申请GoogleAdSense,结果申请一次被拒一次,我的内容太少了
优采云 发布时间: 2021-08-26 00:11申请GoogleAdSense,结果申请一次被拒一次,我的内容太少了
我的博客最近开通了,一直在申请Google AdSense,但是被拒了一次,被拒了一次。 google发邮件说我的内容太少了,让我很不爽,虽然拒绝的原因可能是网站Building station 时间短等其他的,但是我还是想补充一下我的内容瞬间写博客,又是群里的那些朋友用wordpress建网站,好吧,做个小爬虫吧。 !
虽然网上有自动采集文章插件,你不觉得太低了吗! (虽然我的爬虫也很低)
好了,废话少说,进入正题。
首先你要确定一个目标网站,我在爬xxx大学的博客。 网站analysis
先看我们要抓取的网站
这所大学真的很棒!世界排名? :lol:
爬虫操作步骤:
开始了,你准备好了吗!
首先我们需要找到所有文章链接,我们来分析一下网页的规则
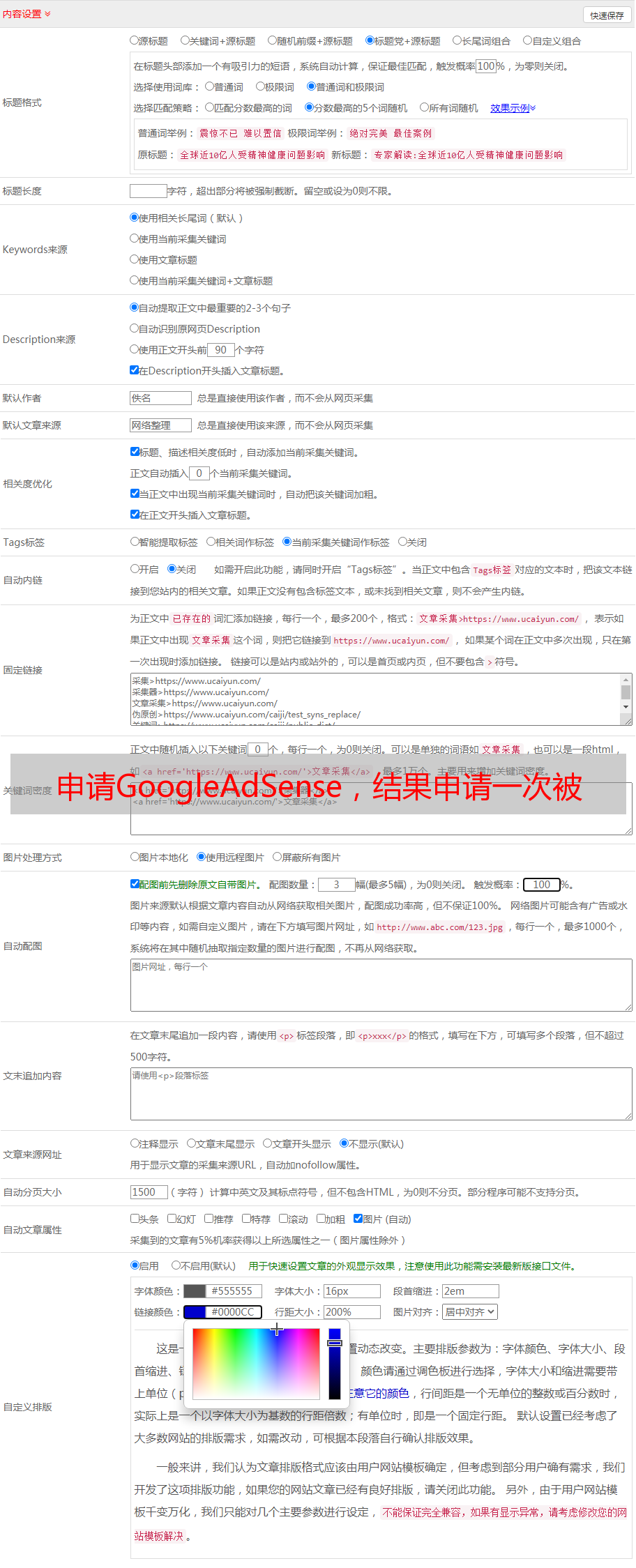
显然:第x页是'#39; + x
下一个词:干
首先需要定义一个类,并初始化数据库连接:这里我使用的是mongodb,只是因为它简单,适合我这样的新手。
class crawl_blog():
def __init__(self):
client = MongoClient()
db = client['vpsdx']# 选择一个数据库
self.blog_collection = db['blog']
self.blog_title = ''
self.blog_content = ''
self.blog_url = ''
self.all_blog_url = []
self.all_blog_title = []
self.old_img_urls = []
self.new_img_urls = []
然后获取文章的所有入口链接,分析页面使用BeautifulSoup。
def get_blog_url(self): #得到所有文章的入口链接
for count in range(1, 100):
page = 'http://www.vpsdx.com/page/' + str(count)
page_response = requests.get(page,allow_redirects=False)
print page_response.status_code
if page_response.status_code != 200:
print '网页状态码错误,不为200'
break
else:
soup = BeautifulSoup(page_response.content, 'html.parser')
article = soup.find_all(name='article')
for tag in article:
url = tag.find(name='a')
print url.get('href')
self.all_blog_url.append(url.get('href'))
print url.get('title')
self.all_blog_title.append(url.get('title'))
print '添加了一篇文章的标题和链接'
print count
self.all_blog_url.reverse()
self.all_blog_title.reverse()
主要逻辑,这里就不说了,太简单了。
def handle_one_page(self): #处理每一篇文章
for article_url in self.all_blog_url:
if self.blog_collection.find_one({'文章网址': article_url}):
print u'这个页面已经爬取过了'
else:
index = self.all_blog_url.index(article_url)
self.blog_url = article_url
print "文章的网址是: {b8c66bcbce874cbcdfdaa03ff0f908635b9ef0379cd01189ad5fe3f67980b247}s" {b8c66bcbce874cbcdfdaa03ff0f908635b9ef0379cd01189ad5fe3f67980b247} self.blog_url
self.blog_title = self.all_blog_title[index]
print "文章的标题是: {b8c66bcbce874cbcdfdaa03ff0f908635b9ef0379cd01189ad5fe3f67980b247}s" {b8c66bcbce874cbcdfdaa03ff0f908635b9ef0379cd01189ad5fe3f67980b247} self.blog_title
self.get_article_content(self.blog_url)
self.change_url() #更改内容中的图片链接
self.blog_content = str(self.blog_content)
self.publish_article(self.blog_title,self.blog_content)
print '成功发表文章'
post = {
'文章标题': self.blog_title,
'文章网址': self.blog_url,
'文章内容': self.blog_content,
'图片旧地址': self.old_img_urls,
'图片新地址': self.new_img_urls,
'获取时间': datetime.datetime.now()
}
self.blog_collection.save(post)
print u'插入数据库成功, 倒计时5s进行下次爬取'
time.sleep(5)
self.blog_title = ''
self.blog_content = ''
self.blog_url = ''
self.old_img_urls = []
self.new_img_urls = []
现在我们分析如何提取文章中的内容,找到我们需要的标签,发现标签中有我们不想要的广告。因此,我们需要处理它们。处理方法也很简单。只需删除不必要的标签。
def get_article_content(self, url):
self.blog_content = ''
browser = webdriver.PhantomJS()
browser.get(url)
soup = BeautifulSoup(browser.page_source, 'html.parser')
article_tag = soup.find('div', class_='entry')
all_children_tag = article_tag.find_all(recursive=False)
for i in all_children_tag:
print i.name
try:
if i['class'][0] == u'gggpost-above':
i.decompose()
print '检测到广告,正在删除'
else:
pass
except:
pass
try:
if i['type']== u'text/javascript':
i.decompose()
print '检测到广告,正在删除'
else:
pass
except:
pass
try:
if i['class'][0] == u'old-message':
i.decompose()
print '检测到广告,正在删除'
else:
pass
except:
pass
print 50*'*'
print '成功去除广告'
self.blog_content = str(article_tag)
接下来的步骤也比较重要。每个文章里面都有图片链接。基本上很多博客都使用CDN加速。大多数 CDN 提供反水蛭设置。因此,如果您直接使用原创博客链接将不起作用,因为您在访问图像时需要提供来自浏览器的引荐。原文章中的所有图片都需要下载到本地并上传到我使用的云存储中。我用七牛云。
def change_url(self):
self.blog_content = BeautifulSoup(str(self.blog_content), 'html.parser')
#获取所有具有特定class属性的a标签
a_tag = self.blog_content.find_all(name='a', class_='highslide-image')
print 50*'*'
for a in a_tag:
try:
#获取原图的链接并且下载
old_url = a['href']
response = requests.get(old_url)
index = a_tag.index(a)
filename = str(index) + '_' + old_url.split('/')[-1]
with open(filename, 'ab') as f:
f.write(response.content)
self.old_img_urls.append(old_url)
new_tag = self.blog_content.new_tag("img")
a.replace_with(new_tag)
#将图片上传到七牛云
self.up_load(filename, filename)
new_tag['src'] = '你的七牛云域名' + filename
print '成功更换图片的链接'
self.new_img_urls.append(new_tag['src'])
except:
print '获取图片失败,可能是图片的链接错误,正在跳过'
代码很丑,就不贴了。也希望各位大胸哥们多多支持。

