从何而来?
所以,这里有一个问题:
所谓动态网页中的动态内容从何而来?
一般来说,它是通过其他方式生成或获取的。
据我所知,有几个:
由本地 Javascript 脚本生成
如果你用IE9的F12来分析访问一个url的过程,你会发现很可能涉及到,
在网页正常完整显示之前,这段时间会访问很多javascript脚本,简称js脚本或js。
这些js脚本实现了很多动态的交互内容。
其中,对于一些你想抓取的内容,有时候,这些js脚本是动态执行的,最后计算出来的。
通过访问另一个url地址获得
很多时候,有些内容是访问另一个url地址后返回的数据;
如何获取我要抓取的动态内容
其实对于如何爬取需要的动态内容,简单来说,有一个解决方案:
根据你通过工具分析的结果,找到对应的数据并提取出来;
不过这个数据有时候可以在分析结果的过程中直接提取出来,有时候可能是通过js计算出来的。
想抓取数据,是js脚本生成的
虽然最终的动态内容是由js脚本执行生成的,但是对于你要抓取的数据:
想爬取数据是通过访问另一个url获取的
如果你要抓取的对应内容是访问另一个url地址和返回的数据,那么很简单,你也需要访问这个url,然后获取对应的返回内容,从中提取你想要的数据。
总结
同一句话,不管你访问的内容是如何生成的,最后你还是可以用工具来分析对应的内容是如何从零开始生成的。
然后用代码模拟这个过程,最后提取出你需要的内容;
具体示例演示见:
【教程】以网易博文的最新读者信息为例,教大家如何抓取动态网页的内容。
转载请注明: 在路上 » 【教程】如何抓取动态网页内容
如何抓取网页flash(如何抓取网页中的动态网页源码中特定的特定内容)
网站优化 • 优采云 发表了文章 • 0 个评论 • 43 次浏览 • 2022-03-30 17:05
背景
很多时候,很多人需要在网络上抓取一些特定的内容。
但是,除了之前介绍的内容之外,您还想从某些静态网页中提取某些内容,例如:
[教程] Python版本爬行网络并提取网页所需的信息
和
[教程] C#版本爬行网络并提取来自网页所需的信息
另外,有些人会发现自己要抓取的网页内容不在网页的源代码中。
所以,在这一点上,我不知道该怎么做。
在这里,我们来解释一下如何爬取所谓的动态网页中的特定内容。
必备知识
在阅读本文之前,您需要具备相关的基础知识:
1.爬取网页,模拟登录等相关逻辑
如果您不熟悉它,则可以参考:
[组织]爬网网页的逻辑/过程和预防措施,分析网页内容和模拟登录网站
2.学会使用工具,例如IE9的F12,抓住相应的网页执行过程
对于那些不熟悉的人,请参阅:
[教程]教导您如何使用工具(IE9 2)的f1来分析模拟登录的内部逻辑进程网站(百度首页))
3.对于正常的静态网页,如何提取所需内容
对于那些不熟悉的人,您可以参考:
(1) python版本:
[教程] Python版本爬行网络并提取网页所需的信息
(2) c#版本:
[教程] C#版本爬行网络并提取来自网页所需的信息
什么是动态网页
这里所谓的动态网页是相对于那些静态网页而言的。
这里所说的静态网页是指通过浏览器查看网页源代码时,你看到的网页源代码中的内容与网页上显示的内容相对应。
也就是说,当我想得到某个网页上显示的内容时,我可以通过查找网页的源代码找到对应的部分。
动态网页,相反,如果要获取动态网页中的具体内容,直接查看网页源代码是找不到的。
动态网页中的动态内容从何而来?
所以,这里有一个问题:
所谓动态网页中的动态内容从何而来?
一般来说,它是通过其他方式生成或获取的。
据我所知,有几个:
由本地 Javascript 脚本生成
如果你用IE9的F12来分析访问一个url的过程,你会发现很可能涉及到,
在网页正常完整显示之前,这段时间会访问很多javascript脚本,简称js脚本或js。
这些js脚本实现了很多动态的交互内容。
其中,对于一些你想抓取的内容,有时候,这些js脚本是动态执行的,最后计算出来的。
通过访问另一个url地址获得
很多时候,有些内容是访问另一个url地址后返回的数据;
如何获取我要抓取的动态内容
其实对于如何爬取需要的动态内容,简单来说,有一个解决方案:
根据您通过工具分析的结果,查找相应的数据并提取它;
但是,有时可以直接在分析结果的过程中提取该数据,有时它可以通过JS计算。
想要抓住数据,它由JS脚本生成
虽然由JS脚本执行生成最终动态内容,但是对于您要刮的数据:
想要通过访问另一个URL来获得刮除数据
如果要抓住的相应内容是访问另一个URL地址和返回的数据,那么它非常简单,还需要访问此URL,然后获取相应的返回内容,从中提取您想要的数据。
总结
同一句话,不管你访问的内容是如何生成的,最后你还是可以用工具来分析对应的内容是如何从零开始生成的。
然后用代码模拟这个过程,最后提取出你需要的内容;
具体示例演示见:
【教程】以网易博文的最新读者信息为例,教大家如何抓取动态网页的内容。 查看全部
如何抓取网页flash(如何抓取网页中的动态网页源码中特定的特定内容)
背景
很多时候,很多人需要在网络上抓取一些特定的内容。
但是,除了之前介绍的内容之外,您还想从某些静态网页中提取某些内容,例如:
[教程] Python版本爬行网络并提取网页所需的信息
和
[教程] C#版本爬行网络并提取来自网页所需的信息
另外,有些人会发现自己要抓取的网页内容不在网页的源代码中。
所以,在这一点上,我不知道该怎么做。
在这里,我们来解释一下如何爬取所谓的动态网页中的特定内容。
必备知识
在阅读本文之前,您需要具备相关的基础知识:
1.爬取网页,模拟登录等相关逻辑
如果您不熟悉它,则可以参考:
[组织]爬网网页的逻辑/过程和预防措施,分析网页内容和模拟登录网站
2.学会使用工具,例如IE9的F12,抓住相应的网页执行过程
对于那些不熟悉的人,请参阅:
[教程]教导您如何使用工具(IE9 2)的f1来分析模拟登录的内部逻辑进程网站(百度首页))
3.对于正常的静态网页,如何提取所需内容
对于那些不熟悉的人,您可以参考:
(1) python版本:
[教程] Python版本爬行网络并提取网页所需的信息
(2) c#版本:
[教程] C#版本爬行网络并提取来自网页所需的信息
什么是动态网页
这里所谓的动态网页是相对于那些静态网页而言的。
这里所说的静态网页是指通过浏览器查看网页源代码时,你看到的网页源代码中的内容与网页上显示的内容相对应。
也就是说,当我想得到某个网页上显示的内容时,我可以通过查找网页的源代码找到对应的部分。
动态网页,相反,如果要获取动态网页中的具体内容,直接查看网页源代码是找不到的。
动态网页中的动态内容从何而来?
所以,这里有一个问题:
所谓动态网页中的动态内容从何而来?
一般来说,它是通过其他方式生成或获取的。
据我所知,有几个:
由本地 Javascript 脚本生成
如果你用IE9的F12来分析访问一个url的过程,你会发现很可能涉及到,
在网页正常完整显示之前,这段时间会访问很多javascript脚本,简称js脚本或js。
这些js脚本实现了很多动态的交互内容。
其中,对于一些你想抓取的内容,有时候,这些js脚本是动态执行的,最后计算出来的。
通过访问另一个url地址获得
很多时候,有些内容是访问另一个url地址后返回的数据;
如何获取我要抓取的动态内容
其实对于如何爬取需要的动态内容,简单来说,有一个解决方案:
根据您通过工具分析的结果,查找相应的数据并提取它;
但是,有时可以直接在分析结果的过程中提取该数据,有时它可以通过JS计算。
想要抓住数据,它由JS脚本生成
虽然由JS脚本执行生成最终动态内容,但是对于您要刮的数据:
想要通过访问另一个URL来获得刮除数据
如果要抓住的相应内容是访问另一个URL地址和返回的数据,那么它非常简单,还需要访问此URL,然后获取相应的返回内容,从中提取您想要的数据。
总结
同一句话,不管你访问的内容是如何生成的,最后你还是可以用工具来分析对应的内容是如何从零开始生成的。
然后用代码模拟这个过程,最后提取出你需要的内容;
具体示例演示见:
【教程】以网易博文的最新读者信息为例,教大家如何抓取动态网页的内容。
如何抓取网页flash(如何通过网页代码来优化seo呢?())
网站优化 • 优采云 发表了文章 • 0 个评论 • 73 次浏览 • 2022-03-24 16:21
在线推广的方式有很多,SEO优化就是其中之一。那么如何通过网页代码来优化seo呢?我们都知道搜索引擎和访问用户的行为方式是一样的,但是当它访问网页时,它主要针对网页的源代码。因此,为了更好地支持蜘蛛的爬取和爬取,需要对网页代码进行简化,并对网页代码中的标签进行优化。
? 代码缩减:
代码简化是指对网页中的代码进行简化,提高网页的加载速度,改善用户体验,从而实现seo优化,提高搜索引擎友好度。
网页代码的简化通常可以分为以下几个方面:
1、 垃圾代码清理
2、HTML标签转换
对于代码量非常大的网站有意义,但是对于普通cms系统生成的小网站模板就没有意义了。
3、CSS代码优化
CSS是cascading style sheet的缩写,即级联样式表。它是目前最常用的控制网页布局、字体、颜色和背景的技术。CSS优化主要是改变调用CSS的方式,使用DIV+CSS使深圳网站防止垃圾代码的产生。
4、JS代码优化
JS 是 Javascript 的缩写。在搜索引擎看来,JS 对搜索引擎并不友好。如果内容放在 JS 中,则无法被搜索引擎抓取。JS优化主要是避免JS代码占用网页空间和重要位置,放置一些搜索引擎不想看到的内容。
? 标签优化:
对于网站的单个页面,在header中三大标签优化完成后,整个网页的代码优化大致完成了一半,其他重要权重标签的优化占其余一半,比如h标签和b标签等。
1、权重标签
权重标签是影响网页权重或相关性的标签。权重标签常用于突出网页中比较重要的内容,从而提高网页的相关性,增加网页的权重。
h标签是所有权重标签中最重要的标签。不同的h标签有不同的功能和出现。例如:h1只出现一次,主要用在标题中;h2出现3、4次就够了,主要用在主段落标题、次分类;h3可能偶尔会出现在更详细的分类网站首页,但是h4后面的h标签一般是不需要使用的。
2、其他标签优化
还有一些其他标签可以适当优化,例如: 查看全部
如何抓取网页flash(如何通过网页代码来优化seo呢?())
在线推广的方式有很多,SEO优化就是其中之一。那么如何通过网页代码来优化seo呢?我们都知道搜索引擎和访问用户的行为方式是一样的,但是当它访问网页时,它主要针对网页的源代码。因此,为了更好地支持蜘蛛的爬取和爬取,需要对网页代码进行简化,并对网页代码中的标签进行优化。
? 代码缩减:
代码简化是指对网页中的代码进行简化,提高网页的加载速度,改善用户体验,从而实现seo优化,提高搜索引擎友好度。
网页代码的简化通常可以分为以下几个方面:
1、 垃圾代码清理
2、HTML标签转换
对于代码量非常大的网站有意义,但是对于普通cms系统生成的小网站模板就没有意义了。
3、CSS代码优化
CSS是cascading style sheet的缩写,即级联样式表。它是目前最常用的控制网页布局、字体、颜色和背景的技术。CSS优化主要是改变调用CSS的方式,使用DIV+CSS使深圳网站防止垃圾代码的产生。
4、JS代码优化
JS 是 Javascript 的缩写。在搜索引擎看来,JS 对搜索引擎并不友好。如果内容放在 JS 中,则无法被搜索引擎抓取。JS优化主要是避免JS代码占用网页空间和重要位置,放置一些搜索引擎不想看到的内容。
? 标签优化:
对于网站的单个页面,在header中三大标签优化完成后,整个网页的代码优化大致完成了一半,其他重要权重标签的优化占其余一半,比如h标签和b标签等。
1、权重标签
权重标签是影响网页权重或相关性的标签。权重标签常用于突出网页中比较重要的内容,从而提高网页的相关性,增加网页的权重。
h标签是所有权重标签中最重要的标签。不同的h标签有不同的功能和出现。例如:h1只出现一次,主要用在标题中;h2出现3、4次就够了,主要用在主段落标题、次分类;h3可能偶尔会出现在更详细的分类网站首页,但是h4后面的h标签一般是不需要使用的。
2、其他标签优化
还有一些其他标签可以适当优化,例如:
如何抓取网页flash(火狐保存网页中的Flash方法(MozillaFirefox)(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 53 次浏览 • 2022-03-22 13:26
Firefox 将 Flash 方法保存在网页中。
①点击“工具->页面信息->媒体”,或者在网页上右击->页面信息->媒体,找到要保存的Flash,然后点击保存。
②如果安装了 Adblock,可以打开 Adblock 的 Obj-Tabs 选项查看 Flash 的地址,然后使用 flashget 等下载软件下载 Flash。
③ 安装扩展下载嵌入式(推荐)。Download Embedded扩展在工具和右键中分别增加了上下文菜单,可以快速抓取页面内嵌的flash动画、电影、mp3等,比通过网页源代码或页面信息抓取更方便。
介绍
Mozilla Firefox 是由 Mozilla 开发的网络浏览器。它使用 Gecko 网页布局引擎,支持多种操作系统。开源代码以多许可方式获得许可,包括 Mozilla 公共许可 (MPL)、GNU 通用公共许可条款 (GPL) 和 GNU 宽松公共许可 (LGPL),目标是创建一个开放、创新和基于机会的网络环境。
目前,火狐浏览器在全球浏览器市场份额排名第三,谷歌Chrome在2011年11月的市场份额正式超越火狐浏览器,跃居第二位。
多年来,Mozilla 对 Firefox 的开发计划的总体原则是每 一、 两年对 Firefox 进行一次重大的功能升级。2010 年 1 月 14 日,Mozilla 表示,未来将调整上述产品发布原则,即通过定期发布安全升级,逐步为 Firefox 添加新功能。此类升级的发布时间为每 6 周。2012年1月11日上午,Mozilla正在进行火狐浏览器长期支持版本(Extended Support Release,以下简称“ESR”)的研发工作。这个版本的浏览器更新速度比较慢,一年更新一次,不会像普通版那样每六周更新一次。 查看全部
如何抓取网页flash(火狐保存网页中的Flash方法(MozillaFirefox)(图))
Firefox 将 Flash 方法保存在网页中。
①点击“工具->页面信息->媒体”,或者在网页上右击->页面信息->媒体,找到要保存的Flash,然后点击保存。
②如果安装了 Adblock,可以打开 Adblock 的 Obj-Tabs 选项查看 Flash 的地址,然后使用 flashget 等下载软件下载 Flash。
③ 安装扩展下载嵌入式(推荐)。Download Embedded扩展在工具和右键中分别增加了上下文菜单,可以快速抓取页面内嵌的flash动画、电影、mp3等,比通过网页源代码或页面信息抓取更方便。
介绍
Mozilla Firefox 是由 Mozilla 开发的网络浏览器。它使用 Gecko 网页布局引擎,支持多种操作系统。开源代码以多许可方式获得许可,包括 Mozilla 公共许可 (MPL)、GNU 通用公共许可条款 (GPL) 和 GNU 宽松公共许可 (LGPL),目标是创建一个开放、创新和基于机会的网络环境。
目前,火狐浏览器在全球浏览器市场份额排名第三,谷歌Chrome在2011年11月的市场份额正式超越火狐浏览器,跃居第二位。
多年来,Mozilla 对 Firefox 的开发计划的总体原则是每 一、 两年对 Firefox 进行一次重大的功能升级。2010 年 1 月 14 日,Mozilla 表示,未来将调整上述产品发布原则,即通过定期发布安全升级,逐步为 Firefox 添加新功能。此类升级的发布时间为每 6 周。2012年1月11日上午,Mozilla正在进行火狐浏览器长期支持版本(Extended Support Release,以下简称“ESR”)的研发工作。这个版本的浏览器更新速度比较慢,一年更新一次,不会像普通版那样每六周更新一次。
如何抓取网页flash(Flash动画在网页制作中的应用及探讨(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 73 次浏览 • 2022-03-11 09:22
Flash动画在网页制作中的应用与探讨
(作者:__________ 单位:__________ 邮编:__________)
过去十年,应用开发领域以及相关技术提供的数字资源和传播渠道都发生了深刻变化。现在,在设计和开发应用程序时,技术是为了充分利用连接计算的优势。
提供,因为它的文件大小非常小。Flash 通过大量使用矢量图形来做到这一点。与位图图形相比,矢量图形需要更少的内存和存储空间,因为它们表示为数学公式而不是大型数据集。位图图形更大,因为图像中的每个像素都需要一组单独的数据来表示。
要在 Flash 中构建应用程序,您可以使用 Flash 绘图工具创建图形并将其媒体元素导入 Flash 文档。在 Flash 中创作内容时,您需要使用 Flash 文档文件。Flash 文档的文件扩展名为 fla(FLA)。在各个领域,Flash在网页动画设计和网页组织方面都将展现出巨大的生命力。其应用前景令人鼓舞。
一、Flash动画在网页设计中的应用
1、Flash动画在网页设计中的部分应用
在网页设计中,Flash 动画作品除了
除了“流式动画”播放,如:Flash动画短片、FlashMV,还具有一定的交互功能形式。有的网站的引导界面做成Flash动画形式,一般由Dreamweaver软件完成,做成静态页面。当然,这些页面大部分都是静态的,但也有一些网站s做了如下设计。如:网页中的Flash网络广告、Flash图片展示动画、网站导航栏动画、图片展示动画、Flash交互动画、网站由Flash制作的注册、登录、计算系统。
在静态页面中,如果将这些做成动画形式,无疑可以起到生动的装饰作用,并且可以充分调动浏览器。不过也不能太花里胡哨,否则会适得其反,不仅使浏览器眼花缭乱,而且会大大降低企业网站的效果,显得心烦意乱,缺乏信任感。
2、Flash动画在整个网站设计中的应用
上一篇文章中提到,除了用Flash制作相关的贞操外,还有一些网站,为了展示自己的个性,用Flash制作整个网站。
整个网站的概念设计包括所有视听元素和布局。
<p>网站别说引导界面的设计了,由它引导的内页整个系统都是用Flash软件制作的,包括上面列出的视频、Flash广告动画、Flash互动动画、 查看全部
如何抓取网页flash(Flash动画在网页制作中的应用及探讨(图))
Flash动画在网页制作中的应用与探讨
(作者:__________ 单位:__________ 邮编:__________)
过去十年,应用开发领域以及相关技术提供的数字资源和传播渠道都发生了深刻变化。现在,在设计和开发应用程序时,技术是为了充分利用连接计算的优势。
提供,因为它的文件大小非常小。Flash 通过大量使用矢量图形来做到这一点。与位图图形相比,矢量图形需要更少的内存和存储空间,因为它们表示为数学公式而不是大型数据集。位图图形更大,因为图像中的每个像素都需要一组单独的数据来表示。
要在 Flash 中构建应用程序,您可以使用 Flash 绘图工具创建图形并将其媒体元素导入 Flash 文档。在 Flash 中创作内容时,您需要使用 Flash 文档文件。Flash 文档的文件扩展名为 fla(FLA)。在各个领域,Flash在网页动画设计和网页组织方面都将展现出巨大的生命力。其应用前景令人鼓舞。
一、Flash动画在网页设计中的应用
1、Flash动画在网页设计中的部分应用
在网页设计中,Flash 动画作品除了
除了“流式动画”播放,如:Flash动画短片、FlashMV,还具有一定的交互功能形式。有的网站的引导界面做成Flash动画形式,一般由Dreamweaver软件完成,做成静态页面。当然,这些页面大部分都是静态的,但也有一些网站s做了如下设计。如:网页中的Flash网络广告、Flash图片展示动画、网站导航栏动画、图片展示动画、Flash交互动画、网站由Flash制作的注册、登录、计算系统。
在静态页面中,如果将这些做成动画形式,无疑可以起到生动的装饰作用,并且可以充分调动浏览器。不过也不能太花里胡哨,否则会适得其反,不仅使浏览器眼花缭乱,而且会大大降低企业网站的效果,显得心烦意乱,缺乏信任感。
2、Flash动画在整个网站设计中的应用
上一篇文章中提到,除了用Flash制作相关的贞操外,还有一些网站,为了展示自己的个性,用Flash制作整个网站。
整个网站的概念设计包括所有视听元素和布局。
<p>网站别说引导界面的设计了,由它引导的内页整个系统都是用Flash软件制作的,包括上面列出的视频、Flash广告动画、Flash互动动画、
如何抓取网页flash(如何抓取网页flash呢?答案就是javascript抓取呢)
网站优化 • 优采云 发表了文章 • 0 个评论 • 57 次浏览 • 2022-03-10 04:08
如何抓取网页flash呢?答案就是javascript,不过很麻烦,我们通过google的html5接口进行抓取,获取html中的所有字符串内容。javascript抓取原理首先,我们需要解释下javascript的原理。google的技术栈中包含了script/css/html4j等,script和css等主要是封装在javascript的javascript.所以,只要我们的网页是javascript开发的,那么我们也可以很轻松的拿到网页的所有内容。
html5javascript抓取项目介绍1.项目目的首先,我们需要明确我们要抓取的网页是什么类型的。在介绍项目的目的之前,我们先解释下我们到底想要抓取的是一些什么样的内容。其实,通过这一节我们将得到以下信息:从浏览器到浏览器的传输信息。主要的机制是一个http头,即请求资源时的header。每一个资源对应一个url,我们将其称之为requestresponse,如下图所示。
根据csdn上的介绍,在一个合法的http服务器下,实际将数据传输给客户端,需要5阶段的处理过程,每个阶段都包含一些特定的信息。接着,我们将其进行分类。分类过程主要分为两类:第一类:相互独立。第二类:不同的单元内部。我们将一些特定的头信息header将其关联在一起。最后,我们将数据从header中进行提取。
这一步,我们最终得到一些内容。当然,在这一阶段,我们将提取信息分为五类:1.资源内容header2.request请求url和responseurl3.http中的header(常是post请求时提供的header)4.属性信息,例如adminroleaccounturl等5.getrequestheader下面我们将其解释如下:首先我们得到一个header头信息,这个头信息包含了一些表单的信息,例如cookie。
随后我们分为两个阶段,从服务器接收数据后的5阶段中,各提取对应的信息。第一阶段:从服务器接收数据。服务器一般采用dns服务器,我们将数据下载后,一般传输至其中的dns服务器,然后由dns服务器来接收数据。http和https中,dns信息我们用(域名\/域名服务器)来表示。第二阶段:提取相关的数据。这一阶段我们分为一下几个步骤,不同的网站,这一步的不同处在于其组成网站的阶段划分不同,这些信息列表如下:由于采用类似的五阶段,基本原理上也是一样的,所以这里不再赘述。
2.项目代码下面我们讲解代码,包括注释和预览图,为了方便说明,我将代码都合并到github上,作为一个仓库。预览图同上一张我们已经抓取了从浏览器到浏览器的所有html资源,我们不仅将它们传输,同时还需要将它们解析。至于要解析什么东西,当然只是我的一些猜测,将。 查看全部
如何抓取网页flash(如何抓取网页flash呢?答案就是javascript抓取呢)
如何抓取网页flash呢?答案就是javascript,不过很麻烦,我们通过google的html5接口进行抓取,获取html中的所有字符串内容。javascript抓取原理首先,我们需要解释下javascript的原理。google的技术栈中包含了script/css/html4j等,script和css等主要是封装在javascript的javascript.所以,只要我们的网页是javascript开发的,那么我们也可以很轻松的拿到网页的所有内容。
html5javascript抓取项目介绍1.项目目的首先,我们需要明确我们要抓取的网页是什么类型的。在介绍项目的目的之前,我们先解释下我们到底想要抓取的是一些什么样的内容。其实,通过这一节我们将得到以下信息:从浏览器到浏览器的传输信息。主要的机制是一个http头,即请求资源时的header。每一个资源对应一个url,我们将其称之为requestresponse,如下图所示。
根据csdn上的介绍,在一个合法的http服务器下,实际将数据传输给客户端,需要5阶段的处理过程,每个阶段都包含一些特定的信息。接着,我们将其进行分类。分类过程主要分为两类:第一类:相互独立。第二类:不同的单元内部。我们将一些特定的头信息header将其关联在一起。最后,我们将数据从header中进行提取。
这一步,我们最终得到一些内容。当然,在这一阶段,我们将提取信息分为五类:1.资源内容header2.request请求url和responseurl3.http中的header(常是post请求时提供的header)4.属性信息,例如adminroleaccounturl等5.getrequestheader下面我们将其解释如下:首先我们得到一个header头信息,这个头信息包含了一些表单的信息,例如cookie。
随后我们分为两个阶段,从服务器接收数据后的5阶段中,各提取对应的信息。第一阶段:从服务器接收数据。服务器一般采用dns服务器,我们将数据下载后,一般传输至其中的dns服务器,然后由dns服务器来接收数据。http和https中,dns信息我们用(域名\/域名服务器)来表示。第二阶段:提取相关的数据。这一阶段我们分为一下几个步骤,不同的网站,这一步的不同处在于其组成网站的阶段划分不同,这些信息列表如下:由于采用类似的五阶段,基本原理上也是一样的,所以这里不再赘述。
2.项目代码下面我们讲解代码,包括注释和预览图,为了方便说明,我将代码都合并到github上,作为一个仓库。预览图同上一张我们已经抓取了从浏览器到浏览器的所有html资源,我们不仅将它们传输,同时还需要将它们解析。至于要解析什么东西,当然只是我的一些猜测,将。
如何抓取网页flash(如何抓取网页flash,我的理解是需要找一些合法的去网页源码)
网站优化 • 优采云 发表了文章 • 0 个评论 • 66 次浏览 • 2022-03-08 03:05
如何抓取网页flash,我的理解是需要找一些合法的去网页抓取源码,现在网上很多能抓取网页的第三方应用,从源码中提取。前段时间我试了人人网的,直接输入用户名密码就行。
你去,网页中有好多这样的。
现在那种下载软件抓到的都是小网站。真正的大网站你不知道,
感觉现在随便一个啥工具都能抓
非安全下,被黑的概率大于安全下,再安全,
你可以说arcgis会不会被破解这个命题,如果你是内网,那么当然不可能如果是外网的话,
目前针对静态网页的抓取工具是最好的。问题中所指抓取静态页面是指源代码html,js等记录下来,非html,js等是没办法读取的。arcgis也是如此,并且即使是静态页面在arcgis的看来都是一串信息,经常还会因为很多碎片没有组织,比如颜色、形状、图标等。目前navicat也只能抓取静态页面。
国内各大安全厂商已经成功破解了静态网页包括广告搜索页面
arcgis不适合。
国内只有安全厂商有抓取静态网页的能力。小网站都是黑客控制的。
商业公司完全可以做,直接拿到源代码,按照数据规模控制抓取成本吧,量比较大,
arcgis不会被adobe的安全公司破解,因为arcgis是商业服务,adobe帮你写好安全套件防护好了,自己用只要给钱,他们可以随便定制去发adobe的安全公司审核。ibm的arcgispro就是被adobe的安全服务包着走,用谁写的安全套件adobe并不知道,adobe只知道用自己的,(仅限于静态网页,不包括dom)就算是被adobe破解了也有据可查。 查看全部
如何抓取网页flash(如何抓取网页flash,我的理解是需要找一些合法的去网页源码)
如何抓取网页flash,我的理解是需要找一些合法的去网页抓取源码,现在网上很多能抓取网页的第三方应用,从源码中提取。前段时间我试了人人网的,直接输入用户名密码就行。
你去,网页中有好多这样的。
现在那种下载软件抓到的都是小网站。真正的大网站你不知道,
感觉现在随便一个啥工具都能抓
非安全下,被黑的概率大于安全下,再安全,
你可以说arcgis会不会被破解这个命题,如果你是内网,那么当然不可能如果是外网的话,
目前针对静态网页的抓取工具是最好的。问题中所指抓取静态页面是指源代码html,js等记录下来,非html,js等是没办法读取的。arcgis也是如此,并且即使是静态页面在arcgis的看来都是一串信息,经常还会因为很多碎片没有组织,比如颜色、形状、图标等。目前navicat也只能抓取静态页面。
国内各大安全厂商已经成功破解了静态网页包括广告搜索页面
arcgis不适合。
国内只有安全厂商有抓取静态网页的能力。小网站都是黑客控制的。
商业公司完全可以做,直接拿到源代码,按照数据规模控制抓取成本吧,量比较大,
arcgis不会被adobe的安全公司破解,因为arcgis是商业服务,adobe帮你写好安全套件防护好了,自己用只要给钱,他们可以随便定制去发adobe的安全公司审核。ibm的arcgispro就是被adobe的安全服务包着走,用谁写的安全套件adobe并不知道,adobe只知道用自己的,(仅限于静态网页,不包括dom)就算是被adobe破解了也有据可查。
如何抓取网页flash(如何抓取网页flash视频,进行解析,制作txt观看文件?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 90 次浏览 • 2022-03-06 20:05
如何抓取网页flash视频,进行解析,制作txt观看文件?-技术的分享-集智专栏分享的是一个做好了,而且很详细的脚本。分享者显然是知道我的。你看到我博客分享的东西,基本上都是对网页flash视频进行解析的,包括各种ppt视频,个人介绍视频。用脚本抓取解析网页,有一个明显的缺点,就是视频的压缩,图片尺寸越小,压缩率越高,但是却有以下的劣势:。
1、网页图片尺寸太小,如果解析过来的视频尺寸过大,就会出现很多不利于文件小。
2、图片尺寸太小,会大大浪费网络带宽资源。
3、可以通过下载flash的目录页来进行下载,如果解析的视频很大,可能会内存读取,占用的cpu资源。分享的是一个做好了,而且很详细的脚本。当然,还有这种。以上的脚本都是需要下载flash文件的。脚本在谷歌里面,都可以搜索到。脚本的github地址:-cnreference这个脚本的基本效果也没有,还是通过打开flash界面来抓取,但是一定要克制,不要太大的文件。
实际上,没有出现乱码,而且有些图片,确实尺寸太小了,但是,图片中显示的都是还原的flash的流量。分享的是一个做好了,而且很详细的脚本。当然,还有这种。以上的脚本都是需要下载flash文件的。脚本在谷歌里面,都可以搜索到。脚本的github地址:-cn分享的是一个做好了,而且很详细的脚本。当然,还有这种。以上的脚本都是需要下载flash文件的。脚本的github地址:-cn。 查看全部
如何抓取网页flash(如何抓取网页flash视频,进行解析,制作txt观看文件?)
如何抓取网页flash视频,进行解析,制作txt观看文件?-技术的分享-集智专栏分享的是一个做好了,而且很详细的脚本。分享者显然是知道我的。你看到我博客分享的东西,基本上都是对网页flash视频进行解析的,包括各种ppt视频,个人介绍视频。用脚本抓取解析网页,有一个明显的缺点,就是视频的压缩,图片尺寸越小,压缩率越高,但是却有以下的劣势:。
1、网页图片尺寸太小,如果解析过来的视频尺寸过大,就会出现很多不利于文件小。
2、图片尺寸太小,会大大浪费网络带宽资源。
3、可以通过下载flash的目录页来进行下载,如果解析的视频很大,可能会内存读取,占用的cpu资源。分享的是一个做好了,而且很详细的脚本。当然,还有这种。以上的脚本都是需要下载flash文件的。脚本在谷歌里面,都可以搜索到。脚本的github地址:-cnreference这个脚本的基本效果也没有,还是通过打开flash界面来抓取,但是一定要克制,不要太大的文件。
实际上,没有出现乱码,而且有些图片,确实尺寸太小了,但是,图片中显示的都是还原的flash的流量。分享的是一个做好了,而且很详细的脚本。当然,还有这种。以上的脚本都是需要下载flash文件的。脚本在谷歌里面,都可以搜索到。脚本的github地址:-cn分享的是一个做好了,而且很详细的脚本。当然,还有这种。以上的脚本都是需要下载flash文件的。脚本的github地址:-cn。
如何抓取网页flash(如何抓取网页flash信息-hunter-flash找了很久,就这个办法可行了)
网站优化 • 优采云 发表了文章 • 0 个评论 • 48 次浏览 • 2022-03-06 07:02
如何抓取网页flash信息-hunter-flash找了很久,就这个办法可行了!无奈,万万没想到是seeinelvis.youku、youtube,禁用或者去掉广告就可以了。
用flash吧,电脑是ie浏览器的话,可以下载chrome浏览器然后以管理员身份运行,
上b站可以用safariappmailchimp啊。使用里面的离线工具功能。b站发送到邮箱就可以了。或者让pc网页的代理服务器发送给b站就好。
直接用搜索引擎可以搜索到;f=zh_cn
哎,不敢想象啊。b站号称有800w的用户。而且这些人活跃在各个类似acg弹幕,jojob战电影等弹幕视频上。大家都直接搜索名字就可以搜到了。他们直接分享出来不是更方便,更多的资源也会找到你的。b站用户比起其他的视频平台要少,因为你会发现有很多关注度比你高,播放量高,或者这一个话题很火,这个要求就较高了,这就决定了你不会获得知乎的用户量。
而且上传视频比注册账号更麻烦,也就意味着资源多。那么,作为用户你希望他分享给你吗?或者,他有吗?或者,你有吗?或者,他有你也想获得呢?没有那么多的资源,又没有那么多的人。那么,你只能看别人,或者追番了。还有因为不是每个视频都是完整的。所以,你搜索时也要尽可能选择完整。 查看全部
如何抓取网页flash(如何抓取网页flash信息-hunter-flash找了很久,就这个办法可行了)
如何抓取网页flash信息-hunter-flash找了很久,就这个办法可行了!无奈,万万没想到是seeinelvis.youku、youtube,禁用或者去掉广告就可以了。
用flash吧,电脑是ie浏览器的话,可以下载chrome浏览器然后以管理员身份运行,
上b站可以用safariappmailchimp啊。使用里面的离线工具功能。b站发送到邮箱就可以了。或者让pc网页的代理服务器发送给b站就好。
直接用搜索引擎可以搜索到;f=zh_cn
哎,不敢想象啊。b站号称有800w的用户。而且这些人活跃在各个类似acg弹幕,jojob战电影等弹幕视频上。大家都直接搜索名字就可以搜到了。他们直接分享出来不是更方便,更多的资源也会找到你的。b站用户比起其他的视频平台要少,因为你会发现有很多关注度比你高,播放量高,或者这一个话题很火,这个要求就较高了,这就决定了你不会获得知乎的用户量。
而且上传视频比注册账号更麻烦,也就意味着资源多。那么,作为用户你希望他分享给你吗?或者,他有吗?或者,你有吗?或者,他有你也想获得呢?没有那么多的资源,又没有那么多的人。那么,你只能看别人,或者追番了。还有因为不是每个视频都是完整的。所以,你搜索时也要尽可能选择完整。
如何抓取网页flash(屏蔽搜索引擎对网站部分页面内容内容的方法有哪些?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 82 次浏览 • 2022-03-04 16:12
做SEO优化的人都知道,网站要想在搜索引擎中有好的排名,就需要搜索引擎爬取更多的网站内容页面,从而收录更多的< @网站的内容,只有这样有利于网站和页面的排名,让更多的用户通过搜索引擎了解网站,从而获得更多的流量和转化。
一些SEO人员在做网站排名优化的时候,为了让网站获得更好的垂直度,让搜索引擎更好的抓取网站的重要页面,会屏蔽一些页面,防止搜索引擎从这些页面中抓取和收录。
那么,有哪些方法可以防止搜索引擎抓取页面中网站部分的内容呢?接下来,让SEO公司告诉你!
1、在页面中设置robots协议
在做SEO优化的时候,如果要防止搜索引擎抓取网站的部分页面,首先想到的方法就是在页面中设置robots协议。当搜索引擎蜘蛛进入 网站 并爬取 网站 页面时,robots 协议会告诉搜索引擎 网站 的哪些页面可以爬取,哪些页面不能爬取,以便搜索引擎可以抓取一些更有意义的页面,有利于网站的整体排名。设置robots协议时,一般情况下一般设置在网站根目录下。
2、不关注
<p>nofollow标签实际上是HTML中的一个属性,nofollow标签的作用不仅可以阻止搜索引擎抓取页面,还可以阻止页面权重的传递。因此,如果想要阻止搜索引擎抓取网站页面,可以在页面上设置nofollow标签,使页面无法参与网站的排名,更有利于浓度 查看全部
如何抓取网页flash(屏蔽搜索引擎对网站部分页面内容内容的方法有哪些?)
做SEO优化的人都知道,网站要想在搜索引擎中有好的排名,就需要搜索引擎爬取更多的网站内容页面,从而收录更多的< @网站的内容,只有这样有利于网站和页面的排名,让更多的用户通过搜索引擎了解网站,从而获得更多的流量和转化。
一些SEO人员在做网站排名优化的时候,为了让网站获得更好的垂直度,让搜索引擎更好的抓取网站的重要页面,会屏蔽一些页面,防止搜索引擎从这些页面中抓取和收录。
那么,有哪些方法可以防止搜索引擎抓取页面中网站部分的内容呢?接下来,让SEO公司告诉你!
1、在页面中设置robots协议
在做SEO优化的时候,如果要防止搜索引擎抓取网站的部分页面,首先想到的方法就是在页面中设置robots协议。当搜索引擎蜘蛛进入 网站 并爬取 网站 页面时,robots 协议会告诉搜索引擎 网站 的哪些页面可以爬取,哪些页面不能爬取,以便搜索引擎可以抓取一些更有意义的页面,有利于网站的整体排名。设置robots协议时,一般情况下一般设置在网站根目录下。
2、不关注
<p>nofollow标签实际上是HTML中的一个属性,nofollow标签的作用不仅可以阻止搜索引擎抓取页面,还可以阻止页面权重的传递。因此,如果想要阻止搜索引擎抓取网站页面,可以在页面上设置nofollow标签,使页面无法参与网站的排名,更有利于浓度
如何抓取网页flash(华军软件园网络辅助频道提供网页FLASH抓取器抓取70历史版)
网站优化 • 优采云 发表了文章 • 0 个评论 • 72 次浏览 • 2022-02-26 01:05
11IDM 包括 网站 spider 和 scraper IDM 以下载使用 网站 过滤器指定的所有必需文件,例如来自 网站 或 网站Son of @> 的所有图像。
Dote软件站安卓下载为您提供网页FLASH抓取器V70安卓版,手机版下载,网页FLASH抓取器V70apk免费下载安装到手机,支持电脑便捷一键安装.
华军软件园网络辅助频道为您提供2016官方网页FLASH抓取器2016官方下载网页FLASH抓取器绿色版等网络辅助软件下载更多网页FLASH抓取器70历史版本。
一个网页抓取工具,网站抓取图片、文字等信息采集处理神器,值得一点,懂就好优采云采集器V9快乐版_pure版本共享,你懂的。
Flash 播放器长期以来一直存在安全问题。我使用 Flashblock 浏览器扩展来防止插件在网页上自动加载,原来的 Flash 内容将被替换。
PC下载网其他渠道,为您提供官方网页最新版FLASH采集卡网页FLASH采集卡绿色免费版等网络软件下载更多网页FLASH采集卡70最新版。
Arachnid 是一个基于 Java 的网络爬虫框架,包括一个简单的 HTML 解析器,可以分为 crawlzilla 是一个免费软件,可以帮助您轻松构建搜索引擎,ExCrawler 是一个网络爬虫,用 Java 开发,项目分为两部分,一是守护进程。 查看全部
如何抓取网页flash(华军软件园网络辅助频道提供网页FLASH抓取器抓取70历史版)
11IDM 包括 网站 spider 和 scraper IDM 以下载使用 网站 过滤器指定的所有必需文件,例如来自 网站 或 网站Son of @> 的所有图像。
Dote软件站安卓下载为您提供网页FLASH抓取器V70安卓版,手机版下载,网页FLASH抓取器V70apk免费下载安装到手机,支持电脑便捷一键安装.
华军软件园网络辅助频道为您提供2016官方网页FLASH抓取器2016官方下载网页FLASH抓取器绿色版等网络辅助软件下载更多网页FLASH抓取器70历史版本。
一个网页抓取工具,网站抓取图片、文字等信息采集处理神器,值得一点,懂就好优采云采集器V9快乐版_pure版本共享,你懂的。
Flash 播放器长期以来一直存在安全问题。我使用 Flashblock 浏览器扩展来防止插件在网页上自动加载,原来的 Flash 内容将被替换。
PC下载网其他渠道,为您提供官方网页最新版FLASH采集卡网页FLASH采集卡绿色免费版等网络软件下载更多网页FLASH采集卡70最新版。
Arachnid 是一个基于 Java 的网络爬虫框架,包括一个简单的 HTML 解析器,可以分为 crawlzilla 是一个免费软件,可以帮助您轻松构建搜索引擎,ExCrawler 是一个网络爬虫,用 Java 开发,项目分为两部分,一是守护进程。
如何抓取网页flash(如何抓取网页flash视频同步方法总结(一)_软件)
网站优化 • 优采云 发表了文章 • 0 个评论 • 62 次浏览 • 2022-02-16 07:01
如何抓取网页flash视频同步方法总结一、通过video标签可以抓取视频1.浏览器抓取方法:提前下载这个插件,导入到chrome浏览器,然后将视频下载到本地。优点:不占内存,文件大小小,可编辑缺点:下载到本地的视频无法再次编辑2.服务器抓取方法:直接到国外网站抓取flash视频,并且可以支持版本监控优点:文件大小大,便于编辑缺点:需要翻墙优点:无需下载到本地,还可以进行视频加密解密,支持中文字幕二、通过网页上的视频标签可以抓取视频1.可以抓取html5视频标签2.视频网站视频图片同步下载方法优点:前端视频不占内存,文件大小小,可编辑缺点:前端视频加密方法无法再破解了???解决办法,这个方法缺点很多,现在已经不适用。
1.uc浏览器登录国内某某音乐平台,并且去标签,会看到“我已下载/国内音乐平台服务器上已下载某某音乐”,所以通过该标签抓取,解密,点击打开即可同步观看,是不是很方便。优点:前端视频不占内存,文件大小小,可编辑缺点:需要翻墙2.qq浏览器登录qq音乐,并且去标签,会看到“我已下载/qq音乐服务器上已下载某某音乐”,所以通过该标签抓取,解密,点击打开即可同步观看,是不是很方便。
优点:前端视频不占内存,文件大小小,可编辑缺点:前端视频加密方法无法再破解了???解决办法,这个方法缺点很多,现在已经不适用了。 查看全部
如何抓取网页flash(如何抓取网页flash视频同步方法总结(一)_软件)
如何抓取网页flash视频同步方法总结一、通过video标签可以抓取视频1.浏览器抓取方法:提前下载这个插件,导入到chrome浏览器,然后将视频下载到本地。优点:不占内存,文件大小小,可编辑缺点:下载到本地的视频无法再次编辑2.服务器抓取方法:直接到国外网站抓取flash视频,并且可以支持版本监控优点:文件大小大,便于编辑缺点:需要翻墙优点:无需下载到本地,还可以进行视频加密解密,支持中文字幕二、通过网页上的视频标签可以抓取视频1.可以抓取html5视频标签2.视频网站视频图片同步下载方法优点:前端视频不占内存,文件大小小,可编辑缺点:前端视频加密方法无法再破解了???解决办法,这个方法缺点很多,现在已经不适用。
1.uc浏览器登录国内某某音乐平台,并且去标签,会看到“我已下载/国内音乐平台服务器上已下载某某音乐”,所以通过该标签抓取,解密,点击打开即可同步观看,是不是很方便。优点:前端视频不占内存,文件大小小,可编辑缺点:需要翻墙2.qq浏览器登录qq音乐,并且去标签,会看到“我已下载/qq音乐服务器上已下载某某音乐”,所以通过该标签抓取,解密,点击打开即可同步观看,是不是很方便。
优点:前端视频不占内存,文件大小小,可编辑缺点:前端视频加密方法无法再破解了???解决办法,这个方法缺点很多,现在已经不适用了。

