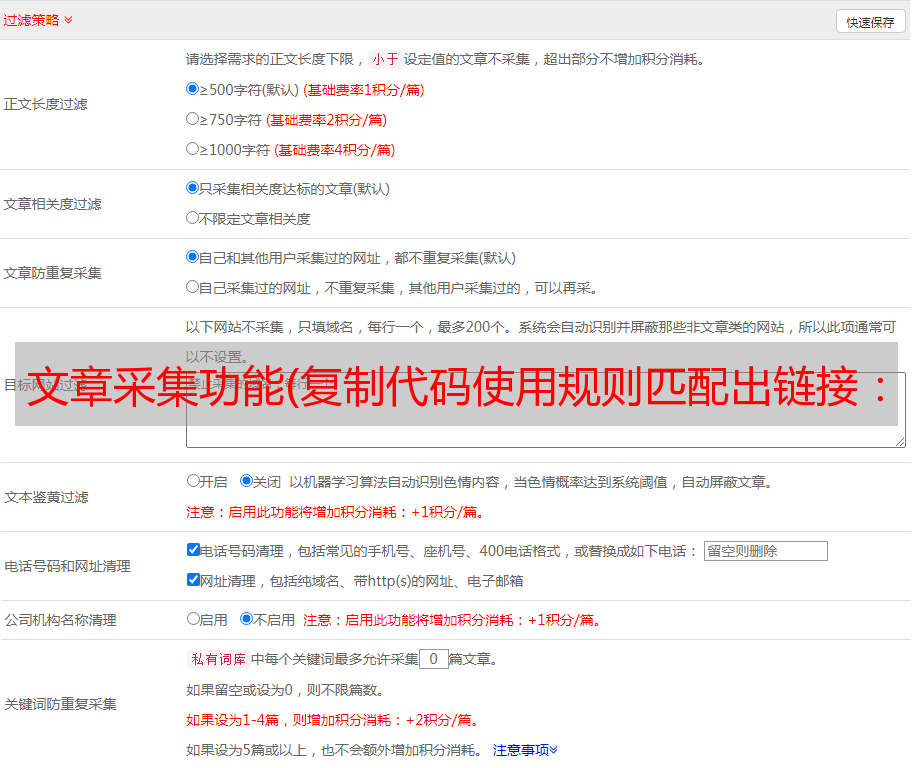
文章采集功能(复制代码使用规则匹配出链接:JS模式自动补全网址)
优采云 发布时间: 2021-09-05 10:37文章采集功能(复制代码使用规则匹配出链接:JS模式自动补全网址)
部分文章内容过长会分页显示,以文章""为例
首先我们在“采集器Settings”获取内容“内容分页”中开启分页
文章通常在body中有分页,我们将“body”字段添加为“页面内容字段”
文章页面图片:
图中我们可以看到分页有4种:完全分页、上下分页、完全分页JS模式和上下分页JS模式
分页链接格式为:article/news/pg/id/number.html?page=number
通过“测试”分析网页的功能获取各个分页区域的xpath:
上面的xpath值可以在“Content Paging”Get Paging Area”中设置获取固定区域的分页链接,否则会获取整个页面的分页链接
分页链接规则:
完整分页和上下分页可以通过a标签直接获取链接:
复制代码
查看JS模式分页源码发现的链接格式为:
复制代码

使用规则匹配分页链接:
复制代码
由于JS模式无法自动补全网址,需要填写“拼接到最终页面链接”:
[内容 1]
复制代码
为了防止非分页链接被匹配,在“内容分页”分页网址过滤“必须收录”中填写“page=”,使用“article/news/pg/id/d+.html?page” =d+ 更精确"
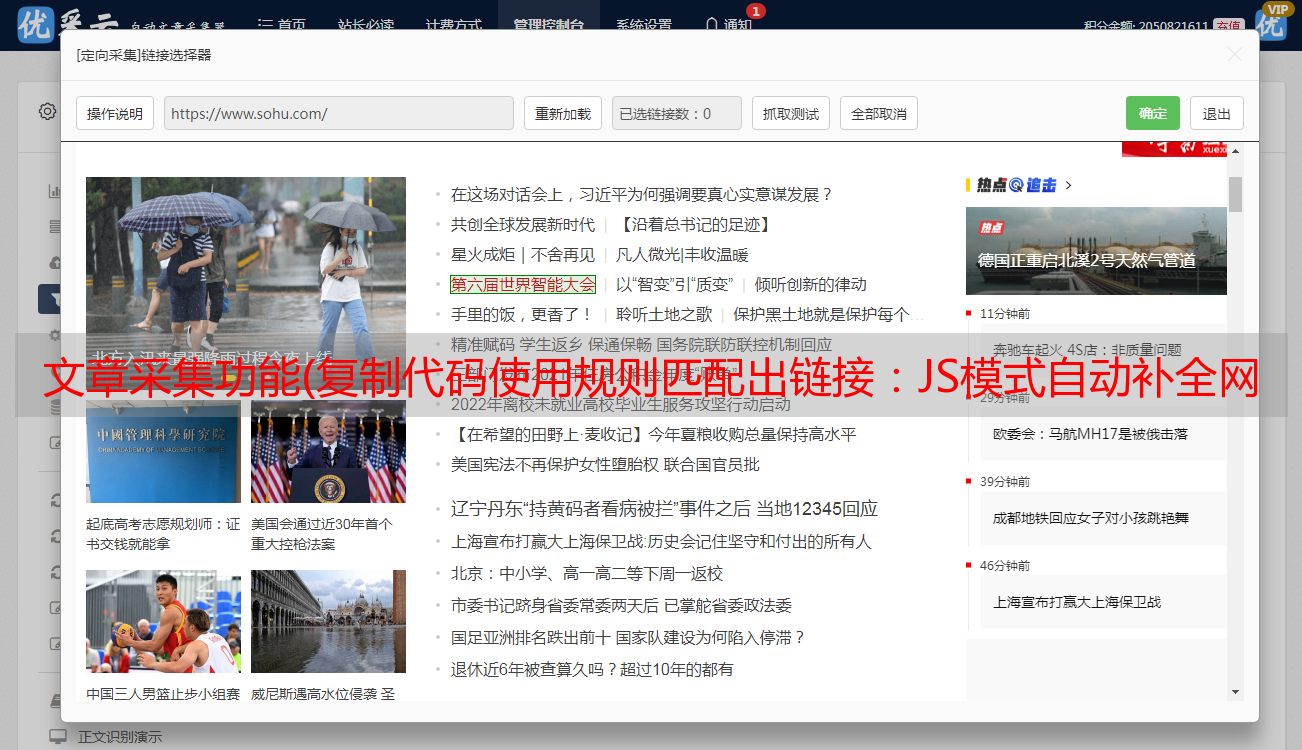
我们测试了“全分页JS模式”的链接爬取
“测试”抓取页面的效果
注:很多网站会因为程序问题会有文章首页链接的两种格式。比如例子中的文章首页链接是:和(来自第二页文章首页的链接),如果这两个链接的内容相同,就会导致文章首页的重复爬取
解决方法:在“内容分页”分页网址过滤“不能收录”中填写“page=1$”排除第一页链接
常见问题:
相关知识点:
本站文章摘自书融网权威资料、书籍或网络原创文章。如果您有任何版权纠纷或侵权,请立即联系我们进行删除。未经许可禁止复制和转载!谢谢...

