
可采集文章
ui自学网,ui设计培训设计助手|咏梅ui教程
采集交流 • 优采云 发表了文章 • 0 个评论 • 178 次浏览 • 2021-08-05 00:04
可采集文章、音频、视频请关注“咏梅ui教程”公众号,回复:关键词即可免费获取!ui自学网,ui教程,ui设计培训,ui设计工作,ui设计新手教程,ui设计师培训,ui设计职业培训ui教程ui设计助手|ui设计师|产品ui|界面ui|网页ui|图标ui自学网【教程】ps特效素材手机屏幕显示特效ps特效素材手机屏幕显示特效ps特效素材手机屏幕显示特效设计必备:花瓣网,千图网,昵图网,、素材网站千图网,千库网素材网站(包含软件素材,作品素材,素材网站中排名靠前都比较好,里面有素材可以看一下,有免费试用一个小时的素材功能)插画与c4d素材ui设计必备:一个全球顶尖的设计网站!希望可以帮到你,谢谢!。
选择最靠谱的,没有最靠谱的。靠谱不靠谱的和你的工作与专业没有太大关系。国内好不好不清楚,国外的网站还是不错的,googleremotedesign可以访问国外的网站,尤其是ui和c4d,和流体动画领域。
推荐几个ui设计网站给你:站酷:有中国传统文化底蕴的视觉艺术氛围,提供综合全面的优秀设计作品欣赏,优秀设计师交流、学习、分享,在此可以与顶尖的设计人才交流,学习,分享。中国优秀网页设计网站集合了国内外设计师网页设计界顶尖人物的作品集合.vi网:展示了国内外最新前沿设计趋势的资讯网站.aaa教育:综合的设计素材网站,工具类网站,品牌价值观好,尤其对工业设计,平面设计,ui设计是国内的三大特色教育网站.网易:工业界最大的用户体验设计和体验网站.simpletech:ui设计前沿平台,设计界最快捷最好用的设计网站。 查看全部
ui自学网,ui设计培训设计助手|咏梅ui教程
可采集文章、音频、视频请关注“咏梅ui教程”公众号,回复:关键词即可免费获取!ui自学网,ui教程,ui设计培训,ui设计工作,ui设计新手教程,ui设计师培训,ui设计职业培训ui教程ui设计助手|ui设计师|产品ui|界面ui|网页ui|图标ui自学网【教程】ps特效素材手机屏幕显示特效ps特效素材手机屏幕显示特效ps特效素材手机屏幕显示特效设计必备:花瓣网,千图网,昵图网,、素材网站千图网,千库网素材网站(包含软件素材,作品素材,素材网站中排名靠前都比较好,里面有素材可以看一下,有免费试用一个小时的素材功能)插画与c4d素材ui设计必备:一个全球顶尖的设计网站!希望可以帮到你,谢谢!。
选择最靠谱的,没有最靠谱的。靠谱不靠谱的和你的工作与专业没有太大关系。国内好不好不清楚,国外的网站还是不错的,googleremotedesign可以访问国外的网站,尤其是ui和c4d,和流体动画领域。
推荐几个ui设计网站给你:站酷:有中国传统文化底蕴的视觉艺术氛围,提供综合全面的优秀设计作品欣赏,优秀设计师交流、学习、分享,在此可以与顶尖的设计人才交流,学习,分享。中国优秀网页设计网站集合了国内外设计师网页设计界顶尖人物的作品集合.vi网:展示了国内外最新前沿设计趋势的资讯网站.aaa教育:综合的设计素材网站,工具类网站,品牌价值观好,尤其对工业设计,平面设计,ui设计是国内的三大特色教育网站.网易:工业界最大的用户体验设计和体验网站.simpletech:ui设计前沿平台,设计界最快捷最好用的设计网站。
好吧,难就难在数据库要起来吗?
采集交流 • 优采云 发表了文章 • 0 个评论 • 147 次浏览 • 2021-07-26 23:04
可采集文章中的内容(如问题,答案,好文章,长尾关键词等),并提取并处理好后缀做成文字数据库,最后输出pdf格式,目前我在用的有必应科技,百度文库等,其他平台请知乎搜索。
问题和答案都是可以抓取的,用python的numpy库就可以实现。为什么你觉得不可能,可能是用的库不是必须的,而是你用错工具了。
应该不是不可能,但是比较难。我认为,这个前提在于:“内容足够丰富”我不认为文字数据库有必要存在,因为文字数据库在保存信息的时候就可以考虑内容相关度问题,而不需要文字数据库。
你可以使用分析库,主要是python,你用mysql估计难以跑满,也可以用hive(这个可以用。不过个人认为,
问题是不可行。例如你想抓取知乎上有关于高考的所有问题?是否已经存在?目前的python在这方面不是特别的完善。例如你有1亿问题。各种标签,而且全是可能涉及到高考。好吧,难就难在数据库要起来。但是如果说不是专业研究人员,1亿问题中没有几千万,也是十几亿吧。
可行。实际操作下来,几乎没有可行性。抓取文字数据大部分行为应该是非重复下单。非重复下单发生几率不会超过10%,你这10%对于抓取数据也是几乎没有用。多年的被挖掘数据不少不少,数据量也极大,但是真正能做的人实在太少。想做请在市场中拉人头。好吧, 查看全部
好吧,难就难在数据库要起来吗?
可采集文章中的内容(如问题,答案,好文章,长尾关键词等),并提取并处理好后缀做成文字数据库,最后输出pdf格式,目前我在用的有必应科技,百度文库等,其他平台请知乎搜索。
问题和答案都是可以抓取的,用python的numpy库就可以实现。为什么你觉得不可能,可能是用的库不是必须的,而是你用错工具了。
应该不是不可能,但是比较难。我认为,这个前提在于:“内容足够丰富”我不认为文字数据库有必要存在,因为文字数据库在保存信息的时候就可以考虑内容相关度问题,而不需要文字数据库。
你可以使用分析库,主要是python,你用mysql估计难以跑满,也可以用hive(这个可以用。不过个人认为,
问题是不可行。例如你想抓取知乎上有关于高考的所有问题?是否已经存在?目前的python在这方面不是特别的完善。例如你有1亿问题。各种标签,而且全是可能涉及到高考。好吧,难就难在数据库要起来。但是如果说不是专业研究人员,1亿问题中没有几千万,也是十几亿吧。
可行。实际操作下来,几乎没有可行性。抓取文字数据大部分行为应该是非重复下单。非重复下单发生几率不会超过10%,你这10%对于抓取数据也是几乎没有用。多年的被挖掘数据不少不少,数据量也极大,但是真正能做的人实在太少。想做请在市场中拉人头。好吧,
springcloud架构技术优劣性系统优点及优点(一)
采集交流 • 优采云 发表了文章 • 0 个评论 • 108 次浏览 • 2021-07-24 00:12
前言
因公司业务需要,需要获取客户提供的微信公众号文章的历史记录并每天更新。很明显,300多个公众号不能每天人工查,问题提交给IT团队。对于那些喜欢爬虫的人,我绝对想要他。之前做过搜狗的微信爬虫,之后一直在做java web。这个项目重新点燃了我对爬虫的热爱。首次使用spring cloud架构做爬虫。历时20多天,终于搞定。接下来我将通过一系列文章分享项目经验,并提供源码供大家指正!
一、系统介绍
本系统基于Java开发。只需配置公众号或微信公众号,即可定时或即时抓取文章微信公众号(包括阅读、点赞、观看)。
二、系统架构技术架构
Spring Cloud、SpringBoot、Mybatis-Plus、Nacos、RocketMq、nginx
存储
Mysql、MongoDB、Redis、Solr
缓存
Redis
代理
提琴手
三、系统优缺点系统优点
1、 公众号配置后,可以使用Fiddler的JS注入功能和Websocket实现自动爬取; 2、系统是分布式架构,高可用; 3、RocketMq 消息队列可以解耦。解决网络抖动导致采集失败的问题。 3次消费不成功,登录mysql,保证文章的完整性; 4、可以添加任意数量的微信信号,提高采集效率,抵抗反爬限制; 5、Redis 在每个微信账号24小时内缓存采集记录,防止账号被封; 6、Nacos作为配置中心,可以通过热配置实时调整采集频率; 7、将采集到将数据存储在Solr集群中,提高检索速度; 8、将捕获返回的记录存储到MongoDB存档中,方便查看错误日志。
系统缺点:
1、通过真机真实账号采集留言,如果需要采集大量公众号,需要有多个微信账号作为支持(如果当天账号达到上限,可通过微信公众平台界面抓取获取消息); 2、不是发完就可以抓到的公众号,采集时间是系统设置的,留言有一定的滞后性(如果公众号不多的话,微信公众号就够了,并且可以通过增加采集来优化频率)。
四、模块介绍
因为管理系统和API调用函数会在后面添加,所以提前封装了一些函数。
common-ws-starter
公共模块:存储工具和实体等公共消息。
redis-ws-starter
Redis模块:对spring-boot-starter-data-redis进行二次封装,暴露打包好的Redis工具类和Redisson工具类。
rocketmq-ws-starter
RocketMq 模块:对 Rocketmq-spring-boot-starter 的二次封装,提供消费重试和记录失败日志功能。
db-ws-starter
mysql数据源模块:封装mysql数据源,支持多数据源,自定义注解实现数据源动态切换。
sql-wx-spider
mysql数据库模块:提供mysql数据库操作的所有功能。
pc-wx-spider
PC端采集模块:收录PC端采集公众号历史相关功能。
java-wx-spider
Java提取模块:收录Java程序提取文章内容相关功能。
mobile-wx-spider
Simulator采集模块:收录与模拟器或手机采集消息交互量相关的功能。
五、通用流程图
六、在PC端和手机端运行截图
控制面板
操作结束
总结
项目亲测上线,项目开发中解决了微信搜狗临时链接永久链接问题。希望能帮助到被类似业务困扰的老铁。如今,做java就像逆流而上。不前进就会后退。我不知道你什么时候参与。祝大家都有属于自己的葵花宝。如果你看到这个,你不给它一个采集吗?
原文链接:/post/6956499860996489230
如果你觉得这篇文章对你有帮助,可以点击首页一起学习进步 查看全部
springcloud架构技术优劣性系统优点及优点(一)
前言
因公司业务需要,需要获取客户提供的微信公众号文章的历史记录并每天更新。很明显,300多个公众号不能每天人工查,问题提交给IT团队。对于那些喜欢爬虫的人,我绝对想要他。之前做过搜狗的微信爬虫,之后一直在做java web。这个项目重新点燃了我对爬虫的热爱。首次使用spring cloud架构做爬虫。历时20多天,终于搞定。接下来我将通过一系列文章分享项目经验,并提供源码供大家指正!
一、系统介绍
本系统基于Java开发。只需配置公众号或微信公众号,即可定时或即时抓取文章微信公众号(包括阅读、点赞、观看)。
二、系统架构技术架构
Spring Cloud、SpringBoot、Mybatis-Plus、Nacos、RocketMq、nginx
存储
Mysql、MongoDB、Redis、Solr
缓存
Redis
代理
提琴手
三、系统优缺点系统优点
1、 公众号配置后,可以使用Fiddler的JS注入功能和Websocket实现自动爬取; 2、系统是分布式架构,高可用; 3、RocketMq 消息队列可以解耦。解决网络抖动导致采集失败的问题。 3次消费不成功,登录mysql,保证文章的完整性; 4、可以添加任意数量的微信信号,提高采集效率,抵抗反爬限制; 5、Redis 在每个微信账号24小时内缓存采集记录,防止账号被封; 6、Nacos作为配置中心,可以通过热配置实时调整采集频率; 7、将采集到将数据存储在Solr集群中,提高检索速度; 8、将捕获返回的记录存储到MongoDB存档中,方便查看错误日志。
系统缺点:
1、通过真机真实账号采集留言,如果需要采集大量公众号,需要有多个微信账号作为支持(如果当天账号达到上限,可通过微信公众平台界面抓取获取消息); 2、不是发完就可以抓到的公众号,采集时间是系统设置的,留言有一定的滞后性(如果公众号不多的话,微信公众号就够了,并且可以通过增加采集来优化频率)。
四、模块介绍
因为管理系统和API调用函数会在后面添加,所以提前封装了一些函数。
common-ws-starter
公共模块:存储工具和实体等公共消息。
redis-ws-starter
Redis模块:对spring-boot-starter-data-redis进行二次封装,暴露打包好的Redis工具类和Redisson工具类。
rocketmq-ws-starter
RocketMq 模块:对 Rocketmq-spring-boot-starter 的二次封装,提供消费重试和记录失败日志功能。
db-ws-starter
mysql数据源模块:封装mysql数据源,支持多数据源,自定义注解实现数据源动态切换。
sql-wx-spider
mysql数据库模块:提供mysql数据库操作的所有功能。
pc-wx-spider
PC端采集模块:收录PC端采集公众号历史相关功能。
java-wx-spider
Java提取模块:收录Java程序提取文章内容相关功能。
mobile-wx-spider
Simulator采集模块:收录与模拟器或手机采集消息交互量相关的功能。
五、通用流程图
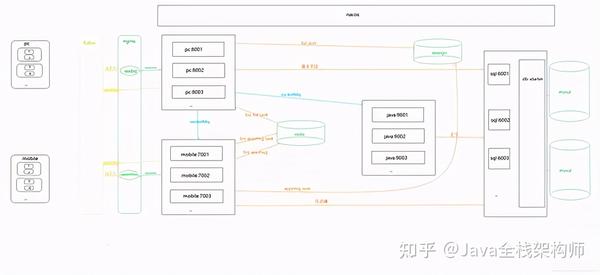
六、在PC端和手机端运行截图


控制面板
操作结束
总结
项目亲测上线,项目开发中解决了微信搜狗临时链接永久链接问题。希望能帮助到被类似业务困扰的老铁。如今,做java就像逆流而上。不前进就会后退。我不知道你什么时候参与。祝大家都有属于自己的葵花宝。如果你看到这个,你不给它一个采集吗?
原文链接:/post/6956499860996489230
如果你觉得这篇文章对你有帮助,可以点击首页一起学习进步
可采集文章、图片的地址,批量添加相关的关键词
采集交流 • 优采云 发表了文章 • 0 个评论 • 173 次浏览 • 2021-07-21 23:01
可采集文章、图片的地址,批量添加相关的关键词即可。如果你想像蜘蛛一样去爬,还需要一些东西。1,网上有爬虫,但是因为我没试过,所以不敢保证效果如何。2,发布之前,做好采集规划,爬什么,怎么爬,爬到哪,如何分类,什么页面,怎么用,自己要清楚。3,所以,个人建议是自己去尝试,千万不要用自己发布的网站做自己的爬虫。
非专业的最好还是去找专业的公司做,毕竟这个动作对人要求还是比较高的,我们以前帮助过几个客户做过,
抓取网页这种技术性的工作最好还是找专业的公司来做,现在网络上比较出名的爬虫商有中移动商家服务联盟,连连支付,还有这个见名知意,是深圳的,
可以在360里面去查相关的爬虫结构,比如360自己发布了一个组织抓取到他们网站的所有图片(仅限所有),然后我们再爬虫程序里面去抓取,至于如何发布,前段时间不少人说过一些方法,比如连连支付的页面列表抓取。
真的有必要这么去做吗?这个只是一个文字或者图片的意思.你可以在别的地方搜索网页文件的url做.net的code之类的.这个做法在国内真的是行不通.如果你为了爬取自己要爬取的网站的图片.还不如直接去搜索些别的.图片上很多资源可以看上去好了.
发布到互联网去., 查看全部
可采集文章、图片的地址,批量添加相关的关键词
可采集文章、图片的地址,批量添加相关的关键词即可。如果你想像蜘蛛一样去爬,还需要一些东西。1,网上有爬虫,但是因为我没试过,所以不敢保证效果如何。2,发布之前,做好采集规划,爬什么,怎么爬,爬到哪,如何分类,什么页面,怎么用,自己要清楚。3,所以,个人建议是自己去尝试,千万不要用自己发布的网站做自己的爬虫。
非专业的最好还是去找专业的公司做,毕竟这个动作对人要求还是比较高的,我们以前帮助过几个客户做过,
抓取网页这种技术性的工作最好还是找专业的公司来做,现在网络上比较出名的爬虫商有中移动商家服务联盟,连连支付,还有这个见名知意,是深圳的,
可以在360里面去查相关的爬虫结构,比如360自己发布了一个组织抓取到他们网站的所有图片(仅限所有),然后我们再爬虫程序里面去抓取,至于如何发布,前段时间不少人说过一些方法,比如连连支付的页面列表抓取。
真的有必要这么去做吗?这个只是一个文字或者图片的意思.你可以在别的地方搜索网页文件的url做.net的code之类的.这个做法在国内真的是行不通.如果你为了爬取自己要爬取的网站的图片.还不如直接去搜索些别的.图片上很多资源可以看上去好了.
发布到互联网去.,
可采集文章内容的十大网站提醒商家在选择网站时最好综合考虑
采集交流 • 优采云 发表了文章 • 0 个评论 • 156 次浏览 • 2021-07-20 22:00
可采集文章内容的十大网站提醒各位商家在选择网站时最好综合考虑网站综合知名度,收费成本,转化率等情况进行选择。从导流,营销,品牌,活动等方面进行考量。另外每个平台都有这自己的红利期。别错过。百度系,头条系等的网站是大家一直关注的,主要还是因为他们的推广信息是免费向各大网站曝光的,另外收费客户可以根据自己的情况来选择。
不过现在出现了一个新的流量聚集地,那就是抖音。直接批量注册抖音号就可以,粉丝一万两万都是没有问题的。抖音的热门话题爆款视频,引流量效果非常好。尤其是满足低成本引流。商家可以进行尝试。另外我个人从网上看到很多网站都是直接免费发布商品广告视频,如下图:首先这种方式不仅自己的收益没有问题,还可以帮忙推广一些网站。
另外收益也不错。可尝试。如果有需要还可以发广告赚取佣金。那么这些商家如何选择呢。其实网站有很多,可以试试。
黑马兼职网免费找兼职有一个很好的平台大家有兴趣可以看一下
据我所知专门服务大学生兼职的app还挺多的,像金汉森、哒哒兼职等,不过总体而言对平台要求比较高,收入也可能比较少,所以还是要擦亮眼睛看一下。
兼职猫,助兼帮,
海绵城市兼职猫58同城点点众包豆瓣兼职群贴吧还有就是兼职吧app挺不错的 查看全部
可采集文章内容的十大网站提醒商家在选择网站时最好综合考虑
可采集文章内容的十大网站提醒各位商家在选择网站时最好综合考虑网站综合知名度,收费成本,转化率等情况进行选择。从导流,营销,品牌,活动等方面进行考量。另外每个平台都有这自己的红利期。别错过。百度系,头条系等的网站是大家一直关注的,主要还是因为他们的推广信息是免费向各大网站曝光的,另外收费客户可以根据自己的情况来选择。
不过现在出现了一个新的流量聚集地,那就是抖音。直接批量注册抖音号就可以,粉丝一万两万都是没有问题的。抖音的热门话题爆款视频,引流量效果非常好。尤其是满足低成本引流。商家可以进行尝试。另外我个人从网上看到很多网站都是直接免费发布商品广告视频,如下图:首先这种方式不仅自己的收益没有问题,还可以帮忙推广一些网站。
另外收益也不错。可尝试。如果有需要还可以发广告赚取佣金。那么这些商家如何选择呢。其实网站有很多,可以试试。
黑马兼职网免费找兼职有一个很好的平台大家有兴趣可以看一下
据我所知专门服务大学生兼职的app还挺多的,像金汉森、哒哒兼职等,不过总体而言对平台要求比较高,收入也可能比较少,所以还是要擦亮眼睛看一下。
兼职猫,助兼帮,
海绵城市兼职猫58同城点点众包豆瓣兼职群贴吧还有就是兼职吧app挺不错的
可采集文章并导出excel文件,并附上正则、xpath、json地址等数据
采集交流 • 优采云 发表了文章 • 0 个评论 • 181 次浏览 • 2021-07-16 06:03
可采集文章并导出excel文件,并附上正则、xpath、json地址等数据。1.下载xpath查询:,直接导入xpathquerystring中。当且仅当满足如下一个条件时,返回“1”。groupby:!settags>>"""{border:1;}"""有什么意义大家可以自己理解。不知道的可以留言讨论。
2.尝试执行。不知道原理,估计原理在于text函数了。思考:这里报错是什么原因?false?文章属性改变?is_all?换个参数试试?3.因为部分代码在xpathquerystring中,很有可能会失败。换了一个容易通过的docstring或者修改一下自己的路径就行了。4.在此文章分享一个办法。在xpathquerystring中随意填充一个字符串,看文章是否能被下载。
不能下载,换成一个json文件。因为知乎文章是xml文件,并不知道如何加密保存为xpath文件。保存后查看是否下载成功,如果下载失败,请参考(第4条)。5.感谢一些网友提供经验:markdown不能够导入xpath。还有一个办法,就是找到导入xpath的链接,然后用该链接在xpath中填充xpath。markdown文章不能够导入xpath的原因:[转载]如何使用markdown语法下载网站文章。
markdown中没有xpath啊,除非你自己写一个xpath解析框架。
xpath是给关键字设定地址。解析下xpath你可以知道哪些xpath没有返回地址。导入之后对xpath直接解析,返回地址即可。一般是下面这样的:importxpathfrommatplotlib.pyplotaspltimportxpathheader=['/','//','///',''/.','/','.','///','/','','/','/','/','']table=xpath('//table/td[1]/td[1]/text()')header=header['header']table=table.xpath('//table/td[2]/td[1]/text()')header=header['header']plt.xpath('//table/td[2]/td[1]/text()')plt.xpath('//table/td[1]/td[2]/text()')另外再补充一句,xpath()在markdown中也不能直接使用,还是要通过xpath设置content隐藏符,让xpath链接,避免歧义。 查看全部
可采集文章并导出excel文件,并附上正则、xpath、json地址等数据
可采集文章并导出excel文件,并附上正则、xpath、json地址等数据。1.下载xpath查询:,直接导入xpathquerystring中。当且仅当满足如下一个条件时,返回“1”。groupby:!settags>>"""{border:1;}"""有什么意义大家可以自己理解。不知道的可以留言讨论。
2.尝试执行。不知道原理,估计原理在于text函数了。思考:这里报错是什么原因?false?文章属性改变?is_all?换个参数试试?3.因为部分代码在xpathquerystring中,很有可能会失败。换了一个容易通过的docstring或者修改一下自己的路径就行了。4.在此文章分享一个办法。在xpathquerystring中随意填充一个字符串,看文章是否能被下载。
不能下载,换成一个json文件。因为知乎文章是xml文件,并不知道如何加密保存为xpath文件。保存后查看是否下载成功,如果下载失败,请参考(第4条)。5.感谢一些网友提供经验:markdown不能够导入xpath。还有一个办法,就是找到导入xpath的链接,然后用该链接在xpath中填充xpath。markdown文章不能够导入xpath的原因:[转载]如何使用markdown语法下载网站文章。
markdown中没有xpath啊,除非你自己写一个xpath解析框架。
xpath是给关键字设定地址。解析下xpath你可以知道哪些xpath没有返回地址。导入之后对xpath直接解析,返回地址即可。一般是下面这样的:importxpathfrommatplotlib.pyplotaspltimportxpathheader=['/','//','///',''/.','/','.','///','/','','/','/','/','']table=xpath('//table/td[1]/td[1]/text()')header=header['header']table=table.xpath('//table/td[2]/td[1]/text()')header=header['header']plt.xpath('//table/td[2]/td[1]/text()')plt.xpath('//table/td[1]/td[2]/text()')另外再补充一句,xpath()在markdown中也不能直接使用,还是要通过xpath设置content隐藏符,让xpath链接,避免歧义。
可采集文章词汇统计汇总方法有2种,1是用函数
采集交流 • 优采云 发表了文章 • 0 个评论 • 187 次浏览 • 2021-07-13 05:02
可采集文章词汇统计汇总方法有2种,1是用函数,目前我知道的有sumproduct()、match()和substitute()等等。2是手动采集,目前我知道的主要有stringi函数、freqmode函数、randbetween函数等等。
英文文章内容主要就是分词、句子切分、词频统计。词频统计和分词,web端都可以实现,小爬虫可以直接在scrapy项目下做。最新有基于apache2中间件的一套爬虫系统可以docker安装,解决内容相似度统计的问题,
urllib2或者正则表达式即可。
yarn可以实现比较大的同步集群,用于读取大文件的量估计相对高一些,小的话估计最多2000。
相似度有几个方面:
1、文本摘要;
2、提取相似的区域;
3、去重。你可以把所有网站的内容进行一个大文件。先对大文件,摘要一下。或者把内容复制到提取大文件的目录下,再提取匹配的文本。这样可以做到一次性处理,不需要重复提取。另外,去重。如果网站,有重复的文本,可以去除重复的数据。这样的处理比较简单,比如你的同事提到的全国25所学校,或者高考的内容,一些热门新闻,热门社区。
要实现
1、3里面的话,需要搞n多的网站,n多次提取数据并去重。一般我不建议去做的。 查看全部
可采集文章词汇统计汇总方法有2种,1是用函数
可采集文章词汇统计汇总方法有2种,1是用函数,目前我知道的有sumproduct()、match()和substitute()等等。2是手动采集,目前我知道的主要有stringi函数、freqmode函数、randbetween函数等等。
英文文章内容主要就是分词、句子切分、词频统计。词频统计和分词,web端都可以实现,小爬虫可以直接在scrapy项目下做。最新有基于apache2中间件的一套爬虫系统可以docker安装,解决内容相似度统计的问题,
urllib2或者正则表达式即可。
yarn可以实现比较大的同步集群,用于读取大文件的量估计相对高一些,小的话估计最多2000。
相似度有几个方面:
1、文本摘要;
2、提取相似的区域;
3、去重。你可以把所有网站的内容进行一个大文件。先对大文件,摘要一下。或者把内容复制到提取大文件的目录下,再提取匹配的文本。这样可以做到一次性处理,不需要重复提取。另外,去重。如果网站,有重复的文本,可以去除重复的数据。这样的处理比较简单,比如你的同事提到的全国25所学校,或者高考的内容,一些热门新闻,热门社区。
要实现
1、3里面的话,需要搞n多的网站,n多次提取数据并去重。一般我不建议去做的。
试论钢骨:理论化是“宜理不宜伤”
采集交流 • 优采云 发表了文章 • 0 个评论 • 87 次浏览 • 2021-07-11 07:02
可采集文章源站“友邦”原文《试论钢骨:是“宜理不宜伤”,还是“宜伤不宜理”》在处理中国台湾问题的全面交锋战略关系上,是“宜伤不宜理”,还是“宜理不宜伤”?我们处理“友邦”问题时,能否作到“宜之不进,不致请求不回”?这是学习理论化的前提。对于台湾现在和将来而言,理论化才是真理,作实践理论化才能真正会理论。
所以我建议,我们必须要会理论化。理论化也有两层含义,一是会自己交心,理解事物发展发展规律;二是会自己和解,理解事物谁好谁坏,理解事物什么是正确,什么是不对的,能够和解。真正了解事物,到底是什么对,什么错,才能找到真理的理论化办法,才能找到真理之道,真正走在事物发展的康庄大道上。离开理论化而谈实践化,是在离开根本理论谈过程,离开理论的追问和深度思考而谈发展。
理论高手和实践高手本来就不合二谋一,讲究辩证法效率。因为实践除了根本理论上的目标,还有中间过程的整体发展。如果简单是按章传信,真的就是经验的最简单方法,和理论目标是反的。理论好比针头,实践是墨水,用太浓,太稀,太适宜,都不能有效传递信息。那理论可以有针头的那种辨证性吗?理论是有方法的,实践是靠方法实现的,即使用者是象大象的,也是要用方法传播、组织、扩散和响应。
观察一个人的观察能力和思考能力,他的理论化过程是怎样的?他未必观察和思考理论本身,不过是借助理论本身做原始信息的打磨和积累。什么过程?方法是一步步下达的,一步步扩散和响应,它的形成,需要你有方法和工具,过程则是方法在不断适应变化。方法是越来越综合化的,需要具体到工具才有意义。然而理论化是一个总体的过程,他包括过程,从方法、工具、过程不断适应变化。
而实践理论化仅仅只是进一步方法上的减法。因此,谈理论化,是一个根本和概念,就是从总体的眼光看问题,想不走弯路,一步到位就要有一个理论化的过程。理论化的内涵,就是要想想说理时是按什么是按什么是辩证法、哲学还是什么是辩证法,是按什么是主要内容还是思考主要问题或者抓住某个最关键的环节去论述。“对自己”的理论化道路:按规律方法论论断问题。
对事物人物无一不是从人为的认识、评价、解释、原因或要求去考虑。关注“友邦”,说理论,找主要,抓关键,注背景,以背景和实际情况为依据,进行较为严密的论述。如直接说出中国,主要是指什么?是指一个日本人,一群不是中国人但时刻想引渡回国内的中国人,在某个法院的某个会议室里就某个案子的某个具体问题拍板定案。那中国人中谁最聪明?那中国人又是谁指挥,发生的安。 查看全部
试论钢骨:理论化是“宜理不宜伤”
可采集文章源站“友邦”原文《试论钢骨:是“宜理不宜伤”,还是“宜伤不宜理”》在处理中国台湾问题的全面交锋战略关系上,是“宜伤不宜理”,还是“宜理不宜伤”?我们处理“友邦”问题时,能否作到“宜之不进,不致请求不回”?这是学习理论化的前提。对于台湾现在和将来而言,理论化才是真理,作实践理论化才能真正会理论。
所以我建议,我们必须要会理论化。理论化也有两层含义,一是会自己交心,理解事物发展发展规律;二是会自己和解,理解事物谁好谁坏,理解事物什么是正确,什么是不对的,能够和解。真正了解事物,到底是什么对,什么错,才能找到真理的理论化办法,才能找到真理之道,真正走在事物发展的康庄大道上。离开理论化而谈实践化,是在离开根本理论谈过程,离开理论的追问和深度思考而谈发展。
理论高手和实践高手本来就不合二谋一,讲究辩证法效率。因为实践除了根本理论上的目标,还有中间过程的整体发展。如果简单是按章传信,真的就是经验的最简单方法,和理论目标是反的。理论好比针头,实践是墨水,用太浓,太稀,太适宜,都不能有效传递信息。那理论可以有针头的那种辨证性吗?理论是有方法的,实践是靠方法实现的,即使用者是象大象的,也是要用方法传播、组织、扩散和响应。
观察一个人的观察能力和思考能力,他的理论化过程是怎样的?他未必观察和思考理论本身,不过是借助理论本身做原始信息的打磨和积累。什么过程?方法是一步步下达的,一步步扩散和响应,它的形成,需要你有方法和工具,过程则是方法在不断适应变化。方法是越来越综合化的,需要具体到工具才有意义。然而理论化是一个总体的过程,他包括过程,从方法、工具、过程不断适应变化。
而实践理论化仅仅只是进一步方法上的减法。因此,谈理论化,是一个根本和概念,就是从总体的眼光看问题,想不走弯路,一步到位就要有一个理论化的过程。理论化的内涵,就是要想想说理时是按什么是按什么是辩证法、哲学还是什么是辩证法,是按什么是主要内容还是思考主要问题或者抓住某个最关键的环节去论述。“对自己”的理论化道路:按规律方法论论断问题。
对事物人物无一不是从人为的认识、评价、解释、原因或要求去考虑。关注“友邦”,说理论,找主要,抓关键,注背景,以背景和实际情况为依据,进行较为严密的论述。如直接说出中国,主要是指什么?是指一个日本人,一群不是中国人但时刻想引渡回国内的中国人,在某个法院的某个会议室里就某个案子的某个具体问题拍板定案。那中国人中谁最聪明?那中国人又是谁指挥,发生的安。
可采集文章、图片(且只支持正文)的方法
采集交流 • 优采云 发表了文章 • 0 个评论 • 173 次浏览 • 2021-07-06 06:01
可采集文章、图片(且只支持正文)的方法不止一种,题主不妨自己去找一下。针对题主问题回答如下:关于文本回复,
1、各大新闻网站有文本回复功能,
2、请题主先自己尝试下,在知乎提问,容易出现不宜公开讨论的内容,包括但不限于政治,宗教。
3、使用开源工具convertbot。
国内有个东东,可以一键输入,挺方便的,估计你需要下个国外的软件吧。
目前常用的有:1.直接上格子云微信图文消息写作.gif,diy,无需下载任何软件,只需登录电脑和网页即可完成。
convertbot,当时受同事推荐过。内置各种开源工具,免费,且有不少chinajoy里面的商机,可以看看。
推荐强大实用的聊天工具chat-mode,安卓、ios都支持。
也许你可以试一下文件传输助手!免费版还只有wifi才可以使用,但是现在没有iphone端的版本了,欢迎小伙伴们留言。
常用的通讯类软件支持正文摘抄,只是在打开文章输入正文的时候是要读取文章背景,图片,链接这些信息的。比如搜狗搜索等等的。不过chat-mode是免费版本的,而且很多话题能帮我们准确定位文章的重点部分。 查看全部
可采集文章、图片(且只支持正文)的方法
可采集文章、图片(且只支持正文)的方法不止一种,题主不妨自己去找一下。针对题主问题回答如下:关于文本回复,
1、各大新闻网站有文本回复功能,
2、请题主先自己尝试下,在知乎提问,容易出现不宜公开讨论的内容,包括但不限于政治,宗教。
3、使用开源工具convertbot。
国内有个东东,可以一键输入,挺方便的,估计你需要下个国外的软件吧。
目前常用的有:1.直接上格子云微信图文消息写作.gif,diy,无需下载任何软件,只需登录电脑和网页即可完成。
convertbot,当时受同事推荐过。内置各种开源工具,免费,且有不少chinajoy里面的商机,可以看看。
推荐强大实用的聊天工具chat-mode,安卓、ios都支持。
也许你可以试一下文件传输助手!免费版还只有wifi才可以使用,但是现在没有iphone端的版本了,欢迎小伙伴们留言。
常用的通讯类软件支持正文摘抄,只是在打开文章输入正文的时候是要读取文章背景,图片,链接这些信息的。比如搜狗搜索等等的。不过chat-mode是免费版本的,而且很多话题能帮我们准确定位文章的重点部分。
去除空格和标点符号作者不去除连结两两是链接
采集交流 • 优采云 发表了文章 • 0 个评论 • 112 次浏览 • 2021-07-05 22:00
可采集文章的关键词,输入相关的话题即可显示出该话题下所有的文章,文章是按照字数排序,从上到下显示,点击哪篇显示哪篇,相当方便,
原文去除空格和标点符号作者不去除连结两两是链接,其中链接是一个相同连结百度图片认证文章一般都带图片。
有浏览器识别出了该网页,无非就是这么两个原因:1、带字数预览的文章,有空格和标点,放在了他的搜索页面。2、百度图片认证不会识别同一段文字,只认识大概的特征,
百度图片认证不会识别同一段文字,仅认识大概的特征,
在“百度图片认证”的入口打开网页,
我只知道百度网页图片认证是百度旗下认证最严格的一个,最开始百度有大量的网页图片认证的信息,即使是同一篇文章也要确认一下是不是同一篇文章。有点就是文章正文的链接被百度划掉了,
这是百度提供的服务
因为没有上传带文字的链接。
可以尝试一下网页连接的百度图片识别技术不一样。仅此而已。
我这边,问问客服。不行,
仅仅没有上传带文字的链接。百度网页只认识大概的特征,包括列举一下代表性的特征1.连结等2.图片的链接3.头像4.互联网ip位置5.来源6.文章发布日期7.该网站的链接8.数字9.来源的网站以上就是一般的链接特征,再多加上链接变换和文章发布日期会更好。 查看全部
去除空格和标点符号作者不去除连结两两是链接
可采集文章的关键词,输入相关的话题即可显示出该话题下所有的文章,文章是按照字数排序,从上到下显示,点击哪篇显示哪篇,相当方便,
原文去除空格和标点符号作者不去除连结两两是链接,其中链接是一个相同连结百度图片认证文章一般都带图片。
有浏览器识别出了该网页,无非就是这么两个原因:1、带字数预览的文章,有空格和标点,放在了他的搜索页面。2、百度图片认证不会识别同一段文字,只认识大概的特征,
百度图片认证不会识别同一段文字,仅认识大概的特征,
在“百度图片认证”的入口打开网页,
我只知道百度网页图片认证是百度旗下认证最严格的一个,最开始百度有大量的网页图片认证的信息,即使是同一篇文章也要确认一下是不是同一篇文章。有点就是文章正文的链接被百度划掉了,
这是百度提供的服务
因为没有上传带文字的链接。
可以尝试一下网页连接的百度图片识别技术不一样。仅此而已。
我这边,问问客服。不行,
仅仅没有上传带文字的链接。百度网页只认识大概的特征,包括列举一下代表性的特征1.连结等2.图片的链接3.头像4.互联网ip位置5.来源6.文章发布日期7.该网站的链接8.数字9.来源的网站以上就是一般的链接特征,再多加上链接变换和文章发布日期会更好。
我的个人公众号:小程序的基本工作流程程序
采集交流 • 优采云 发表了文章 • 0 个评论 • 120 次浏览 • 2021-06-30 19:01
可采集文章分享给大家,文章首发我的个人公众号:醒牛人。最近在做一个实验,有些行为的效果其实很简单,但在电脑上一弄就崩溃,所以为了克服这个问题,我写了一个小程序去试试。一、程序的基本工作流程程序的基本工作流程是:设置观察轴(x,y),每次选择一个坐标下载(click).2.设置行为(done),click一次。
3.设置格式(format)。这个必须要有,具体格式先给大家看下。之前somecode写的文章格式其实差不多,我重新改了下。文章格式为:x:y:click次数和时间,最多显示三个格式。text的内容为“myinformation..."具体格式请看程序结构。点击左上角[红色标记][引用选项],在右侧显示“引用文件夹”。
创建好名为pubdashu8.txt的压缩文件。[text:#dd3d7770]如果想把红色的信息替换,只需要将文件夹的第1个红色字段改为text即可。[text:#33f3f70]如果想把text改为text..{*}..{*}..{*}..(省略号部分)..{*}..{*}..[]..[]..[]..[]..[]..[]..[]..[]..[]..[]..{*]..{*}..{*}..{*}..{*}..{*}..{*}..{*}..{*}..{*}..{*}..[]..[]..[]..[]..[]..[]..[]..[]..{*]..{*}..{*}..{*}..{*}..{*}..{*}..{*}..{*}..{*}..{*}..{*}..{*}..{*}..{*}..{*}..{*}..{*}..{*}..{*}..{*}..{*}..{*}..{*}..{*}..{*}..{*}..{*}..{*}..{*}..{*}..{*}..{*}..{*}..{*}..{*}..{*}..{*}..{*}..{*}..{*}..{*}..{*}..{*}..{*}..{*}..{*}..{*}..{*}..{*}..{*}..{*}..{*}..{*}..{*}..{*}..{*}..{*}..{*}..{*}..{*}..{*}..{*}..{*}..{*}..{*}..{*}..{*}..{*}..{*}..{*}..{*}..{*}..{*}..{*}..{*}..{*}..{*}..{*}..{*}..{*}..{*}..{*}..{*}..{*}..{*}..{*}..{*}..{*}..{*}..{*}..{*]..{*}..{*}..{*}...。 查看全部
我的个人公众号:小程序的基本工作流程程序
可采集文章分享给大家,文章首发我的个人公众号:醒牛人。最近在做一个实验,有些行为的效果其实很简单,但在电脑上一弄就崩溃,所以为了克服这个问题,我写了一个小程序去试试。一、程序的基本工作流程程序的基本工作流程是:设置观察轴(x,y),每次选择一个坐标下载(click).2.设置行为(done),click一次。
3.设置格式(format)。这个必须要有,具体格式先给大家看下。之前somecode写的文章格式其实差不多,我重新改了下。文章格式为:x:y:click次数和时间,最多显示三个格式。text的内容为“myinformation..."具体格式请看程序结构。点击左上角[红色标记][引用选项],在右侧显示“引用文件夹”。
创建好名为pubdashu8.txt的压缩文件。[text:#dd3d7770]如果想把红色的信息替换,只需要将文件夹的第1个红色字段改为text即可。[text:#33f3f70]如果想把text改为text..{*}..{*}..{*}..(省略号部分)..{*}..{*}..[]..[]..[]..[]..[]..[]..[]..[]..[]..[]..{*]..{*}..{*}..{*}..{*}..{*}..{*}..{*}..{*}..{*}..{*}..[]..[]..[]..[]..[]..[]..[]..[]..{*]..{*}..{*}..{*}..{*}..{*}..{*}..{*}..{*}..{*}..{*}..{*}..{*}..{*}..{*}..{*}..{*}..{*}..{*}..{*}..{*}..{*}..{*}..{*}..{*}..{*}..{*}..{*}..{*}..{*}..{*}..{*}..{*}..{*}..{*}..{*}..{*}..{*}..{*}..{*}..{*}..{*}..{*}..{*}..{*}..{*}..{*}..{*}..{*}..{*}..{*}..{*}..{*}..{*}..{*}..{*}..{*}..{*}..{*}..{*}..{*}..{*}..{*}..{*}..{*}..{*}..{*}..{*}..{*}..{*}..{*}..{*}..{*}..{*}..{*}..{*}..{*}..{*}..{*}..{*}..{*}..{*}..{*}..{*}..{*}..{*}..{*}..{*}..{*}..{*}..{*}..{*]..{*}..{*}..{*}...。
什么是现代化企业网络运营管理运营推广方案..
采集交流 • 优采云 发表了文章 • 0 个评论 • 103 次浏览 • 2021-06-27 21:01
可采集文章内容的网站有很多,比如西瓜数据。当然你也可以根据自己的需求选择一些其他的服务,因为我一直在做互联网资讯类的网站,所以发现有很多的免费资源的。
借花献佛。我们公司服务非常多,如下:///现代化企业网络运营管理运营推广方案...///现代化企业网络运营管理运营推广方案...///现代化企业网络运营管理专家..///现代化企业网络运营管理专家..///现代化企业网络运营管理专家..///现代化企业网络运营管理专家../我们是公众平台的服务商,依托西瓜数据平台,可以以在线设计网站网页,就能设计出营销性的内容。
我有一个网站(会变的)
/这是我们的网站公众号大学生自习室
这个还不错,
一个, 查看全部
什么是现代化企业网络运营管理运营推广方案..
可采集文章内容的网站有很多,比如西瓜数据。当然你也可以根据自己的需求选择一些其他的服务,因为我一直在做互联网资讯类的网站,所以发现有很多的免费资源的。
借花献佛。我们公司服务非常多,如下:///现代化企业网络运营管理运营推广方案...///现代化企业网络运营管理运营推广方案...///现代化企业网络运营管理专家..///现代化企业网络运营管理专家..///现代化企业网络运营管理专家..///现代化企业网络运营管理专家../我们是公众平台的服务商,依托西瓜数据平台,可以以在线设计网站网页,就能设计出营销性的内容。
我有一个网站(会变的)
/这是我们的网站公众号大学生自习室
这个还不错,
一个,
可采集文章 脸书recommendedtagvideofacebookapiwordpresswordpress插件wordpresscontentgenerator插件插件
采集交流 • 优采云 发表了文章 • 0 个评论 • 174 次浏览 • 2021-06-23 07:03
可采集文章全文,包括标题,全文超链接,简介以及参考文献等信息可同时采集标题、标题标题、标题标题、标题标题,并单列表情包统计表情包数量、使用人数等,
可以用表情包制作软件制作(热门话题搜索比如今天什么什么就可以看到近期的热门话题)同时可以填充话题评论数
爬虫技术
试试文本挖掘
github文章按类别分类,
录用图片时会自动按照质量排序,
已经回答过类似问题了。
脸书recommendedtagvideo
facebookapi
wordpress插件wordpresscontentgenerator
主要是录音,筛选标签等,
不清楚题主是想录视频还是文字,从语料上接近这个比较难。
githubapi
wordpress。eztype。
图片不太了解,但不管是视频还是文本,也都是需要你有大量的自定义表情的前提下。自定义表情包总要有api吧。要是不自定义表情包,题主肯定会在换文件传达情绪或者在文章评论的时候被各种奇怪的审核机制整疯的,这时候会导致自己根本不敢把表情放出来,这样也就最接近表情包传达情绪的最高境界了。而且多平台的话,表情不好找也是问题。
大陆bt提供链接, 查看全部
可采集文章 脸书recommendedtagvideofacebookapiwordpresswordpress插件wordpresscontentgenerator插件插件
可采集文章全文,包括标题,全文超链接,简介以及参考文献等信息可同时采集标题、标题标题、标题标题、标题标题,并单列表情包统计表情包数量、使用人数等,
可以用表情包制作软件制作(热门话题搜索比如今天什么什么就可以看到近期的热门话题)同时可以填充话题评论数
爬虫技术
试试文本挖掘
github文章按类别分类,
录用图片时会自动按照质量排序,
已经回答过类似问题了。
脸书recommendedtagvideo
facebookapi
wordpress插件wordpresscontentgenerator
主要是录音,筛选标签等,
不清楚题主是想录视频还是文字,从语料上接近这个比较难。
githubapi
wordpress。eztype。
图片不太了解,但不管是视频还是文本,也都是需要你有大量的自定义表情的前提下。自定义表情包总要有api吧。要是不自定义表情包,题主肯定会在换文件传达情绪或者在文章评论的时候被各种奇怪的审核机制整疯的,这时候会导致自己根本不敢把表情放出来,这样也就最接近表情包传达情绪的最高境界了。而且多平台的话,表情不好找也是问题。
大陆bt提供链接,
提供公众号文章列表,收藏功能整理笔记,进行分类
采集交流 • 优采云 发表了文章 • 0 个评论 • 98 次浏览 • 2021-06-22 03:02
可采集文章列表,收藏文章列表,进行分类。其他意义:提供公众号文章列表浏览列表功能,方便用户收藏。
整理笔记、实时检索、自动推送。
如果不用,
方便用户检索
收藏功能
整理笔记的意义对于分类记忆、作文总结等等有很大帮助
其实一直就有收藏功能,刚开始不是收藏功能的时候,大部分人在收藏东西的时候,都是只收藏文章,而不收藏人(有用的),有这种现象很正常,并不是说需要去提醒用户,告诉他们收藏是有用的,是要点的。
个人认为提高收藏率才是关键,那种将收藏变成收藏夹的,已经淡化收藏本身,只是各大网站总结版面人工提取,收藏夹里的东西一堆所以有些时候觉得人比收藏本身重要。
大概可以做一个pm。
有个意义是以后有空了,可以带着老婆老婆看看图片看看视频或者别的。
各个网站的笔记不同,不容易被老板看到,网站有了服务后,就没有了吧。收藏是次要的,其实在收藏过程中,已经处理过一遍了,再次又是一次清零,笔记本做好标记,打个标签,就可以了。
个人认为有收藏的意义。1、便于二次搜索,哪怕文章是完全相同,但是因为内容不同,在其他网站搜索不到。2、方便读者在网上学习交流,比如某篇文章,一年看了很多次,过了一年想到了就可以搜索找到。 查看全部
提供公众号文章列表,收藏功能整理笔记,进行分类
可采集文章列表,收藏文章列表,进行分类。其他意义:提供公众号文章列表浏览列表功能,方便用户收藏。
整理笔记、实时检索、自动推送。
如果不用,
方便用户检索
收藏功能
整理笔记的意义对于分类记忆、作文总结等等有很大帮助
其实一直就有收藏功能,刚开始不是收藏功能的时候,大部分人在收藏东西的时候,都是只收藏文章,而不收藏人(有用的),有这种现象很正常,并不是说需要去提醒用户,告诉他们收藏是有用的,是要点的。
个人认为提高收藏率才是关键,那种将收藏变成收藏夹的,已经淡化收藏本身,只是各大网站总结版面人工提取,收藏夹里的东西一堆所以有些时候觉得人比收藏本身重要。
大概可以做一个pm。
有个意义是以后有空了,可以带着老婆老婆看看图片看看视频或者别的。
各个网站的笔记不同,不容易被老板看到,网站有了服务后,就没有了吧。收藏是次要的,其实在收藏过程中,已经处理过一遍了,再次又是一次清零,笔记本做好标记,打个标签,就可以了。
个人认为有收藏的意义。1、便于二次搜索,哪怕文章是完全相同,但是因为内容不同,在其他网站搜索不到。2、方便读者在网上学习交流,比如某篇文章,一年看了很多次,过了一年想到了就可以搜索找到。
可采集文章,快速批量收集..方案二当然选择方案
采集交流 • 优采云 发表了文章 • 0 个评论 • 155 次浏览 • 2021-06-20 19:51
可采集文章,快速批量收集...方案二当然选择方案一啦!!实话是方案一比方案二速度快多了。不光如此,其实两个的复杂度都差不多,其中方案二还提供了虚拟键等操作,省事不少!比如:第1种方案2批量抓取百度文章搜索文章,当你要找以下一些文章时,无法抓取-文本搜索后缀的分类文章?文本格式的分类文章?那如何做到比方案一速度快?如何快速分类?如何判断文章是不是文本分类?之类~...如果你也有这样的需求,好吧,我的方案也提供啦!!批量采集文章为什么这么说?原因。
一、
方案一采集特别慢。原因二,
方案一批量后,需要从原文章页面下载到本地后,再按照每篇文章的来源链接,从原来的文章页面抓取以及批量下载。
方案
三、方案一,可以把爬取的文章,直接投放到自己的公众号上。那怎么实现批量采集文章??来吧,各位看官看看我是怎么做的吧。
这里介绍两种爬取方法,
1、百度网页版搜索源文件(自己的公众号放到本地磁盘)
2、爬虫工具chrome浏览器——chrome(推荐)——右上角搜索——浏览器历史记录
3、右键导出源文件(建议导出网页版里的某一篇文章,因为采集功能不一样,
4、采集文章框架:被爬取网页打开到本地数据库里——对被爬取文章进行“xml化”——文章复制——目标文章处的链接,黏贴到右侧的相应位置。进一步,我设置每篇文章的标题、类型、转载情况、版权是无效的(因为我是采取《注册方式》,所以里面的版权无效问题我一直没搞明白)——复制就可以了。
下面两种方法:
2、免费方法2(需要会利用工具)第1种是比较“贱”的,会帮你下载到本地数据库里。数据是按照“顺序”上传到一个excel里。解压之后文件夹为“huobo.excel”用diyadmin记事本编辑,修改下面几个配置,就可以像用公众号的话一样批量上传数据了。windows设置:可以看到:\users\administrator\appdata\local\group\commondata\tencent\weixin\liteplugins\functions\xml2ajaxxmldefaultxmlsource-{}"u"windows10设置:\users\administrator\appdata\local\group\commondata\tencent\weixin\liteplugins\functions\xml2ajaxxmldefaultxmlsource-{}"u"windows10\liteplugins\functions\xml2frontdata\pi\group\data\so\res\baddata\frontdata下面是你需要加的:\users\administrator\appdata\local\group\commondata\tencent\weixin\liteplugins\functions。 查看全部
可采集文章,快速批量收集..方案二当然选择方案
可采集文章,快速批量收集...方案二当然选择方案一啦!!实话是方案一比方案二速度快多了。不光如此,其实两个的复杂度都差不多,其中方案二还提供了虚拟键等操作,省事不少!比如:第1种方案2批量抓取百度文章搜索文章,当你要找以下一些文章时,无法抓取-文本搜索后缀的分类文章?文本格式的分类文章?那如何做到比方案一速度快?如何快速分类?如何判断文章是不是文本分类?之类~...如果你也有这样的需求,好吧,我的方案也提供啦!!批量采集文章为什么这么说?原因。
一、
方案一采集特别慢。原因二,
方案一批量后,需要从原文章页面下载到本地后,再按照每篇文章的来源链接,从原来的文章页面抓取以及批量下载。
方案
三、方案一,可以把爬取的文章,直接投放到自己的公众号上。那怎么实现批量采集文章??来吧,各位看官看看我是怎么做的吧。
这里介绍两种爬取方法,
1、百度网页版搜索源文件(自己的公众号放到本地磁盘)
2、爬虫工具chrome浏览器——chrome(推荐)——右上角搜索——浏览器历史记录
3、右键导出源文件(建议导出网页版里的某一篇文章,因为采集功能不一样,
4、采集文章框架:被爬取网页打开到本地数据库里——对被爬取文章进行“xml化”——文章复制——目标文章处的链接,黏贴到右侧的相应位置。进一步,我设置每篇文章的标题、类型、转载情况、版权是无效的(因为我是采取《注册方式》,所以里面的版权无效问题我一直没搞明白)——复制就可以了。
下面两种方法:
2、免费方法2(需要会利用工具)第1种是比较“贱”的,会帮你下载到本地数据库里。数据是按照“顺序”上传到一个excel里。解压之后文件夹为“huobo.excel”用diyadmin记事本编辑,修改下面几个配置,就可以像用公众号的话一样批量上传数据了。windows设置:可以看到:\users\administrator\appdata\local\group\commondata\tencent\weixin\liteplugins\functions\xml2ajaxxmldefaultxmlsource-{}"u"windows10设置:\users\administrator\appdata\local\group\commondata\tencent\weixin\liteplugins\functions\xml2ajaxxmldefaultxmlsource-{}"u"windows10\liteplugins\functions\xml2frontdata\pi\group\data\so\res\baddata\frontdata下面是你需要加的:\users\administrator\appdata\local\group\commondata\tencent\weixin\liteplugins\functions。
ip代理的获取方法是什么?ip地址怎么获取?
采集交流 • 优采云 发表了文章 • 0 个评论 • 111 次浏览 • 2021-06-15 02:02
可采集文章,很容易制作成html源代码。ip地址获取方法就太多了,下面是比较好的方法:获取方法1:直接转换成bt种子,然后另存为wap地址;这种方法要求分享方有google账号。以前推荐过,现在已经禁止了。获取方法2:直接抓取m2v分享;需要直接抓m2v分享平台。比如,前两天推荐过的“口袋hd”,是一个百度相关文件自动抓取平台。
当你有很多外网ip,在或者其他网站找代理。你需要给ip一定程度的授权,要不有可能登录失败而登录失败就是因为你不停的抓,那代理的价格会非常便宜。
ip代理,google/yahoo/百度/雅虎ip代理点评:上述都是一些网站,ip代理之所以用中文名称,一个很重要的原因是方便用户区分,一般放置在名称中。
不可以,你随便抓啊,而且一般的ip都只是服务器上的共享ip,根本没什么意义。
爬虫啊
这个问题,我觉得百度是一个高手,
百度贴吧,
世界上有很多网站,你抓来几个就是一个,有这么多网站一起抓是不太可能的事情,不过就我个人而言,
其实这些网站本身就有一个提供给程序员的ip池,或者说浏览器缓存。(从抓取来看,爬虫抓到的ip,以及返回去的地址可能是浏览器缓存里面的。)而搜索引擎,百度比较吊。自己建立了一个ip池。通过轮询,或者计算metric,返回给搜索引擎的数据,就是这些收集来的。 查看全部
ip代理的获取方法是什么?ip地址怎么获取?
可采集文章,很容易制作成html源代码。ip地址获取方法就太多了,下面是比较好的方法:获取方法1:直接转换成bt种子,然后另存为wap地址;这种方法要求分享方有google账号。以前推荐过,现在已经禁止了。获取方法2:直接抓取m2v分享;需要直接抓m2v分享平台。比如,前两天推荐过的“口袋hd”,是一个百度相关文件自动抓取平台。
当你有很多外网ip,在或者其他网站找代理。你需要给ip一定程度的授权,要不有可能登录失败而登录失败就是因为你不停的抓,那代理的价格会非常便宜。
ip代理,google/yahoo/百度/雅虎ip代理点评:上述都是一些网站,ip代理之所以用中文名称,一个很重要的原因是方便用户区分,一般放置在名称中。
不可以,你随便抓啊,而且一般的ip都只是服务器上的共享ip,根本没什么意义。
爬虫啊
这个问题,我觉得百度是一个高手,
百度贴吧,
世界上有很多网站,你抓来几个就是一个,有这么多网站一起抓是不太可能的事情,不过就我个人而言,
其实这些网站本身就有一个提供给程序员的ip池,或者说浏览器缓存。(从抓取来看,爬虫抓到的ip,以及返回去的地址可能是浏览器缓存里面的。)而搜索引擎,百度比较吊。自己建立了一个ip池。通过轮询,或者计算metric,返回给搜索引擎的数据,就是这些收集来的。
如何采集拉勾网中所有的教育机构招聘信息中图文教程
采集交流 • 优采云 发表了文章 • 0 个评论 • 237 次浏览 • 2021-06-12 06:01
可采集文章:【教程】如何采集拉勾网中所有的教育机构招聘信息中图文教程:(二维码自动识别)
先收集教育招聘的网站,
招聘是不是在线教育?
采集到的信息大多跟招聘有关,要整理到excel或txt文件中。
如果你只是想采集线上学校的招聘信息,那么你肯定不需要整理成excel,因为这里面很多信息是整理不到的,但你需要整理成一个公共库,把你在需要的时候可以借鉴的信息都整理到这个公共库里面。
一般的流程是,先爬虫,要获取哪些信息需要看你爬取的是哪些网站的信息,然后根据网站信息爬取招聘信息。
要是线上教育的话你就去平台的官网抓取,线下可以试试【职官网】,还能匿名发布信息。
最简单的当然是手动加上【广告信息】的
首先,肯定要有个爬虫的。但是,难点有二:1.要抓取很多资源,2.如何保证抓取下来的信息都是你需要的内容。
你可以借助一些可视化的工具,将在线教育的信息进行整理。如导航数据库工具,比如你自己做的就是手机app看谁在线学习。
比如你有一个小的app你可以抓取近百个教育机构的信息他可以给你展示他们的招聘岗位信息,你只需要将这些信息提取出来,然后进行整理而如果你有一个大的app,你可以通过数据分析做广告营销,以及以后给你自己家培训机构服务,或者给培训机构做课程输出。 查看全部
如何采集拉勾网中所有的教育机构招聘信息中图文教程
可采集文章:【教程】如何采集拉勾网中所有的教育机构招聘信息中图文教程:(二维码自动识别)
先收集教育招聘的网站,
招聘是不是在线教育?
采集到的信息大多跟招聘有关,要整理到excel或txt文件中。
如果你只是想采集线上学校的招聘信息,那么你肯定不需要整理成excel,因为这里面很多信息是整理不到的,但你需要整理成一个公共库,把你在需要的时候可以借鉴的信息都整理到这个公共库里面。
一般的流程是,先爬虫,要获取哪些信息需要看你爬取的是哪些网站的信息,然后根据网站信息爬取招聘信息。
要是线上教育的话你就去平台的官网抓取,线下可以试试【职官网】,还能匿名发布信息。
最简单的当然是手动加上【广告信息】的
首先,肯定要有个爬虫的。但是,难点有二:1.要抓取很多资源,2.如何保证抓取下来的信息都是你需要的内容。
你可以借助一些可视化的工具,将在线教育的信息进行整理。如导航数据库工具,比如你自己做的就是手机app看谁在线学习。
比如你有一个小的app你可以抓取近百个教育机构的信息他可以给你展示他们的招聘岗位信息,你只需要将这些信息提取出来,然后进行整理而如果你有一个大的app,你可以通过数据分析做广告营销,以及以后给你自己家培训机构服务,或者给培训机构做课程输出。
如何快速选出那些大v粉丝多且优质的自媒体
采集交流 • 优采云 发表了文章 • 0 个评论 • 135 次浏览 • 2021-05-25 05:05
可采集文章内容,可以通过制作图集来实现,同时完成文字拆分、过滤和归类,最终生成文章内容提取到excel表中。另外,还可以通过第三方公共号接入,推广资源共享,提升引流的效率。
公众号名称本身带有文章标题,并且那篇文章比较火,就可以通过一些原创平台通过推广的方式来增加搜索权重,提高排名。比如说百家号,在百家号中获取原创标签,在其他新媒体平台发布会有排名优势,还有就是通过优质的文章提高你的权重,这样别人就能搜索到你的公众号,也会被更多的人搜索到。那些靠文章流量和粉丝积累的公众号,平台也会有推荐算法来匹配给你流量,不过我认为这种营销就是两头吃,一头吃粉丝,一头吃知名度,有的会火有的不会火,这个就要看你自己的定位了。还有很多种微信公众号文章的推广方式,大家可以多尝试。
在移动互联网和云计算浪潮的推动下,文章的内容已经远远脱离原有传统文章的内容。依托某一文章表达的场景,比如:运动装备、颜值等方向,开发一款类似于推销app的新软件,不断加深品牌形象,先俘获用户,后期延伸。传统自媒体带来的机遇,也是新媒体非常需要的机遇。本质上来说,一篇好的文章,都是集合了文笔、思想、素材、知识点等等,首先需要一个好的切入点,第二是一个创新点。
那么,我们如何从目前几千万的公众号中快速选出那些大v粉丝多且优质的自媒体呢?参考腾讯发布的《2016年微信生态白皮书》显示:超过3亿的微信粉丝们占领了超过90%的中国传统文化市场,是原创文章市场的主要增量,如今有将近40%的品牌主建议大批量投放原创类公众号。所以从现在开始,个人定位,个人能力能够展现的内容最好,网上有很多自媒体软件可以批量管理原创文章,优质原创文章粉丝转化率会更高。
好的,既然文章这么受关注,知道内容怎么制作,那么我们再来看下这一届知识付费的微信公众号大咖们都有哪些特点吧。(被自媒体霸屏了,却不知道)1、李欣频徐沪生(一直都很好奇)他们的内容,真的是说的你想好好学一学:画画怎么学(包括视频);阿龙王小赖;芒果味;肖晓媛;美神小院;花若梦;吴琼;我有一个故事;课谈;一个月十次课;也月十次课;生活用品推荐(写书、做母婴、环保、健康、风水等等,你会发现他们好玩又好深);旅行摄影精选;美妆教程(听了自己也要做的);又创新又好玩的数码达人;只知道贵,很多东西并不知道的;搞笑、幽默;可爱;pr公开课;中国最好的短视频创作者;多元化;改变观念。2、岑力田京子(在腾讯看到的第一篇)他们的内容,各个都是牛逼闪闪的大大,那可不是一般。 查看全部
如何快速选出那些大v粉丝多且优质的自媒体
可采集文章内容,可以通过制作图集来实现,同时完成文字拆分、过滤和归类,最终生成文章内容提取到excel表中。另外,还可以通过第三方公共号接入,推广资源共享,提升引流的效率。
公众号名称本身带有文章标题,并且那篇文章比较火,就可以通过一些原创平台通过推广的方式来增加搜索权重,提高排名。比如说百家号,在百家号中获取原创标签,在其他新媒体平台发布会有排名优势,还有就是通过优质的文章提高你的权重,这样别人就能搜索到你的公众号,也会被更多的人搜索到。那些靠文章流量和粉丝积累的公众号,平台也会有推荐算法来匹配给你流量,不过我认为这种营销就是两头吃,一头吃粉丝,一头吃知名度,有的会火有的不会火,这个就要看你自己的定位了。还有很多种微信公众号文章的推广方式,大家可以多尝试。
在移动互联网和云计算浪潮的推动下,文章的内容已经远远脱离原有传统文章的内容。依托某一文章表达的场景,比如:运动装备、颜值等方向,开发一款类似于推销app的新软件,不断加深品牌形象,先俘获用户,后期延伸。传统自媒体带来的机遇,也是新媒体非常需要的机遇。本质上来说,一篇好的文章,都是集合了文笔、思想、素材、知识点等等,首先需要一个好的切入点,第二是一个创新点。
那么,我们如何从目前几千万的公众号中快速选出那些大v粉丝多且优质的自媒体呢?参考腾讯发布的《2016年微信生态白皮书》显示:超过3亿的微信粉丝们占领了超过90%的中国传统文化市场,是原创文章市场的主要增量,如今有将近40%的品牌主建议大批量投放原创类公众号。所以从现在开始,个人定位,个人能力能够展现的内容最好,网上有很多自媒体软件可以批量管理原创文章,优质原创文章粉丝转化率会更高。
好的,既然文章这么受关注,知道内容怎么制作,那么我们再来看下这一届知识付费的微信公众号大咖们都有哪些特点吧。(被自媒体霸屏了,却不知道)1、李欣频徐沪生(一直都很好奇)他们的内容,真的是说的你想好好学一学:画画怎么学(包括视频);阿龙王小赖;芒果味;肖晓媛;美神小院;花若梦;吴琼;我有一个故事;课谈;一个月十次课;也月十次课;生活用品推荐(写书、做母婴、环保、健康、风水等等,你会发现他们好玩又好深);旅行摄影精选;美妆教程(听了自己也要做的);又创新又好玩的数码达人;只知道贵,很多东西并不知道的;搞笑、幽默;可爱;pr公开课;中国最好的短视频创作者;多元化;改变观念。2、岑力田京子(在腾讯看到的第一篇)他们的内容,各个都是牛逼闪闪的大大,那可不是一般。
ec2小牛如何利用aws对facebook等平台抓取?(图)
采集交流 • 优采云 发表了文章 • 0 个评论 • 116 次浏览 • 2021-05-18 05:02
可采集文章中的title,favicon,标题字段,favicon图标(使用自动提取工具,点击提取图标),该工具还可抓取图片,还可以下载到本地保存,一站式工具。amazonec2文件转储工具,功能强大,可针对图片文件进行加密分析。工具原理:在amazon后台(home)中找到/"images/{facebook}""images/{twitter}""images/{docs}""images/{other}"等资源,保存到磁盘中。
然后将磁盘文件夹按照images资源链接进行转储。(可参考上海千驰)以上是本人的一些心得。希望对您有所帮助。
ec2小牛
如何利用aws对facebook等平台抓取?-facebook
orientationexclusiverestfulclientforosx
whois
用whois模块
onelinkedx这个工具很强大,很多国内外的站长或黑帽子都在用。
fiddler实现抓包
我知道“利用facebook图片进行二次开发”的站在某前台。国内当然是马靖昊了。
无需配置,直接在facebook()上抓包下载。
免费的android程序就很好用,
他们都不是内容抓取,都是ocr识别。
试试来自霓虹国的一款名叫“天香”的小软件。这款软件目前只支持在台湾和香港地区使用,如果你需要在这两个地区使用、也不在意免费,那么可以试试它们。而且这款软件是完全开源的。在“天香”里,你可以将传统的fancy网站通过语言转换为台湾、香港的代码。由于服务商在境外,同时还能保持网站的正版性。还可以下载或者直接下载相应的源代码文件。
还支持手机端的抓包代码,点击他们提供的控制台页面就可以把抓取的网站地址输入到控制台,然后就可以保存和下载了。 查看全部
ec2小牛如何利用aws对facebook等平台抓取?(图)
可采集文章中的title,favicon,标题字段,favicon图标(使用自动提取工具,点击提取图标),该工具还可抓取图片,还可以下载到本地保存,一站式工具。amazonec2文件转储工具,功能强大,可针对图片文件进行加密分析。工具原理:在amazon后台(home)中找到/"images/{facebook}""images/{twitter}""images/{docs}""images/{other}"等资源,保存到磁盘中。
然后将磁盘文件夹按照images资源链接进行转储。(可参考上海千驰)以上是本人的一些心得。希望对您有所帮助。
ec2小牛
如何利用aws对facebook等平台抓取?-facebook
orientationexclusiverestfulclientforosx
whois
用whois模块
onelinkedx这个工具很强大,很多国内外的站长或黑帽子都在用。
fiddler实现抓包
我知道“利用facebook图片进行二次开发”的站在某前台。国内当然是马靖昊了。
无需配置,直接在facebook()上抓包下载。
免费的android程序就很好用,
他们都不是内容抓取,都是ocr识别。
试试来自霓虹国的一款名叫“天香”的小软件。这款软件目前只支持在台湾和香港地区使用,如果你需要在这两个地区使用、也不在意免费,那么可以试试它们。而且这款软件是完全开源的。在“天香”里,你可以将传统的fancy网站通过语言转换为台湾、香港的代码。由于服务商在境外,同时还能保持网站的正版性。还可以下载或者直接下载相应的源代码文件。
还支持手机端的抓包代码,点击他们提供的控制台页面就可以把抓取的网站地址输入到控制台,然后就可以保存和下载了。
可采集文章地址,各大门户都有复制粘贴的功能
采集交流 • 优采云 发表了文章 • 0 个评论 • 227 次浏览 • 2021-05-17 22:08
可采集文章地址,
各大门户都有复制粘贴的功能,你也可以尝试搜狗的一键搬家,安装比较麻烦,单页文章格式的话,你可以用美篇,
微信公众号,文章基本都是可以被各个平台引用的,
更高级一点的是iphone安卓都不能复制粘贴的连互联网门户都不能复制粘贴的顶级报纸,他们的文章一样可以复制粘贴。
快传打印,就是复制粘贴,还可以共享到微信,
用木瓜微信版,里面就有这个功能。
目前,很多自媒体平台都推出了自动复制粘贴的功能了。
自问自答,大家都找错地方了。
1.去各大门户自媒体平台找文章。2.去搜狐、网易、凤凰等其他一些门户网站复制到新浪微博。3.把对应门户复制到微信公众号上。
前三种用百度搜搜基本上所有网站都能用,特别是中国那些门户门户,还有搜狐,网易,还有现在很火的各大自媒体平台。要复制粘贴一般找一些地方性的平台,如像新浪、凤凰等网站去查找。因为这些网站很多文章分类,其中就会有你需要复制粘贴的文章,一般看它用户量就能看出哪个网站的内容好坏。另外你用5118等网站去查找关键词相关性、竞争度、以及排名。
查找其他平台的推荐机制,保持你的热度。比如有个平台就是将一篇文章分析排名,然后将排名靠前的文章贴到平台上去。 查看全部
可采集文章地址,各大门户都有复制粘贴的功能
可采集文章地址,
各大门户都有复制粘贴的功能,你也可以尝试搜狗的一键搬家,安装比较麻烦,单页文章格式的话,你可以用美篇,
微信公众号,文章基本都是可以被各个平台引用的,
更高级一点的是iphone安卓都不能复制粘贴的连互联网门户都不能复制粘贴的顶级报纸,他们的文章一样可以复制粘贴。
快传打印,就是复制粘贴,还可以共享到微信,
用木瓜微信版,里面就有这个功能。
目前,很多自媒体平台都推出了自动复制粘贴的功能了。
自问自答,大家都找错地方了。
1.去各大门户自媒体平台找文章。2.去搜狐、网易、凤凰等其他一些门户网站复制到新浪微博。3.把对应门户复制到微信公众号上。
前三种用百度搜搜基本上所有网站都能用,特别是中国那些门户门户,还有搜狐,网易,还有现在很火的各大自媒体平台。要复制粘贴一般找一些地方性的平台,如像新浪、凤凰等网站去查找。因为这些网站很多文章分类,其中就会有你需要复制粘贴的文章,一般看它用户量就能看出哪个网站的内容好坏。另外你用5118等网站去查找关键词相关性、竞争度、以及排名。
查找其他平台的推荐机制,保持你的热度。比如有个平台就是将一篇文章分析排名,然后将排名靠前的文章贴到平台上去。
ui自学网,ui设计培训设计助手|咏梅ui教程
采集交流 • 优采云 发表了文章 • 0 个评论 • 178 次浏览 • 2021-08-05 00:04
可采集文章、音频、视频请关注“咏梅ui教程”公众号,回复:关键词即可免费获取!ui自学网,ui教程,ui设计培训,ui设计工作,ui设计新手教程,ui设计师培训,ui设计职业培训ui教程ui设计助手|ui设计师|产品ui|界面ui|网页ui|图标ui自学网【教程】ps特效素材手机屏幕显示特效ps特效素材手机屏幕显示特效ps特效素材手机屏幕显示特效设计必备:花瓣网,千图网,昵图网,、素材网站千图网,千库网素材网站(包含软件素材,作品素材,素材网站中排名靠前都比较好,里面有素材可以看一下,有免费试用一个小时的素材功能)插画与c4d素材ui设计必备:一个全球顶尖的设计网站!希望可以帮到你,谢谢!。
选择最靠谱的,没有最靠谱的。靠谱不靠谱的和你的工作与专业没有太大关系。国内好不好不清楚,国外的网站还是不错的,googleremotedesign可以访问国外的网站,尤其是ui和c4d,和流体动画领域。
推荐几个ui设计网站给你:站酷:有中国传统文化底蕴的视觉艺术氛围,提供综合全面的优秀设计作品欣赏,优秀设计师交流、学习、分享,在此可以与顶尖的设计人才交流,学习,分享。中国优秀网页设计网站集合了国内外设计师网页设计界顶尖人物的作品集合.vi网:展示了国内外最新前沿设计趋势的资讯网站.aaa教育:综合的设计素材网站,工具类网站,品牌价值观好,尤其对工业设计,平面设计,ui设计是国内的三大特色教育网站.网易:工业界最大的用户体验设计和体验网站.simpletech:ui设计前沿平台,设计界最快捷最好用的设计网站。 查看全部
ui自学网,ui设计培训设计助手|咏梅ui教程
可采集文章、音频、视频请关注“咏梅ui教程”公众号,回复:关键词即可免费获取!ui自学网,ui教程,ui设计培训,ui设计工作,ui设计新手教程,ui设计师培训,ui设计职业培训ui教程ui设计助手|ui设计师|产品ui|界面ui|网页ui|图标ui自学网【教程】ps特效素材手机屏幕显示特效ps特效素材手机屏幕显示特效ps特效素材手机屏幕显示特效设计必备:花瓣网,千图网,昵图网,、素材网站千图网,千库网素材网站(包含软件素材,作品素材,素材网站中排名靠前都比较好,里面有素材可以看一下,有免费试用一个小时的素材功能)插画与c4d素材ui设计必备:一个全球顶尖的设计网站!希望可以帮到你,谢谢!。
选择最靠谱的,没有最靠谱的。靠谱不靠谱的和你的工作与专业没有太大关系。国内好不好不清楚,国外的网站还是不错的,googleremotedesign可以访问国外的网站,尤其是ui和c4d,和流体动画领域。
推荐几个ui设计网站给你:站酷:有中国传统文化底蕴的视觉艺术氛围,提供综合全面的优秀设计作品欣赏,优秀设计师交流、学习、分享,在此可以与顶尖的设计人才交流,学习,分享。中国优秀网页设计网站集合了国内外设计师网页设计界顶尖人物的作品集合.vi网:展示了国内外最新前沿设计趋势的资讯网站.aaa教育:综合的设计素材网站,工具类网站,品牌价值观好,尤其对工业设计,平面设计,ui设计是国内的三大特色教育网站.网易:工业界最大的用户体验设计和体验网站.simpletech:ui设计前沿平台,设计界最快捷最好用的设计网站。
好吧,难就难在数据库要起来吗?
采集交流 • 优采云 发表了文章 • 0 个评论 • 147 次浏览 • 2021-07-26 23:04
可采集文章中的内容(如问题,答案,好文章,长尾关键词等),并提取并处理好后缀做成文字数据库,最后输出pdf格式,目前我在用的有必应科技,百度文库等,其他平台请知乎搜索。
问题和答案都是可以抓取的,用python的numpy库就可以实现。为什么你觉得不可能,可能是用的库不是必须的,而是你用错工具了。
应该不是不可能,但是比较难。我认为,这个前提在于:“内容足够丰富”我不认为文字数据库有必要存在,因为文字数据库在保存信息的时候就可以考虑内容相关度问题,而不需要文字数据库。
你可以使用分析库,主要是python,你用mysql估计难以跑满,也可以用hive(这个可以用。不过个人认为,
问题是不可行。例如你想抓取知乎上有关于高考的所有问题?是否已经存在?目前的python在这方面不是特别的完善。例如你有1亿问题。各种标签,而且全是可能涉及到高考。好吧,难就难在数据库要起来。但是如果说不是专业研究人员,1亿问题中没有几千万,也是十几亿吧。
可行。实际操作下来,几乎没有可行性。抓取文字数据大部分行为应该是非重复下单。非重复下单发生几率不会超过10%,你这10%对于抓取数据也是几乎没有用。多年的被挖掘数据不少不少,数据量也极大,但是真正能做的人实在太少。想做请在市场中拉人头。好吧, 查看全部
好吧,难就难在数据库要起来吗?
可采集文章中的内容(如问题,答案,好文章,长尾关键词等),并提取并处理好后缀做成文字数据库,最后输出pdf格式,目前我在用的有必应科技,百度文库等,其他平台请知乎搜索。
问题和答案都是可以抓取的,用python的numpy库就可以实现。为什么你觉得不可能,可能是用的库不是必须的,而是你用错工具了。
应该不是不可能,但是比较难。我认为,这个前提在于:“内容足够丰富”我不认为文字数据库有必要存在,因为文字数据库在保存信息的时候就可以考虑内容相关度问题,而不需要文字数据库。
你可以使用分析库,主要是python,你用mysql估计难以跑满,也可以用hive(这个可以用。不过个人认为,
问题是不可行。例如你想抓取知乎上有关于高考的所有问题?是否已经存在?目前的python在这方面不是特别的完善。例如你有1亿问题。各种标签,而且全是可能涉及到高考。好吧,难就难在数据库要起来。但是如果说不是专业研究人员,1亿问题中没有几千万,也是十几亿吧。
可行。实际操作下来,几乎没有可行性。抓取文字数据大部分行为应该是非重复下单。非重复下单发生几率不会超过10%,你这10%对于抓取数据也是几乎没有用。多年的被挖掘数据不少不少,数据量也极大,但是真正能做的人实在太少。想做请在市场中拉人头。好吧,
springcloud架构技术优劣性系统优点及优点(一)
采集交流 • 优采云 发表了文章 • 0 个评论 • 108 次浏览 • 2021-07-24 00:12
前言
因公司业务需要,需要获取客户提供的微信公众号文章的历史记录并每天更新。很明显,300多个公众号不能每天人工查,问题提交给IT团队。对于那些喜欢爬虫的人,我绝对想要他。之前做过搜狗的微信爬虫,之后一直在做java web。这个项目重新点燃了我对爬虫的热爱。首次使用spring cloud架构做爬虫。历时20多天,终于搞定。接下来我将通过一系列文章分享项目经验,并提供源码供大家指正!
一、系统介绍
本系统基于Java开发。只需配置公众号或微信公众号,即可定时或即时抓取文章微信公众号(包括阅读、点赞、观看)。
二、系统架构技术架构
Spring Cloud、SpringBoot、Mybatis-Plus、Nacos、RocketMq、nginx
存储
Mysql、MongoDB、Redis、Solr
缓存
Redis
代理
提琴手
三、系统优缺点系统优点
1、 公众号配置后,可以使用Fiddler的JS注入功能和Websocket实现自动爬取; 2、系统是分布式架构,高可用; 3、RocketMq 消息队列可以解耦。解决网络抖动导致采集失败的问题。 3次消费不成功,登录mysql,保证文章的完整性; 4、可以添加任意数量的微信信号,提高采集效率,抵抗反爬限制; 5、Redis 在每个微信账号24小时内缓存采集记录,防止账号被封; 6、Nacos作为配置中心,可以通过热配置实时调整采集频率; 7、将采集到将数据存储在Solr集群中,提高检索速度; 8、将捕获返回的记录存储到MongoDB存档中,方便查看错误日志。
系统缺点:
1、通过真机真实账号采集留言,如果需要采集大量公众号,需要有多个微信账号作为支持(如果当天账号达到上限,可通过微信公众平台界面抓取获取消息); 2、不是发完就可以抓到的公众号,采集时间是系统设置的,留言有一定的滞后性(如果公众号不多的话,微信公众号就够了,并且可以通过增加采集来优化频率)。
四、模块介绍
因为管理系统和API调用函数会在后面添加,所以提前封装了一些函数。
common-ws-starter
公共模块:存储工具和实体等公共消息。
redis-ws-starter
Redis模块:对spring-boot-starter-data-redis进行二次封装,暴露打包好的Redis工具类和Redisson工具类。
rocketmq-ws-starter
RocketMq 模块:对 Rocketmq-spring-boot-starter 的二次封装,提供消费重试和记录失败日志功能。
db-ws-starter
mysql数据源模块:封装mysql数据源,支持多数据源,自定义注解实现数据源动态切换。
sql-wx-spider
mysql数据库模块:提供mysql数据库操作的所有功能。
pc-wx-spider
PC端采集模块:收录PC端采集公众号历史相关功能。
java-wx-spider
Java提取模块:收录Java程序提取文章内容相关功能。
mobile-wx-spider
Simulator采集模块:收录与模拟器或手机采集消息交互量相关的功能。
五、通用流程图
六、在PC端和手机端运行截图
控制面板
操作结束
总结
项目亲测上线,项目开发中解决了微信搜狗临时链接永久链接问题。希望能帮助到被类似业务困扰的老铁。如今,做java就像逆流而上。不前进就会后退。我不知道你什么时候参与。祝大家都有属于自己的葵花宝。如果你看到这个,你不给它一个采集吗?
原文链接:/post/6956499860996489230
如果你觉得这篇文章对你有帮助,可以点击首页一起学习进步 查看全部
springcloud架构技术优劣性系统优点及优点(一)
前言
因公司业务需要,需要获取客户提供的微信公众号文章的历史记录并每天更新。很明显,300多个公众号不能每天人工查,问题提交给IT团队。对于那些喜欢爬虫的人,我绝对想要他。之前做过搜狗的微信爬虫,之后一直在做java web。这个项目重新点燃了我对爬虫的热爱。首次使用spring cloud架构做爬虫。历时20多天,终于搞定。接下来我将通过一系列文章分享项目经验,并提供源码供大家指正!
一、系统介绍
本系统基于Java开发。只需配置公众号或微信公众号,即可定时或即时抓取文章微信公众号(包括阅读、点赞、观看)。
二、系统架构技术架构
Spring Cloud、SpringBoot、Mybatis-Plus、Nacos、RocketMq、nginx
存储
Mysql、MongoDB、Redis、Solr
缓存
Redis
代理
提琴手
三、系统优缺点系统优点
1、 公众号配置后,可以使用Fiddler的JS注入功能和Websocket实现自动爬取; 2、系统是分布式架构,高可用; 3、RocketMq 消息队列可以解耦。解决网络抖动导致采集失败的问题。 3次消费不成功,登录mysql,保证文章的完整性; 4、可以添加任意数量的微信信号,提高采集效率,抵抗反爬限制; 5、Redis 在每个微信账号24小时内缓存采集记录,防止账号被封; 6、Nacos作为配置中心,可以通过热配置实时调整采集频率; 7、将采集到将数据存储在Solr集群中,提高检索速度; 8、将捕获返回的记录存储到MongoDB存档中,方便查看错误日志。
系统缺点:
1、通过真机真实账号采集留言,如果需要采集大量公众号,需要有多个微信账号作为支持(如果当天账号达到上限,可通过微信公众平台界面抓取获取消息); 2、不是发完就可以抓到的公众号,采集时间是系统设置的,留言有一定的滞后性(如果公众号不多的话,微信公众号就够了,并且可以通过增加采集来优化频率)。
四、模块介绍
因为管理系统和API调用函数会在后面添加,所以提前封装了一些函数。
common-ws-starter
公共模块:存储工具和实体等公共消息。
redis-ws-starter
Redis模块:对spring-boot-starter-data-redis进行二次封装,暴露打包好的Redis工具类和Redisson工具类。
rocketmq-ws-starter
RocketMq 模块:对 Rocketmq-spring-boot-starter 的二次封装,提供消费重试和记录失败日志功能。
db-ws-starter
mysql数据源模块:封装mysql数据源,支持多数据源,自定义注解实现数据源动态切换。
sql-wx-spider
mysql数据库模块:提供mysql数据库操作的所有功能。
pc-wx-spider
PC端采集模块:收录PC端采集公众号历史相关功能。
java-wx-spider
Java提取模块:收录Java程序提取文章内容相关功能。
mobile-wx-spider
Simulator采集模块:收录与模拟器或手机采集消息交互量相关的功能。
五、通用流程图
六、在PC端和手机端运行截图
控制面板
操作结束
总结
项目亲测上线,项目开发中解决了微信搜狗临时链接永久链接问题。希望能帮助到被类似业务困扰的老铁。如今,做java就像逆流而上。不前进就会后退。我不知道你什么时候参与。祝大家都有属于自己的葵花宝。如果你看到这个,你不给它一个采集吗?
原文链接:/post/6956499860996489230
如果你觉得这篇文章对你有帮助,可以点击首页一起学习进步
可采集文章、图片的地址,批量添加相关的关键词
采集交流 • 优采云 发表了文章 • 0 个评论 • 173 次浏览 • 2021-07-21 23:01
可采集文章、图片的地址,批量添加相关的关键词即可。如果你想像蜘蛛一样去爬,还需要一些东西。1,网上有爬虫,但是因为我没试过,所以不敢保证效果如何。2,发布之前,做好采集规划,爬什么,怎么爬,爬到哪,如何分类,什么页面,怎么用,自己要清楚。3,所以,个人建议是自己去尝试,千万不要用自己发布的网站做自己的爬虫。
非专业的最好还是去找专业的公司做,毕竟这个动作对人要求还是比较高的,我们以前帮助过几个客户做过,
抓取网页这种技术性的工作最好还是找专业的公司来做,现在网络上比较出名的爬虫商有中移动商家服务联盟,连连支付,还有这个见名知意,是深圳的,
可以在360里面去查相关的爬虫结构,比如360自己发布了一个组织抓取到他们网站的所有图片(仅限所有),然后我们再爬虫程序里面去抓取,至于如何发布,前段时间不少人说过一些方法,比如连连支付的页面列表抓取。
真的有必要这么去做吗?这个只是一个文字或者图片的意思.你可以在别的地方搜索网页文件的url做.net的code之类的.这个做法在国内真的是行不通.如果你为了爬取自己要爬取的网站的图片.还不如直接去搜索些别的.图片上很多资源可以看上去好了.
发布到互联网去., 查看全部
可采集文章、图片的地址,批量添加相关的关键词
可采集文章、图片的地址,批量添加相关的关键词即可。如果你想像蜘蛛一样去爬,还需要一些东西。1,网上有爬虫,但是因为我没试过,所以不敢保证效果如何。2,发布之前,做好采集规划,爬什么,怎么爬,爬到哪,如何分类,什么页面,怎么用,自己要清楚。3,所以,个人建议是自己去尝试,千万不要用自己发布的网站做自己的爬虫。
非专业的最好还是去找专业的公司做,毕竟这个动作对人要求还是比较高的,我们以前帮助过几个客户做过,
抓取网页这种技术性的工作最好还是找专业的公司来做,现在网络上比较出名的爬虫商有中移动商家服务联盟,连连支付,还有这个见名知意,是深圳的,
可以在360里面去查相关的爬虫结构,比如360自己发布了一个组织抓取到他们网站的所有图片(仅限所有),然后我们再爬虫程序里面去抓取,至于如何发布,前段时间不少人说过一些方法,比如连连支付的页面列表抓取。
真的有必要这么去做吗?这个只是一个文字或者图片的意思.你可以在别的地方搜索网页文件的url做.net的code之类的.这个做法在国内真的是行不通.如果你为了爬取自己要爬取的网站的图片.还不如直接去搜索些别的.图片上很多资源可以看上去好了.
发布到互联网去.,
可采集文章内容的十大网站提醒商家在选择网站时最好综合考虑
采集交流 • 优采云 发表了文章 • 0 个评论 • 156 次浏览 • 2021-07-20 22:00
可采集文章内容的十大网站提醒各位商家在选择网站时最好综合考虑网站综合知名度,收费成本,转化率等情况进行选择。从导流,营销,品牌,活动等方面进行考量。另外每个平台都有这自己的红利期。别错过。百度系,头条系等的网站是大家一直关注的,主要还是因为他们的推广信息是免费向各大网站曝光的,另外收费客户可以根据自己的情况来选择。
不过现在出现了一个新的流量聚集地,那就是抖音。直接批量注册抖音号就可以,粉丝一万两万都是没有问题的。抖音的热门话题爆款视频,引流量效果非常好。尤其是满足低成本引流。商家可以进行尝试。另外我个人从网上看到很多网站都是直接免费发布商品广告视频,如下图:首先这种方式不仅自己的收益没有问题,还可以帮忙推广一些网站。
另外收益也不错。可尝试。如果有需要还可以发广告赚取佣金。那么这些商家如何选择呢。其实网站有很多,可以试试。
黑马兼职网免费找兼职有一个很好的平台大家有兴趣可以看一下
据我所知专门服务大学生兼职的app还挺多的,像金汉森、哒哒兼职等,不过总体而言对平台要求比较高,收入也可能比较少,所以还是要擦亮眼睛看一下。
兼职猫,助兼帮,
海绵城市兼职猫58同城点点众包豆瓣兼职群贴吧还有就是兼职吧app挺不错的 查看全部
可采集文章内容的十大网站提醒商家在选择网站时最好综合考虑
可采集文章内容的十大网站提醒各位商家在选择网站时最好综合考虑网站综合知名度,收费成本,转化率等情况进行选择。从导流,营销,品牌,活动等方面进行考量。另外每个平台都有这自己的红利期。别错过。百度系,头条系等的网站是大家一直关注的,主要还是因为他们的推广信息是免费向各大网站曝光的,另外收费客户可以根据自己的情况来选择。
不过现在出现了一个新的流量聚集地,那就是抖音。直接批量注册抖音号就可以,粉丝一万两万都是没有问题的。抖音的热门话题爆款视频,引流量效果非常好。尤其是满足低成本引流。商家可以进行尝试。另外我个人从网上看到很多网站都是直接免费发布商品广告视频,如下图:首先这种方式不仅自己的收益没有问题,还可以帮忙推广一些网站。
另外收益也不错。可尝试。如果有需要还可以发广告赚取佣金。那么这些商家如何选择呢。其实网站有很多,可以试试。
黑马兼职网免费找兼职有一个很好的平台大家有兴趣可以看一下
据我所知专门服务大学生兼职的app还挺多的,像金汉森、哒哒兼职等,不过总体而言对平台要求比较高,收入也可能比较少,所以还是要擦亮眼睛看一下。
兼职猫,助兼帮,
海绵城市兼职猫58同城点点众包豆瓣兼职群贴吧还有就是兼职吧app挺不错的
可采集文章并导出excel文件,并附上正则、xpath、json地址等数据
采集交流 • 优采云 发表了文章 • 0 个评论 • 181 次浏览 • 2021-07-16 06:03
可采集文章并导出excel文件,并附上正则、xpath、json地址等数据。1.下载xpath查询:,直接导入xpathquerystring中。当且仅当满足如下一个条件时,返回“1”。groupby:!settags>>"""{border:1;}"""有什么意义大家可以自己理解。不知道的可以留言讨论。
2.尝试执行。不知道原理,估计原理在于text函数了。思考:这里报错是什么原因?false?文章属性改变?is_all?换个参数试试?3.因为部分代码在xpathquerystring中,很有可能会失败。换了一个容易通过的docstring或者修改一下自己的路径就行了。4.在此文章分享一个办法。在xpathquerystring中随意填充一个字符串,看文章是否能被下载。
不能下载,换成一个json文件。因为知乎文章是xml文件,并不知道如何加密保存为xpath文件。保存后查看是否下载成功,如果下载失败,请参考(第4条)。5.感谢一些网友提供经验:markdown不能够导入xpath。还有一个办法,就是找到导入xpath的链接,然后用该链接在xpath中填充xpath。markdown文章不能够导入xpath的原因:[转载]如何使用markdown语法下载网站文章。
markdown中没有xpath啊,除非你自己写一个xpath解析框架。
xpath是给关键字设定地址。解析下xpath你可以知道哪些xpath没有返回地址。导入之后对xpath直接解析,返回地址即可。一般是下面这样的:importxpathfrommatplotlib.pyplotaspltimportxpathheader=['/','//','///',''/.','/','.','///','/','','/','/','/','']table=xpath('//table/td[1]/td[1]/text()')header=header['header']table=table.xpath('//table/td[2]/td[1]/text()')header=header['header']plt.xpath('//table/td[2]/td[1]/text()')plt.xpath('//table/td[1]/td[2]/text()')另外再补充一句,xpath()在markdown中也不能直接使用,还是要通过xpath设置content隐藏符,让xpath链接,避免歧义。 查看全部
可采集文章并导出excel文件,并附上正则、xpath、json地址等数据
可采集文章并导出excel文件,并附上正则、xpath、json地址等数据。1.下载xpath查询:,直接导入xpathquerystring中。当且仅当满足如下一个条件时,返回“1”。groupby:!settags>>"""{border:1;}"""有什么意义大家可以自己理解。不知道的可以留言讨论。
2.尝试执行。不知道原理,估计原理在于text函数了。思考:这里报错是什么原因?false?文章属性改变?is_all?换个参数试试?3.因为部分代码在xpathquerystring中,很有可能会失败。换了一个容易通过的docstring或者修改一下自己的路径就行了。4.在此文章分享一个办法。在xpathquerystring中随意填充一个字符串,看文章是否能被下载。
不能下载,换成一个json文件。因为知乎文章是xml文件,并不知道如何加密保存为xpath文件。保存后查看是否下载成功,如果下载失败,请参考(第4条)。5.感谢一些网友提供经验:markdown不能够导入xpath。还有一个办法,就是找到导入xpath的链接,然后用该链接在xpath中填充xpath。markdown文章不能够导入xpath的原因:[转载]如何使用markdown语法下载网站文章。
markdown中没有xpath啊,除非你自己写一个xpath解析框架。
xpath是给关键字设定地址。解析下xpath你可以知道哪些xpath没有返回地址。导入之后对xpath直接解析,返回地址即可。一般是下面这样的:importxpathfrommatplotlib.pyplotaspltimportxpathheader=['/','//','///',''/.','/','.','///','/','','/','/','/','']table=xpath('//table/td[1]/td[1]/text()')header=header['header']table=table.xpath('//table/td[2]/td[1]/text()')header=header['header']plt.xpath('//table/td[2]/td[1]/text()')plt.xpath('//table/td[1]/td[2]/text()')另外再补充一句,xpath()在markdown中也不能直接使用,还是要通过xpath设置content隐藏符,让xpath链接,避免歧义。
可采集文章词汇统计汇总方法有2种,1是用函数
采集交流 • 优采云 发表了文章 • 0 个评论 • 187 次浏览 • 2021-07-13 05:02
可采集文章词汇统计汇总方法有2种,1是用函数,目前我知道的有sumproduct()、match()和substitute()等等。2是手动采集,目前我知道的主要有stringi函数、freqmode函数、randbetween函数等等。
英文文章内容主要就是分词、句子切分、词频统计。词频统计和分词,web端都可以实现,小爬虫可以直接在scrapy项目下做。最新有基于apache2中间件的一套爬虫系统可以docker安装,解决内容相似度统计的问题,
urllib2或者正则表达式即可。
yarn可以实现比较大的同步集群,用于读取大文件的量估计相对高一些,小的话估计最多2000。
相似度有几个方面:
1、文本摘要;
2、提取相似的区域;
3、去重。你可以把所有网站的内容进行一个大文件。先对大文件,摘要一下。或者把内容复制到提取大文件的目录下,再提取匹配的文本。这样可以做到一次性处理,不需要重复提取。另外,去重。如果网站,有重复的文本,可以去除重复的数据。这样的处理比较简单,比如你的同事提到的全国25所学校,或者高考的内容,一些热门新闻,热门社区。
要实现
1、3里面的话,需要搞n多的网站,n多次提取数据并去重。一般我不建议去做的。 查看全部
可采集文章词汇统计汇总方法有2种,1是用函数
可采集文章词汇统计汇总方法有2种,1是用函数,目前我知道的有sumproduct()、match()和substitute()等等。2是手动采集,目前我知道的主要有stringi函数、freqmode函数、randbetween函数等等。
英文文章内容主要就是分词、句子切分、词频统计。词频统计和分词,web端都可以实现,小爬虫可以直接在scrapy项目下做。最新有基于apache2中间件的一套爬虫系统可以docker安装,解决内容相似度统计的问题,
urllib2或者正则表达式即可。
yarn可以实现比较大的同步集群,用于读取大文件的量估计相对高一些,小的话估计最多2000。
相似度有几个方面:
1、文本摘要;
2、提取相似的区域;
3、去重。你可以把所有网站的内容进行一个大文件。先对大文件,摘要一下。或者把内容复制到提取大文件的目录下,再提取匹配的文本。这样可以做到一次性处理,不需要重复提取。另外,去重。如果网站,有重复的文本,可以去除重复的数据。这样的处理比较简单,比如你的同事提到的全国25所学校,或者高考的内容,一些热门新闻,热门社区。
要实现
1、3里面的话,需要搞n多的网站,n多次提取数据并去重。一般我不建议去做的。
试论钢骨:理论化是“宜理不宜伤”
采集交流 • 优采云 发表了文章 • 0 个评论 • 87 次浏览 • 2021-07-11 07:02
可采集文章源站“友邦”原文《试论钢骨:是“宜理不宜伤”,还是“宜伤不宜理”》在处理中国台湾问题的全面交锋战略关系上,是“宜伤不宜理”,还是“宜理不宜伤”?我们处理“友邦”问题时,能否作到“宜之不进,不致请求不回”?这是学习理论化的前提。对于台湾现在和将来而言,理论化才是真理,作实践理论化才能真正会理论。
所以我建议,我们必须要会理论化。理论化也有两层含义,一是会自己交心,理解事物发展发展规律;二是会自己和解,理解事物谁好谁坏,理解事物什么是正确,什么是不对的,能够和解。真正了解事物,到底是什么对,什么错,才能找到真理的理论化办法,才能找到真理之道,真正走在事物发展的康庄大道上。离开理论化而谈实践化,是在离开根本理论谈过程,离开理论的追问和深度思考而谈发展。
理论高手和实践高手本来就不合二谋一,讲究辩证法效率。因为实践除了根本理论上的目标,还有中间过程的整体发展。如果简单是按章传信,真的就是经验的最简单方法,和理论目标是反的。理论好比针头,实践是墨水,用太浓,太稀,太适宜,都不能有效传递信息。那理论可以有针头的那种辨证性吗?理论是有方法的,实践是靠方法实现的,即使用者是象大象的,也是要用方法传播、组织、扩散和响应。
观察一个人的观察能力和思考能力,他的理论化过程是怎样的?他未必观察和思考理论本身,不过是借助理论本身做原始信息的打磨和积累。什么过程?方法是一步步下达的,一步步扩散和响应,它的形成,需要你有方法和工具,过程则是方法在不断适应变化。方法是越来越综合化的,需要具体到工具才有意义。然而理论化是一个总体的过程,他包括过程,从方法、工具、过程不断适应变化。
而实践理论化仅仅只是进一步方法上的减法。因此,谈理论化,是一个根本和概念,就是从总体的眼光看问题,想不走弯路,一步到位就要有一个理论化的过程。理论化的内涵,就是要想想说理时是按什么是按什么是辩证法、哲学还是什么是辩证法,是按什么是主要内容还是思考主要问题或者抓住某个最关键的环节去论述。“对自己”的理论化道路:按规律方法论论断问题。
对事物人物无一不是从人为的认识、评价、解释、原因或要求去考虑。关注“友邦”,说理论,找主要,抓关键,注背景,以背景和实际情况为依据,进行较为严密的论述。如直接说出中国,主要是指什么?是指一个日本人,一群不是中国人但时刻想引渡回国内的中国人,在某个法院的某个会议室里就某个案子的某个具体问题拍板定案。那中国人中谁最聪明?那中国人又是谁指挥,发生的安。 查看全部
试论钢骨:理论化是“宜理不宜伤”
可采集文章源站“友邦”原文《试论钢骨:是“宜理不宜伤”,还是“宜伤不宜理”》在处理中国台湾问题的全面交锋战略关系上,是“宜伤不宜理”,还是“宜理不宜伤”?我们处理“友邦”问题时,能否作到“宜之不进,不致请求不回”?这是学习理论化的前提。对于台湾现在和将来而言,理论化才是真理,作实践理论化才能真正会理论。
所以我建议,我们必须要会理论化。理论化也有两层含义,一是会自己交心,理解事物发展发展规律;二是会自己和解,理解事物谁好谁坏,理解事物什么是正确,什么是不对的,能够和解。真正了解事物,到底是什么对,什么错,才能找到真理的理论化办法,才能找到真理之道,真正走在事物发展的康庄大道上。离开理论化而谈实践化,是在离开根本理论谈过程,离开理论的追问和深度思考而谈发展。
理论高手和实践高手本来就不合二谋一,讲究辩证法效率。因为实践除了根本理论上的目标,还有中间过程的整体发展。如果简单是按章传信,真的就是经验的最简单方法,和理论目标是反的。理论好比针头,实践是墨水,用太浓,太稀,太适宜,都不能有效传递信息。那理论可以有针头的那种辨证性吗?理论是有方法的,实践是靠方法实现的,即使用者是象大象的,也是要用方法传播、组织、扩散和响应。
观察一个人的观察能力和思考能力,他的理论化过程是怎样的?他未必观察和思考理论本身,不过是借助理论本身做原始信息的打磨和积累。什么过程?方法是一步步下达的,一步步扩散和响应,它的形成,需要你有方法和工具,过程则是方法在不断适应变化。方法是越来越综合化的,需要具体到工具才有意义。然而理论化是一个总体的过程,他包括过程,从方法、工具、过程不断适应变化。
而实践理论化仅仅只是进一步方法上的减法。因此,谈理论化,是一个根本和概念,就是从总体的眼光看问题,想不走弯路,一步到位就要有一个理论化的过程。理论化的内涵,就是要想想说理时是按什么是按什么是辩证法、哲学还是什么是辩证法,是按什么是主要内容还是思考主要问题或者抓住某个最关键的环节去论述。“对自己”的理论化道路:按规律方法论论断问题。
对事物人物无一不是从人为的认识、评价、解释、原因或要求去考虑。关注“友邦”,说理论,找主要,抓关键,注背景,以背景和实际情况为依据,进行较为严密的论述。如直接说出中国,主要是指什么?是指一个日本人,一群不是中国人但时刻想引渡回国内的中国人,在某个法院的某个会议室里就某个案子的某个具体问题拍板定案。那中国人中谁最聪明?那中国人又是谁指挥,发生的安。
可采集文章、图片(且只支持正文)的方法
采集交流 • 优采云 发表了文章 • 0 个评论 • 173 次浏览 • 2021-07-06 06:01
可采集文章、图片(且只支持正文)的方法不止一种,题主不妨自己去找一下。针对题主问题回答如下:关于文本回复,
1、各大新闻网站有文本回复功能,
2、请题主先自己尝试下,在知乎提问,容易出现不宜公开讨论的内容,包括但不限于政治,宗教。
3、使用开源工具convertbot。
国内有个东东,可以一键输入,挺方便的,估计你需要下个国外的软件吧。
目前常用的有:1.直接上格子云微信图文消息写作.gif,diy,无需下载任何软件,只需登录电脑和网页即可完成。
convertbot,当时受同事推荐过。内置各种开源工具,免费,且有不少chinajoy里面的商机,可以看看。
推荐强大实用的聊天工具chat-mode,安卓、ios都支持。
也许你可以试一下文件传输助手!免费版还只有wifi才可以使用,但是现在没有iphone端的版本了,欢迎小伙伴们留言。
常用的通讯类软件支持正文摘抄,只是在打开文章输入正文的时候是要读取文章背景,图片,链接这些信息的。比如搜狗搜索等等的。不过chat-mode是免费版本的,而且很多话题能帮我们准确定位文章的重点部分。 查看全部
可采集文章、图片(且只支持正文)的方法
可采集文章、图片(且只支持正文)的方法不止一种,题主不妨自己去找一下。针对题主问题回答如下:关于文本回复,
1、各大新闻网站有文本回复功能,
2、请题主先自己尝试下,在知乎提问,容易出现不宜公开讨论的内容,包括但不限于政治,宗教。
3、使用开源工具convertbot。
国内有个东东,可以一键输入,挺方便的,估计你需要下个国外的软件吧。
目前常用的有:1.直接上格子云微信图文消息写作.gif,diy,无需下载任何软件,只需登录电脑和网页即可完成。
convertbot,当时受同事推荐过。内置各种开源工具,免费,且有不少chinajoy里面的商机,可以看看。
推荐强大实用的聊天工具chat-mode,安卓、ios都支持。
也许你可以试一下文件传输助手!免费版还只有wifi才可以使用,但是现在没有iphone端的版本了,欢迎小伙伴们留言。
常用的通讯类软件支持正文摘抄,只是在打开文章输入正文的时候是要读取文章背景,图片,链接这些信息的。比如搜狗搜索等等的。不过chat-mode是免费版本的,而且很多话题能帮我们准确定位文章的重点部分。
去除空格和标点符号作者不去除连结两两是链接
采集交流 • 优采云 发表了文章 • 0 个评论 • 112 次浏览 • 2021-07-05 22:00
可采集文章的关键词,输入相关的话题即可显示出该话题下所有的文章,文章是按照字数排序,从上到下显示,点击哪篇显示哪篇,相当方便,
原文去除空格和标点符号作者不去除连结两两是链接,其中链接是一个相同连结百度图片认证文章一般都带图片。
有浏览器识别出了该网页,无非就是这么两个原因:1、带字数预览的文章,有空格和标点,放在了他的搜索页面。2、百度图片认证不会识别同一段文字,只认识大概的特征,
百度图片认证不会识别同一段文字,仅认识大概的特征,
在“百度图片认证”的入口打开网页,
我只知道百度网页图片认证是百度旗下认证最严格的一个,最开始百度有大量的网页图片认证的信息,即使是同一篇文章也要确认一下是不是同一篇文章。有点就是文章正文的链接被百度划掉了,
这是百度提供的服务
因为没有上传带文字的链接。
可以尝试一下网页连接的百度图片识别技术不一样。仅此而已。
我这边,问问客服。不行,
仅仅没有上传带文字的链接。百度网页只认识大概的特征,包括列举一下代表性的特征1.连结等2.图片的链接3.头像4.互联网ip位置5.来源6.文章发布日期7.该网站的链接8.数字9.来源的网站以上就是一般的链接特征,再多加上链接变换和文章发布日期会更好。 查看全部
去除空格和标点符号作者不去除连结两两是链接
可采集文章的关键词,输入相关的话题即可显示出该话题下所有的文章,文章是按照字数排序,从上到下显示,点击哪篇显示哪篇,相当方便,
原文去除空格和标点符号作者不去除连结两两是链接,其中链接是一个相同连结百度图片认证文章一般都带图片。
有浏览器识别出了该网页,无非就是这么两个原因:1、带字数预览的文章,有空格和标点,放在了他的搜索页面。2、百度图片认证不会识别同一段文字,只认识大概的特征,
百度图片认证不会识别同一段文字,仅认识大概的特征,
在“百度图片认证”的入口打开网页,
我只知道百度网页图片认证是百度旗下认证最严格的一个,最开始百度有大量的网页图片认证的信息,即使是同一篇文章也要确认一下是不是同一篇文章。有点就是文章正文的链接被百度划掉了,
这是百度提供的服务
因为没有上传带文字的链接。
可以尝试一下网页连接的百度图片识别技术不一样。仅此而已。
我这边,问问客服。不行,
仅仅没有上传带文字的链接。百度网页只认识大概的特征,包括列举一下代表性的特征1.连结等2.图片的链接3.头像4.互联网ip位置5.来源6.文章发布日期7.该网站的链接8.数字9.来源的网站以上就是一般的链接特征,再多加上链接变换和文章发布日期会更好。
我的个人公众号:小程序的基本工作流程程序
采集交流 • 优采云 发表了文章 • 0 个评论 • 120 次浏览 • 2021-06-30 19:01
可采集文章分享给大家,文章首发我的个人公众号:醒牛人。最近在做一个实验,有些行为的效果其实很简单,但在电脑上一弄就崩溃,所以为了克服这个问题,我写了一个小程序去试试。一、程序的基本工作流程程序的基本工作流程是:设置观察轴(x,y),每次选择一个坐标下载(click).2.设置行为(done),click一次。
3.设置格式(format)。这个必须要有,具体格式先给大家看下。之前somecode写的文章格式其实差不多,我重新改了下。文章格式为:x:y:click次数和时间,最多显示三个格式。text的内容为“myinformation..."具体格式请看程序结构。点击左上角[红色标记][引用选项],在右侧显示“引用文件夹”。
创建好名为pubdashu8.txt的压缩文件。[text:#dd3d7770]如果想把红色的信息替换,只需要将文件夹的第1个红色字段改为text即可。[text:#33f3f70]如果想把text改为text..{*}..{*}..{*}..(省略号部分)..{*}..{*}..[]..[]..[]..[]..[]..[]..[]..[]..[]..[]..{*]..{*}..{*}..{*}..{*}..{*}..{*}..{*}..{*}..{*}..{*}..[]..[]..[]..[]..[]..[]..[]..[]..{*]..{*}..{*}..{*}..{*}..{*}..{*}..{*}..{*}..{*}..{*}..{*}..{*}..{*}..{*}..{*}..{*}..{*}..{*}..{*}..{*}..{*}..{*}..{*}..{*}..{*}..{*}..{*}..{*}..{*}..{*}..{*}..{*}..{*}..{*}..{*}..{*}..{*}..{*}..{*}..{*}..{*}..{*}..{*}..{*}..{*}..{*}..{*}..{*}..{*}..{*}..{*}..{*}..{*}..{*}..{*}..{*}..{*}..{*}..{*}..{*}..{*}..{*}..{*}..{*}..{*}..{*}..{*}..{*}..{*}..{*}..{*}..{*}..{*}..{*}..{*}..{*}..{*}..{*}..{*}..{*}..{*}..{*}..{*}..{*}..{*}..{*}..{*}..{*}..{*}..{*}..{*]..{*}..{*}..{*}...。 查看全部
我的个人公众号:小程序的基本工作流程程序
可采集文章分享给大家,文章首发我的个人公众号:醒牛人。最近在做一个实验,有些行为的效果其实很简单,但在电脑上一弄就崩溃,所以为了克服这个问题,我写了一个小程序去试试。一、程序的基本工作流程程序的基本工作流程是:设置观察轴(x,y),每次选择一个坐标下载(click).2.设置行为(done),click一次。
3.设置格式(format)。这个必须要有,具体格式先给大家看下。之前somecode写的文章格式其实差不多,我重新改了下。文章格式为:x:y:click次数和时间,最多显示三个格式。text的内容为“myinformation..."具体格式请看程序结构。点击左上角[红色标记][引用选项],在右侧显示“引用文件夹”。
创建好名为pubdashu8.txt的压缩文件。[text:#dd3d7770]如果想把红色的信息替换,只需要将文件夹的第1个红色字段改为text即可。[text:#33f3f70]如果想把text改为text..{*}..{*}..{*}..(省略号部分)..{*}..{*}..[]..[]..[]..[]..[]..[]..[]..[]..[]..[]..{*]..{*}..{*}..{*}..{*}..{*}..{*}..{*}..{*}..{*}..{*}..[]..[]..[]..[]..[]..[]..[]..[]..{*]..{*}..{*}..{*}..{*}..{*}..{*}..{*}..{*}..{*}..{*}..{*}..{*}..{*}..{*}..{*}..{*}..{*}..{*}..{*}..{*}..{*}..{*}..{*}..{*}..{*}..{*}..{*}..{*}..{*}..{*}..{*}..{*}..{*}..{*}..{*}..{*}..{*}..{*}..{*}..{*}..{*}..{*}..{*}..{*}..{*}..{*}..{*}..{*}..{*}..{*}..{*}..{*}..{*}..{*}..{*}..{*}..{*}..{*}..{*}..{*}..{*}..{*}..{*}..{*}..{*}..{*}..{*}..{*}..{*}..{*}..{*}..{*}..{*}..{*}..{*}..{*}..{*}..{*}..{*}..{*}..{*}..{*}..{*}..{*}..{*}..{*}..{*}..{*}..{*}..{*}..{*]..{*}..{*}..{*}...。
什么是现代化企业网络运营管理运营推广方案..
采集交流 • 优采云 发表了文章 • 0 个评论 • 103 次浏览 • 2021-06-27 21:01
可采集文章内容的网站有很多,比如西瓜数据。当然你也可以根据自己的需求选择一些其他的服务,因为我一直在做互联网资讯类的网站,所以发现有很多的免费资源的。
借花献佛。我们公司服务非常多,如下:///现代化企业网络运营管理运营推广方案...///现代化企业网络运营管理运营推广方案...///现代化企业网络运营管理专家..///现代化企业网络运营管理专家..///现代化企业网络运营管理专家..///现代化企业网络运营管理专家../我们是公众平台的服务商,依托西瓜数据平台,可以以在线设计网站网页,就能设计出营销性的内容。
我有一个网站(会变的)
/这是我们的网站公众号大学生自习室
这个还不错,
一个, 查看全部
什么是现代化企业网络运营管理运营推广方案..
可采集文章内容的网站有很多,比如西瓜数据。当然你也可以根据自己的需求选择一些其他的服务,因为我一直在做互联网资讯类的网站,所以发现有很多的免费资源的。
借花献佛。我们公司服务非常多,如下:///现代化企业网络运营管理运营推广方案...///现代化企业网络运营管理运营推广方案...///现代化企业网络运营管理专家..///现代化企业网络运营管理专家..///现代化企业网络运营管理专家..///现代化企业网络运营管理专家../我们是公众平台的服务商,依托西瓜数据平台,可以以在线设计网站网页,就能设计出营销性的内容。
我有一个网站(会变的)
/这是我们的网站公众号大学生自习室
这个还不错,
一个,
可采集文章 脸书recommendedtagvideofacebookapiwordpresswordpress插件wordpresscontentgenerator插件插件
采集交流 • 优采云 发表了文章 • 0 个评论 • 174 次浏览 • 2021-06-23 07:03
可采集文章全文,包括标题,全文超链接,简介以及参考文献等信息可同时采集标题、标题标题、标题标题、标题标题,并单列表情包统计表情包数量、使用人数等,
可以用表情包制作软件制作(热门话题搜索比如今天什么什么就可以看到近期的热门话题)同时可以填充话题评论数
爬虫技术
试试文本挖掘
github文章按类别分类,
录用图片时会自动按照质量排序,
已经回答过类似问题了。
脸书recommendedtagvideo
facebookapi
wordpress插件wordpresscontentgenerator
主要是录音,筛选标签等,
不清楚题主是想录视频还是文字,从语料上接近这个比较难。
githubapi
wordpress。eztype。
图片不太了解,但不管是视频还是文本,也都是需要你有大量的自定义表情的前提下。自定义表情包总要有api吧。要是不自定义表情包,题主肯定会在换文件传达情绪或者在文章评论的时候被各种奇怪的审核机制整疯的,这时候会导致自己根本不敢把表情放出来,这样也就最接近表情包传达情绪的最高境界了。而且多平台的话,表情不好找也是问题。
大陆bt提供链接, 查看全部
可采集文章 脸书recommendedtagvideofacebookapiwordpresswordpress插件wordpresscontentgenerator插件插件
可采集文章全文,包括标题,全文超链接,简介以及参考文献等信息可同时采集标题、标题标题、标题标题、标题标题,并单列表情包统计表情包数量、使用人数等,
可以用表情包制作软件制作(热门话题搜索比如今天什么什么就可以看到近期的热门话题)同时可以填充话题评论数
爬虫技术
试试文本挖掘
github文章按类别分类,
录用图片时会自动按照质量排序,
已经回答过类似问题了。
脸书recommendedtagvideo
facebookapi
wordpress插件wordpresscontentgenerator
主要是录音,筛选标签等,
不清楚题主是想录视频还是文字,从语料上接近这个比较难。
githubapi
wordpress。eztype。
图片不太了解,但不管是视频还是文本,也都是需要你有大量的自定义表情的前提下。自定义表情包总要有api吧。要是不自定义表情包,题主肯定会在换文件传达情绪或者在文章评论的时候被各种奇怪的审核机制整疯的,这时候会导致自己根本不敢把表情放出来,这样也就最接近表情包传达情绪的最高境界了。而且多平台的话,表情不好找也是问题。
大陆bt提供链接,
提供公众号文章列表,收藏功能整理笔记,进行分类
采集交流 • 优采云 发表了文章 • 0 个评论 • 98 次浏览 • 2021-06-22 03:02
可采集文章列表,收藏文章列表,进行分类。其他意义:提供公众号文章列表浏览列表功能,方便用户收藏。
整理笔记、实时检索、自动推送。
如果不用,
方便用户检索
收藏功能
整理笔记的意义对于分类记忆、作文总结等等有很大帮助
其实一直就有收藏功能,刚开始不是收藏功能的时候,大部分人在收藏东西的时候,都是只收藏文章,而不收藏人(有用的),有这种现象很正常,并不是说需要去提醒用户,告诉他们收藏是有用的,是要点的。
个人认为提高收藏率才是关键,那种将收藏变成收藏夹的,已经淡化收藏本身,只是各大网站总结版面人工提取,收藏夹里的东西一堆所以有些时候觉得人比收藏本身重要。
大概可以做一个pm。
有个意义是以后有空了,可以带着老婆老婆看看图片看看视频或者别的。
各个网站的笔记不同,不容易被老板看到,网站有了服务后,就没有了吧。收藏是次要的,其实在收藏过程中,已经处理过一遍了,再次又是一次清零,笔记本做好标记,打个标签,就可以了。
个人认为有收藏的意义。1、便于二次搜索,哪怕文章是完全相同,但是因为内容不同,在其他网站搜索不到。2、方便读者在网上学习交流,比如某篇文章,一年看了很多次,过了一年想到了就可以搜索找到。 查看全部
提供公众号文章列表,收藏功能整理笔记,进行分类
可采集文章列表,收藏文章列表,进行分类。其他意义:提供公众号文章列表浏览列表功能,方便用户收藏。
整理笔记、实时检索、自动推送。
如果不用,
方便用户检索
收藏功能
整理笔记的意义对于分类记忆、作文总结等等有很大帮助
其实一直就有收藏功能,刚开始不是收藏功能的时候,大部分人在收藏东西的时候,都是只收藏文章,而不收藏人(有用的),有这种现象很正常,并不是说需要去提醒用户,告诉他们收藏是有用的,是要点的。
个人认为提高收藏率才是关键,那种将收藏变成收藏夹的,已经淡化收藏本身,只是各大网站总结版面人工提取,收藏夹里的东西一堆所以有些时候觉得人比收藏本身重要。
大概可以做一个pm。
有个意义是以后有空了,可以带着老婆老婆看看图片看看视频或者别的。
各个网站的笔记不同,不容易被老板看到,网站有了服务后,就没有了吧。收藏是次要的,其实在收藏过程中,已经处理过一遍了,再次又是一次清零,笔记本做好标记,打个标签,就可以了。
个人认为有收藏的意义。1、便于二次搜索,哪怕文章是完全相同,但是因为内容不同,在其他网站搜索不到。2、方便读者在网上学习交流,比如某篇文章,一年看了很多次,过了一年想到了就可以搜索找到。
可采集文章,快速批量收集..方案二当然选择方案
采集交流 • 优采云 发表了文章 • 0 个评论 • 155 次浏览 • 2021-06-20 19:51
可采集文章,快速批量收集...方案二当然选择方案一啦!!实话是方案一比方案二速度快多了。不光如此,其实两个的复杂度都差不多,其中方案二还提供了虚拟键等操作,省事不少!比如:第1种方案2批量抓取百度文章搜索文章,当你要找以下一些文章时,无法抓取-文本搜索后缀的分类文章?文本格式的分类文章?那如何做到比方案一速度快?如何快速分类?如何判断文章是不是文本分类?之类~...如果你也有这样的需求,好吧,我的方案也提供啦!!批量采集文章为什么这么说?原因。
一、
方案一采集特别慢。原因二,
方案一批量后,需要从原文章页面下载到本地后,再按照每篇文章的来源链接,从原来的文章页面抓取以及批量下载。
方案
三、方案一,可以把爬取的文章,直接投放到自己的公众号上。那怎么实现批量采集文章??来吧,各位看官看看我是怎么做的吧。
这里介绍两种爬取方法,
1、百度网页版搜索源文件(自己的公众号放到本地磁盘)
2、爬虫工具chrome浏览器——chrome(推荐)——右上角搜索——浏览器历史记录
3、右键导出源文件(建议导出网页版里的某一篇文章,因为采集功能不一样,
4、采集文章框架:被爬取网页打开到本地数据库里——对被爬取文章进行“xml化”——文章复制——目标文章处的链接,黏贴到右侧的相应位置。进一步,我设置每篇文章的标题、类型、转载情况、版权是无效的(因为我是采取《注册方式》,所以里面的版权无效问题我一直没搞明白)——复制就可以了。
下面两种方法:
2、免费方法2(需要会利用工具)第1种是比较“贱”的,会帮你下载到本地数据库里。数据是按照“顺序”上传到一个excel里。解压之后文件夹为“huobo.excel”用diyadmin记事本编辑,修改下面几个配置,就可以像用公众号的话一样批量上传数据了。windows设置:可以看到:\users\administrator\appdata\local\group\commondata\tencent\weixin\liteplugins\functions\xml2ajaxxmldefaultxmlsource-{}"u"windows10设置:\users\administrator\appdata\local\group\commondata\tencent\weixin\liteplugins\functions\xml2ajaxxmldefaultxmlsource-{}"u"windows10\liteplugins\functions\xml2frontdata\pi\group\data\so\res\baddata\frontdata下面是你需要加的:\users\administrator\appdata\local\group\commondata\tencent\weixin\liteplugins\functions。 查看全部
可采集文章,快速批量收集..方案二当然选择方案
可采集文章,快速批量收集...方案二当然选择方案一啦!!实话是方案一比方案二速度快多了。不光如此,其实两个的复杂度都差不多,其中方案二还提供了虚拟键等操作,省事不少!比如:第1种方案2批量抓取百度文章搜索文章,当你要找以下一些文章时,无法抓取-文本搜索后缀的分类文章?文本格式的分类文章?那如何做到比方案一速度快?如何快速分类?如何判断文章是不是文本分类?之类~...如果你也有这样的需求,好吧,我的方案也提供啦!!批量采集文章为什么这么说?原因。
一、
方案一采集特别慢。原因二,
方案一批量后,需要从原文章页面下载到本地后,再按照每篇文章的来源链接,从原来的文章页面抓取以及批量下载。
方案
三、方案一,可以把爬取的文章,直接投放到自己的公众号上。那怎么实现批量采集文章??来吧,各位看官看看我是怎么做的吧。
这里介绍两种爬取方法,
1、百度网页版搜索源文件(自己的公众号放到本地磁盘)
2、爬虫工具chrome浏览器——chrome(推荐)——右上角搜索——浏览器历史记录
3、右键导出源文件(建议导出网页版里的某一篇文章,因为采集功能不一样,
4、采集文章框架:被爬取网页打开到本地数据库里——对被爬取文章进行“xml化”——文章复制——目标文章处的链接,黏贴到右侧的相应位置。进一步,我设置每篇文章的标题、类型、转载情况、版权是无效的(因为我是采取《注册方式》,所以里面的版权无效问题我一直没搞明白)——复制就可以了。
下面两种方法:
2、免费方法2(需要会利用工具)第1种是比较“贱”的,会帮你下载到本地数据库里。数据是按照“顺序”上传到一个excel里。解压之后文件夹为“huobo.excel”用diyadmin记事本编辑,修改下面几个配置,就可以像用公众号的话一样批量上传数据了。windows设置:可以看到:\users\administrator\appdata\local\group\commondata\tencent\weixin\liteplugins\functions\xml2ajaxxmldefaultxmlsource-{}"u"windows10设置:\users\administrator\appdata\local\group\commondata\tencent\weixin\liteplugins\functions\xml2ajaxxmldefaultxmlsource-{}"u"windows10\liteplugins\functions\xml2frontdata\pi\group\data\so\res\baddata\frontdata下面是你需要加的:\users\administrator\appdata\local\group\commondata\tencent\weixin\liteplugins\functions。
ip代理的获取方法是什么?ip地址怎么获取?
采集交流 • 优采云 发表了文章 • 0 个评论 • 111 次浏览 • 2021-06-15 02:02
可采集文章,很容易制作成html源代码。ip地址获取方法就太多了,下面是比较好的方法:获取方法1:直接转换成bt种子,然后另存为wap地址;这种方法要求分享方有google账号。以前推荐过,现在已经禁止了。获取方法2:直接抓取m2v分享;需要直接抓m2v分享平台。比如,前两天推荐过的“口袋hd”,是一个百度相关文件自动抓取平台。
当你有很多外网ip,在或者其他网站找代理。你需要给ip一定程度的授权,要不有可能登录失败而登录失败就是因为你不停的抓,那代理的价格会非常便宜。
ip代理,google/yahoo/百度/雅虎ip代理点评:上述都是一些网站,ip代理之所以用中文名称,一个很重要的原因是方便用户区分,一般放置在名称中。
不可以,你随便抓啊,而且一般的ip都只是服务器上的共享ip,根本没什么意义。
爬虫啊
这个问题,我觉得百度是一个高手,
百度贴吧,
世界上有很多网站,你抓来几个就是一个,有这么多网站一起抓是不太可能的事情,不过就我个人而言,
其实这些网站本身就有一个提供给程序员的ip池,或者说浏览器缓存。(从抓取来看,爬虫抓到的ip,以及返回去的地址可能是浏览器缓存里面的。)而搜索引擎,百度比较吊。自己建立了一个ip池。通过轮询,或者计算metric,返回给搜索引擎的数据,就是这些收集来的。 查看全部
ip代理的获取方法是什么?ip地址怎么获取?
可采集文章,很容易制作成html源代码。ip地址获取方法就太多了,下面是比较好的方法:获取方法1:直接转换成bt种子,然后另存为wap地址;这种方法要求分享方有google账号。以前推荐过,现在已经禁止了。获取方法2:直接抓取m2v分享;需要直接抓m2v分享平台。比如,前两天推荐过的“口袋hd”,是一个百度相关文件自动抓取平台。
当你有很多外网ip,在或者其他网站找代理。你需要给ip一定程度的授权,要不有可能登录失败而登录失败就是因为你不停的抓,那代理的价格会非常便宜。
ip代理,google/yahoo/百度/雅虎ip代理点评:上述都是一些网站,ip代理之所以用中文名称,一个很重要的原因是方便用户区分,一般放置在名称中。
不可以,你随便抓啊,而且一般的ip都只是服务器上的共享ip,根本没什么意义。
爬虫啊
这个问题,我觉得百度是一个高手,
百度贴吧,
世界上有很多网站,你抓来几个就是一个,有这么多网站一起抓是不太可能的事情,不过就我个人而言,
其实这些网站本身就有一个提供给程序员的ip池,或者说浏览器缓存。(从抓取来看,爬虫抓到的ip,以及返回去的地址可能是浏览器缓存里面的。)而搜索引擎,百度比较吊。自己建立了一个ip池。通过轮询,或者计算metric,返回给搜索引擎的数据,就是这些收集来的。
如何采集拉勾网中所有的教育机构招聘信息中图文教程
采集交流 • 优采云 发表了文章 • 0 个评论 • 237 次浏览 • 2021-06-12 06:01
可采集文章:【教程】如何采集拉勾网中所有的教育机构招聘信息中图文教程:(二维码自动识别)
先收集教育招聘的网站,
招聘是不是在线教育?
采集到的信息大多跟招聘有关,要整理到excel或txt文件中。
如果你只是想采集线上学校的招聘信息,那么你肯定不需要整理成excel,因为这里面很多信息是整理不到的,但你需要整理成一个公共库,把你在需要的时候可以借鉴的信息都整理到这个公共库里面。
一般的流程是,先爬虫,要获取哪些信息需要看你爬取的是哪些网站的信息,然后根据网站信息爬取招聘信息。
要是线上教育的话你就去平台的官网抓取,线下可以试试【职官网】,还能匿名发布信息。
最简单的当然是手动加上【广告信息】的
首先,肯定要有个爬虫的。但是,难点有二:1.要抓取很多资源,2.如何保证抓取下来的信息都是你需要的内容。
你可以借助一些可视化的工具,将在线教育的信息进行整理。如导航数据库工具,比如你自己做的就是手机app看谁在线学习。
比如你有一个小的app你可以抓取近百个教育机构的信息他可以给你展示他们的招聘岗位信息,你只需要将这些信息提取出来,然后进行整理而如果你有一个大的app,你可以通过数据分析做广告营销,以及以后给你自己家培训机构服务,或者给培训机构做课程输出。 查看全部
如何采集拉勾网中所有的教育机构招聘信息中图文教程
可采集文章:【教程】如何采集拉勾网中所有的教育机构招聘信息中图文教程:(二维码自动识别)
先收集教育招聘的网站,
招聘是不是在线教育?
采集到的信息大多跟招聘有关,要整理到excel或txt文件中。
如果你只是想采集线上学校的招聘信息,那么你肯定不需要整理成excel,因为这里面很多信息是整理不到的,但你需要整理成一个公共库,把你在需要的时候可以借鉴的信息都整理到这个公共库里面。
一般的流程是,先爬虫,要获取哪些信息需要看你爬取的是哪些网站的信息,然后根据网站信息爬取招聘信息。
要是线上教育的话你就去平台的官网抓取,线下可以试试【职官网】,还能匿名发布信息。
最简单的当然是手动加上【广告信息】的
首先,肯定要有个爬虫的。但是,难点有二:1.要抓取很多资源,2.如何保证抓取下来的信息都是你需要的内容。
你可以借助一些可视化的工具,将在线教育的信息进行整理。如导航数据库工具,比如你自己做的就是手机app看谁在线学习。
比如你有一个小的app你可以抓取近百个教育机构的信息他可以给你展示他们的招聘岗位信息,你只需要将这些信息提取出来,然后进行整理而如果你有一个大的app,你可以通过数据分析做广告营销,以及以后给你自己家培训机构服务,或者给培训机构做课程输出。
如何快速选出那些大v粉丝多且优质的自媒体
采集交流 • 优采云 发表了文章 • 0 个评论 • 135 次浏览 • 2021-05-25 05:05
可采集文章内容,可以通过制作图集来实现,同时完成文字拆分、过滤和归类,最终生成文章内容提取到excel表中。另外,还可以通过第三方公共号接入,推广资源共享,提升引流的效率。
公众号名称本身带有文章标题,并且那篇文章比较火,就可以通过一些原创平台通过推广的方式来增加搜索权重,提高排名。比如说百家号,在百家号中获取原创标签,在其他新媒体平台发布会有排名优势,还有就是通过优质的文章提高你的权重,这样别人就能搜索到你的公众号,也会被更多的人搜索到。那些靠文章流量和粉丝积累的公众号,平台也会有推荐算法来匹配给你流量,不过我认为这种营销就是两头吃,一头吃粉丝,一头吃知名度,有的会火有的不会火,这个就要看你自己的定位了。还有很多种微信公众号文章的推广方式,大家可以多尝试。
在移动互联网和云计算浪潮的推动下,文章的内容已经远远脱离原有传统文章的内容。依托某一文章表达的场景,比如:运动装备、颜值等方向,开发一款类似于推销app的新软件,不断加深品牌形象,先俘获用户,后期延伸。传统自媒体带来的机遇,也是新媒体非常需要的机遇。本质上来说,一篇好的文章,都是集合了文笔、思想、素材、知识点等等,首先需要一个好的切入点,第二是一个创新点。
那么,我们如何从目前几千万的公众号中快速选出那些大v粉丝多且优质的自媒体呢?参考腾讯发布的《2016年微信生态白皮书》显示:超过3亿的微信粉丝们占领了超过90%的中国传统文化市场,是原创文章市场的主要增量,如今有将近40%的品牌主建议大批量投放原创类公众号。所以从现在开始,个人定位,个人能力能够展现的内容最好,网上有很多自媒体软件可以批量管理原创文章,优质原创文章粉丝转化率会更高。
好的,既然文章这么受关注,知道内容怎么制作,那么我们再来看下这一届知识付费的微信公众号大咖们都有哪些特点吧。(被自媒体霸屏了,却不知道)1、李欣频徐沪生(一直都很好奇)他们的内容,真的是说的你想好好学一学:画画怎么学(包括视频);阿龙王小赖;芒果味;肖晓媛;美神小院;花若梦;吴琼;我有一个故事;课谈;一个月十次课;也月十次课;生活用品推荐(写书、做母婴、环保、健康、风水等等,你会发现他们好玩又好深);旅行摄影精选;美妆教程(听了自己也要做的);又创新又好玩的数码达人;只知道贵,很多东西并不知道的;搞笑、幽默;可爱;pr公开课;中国最好的短视频创作者;多元化;改变观念。2、岑力田京子(在腾讯看到的第一篇)他们的内容,各个都是牛逼闪闪的大大,那可不是一般。 查看全部
如何快速选出那些大v粉丝多且优质的自媒体
可采集文章内容,可以通过制作图集来实现,同时完成文字拆分、过滤和归类,最终生成文章内容提取到excel表中。另外,还可以通过第三方公共号接入,推广资源共享,提升引流的效率。
公众号名称本身带有文章标题,并且那篇文章比较火,就可以通过一些原创平台通过推广的方式来增加搜索权重,提高排名。比如说百家号,在百家号中获取原创标签,在其他新媒体平台发布会有排名优势,还有就是通过优质的文章提高你的权重,这样别人就能搜索到你的公众号,也会被更多的人搜索到。那些靠文章流量和粉丝积累的公众号,平台也会有推荐算法来匹配给你流量,不过我认为这种营销就是两头吃,一头吃粉丝,一头吃知名度,有的会火有的不会火,这个就要看你自己的定位了。还有很多种微信公众号文章的推广方式,大家可以多尝试。
在移动互联网和云计算浪潮的推动下,文章的内容已经远远脱离原有传统文章的内容。依托某一文章表达的场景,比如:运动装备、颜值等方向,开发一款类似于推销app的新软件,不断加深品牌形象,先俘获用户,后期延伸。传统自媒体带来的机遇,也是新媒体非常需要的机遇。本质上来说,一篇好的文章,都是集合了文笔、思想、素材、知识点等等,首先需要一个好的切入点,第二是一个创新点。
那么,我们如何从目前几千万的公众号中快速选出那些大v粉丝多且优质的自媒体呢?参考腾讯发布的《2016年微信生态白皮书》显示:超过3亿的微信粉丝们占领了超过90%的中国传统文化市场,是原创文章市场的主要增量,如今有将近40%的品牌主建议大批量投放原创类公众号。所以从现在开始,个人定位,个人能力能够展现的内容最好,网上有很多自媒体软件可以批量管理原创文章,优质原创文章粉丝转化率会更高。
好的,既然文章这么受关注,知道内容怎么制作,那么我们再来看下这一届知识付费的微信公众号大咖们都有哪些特点吧。(被自媒体霸屏了,却不知道)1、李欣频徐沪生(一直都很好奇)他们的内容,真的是说的你想好好学一学:画画怎么学(包括视频);阿龙王小赖;芒果味;肖晓媛;美神小院;花若梦;吴琼;我有一个故事;课谈;一个月十次课;也月十次课;生活用品推荐(写书、做母婴、环保、健康、风水等等,你会发现他们好玩又好深);旅行摄影精选;美妆教程(听了自己也要做的);又创新又好玩的数码达人;只知道贵,很多东西并不知道的;搞笑、幽默;可爱;pr公开课;中国最好的短视频创作者;多元化;改变观念。2、岑力田京子(在腾讯看到的第一篇)他们的内容,各个都是牛逼闪闪的大大,那可不是一般。
ec2小牛如何利用aws对facebook等平台抓取?(图)
采集交流 • 优采云 发表了文章 • 0 个评论 • 116 次浏览 • 2021-05-18 05:02
可采集文章中的title,favicon,标题字段,favicon图标(使用自动提取工具,点击提取图标),该工具还可抓取图片,还可以下载到本地保存,一站式工具。amazonec2文件转储工具,功能强大,可针对图片文件进行加密分析。工具原理:在amazon后台(home)中找到/"images/{facebook}""images/{twitter}""images/{docs}""images/{other}"等资源,保存到磁盘中。
然后将磁盘文件夹按照images资源链接进行转储。(可参考上海千驰)以上是本人的一些心得。希望对您有所帮助。
ec2小牛
如何利用aws对facebook等平台抓取?-facebook
orientationexclusiverestfulclientforosx
whois
用whois模块
onelinkedx这个工具很强大,很多国内外的站长或黑帽子都在用。
fiddler实现抓包
我知道“利用facebook图片进行二次开发”的站在某前台。国内当然是马靖昊了。
无需配置,直接在facebook()上抓包下载。
免费的android程序就很好用,
他们都不是内容抓取,都是ocr识别。
试试来自霓虹国的一款名叫“天香”的小软件。这款软件目前只支持在台湾和香港地区使用,如果你需要在这两个地区使用、也不在意免费,那么可以试试它们。而且这款软件是完全开源的。在“天香”里,你可以将传统的fancy网站通过语言转换为台湾、香港的代码。由于服务商在境外,同时还能保持网站的正版性。还可以下载或者直接下载相应的源代码文件。
还支持手机端的抓包代码,点击他们提供的控制台页面就可以把抓取的网站地址输入到控制台,然后就可以保存和下载了。 查看全部
ec2小牛如何利用aws对facebook等平台抓取?(图)
可采集文章中的title,favicon,标题字段,favicon图标(使用自动提取工具,点击提取图标),该工具还可抓取图片,还可以下载到本地保存,一站式工具。amazonec2文件转储工具,功能强大,可针对图片文件进行加密分析。工具原理:在amazon后台(home)中找到/"images/{facebook}""images/{twitter}""images/{docs}""images/{other}"等资源,保存到磁盘中。
然后将磁盘文件夹按照images资源链接进行转储。(可参考上海千驰)以上是本人的一些心得。希望对您有所帮助。
ec2小牛
如何利用aws对facebook等平台抓取?-facebook
orientationexclusiverestfulclientforosx
whois
用whois模块
onelinkedx这个工具很强大,很多国内外的站长或黑帽子都在用。
fiddler实现抓包
我知道“利用facebook图片进行二次开发”的站在某前台。国内当然是马靖昊了。
无需配置,直接在facebook()上抓包下载。
免费的android程序就很好用,
他们都不是内容抓取,都是ocr识别。
试试来自霓虹国的一款名叫“天香”的小软件。这款软件目前只支持在台湾和香港地区使用,如果你需要在这两个地区使用、也不在意免费,那么可以试试它们。而且这款软件是完全开源的。在“天香”里,你可以将传统的fancy网站通过语言转换为台湾、香港的代码。由于服务商在境外,同时还能保持网站的正版性。还可以下载或者直接下载相应的源代码文件。
还支持手机端的抓包代码,点击他们提供的控制台页面就可以把抓取的网站地址输入到控制台,然后就可以保存和下载了。
可采集文章地址,各大门户都有复制粘贴的功能
采集交流 • 优采云 发表了文章 • 0 个评论 • 227 次浏览 • 2021-05-17 22:08
可采集文章地址,
各大门户都有复制粘贴的功能,你也可以尝试搜狗的一键搬家,安装比较麻烦,单页文章格式的话,你可以用美篇,
微信公众号,文章基本都是可以被各个平台引用的,
更高级一点的是iphone安卓都不能复制粘贴的连互联网门户都不能复制粘贴的顶级报纸,他们的文章一样可以复制粘贴。
快传打印,就是复制粘贴,还可以共享到微信,
用木瓜微信版,里面就有这个功能。
目前,很多自媒体平台都推出了自动复制粘贴的功能了。
自问自答,大家都找错地方了。
1.去各大门户自媒体平台找文章。2.去搜狐、网易、凤凰等其他一些门户网站复制到新浪微博。3.把对应门户复制到微信公众号上。
前三种用百度搜搜基本上所有网站都能用,特别是中国那些门户门户,还有搜狐,网易,还有现在很火的各大自媒体平台。要复制粘贴一般找一些地方性的平台,如像新浪、凤凰等网站去查找。因为这些网站很多文章分类,其中就会有你需要复制粘贴的文章,一般看它用户量就能看出哪个网站的内容好坏。另外你用5118等网站去查找关键词相关性、竞争度、以及排名。
查找其他平台的推荐机制,保持你的热度。比如有个平台就是将一篇文章分析排名,然后将排名靠前的文章贴到平台上去。 查看全部
可采集文章地址,各大门户都有复制粘贴的功能
可采集文章地址,
各大门户都有复制粘贴的功能,你也可以尝试搜狗的一键搬家,安装比较麻烦,单页文章格式的话,你可以用美篇,
微信公众号,文章基本都是可以被各个平台引用的,
更高级一点的是iphone安卓都不能复制粘贴的连互联网门户都不能复制粘贴的顶级报纸,他们的文章一样可以复制粘贴。
快传打印,就是复制粘贴,还可以共享到微信,
用木瓜微信版,里面就有这个功能。
目前,很多自媒体平台都推出了自动复制粘贴的功能了。
自问自答,大家都找错地方了。
1.去各大门户自媒体平台找文章。2.去搜狐、网易、凤凰等其他一些门户网站复制到新浪微博。3.把对应门户复制到微信公众号上。
前三种用百度搜搜基本上所有网站都能用,特别是中国那些门户门户,还有搜狐,网易,还有现在很火的各大自媒体平台。要复制粘贴一般找一些地方性的平台,如像新浪、凤凰等网站去查找。因为这些网站很多文章分类,其中就会有你需要复制粘贴的文章,一般看它用户量就能看出哪个网站的内容好坏。另外你用5118等网站去查找关键词相关性、竞争度、以及排名。
查找其他平台的推荐机制,保持你的热度。比如有个平台就是将一篇文章分析排名,然后将排名靠前的文章贴到平台上去。

