文章采集接口( 数据采集及自动处理流程(一)——采集接口定义21爬虫BT211待确认问题)
优采云 发布时间: 2021-10-09 21:10文章采集接口(
数据采集及自动处理流程(一)——采集接口定义21爬虫BT211待确认问题)
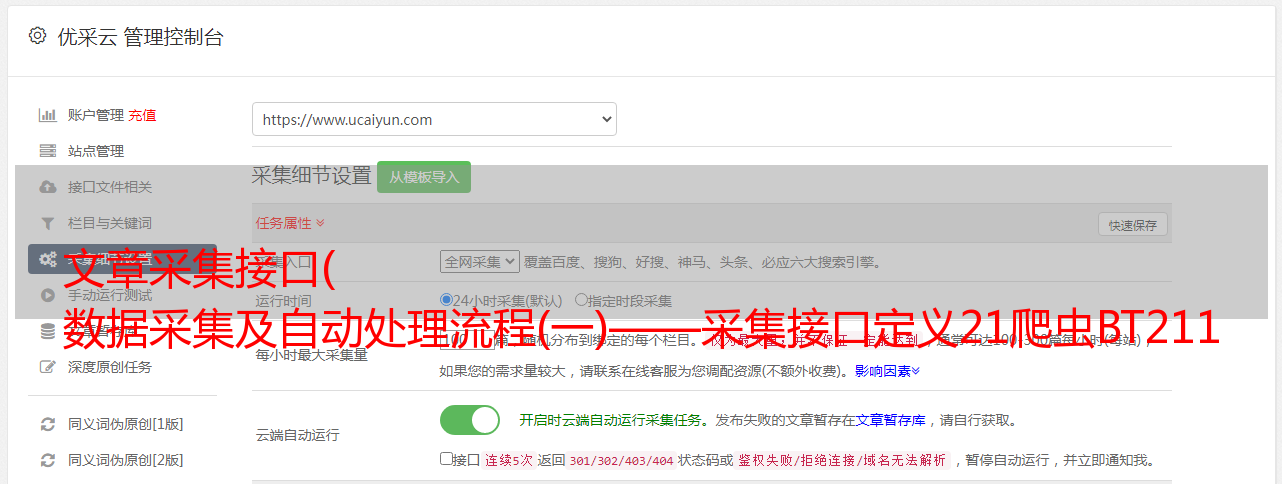
内容网络数据采集接口定义及自动处理流程[宝典]数据采集及自动处理流程 1 概述 本文主要介绍内容网络库的外部定义数据采集接口及采集数据的自动处理过程。通过对目前极速网的分析,我们认为数据的采集主要是通过人工爬取进行的。对于其他采集方法,虽然有建议和,但是我们在当前极速网后台没有找到对应的模块。希望网通相关人员通过阅读文档,及时补充我们采集接口的不足。对于我们下面设计的界面,希望界面与网通有关。人员可以提供测试数据给我们测试 2采集 接口定义 21 Crawler BT接口 211 问题待确认 因为我们在原速网后台没有找到该接口的设置接口,请向相关人员索取以下问题 答案 1 爬虫会爬取BT信息吗?2 如果爬虫会爬取BT信息,是否和HTTP爬取的信息一致?3 Bt爬虫爬取的数据和Bt active cache解析的数据有什么区别?基于以上问题,在没有得到网络相关人员回复的前提下,我们按照以下情况进行设计:1 爬虫会爬取 BT 信息 2 爬虫爬取的信息只收录资源信息 212 接口设计调用者爬虫系统爬取新数据时的调用频率 每次实时调用或每天定时调用,保证每次发送的信息是最新一批数据。输入参数contentscontenttypebtnamenameinfohashinfohashprotocolprotocolformatformatformatcnt_sizecnt_sizedutariondurationdata_ratedata_ratequalityqualitylanguagelanguageurlurlcontentcontents 输入参数详情如下: FORMAT文件格式18NAME名称用于完整性验证判断和去重2PR
我们根据以下条件设计爬虫对HTTP在线资源进行爬取。资源和数据信息不是同时进行的。完整性验证判断去重2PROTOCOL采集协议4LANGUAGE语言5CNT_SIZE大小6QUALITY质量7DATA_RATE码流10INFOHASHInfohash值判断去重11Duration回放时长12URL资源源完整性验证132222爬虫HTTP数据接口actorstvnametvname_hostauthor_hoststvnametvnameactor_hostauthor
nspanplaydateplaydatecountrycountrylanguagelanguagemovietypemovietypecontent_typecontent_typecommentscommentstagtagdescriptiondesprictionhposterhpostervpostervposteris_hotis_hotchildren_countchildren_countavg_marksavg_markscapture_sitecapture_sitechanneldocuments No. Field Name Description standard template job description job descriptions job descriptions 工作描述, 工作描述, 工作描述, 工作描述, 工作描述, 工作描述, 工作描述, 工作描述, 工作描述, 工作描述,人力资源,描述, 工作描述, 工作描述,人力资源,职位,描述,特别,职位描述,人力资源,描述, 工作描述, 工作描述,人力资源,描述, 工作描述, 工作描述,人力资源,职位,描述,特别,职位描述, 人力资源部(IP)2s情节描述是否HPOSTER横竖海报海报5VPOSTER 6IS_HOT热销7TAGTag栏8CHILDREN_COUNT子集数量9AUTHOR编剧10TV_NAME电视台名称11TV_HOST主持人12SPAN时长13播出时间COMMENTS评论14REC LANGUAGE电影语言FK15PLAYD7AC导演14影片上映日期 18 COUNTRY 地区类别 FK19 MOVIETYPE 影片类别 FK20CONTENT_TYPE 主题类别 FK21AVG@ksite_S 评分判断 22 分<capture_MARK_S> 是不是前 10 门户网站网站 频道可以用来区分是否有一系列的字段如24频道作者等主演的剧集数 3 自动处理流程 自动处理流程的目的是通过采集获取的数据,将系统的自动内容传递出去界面筛选自动内容质量控制自动内容发布功能完善数据库中的数据
降低手动编辑的质量。31 规则列表下方的表格定义了我们总结的筛选质量控制版本的规则。平台的规则引擎会根据以下规则自动处理数据。请根据实际情况确认这些规则。补充筛选规则 通过判断电影名称播放地址不为空来屏蔽数据垃圾数量。如果有空数据段,则将数据放入垃圾表进行处理。通过清空电影名称播放地址来屏蔽资源垃圾号。如果有数据段,将数据放入垃圾表处理资源。采集信息数据比较电影名称。如果有相同的数据,将数据放入垃圾表进行处理,数据内容不完整。采集信息资源对比播放地址infohash。如果数据相同,删除其中一条记录。使用电影名称的别名与元数据中的原创数据进行比较。例如,如果元数据数据具有相同的数据,则不会将数据添加到其中。在元数据库中,http通过播放地址进行比较,bt通过infohash值进入到元数据资源中,去除重复行,比如查找相同的记录。此资源状态更改为屏蔽并添加到元数据库中。如果在去重阶段没有找到相同的记录,则查找对应的影子绑定 设置库标题数据以查找资源进行绑定,反之亦然。资源数据是针对父子关系的,比如电视剧数据。如果库中没有子集数据,父子数据会自动生成子集数据供资源绑定审核规则使用,以确定每个字段中是否有关键词等*敏*感*词*词,如果有效性检查结果有效,则转入人工资源信息进行审核。一般资源是否属于前10个门户?发送 ping 以查看它是否有效。首先判断该信息是否属于前10个门户。网站 如果是直接数据内容校验,别名中的逗号会自动转成"",两边空格去掉。如果分数字段小于 5 分数会自动转换为 5 分或以上。如果分数是整数,则加上小数。对于导演和演员,每行前后的空格会自动删除。情节描述的第一行是空白的。2个空格被自动添加或删除。对于演员和导演
如果姓名不完整,比如张艺谋,但数据是张艺,查字典表,自动补全演员姓名。对于区域,如果区域为空,可以使用演员导演来计算是哪个区域。频道对应话剧电影,演员导演不能为空,如果对应的是*敏*感*词*,作者不能为空。如果对应的是综艺节目,那么主持人电视台不能为空。不符合规则,转人工审核。分销管理规则。根据资源的热度,搜索次数根据热度分为几个等级。结合各个站点的缓存情况的级别,发送给各个站点,例如将热度分为三个级别:高、正常、低。对于级别高的资源,所有站点都会下发到共享热资源的缓存空间。对于更多站点,热度较低的资源仅在本地交付。1 当发现某个资源的缓存进度已经比较低时,根据规则替换或删除缓存优化规则。2 当发现某个资源缓存过多时 下次根据资源缓存进度保留进度最高的资源。应删除其他资源缓存。3、当发现站点缓存空间不足时,应根据各个资源的热缓存情况进行资源清理。流程流程图资源在存储前会进行完整性检查和批量重复数据删除资源的可靠性审计等多个步骤,以确保进入元数据的资源是真实可用的。存储后,会定期调用审计规则查看库中的资源。数据是否满足审核条件,去除已经失效的链接,对满足发布条件的资源调用分布式管理机制,保证资源的最大利用率。重复数据删除、元数据重复数据删除等多重步骤确保元数据的元数据是唯一的,并且在存储之前会调用哪些审计规则。尝试提前更正错误的数据。储存后,将定期调用审计规则来检查数据库。数据的完整性和可靠性,部分数据的自动修正和修正,满足放行条件的材料放行

