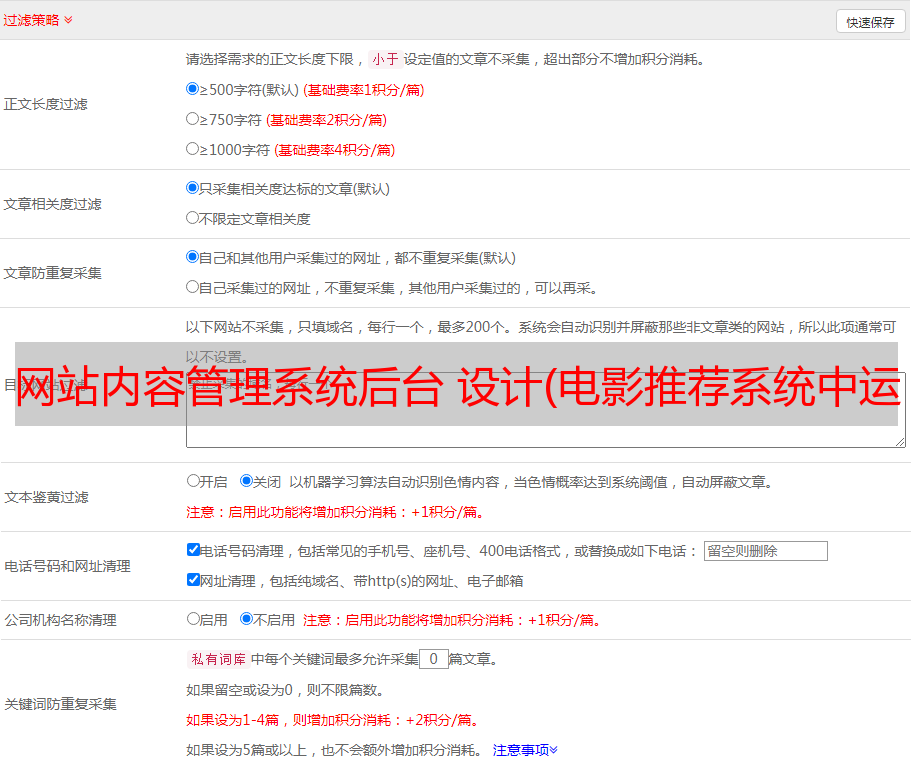
网站内容管理系统后台 设计(电影推荐系统中运用的协同过滤算法的推荐引擎Taste )
优采云 发布时间: 2021-10-11 04:05网站内容管理系统后台 设计(电影推荐系统中运用的协同过滤算法的推荐引擎Taste
)
相关信息
电影推荐系统中使用的推荐算法基于协同过滤算法(Collaborative Filtering Recommendation)。协同过滤正迅速成为信息过滤和信息系统中非常流行的技术。与传统的基于内容过滤进行推荐的内容直接分析不同,协同过滤分析用户兴趣,在用户群中找到指定用户的相似(兴趣)用户,并整合这些相似用户对某一信息的评价,形成系统为指定的用户预测对该信息的偏好程度。
推荐引擎Taste是Apache Mahout提供的协同过滤算法,在电影推荐系统中被引用。它实现了最基本的基于用户和基于内容的推荐算法,并提供了扩展接口,方便用户定义和实现自己的推荐。算法。
电影推荐系统是基于用户的推荐系统,即用户对某部电影进行评分后,系统根据用户对电影的评分判断用户的兴趣,首先利用UserSimilarity计算用户之间的相似度。UserNei*敏*感*词*orhood是根据用户相似度找到与用户口味相似的邻居,最后通过Recommender推荐用户可能感兴趣的电影详细信息。网页结果页显示用户已评分的电影信息和推荐给用户的电影信息,即完成推荐。
Taste的组织架构:
Taste的组织架构如下图所示:
应用层
-------------------------------------------------- -------------------------------
推荐系统层

-------------------------------------------------- -------------------------------------------------
数据存储层
Taste的组织*敏*感*词*
味道由以下五个主要组成部分组成:
DataModel:DataModel 是用户偏好信息的抽象接口。它的具体实现支持从任何类型的数据源中提取用户偏好信息。Taste默认提供了JDBCDataModel和FileDataModel,分别支持从数据库和文件中读取用户偏好信息。
UserSimilarity 和 ItemSimilarity:UserSimilarity 用于定义两个用户之间的相似度。它是基于协同过滤的推荐引擎的核心部分。它可以用来计算用户的“邻居”。这里我们将与当前用户品味相似的用户称为他的邻居。ItemSimilarity 是相似的,计算内容之间的相似度。
UserNei*敏*感*词*orhood:用于基于用户相似度的推荐方法。推荐内容是基于寻找与当前用户偏好相似的“邻居用户”生成的。UserNei*敏*感*词*orhood 定义了一种确定邻居用户的方法,具体实现一般是基于 UserSimilarity 计算的。
Recommender:Recommender是推荐引擎的抽象接口,是Taste的核心组件。程序中为其提供了一个DataModel,可以计算不同用户的推荐内容。在实际应用中,分别使用GenericUserBasedRecommender或GenericItemBasedRecommender实现基于用户相似度的推荐引擎或基于内容的推荐引擎。
电影推荐系统的实现:
1.资料下载:
转到 grouplens网站() 下载数据集。在这个电影系统中,我们使用了近 900 名用户对 1683 部电影的近 100,000 行数据集进行了审查。取出下载的ml-data_0.zip中的乐谱数据和电影信息数据。将评级文件转换为类似于 csv 文件格式的文本文件。CSV是逗号分隔值文件(CommaSeparated value),一种用于存储数据的纯文本文件格式,文件名为 rating.TXT。可以用写字板打开,如图4.1:
图4.1 rating.txt*敏*感*词*
将电影数据文件转换为movies.xml 文件。可扩展标记语言 XML 是一种简单的数据存储语言,它使用一系列简单的标签来描述数据。如4.2所示:
图4.2 movies.xml *敏*感*词*
2.运行
把上面两个文件放到C盘,加载web项目-movies,用Myeclipse运行。在首页输入用户ID和推荐电影数量countr。例如:输入用户 ID:500 计数:50.

全套毕业设计论文请查阅现成资料

