采集图片网址并下载图片——以途牛旅游网为例
优采云 发布时间: 2020-08-19 10:26采集图片网址并下载图片——以途牛旅游网为例
注:集搜客GooSeeker爬虫从V9.0.2版本开始,爬虫术语“主题”统一改为“任务”,在爬虫浏览器里先命名任务再创建规则,然后登陆集搜客官网会员中心的“任务管理”里,就可以查看任务的采集执行情况、管理线索网址以及做调度设置了。
一、操作步骤
集搜客爬虫除了能抓到网页上的文本、网址数据,还可以批量下载图片到笔记本中。无论是列表页还是详情页上的图片,只要能获取图片网址都可以用集搜客爬虫来下载图片。下面就以途牛网的自助游网页为案例,介绍一下怎么用集搜客来手动下载图片。操作步骤如下:
注意事项:从爬虫软件V9.0.0开始,图片下载后的储存位置有了很大改变,但是定义规则过程不变,请注意看第五步上面的说明和相应的链接。
二、案例规则+操作步骤
如果纯粹采集图片,就不知道图片来源于那里,所以,我们一般会把网页上的文本信息“旅游名称”“价格”也采集下来,最后可以用excel把它们匹配上去。文章《采集网页数据》已经详尽讲过前两步操作了,下面就从第三步操作开始讲。
第三步:采集图片网址
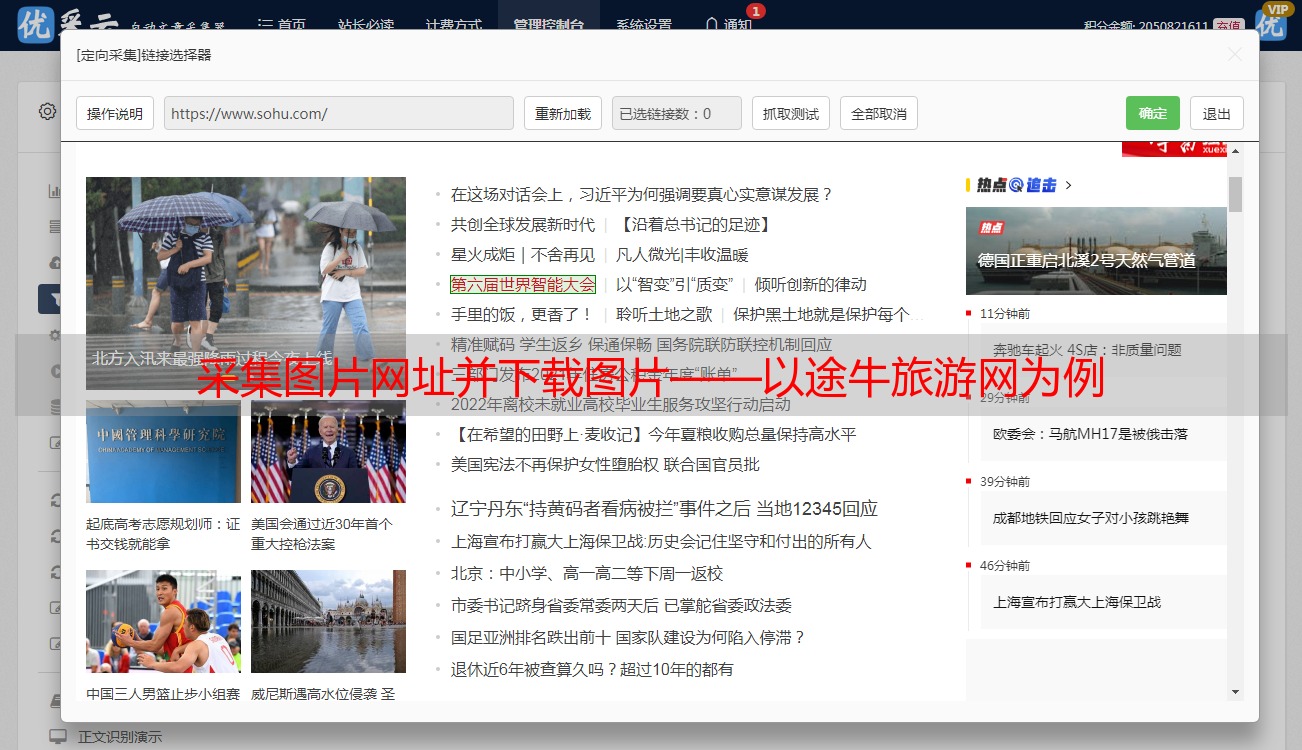
3.1, 点击小图可以定位到它的IMG节点。我们不直接采集大图,因为大图是由小图放大的,并且只显示一张,也就只能抓到一张大图,但是小图可以全部抓到,最后用excel处理才能弄成大图,所以,类似这些网页的情况抓小图就容易多了。
3.2,再双击展开IMG,就会在attributes下边找到@src,它就是储存图片网址的节点
3.3,右击@src,选择内容映射->新建抓取内容,再输入标签名“小图网址”
3.4,选中“小图网址”,打勾下载图片
注意:映射@src节点给标签“小图网址”后,只需打勾下载内容->下载图片,不要勾中级设置->抓取特定内容->网页片断和图片网址,否则输出的图片网址就是错误的,无法下载到图片。
第四步:样例复制
4.1, 在工作台上右击“小图网址”,选择添加->其前,在它的后面添加一个新标签“列”。然后,再右击“小图网址”,选择联通->右移,这样,“列”包容了"小图网址"。 其中,标签“列”只是拿来做样例复制的。因为网页上的旅游名称、价格信息只有一条,而小图是多张,所以,要局部对小图做样例复制。
4.2,在工作台上选中“列”,在网页上点击第一个小图,对应到下边的DOM节点,右击这个节点,选择样例复制映射->第一个。点击第二个小图,对应到下边的DOM节点,右击这个节点,选择样例复制映射->第二个。这样就对小图做了样例复制。关于样例复制可以看文章《采集列表数据》来把握。
第五步:存规则,爬数据
5.1,点击测试,只抓到第一张小图网址,其他的都抓空了,说明数据规则须要微调一下。通常调整定位,选择绝对定位就可以解决。

5.2,点击存规则、爬数据,采集成功后会在本地DataScraperWorks文件夹中生成xml文件和储存图片的文件夹。结果文件储存位置说明参考《查看数据文件》。图片文件储存位置说明参看《集搜客网络爬虫图片下载功能》

5.3,最后把xml文件和图片导出到excel中进行匹配,可以调整图片大小,操作见文章《如何把下载的大量图片手动匹配到excel中?》。
上篇文章:《定位标志采集列表数据》 下篇文章:《xml文件结构怎样看》
若有疑问可以或

