关键词文章采集(优采云软件出品的一款基于高精度正文识别算法的互联网文章采集器)
优采云 发布时间: 2021-08-31 18:07关键词文章采集(优采云软件出品的一款基于高精度正文识别算法的互联网文章采集器)
由优采云software 文章采集器出品的基于高精度文本识别算法的互联网。支持关键词采集百度等搜索引擎的新闻源()和泛页(),支持采集designated网站栏目下的所有文章。更多介绍..
优采云software 是首创的独家智能通用算法,可准确提取网页正文部分并保存为文章。
支持对标签、链接、邮件等进行格式化处理,还有插入关键词的功能,可以识别旁边插入的标签或者标点符号,可以识别英文空格的插入。
还有更多文章转翻译功能,即文章可以从一种语言如中文转成另一种语言如英文或日文,再由英文或日文转回中文。这是一个翻译周期。您可以将翻译周期设置为循环多次(翻译次数)。
采集文章+翻译伪原创可以满足站长和各领域朋友对文章的需求。
一些公关处理和信息研究公司需要的专业公司开发的信息采集系统往往售价几万甚至更多,而优采云的软件也是一个信息采集系统功能和市场上昂贵的软件有相似之处,但价格只有几百元,你会知道如何尝试性价比。
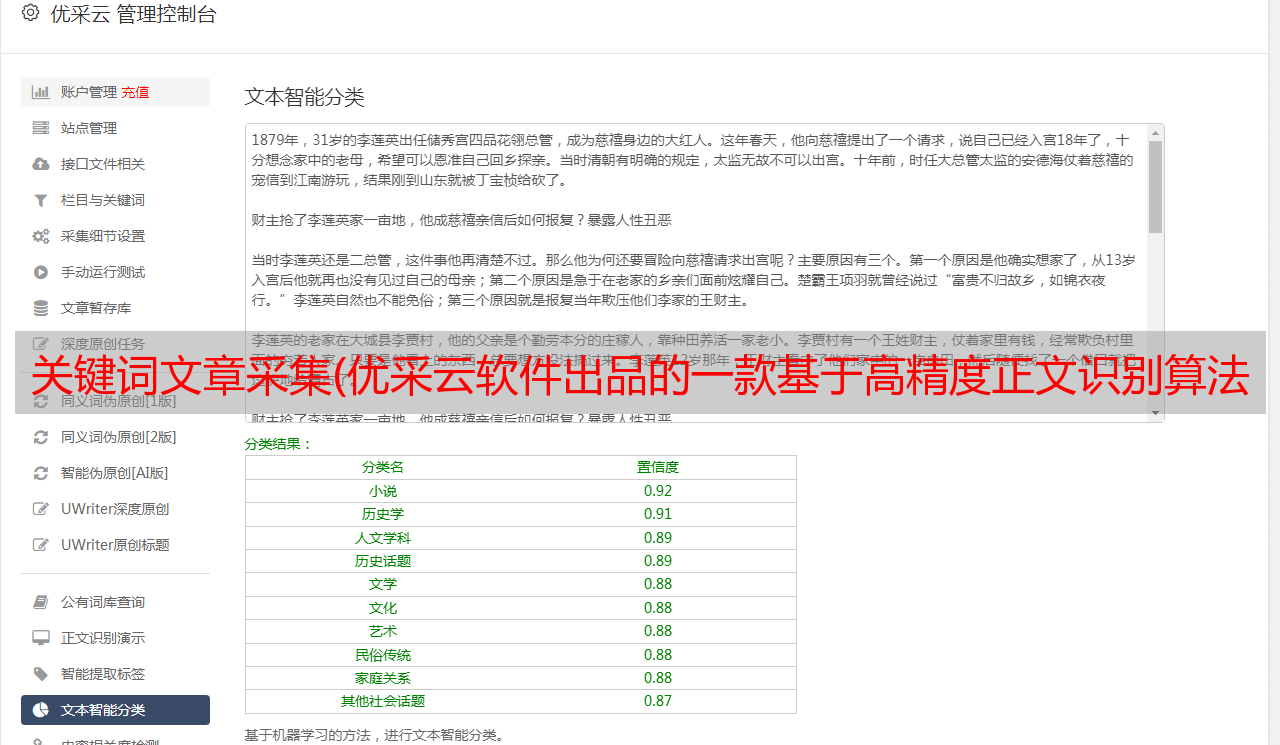
什么是高精度文本识别算法
该算法由优采云自主研发,可以从网页中提取正文部分,通常准确率为95%。如果进一步设置最小字数,采集文章的准确率(正确性)可以达到99%。同时文章title也达到了99%的提取准确率。当然,当一些网页的布局格式混乱、不规则时,可能会降低准确率。
文本提取模式
文本提取算法有标准标签、严格标签和精确标签三种模式。在大多数情况下,标准模式和严格模式是相同的提取结果。以下是特殊情况:
标准模式:一般提取。大部分时候可以准确提取文本,但是一些特殊的页面会导致提取一些不必要的内容(但这种模式可以更好地识别文章页面类似于百度经验)
严格模式:顾名思义,比标准模式严格一点,在很大程度上可以避免提取不相关的内容作为正文,但对于百度体验页等特殊的分段页面(不通用
段落,但有多个独立的div段和格式),一般只能提取某一段,而标准模式可以提取所有段落。
精确标签:当标准和严格模式不起作用时,可以精确指定目标正文的标签头。此模式仅适用于网络批处理。
所以你可以根据实际情况切换模式。您可以使用本地批处理的读取网页正文功能来测试指定网页适合提取哪种模式。
采集 处理选项
采集 可以同时翻译、过滤和搜索单词。对于采集好文章,您可以使用“本地批处理”。
翻译功能是将中文翻译成英文再翻译回中文,也产生了伪原创的效果。支持原创格式翻译,即文章的原创标签结构和排版格式不会改变。
采集Target 是网址
您可以在 URL 模板中插入 #URL#、#title# 以合并引用
分页采集和相对路径转换为绝对路径
勾选“自动采集page”合并分页文章采集,并在编辑框中设置采集pages的最大数量。建议设置一个有限的值,比如10页,避免一些采集分页太多耗时长,合并后的文章体积大。如果需要采集所有页面,可以设置为0。
并且文章中的所有相对路径都会自动转换为绝对路径,可以保证图片等的正常显示
多线程
支持多线程高速采集网页。可以根据网速来确定。 Telecom 2m可以有5个线程,Telecom 4m可以有10个线程,依此类推,但需要适当设置。过多的设置可能会严重影响采集效率甚至影响系统效率。如果采集有其他占用流量的软件,比如在线视频播放,可以适当减少线程数。
文章Title 和文章 内容重复处理
程序可以智能判断过滤重复文章
当采集到达的文章标题(文件名)与本地保存的文章标题相同时,优采云会首先判断两个文章的相似度,当相似度较大时大于60% 当判断优采云是同一个文章时,再比较两个文章的文字大小,自动用文字较多的文章覆盖写入同一个文件名。这个世代情况加起来不及世代数。
而当相似度小于60%时,优采云判断与文章不同,会自动重命名标题(标题末尾随机取3到5个字母)并保存到文件。
文章快速过滤
优采云虽然研究了高精度的人体提取算法,但是提取错误还是很少。这些错误主要是:目标页面的主体是网络视频,或者主体内容太短,无法形成主体特征。因此,可以通过设置最终结果的字数来提高准确率(在“最小文本字符数”参数中,这个字数就是程序去掉标签、行、空格后的纯文本字数来自正文)。
文章quick 过滤器是为了快速查看采集好文章,方便对文字错误的文章进行判断和删除。同时也方便了基于网络信息采集的目的需要进行的提炼过程。
生成文章数量可变的问题
百度和搜搜默认每页 100 个结果,Google 默认每页 10 个结果。
有些网站访问速度超时(尤其是很多谷歌收录被一些网站屏蔽了),或者设置了body的最小字符数,或者程序忽略了里面同名的类似内容local文章,或者黑名单和白名单过滤等,会导致实际生成文章数低于每页搜索的最大结果数。
总体来说,百度采集质量最好,生成的文章数量接近搜索结果数量。
软件截图
升级记录:2014 年 3 月 25 日
1.0 测试版:经过多日的测试,发布了第一个测试版。此版本多线程环境存在强制退出的可能,后续会努力彻底消除这种退出的可能性。
1.0 beta2:修复标题中所有空格都被删除的问题(只删除首尾空格);将翻译器参数分离到主界面;添加单词插入选项;修改提取文本的算法(更容易识别类似百度经验文章);改进删除链接时不删除图片地址;改进删除标签时保留指定标签;添加了谷歌搜索语言选项法语支持和翻译法语支持;许多其他改进。
1.0 beta3:修复个别配置参数没有写入保存的问题;增加翻译选项【保留翻译语言】,即翻译成另一种语言后,不会再翻译回来,保持已翻译的语言版本。
1.0 beta4:修复标题必须收录关键词时pan-page选项会判断错误的问题;增加文本提取模式的选择,选择标准或严格。 其他更新
1.0 beta5.1-5.4:改进多线程稳定性测试版
1.0 beta5.5:提升翻译准确率,支持大文本翻译。
1.0 beta5.6:当采集被限制在屏幕高度时,改变状态栏总是显示。
1.0 beta6:新增智能采集column文章功能,集成在【网络批处理】中;更名文章转译器【本地批处理】;提高插入词的准确性;自该版本发布之日起,本软件价格上涨100元,从300元涨至400元。
1.0 beta6.1:将软件名称“优采云·新闻源文章采集器”改为“优采云·万能文章采集器”
1.07:新增功能:自动将相对链接转换为绝对链接(解决部分文章采集返回后无法显示图片的问题);新增功能:自动采集分页文章
1.073:修复百度引擎采集因百度页面变化导致失败的问题。
1.074:修复2核cpu下多线程的稳定性问题。
1.075: 修复地址中的“//”会被当成注释符号,后面的内容会被清除的问题;修复 Google 采集 问题;其他。
1.076:修复1.075版本更新导致文章内容多出$1符号的问题。
1.08:增强网页批处理的兼容性以处理替代网页标题;增强列URL采集器的匹配能力,更好的智能识别正确的文章地址。
1.09:提高身体识别能力;添加精确标签提取正文选项
1.10:修复翻译功能无法翻译的问题
1.11:增强网络批量处理中文章URL列URL采集器的识别能力
1.12:继续增强web批处理栏目URL采集器识别文章URL的能力,支持多种地址格式同时匹配
1.13:新增翻译语言:俄语、德语、意大利语;其他更新
1.2:修复soso引擎更新导致采集失败的问题;把百度和搜搜的每页网页数改为100,采集相对比较快。
1.22:更新软件注册方式; 关键词insert 每次添加不同的选项;其他更新
Universal文章采集器-Baidu采集-google采集-soso采集
用于提取网页正文的通用算法。百度引擎、谷歌引擎、搜索引擎强大聚合不时更新的文章资源,取之不尽用之不竭的情报采集什么网站的文章文章资源多语言翻译伪原创。你,只要输入关键词。
受影响区域:
1、press关键词采集Internet文章和translate伪原创,站长朋友的首选。
2、适合信息公关公司采集过滤提取信息资料(专业公司有几万个软件,我的是几十元,官网400元)这个软件是一款只需要输入关键词采集百度、谷歌、搜搜等各大搜索引擎新闻源和网络互联网文章以及任何网站Columns文章的软件更多介绍优采云software独家首创智能通用算法,可精准提取网页正文部分并保存为文章。

