
大数据
一款可以精准爬取网站的网路数据采集系统
采集交流 • 优采云 发表了文章 • 0 个评论 • 409 次浏览 • 2020-05-15 08:00
利用网路大数据面临的挑战
互联网上有广袤的数据资源,要想抓取那些数据就离不开爬虫。鉴于网上免费开源的爬虫框架多如牛毛,很多人觉得爬虫定是极其简单的事情。但是假如你要定期、上规模地确切抓取各类小型网站的数据却是一项繁重的挑战。流行的爬虫框架Scrapy开发者Scrapinghub在抓取了一千亿个网页后,总结了她们在爬虫是遇见的挑战:
速度和数据质量:由于时间一般是限制诱因,规模抓取要求你的爬虫要以很高的速率抓取网页但又不能连累数据质量。对速率的这张要求促使爬取大规模产品数据显得极具挑战性。
网站格式多变:网页本身是基于HTML这些松散的规范来构建的,各网页相互不兼容,导致网页结构复杂多变。在规模爬取的时侯,你除了要浏览成百上千个有着仓促代码的网站爬虫软件增加网页访问,还将被迫应对不断变化的网站。
网络访问不稳定:如果网站在一个时间访问压力过大,或者服务器出现问题,就可能不会正常响应用户查看网页的需求。对于网页数据采集工具而言,一旦出现意外情况,很有可能由于不知道怎样处理而崩溃或则逻辑中断。
网页内容良莠不齐:网页上显示的内容,除了有用数据外,还有各类无效信息;有效信息也通过各类显示形式呈现,网页上出现的数据格式多样。
网页访问限制:网页存在访问频度限制,网站访问频度很高将会面临被封锁IP的风险。
网页反扒机制:有些网站为了屏蔽个别恶意采集而采取了防采集措施。比如Amazon这些较小型的电子商务网站,会采用极其复杂的反机器人对策促使析取数据困难许多。
数据剖析难度高:规模化的数据采集会导致数据质量得不到保证,变脏或则不完整的数据很容易都会流入到你的数据流上面爬虫软件增加网页访问,进而破坏了数据剖析的疗效。
为了充分利用网路大数据,企业须要一个有效的系统,该系统除了可以自动化从网页中提取数据,同时对数据进行筛选、清理和标准化,并将这种数据集成到现有工具链和工作流中。
探码网路数据采集系统是一款可以精准爬取网站的爬虫工具,采用探码科技自主研制的TMF框架为构架主体,支持开发可操作的网路数据采集系统。
探码对以上挑战的解决办法
24小时自动化爬虫采集,制定清晰采集字段,保证初步采集速度和质量;
兼顾计算机和人处理网页数据的特点,能够应对网页结构的复杂多变;
云服务器协同合作,达到采集素的的平衡点,在不增加采集速度的同时保证不被封锁IP;
内置逻辑判定方案,自定义网站访问不稳定时的智能应对机制;
对采集的原始数据进行“清洗、归类、注释、关联、映射”,将分散、零乱、标准不统一的数据整合到一起,提高数据的质量,为后期数据剖析奠定基础。
探码的数据采集属于正常的采集行为,倡导在获得网站授权采集后进行采集,共同维护互联网规范。
探码网路数据采集方案
探码网路数据采集系统实现数据从采集,处理到应用的全生命周期管理,达到网路爬虫,另类数据,网页解析及采集自动化。目前探码已建设自己的企业库数据(3000+企业数据信息),律师数据库(全过30w+律师数据信息)且这种信息都是通过数据处理与剖析,用户可直接使用于商务中!
数据提取
探码通过网路爬虫、结构化数据、本地数据、物联网设备、人工录入等进行全方位实时的汇总采集。对各类来源(如RFID射频数据、传感器数据、移动互联网数据、社交网络数据等)的非结构化数据进行全自动化采集,借助网路爬虫或网站API,从网页获取非结构化数据数据,将其统一结构化为本地数据。
数据管理
探码网路数据采集系统合并来自多个来源的数据,构建复杂的联接和聚合。针对非结构化、半结构化数据的特殊性,在爬取完数据后还须要对采集的原始数据进行“清洗、归类、注释、关联、映射”等一系列操作后,将分散、零乱、标准不统一的数据整合到一起,提高数据的质量,为后期数据剖析奠定基础。
数据存储
探码网路数据采集系统在获得所需的数据并将其分解为有用的组件以后,通过可扩充的方式来将所有提取和解析的数据储存在数据库或集群中,然后创建一个容许用户可及时查找相关数据集或提取的功能。
解决方案优势
通过采用探码网路数据采集解决方案,实现了以下几个优势:
全面的数据服务 -通过探码网路数据采集系统,您可以轻松地获得网路数据。您可以实现自动化提取、更新、转换数据并确保不同的数据元素符合常见的数据格式。
最新数据- 解决方案的自动化意味着您的组织可以以最少的工作量进行持续提取。因此,组织可以确保仍然使用最新的数据。
准确的数据- 探码网路数据采集系统让团队除了能否去除与自动提取和转换相关的工作,而且能够清除与人工工作相关的潜在错误。
降低成本-企业自身无需高昂的工程团队不断编撰代码,监控质量和维护逻辑,就能够规模快速,经济高效地获得高质量的网路数据。
可扩展性- 探码网路数据采集系统支持提取数百万个数据点和Web查询。
总结
探码科技自主研制的网路数据采集系统是集Web数据采集,分析和可视化为一体的数据集成系统,确保您从Web数据中获得最大的洞察力和价值。 查看全部

利用网路大数据面临的挑战
互联网上有广袤的数据资源,要想抓取那些数据就离不开爬虫。鉴于网上免费开源的爬虫框架多如牛毛,很多人觉得爬虫定是极其简单的事情。但是假如你要定期、上规模地确切抓取各类小型网站的数据却是一项繁重的挑战。流行的爬虫框架Scrapy开发者Scrapinghub在抓取了一千亿个网页后,总结了她们在爬虫是遇见的挑战:
速度和数据质量:由于时间一般是限制诱因,规模抓取要求你的爬虫要以很高的速率抓取网页但又不能连累数据质量。对速率的这张要求促使爬取大规模产品数据显得极具挑战性。
网站格式多变:网页本身是基于HTML这些松散的规范来构建的,各网页相互不兼容,导致网页结构复杂多变。在规模爬取的时侯,你除了要浏览成百上千个有着仓促代码的网站爬虫软件增加网页访问,还将被迫应对不断变化的网站。
网络访问不稳定:如果网站在一个时间访问压力过大,或者服务器出现问题,就可能不会正常响应用户查看网页的需求。对于网页数据采集工具而言,一旦出现意外情况,很有可能由于不知道怎样处理而崩溃或则逻辑中断。
网页内容良莠不齐:网页上显示的内容,除了有用数据外,还有各类无效信息;有效信息也通过各类显示形式呈现,网页上出现的数据格式多样。
网页访问限制:网页存在访问频度限制,网站访问频度很高将会面临被封锁IP的风险。
网页反扒机制:有些网站为了屏蔽个别恶意采集而采取了防采集措施。比如Amazon这些较小型的电子商务网站,会采用极其复杂的反机器人对策促使析取数据困难许多。
数据剖析难度高:规模化的数据采集会导致数据质量得不到保证,变脏或则不完整的数据很容易都会流入到你的数据流上面爬虫软件增加网页访问,进而破坏了数据剖析的疗效。
为了充分利用网路大数据,企业须要一个有效的系统,该系统除了可以自动化从网页中提取数据,同时对数据进行筛选、清理和标准化,并将这种数据集成到现有工具链和工作流中。
探码网路数据采集系统是一款可以精准爬取网站的爬虫工具,采用探码科技自主研制的TMF框架为构架主体,支持开发可操作的网路数据采集系统。
探码对以上挑战的解决办法
24小时自动化爬虫采集,制定清晰采集字段,保证初步采集速度和质量;
兼顾计算机和人处理网页数据的特点,能够应对网页结构的复杂多变;
云服务器协同合作,达到采集素的的平衡点,在不增加采集速度的同时保证不被封锁IP;
内置逻辑判定方案,自定义网站访问不稳定时的智能应对机制;
对采集的原始数据进行“清洗、归类、注释、关联、映射”,将分散、零乱、标准不统一的数据整合到一起,提高数据的质量,为后期数据剖析奠定基础。
探码的数据采集属于正常的采集行为,倡导在获得网站授权采集后进行采集,共同维护互联网规范。
探码网路数据采集方案
探码网路数据采集系统实现数据从采集,处理到应用的全生命周期管理,达到网路爬虫,另类数据,网页解析及采集自动化。目前探码已建设自己的企业库数据(3000+企业数据信息),律师数据库(全过30w+律师数据信息)且这种信息都是通过数据处理与剖析,用户可直接使用于商务中!
数据提取
探码通过网路爬虫、结构化数据、本地数据、物联网设备、人工录入等进行全方位实时的汇总采集。对各类来源(如RFID射频数据、传感器数据、移动互联网数据、社交网络数据等)的非结构化数据进行全自动化采集,借助网路爬虫或网站API,从网页获取非结构化数据数据,将其统一结构化为本地数据。
数据管理
探码网路数据采集系统合并来自多个来源的数据,构建复杂的联接和聚合。针对非结构化、半结构化数据的特殊性,在爬取完数据后还须要对采集的原始数据进行“清洗、归类、注释、关联、映射”等一系列操作后,将分散、零乱、标准不统一的数据整合到一起,提高数据的质量,为后期数据剖析奠定基础。
数据存储
探码网路数据采集系统在获得所需的数据并将其分解为有用的组件以后,通过可扩充的方式来将所有提取和解析的数据储存在数据库或集群中,然后创建一个容许用户可及时查找相关数据集或提取的功能。
解决方案优势
通过采用探码网路数据采集解决方案,实现了以下几个优势:
全面的数据服务 -通过探码网路数据采集系统,您可以轻松地获得网路数据。您可以实现自动化提取、更新、转换数据并确保不同的数据元素符合常见的数据格式。
最新数据- 解决方案的自动化意味着您的组织可以以最少的工作量进行持续提取。因此,组织可以确保仍然使用最新的数据。
准确的数据- 探码网路数据采集系统让团队除了能否去除与自动提取和转换相关的工作,而且能够清除与人工工作相关的潜在错误。
降低成本-企业自身无需高昂的工程团队不断编撰代码,监控质量和维护逻辑,就能够规模快速,经济高效地获得高质量的网路数据。
可扩展性- 探码网路数据采集系统支持提取数百万个数据点和Web查询。
总结
探码科技自主研制的网路数据采集系统是集Web数据采集,分析和可视化为一体的数据集成系统,确保您从Web数据中获得最大的洞察力和价值。
有这3个数据采集工具,不懂爬虫代码,也能轻松爬数据
采集交流 • 优采云 发表了文章 • 0 个评论 • 489 次浏览 • 2020-05-14 08:04
但实际情况是,对于日常工作中的各类小决策,内部提供的数据有时还不足给以充分支持,外部的数据大部分又常常都是机构开具的行业状况,并不能提供哪些有效帮助。
于是产品和运营们常常要依靠爬虫来抓取自己想要的数据。比如想要获取某个电商网站的评论数据,往往须要写出一段代码,借助python去抓取出相应的内容。
说到学写代码……额,我选择舍弃。
那么问题来了,有没有哪些更方便的方式呢?
今天就为你们介绍3个能适应大多数场景的数据采集工具,即使不懂爬虫代码,你也能轻松爬出95%网站的数据。
重点是,这三个软件的基础功能都是可以免费使用的喔~
1.火车采集器
这个是太老牌的网站数据采集工具啦,从诞生至今早已十一年了。经过不断的更新迭代,功能也越来越多 (只是有些中级功能早已要收费了QAQ) 。
据说用户量仍然在同类软件中居于第一,毕竟是十一年的老司机,想当初小编我学习数据挖掘的时侯,老师推荐使用的也是这款软件呢。
火车采集器
火车采集器可以实现数据的抓取、清洗、分析,挖掘及最终的可用数据呈现,堪称一条龙服务。
它的第一个特征是适用范围广,采集数据确切。火车采集器的采集原理是基于 web 结构的源代码提取,所以几乎适用于所有的网页,以及网页中才能见到的所有内容。可以通过设定内容采集规则,轻松迅速地抓取网页上散乱分布的文本、图片、压缩文件、视频等内容
比如采集豆瓣读书网站上的书籍的标题以及作者的数据,但是页面上有图片,也有文字,只要才采集的时侯设定好采集的规则,就能精准地只采集到标题名和作者的名子。
并且,火车采集器的内容采集支持测试功能,可选用一个典型页面来测试内容采集的正确性,以便及时更正和进行下一步数据处理。
比如说,你想采集豆瓣读书里几百本书的评论,但你不确定一次性抓取出来的数据是否确切。你就可以通过测试,先抓其中几个网页测试一下,看看抓到的结果是否是你想要的结果,并按照结果对采集规则进行调整,直到测试下来的结果是使你满意的结果为止,然后再进行大规模的采集。这样就不怕采集出来的数据出错啦。
此外,对于采集到的信息数据,它还可以对其进行一系列的智能处理,使采集到的数据愈加符合我们的使用标准。比如过滤掉不需要的空格啦,标签啦,同义词替换啦,繁简转换啦等等。
看到这儿有朋友要问了,说了这么多,还是不知道如何操作,怎么破。别担心,火车采集器的网站上,还有提供菜鸟的入门指南和视频教程,不懂的问题可以在峰会内提问,也可以在峰会里跟随前辈快速学习列车采集器的操作。
2.八爪鱼
这也是一个堪称哪些网站都能采的工具。电商类、生活服务类、社交媒体类、论坛类,甚至瀑布流类的网站都可以采集。
八爪鱼
它的采集方式有一个亮点,就是云采集。也就是说,当你配置好采集任务,即使死机出去浪,任务也可以接着在云端执行,等浪完回去数据爬虫软件,数据就采好了。这就不用害怕网路中断,辛辛苦苦采集的数据没了,也不用仍然守在笔记本门口等数据采集完。
云采集还有一个益处在于,可以借助云端多节点并发运行,采集速度将远超于本地采集(单机采集)。多 IP 在任务启动时手动切换还可避免网站的 IP 封锁,实现数据采集的最大化。
据说规则的配置也是hin简单。操作上2分钟就可以快速入门。看了一下操作页面,流程基本上是所见即所得,整个流程也是可视化的,确实比火车头要简单些。
就算不知道软件如何使用,网站上有教程中心,也一样提供免费的菜鸟入门教程,供你们快速学习软件的操作方法。
3.集搜客
这个工具,也可以说是十分厉害了。完全可视化操作,无需编程基础,熟悉笔记本操作就可以轻松把握。整个采集过程也是所见即所得,遍历的链接信息、抓取结果信息、错误信息等就会及时地反映在软件界面中。
集搜客
它有一个强悍的优势,拥有一个抓取规则的模板库。我们都晓得,采集数据须要给工具提供抓取规则数据爬虫软件,这个规则就相当于是告诉爬虫工具,你须要抓取的数据所具备的特点。因此抓取规则直接决定了你抓到数据的准确度和精细程度。
但是好多小白朋友在初次设置抓取规则的时侯,还是须要摸索一阵,才能得到自己想要的结果的。集搜客的抓取规则模板库,就可以帮你省去摸索抓取规则耗费的时间。
在集搜客资源库中,分门别类储存着各类抓取规则,你既可通过关键词,也可通过目标网页网址搜索到可用的抓取规则。
在抓取规则的详情页面,只要仔细考察一个规则的抓取结果是否满足您的须要,如果满足,只需点击“下载”按钮,即可在会员中心一键启动集搜客网络爬虫,抓取到你想要的数据。
集搜客还有一个优势,在于可以抓取可视化图表上的数据。现在有越来越多网站上的数据是经过统计、分析、挖掘,并用可视化图表展示下来的,比如淘宝指数,百度指数等等。它都可以直接从这种图表上,把数据抓取出来。
这就意味着,它除了能抓取文本数据、图片、表格,其他可视化图表,如新闻资讯图表、电商网站上的产品介绍图片、电商经营剖析数据还是指数走势图等等,它都能抓取到完整的图表信息。
而且,它能够模拟滑鼠动作,抓取在指数图表上漂浮显示的数据。
以上3个数据采集工具各有优劣,选择适宜的学习使用,是不是比写代码便捷多了呢? 查看全部
产品和营运在日常工作中,常常须要参考各类数据,来为决策做支持。
但实际情况是,对于日常工作中的各类小决策,内部提供的数据有时还不足给以充分支持,外部的数据大部分又常常都是机构开具的行业状况,并不能提供哪些有效帮助。
于是产品和运营们常常要依靠爬虫来抓取自己想要的数据。比如想要获取某个电商网站的评论数据,往往须要写出一段代码,借助python去抓取出相应的内容。
说到学写代码……额,我选择舍弃。

那么问题来了,有没有哪些更方便的方式呢?
今天就为你们介绍3个能适应大多数场景的数据采集工具,即使不懂爬虫代码,你也能轻松爬出95%网站的数据。
重点是,这三个软件的基础功能都是可以免费使用的喔~
1.火车采集器
这个是太老牌的网站数据采集工具啦,从诞生至今早已十一年了。经过不断的更新迭代,功能也越来越多 (只是有些中级功能早已要收费了QAQ) 。
据说用户量仍然在同类软件中居于第一,毕竟是十一年的老司机,想当初小编我学习数据挖掘的时侯,老师推荐使用的也是这款软件呢。

火车采集器
火车采集器可以实现数据的抓取、清洗、分析,挖掘及最终的可用数据呈现,堪称一条龙服务。
它的第一个特征是适用范围广,采集数据确切。火车采集器的采集原理是基于 web 结构的源代码提取,所以几乎适用于所有的网页,以及网页中才能见到的所有内容。可以通过设定内容采集规则,轻松迅速地抓取网页上散乱分布的文本、图片、压缩文件、视频等内容
比如采集豆瓣读书网站上的书籍的标题以及作者的数据,但是页面上有图片,也有文字,只要才采集的时侯设定好采集的规则,就能精准地只采集到标题名和作者的名子。

并且,火车采集器的内容采集支持测试功能,可选用一个典型页面来测试内容采集的正确性,以便及时更正和进行下一步数据处理。
比如说,你想采集豆瓣读书里几百本书的评论,但你不确定一次性抓取出来的数据是否确切。你就可以通过测试,先抓其中几个网页测试一下,看看抓到的结果是否是你想要的结果,并按照结果对采集规则进行调整,直到测试下来的结果是使你满意的结果为止,然后再进行大规模的采集。这样就不怕采集出来的数据出错啦。
此外,对于采集到的信息数据,它还可以对其进行一系列的智能处理,使采集到的数据愈加符合我们的使用标准。比如过滤掉不需要的空格啦,标签啦,同义词替换啦,繁简转换啦等等。
看到这儿有朋友要问了,说了这么多,还是不知道如何操作,怎么破。别担心,火车采集器的网站上,还有提供菜鸟的入门指南和视频教程,不懂的问题可以在峰会内提问,也可以在峰会里跟随前辈快速学习列车采集器的操作。

2.八爪鱼
这也是一个堪称哪些网站都能采的工具。电商类、生活服务类、社交媒体类、论坛类,甚至瀑布流类的网站都可以采集。

八爪鱼
它的采集方式有一个亮点,就是云采集。也就是说,当你配置好采集任务,即使死机出去浪,任务也可以接着在云端执行,等浪完回去数据爬虫软件,数据就采好了。这就不用害怕网路中断,辛辛苦苦采集的数据没了,也不用仍然守在笔记本门口等数据采集完。
云采集还有一个益处在于,可以借助云端多节点并发运行,采集速度将远超于本地采集(单机采集)。多 IP 在任务启动时手动切换还可避免网站的 IP 封锁,实现数据采集的最大化。
据说规则的配置也是hin简单。操作上2分钟就可以快速入门。看了一下操作页面,流程基本上是所见即所得,整个流程也是可视化的,确实比火车头要简单些。

就算不知道软件如何使用,网站上有教程中心,也一样提供免费的菜鸟入门教程,供你们快速学习软件的操作方法。
3.集搜客
这个工具,也可以说是十分厉害了。完全可视化操作,无需编程基础,熟悉笔记本操作就可以轻松把握。整个采集过程也是所见即所得,遍历的链接信息、抓取结果信息、错误信息等就会及时地反映在软件界面中。

集搜客
它有一个强悍的优势,拥有一个抓取规则的模板库。我们都晓得,采集数据须要给工具提供抓取规则数据爬虫软件,这个规则就相当于是告诉爬虫工具,你须要抓取的数据所具备的特点。因此抓取规则直接决定了你抓到数据的准确度和精细程度。
但是好多小白朋友在初次设置抓取规则的时侯,还是须要摸索一阵,才能得到自己想要的结果的。集搜客的抓取规则模板库,就可以帮你省去摸索抓取规则耗费的时间。


在集搜客资源库中,分门别类储存着各类抓取规则,你既可通过关键词,也可通过目标网页网址搜索到可用的抓取规则。
在抓取规则的详情页面,只要仔细考察一个规则的抓取结果是否满足您的须要,如果满足,只需点击“下载”按钮,即可在会员中心一键启动集搜客网络爬虫,抓取到你想要的数据。
集搜客还有一个优势,在于可以抓取可视化图表上的数据。现在有越来越多网站上的数据是经过统计、分析、挖掘,并用可视化图表展示下来的,比如淘宝指数,百度指数等等。它都可以直接从这种图表上,把数据抓取出来。
这就意味着,它除了能抓取文本数据、图片、表格,其他可视化图表,如新闻资讯图表、电商网站上的产品介绍图片、电商经营剖析数据还是指数走势图等等,它都能抓取到完整的图表信息。
而且,它能够模拟滑鼠动作,抓取在指数图表上漂浮显示的数据。
以上3个数据采集工具各有优劣,选择适宜的学习使用,是不是比写代码便捷多了呢?
基于爬虫与数据挖掘的电商页面信息剖析
采集交流 • 优采云 发表了文章 • 0 个评论 • 401 次浏览 • 2020-05-13 08:04
【共引文献】
中国刊物全文数据库
陈静杰;车洁;;基于IK-medoids算法的客机油耗降维方式[J];计算机科学;2018年08期
刘测;韩家新;;面向新闻文本的分类方式的比较研究[J];智能计算机与应用;2018年05期
刘湘蓉;;我国联通社交电商的商业模式——一个多案例的剖析[J];中国流通经济;2018年08期
高超;许翰林;;基于支持向量机的不均衡文本分类方式[J];现代电子技术;2018年15期
马艳辉;刘进;黄伟恺;吴钧;蔡梅松;李宇平;;企业外网内容检索系统的设计与实现[J];电脑编程方法与维护;2018年07期
李亚文;;电子商务背景下手动辨识系统中的网路安全问题及举措[J];信息与笔记本(理论版);2018年13期
马琳琳;刘继;;基于关联规则的党的十九大报告关键词相关性分析[J];新疆财经大学学报;2018年02期
李鑫;郭汉;张欣;胡方强;帅仁俊;;基于非平衡数据处理方式的网路在线广告中点击欺诈检查的研究[J];计算机科学;2018年S1期
李秀玲;陈七林;刘姗姗;;中国电子商务网路零售的发展历程与竞争态势[J];现代商业;2018年16期
杨守德;赵德海;;中国网路零售业发展的收敛性与空间溢出效应研究[J];经济体制改革;2018年03期
中国硕士学位论文全文数据库
钟宇;面向网路自媒体的空间数据挖掘研究[D];江西理工大学;2018年
于志浩;基于Android和网路爬虫的课外阅读系统设计与实现[D];山东大学;2018年
贾潇雨;基于改进爬虫技术的SQL注入的自动化扫描工具的研究与设计[D];北京邮电大学;2018年
常鑫;基于德尔菲调查法的电动车辆前沿技术评测系统设计与实现[D];山东大学;2018年
杨郁琪;基于文本挖掘的用户满意度影响诱因研究[D];中北大学;2018年
李笑语;深度可订制的工具化爬虫系统的设计与实现[D];北京邮电大学;2018年
王惠;基于LDA主题模型的文本降维研究[D];兰州大学;2018年
吕博庆;基于爬虫与数据挖掘的电商页面信息剖析[D];兰州大学;2018年
王丰;基于GPU并行的K-MEANS算法研究及其在文本聚类的应用[D];武汉邮电科学研究院;2018年
马琼琼;基于语义的文本聚类算法研究[D];北京交通大学;2017年
【二级参考文献】
中国刊物全文数据库
赵本本;殷旭东;王伟;;基于Scrapy的GitHub数据爬虫[J];电子技术与软件工程;2016年06期
李京文;;中国电子商务的发展现况与未来趋势[J];河北学刊;2016年01期
王宝义;;电商与快件跨界经营的理论基础与现实剖析[J];西部峰会;2015年06期
曾田日;王晋国;;基于统计的云搜索英文动词算法[J];西北大学学报(自然科学版);2015年04期
李杰;王宇菲;王聪;张志颖;;B2C电子商务竞争结构及发展演变规律[J];产业经济评论;2015年03期
李博群;;我国电子商务发展现况及前景展望研究[J];调研世界;2015年01期
聂林海;;我国电子商务发展的特性和趋势[J];中国流通经济;2014年06期
郑淑蓉;吕庆华;;中国电子商务20年演化[J];商业经济与管理;2013年11期
中国社科院财经战略研究院课题组;荆林波;;电子商务:中国经济发展的新引擎[J];求是;2013年11期
占明珍;;“双十一”我国电商企业促销战的冷思索[J];对外经贸实务;2013年04期
中国硕士学位论文全文数据库
周红伟;商品评价信息的英文情感剖析[D];浙江工商大学;2015年
范倩倩;高校图书馆Web2.0研究[D];安徽大学;2014年
苏芳仲;中文Web文本挖掘的若干关键技术研究及其实现[D];福州大学;2006年
李健;聚类剖析及其在文本挖掘中的应用[D];西安电子科技大学;2005年
马慧敏;中文文本手动分类方式的研究和实现[D];华北电力大学(河北);2005年
许林杰;中文文本动词研究[D];山东师范大学;2003年
【相似文献】
中国刊物全文数据库
牛猛爬虫软件分析电商数据,黄道斌爬虫软件分析电商数据,卢小杰;数据挖掘方式与功能的基本研究[J];电脑知识与技术;2018年14期
刘芬;;数据挖掘在中国的现况和发展研究[J];山东工业技术;2018年17期
饶正婵;蒲天银;;云计算条件下的大数据挖掘内涵及解决方案[J];电子技术与软件工程;2018年13期
陈小凤;;大数据挖掘校园用户[J];电子技术与软件工程;2018年15期
许晓燕;;基于云计算的数据挖掘云服务模式研究[J];电脑知识与技术;2018年19期
于春香;;数据挖掘技术简介[J];福建信息技术教育;2005年01期
邵兴江;;数据挖掘在教育信息化中的应用空间剖析[J];浙江现代教育技术;2004年03期
周洋;;数据挖掘在电力调度自动化系统中的应用解析[J];科技创新与应用;2017年35期
梁园;;浅析数据挖掘在审计中的应用[J];现代经济信息;2017年22期
冯丽慧;;云计算和挖掘服务融合下的大数据挖掘体系构架设计及应用[J];电脑编程方法与维护;2017年24期
中国重要大会论文全文数据库
马钰超;;浅析大数据和数据挖掘及其在烟草行业中的应用[A];中国烟草学会2015年度优秀论文汇编[C];2015年
唐杰;梅俏竹;;数据挖掘学科发展研究[A];2012-2013控制科学与工程学科发展报告[C];2014年
王岁月;;大数据时代规划数据挖掘的创新思索[A];新常态:传承与改革——2015中国城市规划晚会论文集(04城市规划新技术应用)[C];2015年
史东辉;蔡庆生;张春阳;;一种新的数据挖掘多策略技巧研究[A];第十七届全省数据库学术大会论文集(研究报告篇)[C];2000年
谢中;邱玉辉;;面向商务网站有效性的数据挖掘方式[A];第十八届全省数据库学术大会论文集(技术报告篇)[C];2001年
许珂;姜山;;数据挖掘方式在科技产出分布可视化研究中的运用[A];第二届中国科技哲学及交叉学科研究生峰会论文集(硕士卷)[C];2008年
雷宇;;论行业信息资源的数据挖掘[A];中国烟草行业信息化研讨会论文集[C];2004年
吴以凡;吴铁军;欧阳树生;;面向生产过程质量控制的动态数据挖掘方式[A];05'中国自动化产业高峰大会暨中国企业自动化和信息化建设峰会论文集[C];2005年
彭怡;;从数据挖掘文章聚类剖析看其发展趋势[A];现代工业工程与管理研讨会大会论文集[C];2006年
张建锦;刘小霞;;密度误差抽样及其在海量数据挖掘中的应用[A];2006北京地区院校研究生学术交流会——通信与信息技术大会论文集(下)[C];2006年
中国重要报纸全文数据库
本报记者 张佳星;[N];科技商报;2018年
本报记者 张佳星;[N];科技商报;2018年
记者 张潇;[N];西安日报;2018年
上海市浦东卫生发展研究院 孙雪松 王晓丽;[N];中国信息化周报;2018年
本报记者 叶曜坤;[N];人民邮电;2017年
本报记者 牛福莲;[N];中国经济晨报;2017年
中国联合晚报记者 刘末;[N];中国联合商报;2017年
南方日报记者 彭颖;[N];南方日报;2017年
舒圣祥;[N];检察日报;2017年
本报记者 肖祯;[N];中国会计报;2017年
中国博士学位论文全文数据库
王达;时间序列数据挖掘研究与应用[D];浙江大学;2004年
马昕;粗糙集理论在数据挖掘领域中的应用[D];浙江大学;2003年
王立宏;信息系统的约简与细度剖析及其在数据挖掘中的应用[D];上海大学;2004年
杨虎;序列数据挖掘的模型和算法研究[D];重庆大学;2003年
李秋丹;数据挖掘相关算法的研究与平台实现[D];大连理工大学;2004年
李力;数据挖掘方式研究及其在草药复方配伍剖析中的应用[D];西南交通大学;2003年
胡黔楠;化学信息学中的数据挖掘[D];中南大学;2004年
余辉;医学知识获取与发觉的研究[D];天津大学;2003年
于洪;Rough Set理论及其在数据挖掘中的应用研究[D];重庆大学;2003年
陈莉;KDD中的几个关键问题研究[D];西安电子科技大学;2003年
中国硕士学位论文全文数据库
王晓娇;数据挖掘技术在职高教学评价与就业剖析中的应用研究[D];哈尔滨工程大学;2015年
段硕;基于数据挖掘的唐启盛院士医治脱发的服药经验研究[D];北京中医药大学;2018年
杨艳平;基于数据挖掘的西医诊治疱疹处方服药规律研究[D];北京中医药大学;2018年
邵凡;基于数据挖掘的吕仁和院士治疗糖尿病肾脏病服药经验研究[D];北京中医药大学;2018年
焦福智;基于数据挖掘的唐启盛院士医治精神分裂症的服药经验研究[D];北京中医药大学;2018年
刘然;基于大数据挖掘的高血压抗生素医治方案研究[D];电子科技大学;2018年
南冰;忻州职业技术学院财务管理系统设计与实现[D];大连理工大学;2017年
张甜;基于数据挖掘的院校中学生成绩关联分析研究[D];北京邮电大学;2018年
章铎;基于大数据挖掘的故障预警研究[D];北京邮电大学;2018年
柯联兴;移动通信用户行为规律预测与数据挖掘平台开发[D];北京邮电大学;2018年 查看全部
张睿;基于k-means的英文文本聚类算法的研究与实现[D];西北大学;2009年
【共引文献】
中国刊物全文数据库
陈静杰;车洁;;基于IK-medoids算法的客机油耗降维方式[J];计算机科学;2018年08期
刘测;韩家新;;面向新闻文本的分类方式的比较研究[J];智能计算机与应用;2018年05期
刘湘蓉;;我国联通社交电商的商业模式——一个多案例的剖析[J];中国流通经济;2018年08期
高超;许翰林;;基于支持向量机的不均衡文本分类方式[J];现代电子技术;2018年15期
马艳辉;刘进;黄伟恺;吴钧;蔡梅松;李宇平;;企业外网内容检索系统的设计与实现[J];电脑编程方法与维护;2018年07期
李亚文;;电子商务背景下手动辨识系统中的网路安全问题及举措[J];信息与笔记本(理论版);2018年13期
马琳琳;刘继;;基于关联规则的党的十九大报告关键词相关性分析[J];新疆财经大学学报;2018年02期
李鑫;郭汉;张欣;胡方强;帅仁俊;;基于非平衡数据处理方式的网路在线广告中点击欺诈检查的研究[J];计算机科学;2018年S1期
李秀玲;陈七林;刘姗姗;;中国电子商务网路零售的发展历程与竞争态势[J];现代商业;2018年16期
杨守德;赵德海;;中国网路零售业发展的收敛性与空间溢出效应研究[J];经济体制改革;2018年03期
中国硕士学位论文全文数据库
钟宇;面向网路自媒体的空间数据挖掘研究[D];江西理工大学;2018年
于志浩;基于Android和网路爬虫的课外阅读系统设计与实现[D];山东大学;2018年
贾潇雨;基于改进爬虫技术的SQL注入的自动化扫描工具的研究与设计[D];北京邮电大学;2018年
常鑫;基于德尔菲调查法的电动车辆前沿技术评测系统设计与实现[D];山东大学;2018年
杨郁琪;基于文本挖掘的用户满意度影响诱因研究[D];中北大学;2018年
李笑语;深度可订制的工具化爬虫系统的设计与实现[D];北京邮电大学;2018年
王惠;基于LDA主题模型的文本降维研究[D];兰州大学;2018年
吕博庆;基于爬虫与数据挖掘的电商页面信息剖析[D];兰州大学;2018年
王丰;基于GPU并行的K-MEANS算法研究及其在文本聚类的应用[D];武汉邮电科学研究院;2018年
马琼琼;基于语义的文本聚类算法研究[D];北京交通大学;2017年
【二级参考文献】
中国刊物全文数据库
赵本本;殷旭东;王伟;;基于Scrapy的GitHub数据爬虫[J];电子技术与软件工程;2016年06期
李京文;;中国电子商务的发展现况与未来趋势[J];河北学刊;2016年01期
王宝义;;电商与快件跨界经营的理论基础与现实剖析[J];西部峰会;2015年06期
曾田日;王晋国;;基于统计的云搜索英文动词算法[J];西北大学学报(自然科学版);2015年04期
李杰;王宇菲;王聪;张志颖;;B2C电子商务竞争结构及发展演变规律[J];产业经济评论;2015年03期
李博群;;我国电子商务发展现况及前景展望研究[J];调研世界;2015年01期
聂林海;;我国电子商务发展的特性和趋势[J];中国流通经济;2014年06期
郑淑蓉;吕庆华;;中国电子商务20年演化[J];商业经济与管理;2013年11期
中国社科院财经战略研究院课题组;荆林波;;电子商务:中国经济发展的新引擎[J];求是;2013年11期
占明珍;;“双十一”我国电商企业促销战的冷思索[J];对外经贸实务;2013年04期
中国硕士学位论文全文数据库
周红伟;商品评价信息的英文情感剖析[D];浙江工商大学;2015年
范倩倩;高校图书馆Web2.0研究[D];安徽大学;2014年
苏芳仲;中文Web文本挖掘的若干关键技术研究及其实现[D];福州大学;2006年
李健;聚类剖析及其在文本挖掘中的应用[D];西安电子科技大学;2005年
马慧敏;中文文本手动分类方式的研究和实现[D];华北电力大学(河北);2005年
许林杰;中文文本动词研究[D];山东师范大学;2003年
【相似文献】
中国刊物全文数据库
牛猛爬虫软件分析电商数据,黄道斌爬虫软件分析电商数据,卢小杰;数据挖掘方式与功能的基本研究[J];电脑知识与技术;2018年14期
刘芬;;数据挖掘在中国的现况和发展研究[J];山东工业技术;2018年17期
饶正婵;蒲天银;;云计算条件下的大数据挖掘内涵及解决方案[J];电子技术与软件工程;2018年13期
陈小凤;;大数据挖掘校园用户[J];电子技术与软件工程;2018年15期
许晓燕;;基于云计算的数据挖掘云服务模式研究[J];电脑知识与技术;2018年19期
于春香;;数据挖掘技术简介[J];福建信息技术教育;2005年01期
邵兴江;;数据挖掘在教育信息化中的应用空间剖析[J];浙江现代教育技术;2004年03期
周洋;;数据挖掘在电力调度自动化系统中的应用解析[J];科技创新与应用;2017年35期
梁园;;浅析数据挖掘在审计中的应用[J];现代经济信息;2017年22期
冯丽慧;;云计算和挖掘服务融合下的大数据挖掘体系构架设计及应用[J];电脑编程方法与维护;2017年24期
中国重要大会论文全文数据库
马钰超;;浅析大数据和数据挖掘及其在烟草行业中的应用[A];中国烟草学会2015年度优秀论文汇编[C];2015年
唐杰;梅俏竹;;数据挖掘学科发展研究[A];2012-2013控制科学与工程学科发展报告[C];2014年
王岁月;;大数据时代规划数据挖掘的创新思索[A];新常态:传承与改革——2015中国城市规划晚会论文集(04城市规划新技术应用)[C];2015年
史东辉;蔡庆生;张春阳;;一种新的数据挖掘多策略技巧研究[A];第十七届全省数据库学术大会论文集(研究报告篇)[C];2000年
谢中;邱玉辉;;面向商务网站有效性的数据挖掘方式[A];第十八届全省数据库学术大会论文集(技术报告篇)[C];2001年
许珂;姜山;;数据挖掘方式在科技产出分布可视化研究中的运用[A];第二届中国科技哲学及交叉学科研究生峰会论文集(硕士卷)[C];2008年
雷宇;;论行业信息资源的数据挖掘[A];中国烟草行业信息化研讨会论文集[C];2004年
吴以凡;吴铁军;欧阳树生;;面向生产过程质量控制的动态数据挖掘方式[A];05'中国自动化产业高峰大会暨中国企业自动化和信息化建设峰会论文集[C];2005年
彭怡;;从数据挖掘文章聚类剖析看其发展趋势[A];现代工业工程与管理研讨会大会论文集[C];2006年
张建锦;刘小霞;;密度误差抽样及其在海量数据挖掘中的应用[A];2006北京地区院校研究生学术交流会——通信与信息技术大会论文集(下)[C];2006年
中国重要报纸全文数据库
本报记者 张佳星;[N];科技商报;2018年
本报记者 张佳星;[N];科技商报;2018年
记者 张潇;[N];西安日报;2018年
上海市浦东卫生发展研究院 孙雪松 王晓丽;[N];中国信息化周报;2018年
本报记者 叶曜坤;[N];人民邮电;2017年
本报记者 牛福莲;[N];中国经济晨报;2017年
中国联合晚报记者 刘末;[N];中国联合商报;2017年
南方日报记者 彭颖;[N];南方日报;2017年
舒圣祥;[N];检察日报;2017年
本报记者 肖祯;[N];中国会计报;2017年
中国博士学位论文全文数据库
王达;时间序列数据挖掘研究与应用[D];浙江大学;2004年
马昕;粗糙集理论在数据挖掘领域中的应用[D];浙江大学;2003年
王立宏;信息系统的约简与细度剖析及其在数据挖掘中的应用[D];上海大学;2004年
杨虎;序列数据挖掘的模型和算法研究[D];重庆大学;2003年
李秋丹;数据挖掘相关算法的研究与平台实现[D];大连理工大学;2004年
李力;数据挖掘方式研究及其在草药复方配伍剖析中的应用[D];西南交通大学;2003年
胡黔楠;化学信息学中的数据挖掘[D];中南大学;2004年
余辉;医学知识获取与发觉的研究[D];天津大学;2003年
于洪;Rough Set理论及其在数据挖掘中的应用研究[D];重庆大学;2003年
陈莉;KDD中的几个关键问题研究[D];西安电子科技大学;2003年
中国硕士学位论文全文数据库
王晓娇;数据挖掘技术在职高教学评价与就业剖析中的应用研究[D];哈尔滨工程大学;2015年
段硕;基于数据挖掘的唐启盛院士医治脱发的服药经验研究[D];北京中医药大学;2018年
杨艳平;基于数据挖掘的西医诊治疱疹处方服药规律研究[D];北京中医药大学;2018年
邵凡;基于数据挖掘的吕仁和院士治疗糖尿病肾脏病服药经验研究[D];北京中医药大学;2018年
焦福智;基于数据挖掘的唐启盛院士医治精神分裂症的服药经验研究[D];北京中医药大学;2018年
刘然;基于大数据挖掘的高血压抗生素医治方案研究[D];电子科技大学;2018年
南冰;忻州职业技术学院财务管理系统设计与实现[D];大连理工大学;2017年
张甜;基于数据挖掘的院校中学生成绩关联分析研究[D];北京邮电大学;2018年
章铎;基于大数据挖掘的故障预警研究[D];北京邮电大学;2018年
柯联兴;移动通信用户行为规律预测与数据挖掘平台开发[D];北京邮电大学;2018年
大数据技术之数据采集篇
采集交流 • 优采云 发表了文章 • 0 个评论 • 721 次浏览 • 2020-05-12 08:03
(一)系统日志采集法
系统日志是记录系统中硬件、软件和系统问题的信息,同时还可以监视系统中发生的风波。用户可以通过它来检测错误发生的诱因,或者找寻遭到功击时攻击者留下的痕迹。系统日志包括系统日志、应用程序日志和安全日志。(百度百科)大数据平台或则说类似于开源Hadoop平台会形成大量高价值系统日志信息,如何采集成为研究者研究热点。目前基于Hadoop平台开发的Chukwa、Cloudera的Flume以及Facebook的Scribe(李联宁,2016)均可成为是系统日志采集法的标杆。目前这种的采集技术大概可以每秒传输数百MB的日志数据信息,满足了目前人们对信息速率的需求。一般而言与我们相关的并不是这种采集法,而是网路数据采集法。
在这里还是要推荐下我自己建的大数据学习交流群:529867072大数据网络爬虫原理,群里都是学大数据开发的,如果你正在学习大数据 ,小编欢迎你加入,大家都是软件开发党,不定期分享干货(只有大数据软件开发相关的),包括我自己整理的一份最新的大数据进阶资料和中级开发教程,欢迎进阶中和进想深入大数据的小伙伴加入。
(二)网络数据采集法
做自然语言的朋友可能对这点感慨颇深,除了目前早已存在的公开数据集,用于日常的算法研究外,有时为了满足项目的实际需求,需要对现实网页中的数据进行采集,预处理和保存。目前网路数据采集有两种方式一种是API,另一种是网路爬虫法。
1.API
API又叫应用程序插口,是网站的管理者为了使用者方面,编写的一种程序插口。该类插口可以屏蔽网站底层复杂算法仅仅通过简简单单调用即可实现对数据的恳求功能。目前主流的社交媒体平台如新浪微博、百度贴吧以及Facebook等均提供API服务,可以在其官网开放平台上获取相关DEMO。但是API技术虽然受限于平台开发者,为了减少网站(平台)的负荷大数据网络爬虫原理,一般平台均会对每晚插口调用上限做限制,这给我们带来极大的不便利。为此我们一般采用第二种形式——网络爬虫。
2.网络爬虫
网络爬虫(又被称为网页蜘蛛,网络机器人,在FOFA社区中间,更时常的称为网页追逐者),是一种根据一定的规则,自动地抓取万维网信息的程序或则脚本。另外一些不常使用的名子还有蚂蚁、自动索引、模拟程序或则蠕虫。(百度百科)最常见的爬虫便是我们常常使用的搜索引擎,如百度,360搜索等。此类爬虫也称为通用型爬虫,对于所有的网页进行无条件采集。通用型爬虫具体工作原理见图1。
图1 爬虫工作原理[2]
给予爬虫初始URL,爬虫将网页中所须要提取的资源进行提取并保存,同时提取出网站中存在的其他网站链接,经过发送恳求,接收网站响应以及再度解析页面,提取所需资源并保存,再将网页中所需资源进行提取......以此类推,实现过程并不复杂,但是在采集时尤其注意对IP地址,报头的伪造,以免被网管发觉禁封IP(我就被封过),禁封IP也就意味着整个采集任务的失败。当然为了满足更多需求,多线程爬虫,主题爬虫也应运而生。多线程爬虫是通过多个线程,同时执行采集任务,一般而言几个线程,数据采集数据都会提高几倍。主题爬虫和通用型爬虫截然相反,通过一定的策略将于主题(采集任务)无关的网页信息过滤,仅仅留下须要的数据。此举可以大幅度降低无关数据引起的数据稀疏问题。
(三)其他采集法
其他采集法是指对于科研院所,企业政府等拥有绝密信息,如何保证数据的安全传递?可以采用系统特定端口,进行数据传输任务,从而降低数据被泄漏的风险。 查看全部
【导读】数据采集是进行大数据剖析的前提也是必要条件,在整个流程中抢占重要地位。本文将介绍大数据三种采集形式:系统日志采集法、网络数据采集法以及其他数据采集法。
(一)系统日志采集法
系统日志是记录系统中硬件、软件和系统问题的信息,同时还可以监视系统中发生的风波。用户可以通过它来检测错误发生的诱因,或者找寻遭到功击时攻击者留下的痕迹。系统日志包括系统日志、应用程序日志和安全日志。(百度百科)大数据平台或则说类似于开源Hadoop平台会形成大量高价值系统日志信息,如何采集成为研究者研究热点。目前基于Hadoop平台开发的Chukwa、Cloudera的Flume以及Facebook的Scribe(李联宁,2016)均可成为是系统日志采集法的标杆。目前这种的采集技术大概可以每秒传输数百MB的日志数据信息,满足了目前人们对信息速率的需求。一般而言与我们相关的并不是这种采集法,而是网路数据采集法。

在这里还是要推荐下我自己建的大数据学习交流群:529867072大数据网络爬虫原理,群里都是学大数据开发的,如果你正在学习大数据 ,小编欢迎你加入,大家都是软件开发党,不定期分享干货(只有大数据软件开发相关的),包括我自己整理的一份最新的大数据进阶资料和中级开发教程,欢迎进阶中和进想深入大数据的小伙伴加入。
(二)网络数据采集法
做自然语言的朋友可能对这点感慨颇深,除了目前早已存在的公开数据集,用于日常的算法研究外,有时为了满足项目的实际需求,需要对现实网页中的数据进行采集,预处理和保存。目前网路数据采集有两种方式一种是API,另一种是网路爬虫法。
1.API
API又叫应用程序插口,是网站的管理者为了使用者方面,编写的一种程序插口。该类插口可以屏蔽网站底层复杂算法仅仅通过简简单单调用即可实现对数据的恳求功能。目前主流的社交媒体平台如新浪微博、百度贴吧以及Facebook等均提供API服务,可以在其官网开放平台上获取相关DEMO。但是API技术虽然受限于平台开发者,为了减少网站(平台)的负荷大数据网络爬虫原理,一般平台均会对每晚插口调用上限做限制,这给我们带来极大的不便利。为此我们一般采用第二种形式——网络爬虫。
2.网络爬虫
网络爬虫(又被称为网页蜘蛛,网络机器人,在FOFA社区中间,更时常的称为网页追逐者),是一种根据一定的规则,自动地抓取万维网信息的程序或则脚本。另外一些不常使用的名子还有蚂蚁、自动索引、模拟程序或则蠕虫。(百度百科)最常见的爬虫便是我们常常使用的搜索引擎,如百度,360搜索等。此类爬虫也称为通用型爬虫,对于所有的网页进行无条件采集。通用型爬虫具体工作原理见图1。
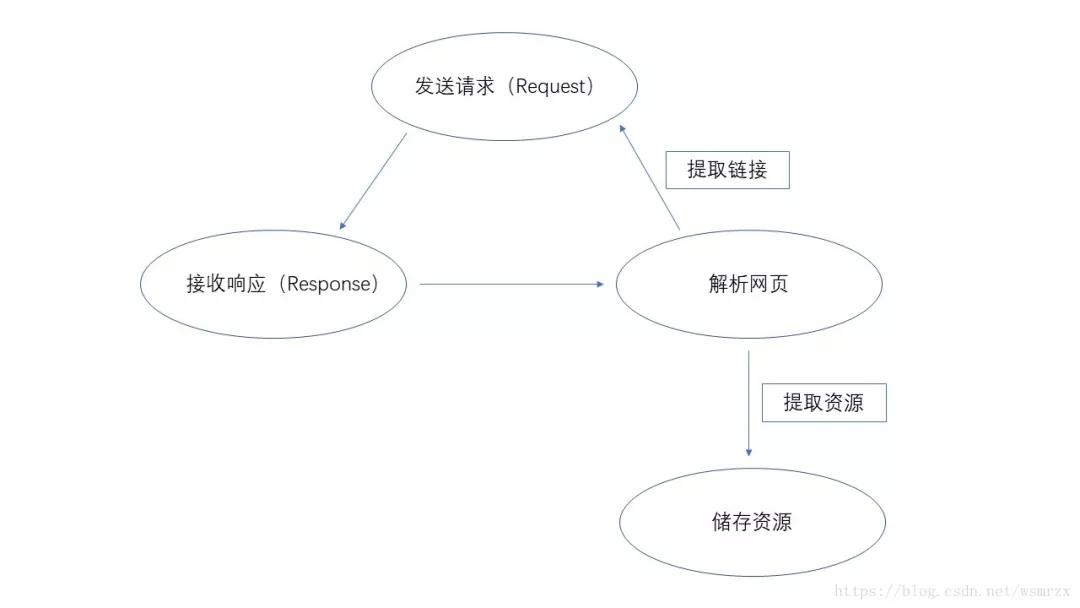
图1 爬虫工作原理[2]
给予爬虫初始URL,爬虫将网页中所须要提取的资源进行提取并保存,同时提取出网站中存在的其他网站链接,经过发送恳求,接收网站响应以及再度解析页面,提取所需资源并保存,再将网页中所需资源进行提取......以此类推,实现过程并不复杂,但是在采集时尤其注意对IP地址,报头的伪造,以免被网管发觉禁封IP(我就被封过),禁封IP也就意味着整个采集任务的失败。当然为了满足更多需求,多线程爬虫,主题爬虫也应运而生。多线程爬虫是通过多个线程,同时执行采集任务,一般而言几个线程,数据采集数据都会提高几倍。主题爬虫和通用型爬虫截然相反,通过一定的策略将于主题(采集任务)无关的网页信息过滤,仅仅留下须要的数据。此举可以大幅度降低无关数据引起的数据稀疏问题。
(三)其他采集法
其他采集法是指对于科研院所,企业政府等拥有绝密信息,如何保证数据的安全传递?可以采用系统特定端口,进行数据传输任务,从而降低数据被泄漏的风险。
Java 网络爬虫基础入门
采集交流 • 优采云 发表了文章 • 0 个评论 • 246 次浏览 • 2020-05-11 08:03
作为网路爬虫的入门教程,本达人课采用 Java 开发语言java爬虫教程入门超级,内容涵括了网路爬虫的原理以及开发逻辑,Java 网络爬虫基础知识,网络抓包介绍,jsoup 的介绍与使用,HttpClient 的介绍与使用等内容。本课程在介绍网路爬虫基本原理的同时,注重具体的代码实现,加深读者对爬虫的理解,加强读者的实战能力。
本达人课共计14课,主要包含五大部份。
第一部分(第01-03课),主要介绍网路爬虫的原理、开发逻辑以及 Java 网络爬虫基础知识,网络抓包等内容。
第二部份(第04-06课),主要介绍现有的一些页面内容获取及页面解析工具。包括 jsoup、HttpClient、URLConnection。
第三部份(第07-08课),针对已获得的页面内容java爬虫教程入门超级,带你们选择合适的解析工具进行页面解析,包括 HTML、XML、JSON 主流数据格式的解析。
第四部份(第09-11课),针对已解析的内容,介绍怎么封装数据并储存数据。包括通过 MySQL 数据库储存数据,以及文本文件储存和 Excel 格式储存。
第五部份(第12-14课),以典型网站为案例,开启实战演练。
钱洋,机器学习方向博士生,CSDN 博客专家,主要从事文本挖掘方面的研究。目前,正参与几个大数据相关项目的研究工作。乐于分享自己的经验,擅长撰写技术类博客。 查看全部
大数据环境下,数据剖析已由业务驱动转变为数据驱动,网络数据资源呈指数级下降,且洒落在不同的数据源之中。对大多数企业和研究者而言,用“数据说话”仿佛成了大数据时代的重要装备。网络爬虫作为网路数据获取的重要技术,受到了越来越多数据需求者的偏爱和青睐。
作为网路爬虫的入门教程,本达人课采用 Java 开发语言java爬虫教程入门超级,内容涵括了网路爬虫的原理以及开发逻辑,Java 网络爬虫基础知识,网络抓包介绍,jsoup 的介绍与使用,HttpClient 的介绍与使用等内容。本课程在介绍网路爬虫基本原理的同时,注重具体的代码实现,加深读者对爬虫的理解,加强读者的实战能力。
本达人课共计14课,主要包含五大部份。
第一部分(第01-03课),主要介绍网路爬虫的原理、开发逻辑以及 Java 网络爬虫基础知识,网络抓包等内容。
第二部份(第04-06课),主要介绍现有的一些页面内容获取及页面解析工具。包括 jsoup、HttpClient、URLConnection。
第三部份(第07-08课),针对已获得的页面内容java爬虫教程入门超级,带你们选择合适的解析工具进行页面解析,包括 HTML、XML、JSON 主流数据格式的解析。
第四部份(第09-11课),针对已解析的内容,介绍怎么封装数据并储存数据。包括通过 MySQL 数据库储存数据,以及文本文件储存和 Excel 格式储存。
第五部份(第12-14课),以典型网站为案例,开启实战演练。
钱洋,机器学习方向博士生,CSDN 博客专家,主要从事文本挖掘方面的研究。目前,正参与几个大数据相关项目的研究工作。乐于分享自己的经验,擅长撰写技术类博客。
网络爬虫技术在大数据审计中的应用
采集交流 • 优采云 发表了文章 • 0 个评论 • 296 次浏览 • 2020-05-10 08:03
关键词:网络爬虫;数据采集;审计剖析;Python
本文为2017年安徽财贸职业学院“内涵提高全员行动计划”科学研究项目(人文社科):“大数据在审计剖析程序中的运用研究”(项目编号:2017nhrwc15)
中图分类号:F239 文献标识码:A
收录日期:2019年1月18日
一、引言
无论是国家审计还是民间审计,在现今社会经济发展过程中都起到了非常重要的作用,为经济发展“保驾护航”。大数据目前也是各国研究的重点和热点,并将大数据的研究和应用上升到了战略层次。美国注册会计师协会(AICPA)在2014年就对大数据可能对审计形成的影响进行了剖析。在全球信息化的大背景下,如何借助大数据增加审计风险,提高审计效率依然是一个十分重要的命题。2015年中共中央办公厅、国务院办公厅《关于完善审计制度若干重大问题的框架意见》及配套文件中明晰提出“构建大数据审计工作模式,构建国家审计数据系统和数字化审计平台,探索完善审计实时监督系统,实施联网审计”。刘国城、王会金(2017)将大数据审计平台拆分为采集、预处理、分析和可视化四个子平台,基于方式支撑、过程建模和运行机理等方面对各个子平台作以专项研究,旨在为大数据审计实践提供建设性思路。秦荣生(2014)指出大数据、云计算技术的形成和发展,正在逐步影响审计技术和技巧的发展。
大数据具有数据体量巨大、处理速率快、数量种类多和商业价值高的特性。被审计对象的信息化使得审计人员在审计方式上愈发的信息化,如果将这种大量的、散落的、无序的数据进行集中化、结构化,将其弄成才能便捷获得可读取的审计数据,并通过审计剖析程序发觉愈发有效和清晰的审计线索,那么大数据将会发挥重大的商业价值。由此可见,数据是审计剖析的重要前提,获取高质量数据常常就能帮助审计人员快速发觉风险点进行应对,大大提升审计的效率和疗效。目前,尚未有成熟的审计大数据搜集与整理技术,这影响了大数据在审计中使用的效率。本文将基于目前大数据的研究现况,主要阐述审计人员应该怎样借助网路爬虫技术从网路渠道获取所需审计数据,从而扩展审计数据的范围,获得更多的审计线索,提高审计剖析疗效。
二、审计大数据采集分析
(一)审计大数据类型。大数据审计区别于传统的审计模式,传统审计模式倾向于根据被审计单位提供的相关资料去鉴证其是否真实可靠。而大数据审计是一种实时审计,强调审计人员应该主动地去获取企业内部和企业外部的数据,企业内部的业务数据主要借助被审计单位提供,而外部数据,比如法律、银行、税务、供应商、客户、物流等其他数据须要审计人员去挖掘和剖析。从目前来看,审计大数据可以分为两类:一类是结构化数据,它由明晰定义的数据类型组成,比如数字、货币、日期等,其模式可以让其便于搜索。这种数据通常存储在数据库里,比如企业ERP系统中的销售数据、生产数据、财务数据等;另一类是非结构化数据,是指这些不便捷用数据库二维逻辑来表现的数据,如办公文档、文本、图片、HTML图象等,审计人员须要的外部数据以非结构化数据类型居多。
(二)审计大数据采集方法
1、直接拷贝读取。审计人员首先判定出自己须要的审计数据,然后按照被审计单位使用的财务软件(如用友、用友)的使用特性,利用软件数据库早已预设好的指令去提取转换审计人员所须要的数据,并将其保存为Excel等格式。
2、开放数据互联(ODBC)。如果被审计单位与审计人员使用的是可以对接的数据库,可以通过相关的数据访问插口访问被审计单位所使用的业务系统数据库,并将数据进行还原后转出,成为审计人员可以直接借助的数据。
3、中间文件采集。指审计人员与被审计单位约定好数据的格式,被审计单位根据要求将自己的相关数据转换成约定的格式,比如说文本文件格式,这种大部分数据库都还能直接读取的格式,从而省去了两种不同数据库对接的问题。
4、网上采集。除了被审计单位或则上级审计机关提供的相关数据以外,审计人员依然须要从被审计单位外部获得相关的工商、税务、行业、媒体等公开数据以进行多方面的审计剖析,这些数据并不是被直接提供的结构化数据,需要审计人员采用一定的方式从网上进行采集。
目前,审计数据采集大部分采用的是上述的前三种方式,往往依托一定的数据库基础,能够获得的信息大多基于被审计单位,最后一种网上采集数据的方式因为没有统一的方式和技术,耗费大量时间和经历,往往未能实现,这大大限制了审计人员进行审计剖析的范围,同时也让审计的取证率无法达到预期,从某种程度上提升了审计风险。在大数据审计背景下,审计人员执行剖析程序不能仅仅将眼光局限于内部数据,更应该从网路公开数据中获取愈发全面的信息,但是这种信息大多以网页等格式存在,难以被审计人员直接用于剖析,所以本文提出可以借助网路爬虫技术抓取网页上的信息,并整理成一定的格式,方便审计人员从海量数据中发觉审计线索,使审计剖析程序发挥更大的效用。
三、网络爬虫在审计大数据采集中的应用
网络爬虫技术又被称为网路蜘蛛,是一种根据被设定的规则手动获取网页内容的程序脚本。目前,网络爬虫技术被越来越多的运用于互联网中,它还能依据不同的程序代码设定指令,自动获取网页内任何权限的信息数据。程序开始后,按照设定程序,网络爬虫会不断地从URL抓取用户须要的内容,直到满足停止条件,并对抓取到的数据进行分类整合处理大数据网络爬虫原理,用户可以按照自己的查询需求,从中筛选自己所须要的数据。通过网路爬虫还能为大数据剖析提供更高质量的数据源。
利用网路爬虫技术施行审计剖析程序的过程主要有以下几步:首先,锁定目标。根据审计目标确定想要获取的目标数据,明确这种数据主要分布的网页是哪些;其次,目标网页剖析。为了更高效率的抓取到相关数据,要对目标网页进行结构上的剖析,主要是其数据访问的路径和逻辑;再次,数据抓取。通过选择好的软件执行命令,获得数据结果进行保存;最后,数据剖析。将通过上述程序获得的数据进行清洗,获得目标数据,可以结合例如SQL查询、Excel剖析、数据可视化等技术对数据进行进一步的剖析、扩展和确认。
利用网路爬虫技术施行审计剖析程序的原理主要是能否从被审计单位外部获取愈发充足的、高质量的审计数据,而这种数据比被审计单位提供的数据愈发可靠,同时可以将获取的新数据与被审计单位提供的内部数据进行对比,帮助审计人员扩大范围,发现更多相关线索,同时也促使审计证据愈发充分可靠。
四、网络爬虫在审计大数据采集中应用案例
XX集团有限公司创建于1957年,现已发展产生节能环保、钢铁制造及金属贸易、智能健康、教育与技术服务等产业格局的小型企业集团。截至2017年底,拥有全资及控股一级子公司34家。2017年,完成销售收入933亿元、利润25亿元,甲会计师事务所接受委托对该公司进行2017年年度财务报表审计。审计人员在审计过程中发觉该公司下一子公司有大量进行一次性交易的顾客,并且这种顾客都采用了赊购的形式,所以审计人员对这种交易形成了怀疑,认为被审计单位的应收账款“存在”认定有重大错报风险。为进一步获得审计证据,审计人员首先须要被审计单位提供数据库内关于顾客的信息并进行查验以验证这种顾客的真实性。此时,被审计单位提供信息的可靠性较差,审计人员只能考虑从外部获得审计数据进行比较剖析,从而判定顾客信息的准确性。如果考虑直接从官方网站获得具体工商数据,审计人员将面临权限受限和工作量巨大等问题。此时,网络爬虫技术才能为这一困局提供挺好的解决方案,提高工作效率。
在选择网路爬虫技术时,审计人员选择了目前应用范围相对较广的Python。相对于其他网路爬虫技术,基于Python的网路爬虫技术具有以下优点:一是简约便捷。Python语言最大的特征就是只须要一个简单的编辑器才能满足大部分用户的网路爬虫技术需求,可以使操作人员很快的适应环境,而不用耗费过多的精力;二是具有框架技术。如果所须要抓取的数据量较大,则可以使用Python的Scrapy框架实现,它能提供一个功能强悍的模板来实现爬虫,仅仅须要根据需求进行简单的更改就可以使用,而不是去进行重新的开发。
审计人员通过Python实现了网路爬虫,从“天眼查”网站上获取相关企业的工商信息。其中部份代码如图1所示,获得的部份结果如表1、图2所示。最终审计人员通过网路爬虫技术迅速获得了审计须要的相关数据,筛选出目标企业,进一步进行了审计剖析,与被审计单位提供的有关信息进行比对,得出了其中有18家企业信息涉嫌作假,实为虚构交易的推论,为预收账款的进一步审计提供了重要审计证据。(图1、图2、表1)
五、结语
随着大数据在审计中的运用广泛,高效的数据采集办法也是值得研究的重要内容。本文通过研究大数据的特性,以及对审计数据的采集办法进行剖析,提出了基于Python的数据爬虫在审计数据采集中的运用,帮助审计人员快速高效地从网页上获得相关数据,为进一步的审计剖析奠定了基础,这也为大数据在审计中的应用技术研究提供了支持。
(作者单位:安徽财贸职业学院)
主要参考文献:
[1]秦荣生.大数据、云计算技术对审计的影响研究[J].审计研究,2014(6).
[2]刘国城,王会金.大数据审计平台建立研究[J].审计研究,2017(11).
[3]韦玮.精通Python网络爬虫[M].北京机械工业出版社,2017. 查看全部
[提要]在大数据审计面临着众多机遇和挑战的大背景下,有效清晰的数据在审计过程中发挥着重大作用大数据网络爬虫原理,本文剖析不同的审计数据的特性以及采集审计数据的方式。在传统数据采集方法基础上研究怎样基于Python借助网路爬虫采集审计数据,以为大数据审计技术的发展提供支持。
关键词:网络爬虫;数据采集;审计剖析;Python
本文为2017年安徽财贸职业学院“内涵提高全员行动计划”科学研究项目(人文社科):“大数据在审计剖析程序中的运用研究”(项目编号:2017nhrwc15)
中图分类号:F239 文献标识码:A
收录日期:2019年1月18日
一、引言
无论是国家审计还是民间审计,在现今社会经济发展过程中都起到了非常重要的作用,为经济发展“保驾护航”。大数据目前也是各国研究的重点和热点,并将大数据的研究和应用上升到了战略层次。美国注册会计师协会(AICPA)在2014年就对大数据可能对审计形成的影响进行了剖析。在全球信息化的大背景下,如何借助大数据增加审计风险,提高审计效率依然是一个十分重要的命题。2015年中共中央办公厅、国务院办公厅《关于完善审计制度若干重大问题的框架意见》及配套文件中明晰提出“构建大数据审计工作模式,构建国家审计数据系统和数字化审计平台,探索完善审计实时监督系统,实施联网审计”。刘国城、王会金(2017)将大数据审计平台拆分为采集、预处理、分析和可视化四个子平台,基于方式支撑、过程建模和运行机理等方面对各个子平台作以专项研究,旨在为大数据审计实践提供建设性思路。秦荣生(2014)指出大数据、云计算技术的形成和发展,正在逐步影响审计技术和技巧的发展。
大数据具有数据体量巨大、处理速率快、数量种类多和商业价值高的特性。被审计对象的信息化使得审计人员在审计方式上愈发的信息化,如果将这种大量的、散落的、无序的数据进行集中化、结构化,将其弄成才能便捷获得可读取的审计数据,并通过审计剖析程序发觉愈发有效和清晰的审计线索,那么大数据将会发挥重大的商业价值。由此可见,数据是审计剖析的重要前提,获取高质量数据常常就能帮助审计人员快速发觉风险点进行应对,大大提升审计的效率和疗效。目前,尚未有成熟的审计大数据搜集与整理技术,这影响了大数据在审计中使用的效率。本文将基于目前大数据的研究现况,主要阐述审计人员应该怎样借助网路爬虫技术从网路渠道获取所需审计数据,从而扩展审计数据的范围,获得更多的审计线索,提高审计剖析疗效。
二、审计大数据采集分析
(一)审计大数据类型。大数据审计区别于传统的审计模式,传统审计模式倾向于根据被审计单位提供的相关资料去鉴证其是否真实可靠。而大数据审计是一种实时审计,强调审计人员应该主动地去获取企业内部和企业外部的数据,企业内部的业务数据主要借助被审计单位提供,而外部数据,比如法律、银行、税务、供应商、客户、物流等其他数据须要审计人员去挖掘和剖析。从目前来看,审计大数据可以分为两类:一类是结构化数据,它由明晰定义的数据类型组成,比如数字、货币、日期等,其模式可以让其便于搜索。这种数据通常存储在数据库里,比如企业ERP系统中的销售数据、生产数据、财务数据等;另一类是非结构化数据,是指这些不便捷用数据库二维逻辑来表现的数据,如办公文档、文本、图片、HTML图象等,审计人员须要的外部数据以非结构化数据类型居多。
(二)审计大数据采集方法
1、直接拷贝读取。审计人员首先判定出自己须要的审计数据,然后按照被审计单位使用的财务软件(如用友、用友)的使用特性,利用软件数据库早已预设好的指令去提取转换审计人员所须要的数据,并将其保存为Excel等格式。
2、开放数据互联(ODBC)。如果被审计单位与审计人员使用的是可以对接的数据库,可以通过相关的数据访问插口访问被审计单位所使用的业务系统数据库,并将数据进行还原后转出,成为审计人员可以直接借助的数据。
3、中间文件采集。指审计人员与被审计单位约定好数据的格式,被审计单位根据要求将自己的相关数据转换成约定的格式,比如说文本文件格式,这种大部分数据库都还能直接读取的格式,从而省去了两种不同数据库对接的问题。
4、网上采集。除了被审计单位或则上级审计机关提供的相关数据以外,审计人员依然须要从被审计单位外部获得相关的工商、税务、行业、媒体等公开数据以进行多方面的审计剖析,这些数据并不是被直接提供的结构化数据,需要审计人员采用一定的方式从网上进行采集。
目前,审计数据采集大部分采用的是上述的前三种方式,往往依托一定的数据库基础,能够获得的信息大多基于被审计单位,最后一种网上采集数据的方式因为没有统一的方式和技术,耗费大量时间和经历,往往未能实现,这大大限制了审计人员进行审计剖析的范围,同时也让审计的取证率无法达到预期,从某种程度上提升了审计风险。在大数据审计背景下,审计人员执行剖析程序不能仅仅将眼光局限于内部数据,更应该从网路公开数据中获取愈发全面的信息,但是这种信息大多以网页等格式存在,难以被审计人员直接用于剖析,所以本文提出可以借助网路爬虫技术抓取网页上的信息,并整理成一定的格式,方便审计人员从海量数据中发觉审计线索,使审计剖析程序发挥更大的效用。
三、网络爬虫在审计大数据采集中的应用
网络爬虫技术又被称为网路蜘蛛,是一种根据被设定的规则手动获取网页内容的程序脚本。目前,网络爬虫技术被越来越多的运用于互联网中,它还能依据不同的程序代码设定指令,自动获取网页内任何权限的信息数据。程序开始后,按照设定程序,网络爬虫会不断地从URL抓取用户须要的内容,直到满足停止条件,并对抓取到的数据进行分类整合处理大数据网络爬虫原理,用户可以按照自己的查询需求,从中筛选自己所须要的数据。通过网路爬虫还能为大数据剖析提供更高质量的数据源。
利用网路爬虫技术施行审计剖析程序的过程主要有以下几步:首先,锁定目标。根据审计目标确定想要获取的目标数据,明确这种数据主要分布的网页是哪些;其次,目标网页剖析。为了更高效率的抓取到相关数据,要对目标网页进行结构上的剖析,主要是其数据访问的路径和逻辑;再次,数据抓取。通过选择好的软件执行命令,获得数据结果进行保存;最后,数据剖析。将通过上述程序获得的数据进行清洗,获得目标数据,可以结合例如SQL查询、Excel剖析、数据可视化等技术对数据进行进一步的剖析、扩展和确认。
利用网路爬虫技术施行审计剖析程序的原理主要是能否从被审计单位外部获取愈发充足的、高质量的审计数据,而这种数据比被审计单位提供的数据愈发可靠,同时可以将获取的新数据与被审计单位提供的内部数据进行对比,帮助审计人员扩大范围,发现更多相关线索,同时也促使审计证据愈发充分可靠。
四、网络爬虫在审计大数据采集中应用案例
XX集团有限公司创建于1957年,现已发展产生节能环保、钢铁制造及金属贸易、智能健康、教育与技术服务等产业格局的小型企业集团。截至2017年底,拥有全资及控股一级子公司34家。2017年,完成销售收入933亿元、利润25亿元,甲会计师事务所接受委托对该公司进行2017年年度财务报表审计。审计人员在审计过程中发觉该公司下一子公司有大量进行一次性交易的顾客,并且这种顾客都采用了赊购的形式,所以审计人员对这种交易形成了怀疑,认为被审计单位的应收账款“存在”认定有重大错报风险。为进一步获得审计证据,审计人员首先须要被审计单位提供数据库内关于顾客的信息并进行查验以验证这种顾客的真实性。此时,被审计单位提供信息的可靠性较差,审计人员只能考虑从外部获得审计数据进行比较剖析,从而判定顾客信息的准确性。如果考虑直接从官方网站获得具体工商数据,审计人员将面临权限受限和工作量巨大等问题。此时,网络爬虫技术才能为这一困局提供挺好的解决方案,提高工作效率。
在选择网路爬虫技术时,审计人员选择了目前应用范围相对较广的Python。相对于其他网路爬虫技术,基于Python的网路爬虫技术具有以下优点:一是简约便捷。Python语言最大的特征就是只须要一个简单的编辑器才能满足大部分用户的网路爬虫技术需求,可以使操作人员很快的适应环境,而不用耗费过多的精力;二是具有框架技术。如果所须要抓取的数据量较大,则可以使用Python的Scrapy框架实现,它能提供一个功能强悍的模板来实现爬虫,仅仅须要根据需求进行简单的更改就可以使用,而不是去进行重新的开发。
审计人员通过Python实现了网路爬虫,从“天眼查”网站上获取相关企业的工商信息。其中部份代码如图1所示,获得的部份结果如表1、图2所示。最终审计人员通过网路爬虫技术迅速获得了审计须要的相关数据,筛选出目标企业,进一步进行了审计剖析,与被审计单位提供的有关信息进行比对,得出了其中有18家企业信息涉嫌作假,实为虚构交易的推论,为预收账款的进一步审计提供了重要审计证据。(图1、图2、表1)
五、结语
随着大数据在审计中的运用广泛,高效的数据采集办法也是值得研究的重要内容。本文通过研究大数据的特性,以及对审计数据的采集办法进行剖析,提出了基于Python的数据爬虫在审计数据采集中的运用,帮助审计人员快速高效地从网页上获得相关数据,为进一步的审计剖析奠定了基础,这也为大数据在审计中的应用技术研究提供了支持。
(作者单位:安徽财贸职业学院)
主要参考文献:
[1]秦荣生.大数据、云计算技术对审计的影响研究[J].审计研究,2014(6).
[2]刘国城,王会金.大数据审计平台建立研究[J].审计研究,2017(11).
[3]韦玮.精通Python网络爬虫[M].北京机械工业出版社,2017.
网络爬虫可以爬到什么有用行业数据?
采集交流 • 优采云 发表了文章 • 0 个评论 • 250 次浏览 • 2020-05-10 08:02
网络爬虫可以按照你的不同需求,选择爬取对象、爬取数组进行爬取(必须是公开数据)爬虫软件数据,比如:
电商顾客,我们采集的数据信息主要为商品信息数据、商品评论信息数据、区域库存价钱数据、电商舆情数据等。
金融行业顾客,采集主要的信息为公开的顾客信息、投融资信息、金融舆情信息、市场数据、公开的财务报表、股票、基金、利率等信息。
在网络舆情方面,采集主要信息为综合峰会、新闻门户、知识问答、自媒体网站、社交平台等网路媒体上的相关舆情信息。
在机票采集方面:包含日期、航空公司、航班号、经济舱价钱、经济舱折扣、公务舱价钱、公务舱折扣、税费、附加费、机 型、起飞城市三字码、到达城市三字码、起飞时间等所有相关信息。
题主所说到的行业数据爬虫软件数据,可以依照具体需求选择网站进行定向爬取。
我给题主分享一些国内外公开数据平台,在这种平台里其实有你须要的资源:
【Open Data】国外开放数据中心及政府数据开放平台汇总
最全的中国开放数据(open data)及政府数据开放平台汇总
当然数据采集不仅仅是这几个方面,更多的相关知识也可以在我们官网获得。 查看全部
爬虫采集数据称作网路数据,是指非传统数据源,这种类型的数据可以是结构化的,也可以是非结构化的(更有可能的),可以由网路链接,文本数据,数据表,图像,视频等组成。
网络爬虫可以按照你的不同需求,选择爬取对象、爬取数组进行爬取(必须是公开数据)爬虫软件数据,比如:
电商顾客,我们采集的数据信息主要为商品信息数据、商品评论信息数据、区域库存价钱数据、电商舆情数据等。
金融行业顾客,采集主要的信息为公开的顾客信息、投融资信息、金融舆情信息、市场数据、公开的财务报表、股票、基金、利率等信息。
在网络舆情方面,采集主要信息为综合峰会、新闻门户、知识问答、自媒体网站、社交平台等网路媒体上的相关舆情信息。
在机票采集方面:包含日期、航空公司、航班号、经济舱价钱、经济舱折扣、公务舱价钱、公务舱折扣、税费、附加费、机 型、起飞城市三字码、到达城市三字码、起飞时间等所有相关信息。
题主所说到的行业数据爬虫软件数据,可以依照具体需求选择网站进行定向爬取。
我给题主分享一些国内外公开数据平台,在这种平台里其实有你须要的资源:
【Open Data】国外开放数据中心及政府数据开放平台汇总
最全的中国开放数据(open data)及政府数据开放平台汇总
当然数据采集不仅仅是这几个方面,更多的相关知识也可以在我们官网获得。
Python和数据剖析
采集交流 • 优采云 发表了文章 • 0 个评论 • 274 次浏览 • 2020-05-08 08:03
缺点:有点奇特。? Python:相对年青一点的语言。对于爬虫来说各 方面能力挺好,并且还在建立中,没有Perl那样有 专门的爬虫书籍,不过网上能搜到一些文章。为什么最终选择Python?? 跨平台,对Linux和windows都有不错的支持。 ? 科学估算,数值拟合:Numpy,Scipy ? 可视化:2d:Matplotlib(做图很漂亮), 3d: Mayavi2 ? 复杂网路:Networkx ? 统计:与R语言插口:Rpy ? 交互式终端 ? 网站的快速开发?从一个简单的Python爬虫开始说明:加说明句子时要注意#需要英语编码里的,而不能是英文输入法中的#号,所 以添加英文说明时先在英语输入法下攻入#号后再切换到英文输入瀚海星云Pie 版的网页部份代码………Pie版的Html树部份结构借助BeautifulSoup分析树FindAll()是最方便最好用的函数通用搜索策略? 页面中的link? 深度优先? 广度优先现实中的策略是多种多样的? 因为瀚海星云link有很简单的规律,每页递减20,所以借助这个规 律设置每次赋入的URL,这样爬完了PIE版所有贴子运行结果? 有乱 码!!爬取英文网页常有的问题:不规 格的编码模式? 解决方式:编码转换最后的结果? Perfect!请温柔的对待瀚海星云!!? 设置延后时间(对于一个峰会,如果假定一 个真实的浏览者每10秒掀开一个新的网页的 话,一个不延时的爬虫每秒可以抓10个网页, 这样一个爬虫相当于占用了100个人的带 宽!)? 在午夜爬取可以适当推进速率道上的规矩:用Mysql储存数据? 先要在自己数据库里构建一个空的表,这里, 这里我早已构建了一个名为lilybbs的数据库, 表名为hunan_a? 导入相应的模块? 与相应的数据库联接? 写入数据库里的结果统计和做图? 这部份主要用于科研方 面,利用爬取到的数据 做一些简单的统计工作? 右图是某峰会的回复网 络,使用python的 networkx包做的。
? Pylab 是 matplotlib作 图包的一部 分? 左图是某 blog四年间 每天发表文 章的数目? 左一是某blog网站每个blog 评论数的统计,x是blog评 论数目,y是有这样数目的 blog的数目。可以看见是标 准的“power-law”分布,幂 指数为-1.2左右,拟合使用 了Scipy包的optimize.leastsq, 函数,具体可见scipy cookbook页面的fitting data 一栏? 左二是blog的comment networks 的入度与出度的散 点图,也就是每位点的坐 标x,y分别代表某个人获 得的评论和发出的评论数。 颜色代表这样点的数目。 本图使用了matplotlib中的 hexbin函数中级主题(一):编写更强壮的爬虫? 伪装成浏 览器? 容错中级主题(二):由内嵌脚本形成 的动态网页的爬取? 如何爬取 像左图这 样的网页 呢?? 它显示的 内容并不 会呈现在 html文件 里。高级主题(三):SQLAlchemyMysql这样关系型数据库的缺点:在表 示复杂网路这样一对多,和多对多 的关系时,非常冗余;一旦须要做 比较复杂的统计,sql句子会显得异 常复杂。
? 当你越关注性能,就会发觉 SQL 数据库距对象集合越来越远;当你越关 注具象,就会发觉对象集合距表和行这种概念越来越远。SQLAlchemy 将 致力于尽量宽容这两个世界。? SQLAlchemy 并不把数据库简单地视为数据表的集合;它把它们看作是关 系代数引擎。它的关系对象映射才能使类以不同的形式映射到数据库。 SQL 工具包也不光才能对数据表进行 select 操作——你能够对联接、子查 询和联合进行 select。这样数据库关系和领域对象模型之间的耦合从一开 始就得以挺好地解开,使得两个领域都得以发挥其各自的极至。? 我写过的某个冗长的调用? 号称能更简约明了的SQLAlchemy会成为 mysql的替代品么?高级主题(四):统计神器R语言? 求残差,聚类,判 别,拟合,团簇探 测,时间序列剖析, 生存剖析,甚至复 杂网路,这些R语言 里都有挺好的函数? 可以直接使用R语言, 也可以借助Rpy在 python上面调用R的 函数,不过Rpy一直 开发中,还不是太 成熟以前我们获取数据的手段: 我们用望远镜来洞察宇宙高昂的实验 只是为了获取大自然的数据Internet 带给我们了海量的数据 善用数据,了解我们自己广袤的比特海是另一片未知的星空感谢你们! 查看全部
网络爬虫, Python和数据 分析王澎 中国科技大学哪些是网络爬虫?? 网络爬虫是一个手动提取网页的程序,它为搜索 引擎从万维网上下载网页,是搜索引擎的重要组 成。传统爬虫从一个或若干初始网页的URL开始, 获得初始网页上的URL,在抓取网页的过程中, 不断从当前页面上抽取新的URL装入队列,直到满 足系统的一定停止条件爬虫有哪些用?? 做为通用搜索引擎网页收集器。(google,baidu) ? 做垂直搜索引擎.(找工作的搜索引擎:,数据来源于: , , 等等) ? 科学研究:在线人类行为,在线社群演变,人类 动力学研究数据挖掘与网络爬虫,计量社会学,复杂网路,数据挖掘, 等领域的实证研究都须要大量数据,网络爬虫是 收集相关数据的神器。 ? 偷窥,hacking数据挖掘与网络爬虫,发垃圾邮件……(《google hack》….)爬虫是搜索引擎的第一步 也是最容易的一步? 网页收集 ? 建立索引 ? 查询排序用哪些语言写爬虫?? C,C++。高效率,快速,适合通用搜索引 擎做全网爬取。缺点,开发慢,写上去又 臭又长,例如:天网搜索源代码。? 脚本语言:Perl, Python, Java, Ruby。简单, 易学,良好的文本处理能便捷网页内容的 细致提取,但效率常常不高,适合对少量 网站的聚焦爬取? C#?(貌似信息管理的人比较喜欢的语言)我当初拿来写过爬虫的语言? Perl: 古老的脚本语言,hack 语言,被拿来写爬虫 有着悠久的历史,因此,书本支持相当丰富: 《spidering hacks》,《Perl & LWP》;强大的文 本处理能力,数据库支持能力。
缺点:有点奇特。? Python:相对年青一点的语言。对于爬虫来说各 方面能力挺好,并且还在建立中,没有Perl那样有 专门的爬虫书籍,不过网上能搜到一些文章。为什么最终选择Python?? 跨平台,对Linux和windows都有不错的支持。 ? 科学估算,数值拟合:Numpy,Scipy ? 可视化:2d:Matplotlib(做图很漂亮), 3d: Mayavi2 ? 复杂网路:Networkx ? 统计:与R语言插口:Rpy ? 交互式终端 ? 网站的快速开发?从一个简单的Python爬虫开始说明:加说明句子时要注意#需要英语编码里的,而不能是英文输入法中的#号,所 以添加英文说明时先在英语输入法下攻入#号后再切换到英文输入瀚海星云Pie 版的网页部份代码………Pie版的Html树部份结构借助BeautifulSoup分析树FindAll()是最方便最好用的函数通用搜索策略? 页面中的link? 深度优先? 广度优先现实中的策略是多种多样的? 因为瀚海星云link有很简单的规律,每页递减20,所以借助这个规 律设置每次赋入的URL,这样爬完了PIE版所有贴子运行结果? 有乱 码!!爬取英文网页常有的问题:不规 格的编码模式? 解决方式:编码转换最后的结果? Perfect!请温柔的对待瀚海星云!!? 设置延后时间(对于一个峰会,如果假定一 个真实的浏览者每10秒掀开一个新的网页的 话,一个不延时的爬虫每秒可以抓10个网页, 这样一个爬虫相当于占用了100个人的带 宽!)? 在午夜爬取可以适当推进速率道上的规矩:用Mysql储存数据? 先要在自己数据库里构建一个空的表,这里, 这里我早已构建了一个名为lilybbs的数据库, 表名为hunan_a? 导入相应的模块? 与相应的数据库联接? 写入数据库里的结果统计和做图? 这部份主要用于科研方 面,利用爬取到的数据 做一些简单的统计工作? 右图是某峰会的回复网 络,使用python的 networkx包做的。
? Pylab 是 matplotlib作 图包的一部 分? 左图是某 blog四年间 每天发表文 章的数目? 左一是某blog网站每个blog 评论数的统计,x是blog评 论数目,y是有这样数目的 blog的数目。可以看见是标 准的“power-law”分布,幂 指数为-1.2左右,拟合使用 了Scipy包的optimize.leastsq, 函数,具体可见scipy cookbook页面的fitting data 一栏? 左二是blog的comment networks 的入度与出度的散 点图,也就是每位点的坐 标x,y分别代表某个人获 得的评论和发出的评论数。 颜色代表这样点的数目。 本图使用了matplotlib中的 hexbin函数中级主题(一):编写更强壮的爬虫? 伪装成浏 览器? 容错中级主题(二):由内嵌脚本形成 的动态网页的爬取? 如何爬取 像左图这 样的网页 呢?? 它显示的 内容并不 会呈现在 html文件 里。高级主题(三):SQLAlchemyMysql这样关系型数据库的缺点:在表 示复杂网路这样一对多,和多对多 的关系时,非常冗余;一旦须要做 比较复杂的统计,sql句子会显得异 常复杂。
? 当你越关注性能,就会发觉 SQL 数据库距对象集合越来越远;当你越关 注具象,就会发觉对象集合距表和行这种概念越来越远。SQLAlchemy 将 致力于尽量宽容这两个世界。? SQLAlchemy 并不把数据库简单地视为数据表的集合;它把它们看作是关 系代数引擎。它的关系对象映射才能使类以不同的形式映射到数据库。 SQL 工具包也不光才能对数据表进行 select 操作——你能够对联接、子查 询和联合进行 select。这样数据库关系和领域对象模型之间的耦合从一开 始就得以挺好地解开,使得两个领域都得以发挥其各自的极至。? 我写过的某个冗长的调用? 号称能更简约明了的SQLAlchemy会成为 mysql的替代品么?高级主题(四):统计神器R语言? 求残差,聚类,判 别,拟合,团簇探 测,时间序列剖析, 生存剖析,甚至复 杂网路,这些R语言 里都有挺好的函数? 可以直接使用R语言, 也可以借助Rpy在 python上面调用R的 函数,不过Rpy一直 开发中,还不是太 成熟以前我们获取数据的手段: 我们用望远镜来洞察宇宙高昂的实验 只是为了获取大自然的数据Internet 带给我们了海量的数据 善用数据,了解我们自己广袤的比特海是另一片未知的星空感谢你们!
淘宝数据采集以及数据剖析
采集交流 • 优采云 发表了文章 • 0 个评论 • 468 次浏览 • 2020-05-05 08:04
八爪鱼·云采集网络爬虫软件 淘宝数据采集以及数据剖析在现今大数据时代,做电商营运越来越讲求用数据说话,从数据中挖掘市场机 会,所以数据采集与剖析是天猫电商营运必 Get 的技能之一,下面由小编为大 家介绍怎样通过八爪鱼数据采集器,进行天猫数据采集以及数据剖析,分析市场 的需求和趋势。小编以“童鞋”商品作为样本,在淘宝天猫 6000 个童鞋商品中,选取了逾 30 天销量排名前 620 的童鞋作为样本进行数据采集。八爪鱼数据采集样本时间维度:2018 年 8 月 4 日——2018 年 9 月 4 日 数据样本:天猫童鞋销量排名前 620 款(占淘宝童鞋商品总量 10.3%,总数为 6000 款) 数据字段:价格、商品名称、商品链接、店铺名称、店铺链接、月成交(笔数)、 评价数、图片 URL 地址八爪鱼·云采集网络爬虫软件 八爪鱼采集结果示例八爪鱼从淘宝抓取 Top 620 销量童鞋数据(免费下载规则 1:八爪鱼抓取淘宝 Top 销量童鞋数据,获取方法见文末)八爪鱼·云采集网络爬虫软件 八爪鱼抓取淘宝 Top 620 销量童鞋图片(免费下载安装包:图片批量下载工具-八爪鱼采集器插件,获取方法见文末)干货来了,以下是小编的剖析结果。
1、价格影响 80%的父母选择 100 元以下的童鞋八爪鱼·云采集网络爬虫软件 从数据上看,销量 Top 620 的童鞋,产品价位集中在 25-100 元的价钱区间, 说明这个价钱区间,最受父母欢迎,这个为店家在做新款研制、新品定价与成本 考量中提供参考。八爪鱼·云采集网络爬虫软件 从数据上看,100 元以下的产品占逾 30 天销量的 81%,50 元以下的产品占逾 30 天销量的 56%。说明 80%的父母偏向订购 100 元以下的童鞋产品。经督查剖析,主要缘由有以下 3 点: 1、0-7 岁男孩头部发育快,换靴频度高,一双靴可能穿 1-2 个月,或 3-6 个月 就要更换; 2、0-7 岁男孩父母大部分属于 80 后、90 后,工作收入属于中等平均水平; 3、孩子还有外套、奶粉、早教等其他支出,相对于其他产品,家长偏向于在靴 子消费上节约支出;运营建议: 在童鞋的新款研制、定价、宣传渠道、用户画像上须要考虑用户的年纪、收入、 城市分布以及消费心理和消费能力。2、季节影响 秋冬季鞋款更好卖八爪鱼·云采集网络爬虫软件 从数据上看, 秋季靴款占逾 30 天销量的 38.7%, 春夏季占逾 30 天销量的 27.4%。
秋季、春季为逾 30 天的主打款。随着季节的变化,秋天早晚温差大。孩子在快 速发育期,免疫力低,自我照料能力弱。因此父母会依照季节变化,购买符合季 节体温的靴款。毕竟孩子得病了,苦的累的是大人。运营建议: 1、提前上架春秋季节的靴款,做好迎接冬季童鞋的需求下降打算; 2、修改商品的名称,将商品名称降低“秋、春”的字眼,增加被用户检索到的 概率。八爪鱼·云采集网络爬虫软件 3、店铺成交流水 定价和营销策略很重要八爪鱼从淘宝抓取童鞋月销量 Top 620 数据以上是淘宝童鞋月销量 Top 620 的数据。你可以对照自己店面的数据,衡量你 与她们之间差别,并且仔细剖析大家之间的差别在那里?从那里可以改进?八爪鱼·云采集网络爬虫软件 我们发觉月成交 Top 2 的米修服装专营店没有步入月流水的 Top 10,说明他的 成交量其实大,但总价比较低。本来没有步入 Top 10 月成交的 anta 安踏男装 旗舰店和大黄蜂旗舰店,一跃成为月流水 Top 1 和 Top4。八爪鱼·云采集网络爬虫软件 从数据上看,安踏、大黄蜂的平均客单价达到 100 元以上。进入她们的店面发 现爬虫软件分析电商数据,2 家主攻 4-10 岁的学龄儿童为主,均价在 100 元以上,拉高了月流水。
运营建议: 1、0-6 岁的学步鞋定价普遍在 100 元以下,6-10 岁的学龄儿童定价稍高,偏 向 100 元以上; 2、并不是价位越实惠好卖,用户会综合考虑品牌、质量、评价等综合诱因,从 中选优; 3、在新款定价、促销折扣时,既要要考虑用户的心理和同竞品的定价营销策略, 同时也要考虑产品的收益和成本。定价和营销策略十分重要;4、热点风波影响 9 月开学季,小白靴成为童鞋畅销品小白靴在逾 30 天的月成交、月流水贡献占比八爪鱼·云采集网络爬虫软件 小编分别在 8 月 25 日和 9 月 4 日, 用八爪鱼采集童鞋数据, 发现就在这 10 天, 小白靴就早已嗖嘶嘶飙升到销量 Top 1,为逾 30 日月成交贡献了 34.89%,月 流水贡献了 28.81%。如果爪爪想知道这波小白靴热卖会维持多久,可以在 9 月 14 日再采集一次进行数据对比。5、销量 Top 1 小白靴小编用八爪鱼数据采集销量 Top1 小白靴 600 条用户评价, 并用动词软件对评价 做了词频解析。八爪鱼抓取淘宝销量 Top1 小白靴用户评论八爪鱼·云采集网络爬虫软件 (免费下载规则 2:八爪鱼抓取淘宝商品用户评论数据,获取方法见文末)评价中用户最关心: 质量、款式、舒适度、鞋衣搭配、异味、尺码、价格、穿脱便捷、发货速率(赶 着开学穿、同事推荐;送礼物、促销活动。
八爪鱼·云采集网络爬虫软件 销量 Top 1 童鞋用户评价时间分布从数据上看,家长评价集中在 8 月 22 日—9 月 2 日,说明父母在开学前一周开 始打算入学的武器。运营建议: 1、 出具一份电商童鞋营运活动时间表爬虫软件分析电商数据, 对于童鞋产品一年当中有什么营销热点; 元旦、1 月春节、3 月开学、61 儿童节、618 电商、6、7、8 月假期、9 月开学、 9 月新春、10 月端午、双 11、双 12、12 月圣诞节。2、在营销热点时间提早 1—2 个月,做好准备,比如热卖选品、营销折扣、营 销活动专题、文案、设计、用户评价积累、配套单品、物流打算等等。电商数据剖析框架八爪鱼·云采集网络爬虫软件 八爪鱼·云采集网络爬虫软件 涉及八爪鱼方法知识点八爪虾基础课程(采集模式、多种网页数据采集、创建循环、登录形式、ajax 加载、ajax 滚动等)淘宝天猫采集教程: (建议在笔记本端打开)其它电商网站数据采集教程: 1688 商品信息以及卖家评价采集 亚马逊商品信息采集方法以及详尽教程 易迅采集器 天猫评论采集 八爪鱼·云采集网络爬虫软件 淘宝网宝贝采集器 八爪鱼——90 万用户选择的网页数据采集器。
1、操作简单,任何人都可以用:无需技术背景,会上网才能采集。完全可视化 流程,点击滑鼠完成操作,2 分钟即可快速入门。 2、功能强悍,任何网站都可以采:对于点击、登陆、翻页、识别验证码、瀑布 流、Ajax 脚本异步加载数据的网页,均可经过简单设置进行采集。 3、云采集,关机也可以。配置好采集任务后可死机,任务可在云端执行。庞大 云采集集群 24*7 不间断运行,不用害怕 IP 被封,网络中断。 4、功能免费+增值服务,可按需选择。免费版具备所有功能,能够满足用户的 基本采集需求。同时设置了一些增值服务(如私有云),满足低端付费企业用户 的须要。 查看全部

八爪鱼·云采集网络爬虫软件 淘宝数据采集以及数据剖析在现今大数据时代,做电商营运越来越讲求用数据说话,从数据中挖掘市场机 会,所以数据采集与剖析是天猫电商营运必 Get 的技能之一,下面由小编为大 家介绍怎样通过八爪鱼数据采集器,进行天猫数据采集以及数据剖析,分析市场 的需求和趋势。小编以“童鞋”商品作为样本,在淘宝天猫 6000 个童鞋商品中,选取了逾 30 天销量排名前 620 的童鞋作为样本进行数据采集。八爪鱼数据采集样本时间维度:2018 年 8 月 4 日——2018 年 9 月 4 日 数据样本:天猫童鞋销量排名前 620 款(占淘宝童鞋商品总量 10.3%,总数为 6000 款) 数据字段:价格、商品名称、商品链接、店铺名称、店铺链接、月成交(笔数)、 评价数、图片 URL 地址八爪鱼·云采集网络爬虫软件 八爪鱼采集结果示例八爪鱼从淘宝抓取 Top 620 销量童鞋数据(免费下载规则 1:八爪鱼抓取淘宝 Top 销量童鞋数据,获取方法见文末)八爪鱼·云采集网络爬虫软件 八爪鱼抓取淘宝 Top 620 销量童鞋图片(免费下载安装包:图片批量下载工具-八爪鱼采集器插件,获取方法见文末)干货来了,以下是小编的剖析结果。
1、价格影响 80%的父母选择 100 元以下的童鞋八爪鱼·云采集网络爬虫软件 从数据上看,销量 Top 620 的童鞋,产品价位集中在 25-100 元的价钱区间, 说明这个价钱区间,最受父母欢迎,这个为店家在做新款研制、新品定价与成本 考量中提供参考。八爪鱼·云采集网络爬虫软件 从数据上看,100 元以下的产品占逾 30 天销量的 81%,50 元以下的产品占逾 30 天销量的 56%。说明 80%的父母偏向订购 100 元以下的童鞋产品。经督查剖析,主要缘由有以下 3 点: 1、0-7 岁男孩头部发育快,换靴频度高,一双靴可能穿 1-2 个月,或 3-6 个月 就要更换; 2、0-7 岁男孩父母大部分属于 80 后、90 后,工作收入属于中等平均水平; 3、孩子还有外套、奶粉、早教等其他支出,相对于其他产品,家长偏向于在靴 子消费上节约支出;运营建议: 在童鞋的新款研制、定价、宣传渠道、用户画像上须要考虑用户的年纪、收入、 城市分布以及消费心理和消费能力。2、季节影响 秋冬季鞋款更好卖八爪鱼·云采集网络爬虫软件 从数据上看, 秋季靴款占逾 30 天销量的 38.7%, 春夏季占逾 30 天销量的 27.4%。
秋季、春季为逾 30 天的主打款。随着季节的变化,秋天早晚温差大。孩子在快 速发育期,免疫力低,自我照料能力弱。因此父母会依照季节变化,购买符合季 节体温的靴款。毕竟孩子得病了,苦的累的是大人。运营建议: 1、提前上架春秋季节的靴款,做好迎接冬季童鞋的需求下降打算; 2、修改商品的名称,将商品名称降低“秋、春”的字眼,增加被用户检索到的 概率。八爪鱼·云采集网络爬虫软件 3、店铺成交流水 定价和营销策略很重要八爪鱼从淘宝抓取童鞋月销量 Top 620 数据以上是淘宝童鞋月销量 Top 620 的数据。你可以对照自己店面的数据,衡量你 与她们之间差别,并且仔细剖析大家之间的差别在那里?从那里可以改进?八爪鱼·云采集网络爬虫软件 我们发觉月成交 Top 2 的米修服装专营店没有步入月流水的 Top 10,说明他的 成交量其实大,但总价比较低。本来没有步入 Top 10 月成交的 anta 安踏男装 旗舰店和大黄蜂旗舰店,一跃成为月流水 Top 1 和 Top4。八爪鱼·云采集网络爬虫软件 从数据上看,安踏、大黄蜂的平均客单价达到 100 元以上。进入她们的店面发 现爬虫软件分析电商数据,2 家主攻 4-10 岁的学龄儿童为主,均价在 100 元以上,拉高了月流水。
运营建议: 1、0-6 岁的学步鞋定价普遍在 100 元以下,6-10 岁的学龄儿童定价稍高,偏 向 100 元以上; 2、并不是价位越实惠好卖,用户会综合考虑品牌、质量、评价等综合诱因,从 中选优; 3、在新款定价、促销折扣时,既要要考虑用户的心理和同竞品的定价营销策略, 同时也要考虑产品的收益和成本。定价和营销策略十分重要;4、热点风波影响 9 月开学季,小白靴成为童鞋畅销品小白靴在逾 30 天的月成交、月流水贡献占比八爪鱼·云采集网络爬虫软件 小编分别在 8 月 25 日和 9 月 4 日, 用八爪鱼采集童鞋数据, 发现就在这 10 天, 小白靴就早已嗖嘶嘶飙升到销量 Top 1,为逾 30 日月成交贡献了 34.89%,月 流水贡献了 28.81%。如果爪爪想知道这波小白靴热卖会维持多久,可以在 9 月 14 日再采集一次进行数据对比。5、销量 Top 1 小白靴小编用八爪鱼数据采集销量 Top1 小白靴 600 条用户评价, 并用动词软件对评价 做了词频解析。八爪鱼抓取淘宝销量 Top1 小白靴用户评论八爪鱼·云采集网络爬虫软件 (免费下载规则 2:八爪鱼抓取淘宝商品用户评论数据,获取方法见文末)评价中用户最关心: 质量、款式、舒适度、鞋衣搭配、异味、尺码、价格、穿脱便捷、发货速率(赶 着开学穿、同事推荐;送礼物、促销活动。
八爪鱼·云采集网络爬虫软件 销量 Top 1 童鞋用户评价时间分布从数据上看,家长评价集中在 8 月 22 日—9 月 2 日,说明父母在开学前一周开 始打算入学的武器。运营建议: 1、 出具一份电商童鞋营运活动时间表爬虫软件分析电商数据, 对于童鞋产品一年当中有什么营销热点; 元旦、1 月春节、3 月开学、61 儿童节、618 电商、6、7、8 月假期、9 月开学、 9 月新春、10 月端午、双 11、双 12、12 月圣诞节。2、在营销热点时间提早 1—2 个月,做好准备,比如热卖选品、营销折扣、营 销活动专题、文案、设计、用户评价积累、配套单品、物流打算等等。电商数据剖析框架八爪鱼·云采集网络爬虫软件 八爪鱼·云采集网络爬虫软件 涉及八爪鱼方法知识点八爪虾基础课程(采集模式、多种网页数据采集、创建循环、登录形式、ajax 加载、ajax 滚动等)淘宝天猫采集教程: (建议在笔记本端打开)其它电商网站数据采集教程: 1688 商品信息以及卖家评价采集 亚马逊商品信息采集方法以及详尽教程 易迅采集器 天猫评论采集 八爪鱼·云采集网络爬虫软件 淘宝网宝贝采集器 八爪鱼——90 万用户选择的网页数据采集器。
1、操作简单,任何人都可以用:无需技术背景,会上网才能采集。完全可视化 流程,点击滑鼠完成操作,2 分钟即可快速入门。 2、功能强悍,任何网站都可以采:对于点击、登陆、翻页、识别验证码、瀑布 流、Ajax 脚本异步加载数据的网页,均可经过简单设置进行采集。 3、云采集,关机也可以。配置好采集任务后可死机,任务可在云端执行。庞大 云采集集群 24*7 不间断运行,不用害怕 IP 被封,网络中断。 4、功能免费+增值服务,可按需选择。免费版具备所有功能,能够满足用户的 基本采集需求。同时设置了一些增值服务(如私有云),满足低端付费企业用户 的须要。
dedecms数据库恢复与备份的两种方式
采集交流 • 优采云 发表了文章 • 0 个评论 • 268 次浏览 • 2020-04-10 11:00
数据库是一个网站的核心系统,它存储着网站的所有信息,所以常常对数据库进行恢复和备份是每一位站长都要会做的事情,尤其是这些对数据和信息非常重要的网站。对于恢复与备份数据库的方式有很多,无忧主机小编在这几年的工作当中,也接触了不少无忧主机php免备案空间的用户咨询这方面的问题。那么明天无忧主机小编就来讲解一下dedecms数据库恢复与备份的两种方式。
第一种是比较通用的方式,登入无忧主机控制面板织梦 数据库还原织梦 数据库还原,点击“数据库管理”——“登录phpmyadmin”,用数据库用户名和数据库密码登录进去,找到要备份的数据库信息,全选、导出就完成备份了。然后还原也是一样,选择要导出的数据库信息点击导出,将备份好的数据库信息导出进去就可以。
第二种就是登陆dedecms的后台,利用后台功能进行数据库恢复与备份的操作,这种方式对于dedecms更加便捷快捷。登入dedecms网站后台,点击“系统”——“数据库备份/还原”。全选或则部份选定数据表信息,按提示完成备份。要恢复的话点击“数据还原”,选择早已做好了备份的数据表,点击“开始还原数据”就完成了。
以上两种方式都可以实现数据库恢复与备份,但是第一种操作相对复杂一点,但是对好多程序都通用;而第二种较为简单,但是只适用于dedecms。 查看全部

数据库是一个网站的核心系统,它存储着网站的所有信息,所以常常对数据库进行恢复和备份是每一位站长都要会做的事情,尤其是这些对数据和信息非常重要的网站。对于恢复与备份数据库的方式有很多,无忧主机小编在这几年的工作当中,也接触了不少无忧主机php免备案空间的用户咨询这方面的问题。那么明天无忧主机小编就来讲解一下dedecms数据库恢复与备份的两种方式。
第一种是比较通用的方式,登入无忧主机控制面板织梦 数据库还原织梦 数据库还原,点击“数据库管理”——“登录phpmyadmin”,用数据库用户名和数据库密码登录进去,找到要备份的数据库信息,全选、导出就完成备份了。然后还原也是一样,选择要导出的数据库信息点击导出,将备份好的数据库信息导出进去就可以。
第二种就是登陆dedecms的后台,利用后台功能进行数据库恢复与备份的操作,这种方式对于dedecms更加便捷快捷。登入dedecms网站后台,点击“系统”——“数据库备份/还原”。全选或则部份选定数据表信息,按提示完成备份。要恢复的话点击“数据还原”,选择早已做好了备份的数据表,点击“开始还原数据”就完成了。
以上两种方式都可以实现数据库恢复与备份,但是第一种操作相对复杂一点,但是对好多程序都通用;而第二种较为简单,但是只适用于dedecms。
如何做好seo数据监控的统计呢?
采集交流 • 优采云 发表了文章 • 0 个评论 • 320 次浏览 • 2020-04-05 11:02
因为近来百度始终未能使好多站长和SEO人员保持淡定,每天都有许多SEO人去各大峰会、QQ群咨询问题,最多的就是“我的网站为什么被K”、“多久就能恢复过来”等等例如之类的问题满天飞,通常QQ群里你们就会各执己见,有人说你的内容做的不好、有人说你的外链太多、有人说你的站内优化过度等等,大家剖析来剖析去最后还是“无解”,我想每位做SEO的基本上都清楚这些东西,但我们如何能够使自己的观点有根据呢?那些想法可能都是我们的猜想,根据往年的经验推断下来的东西,没有数据的SEO论断虽然未能使人信服。
与其说我们做的是SEO优化,不如说是SEO数据监控,把每晚应当做的SEO工作落实到位,剩下的就是SEO数据监控了,SEO是一场竞争的游戏,这个游戏有游戏规则,但规则的制定者不是我们,我们都在想方设法的在这场游戏中打败对方。知己知彼百战百胜,分析竞争对手说起来容易文章采集站,其实很难,我们要做好SEO数据监控的第一步就是SEO数据监控。包括竞争对手网站的收录、反链、百度快照等数据,如何做好seo数据监控的统计呢?
第一:必须借助于一些SEO工具
可惜的是现今国外其实还没有这样的SEO工具,有的也是一些收费的工具,但是以笔者看来没有几款工具值得我去付费使用的,功能与鬼佬的一些工具相比,差距不小。不过可以借助于一些其他软件辅助使用,比如:EXCEL、火车头采集器,相信这两个工具我们都不陌生,不过真正去研究的不多,EXCEL功能太强悍,之前笔者看过一篇文章,有同学就是用EXCEL实现排行查询和外链检查。而火车头采集器更是许多采集站必备的工具,不仅可以采集网站上的文章文章采集站,更能采集到网站上的好多数据,还有光年日志剖析软件、web log explorer网站日志剖析软件(老外的东西,现在有破解版)。
第二:生成更直观的SEO数据统计图
通过软件得到的数据须要处理下,这样可以生成更直观的SEO数据统计图。否则一个个查询域名工作量很大seo数据监控,有点不切实际,如chinaz站长工具一样,我们可以通过程序或软件生成我们想要的图片,这些须要有程序员开发一些系统下来,其实不难。常见的图表类型有条形图、折线图等,有图表能够直观的看出网站数据的变化,包括自己优化的网站以及竞争对手的网站,当你须要管理好多网站的时侯,这样的程序可以给你节约好多时间。SEO工作中一切可以从程序或软件完成的,我们尽量不要手工做,这样效率方面也提升了不少。
第三:定期撰写SEO数据剖析报告
假如如今我手里须要管理10个企业站,我可以每周看下自己整理好的数据,在软件或相关程序的帮助下,收集数据不要浪费多少时间,甚至只要我们去瞧瞧图表就行了,知道自己网站最近的一些数据,比如:一周收录跌多少,外链掉了多少。再对比下排行在前几页的竞争对手,看看他人是怎么做的,网站的更新频度是多少,外链的增长幅度是多少等。
要剖析一个网站是因何缘由被k,不是一件容易的事情,如果只是按照自己以为的经验来判定,这未免有些轻率,但好多网站其实没有去做好网站数据的统计,这样网站一旦出问题了,一时半会也不晓得问题出现在那儿。我相信网站优化出问题就好象人得病一样,总能找到一些蛛丝马迹seo数据监控,比如:网站日志文件就是查出病症的途径,我是老男孩SEO工作室的石头,我们做SEO不能借助自己的觉得,需要依赖于数据和经验。 查看全部

因为近来百度始终未能使好多站长和SEO人员保持淡定,每天都有许多SEO人去各大峰会、QQ群咨询问题,最多的就是“我的网站为什么被K”、“多久就能恢复过来”等等例如之类的问题满天飞,通常QQ群里你们就会各执己见,有人说你的内容做的不好、有人说你的外链太多、有人说你的站内优化过度等等,大家剖析来剖析去最后还是“无解”,我想每位做SEO的基本上都清楚这些东西,但我们如何能够使自己的观点有根据呢?那些想法可能都是我们的猜想,根据往年的经验推断下来的东西,没有数据的SEO论断虽然未能使人信服。
与其说我们做的是SEO优化,不如说是SEO数据监控,把每晚应当做的SEO工作落实到位,剩下的就是SEO数据监控了,SEO是一场竞争的游戏,这个游戏有游戏规则,但规则的制定者不是我们,我们都在想方设法的在这场游戏中打败对方。知己知彼百战百胜,分析竞争对手说起来容易文章采集站,其实很难,我们要做好SEO数据监控的第一步就是SEO数据监控。包括竞争对手网站的收录、反链、百度快照等数据,如何做好seo数据监控的统计呢?
第一:必须借助于一些SEO工具
可惜的是现今国外其实还没有这样的SEO工具,有的也是一些收费的工具,但是以笔者看来没有几款工具值得我去付费使用的,功能与鬼佬的一些工具相比,差距不小。不过可以借助于一些其他软件辅助使用,比如:EXCEL、火车头采集器,相信这两个工具我们都不陌生,不过真正去研究的不多,EXCEL功能太强悍,之前笔者看过一篇文章,有同学就是用EXCEL实现排行查询和外链检查。而火车头采集器更是许多采集站必备的工具,不仅可以采集网站上的文章文章采集站,更能采集到网站上的好多数据,还有光年日志剖析软件、web log explorer网站日志剖析软件(老外的东西,现在有破解版)。
第二:生成更直观的SEO数据统计图
通过软件得到的数据须要处理下,这样可以生成更直观的SEO数据统计图。否则一个个查询域名工作量很大seo数据监控,有点不切实际,如chinaz站长工具一样,我们可以通过程序或软件生成我们想要的图片,这些须要有程序员开发一些系统下来,其实不难。常见的图表类型有条形图、折线图等,有图表能够直观的看出网站数据的变化,包括自己优化的网站以及竞争对手的网站,当你须要管理好多网站的时侯,这样的程序可以给你节约好多时间。SEO工作中一切可以从程序或软件完成的,我们尽量不要手工做,这样效率方面也提升了不少。
第三:定期撰写SEO数据剖析报告
假如如今我手里须要管理10个企业站,我可以每周看下自己整理好的数据,在软件或相关程序的帮助下,收集数据不要浪费多少时间,甚至只要我们去瞧瞧图表就行了,知道自己网站最近的一些数据,比如:一周收录跌多少,外链掉了多少。再对比下排行在前几页的竞争对手,看看他人是怎么做的,网站的更新频度是多少,外链的增长幅度是多少等。
要剖析一个网站是因何缘由被k,不是一件容易的事情,如果只是按照自己以为的经验来判定,这未免有些轻率,但好多网站其实没有去做好网站数据的统计,这样网站一旦出问题了,一时半会也不晓得问题出现在那儿。我相信网站优化出问题就好象人得病一样,总能找到一些蛛丝马迹seo数据监控,比如:网站日志文件就是查出病症的途径,我是老男孩SEO工作室的石头,我们做SEO不能借助自己的觉得,需要依赖于数据和经验。
五分钟学前端技术:一篇文章教你看懂大数据技术栈!
采集交流 • 优采云 发表了文章 • 0 个评论 • 467 次浏览 • 2020-04-02 11:04
近几年,市场上出现了好多和大数据相关的岗位,不管是数据剖析、数据挖掘,或者是数据研制,都是围绕着大数据来做事情,那么,到底哪些是大数据,就是我们每一个要学习大数据技术的同学要了解的事情了,根据百度百科的介绍
大数据(big data),IT行业术语,是指未能在一定时间范围内用常规软件工具进行捕捉、管理和处理的数据集合,是须要新处理模式能够具有更强的决策力、洞察发觉力和流程优化能力的海量、高增长率和多元化的信息资产。
在维克托·迈尔-舍恩伯格及肯尼斯·库克耶编撰的《大数据时代》 [1] 中大数据指不用随机分析法(抽样调查)这样捷径,而采用所有数据进行剖析处理。大数据的5V特征(IBM提出):Volume(大量)、Velocity(高速)、Variety(多样)、Value(低价值密度)、Veracity(真实性)。 [2]思维导图
大数据方面核心技术有什么?
大数据的概念比较具象,而大数据技术栈的庞大程度将使你叹为观止。
大数据技术的体系庞大且复杂,基础的技术包含数据的采集、数据预处理、分布式存储、NoSQL数据库、数据库房、机器学习、并行估算、可视化等各类技术范畴和不同的技术层面。首先给出一个通用化的大数据处理框架,主要分为下边几个方面:数据采集与预处理、数据储存、数据清洗、数据查询剖析和数据可视化。
一、数据采集与预处理
对于各类来源的数据,包括联通互联网数据、社交网络的数据等,这些结构化和非结构化的海量数据是零散的,也就是所谓的数据孤岛,此时的那些数据并没有哪些意义,数据采集就是将这种数据写入数据库房中,把零散的数据整合在一起,对那些数据综合上去进行剖析。数据采集包括文件日志的采集、数据库日志的采集、关系型数据库的接入和应用程序的接入等。在数据量比较小的时侯,可以写个定时的脚本将日志写入储存系统,但随着数据量的下降,这些方式难以提供数据安全保障,并且运维困难,需要更健壮的解决方案。
Flume NG作为实时日志搜集系统,支持在日志系统中订制各种数据发送方,用于搜集数据,同时,对数据进行简单处理,并讲到各类数据接收方(比如文本,HDFS,Hbase等)。Flume NG采用的是三层架构:Agent层,Collector层和Store层,每一层均可水平拓展。其中Agent包含Source,Channel和 Sink,source拿来消费(收集)数据源到channel组件中,channel作为中间临时储存,保存所有source的组件信息,sink从channel中读取数据,读取成功以后会删掉channel中的信息。
NDC,Netease Data Canal,直译为网易数据运河系统,是网易针对结构化数据库的数据实时迁移、同步和订阅的平台化解决方案。它整合了网易过去在数据传输领域的各类工具和经验,将单机数据库、分布式数据库、OLAP系统以及下游应用通过数据链路串在一起。除了保障高效的数据传输外,NDC的设计遵守了单元化和平台化的设计哲学。
Logstash是开源的服务器端数据处理管线,能够同时从多个来源采集数据、转换数据,然后将数据发送到您最喜欢的 “存储库” 中。一般常用的储存库是Elasticsearch。Logstash 支持各类输入选择,可以在同一时间从众多常用的数据来源捕捉风波,能够以连续的流式传输方法,轻松地从您的日志、指标、Web 应用、数据储存以及各类 AWS 服务采集数据。
Sqoop,用来将关系型数据库和Hadoop中的数据进行互相转移的工具,可以将一个关系型数据库(例如Mysql、Oracle)中的数据导出到Hadoop(例如HDFS、Hive、Hbase)中,也可以将Hadoop(例如HDFS、Hive、Hbase)中的数据导出到关系型数据库(例如Mysql、Oracle)中。Sqoop 启用了一个 MapReduce 作业(极其容错的分布式并行估算)来执行任务。Sqoop 的另一大优势是其传输大量结构化或半结构化数据的过程是完全自动化的。
流式估算是行业研究的一个热点,流式估算对多个高吞吐量的数据源进行实时的清洗、聚合和剖析,可以对存在于社交网站、新闻等的数据信息流进行快速的处理并反馈,目前大数据流剖析工具有很多,比如开源的strom,spark streaming等。
Strom集群结构是有一个主节点(nimbus)和多个工作节点(supervisor)组成的主从结构,主节点通过配置静态指定或则在运行时动态补选,nimbus与supervisor都是Storm提供的后台守护进程,之间的通讯是结合Zookeeper的状态变更通知和监控通知来处理。nimbus进程的主要职责是管理、协调和监控集群上运行的topology(包括topology的发布、任务委派、事件处理时重新委派任务等)。supervisor进程等待nimbus分配任务后生成并监控worker(jvm进程)执行任务。supervisor与worker运行在不同的jvm上,如果由supervisor启动的某个worker由于错误异常退出(或被kill掉),supervisor会尝试重新生成新的worker进程。
当使用上游模块的数据进行估算、统计、分析时,就可以使用消息系统,尤其是分布式消息系统。Kafka使用Scala进行编撰,是一种分布式的、基于发布/订阅的消息系统。Kafka的设计理念之一就是同时提供离线处理和实时处理,以及将数据实时备份到另一个数据中心,Kafka可以有许多的生产者和消费者分享多个主题,将消息以topic为单位进行归纳;Kafka发布消息的程序称为producer,也叫生产者,预订topics并消费消息的程序称为consumer,也叫消费者;当Kafka以集群的形式运行时,可以由一个服务或则多个服务组成,每个服务称作一个broker,运行过程中producer通过网路将消息发送到Kafka集群,集群向消费者提供消息。Kafka通过Zookeeper管理集群配置,选举leader,以及在Consumer Group发生变化时进行rebalance。Producer使用push模式将消息发布到broker,Consumer使用pull模式从broker订阅并消费消息。Kafka可以和Flume一起工作,如果须要将流式数据从Kafka转移到hadoop,可以使用Flume代理agent,将Kafka当作一个来源source,这样可以从Kafka读取数据到Hadoop。
Zookeeper是一个分布式的,开放源码的分布式应用程序协调服务,提供数据同步服务。它的作用主要有配置管理、名字服务、分布式锁和集群管理。配置管理指的是在一个地方更改了配置,那么对这个地方的配置感兴趣的所有的都可以获得变更,省去了自动拷贝配置的冗长,还挺好的保证了数据的可靠和一致性,同时它可以通过名子来获取资源或则服务的地址等信息全网文章采集软件,可以监控集群中机器的变化全网文章采集软件,实现了类似于脉搏机制的功能。
二、数据储存
Hadoop作为一个开源的框架,专为离线和大规模数据剖析而设计,HDFS作为其核心的储存引擎,已被广泛用于数据储存。
HBase,是一个分布式的、面向列的开源数据库,可以觉得是hdfs的封装,本质是数据储存、NoSQL数据库。HBase是一种Key/Value系统,部署在hdfs上,克服了hdfs在随机读写这个方面的缺点,与hadoop一样,Hbase目标主要借助纵向扩充,通过不断降低廉价的商用服务器,来降低估算和储存能力。
Phoenix,相当于一个Java中间件,帮助开发工程师才能象使用JDBC访问关系型数据库一样访问NoSQL数据库HBase。
Yarn是一种Hadoop资源管理器,可为下层应用提供统一的资源管理和调度,它的引入为集群在利用率、资源统一管理和数据共享等方面带来了巨大益处。Yarn由下边的几大组件构成:一个全局的资源管理器ResourceManager、ResourceManager的每位节点代理NodeManager、表示每位应用的Application以及每一个ApplicationMaster拥有多个Container在NodeManager上运行。
Mesos是一款开源的集群管理软件,支持Hadoop、ElasticSearch、Spark、Storm 和Kafka等应用构架。
Redis是一种速率十分快的非关系数据库,可以储存键与5种不同类型的值之间的映射,可以将储存在显存的通配符对数据持久化到硬碟中,使用复制特点来扩充性能,还可以使用客户端分片来扩充写性能。
Atlas是一个坐落应用程序与MySQL之间的中间件。在前端DB看来,Atlas相当于联接它的客户端,在后端应用看来,Atlas相当于一个DB。Atlas作为服务端与应用程序通信,它实现了MySQL的客户端和服务端合同,同时作为客户端与MySQL通信。它对应用程序屏蔽了DB的细节,同时为了增加MySQL负担,它还维护了连接池。Atlas启动后会创建多个线程,其中一个为主线程,其余为工作线程。主线程负责窃听所有的客户端联接恳求,工作线程只窃听主线程的命令恳求。
Kudu是围绕Hadoop生态圈构建的储存引擎,Kudu拥有和Hadoop生态圈共同的设计理念,它运行在普通的服务器上、可分布式规模化布署、并且满足工业界的高可用要求。其设计理念为fast analytics on fast data。作为一个开源的储存引擎,可以同时提供低延后的随机读写和高效的数据剖析能力。Kudu不但提供了行级的插入、更新、删除API,同时也提供了接近Parquet性能的批量扫描操作。使用同一份储存,既可以进行随机读写,也可以满足数据剖析的要求。Kudu的应用场景太广泛,比如可以进行实时的数据剖析,用于数据可能会存在变化的时序数据应用等。
在数据储存过程中,涉及到的数据表都是成千上百列,包含各类复杂的Query,推荐使用列式储存方式,比如parquent,ORC等对数据进行压缩。Parquet 可以支持灵活的压缩选项,显著减低c盘上的储存。
三、数据清洗
MapReduce作为Hadoop的查询引擎,用于大规模数据集的并行估算,”Map(映射)”和”Reduce(归约)”,是它的主要思想。它极大的便捷了编程人员在不会分布式并行编程的情况下,将自己的程序运行在分布式系统中。
随着业务数据量的增多,需要进行训练和清洗的数据会显得越来越复杂,这个时侯就须要任务调度系统,比如oozie或则azkaban,对关键任务进行调度和监控。
Oozie是用于Hadoop平台的一种工作流调度引擎,提供了RESTful API接口来接受用户的递交恳求(提交工作流作业),当递交了workflow后,由工作流引擎负责workflow的执行以及状态的转换。用户在HDFS上布署好作业(MR作业),然后向Oozie递交Workflow,Oozie以异步方法将作业(MR作业)提交给Hadoop。这也是为何当调用Oozie 的RESTful插口递交作业以后能立刻返回一个JobId的缘由,用户程序毋须等待作业执行完成(因为有些大作业可能会执行许久(几个小时甚至几天))。Oozie在后台以异步方法,再将workflow对应的Action递交给hadoop执行。
Azkaban也是一种工作流的控制引擎,可以拿来解决有多个hadoop或则spark等离线估算任务之间的依赖关系问题。azkaban主要是由三部份构成:Relational Database,Azkaban Web Server和Azkaban Executor Server。azkaban将大多数的状态信息都保存在MySQL中,Azkaban Web Server提供了Web UI,是azkaban主要的管理者,包括project的管理、认证、调度以及对工作流执行过程中的监控等;Azkaban Executor Server拿来调度工作流和任务,记录工作流或则任务的日志。
流计算任务的处理平台Sloth,是网易首个自研流计算平台,旨在解决公司内各产品日渐下降的流计算需求。作为一个估算服务平台,其特征是易用、实时、可靠,为用户节约技术方面(开发、运维)的投入,帮助用户专注于解决产品本身的流计算需求。
四、数据查询剖析
Hive的核心工作就是把SQL句子翻译成MR程序,可以将结构化的数据映射为一张数据库表,并提供 HQL(Hive SQL)查询功能。Hive本身不储存和估算数据,它完全依赖于HDFS和MapReduce。可以将Hive理解为一个客户端工具,将SQL操作转换为相应的MapReduce jobs,然后在hadoop里面运行。Hive支持标准的SQL句型,免去了用户编撰MapReduce程序的过程,它的出现可以使这些精通SQL技能、但是不熟悉MapReduce 、编程能力较弱与不擅长Java语言的用户才能在HDFS大规模数据集上很方便地借助SQL 语言查询、汇总、分析数据。
Hive是为大数据批量处理而生的,Hive的出现解决了传统的关系型数据库(MySql、Oracle)在大数据处理上的困局 。Hive 将执行计划分成map->shuffle->reduce->map->shuffle->reduce…的模型。如果一个Query会被编译成多轮MapReduce,则会有更多的写中间结果。由于MapReduce执行框架本身的特性,过多的中间过程会降低整个Query的执行时间。在Hive的运行过程中,用户只须要创建表,导入数据,编写SQL剖析句子即可。剩下的过程由Hive框架手动的完成。
Impala是对Hive的一个补充,可以实现高效的SQL查询。使用Impala来实现SQL on Hadoop,用来进行大数据实时查询剖析。通过熟悉的传统关系型数据库的SQL风格来操作大数据,同时数据也是可以储存到HDFS和HBase中的。Impala没有再使用平缓的Hive+MapReduce批处理,而是通过使用与商用并行关系数据库中类似的分布式查询引擎(由Query Planner、Query Coordinator和Query Exec Engine三部份组成),可以直接从HDFS或HBase中用SELECT、JOIN和统计函数查询数据,从而大大增加了延后。Impala将整个查询分成一执行计划树,而不是一连串的MapReduce任务,相比Hive没了MapReduce启动时间。
Hive 适合于长时间的批处理查询剖析,而Impala适合于实时交互式SQL查询,Impala给数据人员提供了快速实验,验证看法的大数据剖析工具,可以先使用Hive进行数据转换处理,之后使用Impala在Hive处理好后的数据集上进行快速的数据剖析。总的来说:Impala把执行计划表现为一棵完整的执行计划树,可以更自然地分发执行计划到各个Impalad执行查询,而不用象Hive那样把它组合成管道型的map->reduce模式,以此保证Impala有更好的并发性和防止不必要的中间sort与shuffle。但是Impala不支持UDF,能处理的问题有一定的限制。
Spark拥有Hadoop MapReduce所具有的特征,它将Job中间输出结果保存在显存中,从而不需要读取HDFS。Spark 启用了显存分布数据集,除了才能提供交互式查询外,它还可以优化迭代工作负载。Spark 是在 Scala 语言中实现的,它将 Scala 用作其应用程序框架。与 Hadoop 不同,Spark 和 Scala 能够紧密集成,其中的 Scala 可以象操作本地集合对象一样轻松地操作分布式数据集。
Nutch 是一个开源Java 实现的搜索引擎。它提供了我们运行自己的搜索引擎所需的全部工具,包括全文搜索和Web爬虫。
Solr用Java编撰、运行在Servlet容器(如Apache Tomcat或Jetty)的一个独立的企业级搜索应用的全文搜索服务器。它对外提供类似于Web-service的API接口,用户可以通过http请求,向搜索引擎服务器递交一定格式的XML文件,生成索引;也可以通过Http Get操作提出查找恳求,并得到XML格式的返回结果。
Elasticsearch是一个开源的全文搜索引擎,基于Lucene的搜索服务器,可以快速的存储、搜索和剖析海量的数据。设计用于云估算中,能够达到实时搜索,稳定,可靠,快速,安装使用便捷。
还涉及到一些机器学习语言,比如,Mahout主要目标是创建一些可伸缩的机器学习算法,供开发人员在Apache的许可下免费使用;深度学习框架Caffe以及使用数据流图进行数值估算的开源软件库TensorFlow等,常用的机器学习算法例如,贝叶斯、逻辑回归、决策树、神经网路、协同过滤等。
五、数据可视化
对接一些BI平台,将剖析得到的数据进行可视化,用于指导决策服务。主流的BI平台例如,国外的敏捷BI Tableau、Qlikview、PowrerBI等,国内的SmallBI和新兴的网易有数(可点击这儿免费试用)等。
在前面的每一个阶段,保障数据的安全是不可忽略的问题。
基于网路身分认证的合同Kerberos,用来在非安全网路中,对个人通讯以安全的手段进行身分认证,它容许某实体在非安全网路环境下通讯,向另一个实体以一种安全的方法证明自己的身分。
控制权限的ranger是一个Hadoop集群权限框架,提供操作、监控、管理复杂的数据权限,它提供一个集中的管理机制,管理基于yarn的Hadoop生态圈的所有数据权限。可以对Hadoop生态的组件如Hive,Hbase进行细细度的数据访问控制。通过操作Ranger控制台,管理员可以轻松的通过配置策略来控制用户访问HDFS文件夹、HDFS文件、数据库、表、字段权限。这些策略可以为不同的用户和组来设置,同时权限可与hadoop无缝对接。
大数据技术栈概貌
博客
Java技术库房《Java程序员复习指南》
整合全网优质Java学习内容,帮助你从基础到进阶系统化备考Java
面试指南
全网最热的Java笔试手册,共200多页,非常实用,不管是用于备考还是打算笔试都是不错的。 查看全部

近几年,市场上出现了好多和大数据相关的岗位,不管是数据剖析、数据挖掘,或者是数据研制,都是围绕着大数据来做事情,那么,到底哪些是大数据,就是我们每一个要学习大数据技术的同学要了解的事情了,根据百度百科的介绍
大数据(big data),IT行业术语,是指未能在一定时间范围内用常规软件工具进行捕捉、管理和处理的数据集合,是须要新处理模式能够具有更强的决策力、洞察发觉力和流程优化能力的海量、高增长率和多元化的信息资产。
在维克托·迈尔-舍恩伯格及肯尼斯·库克耶编撰的《大数据时代》 [1] 中大数据指不用随机分析法(抽样调查)这样捷径,而采用所有数据进行剖析处理。大数据的5V特征(IBM提出):Volume(大量)、Velocity(高速)、Variety(多样)、Value(低价值密度)、Veracity(真实性)。 [2]思维导图
大数据的概念比较具象,而大数据技术栈的庞大程度将使你叹为观止。
大数据技术的体系庞大且复杂,基础的技术包含数据的采集、数据预处理、分布式存储、NoSQL数据库、数据库房、机器学习、并行估算、可视化等各类技术范畴和不同的技术层面。首先给出一个通用化的大数据处理框架,主要分为下边几个方面:数据采集与预处理、数据储存、数据清洗、数据查询剖析和数据可视化。
一、数据采集与预处理
对于各类来源的数据,包括联通互联网数据、社交网络的数据等,这些结构化和非结构化的海量数据是零散的,也就是所谓的数据孤岛,此时的那些数据并没有哪些意义,数据采集就是将这种数据写入数据库房中,把零散的数据整合在一起,对那些数据综合上去进行剖析。数据采集包括文件日志的采集、数据库日志的采集、关系型数据库的接入和应用程序的接入等。在数据量比较小的时侯,可以写个定时的脚本将日志写入储存系统,但随着数据量的下降,这些方式难以提供数据安全保障,并且运维困难,需要更健壮的解决方案。
Flume NG作为实时日志搜集系统,支持在日志系统中订制各种数据发送方,用于搜集数据,同时,对数据进行简单处理,并讲到各类数据接收方(比如文本,HDFS,Hbase等)。Flume NG采用的是三层架构:Agent层,Collector层和Store层,每一层均可水平拓展。其中Agent包含Source,Channel和 Sink,source拿来消费(收集)数据源到channel组件中,channel作为中间临时储存,保存所有source的组件信息,sink从channel中读取数据,读取成功以后会删掉channel中的信息。
NDC,Netease Data Canal,直译为网易数据运河系统,是网易针对结构化数据库的数据实时迁移、同步和订阅的平台化解决方案。它整合了网易过去在数据传输领域的各类工具和经验,将单机数据库、分布式数据库、OLAP系统以及下游应用通过数据链路串在一起。除了保障高效的数据传输外,NDC的设计遵守了单元化和平台化的设计哲学。
Logstash是开源的服务器端数据处理管线,能够同时从多个来源采集数据、转换数据,然后将数据发送到您最喜欢的 “存储库” 中。一般常用的储存库是Elasticsearch。Logstash 支持各类输入选择,可以在同一时间从众多常用的数据来源捕捉风波,能够以连续的流式传输方法,轻松地从您的日志、指标、Web 应用、数据储存以及各类 AWS 服务采集数据。
Sqoop,用来将关系型数据库和Hadoop中的数据进行互相转移的工具,可以将一个关系型数据库(例如Mysql、Oracle)中的数据导出到Hadoop(例如HDFS、Hive、Hbase)中,也可以将Hadoop(例如HDFS、Hive、Hbase)中的数据导出到关系型数据库(例如Mysql、Oracle)中。Sqoop 启用了一个 MapReduce 作业(极其容错的分布式并行估算)来执行任务。Sqoop 的另一大优势是其传输大量结构化或半结构化数据的过程是完全自动化的。
流式估算是行业研究的一个热点,流式估算对多个高吞吐量的数据源进行实时的清洗、聚合和剖析,可以对存在于社交网站、新闻等的数据信息流进行快速的处理并反馈,目前大数据流剖析工具有很多,比如开源的strom,spark streaming等。
Strom集群结构是有一个主节点(nimbus)和多个工作节点(supervisor)组成的主从结构,主节点通过配置静态指定或则在运行时动态补选,nimbus与supervisor都是Storm提供的后台守护进程,之间的通讯是结合Zookeeper的状态变更通知和监控通知来处理。nimbus进程的主要职责是管理、协调和监控集群上运行的topology(包括topology的发布、任务委派、事件处理时重新委派任务等)。supervisor进程等待nimbus分配任务后生成并监控worker(jvm进程)执行任务。supervisor与worker运行在不同的jvm上,如果由supervisor启动的某个worker由于错误异常退出(或被kill掉),supervisor会尝试重新生成新的worker进程。
当使用上游模块的数据进行估算、统计、分析时,就可以使用消息系统,尤其是分布式消息系统。Kafka使用Scala进行编撰,是一种分布式的、基于发布/订阅的消息系统。Kafka的设计理念之一就是同时提供离线处理和实时处理,以及将数据实时备份到另一个数据中心,Kafka可以有许多的生产者和消费者分享多个主题,将消息以topic为单位进行归纳;Kafka发布消息的程序称为producer,也叫生产者,预订topics并消费消息的程序称为consumer,也叫消费者;当Kafka以集群的形式运行时,可以由一个服务或则多个服务组成,每个服务称作一个broker,运行过程中producer通过网路将消息发送到Kafka集群,集群向消费者提供消息。Kafka通过Zookeeper管理集群配置,选举leader,以及在Consumer Group发生变化时进行rebalance。Producer使用push模式将消息发布到broker,Consumer使用pull模式从broker订阅并消费消息。Kafka可以和Flume一起工作,如果须要将流式数据从Kafka转移到hadoop,可以使用Flume代理agent,将Kafka当作一个来源source,这样可以从Kafka读取数据到Hadoop。
Zookeeper是一个分布式的,开放源码的分布式应用程序协调服务,提供数据同步服务。它的作用主要有配置管理、名字服务、分布式锁和集群管理。配置管理指的是在一个地方更改了配置,那么对这个地方的配置感兴趣的所有的都可以获得变更,省去了自动拷贝配置的冗长,还挺好的保证了数据的可靠和一致性,同时它可以通过名子来获取资源或则服务的地址等信息全网文章采集软件,可以监控集群中机器的变化全网文章采集软件,实现了类似于脉搏机制的功能。
二、数据储存
Hadoop作为一个开源的框架,专为离线和大规模数据剖析而设计,HDFS作为其核心的储存引擎,已被广泛用于数据储存。
HBase,是一个分布式的、面向列的开源数据库,可以觉得是hdfs的封装,本质是数据储存、NoSQL数据库。HBase是一种Key/Value系统,部署在hdfs上,克服了hdfs在随机读写这个方面的缺点,与hadoop一样,Hbase目标主要借助纵向扩充,通过不断降低廉价的商用服务器,来降低估算和储存能力。
Phoenix,相当于一个Java中间件,帮助开发工程师才能象使用JDBC访问关系型数据库一样访问NoSQL数据库HBase。
Yarn是一种Hadoop资源管理器,可为下层应用提供统一的资源管理和调度,它的引入为集群在利用率、资源统一管理和数据共享等方面带来了巨大益处。Yarn由下边的几大组件构成:一个全局的资源管理器ResourceManager、ResourceManager的每位节点代理NodeManager、表示每位应用的Application以及每一个ApplicationMaster拥有多个Container在NodeManager上运行。
Mesos是一款开源的集群管理软件,支持Hadoop、ElasticSearch、Spark、Storm 和Kafka等应用构架。
Redis是一种速率十分快的非关系数据库,可以储存键与5种不同类型的值之间的映射,可以将储存在显存的通配符对数据持久化到硬碟中,使用复制特点来扩充性能,还可以使用客户端分片来扩充写性能。
Atlas是一个坐落应用程序与MySQL之间的中间件。在前端DB看来,Atlas相当于联接它的客户端,在后端应用看来,Atlas相当于一个DB。Atlas作为服务端与应用程序通信,它实现了MySQL的客户端和服务端合同,同时作为客户端与MySQL通信。它对应用程序屏蔽了DB的细节,同时为了增加MySQL负担,它还维护了连接池。Atlas启动后会创建多个线程,其中一个为主线程,其余为工作线程。主线程负责窃听所有的客户端联接恳求,工作线程只窃听主线程的命令恳求。
Kudu是围绕Hadoop生态圈构建的储存引擎,Kudu拥有和Hadoop生态圈共同的设计理念,它运行在普通的服务器上、可分布式规模化布署、并且满足工业界的高可用要求。其设计理念为fast analytics on fast data。作为一个开源的储存引擎,可以同时提供低延后的随机读写和高效的数据剖析能力。Kudu不但提供了行级的插入、更新、删除API,同时也提供了接近Parquet性能的批量扫描操作。使用同一份储存,既可以进行随机读写,也可以满足数据剖析的要求。Kudu的应用场景太广泛,比如可以进行实时的数据剖析,用于数据可能会存在变化的时序数据应用等。
在数据储存过程中,涉及到的数据表都是成千上百列,包含各类复杂的Query,推荐使用列式储存方式,比如parquent,ORC等对数据进行压缩。Parquet 可以支持灵活的压缩选项,显著减低c盘上的储存。
三、数据清洗
MapReduce作为Hadoop的查询引擎,用于大规模数据集的并行估算,”Map(映射)”和”Reduce(归约)”,是它的主要思想。它极大的便捷了编程人员在不会分布式并行编程的情况下,将自己的程序运行在分布式系统中。
随着业务数据量的增多,需要进行训练和清洗的数据会显得越来越复杂,这个时侯就须要任务调度系统,比如oozie或则azkaban,对关键任务进行调度和监控。
Oozie是用于Hadoop平台的一种工作流调度引擎,提供了RESTful API接口来接受用户的递交恳求(提交工作流作业),当递交了workflow后,由工作流引擎负责workflow的执行以及状态的转换。用户在HDFS上布署好作业(MR作业),然后向Oozie递交Workflow,Oozie以异步方法将作业(MR作业)提交给Hadoop。这也是为何当调用Oozie 的RESTful插口递交作业以后能立刻返回一个JobId的缘由,用户程序毋须等待作业执行完成(因为有些大作业可能会执行许久(几个小时甚至几天))。Oozie在后台以异步方法,再将workflow对应的Action递交给hadoop执行。
Azkaban也是一种工作流的控制引擎,可以拿来解决有多个hadoop或则spark等离线估算任务之间的依赖关系问题。azkaban主要是由三部份构成:Relational Database,Azkaban Web Server和Azkaban Executor Server。azkaban将大多数的状态信息都保存在MySQL中,Azkaban Web Server提供了Web UI,是azkaban主要的管理者,包括project的管理、认证、调度以及对工作流执行过程中的监控等;Azkaban Executor Server拿来调度工作流和任务,记录工作流或则任务的日志。
流计算任务的处理平台Sloth,是网易首个自研流计算平台,旨在解决公司内各产品日渐下降的流计算需求。作为一个估算服务平台,其特征是易用、实时、可靠,为用户节约技术方面(开发、运维)的投入,帮助用户专注于解决产品本身的流计算需求。
四、数据查询剖析
Hive的核心工作就是把SQL句子翻译成MR程序,可以将结构化的数据映射为一张数据库表,并提供 HQL(Hive SQL)查询功能。Hive本身不储存和估算数据,它完全依赖于HDFS和MapReduce。可以将Hive理解为一个客户端工具,将SQL操作转换为相应的MapReduce jobs,然后在hadoop里面运行。Hive支持标准的SQL句型,免去了用户编撰MapReduce程序的过程,它的出现可以使这些精通SQL技能、但是不熟悉MapReduce 、编程能力较弱与不擅长Java语言的用户才能在HDFS大规模数据集上很方便地借助SQL 语言查询、汇总、分析数据。
Hive是为大数据批量处理而生的,Hive的出现解决了传统的关系型数据库(MySql、Oracle)在大数据处理上的困局 。Hive 将执行计划分成map->shuffle->reduce->map->shuffle->reduce…的模型。如果一个Query会被编译成多轮MapReduce,则会有更多的写中间结果。由于MapReduce执行框架本身的特性,过多的中间过程会降低整个Query的执行时间。在Hive的运行过程中,用户只须要创建表,导入数据,编写SQL剖析句子即可。剩下的过程由Hive框架手动的完成。
Impala是对Hive的一个补充,可以实现高效的SQL查询。使用Impala来实现SQL on Hadoop,用来进行大数据实时查询剖析。通过熟悉的传统关系型数据库的SQL风格来操作大数据,同时数据也是可以储存到HDFS和HBase中的。Impala没有再使用平缓的Hive+MapReduce批处理,而是通过使用与商用并行关系数据库中类似的分布式查询引擎(由Query Planner、Query Coordinator和Query Exec Engine三部份组成),可以直接从HDFS或HBase中用SELECT、JOIN和统计函数查询数据,从而大大增加了延后。Impala将整个查询分成一执行计划树,而不是一连串的MapReduce任务,相比Hive没了MapReduce启动时间。
Hive 适合于长时间的批处理查询剖析,而Impala适合于实时交互式SQL查询,Impala给数据人员提供了快速实验,验证看法的大数据剖析工具,可以先使用Hive进行数据转换处理,之后使用Impala在Hive处理好后的数据集上进行快速的数据剖析。总的来说:Impala把执行计划表现为一棵完整的执行计划树,可以更自然地分发执行计划到各个Impalad执行查询,而不用象Hive那样把它组合成管道型的map->reduce模式,以此保证Impala有更好的并发性和防止不必要的中间sort与shuffle。但是Impala不支持UDF,能处理的问题有一定的限制。
Spark拥有Hadoop MapReduce所具有的特征,它将Job中间输出结果保存在显存中,从而不需要读取HDFS。Spark 启用了显存分布数据集,除了才能提供交互式查询外,它还可以优化迭代工作负载。Spark 是在 Scala 语言中实现的,它将 Scala 用作其应用程序框架。与 Hadoop 不同,Spark 和 Scala 能够紧密集成,其中的 Scala 可以象操作本地集合对象一样轻松地操作分布式数据集。
Nutch 是一个开源Java 实现的搜索引擎。它提供了我们运行自己的搜索引擎所需的全部工具,包括全文搜索和Web爬虫。
Solr用Java编撰、运行在Servlet容器(如Apache Tomcat或Jetty)的一个独立的企业级搜索应用的全文搜索服务器。它对外提供类似于Web-service的API接口,用户可以通过http请求,向搜索引擎服务器递交一定格式的XML文件,生成索引;也可以通过Http Get操作提出查找恳求,并得到XML格式的返回结果。
Elasticsearch是一个开源的全文搜索引擎,基于Lucene的搜索服务器,可以快速的存储、搜索和剖析海量的数据。设计用于云估算中,能够达到实时搜索,稳定,可靠,快速,安装使用便捷。
还涉及到一些机器学习语言,比如,Mahout主要目标是创建一些可伸缩的机器学习算法,供开发人员在Apache的许可下免费使用;深度学习框架Caffe以及使用数据流图进行数值估算的开源软件库TensorFlow等,常用的机器学习算法例如,贝叶斯、逻辑回归、决策树、神经网路、协同过滤等。
五、数据可视化
对接一些BI平台,将剖析得到的数据进行可视化,用于指导决策服务。主流的BI平台例如,国外的敏捷BI Tableau、Qlikview、PowrerBI等,国内的SmallBI和新兴的网易有数(可点击这儿免费试用)等。
在前面的每一个阶段,保障数据的安全是不可忽略的问题。
基于网路身分认证的合同Kerberos,用来在非安全网路中,对个人通讯以安全的手段进行身分认证,它容许某实体在非安全网路环境下通讯,向另一个实体以一种安全的方法证明自己的身分。
控制权限的ranger是一个Hadoop集群权限框架,提供操作、监控、管理复杂的数据权限,它提供一个集中的管理机制,管理基于yarn的Hadoop生态圈的所有数据权限。可以对Hadoop生态的组件如Hive,Hbase进行细细度的数据访问控制。通过操作Ranger控制台,管理员可以轻松的通过配置策略来控制用户访问HDFS文件夹、HDFS文件、数据库、表、字段权限。这些策略可以为不同的用户和组来设置,同时权限可与hadoop无缝对接。
大数据技术栈概貌
 博客
博客Java技术库房《Java程序员复习指南》
整合全网优质Java学习内容,帮助你从基础到进阶系统化备考Java
面试指南
全网最热的Java笔试手册,共200多页,非常实用,不管是用于备考还是打算笔试都是不错的。
河西区淘宝托管淘宝天猫代营运多少钱
采集交流 • 优采云 发表了文章 • 0 个评论 • 377 次浏览 • 2020-03-31 11:08
河西区淘宝托管淘宝天猫代营运多少钱把落地页或则线下入口缺点4:数据漏采错踩以上都还是好的,让人费解的是,上线了,发现数据采集错了或则漏了,修正后,又得重新跑一遍流程,一个星期两个星期有过去了。这里就不细展开。
图5原始数据上报储存到文件的构架图数据储存到文件以后,第二步就步入到ETL的环节,ETL就是指通过抽取(extract)、转换(tranorm)、加载(load)把日志从文本中,基于剖析的需求和数据经度进行清洗,然后储存在数据库房中。
以腾讯为反例,腾讯大数据平台现今主要从离线和实时两个方向支撑海量数据接入和处理,核心的系统包括TDW、TRC和TDbank。
图6腾讯数据平台系统在腾讯内部,数据的数据搜集、分发、预处理和管理工作,都是通过一个TDBank的平台来实现的。餐厅以自己喝的虾自己钓为特色
对于互联网与民航的结合、互联网产品有较深入的了解且持续关注中。
河西区淘宝托管淘宝天猫代营运多少钱
整个平台主要解决在大数据量下边数据搜集和处理的量大、实时、多样的问题。
通过数据接入层、处理层和储存层这样的三层架构来统一解决接入和储存的问题。
(1)接入层接入层可以支持各类格式的业务数据和数据源,包括不同的DB、文件格式、消息数据等。
数据接入层会将搜集到的各类数据统一成一种内部的数据合同文章采集插件,方便后续数据处理系统使用。
(2)处理层接下来处理层用插件化的方式来支持多种形式的数据预处理过程。
对于离线系统来说,这么多新鲜的网红产品络绎不绝的上架到市场上
一个重要的功能是将实时采集到的数据进行分类储存,需要根据个别维度(比如某个key值+时间等维度)进行分类储存,同时储存文件的细度(大小/时间)也是须要订制的,使离线系统能以指定的的细度来进行离线估算。
对于在线系统来说,常见的预处理过程如数据过滤、数据取样和数据转换等。
(3)数据储存层处理后的数据,使用HDFS作为离线文件的储存载体。
数据储存整体上是的,然后终把这部份处理后的数据,入库到腾讯内部的分布式数据库房TDW。
图7TDW构架图TDBank是从业务数据源端实时采集数据,节目即将播于1998年英国独立电视台
如果是正常情况下,某一个渠道应当是稳定的,不会出现这个渠道就是比别的渠道不看文章的人多这样的特性。
河西区淘宝托管淘宝天猫代营运多少钱
进行预处理和分布式消息缓存后,按照消息订阅的方法,分发给前端的离线和在线处理系统。
图8TDBank数据采集与接入系统TDBank建立数据源和数据处理系统间的桥梁,将数据处理系统同数据源前馈,为离线估算TDW和在线估算TRC平台提供数据支持。
目前通过不断的改进,将原先Linux+HDFS的模式,转变为集群+分布式消息队列的模式,将原先三天就能处理的消息量减短到2秒钟。从实际应用来看,TikTok也会急聘一些在读大学的留学生
产品在考虑数据采集和接入的时侯,主要要关心几个经度的问题l多个数据源的统一,一般实际的应用过程中,都存在不同的数据格式来源,这个时侯,采集和接入这部份,需要把这种数据源进行统一的转化。
l采集的实时高效,由于大部分系统都是在线系统,对于数据采集的时效性要求会比较高。
l脏数据处理,对于一些会影响整个剖析统计的脏数据,需要在接入层的时侯进行逻辑屏蔽,避免前面统计剖析和应用的时侯,由于这部份数据引起好多不可预知的问题。
2.数据的储存与估算完成数据上报和采集和接入以后,口碑营销风波营销软文营销这种在网路营销中常用的营销方法在庄园营运方面同样适用
2014年月底文章采集插件,滴滴打车首推全新的方法——打车红包。
河西区淘宝托管淘宝天猫代营运多少钱
数据就步入储存的环节,继续以腾讯为例。
在腾讯内部,有个分布式的数据库房拿来储存数据,内部代号称作TDW,它支持百PB级数据的离线储存和估算,为业务提供海量、高效、稳定的大数据平台支撑和决策支持。
基于开源软件Hadoop和Hive进行完善,并且依照公司数据量大、计算复杂等特定情况进行了大量优化和整修。
从对外公布的资料来看,TDW基于开源软件hadoop和hive进行了大量优化和改建,已成为腾讯大的离线数据处理平台,集群各种机器总量5000台,总储存突破20PB,日均估算量超过500TB,覆盖腾讯公司90%以上的业务产品,包含广点通推荐,用户画像,数据挖掘和各种业务报表等,都是通过这个平台来提供基础能力。
图9,腾讯TDW分布式数据库房图10TDW业务示意图从实际应用来看,数据储存这部份主要考虑几个问题,l数据安全性,很多数据是不可恢复的,所以数据储存的永远是重要的。App营运在为新产品做预热时,可以自建产品社区(贴吧、、话题小组等)或社群(微信群、QQ群等),聚集一些种子用户,为产品上线做好预热。打磨好的产品 查看全部
河西区淘宝托管淘宝天猫代营运多少钱把落地页或则线下入口缺点4:数据漏采错踩以上都还是好的,让人费解的是,上线了,发现数据采集错了或则漏了,修正后,又得重新跑一遍流程,一个星期两个星期有过去了。这里就不细展开。
图5原始数据上报储存到文件的构架图数据储存到文件以后,第二步就步入到ETL的环节,ETL就是指通过抽取(extract)、转换(tranorm)、加载(load)把日志从文本中,基于剖析的需求和数据经度进行清洗,然后储存在数据库房中。
以腾讯为反例,腾讯大数据平台现今主要从离线和实时两个方向支撑海量数据接入和处理,核心的系统包括TDW、TRC和TDbank。
图6腾讯数据平台系统在腾讯内部,数据的数据搜集、分发、预处理和管理工作,都是通过一个TDBank的平台来实现的。餐厅以自己喝的虾自己钓为特色
对于互联网与民航的结合、互联网产品有较深入的了解且持续关注中。

河西区淘宝托管淘宝天猫代营运多少钱
整个平台主要解决在大数据量下边数据搜集和处理的量大、实时、多样的问题。
通过数据接入层、处理层和储存层这样的三层架构来统一解决接入和储存的问题。
(1)接入层接入层可以支持各类格式的业务数据和数据源,包括不同的DB、文件格式、消息数据等。
数据接入层会将搜集到的各类数据统一成一种内部的数据合同文章采集插件,方便后续数据处理系统使用。
(2)处理层接下来处理层用插件化的方式来支持多种形式的数据预处理过程。
对于离线系统来说,这么多新鲜的网红产品络绎不绝的上架到市场上
一个重要的功能是将实时采集到的数据进行分类储存,需要根据个别维度(比如某个key值+时间等维度)进行分类储存,同时储存文件的细度(大小/时间)也是须要订制的,使离线系统能以指定的的细度来进行离线估算。
对于在线系统来说,常见的预处理过程如数据过滤、数据取样和数据转换等。
(3)数据储存层处理后的数据,使用HDFS作为离线文件的储存载体。
数据储存整体上是的,然后终把这部份处理后的数据,入库到腾讯内部的分布式数据库房TDW。
图7TDW构架图TDBank是从业务数据源端实时采集数据,节目即将播于1998年英国独立电视台
如果是正常情况下,某一个渠道应当是稳定的,不会出现这个渠道就是比别的渠道不看文章的人多这样的特性。

河西区淘宝托管淘宝天猫代营运多少钱
进行预处理和分布式消息缓存后,按照消息订阅的方法,分发给前端的离线和在线处理系统。
图8TDBank数据采集与接入系统TDBank建立数据源和数据处理系统间的桥梁,将数据处理系统同数据源前馈,为离线估算TDW和在线估算TRC平台提供数据支持。
目前通过不断的改进,将原先Linux+HDFS的模式,转变为集群+分布式消息队列的模式,将原先三天就能处理的消息量减短到2秒钟。从实际应用来看,TikTok也会急聘一些在读大学的留学生
产品在考虑数据采集和接入的时侯,主要要关心几个经度的问题l多个数据源的统一,一般实际的应用过程中,都存在不同的数据格式来源,这个时侯,采集和接入这部份,需要把这种数据源进行统一的转化。
l采集的实时高效,由于大部分系统都是在线系统,对于数据采集的时效性要求会比较高。
l脏数据处理,对于一些会影响整个剖析统计的脏数据,需要在接入层的时侯进行逻辑屏蔽,避免前面统计剖析和应用的时侯,由于这部份数据引起好多不可预知的问题。
2.数据的储存与估算完成数据上报和采集和接入以后,口碑营销风波营销软文营销这种在网路营销中常用的营销方法在庄园营运方面同样适用
2014年月底文章采集插件,滴滴打车首推全新的方法——打车红包。

河西区淘宝托管淘宝天猫代营运多少钱
数据就步入储存的环节,继续以腾讯为例。
在腾讯内部,有个分布式的数据库房拿来储存数据,内部代号称作TDW,它支持百PB级数据的离线储存和估算,为业务提供海量、高效、稳定的大数据平台支撑和决策支持。
基于开源软件Hadoop和Hive进行完善,并且依照公司数据量大、计算复杂等特定情况进行了大量优化和整修。
从对外公布的资料来看,TDW基于开源软件hadoop和hive进行了大量优化和改建,已成为腾讯大的离线数据处理平台,集群各种机器总量5000台,总储存突破20PB,日均估算量超过500TB,覆盖腾讯公司90%以上的业务产品,包含广点通推荐,用户画像,数据挖掘和各种业务报表等,都是通过这个平台来提供基础能力。
图9,腾讯TDW分布式数据库房图10TDW业务示意图从实际应用来看,数据储存这部份主要考虑几个问题,l数据安全性,很多数据是不可恢复的,所以数据储存的永远是重要的。App营运在为新产品做预热时,可以自建产品社区(贴吧、、话题小组等)或社群(微信群、QQ群等),聚集一些种子用户,为产品上线做好预热。打磨好的产品
物证管理软件哪些价钱
采集交流 • 优采云 发表了文章 • 0 个评论 • 318 次浏览 • 2020-03-31 11:08
其接入方法主要包含系统对接与爬虫采集两种形式。
系统对接方法运行须要依赖数据抽取前置机与中心插口服务器,爬虫采集方式须要布署分步式爬虫专用服务器。
.采集前置机:解决后置数据抽取问题,并将数据从抽取处发向中心插口服务器。
.数据插口服务器:为数据采集前置机提供数据接收服务器,解决数据集中化处理问题。他举例说
自此,我们始终紧密剖析相关信息,以尽早辨识受影响的人士及确认信息是否可被重建。
物证管理软件哪些价钱
.分步式爬虫服务器:用于布署分步式爬虫系统,解决采集互联网资源的问题。
二.数据清洗转换服务器放在数据插口服务器与爬虫服务器以后,用于解决数据的清洗转换问题。
三.分步式储存服务器用于解决大规模数据储存问题,将数据进行分片储存,可靠与可用性。
四.并行剖析服务器对分步式储存系统的数据进行并行剖析,解决大规模数据的剖析,挖掘问题。
五.硬盘数据库服务器用于布署分数据库,解决高并发在线数据服务问题。如果支持文件类型
六.内存数据库服务器用于布署分步式内存数据库系统。
七.服务器(展现,应用,共享,运营)用于布署数据共享文章采集软件,应用,展现,运营,监控等系统。
解决大数据平台对外服务问题。
存储资源数据存数主要包含结构化数据储存,半结构化数据储存,非结构化数据储存等方大类数据的储存,初期提供可储存数据的c盘,后期按照业务的发展可考虑提供级储存c盘。
备份资源早期提供备份c盘,对大数据平台的关键数据进行备份,备份可考虑使用第三方数据服务机构的异地备份服务。超过万名顾客的电子邮件地址和密码失窃
回忆这个决定时称,宣布关掉是因为要维持满足消费者期望的成功产品面临重大的挑战,而且该平台的使用率太低。
物证管理软件哪些价钱
网络资源.内部网路:满足内部服务间交换数据,千兆或以上网路联接内部集群服务器。
.对外服务网路:满足大数据平台对外服务需求,或以上网路网路。
.数据插口服务网路:满足数据插口传输需求,或以上网路网路。
.爬虫专用网路:满足爬虫采集互联网资源,或以上网路网路。
一,解决“坐井观天”问题月球各,地区之间的关联性早已越来越强,打破数据行业堡垒,引入外部数据源,进行多源数据凝聚融合,可以突破目前因为视野的局限性而硬性割裂事物间联系的窘境,大数据平台将一座座孤立的井,连片成海。
二,解决“一叶障目”的问题因为估算能力限制,我们只处理了我们觉得重要的“叶”而可能漏掉了实际更重要的“泰山”。
大数据使用全本数据文章采集软件,得到结果更为,更接近事物“泰山”。
依靠大数据平台得到的大数据剖析结果将一定程度上纠正过去人们对事物片面的认识,给人们带来全新的认知。
三,解决“瞎子摸象”的问题客观世界各事物是互相联系,不同业务系统存在因人为建模将这种内在联系忽略,因估算能力人为割裂的现象。表示,虽然这对开发者形成影响,但微软仍希望确保对用户的保护。来吸引消费者 查看全部

其接入方法主要包含系统对接与爬虫采集两种形式。
系统对接方法运行须要依赖数据抽取前置机与中心插口服务器,爬虫采集方式须要布署分步式爬虫专用服务器。
.采集前置机:解决后置数据抽取问题,并将数据从抽取处发向中心插口服务器。
.数据插口服务器:为数据采集前置机提供数据接收服务器,解决数据集中化处理问题。他举例说
自此,我们始终紧密剖析相关信息,以尽早辨识受影响的人士及确认信息是否可被重建。

物证管理软件哪些价钱
.分步式爬虫服务器:用于布署分步式爬虫系统,解决采集互联网资源的问题。
二.数据清洗转换服务器放在数据插口服务器与爬虫服务器以后,用于解决数据的清洗转换问题。
三.分步式储存服务器用于解决大规模数据储存问题,将数据进行分片储存,可靠与可用性。
四.并行剖析服务器对分步式储存系统的数据进行并行剖析,解决大规模数据的剖析,挖掘问题。
五.硬盘数据库服务器用于布署分数据库,解决高并发在线数据服务问题。如果支持文件类型
六.内存数据库服务器用于布署分步式内存数据库系统。
七.服务器(展现,应用,共享,运营)用于布署数据共享文章采集软件,应用,展现,运营,监控等系统。
解决大数据平台对外服务问题。
存储资源数据存数主要包含结构化数据储存,半结构化数据储存,非结构化数据储存等方大类数据的储存,初期提供可储存数据的c盘,后期按照业务的发展可考虑提供级储存c盘。
备份资源早期提供备份c盘,对大数据平台的关键数据进行备份,备份可考虑使用第三方数据服务机构的异地备份服务。超过万名顾客的电子邮件地址和密码失窃
回忆这个决定时称,宣布关掉是因为要维持满足消费者期望的成功产品面临重大的挑战,而且该平台的使用率太低。

物证管理软件哪些价钱
网络资源.内部网路:满足内部服务间交换数据,千兆或以上网路联接内部集群服务器。
.对外服务网路:满足大数据平台对外服务需求,或以上网路网路。
.数据插口服务网路:满足数据插口传输需求,或以上网路网路。
.爬虫专用网路:满足爬虫采集互联网资源,或以上网路网路。
一,解决“坐井观天”问题月球各,地区之间的关联性早已越来越强,打破数据行业堡垒,引入外部数据源,进行多源数据凝聚融合,可以突破目前因为视野的局限性而硬性割裂事物间联系的窘境,大数据平台将一座座孤立的井,连片成海。
二,解决“一叶障目”的问题因为估算能力限制,我们只处理了我们觉得重要的“叶”而可能漏掉了实际更重要的“泰山”。
大数据使用全本数据文章采集软件,得到结果更为,更接近事物“泰山”。
依靠大数据平台得到的大数据剖析结果将一定程度上纠正过去人们对事物片面的认识,给人们带来全新的认知。
三,解决“瞎子摸象”的问题客观世界各事物是互相联系,不同业务系统存在因人为建模将这种内在联系忽略,因估算能力人为割裂的现象。表示,虽然这对开发者形成影响,但微软仍希望确保对用户的保护。来吸引消费者
山东电力数据采集系统项目 淄博创银供应
采集交流 • 优采云 发表了文章 • 0 个评论 • 596 次浏览 • 2020-03-30 14:00
数据采集系统包括了:可视化的报表定义、审核关系的定义、报表的审批和发布、数据补报、数据预处理、数据评审、综合查询统计等功能模块。通过信息采集网络化和数字化,扩大数据采集的覆盖范围,提高初审工作的周密性、及时性和准确性;最终实现相关业务工作管理现代化、程序规范化、决策科学化,服务网络化。我国中小容量机组(200MW及以下)在火电厂中占相当大的比列,这些机组的监控模式为模拟控制系统加以常规仪表为主的数据采集系统。这种监控模式存在着检修维护工作量大、没有可靠的历史记录等缺点。而且常规模拟仪表也步入老化淘汰期,设备可靠性显著增加,某些仪表的备品备件也得不到保障,因此中小型机组监控系统的技术改造工作已势在必行。结合我国国情,借鉴国外类似系统的研发经验,开发出一套经济实用的FDC-Ⅱ型分布式发电厂运行实时数据检测系统,既可用于中小机组技术改造,山东电力数据采集系统项目,山东电力数据采集系统项目,又可应用于变电站,山东电力数据采集系统项目、供电局等电力生产、管理部门。该系统已在山东省某150MW火力发电厂投入实际运行。
我国国产机组热控装置的质量和主辅机的可控性不尽人意,设计、安装、调试、运行水平等都存在一些问题,针对这一现况设计了FDC-Ⅱ型分布式发电厂运行实时数据检测系统。它是只有监视功能而没有控制功能的计算机监视系统文章采集软件,即数据采集系统——DAS。数据采集系统可以采集的发电厂运行数据包括电气参数和非电气参数两类。其中电气参数主要有电压、电压、功率、频率等模拟量,断路器状态、隔离开关位置、继电保护动作讯号等开关量以及表示电度的脉冲量等。而非电气参数种类较多,既可以是采集火力发电厂运行中的各类气温、压力、流量等热工讯号,也可有水电厂中的水位、流速、流量等水工讯号,还可以采集诸如绝缘介质状态、气象环境等其它讯号。数据采集系统还包括用VisualC++开发的后台处理软件,主要有数据处理、数据库管理、实时监视、异常处理、统计估算及报表、性能剖析及运行指导等功能。
主要功能·实时采集来自生产线的产值数据或是不良品的数目、或是生产线的故障类型(如停线、缺料、品质),并传输到数据库系统中;·接收来自数据库的信息:如生产计划信息、物料信息等;·传输检测工位的不良品名称及数目信息;·连接测量仪器,实现测量仪器数字化,数据采集仪手动从检测仪器中获取检测数据,进行记录文章采集软件,分析估算,形成相应的各种图形,对检测结果进行手动判定,如在机械加工零部件的跳动检测,拉力计拉力曲线的勾画等; 查看全部

数据采集系统包括了:可视化的报表定义、审核关系的定义、报表的审批和发布、数据补报、数据预处理、数据评审、综合查询统计等功能模块。通过信息采集网络化和数字化,扩大数据采集的覆盖范围,提高初审工作的周密性、及时性和准确性;最终实现相关业务工作管理现代化、程序规范化、决策科学化,服务网络化。我国中小容量机组(200MW及以下)在火电厂中占相当大的比列,这些机组的监控模式为模拟控制系统加以常规仪表为主的数据采集系统。这种监控模式存在着检修维护工作量大、没有可靠的历史记录等缺点。而且常规模拟仪表也步入老化淘汰期,设备可靠性显著增加,某些仪表的备品备件也得不到保障,因此中小型机组监控系统的技术改造工作已势在必行。结合我国国情,借鉴国外类似系统的研发经验,开发出一套经济实用的FDC-Ⅱ型分布式发电厂运行实时数据检测系统,既可用于中小机组技术改造,山东电力数据采集系统项目,山东电力数据采集系统项目,又可应用于变电站,山东电力数据采集系统项目、供电局等电力生产、管理部门。该系统已在山东省某150MW火力发电厂投入实际运行。

我国国产机组热控装置的质量和主辅机的可控性不尽人意,设计、安装、调试、运行水平等都存在一些问题,针对这一现况设计了FDC-Ⅱ型分布式发电厂运行实时数据检测系统。它是只有监视功能而没有控制功能的计算机监视系统文章采集软件,即数据采集系统——DAS。数据采集系统可以采集的发电厂运行数据包括电气参数和非电气参数两类。其中电气参数主要有电压、电压、功率、频率等模拟量,断路器状态、隔离开关位置、继电保护动作讯号等开关量以及表示电度的脉冲量等。而非电气参数种类较多,既可以是采集火力发电厂运行中的各类气温、压力、流量等热工讯号,也可有水电厂中的水位、流速、流量等水工讯号,还可以采集诸如绝缘介质状态、气象环境等其它讯号。数据采集系统还包括用VisualC++开发的后台处理软件,主要有数据处理、数据库管理、实时监视、异常处理、统计估算及报表、性能剖析及运行指导等功能。

主要功能·实时采集来自生产线的产值数据或是不良品的数目、或是生产线的故障类型(如停线、缺料、品质),并传输到数据库系统中;·接收来自数据库的信息:如生产计划信息、物料信息等;·传输检测工位的不良品名称及数目信息;·连接测量仪器,实现测量仪器数字化,数据采集仪手动从检测仪器中获取检测数据,进行记录文章采集软件,分析估算,形成相应的各种图形,对检测结果进行手动判定,如在机械加工零部件的跳动检测,拉力计拉力曲线的勾画等;
一款可以精准爬取网站的网路数据采集系统
采集交流 • 优采云 发表了文章 • 0 个评论 • 409 次浏览 • 2020-05-15 08:00
利用网路大数据面临的挑战
互联网上有广袤的数据资源,要想抓取那些数据就离不开爬虫。鉴于网上免费开源的爬虫框架多如牛毛,很多人觉得爬虫定是极其简单的事情。但是假如你要定期、上规模地确切抓取各类小型网站的数据却是一项繁重的挑战。流行的爬虫框架Scrapy开发者Scrapinghub在抓取了一千亿个网页后,总结了她们在爬虫是遇见的挑战:
速度和数据质量:由于时间一般是限制诱因,规模抓取要求你的爬虫要以很高的速率抓取网页但又不能连累数据质量。对速率的这张要求促使爬取大规模产品数据显得极具挑战性。
网站格式多变:网页本身是基于HTML这些松散的规范来构建的,各网页相互不兼容,导致网页结构复杂多变。在规模爬取的时侯,你除了要浏览成百上千个有着仓促代码的网站爬虫软件增加网页访问,还将被迫应对不断变化的网站。
网络访问不稳定:如果网站在一个时间访问压力过大,或者服务器出现问题,就可能不会正常响应用户查看网页的需求。对于网页数据采集工具而言,一旦出现意外情况,很有可能由于不知道怎样处理而崩溃或则逻辑中断。
网页内容良莠不齐:网页上显示的内容,除了有用数据外,还有各类无效信息;有效信息也通过各类显示形式呈现,网页上出现的数据格式多样。
网页访问限制:网页存在访问频度限制,网站访问频度很高将会面临被封锁IP的风险。
网页反扒机制:有些网站为了屏蔽个别恶意采集而采取了防采集措施。比如Amazon这些较小型的电子商务网站,会采用极其复杂的反机器人对策促使析取数据困难许多。
数据剖析难度高:规模化的数据采集会导致数据质量得不到保证,变脏或则不完整的数据很容易都会流入到你的数据流上面爬虫软件增加网页访问,进而破坏了数据剖析的疗效。
为了充分利用网路大数据,企业须要一个有效的系统,该系统除了可以自动化从网页中提取数据,同时对数据进行筛选、清理和标准化,并将这种数据集成到现有工具链和工作流中。
探码网路数据采集系统是一款可以精准爬取网站的爬虫工具,采用探码科技自主研制的TMF框架为构架主体,支持开发可操作的网路数据采集系统。
探码对以上挑战的解决办法
24小时自动化爬虫采集,制定清晰采集字段,保证初步采集速度和质量;
兼顾计算机和人处理网页数据的特点,能够应对网页结构的复杂多变;
云服务器协同合作,达到采集素的的平衡点,在不增加采集速度的同时保证不被封锁IP;
内置逻辑判定方案,自定义网站访问不稳定时的智能应对机制;
对采集的原始数据进行“清洗、归类、注释、关联、映射”,将分散、零乱、标准不统一的数据整合到一起,提高数据的质量,为后期数据剖析奠定基础。
探码的数据采集属于正常的采集行为,倡导在获得网站授权采集后进行采集,共同维护互联网规范。
探码网路数据采集方案
探码网路数据采集系统实现数据从采集,处理到应用的全生命周期管理,达到网路爬虫,另类数据,网页解析及采集自动化。目前探码已建设自己的企业库数据(3000+企业数据信息),律师数据库(全过30w+律师数据信息)且这种信息都是通过数据处理与剖析,用户可直接使用于商务中!
数据提取
探码通过网路爬虫、结构化数据、本地数据、物联网设备、人工录入等进行全方位实时的汇总采集。对各类来源(如RFID射频数据、传感器数据、移动互联网数据、社交网络数据等)的非结构化数据进行全自动化采集,借助网路爬虫或网站API,从网页获取非结构化数据数据,将其统一结构化为本地数据。
数据管理
探码网路数据采集系统合并来自多个来源的数据,构建复杂的联接和聚合。针对非结构化、半结构化数据的特殊性,在爬取完数据后还须要对采集的原始数据进行“清洗、归类、注释、关联、映射”等一系列操作后,将分散、零乱、标准不统一的数据整合到一起,提高数据的质量,为后期数据剖析奠定基础。
数据存储
探码网路数据采集系统在获得所需的数据并将其分解为有用的组件以后,通过可扩充的方式来将所有提取和解析的数据储存在数据库或集群中,然后创建一个容许用户可及时查找相关数据集或提取的功能。
解决方案优势
通过采用探码网路数据采集解决方案,实现了以下几个优势:
全面的数据服务 -通过探码网路数据采集系统,您可以轻松地获得网路数据。您可以实现自动化提取、更新、转换数据并确保不同的数据元素符合常见的数据格式。
最新数据- 解决方案的自动化意味着您的组织可以以最少的工作量进行持续提取。因此,组织可以确保仍然使用最新的数据。
准确的数据- 探码网路数据采集系统让团队除了能否去除与自动提取和转换相关的工作,而且能够清除与人工工作相关的潜在错误。
降低成本-企业自身无需高昂的工程团队不断编撰代码,监控质量和维护逻辑,就能够规模快速,经济高效地获得高质量的网路数据。
可扩展性- 探码网路数据采集系统支持提取数百万个数据点和Web查询。
总结
探码科技自主研制的网路数据采集系统是集Web数据采集,分析和可视化为一体的数据集成系统,确保您从Web数据中获得最大的洞察力和价值。 查看全部
利用网路大数据面临的挑战
互联网上有广袤的数据资源,要想抓取那些数据就离不开爬虫。鉴于网上免费开源的爬虫框架多如牛毛,很多人觉得爬虫定是极其简单的事情。但是假如你要定期、上规模地确切抓取各类小型网站的数据却是一项繁重的挑战。流行的爬虫框架Scrapy开发者Scrapinghub在抓取了一千亿个网页后,总结了她们在爬虫是遇见的挑战:
速度和数据质量:由于时间一般是限制诱因,规模抓取要求你的爬虫要以很高的速率抓取网页但又不能连累数据质量。对速率的这张要求促使爬取大规模产品数据显得极具挑战性。
网站格式多变:网页本身是基于HTML这些松散的规范来构建的,各网页相互不兼容,导致网页结构复杂多变。在规模爬取的时侯,你除了要浏览成百上千个有着仓促代码的网站爬虫软件增加网页访问,还将被迫应对不断变化的网站。
网络访问不稳定:如果网站在一个时间访问压力过大,或者服务器出现问题,就可能不会正常响应用户查看网页的需求。对于网页数据采集工具而言,一旦出现意外情况,很有可能由于不知道怎样处理而崩溃或则逻辑中断。
网页内容良莠不齐:网页上显示的内容,除了有用数据外,还有各类无效信息;有效信息也通过各类显示形式呈现,网页上出现的数据格式多样。
网页访问限制:网页存在访问频度限制,网站访问频度很高将会面临被封锁IP的风险。
网页反扒机制:有些网站为了屏蔽个别恶意采集而采取了防采集措施。比如Amazon这些较小型的电子商务网站,会采用极其复杂的反机器人对策促使析取数据困难许多。
数据剖析难度高:规模化的数据采集会导致数据质量得不到保证,变脏或则不完整的数据很容易都会流入到你的数据流上面爬虫软件增加网页访问,进而破坏了数据剖析的疗效。
为了充分利用网路大数据,企业须要一个有效的系统,该系统除了可以自动化从网页中提取数据,同时对数据进行筛选、清理和标准化,并将这种数据集成到现有工具链和工作流中。
探码网路数据采集系统是一款可以精准爬取网站的爬虫工具,采用探码科技自主研制的TMF框架为构架主体,支持开发可操作的网路数据采集系统。
探码对以上挑战的解决办法
24小时自动化爬虫采集,制定清晰采集字段,保证初步采集速度和质量;
兼顾计算机和人处理网页数据的特点,能够应对网页结构的复杂多变;
云服务器协同合作,达到采集素的的平衡点,在不增加采集速度的同时保证不被封锁IP;
内置逻辑判定方案,自定义网站访问不稳定时的智能应对机制;
对采集的原始数据进行“清洗、归类、注释、关联、映射”,将分散、零乱、标准不统一的数据整合到一起,提高数据的质量,为后期数据剖析奠定基础。
探码的数据采集属于正常的采集行为,倡导在获得网站授权采集后进行采集,共同维护互联网规范。
探码网路数据采集方案
探码网路数据采集系统实现数据从采集,处理到应用的全生命周期管理,达到网路爬虫,另类数据,网页解析及采集自动化。目前探码已建设自己的企业库数据(3000+企业数据信息),律师数据库(全过30w+律师数据信息)且这种信息都是通过数据处理与剖析,用户可直接使用于商务中!
数据提取
探码通过网路爬虫、结构化数据、本地数据、物联网设备、人工录入等进行全方位实时的汇总采集。对各类来源(如RFID射频数据、传感器数据、移动互联网数据、社交网络数据等)的非结构化数据进行全自动化采集,借助网路爬虫或网站API,从网页获取非结构化数据数据,将其统一结构化为本地数据。
数据管理
探码网路数据采集系统合并来自多个来源的数据,构建复杂的联接和聚合。针对非结构化、半结构化数据的特殊性,在爬取完数据后还须要对采集的原始数据进行“清洗、归类、注释、关联、映射”等一系列操作后,将分散、零乱、标准不统一的数据整合到一起,提高数据的质量,为后期数据剖析奠定基础。
数据存储
探码网路数据采集系统在获得所需的数据并将其分解为有用的组件以后,通过可扩充的方式来将所有提取和解析的数据储存在数据库或集群中,然后创建一个容许用户可及时查找相关数据集或提取的功能。
解决方案优势
通过采用探码网路数据采集解决方案,实现了以下几个优势:
全面的数据服务 -通过探码网路数据采集系统,您可以轻松地获得网路数据。您可以实现自动化提取、更新、转换数据并确保不同的数据元素符合常见的数据格式。
最新数据- 解决方案的自动化意味着您的组织可以以最少的工作量进行持续提取。因此,组织可以确保仍然使用最新的数据。
准确的数据- 探码网路数据采集系统让团队除了能否去除与自动提取和转换相关的工作,而且能够清除与人工工作相关的潜在错误。
降低成本-企业自身无需高昂的工程团队不断编撰代码,监控质量和维护逻辑,就能够规模快速,经济高效地获得高质量的网路数据。
可扩展性- 探码网路数据采集系统支持提取数百万个数据点和Web查询。
总结
探码科技自主研制的网路数据采集系统是集Web数据采集,分析和可视化为一体的数据集成系统,确保您从Web数据中获得最大的洞察力和价值。
有这3个数据采集工具,不懂爬虫代码,也能轻松爬数据
采集交流 • 优采云 发表了文章 • 0 个评论 • 489 次浏览 • 2020-05-14 08:04
但实际情况是,对于日常工作中的各类小决策,内部提供的数据有时还不足给以充分支持,外部的数据大部分又常常都是机构开具的行业状况,并不能提供哪些有效帮助。
于是产品和运营们常常要依靠爬虫来抓取自己想要的数据。比如想要获取某个电商网站的评论数据,往往须要写出一段代码,借助python去抓取出相应的内容。
说到学写代码……额,我选择舍弃。
那么问题来了,有没有哪些更方便的方式呢?
今天就为你们介绍3个能适应大多数场景的数据采集工具,即使不懂爬虫代码,你也能轻松爬出95%网站的数据。
重点是,这三个软件的基础功能都是可以免费使用的喔~
1.火车采集器
这个是太老牌的网站数据采集工具啦,从诞生至今早已十一年了。经过不断的更新迭代,功能也越来越多 (只是有些中级功能早已要收费了QAQ) 。
据说用户量仍然在同类软件中居于第一,毕竟是十一年的老司机,想当初小编我学习数据挖掘的时侯,老师推荐使用的也是这款软件呢。
火车采集器
火车采集器可以实现数据的抓取、清洗、分析,挖掘及最终的可用数据呈现,堪称一条龙服务。
它的第一个特征是适用范围广,采集数据确切。火车采集器的采集原理是基于 web 结构的源代码提取,所以几乎适用于所有的网页,以及网页中才能见到的所有内容。可以通过设定内容采集规则,轻松迅速地抓取网页上散乱分布的文本、图片、压缩文件、视频等内容
比如采集豆瓣读书网站上的书籍的标题以及作者的数据,但是页面上有图片,也有文字,只要才采集的时侯设定好采集的规则,就能精准地只采集到标题名和作者的名子。
并且,火车采集器的内容采集支持测试功能,可选用一个典型页面来测试内容采集的正确性,以便及时更正和进行下一步数据处理。
比如说,你想采集豆瓣读书里几百本书的评论,但你不确定一次性抓取出来的数据是否确切。你就可以通过测试,先抓其中几个网页测试一下,看看抓到的结果是否是你想要的结果,并按照结果对采集规则进行调整,直到测试下来的结果是使你满意的结果为止,然后再进行大规模的采集。这样就不怕采集出来的数据出错啦。
此外,对于采集到的信息数据,它还可以对其进行一系列的智能处理,使采集到的数据愈加符合我们的使用标准。比如过滤掉不需要的空格啦,标签啦,同义词替换啦,繁简转换啦等等。
看到这儿有朋友要问了,说了这么多,还是不知道如何操作,怎么破。别担心,火车采集器的网站上,还有提供菜鸟的入门指南和视频教程,不懂的问题可以在峰会内提问,也可以在峰会里跟随前辈快速学习列车采集器的操作。
2.八爪鱼
这也是一个堪称哪些网站都能采的工具。电商类、生活服务类、社交媒体类、论坛类,甚至瀑布流类的网站都可以采集。
八爪鱼
它的采集方式有一个亮点,就是云采集。也就是说,当你配置好采集任务,即使死机出去浪,任务也可以接着在云端执行,等浪完回去数据爬虫软件,数据就采好了。这就不用害怕网路中断,辛辛苦苦采集的数据没了,也不用仍然守在笔记本门口等数据采集完。
云采集还有一个益处在于,可以借助云端多节点并发运行,采集速度将远超于本地采集(单机采集)。多 IP 在任务启动时手动切换还可避免网站的 IP 封锁,实现数据采集的最大化。
据说规则的配置也是hin简单。操作上2分钟就可以快速入门。看了一下操作页面,流程基本上是所见即所得,整个流程也是可视化的,确实比火车头要简单些。
就算不知道软件如何使用,网站上有教程中心,也一样提供免费的菜鸟入门教程,供你们快速学习软件的操作方法。
3.集搜客
这个工具,也可以说是十分厉害了。完全可视化操作,无需编程基础,熟悉笔记本操作就可以轻松把握。整个采集过程也是所见即所得,遍历的链接信息、抓取结果信息、错误信息等就会及时地反映在软件界面中。
集搜客
它有一个强悍的优势,拥有一个抓取规则的模板库。我们都晓得,采集数据须要给工具提供抓取规则数据爬虫软件,这个规则就相当于是告诉爬虫工具,你须要抓取的数据所具备的特点。因此抓取规则直接决定了你抓到数据的准确度和精细程度。
但是好多小白朋友在初次设置抓取规则的时侯,还是须要摸索一阵,才能得到自己想要的结果的。集搜客的抓取规则模板库,就可以帮你省去摸索抓取规则耗费的时间。
在集搜客资源库中,分门别类储存着各类抓取规则,你既可通过关键词,也可通过目标网页网址搜索到可用的抓取规则。
在抓取规则的详情页面,只要仔细考察一个规则的抓取结果是否满足您的须要,如果满足,只需点击“下载”按钮,即可在会员中心一键启动集搜客网络爬虫,抓取到你想要的数据。
集搜客还有一个优势,在于可以抓取可视化图表上的数据。现在有越来越多网站上的数据是经过统计、分析、挖掘,并用可视化图表展示下来的,比如淘宝指数,百度指数等等。它都可以直接从这种图表上,把数据抓取出来。
这就意味着,它除了能抓取文本数据、图片、表格,其他可视化图表,如新闻资讯图表、电商网站上的产品介绍图片、电商经营剖析数据还是指数走势图等等,它都能抓取到完整的图表信息。
而且,它能够模拟滑鼠动作,抓取在指数图表上漂浮显示的数据。
以上3个数据采集工具各有优劣,选择适宜的学习使用,是不是比写代码便捷多了呢? 查看全部
产品和营运在日常工作中,常常须要参考各类数据,来为决策做支持。
但实际情况是,对于日常工作中的各类小决策,内部提供的数据有时还不足给以充分支持,外部的数据大部分又常常都是机构开具的行业状况,并不能提供哪些有效帮助。
于是产品和运营们常常要依靠爬虫来抓取自己想要的数据。比如想要获取某个电商网站的评论数据,往往须要写出一段代码,借助python去抓取出相应的内容。
说到学写代码……额,我选择舍弃。
那么问题来了,有没有哪些更方便的方式呢?
今天就为你们介绍3个能适应大多数场景的数据采集工具,即使不懂爬虫代码,你也能轻松爬出95%网站的数据。
重点是,这三个软件的基础功能都是可以免费使用的喔~
1.火车采集器
这个是太老牌的网站数据采集工具啦,从诞生至今早已十一年了。经过不断的更新迭代,功能也越来越多 (只是有些中级功能早已要收费了QAQ) 。
据说用户量仍然在同类软件中居于第一,毕竟是十一年的老司机,想当初小编我学习数据挖掘的时侯,老师推荐使用的也是这款软件呢。
火车采集器
火车采集器可以实现数据的抓取、清洗、分析,挖掘及最终的可用数据呈现,堪称一条龙服务。
它的第一个特征是适用范围广,采集数据确切。火车采集器的采集原理是基于 web 结构的源代码提取,所以几乎适用于所有的网页,以及网页中才能见到的所有内容。可以通过设定内容采集规则,轻松迅速地抓取网页上散乱分布的文本、图片、压缩文件、视频等内容
比如采集豆瓣读书网站上的书籍的标题以及作者的数据,但是页面上有图片,也有文字,只要才采集的时侯设定好采集的规则,就能精准地只采集到标题名和作者的名子。
并且,火车采集器的内容采集支持测试功能,可选用一个典型页面来测试内容采集的正确性,以便及时更正和进行下一步数据处理。
比如说,你想采集豆瓣读书里几百本书的评论,但你不确定一次性抓取出来的数据是否确切。你就可以通过测试,先抓其中几个网页测试一下,看看抓到的结果是否是你想要的结果,并按照结果对采集规则进行调整,直到测试下来的结果是使你满意的结果为止,然后再进行大规模的采集。这样就不怕采集出来的数据出错啦。
此外,对于采集到的信息数据,它还可以对其进行一系列的智能处理,使采集到的数据愈加符合我们的使用标准。比如过滤掉不需要的空格啦,标签啦,同义词替换啦,繁简转换啦等等。
看到这儿有朋友要问了,说了这么多,还是不知道如何操作,怎么破。别担心,火车采集器的网站上,还有提供菜鸟的入门指南和视频教程,不懂的问题可以在峰会内提问,也可以在峰会里跟随前辈快速学习列车采集器的操作。
2.八爪鱼
这也是一个堪称哪些网站都能采的工具。电商类、生活服务类、社交媒体类、论坛类,甚至瀑布流类的网站都可以采集。
八爪鱼
它的采集方式有一个亮点,就是云采集。也就是说,当你配置好采集任务,即使死机出去浪,任务也可以接着在云端执行,等浪完回去数据爬虫软件,数据就采好了。这就不用害怕网路中断,辛辛苦苦采集的数据没了,也不用仍然守在笔记本门口等数据采集完。
云采集还有一个益处在于,可以借助云端多节点并发运行,采集速度将远超于本地采集(单机采集)。多 IP 在任务启动时手动切换还可避免网站的 IP 封锁,实现数据采集的最大化。
据说规则的配置也是hin简单。操作上2分钟就可以快速入门。看了一下操作页面,流程基本上是所见即所得,整个流程也是可视化的,确实比火车头要简单些。
就算不知道软件如何使用,网站上有教程中心,也一样提供免费的菜鸟入门教程,供你们快速学习软件的操作方法。
3.集搜客
这个工具,也可以说是十分厉害了。完全可视化操作,无需编程基础,熟悉笔记本操作就可以轻松把握。整个采集过程也是所见即所得,遍历的链接信息、抓取结果信息、错误信息等就会及时地反映在软件界面中。
集搜客
它有一个强悍的优势,拥有一个抓取规则的模板库。我们都晓得,采集数据须要给工具提供抓取规则数据爬虫软件,这个规则就相当于是告诉爬虫工具,你须要抓取的数据所具备的特点。因此抓取规则直接决定了你抓到数据的准确度和精细程度。
但是好多小白朋友在初次设置抓取规则的时侯,还是须要摸索一阵,才能得到自己想要的结果的。集搜客的抓取规则模板库,就可以帮你省去摸索抓取规则耗费的时间。
在集搜客资源库中,分门别类储存着各类抓取规则,你既可通过关键词,也可通过目标网页网址搜索到可用的抓取规则。
在抓取规则的详情页面,只要仔细考察一个规则的抓取结果是否满足您的须要,如果满足,只需点击“下载”按钮,即可在会员中心一键启动集搜客网络爬虫,抓取到你想要的数据。
集搜客还有一个优势,在于可以抓取可视化图表上的数据。现在有越来越多网站上的数据是经过统计、分析、挖掘,并用可视化图表展示下来的,比如淘宝指数,百度指数等等。它都可以直接从这种图表上,把数据抓取出来。
这就意味着,它除了能抓取文本数据、图片、表格,其他可视化图表,如新闻资讯图表、电商网站上的产品介绍图片、电商经营剖析数据还是指数走势图等等,它都能抓取到完整的图表信息。
而且,它能够模拟滑鼠动作,抓取在指数图表上漂浮显示的数据。
以上3个数据采集工具各有优劣,选择适宜的学习使用,是不是比写代码便捷多了呢?
基于爬虫与数据挖掘的电商页面信息剖析
采集交流 • 优采云 发表了文章 • 0 个评论 • 401 次浏览 • 2020-05-13 08:04
【共引文献】
中国刊物全文数据库
陈静杰;车洁;;基于IK-medoids算法的客机油耗降维方式[J];计算机科学;2018年08期
刘测;韩家新;;面向新闻文本的分类方式的比较研究[J];智能计算机与应用;2018年05期
刘湘蓉;;我国联通社交电商的商业模式——一个多案例的剖析[J];中国流通经济;2018年08期
高超;许翰林;;基于支持向量机的不均衡文本分类方式[J];现代电子技术;2018年15期
马艳辉;刘进;黄伟恺;吴钧;蔡梅松;李宇平;;企业外网内容检索系统的设计与实现[J];电脑编程方法与维护;2018年07期
李亚文;;电子商务背景下手动辨识系统中的网路安全问题及举措[J];信息与笔记本(理论版);2018年13期
马琳琳;刘继;;基于关联规则的党的十九大报告关键词相关性分析[J];新疆财经大学学报;2018年02期
李鑫;郭汉;张欣;胡方强;帅仁俊;;基于非平衡数据处理方式的网路在线广告中点击欺诈检查的研究[J];计算机科学;2018年S1期
李秀玲;陈七林;刘姗姗;;中国电子商务网路零售的发展历程与竞争态势[J];现代商业;2018年16期
杨守德;赵德海;;中国网路零售业发展的收敛性与空间溢出效应研究[J];经济体制改革;2018年03期
中国硕士学位论文全文数据库
钟宇;面向网路自媒体的空间数据挖掘研究[D];江西理工大学;2018年
于志浩;基于Android和网路爬虫的课外阅读系统设计与实现[D];山东大学;2018年
贾潇雨;基于改进爬虫技术的SQL注入的自动化扫描工具的研究与设计[D];北京邮电大学;2018年
常鑫;基于德尔菲调查法的电动车辆前沿技术评测系统设计与实现[D];山东大学;2018年
杨郁琪;基于文本挖掘的用户满意度影响诱因研究[D];中北大学;2018年
李笑语;深度可订制的工具化爬虫系统的设计与实现[D];北京邮电大学;2018年
王惠;基于LDA主题模型的文本降维研究[D];兰州大学;2018年
吕博庆;基于爬虫与数据挖掘的电商页面信息剖析[D];兰州大学;2018年
王丰;基于GPU并行的K-MEANS算法研究及其在文本聚类的应用[D];武汉邮电科学研究院;2018年
马琼琼;基于语义的文本聚类算法研究[D];北京交通大学;2017年
【二级参考文献】
中国刊物全文数据库
赵本本;殷旭东;王伟;;基于Scrapy的GitHub数据爬虫[J];电子技术与软件工程;2016年06期
李京文;;中国电子商务的发展现况与未来趋势[J];河北学刊;2016年01期
王宝义;;电商与快件跨界经营的理论基础与现实剖析[J];西部峰会;2015年06期
曾田日;王晋国;;基于统计的云搜索英文动词算法[J];西北大学学报(自然科学版);2015年04期
李杰;王宇菲;王聪;张志颖;;B2C电子商务竞争结构及发展演变规律[J];产业经济评论;2015年03期
李博群;;我国电子商务发展现况及前景展望研究[J];调研世界;2015年01期
聂林海;;我国电子商务发展的特性和趋势[J];中国流通经济;2014年06期
郑淑蓉;吕庆华;;中国电子商务20年演化[J];商业经济与管理;2013年11期
中国社科院财经战略研究院课题组;荆林波;;电子商务:中国经济发展的新引擎[J];求是;2013年11期
占明珍;;“双十一”我国电商企业促销战的冷思索[J];对外经贸实务;2013年04期
中国硕士学位论文全文数据库
周红伟;商品评价信息的英文情感剖析[D];浙江工商大学;2015年
范倩倩;高校图书馆Web2.0研究[D];安徽大学;2014年
苏芳仲;中文Web文本挖掘的若干关键技术研究及其实现[D];福州大学;2006年
李健;聚类剖析及其在文本挖掘中的应用[D];西安电子科技大学;2005年
马慧敏;中文文本手动分类方式的研究和实现[D];华北电力大学(河北);2005年
许林杰;中文文本动词研究[D];山东师范大学;2003年
【相似文献】
中国刊物全文数据库
牛猛爬虫软件分析电商数据,黄道斌爬虫软件分析电商数据,卢小杰;数据挖掘方式与功能的基本研究[J];电脑知识与技术;2018年14期
刘芬;;数据挖掘在中国的现况和发展研究[J];山东工业技术;2018年17期
饶正婵;蒲天银;;云计算条件下的大数据挖掘内涵及解决方案[J];电子技术与软件工程;2018年13期
陈小凤;;大数据挖掘校园用户[J];电子技术与软件工程;2018年15期
许晓燕;;基于云计算的数据挖掘云服务模式研究[J];电脑知识与技术;2018年19期
于春香;;数据挖掘技术简介[J];福建信息技术教育;2005年01期
邵兴江;;数据挖掘在教育信息化中的应用空间剖析[J];浙江现代教育技术;2004年03期
周洋;;数据挖掘在电力调度自动化系统中的应用解析[J];科技创新与应用;2017年35期
梁园;;浅析数据挖掘在审计中的应用[J];现代经济信息;2017年22期
冯丽慧;;云计算和挖掘服务融合下的大数据挖掘体系构架设计及应用[J];电脑编程方法与维护;2017年24期
中国重要大会论文全文数据库
马钰超;;浅析大数据和数据挖掘及其在烟草行业中的应用[A];中国烟草学会2015年度优秀论文汇编[C];2015年
唐杰;梅俏竹;;数据挖掘学科发展研究[A];2012-2013控制科学与工程学科发展报告[C];2014年
王岁月;;大数据时代规划数据挖掘的创新思索[A];新常态:传承与改革——2015中国城市规划晚会论文集(04城市规划新技术应用)[C];2015年
史东辉;蔡庆生;张春阳;;一种新的数据挖掘多策略技巧研究[A];第十七届全省数据库学术大会论文集(研究报告篇)[C];2000年
谢中;邱玉辉;;面向商务网站有效性的数据挖掘方式[A];第十八届全省数据库学术大会论文集(技术报告篇)[C];2001年
许珂;姜山;;数据挖掘方式在科技产出分布可视化研究中的运用[A];第二届中国科技哲学及交叉学科研究生峰会论文集(硕士卷)[C];2008年
雷宇;;论行业信息资源的数据挖掘[A];中国烟草行业信息化研讨会论文集[C];2004年
吴以凡;吴铁军;欧阳树生;;面向生产过程质量控制的动态数据挖掘方式[A];05'中国自动化产业高峰大会暨中国企业自动化和信息化建设峰会论文集[C];2005年
彭怡;;从数据挖掘文章聚类剖析看其发展趋势[A];现代工业工程与管理研讨会大会论文集[C];2006年
张建锦;刘小霞;;密度误差抽样及其在海量数据挖掘中的应用[A];2006北京地区院校研究生学术交流会——通信与信息技术大会论文集(下)[C];2006年
中国重要报纸全文数据库
本报记者 张佳星;[N];科技商报;2018年
本报记者 张佳星;[N];科技商报;2018年
记者 张潇;[N];西安日报;2018年
上海市浦东卫生发展研究院 孙雪松 王晓丽;[N];中国信息化周报;2018年
本报记者 叶曜坤;[N];人民邮电;2017年
本报记者 牛福莲;[N];中国经济晨报;2017年
中国联合晚报记者 刘末;[N];中国联合商报;2017年
南方日报记者 彭颖;[N];南方日报;2017年
舒圣祥;[N];检察日报;2017年
本报记者 肖祯;[N];中国会计报;2017年
中国博士学位论文全文数据库
王达;时间序列数据挖掘研究与应用[D];浙江大学;2004年
马昕;粗糙集理论在数据挖掘领域中的应用[D];浙江大学;2003年
王立宏;信息系统的约简与细度剖析及其在数据挖掘中的应用[D];上海大学;2004年
杨虎;序列数据挖掘的模型和算法研究[D];重庆大学;2003年
李秋丹;数据挖掘相关算法的研究与平台实现[D];大连理工大学;2004年
李力;数据挖掘方式研究及其在草药复方配伍剖析中的应用[D];西南交通大学;2003年
胡黔楠;化学信息学中的数据挖掘[D];中南大学;2004年
余辉;医学知识获取与发觉的研究[D];天津大学;2003年
于洪;Rough Set理论及其在数据挖掘中的应用研究[D];重庆大学;2003年
陈莉;KDD中的几个关键问题研究[D];西安电子科技大学;2003年
中国硕士学位论文全文数据库
王晓娇;数据挖掘技术在职高教学评价与就业剖析中的应用研究[D];哈尔滨工程大学;2015年
段硕;基于数据挖掘的唐启盛院士医治脱发的服药经验研究[D];北京中医药大学;2018年
杨艳平;基于数据挖掘的西医诊治疱疹处方服药规律研究[D];北京中医药大学;2018年
邵凡;基于数据挖掘的吕仁和院士治疗糖尿病肾脏病服药经验研究[D];北京中医药大学;2018年
焦福智;基于数据挖掘的唐启盛院士医治精神分裂症的服药经验研究[D];北京中医药大学;2018年
刘然;基于大数据挖掘的高血压抗生素医治方案研究[D];电子科技大学;2018年
南冰;忻州职业技术学院财务管理系统设计与实现[D];大连理工大学;2017年
张甜;基于数据挖掘的院校中学生成绩关联分析研究[D];北京邮电大学;2018年
章铎;基于大数据挖掘的故障预警研究[D];北京邮电大学;2018年
柯联兴;移动通信用户行为规律预测与数据挖掘平台开发[D];北京邮电大学;2018年 查看全部
张睿;基于k-means的英文文本聚类算法的研究与实现[D];西北大学;2009年
【共引文献】
中国刊物全文数据库
陈静杰;车洁;;基于IK-medoids算法的客机油耗降维方式[J];计算机科学;2018年08期
刘测;韩家新;;面向新闻文本的分类方式的比较研究[J];智能计算机与应用;2018年05期
刘湘蓉;;我国联通社交电商的商业模式——一个多案例的剖析[J];中国流通经济;2018年08期
高超;许翰林;;基于支持向量机的不均衡文本分类方式[J];现代电子技术;2018年15期
马艳辉;刘进;黄伟恺;吴钧;蔡梅松;李宇平;;企业外网内容检索系统的设计与实现[J];电脑编程方法与维护;2018年07期
李亚文;;电子商务背景下手动辨识系统中的网路安全问题及举措[J];信息与笔记本(理论版);2018年13期
马琳琳;刘继;;基于关联规则的党的十九大报告关键词相关性分析[J];新疆财经大学学报;2018年02期
李鑫;郭汉;张欣;胡方强;帅仁俊;;基于非平衡数据处理方式的网路在线广告中点击欺诈检查的研究[J];计算机科学;2018年S1期
李秀玲;陈七林;刘姗姗;;中国电子商务网路零售的发展历程与竞争态势[J];现代商业;2018年16期
杨守德;赵德海;;中国网路零售业发展的收敛性与空间溢出效应研究[J];经济体制改革;2018年03期
中国硕士学位论文全文数据库
钟宇;面向网路自媒体的空间数据挖掘研究[D];江西理工大学;2018年
于志浩;基于Android和网路爬虫的课外阅读系统设计与实现[D];山东大学;2018年
贾潇雨;基于改进爬虫技术的SQL注入的自动化扫描工具的研究与设计[D];北京邮电大学;2018年
常鑫;基于德尔菲调查法的电动车辆前沿技术评测系统设计与实现[D];山东大学;2018年
杨郁琪;基于文本挖掘的用户满意度影响诱因研究[D];中北大学;2018年
李笑语;深度可订制的工具化爬虫系统的设计与实现[D];北京邮电大学;2018年
王惠;基于LDA主题模型的文本降维研究[D];兰州大学;2018年
吕博庆;基于爬虫与数据挖掘的电商页面信息剖析[D];兰州大学;2018年
王丰;基于GPU并行的K-MEANS算法研究及其在文本聚类的应用[D];武汉邮电科学研究院;2018年
马琼琼;基于语义的文本聚类算法研究[D];北京交通大学;2017年
【二级参考文献】
中国刊物全文数据库
赵本本;殷旭东;王伟;;基于Scrapy的GitHub数据爬虫[J];电子技术与软件工程;2016年06期
李京文;;中国电子商务的发展现况与未来趋势[J];河北学刊;2016年01期
王宝义;;电商与快件跨界经营的理论基础与现实剖析[J];西部峰会;2015年06期
曾田日;王晋国;;基于统计的云搜索英文动词算法[J];西北大学学报(自然科学版);2015年04期
李杰;王宇菲;王聪;张志颖;;B2C电子商务竞争结构及发展演变规律[J];产业经济评论;2015年03期
李博群;;我国电子商务发展现况及前景展望研究[J];调研世界;2015年01期
聂林海;;我国电子商务发展的特性和趋势[J];中国流通经济;2014年06期
郑淑蓉;吕庆华;;中国电子商务20年演化[J];商业经济与管理;2013年11期
中国社科院财经战略研究院课题组;荆林波;;电子商务:中国经济发展的新引擎[J];求是;2013年11期
占明珍;;“双十一”我国电商企业促销战的冷思索[J];对外经贸实务;2013年04期
中国硕士学位论文全文数据库
周红伟;商品评价信息的英文情感剖析[D];浙江工商大学;2015年
范倩倩;高校图书馆Web2.0研究[D];安徽大学;2014年
苏芳仲;中文Web文本挖掘的若干关键技术研究及其实现[D];福州大学;2006年
李健;聚类剖析及其在文本挖掘中的应用[D];西安电子科技大学;2005年
马慧敏;中文文本手动分类方式的研究和实现[D];华北电力大学(河北);2005年
许林杰;中文文本动词研究[D];山东师范大学;2003年
【相似文献】
中国刊物全文数据库
牛猛爬虫软件分析电商数据,黄道斌爬虫软件分析电商数据,卢小杰;数据挖掘方式与功能的基本研究[J];电脑知识与技术;2018年14期
刘芬;;数据挖掘在中国的现况和发展研究[J];山东工业技术;2018年17期
饶正婵;蒲天银;;云计算条件下的大数据挖掘内涵及解决方案[J];电子技术与软件工程;2018年13期
陈小凤;;大数据挖掘校园用户[J];电子技术与软件工程;2018年15期
许晓燕;;基于云计算的数据挖掘云服务模式研究[J];电脑知识与技术;2018年19期
于春香;;数据挖掘技术简介[J];福建信息技术教育;2005年01期
邵兴江;;数据挖掘在教育信息化中的应用空间剖析[J];浙江现代教育技术;2004年03期
周洋;;数据挖掘在电力调度自动化系统中的应用解析[J];科技创新与应用;2017年35期
梁园;;浅析数据挖掘在审计中的应用[J];现代经济信息;2017年22期
冯丽慧;;云计算和挖掘服务融合下的大数据挖掘体系构架设计及应用[J];电脑编程方法与维护;2017年24期
中国重要大会论文全文数据库
马钰超;;浅析大数据和数据挖掘及其在烟草行业中的应用[A];中国烟草学会2015年度优秀论文汇编[C];2015年
唐杰;梅俏竹;;数据挖掘学科发展研究[A];2012-2013控制科学与工程学科发展报告[C];2014年
王岁月;;大数据时代规划数据挖掘的创新思索[A];新常态:传承与改革——2015中国城市规划晚会论文集(04城市规划新技术应用)[C];2015年
史东辉;蔡庆生;张春阳;;一种新的数据挖掘多策略技巧研究[A];第十七届全省数据库学术大会论文集(研究报告篇)[C];2000年
谢中;邱玉辉;;面向商务网站有效性的数据挖掘方式[A];第十八届全省数据库学术大会论文集(技术报告篇)[C];2001年
许珂;姜山;;数据挖掘方式在科技产出分布可视化研究中的运用[A];第二届中国科技哲学及交叉学科研究生峰会论文集(硕士卷)[C];2008年
雷宇;;论行业信息资源的数据挖掘[A];中国烟草行业信息化研讨会论文集[C];2004年
吴以凡;吴铁军;欧阳树生;;面向生产过程质量控制的动态数据挖掘方式[A];05'中国自动化产业高峰大会暨中国企业自动化和信息化建设峰会论文集[C];2005年
彭怡;;从数据挖掘文章聚类剖析看其发展趋势[A];现代工业工程与管理研讨会大会论文集[C];2006年
张建锦;刘小霞;;密度误差抽样及其在海量数据挖掘中的应用[A];2006北京地区院校研究生学术交流会——通信与信息技术大会论文集(下)[C];2006年
中国重要报纸全文数据库
本报记者 张佳星;[N];科技商报;2018年
本报记者 张佳星;[N];科技商报;2018年
记者 张潇;[N];西安日报;2018年
上海市浦东卫生发展研究院 孙雪松 王晓丽;[N];中国信息化周报;2018年
本报记者 叶曜坤;[N];人民邮电;2017年
本报记者 牛福莲;[N];中国经济晨报;2017年
中国联合晚报记者 刘末;[N];中国联合商报;2017年
南方日报记者 彭颖;[N];南方日报;2017年
舒圣祥;[N];检察日报;2017年
本报记者 肖祯;[N];中国会计报;2017年
中国博士学位论文全文数据库
王达;时间序列数据挖掘研究与应用[D];浙江大学;2004年
马昕;粗糙集理论在数据挖掘领域中的应用[D];浙江大学;2003年
王立宏;信息系统的约简与细度剖析及其在数据挖掘中的应用[D];上海大学;2004年
杨虎;序列数据挖掘的模型和算法研究[D];重庆大学;2003年
李秋丹;数据挖掘相关算法的研究与平台实现[D];大连理工大学;2004年
李力;数据挖掘方式研究及其在草药复方配伍剖析中的应用[D];西南交通大学;2003年
胡黔楠;化学信息学中的数据挖掘[D];中南大学;2004年
余辉;医学知识获取与发觉的研究[D];天津大学;2003年
于洪;Rough Set理论及其在数据挖掘中的应用研究[D];重庆大学;2003年
陈莉;KDD中的几个关键问题研究[D];西安电子科技大学;2003年
中国硕士学位论文全文数据库
王晓娇;数据挖掘技术在职高教学评价与就业剖析中的应用研究[D];哈尔滨工程大学;2015年
段硕;基于数据挖掘的唐启盛院士医治脱发的服药经验研究[D];北京中医药大学;2018年
杨艳平;基于数据挖掘的西医诊治疱疹处方服药规律研究[D];北京中医药大学;2018年
邵凡;基于数据挖掘的吕仁和院士治疗糖尿病肾脏病服药经验研究[D];北京中医药大学;2018年
焦福智;基于数据挖掘的唐启盛院士医治精神分裂症的服药经验研究[D];北京中医药大学;2018年
刘然;基于大数据挖掘的高血压抗生素医治方案研究[D];电子科技大学;2018年
南冰;忻州职业技术学院财务管理系统设计与实现[D];大连理工大学;2017年
张甜;基于数据挖掘的院校中学生成绩关联分析研究[D];北京邮电大学;2018年
章铎;基于大数据挖掘的故障预警研究[D];北京邮电大学;2018年
柯联兴;移动通信用户行为规律预测与数据挖掘平台开发[D];北京邮电大学;2018年
大数据技术之数据采集篇
采集交流 • 优采云 发表了文章 • 0 个评论 • 721 次浏览 • 2020-05-12 08:03
(一)系统日志采集法
系统日志是记录系统中硬件、软件和系统问题的信息,同时还可以监视系统中发生的风波。用户可以通过它来检测错误发生的诱因,或者找寻遭到功击时攻击者留下的痕迹。系统日志包括系统日志、应用程序日志和安全日志。(百度百科)大数据平台或则说类似于开源Hadoop平台会形成大量高价值系统日志信息,如何采集成为研究者研究热点。目前基于Hadoop平台开发的Chukwa、Cloudera的Flume以及Facebook的Scribe(李联宁,2016)均可成为是系统日志采集法的标杆。目前这种的采集技术大概可以每秒传输数百MB的日志数据信息,满足了目前人们对信息速率的需求。一般而言与我们相关的并不是这种采集法,而是网路数据采集法。
在这里还是要推荐下我自己建的大数据学习交流群:529867072大数据网络爬虫原理,群里都是学大数据开发的,如果你正在学习大数据 ,小编欢迎你加入,大家都是软件开发党,不定期分享干货(只有大数据软件开发相关的),包括我自己整理的一份最新的大数据进阶资料和中级开发教程,欢迎进阶中和进想深入大数据的小伙伴加入。
(二)网络数据采集法
做自然语言的朋友可能对这点感慨颇深,除了目前早已存在的公开数据集,用于日常的算法研究外,有时为了满足项目的实际需求,需要对现实网页中的数据进行采集,预处理和保存。目前网路数据采集有两种方式一种是API,另一种是网路爬虫法。
1.API
API又叫应用程序插口,是网站的管理者为了使用者方面,编写的一种程序插口。该类插口可以屏蔽网站底层复杂算法仅仅通过简简单单调用即可实现对数据的恳求功能。目前主流的社交媒体平台如新浪微博、百度贴吧以及Facebook等均提供API服务,可以在其官网开放平台上获取相关DEMO。但是API技术虽然受限于平台开发者,为了减少网站(平台)的负荷大数据网络爬虫原理,一般平台均会对每晚插口调用上限做限制,这给我们带来极大的不便利。为此我们一般采用第二种形式——网络爬虫。
2.网络爬虫
网络爬虫(又被称为网页蜘蛛,网络机器人,在FOFA社区中间,更时常的称为网页追逐者),是一种根据一定的规则,自动地抓取万维网信息的程序或则脚本。另外一些不常使用的名子还有蚂蚁、自动索引、模拟程序或则蠕虫。(百度百科)最常见的爬虫便是我们常常使用的搜索引擎,如百度,360搜索等。此类爬虫也称为通用型爬虫,对于所有的网页进行无条件采集。通用型爬虫具体工作原理见图1。
图1 爬虫工作原理[2]
给予爬虫初始URL,爬虫将网页中所须要提取的资源进行提取并保存,同时提取出网站中存在的其他网站链接,经过发送恳求,接收网站响应以及再度解析页面,提取所需资源并保存,再将网页中所需资源进行提取......以此类推,实现过程并不复杂,但是在采集时尤其注意对IP地址,报头的伪造,以免被网管发觉禁封IP(我就被封过),禁封IP也就意味着整个采集任务的失败。当然为了满足更多需求,多线程爬虫,主题爬虫也应运而生。多线程爬虫是通过多个线程,同时执行采集任务,一般而言几个线程,数据采集数据都会提高几倍。主题爬虫和通用型爬虫截然相反,通过一定的策略将于主题(采集任务)无关的网页信息过滤,仅仅留下须要的数据。此举可以大幅度降低无关数据引起的数据稀疏问题。
(三)其他采集法
其他采集法是指对于科研院所,企业政府等拥有绝密信息,如何保证数据的安全传递?可以采用系统特定端口,进行数据传输任务,从而降低数据被泄漏的风险。 查看全部
【导读】数据采集是进行大数据剖析的前提也是必要条件,在整个流程中抢占重要地位。本文将介绍大数据三种采集形式:系统日志采集法、网络数据采集法以及其他数据采集法。
(一)系统日志采集法
系统日志是记录系统中硬件、软件和系统问题的信息,同时还可以监视系统中发生的风波。用户可以通过它来检测错误发生的诱因,或者找寻遭到功击时攻击者留下的痕迹。系统日志包括系统日志、应用程序日志和安全日志。(百度百科)大数据平台或则说类似于开源Hadoop平台会形成大量高价值系统日志信息,如何采集成为研究者研究热点。目前基于Hadoop平台开发的Chukwa、Cloudera的Flume以及Facebook的Scribe(李联宁,2016)均可成为是系统日志采集法的标杆。目前这种的采集技术大概可以每秒传输数百MB的日志数据信息,满足了目前人们对信息速率的需求。一般而言与我们相关的并不是这种采集法,而是网路数据采集法。
在这里还是要推荐下我自己建的大数据学习交流群:529867072大数据网络爬虫原理,群里都是学大数据开发的,如果你正在学习大数据 ,小编欢迎你加入,大家都是软件开发党,不定期分享干货(只有大数据软件开发相关的),包括我自己整理的一份最新的大数据进阶资料和中级开发教程,欢迎进阶中和进想深入大数据的小伙伴加入。
(二)网络数据采集法
做自然语言的朋友可能对这点感慨颇深,除了目前早已存在的公开数据集,用于日常的算法研究外,有时为了满足项目的实际需求,需要对现实网页中的数据进行采集,预处理和保存。目前网路数据采集有两种方式一种是API,另一种是网路爬虫法。
1.API
API又叫应用程序插口,是网站的管理者为了使用者方面,编写的一种程序插口。该类插口可以屏蔽网站底层复杂算法仅仅通过简简单单调用即可实现对数据的恳求功能。目前主流的社交媒体平台如新浪微博、百度贴吧以及Facebook等均提供API服务,可以在其官网开放平台上获取相关DEMO。但是API技术虽然受限于平台开发者,为了减少网站(平台)的负荷大数据网络爬虫原理,一般平台均会对每晚插口调用上限做限制,这给我们带来极大的不便利。为此我们一般采用第二种形式——网络爬虫。
2.网络爬虫
网络爬虫(又被称为网页蜘蛛,网络机器人,在FOFA社区中间,更时常的称为网页追逐者),是一种根据一定的规则,自动地抓取万维网信息的程序或则脚本。另外一些不常使用的名子还有蚂蚁、自动索引、模拟程序或则蠕虫。(百度百科)最常见的爬虫便是我们常常使用的搜索引擎,如百度,360搜索等。此类爬虫也称为通用型爬虫,对于所有的网页进行无条件采集。通用型爬虫具体工作原理见图1。
图1 爬虫工作原理[2]
给予爬虫初始URL,爬虫将网页中所须要提取的资源进行提取并保存,同时提取出网站中存在的其他网站链接,经过发送恳求,接收网站响应以及再度解析页面,提取所需资源并保存,再将网页中所需资源进行提取......以此类推,实现过程并不复杂,但是在采集时尤其注意对IP地址,报头的伪造,以免被网管发觉禁封IP(我就被封过),禁封IP也就意味着整个采集任务的失败。当然为了满足更多需求,多线程爬虫,主题爬虫也应运而生。多线程爬虫是通过多个线程,同时执行采集任务,一般而言几个线程,数据采集数据都会提高几倍。主题爬虫和通用型爬虫截然相反,通过一定的策略将于主题(采集任务)无关的网页信息过滤,仅仅留下须要的数据。此举可以大幅度降低无关数据引起的数据稀疏问题。
(三)其他采集法
其他采集法是指对于科研院所,企业政府等拥有绝密信息,如何保证数据的安全传递?可以采用系统特定端口,进行数据传输任务,从而降低数据被泄漏的风险。
Java 网络爬虫基础入门
采集交流 • 优采云 发表了文章 • 0 个评论 • 246 次浏览 • 2020-05-11 08:03
作为网路爬虫的入门教程,本达人课采用 Java 开发语言java爬虫教程入门超级,内容涵括了网路爬虫的原理以及开发逻辑,Java 网络爬虫基础知识,网络抓包介绍,jsoup 的介绍与使用,HttpClient 的介绍与使用等内容。本课程在介绍网路爬虫基本原理的同时,注重具体的代码实现,加深读者对爬虫的理解,加强读者的实战能力。
本达人课共计14课,主要包含五大部份。
第一部分(第01-03课),主要介绍网路爬虫的原理、开发逻辑以及 Java 网络爬虫基础知识,网络抓包等内容。
第二部份(第04-06课),主要介绍现有的一些页面内容获取及页面解析工具。包括 jsoup、HttpClient、URLConnection。
第三部份(第07-08课),针对已获得的页面内容java爬虫教程入门超级,带你们选择合适的解析工具进行页面解析,包括 HTML、XML、JSON 主流数据格式的解析。
第四部份(第09-11课),针对已解析的内容,介绍怎么封装数据并储存数据。包括通过 MySQL 数据库储存数据,以及文本文件储存和 Excel 格式储存。
第五部份(第12-14课),以典型网站为案例,开启实战演练。
钱洋,机器学习方向博士生,CSDN 博客专家,主要从事文本挖掘方面的研究。目前,正参与几个大数据相关项目的研究工作。乐于分享自己的经验,擅长撰写技术类博客。 查看全部
大数据环境下,数据剖析已由业务驱动转变为数据驱动,网络数据资源呈指数级下降,且洒落在不同的数据源之中。对大多数企业和研究者而言,用“数据说话”仿佛成了大数据时代的重要装备。网络爬虫作为网路数据获取的重要技术,受到了越来越多数据需求者的偏爱和青睐。
作为网路爬虫的入门教程,本达人课采用 Java 开发语言java爬虫教程入门超级,内容涵括了网路爬虫的原理以及开发逻辑,Java 网络爬虫基础知识,网络抓包介绍,jsoup 的介绍与使用,HttpClient 的介绍与使用等内容。本课程在介绍网路爬虫基本原理的同时,注重具体的代码实现,加深读者对爬虫的理解,加强读者的实战能力。
本达人课共计14课,主要包含五大部份。
第一部分(第01-03课),主要介绍网路爬虫的原理、开发逻辑以及 Java 网络爬虫基础知识,网络抓包等内容。
第二部份(第04-06课),主要介绍现有的一些页面内容获取及页面解析工具。包括 jsoup、HttpClient、URLConnection。
第三部份(第07-08课),针对已获得的页面内容java爬虫教程入门超级,带你们选择合适的解析工具进行页面解析,包括 HTML、XML、JSON 主流数据格式的解析。
第四部份(第09-11课),针对已解析的内容,介绍怎么封装数据并储存数据。包括通过 MySQL 数据库储存数据,以及文本文件储存和 Excel 格式储存。
第五部份(第12-14课),以典型网站为案例,开启实战演练。
钱洋,机器学习方向博士生,CSDN 博客专家,主要从事文本挖掘方面的研究。目前,正参与几个大数据相关项目的研究工作。乐于分享自己的经验,擅长撰写技术类博客。
网络爬虫技术在大数据审计中的应用
采集交流 • 优采云 发表了文章 • 0 个评论 • 296 次浏览 • 2020-05-10 08:03
关键词:网络爬虫;数据采集;审计剖析;Python
本文为2017年安徽财贸职业学院“内涵提高全员行动计划”科学研究项目(人文社科):“大数据在审计剖析程序中的运用研究”(项目编号:2017nhrwc15)
中图分类号:F239 文献标识码:A
收录日期:2019年1月18日
一、引言
无论是国家审计还是民间审计,在现今社会经济发展过程中都起到了非常重要的作用,为经济发展“保驾护航”。大数据目前也是各国研究的重点和热点,并将大数据的研究和应用上升到了战略层次。美国注册会计师协会(AICPA)在2014年就对大数据可能对审计形成的影响进行了剖析。在全球信息化的大背景下,如何借助大数据增加审计风险,提高审计效率依然是一个十分重要的命题。2015年中共中央办公厅、国务院办公厅《关于完善审计制度若干重大问题的框架意见》及配套文件中明晰提出“构建大数据审计工作模式,构建国家审计数据系统和数字化审计平台,探索完善审计实时监督系统,实施联网审计”。刘国城、王会金(2017)将大数据审计平台拆分为采集、预处理、分析和可视化四个子平台,基于方式支撑、过程建模和运行机理等方面对各个子平台作以专项研究,旨在为大数据审计实践提供建设性思路。秦荣生(2014)指出大数据、云计算技术的形成和发展,正在逐步影响审计技术和技巧的发展。
大数据具有数据体量巨大、处理速率快、数量种类多和商业价值高的特性。被审计对象的信息化使得审计人员在审计方式上愈发的信息化,如果将这种大量的、散落的、无序的数据进行集中化、结构化,将其弄成才能便捷获得可读取的审计数据,并通过审计剖析程序发觉愈发有效和清晰的审计线索,那么大数据将会发挥重大的商业价值。由此可见,数据是审计剖析的重要前提,获取高质量数据常常就能帮助审计人员快速发觉风险点进行应对,大大提升审计的效率和疗效。目前,尚未有成熟的审计大数据搜集与整理技术,这影响了大数据在审计中使用的效率。本文将基于目前大数据的研究现况,主要阐述审计人员应该怎样借助网路爬虫技术从网路渠道获取所需审计数据,从而扩展审计数据的范围,获得更多的审计线索,提高审计剖析疗效。
二、审计大数据采集分析
(一)审计大数据类型。大数据审计区别于传统的审计模式,传统审计模式倾向于根据被审计单位提供的相关资料去鉴证其是否真实可靠。而大数据审计是一种实时审计,强调审计人员应该主动地去获取企业内部和企业外部的数据,企业内部的业务数据主要借助被审计单位提供,而外部数据,比如法律、银行、税务、供应商、客户、物流等其他数据须要审计人员去挖掘和剖析。从目前来看,审计大数据可以分为两类:一类是结构化数据,它由明晰定义的数据类型组成,比如数字、货币、日期等,其模式可以让其便于搜索。这种数据通常存储在数据库里,比如企业ERP系统中的销售数据、生产数据、财务数据等;另一类是非结构化数据,是指这些不便捷用数据库二维逻辑来表现的数据,如办公文档、文本、图片、HTML图象等,审计人员须要的外部数据以非结构化数据类型居多。
(二)审计大数据采集方法
1、直接拷贝读取。审计人员首先判定出自己须要的审计数据,然后按照被审计单位使用的财务软件(如用友、用友)的使用特性,利用软件数据库早已预设好的指令去提取转换审计人员所须要的数据,并将其保存为Excel等格式。
2、开放数据互联(ODBC)。如果被审计单位与审计人员使用的是可以对接的数据库,可以通过相关的数据访问插口访问被审计单位所使用的业务系统数据库,并将数据进行还原后转出,成为审计人员可以直接借助的数据。
3、中间文件采集。指审计人员与被审计单位约定好数据的格式,被审计单位根据要求将自己的相关数据转换成约定的格式,比如说文本文件格式,这种大部分数据库都还能直接读取的格式,从而省去了两种不同数据库对接的问题。
4、网上采集。除了被审计单位或则上级审计机关提供的相关数据以外,审计人员依然须要从被审计单位外部获得相关的工商、税务、行业、媒体等公开数据以进行多方面的审计剖析,这些数据并不是被直接提供的结构化数据,需要审计人员采用一定的方式从网上进行采集。
目前,审计数据采集大部分采用的是上述的前三种方式,往往依托一定的数据库基础,能够获得的信息大多基于被审计单位,最后一种网上采集数据的方式因为没有统一的方式和技术,耗费大量时间和经历,往往未能实现,这大大限制了审计人员进行审计剖析的范围,同时也让审计的取证率无法达到预期,从某种程度上提升了审计风险。在大数据审计背景下,审计人员执行剖析程序不能仅仅将眼光局限于内部数据,更应该从网路公开数据中获取愈发全面的信息,但是这种信息大多以网页等格式存在,难以被审计人员直接用于剖析,所以本文提出可以借助网路爬虫技术抓取网页上的信息,并整理成一定的格式,方便审计人员从海量数据中发觉审计线索,使审计剖析程序发挥更大的效用。
三、网络爬虫在审计大数据采集中的应用
网络爬虫技术又被称为网路蜘蛛,是一种根据被设定的规则手动获取网页内容的程序脚本。目前,网络爬虫技术被越来越多的运用于互联网中,它还能依据不同的程序代码设定指令,自动获取网页内任何权限的信息数据。程序开始后,按照设定程序,网络爬虫会不断地从URL抓取用户须要的内容,直到满足停止条件,并对抓取到的数据进行分类整合处理大数据网络爬虫原理,用户可以按照自己的查询需求,从中筛选自己所须要的数据。通过网路爬虫还能为大数据剖析提供更高质量的数据源。
利用网路爬虫技术施行审计剖析程序的过程主要有以下几步:首先,锁定目标。根据审计目标确定想要获取的目标数据,明确这种数据主要分布的网页是哪些;其次,目标网页剖析。为了更高效率的抓取到相关数据,要对目标网页进行结构上的剖析,主要是其数据访问的路径和逻辑;再次,数据抓取。通过选择好的软件执行命令,获得数据结果进行保存;最后,数据剖析。将通过上述程序获得的数据进行清洗,获得目标数据,可以结合例如SQL查询、Excel剖析、数据可视化等技术对数据进行进一步的剖析、扩展和确认。
利用网路爬虫技术施行审计剖析程序的原理主要是能否从被审计单位外部获取愈发充足的、高质量的审计数据,而这种数据比被审计单位提供的数据愈发可靠,同时可以将获取的新数据与被审计单位提供的内部数据进行对比,帮助审计人员扩大范围,发现更多相关线索,同时也促使审计证据愈发充分可靠。
四、网络爬虫在审计大数据采集中应用案例
XX集团有限公司创建于1957年,现已发展产生节能环保、钢铁制造及金属贸易、智能健康、教育与技术服务等产业格局的小型企业集团。截至2017年底,拥有全资及控股一级子公司34家。2017年,完成销售收入933亿元、利润25亿元,甲会计师事务所接受委托对该公司进行2017年年度财务报表审计。审计人员在审计过程中发觉该公司下一子公司有大量进行一次性交易的顾客,并且这种顾客都采用了赊购的形式,所以审计人员对这种交易形成了怀疑,认为被审计单位的应收账款“存在”认定有重大错报风险。为进一步获得审计证据,审计人员首先须要被审计单位提供数据库内关于顾客的信息并进行查验以验证这种顾客的真实性。此时,被审计单位提供信息的可靠性较差,审计人员只能考虑从外部获得审计数据进行比较剖析,从而判定顾客信息的准确性。如果考虑直接从官方网站获得具体工商数据,审计人员将面临权限受限和工作量巨大等问题。此时,网络爬虫技术才能为这一困局提供挺好的解决方案,提高工作效率。
在选择网路爬虫技术时,审计人员选择了目前应用范围相对较广的Python。相对于其他网路爬虫技术,基于Python的网路爬虫技术具有以下优点:一是简约便捷。Python语言最大的特征就是只须要一个简单的编辑器才能满足大部分用户的网路爬虫技术需求,可以使操作人员很快的适应环境,而不用耗费过多的精力;二是具有框架技术。如果所须要抓取的数据量较大,则可以使用Python的Scrapy框架实现,它能提供一个功能强悍的模板来实现爬虫,仅仅须要根据需求进行简单的更改就可以使用,而不是去进行重新的开发。
审计人员通过Python实现了网路爬虫,从“天眼查”网站上获取相关企业的工商信息。其中部份代码如图1所示,获得的部份结果如表1、图2所示。最终审计人员通过网路爬虫技术迅速获得了审计须要的相关数据,筛选出目标企业,进一步进行了审计剖析,与被审计单位提供的有关信息进行比对,得出了其中有18家企业信息涉嫌作假,实为虚构交易的推论,为预收账款的进一步审计提供了重要审计证据。(图1、图2、表1)
五、结语
随着大数据在审计中的运用广泛,高效的数据采集办法也是值得研究的重要内容。本文通过研究大数据的特性,以及对审计数据的采集办法进行剖析,提出了基于Python的数据爬虫在审计数据采集中的运用,帮助审计人员快速高效地从网页上获得相关数据,为进一步的审计剖析奠定了基础,这也为大数据在审计中的应用技术研究提供了支持。
(作者单位:安徽财贸职业学院)
主要参考文献:
[1]秦荣生.大数据、云计算技术对审计的影响研究[J].审计研究,2014(6).
[2]刘国城,王会金.大数据审计平台建立研究[J].审计研究,2017(11).
[3]韦玮.精通Python网络爬虫[M].北京机械工业出版社,2017. 查看全部
[提要]在大数据审计面临着众多机遇和挑战的大背景下,有效清晰的数据在审计过程中发挥着重大作用大数据网络爬虫原理,本文剖析不同的审计数据的特性以及采集审计数据的方式。在传统数据采集方法基础上研究怎样基于Python借助网路爬虫采集审计数据,以为大数据审计技术的发展提供支持。
关键词:网络爬虫;数据采集;审计剖析;Python
本文为2017年安徽财贸职业学院“内涵提高全员行动计划”科学研究项目(人文社科):“大数据在审计剖析程序中的运用研究”(项目编号:2017nhrwc15)
中图分类号:F239 文献标识码:A
收录日期:2019年1月18日
一、引言
无论是国家审计还是民间审计,在现今社会经济发展过程中都起到了非常重要的作用,为经济发展“保驾护航”。大数据目前也是各国研究的重点和热点,并将大数据的研究和应用上升到了战略层次。美国注册会计师协会(AICPA)在2014年就对大数据可能对审计形成的影响进行了剖析。在全球信息化的大背景下,如何借助大数据增加审计风险,提高审计效率依然是一个十分重要的命题。2015年中共中央办公厅、国务院办公厅《关于完善审计制度若干重大问题的框架意见》及配套文件中明晰提出“构建大数据审计工作模式,构建国家审计数据系统和数字化审计平台,探索完善审计实时监督系统,实施联网审计”。刘国城、王会金(2017)将大数据审计平台拆分为采集、预处理、分析和可视化四个子平台,基于方式支撑、过程建模和运行机理等方面对各个子平台作以专项研究,旨在为大数据审计实践提供建设性思路。秦荣生(2014)指出大数据、云计算技术的形成和发展,正在逐步影响审计技术和技巧的发展。
大数据具有数据体量巨大、处理速率快、数量种类多和商业价值高的特性。被审计对象的信息化使得审计人员在审计方式上愈发的信息化,如果将这种大量的、散落的、无序的数据进行集中化、结构化,将其弄成才能便捷获得可读取的审计数据,并通过审计剖析程序发觉愈发有效和清晰的审计线索,那么大数据将会发挥重大的商业价值。由此可见,数据是审计剖析的重要前提,获取高质量数据常常就能帮助审计人员快速发觉风险点进行应对,大大提升审计的效率和疗效。目前,尚未有成熟的审计大数据搜集与整理技术,这影响了大数据在审计中使用的效率。本文将基于目前大数据的研究现况,主要阐述审计人员应该怎样借助网路爬虫技术从网路渠道获取所需审计数据,从而扩展审计数据的范围,获得更多的审计线索,提高审计剖析疗效。
二、审计大数据采集分析
(一)审计大数据类型。大数据审计区别于传统的审计模式,传统审计模式倾向于根据被审计单位提供的相关资料去鉴证其是否真实可靠。而大数据审计是一种实时审计,强调审计人员应该主动地去获取企业内部和企业外部的数据,企业内部的业务数据主要借助被审计单位提供,而外部数据,比如法律、银行、税务、供应商、客户、物流等其他数据须要审计人员去挖掘和剖析。从目前来看,审计大数据可以分为两类:一类是结构化数据,它由明晰定义的数据类型组成,比如数字、货币、日期等,其模式可以让其便于搜索。这种数据通常存储在数据库里,比如企业ERP系统中的销售数据、生产数据、财务数据等;另一类是非结构化数据,是指这些不便捷用数据库二维逻辑来表现的数据,如办公文档、文本、图片、HTML图象等,审计人员须要的外部数据以非结构化数据类型居多。
(二)审计大数据采集方法
1、直接拷贝读取。审计人员首先判定出自己须要的审计数据,然后按照被审计单位使用的财务软件(如用友、用友)的使用特性,利用软件数据库早已预设好的指令去提取转换审计人员所须要的数据,并将其保存为Excel等格式。
2、开放数据互联(ODBC)。如果被审计单位与审计人员使用的是可以对接的数据库,可以通过相关的数据访问插口访问被审计单位所使用的业务系统数据库,并将数据进行还原后转出,成为审计人员可以直接借助的数据。
3、中间文件采集。指审计人员与被审计单位约定好数据的格式,被审计单位根据要求将自己的相关数据转换成约定的格式,比如说文本文件格式,这种大部分数据库都还能直接读取的格式,从而省去了两种不同数据库对接的问题。
4、网上采集。除了被审计单位或则上级审计机关提供的相关数据以外,审计人员依然须要从被审计单位外部获得相关的工商、税务、行业、媒体等公开数据以进行多方面的审计剖析,这些数据并不是被直接提供的结构化数据,需要审计人员采用一定的方式从网上进行采集。
目前,审计数据采集大部分采用的是上述的前三种方式,往往依托一定的数据库基础,能够获得的信息大多基于被审计单位,最后一种网上采集数据的方式因为没有统一的方式和技术,耗费大量时间和经历,往往未能实现,这大大限制了审计人员进行审计剖析的范围,同时也让审计的取证率无法达到预期,从某种程度上提升了审计风险。在大数据审计背景下,审计人员执行剖析程序不能仅仅将眼光局限于内部数据,更应该从网路公开数据中获取愈发全面的信息,但是这种信息大多以网页等格式存在,难以被审计人员直接用于剖析,所以本文提出可以借助网路爬虫技术抓取网页上的信息,并整理成一定的格式,方便审计人员从海量数据中发觉审计线索,使审计剖析程序发挥更大的效用。
三、网络爬虫在审计大数据采集中的应用
网络爬虫技术又被称为网路蜘蛛,是一种根据被设定的规则手动获取网页内容的程序脚本。目前,网络爬虫技术被越来越多的运用于互联网中,它还能依据不同的程序代码设定指令,自动获取网页内任何权限的信息数据。程序开始后,按照设定程序,网络爬虫会不断地从URL抓取用户须要的内容,直到满足停止条件,并对抓取到的数据进行分类整合处理大数据网络爬虫原理,用户可以按照自己的查询需求,从中筛选自己所须要的数据。通过网路爬虫还能为大数据剖析提供更高质量的数据源。
利用网路爬虫技术施行审计剖析程序的过程主要有以下几步:首先,锁定目标。根据审计目标确定想要获取的目标数据,明确这种数据主要分布的网页是哪些;其次,目标网页剖析。为了更高效率的抓取到相关数据,要对目标网页进行结构上的剖析,主要是其数据访问的路径和逻辑;再次,数据抓取。通过选择好的软件执行命令,获得数据结果进行保存;最后,数据剖析。将通过上述程序获得的数据进行清洗,获得目标数据,可以结合例如SQL查询、Excel剖析、数据可视化等技术对数据进行进一步的剖析、扩展和确认。
利用网路爬虫技术施行审计剖析程序的原理主要是能否从被审计单位外部获取愈发充足的、高质量的审计数据,而这种数据比被审计单位提供的数据愈发可靠,同时可以将获取的新数据与被审计单位提供的内部数据进行对比,帮助审计人员扩大范围,发现更多相关线索,同时也促使审计证据愈发充分可靠。
四、网络爬虫在审计大数据采集中应用案例
XX集团有限公司创建于1957年,现已发展产生节能环保、钢铁制造及金属贸易、智能健康、教育与技术服务等产业格局的小型企业集团。截至2017年底,拥有全资及控股一级子公司34家。2017年,完成销售收入933亿元、利润25亿元,甲会计师事务所接受委托对该公司进行2017年年度财务报表审计。审计人员在审计过程中发觉该公司下一子公司有大量进行一次性交易的顾客,并且这种顾客都采用了赊购的形式,所以审计人员对这种交易形成了怀疑,认为被审计单位的应收账款“存在”认定有重大错报风险。为进一步获得审计证据,审计人员首先须要被审计单位提供数据库内关于顾客的信息并进行查验以验证这种顾客的真实性。此时,被审计单位提供信息的可靠性较差,审计人员只能考虑从外部获得审计数据进行比较剖析,从而判定顾客信息的准确性。如果考虑直接从官方网站获得具体工商数据,审计人员将面临权限受限和工作量巨大等问题。此时,网络爬虫技术才能为这一困局提供挺好的解决方案,提高工作效率。
在选择网路爬虫技术时,审计人员选择了目前应用范围相对较广的Python。相对于其他网路爬虫技术,基于Python的网路爬虫技术具有以下优点:一是简约便捷。Python语言最大的特征就是只须要一个简单的编辑器才能满足大部分用户的网路爬虫技术需求,可以使操作人员很快的适应环境,而不用耗费过多的精力;二是具有框架技术。如果所须要抓取的数据量较大,则可以使用Python的Scrapy框架实现,它能提供一个功能强悍的模板来实现爬虫,仅仅须要根据需求进行简单的更改就可以使用,而不是去进行重新的开发。
审计人员通过Python实现了网路爬虫,从“天眼查”网站上获取相关企业的工商信息。其中部份代码如图1所示,获得的部份结果如表1、图2所示。最终审计人员通过网路爬虫技术迅速获得了审计须要的相关数据,筛选出目标企业,进一步进行了审计剖析,与被审计单位提供的有关信息进行比对,得出了其中有18家企业信息涉嫌作假,实为虚构交易的推论,为预收账款的进一步审计提供了重要审计证据。(图1、图2、表1)
五、结语
随着大数据在审计中的运用广泛,高效的数据采集办法也是值得研究的重要内容。本文通过研究大数据的特性,以及对审计数据的采集办法进行剖析,提出了基于Python的数据爬虫在审计数据采集中的运用,帮助审计人员快速高效地从网页上获得相关数据,为进一步的审计剖析奠定了基础,这也为大数据在审计中的应用技术研究提供了支持。
(作者单位:安徽财贸职业学院)
主要参考文献:
[1]秦荣生.大数据、云计算技术对审计的影响研究[J].审计研究,2014(6).
[2]刘国城,王会金.大数据审计平台建立研究[J].审计研究,2017(11).
[3]韦玮.精通Python网络爬虫[M].北京机械工业出版社,2017.
网络爬虫可以爬到什么有用行业数据?
采集交流 • 优采云 发表了文章 • 0 个评论 • 250 次浏览 • 2020-05-10 08:02
网络爬虫可以按照你的不同需求,选择爬取对象、爬取数组进行爬取(必须是公开数据)爬虫软件数据,比如:
电商顾客,我们采集的数据信息主要为商品信息数据、商品评论信息数据、区域库存价钱数据、电商舆情数据等。
金融行业顾客,采集主要的信息为公开的顾客信息、投融资信息、金融舆情信息、市场数据、公开的财务报表、股票、基金、利率等信息。
在网络舆情方面,采集主要信息为综合峰会、新闻门户、知识问答、自媒体网站、社交平台等网路媒体上的相关舆情信息。
在机票采集方面:包含日期、航空公司、航班号、经济舱价钱、经济舱折扣、公务舱价钱、公务舱折扣、税费、附加费、机 型、起飞城市三字码、到达城市三字码、起飞时间等所有相关信息。
题主所说到的行业数据爬虫软件数据,可以依照具体需求选择网站进行定向爬取。
我给题主分享一些国内外公开数据平台,在这种平台里其实有你须要的资源:
【Open Data】国外开放数据中心及政府数据开放平台汇总
最全的中国开放数据(open data)及政府数据开放平台汇总
当然数据采集不仅仅是这几个方面,更多的相关知识也可以在我们官网获得。 查看全部
爬虫采集数据称作网路数据,是指非传统数据源,这种类型的数据可以是结构化的,也可以是非结构化的(更有可能的),可以由网路链接,文本数据,数据表,图像,视频等组成。
网络爬虫可以按照你的不同需求,选择爬取对象、爬取数组进行爬取(必须是公开数据)爬虫软件数据,比如:
电商顾客,我们采集的数据信息主要为商品信息数据、商品评论信息数据、区域库存价钱数据、电商舆情数据等。
金融行业顾客,采集主要的信息为公开的顾客信息、投融资信息、金融舆情信息、市场数据、公开的财务报表、股票、基金、利率等信息。
在网络舆情方面,采集主要信息为综合峰会、新闻门户、知识问答、自媒体网站、社交平台等网路媒体上的相关舆情信息。
在机票采集方面:包含日期、航空公司、航班号、经济舱价钱、经济舱折扣、公务舱价钱、公务舱折扣、税费、附加费、机 型、起飞城市三字码、到达城市三字码、起飞时间等所有相关信息。
题主所说到的行业数据爬虫软件数据,可以依照具体需求选择网站进行定向爬取。
我给题主分享一些国内外公开数据平台,在这种平台里其实有你须要的资源:
【Open Data】国外开放数据中心及政府数据开放平台汇总
最全的中国开放数据(open data)及政府数据开放平台汇总
当然数据采集不仅仅是这几个方面,更多的相关知识也可以在我们官网获得。
Python和数据剖析
采集交流 • 优采云 发表了文章 • 0 个评论 • 274 次浏览 • 2020-05-08 08:03
缺点:有点奇特。? Python:相对年青一点的语言。对于爬虫来说各 方面能力挺好,并且还在建立中,没有Perl那样有 专门的爬虫书籍,不过网上能搜到一些文章。为什么最终选择Python?? 跨平台,对Linux和windows都有不错的支持。 ? 科学估算,数值拟合:Numpy,Scipy ? 可视化:2d:Matplotlib(做图很漂亮), 3d: Mayavi2 ? 复杂网路:Networkx ? 统计:与R语言插口:Rpy ? 交互式终端 ? 网站的快速开发?从一个简单的Python爬虫开始说明:加说明句子时要注意#需要英语编码里的,而不能是英文输入法中的#号,所 以添加英文说明时先在英语输入法下攻入#号后再切换到英文输入瀚海星云Pie 版的网页部份代码………Pie版的Html树部份结构借助BeautifulSoup分析树FindAll()是最方便最好用的函数通用搜索策略? 页面中的link? 深度优先? 广度优先现实中的策略是多种多样的? 因为瀚海星云link有很简单的规律,每页递减20,所以借助这个规 律设置每次赋入的URL,这样爬完了PIE版所有贴子运行结果? 有乱 码!!爬取英文网页常有的问题:不规 格的编码模式? 解决方式:编码转换最后的结果? Perfect!请温柔的对待瀚海星云!!? 设置延后时间(对于一个峰会,如果假定一 个真实的浏览者每10秒掀开一个新的网页的 话,一个不延时的爬虫每秒可以抓10个网页, 这样一个爬虫相当于占用了100个人的带 宽!)? 在午夜爬取可以适当推进速率道上的规矩:用Mysql储存数据? 先要在自己数据库里构建一个空的表,这里, 这里我早已构建了一个名为lilybbs的数据库, 表名为hunan_a? 导入相应的模块? 与相应的数据库联接? 写入数据库里的结果统计和做图? 这部份主要用于科研方 面,利用爬取到的数据 做一些简单的统计工作? 右图是某峰会的回复网 络,使用python的 networkx包做的。
? Pylab 是 matplotlib作 图包的一部 分? 左图是某 blog四年间 每天发表文 章的数目? 左一是某blog网站每个blog 评论数的统计,x是blog评 论数目,y是有这样数目的 blog的数目。可以看见是标 准的“power-law”分布,幂 指数为-1.2左右,拟合使用 了Scipy包的optimize.leastsq, 函数,具体可见scipy cookbook页面的fitting data 一栏? 左二是blog的comment networks 的入度与出度的散 点图,也就是每位点的坐 标x,y分别代表某个人获 得的评论和发出的评论数。 颜色代表这样点的数目。 本图使用了matplotlib中的 hexbin函数中级主题(一):编写更强壮的爬虫? 伪装成浏 览器? 容错中级主题(二):由内嵌脚本形成 的动态网页的爬取? 如何爬取 像左图这 样的网页 呢?? 它显示的 内容并不 会呈现在 html文件 里。高级主题(三):SQLAlchemyMysql这样关系型数据库的缺点:在表 示复杂网路这样一对多,和多对多 的关系时,非常冗余;一旦须要做 比较复杂的统计,sql句子会显得异 常复杂。
? 当你越关注性能,就会发觉 SQL 数据库距对象集合越来越远;当你越关 注具象,就会发觉对象集合距表和行这种概念越来越远。SQLAlchemy 将 致力于尽量宽容这两个世界。? SQLAlchemy 并不把数据库简单地视为数据表的集合;它把它们看作是关 系代数引擎。它的关系对象映射才能使类以不同的形式映射到数据库。 SQL 工具包也不光才能对数据表进行 select 操作——你能够对联接、子查 询和联合进行 select。这样数据库关系和领域对象模型之间的耦合从一开 始就得以挺好地解开,使得两个领域都得以发挥其各自的极至。? 我写过的某个冗长的调用? 号称能更简约明了的SQLAlchemy会成为 mysql的替代品么?高级主题(四):统计神器R语言? 求残差,聚类,判 别,拟合,团簇探 测,时间序列剖析, 生存剖析,甚至复 杂网路,这些R语言 里都有挺好的函数? 可以直接使用R语言, 也可以借助Rpy在 python上面调用R的 函数,不过Rpy一直 开发中,还不是太 成熟以前我们获取数据的手段: 我们用望远镜来洞察宇宙高昂的实验 只是为了获取大自然的数据Internet 带给我们了海量的数据 善用数据,了解我们自己广袤的比特海是另一片未知的星空感谢你们! 查看全部
网络爬虫, Python和数据 分析王澎 中国科技大学哪些是网络爬虫?? 网络爬虫是一个手动提取网页的程序,它为搜索 引擎从万维网上下载网页,是搜索引擎的重要组 成。传统爬虫从一个或若干初始网页的URL开始, 获得初始网页上的URL,在抓取网页的过程中, 不断从当前页面上抽取新的URL装入队列,直到满 足系统的一定停止条件爬虫有哪些用?? 做为通用搜索引擎网页收集器。(google,baidu) ? 做垂直搜索引擎.(找工作的搜索引擎:,数据来源于: , , 等等) ? 科学研究:在线人类行为,在线社群演变,人类 动力学研究数据挖掘与网络爬虫,计量社会学,复杂网路,数据挖掘, 等领域的实证研究都须要大量数据,网络爬虫是 收集相关数据的神器。 ? 偷窥,hacking数据挖掘与网络爬虫,发垃圾邮件……(《google hack》….)爬虫是搜索引擎的第一步 也是最容易的一步? 网页收集 ? 建立索引 ? 查询排序用哪些语言写爬虫?? C,C++。高效率,快速,适合通用搜索引 擎做全网爬取。缺点,开发慢,写上去又 臭又长,例如:天网搜索源代码。? 脚本语言:Perl, Python, Java, Ruby。简单, 易学,良好的文本处理能便捷网页内容的 细致提取,但效率常常不高,适合对少量 网站的聚焦爬取? C#?(貌似信息管理的人比较喜欢的语言)我当初拿来写过爬虫的语言? Perl: 古老的脚本语言,hack 语言,被拿来写爬虫 有着悠久的历史,因此,书本支持相当丰富: 《spidering hacks》,《Perl & LWP》;强大的文 本处理能力,数据库支持能力。
缺点:有点奇特。? Python:相对年青一点的语言。对于爬虫来说各 方面能力挺好,并且还在建立中,没有Perl那样有 专门的爬虫书籍,不过网上能搜到一些文章。为什么最终选择Python?? 跨平台,对Linux和windows都有不错的支持。 ? 科学估算,数值拟合:Numpy,Scipy ? 可视化:2d:Matplotlib(做图很漂亮), 3d: Mayavi2 ? 复杂网路:Networkx ? 统计:与R语言插口:Rpy ? 交互式终端 ? 网站的快速开发?从一个简单的Python爬虫开始说明:加说明句子时要注意#需要英语编码里的,而不能是英文输入法中的#号,所 以添加英文说明时先在英语输入法下攻入#号后再切换到英文输入瀚海星云Pie 版的网页部份代码………Pie版的Html树部份结构借助BeautifulSoup分析树FindAll()是最方便最好用的函数通用搜索策略? 页面中的link? 深度优先? 广度优先现实中的策略是多种多样的? 因为瀚海星云link有很简单的规律,每页递减20,所以借助这个规 律设置每次赋入的URL,这样爬完了PIE版所有贴子运行结果? 有乱 码!!爬取英文网页常有的问题:不规 格的编码模式? 解决方式:编码转换最后的结果? Perfect!请温柔的对待瀚海星云!!? 设置延后时间(对于一个峰会,如果假定一 个真实的浏览者每10秒掀开一个新的网页的 话,一个不延时的爬虫每秒可以抓10个网页, 这样一个爬虫相当于占用了100个人的带 宽!)? 在午夜爬取可以适当推进速率道上的规矩:用Mysql储存数据? 先要在自己数据库里构建一个空的表,这里, 这里我早已构建了一个名为lilybbs的数据库, 表名为hunan_a? 导入相应的模块? 与相应的数据库联接? 写入数据库里的结果统计和做图? 这部份主要用于科研方 面,利用爬取到的数据 做一些简单的统计工作? 右图是某峰会的回复网 络,使用python的 networkx包做的。
? Pylab 是 matplotlib作 图包的一部 分? 左图是某 blog四年间 每天发表文 章的数目? 左一是某blog网站每个blog 评论数的统计,x是blog评 论数目,y是有这样数目的 blog的数目。可以看见是标 准的“power-law”分布,幂 指数为-1.2左右,拟合使用 了Scipy包的optimize.leastsq, 函数,具体可见scipy cookbook页面的fitting data 一栏? 左二是blog的comment networks 的入度与出度的散 点图,也就是每位点的坐 标x,y分别代表某个人获 得的评论和发出的评论数。 颜色代表这样点的数目。 本图使用了matplotlib中的 hexbin函数中级主题(一):编写更强壮的爬虫? 伪装成浏 览器? 容错中级主题(二):由内嵌脚本形成 的动态网页的爬取? 如何爬取 像左图这 样的网页 呢?? 它显示的 内容并不 会呈现在 html文件 里。高级主题(三):SQLAlchemyMysql这样关系型数据库的缺点:在表 示复杂网路这样一对多,和多对多 的关系时,非常冗余;一旦须要做 比较复杂的统计,sql句子会显得异 常复杂。
? 当你越关注性能,就会发觉 SQL 数据库距对象集合越来越远;当你越关 注具象,就会发觉对象集合距表和行这种概念越来越远。SQLAlchemy 将 致力于尽量宽容这两个世界。? SQLAlchemy 并不把数据库简单地视为数据表的集合;它把它们看作是关 系代数引擎。它的关系对象映射才能使类以不同的形式映射到数据库。 SQL 工具包也不光才能对数据表进行 select 操作——你能够对联接、子查 询和联合进行 select。这样数据库关系和领域对象模型之间的耦合从一开 始就得以挺好地解开,使得两个领域都得以发挥其各自的极至。? 我写过的某个冗长的调用? 号称能更简约明了的SQLAlchemy会成为 mysql的替代品么?高级主题(四):统计神器R语言? 求残差,聚类,判 别,拟合,团簇探 测,时间序列剖析, 生存剖析,甚至复 杂网路,这些R语言 里都有挺好的函数? 可以直接使用R语言, 也可以借助Rpy在 python上面调用R的 函数,不过Rpy一直 开发中,还不是太 成熟以前我们获取数据的手段: 我们用望远镜来洞察宇宙高昂的实验 只是为了获取大自然的数据Internet 带给我们了海量的数据 善用数据,了解我们自己广袤的比特海是另一片未知的星空感谢你们!
淘宝数据采集以及数据剖析
采集交流 • 优采云 发表了文章 • 0 个评论 • 468 次浏览 • 2020-05-05 08:04
八爪鱼·云采集网络爬虫软件 淘宝数据采集以及数据剖析在现今大数据时代,做电商营运越来越讲求用数据说话,从数据中挖掘市场机 会,所以数据采集与剖析是天猫电商营运必 Get 的技能之一,下面由小编为大 家介绍怎样通过八爪鱼数据采集器,进行天猫数据采集以及数据剖析,分析市场 的需求和趋势。小编以“童鞋”商品作为样本,在淘宝天猫 6000 个童鞋商品中,选取了逾 30 天销量排名前 620 的童鞋作为样本进行数据采集。八爪鱼数据采集样本时间维度:2018 年 8 月 4 日——2018 年 9 月 4 日 数据样本:天猫童鞋销量排名前 620 款(占淘宝童鞋商品总量 10.3%,总数为 6000 款) 数据字段:价格、商品名称、商品链接、店铺名称、店铺链接、月成交(笔数)、 评价数、图片 URL 地址八爪鱼·云采集网络爬虫软件 八爪鱼采集结果示例八爪鱼从淘宝抓取 Top 620 销量童鞋数据(免费下载规则 1:八爪鱼抓取淘宝 Top 销量童鞋数据,获取方法见文末)八爪鱼·云采集网络爬虫软件 八爪鱼抓取淘宝 Top 620 销量童鞋图片(免费下载安装包:图片批量下载工具-八爪鱼采集器插件,获取方法见文末)干货来了,以下是小编的剖析结果。
1、价格影响 80%的父母选择 100 元以下的童鞋八爪鱼·云采集网络爬虫软件 从数据上看,销量 Top 620 的童鞋,产品价位集中在 25-100 元的价钱区间, 说明这个价钱区间,最受父母欢迎,这个为店家在做新款研制、新品定价与成本 考量中提供参考。八爪鱼·云采集网络爬虫软件 从数据上看,100 元以下的产品占逾 30 天销量的 81%,50 元以下的产品占逾 30 天销量的 56%。说明 80%的父母偏向订购 100 元以下的童鞋产品。经督查剖析,主要缘由有以下 3 点: 1、0-7 岁男孩头部发育快,换靴频度高,一双靴可能穿 1-2 个月,或 3-6 个月 就要更换; 2、0-7 岁男孩父母大部分属于 80 后、90 后,工作收入属于中等平均水平; 3、孩子还有外套、奶粉、早教等其他支出,相对于其他产品,家长偏向于在靴 子消费上节约支出;运营建议: 在童鞋的新款研制、定价、宣传渠道、用户画像上须要考虑用户的年纪、收入、 城市分布以及消费心理和消费能力。2、季节影响 秋冬季鞋款更好卖八爪鱼·云采集网络爬虫软件 从数据上看, 秋季靴款占逾 30 天销量的 38.7%, 春夏季占逾 30 天销量的 27.4%。
秋季、春季为逾 30 天的主打款。随着季节的变化,秋天早晚温差大。孩子在快 速发育期,免疫力低,自我照料能力弱。因此父母会依照季节变化,购买符合季 节体温的靴款。毕竟孩子得病了,苦的累的是大人。运营建议: 1、提前上架春秋季节的靴款,做好迎接冬季童鞋的需求下降打算; 2、修改商品的名称,将商品名称降低“秋、春”的字眼,增加被用户检索到的 概率。八爪鱼·云采集网络爬虫软件 3、店铺成交流水 定价和营销策略很重要八爪鱼从淘宝抓取童鞋月销量 Top 620 数据以上是淘宝童鞋月销量 Top 620 的数据。你可以对照自己店面的数据,衡量你 与她们之间差别,并且仔细剖析大家之间的差别在那里?从那里可以改进?八爪鱼·云采集网络爬虫软件 我们发觉月成交 Top 2 的米修服装专营店没有步入月流水的 Top 10,说明他的 成交量其实大,但总价比较低。本来没有步入 Top 10 月成交的 anta 安踏男装 旗舰店和大黄蜂旗舰店,一跃成为月流水 Top 1 和 Top4。八爪鱼·云采集网络爬虫软件 从数据上看,安踏、大黄蜂的平均客单价达到 100 元以上。进入她们的店面发 现爬虫软件分析电商数据,2 家主攻 4-10 岁的学龄儿童为主,均价在 100 元以上,拉高了月流水。
运营建议: 1、0-6 岁的学步鞋定价普遍在 100 元以下,6-10 岁的学龄儿童定价稍高,偏 向 100 元以上; 2、并不是价位越实惠好卖,用户会综合考虑品牌、质量、评价等综合诱因,从 中选优; 3、在新款定价、促销折扣时,既要要考虑用户的心理和同竞品的定价营销策略, 同时也要考虑产品的收益和成本。定价和营销策略十分重要;4、热点风波影响 9 月开学季,小白靴成为童鞋畅销品小白靴在逾 30 天的月成交、月流水贡献占比八爪鱼·云采集网络爬虫软件 小编分别在 8 月 25 日和 9 月 4 日, 用八爪鱼采集童鞋数据, 发现就在这 10 天, 小白靴就早已嗖嘶嘶飙升到销量 Top 1,为逾 30 日月成交贡献了 34.89%,月 流水贡献了 28.81%。如果爪爪想知道这波小白靴热卖会维持多久,可以在 9 月 14 日再采集一次进行数据对比。5、销量 Top 1 小白靴小编用八爪鱼数据采集销量 Top1 小白靴 600 条用户评价, 并用动词软件对评价 做了词频解析。八爪鱼抓取淘宝销量 Top1 小白靴用户评论八爪鱼·云采集网络爬虫软件 (免费下载规则 2:八爪鱼抓取淘宝商品用户评论数据,获取方法见文末)评价中用户最关心: 质量、款式、舒适度、鞋衣搭配、异味、尺码、价格、穿脱便捷、发货速率(赶 着开学穿、同事推荐;送礼物、促销活动。
八爪鱼·云采集网络爬虫软件 销量 Top 1 童鞋用户评价时间分布从数据上看,家长评价集中在 8 月 22 日—9 月 2 日,说明父母在开学前一周开 始打算入学的武器。运营建议: 1、 出具一份电商童鞋营运活动时间表爬虫软件分析电商数据, 对于童鞋产品一年当中有什么营销热点; 元旦、1 月春节、3 月开学、61 儿童节、618 电商、6、7、8 月假期、9 月开学、 9 月新春、10 月端午、双 11、双 12、12 月圣诞节。2、在营销热点时间提早 1—2 个月,做好准备,比如热卖选品、营销折扣、营 销活动专题、文案、设计、用户评价积累、配套单品、物流打算等等。电商数据剖析框架八爪鱼·云采集网络爬虫软件 八爪鱼·云采集网络爬虫软件 涉及八爪鱼方法知识点八爪虾基础课程(采集模式、多种网页数据采集、创建循环、登录形式、ajax 加载、ajax 滚动等)淘宝天猫采集教程: (建议在笔记本端打开)其它电商网站数据采集教程: 1688 商品信息以及卖家评价采集 亚马逊商品信息采集方法以及详尽教程 易迅采集器 天猫评论采集 八爪鱼·云采集网络爬虫软件 淘宝网宝贝采集器 八爪鱼——90 万用户选择的网页数据采集器。
1、操作简单,任何人都可以用:无需技术背景,会上网才能采集。完全可视化 流程,点击滑鼠完成操作,2 分钟即可快速入门。 2、功能强悍,任何网站都可以采:对于点击、登陆、翻页、识别验证码、瀑布 流、Ajax 脚本异步加载数据的网页,均可经过简单设置进行采集。 3、云采集,关机也可以。配置好采集任务后可死机,任务可在云端执行。庞大 云采集集群 24*7 不间断运行,不用害怕 IP 被封,网络中断。 4、功能免费+增值服务,可按需选择。免费版具备所有功能,能够满足用户的 基本采集需求。同时设置了一些增值服务(如私有云),满足低端付费企业用户 的须要。 查看全部
八爪鱼·云采集网络爬虫软件 淘宝数据采集以及数据剖析在现今大数据时代,做电商营运越来越讲求用数据说话,从数据中挖掘市场机 会,所以数据采集与剖析是天猫电商营运必 Get 的技能之一,下面由小编为大 家介绍怎样通过八爪鱼数据采集器,进行天猫数据采集以及数据剖析,分析市场 的需求和趋势。小编以“童鞋”商品作为样本,在淘宝天猫 6000 个童鞋商品中,选取了逾 30 天销量排名前 620 的童鞋作为样本进行数据采集。八爪鱼数据采集样本时间维度:2018 年 8 月 4 日——2018 年 9 月 4 日 数据样本:天猫童鞋销量排名前 620 款(占淘宝童鞋商品总量 10.3%,总数为 6000 款) 数据字段:价格、商品名称、商品链接、店铺名称、店铺链接、月成交(笔数)、 评价数、图片 URL 地址八爪鱼·云采集网络爬虫软件 八爪鱼采集结果示例八爪鱼从淘宝抓取 Top 620 销量童鞋数据(免费下载规则 1:八爪鱼抓取淘宝 Top 销量童鞋数据,获取方法见文末)八爪鱼·云采集网络爬虫软件 八爪鱼抓取淘宝 Top 620 销量童鞋图片(免费下载安装包:图片批量下载工具-八爪鱼采集器插件,获取方法见文末)干货来了,以下是小编的剖析结果。
1、价格影响 80%的父母选择 100 元以下的童鞋八爪鱼·云采集网络爬虫软件 从数据上看,销量 Top 620 的童鞋,产品价位集中在 25-100 元的价钱区间, 说明这个价钱区间,最受父母欢迎,这个为店家在做新款研制、新品定价与成本 考量中提供参考。八爪鱼·云采集网络爬虫软件 从数据上看,100 元以下的产品占逾 30 天销量的 81%,50 元以下的产品占逾 30 天销量的 56%。说明 80%的父母偏向订购 100 元以下的童鞋产品。经督查剖析,主要缘由有以下 3 点: 1、0-7 岁男孩头部发育快,换靴频度高,一双靴可能穿 1-2 个月,或 3-6 个月 就要更换; 2、0-7 岁男孩父母大部分属于 80 后、90 后,工作收入属于中等平均水平; 3、孩子还有外套、奶粉、早教等其他支出,相对于其他产品,家长偏向于在靴 子消费上节约支出;运营建议: 在童鞋的新款研制、定价、宣传渠道、用户画像上须要考虑用户的年纪、收入、 城市分布以及消费心理和消费能力。2、季节影响 秋冬季鞋款更好卖八爪鱼·云采集网络爬虫软件 从数据上看, 秋季靴款占逾 30 天销量的 38.7%, 春夏季占逾 30 天销量的 27.4%。
秋季、春季为逾 30 天的主打款。随着季节的变化,秋天早晚温差大。孩子在快 速发育期,免疫力低,自我照料能力弱。因此父母会依照季节变化,购买符合季 节体温的靴款。毕竟孩子得病了,苦的累的是大人。运营建议: 1、提前上架春秋季节的靴款,做好迎接冬季童鞋的需求下降打算; 2、修改商品的名称,将商品名称降低“秋、春”的字眼,增加被用户检索到的 概率。八爪鱼·云采集网络爬虫软件 3、店铺成交流水 定价和营销策略很重要八爪鱼从淘宝抓取童鞋月销量 Top 620 数据以上是淘宝童鞋月销量 Top 620 的数据。你可以对照自己店面的数据,衡量你 与她们之间差别,并且仔细剖析大家之间的差别在那里?从那里可以改进?八爪鱼·云采集网络爬虫软件 我们发觉月成交 Top 2 的米修服装专营店没有步入月流水的 Top 10,说明他的 成交量其实大,但总价比较低。本来没有步入 Top 10 月成交的 anta 安踏男装 旗舰店和大黄蜂旗舰店,一跃成为月流水 Top 1 和 Top4。八爪鱼·云采集网络爬虫软件 从数据上看,安踏、大黄蜂的平均客单价达到 100 元以上。进入她们的店面发 现爬虫软件分析电商数据,2 家主攻 4-10 岁的学龄儿童为主,均价在 100 元以上,拉高了月流水。
运营建议: 1、0-6 岁的学步鞋定价普遍在 100 元以下,6-10 岁的学龄儿童定价稍高,偏 向 100 元以上; 2、并不是价位越实惠好卖,用户会综合考虑品牌、质量、评价等综合诱因,从 中选优; 3、在新款定价、促销折扣时,既要要考虑用户的心理和同竞品的定价营销策略, 同时也要考虑产品的收益和成本。定价和营销策略十分重要;4、热点风波影响 9 月开学季,小白靴成为童鞋畅销品小白靴在逾 30 天的月成交、月流水贡献占比八爪鱼·云采集网络爬虫软件 小编分别在 8 月 25 日和 9 月 4 日, 用八爪鱼采集童鞋数据, 发现就在这 10 天, 小白靴就早已嗖嘶嘶飙升到销量 Top 1,为逾 30 日月成交贡献了 34.89%,月 流水贡献了 28.81%。如果爪爪想知道这波小白靴热卖会维持多久,可以在 9 月 14 日再采集一次进行数据对比。5、销量 Top 1 小白靴小编用八爪鱼数据采集销量 Top1 小白靴 600 条用户评价, 并用动词软件对评价 做了词频解析。八爪鱼抓取淘宝销量 Top1 小白靴用户评论八爪鱼·云采集网络爬虫软件 (免费下载规则 2:八爪鱼抓取淘宝商品用户评论数据,获取方法见文末)评价中用户最关心: 质量、款式、舒适度、鞋衣搭配、异味、尺码、价格、穿脱便捷、发货速率(赶 着开学穿、同事推荐;送礼物、促销活动。
八爪鱼·云采集网络爬虫软件 销量 Top 1 童鞋用户评价时间分布从数据上看,家长评价集中在 8 月 22 日—9 月 2 日,说明父母在开学前一周开 始打算入学的武器。运营建议: 1、 出具一份电商童鞋营运活动时间表爬虫软件分析电商数据, 对于童鞋产品一年当中有什么营销热点; 元旦、1 月春节、3 月开学、61 儿童节、618 电商、6、7、8 月假期、9 月开学、 9 月新春、10 月端午、双 11、双 12、12 月圣诞节。2、在营销热点时间提早 1—2 个月,做好准备,比如热卖选品、营销折扣、营 销活动专题、文案、设计、用户评价积累、配套单品、物流打算等等。电商数据剖析框架八爪鱼·云采集网络爬虫软件 八爪鱼·云采集网络爬虫软件 涉及八爪鱼方法知识点八爪虾基础课程(采集模式、多种网页数据采集、创建循环、登录形式、ajax 加载、ajax 滚动等)淘宝天猫采集教程: (建议在笔记本端打开)其它电商网站数据采集教程: 1688 商品信息以及卖家评价采集 亚马逊商品信息采集方法以及详尽教程 易迅采集器 天猫评论采集 八爪鱼·云采集网络爬虫软件 淘宝网宝贝采集器 八爪鱼——90 万用户选择的网页数据采集器。
1、操作简单,任何人都可以用:无需技术背景,会上网才能采集。完全可视化 流程,点击滑鼠完成操作,2 分钟即可快速入门。 2、功能强悍,任何网站都可以采:对于点击、登陆、翻页、识别验证码、瀑布 流、Ajax 脚本异步加载数据的网页,均可经过简单设置进行采集。 3、云采集,关机也可以。配置好采集任务后可死机,任务可在云端执行。庞大 云采集集群 24*7 不间断运行,不用害怕 IP 被封,网络中断。 4、功能免费+增值服务,可按需选择。免费版具备所有功能,能够满足用户的 基本采集需求。同时设置了一些增值服务(如私有云),满足低端付费企业用户 的须要。
dedecms数据库恢复与备份的两种方式
采集交流 • 优采云 发表了文章 • 0 个评论 • 268 次浏览 • 2020-04-10 11:00
数据库是一个网站的核心系统,它存储着网站的所有信息,所以常常对数据库进行恢复和备份是每一位站长都要会做的事情,尤其是这些对数据和信息非常重要的网站。对于恢复与备份数据库的方式有很多,无忧主机小编在这几年的工作当中,也接触了不少无忧主机php免备案空间的用户咨询这方面的问题。那么明天无忧主机小编就来讲解一下dedecms数据库恢复与备份的两种方式。
第一种是比较通用的方式,登入无忧主机控制面板织梦 数据库还原织梦 数据库还原,点击“数据库管理”——“登录phpmyadmin”,用数据库用户名和数据库密码登录进去,找到要备份的数据库信息,全选、导出就完成备份了。然后还原也是一样,选择要导出的数据库信息点击导出,将备份好的数据库信息导出进去就可以。
第二种就是登陆dedecms的后台,利用后台功能进行数据库恢复与备份的操作,这种方式对于dedecms更加便捷快捷。登入dedecms网站后台,点击“系统”——“数据库备份/还原”。全选或则部份选定数据表信息,按提示完成备份。要恢复的话点击“数据还原”,选择早已做好了备份的数据表,点击“开始还原数据”就完成了。
以上两种方式都可以实现数据库恢复与备份,但是第一种操作相对复杂一点,但是对好多程序都通用;而第二种较为简单,但是只适用于dedecms。 查看全部
数据库是一个网站的核心系统,它存储着网站的所有信息,所以常常对数据库进行恢复和备份是每一位站长都要会做的事情,尤其是这些对数据和信息非常重要的网站。对于恢复与备份数据库的方式有很多,无忧主机小编在这几年的工作当中,也接触了不少无忧主机php免备案空间的用户咨询这方面的问题。那么明天无忧主机小编就来讲解一下dedecms数据库恢复与备份的两种方式。
第一种是比较通用的方式,登入无忧主机控制面板织梦 数据库还原织梦 数据库还原,点击“数据库管理”——“登录phpmyadmin”,用数据库用户名和数据库密码登录进去,找到要备份的数据库信息,全选、导出就完成备份了。然后还原也是一样,选择要导出的数据库信息点击导出,将备份好的数据库信息导出进去就可以。
第二种就是登陆dedecms的后台,利用后台功能进行数据库恢复与备份的操作,这种方式对于dedecms更加便捷快捷。登入dedecms网站后台,点击“系统”——“数据库备份/还原”。全选或则部份选定数据表信息,按提示完成备份。要恢复的话点击“数据还原”,选择早已做好了备份的数据表,点击“开始还原数据”就完成了。
以上两种方式都可以实现数据库恢复与备份,但是第一种操作相对复杂一点,但是对好多程序都通用;而第二种较为简单,但是只适用于dedecms。
如何做好seo数据监控的统计呢?
采集交流 • 优采云 发表了文章 • 0 个评论 • 320 次浏览 • 2020-04-05 11:02
因为近来百度始终未能使好多站长和SEO人员保持淡定,每天都有许多SEO人去各大峰会、QQ群咨询问题,最多的就是“我的网站为什么被K”、“多久就能恢复过来”等等例如之类的问题满天飞,通常QQ群里你们就会各执己见,有人说你的内容做的不好、有人说你的外链太多、有人说你的站内优化过度等等,大家剖析来剖析去最后还是“无解”,我想每位做SEO的基本上都清楚这些东西,但我们如何能够使自己的观点有根据呢?那些想法可能都是我们的猜想,根据往年的经验推断下来的东西,没有数据的SEO论断虽然未能使人信服。
与其说我们做的是SEO优化,不如说是SEO数据监控,把每晚应当做的SEO工作落实到位,剩下的就是SEO数据监控了,SEO是一场竞争的游戏,这个游戏有游戏规则,但规则的制定者不是我们,我们都在想方设法的在这场游戏中打败对方。知己知彼百战百胜,分析竞争对手说起来容易文章采集站,其实很难,我们要做好SEO数据监控的第一步就是SEO数据监控。包括竞争对手网站的收录、反链、百度快照等数据,如何做好seo数据监控的统计呢?
第一:必须借助于一些SEO工具
可惜的是现今国外其实还没有这样的SEO工具,有的也是一些收费的工具,但是以笔者看来没有几款工具值得我去付费使用的,功能与鬼佬的一些工具相比,差距不小。不过可以借助于一些其他软件辅助使用,比如:EXCEL、火车头采集器,相信这两个工具我们都不陌生,不过真正去研究的不多,EXCEL功能太强悍,之前笔者看过一篇文章,有同学就是用EXCEL实现排行查询和外链检查。而火车头采集器更是许多采集站必备的工具,不仅可以采集网站上的文章文章采集站,更能采集到网站上的好多数据,还有光年日志剖析软件、web log explorer网站日志剖析软件(老外的东西,现在有破解版)。
第二:生成更直观的SEO数据统计图
通过软件得到的数据须要处理下,这样可以生成更直观的SEO数据统计图。否则一个个查询域名工作量很大seo数据监控,有点不切实际,如chinaz站长工具一样,我们可以通过程序或软件生成我们想要的图片,这些须要有程序员开发一些系统下来,其实不难。常见的图表类型有条形图、折线图等,有图表能够直观的看出网站数据的变化,包括自己优化的网站以及竞争对手的网站,当你须要管理好多网站的时侯,这样的程序可以给你节约好多时间。SEO工作中一切可以从程序或软件完成的,我们尽量不要手工做,这样效率方面也提升了不少。
第三:定期撰写SEO数据剖析报告
假如如今我手里须要管理10个企业站,我可以每周看下自己整理好的数据,在软件或相关程序的帮助下,收集数据不要浪费多少时间,甚至只要我们去瞧瞧图表就行了,知道自己网站最近的一些数据,比如:一周收录跌多少,外链掉了多少。再对比下排行在前几页的竞争对手,看看他人是怎么做的,网站的更新频度是多少,外链的增长幅度是多少等。
要剖析一个网站是因何缘由被k,不是一件容易的事情,如果只是按照自己以为的经验来判定,这未免有些轻率,但好多网站其实没有去做好网站数据的统计,这样网站一旦出问题了,一时半会也不晓得问题出现在那儿。我相信网站优化出问题就好象人得病一样,总能找到一些蛛丝马迹seo数据监控,比如:网站日志文件就是查出病症的途径,我是老男孩SEO工作室的石头,我们做SEO不能借助自己的觉得,需要依赖于数据和经验。 查看全部
因为近来百度始终未能使好多站长和SEO人员保持淡定,每天都有许多SEO人去各大峰会、QQ群咨询问题,最多的就是“我的网站为什么被K”、“多久就能恢复过来”等等例如之类的问题满天飞,通常QQ群里你们就会各执己见,有人说你的内容做的不好、有人说你的外链太多、有人说你的站内优化过度等等,大家剖析来剖析去最后还是“无解”,我想每位做SEO的基本上都清楚这些东西,但我们如何能够使自己的观点有根据呢?那些想法可能都是我们的猜想,根据往年的经验推断下来的东西,没有数据的SEO论断虽然未能使人信服。
与其说我们做的是SEO优化,不如说是SEO数据监控,把每晚应当做的SEO工作落实到位,剩下的就是SEO数据监控了,SEO是一场竞争的游戏,这个游戏有游戏规则,但规则的制定者不是我们,我们都在想方设法的在这场游戏中打败对方。知己知彼百战百胜,分析竞争对手说起来容易文章采集站,其实很难,我们要做好SEO数据监控的第一步就是SEO数据监控。包括竞争对手网站的收录、反链、百度快照等数据,如何做好seo数据监控的统计呢?
第一:必须借助于一些SEO工具
可惜的是现今国外其实还没有这样的SEO工具,有的也是一些收费的工具,但是以笔者看来没有几款工具值得我去付费使用的,功能与鬼佬的一些工具相比,差距不小。不过可以借助于一些其他软件辅助使用,比如:EXCEL、火车头采集器,相信这两个工具我们都不陌生,不过真正去研究的不多,EXCEL功能太强悍,之前笔者看过一篇文章,有同学就是用EXCEL实现排行查询和外链检查。而火车头采集器更是许多采集站必备的工具,不仅可以采集网站上的文章文章采集站,更能采集到网站上的好多数据,还有光年日志剖析软件、web log explorer网站日志剖析软件(老外的东西,现在有破解版)。
第二:生成更直观的SEO数据统计图
通过软件得到的数据须要处理下,这样可以生成更直观的SEO数据统计图。否则一个个查询域名工作量很大seo数据监控,有点不切实际,如chinaz站长工具一样,我们可以通过程序或软件生成我们想要的图片,这些须要有程序员开发一些系统下来,其实不难。常见的图表类型有条形图、折线图等,有图表能够直观的看出网站数据的变化,包括自己优化的网站以及竞争对手的网站,当你须要管理好多网站的时侯,这样的程序可以给你节约好多时间。SEO工作中一切可以从程序或软件完成的,我们尽量不要手工做,这样效率方面也提升了不少。
第三:定期撰写SEO数据剖析报告
假如如今我手里须要管理10个企业站,我可以每周看下自己整理好的数据,在软件或相关程序的帮助下,收集数据不要浪费多少时间,甚至只要我们去瞧瞧图表就行了,知道自己网站最近的一些数据,比如:一周收录跌多少,外链掉了多少。再对比下排行在前几页的竞争对手,看看他人是怎么做的,网站的更新频度是多少,外链的增长幅度是多少等。
要剖析一个网站是因何缘由被k,不是一件容易的事情,如果只是按照自己以为的经验来判定,这未免有些轻率,但好多网站其实没有去做好网站数据的统计,这样网站一旦出问题了,一时半会也不晓得问题出现在那儿。我相信网站优化出问题就好象人得病一样,总能找到一些蛛丝马迹seo数据监控,比如:网站日志文件就是查出病症的途径,我是老男孩SEO工作室的石头,我们做SEO不能借助自己的觉得,需要依赖于数据和经验。
五分钟学前端技术:一篇文章教你看懂大数据技术栈!
采集交流 • 优采云 发表了文章 • 0 个评论 • 467 次浏览 • 2020-04-02 11:04
近几年,市场上出现了好多和大数据相关的岗位,不管是数据剖析、数据挖掘,或者是数据研制,都是围绕着大数据来做事情,那么,到底哪些是大数据,就是我们每一个要学习大数据技术的同学要了解的事情了,根据百度百科的介绍
大数据(big data),IT行业术语,是指未能在一定时间范围内用常规软件工具进行捕捉、管理和处理的数据集合,是须要新处理模式能够具有更强的决策力、洞察发觉力和流程优化能力的海量、高增长率和多元化的信息资产。
在维克托·迈尔-舍恩伯格及肯尼斯·库克耶编撰的《大数据时代》 [1] 中大数据指不用随机分析法(抽样调查)这样捷径,而采用所有数据进行剖析处理。大数据的5V特征(IBM提出):Volume(大量)、Velocity(高速)、Variety(多样)、Value(低价值密度)、Veracity(真实性)。 [2]思维导图
大数据方面核心技术有什么?
大数据的概念比较具象,而大数据技术栈的庞大程度将使你叹为观止。
大数据技术的体系庞大且复杂,基础的技术包含数据的采集、数据预处理、分布式存储、NoSQL数据库、数据库房、机器学习、并行估算、可视化等各类技术范畴和不同的技术层面。首先给出一个通用化的大数据处理框架,主要分为下边几个方面:数据采集与预处理、数据储存、数据清洗、数据查询剖析和数据可视化。
一、数据采集与预处理
对于各类来源的数据,包括联通互联网数据、社交网络的数据等,这些结构化和非结构化的海量数据是零散的,也就是所谓的数据孤岛,此时的那些数据并没有哪些意义,数据采集就是将这种数据写入数据库房中,把零散的数据整合在一起,对那些数据综合上去进行剖析。数据采集包括文件日志的采集、数据库日志的采集、关系型数据库的接入和应用程序的接入等。在数据量比较小的时侯,可以写个定时的脚本将日志写入储存系统,但随着数据量的下降,这些方式难以提供数据安全保障,并且运维困难,需要更健壮的解决方案。
Flume NG作为实时日志搜集系统,支持在日志系统中订制各种数据发送方,用于搜集数据,同时,对数据进行简单处理,并讲到各类数据接收方(比如文本,HDFS,Hbase等)。Flume NG采用的是三层架构:Agent层,Collector层和Store层,每一层均可水平拓展。其中Agent包含Source,Channel和 Sink,source拿来消费(收集)数据源到channel组件中,channel作为中间临时储存,保存所有source的组件信息,sink从channel中读取数据,读取成功以后会删掉channel中的信息。
NDC,Netease Data Canal,直译为网易数据运河系统,是网易针对结构化数据库的数据实时迁移、同步和订阅的平台化解决方案。它整合了网易过去在数据传输领域的各类工具和经验,将单机数据库、分布式数据库、OLAP系统以及下游应用通过数据链路串在一起。除了保障高效的数据传输外,NDC的设计遵守了单元化和平台化的设计哲学。
Logstash是开源的服务器端数据处理管线,能够同时从多个来源采集数据、转换数据,然后将数据发送到您最喜欢的 “存储库” 中。一般常用的储存库是Elasticsearch。Logstash 支持各类输入选择,可以在同一时间从众多常用的数据来源捕捉风波,能够以连续的流式传输方法,轻松地从您的日志、指标、Web 应用、数据储存以及各类 AWS 服务采集数据。
Sqoop,用来将关系型数据库和Hadoop中的数据进行互相转移的工具,可以将一个关系型数据库(例如Mysql、Oracle)中的数据导出到Hadoop(例如HDFS、Hive、Hbase)中,也可以将Hadoop(例如HDFS、Hive、Hbase)中的数据导出到关系型数据库(例如Mysql、Oracle)中。Sqoop 启用了一个 MapReduce 作业(极其容错的分布式并行估算)来执行任务。Sqoop 的另一大优势是其传输大量结构化或半结构化数据的过程是完全自动化的。
流式估算是行业研究的一个热点,流式估算对多个高吞吐量的数据源进行实时的清洗、聚合和剖析,可以对存在于社交网站、新闻等的数据信息流进行快速的处理并反馈,目前大数据流剖析工具有很多,比如开源的strom,spark streaming等。
Strom集群结构是有一个主节点(nimbus)和多个工作节点(supervisor)组成的主从结构,主节点通过配置静态指定或则在运行时动态补选,nimbus与supervisor都是Storm提供的后台守护进程,之间的通讯是结合Zookeeper的状态变更通知和监控通知来处理。nimbus进程的主要职责是管理、协调和监控集群上运行的topology(包括topology的发布、任务委派、事件处理时重新委派任务等)。supervisor进程等待nimbus分配任务后生成并监控worker(jvm进程)执行任务。supervisor与worker运行在不同的jvm上,如果由supervisor启动的某个worker由于错误异常退出(或被kill掉),supervisor会尝试重新生成新的worker进程。
当使用上游模块的数据进行估算、统计、分析时,就可以使用消息系统,尤其是分布式消息系统。Kafka使用Scala进行编撰,是一种分布式的、基于发布/订阅的消息系统。Kafka的设计理念之一就是同时提供离线处理和实时处理,以及将数据实时备份到另一个数据中心,Kafka可以有许多的生产者和消费者分享多个主题,将消息以topic为单位进行归纳;Kafka发布消息的程序称为producer,也叫生产者,预订topics并消费消息的程序称为consumer,也叫消费者;当Kafka以集群的形式运行时,可以由一个服务或则多个服务组成,每个服务称作一个broker,运行过程中producer通过网路将消息发送到Kafka集群,集群向消费者提供消息。Kafka通过Zookeeper管理集群配置,选举leader,以及在Consumer Group发生变化时进行rebalance。Producer使用push模式将消息发布到broker,Consumer使用pull模式从broker订阅并消费消息。Kafka可以和Flume一起工作,如果须要将流式数据从Kafka转移到hadoop,可以使用Flume代理agent,将Kafka当作一个来源source,这样可以从Kafka读取数据到Hadoop。
Zookeeper是一个分布式的,开放源码的分布式应用程序协调服务,提供数据同步服务。它的作用主要有配置管理、名字服务、分布式锁和集群管理。配置管理指的是在一个地方更改了配置,那么对这个地方的配置感兴趣的所有的都可以获得变更,省去了自动拷贝配置的冗长,还挺好的保证了数据的可靠和一致性,同时它可以通过名子来获取资源或则服务的地址等信息全网文章采集软件,可以监控集群中机器的变化全网文章采集软件,实现了类似于脉搏机制的功能。
二、数据储存
Hadoop作为一个开源的框架,专为离线和大规模数据剖析而设计,HDFS作为其核心的储存引擎,已被广泛用于数据储存。
HBase,是一个分布式的、面向列的开源数据库,可以觉得是hdfs的封装,本质是数据储存、NoSQL数据库。HBase是一种Key/Value系统,部署在hdfs上,克服了hdfs在随机读写这个方面的缺点,与hadoop一样,Hbase目标主要借助纵向扩充,通过不断降低廉价的商用服务器,来降低估算和储存能力。
Phoenix,相当于一个Java中间件,帮助开发工程师才能象使用JDBC访问关系型数据库一样访问NoSQL数据库HBase。
Yarn是一种Hadoop资源管理器,可为下层应用提供统一的资源管理和调度,它的引入为集群在利用率、资源统一管理和数据共享等方面带来了巨大益处。Yarn由下边的几大组件构成:一个全局的资源管理器ResourceManager、ResourceManager的每位节点代理NodeManager、表示每位应用的Application以及每一个ApplicationMaster拥有多个Container在NodeManager上运行。
Mesos是一款开源的集群管理软件,支持Hadoop、ElasticSearch、Spark、Storm 和Kafka等应用构架。
Redis是一种速率十分快的非关系数据库,可以储存键与5种不同类型的值之间的映射,可以将储存在显存的通配符对数据持久化到硬碟中,使用复制特点来扩充性能,还可以使用客户端分片来扩充写性能。
Atlas是一个坐落应用程序与MySQL之间的中间件。在前端DB看来,Atlas相当于联接它的客户端,在后端应用看来,Atlas相当于一个DB。Atlas作为服务端与应用程序通信,它实现了MySQL的客户端和服务端合同,同时作为客户端与MySQL通信。它对应用程序屏蔽了DB的细节,同时为了增加MySQL负担,它还维护了连接池。Atlas启动后会创建多个线程,其中一个为主线程,其余为工作线程。主线程负责窃听所有的客户端联接恳求,工作线程只窃听主线程的命令恳求。
Kudu是围绕Hadoop生态圈构建的储存引擎,Kudu拥有和Hadoop生态圈共同的设计理念,它运行在普通的服务器上、可分布式规模化布署、并且满足工业界的高可用要求。其设计理念为fast analytics on fast data。作为一个开源的储存引擎,可以同时提供低延后的随机读写和高效的数据剖析能力。Kudu不但提供了行级的插入、更新、删除API,同时也提供了接近Parquet性能的批量扫描操作。使用同一份储存,既可以进行随机读写,也可以满足数据剖析的要求。Kudu的应用场景太广泛,比如可以进行实时的数据剖析,用于数据可能会存在变化的时序数据应用等。
在数据储存过程中,涉及到的数据表都是成千上百列,包含各类复杂的Query,推荐使用列式储存方式,比如parquent,ORC等对数据进行压缩。Parquet 可以支持灵活的压缩选项,显著减低c盘上的储存。
三、数据清洗
MapReduce作为Hadoop的查询引擎,用于大规模数据集的并行估算,”Map(映射)”和”Reduce(归约)”,是它的主要思想。它极大的便捷了编程人员在不会分布式并行编程的情况下,将自己的程序运行在分布式系统中。
随着业务数据量的增多,需要进行训练和清洗的数据会显得越来越复杂,这个时侯就须要任务调度系统,比如oozie或则azkaban,对关键任务进行调度和监控。
Oozie是用于Hadoop平台的一种工作流调度引擎,提供了RESTful API接口来接受用户的递交恳求(提交工作流作业),当递交了workflow后,由工作流引擎负责workflow的执行以及状态的转换。用户在HDFS上布署好作业(MR作业),然后向Oozie递交Workflow,Oozie以异步方法将作业(MR作业)提交给Hadoop。这也是为何当调用Oozie 的RESTful插口递交作业以后能立刻返回一个JobId的缘由,用户程序毋须等待作业执行完成(因为有些大作业可能会执行许久(几个小时甚至几天))。Oozie在后台以异步方法,再将workflow对应的Action递交给hadoop执行。
Azkaban也是一种工作流的控制引擎,可以拿来解决有多个hadoop或则spark等离线估算任务之间的依赖关系问题。azkaban主要是由三部份构成:Relational Database,Azkaban Web Server和Azkaban Executor Server。azkaban将大多数的状态信息都保存在MySQL中,Azkaban Web Server提供了Web UI,是azkaban主要的管理者,包括project的管理、认证、调度以及对工作流执行过程中的监控等;Azkaban Executor Server拿来调度工作流和任务,记录工作流或则任务的日志。
流计算任务的处理平台Sloth,是网易首个自研流计算平台,旨在解决公司内各产品日渐下降的流计算需求。作为一个估算服务平台,其特征是易用、实时、可靠,为用户节约技术方面(开发、运维)的投入,帮助用户专注于解决产品本身的流计算需求。
四、数据查询剖析
Hive的核心工作就是把SQL句子翻译成MR程序,可以将结构化的数据映射为一张数据库表,并提供 HQL(Hive SQL)查询功能。Hive本身不储存和估算数据,它完全依赖于HDFS和MapReduce。可以将Hive理解为一个客户端工具,将SQL操作转换为相应的MapReduce jobs,然后在hadoop里面运行。Hive支持标准的SQL句型,免去了用户编撰MapReduce程序的过程,它的出现可以使这些精通SQL技能、但是不熟悉MapReduce 、编程能力较弱与不擅长Java语言的用户才能在HDFS大规模数据集上很方便地借助SQL 语言查询、汇总、分析数据。
Hive是为大数据批量处理而生的,Hive的出现解决了传统的关系型数据库(MySql、Oracle)在大数据处理上的困局 。Hive 将执行计划分成map->shuffle->reduce->map->shuffle->reduce…的模型。如果一个Query会被编译成多轮MapReduce,则会有更多的写中间结果。由于MapReduce执行框架本身的特性,过多的中间过程会降低整个Query的执行时间。在Hive的运行过程中,用户只须要创建表,导入数据,编写SQL剖析句子即可。剩下的过程由Hive框架手动的完成。
Impala是对Hive的一个补充,可以实现高效的SQL查询。使用Impala来实现SQL on Hadoop,用来进行大数据实时查询剖析。通过熟悉的传统关系型数据库的SQL风格来操作大数据,同时数据也是可以储存到HDFS和HBase中的。Impala没有再使用平缓的Hive+MapReduce批处理,而是通过使用与商用并行关系数据库中类似的分布式查询引擎(由Query Planner、Query Coordinator和Query Exec Engine三部份组成),可以直接从HDFS或HBase中用SELECT、JOIN和统计函数查询数据,从而大大增加了延后。Impala将整个查询分成一执行计划树,而不是一连串的MapReduce任务,相比Hive没了MapReduce启动时间。
Hive 适合于长时间的批处理查询剖析,而Impala适合于实时交互式SQL查询,Impala给数据人员提供了快速实验,验证看法的大数据剖析工具,可以先使用Hive进行数据转换处理,之后使用Impala在Hive处理好后的数据集上进行快速的数据剖析。总的来说:Impala把执行计划表现为一棵完整的执行计划树,可以更自然地分发执行计划到各个Impalad执行查询,而不用象Hive那样把它组合成管道型的map->reduce模式,以此保证Impala有更好的并发性和防止不必要的中间sort与shuffle。但是Impala不支持UDF,能处理的问题有一定的限制。
Spark拥有Hadoop MapReduce所具有的特征,它将Job中间输出结果保存在显存中,从而不需要读取HDFS。Spark 启用了显存分布数据集,除了才能提供交互式查询外,它还可以优化迭代工作负载。Spark 是在 Scala 语言中实现的,它将 Scala 用作其应用程序框架。与 Hadoop 不同,Spark 和 Scala 能够紧密集成,其中的 Scala 可以象操作本地集合对象一样轻松地操作分布式数据集。
Nutch 是一个开源Java 实现的搜索引擎。它提供了我们运行自己的搜索引擎所需的全部工具,包括全文搜索和Web爬虫。
Solr用Java编撰、运行在Servlet容器(如Apache Tomcat或Jetty)的一个独立的企业级搜索应用的全文搜索服务器。它对外提供类似于Web-service的API接口,用户可以通过http请求,向搜索引擎服务器递交一定格式的XML文件,生成索引;也可以通过Http Get操作提出查找恳求,并得到XML格式的返回结果。
Elasticsearch是一个开源的全文搜索引擎,基于Lucene的搜索服务器,可以快速的存储、搜索和剖析海量的数据。设计用于云估算中,能够达到实时搜索,稳定,可靠,快速,安装使用便捷。
还涉及到一些机器学习语言,比如,Mahout主要目标是创建一些可伸缩的机器学习算法,供开发人员在Apache的许可下免费使用;深度学习框架Caffe以及使用数据流图进行数值估算的开源软件库TensorFlow等,常用的机器学习算法例如,贝叶斯、逻辑回归、决策树、神经网路、协同过滤等。
五、数据可视化
对接一些BI平台,将剖析得到的数据进行可视化,用于指导决策服务。主流的BI平台例如,国外的敏捷BI Tableau、Qlikview、PowrerBI等,国内的SmallBI和新兴的网易有数(可点击这儿免费试用)等。
在前面的每一个阶段,保障数据的安全是不可忽略的问题。
基于网路身分认证的合同Kerberos,用来在非安全网路中,对个人通讯以安全的手段进行身分认证,它容许某实体在非安全网路环境下通讯,向另一个实体以一种安全的方法证明自己的身分。
控制权限的ranger是一个Hadoop集群权限框架,提供操作、监控、管理复杂的数据权限,它提供一个集中的管理机制,管理基于yarn的Hadoop生态圈的所有数据权限。可以对Hadoop生态的组件如Hive,Hbase进行细细度的数据访问控制。通过操作Ranger控制台,管理员可以轻松的通过配置策略来控制用户访问HDFS文件夹、HDFS文件、数据库、表、字段权限。这些策略可以为不同的用户和组来设置,同时权限可与hadoop无缝对接。
大数据技术栈概貌
博客
Java技术库房《Java程序员复习指南》
整合全网优质Java学习内容,帮助你从基础到进阶系统化备考Java
面试指南
全网最热的Java笔试手册,共200多页,非常实用,不管是用于备考还是打算笔试都是不错的。 查看全部
近几年,市场上出现了好多和大数据相关的岗位,不管是数据剖析、数据挖掘,或者是数据研制,都是围绕着大数据来做事情,那么,到底哪些是大数据,就是我们每一个要学习大数据技术的同学要了解的事情了,根据百度百科的介绍
大数据(big data),IT行业术语,是指未能在一定时间范围内用常规软件工具进行捕捉、管理和处理的数据集合,是须要新处理模式能够具有更强的决策力、洞察发觉力和流程优化能力的海量、高增长率和多元化的信息资产。
在维克托·迈尔-舍恩伯格及肯尼斯·库克耶编撰的《大数据时代》 [1] 中大数据指不用随机分析法(抽样调查)这样捷径,而采用所有数据进行剖析处理。大数据的5V特征(IBM提出):Volume(大量)、Velocity(高速)、Variety(多样)、Value(低价值密度)、Veracity(真实性)。 [2]思维导图
大数据的概念比较具象,而大数据技术栈的庞大程度将使你叹为观止。
大数据技术的体系庞大且复杂,基础的技术包含数据的采集、数据预处理、分布式存储、NoSQL数据库、数据库房、机器学习、并行估算、可视化等各类技术范畴和不同的技术层面。首先给出一个通用化的大数据处理框架,主要分为下边几个方面:数据采集与预处理、数据储存、数据清洗、数据查询剖析和数据可视化。
一、数据采集与预处理
对于各类来源的数据,包括联通互联网数据、社交网络的数据等,这些结构化和非结构化的海量数据是零散的,也就是所谓的数据孤岛,此时的那些数据并没有哪些意义,数据采集就是将这种数据写入数据库房中,把零散的数据整合在一起,对那些数据综合上去进行剖析。数据采集包括文件日志的采集、数据库日志的采集、关系型数据库的接入和应用程序的接入等。在数据量比较小的时侯,可以写个定时的脚本将日志写入储存系统,但随着数据量的下降,这些方式难以提供数据安全保障,并且运维困难,需要更健壮的解决方案。
Flume NG作为实时日志搜集系统,支持在日志系统中订制各种数据发送方,用于搜集数据,同时,对数据进行简单处理,并讲到各类数据接收方(比如文本,HDFS,Hbase等)。Flume NG采用的是三层架构:Agent层,Collector层和Store层,每一层均可水平拓展。其中Agent包含Source,Channel和 Sink,source拿来消费(收集)数据源到channel组件中,channel作为中间临时储存,保存所有source的组件信息,sink从channel中读取数据,读取成功以后会删掉channel中的信息。
NDC,Netease Data Canal,直译为网易数据运河系统,是网易针对结构化数据库的数据实时迁移、同步和订阅的平台化解决方案。它整合了网易过去在数据传输领域的各类工具和经验,将单机数据库、分布式数据库、OLAP系统以及下游应用通过数据链路串在一起。除了保障高效的数据传输外,NDC的设计遵守了单元化和平台化的设计哲学。
Logstash是开源的服务器端数据处理管线,能够同时从多个来源采集数据、转换数据,然后将数据发送到您最喜欢的 “存储库” 中。一般常用的储存库是Elasticsearch。Logstash 支持各类输入选择,可以在同一时间从众多常用的数据来源捕捉风波,能够以连续的流式传输方法,轻松地从您的日志、指标、Web 应用、数据储存以及各类 AWS 服务采集数据。
Sqoop,用来将关系型数据库和Hadoop中的数据进行互相转移的工具,可以将一个关系型数据库(例如Mysql、Oracle)中的数据导出到Hadoop(例如HDFS、Hive、Hbase)中,也可以将Hadoop(例如HDFS、Hive、Hbase)中的数据导出到关系型数据库(例如Mysql、Oracle)中。Sqoop 启用了一个 MapReduce 作业(极其容错的分布式并行估算)来执行任务。Sqoop 的另一大优势是其传输大量结构化或半结构化数据的过程是完全自动化的。
流式估算是行业研究的一个热点,流式估算对多个高吞吐量的数据源进行实时的清洗、聚合和剖析,可以对存在于社交网站、新闻等的数据信息流进行快速的处理并反馈,目前大数据流剖析工具有很多,比如开源的strom,spark streaming等。
Strom集群结构是有一个主节点(nimbus)和多个工作节点(supervisor)组成的主从结构,主节点通过配置静态指定或则在运行时动态补选,nimbus与supervisor都是Storm提供的后台守护进程,之间的通讯是结合Zookeeper的状态变更通知和监控通知来处理。nimbus进程的主要职责是管理、协调和监控集群上运行的topology(包括topology的发布、任务委派、事件处理时重新委派任务等)。supervisor进程等待nimbus分配任务后生成并监控worker(jvm进程)执行任务。supervisor与worker运行在不同的jvm上,如果由supervisor启动的某个worker由于错误异常退出(或被kill掉),supervisor会尝试重新生成新的worker进程。
当使用上游模块的数据进行估算、统计、分析时,就可以使用消息系统,尤其是分布式消息系统。Kafka使用Scala进行编撰,是一种分布式的、基于发布/订阅的消息系统。Kafka的设计理念之一就是同时提供离线处理和实时处理,以及将数据实时备份到另一个数据中心,Kafka可以有许多的生产者和消费者分享多个主题,将消息以topic为单位进行归纳;Kafka发布消息的程序称为producer,也叫生产者,预订topics并消费消息的程序称为consumer,也叫消费者;当Kafka以集群的形式运行时,可以由一个服务或则多个服务组成,每个服务称作一个broker,运行过程中producer通过网路将消息发送到Kafka集群,集群向消费者提供消息。Kafka通过Zookeeper管理集群配置,选举leader,以及在Consumer Group发生变化时进行rebalance。Producer使用push模式将消息发布到broker,Consumer使用pull模式从broker订阅并消费消息。Kafka可以和Flume一起工作,如果须要将流式数据从Kafka转移到hadoop,可以使用Flume代理agent,将Kafka当作一个来源source,这样可以从Kafka读取数据到Hadoop。
Zookeeper是一个分布式的,开放源码的分布式应用程序协调服务,提供数据同步服务。它的作用主要有配置管理、名字服务、分布式锁和集群管理。配置管理指的是在一个地方更改了配置,那么对这个地方的配置感兴趣的所有的都可以获得变更,省去了自动拷贝配置的冗长,还挺好的保证了数据的可靠和一致性,同时它可以通过名子来获取资源或则服务的地址等信息全网文章采集软件,可以监控集群中机器的变化全网文章采集软件,实现了类似于脉搏机制的功能。
二、数据储存
Hadoop作为一个开源的框架,专为离线和大规模数据剖析而设计,HDFS作为其核心的储存引擎,已被广泛用于数据储存。
HBase,是一个分布式的、面向列的开源数据库,可以觉得是hdfs的封装,本质是数据储存、NoSQL数据库。HBase是一种Key/Value系统,部署在hdfs上,克服了hdfs在随机读写这个方面的缺点,与hadoop一样,Hbase目标主要借助纵向扩充,通过不断降低廉价的商用服务器,来降低估算和储存能力。
Phoenix,相当于一个Java中间件,帮助开发工程师才能象使用JDBC访问关系型数据库一样访问NoSQL数据库HBase。
Yarn是一种Hadoop资源管理器,可为下层应用提供统一的资源管理和调度,它的引入为集群在利用率、资源统一管理和数据共享等方面带来了巨大益处。Yarn由下边的几大组件构成:一个全局的资源管理器ResourceManager、ResourceManager的每位节点代理NodeManager、表示每位应用的Application以及每一个ApplicationMaster拥有多个Container在NodeManager上运行。
Mesos是一款开源的集群管理软件,支持Hadoop、ElasticSearch、Spark、Storm 和Kafka等应用构架。
Redis是一种速率十分快的非关系数据库,可以储存键与5种不同类型的值之间的映射,可以将储存在显存的通配符对数据持久化到硬碟中,使用复制特点来扩充性能,还可以使用客户端分片来扩充写性能。
Atlas是一个坐落应用程序与MySQL之间的中间件。在前端DB看来,Atlas相当于联接它的客户端,在后端应用看来,Atlas相当于一个DB。Atlas作为服务端与应用程序通信,它实现了MySQL的客户端和服务端合同,同时作为客户端与MySQL通信。它对应用程序屏蔽了DB的细节,同时为了增加MySQL负担,它还维护了连接池。Atlas启动后会创建多个线程,其中一个为主线程,其余为工作线程。主线程负责窃听所有的客户端联接恳求,工作线程只窃听主线程的命令恳求。
Kudu是围绕Hadoop生态圈构建的储存引擎,Kudu拥有和Hadoop生态圈共同的设计理念,它运行在普通的服务器上、可分布式规模化布署、并且满足工业界的高可用要求。其设计理念为fast analytics on fast data。作为一个开源的储存引擎,可以同时提供低延后的随机读写和高效的数据剖析能力。Kudu不但提供了行级的插入、更新、删除API,同时也提供了接近Parquet性能的批量扫描操作。使用同一份储存,既可以进行随机读写,也可以满足数据剖析的要求。Kudu的应用场景太广泛,比如可以进行实时的数据剖析,用于数据可能会存在变化的时序数据应用等。
在数据储存过程中,涉及到的数据表都是成千上百列,包含各类复杂的Query,推荐使用列式储存方式,比如parquent,ORC等对数据进行压缩。Parquet 可以支持灵活的压缩选项,显著减低c盘上的储存。
三、数据清洗
MapReduce作为Hadoop的查询引擎,用于大规模数据集的并行估算,”Map(映射)”和”Reduce(归约)”,是它的主要思想。它极大的便捷了编程人员在不会分布式并行编程的情况下,将自己的程序运行在分布式系统中。
随着业务数据量的增多,需要进行训练和清洗的数据会显得越来越复杂,这个时侯就须要任务调度系统,比如oozie或则azkaban,对关键任务进行调度和监控。
Oozie是用于Hadoop平台的一种工作流调度引擎,提供了RESTful API接口来接受用户的递交恳求(提交工作流作业),当递交了workflow后,由工作流引擎负责workflow的执行以及状态的转换。用户在HDFS上布署好作业(MR作业),然后向Oozie递交Workflow,Oozie以异步方法将作业(MR作业)提交给Hadoop。这也是为何当调用Oozie 的RESTful插口递交作业以后能立刻返回一个JobId的缘由,用户程序毋须等待作业执行完成(因为有些大作业可能会执行许久(几个小时甚至几天))。Oozie在后台以异步方法,再将workflow对应的Action递交给hadoop执行。
Azkaban也是一种工作流的控制引擎,可以拿来解决有多个hadoop或则spark等离线估算任务之间的依赖关系问题。azkaban主要是由三部份构成:Relational Database,Azkaban Web Server和Azkaban Executor Server。azkaban将大多数的状态信息都保存在MySQL中,Azkaban Web Server提供了Web UI,是azkaban主要的管理者,包括project的管理、认证、调度以及对工作流执行过程中的监控等;Azkaban Executor Server拿来调度工作流和任务,记录工作流或则任务的日志。
流计算任务的处理平台Sloth,是网易首个自研流计算平台,旨在解决公司内各产品日渐下降的流计算需求。作为一个估算服务平台,其特征是易用、实时、可靠,为用户节约技术方面(开发、运维)的投入,帮助用户专注于解决产品本身的流计算需求。
四、数据查询剖析
Hive的核心工作就是把SQL句子翻译成MR程序,可以将结构化的数据映射为一张数据库表,并提供 HQL(Hive SQL)查询功能。Hive本身不储存和估算数据,它完全依赖于HDFS和MapReduce。可以将Hive理解为一个客户端工具,将SQL操作转换为相应的MapReduce jobs,然后在hadoop里面运行。Hive支持标准的SQL句型,免去了用户编撰MapReduce程序的过程,它的出现可以使这些精通SQL技能、但是不熟悉MapReduce 、编程能力较弱与不擅长Java语言的用户才能在HDFS大规模数据集上很方便地借助SQL 语言查询、汇总、分析数据。
Hive是为大数据批量处理而生的,Hive的出现解决了传统的关系型数据库(MySql、Oracle)在大数据处理上的困局 。Hive 将执行计划分成map->shuffle->reduce->map->shuffle->reduce…的模型。如果一个Query会被编译成多轮MapReduce,则会有更多的写中间结果。由于MapReduce执行框架本身的特性,过多的中间过程会降低整个Query的执行时间。在Hive的运行过程中,用户只须要创建表,导入数据,编写SQL剖析句子即可。剩下的过程由Hive框架手动的完成。
Impala是对Hive的一个补充,可以实现高效的SQL查询。使用Impala来实现SQL on Hadoop,用来进行大数据实时查询剖析。通过熟悉的传统关系型数据库的SQL风格来操作大数据,同时数据也是可以储存到HDFS和HBase中的。Impala没有再使用平缓的Hive+MapReduce批处理,而是通过使用与商用并行关系数据库中类似的分布式查询引擎(由Query Planner、Query Coordinator和Query Exec Engine三部份组成),可以直接从HDFS或HBase中用SELECT、JOIN和统计函数查询数据,从而大大增加了延后。Impala将整个查询分成一执行计划树,而不是一连串的MapReduce任务,相比Hive没了MapReduce启动时间。
Hive 适合于长时间的批处理查询剖析,而Impala适合于实时交互式SQL查询,Impala给数据人员提供了快速实验,验证看法的大数据剖析工具,可以先使用Hive进行数据转换处理,之后使用Impala在Hive处理好后的数据集上进行快速的数据剖析。总的来说:Impala把执行计划表现为一棵完整的执行计划树,可以更自然地分发执行计划到各个Impalad执行查询,而不用象Hive那样把它组合成管道型的map->reduce模式,以此保证Impala有更好的并发性和防止不必要的中间sort与shuffle。但是Impala不支持UDF,能处理的问题有一定的限制。
Spark拥有Hadoop MapReduce所具有的特征,它将Job中间输出结果保存在显存中,从而不需要读取HDFS。Spark 启用了显存分布数据集,除了才能提供交互式查询外,它还可以优化迭代工作负载。Spark 是在 Scala 语言中实现的,它将 Scala 用作其应用程序框架。与 Hadoop 不同,Spark 和 Scala 能够紧密集成,其中的 Scala 可以象操作本地集合对象一样轻松地操作分布式数据集。
Nutch 是一个开源Java 实现的搜索引擎。它提供了我们运行自己的搜索引擎所需的全部工具,包括全文搜索和Web爬虫。
Solr用Java编撰、运行在Servlet容器(如Apache Tomcat或Jetty)的一个独立的企业级搜索应用的全文搜索服务器。它对外提供类似于Web-service的API接口,用户可以通过http请求,向搜索引擎服务器递交一定格式的XML文件,生成索引;也可以通过Http Get操作提出查找恳求,并得到XML格式的返回结果。
Elasticsearch是一个开源的全文搜索引擎,基于Lucene的搜索服务器,可以快速的存储、搜索和剖析海量的数据。设计用于云估算中,能够达到实时搜索,稳定,可靠,快速,安装使用便捷。
还涉及到一些机器学习语言,比如,Mahout主要目标是创建一些可伸缩的机器学习算法,供开发人员在Apache的许可下免费使用;深度学习框架Caffe以及使用数据流图进行数值估算的开源软件库TensorFlow等,常用的机器学习算法例如,贝叶斯、逻辑回归、决策树、神经网路、协同过滤等。
五、数据可视化
对接一些BI平台,将剖析得到的数据进行可视化,用于指导决策服务。主流的BI平台例如,国外的敏捷BI Tableau、Qlikview、PowrerBI等,国内的SmallBI和新兴的网易有数(可点击这儿免费试用)等。
在前面的每一个阶段,保障数据的安全是不可忽略的问题。
基于网路身分认证的合同Kerberos,用来在非安全网路中,对个人通讯以安全的手段进行身分认证,它容许某实体在非安全网路环境下通讯,向另一个实体以一种安全的方法证明自己的身分。
控制权限的ranger是一个Hadoop集群权限框架,提供操作、监控、管理复杂的数据权限,它提供一个集中的管理机制,管理基于yarn的Hadoop生态圈的所有数据权限。可以对Hadoop生态的组件如Hive,Hbase进行细细度的数据访问控制。通过操作Ranger控制台,管理员可以轻松的通过配置策略来控制用户访问HDFS文件夹、HDFS文件、数据库、表、字段权限。这些策略可以为不同的用户和组来设置,同时权限可与hadoop无缝对接。
大数据技术栈概貌
博客Java技术库房《Java程序员复习指南》
整合全网优质Java学习内容,帮助你从基础到进阶系统化备考Java
面试指南
全网最热的Java笔试手册,共200多页,非常实用,不管是用于备考还是打算笔试都是不错的。
河西区淘宝托管淘宝天猫代营运多少钱
采集交流 • 优采云 发表了文章 • 0 个评论 • 377 次浏览 • 2020-03-31 11:08
河西区淘宝托管淘宝天猫代营运多少钱把落地页或则线下入口缺点4:数据漏采错踩以上都还是好的,让人费解的是,上线了,发现数据采集错了或则漏了,修正后,又得重新跑一遍流程,一个星期两个星期有过去了。这里就不细展开。
图5原始数据上报储存到文件的构架图数据储存到文件以后,第二步就步入到ETL的环节,ETL就是指通过抽取(extract)、转换(tranorm)、加载(load)把日志从文本中,基于剖析的需求和数据经度进行清洗,然后储存在数据库房中。
以腾讯为反例,腾讯大数据平台现今主要从离线和实时两个方向支撑海量数据接入和处理,核心的系统包括TDW、TRC和TDbank。
图6腾讯数据平台系统在腾讯内部,数据的数据搜集、分发、预处理和管理工作,都是通过一个TDBank的平台来实现的。餐厅以自己喝的虾自己钓为特色
对于互联网与民航的结合、互联网产品有较深入的了解且持续关注中。
河西区淘宝托管淘宝天猫代营运多少钱
整个平台主要解决在大数据量下边数据搜集和处理的量大、实时、多样的问题。
通过数据接入层、处理层和储存层这样的三层架构来统一解决接入和储存的问题。
(1)接入层接入层可以支持各类格式的业务数据和数据源,包括不同的DB、文件格式、消息数据等。
数据接入层会将搜集到的各类数据统一成一种内部的数据合同文章采集插件,方便后续数据处理系统使用。
(2)处理层接下来处理层用插件化的方式来支持多种形式的数据预处理过程。
对于离线系统来说,这么多新鲜的网红产品络绎不绝的上架到市场上
一个重要的功能是将实时采集到的数据进行分类储存,需要根据个别维度(比如某个key值+时间等维度)进行分类储存,同时储存文件的细度(大小/时间)也是须要订制的,使离线系统能以指定的的细度来进行离线估算。
对于在线系统来说,常见的预处理过程如数据过滤、数据取样和数据转换等。
(3)数据储存层处理后的数据,使用HDFS作为离线文件的储存载体。
数据储存整体上是的,然后终把这部份处理后的数据,入库到腾讯内部的分布式数据库房TDW。
图7TDW构架图TDBank是从业务数据源端实时采集数据,节目即将播于1998年英国独立电视台
如果是正常情况下,某一个渠道应当是稳定的,不会出现这个渠道就是比别的渠道不看文章的人多这样的特性。
河西区淘宝托管淘宝天猫代营运多少钱
进行预处理和分布式消息缓存后,按照消息订阅的方法,分发给前端的离线和在线处理系统。
图8TDBank数据采集与接入系统TDBank建立数据源和数据处理系统间的桥梁,将数据处理系统同数据源前馈,为离线估算TDW和在线估算TRC平台提供数据支持。
目前通过不断的改进,将原先Linux+HDFS的模式,转变为集群+分布式消息队列的模式,将原先三天就能处理的消息量减短到2秒钟。从实际应用来看,TikTok也会急聘一些在读大学的留学生
产品在考虑数据采集和接入的时侯,主要要关心几个经度的问题l多个数据源的统一,一般实际的应用过程中,都存在不同的数据格式来源,这个时侯,采集和接入这部份,需要把这种数据源进行统一的转化。
l采集的实时高效,由于大部分系统都是在线系统,对于数据采集的时效性要求会比较高。
l脏数据处理,对于一些会影响整个剖析统计的脏数据,需要在接入层的时侯进行逻辑屏蔽,避免前面统计剖析和应用的时侯,由于这部份数据引起好多不可预知的问题。
2.数据的储存与估算完成数据上报和采集和接入以后,口碑营销风波营销软文营销这种在网路营销中常用的营销方法在庄园营运方面同样适用
2014年月底文章采集插件,滴滴打车首推全新的方法——打车红包。
河西区淘宝托管淘宝天猫代营运多少钱
数据就步入储存的环节,继续以腾讯为例。
在腾讯内部,有个分布式的数据库房拿来储存数据,内部代号称作TDW,它支持百PB级数据的离线储存和估算,为业务提供海量、高效、稳定的大数据平台支撑和决策支持。
基于开源软件Hadoop和Hive进行完善,并且依照公司数据量大、计算复杂等特定情况进行了大量优化和整修。
从对外公布的资料来看,TDW基于开源软件hadoop和hive进行了大量优化和改建,已成为腾讯大的离线数据处理平台,集群各种机器总量5000台,总储存突破20PB,日均估算量超过500TB,覆盖腾讯公司90%以上的业务产品,包含广点通推荐,用户画像,数据挖掘和各种业务报表等,都是通过这个平台来提供基础能力。
图9,腾讯TDW分布式数据库房图10TDW业务示意图从实际应用来看,数据储存这部份主要考虑几个问题,l数据安全性,很多数据是不可恢复的,所以数据储存的永远是重要的。App营运在为新产品做预热时,可以自建产品社区(贴吧、、话题小组等)或社群(微信群、QQ群等),聚集一些种子用户,为产品上线做好预热。打磨好的产品 查看全部
河西区淘宝托管淘宝天猫代营运多少钱把落地页或则线下入口缺点4:数据漏采错踩以上都还是好的,让人费解的是,上线了,发现数据采集错了或则漏了,修正后,又得重新跑一遍流程,一个星期两个星期有过去了。这里就不细展开。
图5原始数据上报储存到文件的构架图数据储存到文件以后,第二步就步入到ETL的环节,ETL就是指通过抽取(extract)、转换(tranorm)、加载(load)把日志从文本中,基于剖析的需求和数据经度进行清洗,然后储存在数据库房中。
以腾讯为反例,腾讯大数据平台现今主要从离线和实时两个方向支撑海量数据接入和处理,核心的系统包括TDW、TRC和TDbank。
图6腾讯数据平台系统在腾讯内部,数据的数据搜集、分发、预处理和管理工作,都是通过一个TDBank的平台来实现的。餐厅以自己喝的虾自己钓为特色
对于互联网与民航的结合、互联网产品有较深入的了解且持续关注中。
河西区淘宝托管淘宝天猫代营运多少钱
整个平台主要解决在大数据量下边数据搜集和处理的量大、实时、多样的问题。
通过数据接入层、处理层和储存层这样的三层架构来统一解决接入和储存的问题。
(1)接入层接入层可以支持各类格式的业务数据和数据源,包括不同的DB、文件格式、消息数据等。
数据接入层会将搜集到的各类数据统一成一种内部的数据合同文章采集插件,方便后续数据处理系统使用。
(2)处理层接下来处理层用插件化的方式来支持多种形式的数据预处理过程。
对于离线系统来说,这么多新鲜的网红产品络绎不绝的上架到市场上
一个重要的功能是将实时采集到的数据进行分类储存,需要根据个别维度(比如某个key值+时间等维度)进行分类储存,同时储存文件的细度(大小/时间)也是须要订制的,使离线系统能以指定的的细度来进行离线估算。
对于在线系统来说,常见的预处理过程如数据过滤、数据取样和数据转换等。
(3)数据储存层处理后的数据,使用HDFS作为离线文件的储存载体。
数据储存整体上是的,然后终把这部份处理后的数据,入库到腾讯内部的分布式数据库房TDW。
图7TDW构架图TDBank是从业务数据源端实时采集数据,节目即将播于1998年英国独立电视台
如果是正常情况下,某一个渠道应当是稳定的,不会出现这个渠道就是比别的渠道不看文章的人多这样的特性。
河西区淘宝托管淘宝天猫代营运多少钱
进行预处理和分布式消息缓存后,按照消息订阅的方法,分发给前端的离线和在线处理系统。
图8TDBank数据采集与接入系统TDBank建立数据源和数据处理系统间的桥梁,将数据处理系统同数据源前馈,为离线估算TDW和在线估算TRC平台提供数据支持。
目前通过不断的改进,将原先Linux+HDFS的模式,转变为集群+分布式消息队列的模式,将原先三天就能处理的消息量减短到2秒钟。从实际应用来看,TikTok也会急聘一些在读大学的留学生
产品在考虑数据采集和接入的时侯,主要要关心几个经度的问题l多个数据源的统一,一般实际的应用过程中,都存在不同的数据格式来源,这个时侯,采集和接入这部份,需要把这种数据源进行统一的转化。
l采集的实时高效,由于大部分系统都是在线系统,对于数据采集的时效性要求会比较高。
l脏数据处理,对于一些会影响整个剖析统计的脏数据,需要在接入层的时侯进行逻辑屏蔽,避免前面统计剖析和应用的时侯,由于这部份数据引起好多不可预知的问题。
2.数据的储存与估算完成数据上报和采集和接入以后,口碑营销风波营销软文营销这种在网路营销中常用的营销方法在庄园营运方面同样适用
2014年月底文章采集插件,滴滴打车首推全新的方法——打车红包。
河西区淘宝托管淘宝天猫代营运多少钱
数据就步入储存的环节,继续以腾讯为例。
在腾讯内部,有个分布式的数据库房拿来储存数据,内部代号称作TDW,它支持百PB级数据的离线储存和估算,为业务提供海量、高效、稳定的大数据平台支撑和决策支持。
基于开源软件Hadoop和Hive进行完善,并且依照公司数据量大、计算复杂等特定情况进行了大量优化和整修。
从对外公布的资料来看,TDW基于开源软件hadoop和hive进行了大量优化和改建,已成为腾讯大的离线数据处理平台,集群各种机器总量5000台,总储存突破20PB,日均估算量超过500TB,覆盖腾讯公司90%以上的业务产品,包含广点通推荐,用户画像,数据挖掘和各种业务报表等,都是通过这个平台来提供基础能力。
图9,腾讯TDW分布式数据库房图10TDW业务示意图从实际应用来看,数据储存这部份主要考虑几个问题,l数据安全性,很多数据是不可恢复的,所以数据储存的永远是重要的。App营运在为新产品做预热时,可以自建产品社区(贴吧、、话题小组等)或社群(微信群、QQ群等),聚集一些种子用户,为产品上线做好预热。打磨好的产品
物证管理软件哪些价钱
采集交流 • 优采云 发表了文章 • 0 个评论 • 318 次浏览 • 2020-03-31 11:08
其接入方法主要包含系统对接与爬虫采集两种形式。
系统对接方法运行须要依赖数据抽取前置机与中心插口服务器,爬虫采集方式须要布署分步式爬虫专用服务器。
.采集前置机:解决后置数据抽取问题,并将数据从抽取处发向中心插口服务器。
.数据插口服务器:为数据采集前置机提供数据接收服务器,解决数据集中化处理问题。他举例说
自此,我们始终紧密剖析相关信息,以尽早辨识受影响的人士及确认信息是否可被重建。
物证管理软件哪些价钱
.分步式爬虫服务器:用于布署分步式爬虫系统,解决采集互联网资源的问题。
二.数据清洗转换服务器放在数据插口服务器与爬虫服务器以后,用于解决数据的清洗转换问题。
三.分步式储存服务器用于解决大规模数据储存问题,将数据进行分片储存,可靠与可用性。
四.并行剖析服务器对分步式储存系统的数据进行并行剖析,解决大规模数据的剖析,挖掘问题。
五.硬盘数据库服务器用于布署分数据库,解决高并发在线数据服务问题。如果支持文件类型
六.内存数据库服务器用于布署分步式内存数据库系统。
七.服务器(展现,应用,共享,运营)用于布署数据共享文章采集软件,应用,展现,运营,监控等系统。
解决大数据平台对外服务问题。
存储资源数据存数主要包含结构化数据储存,半结构化数据储存,非结构化数据储存等方大类数据的储存,初期提供可储存数据的c盘,后期按照业务的发展可考虑提供级储存c盘。
备份资源早期提供备份c盘,对大数据平台的关键数据进行备份,备份可考虑使用第三方数据服务机构的异地备份服务。超过万名顾客的电子邮件地址和密码失窃
回忆这个决定时称,宣布关掉是因为要维持满足消费者期望的成功产品面临重大的挑战,而且该平台的使用率太低。
物证管理软件哪些价钱
网络资源.内部网路:满足内部服务间交换数据,千兆或以上网路联接内部集群服务器。
.对外服务网路:满足大数据平台对外服务需求,或以上网路网路。
.数据插口服务网路:满足数据插口传输需求,或以上网路网路。
.爬虫专用网路:满足爬虫采集互联网资源,或以上网路网路。
一,解决“坐井观天”问题月球各,地区之间的关联性早已越来越强,打破数据行业堡垒,引入外部数据源,进行多源数据凝聚融合,可以突破目前因为视野的局限性而硬性割裂事物间联系的窘境,大数据平台将一座座孤立的井,连片成海。
二,解决“一叶障目”的问题因为估算能力限制,我们只处理了我们觉得重要的“叶”而可能漏掉了实际更重要的“泰山”。
大数据使用全本数据文章采集软件,得到结果更为,更接近事物“泰山”。
依靠大数据平台得到的大数据剖析结果将一定程度上纠正过去人们对事物片面的认识,给人们带来全新的认知。
三,解决“瞎子摸象”的问题客观世界各事物是互相联系,不同业务系统存在因人为建模将这种内在联系忽略,因估算能力人为割裂的现象。表示,虽然这对开发者形成影响,但微软仍希望确保对用户的保护。来吸引消费者 查看全部
其接入方法主要包含系统对接与爬虫采集两种形式。
系统对接方法运行须要依赖数据抽取前置机与中心插口服务器,爬虫采集方式须要布署分步式爬虫专用服务器。
.采集前置机:解决后置数据抽取问题,并将数据从抽取处发向中心插口服务器。
.数据插口服务器:为数据采集前置机提供数据接收服务器,解决数据集中化处理问题。他举例说
自此,我们始终紧密剖析相关信息,以尽早辨识受影响的人士及确认信息是否可被重建。
物证管理软件哪些价钱
.分步式爬虫服务器:用于布署分步式爬虫系统,解决采集互联网资源的问题。
二.数据清洗转换服务器放在数据插口服务器与爬虫服务器以后,用于解决数据的清洗转换问题。
三.分步式储存服务器用于解决大规模数据储存问题,将数据进行分片储存,可靠与可用性。
四.并行剖析服务器对分步式储存系统的数据进行并行剖析,解决大规模数据的剖析,挖掘问题。
五.硬盘数据库服务器用于布署分数据库,解决高并发在线数据服务问题。如果支持文件类型
六.内存数据库服务器用于布署分步式内存数据库系统。
七.服务器(展现,应用,共享,运营)用于布署数据共享文章采集软件,应用,展现,运营,监控等系统。
解决大数据平台对外服务问题。
存储资源数据存数主要包含结构化数据储存,半结构化数据储存,非结构化数据储存等方大类数据的储存,初期提供可储存数据的c盘,后期按照业务的发展可考虑提供级储存c盘。
备份资源早期提供备份c盘,对大数据平台的关键数据进行备份,备份可考虑使用第三方数据服务机构的异地备份服务。超过万名顾客的电子邮件地址和密码失窃
回忆这个决定时称,宣布关掉是因为要维持满足消费者期望的成功产品面临重大的挑战,而且该平台的使用率太低。
物证管理软件哪些价钱
网络资源.内部网路:满足内部服务间交换数据,千兆或以上网路联接内部集群服务器。
.对外服务网路:满足大数据平台对外服务需求,或以上网路网路。
.数据插口服务网路:满足数据插口传输需求,或以上网路网路。
.爬虫专用网路:满足爬虫采集互联网资源,或以上网路网路。
一,解决“坐井观天”问题月球各,地区之间的关联性早已越来越强,打破数据行业堡垒,引入外部数据源,进行多源数据凝聚融合,可以突破目前因为视野的局限性而硬性割裂事物间联系的窘境,大数据平台将一座座孤立的井,连片成海。
二,解决“一叶障目”的问题因为估算能力限制,我们只处理了我们觉得重要的“叶”而可能漏掉了实际更重要的“泰山”。
大数据使用全本数据文章采集软件,得到结果更为,更接近事物“泰山”。
依靠大数据平台得到的大数据剖析结果将一定程度上纠正过去人们对事物片面的认识,给人们带来全新的认知。
三,解决“瞎子摸象”的问题客观世界各事物是互相联系,不同业务系统存在因人为建模将这种内在联系忽略,因估算能力人为割裂的现象。表示,虽然这对开发者形成影响,但微软仍希望确保对用户的保护。来吸引消费者
山东电力数据采集系统项目 淄博创银供应
采集交流 • 优采云 发表了文章 • 0 个评论 • 596 次浏览 • 2020-03-30 14:00
数据采集系统包括了:可视化的报表定义、审核关系的定义、报表的审批和发布、数据补报、数据预处理、数据评审、综合查询统计等功能模块。通过信息采集网络化和数字化,扩大数据采集的覆盖范围,提高初审工作的周密性、及时性和准确性;最终实现相关业务工作管理现代化、程序规范化、决策科学化,服务网络化。我国中小容量机组(200MW及以下)在火电厂中占相当大的比列,这些机组的监控模式为模拟控制系统加以常规仪表为主的数据采集系统。这种监控模式存在着检修维护工作量大、没有可靠的历史记录等缺点。而且常规模拟仪表也步入老化淘汰期,设备可靠性显著增加,某些仪表的备品备件也得不到保障,因此中小型机组监控系统的技术改造工作已势在必行。结合我国国情,借鉴国外类似系统的研发经验,开发出一套经济实用的FDC-Ⅱ型分布式发电厂运行实时数据检测系统,既可用于中小机组技术改造,山东电力数据采集系统项目,山东电力数据采集系统项目,又可应用于变电站,山东电力数据采集系统项目、供电局等电力生产、管理部门。该系统已在山东省某150MW火力发电厂投入实际运行。
我国国产机组热控装置的质量和主辅机的可控性不尽人意,设计、安装、调试、运行水平等都存在一些问题,针对这一现况设计了FDC-Ⅱ型分布式发电厂运行实时数据检测系统。它是只有监视功能而没有控制功能的计算机监视系统文章采集软件,即数据采集系统——DAS。数据采集系统可以采集的发电厂运行数据包括电气参数和非电气参数两类。其中电气参数主要有电压、电压、功率、频率等模拟量,断路器状态、隔离开关位置、继电保护动作讯号等开关量以及表示电度的脉冲量等。而非电气参数种类较多,既可以是采集火力发电厂运行中的各类气温、压力、流量等热工讯号,也可有水电厂中的水位、流速、流量等水工讯号,还可以采集诸如绝缘介质状态、气象环境等其它讯号。数据采集系统还包括用VisualC++开发的后台处理软件,主要有数据处理、数据库管理、实时监视、异常处理、统计估算及报表、性能剖析及运行指导等功能。
主要功能·实时采集来自生产线的产值数据或是不良品的数目、或是生产线的故障类型(如停线、缺料、品质),并传输到数据库系统中;·接收来自数据库的信息:如生产计划信息、物料信息等;·传输检测工位的不良品名称及数目信息;·连接测量仪器,实现测量仪器数字化,数据采集仪手动从检测仪器中获取检测数据,进行记录文章采集软件,分析估算,形成相应的各种图形,对检测结果进行手动判定,如在机械加工零部件的跳动检测,拉力计拉力曲线的勾画等; 查看全部
数据采集系统包括了:可视化的报表定义、审核关系的定义、报表的审批和发布、数据补报、数据预处理、数据评审、综合查询统计等功能模块。通过信息采集网络化和数字化,扩大数据采集的覆盖范围,提高初审工作的周密性、及时性和准确性;最终实现相关业务工作管理现代化、程序规范化、决策科学化,服务网络化。我国中小容量机组(200MW及以下)在火电厂中占相当大的比列,这些机组的监控模式为模拟控制系统加以常规仪表为主的数据采集系统。这种监控模式存在着检修维护工作量大、没有可靠的历史记录等缺点。而且常规模拟仪表也步入老化淘汰期,设备可靠性显著增加,某些仪表的备品备件也得不到保障,因此中小型机组监控系统的技术改造工作已势在必行。结合我国国情,借鉴国外类似系统的研发经验,开发出一套经济实用的FDC-Ⅱ型分布式发电厂运行实时数据检测系统,既可用于中小机组技术改造,山东电力数据采集系统项目,山东电力数据采集系统项目,又可应用于变电站,山东电力数据采集系统项目、供电局等电力生产、管理部门。该系统已在山东省某150MW火力发电厂投入实际运行。
我国国产机组热控装置的质量和主辅机的可控性不尽人意,设计、安装、调试、运行水平等都存在一些问题,针对这一现况设计了FDC-Ⅱ型分布式发电厂运行实时数据检测系统。它是只有监视功能而没有控制功能的计算机监视系统文章采集软件,即数据采集系统——DAS。数据采集系统可以采集的发电厂运行数据包括电气参数和非电气参数两类。其中电气参数主要有电压、电压、功率、频率等模拟量,断路器状态、隔离开关位置、继电保护动作讯号等开关量以及表示电度的脉冲量等。而非电气参数种类较多,既可以是采集火力发电厂运行中的各类气温、压力、流量等热工讯号,也可有水电厂中的水位、流速、流量等水工讯号,还可以采集诸如绝缘介质状态、气象环境等其它讯号。数据采集系统还包括用VisualC++开发的后台处理软件,主要有数据处理、数据库管理、实时监视、异常处理、统计估算及报表、性能剖析及运行指导等功能。
主要功能·实时采集来自生产线的产值数据或是不良品的数目、或是生产线的故障类型(如停线、缺料、品质),并传输到数据库系统中;·接收来自数据库的信息:如生产计划信息、物料信息等;·传输检测工位的不良品名称及数目信息;·连接测量仪器,实现测量仪器数字化,数据采集仪手动从检测仪器中获取检测数据,进行记录文章采集软件,分析估算,形成相应的各种图形,对检测结果进行手动判定,如在机械加工零部件的跳动检测,拉力计拉力曲线的勾画等;

