Hawk教程-网页采集器
优采云 发布时间: 2020-08-20 09:43Hawk教程-网页采集器
[模块和算子]常见问题更新日志作者和捐款列表专题:案例:发布文章:故事:网页采集器
网页采集器主界面
1.快速使用说明
网页采集器 模拟了浏览器的设计,填入网址,点击刷新,即可获取对应地址的html源码。
认识到网页是一棵树(DOM)后,每个XPath对应一个属性,即可从网页上获取单个或多个文档。网页采集器的目的就是更快地通过手工或手动配置找到最优XPath。
1.1.工作模式
使用采集器,首先要根据抓取的目标,选择合适的工作模式:
注意:
1.2.基本操作
在多文档模式下,通常直接点击右上角的手气不错,在弹出的结果下选择所需数据,可配置其名称和XPath。点击确定即可配置完毕。即可手动获取绝大多数网页的目标内容。
[图片上传失败...(image-57cdac-30)]
可手工填入搜索字符,即可在网页上快速定位元素和XPath,可在多个结果间快速切换,找到所需数据后,输入属性名称后手工添加属性。
1.3.高级功能点击【Http恳求详情】,可更改网页编码,代理,cookie和恳求方法等,网页出现乱码可用若希望手动登入,或获取动态页面(ajax)的真实地址,填入搜索字符,点击【自动嗅探】,在弹出的浏览器中翻到对应的关键字,Hawk能够手动捕捉真实恳求超级模式下,Hawk会将源码中的js,html,json都转成html,从而使用手气不错, 更通用但性能较差填写【共享源】,本采集器同步共享源的【Http恳求详情】,避免重复设置cookie代理等。详情页(单文档模式)也可以手气不错(Hawk3新功能),搜索所需数组,不需要添加到属性列表,点击手气不错试试!网页地址也可以是本地文件路径,如D:\target.html, 用其他方式保存网页后,再通过Hawk剖析网页内容
单文档模式下的手气不错
网页采集器 不能单独工作,而是沟通 网页采集器 和数据清洗的桥梁。本质上说, 网页采集器 是针对获取网页而非常订制的数据清洗模块。
2.高级配置介绍2.1.列表根路径
列表根路径是所有属性的XPath公共部份,能简化XPath编撰,提升兼容性。只能在多文档模式下工作。
你可以通过Hawk手动剖析根路径,或自动设置。
2.2.自动规约列表路径
以事例来说明,使用手气不错后,嗅探器会找到列表节点的父节点,以及挂载在父节点上的多个子节点,从而产生一个树形结构
每个节点要抽取下边的属性:
为了能获取父节点下所有的div子节点,因此列表根路径就是/html/div[2]/div[3]/div[4]/div。 注意:父节点Path路径末尾是不带序号的,这样就能获取多个子节点。可以如此理解,列表根路径就是不带结尾数字的父节点路径。
有时候,父节点的xpath是不稳定的,举个反例,北京北京的二手房页面,上海会在列表前面降低一个广告banner,从而真正的父节点都会发生变化,比如向后偏斜了div[1]变成了div[2]。为了应对这些变化,通常的做法是手工更改【列表根路径】
2.3.手动设置根路径
继续举例子,父节点的id为house_list,且在网页中全局惟一,你就可以使用另外一种父节点表示法//*[@id='house_list']/li(写法可以参考其他XPath教程),而子节点表达式不变。这样会使程序显得愈发鲁棒。
3.抓取网页数据
网页采集器需配合数据清洗使用,才能 使用 网页采集器 获取网页数据,拖入的列须要为超链接
3.1.一般的get恳求
一般情况下, 将从爬虫转换推入到对应的URL列中,通过下拉菜单选择要调用的爬虫名称,即可完成所有的配置:
请求配置
本模块是沟通网页采集器和数据清洗的桥梁。本质上说,网页采集器是针对获取网页而非常订制的数据清洗模块。
你须要填写爬虫选择,告诉它要调用那个采集器。注意:
3.2.实现post恳求
web恳求中,有两种主要的恳求类型:post和get。 使用POST能支持传输更多的数据。更多的细节,可以参考http合同的相关文档,网上汗牛充栋,这里就不多说了。
post恳求时,Hawk要给服务器须要传递两个参数:url 和post。一般来说,在执行post恳求时,url是稳定的,post值是动态改变的。
首先要配置调用的网页采集器为post模式(打开网页采集器,Http恳求详情,模式->下拉菜单)。
之后,需要将从爬虫转换拖到要调用的url列上。如果没有url列,可以通过添加新列,生成要访问的url列。
之后,我们要将post数据传递到网页采集器中。你总是可以通过合并多列拼接或各类手段,生成要Post的数据列。之后,可以在从爬虫转换中的post数据中,填写[post列], 而post列就是收录post数据的列名。 注意:
4.手气不错
这是Hawk最被人赞誉的功能!在新的Hawk3中,该功能被极大地提高。
4.1.多文档下的手气不错
一般来说,输入网址加载页面后,点击手气不错即可,Hawk会手动根据优先级将列表数据抓取下来
手气不错配置
[图片上传失败...(image-9f6836-30)]
左右切换选择你想要的数据集,之后在下边的属性栏对结果进行微调。
添加一个属性,手气不错能够更准确地进行。添加两个属性,即可选取惟一区域。
4.2.单文档模式的手气不错
Hawk3新增功能,当网页中收录多达几十种属性时,挨个添加会显得非常繁琐,这在某种商品属性页非常常见。
为了解决这个问题,将关键字加入到搜索字符中,此时不要将其添加到属性列表中,直接点击手气不错即可。
单文档模式下的手气不错
4.3.手动模式
在手气不错不能工作或不符合预期时,需要手工给定几个关键字, 让Hawk搜索关键字, 并获取在网页中所在的位置(XPath)。
填入搜索字符,能够成功获取XPath, 编写属性名称,点击添加,即可添加一个属性。类似地,再填入30535,设置属性名称为“单价”,即可添加另外一个属性。
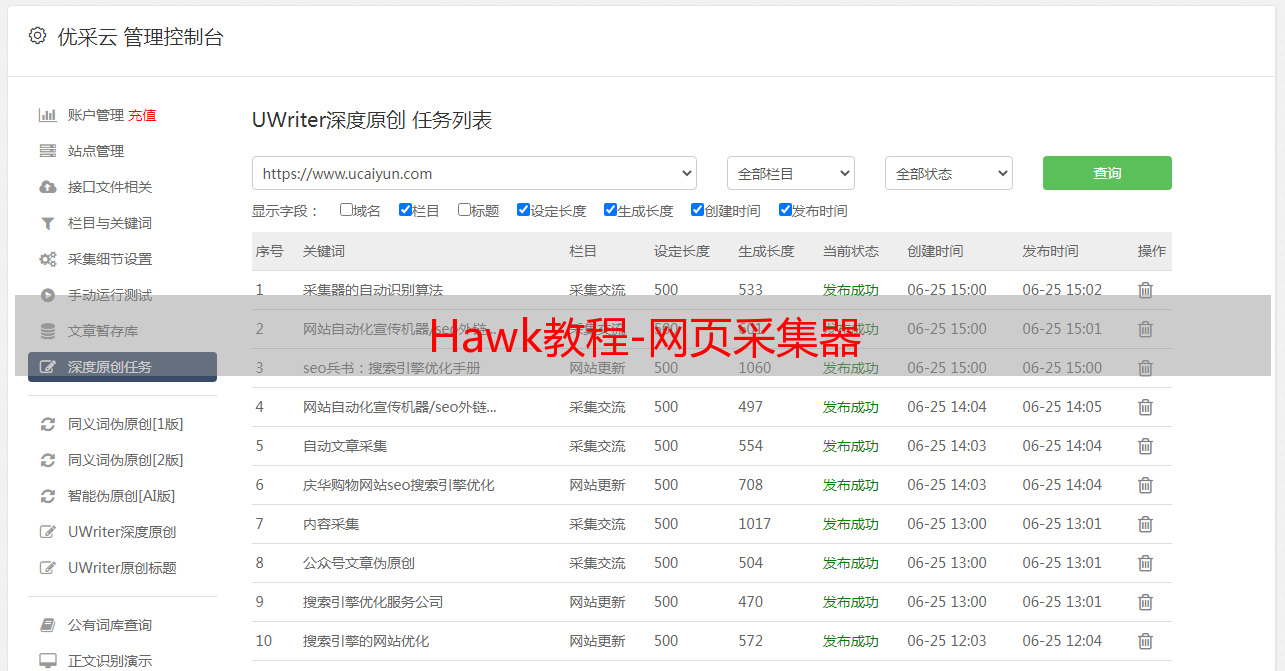
手动添加属性
在搜索字符的文本框中,输入你要获取的关键字,由于关键字在网页中可能出现多次,可连续点击继续搜索,在多个结果间切换,左侧的html源码会对搜索的结果进行高亮。
请注意观察搜索的关键字在网页中的位置,是否符合预期,否则抓取数据可能会有问题。尤其在 多文档模式。如果须要抓取本页面的多块数据,可新建多个网页采集器,分别进行配置。如果发觉有错误,可点击编辑集合,对属性进行删掉,修改和排序。你可以类似的将所有要抓取的特点数组添加进去,或是直接点击 手气不错 ,系统会依照目前的属性,推测其他属性。5.动态嗅探5.1.什么是动态页面?
动态瀑布流和ajax的页面,通常按需返回html和json.
老式网站在刷新时会返回页面的全部内容,但若只更新部份,即可大大节省带宽。该方法叫ajax,服务端传递xml或则json到浏览器,浏览器的js代码执行,并将数据渲染到页面上。 因此,获取数据的真实url,不一定显示在浏览器地址栏,而是隐藏在js调用中。本质上,javascript发起了新的隐藏http请求来获取数据,只要能模拟之,就能象真实浏览器一样获取所要数据。参考百度百科的介绍
5.2.Hawk手动获取动态恳求
通过浏览器和抓包,可以获取那些隐藏恳求,但须要对HTTP请求的原理比较熟悉,不适合于初学者。
Hawk简化了流程,采用手动嗅探的方法来进行。Hawk成为前端代理,会拦截和剖析所有系统级Http请求,并将收录关键字的恳求筛选下来 (基于fiddler)
当搜索字符时,若没有在当前页面中找到该关键字,Hawk会有提示,“是否启动动态嗅探?”此时Hawk会弹出浏览器并打开所在网页。您可将页面拖到收录关键字的位置,Hawk会手动记录和过滤收录关键字的真实恳求, 检索完毕后,Hawk会手动回弹。
5.3.如果难以手动嗅探?
由于Hawk有拦截功能,会被浏览器觉得不安全,如何解决呢?
Hawk底层的嗅探基于fiddler,因此可通过fiddler生成证书后,导入到chrome解决,方法可参考这篇文档:
按如下方法对采集器进行设置:
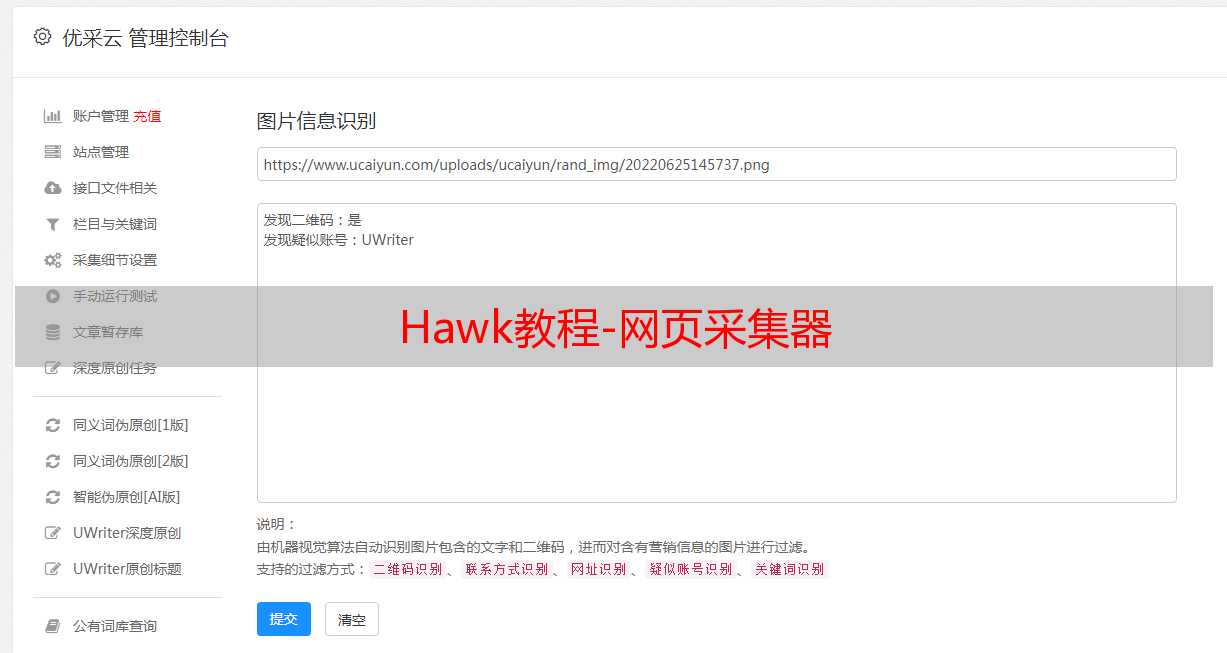
网页采集器恳求设置
5.4.注意事项有时直接将url拷贝到Hawk,并使用手气不错时,也能获取到数据。这是因为好多网站对第一页和其他页分别作了不同的处理。第一页内容会跟随整体frame返回回去。但以后页面内容就通过ajax单独返回了。
有时针对第一页做了大量的XPath开发,却最后发觉难以在其他页面使用,多半就是前面提及的问题(一脸懵逼)。因此经验上,建议翻到其他页面上再做恳求。
超级模式能将网页中所有的javascript, json, xml都转换为HTML DOM树,从而实现属性提取和手气不错。
6.超级模式
为了能使动态网页也能使用添加属性和手气不错,Hawk在嗅探后默认会开启超级模式。 超级模式能将网页中所有的javascript, json, xml都转换为HTML DOM树,从而实现属性提取和手气不错。
超级模式极大的简化了动态恳求的处理,但它仍然可能有以下问题:
7.自动登入
很多网站需要登入能够访问其内部内容。而登陆涉及到十分复杂的逻辑,例如须要传递用户名和密码,验证码等,并经过多次的恳求,获取token等一系列流程,连写代码都要写整整一页纸并须要反复调试。考虑到Hawk是通用的数据采集器,其开发成本十分之高。
但本质上说,登录只是获取了cookie,只要以后的恳求加入该cookie,远端服务器就不能分辨其是浏览器还是爬虫。一般传统的爬虫软件,会外置一个浏览器,用户在内部填入用户名密码。软件在内部获取cookie后进行恳求。 但Hawk不准备再搞外置浏览器,那种方法很重,很难与Hawk的流系统兼容。所以,Hawk不玩手动登入了!
我们使用了全新的思路解决该问题。
Hawk的手动登入和动态嗅探所使用的技术是一样的,其本质上还是在底层替换了系统代理,你可以在搜索字符填写在登陆后页面上的任意文本,点击嗅探即可。若该方法难以工作,还可以自动拷贝浏览器上的恳求参数到网页采集器。
其更多的使用细节,可参考动态嗅探章节。
8.设置共享恳求参数的采集器名称
为了抓取一个网站的不同数据,我们须要多个 网页采集器 。但是访问网站需要登入和cookie,难不成每位采集器都要设置对应的恳求参数吗?
采集器的属性对话框中,可以设置共享源,也就是要共享的 网页采集器 的名称。
例如设置为链家采集器,那么本采集器的恳求参数,都会在执行时,动态地从链家采集器中获得。这样就极大地简化了配置过程。
在按键上手动弹出帮助
9.附录:XPath和CSS写法9.1.XPath
关于XPath句型,可参考教程
XPath可以十分灵活,例如:
9.2.CSSSelector
多数情况下,使用XPath才能解决问题,但是CSSSelector更简练,且鲁棒性更强。关于它的介绍,可参考教程
当然,大部分情况不需要这么复杂,只要记住以下几点:
10.手气不错的原理
网页采集器的功能是获取网页中的数据(废话)。通常来说,目标可能是列表(如购物车列表),或是一个页面中的固定数组(如JD某商品的价钱和介绍,在页面中只有一个)。因此须要设置其读取模式。传统的采集器须要编撰正则表达式,但方式过于复杂。
如果认识到html是一棵树,只要找到了承载数据的节点即可,之后用XPath来描述。
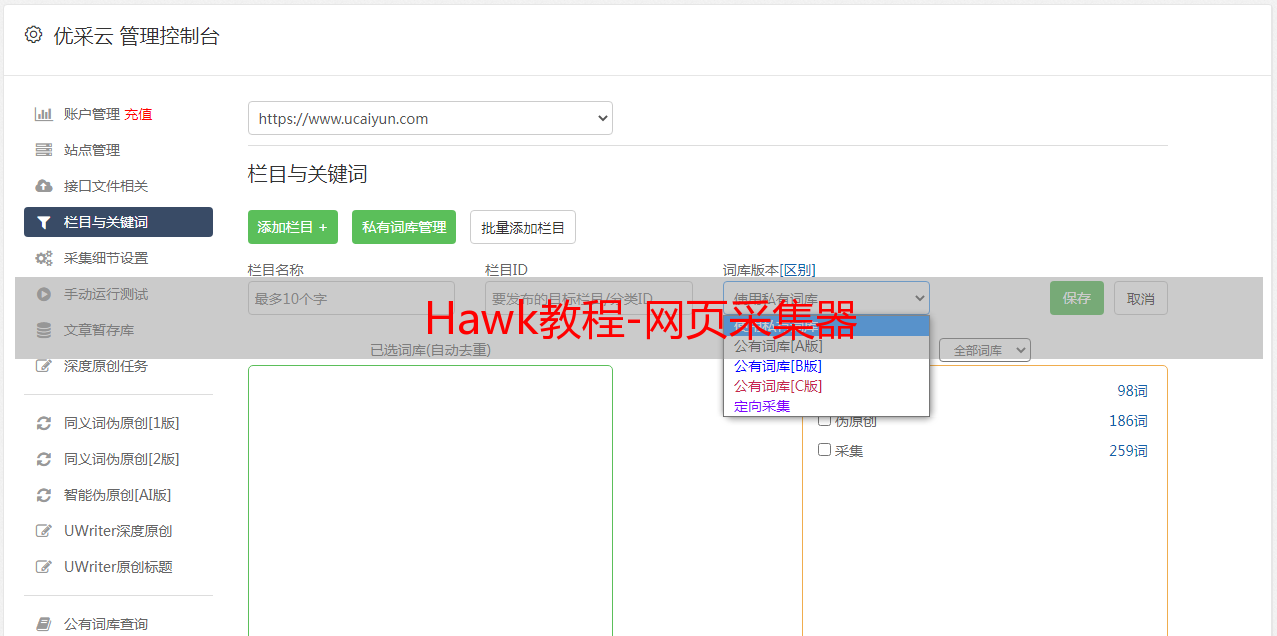
手气不错原理
手工编撰XPath也很复杂,因此软件可以通过关键字,自动检索XPath,提供关键字,软件都会从树中递归搜索收录该数据的叶子节点。因此关键字最好是在页面中独一无二的。
如上图所示,只要提供“北京”和“42”这两个关键字,就能找到parent节点, 进而获取div[0]和div[1]这两个列表元素。通过div[0]和div[1]两个节点的比较,我们能够手动发觉相同的子节点(name,mount)和不同的节点(北京:上海,37:42)。相同的节点会保存为属性名,不同的节点为属性值。但是,不能提供上海和37,此时,公共节点是div[0], 这不是列表。
软件在不提供关键字的情况下,也能通过html文档的特点,去估算最可能是列表父节点(如图中的parent)的节点,但当网页非常复杂时,猜测可能会出错。

