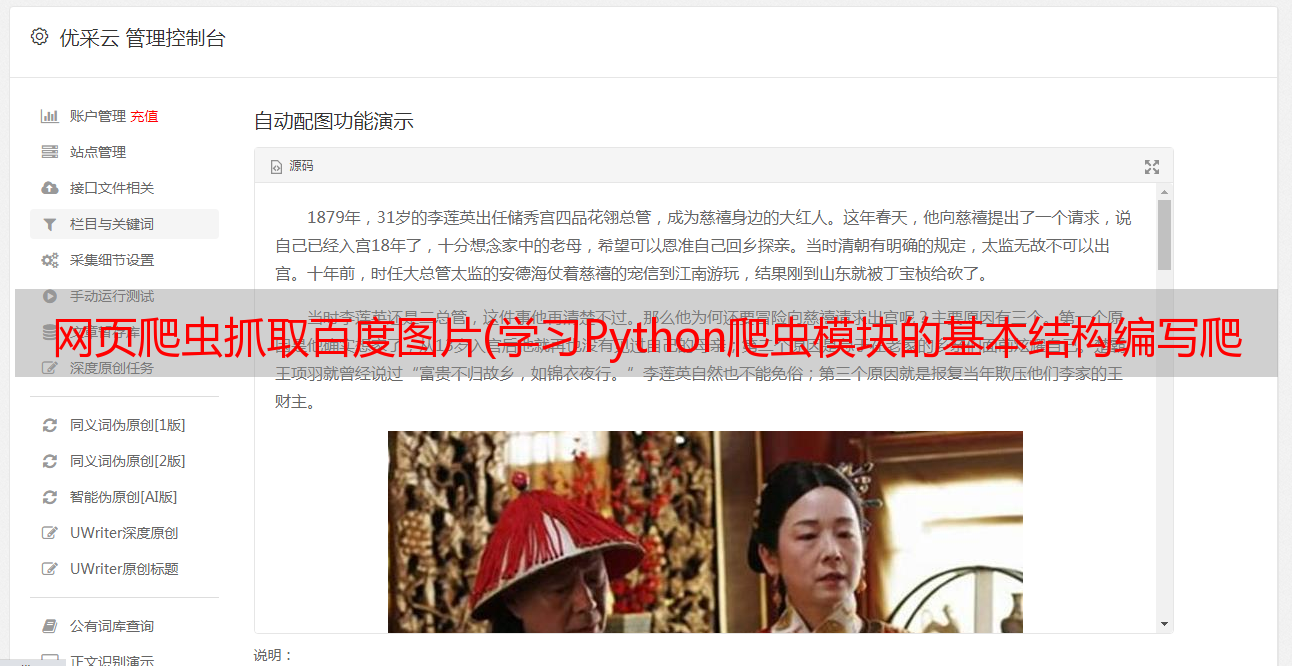
网页爬虫抓取百度图片(学习Python爬虫模块的基本结构编写爬虫程序的必备知识)
优采云 发布时间: 2021-10-01 18:09网页爬虫抓取百度图片(学习Python爬虫模块的基本结构编写爬虫程序的必备知识)
爬虫程序之所以能够抓取数据,是因为爬虫可以对网页进行分析,从网页中提取出想要的数据。在学习Python爬虫模块之前,我们有必要熟悉网页的基本结构,这是编写爬虫程序的必备知识。
网上的初步教程:这里
静态/动态的一个重要区别是是否需要连接后端数据库,
由于静态网页的内容比较固定,不需要连接后端数据库,响应速度非常快。但是静态网页更新比较麻烦,每次更新都需要重新加载整个网页。
动态页面利用“动态页面技术”与服务器交换少量数据,从而实现网页的异步加载。我们来看一个具体的例子:
打开百度图片(),搜索Python。当您滚动鼠标滚轮时,网页将自动从服务器数据库加载数据并呈现页面。这是动态网页和静态网页之间最基本的区别。如下:
除了 HTML 标记语言,动态网页还收录一些特定功能的代码。这些代码使浏览器和服务器能够交互。服务端会根据客户端的不同请求生成网页,涉及到数据库连接、访问、查询等一系列IO操作,因此响应速度比静态网页稍差。
注:一般网站通常采用动静结合的方式来达到平衡状态。
当然,动态网页也可以是纯文字,页面中还可以收录各种*敏*感*词*效果。这些只是网络内容的表达。其实不管网页有没有动态效果,只要使用了动态网站技术,那么这个网页就叫做动态网页。
\[问答\]
爬取动态网页的过程比较复杂,需要动态抓包获取客户端与服务器交互的JSON数据。抓包时可以使用谷歌浏览器开发者模式(快捷键:F12)Network选项,然后点击XHR找到获取JSON数据的URL,如下图:
或者你可以使用专业的抓包工具Fiddler。动态网页的数据抓取将在后续内容中详细讲解。
【网络爬虫学习】一个网页的基本结构
原来的:

