
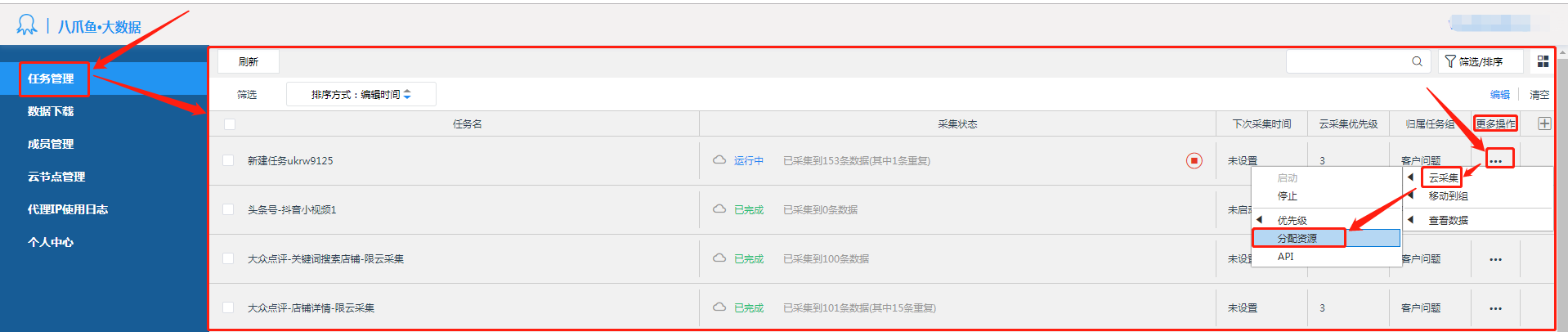
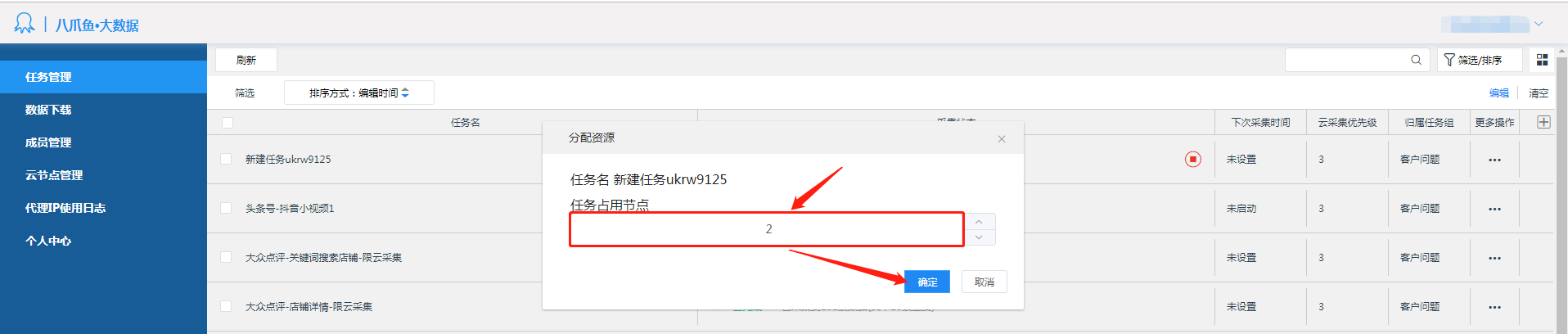
云采集
云采集 【温馨提醒】马甲客户端chrome扩展程序的特点
采集交流 • 优采云 发表了文章 • 0 个评论 • 161 次浏览 • 2021-05-23 18:23
[温馨提醒]
0 1、安装此插件后,您可以自己编写采集规则,也可以输入网站 关键词,然后一键单击采集将任何内容批量添加到论坛部分或门户网站列的“组”中发布。
0 2、可以将已成功发布的内容推送到百度数据收录界面以进行SEO优化,采集和收录双赢。
0 3、插件可以设置时间采集 关键词,同步升级任何网站列的内容,然后自动发布内容以实现无人值守的自动升级网站内容。
0 4、可以自动批量注册大量的背心客户,然后使用背心客户批量发布内容,从而可以在短时间内添加大量的高质量内容和客户,其他人不知道采集做到了。
0 5、具有匹配的客户端chrome扩展名。除了价值1000元人民币的官方免费采集规则外,您还可以编写采集规则来实现任何网站 采集并发布。
自从推出0 6、插件以来,已经过去了三年多的时间。它经历了一千多天的辛苦工作。根据大量客户的反馈,该插件经过反复更新和升级,具有成熟稳定的功能,易于理解,易于使用,功能强大。它已被许多网站管理员安装和使用,并且它是每个网站管理员必备的插件!
[此插件的功能]
0 1、可以批量注册背心客户,张贴海报和评论的背心看起来与真实注册客户发布的背心完全相同。
0 2、可以批量采集和批量发布,可以在短时间内将任何高质量的内容重新发布到您的论坛和门户中。
0 3、可以安排为采集并自动释放,实现无人值守。
由0 4、 采集返回的内容可以转换为简体和繁体字符,伪原创和其他辅助解决方案。
0 5、支持前端采集,该前端可以授权指定普通注册客户在前端中使用此采集器,并让普通注册成员帮助您采集内容。
0 6、 采集中的内容图片可以正常显示并另存为后期图片附件或门户网站文章附件,这些图片将永远不会丢失。
0 7、图片附件支持远程FTP存储,使您可以将图片分离到另一台服务器。
0 8、图片将被您的论坛或门户网站加水印。
0 9、已经重复采集的内容将不会重复两次采集,并且不会重复和冗余的内容。
1 0、 采集的帖子或门户文章,组与真实客户发布的组完全相同,其他人不知道他们是否可以使用采集器进行发布。
1 1、网页浏览量将自动随机设置。感觉您的帖子或门户网站文章上的观看次数与实际观看次数相同。
1 2、可以指定帖子发布者(主持人),门户网站文章作者和组发布者。
1 3、 采集内容可以发布到论坛的任何部分,门户的任何列以及论坛的任何圈子。
1 4、个发布的内容可以推送到百度数据收录界面以进行SEO优化,从而加快网站和收录的百度索引量。
1 5、不限制采集的内容数量,也不限制采集的次数,使您的网站可以快速填充高质量的内容。
1 6、插件具有内置的文本提取算法,该算法支持采集任何网站任何列内容。
1 7、可以用一个键获取当前的实时热点内容,然后用一个键进行发布。
1 8、可以自己编写采集规则,并实时更新采集 网站的任何内容。
[此插件为您带来的价值]
1、使您的论坛成为很多注册会员,非常受欢迎,并且内容丰富。
2、用定时发布,全自动采集,一键式批处理采集等替换了手动发布,从而节省了时间,精力和效率,而且不容易出错。
3、允许您的网站与大型新闻网站共享高质量的内容,这可以迅速增加网站的比重和排名。
查看全部
云采集 【温馨提醒】马甲客户端chrome扩展程序的特点
[温馨提醒]
0 1、安装此插件后,您可以自己编写采集规则,也可以输入网站 关键词,然后一键单击采集将任何内容批量添加到论坛部分或门户网站列的“组”中发布。
0 2、可以将已成功发布的内容推送到百度数据收录界面以进行SEO优化,采集和收录双赢。
0 3、插件可以设置时间采集 关键词,同步升级任何网站列的内容,然后自动发布内容以实现无人值守的自动升级网站内容。
0 4、可以自动批量注册大量的背心客户,然后使用背心客户批量发布内容,从而可以在短时间内添加大量的高质量内容和客户,其他人不知道采集做到了。
0 5、具有匹配的客户端chrome扩展名。除了价值1000元人民币的官方免费采集规则外,您还可以编写采集规则来实现任何网站 采集并发布。
自从推出0 6、插件以来,已经过去了三年多的时间。它经历了一千多天的辛苦工作。根据大量客户的反馈,该插件经过反复更新和升级,具有成熟稳定的功能,易于理解,易于使用,功能强大。它已被许多网站管理员安装和使用,并且它是每个网站管理员必备的插件!
[此插件的功能]
0 1、可以批量注册背心客户,张贴海报和评论的背心看起来与真实注册客户发布的背心完全相同。
0 2、可以批量采集和批量发布,可以在短时间内将任何高质量的内容重新发布到您的论坛和门户中。
0 3、可以安排为采集并自动释放,实现无人值守。
由0 4、 采集返回的内容可以转换为简体和繁体字符,伪原创和其他辅助解决方案。
0 5、支持前端采集,该前端可以授权指定普通注册客户在前端中使用此采集器,并让普通注册成员帮助您采集内容。
0 6、 采集中的内容图片可以正常显示并另存为后期图片附件或门户网站文章附件,这些图片将永远不会丢失。
0 7、图片附件支持远程FTP存储,使您可以将图片分离到另一台服务器。
0 8、图片将被您的论坛或门户网站加水印。
0 9、已经重复采集的内容将不会重复两次采集,并且不会重复和冗余的内容。
1 0、 采集的帖子或门户文章,组与真实客户发布的组完全相同,其他人不知道他们是否可以使用采集器进行发布。
1 1、网页浏览量将自动随机设置。感觉您的帖子或门户网站文章上的观看次数与实际观看次数相同。
1 2、可以指定帖子发布者(主持人),门户网站文章作者和组发布者。
1 3、 采集内容可以发布到论坛的任何部分,门户的任何列以及论坛的任何圈子。
1 4、个发布的内容可以推送到百度数据收录界面以进行SEO优化,从而加快网站和收录的百度索引量。
1 5、不限制采集的内容数量,也不限制采集的次数,使您的网站可以快速填充高质量的内容。
1 6、插件具有内置的文本提取算法,该算法支持采集任何网站任何列内容。
1 7、可以用一个键获取当前的实时热点内容,然后用一个键进行发布。
1 8、可以自己编写采集规则,并实时更新采集 网站的任何内容。
[此插件为您带来的价值]
1、使您的论坛成为很多注册会员,非常受欢迎,并且内容丰富。
2、用定时发布,全自动采集,一键式批处理采集等替换了手动发布,从而节省了时间,精力和效率,而且不容易出错。
3、允许您的网站与大型新闻网站共享高质量的内容,这可以迅速增加网站的比重和排名。
使用优采云采集瀑布流网站图片采集详细说明(组图)
采集交流 • 优采云 发表了文章 • 0 个评论 • 226 次浏览 • 2021-05-06 03:01
本文介绍了使用优采云 采集瀑布流网站图片的方法(以百度图片采集为例)。
采集 网站:%E5%A4%8F%E7%9B%AE%E5%8F%8B%E4%BA%BA%E5%B8%90
使用功能点:
lAjax向下滚动
/ tutorialdetail-1 / ajgd_ 7. html
l分页列表信息采集
/ tutorialdetail-1 / fylb-7 0. html
百度图片:百度图片发现了五彩缤纷的世界,百度从8亿中文网页中提取了各种图片,并建立了中文图片库。百度影视(Baidu Pictures)拥有数十亿个中文网页,收录亿万张图片的庞大画廊,并且还在不断增加。
百度图片采集数据描述:本文以瀑布图片网站图片为例,以百度图片采集为例进行了分析。本文仅以“百度图片采集”为例。在实际操作中,您可以根据自己的需要更改百度其他内容的数据采集。
百度图片采集字段的详细说明:图片地址,图片文件。
第1步:创建采集任务
1)进入主界面并选择自定义模式
2)复制上述URL的URL并将其粘贴到网站输入框中,单击“保存URL”
3)系统自动打开网页。我们发现百度图片网络是一个瀑布式网页。每次下拉加载后,将显示新数据。当有足够的图片时,可以将它们下拉并加载无数次。因此,此页面涉及AJAX技术,需要设置AJAX超时时间以确保不会丢失数据采集。
选择“打开网页”步骤,打开“高级选项”,选中“页面加载完成向下滚动”,将滚动次数设置为“ 5次”(根据自己的需要设置),时间为“ 2秒”,滚动方式为“向下滚动一屏”;最后点击“确定”
注意:例如网站,没有翻页按钮。滚动数和滚动方法会影响数据数采集,可以根据需要设置。
第2步:采集图片网址
1)选择页面上的第一张照片,系统将自动识别相似的照片。在操作提示框中,选择“全选”
2)选择“ 采集以下图片地址”
第3步:修改Xpath
1)选择“循环”步骤并打开“高级选项”。可以看出,优采云系统自动采用“非固定元素列表”循环,并且Xpath为:// DIV [@ id ='imgid'] / DIV [1] / UL [1] / LI
2)此Xpath:// DIV [@ id ='imgid'] / DIV [1] / UL [1] / LI,将其复制到Firefox浏览器中以进行观察-仅可找到该网页22张图片在
3)我们需要一个Xpath,它可以在网页中找到所有必需的图片。观察网页的源代码,并将Xpath修改为:// DIV [@ id ='imgid'] / DIV / UL [1] / LI,找到网页中所有必需的图片
4)复制并粘贴修改后的Xpath:// DIV [@ id ='imgid'] / DIV / UL [1] / LI到优采云中的相应位置,完成后单击“确定”。
5)单击“保存”,然后单击“启动采集”,在这里选择“启动本地采集”
注意:本地采集占用了采集的当前计算机资源,如果有采集时间要求或当前计算机无法长时间运行采集,则可以使用云采集 ]功能,并且云采集在网络中对于采集,不需要当前的计算机支持,可以关闭计算机,并且可以设置多个云节点来共享任务。 10个节点相当于10台计算机来分配任务以帮助您采集,并且速度降低到原创速度的十分之一; [k15中获得的数据]可以在云中存储三个月,并且可以导出随时。第4步:数据采集并导出
1) 采集完成后,将弹出提示并选择导出数据
2)选择合适的导出方法并导出采集良好数据
第5步:将图片网址批量转换为图片
完成上述操作后,我们获得了采集图片的URL。接下来,使用用于优采云的特殊图像批处理下载工具将图片URL中的图片下载并保存到采集到本地计算机。
图片批量下载工具:
1)下载优采云图片批量下载工具,双击文件中的MyDownloader.app.exe文件以打开软件
2)打开“文件”菜单,然后选择从EXCEL导入(当前仅支持EXCEL格式的文件)
3)进行相关设置,设置完成后,单击“确定”以导入文件
选择EXCEL文件:导入需要下载图片地址的EXCEL文件
EXCEL表名:对应数据表的名称
文件URL列名:表中相应URL的列名
保存文件夹名称:EXCEL中需要一个单独的列,以列出要保存到文件夹的图片的路径。您可以设置不同的图片以存储在不同的文件夹中
如果要将文件保存到文件夹,则路径需要以“ \”结尾,例如:“ D:\ Sync \”,如果要在下载后根据指定的文件名保存文件,则需要收录特定的文件名,例如“ D:\ Sync \ 1. jpg”
如果下载的文件路径和文件名完全相同,则原创文件将被删除
查看全部
使用优采云采集瀑布流网站图片采集详细说明(组图)
本文介绍了使用优采云 采集瀑布流网站图片的方法(以百度图片采集为例)。
采集 网站:%E5%A4%8F%E7%9B%AE%E5%8F%8B%E4%BA%BA%E5%B8%90
使用功能点:
lAjax向下滚动
/ tutorialdetail-1 / ajgd_ 7. html
l分页列表信息采集
/ tutorialdetail-1 / fylb-7 0. html
百度图片:百度图片发现了五彩缤纷的世界,百度从8亿中文网页中提取了各种图片,并建立了中文图片库。百度影视(Baidu Pictures)拥有数十亿个中文网页,收录亿万张图片的庞大画廊,并且还在不断增加。
百度图片采集数据描述:本文以瀑布图片网站图片为例,以百度图片采集为例进行了分析。本文仅以“百度图片采集”为例。在实际操作中,您可以根据自己的需要更改百度其他内容的数据采集。
百度图片采集字段的详细说明:图片地址,图片文件。
第1步:创建采集任务
1)进入主界面并选择自定义模式

2)复制上述URL的URL并将其粘贴到网站输入框中,单击“保存URL”

3)系统自动打开网页。我们发现百度图片网络是一个瀑布式网页。每次下拉加载后,将显示新数据。当有足够的图片时,可以将它们下拉并加载无数次。因此,此页面涉及AJAX技术,需要设置AJAX超时时间以确保不会丢失数据采集。
选择“打开网页”步骤,打开“高级选项”,选中“页面加载完成向下滚动”,将滚动次数设置为“ 5次”(根据自己的需要设置),时间为“ 2秒”,滚动方式为“向下滚动一屏”;最后点击“确定”

注意:例如网站,没有翻页按钮。滚动数和滚动方法会影响数据数采集,可以根据需要设置。
第2步:采集图片网址
1)选择页面上的第一张照片,系统将自动识别相似的照片。在操作提示框中,选择“全选”

2)选择“ 采集以下图片地址”

第3步:修改Xpath
1)选择“循环”步骤并打开“高级选项”。可以看出,优采云系统自动采用“非固定元素列表”循环,并且Xpath为:// DIV [@ id ='imgid'] / DIV [1] / UL [1] / LI

2)此Xpath:// DIV [@ id ='imgid'] / DIV [1] / UL [1] / LI,将其复制到Firefox浏览器中以进行观察-仅可找到该网页22张图片在

3)我们需要一个Xpath,它可以在网页中找到所有必需的图片。观察网页的源代码,并将Xpath修改为:// DIV [@ id ='imgid'] / DIV / UL [1] / LI,找到网页中所有必需的图片

4)复制并粘贴修改后的Xpath:// DIV [@ id ='imgid'] / DIV / UL [1] / LI到优采云中的相应位置,完成后单击“确定”。

5)单击“保存”,然后单击“启动采集”,在这里选择“启动本地采集”

注意:本地采集占用了采集的当前计算机资源,如果有采集时间要求或当前计算机无法长时间运行采集,则可以使用云采集 ]功能,并且云采集在网络中对于采集,不需要当前的计算机支持,可以关闭计算机,并且可以设置多个云节点来共享任务。 10个节点相当于10台计算机来分配任务以帮助您采集,并且速度降低到原创速度的十分之一; [k15中获得的数据]可以在云中存储三个月,并且可以导出随时。第4步:数据采集并导出
1) 采集完成后,将弹出提示并选择导出数据

2)选择合适的导出方法并导出采集良好数据

第5步:将图片网址批量转换为图片
完成上述操作后,我们获得了采集图片的URL。接下来,使用用于优采云的特殊图像批处理下载工具将图片URL中的图片下载并保存到采集到本地计算机。
图片批量下载工具:
1)下载优采云图片批量下载工具,双击文件中的MyDownloader.app.exe文件以打开软件

2)打开“文件”菜单,然后选择从EXCEL导入(当前仅支持EXCEL格式的文件)

3)进行相关设置,设置完成后,单击“确定”以导入文件
选择EXCEL文件:导入需要下载图片地址的EXCEL文件
EXCEL表名:对应数据表的名称
文件URL列名:表中相应URL的列名
保存文件夹名称:EXCEL中需要一个单独的列,以列出要保存到文件夹的图片的路径。您可以设置不同的图片以存储在不同的文件夹中
如果要将文件保存到文件夹,则路径需要以“ \”结尾,例如:“ D:\ Sync \”,如果要在下载后根据指定的文件名保存文件,则需要收录特定的文件名,例如“ D:\ Sync \ 1. jpg”
如果下载的文件路径和文件名完全相同,则原创文件将被删除

优采云采集器需要精通到什么程度?分布式解决方案
采集交流 • 优采云 发表了文章 • 0 个评论 • 216 次浏览 • 2021-05-05 02:05
2.工具方向
这很容易理解。我们精通某些主流采集工具,例如优采云 采集器
我需要什么程度的精通?
1.如果可以使用我们的优采云和XPATH来找到网页的任何元素
2.如果您知道如何优采云 采集原理并了解拆分规则,则整个采集的效率可以提高10倍
3.实际上已经超过三个月没有每天使用我们的优采云并编写了一两百条规则,因此不应认为它是熟练的
除了熟悉以上两个工具级别之外,您还需要熟悉以下内容:
1. Anti- 采集原理(验证码,多个IP等)
2. html前端解析知识
3.分布式解决方案
4.正则表达式匹配
基本上,如果您熟悉上述技能,您几乎可以成为一名合格且思维清晰的履带工程师。那些编写代码的人具有编写代码的好处,以及使用工具和工具的好处。编写代码的好处是更大的自由度,更大的挑战,更难上手,并且效果实际上并不好,因为很多时候它们实际上是在重新创建轮子。
毕竟,只要您可以使用采集器工具,就可以完成许多常见操作,并且可以为您完成功能性采集器工具。至于工具,工具总是有一点限制。为了实现多功能性,工具会在一定程度上牺牲某些功能。在某些非常特殊的情况下,工具实际上很难完成。
因此,我始终建议工具+代码是主流爬虫工程师的配置。您可以使用诸如优采云之类的工具来满足99%的要求,但是如果遇到特定要求,可以留下手写代码来解决。
毕竟,我们想要的是解决问题,更不用说python等了。根本不难配置采集器程序。有很多在线教程。 (国内主流采集伟大的上帝就是这样做的,可以使用这些工具的工具是第一个使用该工具的人,除非这些工具不可用,否则它们将编写自己的代码)
履带工程师的相关技能
除了要了解采集,爬虫工程师还需要一些其他技能。这是爬虫工程师是入门级,普通级还是优秀级的真实衡量标准。实际上,在这个时代,复合型人才更受欢迎。
一位出色的履带工程师,他还需要以下技术来升华
1.数据清理
由于采集中的数据通常是一大部分文本,因此您需要优化文本,这就是我们所谓的清理数据,以获取更清晰的结构化数据并将其保存在数据库中。
有时候,我们采集有多个数据副本,我们还需要通过清理将它们关联起来。例如,我们善于使用Excel的一些高级技能,并且我们还使用诸如R之类的编程语言来处理文本。我们优采云数据中心小组的学生都具有数据清除技能。
2.数据挖掘
爬网后的数据挖掘通常是指NLP的重影。 NLP属于人工智能领域。中文被称为自然语言处理。简单理解就是处理大量文本并从大量文本中挖掘出价值。
在中国,我们能做得很好的事情属于奉茂琳娇。我们优采云也有我们自己的NLP团队。投资是巨大的,并且做得不好。我们只是开始实现一些特定的场景功能。下订单。我们是中国的一些主流AI公司,采集,挖掘后,我们输出AI数据。我们的数据中心有一些很棒的人专门从事这项工作。
3.数据分析可视化
仅下载数据采集并将其保存在数据库中,仅是为了实现第一步的价值。数据分析和可视化是数据背后的更大价值。
因此有必要将数据保存在数据库中,然后通过相应的框架或程序进行开发,组织和调出,以协助企业进行决策。因此,我们优采云有一个专门的数据BI团队,许多爬虫工程师都擅长使用通用可视BI工具EXCEL为项目提供可视数据支持。
4.深入了解业务
无论是了解在Internet上获取公共数据的能力还是对业务需求的了解,这也是考虑优秀的爬虫工程师的一项重要措施。坦率地说,不仅要了解技术,还要了解业务,并成为一名复合式爬虫工程师。只有在此程度上,履带工程师的价值才能被无限放大。例如,了解风险控制业务,例如了解AI业务等。我们为此职位设有售前和顾问。
如何规划履带工程师的路线
在我的团队中,有两条路线:L岗位和T岗位。 L职位通常是指偏向业务的爬行动物工程师职位,而职位通常是指偏向技术的爬行动物工程师职位。一些学生更喜欢与企业保持联系,并具有良好的表达能力,快速反应和清晰的思维,因此他将去L职位。一些学生对突破各种问题并提供更好的解决方案更加热衷于技术。将转到T帖子。
L职位的一般职位是什么?
1.技术支持(针对中小型客户)
2.预售(针对主要客户)
3.数据中心负责人/项目负责人
4.解决方案顾问(深入的业务场景)
T岗位通常担任什么职位?
1.爬虫项目的一线开发和交付人员
2.数据专员
3.高级数据专家
4.爬虫训练讲师
工作机会
如果看到此消息,则表明您对爬虫感兴趣。我们正在招聘上述职位。如果您是合格的履带工程师或渴望成为一名出色的履带工程师,请给您的履历表发送艰苦的努力!
优采云是国内领先的采集器云采集工具平台,可为许多大型公司和政府提供数据服务,并建立Internet数据资产仓库。如果您有兴趣这样做,请让我们私下讨论。 查看全部
优采云采集器需要精通到什么程度?分布式解决方案
2.工具方向
这很容易理解。我们精通某些主流采集工具,例如优采云 采集器
我需要什么程度的精通?
1.如果可以使用我们的优采云和XPATH来找到网页的任何元素
2.如果您知道如何优采云 采集原理并了解拆分规则,则整个采集的效率可以提高10倍
3.实际上已经超过三个月没有每天使用我们的优采云并编写了一两百条规则,因此不应认为它是熟练的
除了熟悉以上两个工具级别之外,您还需要熟悉以下内容:
1. Anti- 采集原理(验证码,多个IP等)
2. html前端解析知识
3.分布式解决方案
4.正则表达式匹配
基本上,如果您熟悉上述技能,您几乎可以成为一名合格且思维清晰的履带工程师。那些编写代码的人具有编写代码的好处,以及使用工具和工具的好处。编写代码的好处是更大的自由度,更大的挑战,更难上手,并且效果实际上并不好,因为很多时候它们实际上是在重新创建轮子。
毕竟,只要您可以使用采集器工具,就可以完成许多常见操作,并且可以为您完成功能性采集器工具。至于工具,工具总是有一点限制。为了实现多功能性,工具会在一定程度上牺牲某些功能。在某些非常特殊的情况下,工具实际上很难完成。
因此,我始终建议工具+代码是主流爬虫工程师的配置。您可以使用诸如优采云之类的工具来满足99%的要求,但是如果遇到特定要求,可以留下手写代码来解决。
毕竟,我们想要的是解决问题,更不用说python等了。根本不难配置采集器程序。有很多在线教程。 (国内主流采集伟大的上帝就是这样做的,可以使用这些工具的工具是第一个使用该工具的人,除非这些工具不可用,否则它们将编写自己的代码)
履带工程师的相关技能
除了要了解采集,爬虫工程师还需要一些其他技能。这是爬虫工程师是入门级,普通级还是优秀级的真实衡量标准。实际上,在这个时代,复合型人才更受欢迎。
一位出色的履带工程师,他还需要以下技术来升华

1.数据清理
由于采集中的数据通常是一大部分文本,因此您需要优化文本,这就是我们所谓的清理数据,以获取更清晰的结构化数据并将其保存在数据库中。
有时候,我们采集有多个数据副本,我们还需要通过清理将它们关联起来。例如,我们善于使用Excel的一些高级技能,并且我们还使用诸如R之类的编程语言来处理文本。我们优采云数据中心小组的学生都具有数据清除技能。
2.数据挖掘
爬网后的数据挖掘通常是指NLP的重影。 NLP属于人工智能领域。中文被称为自然语言处理。简单理解就是处理大量文本并从大量文本中挖掘出价值。
在中国,我们能做得很好的事情属于奉茂琳娇。我们优采云也有我们自己的NLP团队。投资是巨大的,并且做得不好。我们只是开始实现一些特定的场景功能。下订单。我们是中国的一些主流AI公司,采集,挖掘后,我们输出AI数据。我们的数据中心有一些很棒的人专门从事这项工作。
3.数据分析可视化
仅下载数据采集并将其保存在数据库中,仅是为了实现第一步的价值。数据分析和可视化是数据背后的更大价值。
因此有必要将数据保存在数据库中,然后通过相应的框架或程序进行开发,组织和调出,以协助企业进行决策。因此,我们优采云有一个专门的数据BI团队,许多爬虫工程师都擅长使用通用可视BI工具EXCEL为项目提供可视数据支持。
4.深入了解业务
无论是了解在Internet上获取公共数据的能力还是对业务需求的了解,这也是考虑优秀的爬虫工程师的一项重要措施。坦率地说,不仅要了解技术,还要了解业务,并成为一名复合式爬虫工程师。只有在此程度上,履带工程师的价值才能被无限放大。例如,了解风险控制业务,例如了解AI业务等。我们为此职位设有售前和顾问。
如何规划履带工程师的路线
在我的团队中,有两条路线:L岗位和T岗位。 L职位通常是指偏向业务的爬行动物工程师职位,而职位通常是指偏向技术的爬行动物工程师职位。一些学生更喜欢与企业保持联系,并具有良好的表达能力,快速反应和清晰的思维,因此他将去L职位。一些学生对突破各种问题并提供更好的解决方案更加热衷于技术。将转到T帖子。
L职位的一般职位是什么?
1.技术支持(针对中小型客户)
2.预售(针对主要客户)
3.数据中心负责人/项目负责人
4.解决方案顾问(深入的业务场景)
T岗位通常担任什么职位?
1.爬虫项目的一线开发和交付人员
2.数据专员
3.高级数据专家
4.爬虫训练讲师
工作机会
如果看到此消息,则表明您对爬虫感兴趣。我们正在招聘上述职位。如果您是合格的履带工程师或渴望成为一名出色的履带工程师,请给您的履历表发送艰苦的努力!
优采云是国内领先的采集器云采集工具平台,可为许多大型公司和政府提供数据服务,并建立Internet数据资产仓库。如果您有兴趣这样做,请让我们私下讨论。
Excel批量上传的使用方法有哪些?-八维教育
采集交流 • 优采云 发表了文章 • 0 个评论 • 126 次浏览 • 2021-05-02 05:46
批处理采集可以将外部数据(支持结构化,半结构化和非结构化数据)分批推送到ks3。 采集模式支持:文件推送,文件拉取,页面文件上传等。
文件推送任务配置
单击[批处理采集]按钮,然后在弹出窗口中选择[文件推送],进入文件推送任务编辑页面。
在新的弹出窗口中,单击[添加文件推送任务]创建采集任务,该任务支持手动创建多个文件采集任务。
创建采集任务时,您需要填写:
参数名称说明
采集名称
支持中文,英文,数字,下划线,最多50个字符。
目标ks3的名称
下拉选择,它需要在数据管理中预先创建。
目标存储桶
下拉选项,它需要在数据管理中预先创建,您可以在项目下选择具有权限的时段。
数据交换界面
下拉选择,需要预先在数据管理中创建,您可以在项目下选择授权的数据交换界面。
选择数据交换接口后,可以单击下面的[数据交换接口预览]以查看数据交换接口的架构信息。
配置后,单击[下一步]完成此采集任务的创建。重复上述步骤,一次创建多个采集任务。
完成采集任务创建后,您可以单击以下载文件上传工具包,API或SDK,然后在用户客户端上启动文件推送任务。
文件推送(Excel批量上传)配置
在页面上下载Excel模板,汇总要添加的任务信息,然后根据以下规范进行填写:采集任务名称,目标ks3名称,目标存储桶,数据交换界面和采集描述,然后上传Excel
转到大数据云平台执行批量创建操作。
填写Excel模板并上传后,将在页面上预览Excel中的内容。确认正确无误后,单击“下一步”完成批量创建。
运行批处理采集个任务
批处理采集个任务可以通过:
1.文件上传工具包。
2. SDK启动。
有关文件上传工具包和SDK的特定用法,可以在“批量采集通用下载”页面上下载它。
文件拉入
1.单击文件拉动按钮进入文件拉动配置页面。文件提取支持从FTP提取数据并将其发送到ks3。
2.单击“下一步”进行特定的拉取配置
3.文件提取支持两种方法:[定期执行]和[单次执行]。两种方法都需要指定推送目标ks 3、 bucket,数据交换接口和特定的推送路径。其中,定期执行的任务需要其他配置[执行周期]。详细信息如下图所示:
查看批处理采集运行示例
单击[采集详细信息]按钮,将弹出一个表格,以查看批处理采集的运行示例,您可以查看目标数据路径。
注意:当脱机计算作业依赖于批处理采集任务(通常取决于文件提取任务)时,“目标路径”页面上的处理事件名称字段可以是脱机计算的从属监视值工作。
通过页面上传文件
除上述方法外,对于文件数量少的临时数据采集要求,还可以通过批处理采集>页面上载文件功能来上载文件。单击[页面上传文件]按钮后,选择要上传的文件(可以支持多个文件)和上传目标地址(ks 3))。
默认情况下,页面文件上传的任务显示在任务列表的第一行。在[操作]中单击[采集详细信息],以查看每个文件上传的信息。
任务在线,应用程序文件推送任务在线,文件提取任务在线
对于文件提取,您需要先将任务发布到测试中以进行测试验证,然后才能在线申请。
在批处理采集列表中单击[发布测试],然后根据需要选择资源,然后可以在测试环境中运行文件提取作业。
任务在线审查
从屏幕左下角进入[发布管理]模块,然后单击以进入[发布批准]页面。在[未批准]列表中,您可以查看在线任务的应用程序。审核时,您可以选择通过审核或拒绝审核。
通过批准后,您可以在[已发布列表]中查看任务信息或执行脱机操作。
任务联机以开始任务生产运行
联机后,您可以在[运营和维护中心]> [数据采集]> [生产任务]中查看任务列表。 查看全部
Excel批量上传的使用方法有哪些?-八维教育
批处理采集可以将外部数据(支持结构化,半结构化和非结构化数据)分批推送到ks3。 采集模式支持:文件推送,文件拉取,页面文件上传等。
文件推送任务配置
单击[批处理采集]按钮,然后在弹出窗口中选择[文件推送],进入文件推送任务编辑页面。
在新的弹出窗口中,单击[添加文件推送任务]创建采集任务,该任务支持手动创建多个文件采集任务。
创建采集任务时,您需要填写:
参数名称说明
采集名称
支持中文,英文,数字,下划线,最多50个字符。
目标ks3的名称
下拉选择,它需要在数据管理中预先创建。
目标存储桶
下拉选项,它需要在数据管理中预先创建,您可以在项目下选择具有权限的时段。
数据交换界面
下拉选择,需要预先在数据管理中创建,您可以在项目下选择授权的数据交换界面。
选择数据交换接口后,可以单击下面的[数据交换接口预览]以查看数据交换接口的架构信息。
配置后,单击[下一步]完成此采集任务的创建。重复上述步骤,一次创建多个采集任务。
完成采集任务创建后,您可以单击以下载文件上传工具包,API或SDK,然后在用户客户端上启动文件推送任务。
文件推送(Excel批量上传)配置
在页面上下载Excel模板,汇总要添加的任务信息,然后根据以下规范进行填写:采集任务名称,目标ks3名称,目标存储桶,数据交换界面和采集描述,然后上传Excel
转到大数据云平台执行批量创建操作。
填写Excel模板并上传后,将在页面上预览Excel中的内容。确认正确无误后,单击“下一步”完成批量创建。
运行批处理采集个任务
批处理采集个任务可以通过:
1.文件上传工具包。
2. SDK启动。
有关文件上传工具包和SDK的特定用法,可以在“批量采集通用下载”页面上下载它。
文件拉入
1.单击文件拉动按钮进入文件拉动配置页面。文件提取支持从FTP提取数据并将其发送到ks3。
2.单击“下一步”进行特定的拉取配置
3.文件提取支持两种方法:[定期执行]和[单次执行]。两种方法都需要指定推送目标ks 3、 bucket,数据交换接口和特定的推送路径。其中,定期执行的任务需要其他配置[执行周期]。详细信息如下图所示:
查看批处理采集运行示例
单击[采集详细信息]按钮,将弹出一个表格,以查看批处理采集的运行示例,您可以查看目标数据路径。
注意:当脱机计算作业依赖于批处理采集任务(通常取决于文件提取任务)时,“目标路径”页面上的处理事件名称字段可以是脱机计算的从属监视值工作。
通过页面上传文件
除上述方法外,对于文件数量少的临时数据采集要求,还可以通过批处理采集>页面上载文件功能来上载文件。单击[页面上传文件]按钮后,选择要上传的文件(可以支持多个文件)和上传目标地址(ks 3))。
默认情况下,页面文件上传的任务显示在任务列表的第一行。在[操作]中单击[采集详细信息],以查看每个文件上传的信息。
任务在线,应用程序文件推送任务在线,文件提取任务在线
对于文件提取,您需要先将任务发布到测试中以进行测试验证,然后才能在线申请。
在批处理采集列表中单击[发布测试],然后根据需要选择资源,然后可以在测试环境中运行文件提取作业。
任务在线审查
从屏幕左下角进入[发布管理]模块,然后单击以进入[发布批准]页面。在[未批准]列表中,您可以查看在线任务的应用程序。审核时,您可以选择通过审核或拒绝审核。
通过批准后,您可以在[已发布列表]中查看任务信息或执行脱机操作。
任务联机以开始任务生产运行
联机后,您可以在[运营和维护中心]> [数据采集]> [生产任务]中查看任务列表。
优采云采集器需要精通到什么程度?分布式解决方案
采集交流 • 优采云 发表了文章 • 0 个评论 • 279 次浏览 • 2021-05-01 22:10
2.工具方向
这很容易理解。我们精通某个主流采集工具,例如优采云 采集器
我需要什么程度的精通?
1.如果可以使用我们的优采云和XPATH来找到网页的任何元素
2.如果您知道如何优采云 采集原理并了解拆分规则,则整个采集的效率可以提高10倍
3.实际上已经超过三个月没有每天使用我们的优采云并编写了一两百条规则,因此不应认为它是熟练的
除了熟悉以上两个工具级别之外,您还需要熟悉以下内容:
1. Anti- 采集原理(验证码,多个IP等)
2. html前端解析知识
3.分布式解决方案
4.正则表达式匹配
基本上,如果您熟悉上述技能,您几乎可以成为一名合格且思维清晰的履带工程师。那些编写代码的人具有编写代码的好处,以及使用工具和工具的好处。编写代码的好处是更大的自由度,更大的挑战,更难上手,并且效果实际上并不好,因为很多时候它们实际上是在重新创建轮子。
毕竟,只要您可以使用采集器工具,就可以完成许多常见操作,并且可以为您完成功能性采集器工具。至于工具,工具总是有一点限制。为了实现多功能性,工具会在一定程度上牺牲某些功能。在某些非常特殊的情况下,工具实际上很难完成。
因此,我始终建议工具+代码是主流爬虫工程师的配置。您可以使用诸如优采云之类的工具来满足99%的要求,但是如果遇到特定要求,可以留下手写代码来解决。
毕竟,我们想要的是解决问题,更不用说python等了。根本不难配置采集器程序。有很多在线教程。 (国内主流采集伟大的上帝就是这样做的。那些可以使用工具的人优先使用工具。除非工具不清楚,否则他们会编写自己的代码)
履带工程师的相关技能
除了要了解采集,爬虫工程师还需要一些其他技能。这是爬虫工程师是入门级,普通级还是优秀级的真实度量。实际上,在这个时代,复合型人才更受欢迎。
一位出色的履带工程师,他还需要以下技术来升华
1.数据清理
由于采集中的数据通常是一大部分文本,因此您需要优化文本,这就是我们所谓的清理数据,以获取更清晰的结构化数据并将其保存在数据库中。
有时候,我们采集有多个数据副本,我们还需要通过清理将它们关联起来。例如,我们擅长在Excel中使用一些高级技能,以及使用诸如R的编程语言来处理文本。我们优采云数据中心小组的学生都具有数据清除技能。
2.数据挖掘
爬网后的数据挖掘通常是指NLP的重影。 NLP属于人工智能领域。中文被称为自然语言处理。简单理解就是处理大量文本并从大量文本中挖掘出价值。
在中国,我们能做得很好的事情属于奉茂琳娇。我们优采云也有我们自己的NLP团队。这项投资是巨大的,而且我们做得还不够好。我们刚刚开始实现一些特定的场景功能。下订单。我们是中国的一些主流AI公司,采集,挖掘后,我们输出AI数据。我们的数据中心有一些很棒的人专门从事这项工作。
3.数据分析可视化
仅下载数据采集并将其保存在数据库中,仅是为了实现第一步的价值。数据分析和可视化是数据背后的更大价值。
因此有必要将数据保存在数据库中,然后通过相应的框架或程序进行开发,组织和调出,以协助企业进行决策。因此,我们优采云有一个专门的数据BI团队,许多爬虫工程师都擅长使用通用可视BI工具EXCEL为项目提供可视数据支持。
4.深入了解业务
无论是对在Internet上获取公共数据的能力的理解还是对业务需求的理解,它也是考虑优秀的爬虫工程师的重要措施。坦率地说,不仅要了解技术,还要了解业务,并成为一名复合式爬虫工程师。只有在此程度上,履带工程师的价值才能被无限放大。例如,了解风险控制业务,例如了解AI业务等。我们为此职位设有售前和顾问。
如何规划履带工程师的路线
在我的团队中,有两条路线,即L岗位和T岗位。 L职位通常是指倾向于业务的爬虫工程师职位,而T职位通常是指倾向于技术的爬虫工程师职位。一些学生更喜欢与企业保持联系,并具有良好的表达能力,快速反应和清晰的思维,因此他将去L职位。一些学生对突破各种问题并提供更好的解决方案更加热衷于技术。将转到T帖子。
L职位的一般职位是什么?
1.技术支持(针对中小型客户)
2.预售(针对主要客户)
3.数据中心负责人/项目负责人
4.解决方案顾问(深入的业务场景)
T岗位通常担任什么职位?
1.爬虫项目的一线开发和交付人员
2.数据专员
3.高级数据专家
4.爬虫训练讲师
工作机会
如果看到此消息,则表明您对爬虫感兴趣。我们正在招聘上述职位。如果您是合格的履带工程师或渴望成为一名出色的履带工程师,请给您的履历表发送艰苦的努力!
优采云是国内领先的采集器云采集工具平台,可为许多大型公司和政府提供数据服务,并建立Internet数据资产仓库。如果您有兴趣这样做,请让我们私下讨论。 查看全部
优采云采集器需要精通到什么程度?分布式解决方案
2.工具方向
这很容易理解。我们精通某个主流采集工具,例如优采云 采集器
我需要什么程度的精通?
1.如果可以使用我们的优采云和XPATH来找到网页的任何元素
2.如果您知道如何优采云 采集原理并了解拆分规则,则整个采集的效率可以提高10倍
3.实际上已经超过三个月没有每天使用我们的优采云并编写了一两百条规则,因此不应认为它是熟练的
除了熟悉以上两个工具级别之外,您还需要熟悉以下内容:
1. Anti- 采集原理(验证码,多个IP等)
2. html前端解析知识
3.分布式解决方案
4.正则表达式匹配
基本上,如果您熟悉上述技能,您几乎可以成为一名合格且思维清晰的履带工程师。那些编写代码的人具有编写代码的好处,以及使用工具和工具的好处。编写代码的好处是更大的自由度,更大的挑战,更难上手,并且效果实际上并不好,因为很多时候它们实际上是在重新创建轮子。
毕竟,只要您可以使用采集器工具,就可以完成许多常见操作,并且可以为您完成功能性采集器工具。至于工具,工具总是有一点限制。为了实现多功能性,工具会在一定程度上牺牲某些功能。在某些非常特殊的情况下,工具实际上很难完成。
因此,我始终建议工具+代码是主流爬虫工程师的配置。您可以使用诸如优采云之类的工具来满足99%的要求,但是如果遇到特定要求,可以留下手写代码来解决。
毕竟,我们想要的是解决问题,更不用说python等了。根本不难配置采集器程序。有很多在线教程。 (国内主流采集伟大的上帝就是这样做的。那些可以使用工具的人优先使用工具。除非工具不清楚,否则他们会编写自己的代码)
履带工程师的相关技能
除了要了解采集,爬虫工程师还需要一些其他技能。这是爬虫工程师是入门级,普通级还是优秀级的真实度量。实际上,在这个时代,复合型人才更受欢迎。
一位出色的履带工程师,他还需要以下技术来升华
1.数据清理
由于采集中的数据通常是一大部分文本,因此您需要优化文本,这就是我们所谓的清理数据,以获取更清晰的结构化数据并将其保存在数据库中。
有时候,我们采集有多个数据副本,我们还需要通过清理将它们关联起来。例如,我们擅长在Excel中使用一些高级技能,以及使用诸如R的编程语言来处理文本。我们优采云数据中心小组的学生都具有数据清除技能。
2.数据挖掘
爬网后的数据挖掘通常是指NLP的重影。 NLP属于人工智能领域。中文被称为自然语言处理。简单理解就是处理大量文本并从大量文本中挖掘出价值。
在中国,我们能做得很好的事情属于奉茂琳娇。我们优采云也有我们自己的NLP团队。这项投资是巨大的,而且我们做得还不够好。我们刚刚开始实现一些特定的场景功能。下订单。我们是中国的一些主流AI公司,采集,挖掘后,我们输出AI数据。我们的数据中心有一些很棒的人专门从事这项工作。
3.数据分析可视化
仅下载数据采集并将其保存在数据库中,仅是为了实现第一步的价值。数据分析和可视化是数据背后的更大价值。
因此有必要将数据保存在数据库中,然后通过相应的框架或程序进行开发,组织和调出,以协助企业进行决策。因此,我们优采云有一个专门的数据BI团队,许多爬虫工程师都擅长使用通用可视BI工具EXCEL为项目提供可视数据支持。
4.深入了解业务
无论是对在Internet上获取公共数据的能力的理解还是对业务需求的理解,它也是考虑优秀的爬虫工程师的重要措施。坦率地说,不仅要了解技术,还要了解业务,并成为一名复合式爬虫工程师。只有在此程度上,履带工程师的价值才能被无限放大。例如,了解风险控制业务,例如了解AI业务等。我们为此职位设有售前和顾问。
如何规划履带工程师的路线
在我的团队中,有两条路线,即L岗位和T岗位。 L职位通常是指倾向于业务的爬虫工程师职位,而T职位通常是指倾向于技术的爬虫工程师职位。一些学生更喜欢与企业保持联系,并具有良好的表达能力,快速反应和清晰的思维,因此他将去L职位。一些学生对突破各种问题并提供更好的解决方案更加热衷于技术。将转到T帖子。
L职位的一般职位是什么?
1.技术支持(针对中小型客户)
2.预售(针对主要客户)
3.数据中心负责人/项目负责人
4.解决方案顾问(深入的业务场景)
T岗位通常担任什么职位?
1.爬虫项目的一线开发和交付人员
2.数据专员
3.高级数据专家
4.爬虫训练讲师
工作机会
如果看到此消息,则表明您对爬虫感兴趣。我们正在招聘上述职位。如果您是合格的履带工程师或渴望成为一名出色的履带工程师,请给您的履历表发送艰苦的努力!
优采云是国内领先的采集器云采集工具平台,可为许多大型公司和政府提供数据服务,并建立Internet数据资产仓库。如果您有兴趣这样做,请让我们私下讨论。
《优采云·云采集原理以及规则加速设置教程》
采集交流 • 优采云 发表了文章 • 0 个评论 • 316 次浏览 • 2021-03-24 01:01
优采云·Cloud 采集 Service Platform的警告:[文档是使用Spire创建的。.优采云 Cloud 采集原理和规则加速设置教程对于旗舰版以上的用户,您可以使用Cloud 采集实现多任务采集任务加速的效果,使用户可以快速采集和整理Internet公共数据。本教程主要讨论云采集的原理和规则加速设置。 一、 Cloud 采集原理A.一个针对云采集的规则任务至少占用一个云节点,并且最多可以占用所有云节点。 B.如果规则任务满足拆分为子任务的要求,则最多可以拆分为199 A子任务C。一个子任务占据一个节点,并且子任务的完成意味着该任务已完成。 D.常规任务分为多个子任务,并分配给不同的云节点以达到加速效果采集 E.如果云节点已被占用,则新启动的任务或拆分子任务将进入等待队列直到用户的某个云节点完成用户的特定任务并释放节点资源为止。图1云采集正在运行,如红线所示任务分配给云节点,多任务并发采集数据,如红色框所示,由于节点已满,只能进入等待队列,等待云节点完成资源释放的执行。 二、从云采集的原理D知道云采集的加速度设置。如果要使任务加速采集的效果,则该任务必须满足拆分条件或将任务更改为满足拆分条件的任务。为了达到单任务加速的效果。满足拆分条件的任务是:A. URL列表循环B.文本列表循环C.固定元素列表循环1、 URL列表循环,文本循环示例URL:rch / category / 15/30对于非AJAX 网站,以公共商店为例,假设我要采集所有网站类别下的商店,那么我们可以先采集该类别的URL,然后执行URL循环以继续进行采集存储信息,具体步骤如下:步骤1:首先,将采集的所有特定类别下移,如图2所示采集注释类别URL图2 采集注释类别URL技巧采集在类别URL之后,我们可以使用此URL,因为URL数据提取是循环执行的。这样,通过优采云自动任务拆分,可以将不同的URL拆分为不同的子任务,并为数据采集分配给不同的云节点,从而实现单任务加速采集效果步骤2:通过步骤采集 1,建立数据的URL循环采集,如屏幕快照所示3 URL循环列表图3 URL循环列表采集步骤3:比较效果,如图4所示本机采集与URL循环列表的效率比较cloud 采集 采集图4 Cloud 采集 采集速度提示cloud 采集除了采集比机器采集更高效之外,它还可以节省用户自己的计算机和网络资源,与消耗用户本地计算机资源和网络资源的本地采集相比,云采集使用的资源都是云节点资源,用户启动云采集,优采云将自动组织和汇总优采云客户端上的数据。提取数据后,用户仅需要通过客户端查看或导出数据。结论:已经解释了URL循环教程。对于文本循环,原理和URL循环是一致的,通过拆分文本循环,可以实现单任务加速采集的效果,从而提高了采集 2、的速率。固定元素列表循环固定元素list循环也满足拆分条件,因此需要固定元素列表。循环单击与固定元素列表结合使用。例如:图5固定元素列表-单击某个元素,但是以下条件不会加快采集的速率,例如:图6固定元素列表数据提取原因是因为固定元素列表提取尽管可以将数据拆分为多个子任务,但由于提取同一页面数据的操作非常快,因此几乎没有任务加速效果。例如:子任务A:打开网页(20s)-提取数据位置(0. 1s)子任务B:打开网页(20s)-提取位置b数据(0. 1s)子任务C:打开网页(20s)-提取位置c数据(0. 1s)...子任务N:打开网页(20秒)-提取位置n个数据(0. 1秒) 查看全部
《优采云·云采集原理以及规则加速设置教程》
优采云·Cloud 采集 Service Platform的警告:[文档是使用Spire创建的。.优采云 Cloud 采集原理和规则加速设置教程对于旗舰版以上的用户,您可以使用Cloud 采集实现多任务采集任务加速的效果,使用户可以快速采集和整理Internet公共数据。本教程主要讨论云采集的原理和规则加速设置。 一、 Cloud 采集原理A.一个针对云采集的规则任务至少占用一个云节点,并且最多可以占用所有云节点。 B.如果规则任务满足拆分为子任务的要求,则最多可以拆分为199 A子任务C。一个子任务占据一个节点,并且子任务的完成意味着该任务已完成。 D.常规任务分为多个子任务,并分配给不同的云节点以达到加速效果采集 E.如果云节点已被占用,则新启动的任务或拆分子任务将进入等待队列直到用户的某个云节点完成用户的特定任务并释放节点资源为止。图1云采集正在运行,如红线所示任务分配给云节点,多任务并发采集数据,如红色框所示,由于节点已满,只能进入等待队列,等待云节点完成资源释放的执行。 二、从云采集的原理D知道云采集的加速度设置。如果要使任务加速采集的效果,则该任务必须满足拆分条件或将任务更改为满足拆分条件的任务。为了达到单任务加速的效果。满足拆分条件的任务是:A. URL列表循环B.文本列表循环C.固定元素列表循环1、 URL列表循环,文本循环示例URL:rch / category / 15/30对于非AJAX 网站,以公共商店为例,假设我要采集所有网站类别下的商店,那么我们可以先采集该类别的URL,然后执行URL循环以继续进行采集存储信息,具体步骤如下:步骤1:首先,将采集的所有特定类别下移,如图2所示采集注释类别URL图2 采集注释类别URL技巧采集在类别URL之后,我们可以使用此URL,因为URL数据提取是循环执行的。这样,通过优采云自动任务拆分,可以将不同的URL拆分为不同的子任务,并为数据采集分配给不同的云节点,从而实现单任务加速采集效果步骤2:通过步骤采集 1,建立数据的URL循环采集,如屏幕快照所示3 URL循环列表图3 URL循环列表采集步骤3:比较效果,如图4所示本机采集与URL循环列表的效率比较cloud 采集 采集图4 Cloud 采集 采集速度提示cloud 采集除了采集比机器采集更高效之外,它还可以节省用户自己的计算机和网络资源,与消耗用户本地计算机资源和网络资源的本地采集相比,云采集使用的资源都是云节点资源,用户启动云采集,优采云将自动组织和汇总优采云客户端上的数据。提取数据后,用户仅需要通过客户端查看或导出数据。结论:已经解释了URL循环教程。对于文本循环,原理和URL循环是一致的,通过拆分文本循环,可以实现单任务加速采集的效果,从而提高了采集 2、的速率。固定元素列表循环固定元素list循环也满足拆分条件,因此需要固定元素列表。循环单击与固定元素列表结合使用。例如:图5固定元素列表-单击某个元素,但是以下条件不会加快采集的速率,例如:图6固定元素列表数据提取原因是因为固定元素列表提取尽管可以将数据拆分为多个子任务,但由于提取同一页面数据的操作非常快,因此几乎没有任务加速效果。例如:子任务A:打开网页(20s)-提取数据位置(0. 1s)子任务B:打开网页(20s)-提取位置b数据(0. 1s)子任务C:打开网页(20s)-提取位置c数据(0. 1s)...子任务N:打开网页(20秒)-提取位置n个数据(0. 1秒)
优采云采集平台对图片云存储支持以下4个服务商
采集交流 • 优采云 发表了文章 • 0 个评论 • 346 次浏览 • 2021-03-21 02:05
在数据采集的处理过程中,经常会遇到源网站设置图片防盗链接的情况,只有采集页面内容会导致图片无法显示,然后下载此采集 k14]或OSS云存储的图片。建议将图片存储在云存储中。配置和操作相对简单。您也可以直接测试配置是否正确。
优采云 采集平台支持以下4个服务提供商进行图像云存储:
当存储在阿里云OSS中时:采集,优采云直接将图片上传到用户配置的阿里云OSS中,并自动修改内容的图像链接。不再需要通过http或ftp发送回图片,可以在采集之后直接发布。
秦牛对象存储:一种类似于阿里云OSS存储的机制。
腾讯云对象存储:一种类似于存储到阿里云OSS的机制。
再次存储云对象:一种类似于存储到阿里云OSS的机制。
详细的使用步骤:
1、在“详细信息提取器”中配置字段
在“ Detail Extractor”字段中获取图片,需要在“ Get Html”上检查其属性配置。
2、“图片下载配置”
I。创建新的图片存储配置
配置“存储到阿里云OSS”或“存储到秦牛云”或“腾讯云COS”。以下是存储到阿里云OSS的示例:
输入“图片下载配置”列,单击“云存储添加管理” ==“单击[+ Alibaba Cloud OSS]按钮==”填写相关信息;
您还可以从控制台左侧的菜单中选择“第三方服务配置”-“ Picture Cloud存储管理”,如下所示:
填写相应的配置并保存,单击“测试上传图片”,如果图片弹出,则测试成功。
II,选择存储配置
选择相应的服务提供商云存储配置。
3、检查图像下载是否有效
点击“详细信息提升器”右上角的测试采集,它将采集当前加载页面的数据内容;
完成采集后,将弹出数据预览界面==》检查源代码,图片地址是否被正确替换:
查看全部
优采云采集平台对图片云存储支持以下4个服务商
在数据采集的处理过程中,经常会遇到源网站设置图片防盗链接的情况,只有采集页面内容会导致图片无法显示,然后下载此采集 k14]或OSS云存储的图片。建议将图片存储在云存储中。配置和操作相对简单。您也可以直接测试配置是否正确。
优采云 采集平台支持以下4个服务提供商进行图像云存储:
当存储在阿里云OSS中时:采集,优采云直接将图片上传到用户配置的阿里云OSS中,并自动修改内容的图像链接。不再需要通过http或ftp发送回图片,可以在采集之后直接发布。
秦牛对象存储:一种类似于阿里云OSS存储的机制。
腾讯云对象存储:一种类似于存储到阿里云OSS的机制。
再次存储云对象:一种类似于存储到阿里云OSS的机制。
详细的使用步骤:
1、在“详细信息提取器”中配置字段
在“ Detail Extractor”字段中获取图片,需要在“ Get Html”上检查其属性配置。

2、“图片下载配置”
I。创建新的图片存储配置
配置“存储到阿里云OSS”或“存储到秦牛云”或“腾讯云COS”。以下是存储到阿里云OSS的示例:
输入“图片下载配置”列,单击“云存储添加管理” ==“单击[+ Alibaba Cloud OSS]按钮==”填写相关信息;
您还可以从控制台左侧的菜单中选择“第三方服务配置”-“ Picture Cloud存储管理”,如下所示:
填写相应的配置并保存,单击“测试上传图片”,如果图片弹出,则测试成功。
II,选择存储配置
选择相应的服务提供商云存储配置。
3、检查图像下载是否有效
点击“详细信息提升器”右上角的测试采集,它将采集当前加载页面的数据内容;
完成采集后,将弹出数据预览界面==》检查源代码,图片地址是否被正确替换:
发源地开源分布式云采集引擎下配置主机域名指向站点
采集交流 • 优采云 发表了文章 • 0 个评论 • 253 次浏览 • 2021-01-19 09:07
出生地云采集开源分布式云采集引擎
出生地云采集引擎是由出生地研发团队开发的一组开源云采集工具引擎,它支持本地化私有化部署,并且可以快速构建自己的大数据云采集采集器系统。 Birthplace Cloud 采集引擎完全基于云,它将数据采集,清理,重复数据删除和处理集成到一个Internet WEB / APP数据采集引擎中,该引擎可以以较低的费用完成网页文本,图片和其他资源成本高且效率高的信息采集,并执行过滤和处理以挖掘精确的所需数据,以便将数据输出到结构化文件包,采集规则算法或API接口中,并可以选择将其发布到来源地的大数据交易平台进行交易,或导出为Excel,CSV,Mysql等格式并将其保存在本地。
V1.0更新列表功能安装说明
在nginx下配置WWW主机域名,使其指向站点下的[根目录]或[公共目录](更安全)。
以下目录需要可写操作权限
关于出生地
出生地属于上海联远信息技术有限公司的品牌。核心团队由互联网高管和来自腾讯,百度,阿里等公司的专家组成。诞生地大数据交易平台,作为国内第一个基于人工智能AI技术的大数据交易平台,支持海量数据的分布式采集,计算和处理,从而促进了机器学习的数据交易发展并实现了最大化数据的价值。 Internet公开数据和企业内部数据通过众包UGC模式采集 /访问进行访问,经过清洗,过滤,脱敏,然后以数据和算法规则的形式存放在数据交易市场中,以满足企业的需求。数据分析,数据运营和精准营销需求。 查看全部
发源地开源分布式云采集引擎下配置主机域名指向站点
出生地云采集开源分布式云采集引擎
出生地云采集引擎是由出生地研发团队开发的一组开源云采集工具引擎,它支持本地化私有化部署,并且可以快速构建自己的大数据云采集采集器系统。 Birthplace Cloud 采集引擎完全基于云,它将数据采集,清理,重复数据删除和处理集成到一个Internet WEB / APP数据采集引擎中,该引擎可以以较低的费用完成网页文本,图片和其他资源成本高且效率高的信息采集,并执行过滤和处理以挖掘精确的所需数据,以便将数据输出到结构化文件包,采集规则算法或API接口中,并可以选择将其发布到来源地的大数据交易平台进行交易,或导出为Excel,CSV,Mysql等格式并将其保存在本地。
V1.0更新列表功能安装说明
在nginx下配置WWW主机域名,使其指向站点下的[根目录]或[公共目录](更安全)。
以下目录需要可写操作权限
关于出生地
出生地属于上海联远信息技术有限公司的品牌。核心团队由互联网高管和来自腾讯,百度,阿里等公司的专家组成。诞生地大数据交易平台,作为国内第一个基于人工智能AI技术的大数据交易平台,支持海量数据的分布式采集,计算和处理,从而促进了机器学习的数据交易发展并实现了最大化数据的价值。 Internet公开数据和企业内部数据通过众包UGC模式采集 /访问进行访问,经过清洗,过滤,脱敏,然后以数据和算法规则的形式存放在数据交易市场中,以满足企业的需求。数据分析,数据运营和精准营销需求。
完整解决方案:ROS下利用realsense采集RGBD图像合成点云
采集交流 • 优采云 发表了文章 • 0 个评论 • 605 次浏览 • 2020-11-13 08:00
摘要:在ROS动力学下,使用realsense D435深度相机采集校准的RGBD图像合成点云,在rviz中查看点云,最后将其保存为pcd文件。
一、各种错误
成功编译代码后,打开rviz并添加pointcloud2选项卡。当我订阅合成点云时,可视化失败,并且选项卡报告错误:
1)数据大小(9394656字节)与宽度(640)乘以高度(480)乘以point_step(32)。丢弃消息。)。
解释:通过rostopic echo / pointcloud_topic读取摄像机节点发布的原创点云的相关数据,可以发现每帧原创点云中的点数为307,200。合成的点云中的点数为9394656/32,约为260,000。可以推测,由于某种原因,系统丢弃了合成点云每一帧的数据。
原因:我预先将复合点云的大小设置为高度= 480,宽度= 640.。但是,在合成点云的过程中,删除了一些非法值(d =0))。合成点云中的点数与指定点数不匹配,因此丢弃了合成点云中的数据。
解决方案:使用以下方法指定点云大小,cloud-> height = 1; cloud-> width = cloud-> points.size();
2)转换xxxxx;
解释:通过rostopic echo / pointcloud_topic,发现原创点云数据具有以下信息,
header:
seq: 50114
stamp:
secs: 1528439158
nsecs: 557543003
frame_id: "camera_color_optical_frame"
由此推断,复合点云缺少参考坐标系header.frame_id。点云的点的XYZ属性是相对于某个坐标系描述的,因此,需要指定点云的参考坐标系。
解决方案:添加点云的标题信息,
pub_pointcloud.header.frame_id = "camera_color_optical_frame";
pub_pointcloud.header.stamp = ros::Time::now();
3)将合成点云存储为pcd文件时遇到以下错误:
[ INFO] [1528442016.931874649]: point cloud size = 0
terminate called after throwing an instance of 'pcl::IOException'
what(): : [pcl::PCDWriter::writeASCII] Input point cloud has no data!
Aborted (core dumped)
在进行了多种搜索之后,我探索了一个窍门并与所有人分享。该错误的真正原因尚未确定,我期待着老年人的指导。
高博的源代码如下所示,里面的云是pcl的数据类型,
pcl :: io :: savePCDFile(“ ./ pointcloud.pcd”,* cloud);。
我的源代码如下所示。首先,通过pcl :: toROSMsg()将pcl的数据类型转换为ros的数据类型,然后将其写入pcd以跳过错误报告。
4)照相机内部参考
由于在颜色图和深度图的配准过程中使用了颜色图坐标系,因此在合成点云(像素坐标转换为相机坐标)时应选择颜色图的相机内部参数。
Realsense正式提供了一个用于查看所有视频流内部参数的应用程序。
gordon@gordon-5577:/usr/local/bin$ ./rs-sensor-control
如下所示
84:颜色#0(视频流:Y16 640x480 @ 60Hz)
85:颜色0(视频流:BGRA8 640x480 @ 60Hz)
86:颜色#0(视频流:RGBA8 640x480 @ 60Hz)
87:颜色#0(视频流:BGR8 640x480 @ 60Hz)
88:颜色#0(视频流:RGB8 640x480 @ 60Hz)
89:颜色#0(视频流:YUYV 640x480 @ 60Hz)
90:颜色#0(视频流:Y16 640x480 @ 30Hz)
91:颜色#0(视频流:BGRA8 640x480 @ 30Hz)
92:颜色#0(视频流:RGBA8 640x480 @ 30Hz)
93:颜色#0(视频流:BGR8 640x480 @ 30Hz)
94:颜色#0(视频流:RGB8 640x480 @ 30Hz)
95:颜色#0(视频流:YUYV 640x480 @ 30Hz)
96:颜色#0(视频流:Y16 640x480 @ 15Hz)
97:颜色#0(视频流:BGRA8 640x480 @ 15Hz)
98:颜色#0(视频流:RGBA8 640x480 @ 15Hz)
99:颜色#0(视频流:BGR8 640x480 @ 15Hz)
100:颜色#0(视频流:RGB8 640x480 @ 15Hz)
101:颜色#0(视频流:YUYV 640x480 @ 15Hz)
102:颜色#0(视频流:Y16 640x480 @ 6Hz)
103:颜色#0(视频流:BGRA8 640x480 @ 6Hz)
104:颜色#0(视频流:RGBA8 640x480 @ 6Hz)
105:颜色#0(视频流:BGR8 640x480 @ 6Hz)
106:颜色#0(视频流:RGB8 640x480 @ 6Hz)
107:颜色#0(视频流:YUYV 640x480 @ 6Hz)
5)深度图从ROS数据类型转换为CV数据类型
查看链接
二、程序代码
<p>#include
#include
#include
#include
#include
#include
// PCL 库
#include
#include
#include
#include
// 定义点云类型
typedef pcl::PointCloud PointCloud;
using namespace std;
//namespace enc = sensor_msgs::image_encodings;
// 相机内参
const double camera_factor = 1000;
const double camera_cx = 321.798;
const double camera_cy = 239.607;
const double camera_fx = 615.899;
const double camera_fy = 616.468;
// 全局变量:图像矩阵和点云
cv_bridge::CvImagePtr color_ptr, depth_ptr;
cv::Mat color_pic, depth_pic;
void color_Callback(const sensor_msgs::ImageConstPtr& color_msg)
{
//cv_bridge::CvImagePtr color_ptr;
try
{
cv::imshow("color_view", cv_bridge::toCvShare(color_msg, sensor_msgs::image_encodings::BGR8)->image);
color_ptr = cv_bridge::toCvCopy(color_msg, sensor_msgs::image_encodings::BGR8);
cv::waitKey(1050); // 不断刷新图像,频率时间为int delay,单位为ms
}
catch (cv_bridge::Exception& e )
{
ROS_ERROR("Could not convert from '%s' to 'bgr8'.", color_msg->encoding.c_str());
}
color_pic = color_ptr->image;
// output some info about the rgb image in cv format
coutencoding.c_str());
}
depth_pic = depth_ptr->image;
// output some info about the depth image in cv format
coutwidth = cloud->points.size();
ROS_INFO("point cloud size = %d",cloud->width);
cloud->is_dense = false;// 转换点云的数据类型并存储成pcd文件
pcl::toROSMsg(*cloud,pub_pointcloud);
pub_pointcloud.header.frame_id = "camera_color_optical_frame";
pub_pointcloud.header.stamp = ros::Time::now();
pcl::io::savePCDFile("./pointcloud.pcd", pub_pointcloud);
cout 查看全部
在ROS下使用realsense采集RGBD图像合成点云
摘要:在ROS动力学下,使用realsense D435深度相机采集校准的RGBD图像合成点云,在rviz中查看点云,最后将其保存为pcd文件。
一、各种错误
成功编译代码后,打开rviz并添加pointcloud2选项卡。当我订阅合成点云时,可视化失败,并且选项卡报告错误:
1)数据大小(9394656字节)与宽度(640)乘以高度(480)乘以point_step(32)。丢弃消息。)。
解释:通过rostopic echo / pointcloud_topic读取摄像机节点发布的原创点云的相关数据,可以发现每帧原创点云中的点数为307,200。合成的点云中的点数为9394656/32,约为260,000。可以推测,由于某种原因,系统丢弃了合成点云每一帧的数据。
原因:我预先将复合点云的大小设置为高度= 480,宽度= 640.。但是,在合成点云的过程中,删除了一些非法值(d =0))。合成点云中的点数与指定点数不匹配,因此丢弃了合成点云中的数据。
解决方案:使用以下方法指定点云大小,cloud-> height = 1; cloud-> width = cloud-> points.size();
2)转换xxxxx;
解释:通过rostopic echo / pointcloud_topic,发现原创点云数据具有以下信息,
header:
seq: 50114
stamp:
secs: 1528439158
nsecs: 557543003
frame_id: "camera_color_optical_frame"
由此推断,复合点云缺少参考坐标系header.frame_id。点云的点的XYZ属性是相对于某个坐标系描述的,因此,需要指定点云的参考坐标系。
解决方案:添加点云的标题信息,
pub_pointcloud.header.frame_id = "camera_color_optical_frame";
pub_pointcloud.header.stamp = ros::Time::now();
3)将合成点云存储为pcd文件时遇到以下错误:
[ INFO] [1528442016.931874649]: point cloud size = 0
terminate called after throwing an instance of 'pcl::IOException'
what(): : [pcl::PCDWriter::writeASCII] Input point cloud has no data!
Aborted (core dumped)
在进行了多种搜索之后,我探索了一个窍门并与所有人分享。该错误的真正原因尚未确定,我期待着老年人的指导。
高博的源代码如下所示,里面的云是pcl的数据类型,
pcl :: io :: savePCDFile(“ ./ pointcloud.pcd”,* cloud);。
我的源代码如下所示。首先,通过pcl :: toROSMsg()将pcl的数据类型转换为ros的数据类型,然后将其写入pcd以跳过错误报告。
4)照相机内部参考
由于在颜色图和深度图的配准过程中使用了颜色图坐标系,因此在合成点云(像素坐标转换为相机坐标)时应选择颜色图的相机内部参数。
Realsense正式提供了一个用于查看所有视频流内部参数的应用程序。
gordon@gordon-5577:/usr/local/bin$ ./rs-sensor-control
如下所示
84:颜色#0(视频流:Y16 640x480 @ 60Hz)
85:颜色0(视频流:BGRA8 640x480 @ 60Hz)
86:颜色#0(视频流:RGBA8 640x480 @ 60Hz)
87:颜色#0(视频流:BGR8 640x480 @ 60Hz)
88:颜色#0(视频流:RGB8 640x480 @ 60Hz)
89:颜色#0(视频流:YUYV 640x480 @ 60Hz)
90:颜色#0(视频流:Y16 640x480 @ 30Hz)
91:颜色#0(视频流:BGRA8 640x480 @ 30Hz)
92:颜色#0(视频流:RGBA8 640x480 @ 30Hz)
93:颜色#0(视频流:BGR8 640x480 @ 30Hz)
94:颜色#0(视频流:RGB8 640x480 @ 30Hz)
95:颜色#0(视频流:YUYV 640x480 @ 30Hz)
96:颜色#0(视频流:Y16 640x480 @ 15Hz)
97:颜色#0(视频流:BGRA8 640x480 @ 15Hz)
98:颜色#0(视频流:RGBA8 640x480 @ 15Hz)
99:颜色#0(视频流:BGR8 640x480 @ 15Hz)
100:颜色#0(视频流:RGB8 640x480 @ 15Hz)
101:颜色#0(视频流:YUYV 640x480 @ 15Hz)
102:颜色#0(视频流:Y16 640x480 @ 6Hz)
103:颜色#0(视频流:BGRA8 640x480 @ 6Hz)
104:颜色#0(视频流:RGBA8 640x480 @ 6Hz)
105:颜色#0(视频流:BGR8 640x480 @ 6Hz)
106:颜色#0(视频流:RGB8 640x480 @ 6Hz)
107:颜色#0(视频流:YUYV 640x480 @ 6Hz)
5)深度图从ROS数据类型转换为CV数据类型
查看链接
二、程序代码
<p>#include
#include
#include
#include
#include
#include
// PCL 库
#include
#include
#include
#include
// 定义点云类型
typedef pcl::PointCloud PointCloud;
using namespace std;
//namespace enc = sensor_msgs::image_encodings;
// 相机内参
const double camera_factor = 1000;
const double camera_cx = 321.798;
const double camera_cy = 239.607;
const double camera_fx = 615.899;
const double camera_fy = 616.468;
// 全局变量:图像矩阵和点云
cv_bridge::CvImagePtr color_ptr, depth_ptr;
cv::Mat color_pic, depth_pic;
void color_Callback(const sensor_msgs::ImageConstPtr& color_msg)
{
//cv_bridge::CvImagePtr color_ptr;
try
{
cv::imshow("color_view", cv_bridge::toCvShare(color_msg, sensor_msgs::image_encodings::BGR8)->image);
color_ptr = cv_bridge::toCvCopy(color_msg, sensor_msgs::image_encodings::BGR8);
cv::waitKey(1050); // 不断刷新图像,频率时间为int delay,单位为ms
}
catch (cv_bridge::Exception& e )
{
ROS_ERROR("Could not convert from '%s' to 'bgr8'.", color_msg->encoding.c_str());
}
color_pic = color_ptr->image;
// output some info about the rgb image in cv format
coutencoding.c_str());
}
depth_pic = depth_ptr->image;
// output some info about the depth image in cv format
coutwidth = cloud->points.size();
ROS_INFO("point cloud size = %d",cloud->width);
cloud->is_dense = false;// 转换点云的数据类型并存储成pcd文件
pcl::toROSMsg(*cloud,pub_pointcloud);
pub_pointcloud.header.frame_id = "camera_color_optical_frame";
pub_pointcloud.header.stamp = ros::Time::now();
pcl::io::savePCDFile("./pointcloud.pcd", pub_pointcloud);
cout
测评:收藏!5款常用的数据采集工具推荐
采集交流 • 优采云 发表了文章 • 0 个评论 • 414 次浏览 • 2020-09-03 16:37
1.内容采集器
Content Grabber是支持智能爬网的Web爬网软件。它的程序操作环境可以在开发,测试和生产服务器上使用。您可以使用c#或VB.NET调试或编写脚本来控制采集器。它还支持将第三方扩展插件添加到采集器工具。凭借其全面的功能,Content Grabber对于具有技术基础的用户而言极为强大。
2. Mozenda
Mozenda是一个Web抓取软件,还提供用于商业级数据抓取的定制服务。它可以从云和本地软件中获取数据并执行数据托管。
3. Parsehub
Parsehub是基于Web的采集器程序。它使用AJax和JavaScripts技术支持采集网页数据,还支持需要登录的采集网页数据。它具有为期一周的免费试用期,供用户体验其功能
4. Import.io
Import.io是基于Web的数据抓取工具。它于2012年在伦敦首次启动。现在Import.io已将其业务模式从B2C转变为B2B。在2019年,Import.io收购了Connotate,并成为Web数据集成平台。 Import.io拥有广泛的Web数据服务,已成为进行业务分析的绝佳选择。
5。优采云
优采云是一个免费,简单且直观的Web爬网程序工具,无需进行编码即可从许多网站抓取数据。无论您是初学者还是经验丰富的技术人员或业务主管,它都可以满足您的需求。为了降低使用难度,优采云为初学者准备了“ 网站简单模板”,涵盖了市场上大多数主流的网站。使用简单的模板,用户无需任务配置即可采集数据。这个简单的模板为采集小白树立了信心,然后您可以开始使用“高级模式”,它可以帮助您在几分钟内捕获大量数据。此外,您还可以设置时序云采集以实时获取动态数据,并将数据导出到数据库或任何第三方平台。
在5种常用数据采集工具中推荐以上内容!享受,如果您对搜索推广有任何疑问或需求,请单击在线客户服务或致电问题热线,并期待着您的问题! 查看全部
采集! 5个常用数据采集工具推荐
1.内容采集器
Content Grabber是支持智能爬网的Web爬网软件。它的程序操作环境可以在开发,测试和生产服务器上使用。您可以使用c#或VB.NET调试或编写脚本来控制采集器。它还支持将第三方扩展插件添加到采集器工具。凭借其全面的功能,Content Grabber对于具有技术基础的用户而言极为强大。
2. Mozenda
Mozenda是一个Web抓取软件,还提供用于商业级数据抓取的定制服务。它可以从云和本地软件中获取数据并执行数据托管。
3. Parsehub
Parsehub是基于Web的采集器程序。它使用AJax和JavaScripts技术支持采集网页数据,还支持需要登录的采集网页数据。它具有为期一周的免费试用期,供用户体验其功能
4. Import.io
Import.io是基于Web的数据抓取工具。它于2012年在伦敦首次启动。现在Import.io已将其业务模式从B2C转变为B2B。在2019年,Import.io收购了Connotate,并成为Web数据集成平台。 Import.io拥有广泛的Web数据服务,已成为进行业务分析的绝佳选择。
5。优采云
优采云是一个免费,简单且直观的Web爬网程序工具,无需进行编码即可从许多网站抓取数据。无论您是初学者还是经验丰富的技术人员或业务主管,它都可以满足您的需求。为了降低使用难度,优采云为初学者准备了“ 网站简单模板”,涵盖了市场上大多数主流的网站。使用简单的模板,用户无需任务配置即可采集数据。这个简单的模板为采集小白树立了信心,然后您可以开始使用“高级模式”,它可以帮助您在几分钟内捕获大量数据。此外,您还可以设置时序云采集以实时获取动态数据,并将数据导出到数据库或任何第三方平台。
在5种常用数据采集工具中推荐以上内容!享受,如果您对搜索推广有任何疑问或需求,请单击在线客户服务或致电问题热线,并期待着您的问题!
syslog网站日志采集
采集交流 • 优采云 发表了文章 • 0 个评论 • 421 次浏览 • 2020-08-28 19:07
syslog网站日志采集 相关的博客
开放、普惠、高性能-SLS时序储存推动构建企业级全方位监控方案
无所不在的时序数据 时间带走一切,长年累月会把你的名字、外貌、性格、命运都改变。 ---柏拉图 随着时间的推移,万事万物都在不停的变化,而我们也会用各类数字去评判这种变化信息,比如年纪、重量、速度、温度、金钱...在数字化时代中,我们会把那些随着时间变化的数
元乙1个月前 19
游侠原创:SyslogGather--基于Windows的绿色版SYSLOG日志采集器
实在是想不起来在那里下载的SyslogGather.exe,但是我的“未整理文件”中,有那么个文件,看名称就晓得,是和Syslog有关的,打开以后界面十分简单: 我们可以看见,SyslogGather.exe虽然就是一款测试SYSLOG的绿色版软件。可
科技小能手2年前 1059
【技术干货】想要高效采集数据到阿里云Elasticsearch,这些技巧你晓得吗?
简介: 本文全面介绍了Elastic Beats、Logstash、语言客户端以及Kibana开发者工具的特点及数据采集到阿里云Elasticsearch(简称ES)服务中的解决方案。帮助您全面了解原理并选择符合自身业务特色的数据采集方案。 本文字数:276
工程师乙10个月前 1279
游侠原创:Windows日志转SYSLOG工具——nxlog
此前游侠以前在博客上给你们介绍过Windows平台下的日志转换为syslog的工具(常见Windows日志转SYSLOG工具使用、Evtsys--轻松将Windows日志转换为SYSLOG、SyslogGather--基于Windows的绿色版SYSLOG日志
科技小能手2年前 2749
游侠原创:Evtsys--轻松将Windows日志转换为SYSLOG
我们晓得,无论是Unix、Linux、FreeBSD、Ubuntu,还是路由器、交换机,都会形成大量的日志,而这种,一般会以syslog的方式存在。调试过防火墙、入侵检查、安全审计等产品的同事应当对SYSLOG熟悉,如果您还不了解SYSLOG,请登陆百度或Go
科技小能手2年前 1028
使用LogHub进行日志实时采集
日志服务LogHub功能提供日志数据实时采集与消费,其中实时采集功能支持30+种手段,这里简单介绍下各场景的接入方法。 数据采集一般有两种形式,区别如下。我们这儿主要讨论通过LogHub流式导入(实时)采集。 方式 优势 劣势 例子 批量导出 吞吐率大,面向
简志3年前 16667
Linux 日志管理手册
管理日志的一个最好做法是将你的日志集中或整合到一个地方,特别是在你有许多服务器或多层级构架时。我们将告诉你为何这是一个好主意,然后给出怎么更容易的做这件事的一些小技巧。 集中管理日志的益处 如果你有好多服务器,查看某个日志文件可能会很麻烦。现代的网站和服务经
寒凝雪3年前 1941
日志剖析:SLS vs ELK
背景 提到日志实时剖析,大部分人第一想到是社区太火ELK Stack(Elastic/Logstash/Kibana)。ELK方案上手难度小、开源材料诸多、在社区中有大量的使用案例。 阿里云日志服务(SLS/Log) 是阿里巴巴集团对日志场景的解决方案产品,
简志1年前 13783 查看全部
syslog网站日志采集
syslog网站日志采集 相关的博客
开放、普惠、高性能-SLS时序储存推动构建企业级全方位监控方案

无所不在的时序数据 时间带走一切,长年累月会把你的名字、外貌、性格、命运都改变。 ---柏拉图 随着时间的推移,万事万物都在不停的变化,而我们也会用各类数字去评判这种变化信息,比如年纪、重量、速度、温度、金钱...在数字化时代中,我们会把那些随着时间变化的数

元乙1个月前 19
游侠原创:SyslogGather--基于Windows的绿色版SYSLOG日志采集器

实在是想不起来在那里下载的SyslogGather.exe,但是我的“未整理文件”中,有那么个文件,看名称就晓得,是和Syslog有关的,打开以后界面十分简单: 我们可以看见,SyslogGather.exe虽然就是一款测试SYSLOG的绿色版软件。可
科技小能手2年前 1059
【技术干货】想要高效采集数据到阿里云Elasticsearch,这些技巧你晓得吗?

简介: 本文全面介绍了Elastic Beats、Logstash、语言客户端以及Kibana开发者工具的特点及数据采集到阿里云Elasticsearch(简称ES)服务中的解决方案。帮助您全面了解原理并选择符合自身业务特色的数据采集方案。 本文字数:276

工程师乙10个月前 1279
游侠原创:Windows日志转SYSLOG工具——nxlog

此前游侠以前在博客上给你们介绍过Windows平台下的日志转换为syslog的工具(常见Windows日志转SYSLOG工具使用、Evtsys--轻松将Windows日志转换为SYSLOG、SyslogGather--基于Windows的绿色版SYSLOG日志
科技小能手2年前 2749
游侠原创:Evtsys--轻松将Windows日志转换为SYSLOG

我们晓得,无论是Unix、Linux、FreeBSD、Ubuntu,还是路由器、交换机,都会形成大量的日志,而这种,一般会以syslog的方式存在。调试过防火墙、入侵检查、安全审计等产品的同事应当对SYSLOG熟悉,如果您还不了解SYSLOG,请登陆百度或Go
科技小能手2年前 1028
使用LogHub进行日志实时采集
日志服务LogHub功能提供日志数据实时采集与消费,其中实时采集功能支持30+种手段,这里简单介绍下各场景的接入方法。 数据采集一般有两种形式,区别如下。我们这儿主要讨论通过LogHub流式导入(实时)采集。 方式 优势 劣势 例子 批量导出 吞吐率大,面向

简志3年前 16667
Linux 日志管理手册
管理日志的一个最好做法是将你的日志集中或整合到一个地方,特别是在你有许多服务器或多层级构架时。我们将告诉你为何这是一个好主意,然后给出怎么更容易的做这件事的一些小技巧。 集中管理日志的益处 如果你有好多服务器,查看某个日志文件可能会很麻烦。现代的网站和服务经
寒凝雪3年前 1941
日志剖析:SLS vs ELK

背景 提到日志实时剖析,大部分人第一想到是社区太火ELK Stack(Elastic/Logstash/Kibana)。ELK方案上手难度小、开源材料诸多、在社区中有大量的使用案例。 阿里云日志服务(SLS/Log) 是阿里巴巴集团对日志场景的解决方案产品,
简志1年前 13783
云脉文档识别:最短时间内完成信息采集
采集交流 • 优采云 发表了文章 • 0 个评论 • 340 次浏览 • 2020-08-26 07:48
生活学习中,我们遇见须要的资料,就会不由自主启动终极大招——Ctrl+ C/V,选择复制粘贴一顿操作猛如虎,学习资料手到擒来。
但是,这些年出于维护版权、防止捕捉等目的,不少网站/阅读APP开启了内容保护,Ctrl+ C/V不顶用了,那么如何做能够在最短的时间内完成资料采集呢?
手打?显然不现实,在这里推荐一款文档辨识小工具,帮助你读取采集资料信息,再现Ctrl+ C/V带来的“简单快乐”哦!
这款云脉文档辨识工具,是厦门云脉技术有限公司编撰的一款OCR软件,以文档辨识深度学习为基础,可以快速辨识并读取图片上的文字。文字辨识准确率很高,工具小,易安装易操作,对于须要文字辨识工具的小伙伴们来说,不失为一个好帮手。
上图是OCR文字辨识功能,可以辨识采集到图象上的所有文字。这款工具不仅仅是拿来辨识文字如此简单,云脉文档辨识还带有手动分段、后期校对、自助分组、云端储存、备注等功能。
采集资料文档其实是为了日后的使用,小文档太多很杂如何办?当然是须要“检索”功能啦!
上面提及的分类、分组功能,可以将文档根据不同的用途和内容进行分类命名,初步协助使用者找到自己所需文档的大约位置,“检索”功能则不同。
“检索”功能帮助使用者省却了“按类查找”这一步骤,直接从关键词下手,在最短的时间内找到须要的文件。 查看全部
云脉文档识别:最短时间内完成信息采集
生活学习中,我们遇见须要的资料,就会不由自主启动终极大招——Ctrl+ C/V,选择复制粘贴一顿操作猛如虎,学习资料手到擒来。
但是,这些年出于维护版权、防止捕捉等目的,不少网站/阅读APP开启了内容保护,Ctrl+ C/V不顶用了,那么如何做能够在最短的时间内完成资料采集呢?
手打?显然不现实,在这里推荐一款文档辨识小工具,帮助你读取采集资料信息,再现Ctrl+ C/V带来的“简单快乐”哦!
这款云脉文档辨识工具,是厦门云脉技术有限公司编撰的一款OCR软件,以文档辨识深度学习为基础,可以快速辨识并读取图片上的文字。文字辨识准确率很高,工具小,易安装易操作,对于须要文字辨识工具的小伙伴们来说,不失为一个好帮手。
上图是OCR文字辨识功能,可以辨识采集到图象上的所有文字。这款工具不仅仅是拿来辨识文字如此简单,云脉文档辨识还带有手动分段、后期校对、自助分组、云端储存、备注等功能。
采集资料文档其实是为了日后的使用,小文档太多很杂如何办?当然是须要“检索”功能啦!
上面提及的分类、分组功能,可以将文档根据不同的用途和内容进行分类命名,初步协助使用者找到自己所需文档的大约位置,“检索”功能则不同。
“检索”功能帮助使用者省却了“按类查找”这一步骤,直接从关键词下手,在最短的时间内找到须要的文件。
云采集 2019房产中介应当使用哪些房源采集软件?
采集交流 • 优采云 发表了文章 • 0 个评论 • 335 次浏览 • 2020-08-21 06:14
在房源采集工作中,你是否常常会碰到以下问题?
1、急需房源信息,数据采集慢?
店长要求马上提供5000条房源数据,你却发觉用普通采集需要27.77个小时!这可谓不可能完成的任务!
2、买了中级版本,结果不会用?
花钱买了中级版本,结果不会用云采集、速度还是没有改善?
现在小编借此机会向你们“普及一下“易房大师房源采集”的优势究竟在那里?如何将它的价值100%发挥下来?
1、数据云同步
云采集数据手动保存在云端,即使切换了办公场景或笔记本,只要登入易房大师帐号,便能将数据从云端下载出来。
2.简单上手
采集流程只需按照软件提示进行点击操作,完全符合常规浏览网页的行为习惯,简单几步几十个房产网站上的房源数据都能轻松采集。
3.数据手动去重,智能过滤中介房源
数据如有重复,易房大师房源采集将会手动筛选出重复数据,只保留有效数据,采集功能外置“搜狗号码辨识”、“中介号码标记”、“网络中介检查”、“网站来源”、“百度搜索”多重中介房源辨识方式,让您鉴别真伪房源省心、省时、省力又省钱!
4.可随时随地采集
易房大师手机版可以帮助中介移动化办公,电脑数据和手机数据同步,员工出门在外也可以进行房客源的管理及跟进,搜索房源,网络采集房源,房客源的录入,写日志记录等操作。在录入房源时,还可以上传视频房源,为顾客构建立体式房源体验。
5、数据备份永久保存
用户通过云采集获得的数据可永久保存,即使当下忘掉下载,也不怕数据遗失。
更多关于易房大师房源采集可以点击。 查看全部
云采集 2019房产中介应当使用哪些房源采集软件?
在房源采集工作中,你是否常常会碰到以下问题?
1、急需房源信息,数据采集慢?
店长要求马上提供5000条房源数据,你却发觉用普通采集需要27.77个小时!这可谓不可能完成的任务!
2、买了中级版本,结果不会用?
花钱买了中级版本,结果不会用云采集、速度还是没有改善?
现在小编借此机会向你们“普及一下“易房大师房源采集”的优势究竟在那里?如何将它的价值100%发挥下来?
1、数据云同步
云采集数据手动保存在云端,即使切换了办公场景或笔记本,只要登入易房大师帐号,便能将数据从云端下载出来。
2.简单上手
采集流程只需按照软件提示进行点击操作,完全符合常规浏览网页的行为习惯,简单几步几十个房产网站上的房源数据都能轻松采集。
3.数据手动去重,智能过滤中介房源
数据如有重复,易房大师房源采集将会手动筛选出重复数据,只保留有效数据,采集功能外置“搜狗号码辨识”、“中介号码标记”、“网络中介检查”、“网站来源”、“百度搜索”多重中介房源辨识方式,让您鉴别真伪房源省心、省时、省力又省钱!
4.可随时随地采集
易房大师手机版可以帮助中介移动化办公,电脑数据和手机数据同步,员工出门在外也可以进行房客源的管理及跟进,搜索房源,网络采集房源,房客源的录入,写日志记录等操作。在录入房源时,还可以上传视频房源,为顾客构建立体式房源体验。
5、数据备份永久保存
用户通过云采集获得的数据可永久保存,即使当下忘掉下载,也不怕数据遗失。
更多关于易房大师房源采集可以点击。
①ONEXIN开放云采集(常见问题)
采集交流 • 优采云 发表了文章 • 0 个评论 • 319 次浏览 • 2020-08-13 20:41
Q:免费版和专业版有哪些区别?
A:应用中心客户端版本通用。免费试用仅限服务器一。付费可选择不同套餐,定制站点,获得更高日使用上限。
Q:对服务器环境有要求吗?
A:体验版对环境没有特殊要求,文章的采集在云端。如果您的网站能发贴,插件就可以正常运行。
Q:我在美国,可以为我分配快一点的服务器吗?
A:目前我们早已拥有新浪,新网,百度云,阿里云及台湾顶尖数据中心等线路。我们会按照您的实际情况,检测后,为您分配合适的线路。
Q:为什么要订制站点?
A:定制,是确保你采集的内容更符合你的要求。
例如资讯类站点:经确认后,可以获取包括二级域名下所有文章 。
例如峰会:需要登入的,必须提供一个用户名和密码。
如有未能采集会明晰答复你。
Q:能否保存远程图片?
A:可以,在编辑器"高级"模式中,使用"下载远程图片"就可以了。
Q:如何添加我想要采集的站点?
A:目前支持资讯类或图集类站点(其它类型站暂不适用),防采集和防盗链的暂不处理。
如需新增采集目标站点,申请格式如下(或者发邮件到: onexin#):
-------------------------------------------------------------------
我的域名:
需采集站点,如下:
(详细标明所需内容页更佳)
Q:采集失败,获取不到内容如何办?
A:针对当前体验版采集的内容,如有采集失败,反馈时,请将您输入的采集网址发到邮箱onexin#等待处理。
注:不支持本地测试,形如localhost或127.0.0.1的host被禁用。
================更多功能正在测试中,请关注!=============== 查看全部
================常见问题解答(请使用最新版本)===========
Q:免费版和专业版有哪些区别?
A:应用中心客户端版本通用。免费试用仅限服务器一。付费可选择不同套餐,定制站点,获得更高日使用上限。
Q:对服务器环境有要求吗?
A:体验版对环境没有特殊要求,文章的采集在云端。如果您的网站能发贴,插件就可以正常运行。
Q:我在美国,可以为我分配快一点的服务器吗?
A:目前我们早已拥有新浪,新网,百度云,阿里云及台湾顶尖数据中心等线路。我们会按照您的实际情况,检测后,为您分配合适的线路。
Q:为什么要订制站点?
A:定制,是确保你采集的内容更符合你的要求。
例如资讯类站点:经确认后,可以获取包括二级域名下所有文章 。
例如峰会:需要登入的,必须提供一个用户名和密码。
如有未能采集会明晰答复你。
Q:能否保存远程图片?
A:可以,在编辑器"高级"模式中,使用"下载远程图片"就可以了。
Q:如何添加我想要采集的站点?
A:目前支持资讯类或图集类站点(其它类型站暂不适用),防采集和防盗链的暂不处理。
如需新增采集目标站点,申请格式如下(或者发邮件到: onexin#):
-------------------------------------------------------------------
我的域名:
需采集站点,如下:
(详细标明所需内容页更佳)
Q:采集失败,获取不到内容如何办?
A:针对当前体验版采集的内容,如有采集失败,反馈时,请将您输入的采集网址发到邮箱onexin#等待处理。
注:不支持本地测试,形如localhost或127.0.0.1的host被禁用。
================更多功能正在测试中,请关注!===============
如何管理私有云帐号下的云采集节点
采集交流 • 优采云 发表了文章 • 0 个评论 • 630 次浏览 • 2020-08-11 20:01
一、私有云基本介绍
私有云是优采云SaaS版本中的最高版本。私有云处于特定集群,拥有固定的云节点数,通常为30个或100个。
而旗舰/旗舰+版,则处于公共集群,其节点数是浮动变化的,所有旗舰/旗舰+用户一起角逐节点的使用权。
二、私有云可自动调整每位任务的云节点数
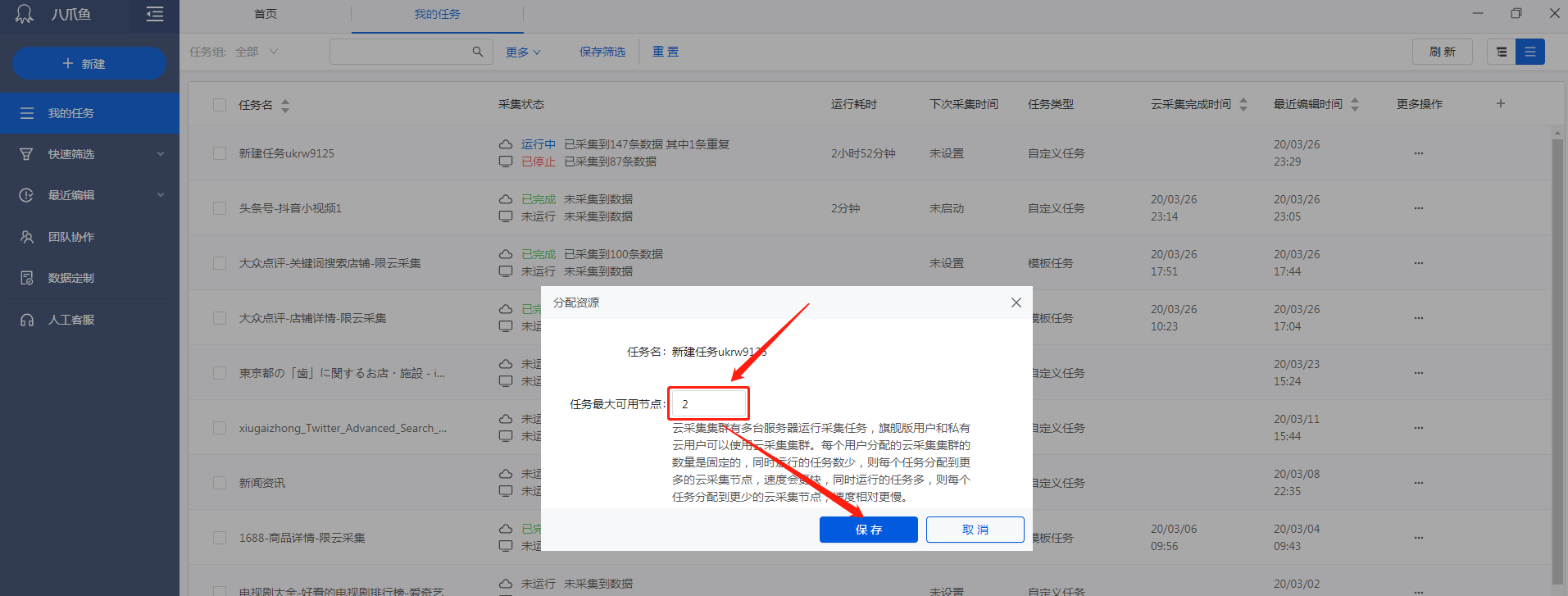
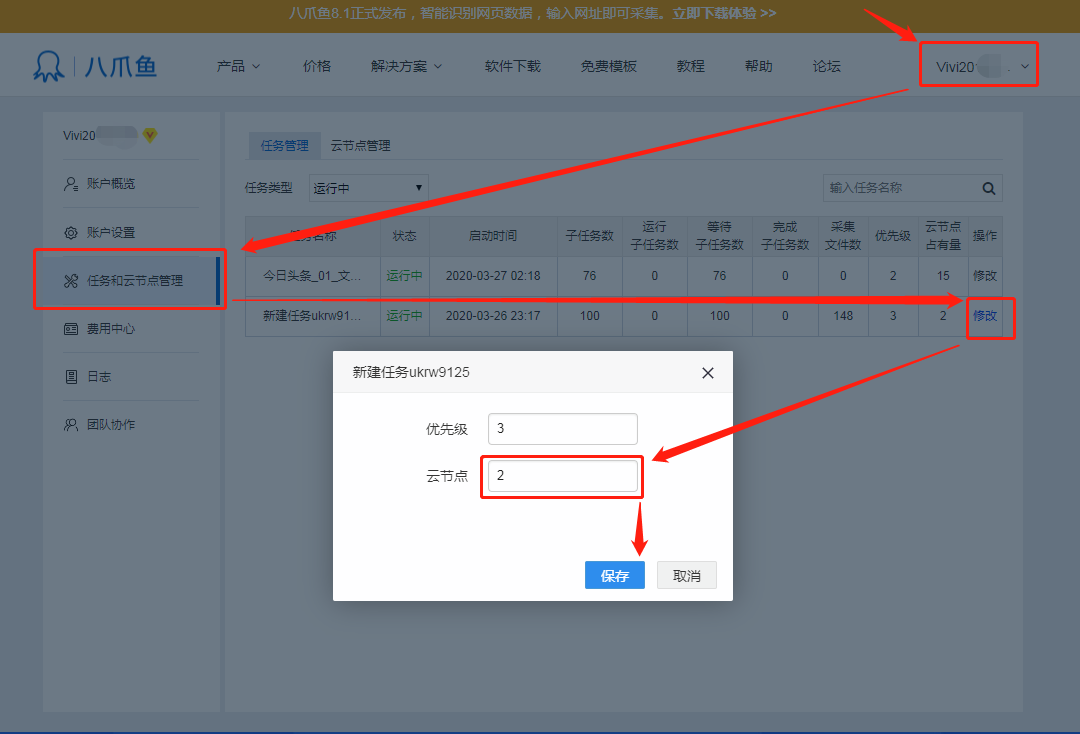
私有云帐号下的每位任务,云采集的最大可用节点数,默认为2(即每位任务最多有2个云节点同时进行采集)。
我们可以自动调整每位任务分配的云节点数,以更合理有效借助云节点。例如,给紧急的任务多分配一些云节点,提高任务优先级,以便在更短时间内完成紧急任务的数据采集。
调整后的节点数常年有效,再次启动或复制/导入导入任务,也无需重新设置节点数。
1、云节点分配入口
节点数的调整位置有三处:分别是客户端内的任务列表,官网的用户中心,团队协作管理平台。
a. 客户端内的任务列表(推荐)
点击【我的任务】进入任务列表。找到最右边的【更多操作】,点击【...】,鼠标联通到【云采集】上,再联通到【分配资源】上,然后点击它。
最后在弹窗中设置该任务的最大可用节点。
b. 官网的用户中心
在官网登陆,进入用户中心后,点击【任务和云节点管理】即可跳转到任务管理页面。找到所须要调整的任务,点击【修改】,然后在弹窗中更改云节点的数目。
c. 团队协作管理平台
团队协作管理平台的操作权限默认关掉,如有须要可找对接的商务和专属技术支持免费开通。团队协作管理平台登陆入口: 操作说明:
登录团队协作管理平台后,点击【任务管理】,进入任务列表。找到最右边的【更多操作】,点击【...】,鼠标联通到【云采集】上,再联通到【分配资源】上,然后点击它。
最后在弹窗中设置该任务的任务占用节点。
2、云节点分配原则
根据云采集加速原理可知:任务能分拆的子任务越大,能同时执行云采集的云节点越多,采集的速率就越快。在实际采集过程中,账号内云节点的数目是有限的,也就是说,云采集速度的快慢,主要由当前在采集的子任务数决定,此数值越大,采集越快。
如何查看每位任务正在运行的子任务数?
通过 云采集实况功能,可查看子任务的分拆和运行情况:
如何得悉帐号正在运行的云节点数?
在【我的任务】界面,【云采集状态】中筛选出全部的【运行中】任务,依次查看每位任务的 云采集实况,然后将每位任务的【运行中】子任务数相乘,即可得到当前时间帐号有多少个云节点正在采集数据。
云节点分配原则:
a. 最大可用节点数不小于任务的已分拆子任务数。如默认已拆分子任务数是10,那它最多同时使用10个云节点,就算分配了20个,它也用不上全部的。多余的节点会手动给其他任务。
b. 云采集实际运行速率,取决于运行中的子任务数。如某任务设置的最大可用节点数是5,运行中的子任务数是5,等待中的子任务数是0。此时是通过调整最大可用节点数是难以提高任务的采集速度。因为任务全部子任务都已启动了采集。但若果运行子任务数5,等待子任务数为7。此时希望它运行快些,可调大最大可用节点数,此时调整成12即可(云节点占有量
c. 一般而言,在帐号内空闲节点充足的情况,建议给某个任务设置最大可用节点数为已分拆子任务数的50%~100%。账号内空闲节点十分紧张的情况,每个任务的最大可用节点数=账号总节点/同时运行任务数。这样会相对均衡,让每位任务都能有一定量的节点来采集数据。
d. 已经分配出去的云节点,完成该子任务的采集之后,才会被回收到帐号中供其他任务使用。如:任务A的最大可用节点数是30,启动云采集后,这30个节点都在进行采集(即该任务运行中的子任务数是30)。随后又想增加任务A的云节点,分配一些节点给任务B使用。此时将任务A的最大可用节点数调成10个,那20个节点并不会马上转给任务B使用。而是继续运行任务A的子任务,该子任务完成后,才会转给任务B使用。
特殊情况说明:
1、有时可能出现所有运行中的子任务数之和大于帐号节点数。所有的云节点都分配出去,并且 等待中子任务数+运行中子任务数>账号节点数。
原因:实际上节点是早已占用满了。但因为子任务分配节点的时间小于节点完成采集的时间,所以在查询的顿时会出现节点用不满的表象。
举个事例,任务A的每个子任务只须要10秒就可以完成采集,但每位子任务分配上云节点并启动须要耗费20秒。故在查询的顿时都会出在采集的节点少,分配并启动的多。而我们的【运行中子任务数】,只是查询并显示正在采集过程中的,那类分配并启动中的不会查询到。故看起来象是节点用不满。
2、启动云采集后,【运行中】没有听到这个任务。
原因① :查看过快。任务在启动后,服务器须要先对任务进行预处理,判断能不能分拆,能分拆的执行分拆程序,然后分配云节点来执行子任务。这些过程会花费些时间,如果立刻查看,在【运行中】是看不到的,但在【等待运行】里可以看见。稍等一会后,就可以在【运行中】查看到了。
原因②:查看得很晚了,任务已经完成采集。此时可以在【完成中】可查看。 查看全部
本教程将介绍私有云套餐,并讲解怎样查看/管理帐号下的云采集节点,优化分配策略,提高采集效率。
一、私有云基本介绍
私有云是优采云SaaS版本中的最高版本。私有云处于特定集群,拥有固定的云节点数,通常为30个或100个。
而旗舰/旗舰+版,则处于公共集群,其节点数是浮动变化的,所有旗舰/旗舰+用户一起角逐节点的使用权。
二、私有云可自动调整每位任务的云节点数
私有云帐号下的每位任务,云采集的最大可用节点数,默认为2(即每位任务最多有2个云节点同时进行采集)。
我们可以自动调整每位任务分配的云节点数,以更合理有效借助云节点。例如,给紧急的任务多分配一些云节点,提高任务优先级,以便在更短时间内完成紧急任务的数据采集。
调整后的节点数常年有效,再次启动或复制/导入导入任务,也无需重新设置节点数。
1、云节点分配入口
节点数的调整位置有三处:分别是客户端内的任务列表,官网的用户中心,团队协作管理平台。
a. 客户端内的任务列表(推荐)
点击【我的任务】进入任务列表。找到最右边的【更多操作】,点击【...】,鼠标联通到【云采集】上,再联通到【分配资源】上,然后点击它。
最后在弹窗中设置该任务的最大可用节点。
b. 官网的用户中心
在官网登陆,进入用户中心后,点击【任务和云节点管理】即可跳转到任务管理页面。找到所须要调整的任务,点击【修改】,然后在弹窗中更改云节点的数目。
c. 团队协作管理平台
团队协作管理平台的操作权限默认关掉,如有须要可找对接的商务和专属技术支持免费开通。团队协作管理平台登陆入口: 操作说明:
登录团队协作管理平台后,点击【任务管理】,进入任务列表。找到最右边的【更多操作】,点击【...】,鼠标联通到【云采集】上,再联通到【分配资源】上,然后点击它。
最后在弹窗中设置该任务的任务占用节点。
2、云节点分配原则
根据云采集加速原理可知:任务能分拆的子任务越大,能同时执行云采集的云节点越多,采集的速率就越快。在实际采集过程中,账号内云节点的数目是有限的,也就是说,云采集速度的快慢,主要由当前在采集的子任务数决定,此数值越大,采集越快。
如何查看每位任务正在运行的子任务数?
通过 云采集实况功能,可查看子任务的分拆和运行情况:
如何得悉帐号正在运行的云节点数?
在【我的任务】界面,【云采集状态】中筛选出全部的【运行中】任务,依次查看每位任务的 云采集实况,然后将每位任务的【运行中】子任务数相乘,即可得到当前时间帐号有多少个云节点正在采集数据。
云节点分配原则:
a. 最大可用节点数不小于任务的已分拆子任务数。如默认已拆分子任务数是10,那它最多同时使用10个云节点,就算分配了20个,它也用不上全部的。多余的节点会手动给其他任务。
b. 云采集实际运行速率,取决于运行中的子任务数。如某任务设置的最大可用节点数是5,运行中的子任务数是5,等待中的子任务数是0。此时是通过调整最大可用节点数是难以提高任务的采集速度。因为任务全部子任务都已启动了采集。但若果运行子任务数5,等待子任务数为7。此时希望它运行快些,可调大最大可用节点数,此时调整成12即可(云节点占有量
c. 一般而言,在帐号内空闲节点充足的情况,建议给某个任务设置最大可用节点数为已分拆子任务数的50%~100%。账号内空闲节点十分紧张的情况,每个任务的最大可用节点数=账号总节点/同时运行任务数。这样会相对均衡,让每位任务都能有一定量的节点来采集数据。
d. 已经分配出去的云节点,完成该子任务的采集之后,才会被回收到帐号中供其他任务使用。如:任务A的最大可用节点数是30,启动云采集后,这30个节点都在进行采集(即该任务运行中的子任务数是30)。随后又想增加任务A的云节点,分配一些节点给任务B使用。此时将任务A的最大可用节点数调成10个,那20个节点并不会马上转给任务B使用。而是继续运行任务A的子任务,该子任务完成后,才会转给任务B使用。
特殊情况说明:
1、有时可能出现所有运行中的子任务数之和大于帐号节点数。所有的云节点都分配出去,并且 等待中子任务数+运行中子任务数>账号节点数。
原因:实际上节点是早已占用满了。但因为子任务分配节点的时间小于节点完成采集的时间,所以在查询的顿时会出现节点用不满的表象。
举个事例,任务A的每个子任务只须要10秒就可以完成采集,但每位子任务分配上云节点并启动须要耗费20秒。故在查询的顿时都会出在采集的节点少,分配并启动的多。而我们的【运行中子任务数】,只是查询并显示正在采集过程中的,那类分配并启动中的不会查询到。故看起来象是节点用不满。
2、启动云采集后,【运行中】没有听到这个任务。
原因① :查看过快。任务在启动后,服务器须要先对任务进行预处理,判断能不能分拆,能分拆的执行分拆程序,然后分配云节点来执行子任务。这些过程会花费些时间,如果立刻查看,在【运行中】是看不到的,但在【等待运行】里可以看见。稍等一会后,就可以在【运行中】查看到了。
原因②:查看得很晚了,任务已经完成采集。此时可以在【完成中】可查看。
优采云,国内领先的爬虫云采集工具平台,为许多小型公司,政府,提供数据服务
采集交流 • 优采云 发表了文章 • 0 个评论 • 414 次浏览 • 2020-08-11 13:03
这个就挺好理解,精通某一款主流的采集工具,比如说我们优采云采集器
需要精通到哪些程度?
1.如果你会用我们优采云与XPATH,定位网页任意元素
2.如果你晓得怎样优采云采集原理,懂得分拆规则,让整个采集效率翻10倍
3.其实没有天天使用我们优采云超过三个月以上,写过一两百个规则的,都不应当算精通吧
除以上两个工具层面熟悉外,还须要熟悉以下东西:
1.防采集原理(验证码,多IP等)
2.html后端解析知识
3.分布式解决方案
4.正则表达式匹配
基本上熟悉把握了以上这种技能,也差不多能成为一名合格,思路清晰的爬虫工程师了。写代码的有写代码的益处,用工具有用工具的益处,写代码的用处在于自由度比较大,挑战比较大,入门比较难,而且作用似乎不大,因为好多时侯虽然是在重复造轮子。
毕竟好多通用性的动作都是可以用爬虫工具完成的,功能爬虫工具都帮你做好了,你只要会用就行。而工具呢,工具仍然有一点点局限性,工具为了通用性,在一定程度是牺牲了个别功能的,在一些太特殊的场景,工具虽然很难完成。
所以我一向的推荐就是,工具+代码,才是一个现今主流的爬虫工程师的配置。你可以使用工具,比如我们优采云,实现那99%的需求,但若果遇见特定的,自已留一手写代码解决,也是无妨的。
毕竟我们要的是解决问题,更别说python等等,配置个爬虫程序一点都不难,网上教程一大把。(国内主流采集大神都是如此做,能用工具的优先用工具,除非工具搞不定,才自已码代码)
爬虫工程师的关联技能
除了须要懂采集外,爬虫工程师还须要一些其他的技能,这才是真正评判一名爬虫工程师是入门,还是普通,还是优秀的标准。其实在现今这个时代,复合型人才都是比较吃香的。
一个优秀的爬虫工程师,他还须要以下几项技术进行升华
1.数据清洗
因为采集下来的数据,很多时侯都是一大段文本,你须要对文本进行提炼,也就是我们说的对数据进行清洗,才能得到愈发干净的结构化数据,保存在数据库上面。
有时候我们采集多份数据,也须要通过清洗进行关联。这上面例如我们善于使用Excel的一些中级方法,也包括会使用R等程序语言,对文本进行处理。在我们优采云数据中心团队的朋友,都具备数据清洗的技能。
2.数据挖掘
爬虫后的数据挖掘,一般是指NLP这鬼东西。NLP是属于人工智能范筹的,中文叫自然语言处理,简单理解就是处理大量文本,从大量文本上面挖掘出价值的一个东西。
在国外能做好的,都是属于凤毛鳞角的,我们优采云也有我们自已的NLP团队,投入相当巨大,还没做得非常出众,仅仅开始实现一些特定场景功能,能做一些单子了。我们为国外一些主流的AI公司,采集并挖掘后,输出AI数据。我们的数据中心就有牛人专门干这个的。
3.数据剖析可视化
仅仅只是将数据采集下来,保存在数据库上面,仅仅只是实现第一步的价值。数据剖析与可视化,才是数据背后更大的价值。
所以须要对数据保存进数据库,然后通过相应的框架或程序开发,组织调用下来,辅助企业进行决策。所以我们优采云有专门的数据BI团队,也有好多爬虫工程师擅于使用EXCEL,一般可视化BI工具,为项目提供可视化数据支持。
4.深刻理解业务
无论是对互联网公开数据的获取能力的理解,还是对业务需求的理解,也是审视一个优秀的爬虫工程师的重要评判标准,说白了就是,不仅要懂技术,而且要懂业务,成为复合型的爬虫工程师。能到这个程度,才能将爬虫工程师的价值无限放大。比如理解风控业务,比如理解AI业务等。这个岗位我们有售前,有顾问等。
如何规划爬虫工程师的路线
在我的团队上面,是有L岗与T岗这两个路线的,L岗通常是指偏业务的爬虫工程师的岗位,T岗通常是指偏技术的爬虫工程师岗位,这跟人的性格有关,一些朋友更喜欢紧靠业务,表达能力好,反应快思路清晰,他都会往L岗走,一些朋友更偏向技术,狂热于突破各类困局,输出更好的解决方案,他都会往T岗走。
L岗通常有哪些职位
1.技术支持(中小顾客方向)
2.售前(大顾客方向)
3.数据中心Leader/项目Leader
4.方案顾问(深入业务场景)
T岗通常有哪些职位
1.爬虫项目一线开发交付人员
2.数据专员
3.中级数据专员
4.爬虫培训讲师
工作机会
如果你听到这儿,那证明你对爬虫是有兴趣的,以上职位我们均有在急聘,如果你是一个合格的爬虫工程师,或立志成为一名优秀的爬虫工程师,请将简历狠狠地砸过来吧!
优采云,国内领先的爬虫云采集工具平台,为许多小型公司,政府,提供数据服务,建立互联网数据资产库房,有兴趣做这件事的,我们私聊。 查看全部
2.工具方向
这个就挺好理解,精通某一款主流的采集工具,比如说我们优采云采集器
需要精通到哪些程度?
1.如果你会用我们优采云与XPATH,定位网页任意元素
2.如果你晓得怎样优采云采集原理,懂得分拆规则,让整个采集效率翻10倍
3.其实没有天天使用我们优采云超过三个月以上,写过一两百个规则的,都不应当算精通吧
除以上两个工具层面熟悉外,还须要熟悉以下东西:
1.防采集原理(验证码,多IP等)
2.html后端解析知识
3.分布式解决方案
4.正则表达式匹配
基本上熟悉把握了以上这种技能,也差不多能成为一名合格,思路清晰的爬虫工程师了。写代码的有写代码的益处,用工具有用工具的益处,写代码的用处在于自由度比较大,挑战比较大,入门比较难,而且作用似乎不大,因为好多时侯虽然是在重复造轮子。
毕竟好多通用性的动作都是可以用爬虫工具完成的,功能爬虫工具都帮你做好了,你只要会用就行。而工具呢,工具仍然有一点点局限性,工具为了通用性,在一定程度是牺牲了个别功能的,在一些太特殊的场景,工具虽然很难完成。
所以我一向的推荐就是,工具+代码,才是一个现今主流的爬虫工程师的配置。你可以使用工具,比如我们优采云,实现那99%的需求,但若果遇见特定的,自已留一手写代码解决,也是无妨的。
毕竟我们要的是解决问题,更别说python等等,配置个爬虫程序一点都不难,网上教程一大把。(国内主流采集大神都是如此做,能用工具的优先用工具,除非工具搞不定,才自已码代码)
爬虫工程师的关联技能
除了须要懂采集外,爬虫工程师还须要一些其他的技能,这才是真正评判一名爬虫工程师是入门,还是普通,还是优秀的标准。其实在现今这个时代,复合型人才都是比较吃香的。
一个优秀的爬虫工程师,他还须要以下几项技术进行升华
1.数据清洗
因为采集下来的数据,很多时侯都是一大段文本,你须要对文本进行提炼,也就是我们说的对数据进行清洗,才能得到愈发干净的结构化数据,保存在数据库上面。
有时候我们采集多份数据,也须要通过清洗进行关联。这上面例如我们善于使用Excel的一些中级方法,也包括会使用R等程序语言,对文本进行处理。在我们优采云数据中心团队的朋友,都具备数据清洗的技能。
2.数据挖掘
爬虫后的数据挖掘,一般是指NLP这鬼东西。NLP是属于人工智能范筹的,中文叫自然语言处理,简单理解就是处理大量文本,从大量文本上面挖掘出价值的一个东西。
在国外能做好的,都是属于凤毛鳞角的,我们优采云也有我们自已的NLP团队,投入相当巨大,还没做得非常出众,仅仅开始实现一些特定场景功能,能做一些单子了。我们为国外一些主流的AI公司,采集并挖掘后,输出AI数据。我们的数据中心就有牛人专门干这个的。
3.数据剖析可视化
仅仅只是将数据采集下来,保存在数据库上面,仅仅只是实现第一步的价值。数据剖析与可视化,才是数据背后更大的价值。
所以须要对数据保存进数据库,然后通过相应的框架或程序开发,组织调用下来,辅助企业进行决策。所以我们优采云有专门的数据BI团队,也有好多爬虫工程师擅于使用EXCEL,一般可视化BI工具,为项目提供可视化数据支持。
4.深刻理解业务
无论是对互联网公开数据的获取能力的理解,还是对业务需求的理解,也是审视一个优秀的爬虫工程师的重要评判标准,说白了就是,不仅要懂技术,而且要懂业务,成为复合型的爬虫工程师。能到这个程度,才能将爬虫工程师的价值无限放大。比如理解风控业务,比如理解AI业务等。这个岗位我们有售前,有顾问等。
如何规划爬虫工程师的路线
在我的团队上面,是有L岗与T岗这两个路线的,L岗通常是指偏业务的爬虫工程师的岗位,T岗通常是指偏技术的爬虫工程师岗位,这跟人的性格有关,一些朋友更喜欢紧靠业务,表达能力好,反应快思路清晰,他都会往L岗走,一些朋友更偏向技术,狂热于突破各类困局,输出更好的解决方案,他都会往T岗走。
L岗通常有哪些职位
1.技术支持(中小顾客方向)
2.售前(大顾客方向)
3.数据中心Leader/项目Leader
4.方案顾问(深入业务场景)
T岗通常有哪些职位
1.爬虫项目一线开发交付人员
2.数据专员
3.中级数据专员
4.爬虫培训讲师
工作机会
如果你听到这儿,那证明你对爬虫是有兴趣的,以上职位我们均有在急聘,如果你是一个合格的爬虫工程师,或立志成为一名优秀的爬虫工程师,请将简历狠狠地砸过来吧!
优采云,国内领先的爬虫云采集工具平台,为许多小型公司,政府,提供数据服务,建立互联网数据资产库房,有兴趣做这件事的,我们私聊。
大鹏教你python数据剖析
采集交流 • 优采云 发表了文章 • 0 个评论 • 222 次浏览 • 2020-08-11 03:21
出差中…………,换pc了,没有开发环境,看看其他口味的课程
数据工作流
抛出问题——数据——数据研究——问题推论——解决方案
用py
用py来剖析数据,结合好多包,py类比手机,安装不同app就是安装不同的包
知道2利器,优采云,Gephi。数据采集与剖析
优采云简单教程:
A、网址辨识
(*)强大的变量,和bs4一样,唯一定位即可
原理:超链接
1、1级网址辨识,(启始网址,然后上面找)
2、2级网址辨识(启始网址多个,然后上面找,收录规则,不收录规则),(*)通配所有,要不收录
B、数据标签及数据清洗
点击网址,去原网页找须要标签
设置格式文件
自己爬虫效率更高,不要三方各类调用
数据处理
有价值信息数据是采集不到的,大公司有专门网路工程师,不会给你机会滴! 我认为有没有用看你来干啥,所以叫数据挖掘
python数据结构
标量123,变量abc
python路劲写法
哎,调库侠,好多库啊
Python爬虫防封杀方式集合
转:附加采集工具对比
本人也算是个采集器小白,之前研究过一段时间的优采云,不过还是比较青涩。今天和你们分享几款采集器及它们的特征:
1.优采云采集器:
一款互联网数据抓取、处理、分析,挖掘软件,可以抓取网页上散乱分布的数据信息,并通过一系列的剖析处理,准确挖掘出所需数据。
特点:采集不限网页,不限内容;
分布式采集系统,提高效率;
支持PHP和C#插件扩充,方便更改处理数据。
2.优采云云采集:
一款新颖的云端在线智能爬虫/采集器,基于优采云分布式云爬虫框架,帮助用户快速获取大量规范化的网页数据,帮助顾客快速轻松地获取大量规范化数据。
特点:直接接入代理IP,无需设置便可防止因IP被限制访问引起的难以采集的问题;
自动登入验证码识别,网站自动完成验证码输入,无需人工看管;
可在线生成图标,采集结果以丰富表格化方式诠释;
本地化隐私保护,云端采集,可隐藏用户IP。
3.优采云采集器:
一套专业的网站内容采集软件,支持各种峰会的贴子和回复采集,网站和博客文章内容抓取,分峰会采集器、CMS采集器和博客采集器三类。
特点:支持对文章内容中的文字、链接批量替换和过滤;
可以同时向网站或峰会的多个版块一起批量发帖;
具备采集或发贴任务完成后自动关机功能;
4.三人行采集器:
一套可以把他人网站、论坛、博客的图文内容轻松采集到自己的网站、论坛和博客的站长工具,包括峰会注册王、采集发帖王和采集搬家王三类软件。
特点:以采集需要注册登录后才会查看的峰会贴子;(强)
可以同时向峰会的多个版块一起批量发帖;
支持对文章内容中的文字、链接批量替换和过滤。
5.集搜客:
一款简单易用的网页信息抓取软件,能够抓取网页文字、图表、超链接等多种网页元素,提供好用的网页抓取软件、数据挖掘功略、行业资讯和前沿科技等。
特点:可以抓取手机网站上的数据;
支持抓取在指数图表上漂浮显示的数据;
会员互助抓取,提升采集效率。
6.优采云采集器:
一款网页采集软件,可以从不同的网站获取规范化数据,帮助顾客实现数据自动化采集,编辑,规范化,从而减少成本,提高效率。
特点:容易上手,完全可视化图形操作;
内置可扩充的OCR插口,支持解析图片中的文字;
采集任务手动运行,可以根据指定的周期手动采集。 查看全部

出差中…………,换pc了,没有开发环境,看看其他口味的课程

数据工作流
抛出问题——数据——数据研究——问题推论——解决方案
用py

用py来剖析数据,结合好多包,py类比手机,安装不同app就是安装不同的包
知道2利器,优采云,Gephi。数据采集与剖析
优采云简单教程:
A、网址辨识
(*)强大的变量,和bs4一样,唯一定位即可
原理:超链接
1、1级网址辨识,(启始网址,然后上面找)
2、2级网址辨识(启始网址多个,然后上面找,收录规则,不收录规则),(*)通配所有,要不收录
B、数据标签及数据清洗
点击网址,去原网页找须要标签
设置格式文件
自己爬虫效率更高,不要三方各类调用
数据处理
有价值信息数据是采集不到的,大公司有专门网路工程师,不会给你机会滴! 我认为有没有用看你来干啥,所以叫数据挖掘
python数据结构
标量123,变量abc

python路劲写法

哎,调库侠,好多库啊
Python爬虫防封杀方式集合
转:附加采集工具对比
本人也算是个采集器小白,之前研究过一段时间的优采云,不过还是比较青涩。今天和你们分享几款采集器及它们的特征:
1.优采云采集器:
一款互联网数据抓取、处理、分析,挖掘软件,可以抓取网页上散乱分布的数据信息,并通过一系列的剖析处理,准确挖掘出所需数据。
特点:采集不限网页,不限内容;
分布式采集系统,提高效率;
支持PHP和C#插件扩充,方便更改处理数据。
2.优采云云采集:
一款新颖的云端在线智能爬虫/采集器,基于优采云分布式云爬虫框架,帮助用户快速获取大量规范化的网页数据,帮助顾客快速轻松地获取大量规范化数据。
特点:直接接入代理IP,无需设置便可防止因IP被限制访问引起的难以采集的问题;
自动登入验证码识别,网站自动完成验证码输入,无需人工看管;
可在线生成图标,采集结果以丰富表格化方式诠释;
本地化隐私保护,云端采集,可隐藏用户IP。
3.优采云采集器:
一套专业的网站内容采集软件,支持各种峰会的贴子和回复采集,网站和博客文章内容抓取,分峰会采集器、CMS采集器和博客采集器三类。
特点:支持对文章内容中的文字、链接批量替换和过滤;
可以同时向网站或峰会的多个版块一起批量发帖;
具备采集或发贴任务完成后自动关机功能;
4.三人行采集器:
一套可以把他人网站、论坛、博客的图文内容轻松采集到自己的网站、论坛和博客的站长工具,包括峰会注册王、采集发帖王和采集搬家王三类软件。
特点:以采集需要注册登录后才会查看的峰会贴子;(强)
可以同时向峰会的多个版块一起批量发帖;
支持对文章内容中的文字、链接批量替换和过滤。
5.集搜客:
一款简单易用的网页信息抓取软件,能够抓取网页文字、图表、超链接等多种网页元素,提供好用的网页抓取软件、数据挖掘功略、行业资讯和前沿科技等。
特点:可以抓取手机网站上的数据;
支持抓取在指数图表上漂浮显示的数据;
会员互助抓取,提升采集效率。
6.优采云采集器:
一款网页采集软件,可以从不同的网站获取规范化数据,帮助顾客实现数据自动化采集,编辑,规范化,从而减少成本,提高效率。
特点:容易上手,完全可视化图形操作;
内置可扩充的OCR插口,支持解析图片中的文字;
采集任务手动运行,可以根据指定的周期手动采集。
Mac上有没有类似优采云的数据采集软件?
采集交流 • 优采云 发表了文章 • 0 个评论 • 365 次浏览 • 2020-08-11 01:52
优采云面向开发者,拥有技术基础的朋友可以大显身手,实现十分强悍的网路爬虫。
没有开发经验的小白朋友一开始可能认为不容易上手,不过好在她们提供了官方云爬虫市场,可以零基础直接使用。
造数是网页点选操作流程,小白用户易上手和理解,具有非常好的可视化操作过程。就是有点慢呐!在我写这篇回答又上了个公厕的几十分钟里,尝试采集了一个网站,结果还没下来 -_-||
@小小造数君
在线网路爬虫/大数据剖析/机器学习开发平台-优采云云
造数 - 新一代智能云爬虫 - 控制面板dashboard.zaoshu.io
另一种就是使用支持MAC系统的采集器软件,目前只有优采云采集器和集搜客支持。
优采云采集器_真免费!导出无限制网路爬虫软件_人工智能数据采集软件
免费下载网页抓取软件,专业网路爬虫,写论文采数据工具-集搜客GooSeeker
那么,这些备选项里该怎么选择呢?
1、免费不花钱,不需要积分的
(这里说的免费功能包括采集数据、导出各类格式的数据到本地,下载图片到本地等采集数据所必备的基本功能):
你可以选择优采云云爬虫和优采云采集器
(造数官方没有找到是否收费的具体说明,但是有提及:“造数计费单位是“次”,1次爬取指的是:成功爬取1个网页并获得数据。”,所以我理解她们不是免费的)
这三者上面,我推荐你使用优采云采集器,因为我目测楼主虽然没有编程基础,
但是若果优采云云市场中有你须要的采集的网站的采集规则,而且也刚好是免费的(优采云云爬虫市场有官方的采集规则也有开发者上传的采集规则),那么你可以尝试一下优采云云爬虫。
2、不差钱,关键是喜欢
那么可以尝试使用优采云采集器和集搜客,然后从二者上面选购一个自己喜欢的。
用户体验和性价比这些东西还是要自己用一下比较好,萝卜青椒各有所爱么。 查看全部
一种是使用基于Web的云端采集系统,目前有优采云云爬虫和造数,这种基于Web端的网路爬虫工具,没有操作系统限制。别说是要在MAC上抓取数据,你就是手机上都没有问题。
优采云面向开发者,拥有技术基础的朋友可以大显身手,实现十分强悍的网路爬虫。
没有开发经验的小白朋友一开始可能认为不容易上手,不过好在她们提供了官方云爬虫市场,可以零基础直接使用。
造数是网页点选操作流程,小白用户易上手和理解,具有非常好的可视化操作过程。就是有点慢呐!在我写这篇回答又上了个公厕的几十分钟里,尝试采集了一个网站,结果还没下来 -_-||
@小小造数君
在线网路爬虫/大数据剖析/机器学习开发平台-优采云云

造数 - 新一代智能云爬虫 - 控制面板dashboard.zaoshu.io
另一种就是使用支持MAC系统的采集器软件,目前只有优采云采集器和集搜客支持。
优采云采集器_真免费!导出无限制网路爬虫软件_人工智能数据采集软件

免费下载网页抓取软件,专业网路爬虫,写论文采数据工具-集搜客GooSeeker
那么,这些备选项里该怎么选择呢?
1、免费不花钱,不需要积分的
(这里说的免费功能包括采集数据、导出各类格式的数据到本地,下载图片到本地等采集数据所必备的基本功能):
你可以选择优采云云爬虫和优采云采集器
(造数官方没有找到是否收费的具体说明,但是有提及:“造数计费单位是“次”,1次爬取指的是:成功爬取1个网页并获得数据。”,所以我理解她们不是免费的)
这三者上面,我推荐你使用优采云采集器,因为我目测楼主虽然没有编程基础,
但是若果优采云云市场中有你须要的采集的网站的采集规则,而且也刚好是免费的(优采云云爬虫市场有官方的采集规则也有开发者上传的采集规则),那么你可以尝试一下优采云云爬虫。
2、不差钱,关键是喜欢
那么可以尝试使用优采云采集器和集搜客,然后从二者上面选购一个自己喜欢的。
用户体验和性价比这些东西还是要自己用一下比较好,萝卜青椒各有所爱么。
合肥乐维信息技术有限公司
采集交流 • 优采云 发表了文章 • 0 个评论 • 136 次浏览 • 2020-08-10 22:47
让网站数据, 所见即所得
无论是国外网站, 还是美国网站, 只要有您想要的网站数据, 您都可以交给优采云采集器来帮您采集处理, 经过多年采集程序的构建,优采云采集器现已做到兼容95%以上的网站, 稳居国外采集行业第一!
全程自动化, 解放手掌
您只须要通过4大步骤来对采集器进行采集配置, 接下来的事情就可以全程交给优采云采集器去处理啦, 您只须要坐收数据即可, 早点结束人工自动复制来,粘贴去的沉闷工作方式吧!
操作方便易上手, 教程全面且丰富
仅需四步, 即可轻松完成对采集器的采集规则配置, 而且官方还有大量教程文档和视频教程, 更重要的是, 还有一群优秀采集高手作为售后支持,为您的数据采集道路保驾护航!
多种数据保存方式, 让数据为你所用
您可以将采集回来的数据, 保存至Word, Excel, Txt等本地文件中, 也可以将数据立刻发布至您的线上网站, 甚至于,您还可以定义发布扩充, 将数据保存到任何您想保存的地方!
独特插件机制, 让数据更有型
为满足顾客对数据不同程度的个性化需求, 优采云集采器已经为 "采集"与 "发布" 两大模块提供插件支持, 您可以使用PHP语言或C#语言来对"采集","发布"模块进行细节控制!
网站发布模块, 应有尽有
优采云采集器现已集成绝大部分国内外主流CMS, 论坛, 商城, 问答等各种开源系统的发布模块, 若您的网站是自己团队独立开发,并非网上下载的开源程序, 您也不用害怕, 您可以为您的网站开发专属发布模块!
更多功能等您探求
优采云采集器还有更多实用功能, 如: HTTP二级代理服务器, OCR验证码识别, HTTP模拟恳求工具, 中文动词处理, 正文提取,计划任务管理器, 远程控制采集器, 资源库..., 欢迎您来探求! 查看全部
功能介绍
让网站数据, 所见即所得
无论是国外网站, 还是美国网站, 只要有您想要的网站数据, 您都可以交给优采云采集器来帮您采集处理, 经过多年采集程序的构建,优采云采集器现已做到兼容95%以上的网站, 稳居国外采集行业第一!
全程自动化, 解放手掌
您只须要通过4大步骤来对采集器进行采集配置, 接下来的事情就可以全程交给优采云采集器去处理啦, 您只须要坐收数据即可, 早点结束人工自动复制来,粘贴去的沉闷工作方式吧!
操作方便易上手, 教程全面且丰富
仅需四步, 即可轻松完成对采集器的采集规则配置, 而且官方还有大量教程文档和视频教程, 更重要的是, 还有一群优秀采集高手作为售后支持,为您的数据采集道路保驾护航!
多种数据保存方式, 让数据为你所用
您可以将采集回来的数据, 保存至Word, Excel, Txt等本地文件中, 也可以将数据立刻发布至您的线上网站, 甚至于,您还可以定义发布扩充, 将数据保存到任何您想保存的地方!
独特插件机制, 让数据更有型
为满足顾客对数据不同程度的个性化需求, 优采云集采器已经为 "采集"与 "发布" 两大模块提供插件支持, 您可以使用PHP语言或C#语言来对"采集","发布"模块进行细节控制!
网站发布模块, 应有尽有
优采云采集器现已集成绝大部分国内外主流CMS, 论坛, 商城, 问答等各种开源系统的发布模块, 若您的网站是自己团队独立开发,并非网上下载的开源程序, 您也不用害怕, 您可以为您的网站开发专属发布模块!
更多功能等您探求
优采云采集器还有更多实用功能, 如: HTTP二级代理服务器, OCR验证码识别, HTTP模拟恳求工具, 中文动词处理, 正文提取,计划任务管理器, 远程控制采集器, 资源库..., 欢迎您来探求!
云采集实况与历史运行记录
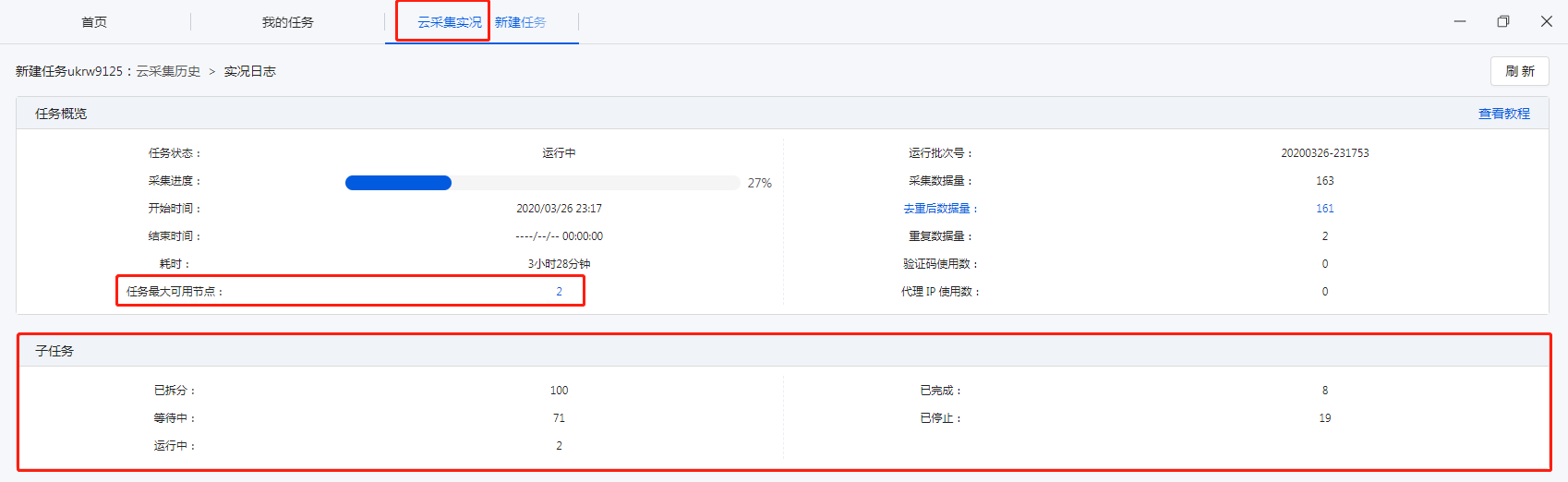
采集交流 • 优采云 发表了文章 • 0 个评论 • 731 次浏览 • 2020-08-10 07:42
任务正在运行云采集的时侯,可以查看当前运行详情;任务运行了多次云采集的时侯,可以查看历史运行记录。
使用版本限制
云采集(旗舰版及以上版本)可使用此功能。
一、查看云采集详情
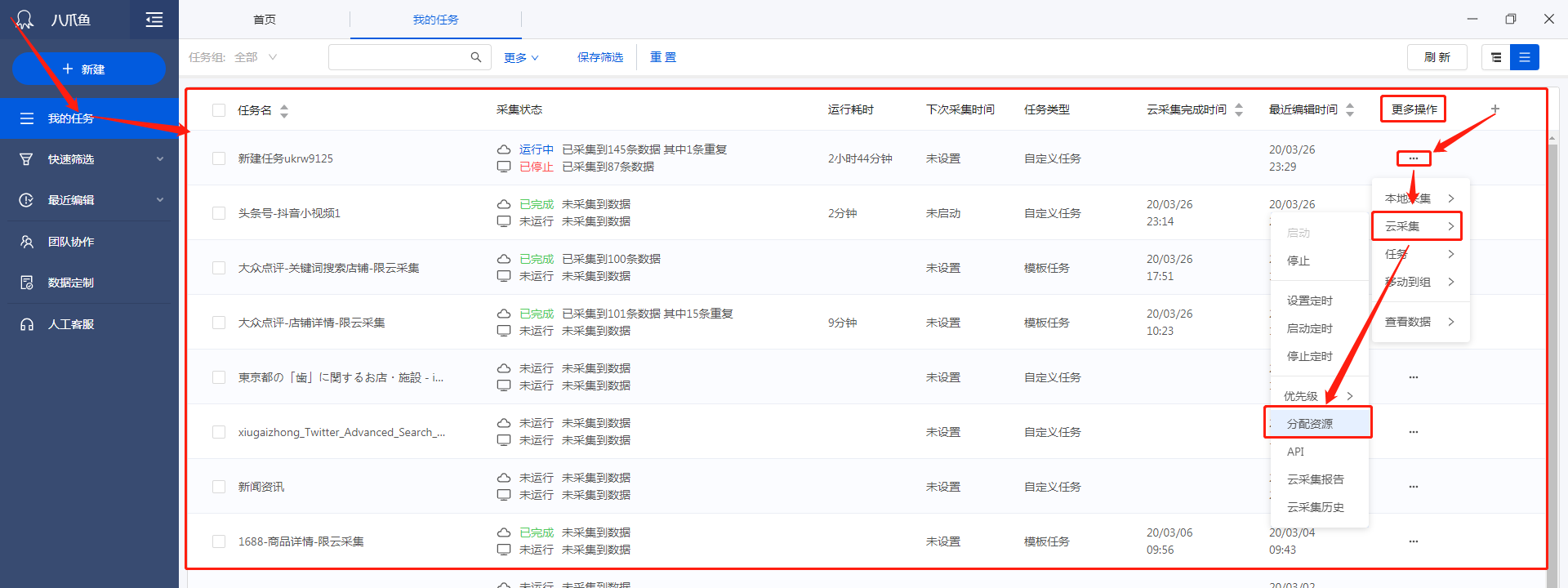
在任务列表,点击任务云采集的【详情】,进入该任务当前的(任务正在运行)或者近来一次的(任务运行完成)云采集详情页面,查看任务概览、子任务、运行任务日志和运行子任务。
1、任务概览
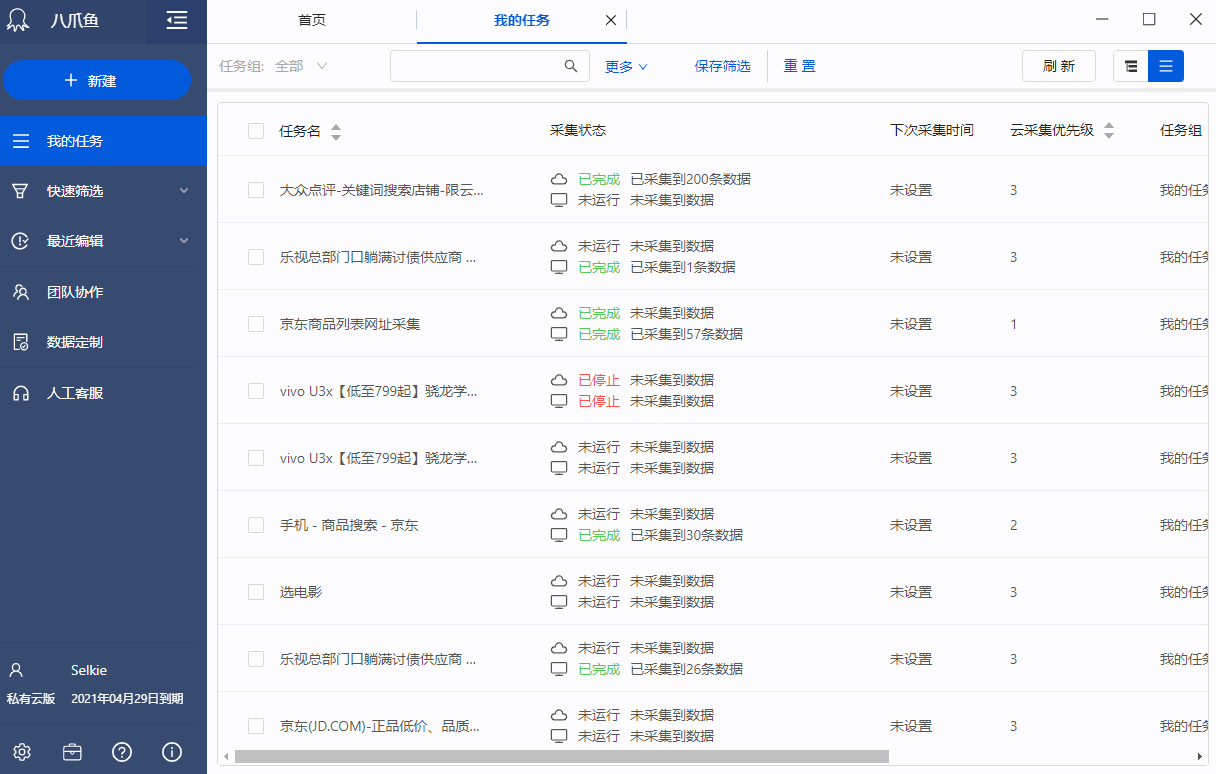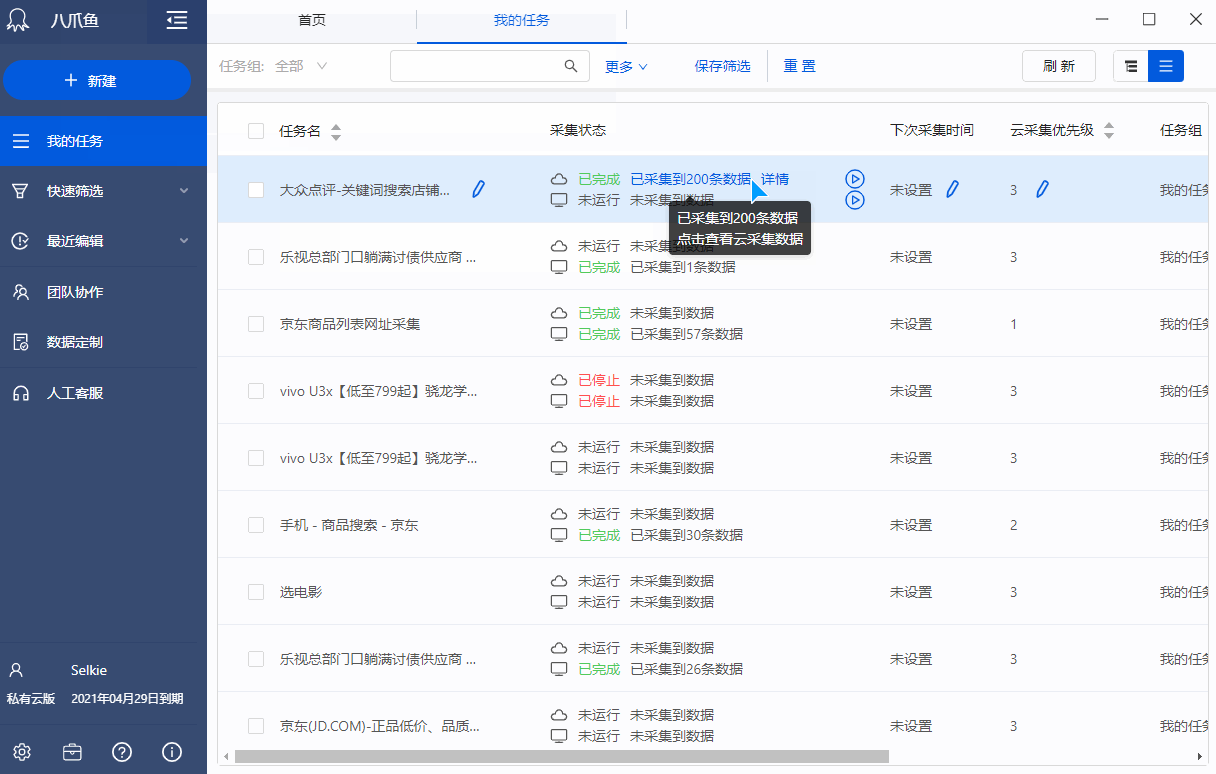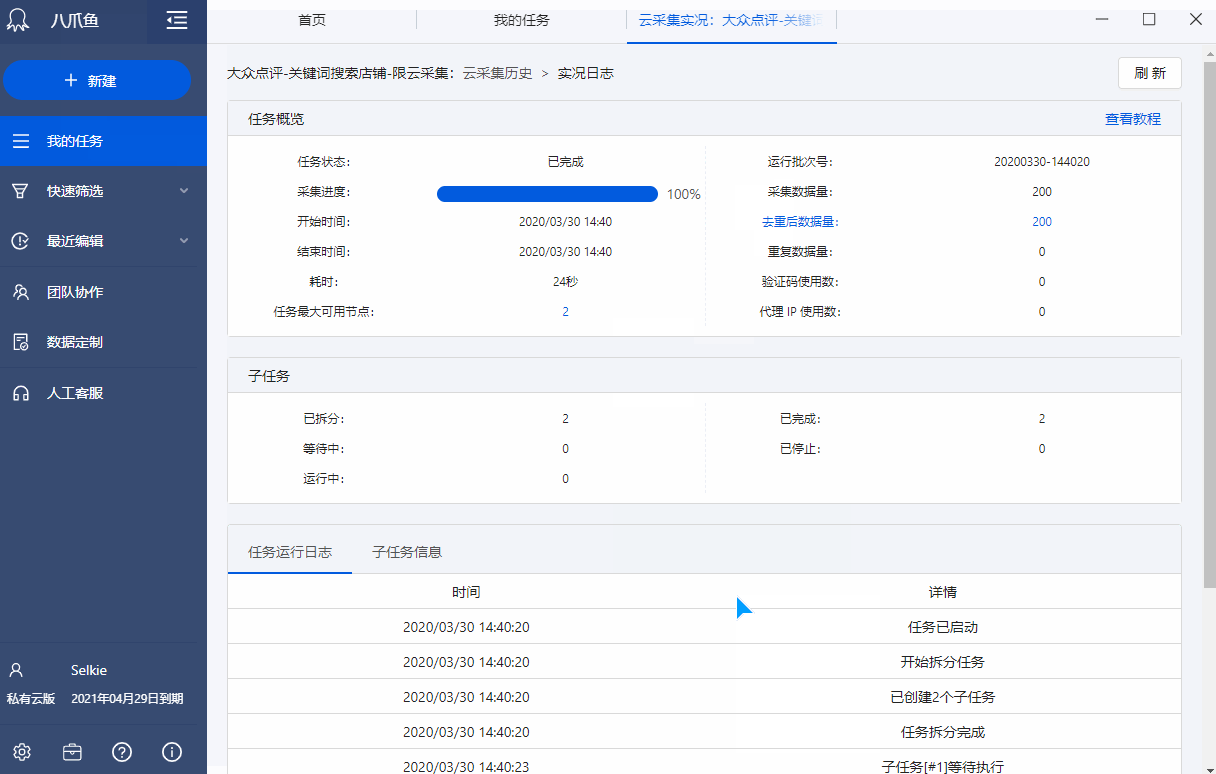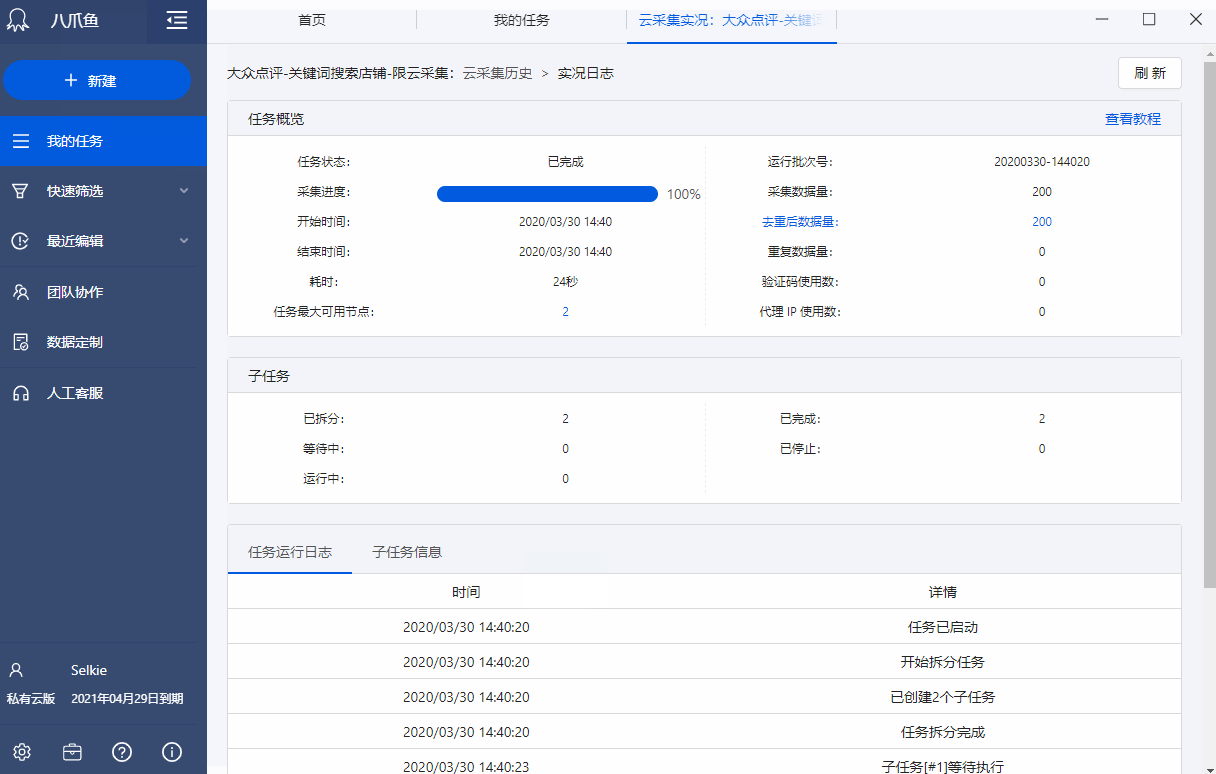
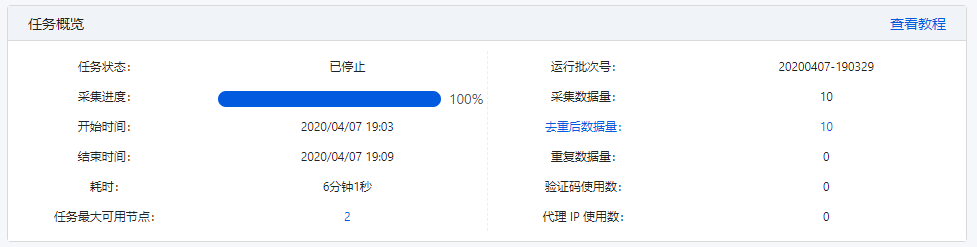
任务云采集情况总括:任务状态(运行中、已停止、已完成)、采集进度(进度条)、开始时间、结束时间、耗时、采集数据量、消耗代理IP、消耗验证码、云节点占有量等。
2、子任务
子任务的当前情况。
3、运行任务日志
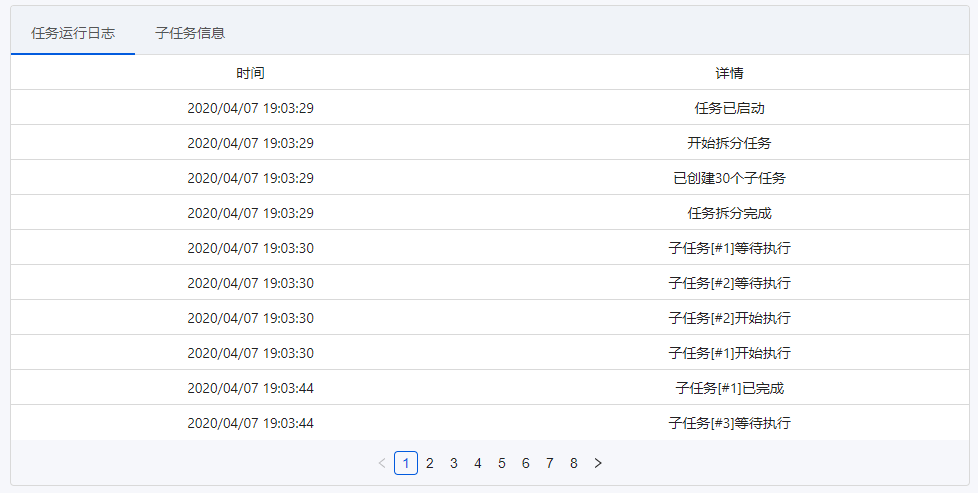
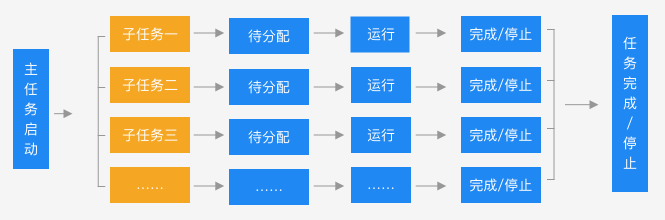
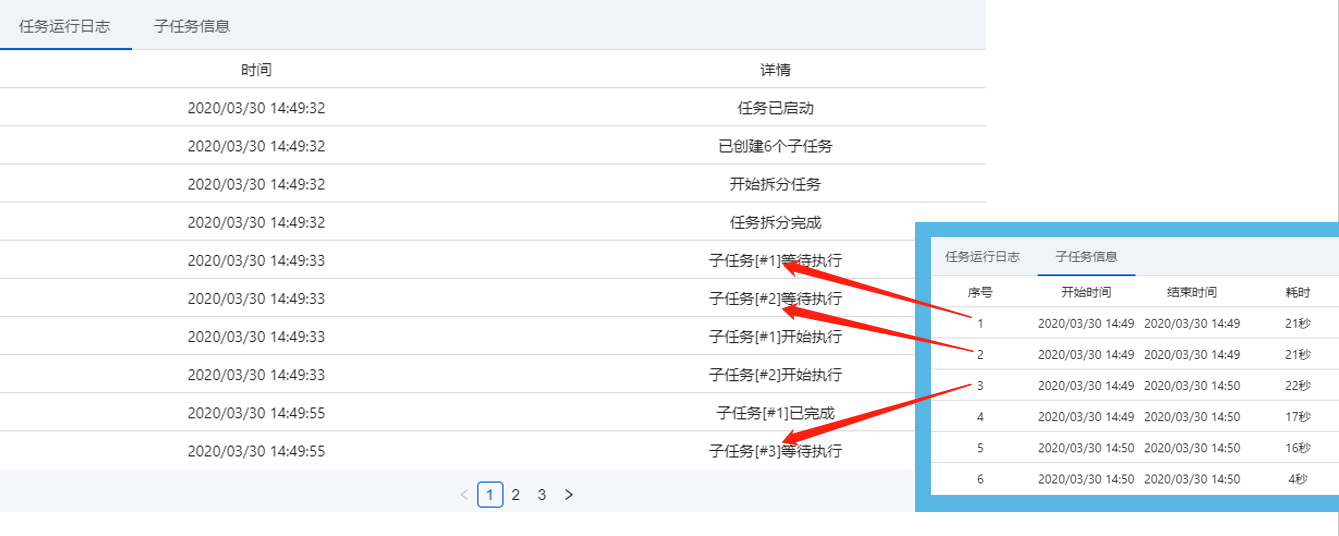
运行任务日志,记录任务运行云采集的详尽过程,实时把握运行情况:任务已启动、开始分拆任务、子任务创建完成、任务分拆完成、子任务[#1]等待执行、子任务[#1]开始执行、子任务[#1]已停止、子任务[#1]已完成等。
任务的云采集运行流程如下:
4、子任务信息
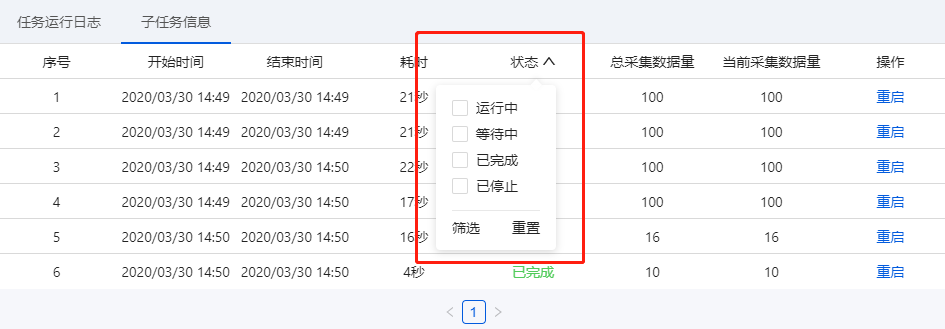
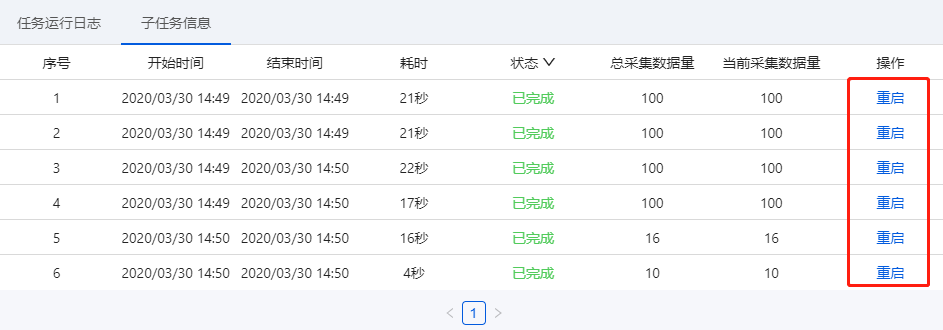
展示子任务运行的详尽情况:子任务序号、开始时间、结束时间、耗时、状态、总采集数据量(包括每次重启后采集的数据量累加)、当前采集数据量(重启后那一次采集到的数据量)。
① 序号与运行任务日志上面的子任务序号一一对应。
② 可按照子任务状态进行筛选,支持多选。
③ 展示子任务状态
已分拆:当前任务分拆成了多少个子任务。为1时,表示该任务未进行分拆(任务本身不支持分拆或勾选了云采集不分拆)。大于1时,表示已进行分拆。图中任务分拆成了100个子任务。
等待中:还未运行采集的子任务个数。
运行中:当前正在采集数据的子任务个数。每个任务会占用一个云节点,故所有任务在运行的子任务数之和大于等于帐号节点数。
已完成:已完成采集的子任务个数。
已停止:程序手动停止采集或人为自动停止采集的子任务个数。
注:
a. 支持对子任务进行停止、重启操作。子任务是【已完成】或【已停止】状态时,可点击【重启】让其重新进行采集。子任务重启后,主任务假如是【已完成】或【已停止】,也会弄成【运行中】。
b. 如果想要重启正在运行的子任务,需先点击【停止】,让子任务弄成【已停止】状态,再重启子任务。
二、云采集历史
在任务列表,点击任务两侧更多操作的【...】,点击【云采集】,再点击【查看云采集历史】,进入云采集历史运行记录页面。
1、云采集历史界面
云采集历史页面,记录任务运行云采集的历史次数,包括每次的批次、运行状态、开始时间、结束时间、耗时、本次采集量、操作等信息。
不同的版本可记录的最多次数不一样(旗舰10次;旗舰+20次;私有云100次)。可 点我马上升级,升级到更高版本。
2、查看采集数据
在云采集历史界面,点击【查看采集数据】,可查看每一次云采集采集到的数据,并才能导入当次所有数据。 查看全部
功能简介
任务正在运行云采集的时侯,可以查看当前运行详情;任务运行了多次云采集的时侯,可以查看历史运行记录。
使用版本限制
云采集(旗舰版及以上版本)可使用此功能。
一、查看云采集详情
在任务列表,点击任务云采集的【详情】,进入该任务当前的(任务正在运行)或者近来一次的(任务运行完成)云采集详情页面,查看任务概览、子任务、运行任务日志和运行子任务。
1、任务概览
任务云采集情况总括:任务状态(运行中、已停止、已完成)、采集进度(进度条)、开始时间、结束时间、耗时、采集数据量、消耗代理IP、消耗验证码、云节点占有量等。
2、子任务
子任务的当前情况。

3、运行任务日志
运行任务日志,记录任务运行云采集的详尽过程,实时把握运行情况:任务已启动、开始分拆任务、子任务创建完成、任务分拆完成、子任务[#1]等待执行、子任务[#1]开始执行、子任务[#1]已停止、子任务[#1]已完成等。
任务的云采集运行流程如下:
4、子任务信息
展示子任务运行的详尽情况:子任务序号、开始时间、结束时间、耗时、状态、总采集数据量(包括每次重启后采集的数据量累加)、当前采集数据量(重启后那一次采集到的数据量)。
① 序号与运行任务日志上面的子任务序号一一对应。
② 可按照子任务状态进行筛选,支持多选。
③ 展示子任务状态
已分拆:当前任务分拆成了多少个子任务。为1时,表示该任务未进行分拆(任务本身不支持分拆或勾选了云采集不分拆)。大于1时,表示已进行分拆。图中任务分拆成了100个子任务。
等待中:还未运行采集的子任务个数。
运行中:当前正在采集数据的子任务个数。每个任务会占用一个云节点,故所有任务在运行的子任务数之和大于等于帐号节点数。
已完成:已完成采集的子任务个数。
已停止:程序手动停止采集或人为自动停止采集的子任务个数。
注:
a. 支持对子任务进行停止、重启操作。子任务是【已完成】或【已停止】状态时,可点击【重启】让其重新进行采集。子任务重启后,主任务假如是【已完成】或【已停止】,也会弄成【运行中】。
b. 如果想要重启正在运行的子任务,需先点击【停止】,让子任务弄成【已停止】状态,再重启子任务。
二、云采集历史
在任务列表,点击任务两侧更多操作的【...】,点击【云采集】,再点击【查看云采集历史】,进入云采集历史运行记录页面。
1、云采集历史界面
云采集历史页面,记录任务运行云采集的历史次数,包括每次的批次、运行状态、开始时间、结束时间、耗时、本次采集量、操作等信息。
不同的版本可记录的最多次数不一样(旗舰10次;旗舰+20次;私有云100次)。可 点我马上升级,升级到更高版本。
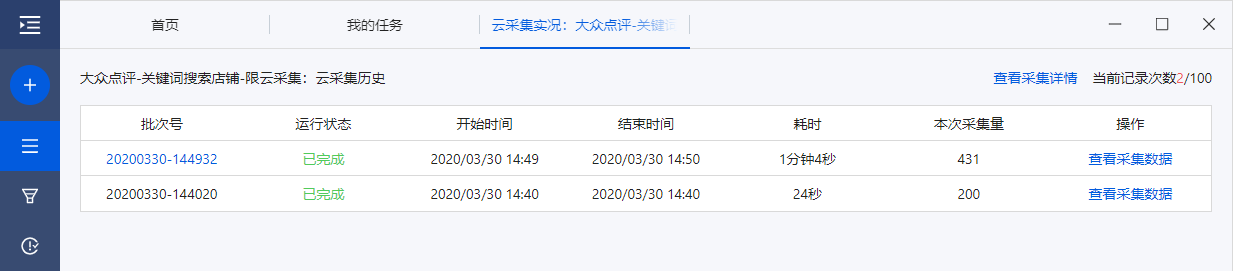
2、查看采集数据
在云采集历史界面,点击【查看采集数据】,可查看每一次云采集采集到的数据,并才能导入当次所有数据。
云采集 【温馨提醒】马甲客户端chrome扩展程序的特点
采集交流 • 优采云 发表了文章 • 0 个评论 • 161 次浏览 • 2021-05-23 18:23
[温馨提醒]
0 1、安装此插件后,您可以自己编写采集规则,也可以输入网站 关键词,然后一键单击采集将任何内容批量添加到论坛部分或门户网站列的“组”中发布。
0 2、可以将已成功发布的内容推送到百度数据收录界面以进行SEO优化,采集和收录双赢。
0 3、插件可以设置时间采集 关键词,同步升级任何网站列的内容,然后自动发布内容以实现无人值守的自动升级网站内容。
0 4、可以自动批量注册大量的背心客户,然后使用背心客户批量发布内容,从而可以在短时间内添加大量的高质量内容和客户,其他人不知道采集做到了。
0 5、具有匹配的客户端chrome扩展名。除了价值1000元人民币的官方免费采集规则外,您还可以编写采集规则来实现任何网站 采集并发布。
自从推出0 6、插件以来,已经过去了三年多的时间。它经历了一千多天的辛苦工作。根据大量客户的反馈,该插件经过反复更新和升级,具有成熟稳定的功能,易于理解,易于使用,功能强大。它已被许多网站管理员安装和使用,并且它是每个网站管理员必备的插件!
[此插件的功能]
0 1、可以批量注册背心客户,张贴海报和评论的背心看起来与真实注册客户发布的背心完全相同。
0 2、可以批量采集和批量发布,可以在短时间内将任何高质量的内容重新发布到您的论坛和门户中。
0 3、可以安排为采集并自动释放,实现无人值守。
由0 4、 采集返回的内容可以转换为简体和繁体字符,伪原创和其他辅助解决方案。
0 5、支持前端采集,该前端可以授权指定普通注册客户在前端中使用此采集器,并让普通注册成员帮助您采集内容。
0 6、 采集中的内容图片可以正常显示并另存为后期图片附件或门户网站文章附件,这些图片将永远不会丢失。
0 7、图片附件支持远程FTP存储,使您可以将图片分离到另一台服务器。
0 8、图片将被您的论坛或门户网站加水印。
0 9、已经重复采集的内容将不会重复两次采集,并且不会重复和冗余的内容。
1 0、 采集的帖子或门户文章,组与真实客户发布的组完全相同,其他人不知道他们是否可以使用采集器进行发布。
1 1、网页浏览量将自动随机设置。感觉您的帖子或门户网站文章上的观看次数与实际观看次数相同。
1 2、可以指定帖子发布者(主持人),门户网站文章作者和组发布者。
1 3、 采集内容可以发布到论坛的任何部分,门户的任何列以及论坛的任何圈子。
1 4、个发布的内容可以推送到百度数据收录界面以进行SEO优化,从而加快网站和收录的百度索引量。
1 5、不限制采集的内容数量,也不限制采集的次数,使您的网站可以快速填充高质量的内容。
1 6、插件具有内置的文本提取算法,该算法支持采集任何网站任何列内容。
1 7、可以用一个键获取当前的实时热点内容,然后用一个键进行发布。
1 8、可以自己编写采集规则,并实时更新采集 网站的任何内容。
[此插件为您带来的价值]
1、使您的论坛成为很多注册会员,非常受欢迎,并且内容丰富。
2、用定时发布,全自动采集,一键式批处理采集等替换了手动发布,从而节省了时间,精力和效率,而且不容易出错。
3、允许您的网站与大型新闻网站共享高质量的内容,这可以迅速增加网站的比重和排名。
查看全部
云采集 【温馨提醒】马甲客户端chrome扩展程序的特点
[温馨提醒]
0 1、安装此插件后,您可以自己编写采集规则,也可以输入网站 关键词,然后一键单击采集将任何内容批量添加到论坛部分或门户网站列的“组”中发布。
0 2、可以将已成功发布的内容推送到百度数据收录界面以进行SEO优化,采集和收录双赢。
0 3、插件可以设置时间采集 关键词,同步升级任何网站列的内容,然后自动发布内容以实现无人值守的自动升级网站内容。
0 4、可以自动批量注册大量的背心客户,然后使用背心客户批量发布内容,从而可以在短时间内添加大量的高质量内容和客户,其他人不知道采集做到了。
0 5、具有匹配的客户端chrome扩展名。除了价值1000元人民币的官方免费采集规则外,您还可以编写采集规则来实现任何网站 采集并发布。
自从推出0 6、插件以来,已经过去了三年多的时间。它经历了一千多天的辛苦工作。根据大量客户的反馈,该插件经过反复更新和升级,具有成熟稳定的功能,易于理解,易于使用,功能强大。它已被许多网站管理员安装和使用,并且它是每个网站管理员必备的插件!
[此插件的功能]
0 1、可以批量注册背心客户,张贴海报和评论的背心看起来与真实注册客户发布的背心完全相同。
0 2、可以批量采集和批量发布,可以在短时间内将任何高质量的内容重新发布到您的论坛和门户中。
0 3、可以安排为采集并自动释放,实现无人值守。
由0 4、 采集返回的内容可以转换为简体和繁体字符,伪原创和其他辅助解决方案。
0 5、支持前端采集,该前端可以授权指定普通注册客户在前端中使用此采集器,并让普通注册成员帮助您采集内容。
0 6、 采集中的内容图片可以正常显示并另存为后期图片附件或门户网站文章附件,这些图片将永远不会丢失。
0 7、图片附件支持远程FTP存储,使您可以将图片分离到另一台服务器。
0 8、图片将被您的论坛或门户网站加水印。
0 9、已经重复采集的内容将不会重复两次采集,并且不会重复和冗余的内容。
1 0、 采集的帖子或门户文章,组与真实客户发布的组完全相同,其他人不知道他们是否可以使用采集器进行发布。
1 1、网页浏览量将自动随机设置。感觉您的帖子或门户网站文章上的观看次数与实际观看次数相同。
1 2、可以指定帖子发布者(主持人),门户网站文章作者和组发布者。
1 3、 采集内容可以发布到论坛的任何部分,门户的任何列以及论坛的任何圈子。
1 4、个发布的内容可以推送到百度数据收录界面以进行SEO优化,从而加快网站和收录的百度索引量。
1 5、不限制采集的内容数量,也不限制采集的次数,使您的网站可以快速填充高质量的内容。
1 6、插件具有内置的文本提取算法,该算法支持采集任何网站任何列内容。
1 7、可以用一个键获取当前的实时热点内容,然后用一个键进行发布。
1 8、可以自己编写采集规则,并实时更新采集 网站的任何内容。
[此插件为您带来的价值]
1、使您的论坛成为很多注册会员,非常受欢迎,并且内容丰富。
2、用定时发布,全自动采集,一键式批处理采集等替换了手动发布,从而节省了时间,精力和效率,而且不容易出错。
3、允许您的网站与大型新闻网站共享高质量的内容,这可以迅速增加网站的比重和排名。
使用优采云采集瀑布流网站图片采集详细说明(组图)
采集交流 • 优采云 发表了文章 • 0 个评论 • 226 次浏览 • 2021-05-06 03:01
本文介绍了使用优采云 采集瀑布流网站图片的方法(以百度图片采集为例)。
采集 网站:%E5%A4%8F%E7%9B%AE%E5%8F%8B%E4%BA%BA%E5%B8%90
使用功能点:
lAjax向下滚动
/ tutorialdetail-1 / ajgd_ 7. html
l分页列表信息采集
/ tutorialdetail-1 / fylb-7 0. html
百度图片:百度图片发现了五彩缤纷的世界,百度从8亿中文网页中提取了各种图片,并建立了中文图片库。百度影视(Baidu Pictures)拥有数十亿个中文网页,收录亿万张图片的庞大画廊,并且还在不断增加。
百度图片采集数据描述:本文以瀑布图片网站图片为例,以百度图片采集为例进行了分析。本文仅以“百度图片采集”为例。在实际操作中,您可以根据自己的需要更改百度其他内容的数据采集。
百度图片采集字段的详细说明:图片地址,图片文件。
第1步:创建采集任务
1)进入主界面并选择自定义模式
2)复制上述URL的URL并将其粘贴到网站输入框中,单击“保存URL”
3)系统自动打开网页。我们发现百度图片网络是一个瀑布式网页。每次下拉加载后,将显示新数据。当有足够的图片时,可以将它们下拉并加载无数次。因此,此页面涉及AJAX技术,需要设置AJAX超时时间以确保不会丢失数据采集。
选择“打开网页”步骤,打开“高级选项”,选中“页面加载完成向下滚动”,将滚动次数设置为“ 5次”(根据自己的需要设置),时间为“ 2秒”,滚动方式为“向下滚动一屏”;最后点击“确定”
注意:例如网站,没有翻页按钮。滚动数和滚动方法会影响数据数采集,可以根据需要设置。
第2步:采集图片网址
1)选择页面上的第一张照片,系统将自动识别相似的照片。在操作提示框中,选择“全选”
2)选择“ 采集以下图片地址”
第3步:修改Xpath
1)选择“循环”步骤并打开“高级选项”。可以看出,优采云系统自动采用“非固定元素列表”循环,并且Xpath为:// DIV [@ id ='imgid'] / DIV [1] / UL [1] / LI
2)此Xpath:// DIV [@ id ='imgid'] / DIV [1] / UL [1] / LI,将其复制到Firefox浏览器中以进行观察-仅可找到该网页22张图片在
3)我们需要一个Xpath,它可以在网页中找到所有必需的图片。观察网页的源代码,并将Xpath修改为:// DIV [@ id ='imgid'] / DIV / UL [1] / LI,找到网页中所有必需的图片
4)复制并粘贴修改后的Xpath:// DIV [@ id ='imgid'] / DIV / UL [1] / LI到优采云中的相应位置,完成后单击“确定”。
5)单击“保存”,然后单击“启动采集”,在这里选择“启动本地采集”
注意:本地采集占用了采集的当前计算机资源,如果有采集时间要求或当前计算机无法长时间运行采集,则可以使用云采集 ]功能,并且云采集在网络中对于采集,不需要当前的计算机支持,可以关闭计算机,并且可以设置多个云节点来共享任务。 10个节点相当于10台计算机来分配任务以帮助您采集,并且速度降低到原创速度的十分之一; [k15中获得的数据]可以在云中存储三个月,并且可以导出随时。第4步:数据采集并导出
1) 采集完成后,将弹出提示并选择导出数据
2)选择合适的导出方法并导出采集良好数据
第5步:将图片网址批量转换为图片
完成上述操作后,我们获得了采集图片的URL。接下来,使用用于优采云的特殊图像批处理下载工具将图片URL中的图片下载并保存到采集到本地计算机。
图片批量下载工具:
1)下载优采云图片批量下载工具,双击文件中的MyDownloader.app.exe文件以打开软件
2)打开“文件”菜单,然后选择从EXCEL导入(当前仅支持EXCEL格式的文件)
3)进行相关设置,设置完成后,单击“确定”以导入文件
选择EXCEL文件:导入需要下载图片地址的EXCEL文件
EXCEL表名:对应数据表的名称
文件URL列名:表中相应URL的列名
保存文件夹名称:EXCEL中需要一个单独的列,以列出要保存到文件夹的图片的路径。您可以设置不同的图片以存储在不同的文件夹中
如果要将文件保存到文件夹,则路径需要以“ \”结尾,例如:“ D:\ Sync \”,如果要在下载后根据指定的文件名保存文件,则需要收录特定的文件名,例如“ D:\ Sync \ 1. jpg”
如果下载的文件路径和文件名完全相同,则原创文件将被删除
查看全部
使用优采云采集瀑布流网站图片采集详细说明(组图)
本文介绍了使用优采云 采集瀑布流网站图片的方法(以百度图片采集为例)。
采集 网站:%E5%A4%8F%E7%9B%AE%E5%8F%8B%E4%BA%BA%E5%B8%90
使用功能点:
lAjax向下滚动
/ tutorialdetail-1 / ajgd_ 7. html
l分页列表信息采集
/ tutorialdetail-1 / fylb-7 0. html
百度图片:百度图片发现了五彩缤纷的世界,百度从8亿中文网页中提取了各种图片,并建立了中文图片库。百度影视(Baidu Pictures)拥有数十亿个中文网页,收录亿万张图片的庞大画廊,并且还在不断增加。
百度图片采集数据描述:本文以瀑布图片网站图片为例,以百度图片采集为例进行了分析。本文仅以“百度图片采集”为例。在实际操作中,您可以根据自己的需要更改百度其他内容的数据采集。
百度图片采集字段的详细说明:图片地址,图片文件。
第1步:创建采集任务
1)进入主界面并选择自定义模式
2)复制上述URL的URL并将其粘贴到网站输入框中,单击“保存URL”
3)系统自动打开网页。我们发现百度图片网络是一个瀑布式网页。每次下拉加载后,将显示新数据。当有足够的图片时,可以将它们下拉并加载无数次。因此,此页面涉及AJAX技术,需要设置AJAX超时时间以确保不会丢失数据采集。
选择“打开网页”步骤,打开“高级选项”,选中“页面加载完成向下滚动”,将滚动次数设置为“ 5次”(根据自己的需要设置),时间为“ 2秒”,滚动方式为“向下滚动一屏”;最后点击“确定”
注意:例如网站,没有翻页按钮。滚动数和滚动方法会影响数据数采集,可以根据需要设置。
第2步:采集图片网址
1)选择页面上的第一张照片,系统将自动识别相似的照片。在操作提示框中,选择“全选”
2)选择“ 采集以下图片地址”
第3步:修改Xpath
1)选择“循环”步骤并打开“高级选项”。可以看出,优采云系统自动采用“非固定元素列表”循环,并且Xpath为:// DIV [@ id ='imgid'] / DIV [1] / UL [1] / LI
2)此Xpath:// DIV [@ id ='imgid'] / DIV [1] / UL [1] / LI,将其复制到Firefox浏览器中以进行观察-仅可找到该网页22张图片在
3)我们需要一个Xpath,它可以在网页中找到所有必需的图片。观察网页的源代码,并将Xpath修改为:// DIV [@ id ='imgid'] / DIV / UL [1] / LI,找到网页中所有必需的图片
4)复制并粘贴修改后的Xpath:// DIV [@ id ='imgid'] / DIV / UL [1] / LI到优采云中的相应位置,完成后单击“确定”。
5)单击“保存”,然后单击“启动采集”,在这里选择“启动本地采集”
注意:本地采集占用了采集的当前计算机资源,如果有采集时间要求或当前计算机无法长时间运行采集,则可以使用云采集 ]功能,并且云采集在网络中对于采集,不需要当前的计算机支持,可以关闭计算机,并且可以设置多个云节点来共享任务。 10个节点相当于10台计算机来分配任务以帮助您采集,并且速度降低到原创速度的十分之一; [k15中获得的数据]可以在云中存储三个月,并且可以导出随时。第4步:数据采集并导出
1) 采集完成后,将弹出提示并选择导出数据
2)选择合适的导出方法并导出采集良好数据
第5步:将图片网址批量转换为图片
完成上述操作后,我们获得了采集图片的URL。接下来,使用用于优采云的特殊图像批处理下载工具将图片URL中的图片下载并保存到采集到本地计算机。
图片批量下载工具:
1)下载优采云图片批量下载工具,双击文件中的MyDownloader.app.exe文件以打开软件
2)打开“文件”菜单,然后选择从EXCEL导入(当前仅支持EXCEL格式的文件)
3)进行相关设置,设置完成后,单击“确定”以导入文件
选择EXCEL文件:导入需要下载图片地址的EXCEL文件
EXCEL表名:对应数据表的名称
文件URL列名:表中相应URL的列名
保存文件夹名称:EXCEL中需要一个单独的列,以列出要保存到文件夹的图片的路径。您可以设置不同的图片以存储在不同的文件夹中
如果要将文件保存到文件夹,则路径需要以“ \”结尾,例如:“ D:\ Sync \”,如果要在下载后根据指定的文件名保存文件,则需要收录特定的文件名,例如“ D:\ Sync \ 1. jpg”
如果下载的文件路径和文件名完全相同,则原创文件将被删除
优采云采集器需要精通到什么程度?分布式解决方案
采集交流 • 优采云 发表了文章 • 0 个评论 • 216 次浏览 • 2021-05-05 02:05
2.工具方向
这很容易理解。我们精通某些主流采集工具,例如优采云 采集器
我需要什么程度的精通?
1.如果可以使用我们的优采云和XPATH来找到网页的任何元素
2.如果您知道如何优采云 采集原理并了解拆分规则,则整个采集的效率可以提高10倍
3.实际上已经超过三个月没有每天使用我们的优采云并编写了一两百条规则,因此不应认为它是熟练的
除了熟悉以上两个工具级别之外,您还需要熟悉以下内容:
1. Anti- 采集原理(验证码,多个IP等)
2. html前端解析知识
3.分布式解决方案
4.正则表达式匹配
基本上,如果您熟悉上述技能,您几乎可以成为一名合格且思维清晰的履带工程师。那些编写代码的人具有编写代码的好处,以及使用工具和工具的好处。编写代码的好处是更大的自由度,更大的挑战,更难上手,并且效果实际上并不好,因为很多时候它们实际上是在重新创建轮子。
毕竟,只要您可以使用采集器工具,就可以完成许多常见操作,并且可以为您完成功能性采集器工具。至于工具,工具总是有一点限制。为了实现多功能性,工具会在一定程度上牺牲某些功能。在某些非常特殊的情况下,工具实际上很难完成。
因此,我始终建议工具+代码是主流爬虫工程师的配置。您可以使用诸如优采云之类的工具来满足99%的要求,但是如果遇到特定要求,可以留下手写代码来解决。
毕竟,我们想要的是解决问题,更不用说python等了。根本不难配置采集器程序。有很多在线教程。 (国内主流采集伟大的上帝就是这样做的,可以使用这些工具的工具是第一个使用该工具的人,除非这些工具不可用,否则它们将编写自己的代码)
履带工程师的相关技能
除了要了解采集,爬虫工程师还需要一些其他技能。这是爬虫工程师是入门级,普通级还是优秀级的真实衡量标准。实际上,在这个时代,复合型人才更受欢迎。
一位出色的履带工程师,他还需要以下技术来升华
1.数据清理
由于采集中的数据通常是一大部分文本,因此您需要优化文本,这就是我们所谓的清理数据,以获取更清晰的结构化数据并将其保存在数据库中。
有时候,我们采集有多个数据副本,我们还需要通过清理将它们关联起来。例如,我们善于使用Excel的一些高级技能,并且我们还使用诸如R之类的编程语言来处理文本。我们优采云数据中心小组的学生都具有数据清除技能。
2.数据挖掘
爬网后的数据挖掘通常是指NLP的重影。 NLP属于人工智能领域。中文被称为自然语言处理。简单理解就是处理大量文本并从大量文本中挖掘出价值。
在中国,我们能做得很好的事情属于奉茂琳娇。我们优采云也有我们自己的NLP团队。投资是巨大的,并且做得不好。我们只是开始实现一些特定的场景功能。下订单。我们是中国的一些主流AI公司,采集,挖掘后,我们输出AI数据。我们的数据中心有一些很棒的人专门从事这项工作。
3.数据分析可视化
仅下载数据采集并将其保存在数据库中,仅是为了实现第一步的价值。数据分析和可视化是数据背后的更大价值。
因此有必要将数据保存在数据库中,然后通过相应的框架或程序进行开发,组织和调出,以协助企业进行决策。因此,我们优采云有一个专门的数据BI团队,许多爬虫工程师都擅长使用通用可视BI工具EXCEL为项目提供可视数据支持。
4.深入了解业务
无论是了解在Internet上获取公共数据的能力还是对业务需求的了解,这也是考虑优秀的爬虫工程师的一项重要措施。坦率地说,不仅要了解技术,还要了解业务,并成为一名复合式爬虫工程师。只有在此程度上,履带工程师的价值才能被无限放大。例如,了解风险控制业务,例如了解AI业务等。我们为此职位设有售前和顾问。
如何规划履带工程师的路线
在我的团队中,有两条路线:L岗位和T岗位。 L职位通常是指偏向业务的爬行动物工程师职位,而职位通常是指偏向技术的爬行动物工程师职位。一些学生更喜欢与企业保持联系,并具有良好的表达能力,快速反应和清晰的思维,因此他将去L职位。一些学生对突破各种问题并提供更好的解决方案更加热衷于技术。将转到T帖子。
L职位的一般职位是什么?
1.技术支持(针对中小型客户)
2.预售(针对主要客户)
3.数据中心负责人/项目负责人
4.解决方案顾问(深入的业务场景)
T岗位通常担任什么职位?
1.爬虫项目的一线开发和交付人员
2.数据专员
3.高级数据专家
4.爬虫训练讲师
工作机会
如果看到此消息,则表明您对爬虫感兴趣。我们正在招聘上述职位。如果您是合格的履带工程师或渴望成为一名出色的履带工程师,请给您的履历表发送艰苦的努力!
优采云是国内领先的采集器云采集工具平台,可为许多大型公司和政府提供数据服务,并建立Internet数据资产仓库。如果您有兴趣这样做,请让我们私下讨论。 查看全部
优采云采集器需要精通到什么程度?分布式解决方案
2.工具方向
这很容易理解。我们精通某些主流采集工具,例如优采云 采集器
我需要什么程度的精通?
1.如果可以使用我们的优采云和XPATH来找到网页的任何元素
2.如果您知道如何优采云 采集原理并了解拆分规则,则整个采集的效率可以提高10倍
3.实际上已经超过三个月没有每天使用我们的优采云并编写了一两百条规则,因此不应认为它是熟练的
除了熟悉以上两个工具级别之外,您还需要熟悉以下内容:
1. Anti- 采集原理(验证码,多个IP等)
2. html前端解析知识
3.分布式解决方案
4.正则表达式匹配
基本上,如果您熟悉上述技能,您几乎可以成为一名合格且思维清晰的履带工程师。那些编写代码的人具有编写代码的好处,以及使用工具和工具的好处。编写代码的好处是更大的自由度,更大的挑战,更难上手,并且效果实际上并不好,因为很多时候它们实际上是在重新创建轮子。
毕竟,只要您可以使用采集器工具,就可以完成许多常见操作,并且可以为您完成功能性采集器工具。至于工具,工具总是有一点限制。为了实现多功能性,工具会在一定程度上牺牲某些功能。在某些非常特殊的情况下,工具实际上很难完成。
因此,我始终建议工具+代码是主流爬虫工程师的配置。您可以使用诸如优采云之类的工具来满足99%的要求,但是如果遇到特定要求,可以留下手写代码来解决。
毕竟,我们想要的是解决问题,更不用说python等了。根本不难配置采集器程序。有很多在线教程。 (国内主流采集伟大的上帝就是这样做的,可以使用这些工具的工具是第一个使用该工具的人,除非这些工具不可用,否则它们将编写自己的代码)
履带工程师的相关技能
除了要了解采集,爬虫工程师还需要一些其他技能。这是爬虫工程师是入门级,普通级还是优秀级的真实衡量标准。实际上,在这个时代,复合型人才更受欢迎。
一位出色的履带工程师,他还需要以下技术来升华
1.数据清理
由于采集中的数据通常是一大部分文本,因此您需要优化文本,这就是我们所谓的清理数据,以获取更清晰的结构化数据并将其保存在数据库中。
有时候,我们采集有多个数据副本,我们还需要通过清理将它们关联起来。例如,我们善于使用Excel的一些高级技能,并且我们还使用诸如R之类的编程语言来处理文本。我们优采云数据中心小组的学生都具有数据清除技能。
2.数据挖掘
爬网后的数据挖掘通常是指NLP的重影。 NLP属于人工智能领域。中文被称为自然语言处理。简单理解就是处理大量文本并从大量文本中挖掘出价值。
在中国,我们能做得很好的事情属于奉茂琳娇。我们优采云也有我们自己的NLP团队。投资是巨大的,并且做得不好。我们只是开始实现一些特定的场景功能。下订单。我们是中国的一些主流AI公司,采集,挖掘后,我们输出AI数据。我们的数据中心有一些很棒的人专门从事这项工作。
3.数据分析可视化
仅下载数据采集并将其保存在数据库中,仅是为了实现第一步的价值。数据分析和可视化是数据背后的更大价值。
因此有必要将数据保存在数据库中,然后通过相应的框架或程序进行开发,组织和调出,以协助企业进行决策。因此,我们优采云有一个专门的数据BI团队,许多爬虫工程师都擅长使用通用可视BI工具EXCEL为项目提供可视数据支持。
4.深入了解业务
无论是了解在Internet上获取公共数据的能力还是对业务需求的了解,这也是考虑优秀的爬虫工程师的一项重要措施。坦率地说,不仅要了解技术,还要了解业务,并成为一名复合式爬虫工程师。只有在此程度上,履带工程师的价值才能被无限放大。例如,了解风险控制业务,例如了解AI业务等。我们为此职位设有售前和顾问。
如何规划履带工程师的路线
在我的团队中,有两条路线:L岗位和T岗位。 L职位通常是指偏向业务的爬行动物工程师职位,而职位通常是指偏向技术的爬行动物工程师职位。一些学生更喜欢与企业保持联系,并具有良好的表达能力,快速反应和清晰的思维,因此他将去L职位。一些学生对突破各种问题并提供更好的解决方案更加热衷于技术。将转到T帖子。
L职位的一般职位是什么?
1.技术支持(针对中小型客户)
2.预售(针对主要客户)
3.数据中心负责人/项目负责人
4.解决方案顾问(深入的业务场景)
T岗位通常担任什么职位?
1.爬虫项目的一线开发和交付人员
2.数据专员
3.高级数据专家
4.爬虫训练讲师
工作机会
如果看到此消息,则表明您对爬虫感兴趣。我们正在招聘上述职位。如果您是合格的履带工程师或渴望成为一名出色的履带工程师,请给您的履历表发送艰苦的努力!
优采云是国内领先的采集器云采集工具平台,可为许多大型公司和政府提供数据服务,并建立Internet数据资产仓库。如果您有兴趣这样做,请让我们私下讨论。
Excel批量上传的使用方法有哪些?-八维教育
采集交流 • 优采云 发表了文章 • 0 个评论 • 126 次浏览 • 2021-05-02 05:46
批处理采集可以将外部数据(支持结构化,半结构化和非结构化数据)分批推送到ks3。 采集模式支持:文件推送,文件拉取,页面文件上传等。
文件推送任务配置
单击[批处理采集]按钮,然后在弹出窗口中选择[文件推送],进入文件推送任务编辑页面。
在新的弹出窗口中,单击[添加文件推送任务]创建采集任务,该任务支持手动创建多个文件采集任务。
创建采集任务时,您需要填写:
参数名称说明
采集名称
支持中文,英文,数字,下划线,最多50个字符。
目标ks3的名称
下拉选择,它需要在数据管理中预先创建。
目标存储桶
下拉选项,它需要在数据管理中预先创建,您可以在项目下选择具有权限的时段。
数据交换界面
下拉选择,需要预先在数据管理中创建,您可以在项目下选择授权的数据交换界面。
选择数据交换接口后,可以单击下面的[数据交换接口预览]以查看数据交换接口的架构信息。
配置后,单击[下一步]完成此采集任务的创建。重复上述步骤,一次创建多个采集任务。
完成采集任务创建后,您可以单击以下载文件上传工具包,API或SDK,然后在用户客户端上启动文件推送任务。
文件推送(Excel批量上传)配置
在页面上下载Excel模板,汇总要添加的任务信息,然后根据以下规范进行填写:采集任务名称,目标ks3名称,目标存储桶,数据交换界面和采集描述,然后上传Excel
转到大数据云平台执行批量创建操作。
填写Excel模板并上传后,将在页面上预览Excel中的内容。确认正确无误后,单击“下一步”完成批量创建。
运行批处理采集个任务
批处理采集个任务可以通过:
1.文件上传工具包。
2. SDK启动。
有关文件上传工具包和SDK的特定用法,可以在“批量采集通用下载”页面上下载它。
文件拉入
1.单击文件拉动按钮进入文件拉动配置页面。文件提取支持从FTP提取数据并将其发送到ks3。
2.单击“下一步”进行特定的拉取配置
3.文件提取支持两种方法:[定期执行]和[单次执行]。两种方法都需要指定推送目标ks 3、 bucket,数据交换接口和特定的推送路径。其中,定期执行的任务需要其他配置[执行周期]。详细信息如下图所示:
查看批处理采集运行示例
单击[采集详细信息]按钮,将弹出一个表格,以查看批处理采集的运行示例,您可以查看目标数据路径。
注意:当脱机计算作业依赖于批处理采集任务(通常取决于文件提取任务)时,“目标路径”页面上的处理事件名称字段可以是脱机计算的从属监视值工作。
通过页面上传文件
除上述方法外,对于文件数量少的临时数据采集要求,还可以通过批处理采集>页面上载文件功能来上载文件。单击[页面上传文件]按钮后,选择要上传的文件(可以支持多个文件)和上传目标地址(ks 3))。
默认情况下,页面文件上传的任务显示在任务列表的第一行。在[操作]中单击[采集详细信息],以查看每个文件上传的信息。
任务在线,应用程序文件推送任务在线,文件提取任务在线
对于文件提取,您需要先将任务发布到测试中以进行测试验证,然后才能在线申请。
在批处理采集列表中单击[发布测试],然后根据需要选择资源,然后可以在测试环境中运行文件提取作业。
任务在线审查
从屏幕左下角进入[发布管理]模块,然后单击以进入[发布批准]页面。在[未批准]列表中,您可以查看在线任务的应用程序。审核时,您可以选择通过审核或拒绝审核。
通过批准后,您可以在[已发布列表]中查看任务信息或执行脱机操作。
任务联机以开始任务生产运行
联机后,您可以在[运营和维护中心]> [数据采集]> [生产任务]中查看任务列表。 查看全部
Excel批量上传的使用方法有哪些?-八维教育
批处理采集可以将外部数据(支持结构化,半结构化和非结构化数据)分批推送到ks3。 采集模式支持:文件推送,文件拉取,页面文件上传等。
文件推送任务配置
单击[批处理采集]按钮,然后在弹出窗口中选择[文件推送],进入文件推送任务编辑页面。
在新的弹出窗口中,单击[添加文件推送任务]创建采集任务,该任务支持手动创建多个文件采集任务。
创建采集任务时,您需要填写:
参数名称说明
采集名称
支持中文,英文,数字,下划线,最多50个字符。
目标ks3的名称
下拉选择,它需要在数据管理中预先创建。
目标存储桶
下拉选项,它需要在数据管理中预先创建,您可以在项目下选择具有权限的时段。
数据交换界面
下拉选择,需要预先在数据管理中创建,您可以在项目下选择授权的数据交换界面。
选择数据交换接口后,可以单击下面的[数据交换接口预览]以查看数据交换接口的架构信息。
配置后,单击[下一步]完成此采集任务的创建。重复上述步骤,一次创建多个采集任务。
完成采集任务创建后,您可以单击以下载文件上传工具包,API或SDK,然后在用户客户端上启动文件推送任务。
文件推送(Excel批量上传)配置
在页面上下载Excel模板,汇总要添加的任务信息,然后根据以下规范进行填写:采集任务名称,目标ks3名称,目标存储桶,数据交换界面和采集描述,然后上传Excel
转到大数据云平台执行批量创建操作。
填写Excel模板并上传后,将在页面上预览Excel中的内容。确认正确无误后,单击“下一步”完成批量创建。
运行批处理采集个任务
批处理采集个任务可以通过:
1.文件上传工具包。
2. SDK启动。
有关文件上传工具包和SDK的特定用法,可以在“批量采集通用下载”页面上下载它。
文件拉入
1.单击文件拉动按钮进入文件拉动配置页面。文件提取支持从FTP提取数据并将其发送到ks3。
2.单击“下一步”进行特定的拉取配置
3.文件提取支持两种方法:[定期执行]和[单次执行]。两种方法都需要指定推送目标ks 3、 bucket,数据交换接口和特定的推送路径。其中,定期执行的任务需要其他配置[执行周期]。详细信息如下图所示:
查看批处理采集运行示例
单击[采集详细信息]按钮,将弹出一个表格,以查看批处理采集的运行示例,您可以查看目标数据路径。
注意:当脱机计算作业依赖于批处理采集任务(通常取决于文件提取任务)时,“目标路径”页面上的处理事件名称字段可以是脱机计算的从属监视值工作。
通过页面上传文件
除上述方法外,对于文件数量少的临时数据采集要求,还可以通过批处理采集>页面上载文件功能来上载文件。单击[页面上传文件]按钮后,选择要上传的文件(可以支持多个文件)和上传目标地址(ks 3))。
默认情况下,页面文件上传的任务显示在任务列表的第一行。在[操作]中单击[采集详细信息],以查看每个文件上传的信息。
任务在线,应用程序文件推送任务在线,文件提取任务在线
对于文件提取,您需要先将任务发布到测试中以进行测试验证,然后才能在线申请。
在批处理采集列表中单击[发布测试],然后根据需要选择资源,然后可以在测试环境中运行文件提取作业。
任务在线审查
从屏幕左下角进入[发布管理]模块,然后单击以进入[发布批准]页面。在[未批准]列表中,您可以查看在线任务的应用程序。审核时,您可以选择通过审核或拒绝审核。
通过批准后,您可以在[已发布列表]中查看任务信息或执行脱机操作。
任务联机以开始任务生产运行
联机后,您可以在[运营和维护中心]> [数据采集]> [生产任务]中查看任务列表。
优采云采集器需要精通到什么程度?分布式解决方案
采集交流 • 优采云 发表了文章 • 0 个评论 • 279 次浏览 • 2021-05-01 22:10
2.工具方向
这很容易理解。我们精通某个主流采集工具,例如优采云 采集器
我需要什么程度的精通?
1.如果可以使用我们的优采云和XPATH来找到网页的任何元素
2.如果您知道如何优采云 采集原理并了解拆分规则,则整个采集的效率可以提高10倍
3.实际上已经超过三个月没有每天使用我们的优采云并编写了一两百条规则,因此不应认为它是熟练的
除了熟悉以上两个工具级别之外,您还需要熟悉以下内容:
1. Anti- 采集原理(验证码,多个IP等)
2. html前端解析知识
3.分布式解决方案
4.正则表达式匹配
基本上,如果您熟悉上述技能,您几乎可以成为一名合格且思维清晰的履带工程师。那些编写代码的人具有编写代码的好处,以及使用工具和工具的好处。编写代码的好处是更大的自由度,更大的挑战,更难上手,并且效果实际上并不好,因为很多时候它们实际上是在重新创建轮子。
毕竟,只要您可以使用采集器工具,就可以完成许多常见操作,并且可以为您完成功能性采集器工具。至于工具,工具总是有一点限制。为了实现多功能性,工具会在一定程度上牺牲某些功能。在某些非常特殊的情况下,工具实际上很难完成。
因此,我始终建议工具+代码是主流爬虫工程师的配置。您可以使用诸如优采云之类的工具来满足99%的要求,但是如果遇到特定要求,可以留下手写代码来解决。
毕竟,我们想要的是解决问题,更不用说python等了。根本不难配置采集器程序。有很多在线教程。 (国内主流采集伟大的上帝就是这样做的。那些可以使用工具的人优先使用工具。除非工具不清楚,否则他们会编写自己的代码)
履带工程师的相关技能
除了要了解采集,爬虫工程师还需要一些其他技能。这是爬虫工程师是入门级,普通级还是优秀级的真实度量。实际上,在这个时代,复合型人才更受欢迎。
一位出色的履带工程师,他还需要以下技术来升华
1.数据清理
由于采集中的数据通常是一大部分文本,因此您需要优化文本,这就是我们所谓的清理数据,以获取更清晰的结构化数据并将其保存在数据库中。
有时候,我们采集有多个数据副本,我们还需要通过清理将它们关联起来。例如,我们擅长在Excel中使用一些高级技能,以及使用诸如R的编程语言来处理文本。我们优采云数据中心小组的学生都具有数据清除技能。
2.数据挖掘
爬网后的数据挖掘通常是指NLP的重影。 NLP属于人工智能领域。中文被称为自然语言处理。简单理解就是处理大量文本并从大量文本中挖掘出价值。
在中国,我们能做得很好的事情属于奉茂琳娇。我们优采云也有我们自己的NLP团队。这项投资是巨大的,而且我们做得还不够好。我们刚刚开始实现一些特定的场景功能。下订单。我们是中国的一些主流AI公司,采集,挖掘后,我们输出AI数据。我们的数据中心有一些很棒的人专门从事这项工作。
3.数据分析可视化
仅下载数据采集并将其保存在数据库中,仅是为了实现第一步的价值。数据分析和可视化是数据背后的更大价值。
因此有必要将数据保存在数据库中,然后通过相应的框架或程序进行开发,组织和调出,以协助企业进行决策。因此,我们优采云有一个专门的数据BI团队,许多爬虫工程师都擅长使用通用可视BI工具EXCEL为项目提供可视数据支持。
4.深入了解业务
无论是对在Internet上获取公共数据的能力的理解还是对业务需求的理解,它也是考虑优秀的爬虫工程师的重要措施。坦率地说,不仅要了解技术,还要了解业务,并成为一名复合式爬虫工程师。只有在此程度上,履带工程师的价值才能被无限放大。例如,了解风险控制业务,例如了解AI业务等。我们为此职位设有售前和顾问。
如何规划履带工程师的路线
在我的团队中,有两条路线,即L岗位和T岗位。 L职位通常是指倾向于业务的爬虫工程师职位,而T职位通常是指倾向于技术的爬虫工程师职位。一些学生更喜欢与企业保持联系,并具有良好的表达能力,快速反应和清晰的思维,因此他将去L职位。一些学生对突破各种问题并提供更好的解决方案更加热衷于技术。将转到T帖子。
L职位的一般职位是什么?
1.技术支持(针对中小型客户)
2.预售(针对主要客户)
3.数据中心负责人/项目负责人
4.解决方案顾问(深入的业务场景)
T岗位通常担任什么职位?
1.爬虫项目的一线开发和交付人员
2.数据专员
3.高级数据专家
4.爬虫训练讲师
工作机会
如果看到此消息,则表明您对爬虫感兴趣。我们正在招聘上述职位。如果您是合格的履带工程师或渴望成为一名出色的履带工程师,请给您的履历表发送艰苦的努力!
优采云是国内领先的采集器云采集工具平台,可为许多大型公司和政府提供数据服务,并建立Internet数据资产仓库。如果您有兴趣这样做,请让我们私下讨论。 查看全部
优采云采集器需要精通到什么程度?分布式解决方案
2.工具方向
这很容易理解。我们精通某个主流采集工具,例如优采云 采集器
我需要什么程度的精通?
1.如果可以使用我们的优采云和XPATH来找到网页的任何元素
2.如果您知道如何优采云 采集原理并了解拆分规则,则整个采集的效率可以提高10倍
3.实际上已经超过三个月没有每天使用我们的优采云并编写了一两百条规则,因此不应认为它是熟练的
除了熟悉以上两个工具级别之外,您还需要熟悉以下内容:
1. Anti- 采集原理(验证码,多个IP等)
2. html前端解析知识
3.分布式解决方案
4.正则表达式匹配
基本上,如果您熟悉上述技能,您几乎可以成为一名合格且思维清晰的履带工程师。那些编写代码的人具有编写代码的好处,以及使用工具和工具的好处。编写代码的好处是更大的自由度,更大的挑战,更难上手,并且效果实际上并不好,因为很多时候它们实际上是在重新创建轮子。
毕竟,只要您可以使用采集器工具,就可以完成许多常见操作,并且可以为您完成功能性采集器工具。至于工具,工具总是有一点限制。为了实现多功能性,工具会在一定程度上牺牲某些功能。在某些非常特殊的情况下,工具实际上很难完成。
因此,我始终建议工具+代码是主流爬虫工程师的配置。您可以使用诸如优采云之类的工具来满足99%的要求,但是如果遇到特定要求,可以留下手写代码来解决。
毕竟,我们想要的是解决问题,更不用说python等了。根本不难配置采集器程序。有很多在线教程。 (国内主流采集伟大的上帝就是这样做的。那些可以使用工具的人优先使用工具。除非工具不清楚,否则他们会编写自己的代码)
履带工程师的相关技能
除了要了解采集,爬虫工程师还需要一些其他技能。这是爬虫工程师是入门级,普通级还是优秀级的真实度量。实际上,在这个时代,复合型人才更受欢迎。
一位出色的履带工程师,他还需要以下技术来升华
1.数据清理
由于采集中的数据通常是一大部分文本,因此您需要优化文本,这就是我们所谓的清理数据,以获取更清晰的结构化数据并将其保存在数据库中。
有时候,我们采集有多个数据副本,我们还需要通过清理将它们关联起来。例如,我们擅长在Excel中使用一些高级技能,以及使用诸如R的编程语言来处理文本。我们优采云数据中心小组的学生都具有数据清除技能。
2.数据挖掘
爬网后的数据挖掘通常是指NLP的重影。 NLP属于人工智能领域。中文被称为自然语言处理。简单理解就是处理大量文本并从大量文本中挖掘出价值。
在中国,我们能做得很好的事情属于奉茂琳娇。我们优采云也有我们自己的NLP团队。这项投资是巨大的,而且我们做得还不够好。我们刚刚开始实现一些特定的场景功能。下订单。我们是中国的一些主流AI公司,采集,挖掘后,我们输出AI数据。我们的数据中心有一些很棒的人专门从事这项工作。
3.数据分析可视化
仅下载数据采集并将其保存在数据库中,仅是为了实现第一步的价值。数据分析和可视化是数据背后的更大价值。
因此有必要将数据保存在数据库中,然后通过相应的框架或程序进行开发,组织和调出,以协助企业进行决策。因此,我们优采云有一个专门的数据BI团队,许多爬虫工程师都擅长使用通用可视BI工具EXCEL为项目提供可视数据支持。
4.深入了解业务
无论是对在Internet上获取公共数据的能力的理解还是对业务需求的理解,它也是考虑优秀的爬虫工程师的重要措施。坦率地说,不仅要了解技术,还要了解业务,并成为一名复合式爬虫工程师。只有在此程度上,履带工程师的价值才能被无限放大。例如,了解风险控制业务,例如了解AI业务等。我们为此职位设有售前和顾问。
如何规划履带工程师的路线
在我的团队中,有两条路线,即L岗位和T岗位。 L职位通常是指倾向于业务的爬虫工程师职位,而T职位通常是指倾向于技术的爬虫工程师职位。一些学生更喜欢与企业保持联系,并具有良好的表达能力,快速反应和清晰的思维,因此他将去L职位。一些学生对突破各种问题并提供更好的解决方案更加热衷于技术。将转到T帖子。
L职位的一般职位是什么?
1.技术支持(针对中小型客户)
2.预售(针对主要客户)
3.数据中心负责人/项目负责人
4.解决方案顾问(深入的业务场景)
T岗位通常担任什么职位?
1.爬虫项目的一线开发和交付人员
2.数据专员
3.高级数据专家
4.爬虫训练讲师
工作机会
如果看到此消息,则表明您对爬虫感兴趣。我们正在招聘上述职位。如果您是合格的履带工程师或渴望成为一名出色的履带工程师,请给您的履历表发送艰苦的努力!
优采云是国内领先的采集器云采集工具平台,可为许多大型公司和政府提供数据服务,并建立Internet数据资产仓库。如果您有兴趣这样做,请让我们私下讨论。
《优采云·云采集原理以及规则加速设置教程》
采集交流 • 优采云 发表了文章 • 0 个评论 • 316 次浏览 • 2021-03-24 01:01
优采云·Cloud 采集 Service Platform的警告:[文档是使用Spire创建的。.优采云 Cloud 采集原理和规则加速设置教程对于旗舰版以上的用户,您可以使用Cloud 采集实现多任务采集任务加速的效果,使用户可以快速采集和整理Internet公共数据。本教程主要讨论云采集的原理和规则加速设置。 一、 Cloud 采集原理A.一个针对云采集的规则任务至少占用一个云节点,并且最多可以占用所有云节点。 B.如果规则任务满足拆分为子任务的要求,则最多可以拆分为199 A子任务C。一个子任务占据一个节点,并且子任务的完成意味着该任务已完成。 D.常规任务分为多个子任务,并分配给不同的云节点以达到加速效果采集 E.如果云节点已被占用,则新启动的任务或拆分子任务将进入等待队列直到用户的某个云节点完成用户的特定任务并释放节点资源为止。图1云采集正在运行,如红线所示任务分配给云节点,多任务并发采集数据,如红色框所示,由于节点已满,只能进入等待队列,等待云节点完成资源释放的执行。 二、从云采集的原理D知道云采集的加速度设置。如果要使任务加速采集的效果,则该任务必须满足拆分条件或将任务更改为满足拆分条件的任务。为了达到单任务加速的效果。满足拆分条件的任务是:A. URL列表循环B.文本列表循环C.固定元素列表循环1、 URL列表循环,文本循环示例URL:rch / category / 15/30对于非AJAX 网站,以公共商店为例,假设我要采集所有网站类别下的商店,那么我们可以先采集该类别的URL,然后执行URL循环以继续进行采集存储信息,具体步骤如下:步骤1:首先,将采集的所有特定类别下移,如图2所示采集注释类别URL图2 采集注释类别URL技巧采集在类别URL之后,我们可以使用此URL,因为URL数据提取是循环执行的。这样,通过优采云自动任务拆分,可以将不同的URL拆分为不同的子任务,并为数据采集分配给不同的云节点,从而实现单任务加速采集效果步骤2:通过步骤采集 1,建立数据的URL循环采集,如屏幕快照所示3 URL循环列表图3 URL循环列表采集步骤3:比较效果,如图4所示本机采集与URL循环列表的效率比较cloud 采集 采集图4 Cloud 采集 采集速度提示cloud 采集除了采集比机器采集更高效之外,它还可以节省用户自己的计算机和网络资源,与消耗用户本地计算机资源和网络资源的本地采集相比,云采集使用的资源都是云节点资源,用户启动云采集,优采云将自动组织和汇总优采云客户端上的数据。提取数据后,用户仅需要通过客户端查看或导出数据。结论:已经解释了URL循环教程。对于文本循环,原理和URL循环是一致的,通过拆分文本循环,可以实现单任务加速采集的效果,从而提高了采集 2、的速率。固定元素列表循环固定元素list循环也满足拆分条件,因此需要固定元素列表。循环单击与固定元素列表结合使用。例如:图5固定元素列表-单击某个元素,但是以下条件不会加快采集的速率,例如:图6固定元素列表数据提取原因是因为固定元素列表提取尽管可以将数据拆分为多个子任务,但由于提取同一页面数据的操作非常快,因此几乎没有任务加速效果。例如:子任务A:打开网页(20s)-提取数据位置(0. 1s)子任务B:打开网页(20s)-提取位置b数据(0. 1s)子任务C:打开网页(20s)-提取位置c数据(0. 1s)...子任务N:打开网页(20秒)-提取位置n个数据(0. 1秒) 查看全部
《优采云·云采集原理以及规则加速设置教程》
优采云·Cloud 采集 Service Platform的警告:[文档是使用Spire创建的。.优采云 Cloud 采集原理和规则加速设置教程对于旗舰版以上的用户,您可以使用Cloud 采集实现多任务采集任务加速的效果,使用户可以快速采集和整理Internet公共数据。本教程主要讨论云采集的原理和规则加速设置。 一、 Cloud 采集原理A.一个针对云采集的规则任务至少占用一个云节点,并且最多可以占用所有云节点。 B.如果规则任务满足拆分为子任务的要求,则最多可以拆分为199 A子任务C。一个子任务占据一个节点,并且子任务的完成意味着该任务已完成。 D.常规任务分为多个子任务,并分配给不同的云节点以达到加速效果采集 E.如果云节点已被占用,则新启动的任务或拆分子任务将进入等待队列直到用户的某个云节点完成用户的特定任务并释放节点资源为止。图1云采集正在运行,如红线所示任务分配给云节点,多任务并发采集数据,如红色框所示,由于节点已满,只能进入等待队列,等待云节点完成资源释放的执行。 二、从云采集的原理D知道云采集的加速度设置。如果要使任务加速采集的效果,则该任务必须满足拆分条件或将任务更改为满足拆分条件的任务。为了达到单任务加速的效果。满足拆分条件的任务是:A. URL列表循环B.文本列表循环C.固定元素列表循环1、 URL列表循环,文本循环示例URL:rch / category / 15/30对于非AJAX 网站,以公共商店为例,假设我要采集所有网站类别下的商店,那么我们可以先采集该类别的URL,然后执行URL循环以继续进行采集存储信息,具体步骤如下:步骤1:首先,将采集的所有特定类别下移,如图2所示采集注释类别URL图2 采集注释类别URL技巧采集在类别URL之后,我们可以使用此URL,因为URL数据提取是循环执行的。这样,通过优采云自动任务拆分,可以将不同的URL拆分为不同的子任务,并为数据采集分配给不同的云节点,从而实现单任务加速采集效果步骤2:通过步骤采集 1,建立数据的URL循环采集,如屏幕快照所示3 URL循环列表图3 URL循环列表采集步骤3:比较效果,如图4所示本机采集与URL循环列表的效率比较cloud 采集 采集图4 Cloud 采集 采集速度提示cloud 采集除了采集比机器采集更高效之外,它还可以节省用户自己的计算机和网络资源,与消耗用户本地计算机资源和网络资源的本地采集相比,云采集使用的资源都是云节点资源,用户启动云采集,优采云将自动组织和汇总优采云客户端上的数据。提取数据后,用户仅需要通过客户端查看或导出数据。结论:已经解释了URL循环教程。对于文本循环,原理和URL循环是一致的,通过拆分文本循环,可以实现单任务加速采集的效果,从而提高了采集 2、的速率。固定元素列表循环固定元素list循环也满足拆分条件,因此需要固定元素列表。循环单击与固定元素列表结合使用。例如:图5固定元素列表-单击某个元素,但是以下条件不会加快采集的速率,例如:图6固定元素列表数据提取原因是因为固定元素列表提取尽管可以将数据拆分为多个子任务,但由于提取同一页面数据的操作非常快,因此几乎没有任务加速效果。例如:子任务A:打开网页(20s)-提取数据位置(0. 1s)子任务B:打开网页(20s)-提取位置b数据(0. 1s)子任务C:打开网页(20s)-提取位置c数据(0. 1s)...子任务N:打开网页(20秒)-提取位置n个数据(0. 1秒)
优采云采集平台对图片云存储支持以下4个服务商
采集交流 • 优采云 发表了文章 • 0 个评论 • 346 次浏览 • 2021-03-21 02:05
在数据采集的处理过程中,经常会遇到源网站设置图片防盗链接的情况,只有采集页面内容会导致图片无法显示,然后下载此采集 k14]或OSS云存储的图片。建议将图片存储在云存储中。配置和操作相对简单。您也可以直接测试配置是否正确。
优采云 采集平台支持以下4个服务提供商进行图像云存储:
当存储在阿里云OSS中时:采集,优采云直接将图片上传到用户配置的阿里云OSS中,并自动修改内容的图像链接。不再需要通过http或ftp发送回图片,可以在采集之后直接发布。
秦牛对象存储:一种类似于阿里云OSS存储的机制。
腾讯云对象存储:一种类似于存储到阿里云OSS的机制。
再次存储云对象:一种类似于存储到阿里云OSS的机制。
详细的使用步骤:
1、在“详细信息提取器”中配置字段
在“ Detail Extractor”字段中获取图片,需要在“ Get Html”上检查其属性配置。
2、“图片下载配置”
I。创建新的图片存储配置
配置“存储到阿里云OSS”或“存储到秦牛云”或“腾讯云COS”。以下是存储到阿里云OSS的示例:
输入“图片下载配置”列,单击“云存储添加管理” ==“单击[+ Alibaba Cloud OSS]按钮==”填写相关信息;
您还可以从控制台左侧的菜单中选择“第三方服务配置”-“ Picture Cloud存储管理”,如下所示:
填写相应的配置并保存,单击“测试上传图片”,如果图片弹出,则测试成功。
II,选择存储配置
选择相应的服务提供商云存储配置。
3、检查图像下载是否有效
点击“详细信息提升器”右上角的测试采集,它将采集当前加载页面的数据内容;
完成采集后,将弹出数据预览界面==》检查源代码,图片地址是否被正确替换:
查看全部
优采云采集平台对图片云存储支持以下4个服务商
在数据采集的处理过程中,经常会遇到源网站设置图片防盗链接的情况,只有采集页面内容会导致图片无法显示,然后下载此采集 k14]或OSS云存储的图片。建议将图片存储在云存储中。配置和操作相对简单。您也可以直接测试配置是否正确。
优采云 采集平台支持以下4个服务提供商进行图像云存储:
当存储在阿里云OSS中时:采集,优采云直接将图片上传到用户配置的阿里云OSS中,并自动修改内容的图像链接。不再需要通过http或ftp发送回图片,可以在采集之后直接发布。
秦牛对象存储:一种类似于阿里云OSS存储的机制。
腾讯云对象存储:一种类似于存储到阿里云OSS的机制。
再次存储云对象:一种类似于存储到阿里云OSS的机制。
详细的使用步骤:
1、在“详细信息提取器”中配置字段
在“ Detail Extractor”字段中获取图片,需要在“ Get Html”上检查其属性配置。
2、“图片下载配置”
I。创建新的图片存储配置
配置“存储到阿里云OSS”或“存储到秦牛云”或“腾讯云COS”。以下是存储到阿里云OSS的示例:
输入“图片下载配置”列,单击“云存储添加管理” ==“单击[+ Alibaba Cloud OSS]按钮==”填写相关信息;
您还可以从控制台左侧的菜单中选择“第三方服务配置”-“ Picture Cloud存储管理”,如下所示:
填写相应的配置并保存,单击“测试上传图片”,如果图片弹出,则测试成功。
II,选择存储配置
选择相应的服务提供商云存储配置。
3、检查图像下载是否有效
点击“详细信息提升器”右上角的测试采集,它将采集当前加载页面的数据内容;
完成采集后,将弹出数据预览界面==》检查源代码,图片地址是否被正确替换:
发源地开源分布式云采集引擎下配置主机域名指向站点
采集交流 • 优采云 发表了文章 • 0 个评论 • 253 次浏览 • 2021-01-19 09:07
出生地云采集开源分布式云采集引擎
出生地云采集引擎是由出生地研发团队开发的一组开源云采集工具引擎,它支持本地化私有化部署,并且可以快速构建自己的大数据云采集采集器系统。 Birthplace Cloud 采集引擎完全基于云,它将数据采集,清理,重复数据删除和处理集成到一个Internet WEB / APP数据采集引擎中,该引擎可以以较低的费用完成网页文本,图片和其他资源成本高且效率高的信息采集,并执行过滤和处理以挖掘精确的所需数据,以便将数据输出到结构化文件包,采集规则算法或API接口中,并可以选择将其发布到来源地的大数据交易平台进行交易,或导出为Excel,CSV,Mysql等格式并将其保存在本地。
V1.0更新列表功能安装说明
在nginx下配置WWW主机域名,使其指向站点下的[根目录]或[公共目录](更安全)。
以下目录需要可写操作权限
关于出生地
出生地属于上海联远信息技术有限公司的品牌。核心团队由互联网高管和来自腾讯,百度,阿里等公司的专家组成。诞生地大数据交易平台,作为国内第一个基于人工智能AI技术的大数据交易平台,支持海量数据的分布式采集,计算和处理,从而促进了机器学习的数据交易发展并实现了最大化数据的价值。 Internet公开数据和企业内部数据通过众包UGC模式采集 /访问进行访问,经过清洗,过滤,脱敏,然后以数据和算法规则的形式存放在数据交易市场中,以满足企业的需求。数据分析,数据运营和精准营销需求。 查看全部
发源地开源分布式云采集引擎下配置主机域名指向站点
出生地云采集开源分布式云采集引擎
出生地云采集引擎是由出生地研发团队开发的一组开源云采集工具引擎,它支持本地化私有化部署,并且可以快速构建自己的大数据云采集采集器系统。 Birthplace Cloud 采集引擎完全基于云,它将数据采集,清理,重复数据删除和处理集成到一个Internet WEB / APP数据采集引擎中,该引擎可以以较低的费用完成网页文本,图片和其他资源成本高且效率高的信息采集,并执行过滤和处理以挖掘精确的所需数据,以便将数据输出到结构化文件包,采集规则算法或API接口中,并可以选择将其发布到来源地的大数据交易平台进行交易,或导出为Excel,CSV,Mysql等格式并将其保存在本地。
V1.0更新列表功能安装说明
在nginx下配置WWW主机域名,使其指向站点下的[根目录]或[公共目录](更安全)。
以下目录需要可写操作权限
关于出生地
出生地属于上海联远信息技术有限公司的品牌。核心团队由互联网高管和来自腾讯,百度,阿里等公司的专家组成。诞生地大数据交易平台,作为国内第一个基于人工智能AI技术的大数据交易平台,支持海量数据的分布式采集,计算和处理,从而促进了机器学习的数据交易发展并实现了最大化数据的价值。 Internet公开数据和企业内部数据通过众包UGC模式采集 /访问进行访问,经过清洗,过滤,脱敏,然后以数据和算法规则的形式存放在数据交易市场中,以满足企业的需求。数据分析,数据运营和精准营销需求。
完整解决方案:ROS下利用realsense采集RGBD图像合成点云
采集交流 • 优采云 发表了文章 • 0 个评论 • 605 次浏览 • 2020-11-13 08:00
摘要:在ROS动力学下,使用realsense D435深度相机采集校准的RGBD图像合成点云,在rviz中查看点云,最后将其保存为pcd文件。
一、各种错误
成功编译代码后,打开rviz并添加pointcloud2选项卡。当我订阅合成点云时,可视化失败,并且选项卡报告错误:
1)数据大小(9394656字节)与宽度(640)乘以高度(480)乘以point_step(32)。丢弃消息。)。
解释:通过rostopic echo / pointcloud_topic读取摄像机节点发布的原创点云的相关数据,可以发现每帧原创点云中的点数为307,200。合成的点云中的点数为9394656/32,约为260,000。可以推测,由于某种原因,系统丢弃了合成点云每一帧的数据。
原因:我预先将复合点云的大小设置为高度= 480,宽度= 640.。但是,在合成点云的过程中,删除了一些非法值(d =0))。合成点云中的点数与指定点数不匹配,因此丢弃了合成点云中的数据。
解决方案:使用以下方法指定点云大小,cloud-> height = 1; cloud-> width = cloud-> points.size();
2)转换xxxxx;
解释:通过rostopic echo / pointcloud_topic,发现原创点云数据具有以下信息,
header:
seq: 50114
stamp:
secs: 1528439158
nsecs: 557543003
frame_id: "camera_color_optical_frame"
由此推断,复合点云缺少参考坐标系header.frame_id。点云的点的XYZ属性是相对于某个坐标系描述的,因此,需要指定点云的参考坐标系。
解决方案:添加点云的标题信息,
pub_pointcloud.header.frame_id = "camera_color_optical_frame";
pub_pointcloud.header.stamp = ros::Time::now();
3)将合成点云存储为pcd文件时遇到以下错误:
[ INFO] [1528442016.931874649]: point cloud size = 0
terminate called after throwing an instance of 'pcl::IOException'
what(): : [pcl::PCDWriter::writeASCII] Input point cloud has no data!
Aborted (core dumped)
在进行了多种搜索之后,我探索了一个窍门并与所有人分享。该错误的真正原因尚未确定,我期待着老年人的指导。
高博的源代码如下所示,里面的云是pcl的数据类型,
pcl :: io :: savePCDFile(“ ./ pointcloud.pcd”,* cloud);。
我的源代码如下所示。首先,通过pcl :: toROSMsg()将pcl的数据类型转换为ros的数据类型,然后将其写入pcd以跳过错误报告。
4)照相机内部参考
由于在颜色图和深度图的配准过程中使用了颜色图坐标系,因此在合成点云(像素坐标转换为相机坐标)时应选择颜色图的相机内部参数。
Realsense正式提供了一个用于查看所有视频流内部参数的应用程序。
gordon@gordon-5577:/usr/local/bin$ ./rs-sensor-control
如下所示
84:颜色#0(视频流:Y16 640x480 @ 60Hz)
85:颜色0(视频流:BGRA8 640x480 @ 60Hz)
86:颜色#0(视频流:RGBA8 640x480 @ 60Hz)
87:颜色#0(视频流:BGR8 640x480 @ 60Hz)
88:颜色#0(视频流:RGB8 640x480 @ 60Hz)
89:颜色#0(视频流:YUYV 640x480 @ 60Hz)
90:颜色#0(视频流:Y16 640x480 @ 30Hz)
91:颜色#0(视频流:BGRA8 640x480 @ 30Hz)
92:颜色#0(视频流:RGBA8 640x480 @ 30Hz)
93:颜色#0(视频流:BGR8 640x480 @ 30Hz)
94:颜色#0(视频流:RGB8 640x480 @ 30Hz)
95:颜色#0(视频流:YUYV 640x480 @ 30Hz)
96:颜色#0(视频流:Y16 640x480 @ 15Hz)
97:颜色#0(视频流:BGRA8 640x480 @ 15Hz)
98:颜色#0(视频流:RGBA8 640x480 @ 15Hz)
99:颜色#0(视频流:BGR8 640x480 @ 15Hz)
100:颜色#0(视频流:RGB8 640x480 @ 15Hz)
101:颜色#0(视频流:YUYV 640x480 @ 15Hz)
102:颜色#0(视频流:Y16 640x480 @ 6Hz)
103:颜色#0(视频流:BGRA8 640x480 @ 6Hz)
104:颜色#0(视频流:RGBA8 640x480 @ 6Hz)
105:颜色#0(视频流:BGR8 640x480 @ 6Hz)
106:颜色#0(视频流:RGB8 640x480 @ 6Hz)
107:颜色#0(视频流:YUYV 640x480 @ 6Hz)
5)深度图从ROS数据类型转换为CV数据类型
查看链接
二、程序代码
<p>#include
#include
#include
#include
#include
#include
// PCL 库
#include
#include
#include
#include
// 定义点云类型
typedef pcl::PointCloud PointCloud;
using namespace std;
//namespace enc = sensor_msgs::image_encodings;
// 相机内参
const double camera_factor = 1000;
const double camera_cx = 321.798;
const double camera_cy = 239.607;
const double camera_fx = 615.899;
const double camera_fy = 616.468;
// 全局变量:图像矩阵和点云
cv_bridge::CvImagePtr color_ptr, depth_ptr;
cv::Mat color_pic, depth_pic;
void color_Callback(const sensor_msgs::ImageConstPtr& color_msg)
{
//cv_bridge::CvImagePtr color_ptr;
try
{
cv::imshow("color_view", cv_bridge::toCvShare(color_msg, sensor_msgs::image_encodings::BGR8)->image);
color_ptr = cv_bridge::toCvCopy(color_msg, sensor_msgs::image_encodings::BGR8);
cv::waitKey(1050); // 不断刷新图像,频率时间为int delay,单位为ms
}
catch (cv_bridge::Exception& e )
{
ROS_ERROR("Could not convert from '%s' to 'bgr8'.", color_msg->encoding.c_str());
}
color_pic = color_ptr->image;
// output some info about the rgb image in cv format
coutencoding.c_str());
}
depth_pic = depth_ptr->image;
// output some info about the depth image in cv format
coutwidth = cloud->points.size();
ROS_INFO("point cloud size = %d",cloud->width);
cloud->is_dense = false;// 转换点云的数据类型并存储成pcd文件
pcl::toROSMsg(*cloud,pub_pointcloud);
pub_pointcloud.header.frame_id = "camera_color_optical_frame";
pub_pointcloud.header.stamp = ros::Time::now();
pcl::io::savePCDFile("./pointcloud.pcd", pub_pointcloud);
cout 查看全部
在ROS下使用realsense采集RGBD图像合成点云
摘要:在ROS动力学下,使用realsense D435深度相机采集校准的RGBD图像合成点云,在rviz中查看点云,最后将其保存为pcd文件。
一、各种错误
成功编译代码后,打开rviz并添加pointcloud2选项卡。当我订阅合成点云时,可视化失败,并且选项卡报告错误:
1)数据大小(9394656字节)与宽度(640)乘以高度(480)乘以point_step(32)。丢弃消息。)。
解释:通过rostopic echo / pointcloud_topic读取摄像机节点发布的原创点云的相关数据,可以发现每帧原创点云中的点数为307,200。合成的点云中的点数为9394656/32,约为260,000。可以推测,由于某种原因,系统丢弃了合成点云每一帧的数据。
原因:我预先将复合点云的大小设置为高度= 480,宽度= 640.。但是,在合成点云的过程中,删除了一些非法值(d =0))。合成点云中的点数与指定点数不匹配,因此丢弃了合成点云中的数据。
解决方案:使用以下方法指定点云大小,cloud-> height = 1; cloud-> width = cloud-> points.size();
2)转换xxxxx;
解释:通过rostopic echo / pointcloud_topic,发现原创点云数据具有以下信息,
header:
seq: 50114
stamp:
secs: 1528439158
nsecs: 557543003
frame_id: "camera_color_optical_frame"
由此推断,复合点云缺少参考坐标系header.frame_id。点云的点的XYZ属性是相对于某个坐标系描述的,因此,需要指定点云的参考坐标系。
解决方案:添加点云的标题信息,
pub_pointcloud.header.frame_id = "camera_color_optical_frame";
pub_pointcloud.header.stamp = ros::Time::now();
3)将合成点云存储为pcd文件时遇到以下错误:
[ INFO] [1528442016.931874649]: point cloud size = 0
terminate called after throwing an instance of 'pcl::IOException'
what(): : [pcl::PCDWriter::writeASCII] Input point cloud has no data!
Aborted (core dumped)
在进行了多种搜索之后,我探索了一个窍门并与所有人分享。该错误的真正原因尚未确定,我期待着老年人的指导。
高博的源代码如下所示,里面的云是pcl的数据类型,
pcl :: io :: savePCDFile(“ ./ pointcloud.pcd”,* cloud);。
我的源代码如下所示。首先,通过pcl :: toROSMsg()将pcl的数据类型转换为ros的数据类型,然后将其写入pcd以跳过错误报告。
4)照相机内部参考
由于在颜色图和深度图的配准过程中使用了颜色图坐标系,因此在合成点云(像素坐标转换为相机坐标)时应选择颜色图的相机内部参数。
Realsense正式提供了一个用于查看所有视频流内部参数的应用程序。
gordon@gordon-5577:/usr/local/bin$ ./rs-sensor-control
如下所示
84:颜色#0(视频流:Y16 640x480 @ 60Hz)
85:颜色0(视频流:BGRA8 640x480 @ 60Hz)
86:颜色#0(视频流:RGBA8 640x480 @ 60Hz)
87:颜色#0(视频流:BGR8 640x480 @ 60Hz)
88:颜色#0(视频流:RGB8 640x480 @ 60Hz)
89:颜色#0(视频流:YUYV 640x480 @ 60Hz)
90:颜色#0(视频流:Y16 640x480 @ 30Hz)
91:颜色#0(视频流:BGRA8 640x480 @ 30Hz)
92:颜色#0(视频流:RGBA8 640x480 @ 30Hz)
93:颜色#0(视频流:BGR8 640x480 @ 30Hz)
94:颜色#0(视频流:RGB8 640x480 @ 30Hz)
95:颜色#0(视频流:YUYV 640x480 @ 30Hz)
96:颜色#0(视频流:Y16 640x480 @ 15Hz)
97:颜色#0(视频流:BGRA8 640x480 @ 15Hz)
98:颜色#0(视频流:RGBA8 640x480 @ 15Hz)
99:颜色#0(视频流:BGR8 640x480 @ 15Hz)
100:颜色#0(视频流:RGB8 640x480 @ 15Hz)
101:颜色#0(视频流:YUYV 640x480 @ 15Hz)
102:颜色#0(视频流:Y16 640x480 @ 6Hz)
103:颜色#0(视频流:BGRA8 640x480 @ 6Hz)
104:颜色#0(视频流:RGBA8 640x480 @ 6Hz)
105:颜色#0(视频流:BGR8 640x480 @ 6Hz)
106:颜色#0(视频流:RGB8 640x480 @ 6Hz)
107:颜色#0(视频流:YUYV 640x480 @ 6Hz)
5)深度图从ROS数据类型转换为CV数据类型
查看链接
二、程序代码
<p>#include
#include
#include
#include
#include
#include
// PCL 库
#include
#include
#include
#include
// 定义点云类型
typedef pcl::PointCloud PointCloud;
using namespace std;
//namespace enc = sensor_msgs::image_encodings;
// 相机内参
const double camera_factor = 1000;
const double camera_cx = 321.798;
const double camera_cy = 239.607;
const double camera_fx = 615.899;
const double camera_fy = 616.468;
// 全局变量:图像矩阵和点云
cv_bridge::CvImagePtr color_ptr, depth_ptr;
cv::Mat color_pic, depth_pic;
void color_Callback(const sensor_msgs::ImageConstPtr& color_msg)
{
//cv_bridge::CvImagePtr color_ptr;
try
{
cv::imshow("color_view", cv_bridge::toCvShare(color_msg, sensor_msgs::image_encodings::BGR8)->image);
color_ptr = cv_bridge::toCvCopy(color_msg, sensor_msgs::image_encodings::BGR8);
cv::waitKey(1050); // 不断刷新图像,频率时间为int delay,单位为ms
}
catch (cv_bridge::Exception& e )
{
ROS_ERROR("Could not convert from '%s' to 'bgr8'.", color_msg->encoding.c_str());
}
color_pic = color_ptr->image;
// output some info about the rgb image in cv format
coutencoding.c_str());
}
depth_pic = depth_ptr->image;
// output some info about the depth image in cv format
coutwidth = cloud->points.size();
ROS_INFO("point cloud size = %d",cloud->width);
cloud->is_dense = false;// 转换点云的数据类型并存储成pcd文件
pcl::toROSMsg(*cloud,pub_pointcloud);
pub_pointcloud.header.frame_id = "camera_color_optical_frame";
pub_pointcloud.header.stamp = ros::Time::now();
pcl::io::savePCDFile("./pointcloud.pcd", pub_pointcloud);
cout
测评:收藏!5款常用的数据采集工具推荐
采集交流 • 优采云 发表了文章 • 0 个评论 • 414 次浏览 • 2020-09-03 16:37
1.内容采集器
Content Grabber是支持智能爬网的Web爬网软件。它的程序操作环境可以在开发,测试和生产服务器上使用。您可以使用c#或VB.NET调试或编写脚本来控制采集器。它还支持将第三方扩展插件添加到采集器工具。凭借其全面的功能,Content Grabber对于具有技术基础的用户而言极为强大。
2. Mozenda
Mozenda是一个Web抓取软件,还提供用于商业级数据抓取的定制服务。它可以从云和本地软件中获取数据并执行数据托管。
3. Parsehub
Parsehub是基于Web的采集器程序。它使用AJax和JavaScripts技术支持采集网页数据,还支持需要登录的采集网页数据。它具有为期一周的免费试用期,供用户体验其功能
4. Import.io
Import.io是基于Web的数据抓取工具。它于2012年在伦敦首次启动。现在Import.io已将其业务模式从B2C转变为B2B。在2019年,Import.io收购了Connotate,并成为Web数据集成平台。 Import.io拥有广泛的Web数据服务,已成为进行业务分析的绝佳选择。
5。优采云
优采云是一个免费,简单且直观的Web爬网程序工具,无需进行编码即可从许多网站抓取数据。无论您是初学者还是经验丰富的技术人员或业务主管,它都可以满足您的需求。为了降低使用难度,优采云为初学者准备了“ 网站简单模板”,涵盖了市场上大多数主流的网站。使用简单的模板,用户无需任务配置即可采集数据。这个简单的模板为采集小白树立了信心,然后您可以开始使用“高级模式”,它可以帮助您在几分钟内捕获大量数据。此外,您还可以设置时序云采集以实时获取动态数据,并将数据导出到数据库或任何第三方平台。
在5种常用数据采集工具中推荐以上内容!享受,如果您对搜索推广有任何疑问或需求,请单击在线客户服务或致电问题热线,并期待着您的问题! 查看全部
采集! 5个常用数据采集工具推荐
1.内容采集器
Content Grabber是支持智能爬网的Web爬网软件。它的程序操作环境可以在开发,测试和生产服务器上使用。您可以使用c#或VB.NET调试或编写脚本来控制采集器。它还支持将第三方扩展插件添加到采集器工具。凭借其全面的功能,Content Grabber对于具有技术基础的用户而言极为强大。
2. Mozenda
Mozenda是一个Web抓取软件,还提供用于商业级数据抓取的定制服务。它可以从云和本地软件中获取数据并执行数据托管。
3. Parsehub
Parsehub是基于Web的采集器程序。它使用AJax和JavaScripts技术支持采集网页数据,还支持需要登录的采集网页数据。它具有为期一周的免费试用期,供用户体验其功能
4. Import.io
Import.io是基于Web的数据抓取工具。它于2012年在伦敦首次启动。现在Import.io已将其业务模式从B2C转变为B2B。在2019年,Import.io收购了Connotate,并成为Web数据集成平台。 Import.io拥有广泛的Web数据服务,已成为进行业务分析的绝佳选择。
5。优采云
优采云是一个免费,简单且直观的Web爬网程序工具,无需进行编码即可从许多网站抓取数据。无论您是初学者还是经验丰富的技术人员或业务主管,它都可以满足您的需求。为了降低使用难度,优采云为初学者准备了“ 网站简单模板”,涵盖了市场上大多数主流的网站。使用简单的模板,用户无需任务配置即可采集数据。这个简单的模板为采集小白树立了信心,然后您可以开始使用“高级模式”,它可以帮助您在几分钟内捕获大量数据。此外,您还可以设置时序云采集以实时获取动态数据,并将数据导出到数据库或任何第三方平台。
在5种常用数据采集工具中推荐以上内容!享受,如果您对搜索推广有任何疑问或需求,请单击在线客户服务或致电问题热线,并期待着您的问题!
syslog网站日志采集
采集交流 • 优采云 发表了文章 • 0 个评论 • 421 次浏览 • 2020-08-28 19:07
syslog网站日志采集 相关的博客
开放、普惠、高性能-SLS时序储存推动构建企业级全方位监控方案
无所不在的时序数据 时间带走一切,长年累月会把你的名字、外貌、性格、命运都改变。 ---柏拉图 随着时间的推移,万事万物都在不停的变化,而我们也会用各类数字去评判这种变化信息,比如年纪、重量、速度、温度、金钱...在数字化时代中,我们会把那些随着时间变化的数
元乙1个月前 19
游侠原创:SyslogGather--基于Windows的绿色版SYSLOG日志采集器
实在是想不起来在那里下载的SyslogGather.exe,但是我的“未整理文件”中,有那么个文件,看名称就晓得,是和Syslog有关的,打开以后界面十分简单: 我们可以看见,SyslogGather.exe虽然就是一款测试SYSLOG的绿色版软件。可
科技小能手2年前 1059
【技术干货】想要高效采集数据到阿里云Elasticsearch,这些技巧你晓得吗?
简介: 本文全面介绍了Elastic Beats、Logstash、语言客户端以及Kibana开发者工具的特点及数据采集到阿里云Elasticsearch(简称ES)服务中的解决方案。帮助您全面了解原理并选择符合自身业务特色的数据采集方案。 本文字数:276
工程师乙10个月前 1279
游侠原创:Windows日志转SYSLOG工具——nxlog
此前游侠以前在博客上给你们介绍过Windows平台下的日志转换为syslog的工具(常见Windows日志转SYSLOG工具使用、Evtsys--轻松将Windows日志转换为SYSLOG、SyslogGather--基于Windows的绿色版SYSLOG日志
科技小能手2年前 2749
游侠原创:Evtsys--轻松将Windows日志转换为SYSLOG
我们晓得,无论是Unix、Linux、FreeBSD、Ubuntu,还是路由器、交换机,都会形成大量的日志,而这种,一般会以syslog的方式存在。调试过防火墙、入侵检查、安全审计等产品的同事应当对SYSLOG熟悉,如果您还不了解SYSLOG,请登陆百度或Go
科技小能手2年前 1028
使用LogHub进行日志实时采集
日志服务LogHub功能提供日志数据实时采集与消费,其中实时采集功能支持30+种手段,这里简单介绍下各场景的接入方法。 数据采集一般有两种形式,区别如下。我们这儿主要讨论通过LogHub流式导入(实时)采集。 方式 优势 劣势 例子 批量导出 吞吐率大,面向
简志3年前 16667
Linux 日志管理手册
管理日志的一个最好做法是将你的日志集中或整合到一个地方,特别是在你有许多服务器或多层级构架时。我们将告诉你为何这是一个好主意,然后给出怎么更容易的做这件事的一些小技巧。 集中管理日志的益处 如果你有好多服务器,查看某个日志文件可能会很麻烦。现代的网站和服务经
寒凝雪3年前 1941
日志剖析:SLS vs ELK
背景 提到日志实时剖析,大部分人第一想到是社区太火ELK Stack(Elastic/Logstash/Kibana)。ELK方案上手难度小、开源材料诸多、在社区中有大量的使用案例。 阿里云日志服务(SLS/Log) 是阿里巴巴集团对日志场景的解决方案产品,
简志1年前 13783 查看全部
syslog网站日志采集
syslog网站日志采集 相关的博客
开放、普惠、高性能-SLS时序储存推动构建企业级全方位监控方案
无所不在的时序数据 时间带走一切,长年累月会把你的名字、外貌、性格、命运都改变。 ---柏拉图 随着时间的推移,万事万物都在不停的变化,而我们也会用各类数字去评判这种变化信息,比如年纪、重量、速度、温度、金钱...在数字化时代中,我们会把那些随着时间变化的数
元乙1个月前 19
游侠原创:SyslogGather--基于Windows的绿色版SYSLOG日志采集器
实在是想不起来在那里下载的SyslogGather.exe,但是我的“未整理文件”中,有那么个文件,看名称就晓得,是和Syslog有关的,打开以后界面十分简单: 我们可以看见,SyslogGather.exe虽然就是一款测试SYSLOG的绿色版软件。可
科技小能手2年前 1059
【技术干货】想要高效采集数据到阿里云Elasticsearch,这些技巧你晓得吗?
简介: 本文全面介绍了Elastic Beats、Logstash、语言客户端以及Kibana开发者工具的特点及数据采集到阿里云Elasticsearch(简称ES)服务中的解决方案。帮助您全面了解原理并选择符合自身业务特色的数据采集方案。 本文字数:276
工程师乙10个月前 1279
游侠原创:Windows日志转SYSLOG工具——nxlog
此前游侠以前在博客上给你们介绍过Windows平台下的日志转换为syslog的工具(常见Windows日志转SYSLOG工具使用、Evtsys--轻松将Windows日志转换为SYSLOG、SyslogGather--基于Windows的绿色版SYSLOG日志
科技小能手2年前 2749
游侠原创:Evtsys--轻松将Windows日志转换为SYSLOG
我们晓得,无论是Unix、Linux、FreeBSD、Ubuntu,还是路由器、交换机,都会形成大量的日志,而这种,一般会以syslog的方式存在。调试过防火墙、入侵检查、安全审计等产品的同事应当对SYSLOG熟悉,如果您还不了解SYSLOG,请登陆百度或Go
科技小能手2年前 1028
使用LogHub进行日志实时采集
日志服务LogHub功能提供日志数据实时采集与消费,其中实时采集功能支持30+种手段,这里简单介绍下各场景的接入方法。 数据采集一般有两种形式,区别如下。我们这儿主要讨论通过LogHub流式导入(实时)采集。 方式 优势 劣势 例子 批量导出 吞吐率大,面向
简志3年前 16667
Linux 日志管理手册
管理日志的一个最好做法是将你的日志集中或整合到一个地方,特别是在你有许多服务器或多层级构架时。我们将告诉你为何这是一个好主意,然后给出怎么更容易的做这件事的一些小技巧。 集中管理日志的益处 如果你有好多服务器,查看某个日志文件可能会很麻烦。现代的网站和服务经
寒凝雪3年前 1941
日志剖析:SLS vs ELK
背景 提到日志实时剖析,大部分人第一想到是社区太火ELK Stack(Elastic/Logstash/Kibana)。ELK方案上手难度小、开源材料诸多、在社区中有大量的使用案例。 阿里云日志服务(SLS/Log) 是阿里巴巴集团对日志场景的解决方案产品,
简志1年前 13783
云脉文档识别:最短时间内完成信息采集
采集交流 • 优采云 发表了文章 • 0 个评论 • 340 次浏览 • 2020-08-26 07:48
生活学习中,我们遇见须要的资料,就会不由自主启动终极大招——Ctrl+ C/V,选择复制粘贴一顿操作猛如虎,学习资料手到擒来。
但是,这些年出于维护版权、防止捕捉等目的,不少网站/阅读APP开启了内容保护,Ctrl+ C/V不顶用了,那么如何做能够在最短的时间内完成资料采集呢?
手打?显然不现实,在这里推荐一款文档辨识小工具,帮助你读取采集资料信息,再现Ctrl+ C/V带来的“简单快乐”哦!
这款云脉文档辨识工具,是厦门云脉技术有限公司编撰的一款OCR软件,以文档辨识深度学习为基础,可以快速辨识并读取图片上的文字。文字辨识准确率很高,工具小,易安装易操作,对于须要文字辨识工具的小伙伴们来说,不失为一个好帮手。
上图是OCR文字辨识功能,可以辨识采集到图象上的所有文字。这款工具不仅仅是拿来辨识文字如此简单,云脉文档辨识还带有手动分段、后期校对、自助分组、云端储存、备注等功能。
采集资料文档其实是为了日后的使用,小文档太多很杂如何办?当然是须要“检索”功能啦!
上面提及的分类、分组功能,可以将文档根据不同的用途和内容进行分类命名,初步协助使用者找到自己所需文档的大约位置,“检索”功能则不同。
“检索”功能帮助使用者省却了“按类查找”这一步骤,直接从关键词下手,在最短的时间内找到须要的文件。 查看全部
云脉文档识别:最短时间内完成信息采集
生活学习中,我们遇见须要的资料,就会不由自主启动终极大招——Ctrl+ C/V,选择复制粘贴一顿操作猛如虎,学习资料手到擒来。
但是,这些年出于维护版权、防止捕捉等目的,不少网站/阅读APP开启了内容保护,Ctrl+ C/V不顶用了,那么如何做能够在最短的时间内完成资料采集呢?
手打?显然不现实,在这里推荐一款文档辨识小工具,帮助你读取采集资料信息,再现Ctrl+ C/V带来的“简单快乐”哦!
这款云脉文档辨识工具,是厦门云脉技术有限公司编撰的一款OCR软件,以文档辨识深度学习为基础,可以快速辨识并读取图片上的文字。文字辨识准确率很高,工具小,易安装易操作,对于须要文字辨识工具的小伙伴们来说,不失为一个好帮手。
上图是OCR文字辨识功能,可以辨识采集到图象上的所有文字。这款工具不仅仅是拿来辨识文字如此简单,云脉文档辨识还带有手动分段、后期校对、自助分组、云端储存、备注等功能。
采集资料文档其实是为了日后的使用,小文档太多很杂如何办?当然是须要“检索”功能啦!
上面提及的分类、分组功能,可以将文档根据不同的用途和内容进行分类命名,初步协助使用者找到自己所需文档的大约位置,“检索”功能则不同。
“检索”功能帮助使用者省却了“按类查找”这一步骤,直接从关键词下手,在最短的时间内找到须要的文件。
云采集 2019房产中介应当使用哪些房源采集软件?
采集交流 • 优采云 发表了文章 • 0 个评论 • 335 次浏览 • 2020-08-21 06:14
在房源采集工作中,你是否常常会碰到以下问题?
1、急需房源信息,数据采集慢?
店长要求马上提供5000条房源数据,你却发觉用普通采集需要27.77个小时!这可谓不可能完成的任务!
2、买了中级版本,结果不会用?
花钱买了中级版本,结果不会用云采集、速度还是没有改善?
现在小编借此机会向你们“普及一下“易房大师房源采集”的优势究竟在那里?如何将它的价值100%发挥下来?
1、数据云同步
云采集数据手动保存在云端,即使切换了办公场景或笔记本,只要登入易房大师帐号,便能将数据从云端下载出来。
2.简单上手
采集流程只需按照软件提示进行点击操作,完全符合常规浏览网页的行为习惯,简单几步几十个房产网站上的房源数据都能轻松采集。
3.数据手动去重,智能过滤中介房源
数据如有重复,易房大师房源采集将会手动筛选出重复数据,只保留有效数据,采集功能外置“搜狗号码辨识”、“中介号码标记”、“网络中介检查”、“网站来源”、“百度搜索”多重中介房源辨识方式,让您鉴别真伪房源省心、省时、省力又省钱!
4.可随时随地采集
易房大师手机版可以帮助中介移动化办公,电脑数据和手机数据同步,员工出门在外也可以进行房客源的管理及跟进,搜索房源,网络采集房源,房客源的录入,写日志记录等操作。在录入房源时,还可以上传视频房源,为顾客构建立体式房源体验。
5、数据备份永久保存
用户通过云采集获得的数据可永久保存,即使当下忘掉下载,也不怕数据遗失。
更多关于易房大师房源采集可以点击。 查看全部
云采集 2019房产中介应当使用哪些房源采集软件?
在房源采集工作中,你是否常常会碰到以下问题?
1、急需房源信息,数据采集慢?
店长要求马上提供5000条房源数据,你却发觉用普通采集需要27.77个小时!这可谓不可能完成的任务!
2、买了中级版本,结果不会用?
花钱买了中级版本,结果不会用云采集、速度还是没有改善?
现在小编借此机会向你们“普及一下“易房大师房源采集”的优势究竟在那里?如何将它的价值100%发挥下来?
1、数据云同步
云采集数据手动保存在云端,即使切换了办公场景或笔记本,只要登入易房大师帐号,便能将数据从云端下载出来。
2.简单上手
采集流程只需按照软件提示进行点击操作,完全符合常规浏览网页的行为习惯,简单几步几十个房产网站上的房源数据都能轻松采集。
3.数据手动去重,智能过滤中介房源
数据如有重复,易房大师房源采集将会手动筛选出重复数据,只保留有效数据,采集功能外置“搜狗号码辨识”、“中介号码标记”、“网络中介检查”、“网站来源”、“百度搜索”多重中介房源辨识方式,让您鉴别真伪房源省心、省时、省力又省钱!
4.可随时随地采集
易房大师手机版可以帮助中介移动化办公,电脑数据和手机数据同步,员工出门在外也可以进行房客源的管理及跟进,搜索房源,网络采集房源,房客源的录入,写日志记录等操作。在录入房源时,还可以上传视频房源,为顾客构建立体式房源体验。
5、数据备份永久保存
用户通过云采集获得的数据可永久保存,即使当下忘掉下载,也不怕数据遗失。
更多关于易房大师房源采集可以点击。
①ONEXIN开放云采集(常见问题)
采集交流 • 优采云 发表了文章 • 0 个评论 • 319 次浏览 • 2020-08-13 20:41
Q:免费版和专业版有哪些区别?
A:应用中心客户端版本通用。免费试用仅限服务器一。付费可选择不同套餐,定制站点,获得更高日使用上限。
Q:对服务器环境有要求吗?
A:体验版对环境没有特殊要求,文章的采集在云端。如果您的网站能发贴,插件就可以正常运行。
Q:我在美国,可以为我分配快一点的服务器吗?
A:目前我们早已拥有新浪,新网,百度云,阿里云及台湾顶尖数据中心等线路。我们会按照您的实际情况,检测后,为您分配合适的线路。
Q:为什么要订制站点?
A:定制,是确保你采集的内容更符合你的要求。
例如资讯类站点:经确认后,可以获取包括二级域名下所有文章 。
例如峰会:需要登入的,必须提供一个用户名和密码。
如有未能采集会明晰答复你。
Q:能否保存远程图片?
A:可以,在编辑器"高级"模式中,使用"下载远程图片"就可以了。
Q:如何添加我想要采集的站点?
A:目前支持资讯类或图集类站点(其它类型站暂不适用),防采集和防盗链的暂不处理。
如需新增采集目标站点,申请格式如下(或者发邮件到: onexin#):
-------------------------------------------------------------------
我的域名:
需采集站点,如下:
(详细标明所需内容页更佳)
Q:采集失败,获取不到内容如何办?
A:针对当前体验版采集的内容,如有采集失败,反馈时,请将您输入的采集网址发到邮箱onexin#等待处理。
注:不支持本地测试,形如localhost或127.0.0.1的host被禁用。
================更多功能正在测试中,请关注!=============== 查看全部
================常见问题解答(请使用最新版本)===========
Q:免费版和专业版有哪些区别?
A:应用中心客户端版本通用。免费试用仅限服务器一。付费可选择不同套餐,定制站点,获得更高日使用上限。
Q:对服务器环境有要求吗?
A:体验版对环境没有特殊要求,文章的采集在云端。如果您的网站能发贴,插件就可以正常运行。
Q:我在美国,可以为我分配快一点的服务器吗?
A:目前我们早已拥有新浪,新网,百度云,阿里云及台湾顶尖数据中心等线路。我们会按照您的实际情况,检测后,为您分配合适的线路。
Q:为什么要订制站点?
A:定制,是确保你采集的内容更符合你的要求。
例如资讯类站点:经确认后,可以获取包括二级域名下所有文章 。
例如峰会:需要登入的,必须提供一个用户名和密码。
如有未能采集会明晰答复你。
Q:能否保存远程图片?
A:可以,在编辑器"高级"模式中,使用"下载远程图片"就可以了。
Q:如何添加我想要采集的站点?
A:目前支持资讯类或图集类站点(其它类型站暂不适用),防采集和防盗链的暂不处理。
如需新增采集目标站点,申请格式如下(或者发邮件到: onexin#):
-------------------------------------------------------------------
我的域名:
需采集站点,如下:
(详细标明所需内容页更佳)
Q:采集失败,获取不到内容如何办?
A:针对当前体验版采集的内容,如有采集失败,反馈时,请将您输入的采集网址发到邮箱onexin#等待处理。
注:不支持本地测试,形如localhost或127.0.0.1的host被禁用。
================更多功能正在测试中,请关注!===============
如何管理私有云帐号下的云采集节点
采集交流 • 优采云 发表了文章 • 0 个评论 • 630 次浏览 • 2020-08-11 20:01
一、私有云基本介绍
私有云是优采云SaaS版本中的最高版本。私有云处于特定集群,拥有固定的云节点数,通常为30个或100个。
而旗舰/旗舰+版,则处于公共集群,其节点数是浮动变化的,所有旗舰/旗舰+用户一起角逐节点的使用权。
二、私有云可自动调整每位任务的云节点数
私有云帐号下的每位任务,云采集的最大可用节点数,默认为2(即每位任务最多有2个云节点同时进行采集)。
我们可以自动调整每位任务分配的云节点数,以更合理有效借助云节点。例如,给紧急的任务多分配一些云节点,提高任务优先级,以便在更短时间内完成紧急任务的数据采集。
调整后的节点数常年有效,再次启动或复制/导入导入任务,也无需重新设置节点数。
1、云节点分配入口
节点数的调整位置有三处:分别是客户端内的任务列表,官网的用户中心,团队协作管理平台。
a. 客户端内的任务列表(推荐)
点击【我的任务】进入任务列表。找到最右边的【更多操作】,点击【...】,鼠标联通到【云采集】上,再联通到【分配资源】上,然后点击它。
最后在弹窗中设置该任务的最大可用节点。
b. 官网的用户中心
在官网登陆,进入用户中心后,点击【任务和云节点管理】即可跳转到任务管理页面。找到所须要调整的任务,点击【修改】,然后在弹窗中更改云节点的数目。
c. 团队协作管理平台
团队协作管理平台的操作权限默认关掉,如有须要可找对接的商务和专属技术支持免费开通。团队协作管理平台登陆入口: 操作说明:
登录团队协作管理平台后,点击【任务管理】,进入任务列表。找到最右边的【更多操作】,点击【...】,鼠标联通到【云采集】上,再联通到【分配资源】上,然后点击它。
最后在弹窗中设置该任务的任务占用节点。
2、云节点分配原则
根据云采集加速原理可知:任务能分拆的子任务越大,能同时执行云采集的云节点越多,采集的速率就越快。在实际采集过程中,账号内云节点的数目是有限的,也就是说,云采集速度的快慢,主要由当前在采集的子任务数决定,此数值越大,采集越快。
如何查看每位任务正在运行的子任务数?
通过 云采集实况功能,可查看子任务的分拆和运行情况:
如何得悉帐号正在运行的云节点数?
在【我的任务】界面,【云采集状态】中筛选出全部的【运行中】任务,依次查看每位任务的 云采集实况,然后将每位任务的【运行中】子任务数相乘,即可得到当前时间帐号有多少个云节点正在采集数据。
云节点分配原则:
a. 最大可用节点数不小于任务的已分拆子任务数。如默认已拆分子任务数是10,那它最多同时使用10个云节点,就算分配了20个,它也用不上全部的。多余的节点会手动给其他任务。
b. 云采集实际运行速率,取决于运行中的子任务数。如某任务设置的最大可用节点数是5,运行中的子任务数是5,等待中的子任务数是0。此时是通过调整最大可用节点数是难以提高任务的采集速度。因为任务全部子任务都已启动了采集。但若果运行子任务数5,等待子任务数为7。此时希望它运行快些,可调大最大可用节点数,此时调整成12即可(云节点占有量
c. 一般而言,在帐号内空闲节点充足的情况,建议给某个任务设置最大可用节点数为已分拆子任务数的50%~100%。账号内空闲节点十分紧张的情况,每个任务的最大可用节点数=账号总节点/同时运行任务数。这样会相对均衡,让每位任务都能有一定量的节点来采集数据。
d. 已经分配出去的云节点,完成该子任务的采集之后,才会被回收到帐号中供其他任务使用。如:任务A的最大可用节点数是30,启动云采集后,这30个节点都在进行采集(即该任务运行中的子任务数是30)。随后又想增加任务A的云节点,分配一些节点给任务B使用。此时将任务A的最大可用节点数调成10个,那20个节点并不会马上转给任务B使用。而是继续运行任务A的子任务,该子任务完成后,才会转给任务B使用。
特殊情况说明:
1、有时可能出现所有运行中的子任务数之和大于帐号节点数。所有的云节点都分配出去,并且 等待中子任务数+运行中子任务数>账号节点数。
原因:实际上节点是早已占用满了。但因为子任务分配节点的时间小于节点完成采集的时间,所以在查询的顿时会出现节点用不满的表象。
举个事例,任务A的每个子任务只须要10秒就可以完成采集,但每位子任务分配上云节点并启动须要耗费20秒。故在查询的顿时都会出在采集的节点少,分配并启动的多。而我们的【运行中子任务数】,只是查询并显示正在采集过程中的,那类分配并启动中的不会查询到。故看起来象是节点用不满。
2、启动云采集后,【运行中】没有听到这个任务。
原因① :查看过快。任务在启动后,服务器须要先对任务进行预处理,判断能不能分拆,能分拆的执行分拆程序,然后分配云节点来执行子任务。这些过程会花费些时间,如果立刻查看,在【运行中】是看不到的,但在【等待运行】里可以看见。稍等一会后,就可以在【运行中】查看到了。
原因②:查看得很晚了,任务已经完成采集。此时可以在【完成中】可查看。 查看全部
本教程将介绍私有云套餐,并讲解怎样查看/管理帐号下的云采集节点,优化分配策略,提高采集效率。
一、私有云基本介绍
私有云是优采云SaaS版本中的最高版本。私有云处于特定集群,拥有固定的云节点数,通常为30个或100个。
而旗舰/旗舰+版,则处于公共集群,其节点数是浮动变化的,所有旗舰/旗舰+用户一起角逐节点的使用权。
二、私有云可自动调整每位任务的云节点数
私有云帐号下的每位任务,云采集的最大可用节点数,默认为2(即每位任务最多有2个云节点同时进行采集)。
我们可以自动调整每位任务分配的云节点数,以更合理有效借助云节点。例如,给紧急的任务多分配一些云节点,提高任务优先级,以便在更短时间内完成紧急任务的数据采集。
调整后的节点数常年有效,再次启动或复制/导入导入任务,也无需重新设置节点数。
1、云节点分配入口
节点数的调整位置有三处:分别是客户端内的任务列表,官网的用户中心,团队协作管理平台。
a. 客户端内的任务列表(推荐)
点击【我的任务】进入任务列表。找到最右边的【更多操作】,点击【...】,鼠标联通到【云采集】上,再联通到【分配资源】上,然后点击它。
最后在弹窗中设置该任务的最大可用节点。
b. 官网的用户中心
在官网登陆,进入用户中心后,点击【任务和云节点管理】即可跳转到任务管理页面。找到所须要调整的任务,点击【修改】,然后在弹窗中更改云节点的数目。
c. 团队协作管理平台
团队协作管理平台的操作权限默认关掉,如有须要可找对接的商务和专属技术支持免费开通。团队协作管理平台登陆入口: 操作说明:
登录团队协作管理平台后,点击【任务管理】,进入任务列表。找到最右边的【更多操作】,点击【...】,鼠标联通到【云采集】上,再联通到【分配资源】上,然后点击它。
最后在弹窗中设置该任务的任务占用节点。
2、云节点分配原则
根据云采集加速原理可知:任务能分拆的子任务越大,能同时执行云采集的云节点越多,采集的速率就越快。在实际采集过程中,账号内云节点的数目是有限的,也就是说,云采集速度的快慢,主要由当前在采集的子任务数决定,此数值越大,采集越快。
如何查看每位任务正在运行的子任务数?
通过 云采集实况功能,可查看子任务的分拆和运行情况:
如何得悉帐号正在运行的云节点数?
在【我的任务】界面,【云采集状态】中筛选出全部的【运行中】任务,依次查看每位任务的 云采集实况,然后将每位任务的【运行中】子任务数相乘,即可得到当前时间帐号有多少个云节点正在采集数据。
云节点分配原则:
a. 最大可用节点数不小于任务的已分拆子任务数。如默认已拆分子任务数是10,那它最多同时使用10个云节点,就算分配了20个,它也用不上全部的。多余的节点会手动给其他任务。
b. 云采集实际运行速率,取决于运行中的子任务数。如某任务设置的最大可用节点数是5,运行中的子任务数是5,等待中的子任务数是0。此时是通过调整最大可用节点数是难以提高任务的采集速度。因为任务全部子任务都已启动了采集。但若果运行子任务数5,等待子任务数为7。此时希望它运行快些,可调大最大可用节点数,此时调整成12即可(云节点占有量
c. 一般而言,在帐号内空闲节点充足的情况,建议给某个任务设置最大可用节点数为已分拆子任务数的50%~100%。账号内空闲节点十分紧张的情况,每个任务的最大可用节点数=账号总节点/同时运行任务数。这样会相对均衡,让每位任务都能有一定量的节点来采集数据。
d. 已经分配出去的云节点,完成该子任务的采集之后,才会被回收到帐号中供其他任务使用。如:任务A的最大可用节点数是30,启动云采集后,这30个节点都在进行采集(即该任务运行中的子任务数是30)。随后又想增加任务A的云节点,分配一些节点给任务B使用。此时将任务A的最大可用节点数调成10个,那20个节点并不会马上转给任务B使用。而是继续运行任务A的子任务,该子任务完成后,才会转给任务B使用。
特殊情况说明:
1、有时可能出现所有运行中的子任务数之和大于帐号节点数。所有的云节点都分配出去,并且 等待中子任务数+运行中子任务数>账号节点数。
原因:实际上节点是早已占用满了。但因为子任务分配节点的时间小于节点完成采集的时间,所以在查询的顿时会出现节点用不满的表象。
举个事例,任务A的每个子任务只须要10秒就可以完成采集,但每位子任务分配上云节点并启动须要耗费20秒。故在查询的顿时都会出在采集的节点少,分配并启动的多。而我们的【运行中子任务数】,只是查询并显示正在采集过程中的,那类分配并启动中的不会查询到。故看起来象是节点用不满。
2、启动云采集后,【运行中】没有听到这个任务。
原因① :查看过快。任务在启动后,服务器须要先对任务进行预处理,判断能不能分拆,能分拆的执行分拆程序,然后分配云节点来执行子任务。这些过程会花费些时间,如果立刻查看,在【运行中】是看不到的,但在【等待运行】里可以看见。稍等一会后,就可以在【运行中】查看到了。
原因②:查看得很晚了,任务已经完成采集。此时可以在【完成中】可查看。
优采云,国内领先的爬虫云采集工具平台,为许多小型公司,政府,提供数据服务
采集交流 • 优采云 发表了文章 • 0 个评论 • 414 次浏览 • 2020-08-11 13:03
这个就挺好理解,精通某一款主流的采集工具,比如说我们优采云采集器
需要精通到哪些程度?
1.如果你会用我们优采云与XPATH,定位网页任意元素
2.如果你晓得怎样优采云采集原理,懂得分拆规则,让整个采集效率翻10倍
3.其实没有天天使用我们优采云超过三个月以上,写过一两百个规则的,都不应当算精通吧
除以上两个工具层面熟悉外,还须要熟悉以下东西:
1.防采集原理(验证码,多IP等)
2.html后端解析知识
3.分布式解决方案
4.正则表达式匹配
基本上熟悉把握了以上这种技能,也差不多能成为一名合格,思路清晰的爬虫工程师了。写代码的有写代码的益处,用工具有用工具的益处,写代码的用处在于自由度比较大,挑战比较大,入门比较难,而且作用似乎不大,因为好多时侯虽然是在重复造轮子。
毕竟好多通用性的动作都是可以用爬虫工具完成的,功能爬虫工具都帮你做好了,你只要会用就行。而工具呢,工具仍然有一点点局限性,工具为了通用性,在一定程度是牺牲了个别功能的,在一些太特殊的场景,工具虽然很难完成。
所以我一向的推荐就是,工具+代码,才是一个现今主流的爬虫工程师的配置。你可以使用工具,比如我们优采云,实现那99%的需求,但若果遇见特定的,自已留一手写代码解决,也是无妨的。
毕竟我们要的是解决问题,更别说python等等,配置个爬虫程序一点都不难,网上教程一大把。(国内主流采集大神都是如此做,能用工具的优先用工具,除非工具搞不定,才自已码代码)
爬虫工程师的关联技能
除了须要懂采集外,爬虫工程师还须要一些其他的技能,这才是真正评判一名爬虫工程师是入门,还是普通,还是优秀的标准。其实在现今这个时代,复合型人才都是比较吃香的。
一个优秀的爬虫工程师,他还须要以下几项技术进行升华
1.数据清洗
因为采集下来的数据,很多时侯都是一大段文本,你须要对文本进行提炼,也就是我们说的对数据进行清洗,才能得到愈发干净的结构化数据,保存在数据库上面。
有时候我们采集多份数据,也须要通过清洗进行关联。这上面例如我们善于使用Excel的一些中级方法,也包括会使用R等程序语言,对文本进行处理。在我们优采云数据中心团队的朋友,都具备数据清洗的技能。
2.数据挖掘
爬虫后的数据挖掘,一般是指NLP这鬼东西。NLP是属于人工智能范筹的,中文叫自然语言处理,简单理解就是处理大量文本,从大量文本上面挖掘出价值的一个东西。
在国外能做好的,都是属于凤毛鳞角的,我们优采云也有我们自已的NLP团队,投入相当巨大,还没做得非常出众,仅仅开始实现一些特定场景功能,能做一些单子了。我们为国外一些主流的AI公司,采集并挖掘后,输出AI数据。我们的数据中心就有牛人专门干这个的。
3.数据剖析可视化
仅仅只是将数据采集下来,保存在数据库上面,仅仅只是实现第一步的价值。数据剖析与可视化,才是数据背后更大的价值。
所以须要对数据保存进数据库,然后通过相应的框架或程序开发,组织调用下来,辅助企业进行决策。所以我们优采云有专门的数据BI团队,也有好多爬虫工程师擅于使用EXCEL,一般可视化BI工具,为项目提供可视化数据支持。
4.深刻理解业务
无论是对互联网公开数据的获取能力的理解,还是对业务需求的理解,也是审视一个优秀的爬虫工程师的重要评判标准,说白了就是,不仅要懂技术,而且要懂业务,成为复合型的爬虫工程师。能到这个程度,才能将爬虫工程师的价值无限放大。比如理解风控业务,比如理解AI业务等。这个岗位我们有售前,有顾问等。
如何规划爬虫工程师的路线
在我的团队上面,是有L岗与T岗这两个路线的,L岗通常是指偏业务的爬虫工程师的岗位,T岗通常是指偏技术的爬虫工程师岗位,这跟人的性格有关,一些朋友更喜欢紧靠业务,表达能力好,反应快思路清晰,他都会往L岗走,一些朋友更偏向技术,狂热于突破各类困局,输出更好的解决方案,他都会往T岗走。
L岗通常有哪些职位
1.技术支持(中小顾客方向)
2.售前(大顾客方向)
3.数据中心Leader/项目Leader
4.方案顾问(深入业务场景)
T岗通常有哪些职位
1.爬虫项目一线开发交付人员
2.数据专员
3.中级数据专员
4.爬虫培训讲师
工作机会
如果你听到这儿,那证明你对爬虫是有兴趣的,以上职位我们均有在急聘,如果你是一个合格的爬虫工程师,或立志成为一名优秀的爬虫工程师,请将简历狠狠地砸过来吧!
优采云,国内领先的爬虫云采集工具平台,为许多小型公司,政府,提供数据服务,建立互联网数据资产库房,有兴趣做这件事的,我们私聊。 查看全部
2.工具方向
这个就挺好理解,精通某一款主流的采集工具,比如说我们优采云采集器
需要精通到哪些程度?
1.如果你会用我们优采云与XPATH,定位网页任意元素
2.如果你晓得怎样优采云采集原理,懂得分拆规则,让整个采集效率翻10倍
3.其实没有天天使用我们优采云超过三个月以上,写过一两百个规则的,都不应当算精通吧
除以上两个工具层面熟悉外,还须要熟悉以下东西:
1.防采集原理(验证码,多IP等)
2.html后端解析知识
3.分布式解决方案
4.正则表达式匹配
基本上熟悉把握了以上这种技能,也差不多能成为一名合格,思路清晰的爬虫工程师了。写代码的有写代码的益处,用工具有用工具的益处,写代码的用处在于自由度比较大,挑战比较大,入门比较难,而且作用似乎不大,因为好多时侯虽然是在重复造轮子。
毕竟好多通用性的动作都是可以用爬虫工具完成的,功能爬虫工具都帮你做好了,你只要会用就行。而工具呢,工具仍然有一点点局限性,工具为了通用性,在一定程度是牺牲了个别功能的,在一些太特殊的场景,工具虽然很难完成。
所以我一向的推荐就是,工具+代码,才是一个现今主流的爬虫工程师的配置。你可以使用工具,比如我们优采云,实现那99%的需求,但若果遇见特定的,自已留一手写代码解决,也是无妨的。
毕竟我们要的是解决问题,更别说python等等,配置个爬虫程序一点都不难,网上教程一大把。(国内主流采集大神都是如此做,能用工具的优先用工具,除非工具搞不定,才自已码代码)
爬虫工程师的关联技能
除了须要懂采集外,爬虫工程师还须要一些其他的技能,这才是真正评判一名爬虫工程师是入门,还是普通,还是优秀的标准。其实在现今这个时代,复合型人才都是比较吃香的。
一个优秀的爬虫工程师,他还须要以下几项技术进行升华
1.数据清洗
因为采集下来的数据,很多时侯都是一大段文本,你须要对文本进行提炼,也就是我们说的对数据进行清洗,才能得到愈发干净的结构化数据,保存在数据库上面。
有时候我们采集多份数据,也须要通过清洗进行关联。这上面例如我们善于使用Excel的一些中级方法,也包括会使用R等程序语言,对文本进行处理。在我们优采云数据中心团队的朋友,都具备数据清洗的技能。
2.数据挖掘
爬虫后的数据挖掘,一般是指NLP这鬼东西。NLP是属于人工智能范筹的,中文叫自然语言处理,简单理解就是处理大量文本,从大量文本上面挖掘出价值的一个东西。
在国外能做好的,都是属于凤毛鳞角的,我们优采云也有我们自已的NLP团队,投入相当巨大,还没做得非常出众,仅仅开始实现一些特定场景功能,能做一些单子了。我们为国外一些主流的AI公司,采集并挖掘后,输出AI数据。我们的数据中心就有牛人专门干这个的。
3.数据剖析可视化
仅仅只是将数据采集下来,保存在数据库上面,仅仅只是实现第一步的价值。数据剖析与可视化,才是数据背后更大的价值。
所以须要对数据保存进数据库,然后通过相应的框架或程序开发,组织调用下来,辅助企业进行决策。所以我们优采云有专门的数据BI团队,也有好多爬虫工程师擅于使用EXCEL,一般可视化BI工具,为项目提供可视化数据支持。
4.深刻理解业务
无论是对互联网公开数据的获取能力的理解,还是对业务需求的理解,也是审视一个优秀的爬虫工程师的重要评判标准,说白了就是,不仅要懂技术,而且要懂业务,成为复合型的爬虫工程师。能到这个程度,才能将爬虫工程师的价值无限放大。比如理解风控业务,比如理解AI业务等。这个岗位我们有售前,有顾问等。
如何规划爬虫工程师的路线
在我的团队上面,是有L岗与T岗这两个路线的,L岗通常是指偏业务的爬虫工程师的岗位,T岗通常是指偏技术的爬虫工程师岗位,这跟人的性格有关,一些朋友更喜欢紧靠业务,表达能力好,反应快思路清晰,他都会往L岗走,一些朋友更偏向技术,狂热于突破各类困局,输出更好的解决方案,他都会往T岗走。
L岗通常有哪些职位
1.技术支持(中小顾客方向)
2.售前(大顾客方向)
3.数据中心Leader/项目Leader
4.方案顾问(深入业务场景)
T岗通常有哪些职位
1.爬虫项目一线开发交付人员
2.数据专员
3.中级数据专员
4.爬虫培训讲师
工作机会
如果你听到这儿,那证明你对爬虫是有兴趣的,以上职位我们均有在急聘,如果你是一个合格的爬虫工程师,或立志成为一名优秀的爬虫工程师,请将简历狠狠地砸过来吧!
优采云,国内领先的爬虫云采集工具平台,为许多小型公司,政府,提供数据服务,建立互联网数据资产库房,有兴趣做这件事的,我们私聊。
大鹏教你python数据剖析
采集交流 • 优采云 发表了文章 • 0 个评论 • 222 次浏览 • 2020-08-11 03:21
出差中…………,换pc了,没有开发环境,看看其他口味的课程
数据工作流
抛出问题——数据——数据研究——问题推论——解决方案
用py
用py来剖析数据,结合好多包,py类比手机,安装不同app就是安装不同的包
知道2利器,优采云,Gephi。数据采集与剖析
优采云简单教程:
A、网址辨识
(*)强大的变量,和bs4一样,唯一定位即可
原理:超链接
1、1级网址辨识,(启始网址,然后上面找)
2、2级网址辨识(启始网址多个,然后上面找,收录规则,不收录规则),(*)通配所有,要不收录
B、数据标签及数据清洗
点击网址,去原网页找须要标签
设置格式文件
自己爬虫效率更高,不要三方各类调用
数据处理
有价值信息数据是采集不到的,大公司有专门网路工程师,不会给你机会滴! 我认为有没有用看你来干啥,所以叫数据挖掘
python数据结构
标量123,变量abc
python路劲写法
哎,调库侠,好多库啊
Python爬虫防封杀方式集合
转:附加采集工具对比
本人也算是个采集器小白,之前研究过一段时间的优采云,不过还是比较青涩。今天和你们分享几款采集器及它们的特征:
1.优采云采集器:
一款互联网数据抓取、处理、分析,挖掘软件,可以抓取网页上散乱分布的数据信息,并通过一系列的剖析处理,准确挖掘出所需数据。
特点:采集不限网页,不限内容;
分布式采集系统,提高效率;
支持PHP和C#插件扩充,方便更改处理数据。
2.优采云云采集:
一款新颖的云端在线智能爬虫/采集器,基于优采云分布式云爬虫框架,帮助用户快速获取大量规范化的网页数据,帮助顾客快速轻松地获取大量规范化数据。
特点:直接接入代理IP,无需设置便可防止因IP被限制访问引起的难以采集的问题;
自动登入验证码识别,网站自动完成验证码输入,无需人工看管;
可在线生成图标,采集结果以丰富表格化方式诠释;
本地化隐私保护,云端采集,可隐藏用户IP。
3.优采云采集器:
一套专业的网站内容采集软件,支持各种峰会的贴子和回复采集,网站和博客文章内容抓取,分峰会采集器、CMS采集器和博客采集器三类。
特点:支持对文章内容中的文字、链接批量替换和过滤;
可以同时向网站或峰会的多个版块一起批量发帖;
具备采集或发贴任务完成后自动关机功能;
4.三人行采集器:
一套可以把他人网站、论坛、博客的图文内容轻松采集到自己的网站、论坛和博客的站长工具,包括峰会注册王、采集发帖王和采集搬家王三类软件。
特点:以采集需要注册登录后才会查看的峰会贴子;(强)
可以同时向峰会的多个版块一起批量发帖;
支持对文章内容中的文字、链接批量替换和过滤。
5.集搜客:
一款简单易用的网页信息抓取软件,能够抓取网页文字、图表、超链接等多种网页元素,提供好用的网页抓取软件、数据挖掘功略、行业资讯和前沿科技等。
特点:可以抓取手机网站上的数据;
支持抓取在指数图表上漂浮显示的数据;
会员互助抓取,提升采集效率。
6.优采云采集器:
一款网页采集软件,可以从不同的网站获取规范化数据,帮助顾客实现数据自动化采集,编辑,规范化,从而减少成本,提高效率。
特点:容易上手,完全可视化图形操作;
内置可扩充的OCR插口,支持解析图片中的文字;
采集任务手动运行,可以根据指定的周期手动采集。 查看全部
出差中…………,换pc了,没有开发环境,看看其他口味的课程
数据工作流
抛出问题——数据——数据研究——问题推论——解决方案
用py
用py来剖析数据,结合好多包,py类比手机,安装不同app就是安装不同的包
知道2利器,优采云,Gephi。数据采集与剖析
优采云简单教程:
A、网址辨识
(*)强大的变量,和bs4一样,唯一定位即可
原理:超链接
1、1级网址辨识,(启始网址,然后上面找)
2、2级网址辨识(启始网址多个,然后上面找,收录规则,不收录规则),(*)通配所有,要不收录
B、数据标签及数据清洗
点击网址,去原网页找须要标签
设置格式文件
自己爬虫效率更高,不要三方各类调用
数据处理
有价值信息数据是采集不到的,大公司有专门网路工程师,不会给你机会滴! 我认为有没有用看你来干啥,所以叫数据挖掘
python数据结构
标量123,变量abc
python路劲写法
哎,调库侠,好多库啊
Python爬虫防封杀方式集合
转:附加采集工具对比
本人也算是个采集器小白,之前研究过一段时间的优采云,不过还是比较青涩。今天和你们分享几款采集器及它们的特征:
1.优采云采集器:
一款互联网数据抓取、处理、分析,挖掘软件,可以抓取网页上散乱分布的数据信息,并通过一系列的剖析处理,准确挖掘出所需数据。
特点:采集不限网页,不限内容;
分布式采集系统,提高效率;
支持PHP和C#插件扩充,方便更改处理数据。
2.优采云云采集:
一款新颖的云端在线智能爬虫/采集器,基于优采云分布式云爬虫框架,帮助用户快速获取大量规范化的网页数据,帮助顾客快速轻松地获取大量规范化数据。
特点:直接接入代理IP,无需设置便可防止因IP被限制访问引起的难以采集的问题;
自动登入验证码识别,网站自动完成验证码输入,无需人工看管;
可在线生成图标,采集结果以丰富表格化方式诠释;
本地化隐私保护,云端采集,可隐藏用户IP。
3.优采云采集器:
一套专业的网站内容采集软件,支持各种峰会的贴子和回复采集,网站和博客文章内容抓取,分峰会采集器、CMS采集器和博客采集器三类。
特点:支持对文章内容中的文字、链接批量替换和过滤;
可以同时向网站或峰会的多个版块一起批量发帖;
具备采集或发贴任务完成后自动关机功能;
4.三人行采集器:
一套可以把他人网站、论坛、博客的图文内容轻松采集到自己的网站、论坛和博客的站长工具,包括峰会注册王、采集发帖王和采集搬家王三类软件。
特点:以采集需要注册登录后才会查看的峰会贴子;(强)
可以同时向峰会的多个版块一起批量发帖;
支持对文章内容中的文字、链接批量替换和过滤。
5.集搜客:
一款简单易用的网页信息抓取软件,能够抓取网页文字、图表、超链接等多种网页元素,提供好用的网页抓取软件、数据挖掘功略、行业资讯和前沿科技等。
特点:可以抓取手机网站上的数据;
支持抓取在指数图表上漂浮显示的数据;
会员互助抓取,提升采集效率。
6.优采云采集器:
一款网页采集软件,可以从不同的网站获取规范化数据,帮助顾客实现数据自动化采集,编辑,规范化,从而减少成本,提高效率。
特点:容易上手,完全可视化图形操作;
内置可扩充的OCR插口,支持解析图片中的文字;
采集任务手动运行,可以根据指定的周期手动采集。
Mac上有没有类似优采云的数据采集软件?
采集交流 • 优采云 发表了文章 • 0 个评论 • 365 次浏览 • 2020-08-11 01:52
优采云面向开发者,拥有技术基础的朋友可以大显身手,实现十分强悍的网路爬虫。
没有开发经验的小白朋友一开始可能认为不容易上手,不过好在她们提供了官方云爬虫市场,可以零基础直接使用。
造数是网页点选操作流程,小白用户易上手和理解,具有非常好的可视化操作过程。就是有点慢呐!在我写这篇回答又上了个公厕的几十分钟里,尝试采集了一个网站,结果还没下来 -_-||
@小小造数君
在线网路爬虫/大数据剖析/机器学习开发平台-优采云云
造数 - 新一代智能云爬虫 - 控制面板dashboard.zaoshu.io
另一种就是使用支持MAC系统的采集器软件,目前只有优采云采集器和集搜客支持。
优采云采集器_真免费!导出无限制网路爬虫软件_人工智能数据采集软件
免费下载网页抓取软件,专业网路爬虫,写论文采数据工具-集搜客GooSeeker
那么,这些备选项里该怎么选择呢?
1、免费不花钱,不需要积分的
(这里说的免费功能包括采集数据、导出各类格式的数据到本地,下载图片到本地等采集数据所必备的基本功能):
你可以选择优采云云爬虫和优采云采集器
(造数官方没有找到是否收费的具体说明,但是有提及:“造数计费单位是“次”,1次爬取指的是:成功爬取1个网页并获得数据。”,所以我理解她们不是免费的)
这三者上面,我推荐你使用优采云采集器,因为我目测楼主虽然没有编程基础,
但是若果优采云云市场中有你须要的采集的网站的采集规则,而且也刚好是免费的(优采云云爬虫市场有官方的采集规则也有开发者上传的采集规则),那么你可以尝试一下优采云云爬虫。
2、不差钱,关键是喜欢
那么可以尝试使用优采云采集器和集搜客,然后从二者上面选购一个自己喜欢的。
用户体验和性价比这些东西还是要自己用一下比较好,萝卜青椒各有所爱么。 查看全部
一种是使用基于Web的云端采集系统,目前有优采云云爬虫和造数,这种基于Web端的网路爬虫工具,没有操作系统限制。别说是要在MAC上抓取数据,你就是手机上都没有问题。
优采云面向开发者,拥有技术基础的朋友可以大显身手,实现十分强悍的网路爬虫。
没有开发经验的小白朋友一开始可能认为不容易上手,不过好在她们提供了官方云爬虫市场,可以零基础直接使用。
造数是网页点选操作流程,小白用户易上手和理解,具有非常好的可视化操作过程。就是有点慢呐!在我写这篇回答又上了个公厕的几十分钟里,尝试采集了一个网站,结果还没下来 -_-||
@小小造数君
在线网路爬虫/大数据剖析/机器学习开发平台-优采云云
造数 - 新一代智能云爬虫 - 控制面板dashboard.zaoshu.io
另一种就是使用支持MAC系统的采集器软件,目前只有优采云采集器和集搜客支持。
优采云采集器_真免费!导出无限制网路爬虫软件_人工智能数据采集软件
免费下载网页抓取软件,专业网路爬虫,写论文采数据工具-集搜客GooSeeker
那么,这些备选项里该怎么选择呢?
1、免费不花钱,不需要积分的
(这里说的免费功能包括采集数据、导出各类格式的数据到本地,下载图片到本地等采集数据所必备的基本功能):
你可以选择优采云云爬虫和优采云采集器
(造数官方没有找到是否收费的具体说明,但是有提及:“造数计费单位是“次”,1次爬取指的是:成功爬取1个网页并获得数据。”,所以我理解她们不是免费的)
这三者上面,我推荐你使用优采云采集器,因为我目测楼主虽然没有编程基础,
但是若果优采云云市场中有你须要的采集的网站的采集规则,而且也刚好是免费的(优采云云爬虫市场有官方的采集规则也有开发者上传的采集规则),那么你可以尝试一下优采云云爬虫。
2、不差钱,关键是喜欢
那么可以尝试使用优采云采集器和集搜客,然后从二者上面选购一个自己喜欢的。
用户体验和性价比这些东西还是要自己用一下比较好,萝卜青椒各有所爱么。
合肥乐维信息技术有限公司
采集交流 • 优采云 发表了文章 • 0 个评论 • 136 次浏览 • 2020-08-10 22:47
让网站数据, 所见即所得
无论是国外网站, 还是美国网站, 只要有您想要的网站数据, 您都可以交给优采云采集器来帮您采集处理, 经过多年采集程序的构建,优采云采集器现已做到兼容95%以上的网站, 稳居国外采集行业第一!
全程自动化, 解放手掌
您只须要通过4大步骤来对采集器进行采集配置, 接下来的事情就可以全程交给优采云采集器去处理啦, 您只须要坐收数据即可, 早点结束人工自动复制来,粘贴去的沉闷工作方式吧!
操作方便易上手, 教程全面且丰富
仅需四步, 即可轻松完成对采集器的采集规则配置, 而且官方还有大量教程文档和视频教程, 更重要的是, 还有一群优秀采集高手作为售后支持,为您的数据采集道路保驾护航!
多种数据保存方式, 让数据为你所用
您可以将采集回来的数据, 保存至Word, Excel, Txt等本地文件中, 也可以将数据立刻发布至您的线上网站, 甚至于,您还可以定义发布扩充, 将数据保存到任何您想保存的地方!
独特插件机制, 让数据更有型
为满足顾客对数据不同程度的个性化需求, 优采云集采器已经为 "采集"与 "发布" 两大模块提供插件支持, 您可以使用PHP语言或C#语言来对"采集","发布"模块进行细节控制!
网站发布模块, 应有尽有
优采云采集器现已集成绝大部分国内外主流CMS, 论坛, 商城, 问答等各种开源系统的发布模块, 若您的网站是自己团队独立开发,并非网上下载的开源程序, 您也不用害怕, 您可以为您的网站开发专属发布模块!
更多功能等您探求
优采云采集器还有更多实用功能, 如: HTTP二级代理服务器, OCR验证码识别, HTTP模拟恳求工具, 中文动词处理, 正文提取,计划任务管理器, 远程控制采集器, 资源库..., 欢迎您来探求! 查看全部
功能介绍
让网站数据, 所见即所得
无论是国外网站, 还是美国网站, 只要有您想要的网站数据, 您都可以交给优采云采集器来帮您采集处理, 经过多年采集程序的构建,优采云采集器现已做到兼容95%以上的网站, 稳居国外采集行业第一!
全程自动化, 解放手掌
您只须要通过4大步骤来对采集器进行采集配置, 接下来的事情就可以全程交给优采云采集器去处理啦, 您只须要坐收数据即可, 早点结束人工自动复制来,粘贴去的沉闷工作方式吧!
操作方便易上手, 教程全面且丰富
仅需四步, 即可轻松完成对采集器的采集规则配置, 而且官方还有大量教程文档和视频教程, 更重要的是, 还有一群优秀采集高手作为售后支持,为您的数据采集道路保驾护航!
多种数据保存方式, 让数据为你所用
您可以将采集回来的数据, 保存至Word, Excel, Txt等本地文件中, 也可以将数据立刻发布至您的线上网站, 甚至于,您还可以定义发布扩充, 将数据保存到任何您想保存的地方!
独特插件机制, 让数据更有型
为满足顾客对数据不同程度的个性化需求, 优采云集采器已经为 "采集"与 "发布" 两大模块提供插件支持, 您可以使用PHP语言或C#语言来对"采集","发布"模块进行细节控制!
网站发布模块, 应有尽有
优采云采集器现已集成绝大部分国内外主流CMS, 论坛, 商城, 问答等各种开源系统的发布模块, 若您的网站是自己团队独立开发,并非网上下载的开源程序, 您也不用害怕, 您可以为您的网站开发专属发布模块!
更多功能等您探求
优采云采集器还有更多实用功能, 如: HTTP二级代理服务器, OCR验证码识别, HTTP模拟恳求工具, 中文动词处理, 正文提取,计划任务管理器, 远程控制采集器, 资源库..., 欢迎您来探求!
云采集实况与历史运行记录
采集交流 • 优采云 发表了文章 • 0 个评论 • 731 次浏览 • 2020-08-10 07:42
任务正在运行云采集的时侯,可以查看当前运行详情;任务运行了多次云采集的时侯,可以查看历史运行记录。
使用版本限制
云采集(旗舰版及以上版本)可使用此功能。
一、查看云采集详情
在任务列表,点击任务云采集的【详情】,进入该任务当前的(任务正在运行)或者近来一次的(任务运行完成)云采集详情页面,查看任务概览、子任务、运行任务日志和运行子任务。
1、任务概览
任务云采集情况总括:任务状态(运行中、已停止、已完成)、采集进度(进度条)、开始时间、结束时间、耗时、采集数据量、消耗代理IP、消耗验证码、云节点占有量等。
2、子任务
子任务的当前情况。
3、运行任务日志
运行任务日志,记录任务运行云采集的详尽过程,实时把握运行情况:任务已启动、开始分拆任务、子任务创建完成、任务分拆完成、子任务[#1]等待执行、子任务[#1]开始执行、子任务[#1]已停止、子任务[#1]已完成等。
任务的云采集运行流程如下:
4、子任务信息
展示子任务运行的详尽情况:子任务序号、开始时间、结束时间、耗时、状态、总采集数据量(包括每次重启后采集的数据量累加)、当前采集数据量(重启后那一次采集到的数据量)。
① 序号与运行任务日志上面的子任务序号一一对应。
② 可按照子任务状态进行筛选,支持多选。
③ 展示子任务状态
已分拆:当前任务分拆成了多少个子任务。为1时,表示该任务未进行分拆(任务本身不支持分拆或勾选了云采集不分拆)。大于1时,表示已进行分拆。图中任务分拆成了100个子任务。
等待中:还未运行采集的子任务个数。
运行中:当前正在采集数据的子任务个数。每个任务会占用一个云节点,故所有任务在运行的子任务数之和大于等于帐号节点数。
已完成:已完成采集的子任务个数。
已停止:程序手动停止采集或人为自动停止采集的子任务个数。
注:
a. 支持对子任务进行停止、重启操作。子任务是【已完成】或【已停止】状态时,可点击【重启】让其重新进行采集。子任务重启后,主任务假如是【已完成】或【已停止】,也会弄成【运行中】。
b. 如果想要重启正在运行的子任务,需先点击【停止】,让子任务弄成【已停止】状态,再重启子任务。
二、云采集历史
在任务列表,点击任务两侧更多操作的【...】,点击【云采集】,再点击【查看云采集历史】,进入云采集历史运行记录页面。
1、云采集历史界面
云采集历史页面,记录任务运行云采集的历史次数,包括每次的批次、运行状态、开始时间、结束时间、耗时、本次采集量、操作等信息。
不同的版本可记录的最多次数不一样(旗舰10次;旗舰+20次;私有云100次)。可 点我马上升级,升级到更高版本。
2、查看采集数据
在云采集历史界面,点击【查看采集数据】,可查看每一次云采集采集到的数据,并才能导入当次所有数据。 查看全部
功能简介
任务正在运行云采集的时侯,可以查看当前运行详情;任务运行了多次云采集的时侯,可以查看历史运行记录。
使用版本限制
云采集(旗舰版及以上版本)可使用此功能。
一、查看云采集详情
在任务列表,点击任务云采集的【详情】,进入该任务当前的(任务正在运行)或者近来一次的(任务运行完成)云采集详情页面,查看任务概览、子任务、运行任务日志和运行子任务。
1、任务概览
任务云采集情况总括:任务状态(运行中、已停止、已完成)、采集进度(进度条)、开始时间、结束时间、耗时、采集数据量、消耗代理IP、消耗验证码、云节点占有量等。
2、子任务
子任务的当前情况。
3、运行任务日志
运行任务日志,记录任务运行云采集的详尽过程,实时把握运行情况:任务已启动、开始分拆任务、子任务创建完成、任务分拆完成、子任务[#1]等待执行、子任务[#1]开始执行、子任务[#1]已停止、子任务[#1]已完成等。
任务的云采集运行流程如下:
4、子任务信息
展示子任务运行的详尽情况:子任务序号、开始时间、结束时间、耗时、状态、总采集数据量(包括每次重启后采集的数据量累加)、当前采集数据量(重启后那一次采集到的数据量)。
① 序号与运行任务日志上面的子任务序号一一对应。
② 可按照子任务状态进行筛选,支持多选。
③ 展示子任务状态
已分拆:当前任务分拆成了多少个子任务。为1时,表示该任务未进行分拆(任务本身不支持分拆或勾选了云采集不分拆)。大于1时,表示已进行分拆。图中任务分拆成了100个子任务。
等待中:还未运行采集的子任务个数。
运行中:当前正在采集数据的子任务个数。每个任务会占用一个云节点,故所有任务在运行的子任务数之和大于等于帐号节点数。
已完成:已完成采集的子任务个数。
已停止:程序手动停止采集或人为自动停止采集的子任务个数。
注:
a. 支持对子任务进行停止、重启操作。子任务是【已完成】或【已停止】状态时,可点击【重启】让其重新进行采集。子任务重启后,主任务假如是【已完成】或【已停止】,也会弄成【运行中】。
b. 如果想要重启正在运行的子任务,需先点击【停止】,让子任务弄成【已停止】状态,再重启子任务。
二、云采集历史
在任务列表,点击任务两侧更多操作的【...】,点击【云采集】,再点击【查看云采集历史】,进入云采集历史运行记录页面。
1、云采集历史界面
云采集历史页面,记录任务运行云采集的历史次数,包括每次的批次、运行状态、开始时间、结束时间、耗时、本次采集量、操作等信息。
不同的版本可记录的最多次数不一样(旗舰10次;旗舰+20次;私有云100次)。可 点我马上升级,升级到更高版本。
2、查看采集数据
在云采集历史界面,点击【查看采集数据】,可查看每一次云采集采集到的数据,并才能导入当次所有数据。

