网页抓取数据百度百科(科学百科健康医疗分类的tagId分类(二))
优采云 发布时间: 2021-09-28 10:10网页抓取数据百度百科(科学百科健康医疗分类的tagId分类(二))
前言:为了满足我的强迫症,我有问答界面,没有数据怎么办,所以写了一个爬虫来爬取百度百科页面
注意:不用注意的是百度百科采用异步加载,比较麻烦
什么是异步加载?emmmmmmmmmmm的意思是可以在我们普通页面的源码中找到网页上显示的超链接。异步加载是不可用的。链接是放在源码里的,普通的方法肯定不行。,那他的链接到底是被捏在什么地方了?? ? ? ?
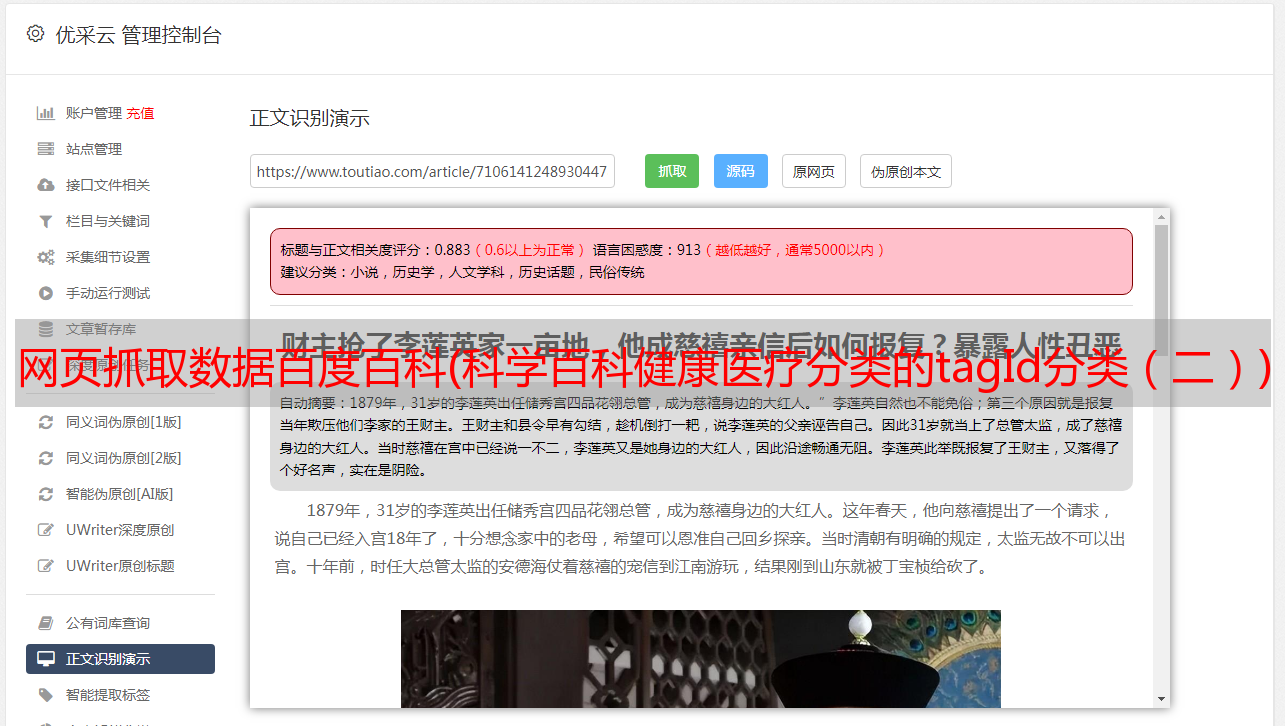
可以看到源码中没有与页面相关的url。
并且所有的url和入口信息都在另一个网站上
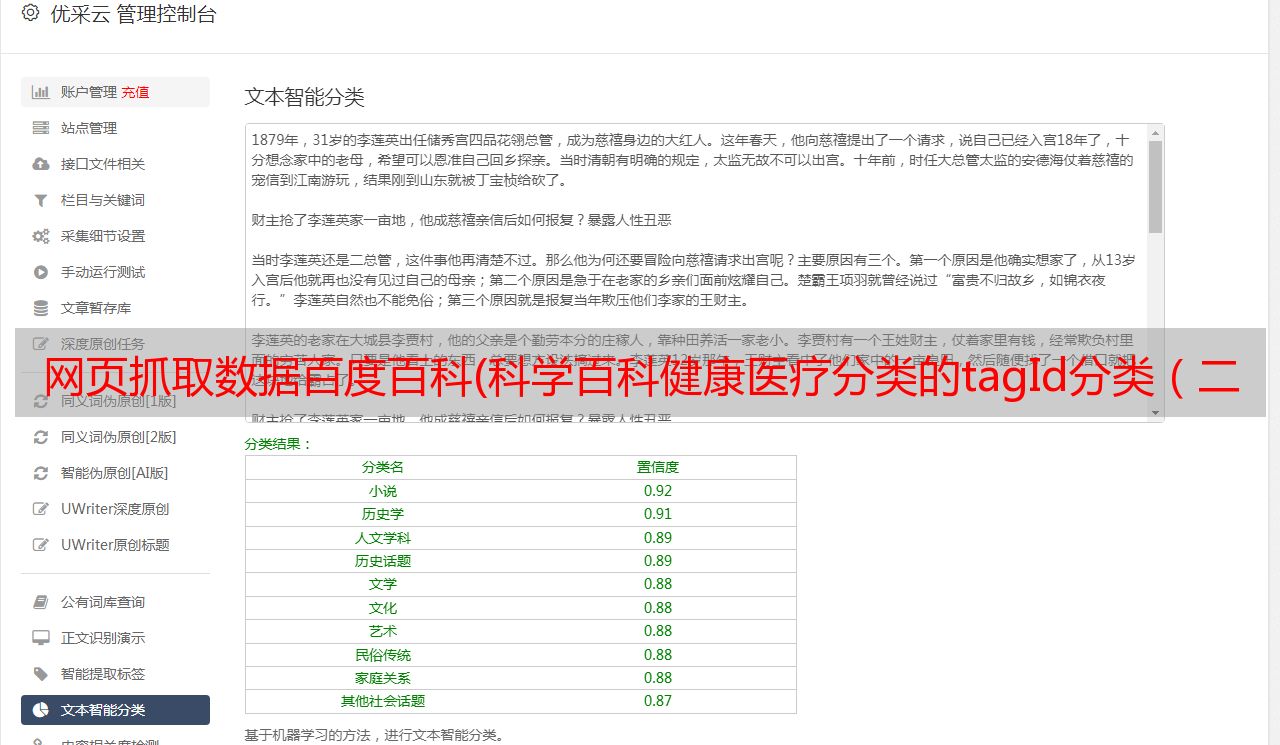
打开检查,可以看到网络中有很多请求
异步加载的 URL 在 xhr 的 getlemmas 中,异步请求的 URL:
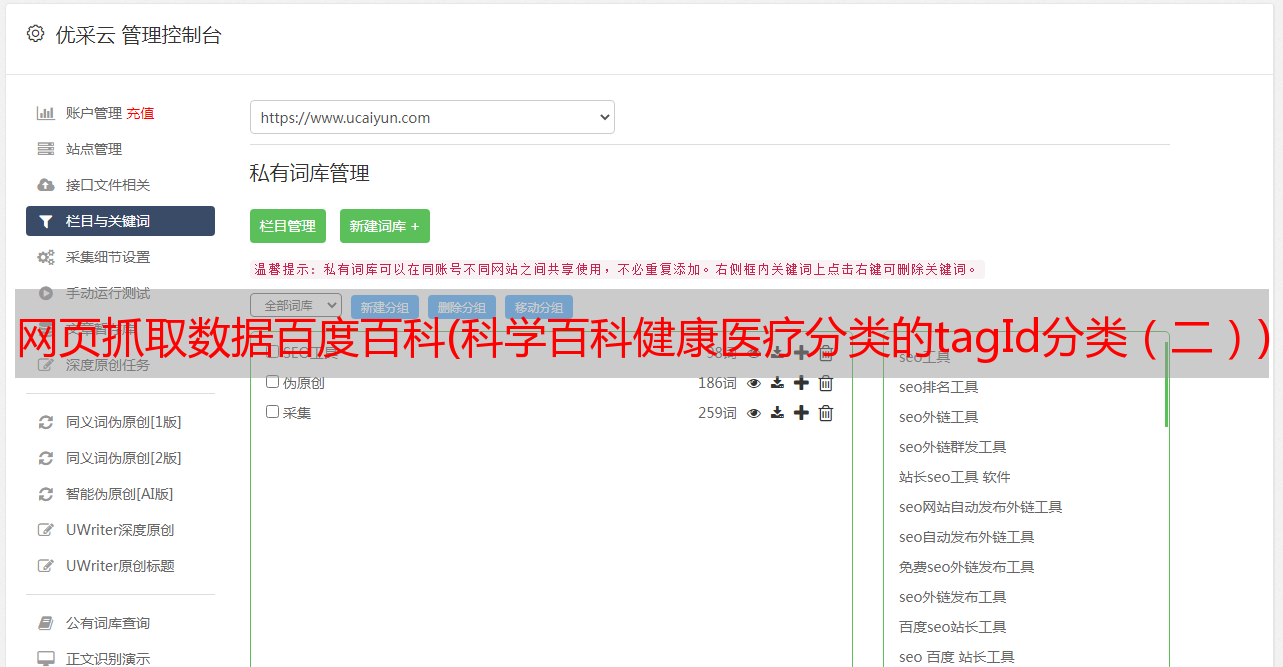
点击网址查看内容,看真锤
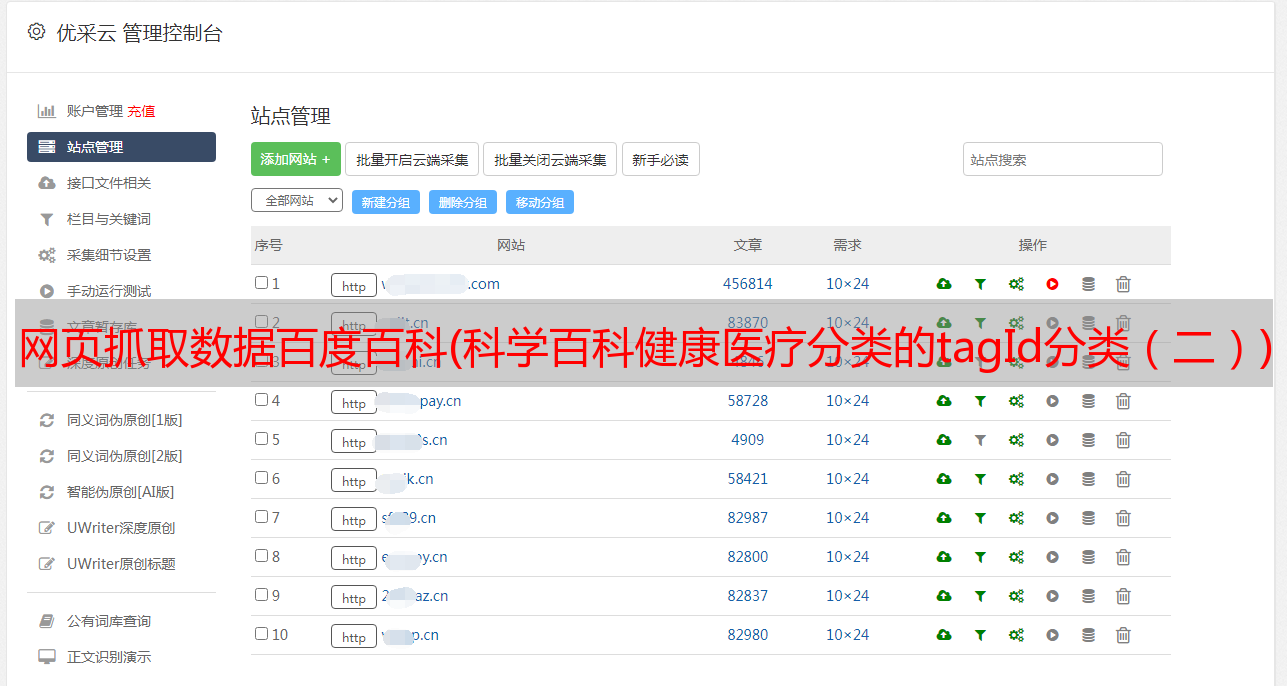
找到异步数据的url后,就可以发送请求了
但是不能用普通的get方法来关注。他的请求方式是POST,需要提交表单。表格内容哪里可以捏?
下拉查看表单数据
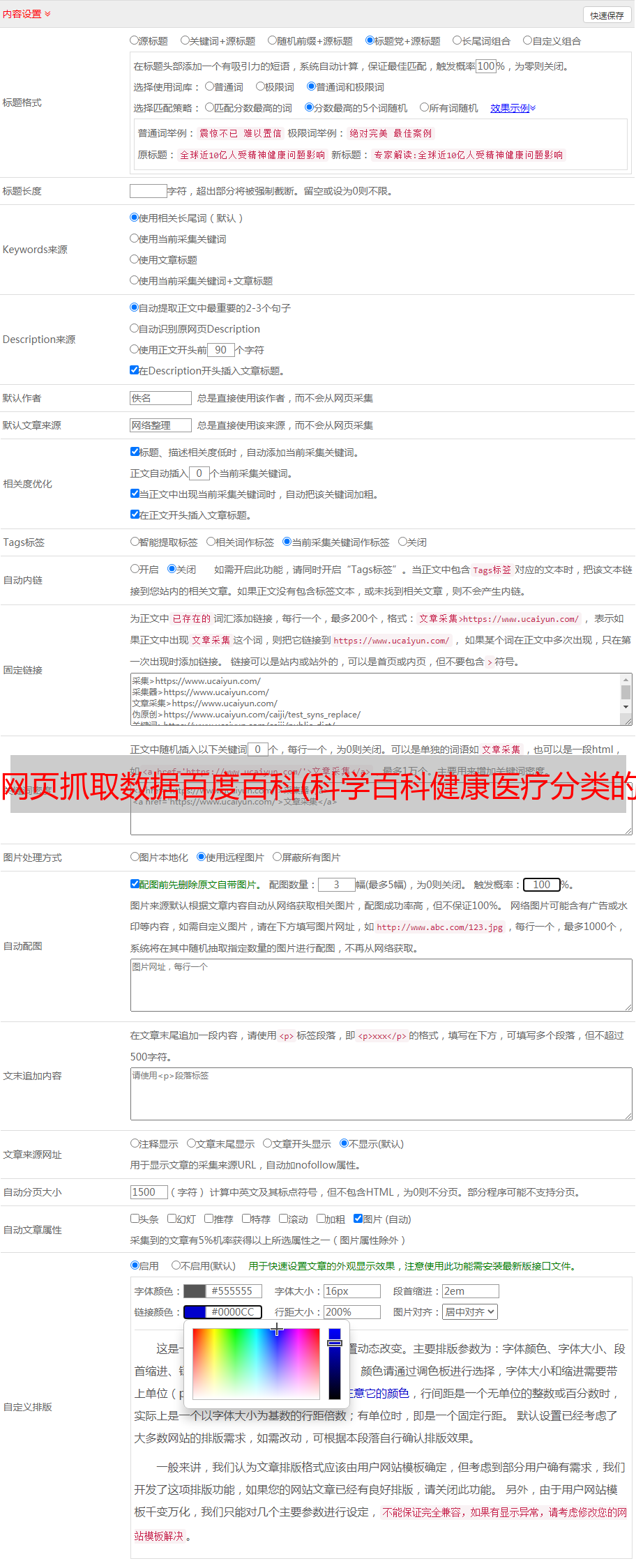
这里解释一下,表格中的限制是每页有多少条目(一页是 24)。tagID 是分类。比如科学百科健康医疗分类tagId=76625和科学百科航天航空分类tagId=76572,那么页面自然就只有页数
实现这些还不够,返回的数据是json类型的
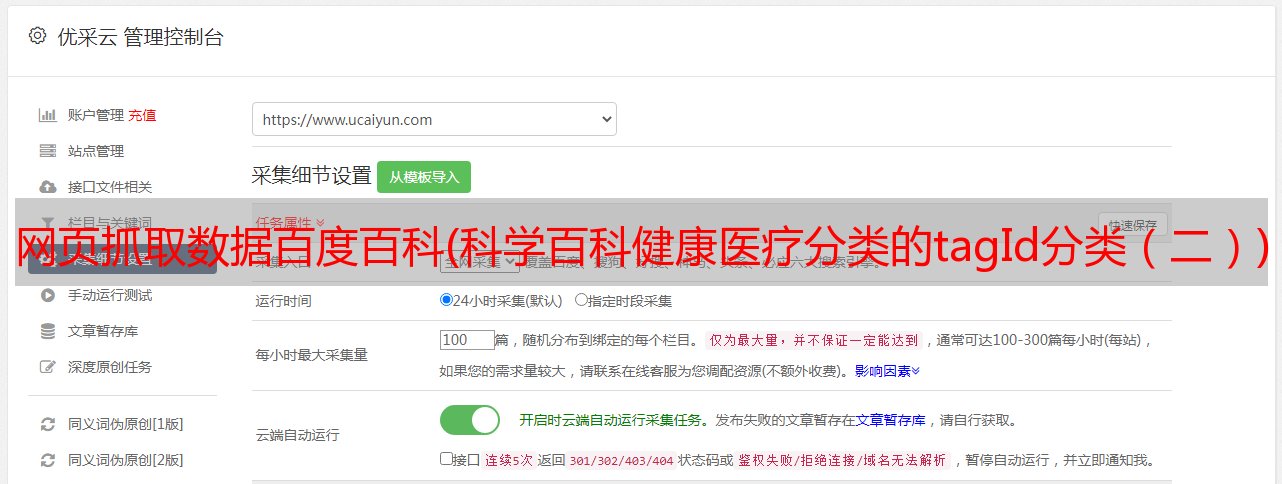
知道了这一点,就可以构造条目的 URL
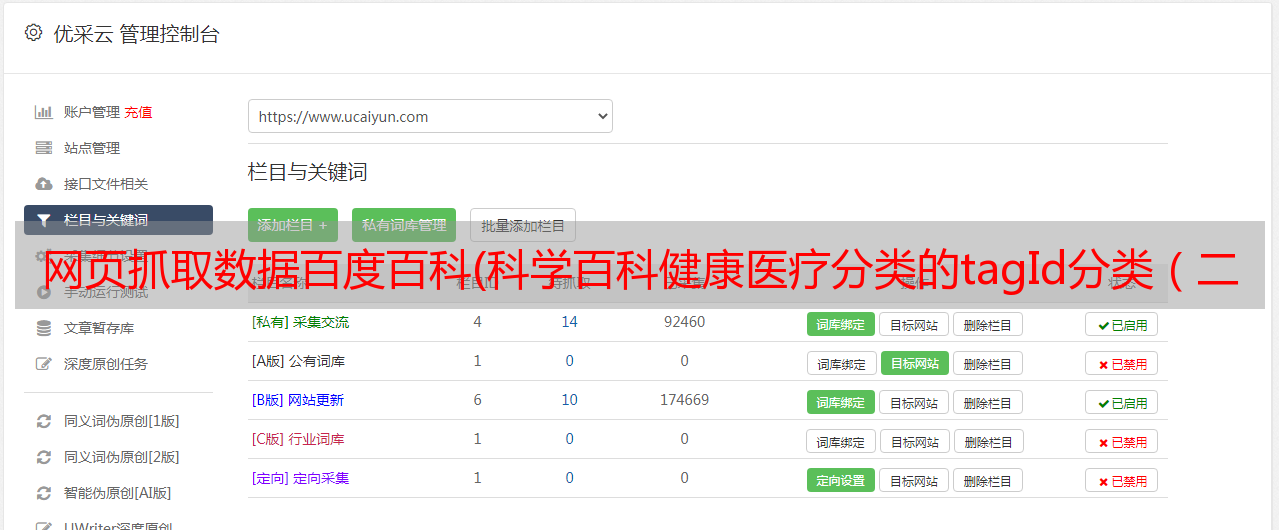
通过条目名称和ID解析条目的URL,获取条目名称和ID以构建完整的URL
话虽如此,关于代码
<p># -*- coding: UTF-8 -*-
import requests
from lxml import etree
import json
import sys
import time
class Spider:
def __init__(self):
# 定义请求头
self.UserAgent = {"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/77.0.3865.90 Safari/537.36"}
def main(self):
index_url = "https://baike.baidu.com/wikitag/taglist?tagId=76613" #从这里开始
post_url = "https://baike.baidu.com/wikitag/api/getlemmas" #异步数据加载的URL
params = {
"limit": 24,
"timeout": 3000,
"tagId": 76613,
"fromLemma": False,
"contentLength": 40,
"page": 0
} #异步时需要的请求对象
res = requests.post(post_url, params, headers=self.UserAgent) #POST异步请求数据
jsonObj = res.json() #解析成字典类型
totalpage = jsonObj['totalPage'] #读出来你所有页数
print("=======================\n总页面有"+str(totalpage)+"\n=======================\n")
hope=int(input('请输入要下载多少页:'))#希望下载多少页
page = 0#更改起始页面hope+1
while page

