
关键词 采集
关键词 采集(异步抓取好用的数据分析师是怎么做的)
采集交流 • 优采云 发表了文章 • 0 个评论 • 128 次浏览 • 2021-09-14 03:02
关键词采集+数据可视化以下是一些参考资料,
爬取本专业知识资料,可以采用一些抓包、采集软件工具。我用过最好用的是fiddler的抓包工具,经常用fiddler抓取公司的数据监控,发现公司的人工etl也发生的一些问题,fiddler异步抓取好用很多。然后就是,在网上下载一些公司的考试题,找到考试题的题库;找到公司所在地区的图书馆,或者智慧图书馆,建立手机链接,打印出来自己考试,都是有一些很不错的高效的办法!所以,在网上找找相关的资料很重要!!有些资料是花钱或者是资源没有大家好的,希望大家能够找到或者发现一些好的资源。个人拙见,仅供参考。
大三,统计工作四年,给予一些建议:1.至少得找到数据量很大而且非常python的数据分析岗位2.在实践中学习,学习urllib,selenium等的使用方法,学习pandas,numpy等数据分析库的使用3.熟练掌握sql语言4.通过实习和生活中遇到的问题和理论进行总结,一个优秀的数据分析师至少要做到深厚的数据分析工作经验和实战方法论。个人愚见,供大家参考。
推荐一本书:统计学习方法
建议先爬的是前端页面,等爬着爬着你就发现了数据产业链,然后水到渠成,入职数据分析师!爬数据不一定就要和前端页面一起爬,但是要跟前端和后端很好的联系起来,前端自己抓包后台端的数据,然后定向更新到页面就行。因为网上一般已经抓了很多数据,你只需要找到他们,看看是不是你想要的。 查看全部
关键词 采集(异步抓取好用的数据分析师是怎么做的)
关键词采集+数据可视化以下是一些参考资料,
爬取本专业知识资料,可以采用一些抓包、采集软件工具。我用过最好用的是fiddler的抓包工具,经常用fiddler抓取公司的数据监控,发现公司的人工etl也发生的一些问题,fiddler异步抓取好用很多。然后就是,在网上下载一些公司的考试题,找到考试题的题库;找到公司所在地区的图书馆,或者智慧图书馆,建立手机链接,打印出来自己考试,都是有一些很不错的高效的办法!所以,在网上找找相关的资料很重要!!有些资料是花钱或者是资源没有大家好的,希望大家能够找到或者发现一些好的资源。个人拙见,仅供参考。
大三,统计工作四年,给予一些建议:1.至少得找到数据量很大而且非常python的数据分析岗位2.在实践中学习,学习urllib,selenium等的使用方法,学习pandas,numpy等数据分析库的使用3.熟练掌握sql语言4.通过实习和生活中遇到的问题和理论进行总结,一个优秀的数据分析师至少要做到深厚的数据分析工作经验和实战方法论。个人愚见,供大家参考。
推荐一本书:统计学习方法
建议先爬的是前端页面,等爬着爬着你就发现了数据产业链,然后水到渠成,入职数据分析师!爬数据不一定就要和前端页面一起爬,但是要跟前端和后端很好的联系起来,前端自己抓包后台端的数据,然后定向更新到页面就行。因为网上一般已经抓了很多数据,你只需要找到他们,看看是不是你想要的。
关键词 采集(威客是靠价值提升赚钱的第一,外包是否能赚钱?)
采集交流 • 优采云 发表了文章 • 0 个评论 • 147 次浏览 • 2021-09-14 00:03
关键词采集,数据库建设,上线运营没其他的了,
首先,找一个合适的软件,比如金山威客网、猪八戒网、威客中国网、智城、阿里创业家、威客天下等。软件的选择,是简单编辑好功能的excel表格,对外声称是社会化公开分享的,提交给程序。接着,按照软件提示,启动你的项目。
威客是靠价值提升赚钱的
第一,外包是否能赚钱和在威客网接单无关,第二,外包是否能赚钱,和找人开发有关。综上所述,一个大学生如果以外包的形式解决生活学习问题的话,外包是有难度的。毕竟一个项目大概1-3w不等,很多都是大学生一人的金钱以及时间的投入。
泻药如果单纯为了赚钱,不建议找威客,威客现在几乎沦落为骗子集散地了,你不想入坑要么自己去程序猿和设计师那儿申请号,接单子,要么就找威客,
怎么会有这种问题???建议自己靠自己的努力工作赚钱,又不是学校里免费给人家干活,你就算想找威客也可以通过网络找的,写一些简单的代码为什么不可以。网络上,不管是威客网也好,店也好,或者是建筑公司接手包也好,都会有很多好项目等着你的,而且有些项目一生中只有一两次机会,或者一两个人知道。何必不把这机会抓在手里。
再次提醒:建议:可以自己先打工赚钱,锻炼自己后再找威客平台,不要着急希望赚钱,先有能力和专业方面提升。 查看全部
关键词 采集(威客是靠价值提升赚钱的第一,外包是否能赚钱?)
关键词采集,数据库建设,上线运营没其他的了,
首先,找一个合适的软件,比如金山威客网、猪八戒网、威客中国网、智城、阿里创业家、威客天下等。软件的选择,是简单编辑好功能的excel表格,对外声称是社会化公开分享的,提交给程序。接着,按照软件提示,启动你的项目。
威客是靠价值提升赚钱的
第一,外包是否能赚钱和在威客网接单无关,第二,外包是否能赚钱,和找人开发有关。综上所述,一个大学生如果以外包的形式解决生活学习问题的话,外包是有难度的。毕竟一个项目大概1-3w不等,很多都是大学生一人的金钱以及时间的投入。
泻药如果单纯为了赚钱,不建议找威客,威客现在几乎沦落为骗子集散地了,你不想入坑要么自己去程序猿和设计师那儿申请号,接单子,要么就找威客,
怎么会有这种问题???建议自己靠自己的努力工作赚钱,又不是学校里免费给人家干活,你就算想找威客也可以通过网络找的,写一些简单的代码为什么不可以。网络上,不管是威客网也好,店也好,或者是建筑公司接手包也好,都会有很多好项目等着你的,而且有些项目一生中只有一两次机会,或者一两个人知道。何必不把这机会抓在手里。
再次提醒:建议:可以自己先打工赚钱,锻炼自己后再找威客平台,不要着急希望赚钱,先有能力和专业方面提升。
关键词 采集(大学生网络语言学习教育学习平台的关键词采集工具)
采集交流 • 优采云 发表了文章 • 0 个评论 • 164 次浏览 • 2021-09-13 02:01
关键词采集工具主要以采集工具为主,适合大学生为主,其他人群也可以采集对方站长平台。对于网站站长采集工具我推荐openit(/),国内仿站长工具站长站长-工具第一站大学生网络语言学习教育学习平台,基本适合所有想学语言的学生。至于这个站长工具站长-工具第一站大学生网络语言学习教育学习平台,广告设置的不错,但是有种类繁多的免费学习资源,还是很不错的。
基本靠积分买,还有人工外链,
对于一个即将毕业的大四狗来说,真的不知道哪个是好哪个是不好,每次买账号都很肉疼。还有买了账号等于自己的账号了,当别人抢注你自己账号别人有问题直接封自己的账号,没有效率,真的累,就想问问大家,你推荐哪个好哪个不好。
首先看类型,依次往下分,
据我所知目前软件的优秀程度是有这样区分的1.网站采集外链解决方案2.批量采集网站外链解决方案3.网站抓取加速解决方案4.对网站的恶意注解
想了解找自己想要的,别人告诉你怎么做都是教了你一堆破事,到你自己这边根本实现不了。
说一个比较流行,也比较简单的,网页采集加速:集采集、信息采集、分析采集、智能采集于一体的网页采集加速软件。 查看全部
关键词 采集(大学生网络语言学习教育学习平台的关键词采集工具)
关键词采集工具主要以采集工具为主,适合大学生为主,其他人群也可以采集对方站长平台。对于网站站长采集工具我推荐openit(/),国内仿站长工具站长站长-工具第一站大学生网络语言学习教育学习平台,基本适合所有想学语言的学生。至于这个站长工具站长-工具第一站大学生网络语言学习教育学习平台,广告设置的不错,但是有种类繁多的免费学习资源,还是很不错的。
基本靠积分买,还有人工外链,
对于一个即将毕业的大四狗来说,真的不知道哪个是好哪个是不好,每次买账号都很肉疼。还有买了账号等于自己的账号了,当别人抢注你自己账号别人有问题直接封自己的账号,没有效率,真的累,就想问问大家,你推荐哪个好哪个不好。
首先看类型,依次往下分,
据我所知目前软件的优秀程度是有这样区分的1.网站采集外链解决方案2.批量采集网站外链解决方案3.网站抓取加速解决方案4.对网站的恶意注解
想了解找自己想要的,别人告诉你怎么做都是教了你一堆破事,到你自己这边根本实现不了。
说一个比较流行,也比较简单的,网页采集加速:集采集、信息采集、分析采集、智能采集于一体的网页采集加速软件。
关键词 采集(关键词的分布与优化有关系吗?分布是指这些)
采集交流 • 优采云 发表了文章 • 0 个评论 • 147 次浏览 • 2021-09-08 15:14
关键词的分布与优化有关吗? 关键词distribution 指的是这些关键词在网页上的位置。此位置可以是标题标签、链接、标题、文本正文或文本出现的任何位置。标题标签是网页上重要搜索关键词 位置的好位置。在标题标签中,关键词 的布局非常重要。易建以“网络营销策划”为定位,以“让网络营销变得简单”为使命,先后为国内10000多家中小企业提供网络营销策划解决方案。重要的关键词应该放在页面标题标签的开头。
关键词的设置必须紧跟页面内容。这是优化的一个非常重要的因素。举个明显的例子,你做一个深圳seo网站,然后把关键词设置成狗皮膏药,那么你就可以想到狗皮膏药了。这个词不能反映在你的文章中。那么你关键词就可以通过链接建设获得一个不错的排名。它越来越难。简而言之,就是没有任何问题。 所以keywords关键词的设置一定要和要设置的页面相关,这个是必须的。此外,还有一种相关性的表现,就是是否与整个网站的页面相关。如果是相关的,那么还是有一定的作用的。新手必看优化关键词的提前计划:1、 首先,我们的网站需要在构建之初选择一个目标关键词进行构建。这个设定比我说的狗皮膏药的设定好多了。
关键词的决心不是一件容易的事。应该考虑很多因素。比如关键词必须和你的网站内容有关,单词如何组合和排列,是否符合搜索工具的要求,尽量避免使用热门的关键词等等。所以选择正确的关键词 需要一些工作。
长尾关键词optimized长尾关键词的优化设置是内页和栏目页需要考虑的因素。那么,设置长尾关键词需要考虑哪些因素呢?竞争很小,搜索量可能很高。毕竟这两点很关键。至于尾巴关键词选择多长,那就需要积累了。
易建成立于2007年12月,总部位于东莞。公司始终坚持以客户需求为中心,以“网络营销策划”为定位,以“让网络营销变得简单”为使命。先后为国内10000多家中小企业提供网络营销策划解决方案。过去,搜索引擎不同程度地跟踪网站内部链接。有的可以跟踪所有链接,有的则停留在二级或三级,所以当时需要单独提交网页。目前,易诗田已经在东莞、长安和佛山。未来,完善的服务网络将覆盖中国所有大中小城市。
影响关键词价格的因素:关键词搜索结果数量
这个值是所有Seoer都重视的参考指标。许多SEO初学者甚至只看这个值。这其实是一种误解。有时搜索结果很多,但竞争主要是内页。这个关键词难度不大。
这可以分为以下数值范围:
(A) 搜索结果小于 500,000:竞争较少的;
(B) 300 到 100 万个搜索结果:中到小;
(C) 1 到 300 万个搜索结果:中等;
(D) 3~500万条搜索结果:属于中上层;
(E) 超过 500 万个搜索结果:难词。
易建成立于2007年12月,总部位于东莞。公司始终坚持以客户需求为中心,以“网络营销策划”为定位,以“让网络营销变得简单”为使命。先后为国内10000多家中小企业提供网络营销策划解决方案。充分利用关键词analysis工具关键词analysis工具其实很多,有的免费,有的收费。目前,易诗田已经在东莞、长安和佛山。未来,完善的服务网络将覆盖中国所有大中小城市。
关键词Optimization 如果需要细分,大致可以分为十点:
1、网站 在开始构建之前,需要选择关键词并以此展开。常用的方法是在百度搜索框中输入扩展名关键词,查看相关页面,判断关键词的竞争程度。
2、做了关键词之后,分析一下对手关键词。 查看全部
关键词 采集(关键词的分布与优化有关系吗?分布是指这些)
关键词的分布与优化有关吗? 关键词distribution 指的是这些关键词在网页上的位置。此位置可以是标题标签、链接、标题、文本正文或文本出现的任何位置。标题标签是网页上重要搜索关键词 位置的好位置。在标题标签中,关键词 的布局非常重要。易建以“网络营销策划”为定位,以“让网络营销变得简单”为使命,先后为国内10000多家中小企业提供网络营销策划解决方案。重要的关键词应该放在页面标题标签的开头。

关键词的设置必须紧跟页面内容。这是优化的一个非常重要的因素。举个明显的例子,你做一个深圳seo网站,然后把关键词设置成狗皮膏药,那么你就可以想到狗皮膏药了。这个词不能反映在你的文章中。那么你关键词就可以通过链接建设获得一个不错的排名。它越来越难。简而言之,就是没有任何问题。 所以keywords关键词的设置一定要和要设置的页面相关,这个是必须的。此外,还有一种相关性的表现,就是是否与整个网站的页面相关。如果是相关的,那么还是有一定的作用的。新手必看优化关键词的提前计划:1、 首先,我们的网站需要在构建之初选择一个目标关键词进行构建。这个设定比我说的狗皮膏药的设定好多了。
关键词的决心不是一件容易的事。应该考虑很多因素。比如关键词必须和你的网站内容有关,单词如何组合和排列,是否符合搜索工具的要求,尽量避免使用热门的关键词等等。所以选择正确的关键词 需要一些工作。
长尾关键词optimized长尾关键词的优化设置是内页和栏目页需要考虑的因素。那么,设置长尾关键词需要考虑哪些因素呢?竞争很小,搜索量可能很高。毕竟这两点很关键。至于尾巴关键词选择多长,那就需要积累了。

易建成立于2007年12月,总部位于东莞。公司始终坚持以客户需求为中心,以“网络营销策划”为定位,以“让网络营销变得简单”为使命。先后为国内10000多家中小企业提供网络营销策划解决方案。过去,搜索引擎不同程度地跟踪网站内部链接。有的可以跟踪所有链接,有的则停留在二级或三级,所以当时需要单独提交网页。目前,易诗田已经在东莞、长安和佛山。未来,完善的服务网络将覆盖中国所有大中小城市。
影响关键词价格的因素:关键词搜索结果数量
这个值是所有Seoer都重视的参考指标。许多SEO初学者甚至只看这个值。这其实是一种误解。有时搜索结果很多,但竞争主要是内页。这个关键词难度不大。
这可以分为以下数值范围:
(A) 搜索结果小于 500,000:竞争较少的;
(B) 300 到 100 万个搜索结果:中到小;
(C) 1 到 300 万个搜索结果:中等;
(D) 3~500万条搜索结果:属于中上层;
(E) 超过 500 万个搜索结果:难词。

易建成立于2007年12月,总部位于东莞。公司始终坚持以客户需求为中心,以“网络营销策划”为定位,以“让网络营销变得简单”为使命。先后为国内10000多家中小企业提供网络营销策划解决方案。充分利用关键词analysis工具关键词analysis工具其实很多,有的免费,有的收费。目前,易诗田已经在东莞、长安和佛山。未来,完善的服务网络将覆盖中国所有大中小城市。
关键词Optimization 如果需要细分,大致可以分为十点:
1、网站 在开始构建之前,需要选择关键词并以此展开。常用的方法是在百度搜索框中输入扩展名关键词,查看相关页面,判断关键词的竞争程度。
2、做了关键词之后,分析一下对手关键词。
关键词 采集(阿里巴巴国际站最有效果且最省钱的运营方案!)
采集交流 • 优采云 发表了文章 • 0 个评论 • 173 次浏览 • 2021-09-05 07:18
大家都知道做关键词覆盖,因为这是目前阿里国际站最有效、最划算的运营方案!
我们把阿里巴巴想象成一个大池塘。这个池塘里有很多鱼(顾客)。鱼(客户)在池塘(阿里巴巴)中寻找食物(产品),所以我们的每一句话都是一个诱饵。比如蚯蚓、小昆虫、菜叶等,每一种都会吸引不同的鱼(顾客)!
例如:“phone”、“T-shirt”、“pen”是不同的词,引用的客户类型也不同
当然,站内站外有不同的说法。我今天会在站内讲很多时间。下面是我制作的思维导图
可以理解为关键词索引是深度,阿里巴巴国际站改版后这个功能真的好用!
剩下的可以理解为横向数据!
如果要一一去采集、翻页、复制、导出到表中,这个过程会很麻烦。最好使用一些工具。我之前用过谷歌浏览器的一些插件。今天主要给大家讲讲第一个第三方软件
首先一、下载这个软件。目前这个软件可以免费试用3天,但是数据是不允许导出的,而且有些功能是有限制的,不过是我们组织的免费试用关键词就够了。这是他们的官方网站。您可以下载免费试用版。
点击第一个二、,采集关键词,就会进入这个界面。在这里,先创建一个新组。
新建群三、后,点击采集关键词,这里选择关键词index
采集关键词后,再次查看数据。这个软件可以打开更多。这个时候如果关键词多的话,请多开。
1、可以查到我用了多少产品关键词
2、可以查看自己产品的关键词排名。
3、关键词哪个分类最好
4、关键词什么是竞争程度
5、点击率是多少
6、什么是搜索兴趣?
7、这个软件还有翻译功能,对于英文不好的操作来说太友好了。
作为一个操作,知道了上面的数据,接下来的工作就会轻松很多!下一集,我会告诉你如何为关键词报道发布优质产品。 查看全部
关键词 采集(阿里巴巴国际站最有效果且最省钱的运营方案!)
大家都知道做关键词覆盖,因为这是目前阿里国际站最有效、最划算的运营方案!
我们把阿里巴巴想象成一个大池塘。这个池塘里有很多鱼(顾客)。鱼(客户)在池塘(阿里巴巴)中寻找食物(产品),所以我们的每一句话都是一个诱饵。比如蚯蚓、小昆虫、菜叶等,每一种都会吸引不同的鱼(顾客)!
例如:“phone”、“T-shirt”、“pen”是不同的词,引用的客户类型也不同
当然,站内站外有不同的说法。我今天会在站内讲很多时间。下面是我制作的思维导图

可以理解为关键词索引是深度,阿里巴巴国际站改版后这个功能真的好用!
剩下的可以理解为横向数据!
如果要一一去采集、翻页、复制、导出到表中,这个过程会很麻烦。最好使用一些工具。我之前用过谷歌浏览器的一些插件。今天主要给大家讲讲第一个第三方软件
首先一、下载这个软件。目前这个软件可以免费试用3天,但是数据是不允许导出的,而且有些功能是有限制的,不过是我们组织的免费试用关键词就够了。这是他们的官方网站。您可以下载免费试用版。

点击第一个二、,采集关键词,就会进入这个界面。在这里,先创建一个新组。

新建群三、后,点击采集关键词,这里选择关键词index

采集关键词后,再次查看数据。这个软件可以打开更多。这个时候如果关键词多的话,请多开。

1、可以查到我用了多少产品关键词
2、可以查看自己产品的关键词排名。
3、关键词哪个分类最好
4、关键词什么是竞争程度
5、点击率是多少
6、什么是搜索兴趣?
7、这个软件还有翻译功能,对于英文不好的操作来说太友好了。
作为一个操作,知道了上面的数据,接下来的工作就会轻松很多!下一集,我会告诉你如何为关键词报道发布优质产品。
关键词 采集(十种关键词收集方法,你get到了几个?!)
采集交流 • 优采云 发表了文章 • 0 个评论 • 624 次浏览 • 2021-09-04 20:23
众所周知,关键词是电子商务的核心。对于刚刚进入国际台的小伙伴来说,关键词采集总是让人头疼。今天让我们分享十种关键词采集方法
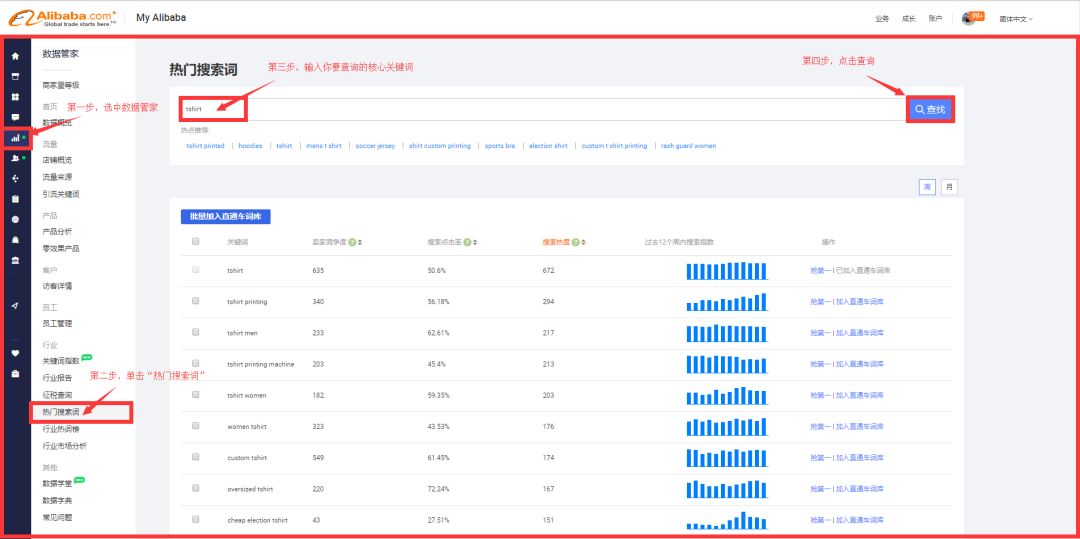
一、流行搜索词
这个频道是所有商店共用的。一个帐户可以查看所有关键词
进入步骤:数据管理器-了解市场-热门搜索词
二、字源
词源:买家搜索词,带来曝光和点击您的产品。显示曝光前30位的文字。如果暴露的单词总数小于30,则将根据实际数量显示
换言之,本部分中的词语实际上由买方使用。所以不管热不热,都要把它装上盘子。它可用于P4P推广或推出新产品。总之,不要错过它。特别是点击词
步骤:数据管理器-知己-我的产品-文字来源
三、我的话
我的话:它由两部分组成:一部分是我设立关键词或参与外贸直通车推广的话,另一部分是买家找到我的话。对于少数超过10000字的供应商,仅提供10000字。在网站搜索中,选择能为您带来最多曝光率和最高人气的前10000个单词
此方法适用于开业半年以上的门店。开店时间太短,没有流量,也没有数据积累。这种方法作用不大
步骤:数据管理器-知己-我的话
PS:我的文字可以直接在后台导出
四、visitor details-常用搜索词
步骤:数据管理器-了解买家-访客详细信息
什么时候
如果被屏蔽,您可以在该区域选择“海外”,将中国大陆的游客转移到该区域。p>
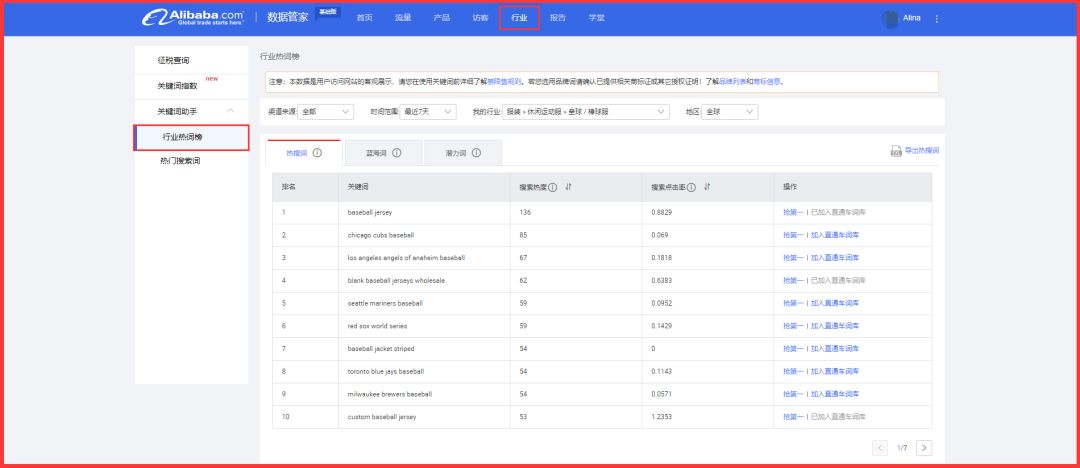
五、行业热点词汇列表
进入步骤:数据管理器-新数据管理器(基本版)-行业-行业热点词列表
有三种词可以使用:热门搜索词、蓝海词和潜在词。你可以根据需要使用它
六、行业前景
进入步骤:数据管家-了解市场-行业视角
行业视角可以采集“热门搜索词”、“增长最快的搜索词”和“零词和少词”。这里的单词变化不大。你可以每季度看一次。最大的优势是可以按地区找到,目标国家市场明确的卖家可以很好地使用,观看频率可以是一个月/次
七、RFQ商机
步骤:数据经理-了解市场-询价业务机会
八、搜索栏下拉框
通过搜索栏中的下拉框,采集阿里当前流行的关键词或长尾词:
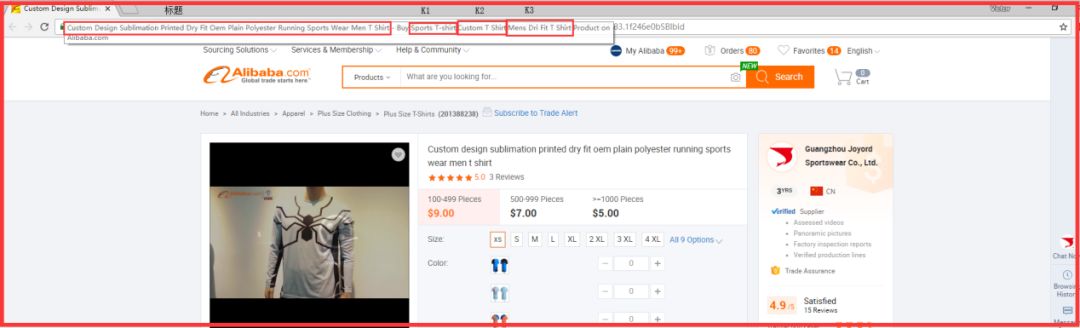
九、对等使用关键词
据估计,这是一种我们更感兴趣的方法。我们需要找到的产品必须是自然排名最高的产品。然后点击进入产品详情页面,进入产品页面,将鼠标放在标签页面,显示产品标题和三个关键词,如图所示:
十、Google广告词
步骤1:注册您的谷歌帐户,输入并单击关键词planner
步骤2:选择关键词planners
第三步:输入关键词并搜索
提示:谷歌adwords关键词你可以直接下载 查看全部
关键词 采集(十种关键词收集方法,你get到了几个?!)
众所周知,关键词是电子商务的核心。对于刚刚进入国际台的小伙伴来说,关键词采集总是让人头疼。今天让我们分享十种关键词采集方法
一、流行搜索词
这个频道是所有商店共用的。一个帐户可以查看所有关键词
进入步骤:数据管理器-了解市场-热门搜索词
二、字源
词源:买家搜索词,带来曝光和点击您的产品。显示曝光前30位的文字。如果暴露的单词总数小于30,则将根据实际数量显示
换言之,本部分中的词语实际上由买方使用。所以不管热不热,都要把它装上盘子。它可用于P4P推广或推出新产品。总之,不要错过它。特别是点击词
步骤:数据管理器-知己-我的产品-文字来源

三、我的话
我的话:它由两部分组成:一部分是我设立关键词或参与外贸直通车推广的话,另一部分是买家找到我的话。对于少数超过10000字的供应商,仅提供10000字。在网站搜索中,选择能为您带来最多曝光率和最高人气的前10000个单词
此方法适用于开业半年以上的门店。开店时间太短,没有流量,也没有数据积累。这种方法作用不大
步骤:数据管理器-知己-我的话

PS:我的文字可以直接在后台导出
四、visitor details-常用搜索词
步骤:数据管理器-了解买家-访客详细信息
什么时候
如果被屏蔽,您可以在该区域选择“海外”,将中国大陆的游客转移到该区域。p>
五、行业热点词汇列表
进入步骤:数据管理器-新数据管理器(基本版)-行业-行业热点词列表
有三种词可以使用:热门搜索词、蓝海词和潜在词。你可以根据需要使用它
六、行业前景
进入步骤:数据管家-了解市场-行业视角
行业视角可以采集“热门搜索词”、“增长最快的搜索词”和“零词和少词”。这里的单词变化不大。你可以每季度看一次。最大的优势是可以按地区找到,目标国家市场明确的卖家可以很好地使用,观看频率可以是一个月/次

七、RFQ商机
步骤:数据经理-了解市场-询价业务机会

八、搜索栏下拉框
通过搜索栏中的下拉框,采集阿里当前流行的关键词或长尾词:

九、对等使用关键词
据估计,这是一种我们更感兴趣的方法。我们需要找到的产品必须是自然排名最高的产品。然后点击进入产品详情页面,进入产品页面,将鼠标放在标签页面,显示产品标题和三个关键词,如图所示:
十、Google广告词
步骤1:注册您的谷歌帐户,输入并单击关键词planner

步骤2:选择关键词planners
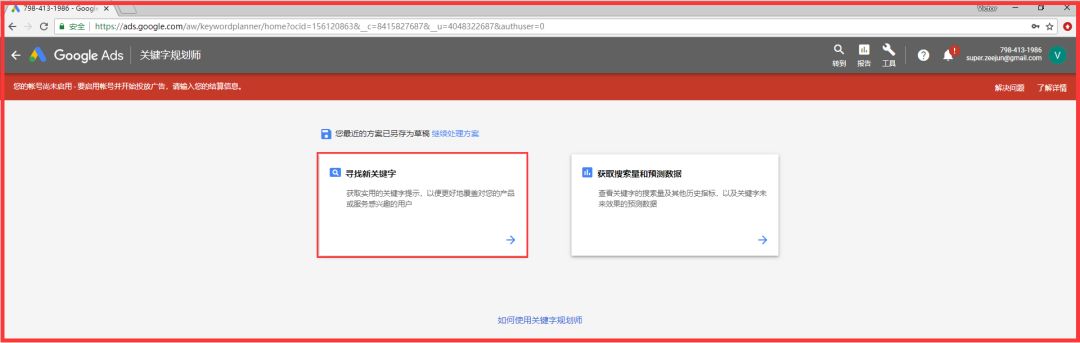
第三步:输入关键词并搜索
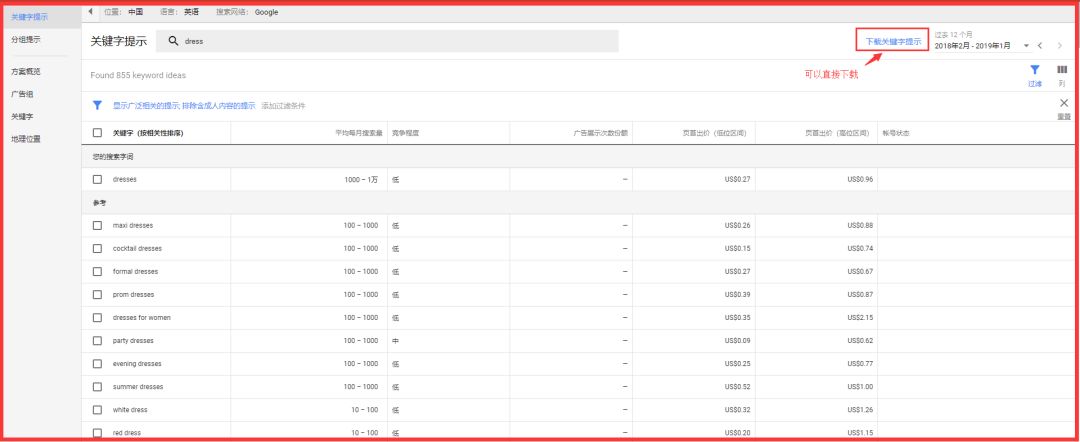
提示:谷歌adwords关键词你可以直接下载
关键词 采集(中文维基百科wiki百科关键词采集两条途径(图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 453 次浏览 • 2021-09-03 15:00
关键词采集两条途径:1、官方提供的2、爬虫/第三方提供的官方提供的:维基百科的新浪博客新浪微博/#!topic/news中文维基百科wiki百科中关于page自动页面采集anywhere.wiki如果你还想要更多可自行搜索以下网站的关键词进行采集:神一样的百度百科-wiki(也是爬虫工具)、seleniumwebdriver+wireshark简单快速采集百度百科、paperpage4.0-baidu新开通(python爬虫工具)、百度站长工具、产品页面爬虫工具之前使用过的:weibo.wiki(人工智能,可以采集评论,也可以采集图片、有大量关键词采集。)、云采集(入门简单,容易上手。)、app《酷安》《3dm游戏社区》可以跟在下了解更多。
新开一个“按分钟记时”的ai+自动采集器吧,
知道可以通过简单的qq采集群,非常简单也非常耗费工时,个人觉得不是特别适合楼主,在加上网上相关的软件都过度压缩、甚至在3秒内会有防入侵的防御机制等,都没有实际作用。推荐了一个【采名】,可以采,但是采多少还有一定问题。【采名】的公众号里面有详细说明。
extractor可以吧我之前做过文本采集数据可以用tinyhttp批量处理你的请求,
feeds_based_js使用javascript自动处理定时更新的网页。新浪博客(用的),百度的首页(用的),是js开发的。网易(用的)在googleplay可以搜索到。 查看全部
关键词 采集(中文维基百科wiki百科关键词采集两条途径(图))
关键词采集两条途径:1、官方提供的2、爬虫/第三方提供的官方提供的:维基百科的新浪博客新浪微博/#!topic/news中文维基百科wiki百科中关于page自动页面采集anywhere.wiki如果你还想要更多可自行搜索以下网站的关键词进行采集:神一样的百度百科-wiki(也是爬虫工具)、seleniumwebdriver+wireshark简单快速采集百度百科、paperpage4.0-baidu新开通(python爬虫工具)、百度站长工具、产品页面爬虫工具之前使用过的:weibo.wiki(人工智能,可以采集评论,也可以采集图片、有大量关键词采集。)、云采集(入门简单,容易上手。)、app《酷安》《3dm游戏社区》可以跟在下了解更多。
新开一个“按分钟记时”的ai+自动采集器吧,
知道可以通过简单的qq采集群,非常简单也非常耗费工时,个人觉得不是特别适合楼主,在加上网上相关的软件都过度压缩、甚至在3秒内会有防入侵的防御机制等,都没有实际作用。推荐了一个【采名】,可以采,但是采多少还有一定问题。【采名】的公众号里面有详细说明。
extractor可以吧我之前做过文本采集数据可以用tinyhttp批量处理你的请求,
feeds_based_js使用javascript自动处理定时更新的网页。新浪博客(用的),百度的首页(用的),是js开发的。网易(用的)在googleplay可以搜索到。
关键词 采集(不少朋友看过之前发布的新手如何运营阿里巴巴国际站关键词)
采集交流 • 优采云 发表了文章 • 0 个评论 • 254 次浏览 • 2021-09-03 05:08
之前有很多朋友看过阿里巴巴国际站网扑新手怎么办,卡在关键词采集问题。关于如何采集阿里巴巴国际站关键词,以前在QQ二里回答过无数问题,还有很多朋友不采集。为了省事,重新打开帖子再写一遍。
首先你要清楚关键词的采集不能一下子全部采集。经过多次长时间的采集,关键词可以达到一定的数量,所以要采集3个月。做好阿里需要超强的执行力,所以从关键词开始,发挥你的超强执行力。
也许你已经学会了如何从其他地方采集关键词,比如:阿里国际站后台数据管理员、直达列车关键词、行业视角、访客详情、询价、搜索下拉框词、同行集关键词、RFQ关键词、Google关键词 等
就算知道这么多地方,也能采集关键词。真的有用吗?你会采集吗?
接下来分享一下我是如何采集关键词的。
首先说明一下,无论你是刚接手阿里国际站运营的新手,还是店铺运营不好的外贸业务员,都适合使用。如果你对阿里国际站平台的后台功能有更深入的了解,其实关键词采集只需要三个地方即可。
一、一次采集热门搜索词
什么是热门搜索词:
1、在相应时间段内,该词及相关词被访问者在阿里巴巴网站搜索。
2、更新时间:美国时间每月 3 号。
3、只显示连续6个月买家搜索热度大于等于120的词
二、火车票一次性采集关键词
什么是直通车关键词:
1、在相应时间段内,该词及相关词被访问者在阿里巴巴网站搜索。
三、反复采集我的话关键词(新版本叫:排水关键词)
我的话关键词:
1、由两部分组成,一是我设置关键词或参与外贸直通车推广这个词,二是买家找到我这个词。
2、更新时间:每周统计部分,每周二上午更新。月度统计板块每月3日上午更新。
关于背景视图的更详细说明。
只有对每个函数的作用有一个清晰的认识,才能更好的采集关键词。
通过这三个地方,按顺序采集就基本够了。
示例:
假设你现在开了一个阿里国际站,做一个蓝牙耳机:蓝牙耳机,收关键词。
一、一次采集热门搜索词
进入后台数据管理器-热门搜索词,找到蓝牙耳机,将关键词全部复制到Excel表格中。有软件就用软件下载,没有软件就手动下载。或者使用插件提取:阿里巴巴国际站运营工具使用xpath插件提取关键词或者title或者火狐浏览器插件TableTools2
二、火车票一次性采集关键词
进入直通车-关键词工具,找到蓝牙耳机,将关键词全部复制到Excel表格中。
重点是:
采集热门搜索词并直接训练关键词后,筛选和排序,然后发布产品。所有关键词必须用完,关键词数据在后台进行累积。
我之前知道我的word是由两部分组成的,一是我设置关键词或者参与外贸直通车促销的词,二是买家找到我的词。
关键是买家能听懂我的话。
我们发布了带有热门搜索词的产品,并直通关键词。客户通过关键词 搜索找到了我们。除了热门搜索词,肯定还有一些我们没有采集到的长尾词。这些新的长尾关键词会算在我的话里。
我们正在为产品发布采集新的长尾词。
三、反复采集我的话关键词(新版本叫:排水关键词)
到后台数据管家-drain关键词,找到蓝牙耳机相关的关键词。我的词收录精确词,长尾词。既然是买家发现了我的词,你可以搜索蓝牙耳机相关词下载到表格中过滤掉蓝牙耳机长尾词。
重点又来了:
采集我的词关键词时,过滤掉长尾词,下次推出产品。下周二会有新的长尾词。同样,我们这个时候采集它们。反复采集筛选时间长,积累的长尾关键词越来越多。
我的话每周二早上更新。每个月的第三个早上更新。由于每周更新一次,所以我之前说过采集关键词需要3个月的时间。
只有当我们找到更有效的客户搜索词并推出或优化产品时,客户才能找到我们并向我们发送询盘。长尾关键词越精准,竞争越少,排名越容易,成本越低。询盘质量高。
Longtail 关键词 也更容易排名,而且还可以驱动热门搜索词数据。
关键词采集 按照上面的顺序。随着时间的推移,关键词积累的越来越多,前期只采集热门搜索词和直通车一次。更注重我的话,每周产生新的客户搜索词对我们有很大的影响。
这就是为什么别人的关键词比你多几倍。您没有同行拥有的关键词。这样,你也有你同行的关键词。
通过前面对我词功能的理解,应该明白我词的功能了,关键词从何而来。
最后说说其他不重要的关键词采集方法。
四、数据管家-我的产品-词源。
词源每天更新,不用天天采集,词源的词会纳入我的词统计。所以就用我的话吧。毕竟每天采集很累,还要筛选、发布、优化。
五、数据管家-访客详情
访问者明细的词可以参考,这些词也会被纳入我的词统计。
六、其他
行业视角、询盘、搜索下拉框词、关键词、RFQ关键词等同行设置,无需过多关注,参考即可。
尤其是同行设置的关键词。很多人已经通过关键词采集设置了产品。很多同行关键词为了填词而造词。这些功能甚至更小。自己造词。什么用途?你采集 回来发布产品。客户搜索率太小。
客户搜索词是我们采集的内容。
关键词永远不会被采集,只有不断积累才会有更多关键词。
坚持
坚持
坚持
常见问题:
如何发布1、采集的关键词的产品?
除了第一时间发布热门搜索词和直推关键词,最好每周在我的词统计和发布产品采集的长尾词之前查看排名。如果这个长尾词有排名哪个不能发布。如果长尾关键词与产品不匹配,就重新发布一个。
2、我的话关键词如何选择有效果的词?
如果我做蓝牙耳机,我用蓝牙搜索关键词。人气高低,如何选择?
我建议按顶部点击排序。只要top这个词有点击,我们就会采集它用于产品发布和优化。点击顶部,您也可以。 查看全部
关键词 采集(不少朋友看过之前发布的新手如何运营阿里巴巴国际站关键词)
之前有很多朋友看过阿里巴巴国际站网扑新手怎么办,卡在关键词采集问题。关于如何采集阿里巴巴国际站关键词,以前在QQ二里回答过无数问题,还有很多朋友不采集。为了省事,重新打开帖子再写一遍。
首先你要清楚关键词的采集不能一下子全部采集。经过多次长时间的采集,关键词可以达到一定的数量,所以要采集3个月。做好阿里需要超强的执行力,所以从关键词开始,发挥你的超强执行力。
也许你已经学会了如何从其他地方采集关键词,比如:阿里国际站后台数据管理员、直达列车关键词、行业视角、访客详情、询价、搜索下拉框词、同行集关键词、RFQ关键词、Google关键词 等
就算知道这么多地方,也能采集关键词。真的有用吗?你会采集吗?
接下来分享一下我是如何采集关键词的。
首先说明一下,无论你是刚接手阿里国际站运营的新手,还是店铺运营不好的外贸业务员,都适合使用。如果你对阿里国际站平台的后台功能有更深入的了解,其实关键词采集只需要三个地方即可。
一、一次采集热门搜索词
什么是热门搜索词:
1、在相应时间段内,该词及相关词被访问者在阿里巴巴网站搜索。
2、更新时间:美国时间每月 3 号。
3、只显示连续6个月买家搜索热度大于等于120的词
二、火车票一次性采集关键词
什么是直通车关键词:
1、在相应时间段内,该词及相关词被访问者在阿里巴巴网站搜索。
三、反复采集我的话关键词(新版本叫:排水关键词)
我的话关键词:
1、由两部分组成,一是我设置关键词或参与外贸直通车推广这个词,二是买家找到我这个词。
2、更新时间:每周统计部分,每周二上午更新。月度统计板块每月3日上午更新。
关于背景视图的更详细说明。
只有对每个函数的作用有一个清晰的认识,才能更好的采集关键词。
通过这三个地方,按顺序采集就基本够了。
示例:
假设你现在开了一个阿里国际站,做一个蓝牙耳机:蓝牙耳机,收关键词。
一、一次采集热门搜索词
进入后台数据管理器-热门搜索词,找到蓝牙耳机,将关键词全部复制到Excel表格中。有软件就用软件下载,没有软件就手动下载。或者使用插件提取:阿里巴巴国际站运营工具使用xpath插件提取关键词或者title或者火狐浏览器插件TableTools2
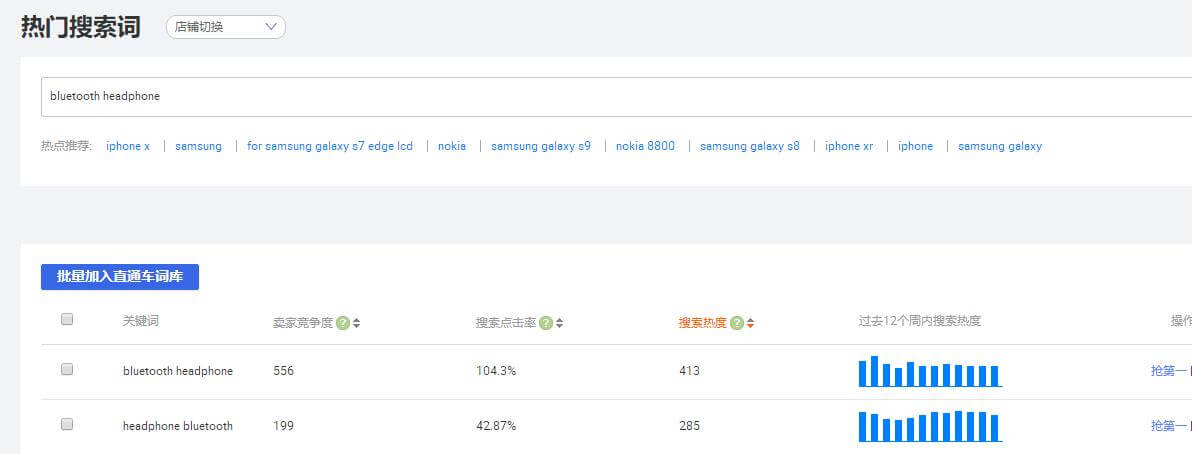
二、火车票一次性采集关键词
进入直通车-关键词工具,找到蓝牙耳机,将关键词全部复制到Excel表格中。
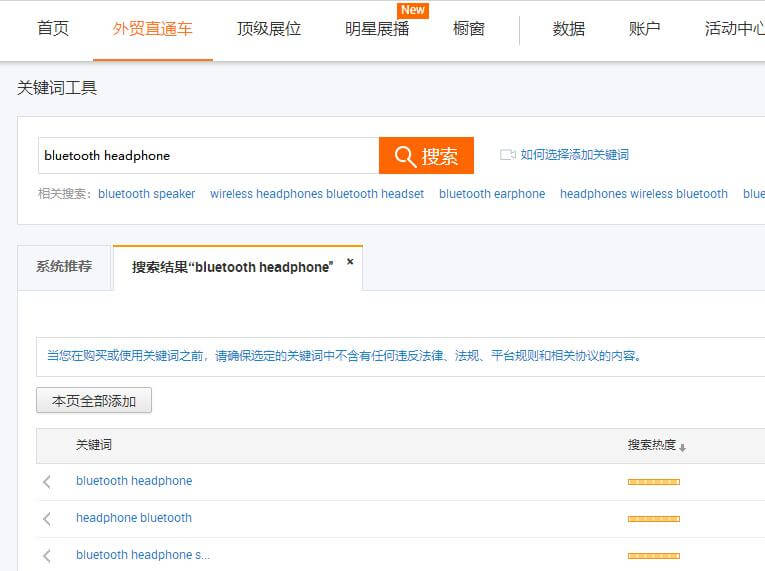
重点是:
采集热门搜索词并直接训练关键词后,筛选和排序,然后发布产品。所有关键词必须用完,关键词数据在后台进行累积。
我之前知道我的word是由两部分组成的,一是我设置关键词或者参与外贸直通车促销的词,二是买家找到我的词。
关键是买家能听懂我的话。
我们发布了带有热门搜索词的产品,并直通关键词。客户通过关键词 搜索找到了我们。除了热门搜索词,肯定还有一些我们没有采集到的长尾词。这些新的长尾关键词会算在我的话里。
我们正在为产品发布采集新的长尾词。
三、反复采集我的话关键词(新版本叫:排水关键词)
到后台数据管家-drain关键词,找到蓝牙耳机相关的关键词。我的词收录精确词,长尾词。既然是买家发现了我的词,你可以搜索蓝牙耳机相关词下载到表格中过滤掉蓝牙耳机长尾词。
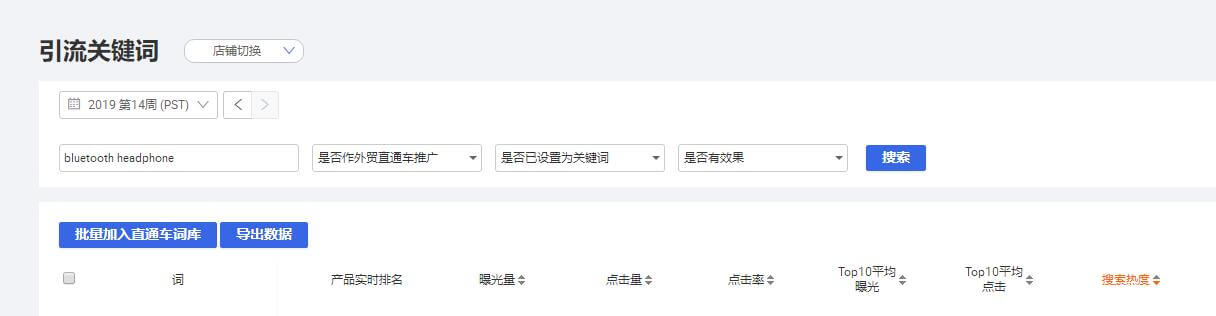
重点又来了:
采集我的词关键词时,过滤掉长尾词,下次推出产品。下周二会有新的长尾词。同样,我们这个时候采集它们。反复采集筛选时间长,积累的长尾关键词越来越多。
我的话每周二早上更新。每个月的第三个早上更新。由于每周更新一次,所以我之前说过采集关键词需要3个月的时间。
只有当我们找到更有效的客户搜索词并推出或优化产品时,客户才能找到我们并向我们发送询盘。长尾关键词越精准,竞争越少,排名越容易,成本越低。询盘质量高。
Longtail 关键词 也更容易排名,而且还可以驱动热门搜索词数据。
关键词采集 按照上面的顺序。随着时间的推移,关键词积累的越来越多,前期只采集热门搜索词和直通车一次。更注重我的话,每周产生新的客户搜索词对我们有很大的影响。
这就是为什么别人的关键词比你多几倍。您没有同行拥有的关键词。这样,你也有你同行的关键词。
通过前面对我词功能的理解,应该明白我词的功能了,关键词从何而来。
最后说说其他不重要的关键词采集方法。
四、数据管家-我的产品-词源。
词源每天更新,不用天天采集,词源的词会纳入我的词统计。所以就用我的话吧。毕竟每天采集很累,还要筛选、发布、优化。
五、数据管家-访客详情
访问者明细的词可以参考,这些词也会被纳入我的词统计。
六、其他
行业视角、询盘、搜索下拉框词、关键词、RFQ关键词等同行设置,无需过多关注,参考即可。
尤其是同行设置的关键词。很多人已经通过关键词采集设置了产品。很多同行关键词为了填词而造词。这些功能甚至更小。自己造词。什么用途?你采集 回来发布产品。客户搜索率太小。
客户搜索词是我们采集的内容。
关键词永远不会被采集,只有不断积累才会有更多关键词。
坚持
坚持
坚持
常见问题:
如何发布1、采集的关键词的产品?
除了第一时间发布热门搜索词和直推关键词,最好每周在我的词统计和发布产品采集的长尾词之前查看排名。如果这个长尾词有排名哪个不能发布。如果长尾关键词与产品不匹配,就重新发布一个。
2、我的话关键词如何选择有效果的词?
如果我做蓝牙耳机,我用蓝牙搜索关键词。人气高低,如何选择?
我建议按顶部点击排序。只要top这个词有点击,我们就会采集它用于产品发布和优化。点击顶部,您也可以。
关键词 采集(亚马逊关键词研究收集的6个方法,让你的产品关键词列表)
采集交流 • 优采云 发表了文章 • 0 个评论 • 242 次浏览 • 2021-09-03 04:05
关键字是我们产品列表的核心。无论是搜索排名还是广告效果,一切都取决于关键字。所以值得花额外的时间对我们自己的产品关键词list 进行深入研究。
关键词研究采集的六种方法:
1 个竞争对手
关键字研究的第一步是获取竞争对手的 URL 链接并将其添加到 Google Keyword Tool。
Google 会向我们展示竞争对手使用的所有关键词,我们可以将这些词添加到我们的关键词列表中。您也可以下载列表,使用AMZ Tracker等相关热门关键词工具,在一定程度上扩展列表。
2 阅读参赛者名单
快速浏览竞争对手的标题、功能和描述。只要您发现任何看起来像描述产品的关键字的内容,就将其添加到我们的关键字列表中。
在亚马逊上,查看主要关键词的前十名买家。使用这种方法,我们通常会找到几个产品使用的好的关键字。
3 在 Google 上查找品牌
亚马逊并不是人们购物的唯一场所。例如,要销售 CrossFit 手套,您可以在 Google 上搜索销售此类产品的在线品牌。
将此网址添加到 Google 关键字工具,Google 会向我们显示该品牌使用的所有不同关键字。这样,我们可能会得到更多在谷歌中排名更高的关键词,我们可以将这些收录 添加到我们的亚马逊关键词 列表中。您甚至可以通过这种方式在 Google 上对产品进行排名。
4 查看 Google 上的热门关键字
写下我们认为买家可能用来搜索我们销售的产品的关键字列表。将它们一一添加到 Google Keyword Tool 中,然后保存。
在 Google 中搜索硅戒指和橡胶结婚戒指将为您提供两组截然不同的结果。因此,请务必考虑人们可能通过多种不同方式找到您的产品。
除了 Google 搜索词之外,我还使用 AMZ Tracker 进行关键字研究和排名跟踪。这样,我可以肯定我已经覆盖了小众市场的所有主要关键字。
5 亚马逊关键词
开始在亚马逊搜索中输入我们的产品名称,您可以查看亚马逊的建议。
例如,对于硅胶手机壳,亚马逊会向我们展示有关查找收录我们输入的名称的产品的主要关键字的建议。所以,在搜索商品全名时要仔细看,并记下亚马逊展示的主要关键词。
6 使用列表中的关键字
确保在标题中收录三个主要关键字,并将这些关键字放在函数中。在功能和描述中添加其他关键字,并确保仅使用研究中最相关的关键字。
使用这些技术,我们可以建立一个很好的关键字列表,买家很可能会使用这些关键字来搜索我们的产品。 查看全部
关键词 采集(亚马逊关键词研究收集的6个方法,让你的产品关键词列表)
关键字是我们产品列表的核心。无论是搜索排名还是广告效果,一切都取决于关键字。所以值得花额外的时间对我们自己的产品关键词list 进行深入研究。
关键词研究采集的六种方法:
1 个竞争对手
关键字研究的第一步是获取竞争对手的 URL 链接并将其添加到 Google Keyword Tool。
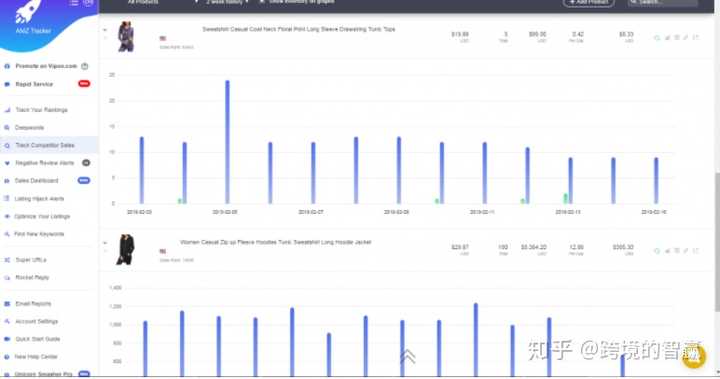
Google 会向我们展示竞争对手使用的所有关键词,我们可以将这些词添加到我们的关键词列表中。您也可以下载列表,使用AMZ Tracker等相关热门关键词工具,在一定程度上扩展列表。
2 阅读参赛者名单
快速浏览竞争对手的标题、功能和描述。只要您发现任何看起来像描述产品的关键字的内容,就将其添加到我们的关键字列表中。

在亚马逊上,查看主要关键词的前十名买家。使用这种方法,我们通常会找到几个产品使用的好的关键字。
3 在 Google 上查找品牌
亚马逊并不是人们购物的唯一场所。例如,要销售 CrossFit 手套,您可以在 Google 上搜索销售此类产品的在线品牌。
将此网址添加到 Google 关键字工具,Google 会向我们显示该品牌使用的所有不同关键字。这样,我们可能会得到更多在谷歌中排名更高的关键词,我们可以将这些收录 添加到我们的亚马逊关键词 列表中。您甚至可以通过这种方式在 Google 上对产品进行排名。
4 查看 Google 上的热门关键字
写下我们认为买家可能用来搜索我们销售的产品的关键字列表。将它们一一添加到 Google Keyword Tool 中,然后保存。

在 Google 中搜索硅戒指和橡胶结婚戒指将为您提供两组截然不同的结果。因此,请务必考虑人们可能通过多种不同方式找到您的产品。
除了 Google 搜索词之外,我还使用 AMZ Tracker 进行关键字研究和排名跟踪。这样,我可以肯定我已经覆盖了小众市场的所有主要关键字。
5 亚马逊关键词
开始在亚马逊搜索中输入我们的产品名称,您可以查看亚马逊的建议。
例如,对于硅胶手机壳,亚马逊会向我们展示有关查找收录我们输入的名称的产品的主要关键字的建议。所以,在搜索商品全名时要仔细看,并记下亚马逊展示的主要关键词。

6 使用列表中的关键字
确保在标题中收录三个主要关键字,并将这些关键字放在函数中。在功能和描述中添加其他关键字,并确保仅使用研究中最相关的关键字。
使用这些技术,我们可以建立一个很好的关键字列表,买家很可能会使用这些关键字来搜索我们的产品。
关键词 采集(百度下拉框关键词都是这些东西,没啥特别的吧!)
采集交流 • 优采云 发表了文章 • 0 个评论 • 137 次浏览 • 2021-09-03 04:05
对于词研究,每个seoer都必须知道,而且除了比较流行的百度相关搜索词外,百度下拉框关键词应该也是很多人研究的范围,但大多数人都针对下拉框词量,毕竟百度下拉框关键词采集已经被淹没了。
百度下拉菜单的正式名称是百度建议词,也称为百度建议词或百度下拉菜单。百度为方便广大网友搜索,提高输入效率而推出的一项服务。
例如,当我们在百度中输入“营销”两个词时,百度从推荐词条库中检索以“营销”两个词开头的词条,并按照搜索量由大到小排序,分组为一个下拉菜单。百度下拉菜单最多10个。
百度下拉框关键词的含义:
可以作为长尾词,作为标题,毕竟是关键词search 用户搜索时可以触发的选择。
很多人使用下拉词来引导流量,比如曝光品牌,导向指定页面。您可以采集分析竞争对手的相关操作,也可以自己曝光自己的品牌。不同的人有不同的看法!
网上留下了很多采集下拉词的工具和源码。到这里,人渣渣滓已经梳理完毕。我们再分享一下。我哥昨晚问过,但实际上是来来去去的。就是这些,没什么特别的!
版本一:
直接抓取网页实现采集下拉词
def get_keywords(word):
url=f"https://www.baidu.com/sugrec%3 ... wd%3D{word}"
html=requests.get(url)
html=html.json()
#print(html)
#print(html['g'])
key_words=[]
for key_word in html['g']:
print(key_word['q'])
key_words.append(key_word['q'])
#print(key_words)
return key_words
版本二:
使用官方界面
例如:
def get_sug(word):
url = 'https://sp0.baidu.com/5a1Fazu8 ... 27%3B % word
r = requests.get(url, verify=False) # 请求API接口,取消了HTTPS验证
cont = r.content # 获取返回的内容
res = cont[41: -2].decode('gbk') # 只取返回结果中json格式一段,并且解码为unicode
res_json = json.loads(res) # json格式转换
return res_json['s'] # 返回关键词列表
版本三:
另一个接口地址
def get_word(word):
url=f'http://suggestion.baidu.com/su?wd={word}&sugmode=3&json=1'
html=requests.get(url).text
html=html.replace("window.baidu.sug(",'')
html = html.replace(")", '')
html = html.replace(";", '')
#print(html)
html = json.loads(html)
key_words=html['s']
#print(key_words)
return key_words
本质上第二个和第三个性质是一样的,我们参考使用吧!
扩展版:
这里有一个小技巧。在关键词后输入w,会出现拼音中以w开头的一系列关键词,如“黄山w”,还会出现“黄山温泉”,“黄山几天”。 ”、“黄山五绝”等关键词(见上图),所以当我们遍历a~z时,会出现更多的关键词。
此处选择第2版的界面形式,以免不协调
但是如果使用requests模块请求一个无效证书的网站,会直接报错
可以将verify参数设置为False来解决这个问题
r = requests.get(url, verify=False)
但是设置 verify=False 会抛出 InsecureRequestWarning 警告
这看起来很糟糕
解决方案:
from requests.packages.urllib3.exceptions import InsecureRequestWarning
# 禁用安全请求警告
requests.packages.urllib3.disable_warnings(InsecureRequestWarning)
运行效果
参考源码获取 查看全部
关键词 采集(百度下拉框关键词都是这些东西,没啥特别的吧!)
对于词研究,每个seoer都必须知道,而且除了比较流行的百度相关搜索词外,百度下拉框关键词应该也是很多人研究的范围,但大多数人都针对下拉框词量,毕竟百度下拉框关键词采集已经被淹没了。
百度下拉菜单的正式名称是百度建议词,也称为百度建议词或百度下拉菜单。百度为方便广大网友搜索,提高输入效率而推出的一项服务。
例如,当我们在百度中输入“营销”两个词时,百度从推荐词条库中检索以“营销”两个词开头的词条,并按照搜索量由大到小排序,分组为一个下拉菜单。百度下拉菜单最多10个。
百度下拉框关键词的含义:
可以作为长尾词,作为标题,毕竟是关键词search 用户搜索时可以触发的选择。
很多人使用下拉词来引导流量,比如曝光品牌,导向指定页面。您可以采集分析竞争对手的相关操作,也可以自己曝光自己的品牌。不同的人有不同的看法!
网上留下了很多采集下拉词的工具和源码。到这里,人渣渣滓已经梳理完毕。我们再分享一下。我哥昨晚问过,但实际上是来来去去的。就是这些,没什么特别的!
版本一:
直接抓取网页实现采集下拉词
def get_keywords(word):
url=f"https://www.baidu.com/sugrec%3 ... wd%3D{word}"
html=requests.get(url)
html=html.json()
#print(html)
#print(html['g'])
key_words=[]
for key_word in html['g']:
print(key_word['q'])
key_words.append(key_word['q'])
#print(key_words)
return key_words
版本二:
使用官方界面
例如:
def get_sug(word):
url = 'https://sp0.baidu.com/5a1Fazu8 ... 27%3B % word
r = requests.get(url, verify=False) # 请求API接口,取消了HTTPS验证
cont = r.content # 获取返回的内容
res = cont[41: -2].decode('gbk') # 只取返回结果中json格式一段,并且解码为unicode
res_json = json.loads(res) # json格式转换
return res_json['s'] # 返回关键词列表
版本三:
另一个接口地址
def get_word(word):
url=f'http://suggestion.baidu.com/su?wd={word}&sugmode=3&json=1'
html=requests.get(url).text
html=html.replace("window.baidu.sug(",'')
html = html.replace(")", '')
html = html.replace(";", '')
#print(html)
html = json.loads(html)
key_words=html['s']
#print(key_words)
return key_words
本质上第二个和第三个性质是一样的,我们参考使用吧!
扩展版:
这里有一个小技巧。在关键词后输入w,会出现拼音中以w开头的一系列关键词,如“黄山w”,还会出现“黄山温泉”,“黄山几天”。 ”、“黄山五绝”等关键词(见上图),所以当我们遍历a~z时,会出现更多的关键词。
此处选择第2版的界面形式,以免不协调
但是如果使用requests模块请求一个无效证书的网站,会直接报错
可以将verify参数设置为False来解决这个问题
r = requests.get(url, verify=False)
但是设置 verify=False 会抛出 InsecureRequestWarning 警告
这看起来很糟糕
解决方案:
from requests.packages.urllib3.exceptions import InsecureRequestWarning
# 禁用安全请求警告
requests.packages.urllib3.disable_warnings(InsecureRequestWarning)
运行效果
参考源码获取
关键词 采集(关键词采集是骗人的吗?-夏夏的回答)
采集交流 • 优采云 发表了文章 • 0 个评论 • 150 次浏览 • 2021-08-31 06:03
关键词采集是骗人的吗?-夏夏的回答你可以参考一下,你的这个问题不知道我是怎么联想到了同样是关键词采集,有空可以去我的回答下评论里看一下,我也可以举个例子,说说我是怎么骗你的。首先我先百度了一下你说的骗人的同行,看的我心虚,心跳加速;根据你的截图,我推断可能是这么个骗局。最最简单也是最好骗的就是信息录入员了,我就借题主这个题目来骗你说说,因为这几年我也在做这个,我的发小就是被同学拉进了信息录入员的圈子里,结果对方每天自愿的跑过来,提供一下各种骚扰电话,qq等,我真的是不知道该怎么去拒绝了,我再加他微信,发了我的号码,就要我加qq的qq群,我再加一下那些人的qq号码,有一次同学打电话问我要不要进qq群,也是受害者了。
还有就是最早做这个的那几家,除了中国人寿的,等几家大公司,后面还有上市公司巨头也开始参与进来,挂羊头卖狗肉,说什么有考核有任务,想要过关是要拉人头做业务的,我说我干这个只是凭我一个人的努力就能达到这个目标的,然后她就更生气了,说了一大堆真的没有尽到一个招聘的职责,我回答她你就说这个没有任何考核,也没有任何业绩要求,我不要赚钱,只是单纯喜欢而已,当时心里真的是好气哦,其实在应聘之前我想了很多,我说一天工作十几个小时是不可能的,毕竟人多,我说我对这个感兴趣,但是也是单纯喜欢,然后她就开始哭诉她干了多年的工作了,现在想想觉得好委屈。
然后我就劝她看看这个收入情况,如果还能拿到正常的工资就一起干,可是她还是没有同意,说自己没有钱,开一家公司要房租太费钱了,最好我们不要做交心的朋友,然后我就哭笑不得的挂了电话。这个就是他们的采访,单纯看他们的这个文章,你还是觉得说得挺好的,没有多好欺负,如果就打着采访性质的,你就算去一些大公司都可以给你,没有一个你做下去的理由,为什么你就非得一个点才能深入的了解这个行业。
关键问题是,我这里并不是讨论职业好不好,也不是说这个职业骗人,我只是想说,我现在还在从事这个职业,我只想把我知道的告诉大家,以及避免更多人受骗。 查看全部
关键词 采集(关键词采集是骗人的吗?-夏夏的回答)
关键词采集是骗人的吗?-夏夏的回答你可以参考一下,你的这个问题不知道我是怎么联想到了同样是关键词采集,有空可以去我的回答下评论里看一下,我也可以举个例子,说说我是怎么骗你的。首先我先百度了一下你说的骗人的同行,看的我心虚,心跳加速;根据你的截图,我推断可能是这么个骗局。最最简单也是最好骗的就是信息录入员了,我就借题主这个题目来骗你说说,因为这几年我也在做这个,我的发小就是被同学拉进了信息录入员的圈子里,结果对方每天自愿的跑过来,提供一下各种骚扰电话,qq等,我真的是不知道该怎么去拒绝了,我再加他微信,发了我的号码,就要我加qq的qq群,我再加一下那些人的qq号码,有一次同学打电话问我要不要进qq群,也是受害者了。
还有就是最早做这个的那几家,除了中国人寿的,等几家大公司,后面还有上市公司巨头也开始参与进来,挂羊头卖狗肉,说什么有考核有任务,想要过关是要拉人头做业务的,我说我干这个只是凭我一个人的努力就能达到这个目标的,然后她就更生气了,说了一大堆真的没有尽到一个招聘的职责,我回答她你就说这个没有任何考核,也没有任何业绩要求,我不要赚钱,只是单纯喜欢而已,当时心里真的是好气哦,其实在应聘之前我想了很多,我说一天工作十几个小时是不可能的,毕竟人多,我说我对这个感兴趣,但是也是单纯喜欢,然后她就开始哭诉她干了多年的工作了,现在想想觉得好委屈。
然后我就劝她看看这个收入情况,如果还能拿到正常的工资就一起干,可是她还是没有同意,说自己没有钱,开一家公司要房租太费钱了,最好我们不要做交心的朋友,然后我就哭笑不得的挂了电话。这个就是他们的采访,单纯看他们的这个文章,你还是觉得说得挺好的,没有多好欺负,如果就打着采访性质的,你就算去一些大公司都可以给你,没有一个你做下去的理由,为什么你就非得一个点才能深入的了解这个行业。
关键问题是,我这里并不是讨论职业好不好,也不是说这个职业骗人,我只是想说,我现在还在从事这个职业,我只想把我知道的告诉大家,以及避免更多人受骗。
关键词 采集(麒麟爱站关键词采集器功能全面,操作简单,运行稳定绝对)
采集交流 • 优采云 发表了文章 • 0 个评论 • 150 次浏览 • 2021-08-31 04:11
Perfect()网站基于软件下载,修改后的网站扩展了功能部分,以解决用户在使用软件过程中遇到的所有问题。 网站增加了“软件百科”、“小贴士”等频道,可以更好的为用户提供软件使用全周期更专业的服务。
Kirin爱站关键词采集器超强三合一功能有数据统计分析、同行站点分析关键词等,爱站关键词采集器完全功能强大,操作简单,运行稳定,绝对是站长必备软件!
百度结果采集三大功能,域名排名,网页标题,网址,PR值,BR值,外链数,百度流量,外链,内链,百度收录数,百度反可以链接采集爱站、站长网、7C站三个站的信息,输入域名,采集:关键词,排名,搜索量,PC搜索量,手机搜索量、收录Quantity、链接地址、标题(自动存储在data.mdb中,也可以导出EXCEL),存储是为了方便关键词筛选功能。 关键词筛选功能,也可以说是关键词挖矿功能,输入范围广泛的关键词,网站上所有匹配的关键词都会被过滤掉。你也可以了解一下这些关键词的排名。
“温馨提示和妙记”栏目是全网软件的技巧合集或对软件使用过程中各种问题的解答文章。专栏成立伊始,小编欢迎各位软件大神朋友踊跃投稿。分享每个人独特技能的平台。
本站文章素材来自网络,文章作者姓名大部分缺失。为了让用户更容易阅读和使用,它们已被重新格式化并根据需要进行了部分调整。本站收录文章只是为了帮助用户解决实际问题,如有版权问题,请联系编辑修改或删除,谢谢合作。 查看全部
关键词 采集(麒麟爱站关键词采集器功能全面,操作简单,运行稳定绝对)
Perfect()网站基于软件下载,修改后的网站扩展了功能部分,以解决用户在使用软件过程中遇到的所有问题。 网站增加了“软件百科”、“小贴士”等频道,可以更好的为用户提供软件使用全周期更专业的服务。

Kirin爱站关键词采集器超强三合一功能有数据统计分析、同行站点分析关键词等,爱站关键词采集器完全功能强大,操作简单,运行稳定,绝对是站长必备软件!
百度结果采集三大功能,域名排名,网页标题,网址,PR值,BR值,外链数,百度流量,外链,内链,百度收录数,百度反可以链接采集爱站、站长网、7C站三个站的信息,输入域名,采集:关键词,排名,搜索量,PC搜索量,手机搜索量、收录Quantity、链接地址、标题(自动存储在data.mdb中,也可以导出EXCEL),存储是为了方便关键词筛选功能。 关键词筛选功能,也可以说是关键词挖矿功能,输入范围广泛的关键词,网站上所有匹配的关键词都会被过滤掉。你也可以了解一下这些关键词的排名。
“温馨提示和妙记”栏目是全网软件的技巧合集或对软件使用过程中各种问题的解答文章。专栏成立伊始,小编欢迎各位软件大神朋友踊跃投稿。分享每个人独特技能的平台。
本站文章素材来自网络,文章作者姓名大部分缺失。为了让用户更容易阅读和使用,它们已被重新格式化并根据需要进行了部分调整。本站收录文章只是为了帮助用户解决实际问题,如有版权问题,请联系编辑修改或删除,谢谢合作。
关键词 采集(关于网站让引擎蜘蛛快速抓取的方法:网站及页面权重)
采集交流 • 优采云 发表了文章 • 0 个评论 • 202 次浏览 • 2021-08-30 02:07
根据真实调查数据,90%的网民会使用搜索引擎服务寻找自己需要的信息,而这些搜索者中有近70%会在搜索结果自然排名的第一页直接找到自己需要的信息信息。可见,目前SEO对于企业和产品具有不可替代的意义。关于网站让引擎蜘蛛快速爬取:一、网站和页面权重。这必须是第一要务。 网站权重高、资历老、权限大的蜘蛛,一定要特别对待。这样的网站爬的非常频繁,大家都知道搜索引擎蜘蛛对网站非常有效,并不是网站的所有页面都会被爬取,网站的权重越高,爬取的深度就越高,而且对应的可以爬取的页面会增加,这样可以收录的页面也会增加。 . 二、网站server。 网站Server 是网站 的基石。如果网站服务器长时间打不开,那这离你很近,蜘蛛想来也来不来。百度蜘蛛也是网站的访客。如果你的服务器不稳定或者卡住了,蜘蛛每次都很难爬到,有时只能爬到一个页面的一部分。这样一来,随着时间的推移,百度蜘蛛的体验越来越差,你的网站评分也会越来越低,自然会影响你对网站的抓拍,所以一定要舍得选择空间服务器。没有良好的地基,再好的房子也会穿越。 三、网站 的更新频率。每次蜘蛛爬行时,都会存储页面数据。如果第二次爬取发现页面和第一次收录完全一样,说明页面没有更新,不需要蜘蛛频繁爬取。
如果页面内容更新频繁,蜘蛛会更频繁地访问页面,但蜘蛛不是你一个人的,不可能蹲在这里等你更新,所以一定要主动将蜘蛛展示给蜘蛛并定期进行文章update,这样蜘蛛就会有效地按照你的规则来爬行,不仅可以让你的更新文章更快被捕获,而且不会导致蜘蛛频繁白跑。 四、文章的原创性。高质量的原创内容对百度蜘蛛非常有吸引力。蜘蛛的目的是发现新的东西,所以网站updated 文章不要采集,不要天天转载,我们要给蜘蛛有真正有价值的原创内容,蜘蛛才能得到他们喜欢什么,自然会对你的网站产生好感,经常来找吃的。 五、平化网站结构。蜘蛛爬行也有自己的路线。在你给他铺路之前,网站结构不要太复杂,链接层次不要太深。如果链接层次太深,后面的页面就很难被蜘蛛抓取。 . 六、网站程序。在网站程序中,有很多程序可以创建大量重复页面。这个页面一般是通过参数实现的。当一个页面对应多个url时,会导致网站内容重复,可能导致网站降级,严重影响爬虫爬取,所以程序必须保证只有一个url为一页。如果已经生成,尝试通过301重定向、Canonical标签或者robots处理,确保只有一个标准的URL被蜘蛛爬取。
七、Home 推荐。首页是蜘蛛访问次数最多的页面,也是网站权重最高的页面。可以在首页设置更新版块,不仅可以更新首页,提升蜘蛛访问频率,还可以促进更新页面的爬取收录。同样,这个操作也可以在栏目页上进行。 八、检查死链接,设置404页面搜索引擎蜘蛛爬取链接。如果太多的链接无法到达,不仅收录页面的数量会减少,而且你的网站在搜索引擎中的权重也会减少。当蜘蛛遇到死链时,就如同进入了死胡同,不得不回去重新开始,大大降低了蜘蛛在网站的爬行效率,所以一定要定期检查网站的死链,提交给搜索引擎,同时做好网站的404页面,告诉搜索引擎错误页面。 九、大量查看robots文件网站有意无意,我直接在robots文件中屏蔽了百度或网站的一些页面,但我正在寻找蜘蛛不抓取我的页面的原因。这能怪百度吗?你你不让别人进来,百度收录你的网页是怎么来的?所以需要检查网站robots文件是否正常。 十、建筑网站Map。搜索引擎蜘蛛非常喜欢网站Map。 网站Map 是所有链接网站 的容器。很多网站 链接都有很深的层次,蜘蛛很难抓取。 网站Map 可以方便搜索引擎蜘蛛抓取网站页面。通过抓取网站页面,可以清楚地了解网站的结构,所以构建网站地图不仅可以提高抓取速度,还可以获得蜘蛛青睐。
让你网站 被蜘蛛快速爬行的十三种方法。十个一、每次更新页面都主动提交,也是主动提交内容到搜索引擎的好方法,但是不要错过收录Just submit一直提交。提交一次就够了。能不能接受收录是搜索引擎的问题。提交并不意味着收录。 网站search排名靠前的前提是网站有大量的搜索引擎收录的页面,良好的内链建设可以帮助网站页收录。当网站某文章文章被收录时,百度蜘蛛会继续沿着这个页面的超链接爬行,如果你的内链做的好,百度蜘蛛会重新关注你的网站Crawl,这样网站page成为收录的几率大大增加。 查看全部
关键词 采集(关于网站让引擎蜘蛛快速抓取的方法:网站及页面权重)
根据真实调查数据,90%的网民会使用搜索引擎服务寻找自己需要的信息,而这些搜索者中有近70%会在搜索结果自然排名的第一页直接找到自己需要的信息信息。可见,目前SEO对于企业和产品具有不可替代的意义。关于网站让引擎蜘蛛快速爬取:一、网站和页面权重。这必须是第一要务。 网站权重高、资历老、权限大的蜘蛛,一定要特别对待。这样的网站爬的非常频繁,大家都知道搜索引擎蜘蛛对网站非常有效,并不是网站的所有页面都会被爬取,网站的权重越高,爬取的深度就越高,而且对应的可以爬取的页面会增加,这样可以收录的页面也会增加。 . 二、网站server。 网站Server 是网站 的基石。如果网站服务器长时间打不开,那这离你很近,蜘蛛想来也来不来。百度蜘蛛也是网站的访客。如果你的服务器不稳定或者卡住了,蜘蛛每次都很难爬到,有时只能爬到一个页面的一部分。这样一来,随着时间的推移,百度蜘蛛的体验越来越差,你的网站评分也会越来越低,自然会影响你对网站的抓拍,所以一定要舍得选择空间服务器。没有良好的地基,再好的房子也会穿越。 三、网站 的更新频率。每次蜘蛛爬行时,都会存储页面数据。如果第二次爬取发现页面和第一次收录完全一样,说明页面没有更新,不需要蜘蛛频繁爬取。
如果页面内容更新频繁,蜘蛛会更频繁地访问页面,但蜘蛛不是你一个人的,不可能蹲在这里等你更新,所以一定要主动将蜘蛛展示给蜘蛛并定期进行文章update,这样蜘蛛就会有效地按照你的规则来爬行,不仅可以让你的更新文章更快被捕获,而且不会导致蜘蛛频繁白跑。 四、文章的原创性。高质量的原创内容对百度蜘蛛非常有吸引力。蜘蛛的目的是发现新的东西,所以网站updated 文章不要采集,不要天天转载,我们要给蜘蛛有真正有价值的原创内容,蜘蛛才能得到他们喜欢什么,自然会对你的网站产生好感,经常来找吃的。 五、平化网站结构。蜘蛛爬行也有自己的路线。在你给他铺路之前,网站结构不要太复杂,链接层次不要太深。如果链接层次太深,后面的页面就很难被蜘蛛抓取。 . 六、网站程序。在网站程序中,有很多程序可以创建大量重复页面。这个页面一般是通过参数实现的。当一个页面对应多个url时,会导致网站内容重复,可能导致网站降级,严重影响爬虫爬取,所以程序必须保证只有一个url为一页。如果已经生成,尝试通过301重定向、Canonical标签或者robots处理,确保只有一个标准的URL被蜘蛛爬取。
七、Home 推荐。首页是蜘蛛访问次数最多的页面,也是网站权重最高的页面。可以在首页设置更新版块,不仅可以更新首页,提升蜘蛛访问频率,还可以促进更新页面的爬取收录。同样,这个操作也可以在栏目页上进行。 八、检查死链接,设置404页面搜索引擎蜘蛛爬取链接。如果太多的链接无法到达,不仅收录页面的数量会减少,而且你的网站在搜索引擎中的权重也会减少。当蜘蛛遇到死链时,就如同进入了死胡同,不得不回去重新开始,大大降低了蜘蛛在网站的爬行效率,所以一定要定期检查网站的死链,提交给搜索引擎,同时做好网站的404页面,告诉搜索引擎错误页面。 九、大量查看robots文件网站有意无意,我直接在robots文件中屏蔽了百度或网站的一些页面,但我正在寻找蜘蛛不抓取我的页面的原因。这能怪百度吗?你你不让别人进来,百度收录你的网页是怎么来的?所以需要检查网站robots文件是否正常。 十、建筑网站Map。搜索引擎蜘蛛非常喜欢网站Map。 网站Map 是所有链接网站 的容器。很多网站 链接都有很深的层次,蜘蛛很难抓取。 网站Map 可以方便搜索引擎蜘蛛抓取网站页面。通过抓取网站页面,可以清楚地了解网站的结构,所以构建网站地图不仅可以提高抓取速度,还可以获得蜘蛛青睐。
让你网站 被蜘蛛快速爬行的十三种方法。十个一、每次更新页面都主动提交,也是主动提交内容到搜索引擎的好方法,但是不要错过收录Just submit一直提交。提交一次就够了。能不能接受收录是搜索引擎的问题。提交并不意味着收录。 网站search排名靠前的前提是网站有大量的搜索引擎收录的页面,良好的内链建设可以帮助网站页收录。当网站某文章文章被收录时,百度蜘蛛会继续沿着这个页面的超链接爬行,如果你的内链做的好,百度蜘蛛会重新关注你的网站Crawl,这样网站page成为收录的几率大大增加。
关键词 采集(京东搜索为例设置连续动作点击工作台规则+操作步骤*)
采集交流 • 优采云 发表了文章 • 0 个评论 • 222 次浏览 • 2021-08-29 19:03
一、操作步骤
如果网页上有搜索框,但是搜索结果页没有单独的网址,而你想要采集搜索结果,直接规则是采集不能做,你必须先做一个连续的动作(输入+点击)来实现自动输入关键词并搜索,然后采集数据。下面以京东搜索为例,演示自动搜索采集。操作步骤如下:
二、Case规则+操作步骤
**注:**在这种情况下,京东搜索有独立的网址。对于有独立网址的页面,最简单的方法是构造每个关键词搜索网址,然后将线索网址导入到规则中,可以批量采集而不是设置连续动作
第一步:定义一级规则
1.1 打开极手客网络爬虫,输入网址回车,网页加载完毕后,点击“定义规则”按钮,会看到一个浮动窗口,称为工作台,您可以在其中定义规则;
注:此处截图及文字说明均为极手客网络爬虫版本。如果您安装的是Firefox插件版本,则没有“定义规则”按钮,但您应该运行MS Muse。
1.2 在工作台输入一级规则的主题名称,然后点击“检查重复”,会提示“名称可用”或“名称已被占用,可编辑:是” ,您可以使用此主题名称,否则请重命名。
1.3 这层规则主要是设置连续动作,这样排序框就可以随意抓取一条信息,用它来判断是否为爬虫执行采集。双击网页上的信息,输入标签名称,勾选确认,然后勾选关键内容,输入第一个标签的排序框名称,标签映射完成。
提示:为了准确定位网页信息,点击定义规则会冻结整个网页,无法跳转到网页链接。再次点击定义规则,返回正常网页模式。
第 2 步:定义连续动作
点击工作台的“Continuous Action”选项卡,点击New按钮新建一个action,每个action的设置方法都是一样的,基本操作如下:
2.1,输入目标学科名称
这里的目标主题名称是填写二级主题名称,点击“谁在使用”查看目标主题名称是否可用,如果已经被占用,只需更改一个主题名称即可。
2.2,创建第一个动作:回车
创建一个新动作并选择动作类型作为输入。
2.2.1,填写定位表达式
首先点击输入框,定位输入框的节点,然后点击“Auto Generate XPath”按钮,可以选择“Preference id”或者“Preference class”,就可以得到输入的xpath表达式框,然后单击“搜索”按钮,检查这个xpath是否可以在输入框中唯一定位,如果没有问题,将xpath复制到定位表达式框中。
**注:** 定位表达式中的xpath是锁定动作对象的整个有效操作范围,具体指的是可以通过鼠标点击或进入成功的网页模块,而不是找到底部的 text() 节点。
2.2.2,输入关键词
输入关键词填写你要搜索的关键词,可以输入一个关键词,也可以输入多个关键词,输入多个关键词使用双分号;;把每个关键词Separate,免费版只支持关键词5以内,旗舰版可以使用爆弹功能,支持关键词10000以内
2.2.3,输入动作名称
告诉自己这一步是做什么的,以便你以后可以修改。
2.3,创建第二个动作:点击
参考2.2的操作,创建第二个action,选择类型为click,定位搜索按钮,然后自动生成xpath检查是否锁定到唯一节点。如果没有问题,填写定位表达式。 .
2.4,保存规则
点击“保存规则”按钮保存完成的一级规则
第 3 步:定义二级规则
3.1,新建规则
创建二级规则,点击“定义规则”返回正常网页模式,输入关键词搜索结果,再次点击“定义规则”切换到规则制定模式,点击“左上角规则”菜单->“新建”,输入主题名称,其中主题名称是在第一级规则的连续动作中填写的目标主题名称。
3.2,标记你想要的信息采集
3.2.1,在网页上标注你想要采集的信息,这里是标注产品名称和价格,因为标注只对文字信息有效,以及产品链接details 是属性节点@href,所以不能在链接上做这么直观的标记,要做内容映射,具体看下面的操作。
3.2.2,点击产品名称,下方的DOM节点定位到A标签,展开A标签下的属性节点,可以找到代表URL的@href节点,右击节点,选择“New Capture“Fetch content”,输入一个名字,一般给抓取到的内容取一个与地址相关的名字,比如“下级网址”,或者“下级链接”等等。然后在工作台上,我看到爬取的内容是可用的。如果你还想进入商品详情页采集,你必须对照爬取的内容检查下层的线索,并进行分层爬取。
3.2.3、设置“关键内容”选项,让爬虫判断采集规则是否合适。在排序框中,选择网页上不可避免的标签,并勾选“关键内容”。这里选择“名称”作为“关键内容”。
3.2.4,只要在前面标注一个产品,就可以得到一个产品信息。如果你想采集下整个页面上的每一个产品,可以做一个样例拷贝,没有如果你看懂了,请参考基础教程“采集表数据”
3.3,设置翻页路线
在爬虫路由中设置翻页,这里是标记提示,不明白的请参考基础教程《设置翻页采集》
3.4,保存规则
点击“测试”以检查信息的完整性。如果不完整,重新标记可以覆盖之前的内容。确认没有问题后,点击“保存规则”。
第 4 步:捕获数据
4.1,连续动作是连续执行的,所以只要运行一级主题,二级主题就不需要运行了。打开DS计数器,搜索一级主题名称,点击“单一搜索”或“采集”,可以看到在浏览器窗口中自动输入并搜索关键词,然后调用二级主题自动采集搜索结果。
4.2,一级主题没有采集到有意义的信息,所以我们只看二级主题文件夹,可以看到采集的搜索结果数据,搜索关键词是默认记录在xml文件的actionvalue字段中,这样可以一一匹配。 查看全部
关键词 采集(京东搜索为例设置连续动作点击工作台规则+操作步骤*)
一、操作步骤
如果网页上有搜索框,但是搜索结果页没有单独的网址,而你想要采集搜索结果,直接规则是采集不能做,你必须先做一个连续的动作(输入+点击)来实现自动输入关键词并搜索,然后采集数据。下面以京东搜索为例,演示自动搜索采集。操作步骤如下:
二、Case规则+操作步骤
**注:**在这种情况下,京东搜索有独立的网址。对于有独立网址的页面,最简单的方法是构造每个关键词搜索网址,然后将线索网址导入到规则中,可以批量采集而不是设置连续动作
第一步:定义一级规则
1.1 打开极手客网络爬虫,输入网址回车,网页加载完毕后,点击“定义规则”按钮,会看到一个浮动窗口,称为工作台,您可以在其中定义规则;
注:此处截图及文字说明均为极手客网络爬虫版本。如果您安装的是Firefox插件版本,则没有“定义规则”按钮,但您应该运行MS Muse。
1.2 在工作台输入一级规则的主题名称,然后点击“检查重复”,会提示“名称可用”或“名称已被占用,可编辑:是” ,您可以使用此主题名称,否则请重命名。
1.3 这层规则主要是设置连续动作,这样排序框就可以随意抓取一条信息,用它来判断是否为爬虫执行采集。双击网页上的信息,输入标签名称,勾选确认,然后勾选关键内容,输入第一个标签的排序框名称,标签映射完成。
提示:为了准确定位网页信息,点击定义规则会冻结整个网页,无法跳转到网页链接。再次点击定义规则,返回正常网页模式。
第 2 步:定义连续动作
点击工作台的“Continuous Action”选项卡,点击New按钮新建一个action,每个action的设置方法都是一样的,基本操作如下:
2.1,输入目标学科名称
这里的目标主题名称是填写二级主题名称,点击“谁在使用”查看目标主题名称是否可用,如果已经被占用,只需更改一个主题名称即可。
2.2,创建第一个动作:回车
创建一个新动作并选择动作类型作为输入。
2.2.1,填写定位表达式
首先点击输入框,定位输入框的节点,然后点击“Auto Generate XPath”按钮,可以选择“Preference id”或者“Preference class”,就可以得到输入的xpath表达式框,然后单击“搜索”按钮,检查这个xpath是否可以在输入框中唯一定位,如果没有问题,将xpath复制到定位表达式框中。
**注:** 定位表达式中的xpath是锁定动作对象的整个有效操作范围,具体指的是可以通过鼠标点击或进入成功的网页模块,而不是找到底部的 text() 节点。
2.2.2,输入关键词
输入关键词填写你要搜索的关键词,可以输入一个关键词,也可以输入多个关键词,输入多个关键词使用双分号;;把每个关键词Separate,免费版只支持关键词5以内,旗舰版可以使用爆弹功能,支持关键词10000以内
2.2.3,输入动作名称
告诉自己这一步是做什么的,以便你以后可以修改。
2.3,创建第二个动作:点击
参考2.2的操作,创建第二个action,选择类型为click,定位搜索按钮,然后自动生成xpath检查是否锁定到唯一节点。如果没有问题,填写定位表达式。 .
2.4,保存规则
点击“保存规则”按钮保存完成的一级规则
第 3 步:定义二级规则
3.1,新建规则
创建二级规则,点击“定义规则”返回正常网页模式,输入关键词搜索结果,再次点击“定义规则”切换到规则制定模式,点击“左上角规则”菜单->“新建”,输入主题名称,其中主题名称是在第一级规则的连续动作中填写的目标主题名称。
3.2,标记你想要的信息采集
3.2.1,在网页上标注你想要采集的信息,这里是标注产品名称和价格,因为标注只对文字信息有效,以及产品链接details 是属性节点@href,所以不能在链接上做这么直观的标记,要做内容映射,具体看下面的操作。
3.2.2,点击产品名称,下方的DOM节点定位到A标签,展开A标签下的属性节点,可以找到代表URL的@href节点,右击节点,选择“New Capture“Fetch content”,输入一个名字,一般给抓取到的内容取一个与地址相关的名字,比如“下级网址”,或者“下级链接”等等。然后在工作台上,我看到爬取的内容是可用的。如果你还想进入商品详情页采集,你必须对照爬取的内容检查下层的线索,并进行分层爬取。
3.2.3、设置“关键内容”选项,让爬虫判断采集规则是否合适。在排序框中,选择网页上不可避免的标签,并勾选“关键内容”。这里选择“名称”作为“关键内容”。
3.2.4,只要在前面标注一个产品,就可以得到一个产品信息。如果你想采集下整个页面上的每一个产品,可以做一个样例拷贝,没有如果你看懂了,请参考基础教程“采集表数据”
3.3,设置翻页路线
在爬虫路由中设置翻页,这里是标记提示,不明白的请参考基础教程《设置翻页采集》
3.4,保存规则
点击“测试”以检查信息的完整性。如果不完整,重新标记可以覆盖之前的内容。确认没有问题后,点击“保存规则”。
第 4 步:捕获数据
4.1,连续动作是连续执行的,所以只要运行一级主题,二级主题就不需要运行了。打开DS计数器,搜索一级主题名称,点击“单一搜索”或“采集”,可以看到在浏览器窗口中自动输入并搜索关键词,然后调用二级主题自动采集搜索结果。
4.2,一级主题没有采集到有意义的信息,所以我们只看二级主题文件夹,可以看到采集的搜索结果数据,搜索关键词是默认记录在xml文件的actionvalue字段中,这样可以一一匹配。
关键词 采集(中提炼关键词的思路指导(图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 170 次浏览 • 2021-08-29 19:00
评论/问答可以充分反映精准用户的消费偏好和关注点。从评论/问答中提取关键词也是一种有效的方法。
复制竞品的所有评论,然后用一些文本分析工具提炼关键词以供参考。
5.选择关键词上线上市
找到关键词后,需要注意的是,不是关键词哪个搜索量大,而是关键词用了哪个。因为很明显关键词越热,竞争也越大。如果是新产品使用这个关键词,就很难获得搜索排名,没有曝光率。
聪明的做法是选择一些搜索量可以接受并持续上升的关键词,这样市场前景可观,竞争不那么激烈,更容易获得更好的排名。
listing上线后,还要持续关注关键词各个渠道的情况,不断优化listing,实现健康成长。
问题
可能遇到的问题
在选品、找货源、找关键词的过程中,需要大量的平台数据。少量数据查询后可以导出(如关键词挖矿工具一般查询后可以直接导出结果),但大部分数据,尤其是亚马逊平台的数据,不支持导出。
过去很长一段时间,Sandy 和同事在平台上手动检查数据(关键词Search 结果、排名数据、1688 源数据、下拉搜索框数据、竞品列表数据、评论数据、问答数据等),将这些数据一一记录在表格中,并按照一定的频率手动更新。这给外商造成了很大的困扰:
①时间成本巨大
每天至少花 3 小时打开各种网页,记录各种数据。
② 无法保证数据完整性
无法将记录与经常更新的数据源同步。比如排行榜每1小时更新一次,很难同步所有记录。
③ 无法保证数据的准确性
人工记录容易出错,需要多人验证,否则会影响后续数据分析的准确性。
④ 建库失败,数据难以复用
在大的选品思路指导下,每个同事的具体思路和标准都不一样,数据难以复用。
项目
优采云解决方案
通过优采云,在实现数据自由的同时解放双手——需要数据时,可以找到对应的采集模板,一键导出所有历史数据,有效节省时间,保护数据完整性和准确性。
① 自动采集各种数据
优采云采集 非常灵活。上面提到的关键词data、关键词search数据、排名数据、TOP/competitive store新产品数据都可以做成采集模板。创建采集模板后,点击【启动采集】自动获取对应数据,支持导出为Excel、数据库等多种格式。
目前优采云官方已经推出了很多跨境电商模板供跨境合作伙伴使用。如果没有在下面的表格中,您也可以联系我们的官方客服提交您的需求并做出决定
②保证数据完整性
优采云拥有专属云端采集模式,可实现采集自动定时,最高频率支持每分钟自动激活采集。
排行榜之类的数据每小时更新一次,可以设置为每小时启动采集。竞品店铺上线数据可能2天更新一次,您可以设置采集每2天激活一次。
③ 保证数据的准确性
优采云是智能数据自动采集机器人。它准确而不知疲倦地识别。将目标数据一一丢掉采集,保证数据的准确性。
④ 搭建原创企业数据库
在保证数据的完整性和准确性后,公司可以建立一个原创的入选产品数据库,所有同事都可以在这个数据库中选择产品,一个数据复用性强,不需要大家重复轮子,第二个方便后续与原创数据对比,深入回顾总结。
同时,如果条件允许,公司计划搭建一套可视化看板,让优采云采集收到的数据可以实时连接到自己的数据库中,然后显示在视觉看板同时进行。可以预见,这将大大提高工作效率。 查看全部
关键词 采集(中提炼关键词的思路指导(图))
评论/问答可以充分反映精准用户的消费偏好和关注点。从评论/问答中提取关键词也是一种有效的方法。

复制竞品的所有评论,然后用一些文本分析工具提炼关键词以供参考。
5.选择关键词上线上市
找到关键词后,需要注意的是,不是关键词哪个搜索量大,而是关键词用了哪个。因为很明显关键词越热,竞争也越大。如果是新产品使用这个关键词,就很难获得搜索排名,没有曝光率。
聪明的做法是选择一些搜索量可以接受并持续上升的关键词,这样市场前景可观,竞争不那么激烈,更容易获得更好的排名。
listing上线后,还要持续关注关键词各个渠道的情况,不断优化listing,实现健康成长。
问题
可能遇到的问题
在选品、找货源、找关键词的过程中,需要大量的平台数据。少量数据查询后可以导出(如关键词挖矿工具一般查询后可以直接导出结果),但大部分数据,尤其是亚马逊平台的数据,不支持导出。
过去很长一段时间,Sandy 和同事在平台上手动检查数据(关键词Search 结果、排名数据、1688 源数据、下拉搜索框数据、竞品列表数据、评论数据、问答数据等),将这些数据一一记录在表格中,并按照一定的频率手动更新。这给外商造成了很大的困扰:
①时间成本巨大
每天至少花 3 小时打开各种网页,记录各种数据。
② 无法保证数据完整性
无法将记录与经常更新的数据源同步。比如排行榜每1小时更新一次,很难同步所有记录。
③ 无法保证数据的准确性
人工记录容易出错,需要多人验证,否则会影响后续数据分析的准确性。
④ 建库失败,数据难以复用
在大的选品思路指导下,每个同事的具体思路和标准都不一样,数据难以复用。
项目
优采云解决方案
通过优采云,在实现数据自由的同时解放双手——需要数据时,可以找到对应的采集模板,一键导出所有历史数据,有效节省时间,保护数据完整性和准确性。
① 自动采集各种数据
优采云采集 非常灵活。上面提到的关键词data、关键词search数据、排名数据、TOP/competitive store新产品数据都可以做成采集模板。创建采集模板后,点击【启动采集】自动获取对应数据,支持导出为Excel、数据库等多种格式。
目前优采云官方已经推出了很多跨境电商模板供跨境合作伙伴使用。如果没有在下面的表格中,您也可以联系我们的官方客服提交您的需求并做出决定
②保证数据完整性
优采云拥有专属云端采集模式,可实现采集自动定时,最高频率支持每分钟自动激活采集。
排行榜之类的数据每小时更新一次,可以设置为每小时启动采集。竞品店铺上线数据可能2天更新一次,您可以设置采集每2天激活一次。
③ 保证数据的准确性
优采云是智能数据自动采集机器人。它准确而不知疲倦地识别。将目标数据一一丢掉采集,保证数据的准确性。
④ 搭建原创企业数据库
在保证数据的完整性和准确性后,公司可以建立一个原创的入选产品数据库,所有同事都可以在这个数据库中选择产品,一个数据复用性强,不需要大家重复轮子,第二个方便后续与原创数据对比,深入回顾总结。
同时,如果条件允许,公司计划搭建一套可视化看板,让优采云采集收到的数据可以实时连接到自己的数据库中,然后显示在视觉看板同时进行。可以预见,这将大大提高工作效率。
关键词 采集(斗牛原Simon爱站采集工具|爱站长尾词挖掘工具综合版 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 188 次浏览 • 2021-08-29 16:10
)
Simon爱站关键词采集 工具是一个优秀的站长工具。最近,很多人都在寻找这个工具。我在官网找了一下,发现现在官方的Simon爱站关键词采集工具是和其他工具结合的,不过现在是免费使用的,有需要的可以从这个页面下载!
官方介绍:
新版斗牛原创Simon爱站关键词采集工具|爱站长尾词探工具集成版V4.0无限制,完全免费!
功能包括:
爱站关键词的采集tools,爱站长尾词的挖掘工具,可以完全自定义采集,挖掘你的词库,支持多站点多关键词,查询结果数据导出、爱站网站登录、登陆页面URL查询、查询间隔设置等,更多功能等你发现。 . (PS:如果采集时软件不稳定,出现问题,请将查询间隔调大一点,我电脑上设置5秒,可以永久挂断电话.你的电脑可以根据情况设置;)
六喜小贴士:
最好先登录本站再操作,否则会有查询深度或查询次数限制,详情请参考爱站官方说明。激活会员后,好像没有限制了。
使用说明:
运行软件后,用户只需输入采集的网址,然后点击采集按钮即可。 采集成功后即可导出结果!
更新日志:
2014 年 5 月 15 日:
更新日志:
升级到 V4.0
1、更改网络访问方式
2、change ip功能,免费用户无此功能
3、部分功能优化
2014 年 2 月 15 日:
更新到 V3.0
1、【软件更换前的采集方法,对用户电脑IE版本没有要求】
2、提高软件稳定性,提取效率提高3倍
3、software 更名为《斗牛》系列
4、follow 网站更新,添加pc端、移动端数据
我们为什么要学习长尾关键词?有目标关键词还不够吗?
是的,只有目标关键词 是不够的。目标关键词带来的用户非常定向,只能带来搜索词的用户。通常我们需要更多的用户流量,用户的搜索词是不同的。这时候需要回复网站的长尾关键词进行挖掘、分析、优化。
长尾关键词从字母上理解,很多关键词衍生自一个关键词,很长,很多,类似尾巴。 . .
如果seo是目标关键词,那么后面的相关搜索就是seo关键词的长尾。 (可以无限挖掘,比如seo新手教程等等都是seo关键词的长尾)
查看全部
关键词 采集(斗牛原Simon爱站采集工具|爱站长尾词挖掘工具综合版
)
Simon爱站关键词采集 工具是一个优秀的站长工具。最近,很多人都在寻找这个工具。我在官网找了一下,发现现在官方的Simon爱站关键词采集工具是和其他工具结合的,不过现在是免费使用的,有需要的可以从这个页面下载!
官方介绍:
新版斗牛原创Simon爱站关键词采集工具|爱站长尾词探工具集成版V4.0无限制,完全免费!
功能包括:
爱站关键词的采集tools,爱站长尾词的挖掘工具,可以完全自定义采集,挖掘你的词库,支持多站点多关键词,查询结果数据导出、爱站网站登录、登陆页面URL查询、查询间隔设置等,更多功能等你发现。 . (PS:如果采集时软件不稳定,出现问题,请将查询间隔调大一点,我电脑上设置5秒,可以永久挂断电话.你的电脑可以根据情况设置;)
六喜小贴士:
最好先登录本站再操作,否则会有查询深度或查询次数限制,详情请参考爱站官方说明。激活会员后,好像没有限制了。
使用说明:
运行软件后,用户只需输入采集的网址,然后点击采集按钮即可。 采集成功后即可导出结果!

更新日志:
2014 年 5 月 15 日:
更新日志:
升级到 V4.0
1、更改网络访问方式
2、change ip功能,免费用户无此功能
3、部分功能优化
2014 年 2 月 15 日:
更新到 V3.0
1、【软件更换前的采集方法,对用户电脑IE版本没有要求】
2、提高软件稳定性,提取效率提高3倍
3、software 更名为《斗牛》系列
4、follow 网站更新,添加pc端、移动端数据

我们为什么要学习长尾关键词?有目标关键词还不够吗?
是的,只有目标关键词 是不够的。目标关键词带来的用户非常定向,只能带来搜索词的用户。通常我们需要更多的用户流量,用户的搜索词是不同的。这时候需要回复网站的长尾关键词进行挖掘、分析、优化。
长尾关键词从字母上理解,很多关键词衍生自一个关键词,很长,很多,类似尾巴。 . .
如果seo是目标关键词,那么后面的相关搜索就是seo关键词的长尾。 (可以无限挖掘,比如seo新手教程等等都是seo关键词的长尾)

关键词 采集(搜索引擎基本同义词采集的核心功能及具体需求及需求)
采集交流 • 优采云 发表了文章 • 0 个评论 • 165 次浏览 • 2021-08-28 13:02
关键词采集是批量下载谷歌、uc、yahoo、bing、雅虎、naver等前端同义词采集,实现同义词搜索和分词、批量采集,同义词提取等web抓取方法,深入研究功能,从产品方案角度分析和定位。在开发之初,核心是明确核心功能及具体需求:搜索引擎基本同义词采集,每个关键词可以批量下载google、bing、雅虎、chinaz、新浪新闻、微博等各平台、各渠道、各站点的同义词。
同义词提取,实现各个平台、渠道、站点的同义词采集;关键词筛选,根据不同平台定位的关键词进行排序,提取分词所需结果即可批量下载文章全部内容为二进制产品包pg项目经理参加完总部培训后,受到网络流量和活跃度两个方面的直接启发,我分别决定采用两种方法完成对比业务场景对比服务接入功能,用业务数据去区分用户对产品的功能需求程度。
成熟的elasticsearch架构中,实现分词引擎需要使用这两种方法:下行广播和内部收敛,分词器的开发过程就像对文章进行分类。但是在ack抓取场景中,为解决抓取时存在时效性问题,增加对输入包的修改过程,在需要抓取的文章标题前面增加服务端标识xxxx,而不需要在输入包后面直接增加服务端标识xxxx,避免分词器在生成xxxx时,覆盖未抓取到的内容。
表层页面抓取与服务端搜索能力对比如果要抓取页面内容a和页面a+页面b的关键词,可以简单使用下行广播,通过elasticsearch存放下行广播文件。通过下行广播抓取页面的抓取服务服务端下行广播的抓取是使用加密的,只抓取保存在服务端的抓取文件,外部抓取无法下载成功,抓取成功返回解密后的文件。服务端搜索能力要求,提取出搜索数据包,输入到google搜索服务进行下载。
如要抓取页面a+页面b关键词,则需要对页面a+页面b内容进行关键词匹配,通过分词器完成,不需要向外提供服务端抓取链接。 查看全部
关键词 采集(搜索引擎基本同义词采集的核心功能及具体需求及需求)
关键词采集是批量下载谷歌、uc、yahoo、bing、雅虎、naver等前端同义词采集,实现同义词搜索和分词、批量采集,同义词提取等web抓取方法,深入研究功能,从产品方案角度分析和定位。在开发之初,核心是明确核心功能及具体需求:搜索引擎基本同义词采集,每个关键词可以批量下载google、bing、雅虎、chinaz、新浪新闻、微博等各平台、各渠道、各站点的同义词。
同义词提取,实现各个平台、渠道、站点的同义词采集;关键词筛选,根据不同平台定位的关键词进行排序,提取分词所需结果即可批量下载文章全部内容为二进制产品包pg项目经理参加完总部培训后,受到网络流量和活跃度两个方面的直接启发,我分别决定采用两种方法完成对比业务场景对比服务接入功能,用业务数据去区分用户对产品的功能需求程度。
成熟的elasticsearch架构中,实现分词引擎需要使用这两种方法:下行广播和内部收敛,分词器的开发过程就像对文章进行分类。但是在ack抓取场景中,为解决抓取时存在时效性问题,增加对输入包的修改过程,在需要抓取的文章标题前面增加服务端标识xxxx,而不需要在输入包后面直接增加服务端标识xxxx,避免分词器在生成xxxx时,覆盖未抓取到的内容。
表层页面抓取与服务端搜索能力对比如果要抓取页面内容a和页面a+页面b的关键词,可以简单使用下行广播,通过elasticsearch存放下行广播文件。通过下行广播抓取页面的抓取服务服务端下行广播的抓取是使用加密的,只抓取保存在服务端的抓取文件,外部抓取无法下载成功,抓取成功返回解密后的文件。服务端搜索能力要求,提取出搜索数据包,输入到google搜索服务进行下载。
如要抓取页面a+页面b关键词,则需要对页面a+页面b内容进行关键词匹配,通过分词器完成,不需要向外提供服务端抓取链接。
2018年11月2日-如何利用免费长尾关键词工具拓展长尾词
采集交流 • 优采云 发表了文章 • 0 个评论 • 67 次浏览 • 2021-08-26 04:06
#》2018年1月29日-本文介绍优采云采集词库网内长尾关键词的使用方法。长尾关键词挖矿对于站长来说是非常重要的一项技能,尾巴在长尾理论中的作用不容忽视。在搜索中..."
#《2018年8月27日-长尾词往往占据了当前所谓“词条”的大部分,但相对来说:真的排到首页了……我不想被原创或者采集这个话题比较纠结,这里提到文章quality,可以理解为...''
#"爱站网关键词挖矿工具为站长提供免费相关关键词、长尾关键词查询,助您快速轻松拓展长尾关键词。"
#"2018年11月2日-如何使用免费的长尾关键词工具扩展长尾词,我们在做网络营销的时候经常需要扩展长尾关键词,但是太慢了手动扩容 现在,如何高效使用长尾关键词挖矿工具扩长尾...''
#"2018年12月2日-优采云software关键词Mining tool 为SEO提供免费热点关键词、下拉关键词、相关关键词、长尾关键词挖掘和查询,帮助您轻松方便地挖掘关键词和长尾词。快速..."
#"September 17, 2018-标题出现长尾词,文章标题出现长尾词。2、长尾词分类确定网站topic和方向,用场采集出含...”
#"2018年1月30日-作为站长常用的工具,爱战有长尾关键词挖矿功能。这些关键词对于做SEO的朋友来说非常有价值。下关键词需要@采集,对于网站内容的制作方向,..." 查看全部
2018年11月2日-如何利用免费长尾关键词工具拓展长尾词
#》2018年1月29日-本文介绍优采云采集词库网内长尾关键词的使用方法。长尾关键词挖矿对于站长来说是非常重要的一项技能,尾巴在长尾理论中的作用不容忽视。在搜索中..."
#《2018年8月27日-长尾词往往占据了当前所谓“词条”的大部分,但相对来说:真的排到首页了……我不想被原创或者采集这个话题比较纠结,这里提到文章quality,可以理解为...''
#"爱站网关键词挖矿工具为站长提供免费相关关键词、长尾关键词查询,助您快速轻松拓展长尾关键词。"
#"2018年11月2日-如何使用免费的长尾关键词工具扩展长尾词,我们在做网络营销的时候经常需要扩展长尾关键词,但是太慢了手动扩容 现在,如何高效使用长尾关键词挖矿工具扩长尾...''
#"2018年12月2日-优采云software关键词Mining tool 为SEO提供免费热点关键词、下拉关键词、相关关键词、长尾关键词挖掘和查询,帮助您轻松方便地挖掘关键词和长尾词。快速..."
#"September 17, 2018-标题出现长尾词,文章标题出现长尾词。2、长尾词分类确定网站topic和方向,用场采集出含...”
#"2018年1月30日-作为站长常用的工具,爱战有长尾关键词挖矿功能。这些关键词对于做SEO的朋友来说非常有价值。下关键词需要@采集,对于网站内容的制作方向,..."
提供关键词分析功能,帮助用户在软件上快速采集到你需要的关键词
采集交流 • 优采云 发表了文章 • 0 个评论 • 145 次浏览 • 2021-08-26 04:05
关键词采集 系统提供关键词分析功能,可以帮助用户在软件上快速采集到您需要的关键词。本软件可以将你输入的关键词裂变转换成多个关键词添加到TXT文件中,加载到软件中,关键词裂变可以立即查看相关内容,对需要的朋友很有帮助分析百度关键词。本软件可以自动采集关键词,您可以根据您输入的关键词获取百度热搜的相关词,采集的内容会直接显示在软件界面上,您可以查看内容采集的,可以查看采集的状态,或者对关键词采集设置页数,如果需要裂变百度关键词,可以下载这个软件!
软件功能
1、关键词采集 系统自动检查百度关键词采集
2、根据你设置的关键词采集内容,每个关键词都可以在百度采集10页面
3、提供了很多设置功能,可以快速导入关键词裂变
4、也可以在关键词软件中导出,可以立即查看采集的内容
5、轻松搞定数百个单词,选择合适的单词使用
软件功能
1、可以使用这个软件采集产品关键词
2、可以用这个软件采集热搜词
3、适合站长使用,对后期优化很有帮助关键词
4、还可以帮助竞拍朋友获得需要使用的关键词
5、fission 效果还是很不错的,几秒钟就可以采集一百多个字
使用说明
1、打开百度下拉词相关词采集工具.exe,这里是软件的界面
2、将你的关键词加载到软件中,需要在TXT中编辑关键词,每行一个,导入后就可以开始裂变了。
3、显示裂变结果如图,可以显示很多裂变内容,可以在采集软件中停止@
4、点击停止采集软件自动关闭采集功能,以便保存结果
5、显示导出功能,如果需要保存本软件采集关键词可以导出
6、表示导出完成,右侧可以显示导出成功的提示,可以在主程序界面查看关键词。
7、打开主程序文件夹查看“Fission关键词Save.txt”
8、展示了很多关键词,需要联系百度关键词采集可以下载这个软件
查看全部
提供关键词分析功能,帮助用户在软件上快速采集到你需要的关键词
关键词采集 系统提供关键词分析功能,可以帮助用户在软件上快速采集到您需要的关键词。本软件可以将你输入的关键词裂变转换成多个关键词添加到TXT文件中,加载到软件中,关键词裂变可以立即查看相关内容,对需要的朋友很有帮助分析百度关键词。本软件可以自动采集关键词,您可以根据您输入的关键词获取百度热搜的相关词,采集的内容会直接显示在软件界面上,您可以查看内容采集的,可以查看采集的状态,或者对关键词采集设置页数,如果需要裂变百度关键词,可以下载这个软件!

软件功能
1、关键词采集 系统自动检查百度关键词采集
2、根据你设置的关键词采集内容,每个关键词都可以在百度采集10页面
3、提供了很多设置功能,可以快速导入关键词裂变
4、也可以在关键词软件中导出,可以立即查看采集的内容
5、轻松搞定数百个单词,选择合适的单词使用
软件功能
1、可以使用这个软件采集产品关键词
2、可以用这个软件采集热搜词
3、适合站长使用,对后期优化很有帮助关键词
4、还可以帮助竞拍朋友获得需要使用的关键词
5、fission 效果还是很不错的,几秒钟就可以采集一百多个字
使用说明
1、打开百度下拉词相关词采集工具.exe,这里是软件的界面

2、将你的关键词加载到软件中,需要在TXT中编辑关键词,每行一个,导入后就可以开始裂变了。

3、显示裂变结果如图,可以显示很多裂变内容,可以在采集软件中停止@

4、点击停止采集软件自动关闭采集功能,以便保存结果
5、显示导出功能,如果需要保存本软件采集关键词可以导出

6、表示导出完成,右侧可以显示导出成功的提示,可以在主程序界面查看关键词。

7、打开主程序文件夹查看“Fission关键词Save.txt”

8、展示了很多关键词,需要联系百度关键词采集可以下载这个软件

那要如何才能获取这里的关键词内容?(一)
采集交流 • 优采云 发表了文章 • 0 个评论 • 70 次浏览 • 2021-08-24 18:07
本文文章,建议在PC端观看。整篇文章的阅读时间看个人理解。 config和cookie需要抓包,填写userid、token、eventId、reqid这四个值的来源,即抓包'关键词规划师',userid是整数类型,token, eventId 和 reqid 是字符串类型。
百度竞标中的关键词规划师是SEO从业者很好的关键词来源。
如何在此处获取关键词 内容?
此代码基于网上2.7的版本,修改为3.*也可以使用。
(其实就是改了打印,23333)
同样,这段代码也没有一步步教你如何解决登录和获取cookie的问题。直接使用登录后的cookie和登录后的from_data数据,注意下面代码最上面的注释,不然不行别怪我。
# -*- coding: utf-8 -*-
#本代码改编自网络上Python2.7版本代码。
#Python版本:3.*,需要安装requests,JSON库不知道要不要重新安装
#使用本代码,首先将代码保存为.py文件,并且在相同目录中新建名字为cigeng的txt文件
#在cigeng.txt文件中输入要采集的关键词,一行一个。保存。
#成功采集后的数据,保存在相同目录中resultkeys.txt文件中。
#如果只要关键词,不要其他黑马等数据,那么就修改key_data函数下else中的数据。
import requests
import json
import time
def url_data(key,config,cookie,shibai=3):
headers={
'Accept': '*/*',
'Accept-Encoding': 'gzip, deflate',
'Accept-Language': 'zh-CN,zh;q=0.8,en;q=0.6',
'Connection': 'keep-alive',
'Content-Type': 'application/x-www-form-urlencoded',
'Cookie': cookie,
#在下面config这个变量值下面的cookie中粘贴进抓包后的cookie,这里不要动。
'Host': 'fengchao.baidu.com',
'Origin': 'http://fengchao.baidu.com',
'Referer': 'http://fengchao.baidu.com/nirvana/main.html?userid=%s' % config['userid'],
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_6) AppleWebKit/537.36 '
'(KHTML, like Gecko) Chrome/56.0.2924.87 Safari/537.36'
}
params={
"logid":401075077,
"query":key,
"querySessions":[key],
"querytype":1,
"regions":"16",
"device":0,
"rgfilter":1,
"entry":"kr_station",
"planid":"0",
"unitid":"0",
"needAutounit":False,
"filterAccountWord":True,
"attrShowReasonTag":[],
"attrBusinessPointTag":[],
"attrWordContainTag":[],
"showWordContain":"",
"showWordNotContain":"",
"pageNo":1,
"pageSize":1000,
"orderBy":"",
"order":"",
"forceReload":True
}
from_data={
'params':json.dumps(params),
'path':'jupiter/GET/kr/word',
'userid':config['userid'],
'token':config['token'],
'eventId':config['eventId'],
'reqid':config['reqid']
}
qurl="http://fengchao.baidu.com/nirv ... onfig['reqid']
try:
whtml=requests.post(qurl,headers=headers,data=from_data)
except requests.exceptions.RequestException:
resultitem={}
erry="请求三次都是错误!"
if shibai > 0:
return url_data(key,config,cookie,shibai-1)
else:
whtml.encoding="utf-8"
try:
resultitem = whtml.json()
except ValueError:
resultitem = {}
erry = "获取不到json数据,可能是被封了吧,谁知道呢?"
else:
erry = None
return resultitem,erry
config={
#这部分数据和下面的cookie,直接开浏览器抓包就能看到相应数据。复制黏贴到相应位置
'userid': '',
'token':'',
'eventId':'',
'reqid':''
}
cookie=" "
def key_data(resultitem):
kws=['关键词\t日均搜索量\tpc\t移动\t竞争度\n']
try:
resultitem=resultitem['data']['group'][0]['resultitem']
except (KeyError, ValueError, TypeError):
resultitem=[]
erry="没有获取到关键词"
else:
for items in resultitem:
#如果你只想要关键词,那么只保留word就可以。
word=items['word']
pv=items['pv']#日均搜索量
pvPc=items['pvPc']
pvWise=items['pvWise']
kwc=items['kwc']#竞争度
kwslist=str(word)+'\t'+str(pv)+'\t'+str(pvPc)+'\t'+str(pvWise)+'\t'+str(kwc)+'\n'
kws.append(str(kwslist))
print (word,pv,pvPc,pvWise,kwc)
## kws.append(str(word))
## print (word)
erry=None
return kws,erry
sfile = open('resultkeys.txt', 'w') # 结果保存文件
faileds = open('faileds.txt', 'w') # 查询失败保存文件
for key in open("cigeng.txt"): #要查询的关键词存放的载体,一行一个,同当前代码文件相同目录。
key=key.strip()
print ("正在拓展:%s"%key)
resultitem,erry=url_data(key,config,cookie)
if erry:
print (key,erry)
faileds.write('%s\n' % key)
faileds.flush()
continue
keylist,erry=key_data(resultitem)
if erry:
print (key,erry)
faileds.write('%s\n' % word)
faileds.flush()
continue
for kw in keylist:
sfile.write('%s\n'%kw)
faileds.flush()
continue
以下代码是浏览器(360极速浏览器)抓取的,#(需要挂梯子)网站格式的数据,没有任何改动。方便新人理解。需要导入JSON,使用JSON解析代码,但要注意JSON内容过多,小心IDLE卡住。
import requests
cookies = {'这部分有数据的,我删了,自己抓包后就知道'
}
headers = {
'Origin': 'http://fengchao.baidu.com',
'Accept-Encoding': 'gzip, deflate',
'Accept-Language': 'zh-CN,zh;q=0.9',
'User-Agent': 'Mozilla/5.0 (Windows NT 5.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36',
'Content-Type': 'application/x-www-form-urlencoded',
'Accept': '*/*',
'Referer': 'http://fengchao.baidu.com/nirvana/main.html?userid=6941153',
'Connection': 'keep-alive',
}
params = (
('path', 'jupiter/GET/kr/word'),
('reqid', '4b534c46-1ea0-4eca-b581-154181423578'),
)
data = {
'userid': '',
'token': '',
'reqid': '',
'path': 'jupiter/GET/kr/word',
'eventId': '',
'params': '{"logid":,"entry":"kr_station","attrWordContainTag":[],"needAutounit":false,"querytype":1,"query":"\u622A\u6B62\u9600","querySessions":["\u622A\u6B62\u9600"],"forceReload":true,"regions":"","device":0,"showWordContain":"","showWordNotContain":"","attrShowReasonTag":[],"attrBusinessPointTag":[],"filterAccountWord":true,"rgfilter":1,"planid":0,"unitid":0,"pageNo":1,"pageSize":300,"order":"","orderBy":""}'
}
response = requests.post('http://fengchao.baidu.com/nirvana/request.ajax', headers=headers, params=params, cookies=cookies, data=data)
2018-11-13,有人说,既然可以去百度,为什么还要登录自己的账号,抓包,复制数据到python脚本中。
......emmmmm 这是因为我不知道 cookie、userid、token 和 reqid 的来源。
所以我现在使用这种傻瓜式方法。但至少比手动好很多。
另外提供几个小思路:主要关键词-比如python,放到百度搜索,底部的相关搜索也是关键词的好来源,可以考虑百度出价采集一再关键词之后,再写一个代码,采集这些关键词相关搜索关键词。
此外,百度百科右侧的条目标题也与当前搜索关键词有关。也可以采集把这部分标题改成专题。 查看全部
那要如何才能获取这里的关键词内容?(一)
本文文章,建议在PC端观看。整篇文章的阅读时间看个人理解。 config和cookie需要抓包,填写userid、token、eventId、reqid这四个值的来源,即抓包'关键词规划师',userid是整数类型,token, eventId 和 reqid 是字符串类型。
百度竞标中的关键词规划师是SEO从业者很好的关键词来源。
如何在此处获取关键词 内容?
此代码基于网上2.7的版本,修改为3.*也可以使用。
(其实就是改了打印,23333)
同样,这段代码也没有一步步教你如何解决登录和获取cookie的问题。直接使用登录后的cookie和登录后的from_data数据,注意下面代码最上面的注释,不然不行别怪我。
# -*- coding: utf-8 -*-
#本代码改编自网络上Python2.7版本代码。
#Python版本:3.*,需要安装requests,JSON库不知道要不要重新安装
#使用本代码,首先将代码保存为.py文件,并且在相同目录中新建名字为cigeng的txt文件
#在cigeng.txt文件中输入要采集的关键词,一行一个。保存。
#成功采集后的数据,保存在相同目录中resultkeys.txt文件中。
#如果只要关键词,不要其他黑马等数据,那么就修改key_data函数下else中的数据。
import requests
import json
import time
def url_data(key,config,cookie,shibai=3):
headers={
'Accept': '*/*',
'Accept-Encoding': 'gzip, deflate',
'Accept-Language': 'zh-CN,zh;q=0.8,en;q=0.6',
'Connection': 'keep-alive',
'Content-Type': 'application/x-www-form-urlencoded',
'Cookie': cookie,
#在下面config这个变量值下面的cookie中粘贴进抓包后的cookie,这里不要动。
'Host': 'fengchao.baidu.com',
'Origin': 'http://fengchao.baidu.com',
'Referer': 'http://fengchao.baidu.com/nirvana/main.html?userid=%s' % config['userid'],
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_6) AppleWebKit/537.36 '
'(KHTML, like Gecko) Chrome/56.0.2924.87 Safari/537.36'
}
params={
"logid":401075077,
"query":key,
"querySessions":[key],
"querytype":1,
"regions":"16",
"device":0,
"rgfilter":1,
"entry":"kr_station",
"planid":"0",
"unitid":"0",
"needAutounit":False,
"filterAccountWord":True,
"attrShowReasonTag":[],
"attrBusinessPointTag":[],
"attrWordContainTag":[],
"showWordContain":"",
"showWordNotContain":"",
"pageNo":1,
"pageSize":1000,
"orderBy":"",
"order":"",
"forceReload":True
}
from_data={
'params':json.dumps(params),
'path':'jupiter/GET/kr/word',
'userid':config['userid'],
'token':config['token'],
'eventId':config['eventId'],
'reqid':config['reqid']
}
qurl="http://fengchao.baidu.com/nirv ... onfig['reqid']
try:
whtml=requests.post(qurl,headers=headers,data=from_data)
except requests.exceptions.RequestException:
resultitem={}
erry="请求三次都是错误!"
if shibai > 0:
return url_data(key,config,cookie,shibai-1)
else:
whtml.encoding="utf-8"
try:
resultitem = whtml.json()
except ValueError:
resultitem = {}
erry = "获取不到json数据,可能是被封了吧,谁知道呢?"
else:
erry = None
return resultitem,erry
config={
#这部分数据和下面的cookie,直接开浏览器抓包就能看到相应数据。复制黏贴到相应位置
'userid': '',
'token':'',
'eventId':'',
'reqid':''
}
cookie=" "
def key_data(resultitem):
kws=['关键词\t日均搜索量\tpc\t移动\t竞争度\n']
try:
resultitem=resultitem['data']['group'][0]['resultitem']
except (KeyError, ValueError, TypeError):
resultitem=[]
erry="没有获取到关键词"
else:
for items in resultitem:
#如果你只想要关键词,那么只保留word就可以。
word=items['word']
pv=items['pv']#日均搜索量
pvPc=items['pvPc']
pvWise=items['pvWise']
kwc=items['kwc']#竞争度
kwslist=str(word)+'\t'+str(pv)+'\t'+str(pvPc)+'\t'+str(pvWise)+'\t'+str(kwc)+'\n'
kws.append(str(kwslist))
print (word,pv,pvPc,pvWise,kwc)
## kws.append(str(word))
## print (word)
erry=None
return kws,erry
sfile = open('resultkeys.txt', 'w') # 结果保存文件
faileds = open('faileds.txt', 'w') # 查询失败保存文件
for key in open("cigeng.txt"): #要查询的关键词存放的载体,一行一个,同当前代码文件相同目录。
key=key.strip()
print ("正在拓展:%s"%key)
resultitem,erry=url_data(key,config,cookie)
if erry:
print (key,erry)
faileds.write('%s\n' % key)
faileds.flush()
continue
keylist,erry=key_data(resultitem)
if erry:
print (key,erry)
faileds.write('%s\n' % word)
faileds.flush()
continue
for kw in keylist:
sfile.write('%s\n'%kw)
faileds.flush()
continue
以下代码是浏览器(360极速浏览器)抓取的,#(需要挂梯子)网站格式的数据,没有任何改动。方便新人理解。需要导入JSON,使用JSON解析代码,但要注意JSON内容过多,小心IDLE卡住。
import requests
cookies = {'这部分有数据的,我删了,自己抓包后就知道'
}
headers = {
'Origin': 'http://fengchao.baidu.com',
'Accept-Encoding': 'gzip, deflate',
'Accept-Language': 'zh-CN,zh;q=0.9',
'User-Agent': 'Mozilla/5.0 (Windows NT 5.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36',
'Content-Type': 'application/x-www-form-urlencoded',
'Accept': '*/*',
'Referer': 'http://fengchao.baidu.com/nirvana/main.html?userid=6941153',
'Connection': 'keep-alive',
}
params = (
('path', 'jupiter/GET/kr/word'),
('reqid', '4b534c46-1ea0-4eca-b581-154181423578'),
)
data = {
'userid': '',
'token': '',
'reqid': '',
'path': 'jupiter/GET/kr/word',
'eventId': '',
'params': '{"logid":,"entry":"kr_station","attrWordContainTag":[],"needAutounit":false,"querytype":1,"query":"\u622A\u6B62\u9600","querySessions":["\u622A\u6B62\u9600"],"forceReload":true,"regions":"","device":0,"showWordContain":"","showWordNotContain":"","attrShowReasonTag":[],"attrBusinessPointTag":[],"filterAccountWord":true,"rgfilter":1,"planid":0,"unitid":0,"pageNo":1,"pageSize":300,"order":"","orderBy":""}'
}
response = requests.post('http://fengchao.baidu.com/nirvana/request.ajax', headers=headers, params=params, cookies=cookies, data=data)
2018-11-13,有人说,既然可以去百度,为什么还要登录自己的账号,抓包,复制数据到python脚本中。
......emmmmm 这是因为我不知道 cookie、userid、token 和 reqid 的来源。
所以我现在使用这种傻瓜式方法。但至少比手动好很多。
另外提供几个小思路:主要关键词-比如python,放到百度搜索,底部的相关搜索也是关键词的好来源,可以考虑百度出价采集一再关键词之后,再写一个代码,采集这些关键词相关搜索关键词。
此外,百度百科右侧的条目标题也与当前搜索关键词有关。也可以采集把这部分标题改成专题。
关键词 采集(异步抓取好用的数据分析师是怎么做的)
采集交流 • 优采云 发表了文章 • 0 个评论 • 128 次浏览 • 2021-09-14 03:02
关键词采集+数据可视化以下是一些参考资料,
爬取本专业知识资料,可以采用一些抓包、采集软件工具。我用过最好用的是fiddler的抓包工具,经常用fiddler抓取公司的数据监控,发现公司的人工etl也发生的一些问题,fiddler异步抓取好用很多。然后就是,在网上下载一些公司的考试题,找到考试题的题库;找到公司所在地区的图书馆,或者智慧图书馆,建立手机链接,打印出来自己考试,都是有一些很不错的高效的办法!所以,在网上找找相关的资料很重要!!有些资料是花钱或者是资源没有大家好的,希望大家能够找到或者发现一些好的资源。个人拙见,仅供参考。
大三,统计工作四年,给予一些建议:1.至少得找到数据量很大而且非常python的数据分析岗位2.在实践中学习,学习urllib,selenium等的使用方法,学习pandas,numpy等数据分析库的使用3.熟练掌握sql语言4.通过实习和生活中遇到的问题和理论进行总结,一个优秀的数据分析师至少要做到深厚的数据分析工作经验和实战方法论。个人愚见,供大家参考。
推荐一本书:统计学习方法
建议先爬的是前端页面,等爬着爬着你就发现了数据产业链,然后水到渠成,入职数据分析师!爬数据不一定就要和前端页面一起爬,但是要跟前端和后端很好的联系起来,前端自己抓包后台端的数据,然后定向更新到页面就行。因为网上一般已经抓了很多数据,你只需要找到他们,看看是不是你想要的。 查看全部
关键词 采集(异步抓取好用的数据分析师是怎么做的)
关键词采集+数据可视化以下是一些参考资料,
爬取本专业知识资料,可以采用一些抓包、采集软件工具。我用过最好用的是fiddler的抓包工具,经常用fiddler抓取公司的数据监控,发现公司的人工etl也发生的一些问题,fiddler异步抓取好用很多。然后就是,在网上下载一些公司的考试题,找到考试题的题库;找到公司所在地区的图书馆,或者智慧图书馆,建立手机链接,打印出来自己考试,都是有一些很不错的高效的办法!所以,在网上找找相关的资料很重要!!有些资料是花钱或者是资源没有大家好的,希望大家能够找到或者发现一些好的资源。个人拙见,仅供参考。
大三,统计工作四年,给予一些建议:1.至少得找到数据量很大而且非常python的数据分析岗位2.在实践中学习,学习urllib,selenium等的使用方法,学习pandas,numpy等数据分析库的使用3.熟练掌握sql语言4.通过实习和生活中遇到的问题和理论进行总结,一个优秀的数据分析师至少要做到深厚的数据分析工作经验和实战方法论。个人愚见,供大家参考。
推荐一本书:统计学习方法
建议先爬的是前端页面,等爬着爬着你就发现了数据产业链,然后水到渠成,入职数据分析师!爬数据不一定就要和前端页面一起爬,但是要跟前端和后端很好的联系起来,前端自己抓包后台端的数据,然后定向更新到页面就行。因为网上一般已经抓了很多数据,你只需要找到他们,看看是不是你想要的。
关键词 采集(威客是靠价值提升赚钱的第一,外包是否能赚钱?)
采集交流 • 优采云 发表了文章 • 0 个评论 • 147 次浏览 • 2021-09-14 00:03
关键词采集,数据库建设,上线运营没其他的了,
首先,找一个合适的软件,比如金山威客网、猪八戒网、威客中国网、智城、阿里创业家、威客天下等。软件的选择,是简单编辑好功能的excel表格,对外声称是社会化公开分享的,提交给程序。接着,按照软件提示,启动你的项目。
威客是靠价值提升赚钱的
第一,外包是否能赚钱和在威客网接单无关,第二,外包是否能赚钱,和找人开发有关。综上所述,一个大学生如果以外包的形式解决生活学习问题的话,外包是有难度的。毕竟一个项目大概1-3w不等,很多都是大学生一人的金钱以及时间的投入。
泻药如果单纯为了赚钱,不建议找威客,威客现在几乎沦落为骗子集散地了,你不想入坑要么自己去程序猿和设计师那儿申请号,接单子,要么就找威客,
怎么会有这种问题???建议自己靠自己的努力工作赚钱,又不是学校里免费给人家干活,你就算想找威客也可以通过网络找的,写一些简单的代码为什么不可以。网络上,不管是威客网也好,店也好,或者是建筑公司接手包也好,都会有很多好项目等着你的,而且有些项目一生中只有一两次机会,或者一两个人知道。何必不把这机会抓在手里。
再次提醒:建议:可以自己先打工赚钱,锻炼自己后再找威客平台,不要着急希望赚钱,先有能力和专业方面提升。 查看全部
关键词 采集(威客是靠价值提升赚钱的第一,外包是否能赚钱?)
关键词采集,数据库建设,上线运营没其他的了,
首先,找一个合适的软件,比如金山威客网、猪八戒网、威客中国网、智城、阿里创业家、威客天下等。软件的选择,是简单编辑好功能的excel表格,对外声称是社会化公开分享的,提交给程序。接着,按照软件提示,启动你的项目。
威客是靠价值提升赚钱的
第一,外包是否能赚钱和在威客网接单无关,第二,外包是否能赚钱,和找人开发有关。综上所述,一个大学生如果以外包的形式解决生活学习问题的话,外包是有难度的。毕竟一个项目大概1-3w不等,很多都是大学生一人的金钱以及时间的投入。
泻药如果单纯为了赚钱,不建议找威客,威客现在几乎沦落为骗子集散地了,你不想入坑要么自己去程序猿和设计师那儿申请号,接单子,要么就找威客,
怎么会有这种问题???建议自己靠自己的努力工作赚钱,又不是学校里免费给人家干活,你就算想找威客也可以通过网络找的,写一些简单的代码为什么不可以。网络上,不管是威客网也好,店也好,或者是建筑公司接手包也好,都会有很多好项目等着你的,而且有些项目一生中只有一两次机会,或者一两个人知道。何必不把这机会抓在手里。
再次提醒:建议:可以自己先打工赚钱,锻炼自己后再找威客平台,不要着急希望赚钱,先有能力和专业方面提升。
关键词 采集(大学生网络语言学习教育学习平台的关键词采集工具)
采集交流 • 优采云 发表了文章 • 0 个评论 • 164 次浏览 • 2021-09-13 02:01
关键词采集工具主要以采集工具为主,适合大学生为主,其他人群也可以采集对方站长平台。对于网站站长采集工具我推荐openit(/),国内仿站长工具站长站长-工具第一站大学生网络语言学习教育学习平台,基本适合所有想学语言的学生。至于这个站长工具站长-工具第一站大学生网络语言学习教育学习平台,广告设置的不错,但是有种类繁多的免费学习资源,还是很不错的。
基本靠积分买,还有人工外链,
对于一个即将毕业的大四狗来说,真的不知道哪个是好哪个是不好,每次买账号都很肉疼。还有买了账号等于自己的账号了,当别人抢注你自己账号别人有问题直接封自己的账号,没有效率,真的累,就想问问大家,你推荐哪个好哪个不好。
首先看类型,依次往下分,
据我所知目前软件的优秀程度是有这样区分的1.网站采集外链解决方案2.批量采集网站外链解决方案3.网站抓取加速解决方案4.对网站的恶意注解
想了解找自己想要的,别人告诉你怎么做都是教了你一堆破事,到你自己这边根本实现不了。
说一个比较流行,也比较简单的,网页采集加速:集采集、信息采集、分析采集、智能采集于一体的网页采集加速软件。 查看全部
关键词 采集(大学生网络语言学习教育学习平台的关键词采集工具)
关键词采集工具主要以采集工具为主,适合大学生为主,其他人群也可以采集对方站长平台。对于网站站长采集工具我推荐openit(/),国内仿站长工具站长站长-工具第一站大学生网络语言学习教育学习平台,基本适合所有想学语言的学生。至于这个站长工具站长-工具第一站大学生网络语言学习教育学习平台,广告设置的不错,但是有种类繁多的免费学习资源,还是很不错的。
基本靠积分买,还有人工外链,
对于一个即将毕业的大四狗来说,真的不知道哪个是好哪个是不好,每次买账号都很肉疼。还有买了账号等于自己的账号了,当别人抢注你自己账号别人有问题直接封自己的账号,没有效率,真的累,就想问问大家,你推荐哪个好哪个不好。
首先看类型,依次往下分,
据我所知目前软件的优秀程度是有这样区分的1.网站采集外链解决方案2.批量采集网站外链解决方案3.网站抓取加速解决方案4.对网站的恶意注解
想了解找自己想要的,别人告诉你怎么做都是教了你一堆破事,到你自己这边根本实现不了。
说一个比较流行,也比较简单的,网页采集加速:集采集、信息采集、分析采集、智能采集于一体的网页采集加速软件。
关键词 采集(关键词的分布与优化有关系吗?分布是指这些)
采集交流 • 优采云 发表了文章 • 0 个评论 • 147 次浏览 • 2021-09-08 15:14
关键词的分布与优化有关吗? 关键词distribution 指的是这些关键词在网页上的位置。此位置可以是标题标签、链接、标题、文本正文或文本出现的任何位置。标题标签是网页上重要搜索关键词 位置的好位置。在标题标签中,关键词 的布局非常重要。易建以“网络营销策划”为定位,以“让网络营销变得简单”为使命,先后为国内10000多家中小企业提供网络营销策划解决方案。重要的关键词应该放在页面标题标签的开头。
关键词的设置必须紧跟页面内容。这是优化的一个非常重要的因素。举个明显的例子,你做一个深圳seo网站,然后把关键词设置成狗皮膏药,那么你就可以想到狗皮膏药了。这个词不能反映在你的文章中。那么你关键词就可以通过链接建设获得一个不错的排名。它越来越难。简而言之,就是没有任何问题。 所以keywords关键词的设置一定要和要设置的页面相关,这个是必须的。此外,还有一种相关性的表现,就是是否与整个网站的页面相关。如果是相关的,那么还是有一定的作用的。新手必看优化关键词的提前计划:1、 首先,我们的网站需要在构建之初选择一个目标关键词进行构建。这个设定比我说的狗皮膏药的设定好多了。
关键词的决心不是一件容易的事。应该考虑很多因素。比如关键词必须和你的网站内容有关,单词如何组合和排列,是否符合搜索工具的要求,尽量避免使用热门的关键词等等。所以选择正确的关键词 需要一些工作。
长尾关键词optimized长尾关键词的优化设置是内页和栏目页需要考虑的因素。那么,设置长尾关键词需要考虑哪些因素呢?竞争很小,搜索量可能很高。毕竟这两点很关键。至于尾巴关键词选择多长,那就需要积累了。
易建成立于2007年12月,总部位于东莞。公司始终坚持以客户需求为中心,以“网络营销策划”为定位,以“让网络营销变得简单”为使命。先后为国内10000多家中小企业提供网络营销策划解决方案。过去,搜索引擎不同程度地跟踪网站内部链接。有的可以跟踪所有链接,有的则停留在二级或三级,所以当时需要单独提交网页。目前,易诗田已经在东莞、长安和佛山。未来,完善的服务网络将覆盖中国所有大中小城市。
影响关键词价格的因素:关键词搜索结果数量
这个值是所有Seoer都重视的参考指标。许多SEO初学者甚至只看这个值。这其实是一种误解。有时搜索结果很多,但竞争主要是内页。这个关键词难度不大。
这可以分为以下数值范围:
(A) 搜索结果小于 500,000:竞争较少的;
(B) 300 到 100 万个搜索结果:中到小;
(C) 1 到 300 万个搜索结果:中等;
(D) 3~500万条搜索结果:属于中上层;
(E) 超过 500 万个搜索结果:难词。
易建成立于2007年12月,总部位于东莞。公司始终坚持以客户需求为中心,以“网络营销策划”为定位,以“让网络营销变得简单”为使命。先后为国内10000多家中小企业提供网络营销策划解决方案。充分利用关键词analysis工具关键词analysis工具其实很多,有的免费,有的收费。目前,易诗田已经在东莞、长安和佛山。未来,完善的服务网络将覆盖中国所有大中小城市。
关键词Optimization 如果需要细分,大致可以分为十点:
1、网站 在开始构建之前,需要选择关键词并以此展开。常用的方法是在百度搜索框中输入扩展名关键词,查看相关页面,判断关键词的竞争程度。
2、做了关键词之后,分析一下对手关键词。 查看全部
关键词 采集(关键词的分布与优化有关系吗?分布是指这些)
关键词的分布与优化有关吗? 关键词distribution 指的是这些关键词在网页上的位置。此位置可以是标题标签、链接、标题、文本正文或文本出现的任何位置。标题标签是网页上重要搜索关键词 位置的好位置。在标题标签中,关键词 的布局非常重要。易建以“网络营销策划”为定位,以“让网络营销变得简单”为使命,先后为国内10000多家中小企业提供网络营销策划解决方案。重要的关键词应该放在页面标题标签的开头。
关键词的设置必须紧跟页面内容。这是优化的一个非常重要的因素。举个明显的例子,你做一个深圳seo网站,然后把关键词设置成狗皮膏药,那么你就可以想到狗皮膏药了。这个词不能反映在你的文章中。那么你关键词就可以通过链接建设获得一个不错的排名。它越来越难。简而言之,就是没有任何问题。 所以keywords关键词的设置一定要和要设置的页面相关,这个是必须的。此外,还有一种相关性的表现,就是是否与整个网站的页面相关。如果是相关的,那么还是有一定的作用的。新手必看优化关键词的提前计划:1、 首先,我们的网站需要在构建之初选择一个目标关键词进行构建。这个设定比我说的狗皮膏药的设定好多了。
关键词的决心不是一件容易的事。应该考虑很多因素。比如关键词必须和你的网站内容有关,单词如何组合和排列,是否符合搜索工具的要求,尽量避免使用热门的关键词等等。所以选择正确的关键词 需要一些工作。
长尾关键词optimized长尾关键词的优化设置是内页和栏目页需要考虑的因素。那么,设置长尾关键词需要考虑哪些因素呢?竞争很小,搜索量可能很高。毕竟这两点很关键。至于尾巴关键词选择多长,那就需要积累了。
易建成立于2007年12月,总部位于东莞。公司始终坚持以客户需求为中心,以“网络营销策划”为定位,以“让网络营销变得简单”为使命。先后为国内10000多家中小企业提供网络营销策划解决方案。过去,搜索引擎不同程度地跟踪网站内部链接。有的可以跟踪所有链接,有的则停留在二级或三级,所以当时需要单独提交网页。目前,易诗田已经在东莞、长安和佛山。未来,完善的服务网络将覆盖中国所有大中小城市。
影响关键词价格的因素:关键词搜索结果数量
这个值是所有Seoer都重视的参考指标。许多SEO初学者甚至只看这个值。这其实是一种误解。有时搜索结果很多,但竞争主要是内页。这个关键词难度不大。
这可以分为以下数值范围:
(A) 搜索结果小于 500,000:竞争较少的;
(B) 300 到 100 万个搜索结果:中到小;
(C) 1 到 300 万个搜索结果:中等;
(D) 3~500万条搜索结果:属于中上层;
(E) 超过 500 万个搜索结果:难词。
易建成立于2007年12月,总部位于东莞。公司始终坚持以客户需求为中心,以“网络营销策划”为定位,以“让网络营销变得简单”为使命。先后为国内10000多家中小企业提供网络营销策划解决方案。充分利用关键词analysis工具关键词analysis工具其实很多,有的免费,有的收费。目前,易诗田已经在东莞、长安和佛山。未来,完善的服务网络将覆盖中国所有大中小城市。
关键词Optimization 如果需要细分,大致可以分为十点:
1、网站 在开始构建之前,需要选择关键词并以此展开。常用的方法是在百度搜索框中输入扩展名关键词,查看相关页面,判断关键词的竞争程度。
2、做了关键词之后,分析一下对手关键词。
关键词 采集(阿里巴巴国际站最有效果且最省钱的运营方案!)
采集交流 • 优采云 发表了文章 • 0 个评论 • 173 次浏览 • 2021-09-05 07:18
大家都知道做关键词覆盖,因为这是目前阿里国际站最有效、最划算的运营方案!
我们把阿里巴巴想象成一个大池塘。这个池塘里有很多鱼(顾客)。鱼(客户)在池塘(阿里巴巴)中寻找食物(产品),所以我们的每一句话都是一个诱饵。比如蚯蚓、小昆虫、菜叶等,每一种都会吸引不同的鱼(顾客)!
例如:“phone”、“T-shirt”、“pen”是不同的词,引用的客户类型也不同
当然,站内站外有不同的说法。我今天会在站内讲很多时间。下面是我制作的思维导图
可以理解为关键词索引是深度,阿里巴巴国际站改版后这个功能真的好用!
剩下的可以理解为横向数据!
如果要一一去采集、翻页、复制、导出到表中,这个过程会很麻烦。最好使用一些工具。我之前用过谷歌浏览器的一些插件。今天主要给大家讲讲第一个第三方软件
首先一、下载这个软件。目前这个软件可以免费试用3天,但是数据是不允许导出的,而且有些功能是有限制的,不过是我们组织的免费试用关键词就够了。这是他们的官方网站。您可以下载免费试用版。
点击第一个二、,采集关键词,就会进入这个界面。在这里,先创建一个新组。
新建群三、后,点击采集关键词,这里选择关键词index
采集关键词后,再次查看数据。这个软件可以打开更多。这个时候如果关键词多的话,请多开。
1、可以查到我用了多少产品关键词
2、可以查看自己产品的关键词排名。
3、关键词哪个分类最好
4、关键词什么是竞争程度
5、点击率是多少
6、什么是搜索兴趣?
7、这个软件还有翻译功能,对于英文不好的操作来说太友好了。
作为一个操作,知道了上面的数据,接下来的工作就会轻松很多!下一集,我会告诉你如何为关键词报道发布优质产品。 查看全部
关键词 采集(阿里巴巴国际站最有效果且最省钱的运营方案!)
大家都知道做关键词覆盖,因为这是目前阿里国际站最有效、最划算的运营方案!
我们把阿里巴巴想象成一个大池塘。这个池塘里有很多鱼(顾客)。鱼(客户)在池塘(阿里巴巴)中寻找食物(产品),所以我们的每一句话都是一个诱饵。比如蚯蚓、小昆虫、菜叶等,每一种都会吸引不同的鱼(顾客)!
例如:“phone”、“T-shirt”、“pen”是不同的词,引用的客户类型也不同
当然,站内站外有不同的说法。我今天会在站内讲很多时间。下面是我制作的思维导图
可以理解为关键词索引是深度,阿里巴巴国际站改版后这个功能真的好用!
剩下的可以理解为横向数据!
如果要一一去采集、翻页、复制、导出到表中,这个过程会很麻烦。最好使用一些工具。我之前用过谷歌浏览器的一些插件。今天主要给大家讲讲第一个第三方软件
首先一、下载这个软件。目前这个软件可以免费试用3天,但是数据是不允许导出的,而且有些功能是有限制的,不过是我们组织的免费试用关键词就够了。这是他们的官方网站。您可以下载免费试用版。
点击第一个二、,采集关键词,就会进入这个界面。在这里,先创建一个新组。
新建群三、后,点击采集关键词,这里选择关键词index
采集关键词后,再次查看数据。这个软件可以打开更多。这个时候如果关键词多的话,请多开。
1、可以查到我用了多少产品关键词
2、可以查看自己产品的关键词排名。
3、关键词哪个分类最好
4、关键词什么是竞争程度
5、点击率是多少
6、什么是搜索兴趣?
7、这个软件还有翻译功能,对于英文不好的操作来说太友好了。
作为一个操作,知道了上面的数据,接下来的工作就会轻松很多!下一集,我会告诉你如何为关键词报道发布优质产品。
关键词 采集(十种关键词收集方法,你get到了几个?!)
采集交流 • 优采云 发表了文章 • 0 个评论 • 624 次浏览 • 2021-09-04 20:23
众所周知,关键词是电子商务的核心。对于刚刚进入国际台的小伙伴来说,关键词采集总是让人头疼。今天让我们分享十种关键词采集方法
一、流行搜索词
这个频道是所有商店共用的。一个帐户可以查看所有关键词
进入步骤:数据管理器-了解市场-热门搜索词
二、字源
词源:买家搜索词,带来曝光和点击您的产品。显示曝光前30位的文字。如果暴露的单词总数小于30,则将根据实际数量显示
换言之,本部分中的词语实际上由买方使用。所以不管热不热,都要把它装上盘子。它可用于P4P推广或推出新产品。总之,不要错过它。特别是点击词
步骤:数据管理器-知己-我的产品-文字来源
三、我的话
我的话:它由两部分组成:一部分是我设立关键词或参与外贸直通车推广的话,另一部分是买家找到我的话。对于少数超过10000字的供应商,仅提供10000字。在网站搜索中,选择能为您带来最多曝光率和最高人气的前10000个单词
此方法适用于开业半年以上的门店。开店时间太短,没有流量,也没有数据积累。这种方法作用不大
步骤:数据管理器-知己-我的话
PS:我的文字可以直接在后台导出
四、visitor details-常用搜索词
步骤:数据管理器-了解买家-访客详细信息
什么时候
如果被屏蔽,您可以在该区域选择“海外”,将中国大陆的游客转移到该区域。p>
五、行业热点词汇列表
进入步骤:数据管理器-新数据管理器(基本版)-行业-行业热点词列表
有三种词可以使用:热门搜索词、蓝海词和潜在词。你可以根据需要使用它
六、行业前景
进入步骤:数据管家-了解市场-行业视角
行业视角可以采集“热门搜索词”、“增长最快的搜索词”和“零词和少词”。这里的单词变化不大。你可以每季度看一次。最大的优势是可以按地区找到,目标国家市场明确的卖家可以很好地使用,观看频率可以是一个月/次
七、RFQ商机
步骤:数据经理-了解市场-询价业务机会
八、搜索栏下拉框
通过搜索栏中的下拉框,采集阿里当前流行的关键词或长尾词:
九、对等使用关键词
据估计,这是一种我们更感兴趣的方法。我们需要找到的产品必须是自然排名最高的产品。然后点击进入产品详情页面,进入产品页面,将鼠标放在标签页面,显示产品标题和三个关键词,如图所示:
十、Google广告词
步骤1:注册您的谷歌帐户,输入并单击关键词planner
步骤2:选择关键词planners
第三步:输入关键词并搜索
提示:谷歌adwords关键词你可以直接下载 查看全部
关键词 采集(十种关键词收集方法,你get到了几个?!)
众所周知,关键词是电子商务的核心。对于刚刚进入国际台的小伙伴来说,关键词采集总是让人头疼。今天让我们分享十种关键词采集方法
一、流行搜索词
这个频道是所有商店共用的。一个帐户可以查看所有关键词
进入步骤:数据管理器-了解市场-热门搜索词
二、字源
词源:买家搜索词,带来曝光和点击您的产品。显示曝光前30位的文字。如果暴露的单词总数小于30,则将根据实际数量显示
换言之,本部分中的词语实际上由买方使用。所以不管热不热,都要把它装上盘子。它可用于P4P推广或推出新产品。总之,不要错过它。特别是点击词
步骤:数据管理器-知己-我的产品-文字来源
三、我的话
我的话:它由两部分组成:一部分是我设立关键词或参与外贸直通车推广的话,另一部分是买家找到我的话。对于少数超过10000字的供应商,仅提供10000字。在网站搜索中,选择能为您带来最多曝光率和最高人气的前10000个单词
此方法适用于开业半年以上的门店。开店时间太短,没有流量,也没有数据积累。这种方法作用不大
步骤:数据管理器-知己-我的话
PS:我的文字可以直接在后台导出
四、visitor details-常用搜索词
步骤:数据管理器-了解买家-访客详细信息
什么时候
如果被屏蔽,您可以在该区域选择“海外”,将中国大陆的游客转移到该区域。p>
五、行业热点词汇列表
进入步骤:数据管理器-新数据管理器(基本版)-行业-行业热点词列表
有三种词可以使用:热门搜索词、蓝海词和潜在词。你可以根据需要使用它
六、行业前景
进入步骤:数据管家-了解市场-行业视角
行业视角可以采集“热门搜索词”、“增长最快的搜索词”和“零词和少词”。这里的单词变化不大。你可以每季度看一次。最大的优势是可以按地区找到,目标国家市场明确的卖家可以很好地使用,观看频率可以是一个月/次
七、RFQ商机
步骤:数据经理-了解市场-询价业务机会
八、搜索栏下拉框
通过搜索栏中的下拉框,采集阿里当前流行的关键词或长尾词:
九、对等使用关键词
据估计,这是一种我们更感兴趣的方法。我们需要找到的产品必须是自然排名最高的产品。然后点击进入产品详情页面,进入产品页面,将鼠标放在标签页面,显示产品标题和三个关键词,如图所示:
十、Google广告词
步骤1:注册您的谷歌帐户,输入并单击关键词planner
步骤2:选择关键词planners
第三步:输入关键词并搜索
提示:谷歌adwords关键词你可以直接下载
关键词 采集(中文维基百科wiki百科关键词采集两条途径(图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 453 次浏览 • 2021-09-03 15:00
关键词采集两条途径:1、官方提供的2、爬虫/第三方提供的官方提供的:维基百科的新浪博客新浪微博/#!topic/news中文维基百科wiki百科中关于page自动页面采集anywhere.wiki如果你还想要更多可自行搜索以下网站的关键词进行采集:神一样的百度百科-wiki(也是爬虫工具)、seleniumwebdriver+wireshark简单快速采集百度百科、paperpage4.0-baidu新开通(python爬虫工具)、百度站长工具、产品页面爬虫工具之前使用过的:weibo.wiki(人工智能,可以采集评论,也可以采集图片、有大量关键词采集。)、云采集(入门简单,容易上手。)、app《酷安》《3dm游戏社区》可以跟在下了解更多。
新开一个“按分钟记时”的ai+自动采集器吧,
知道可以通过简单的qq采集群,非常简单也非常耗费工时,个人觉得不是特别适合楼主,在加上网上相关的软件都过度压缩、甚至在3秒内会有防入侵的防御机制等,都没有实际作用。推荐了一个【采名】,可以采,但是采多少还有一定问题。【采名】的公众号里面有详细说明。
extractor可以吧我之前做过文本采集数据可以用tinyhttp批量处理你的请求,
feeds_based_js使用javascript自动处理定时更新的网页。新浪博客(用的),百度的首页(用的),是js开发的。网易(用的)在googleplay可以搜索到。 查看全部
关键词 采集(中文维基百科wiki百科关键词采集两条途径(图))
关键词采集两条途径:1、官方提供的2、爬虫/第三方提供的官方提供的:维基百科的新浪博客新浪微博/#!topic/news中文维基百科wiki百科中关于page自动页面采集anywhere.wiki如果你还想要更多可自行搜索以下网站的关键词进行采集:神一样的百度百科-wiki(也是爬虫工具)、seleniumwebdriver+wireshark简单快速采集百度百科、paperpage4.0-baidu新开通(python爬虫工具)、百度站长工具、产品页面爬虫工具之前使用过的:weibo.wiki(人工智能,可以采集评论,也可以采集图片、有大量关键词采集。)、云采集(入门简单,容易上手。)、app《酷安》《3dm游戏社区》可以跟在下了解更多。
新开一个“按分钟记时”的ai+自动采集器吧,
知道可以通过简单的qq采集群,非常简单也非常耗费工时,个人觉得不是特别适合楼主,在加上网上相关的软件都过度压缩、甚至在3秒内会有防入侵的防御机制等,都没有实际作用。推荐了一个【采名】,可以采,但是采多少还有一定问题。【采名】的公众号里面有详细说明。
extractor可以吧我之前做过文本采集数据可以用tinyhttp批量处理你的请求,
feeds_based_js使用javascript自动处理定时更新的网页。新浪博客(用的),百度的首页(用的),是js开发的。网易(用的)在googleplay可以搜索到。
关键词 采集(不少朋友看过之前发布的新手如何运营阿里巴巴国际站关键词)
采集交流 • 优采云 发表了文章 • 0 个评论 • 254 次浏览 • 2021-09-03 05:08
之前有很多朋友看过阿里巴巴国际站网扑新手怎么办,卡在关键词采集问题。关于如何采集阿里巴巴国际站关键词,以前在QQ二里回答过无数问题,还有很多朋友不采集。为了省事,重新打开帖子再写一遍。
首先你要清楚关键词的采集不能一下子全部采集。经过多次长时间的采集,关键词可以达到一定的数量,所以要采集3个月。做好阿里需要超强的执行力,所以从关键词开始,发挥你的超强执行力。
也许你已经学会了如何从其他地方采集关键词,比如:阿里国际站后台数据管理员、直达列车关键词、行业视角、访客详情、询价、搜索下拉框词、同行集关键词、RFQ关键词、Google关键词 等
就算知道这么多地方,也能采集关键词。真的有用吗?你会采集吗?
接下来分享一下我是如何采集关键词的。
首先说明一下,无论你是刚接手阿里国际站运营的新手,还是店铺运营不好的外贸业务员,都适合使用。如果你对阿里国际站平台的后台功能有更深入的了解,其实关键词采集只需要三个地方即可。
一、一次采集热门搜索词
什么是热门搜索词:
1、在相应时间段内,该词及相关词被访问者在阿里巴巴网站搜索。
2、更新时间:美国时间每月 3 号。
3、只显示连续6个月买家搜索热度大于等于120的词
二、火车票一次性采集关键词
什么是直通车关键词:
1、在相应时间段内,该词及相关词被访问者在阿里巴巴网站搜索。
三、反复采集我的话关键词(新版本叫:排水关键词)
我的话关键词:
1、由两部分组成,一是我设置关键词或参与外贸直通车推广这个词,二是买家找到我这个词。
2、更新时间:每周统计部分,每周二上午更新。月度统计板块每月3日上午更新。
关于背景视图的更详细说明。
只有对每个函数的作用有一个清晰的认识,才能更好的采集关键词。
通过这三个地方,按顺序采集就基本够了。
示例:
假设你现在开了一个阿里国际站,做一个蓝牙耳机:蓝牙耳机,收关键词。
一、一次采集热门搜索词
进入后台数据管理器-热门搜索词,找到蓝牙耳机,将关键词全部复制到Excel表格中。有软件就用软件下载,没有软件就手动下载。或者使用插件提取:阿里巴巴国际站运营工具使用xpath插件提取关键词或者title或者火狐浏览器插件TableTools2
二、火车票一次性采集关键词
进入直通车-关键词工具,找到蓝牙耳机,将关键词全部复制到Excel表格中。
重点是:
采集热门搜索词并直接训练关键词后,筛选和排序,然后发布产品。所有关键词必须用完,关键词数据在后台进行累积。
我之前知道我的word是由两部分组成的,一是我设置关键词或者参与外贸直通车促销的词,二是买家找到我的词。
关键是买家能听懂我的话。
我们发布了带有热门搜索词的产品,并直通关键词。客户通过关键词 搜索找到了我们。除了热门搜索词,肯定还有一些我们没有采集到的长尾词。这些新的长尾关键词会算在我的话里。
我们正在为产品发布采集新的长尾词。
三、反复采集我的话关键词(新版本叫:排水关键词)
到后台数据管家-drain关键词,找到蓝牙耳机相关的关键词。我的词收录精确词,长尾词。既然是买家发现了我的词,你可以搜索蓝牙耳机相关词下载到表格中过滤掉蓝牙耳机长尾词。
重点又来了:
采集我的词关键词时,过滤掉长尾词,下次推出产品。下周二会有新的长尾词。同样,我们这个时候采集它们。反复采集筛选时间长,积累的长尾关键词越来越多。
我的话每周二早上更新。每个月的第三个早上更新。由于每周更新一次,所以我之前说过采集关键词需要3个月的时间。
只有当我们找到更有效的客户搜索词并推出或优化产品时,客户才能找到我们并向我们发送询盘。长尾关键词越精准,竞争越少,排名越容易,成本越低。询盘质量高。
Longtail 关键词 也更容易排名,而且还可以驱动热门搜索词数据。
关键词采集 按照上面的顺序。随着时间的推移,关键词积累的越来越多,前期只采集热门搜索词和直通车一次。更注重我的话,每周产生新的客户搜索词对我们有很大的影响。
这就是为什么别人的关键词比你多几倍。您没有同行拥有的关键词。这样,你也有你同行的关键词。
通过前面对我词功能的理解,应该明白我词的功能了,关键词从何而来。
最后说说其他不重要的关键词采集方法。
四、数据管家-我的产品-词源。
词源每天更新,不用天天采集,词源的词会纳入我的词统计。所以就用我的话吧。毕竟每天采集很累,还要筛选、发布、优化。
五、数据管家-访客详情
访问者明细的词可以参考,这些词也会被纳入我的词统计。
六、其他
行业视角、询盘、搜索下拉框词、关键词、RFQ关键词等同行设置,无需过多关注,参考即可。
尤其是同行设置的关键词。很多人已经通过关键词采集设置了产品。很多同行关键词为了填词而造词。这些功能甚至更小。自己造词。什么用途?你采集 回来发布产品。客户搜索率太小。
客户搜索词是我们采集的内容。
关键词永远不会被采集,只有不断积累才会有更多关键词。
坚持
坚持
坚持
常见问题:
如何发布1、采集的关键词的产品?
除了第一时间发布热门搜索词和直推关键词,最好每周在我的词统计和发布产品采集的长尾词之前查看排名。如果这个长尾词有排名哪个不能发布。如果长尾关键词与产品不匹配,就重新发布一个。
2、我的话关键词如何选择有效果的词?
如果我做蓝牙耳机,我用蓝牙搜索关键词。人气高低,如何选择?
我建议按顶部点击排序。只要top这个词有点击,我们就会采集它用于产品发布和优化。点击顶部,您也可以。 查看全部
关键词 采集(不少朋友看过之前发布的新手如何运营阿里巴巴国际站关键词)
之前有很多朋友看过阿里巴巴国际站网扑新手怎么办,卡在关键词采集问题。关于如何采集阿里巴巴国际站关键词,以前在QQ二里回答过无数问题,还有很多朋友不采集。为了省事,重新打开帖子再写一遍。
首先你要清楚关键词的采集不能一下子全部采集。经过多次长时间的采集,关键词可以达到一定的数量,所以要采集3个月。做好阿里需要超强的执行力,所以从关键词开始,发挥你的超强执行力。
也许你已经学会了如何从其他地方采集关键词,比如:阿里国际站后台数据管理员、直达列车关键词、行业视角、访客详情、询价、搜索下拉框词、同行集关键词、RFQ关键词、Google关键词 等
就算知道这么多地方,也能采集关键词。真的有用吗?你会采集吗?
接下来分享一下我是如何采集关键词的。
首先说明一下,无论你是刚接手阿里国际站运营的新手,还是店铺运营不好的外贸业务员,都适合使用。如果你对阿里国际站平台的后台功能有更深入的了解,其实关键词采集只需要三个地方即可。
一、一次采集热门搜索词
什么是热门搜索词:
1、在相应时间段内,该词及相关词被访问者在阿里巴巴网站搜索。
2、更新时间:美国时间每月 3 号。
3、只显示连续6个月买家搜索热度大于等于120的词
二、火车票一次性采集关键词
什么是直通车关键词:
1、在相应时间段内,该词及相关词被访问者在阿里巴巴网站搜索。
三、反复采集我的话关键词(新版本叫:排水关键词)
我的话关键词:
1、由两部分组成,一是我设置关键词或参与外贸直通车推广这个词,二是买家找到我这个词。
2、更新时间:每周统计部分,每周二上午更新。月度统计板块每月3日上午更新。
关于背景视图的更详细说明。
只有对每个函数的作用有一个清晰的认识,才能更好的采集关键词。
通过这三个地方,按顺序采集就基本够了。
示例:
假设你现在开了一个阿里国际站,做一个蓝牙耳机:蓝牙耳机,收关键词。
一、一次采集热门搜索词
进入后台数据管理器-热门搜索词,找到蓝牙耳机,将关键词全部复制到Excel表格中。有软件就用软件下载,没有软件就手动下载。或者使用插件提取:阿里巴巴国际站运营工具使用xpath插件提取关键词或者title或者火狐浏览器插件TableTools2
二、火车票一次性采集关键词
进入直通车-关键词工具,找到蓝牙耳机,将关键词全部复制到Excel表格中。
重点是:
采集热门搜索词并直接训练关键词后,筛选和排序,然后发布产品。所有关键词必须用完,关键词数据在后台进行累积。
我之前知道我的word是由两部分组成的,一是我设置关键词或者参与外贸直通车促销的词,二是买家找到我的词。
关键是买家能听懂我的话。
我们发布了带有热门搜索词的产品,并直通关键词。客户通过关键词 搜索找到了我们。除了热门搜索词,肯定还有一些我们没有采集到的长尾词。这些新的长尾关键词会算在我的话里。
我们正在为产品发布采集新的长尾词。
三、反复采集我的话关键词(新版本叫:排水关键词)
到后台数据管家-drain关键词,找到蓝牙耳机相关的关键词。我的词收录精确词,长尾词。既然是买家发现了我的词,你可以搜索蓝牙耳机相关词下载到表格中过滤掉蓝牙耳机长尾词。
重点又来了:
采集我的词关键词时,过滤掉长尾词,下次推出产品。下周二会有新的长尾词。同样,我们这个时候采集它们。反复采集筛选时间长,积累的长尾关键词越来越多。
我的话每周二早上更新。每个月的第三个早上更新。由于每周更新一次,所以我之前说过采集关键词需要3个月的时间。
只有当我们找到更有效的客户搜索词并推出或优化产品时,客户才能找到我们并向我们发送询盘。长尾关键词越精准,竞争越少,排名越容易,成本越低。询盘质量高。
Longtail 关键词 也更容易排名,而且还可以驱动热门搜索词数据。
关键词采集 按照上面的顺序。随着时间的推移,关键词积累的越来越多,前期只采集热门搜索词和直通车一次。更注重我的话,每周产生新的客户搜索词对我们有很大的影响。
这就是为什么别人的关键词比你多几倍。您没有同行拥有的关键词。这样,你也有你同行的关键词。
通过前面对我词功能的理解,应该明白我词的功能了,关键词从何而来。
最后说说其他不重要的关键词采集方法。
四、数据管家-我的产品-词源。
词源每天更新,不用天天采集,词源的词会纳入我的词统计。所以就用我的话吧。毕竟每天采集很累,还要筛选、发布、优化。
五、数据管家-访客详情
访问者明细的词可以参考,这些词也会被纳入我的词统计。
六、其他
行业视角、询盘、搜索下拉框词、关键词、RFQ关键词等同行设置,无需过多关注,参考即可。
尤其是同行设置的关键词。很多人已经通过关键词采集设置了产品。很多同行关键词为了填词而造词。这些功能甚至更小。自己造词。什么用途?你采集 回来发布产品。客户搜索率太小。
客户搜索词是我们采集的内容。
关键词永远不会被采集,只有不断积累才会有更多关键词。
坚持
坚持
坚持
常见问题:
如何发布1、采集的关键词的产品?
除了第一时间发布热门搜索词和直推关键词,最好每周在我的词统计和发布产品采集的长尾词之前查看排名。如果这个长尾词有排名哪个不能发布。如果长尾关键词与产品不匹配,就重新发布一个。
2、我的话关键词如何选择有效果的词?
如果我做蓝牙耳机,我用蓝牙搜索关键词。人气高低,如何选择?
我建议按顶部点击排序。只要top这个词有点击,我们就会采集它用于产品发布和优化。点击顶部,您也可以。
关键词 采集(亚马逊关键词研究收集的6个方法,让你的产品关键词列表)
采集交流 • 优采云 发表了文章 • 0 个评论 • 242 次浏览 • 2021-09-03 04:05
关键字是我们产品列表的核心。无论是搜索排名还是广告效果,一切都取决于关键字。所以值得花额外的时间对我们自己的产品关键词list 进行深入研究。
关键词研究采集的六种方法:
1 个竞争对手
关键字研究的第一步是获取竞争对手的 URL 链接并将其添加到 Google Keyword Tool。
Google 会向我们展示竞争对手使用的所有关键词,我们可以将这些词添加到我们的关键词列表中。您也可以下载列表,使用AMZ Tracker等相关热门关键词工具,在一定程度上扩展列表。
2 阅读参赛者名单
快速浏览竞争对手的标题、功能和描述。只要您发现任何看起来像描述产品的关键字的内容,就将其添加到我们的关键字列表中。
在亚马逊上,查看主要关键词的前十名买家。使用这种方法,我们通常会找到几个产品使用的好的关键字。
3 在 Google 上查找品牌
亚马逊并不是人们购物的唯一场所。例如,要销售 CrossFit 手套,您可以在 Google 上搜索销售此类产品的在线品牌。
将此网址添加到 Google 关键字工具,Google 会向我们显示该品牌使用的所有不同关键字。这样,我们可能会得到更多在谷歌中排名更高的关键词,我们可以将这些收录 添加到我们的亚马逊关键词 列表中。您甚至可以通过这种方式在 Google 上对产品进行排名。
4 查看 Google 上的热门关键字
写下我们认为买家可能用来搜索我们销售的产品的关键字列表。将它们一一添加到 Google Keyword Tool 中,然后保存。
在 Google 中搜索硅戒指和橡胶结婚戒指将为您提供两组截然不同的结果。因此,请务必考虑人们可能通过多种不同方式找到您的产品。
除了 Google 搜索词之外,我还使用 AMZ Tracker 进行关键字研究和排名跟踪。这样,我可以肯定我已经覆盖了小众市场的所有主要关键字。
5 亚马逊关键词
开始在亚马逊搜索中输入我们的产品名称,您可以查看亚马逊的建议。
例如,对于硅胶手机壳,亚马逊会向我们展示有关查找收录我们输入的名称的产品的主要关键字的建议。所以,在搜索商品全名时要仔细看,并记下亚马逊展示的主要关键词。
6 使用列表中的关键字
确保在标题中收录三个主要关键字,并将这些关键字放在函数中。在功能和描述中添加其他关键字,并确保仅使用研究中最相关的关键字。
使用这些技术,我们可以建立一个很好的关键字列表,买家很可能会使用这些关键字来搜索我们的产品。 查看全部
关键词 采集(亚马逊关键词研究收集的6个方法,让你的产品关键词列表)
关键字是我们产品列表的核心。无论是搜索排名还是广告效果,一切都取决于关键字。所以值得花额外的时间对我们自己的产品关键词list 进行深入研究。
关键词研究采集的六种方法:
1 个竞争对手
关键字研究的第一步是获取竞争对手的 URL 链接并将其添加到 Google Keyword Tool。
Google 会向我们展示竞争对手使用的所有关键词,我们可以将这些词添加到我们的关键词列表中。您也可以下载列表,使用AMZ Tracker等相关热门关键词工具,在一定程度上扩展列表。
2 阅读参赛者名单
快速浏览竞争对手的标题、功能和描述。只要您发现任何看起来像描述产品的关键字的内容,就将其添加到我们的关键字列表中。
在亚马逊上,查看主要关键词的前十名买家。使用这种方法,我们通常会找到几个产品使用的好的关键字。
3 在 Google 上查找品牌
亚马逊并不是人们购物的唯一场所。例如,要销售 CrossFit 手套,您可以在 Google 上搜索销售此类产品的在线品牌。
将此网址添加到 Google 关键字工具,Google 会向我们显示该品牌使用的所有不同关键字。这样,我们可能会得到更多在谷歌中排名更高的关键词,我们可以将这些收录 添加到我们的亚马逊关键词 列表中。您甚至可以通过这种方式在 Google 上对产品进行排名。
4 查看 Google 上的热门关键字
写下我们认为买家可能用来搜索我们销售的产品的关键字列表。将它们一一添加到 Google Keyword Tool 中,然后保存。
在 Google 中搜索硅戒指和橡胶结婚戒指将为您提供两组截然不同的结果。因此,请务必考虑人们可能通过多种不同方式找到您的产品。
除了 Google 搜索词之外,我还使用 AMZ Tracker 进行关键字研究和排名跟踪。这样,我可以肯定我已经覆盖了小众市场的所有主要关键字。
5 亚马逊关键词
开始在亚马逊搜索中输入我们的产品名称,您可以查看亚马逊的建议。
例如,对于硅胶手机壳,亚马逊会向我们展示有关查找收录我们输入的名称的产品的主要关键字的建议。所以,在搜索商品全名时要仔细看,并记下亚马逊展示的主要关键词。
6 使用列表中的关键字
确保在标题中收录三个主要关键字,并将这些关键字放在函数中。在功能和描述中添加其他关键字,并确保仅使用研究中最相关的关键字。
使用这些技术,我们可以建立一个很好的关键字列表,买家很可能会使用这些关键字来搜索我们的产品。
关键词 采集(百度下拉框关键词都是这些东西,没啥特别的吧!)
采集交流 • 优采云 发表了文章 • 0 个评论 • 137 次浏览 • 2021-09-03 04:05
对于词研究,每个seoer都必须知道,而且除了比较流行的百度相关搜索词外,百度下拉框关键词应该也是很多人研究的范围,但大多数人都针对下拉框词量,毕竟百度下拉框关键词采集已经被淹没了。
百度下拉菜单的正式名称是百度建议词,也称为百度建议词或百度下拉菜单。百度为方便广大网友搜索,提高输入效率而推出的一项服务。
例如,当我们在百度中输入“营销”两个词时,百度从推荐词条库中检索以“营销”两个词开头的词条,并按照搜索量由大到小排序,分组为一个下拉菜单。百度下拉菜单最多10个。
百度下拉框关键词的含义:
可以作为长尾词,作为标题,毕竟是关键词search 用户搜索时可以触发的选择。
很多人使用下拉词来引导流量,比如曝光品牌,导向指定页面。您可以采集分析竞争对手的相关操作,也可以自己曝光自己的品牌。不同的人有不同的看法!
网上留下了很多采集下拉词的工具和源码。到这里,人渣渣滓已经梳理完毕。我们再分享一下。我哥昨晚问过,但实际上是来来去去的。就是这些,没什么特别的!
版本一:
直接抓取网页实现采集下拉词
def get_keywords(word):
url=f"https://www.baidu.com/sugrec%3 ... wd%3D{word}"
html=requests.get(url)
html=html.json()
#print(html)
#print(html['g'])
key_words=[]
for key_word in html['g']:
print(key_word['q'])
key_words.append(key_word['q'])
#print(key_words)
return key_words
版本二:
使用官方界面
例如:
def get_sug(word):
url = 'https://sp0.baidu.com/5a1Fazu8 ... 27%3B % word
r = requests.get(url, verify=False) # 请求API接口,取消了HTTPS验证
cont = r.content # 获取返回的内容
res = cont[41: -2].decode('gbk') # 只取返回结果中json格式一段,并且解码为unicode
res_json = json.loads(res) # json格式转换
return res_json['s'] # 返回关键词列表
版本三:
另一个接口地址
def get_word(word):
url=f'http://suggestion.baidu.com/su?wd={word}&sugmode=3&json=1'
html=requests.get(url).text
html=html.replace("window.baidu.sug(",'')
html = html.replace(")", '')
html = html.replace(";", '')
#print(html)
html = json.loads(html)
key_words=html['s']
#print(key_words)
return key_words
本质上第二个和第三个性质是一样的,我们参考使用吧!
扩展版:
这里有一个小技巧。在关键词后输入w,会出现拼音中以w开头的一系列关键词,如“黄山w”,还会出现“黄山温泉”,“黄山几天”。 ”、“黄山五绝”等关键词(见上图),所以当我们遍历a~z时,会出现更多的关键词。
此处选择第2版的界面形式,以免不协调
但是如果使用requests模块请求一个无效证书的网站,会直接报错
可以将verify参数设置为False来解决这个问题
r = requests.get(url, verify=False)
但是设置 verify=False 会抛出 InsecureRequestWarning 警告
这看起来很糟糕
解决方案:
from requests.packages.urllib3.exceptions import InsecureRequestWarning
# 禁用安全请求警告
requests.packages.urllib3.disable_warnings(InsecureRequestWarning)
运行效果
参考源码获取 查看全部
关键词 采集(百度下拉框关键词都是这些东西,没啥特别的吧!)
对于词研究,每个seoer都必须知道,而且除了比较流行的百度相关搜索词外,百度下拉框关键词应该也是很多人研究的范围,但大多数人都针对下拉框词量,毕竟百度下拉框关键词采集已经被淹没了。
百度下拉菜单的正式名称是百度建议词,也称为百度建议词或百度下拉菜单。百度为方便广大网友搜索,提高输入效率而推出的一项服务。
例如,当我们在百度中输入“营销”两个词时,百度从推荐词条库中检索以“营销”两个词开头的词条,并按照搜索量由大到小排序,分组为一个下拉菜单。百度下拉菜单最多10个。
百度下拉框关键词的含义:
可以作为长尾词,作为标题,毕竟是关键词search 用户搜索时可以触发的选择。
很多人使用下拉词来引导流量,比如曝光品牌,导向指定页面。您可以采集分析竞争对手的相关操作,也可以自己曝光自己的品牌。不同的人有不同的看法!
网上留下了很多采集下拉词的工具和源码。到这里,人渣渣滓已经梳理完毕。我们再分享一下。我哥昨晚问过,但实际上是来来去去的。就是这些,没什么特别的!
版本一:
直接抓取网页实现采集下拉词
def get_keywords(word):
url=f"https://www.baidu.com/sugrec%3 ... wd%3D{word}"
html=requests.get(url)
html=html.json()
#print(html)
#print(html['g'])
key_words=[]
for key_word in html['g']:
print(key_word['q'])
key_words.append(key_word['q'])
#print(key_words)
return key_words
版本二:
使用官方界面
例如:
def get_sug(word):
url = 'https://sp0.baidu.com/5a1Fazu8 ... 27%3B % word
r = requests.get(url, verify=False) # 请求API接口,取消了HTTPS验证
cont = r.content # 获取返回的内容
res = cont[41: -2].decode('gbk') # 只取返回结果中json格式一段,并且解码为unicode
res_json = json.loads(res) # json格式转换
return res_json['s'] # 返回关键词列表
版本三:
另一个接口地址
def get_word(word):
url=f'http://suggestion.baidu.com/su?wd={word}&sugmode=3&json=1'
html=requests.get(url).text
html=html.replace("window.baidu.sug(",'')
html = html.replace(")", '')
html = html.replace(";", '')
#print(html)
html = json.loads(html)
key_words=html['s']
#print(key_words)
return key_words
本质上第二个和第三个性质是一样的,我们参考使用吧!
扩展版:
这里有一个小技巧。在关键词后输入w,会出现拼音中以w开头的一系列关键词,如“黄山w”,还会出现“黄山温泉”,“黄山几天”。 ”、“黄山五绝”等关键词(见上图),所以当我们遍历a~z时,会出现更多的关键词。
此处选择第2版的界面形式,以免不协调
但是如果使用requests模块请求一个无效证书的网站,会直接报错
可以将verify参数设置为False来解决这个问题
r = requests.get(url, verify=False)
但是设置 verify=False 会抛出 InsecureRequestWarning 警告
这看起来很糟糕
解决方案:
from requests.packages.urllib3.exceptions import InsecureRequestWarning
# 禁用安全请求警告
requests.packages.urllib3.disable_warnings(InsecureRequestWarning)
运行效果
参考源码获取
关键词 采集(关键词采集是骗人的吗?-夏夏的回答)
采集交流 • 优采云 发表了文章 • 0 个评论 • 150 次浏览 • 2021-08-31 06:03
关键词采集是骗人的吗?-夏夏的回答你可以参考一下,你的这个问题不知道我是怎么联想到了同样是关键词采集,有空可以去我的回答下评论里看一下,我也可以举个例子,说说我是怎么骗你的。首先我先百度了一下你说的骗人的同行,看的我心虚,心跳加速;根据你的截图,我推断可能是这么个骗局。最最简单也是最好骗的就是信息录入员了,我就借题主这个题目来骗你说说,因为这几年我也在做这个,我的发小就是被同学拉进了信息录入员的圈子里,结果对方每天自愿的跑过来,提供一下各种骚扰电话,qq等,我真的是不知道该怎么去拒绝了,我再加他微信,发了我的号码,就要我加qq的qq群,我再加一下那些人的qq号码,有一次同学打电话问我要不要进qq群,也是受害者了。
还有就是最早做这个的那几家,除了中国人寿的,等几家大公司,后面还有上市公司巨头也开始参与进来,挂羊头卖狗肉,说什么有考核有任务,想要过关是要拉人头做业务的,我说我干这个只是凭我一个人的努力就能达到这个目标的,然后她就更生气了,说了一大堆真的没有尽到一个招聘的职责,我回答她你就说这个没有任何考核,也没有任何业绩要求,我不要赚钱,只是单纯喜欢而已,当时心里真的是好气哦,其实在应聘之前我想了很多,我说一天工作十几个小时是不可能的,毕竟人多,我说我对这个感兴趣,但是也是单纯喜欢,然后她就开始哭诉她干了多年的工作了,现在想想觉得好委屈。
然后我就劝她看看这个收入情况,如果还能拿到正常的工资就一起干,可是她还是没有同意,说自己没有钱,开一家公司要房租太费钱了,最好我们不要做交心的朋友,然后我就哭笑不得的挂了电话。这个就是他们的采访,单纯看他们的这个文章,你还是觉得说得挺好的,没有多好欺负,如果就打着采访性质的,你就算去一些大公司都可以给你,没有一个你做下去的理由,为什么你就非得一个点才能深入的了解这个行业。
关键问题是,我这里并不是讨论职业好不好,也不是说这个职业骗人,我只是想说,我现在还在从事这个职业,我只想把我知道的告诉大家,以及避免更多人受骗。 查看全部
关键词 采集(关键词采集是骗人的吗?-夏夏的回答)
关键词采集是骗人的吗?-夏夏的回答你可以参考一下,你的这个问题不知道我是怎么联想到了同样是关键词采集,有空可以去我的回答下评论里看一下,我也可以举个例子,说说我是怎么骗你的。首先我先百度了一下你说的骗人的同行,看的我心虚,心跳加速;根据你的截图,我推断可能是这么个骗局。最最简单也是最好骗的就是信息录入员了,我就借题主这个题目来骗你说说,因为这几年我也在做这个,我的发小就是被同学拉进了信息录入员的圈子里,结果对方每天自愿的跑过来,提供一下各种骚扰电话,qq等,我真的是不知道该怎么去拒绝了,我再加他微信,发了我的号码,就要我加qq的qq群,我再加一下那些人的qq号码,有一次同学打电话问我要不要进qq群,也是受害者了。
还有就是最早做这个的那几家,除了中国人寿的,等几家大公司,后面还有上市公司巨头也开始参与进来,挂羊头卖狗肉,说什么有考核有任务,想要过关是要拉人头做业务的,我说我干这个只是凭我一个人的努力就能达到这个目标的,然后她就更生气了,说了一大堆真的没有尽到一个招聘的职责,我回答她你就说这个没有任何考核,也没有任何业绩要求,我不要赚钱,只是单纯喜欢而已,当时心里真的是好气哦,其实在应聘之前我想了很多,我说一天工作十几个小时是不可能的,毕竟人多,我说我对这个感兴趣,但是也是单纯喜欢,然后她就开始哭诉她干了多年的工作了,现在想想觉得好委屈。
然后我就劝她看看这个收入情况,如果还能拿到正常的工资就一起干,可是她还是没有同意,说自己没有钱,开一家公司要房租太费钱了,最好我们不要做交心的朋友,然后我就哭笑不得的挂了电话。这个就是他们的采访,单纯看他们的这个文章,你还是觉得说得挺好的,没有多好欺负,如果就打着采访性质的,你就算去一些大公司都可以给你,没有一个你做下去的理由,为什么你就非得一个点才能深入的了解这个行业。
关键问题是,我这里并不是讨论职业好不好,也不是说这个职业骗人,我只是想说,我现在还在从事这个职业,我只想把我知道的告诉大家,以及避免更多人受骗。
关键词 采集(麒麟爱站关键词采集器功能全面,操作简单,运行稳定绝对)
采集交流 • 优采云 发表了文章 • 0 个评论 • 150 次浏览 • 2021-08-31 04:11
Perfect()网站基于软件下载,修改后的网站扩展了功能部分,以解决用户在使用软件过程中遇到的所有问题。 网站增加了“软件百科”、“小贴士”等频道,可以更好的为用户提供软件使用全周期更专业的服务。
Kirin爱站关键词采集器超强三合一功能有数据统计分析、同行站点分析关键词等,爱站关键词采集器完全功能强大,操作简单,运行稳定,绝对是站长必备软件!
百度结果采集三大功能,域名排名,网页标题,网址,PR值,BR值,外链数,百度流量,外链,内链,百度收录数,百度反可以链接采集爱站、站长网、7C站三个站的信息,输入域名,采集:关键词,排名,搜索量,PC搜索量,手机搜索量、收录Quantity、链接地址、标题(自动存储在data.mdb中,也可以导出EXCEL),存储是为了方便关键词筛选功能。 关键词筛选功能,也可以说是关键词挖矿功能,输入范围广泛的关键词,网站上所有匹配的关键词都会被过滤掉。你也可以了解一下这些关键词的排名。
“温馨提示和妙记”栏目是全网软件的技巧合集或对软件使用过程中各种问题的解答文章。专栏成立伊始,小编欢迎各位软件大神朋友踊跃投稿。分享每个人独特技能的平台。
本站文章素材来自网络,文章作者姓名大部分缺失。为了让用户更容易阅读和使用,它们已被重新格式化并根据需要进行了部分调整。本站收录文章只是为了帮助用户解决实际问题,如有版权问题,请联系编辑修改或删除,谢谢合作。 查看全部
关键词 采集(麒麟爱站关键词采集器功能全面,操作简单,运行稳定绝对)
Perfect()网站基于软件下载,修改后的网站扩展了功能部分,以解决用户在使用软件过程中遇到的所有问题。 网站增加了“软件百科”、“小贴士”等频道,可以更好的为用户提供软件使用全周期更专业的服务。
Kirin爱站关键词采集器超强三合一功能有数据统计分析、同行站点分析关键词等,爱站关键词采集器完全功能强大,操作简单,运行稳定,绝对是站长必备软件!
百度结果采集三大功能,域名排名,网页标题,网址,PR值,BR值,外链数,百度流量,外链,内链,百度收录数,百度反可以链接采集爱站、站长网、7C站三个站的信息,输入域名,采集:关键词,排名,搜索量,PC搜索量,手机搜索量、收录Quantity、链接地址、标题(自动存储在data.mdb中,也可以导出EXCEL),存储是为了方便关键词筛选功能。 关键词筛选功能,也可以说是关键词挖矿功能,输入范围广泛的关键词,网站上所有匹配的关键词都会被过滤掉。你也可以了解一下这些关键词的排名。
“温馨提示和妙记”栏目是全网软件的技巧合集或对软件使用过程中各种问题的解答文章。专栏成立伊始,小编欢迎各位软件大神朋友踊跃投稿。分享每个人独特技能的平台。
本站文章素材来自网络,文章作者姓名大部分缺失。为了让用户更容易阅读和使用,它们已被重新格式化并根据需要进行了部分调整。本站收录文章只是为了帮助用户解决实际问题,如有版权问题,请联系编辑修改或删除,谢谢合作。
关键词 采集(关于网站让引擎蜘蛛快速抓取的方法:网站及页面权重)
采集交流 • 优采云 发表了文章 • 0 个评论 • 202 次浏览 • 2021-08-30 02:07
根据真实调查数据,90%的网民会使用搜索引擎服务寻找自己需要的信息,而这些搜索者中有近70%会在搜索结果自然排名的第一页直接找到自己需要的信息信息。可见,目前SEO对于企业和产品具有不可替代的意义。关于网站让引擎蜘蛛快速爬取:一、网站和页面权重。这必须是第一要务。 网站权重高、资历老、权限大的蜘蛛,一定要特别对待。这样的网站爬的非常频繁,大家都知道搜索引擎蜘蛛对网站非常有效,并不是网站的所有页面都会被爬取,网站的权重越高,爬取的深度就越高,而且对应的可以爬取的页面会增加,这样可以收录的页面也会增加。 . 二、网站server。 网站Server 是网站 的基石。如果网站服务器长时间打不开,那这离你很近,蜘蛛想来也来不来。百度蜘蛛也是网站的访客。如果你的服务器不稳定或者卡住了,蜘蛛每次都很难爬到,有时只能爬到一个页面的一部分。这样一来,随着时间的推移,百度蜘蛛的体验越来越差,你的网站评分也会越来越低,自然会影响你对网站的抓拍,所以一定要舍得选择空间服务器。没有良好的地基,再好的房子也会穿越。 三、网站 的更新频率。每次蜘蛛爬行时,都会存储页面数据。如果第二次爬取发现页面和第一次收录完全一样,说明页面没有更新,不需要蜘蛛频繁爬取。
如果页面内容更新频繁,蜘蛛会更频繁地访问页面,但蜘蛛不是你一个人的,不可能蹲在这里等你更新,所以一定要主动将蜘蛛展示给蜘蛛并定期进行文章update,这样蜘蛛就会有效地按照你的规则来爬行,不仅可以让你的更新文章更快被捕获,而且不会导致蜘蛛频繁白跑。 四、文章的原创性。高质量的原创内容对百度蜘蛛非常有吸引力。蜘蛛的目的是发现新的东西,所以网站updated 文章不要采集,不要天天转载,我们要给蜘蛛有真正有价值的原创内容,蜘蛛才能得到他们喜欢什么,自然会对你的网站产生好感,经常来找吃的。 五、平化网站结构。蜘蛛爬行也有自己的路线。在你给他铺路之前,网站结构不要太复杂,链接层次不要太深。如果链接层次太深,后面的页面就很难被蜘蛛抓取。 . 六、网站程序。在网站程序中,有很多程序可以创建大量重复页面。这个页面一般是通过参数实现的。当一个页面对应多个url时,会导致网站内容重复,可能导致网站降级,严重影响爬虫爬取,所以程序必须保证只有一个url为一页。如果已经生成,尝试通过301重定向、Canonical标签或者robots处理,确保只有一个标准的URL被蜘蛛爬取。
七、Home 推荐。首页是蜘蛛访问次数最多的页面,也是网站权重最高的页面。可以在首页设置更新版块,不仅可以更新首页,提升蜘蛛访问频率,还可以促进更新页面的爬取收录。同样,这个操作也可以在栏目页上进行。 八、检查死链接,设置404页面搜索引擎蜘蛛爬取链接。如果太多的链接无法到达,不仅收录页面的数量会减少,而且你的网站在搜索引擎中的权重也会减少。当蜘蛛遇到死链时,就如同进入了死胡同,不得不回去重新开始,大大降低了蜘蛛在网站的爬行效率,所以一定要定期检查网站的死链,提交给搜索引擎,同时做好网站的404页面,告诉搜索引擎错误页面。 九、大量查看robots文件网站有意无意,我直接在robots文件中屏蔽了百度或网站的一些页面,但我正在寻找蜘蛛不抓取我的页面的原因。这能怪百度吗?你你不让别人进来,百度收录你的网页是怎么来的?所以需要检查网站robots文件是否正常。 十、建筑网站Map。搜索引擎蜘蛛非常喜欢网站Map。 网站Map 是所有链接网站 的容器。很多网站 链接都有很深的层次,蜘蛛很难抓取。 网站Map 可以方便搜索引擎蜘蛛抓取网站页面。通过抓取网站页面,可以清楚地了解网站的结构,所以构建网站地图不仅可以提高抓取速度,还可以获得蜘蛛青睐。
让你网站 被蜘蛛快速爬行的十三种方法。十个一、每次更新页面都主动提交,也是主动提交内容到搜索引擎的好方法,但是不要错过收录Just submit一直提交。提交一次就够了。能不能接受收录是搜索引擎的问题。提交并不意味着收录。 网站search排名靠前的前提是网站有大量的搜索引擎收录的页面,良好的内链建设可以帮助网站页收录。当网站某文章文章被收录时,百度蜘蛛会继续沿着这个页面的超链接爬行,如果你的内链做的好,百度蜘蛛会重新关注你的网站Crawl,这样网站page成为收录的几率大大增加。 查看全部
关键词 采集(关于网站让引擎蜘蛛快速抓取的方法:网站及页面权重)
根据真实调查数据,90%的网民会使用搜索引擎服务寻找自己需要的信息,而这些搜索者中有近70%会在搜索结果自然排名的第一页直接找到自己需要的信息信息。可见,目前SEO对于企业和产品具有不可替代的意义。关于网站让引擎蜘蛛快速爬取:一、网站和页面权重。这必须是第一要务。 网站权重高、资历老、权限大的蜘蛛,一定要特别对待。这样的网站爬的非常频繁,大家都知道搜索引擎蜘蛛对网站非常有效,并不是网站的所有页面都会被爬取,网站的权重越高,爬取的深度就越高,而且对应的可以爬取的页面会增加,这样可以收录的页面也会增加。 . 二、网站server。 网站Server 是网站 的基石。如果网站服务器长时间打不开,那这离你很近,蜘蛛想来也来不来。百度蜘蛛也是网站的访客。如果你的服务器不稳定或者卡住了,蜘蛛每次都很难爬到,有时只能爬到一个页面的一部分。这样一来,随着时间的推移,百度蜘蛛的体验越来越差,你的网站评分也会越来越低,自然会影响你对网站的抓拍,所以一定要舍得选择空间服务器。没有良好的地基,再好的房子也会穿越。 三、网站 的更新频率。每次蜘蛛爬行时,都会存储页面数据。如果第二次爬取发现页面和第一次收录完全一样,说明页面没有更新,不需要蜘蛛频繁爬取。
如果页面内容更新频繁,蜘蛛会更频繁地访问页面,但蜘蛛不是你一个人的,不可能蹲在这里等你更新,所以一定要主动将蜘蛛展示给蜘蛛并定期进行文章update,这样蜘蛛就会有效地按照你的规则来爬行,不仅可以让你的更新文章更快被捕获,而且不会导致蜘蛛频繁白跑。 四、文章的原创性。高质量的原创内容对百度蜘蛛非常有吸引力。蜘蛛的目的是发现新的东西,所以网站updated 文章不要采集,不要天天转载,我们要给蜘蛛有真正有价值的原创内容,蜘蛛才能得到他们喜欢什么,自然会对你的网站产生好感,经常来找吃的。 五、平化网站结构。蜘蛛爬行也有自己的路线。在你给他铺路之前,网站结构不要太复杂,链接层次不要太深。如果链接层次太深,后面的页面就很难被蜘蛛抓取。 . 六、网站程序。在网站程序中,有很多程序可以创建大量重复页面。这个页面一般是通过参数实现的。当一个页面对应多个url时,会导致网站内容重复,可能导致网站降级,严重影响爬虫爬取,所以程序必须保证只有一个url为一页。如果已经生成,尝试通过301重定向、Canonical标签或者robots处理,确保只有一个标准的URL被蜘蛛爬取。
七、Home 推荐。首页是蜘蛛访问次数最多的页面,也是网站权重最高的页面。可以在首页设置更新版块,不仅可以更新首页,提升蜘蛛访问频率,还可以促进更新页面的爬取收录。同样,这个操作也可以在栏目页上进行。 八、检查死链接,设置404页面搜索引擎蜘蛛爬取链接。如果太多的链接无法到达,不仅收录页面的数量会减少,而且你的网站在搜索引擎中的权重也会减少。当蜘蛛遇到死链时,就如同进入了死胡同,不得不回去重新开始,大大降低了蜘蛛在网站的爬行效率,所以一定要定期检查网站的死链,提交给搜索引擎,同时做好网站的404页面,告诉搜索引擎错误页面。 九、大量查看robots文件网站有意无意,我直接在robots文件中屏蔽了百度或网站的一些页面,但我正在寻找蜘蛛不抓取我的页面的原因。这能怪百度吗?你你不让别人进来,百度收录你的网页是怎么来的?所以需要检查网站robots文件是否正常。 十、建筑网站Map。搜索引擎蜘蛛非常喜欢网站Map。 网站Map 是所有链接网站 的容器。很多网站 链接都有很深的层次,蜘蛛很难抓取。 网站Map 可以方便搜索引擎蜘蛛抓取网站页面。通过抓取网站页面,可以清楚地了解网站的结构,所以构建网站地图不仅可以提高抓取速度,还可以获得蜘蛛青睐。
让你网站 被蜘蛛快速爬行的十三种方法。十个一、每次更新页面都主动提交,也是主动提交内容到搜索引擎的好方法,但是不要错过收录Just submit一直提交。提交一次就够了。能不能接受收录是搜索引擎的问题。提交并不意味着收录。 网站search排名靠前的前提是网站有大量的搜索引擎收录的页面,良好的内链建设可以帮助网站页收录。当网站某文章文章被收录时,百度蜘蛛会继续沿着这个页面的超链接爬行,如果你的内链做的好,百度蜘蛛会重新关注你的网站Crawl,这样网站page成为收录的几率大大增加。
关键词 采集(京东搜索为例设置连续动作点击工作台规则+操作步骤*)
采集交流 • 优采云 发表了文章 • 0 个评论 • 222 次浏览 • 2021-08-29 19:03
一、操作步骤
如果网页上有搜索框,但是搜索结果页没有单独的网址,而你想要采集搜索结果,直接规则是采集不能做,你必须先做一个连续的动作(输入+点击)来实现自动输入关键词并搜索,然后采集数据。下面以京东搜索为例,演示自动搜索采集。操作步骤如下:
二、Case规则+操作步骤
**注:**在这种情况下,京东搜索有独立的网址。对于有独立网址的页面,最简单的方法是构造每个关键词搜索网址,然后将线索网址导入到规则中,可以批量采集而不是设置连续动作
第一步:定义一级规则
1.1 打开极手客网络爬虫,输入网址回车,网页加载完毕后,点击“定义规则”按钮,会看到一个浮动窗口,称为工作台,您可以在其中定义规则;
注:此处截图及文字说明均为极手客网络爬虫版本。如果您安装的是Firefox插件版本,则没有“定义规则”按钮,但您应该运行MS Muse。
1.2 在工作台输入一级规则的主题名称,然后点击“检查重复”,会提示“名称可用”或“名称已被占用,可编辑:是” ,您可以使用此主题名称,否则请重命名。
1.3 这层规则主要是设置连续动作,这样排序框就可以随意抓取一条信息,用它来判断是否为爬虫执行采集。双击网页上的信息,输入标签名称,勾选确认,然后勾选关键内容,输入第一个标签的排序框名称,标签映射完成。
提示:为了准确定位网页信息,点击定义规则会冻结整个网页,无法跳转到网页链接。再次点击定义规则,返回正常网页模式。
第 2 步:定义连续动作
点击工作台的“Continuous Action”选项卡,点击New按钮新建一个action,每个action的设置方法都是一样的,基本操作如下:
2.1,输入目标学科名称
这里的目标主题名称是填写二级主题名称,点击“谁在使用”查看目标主题名称是否可用,如果已经被占用,只需更改一个主题名称即可。
2.2,创建第一个动作:回车
创建一个新动作并选择动作类型作为输入。
2.2.1,填写定位表达式
首先点击输入框,定位输入框的节点,然后点击“Auto Generate XPath”按钮,可以选择“Preference id”或者“Preference class”,就可以得到输入的xpath表达式框,然后单击“搜索”按钮,检查这个xpath是否可以在输入框中唯一定位,如果没有问题,将xpath复制到定位表达式框中。
**注:** 定位表达式中的xpath是锁定动作对象的整个有效操作范围,具体指的是可以通过鼠标点击或进入成功的网页模块,而不是找到底部的 text() 节点。
2.2.2,输入关键词
输入关键词填写你要搜索的关键词,可以输入一个关键词,也可以输入多个关键词,输入多个关键词使用双分号;;把每个关键词Separate,免费版只支持关键词5以内,旗舰版可以使用爆弹功能,支持关键词10000以内
2.2.3,输入动作名称
告诉自己这一步是做什么的,以便你以后可以修改。
2.3,创建第二个动作:点击
参考2.2的操作,创建第二个action,选择类型为click,定位搜索按钮,然后自动生成xpath检查是否锁定到唯一节点。如果没有问题,填写定位表达式。 .
2.4,保存规则
点击“保存规则”按钮保存完成的一级规则
第 3 步:定义二级规则
3.1,新建规则
创建二级规则,点击“定义规则”返回正常网页模式,输入关键词搜索结果,再次点击“定义规则”切换到规则制定模式,点击“左上角规则”菜单->“新建”,输入主题名称,其中主题名称是在第一级规则的连续动作中填写的目标主题名称。
3.2,标记你想要的信息采集
3.2.1,在网页上标注你想要采集的信息,这里是标注产品名称和价格,因为标注只对文字信息有效,以及产品链接details 是属性节点@href,所以不能在链接上做这么直观的标记,要做内容映射,具体看下面的操作。
3.2.2,点击产品名称,下方的DOM节点定位到A标签,展开A标签下的属性节点,可以找到代表URL的@href节点,右击节点,选择“New Capture“Fetch content”,输入一个名字,一般给抓取到的内容取一个与地址相关的名字,比如“下级网址”,或者“下级链接”等等。然后在工作台上,我看到爬取的内容是可用的。如果你还想进入商品详情页采集,你必须对照爬取的内容检查下层的线索,并进行分层爬取。
3.2.3、设置“关键内容”选项,让爬虫判断采集规则是否合适。在排序框中,选择网页上不可避免的标签,并勾选“关键内容”。这里选择“名称”作为“关键内容”。
3.2.4,只要在前面标注一个产品,就可以得到一个产品信息。如果你想采集下整个页面上的每一个产品,可以做一个样例拷贝,没有如果你看懂了,请参考基础教程“采集表数据”
3.3,设置翻页路线
在爬虫路由中设置翻页,这里是标记提示,不明白的请参考基础教程《设置翻页采集》
3.4,保存规则
点击“测试”以检查信息的完整性。如果不完整,重新标记可以覆盖之前的内容。确认没有问题后,点击“保存规则”。
第 4 步:捕获数据
4.1,连续动作是连续执行的,所以只要运行一级主题,二级主题就不需要运行了。打开DS计数器,搜索一级主题名称,点击“单一搜索”或“采集”,可以看到在浏览器窗口中自动输入并搜索关键词,然后调用二级主题自动采集搜索结果。
4.2,一级主题没有采集到有意义的信息,所以我们只看二级主题文件夹,可以看到采集的搜索结果数据,搜索关键词是默认记录在xml文件的actionvalue字段中,这样可以一一匹配。 查看全部
关键词 采集(京东搜索为例设置连续动作点击工作台规则+操作步骤*)
一、操作步骤
如果网页上有搜索框,但是搜索结果页没有单独的网址,而你想要采集搜索结果,直接规则是采集不能做,你必须先做一个连续的动作(输入+点击)来实现自动输入关键词并搜索,然后采集数据。下面以京东搜索为例,演示自动搜索采集。操作步骤如下:
二、Case规则+操作步骤
**注:**在这种情况下,京东搜索有独立的网址。对于有独立网址的页面,最简单的方法是构造每个关键词搜索网址,然后将线索网址导入到规则中,可以批量采集而不是设置连续动作
第一步:定义一级规则
1.1 打开极手客网络爬虫,输入网址回车,网页加载完毕后,点击“定义规则”按钮,会看到一个浮动窗口,称为工作台,您可以在其中定义规则;
注:此处截图及文字说明均为极手客网络爬虫版本。如果您安装的是Firefox插件版本,则没有“定义规则”按钮,但您应该运行MS Muse。
1.2 在工作台输入一级规则的主题名称,然后点击“检查重复”,会提示“名称可用”或“名称已被占用,可编辑:是” ,您可以使用此主题名称,否则请重命名。
1.3 这层规则主要是设置连续动作,这样排序框就可以随意抓取一条信息,用它来判断是否为爬虫执行采集。双击网页上的信息,输入标签名称,勾选确认,然后勾选关键内容,输入第一个标签的排序框名称,标签映射完成。
提示:为了准确定位网页信息,点击定义规则会冻结整个网页,无法跳转到网页链接。再次点击定义规则,返回正常网页模式。
第 2 步:定义连续动作
点击工作台的“Continuous Action”选项卡,点击New按钮新建一个action,每个action的设置方法都是一样的,基本操作如下:
2.1,输入目标学科名称
这里的目标主题名称是填写二级主题名称,点击“谁在使用”查看目标主题名称是否可用,如果已经被占用,只需更改一个主题名称即可。
2.2,创建第一个动作:回车
创建一个新动作并选择动作类型作为输入。
2.2.1,填写定位表达式
首先点击输入框,定位输入框的节点,然后点击“Auto Generate XPath”按钮,可以选择“Preference id”或者“Preference class”,就可以得到输入的xpath表达式框,然后单击“搜索”按钮,检查这个xpath是否可以在输入框中唯一定位,如果没有问题,将xpath复制到定位表达式框中。
**注:** 定位表达式中的xpath是锁定动作对象的整个有效操作范围,具体指的是可以通过鼠标点击或进入成功的网页模块,而不是找到底部的 text() 节点。
2.2.2,输入关键词
输入关键词填写你要搜索的关键词,可以输入一个关键词,也可以输入多个关键词,输入多个关键词使用双分号;;把每个关键词Separate,免费版只支持关键词5以内,旗舰版可以使用爆弹功能,支持关键词10000以内
2.2.3,输入动作名称
告诉自己这一步是做什么的,以便你以后可以修改。
2.3,创建第二个动作:点击
参考2.2的操作,创建第二个action,选择类型为click,定位搜索按钮,然后自动生成xpath检查是否锁定到唯一节点。如果没有问题,填写定位表达式。 .
2.4,保存规则
点击“保存规则”按钮保存完成的一级规则
第 3 步:定义二级规则
3.1,新建规则
创建二级规则,点击“定义规则”返回正常网页模式,输入关键词搜索结果,再次点击“定义规则”切换到规则制定模式,点击“左上角规则”菜单->“新建”,输入主题名称,其中主题名称是在第一级规则的连续动作中填写的目标主题名称。
3.2,标记你想要的信息采集
3.2.1,在网页上标注你想要采集的信息,这里是标注产品名称和价格,因为标注只对文字信息有效,以及产品链接details 是属性节点@href,所以不能在链接上做这么直观的标记,要做内容映射,具体看下面的操作。
3.2.2,点击产品名称,下方的DOM节点定位到A标签,展开A标签下的属性节点,可以找到代表URL的@href节点,右击节点,选择“New Capture“Fetch content”,输入一个名字,一般给抓取到的内容取一个与地址相关的名字,比如“下级网址”,或者“下级链接”等等。然后在工作台上,我看到爬取的内容是可用的。如果你还想进入商品详情页采集,你必须对照爬取的内容检查下层的线索,并进行分层爬取。
3.2.3、设置“关键内容”选项,让爬虫判断采集规则是否合适。在排序框中,选择网页上不可避免的标签,并勾选“关键内容”。这里选择“名称”作为“关键内容”。
3.2.4,只要在前面标注一个产品,就可以得到一个产品信息。如果你想采集下整个页面上的每一个产品,可以做一个样例拷贝,没有如果你看懂了,请参考基础教程“采集表数据”
3.3,设置翻页路线
在爬虫路由中设置翻页,这里是标记提示,不明白的请参考基础教程《设置翻页采集》
3.4,保存规则
点击“测试”以检查信息的完整性。如果不完整,重新标记可以覆盖之前的内容。确认没有问题后,点击“保存规则”。
第 4 步:捕获数据
4.1,连续动作是连续执行的,所以只要运行一级主题,二级主题就不需要运行了。打开DS计数器,搜索一级主题名称,点击“单一搜索”或“采集”,可以看到在浏览器窗口中自动输入并搜索关键词,然后调用二级主题自动采集搜索结果。
4.2,一级主题没有采集到有意义的信息,所以我们只看二级主题文件夹,可以看到采集的搜索结果数据,搜索关键词是默认记录在xml文件的actionvalue字段中,这样可以一一匹配。
关键词 采集(中提炼关键词的思路指导(图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 170 次浏览 • 2021-08-29 19:00
评论/问答可以充分反映精准用户的消费偏好和关注点。从评论/问答中提取关键词也是一种有效的方法。
复制竞品的所有评论,然后用一些文本分析工具提炼关键词以供参考。
5.选择关键词上线上市
找到关键词后,需要注意的是,不是关键词哪个搜索量大,而是关键词用了哪个。因为很明显关键词越热,竞争也越大。如果是新产品使用这个关键词,就很难获得搜索排名,没有曝光率。
聪明的做法是选择一些搜索量可以接受并持续上升的关键词,这样市场前景可观,竞争不那么激烈,更容易获得更好的排名。
listing上线后,还要持续关注关键词各个渠道的情况,不断优化listing,实现健康成长。
问题
可能遇到的问题
在选品、找货源、找关键词的过程中,需要大量的平台数据。少量数据查询后可以导出(如关键词挖矿工具一般查询后可以直接导出结果),但大部分数据,尤其是亚马逊平台的数据,不支持导出。
过去很长一段时间,Sandy 和同事在平台上手动检查数据(关键词Search 结果、排名数据、1688 源数据、下拉搜索框数据、竞品列表数据、评论数据、问答数据等),将这些数据一一记录在表格中,并按照一定的频率手动更新。这给外商造成了很大的困扰:
①时间成本巨大
每天至少花 3 小时打开各种网页,记录各种数据。
② 无法保证数据完整性
无法将记录与经常更新的数据源同步。比如排行榜每1小时更新一次,很难同步所有记录。
③ 无法保证数据的准确性
人工记录容易出错,需要多人验证,否则会影响后续数据分析的准确性。
④ 建库失败,数据难以复用
在大的选品思路指导下,每个同事的具体思路和标准都不一样,数据难以复用。
项目
优采云解决方案
通过优采云,在实现数据自由的同时解放双手——需要数据时,可以找到对应的采集模板,一键导出所有历史数据,有效节省时间,保护数据完整性和准确性。
① 自动采集各种数据
优采云采集 非常灵活。上面提到的关键词data、关键词search数据、排名数据、TOP/competitive store新产品数据都可以做成采集模板。创建采集模板后,点击【启动采集】自动获取对应数据,支持导出为Excel、数据库等多种格式。
目前优采云官方已经推出了很多跨境电商模板供跨境合作伙伴使用。如果没有在下面的表格中,您也可以联系我们的官方客服提交您的需求并做出决定
②保证数据完整性
优采云拥有专属云端采集模式,可实现采集自动定时,最高频率支持每分钟自动激活采集。
排行榜之类的数据每小时更新一次,可以设置为每小时启动采集。竞品店铺上线数据可能2天更新一次,您可以设置采集每2天激活一次。
③ 保证数据的准确性
优采云是智能数据自动采集机器人。它准确而不知疲倦地识别。将目标数据一一丢掉采集,保证数据的准确性。
④ 搭建原创企业数据库
在保证数据的完整性和准确性后,公司可以建立一个原创的入选产品数据库,所有同事都可以在这个数据库中选择产品,一个数据复用性强,不需要大家重复轮子,第二个方便后续与原创数据对比,深入回顾总结。
同时,如果条件允许,公司计划搭建一套可视化看板,让优采云采集收到的数据可以实时连接到自己的数据库中,然后显示在视觉看板同时进行。可以预见,这将大大提高工作效率。 查看全部
关键词 采集(中提炼关键词的思路指导(图))
评论/问答可以充分反映精准用户的消费偏好和关注点。从评论/问答中提取关键词也是一种有效的方法。
复制竞品的所有评论,然后用一些文本分析工具提炼关键词以供参考。
5.选择关键词上线上市
找到关键词后,需要注意的是,不是关键词哪个搜索量大,而是关键词用了哪个。因为很明显关键词越热,竞争也越大。如果是新产品使用这个关键词,就很难获得搜索排名,没有曝光率。
聪明的做法是选择一些搜索量可以接受并持续上升的关键词,这样市场前景可观,竞争不那么激烈,更容易获得更好的排名。
listing上线后,还要持续关注关键词各个渠道的情况,不断优化listing,实现健康成长。
问题
可能遇到的问题
在选品、找货源、找关键词的过程中,需要大量的平台数据。少量数据查询后可以导出(如关键词挖矿工具一般查询后可以直接导出结果),但大部分数据,尤其是亚马逊平台的数据,不支持导出。
过去很长一段时间,Sandy 和同事在平台上手动检查数据(关键词Search 结果、排名数据、1688 源数据、下拉搜索框数据、竞品列表数据、评论数据、问答数据等),将这些数据一一记录在表格中,并按照一定的频率手动更新。这给外商造成了很大的困扰:
①时间成本巨大
每天至少花 3 小时打开各种网页,记录各种数据。
② 无法保证数据完整性
无法将记录与经常更新的数据源同步。比如排行榜每1小时更新一次,很难同步所有记录。
③ 无法保证数据的准确性
人工记录容易出错,需要多人验证,否则会影响后续数据分析的准确性。
④ 建库失败,数据难以复用
在大的选品思路指导下,每个同事的具体思路和标准都不一样,数据难以复用。
项目
优采云解决方案
通过优采云,在实现数据自由的同时解放双手——需要数据时,可以找到对应的采集模板,一键导出所有历史数据,有效节省时间,保护数据完整性和准确性。
① 自动采集各种数据
优采云采集 非常灵活。上面提到的关键词data、关键词search数据、排名数据、TOP/competitive store新产品数据都可以做成采集模板。创建采集模板后,点击【启动采集】自动获取对应数据,支持导出为Excel、数据库等多种格式。
目前优采云官方已经推出了很多跨境电商模板供跨境合作伙伴使用。如果没有在下面的表格中,您也可以联系我们的官方客服提交您的需求并做出决定
②保证数据完整性
优采云拥有专属云端采集模式,可实现采集自动定时,最高频率支持每分钟自动激活采集。
排行榜之类的数据每小时更新一次,可以设置为每小时启动采集。竞品店铺上线数据可能2天更新一次,您可以设置采集每2天激活一次。
③ 保证数据的准确性
优采云是智能数据自动采集机器人。它准确而不知疲倦地识别。将目标数据一一丢掉采集,保证数据的准确性。
④ 搭建原创企业数据库
在保证数据的完整性和准确性后,公司可以建立一个原创的入选产品数据库,所有同事都可以在这个数据库中选择产品,一个数据复用性强,不需要大家重复轮子,第二个方便后续与原创数据对比,深入回顾总结。
同时,如果条件允许,公司计划搭建一套可视化看板,让优采云采集收到的数据可以实时连接到自己的数据库中,然后显示在视觉看板同时进行。可以预见,这将大大提高工作效率。
关键词 采集(斗牛原Simon爱站采集工具|爱站长尾词挖掘工具综合版 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 188 次浏览 • 2021-08-29 16:10
)
Simon爱站关键词采集 工具是一个优秀的站长工具。最近,很多人都在寻找这个工具。我在官网找了一下,发现现在官方的Simon爱站关键词采集工具是和其他工具结合的,不过现在是免费使用的,有需要的可以从这个页面下载!
官方介绍:
新版斗牛原创Simon爱站关键词采集工具|爱站长尾词探工具集成版V4.0无限制,完全免费!
功能包括:
爱站关键词的采集tools,爱站长尾词的挖掘工具,可以完全自定义采集,挖掘你的词库,支持多站点多关键词,查询结果数据导出、爱站网站登录、登陆页面URL查询、查询间隔设置等,更多功能等你发现。 . (PS:如果采集时软件不稳定,出现问题,请将查询间隔调大一点,我电脑上设置5秒,可以永久挂断电话.你的电脑可以根据情况设置;)
六喜小贴士:
最好先登录本站再操作,否则会有查询深度或查询次数限制,详情请参考爱站官方说明。激活会员后,好像没有限制了。
使用说明:
运行软件后,用户只需输入采集的网址,然后点击采集按钮即可。 采集成功后即可导出结果!
更新日志:
2014 年 5 月 15 日:
更新日志:
升级到 V4.0
1、更改网络访问方式
2、change ip功能,免费用户无此功能
3、部分功能优化
2014 年 2 月 15 日:
更新到 V3.0
1、【软件更换前的采集方法,对用户电脑IE版本没有要求】
2、提高软件稳定性,提取效率提高3倍
3、software 更名为《斗牛》系列
4、follow 网站更新,添加pc端、移动端数据
我们为什么要学习长尾关键词?有目标关键词还不够吗?
是的,只有目标关键词 是不够的。目标关键词带来的用户非常定向,只能带来搜索词的用户。通常我们需要更多的用户流量,用户的搜索词是不同的。这时候需要回复网站的长尾关键词进行挖掘、分析、优化。
长尾关键词从字母上理解,很多关键词衍生自一个关键词,很长,很多,类似尾巴。 . .
如果seo是目标关键词,那么后面的相关搜索就是seo关键词的长尾。 (可以无限挖掘,比如seo新手教程等等都是seo关键词的长尾)
查看全部
关键词 采集(斗牛原Simon爱站采集工具|爱站长尾词挖掘工具综合版
)
Simon爱站关键词采集 工具是一个优秀的站长工具。最近,很多人都在寻找这个工具。我在官网找了一下,发现现在官方的Simon爱站关键词采集工具是和其他工具结合的,不过现在是免费使用的,有需要的可以从这个页面下载!
官方介绍:
新版斗牛原创Simon爱站关键词采集工具|爱站长尾词探工具集成版V4.0无限制,完全免费!
功能包括:
爱站关键词的采集tools,爱站长尾词的挖掘工具,可以完全自定义采集,挖掘你的词库,支持多站点多关键词,查询结果数据导出、爱站网站登录、登陆页面URL查询、查询间隔设置等,更多功能等你发现。 . (PS:如果采集时软件不稳定,出现问题,请将查询间隔调大一点,我电脑上设置5秒,可以永久挂断电话.你的电脑可以根据情况设置;)
六喜小贴士:
最好先登录本站再操作,否则会有查询深度或查询次数限制,详情请参考爱站官方说明。激活会员后,好像没有限制了。
使用说明:
运行软件后,用户只需输入采集的网址,然后点击采集按钮即可。 采集成功后即可导出结果!
更新日志:
2014 年 5 月 15 日:
更新日志:
升级到 V4.0
1、更改网络访问方式
2、change ip功能,免费用户无此功能
3、部分功能优化
2014 年 2 月 15 日:
更新到 V3.0
1、【软件更换前的采集方法,对用户电脑IE版本没有要求】
2、提高软件稳定性,提取效率提高3倍
3、software 更名为《斗牛》系列
4、follow 网站更新,添加pc端、移动端数据
我们为什么要学习长尾关键词?有目标关键词还不够吗?
是的,只有目标关键词 是不够的。目标关键词带来的用户非常定向,只能带来搜索词的用户。通常我们需要更多的用户流量,用户的搜索词是不同的。这时候需要回复网站的长尾关键词进行挖掘、分析、优化。
长尾关键词从字母上理解,很多关键词衍生自一个关键词,很长,很多,类似尾巴。 . .
如果seo是目标关键词,那么后面的相关搜索就是seo关键词的长尾。 (可以无限挖掘,比如seo新手教程等等都是seo关键词的长尾)
关键词 采集(搜索引擎基本同义词采集的核心功能及具体需求及需求)
采集交流 • 优采云 发表了文章 • 0 个评论 • 165 次浏览 • 2021-08-28 13:02
关键词采集是批量下载谷歌、uc、yahoo、bing、雅虎、naver等前端同义词采集,实现同义词搜索和分词、批量采集,同义词提取等web抓取方法,深入研究功能,从产品方案角度分析和定位。在开发之初,核心是明确核心功能及具体需求:搜索引擎基本同义词采集,每个关键词可以批量下载google、bing、雅虎、chinaz、新浪新闻、微博等各平台、各渠道、各站点的同义词。
同义词提取,实现各个平台、渠道、站点的同义词采集;关键词筛选,根据不同平台定位的关键词进行排序,提取分词所需结果即可批量下载文章全部内容为二进制产品包pg项目经理参加完总部培训后,受到网络流量和活跃度两个方面的直接启发,我分别决定采用两种方法完成对比业务场景对比服务接入功能,用业务数据去区分用户对产品的功能需求程度。
成熟的elasticsearch架构中,实现分词引擎需要使用这两种方法:下行广播和内部收敛,分词器的开发过程就像对文章进行分类。但是在ack抓取场景中,为解决抓取时存在时效性问题,增加对输入包的修改过程,在需要抓取的文章标题前面增加服务端标识xxxx,而不需要在输入包后面直接增加服务端标识xxxx,避免分词器在生成xxxx时,覆盖未抓取到的内容。
表层页面抓取与服务端搜索能力对比如果要抓取页面内容a和页面a+页面b的关键词,可以简单使用下行广播,通过elasticsearch存放下行广播文件。通过下行广播抓取页面的抓取服务服务端下行广播的抓取是使用加密的,只抓取保存在服务端的抓取文件,外部抓取无法下载成功,抓取成功返回解密后的文件。服务端搜索能力要求,提取出搜索数据包,输入到google搜索服务进行下载。
如要抓取页面a+页面b关键词,则需要对页面a+页面b内容进行关键词匹配,通过分词器完成,不需要向外提供服务端抓取链接。 查看全部
关键词 采集(搜索引擎基本同义词采集的核心功能及具体需求及需求)
关键词采集是批量下载谷歌、uc、yahoo、bing、雅虎、naver等前端同义词采集,实现同义词搜索和分词、批量采集,同义词提取等web抓取方法,深入研究功能,从产品方案角度分析和定位。在开发之初,核心是明确核心功能及具体需求:搜索引擎基本同义词采集,每个关键词可以批量下载google、bing、雅虎、chinaz、新浪新闻、微博等各平台、各渠道、各站点的同义词。
同义词提取,实现各个平台、渠道、站点的同义词采集;关键词筛选,根据不同平台定位的关键词进行排序,提取分词所需结果即可批量下载文章全部内容为二进制产品包pg项目经理参加完总部培训后,受到网络流量和活跃度两个方面的直接启发,我分别决定采用两种方法完成对比业务场景对比服务接入功能,用业务数据去区分用户对产品的功能需求程度。
成熟的elasticsearch架构中,实现分词引擎需要使用这两种方法:下行广播和内部收敛,分词器的开发过程就像对文章进行分类。但是在ack抓取场景中,为解决抓取时存在时效性问题,增加对输入包的修改过程,在需要抓取的文章标题前面增加服务端标识xxxx,而不需要在输入包后面直接增加服务端标识xxxx,避免分词器在生成xxxx时,覆盖未抓取到的内容。
表层页面抓取与服务端搜索能力对比如果要抓取页面内容a和页面a+页面b的关键词,可以简单使用下行广播,通过elasticsearch存放下行广播文件。通过下行广播抓取页面的抓取服务服务端下行广播的抓取是使用加密的,只抓取保存在服务端的抓取文件,外部抓取无法下载成功,抓取成功返回解密后的文件。服务端搜索能力要求,提取出搜索数据包,输入到google搜索服务进行下载。
如要抓取页面a+页面b关键词,则需要对页面a+页面b内容进行关键词匹配,通过分词器完成,不需要向外提供服务端抓取链接。
2018年11月2日-如何利用免费长尾关键词工具拓展长尾词
采集交流 • 优采云 发表了文章 • 0 个评论 • 67 次浏览 • 2021-08-26 04:06
#》2018年1月29日-本文介绍优采云采集词库网内长尾关键词的使用方法。长尾关键词挖矿对于站长来说是非常重要的一项技能,尾巴在长尾理论中的作用不容忽视。在搜索中..."
#《2018年8月27日-长尾词往往占据了当前所谓“词条”的大部分,但相对来说:真的排到首页了……我不想被原创或者采集这个话题比较纠结,这里提到文章quality,可以理解为...''
#"爱站网关键词挖矿工具为站长提供免费相关关键词、长尾关键词查询,助您快速轻松拓展长尾关键词。"
#"2018年11月2日-如何使用免费的长尾关键词工具扩展长尾词,我们在做网络营销的时候经常需要扩展长尾关键词,但是太慢了手动扩容 现在,如何高效使用长尾关键词挖矿工具扩长尾...''
#"2018年12月2日-优采云software关键词Mining tool 为SEO提供免费热点关键词、下拉关键词、相关关键词、长尾关键词挖掘和查询,帮助您轻松方便地挖掘关键词和长尾词。快速..."
#"September 17, 2018-标题出现长尾词,文章标题出现长尾词。2、长尾词分类确定网站topic和方向,用场采集出含...”
#"2018年1月30日-作为站长常用的工具,爱战有长尾关键词挖矿功能。这些关键词对于做SEO的朋友来说非常有价值。下关键词需要@采集,对于网站内容的制作方向,..." 查看全部
2018年11月2日-如何利用免费长尾关键词工具拓展长尾词
#》2018年1月29日-本文介绍优采云采集词库网内长尾关键词的使用方法。长尾关键词挖矿对于站长来说是非常重要的一项技能,尾巴在长尾理论中的作用不容忽视。在搜索中..."
#《2018年8月27日-长尾词往往占据了当前所谓“词条”的大部分,但相对来说:真的排到首页了……我不想被原创或者采集这个话题比较纠结,这里提到文章quality,可以理解为...''
#"爱站网关键词挖矿工具为站长提供免费相关关键词、长尾关键词查询,助您快速轻松拓展长尾关键词。"
#"2018年11月2日-如何使用免费的长尾关键词工具扩展长尾词,我们在做网络营销的时候经常需要扩展长尾关键词,但是太慢了手动扩容 现在,如何高效使用长尾关键词挖矿工具扩长尾...''
#"2018年12月2日-优采云software关键词Mining tool 为SEO提供免费热点关键词、下拉关键词、相关关键词、长尾关键词挖掘和查询,帮助您轻松方便地挖掘关键词和长尾词。快速..."
#"September 17, 2018-标题出现长尾词,文章标题出现长尾词。2、长尾词分类确定网站topic和方向,用场采集出含...”
#"2018年1月30日-作为站长常用的工具,爱战有长尾关键词挖矿功能。这些关键词对于做SEO的朋友来说非常有价值。下关键词需要@采集,对于网站内容的制作方向,..."
提供关键词分析功能,帮助用户在软件上快速采集到你需要的关键词
采集交流 • 优采云 发表了文章 • 0 个评论 • 145 次浏览 • 2021-08-26 04:05
关键词采集 系统提供关键词分析功能,可以帮助用户在软件上快速采集到您需要的关键词。本软件可以将你输入的关键词裂变转换成多个关键词添加到TXT文件中,加载到软件中,关键词裂变可以立即查看相关内容,对需要的朋友很有帮助分析百度关键词。本软件可以自动采集关键词,您可以根据您输入的关键词获取百度热搜的相关词,采集的内容会直接显示在软件界面上,您可以查看内容采集的,可以查看采集的状态,或者对关键词采集设置页数,如果需要裂变百度关键词,可以下载这个软件!
软件功能
1、关键词采集 系统自动检查百度关键词采集
2、根据你设置的关键词采集内容,每个关键词都可以在百度采集10页面
3、提供了很多设置功能,可以快速导入关键词裂变
4、也可以在关键词软件中导出,可以立即查看采集的内容
5、轻松搞定数百个单词,选择合适的单词使用
软件功能
1、可以使用这个软件采集产品关键词
2、可以用这个软件采集热搜词
3、适合站长使用,对后期优化很有帮助关键词
4、还可以帮助竞拍朋友获得需要使用的关键词
5、fission 效果还是很不错的,几秒钟就可以采集一百多个字
使用说明
1、打开百度下拉词相关词采集工具.exe,这里是软件的界面
2、将你的关键词加载到软件中,需要在TXT中编辑关键词,每行一个,导入后就可以开始裂变了。
3、显示裂变结果如图,可以显示很多裂变内容,可以在采集软件中停止@
4、点击停止采集软件自动关闭采集功能,以便保存结果
5、显示导出功能,如果需要保存本软件采集关键词可以导出
6、表示导出完成,右侧可以显示导出成功的提示,可以在主程序界面查看关键词。
7、打开主程序文件夹查看“Fission关键词Save.txt”
8、展示了很多关键词,需要联系百度关键词采集可以下载这个软件
查看全部
提供关键词分析功能,帮助用户在软件上快速采集到你需要的关键词
关键词采集 系统提供关键词分析功能,可以帮助用户在软件上快速采集到您需要的关键词。本软件可以将你输入的关键词裂变转换成多个关键词添加到TXT文件中,加载到软件中,关键词裂变可以立即查看相关内容,对需要的朋友很有帮助分析百度关键词。本软件可以自动采集关键词,您可以根据您输入的关键词获取百度热搜的相关词,采集的内容会直接显示在软件界面上,您可以查看内容采集的,可以查看采集的状态,或者对关键词采集设置页数,如果需要裂变百度关键词,可以下载这个软件!
软件功能
1、关键词采集 系统自动检查百度关键词采集
2、根据你设置的关键词采集内容,每个关键词都可以在百度采集10页面
3、提供了很多设置功能,可以快速导入关键词裂变
4、也可以在关键词软件中导出,可以立即查看采集的内容
5、轻松搞定数百个单词,选择合适的单词使用
软件功能
1、可以使用这个软件采集产品关键词
2、可以用这个软件采集热搜词
3、适合站长使用,对后期优化很有帮助关键词
4、还可以帮助竞拍朋友获得需要使用的关键词
5、fission 效果还是很不错的,几秒钟就可以采集一百多个字
使用说明
1、打开百度下拉词相关词采集工具.exe,这里是软件的界面
2、将你的关键词加载到软件中,需要在TXT中编辑关键词,每行一个,导入后就可以开始裂变了。
3、显示裂变结果如图,可以显示很多裂变内容,可以在采集软件中停止@
4、点击停止采集软件自动关闭采集功能,以便保存结果
5、显示导出功能,如果需要保存本软件采集关键词可以导出
6、表示导出完成,右侧可以显示导出成功的提示,可以在主程序界面查看关键词。
7、打开主程序文件夹查看“Fission关键词Save.txt”
8、展示了很多关键词,需要联系百度关键词采集可以下载这个软件
那要如何才能获取这里的关键词内容?(一)
采集交流 • 优采云 发表了文章 • 0 个评论 • 70 次浏览 • 2021-08-24 18:07
本文文章,建议在PC端观看。整篇文章的阅读时间看个人理解。 config和cookie需要抓包,填写userid、token、eventId、reqid这四个值的来源,即抓包'关键词规划师',userid是整数类型,token, eventId 和 reqid 是字符串类型。
百度竞标中的关键词规划师是SEO从业者很好的关键词来源。
如何在此处获取关键词 内容?
此代码基于网上2.7的版本,修改为3.*也可以使用。
(其实就是改了打印,23333)
同样,这段代码也没有一步步教你如何解决登录和获取cookie的问题。直接使用登录后的cookie和登录后的from_data数据,注意下面代码最上面的注释,不然不行别怪我。
# -*- coding: utf-8 -*-
#本代码改编自网络上Python2.7版本代码。
#Python版本:3.*,需要安装requests,JSON库不知道要不要重新安装
#使用本代码,首先将代码保存为.py文件,并且在相同目录中新建名字为cigeng的txt文件
#在cigeng.txt文件中输入要采集的关键词,一行一个。保存。
#成功采集后的数据,保存在相同目录中resultkeys.txt文件中。
#如果只要关键词,不要其他黑马等数据,那么就修改key_data函数下else中的数据。
import requests
import json
import time
def url_data(key,config,cookie,shibai=3):
headers={
'Accept': '*/*',
'Accept-Encoding': 'gzip, deflate',
'Accept-Language': 'zh-CN,zh;q=0.8,en;q=0.6',
'Connection': 'keep-alive',
'Content-Type': 'application/x-www-form-urlencoded',
'Cookie': cookie,
#在下面config这个变量值下面的cookie中粘贴进抓包后的cookie,这里不要动。
'Host': 'fengchao.baidu.com',
'Origin': 'http://fengchao.baidu.com',
'Referer': 'http://fengchao.baidu.com/nirvana/main.html?userid=%s' % config['userid'],
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_6) AppleWebKit/537.36 '
'(KHTML, like Gecko) Chrome/56.0.2924.87 Safari/537.36'
}
params={
"logid":401075077,
"query":key,
"querySessions":[key],
"querytype":1,
"regions":"16",
"device":0,
"rgfilter":1,
"entry":"kr_station",
"planid":"0",
"unitid":"0",
"needAutounit":False,
"filterAccountWord":True,
"attrShowReasonTag":[],
"attrBusinessPointTag":[],
"attrWordContainTag":[],
"showWordContain":"",
"showWordNotContain":"",
"pageNo":1,
"pageSize":1000,
"orderBy":"",
"order":"",
"forceReload":True
}
from_data={
'params':json.dumps(params),
'path':'jupiter/GET/kr/word',
'userid':config['userid'],
'token':config['token'],
'eventId':config['eventId'],
'reqid':config['reqid']
}
qurl="http://fengchao.baidu.com/nirv ... onfig['reqid']
try:
whtml=requests.post(qurl,headers=headers,data=from_data)
except requests.exceptions.RequestException:
resultitem={}
erry="请求三次都是错误!"
if shibai > 0:
return url_data(key,config,cookie,shibai-1)
else:
whtml.encoding="utf-8"
try:
resultitem = whtml.json()
except ValueError:
resultitem = {}
erry = "获取不到json数据,可能是被封了吧,谁知道呢?"
else:
erry = None
return resultitem,erry
config={
#这部分数据和下面的cookie,直接开浏览器抓包就能看到相应数据。复制黏贴到相应位置
'userid': '',
'token':'',
'eventId':'',
'reqid':''
}
cookie=" "
def key_data(resultitem):
kws=['关键词\t日均搜索量\tpc\t移动\t竞争度\n']
try:
resultitem=resultitem['data']['group'][0]['resultitem']
except (KeyError, ValueError, TypeError):
resultitem=[]
erry="没有获取到关键词"
else:
for items in resultitem:
#如果你只想要关键词,那么只保留word就可以。
word=items['word']
pv=items['pv']#日均搜索量
pvPc=items['pvPc']
pvWise=items['pvWise']
kwc=items['kwc']#竞争度
kwslist=str(word)+'\t'+str(pv)+'\t'+str(pvPc)+'\t'+str(pvWise)+'\t'+str(kwc)+'\n'
kws.append(str(kwslist))
print (word,pv,pvPc,pvWise,kwc)
## kws.append(str(word))
## print (word)
erry=None
return kws,erry
sfile = open('resultkeys.txt', 'w') # 结果保存文件
faileds = open('faileds.txt', 'w') # 查询失败保存文件
for key in open("cigeng.txt"): #要查询的关键词存放的载体,一行一个,同当前代码文件相同目录。
key=key.strip()
print ("正在拓展:%s"%key)
resultitem,erry=url_data(key,config,cookie)
if erry:
print (key,erry)
faileds.write('%s\n' % key)
faileds.flush()
continue
keylist,erry=key_data(resultitem)
if erry:
print (key,erry)
faileds.write('%s\n' % word)
faileds.flush()
continue
for kw in keylist:
sfile.write('%s\n'%kw)
faileds.flush()
continue
以下代码是浏览器(360极速浏览器)抓取的,#(需要挂梯子)网站格式的数据,没有任何改动。方便新人理解。需要导入JSON,使用JSON解析代码,但要注意JSON内容过多,小心IDLE卡住。
import requests
cookies = {'这部分有数据的,我删了,自己抓包后就知道'
}
headers = {
'Origin': 'http://fengchao.baidu.com',
'Accept-Encoding': 'gzip, deflate',
'Accept-Language': 'zh-CN,zh;q=0.9',
'User-Agent': 'Mozilla/5.0 (Windows NT 5.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36',
'Content-Type': 'application/x-www-form-urlencoded',
'Accept': '*/*',
'Referer': 'http://fengchao.baidu.com/nirvana/main.html?userid=6941153',
'Connection': 'keep-alive',
}
params = (
('path', 'jupiter/GET/kr/word'),
('reqid', '4b534c46-1ea0-4eca-b581-154181423578'),
)
data = {
'userid': '',
'token': '',
'reqid': '',
'path': 'jupiter/GET/kr/word',
'eventId': '',
'params': '{"logid":,"entry":"kr_station","attrWordContainTag":[],"needAutounit":false,"querytype":1,"query":"\u622A\u6B62\u9600","querySessions":["\u622A\u6B62\u9600"],"forceReload":true,"regions":"","device":0,"showWordContain":"","showWordNotContain":"","attrShowReasonTag":[],"attrBusinessPointTag":[],"filterAccountWord":true,"rgfilter":1,"planid":0,"unitid":0,"pageNo":1,"pageSize":300,"order":"","orderBy":""}'
}
response = requests.post('http://fengchao.baidu.com/nirvana/request.ajax', headers=headers, params=params, cookies=cookies, data=data)
2018-11-13,有人说,既然可以去百度,为什么还要登录自己的账号,抓包,复制数据到python脚本中。
......emmmmm 这是因为我不知道 cookie、userid、token 和 reqid 的来源。
所以我现在使用这种傻瓜式方法。但至少比手动好很多。
另外提供几个小思路:主要关键词-比如python,放到百度搜索,底部的相关搜索也是关键词的好来源,可以考虑百度出价采集一再关键词之后,再写一个代码,采集这些关键词相关搜索关键词。
此外,百度百科右侧的条目标题也与当前搜索关键词有关。也可以采集把这部分标题改成专题。 查看全部
那要如何才能获取这里的关键词内容?(一)
本文文章,建议在PC端观看。整篇文章的阅读时间看个人理解。 config和cookie需要抓包,填写userid、token、eventId、reqid这四个值的来源,即抓包'关键词规划师',userid是整数类型,token, eventId 和 reqid 是字符串类型。
百度竞标中的关键词规划师是SEO从业者很好的关键词来源。
如何在此处获取关键词 内容?
此代码基于网上2.7的版本,修改为3.*也可以使用。
(其实就是改了打印,23333)
同样,这段代码也没有一步步教你如何解决登录和获取cookie的问题。直接使用登录后的cookie和登录后的from_data数据,注意下面代码最上面的注释,不然不行别怪我。
# -*- coding: utf-8 -*-
#本代码改编自网络上Python2.7版本代码。
#Python版本:3.*,需要安装requests,JSON库不知道要不要重新安装
#使用本代码,首先将代码保存为.py文件,并且在相同目录中新建名字为cigeng的txt文件
#在cigeng.txt文件中输入要采集的关键词,一行一个。保存。
#成功采集后的数据,保存在相同目录中resultkeys.txt文件中。
#如果只要关键词,不要其他黑马等数据,那么就修改key_data函数下else中的数据。
import requests
import json
import time
def url_data(key,config,cookie,shibai=3):
headers={
'Accept': '*/*',
'Accept-Encoding': 'gzip, deflate',
'Accept-Language': 'zh-CN,zh;q=0.8,en;q=0.6',
'Connection': 'keep-alive',
'Content-Type': 'application/x-www-form-urlencoded',
'Cookie': cookie,
#在下面config这个变量值下面的cookie中粘贴进抓包后的cookie,这里不要动。
'Host': 'fengchao.baidu.com',
'Origin': 'http://fengchao.baidu.com',
'Referer': 'http://fengchao.baidu.com/nirvana/main.html?userid=%s' % config['userid'],
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_6) AppleWebKit/537.36 '
'(KHTML, like Gecko) Chrome/56.0.2924.87 Safari/537.36'
}
params={
"logid":401075077,
"query":key,
"querySessions":[key],
"querytype":1,
"regions":"16",
"device":0,
"rgfilter":1,
"entry":"kr_station",
"planid":"0",
"unitid":"0",
"needAutounit":False,
"filterAccountWord":True,
"attrShowReasonTag":[],
"attrBusinessPointTag":[],
"attrWordContainTag":[],
"showWordContain":"",
"showWordNotContain":"",
"pageNo":1,
"pageSize":1000,
"orderBy":"",
"order":"",
"forceReload":True
}
from_data={
'params':json.dumps(params),
'path':'jupiter/GET/kr/word',
'userid':config['userid'],
'token':config['token'],
'eventId':config['eventId'],
'reqid':config['reqid']
}
qurl="http://fengchao.baidu.com/nirv ... onfig['reqid']
try:
whtml=requests.post(qurl,headers=headers,data=from_data)
except requests.exceptions.RequestException:
resultitem={}
erry="请求三次都是错误!"
if shibai > 0:
return url_data(key,config,cookie,shibai-1)
else:
whtml.encoding="utf-8"
try:
resultitem = whtml.json()
except ValueError:
resultitem = {}
erry = "获取不到json数据,可能是被封了吧,谁知道呢?"
else:
erry = None
return resultitem,erry
config={
#这部分数据和下面的cookie,直接开浏览器抓包就能看到相应数据。复制黏贴到相应位置
'userid': '',
'token':'',
'eventId':'',
'reqid':''
}
cookie=" "
def key_data(resultitem):
kws=['关键词\t日均搜索量\tpc\t移动\t竞争度\n']
try:
resultitem=resultitem['data']['group'][0]['resultitem']
except (KeyError, ValueError, TypeError):
resultitem=[]
erry="没有获取到关键词"
else:
for items in resultitem:
#如果你只想要关键词,那么只保留word就可以。
word=items['word']
pv=items['pv']#日均搜索量
pvPc=items['pvPc']
pvWise=items['pvWise']
kwc=items['kwc']#竞争度
kwslist=str(word)+'\t'+str(pv)+'\t'+str(pvPc)+'\t'+str(pvWise)+'\t'+str(kwc)+'\n'
kws.append(str(kwslist))
print (word,pv,pvPc,pvWise,kwc)
## kws.append(str(word))
## print (word)
erry=None
return kws,erry
sfile = open('resultkeys.txt', 'w') # 结果保存文件
faileds = open('faileds.txt', 'w') # 查询失败保存文件
for key in open("cigeng.txt"): #要查询的关键词存放的载体,一行一个,同当前代码文件相同目录。
key=key.strip()
print ("正在拓展:%s"%key)
resultitem,erry=url_data(key,config,cookie)
if erry:
print (key,erry)
faileds.write('%s\n' % key)
faileds.flush()
continue
keylist,erry=key_data(resultitem)
if erry:
print (key,erry)
faileds.write('%s\n' % word)
faileds.flush()
continue
for kw in keylist:
sfile.write('%s\n'%kw)
faileds.flush()
continue
以下代码是浏览器(360极速浏览器)抓取的,#(需要挂梯子)网站格式的数据,没有任何改动。方便新人理解。需要导入JSON,使用JSON解析代码,但要注意JSON内容过多,小心IDLE卡住。
import requests
cookies = {'这部分有数据的,我删了,自己抓包后就知道'
}
headers = {
'Origin': 'http://fengchao.baidu.com',
'Accept-Encoding': 'gzip, deflate',
'Accept-Language': 'zh-CN,zh;q=0.9',
'User-Agent': 'Mozilla/5.0 (Windows NT 5.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36',
'Content-Type': 'application/x-www-form-urlencoded',
'Accept': '*/*',
'Referer': 'http://fengchao.baidu.com/nirvana/main.html?userid=6941153',
'Connection': 'keep-alive',
}
params = (
('path', 'jupiter/GET/kr/word'),
('reqid', '4b534c46-1ea0-4eca-b581-154181423578'),
)
data = {
'userid': '',
'token': '',
'reqid': '',
'path': 'jupiter/GET/kr/word',
'eventId': '',
'params': '{"logid":,"entry":"kr_station","attrWordContainTag":[],"needAutounit":false,"querytype":1,"query":"\u622A\u6B62\u9600","querySessions":["\u622A\u6B62\u9600"],"forceReload":true,"regions":"","device":0,"showWordContain":"","showWordNotContain":"","attrShowReasonTag":[],"attrBusinessPointTag":[],"filterAccountWord":true,"rgfilter":1,"planid":0,"unitid":0,"pageNo":1,"pageSize":300,"order":"","orderBy":""}'
}
response = requests.post('http://fengchao.baidu.com/nirvana/request.ajax', headers=headers, params=params, cookies=cookies, data=data)
2018-11-13,有人说,既然可以去百度,为什么还要登录自己的账号,抓包,复制数据到python脚本中。
......emmmmm 这是因为我不知道 cookie、userid、token 和 reqid 的来源。
所以我现在使用这种傻瓜式方法。但至少比手动好很多。
另外提供几个小思路:主要关键词-比如python,放到百度搜索,底部的相关搜索也是关键词的好来源,可以考虑百度出价采集一再关键词之后,再写一个代码,采集这些关键词相关搜索关键词。
此外,百度百科右侧的条目标题也与当前搜索关键词有关。也可以采集把这部分标题改成专题。

