任何一个网站想在推广中成功,搜索引擎优化都是至为关键的一个环节
优采云 发布时间: 2021-08-18 18:14任何一个网站想在推广中成功,搜索引擎优化都是至为关键的一个环节
任何网站想要推广成功,搜索引擎优化是最关键的环节。
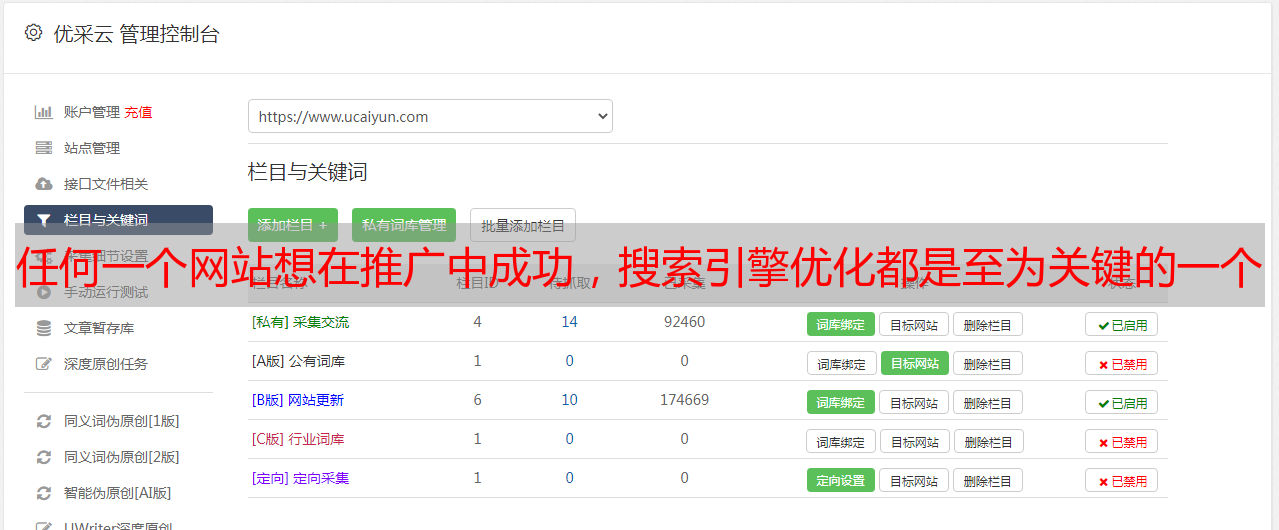
概述
SEO(Search Enginer Optimization)是通过了解搜索引擎的运行规律,调整网站,提高目标网站在相关搜索引擎中的排名的一种方式。对于任何网站来说,要想在网站推广中取得成功,搜索引擎优化是最关键的环节。
为搜索引擎优化处理意味着让网站更容易被搜索引擎接受。搜索引擎会将网站的内容与一些相关数据进行比较,然后浏览器将这些内容以最快最完整的方式呈现给搜索者。
搜索引擎原理
所谓的搜索引擎是这样工作的:
一般来说,人类看到的网页是这样的(经过浏览器的翻译和渲染):
在搜索引擎机器人眼中,网页是这样的:
是的!这只是一堆代码。
所以搜索引擎需要通过代码知道这个页面上的“点”是什么。
HTML
许多刚接触 HTML 的人倾向于认为这只是一种用于构建网页的标记语言。事实上,在设计 HTML 时,它是“语义化的”。
很好的理解:
H1 是标题
H2 和 H3 中标(标题)
H4、H5、H6 是小标签
指段落(paragraph)
很重要的粗体
中的 alt
指替代文本,title就是标题
...
因此,如果开发人员希望产品中的关键字被搜索引擎检索到,他们应该尝试使用“正确的 HTML 标签”。例如,产品页面应如下所示:
1
2
3
4
5
美国原装*敏*感*词*人体工学舒适 Aeron
<p> 工作椅的全新演绎 独特的外观、先进的人体工学理念、94%的材料可降解回收,Aeron座椅彻底改变了人们关于办公椅的思维定式。 针对人们每天的各种坐姿随时进行调节,能够使人们获得健康的舒适感和平衡的身体支撑。创新的悬浮式设计及便捷的调节控制,无需费力,Aeron座椅即可随着全身的活动进行调整。
<img src=span class="string""aeron.jpg"/span title=span class="string""Aeron 人体工学座椅"/span>
</p>
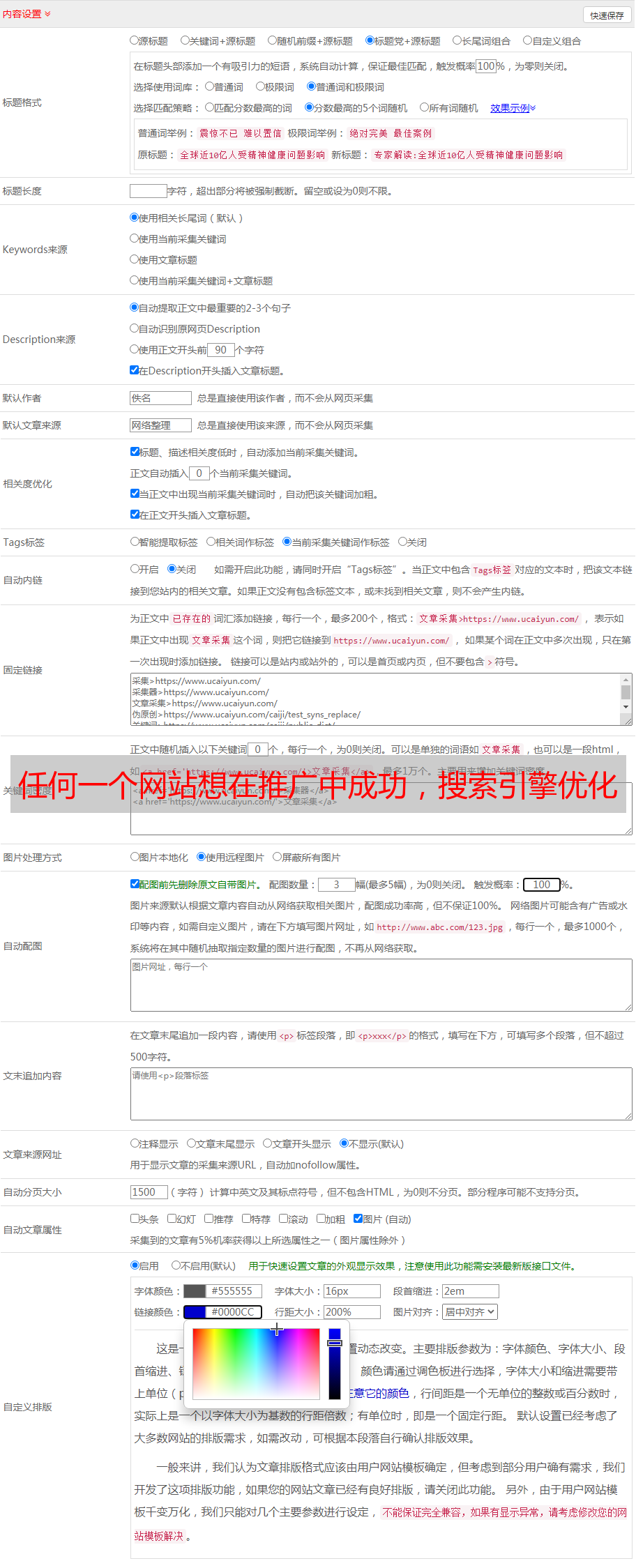
SEO 技术的本质是“画出网络的关键点”,以最大限度地提高搜索引擎对您网站 内容的理解。
HTML 使用 meta 的注意事项
HTML 中的元数据还可以帮助搜索引擎理解网站 中的内容。
重量
以下是网页中关键字的优先级顺序:
1
title > mete > h1 > h2 > h3 > strong > p
所以有些网站 是这样做的:
网站common 缺点的秘密是完全一样的叙述
网站最大的缺点是:
如果你不了解SEO技术,你会认为这是一个不起眼的细节。在线部署完成后,您可以稍后更改它。但其实很多人的网站不是收录就是因为这个小细节。
如果整个网站的标题和描述都一样,搜索引擎“分不清谁是谁”,自然是“收录一个都没有”。
滥用 H
另一个是H家族。
有人认为,既然H很容易成为收录,那就多加点h1、h2吧。众所周知,h1和h2都有“极限”。如果网页中的 h1 和 h2 过多。搜索引擎会认为站长在作弊,直接不是收录this网站。
一般的h1、h2、h3原则是这样的:
SOP(标准操作程序)
网站上线前,最好做以下检查:
展开 ruby 上使用的 seo gem 效果步骤
1
gem "seo_helper"
1
touch config/initializers/seo_helper.rb
内容如下:
1
2
3
SeoHelper.configure do |config|
config.site_name = "My Awesome Web Application"
end
site_name 是你要出现的站点的名称,如果是小零食店,那就是 config.site_name = "小零食店"
重新打开:
1
rails s
放入。
1
2
3
4
5
def show
set_page_title @product.title
set_page_description “#{@product.description}”
end
每个页面的标题和描述会变得不同:
如果描述太长,你可以这样做
1
2
3
def show
page_description = view_context.truncate(@product.description, :length => 100)
end
站点地图
Google 的算法是基于 PageRank,其运行原理是发送一个“爬虫”来抓取网页上的链接。也就是说网站上的“link”这个链接,基本上是有办法抓到的。
但是还是会有一些问题:
如何解决这些问题?
站点地图并不像大多数人理解的那样引用“网站Map”。它是用于生成网站 的“链接结构”的常用格式(xml)。一般网站可以提交自己的站点地图给搜索引擎。让搜索引擎知道:
谷歌提供了一套SEO工具,可以进一步加强你的SEO效果,并提供网站health check报告叫站长(不管你的网站在国内还是国外,都推荐使用):
您可以在此网站上注册您的网站,并使用此网站进行健康检查和提交站点地图。
(Rails 中有一个gem sitemap_generator 可以做这些事情。这里是Logdown网站(一个博客平台)的sitemap配置文件,你可以试着理解一下:)
config/sitemap.rb:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
# -*- encoding : utf-8 -*-
# Set the host name for URL creation
SitemapGenerator::Sitemap.default_host = "http://logdown.com"
SitemapGenerator::Sitemap.create_index = true
# Generate Sitemaps on read only filesystems like Heroku
# Reference:
# https://github.com/kjvarga/sitemap_generator/wiki/Generate-Sitemaps-on-read-only-filesystems-like-Heroku#using-carrierwave
# pick a place safe to write the files
SitemapGenerator::Sitemap.public_path = 'tmp/'
# store on S3 using CarrierWave
SitemapGenerator::Sitemap.adapter = SitemapGenerator::WaveAdapter.new
# inform the map cross-linking where to find the other maps
SitemapGenerator::Sitemap.sitemaps_host = "http://#{Setting.aws.bucket}.s3.amazonaws.com/"
# pick a namespace within your bucket to organize your maps
SitemapGenerator::Sitemap.sitemaps_path = 'sitemap/'
SitemapGenerator::Sitemap.create do
add "/pages/about"
add "/pages/pricing"
add "/pages/privacy"
add "/tours"
# Put links creation logic here.
#
# The root path '/' and sitemap index file are added automatically for you.
# Links are added to the Sitemap in the order they are specified.
#
# Usage: add(path, options={})
# (default options are used if you don't specify)
#
# Defaults: :priority => 0.5, :changefreq => 'weekly',
# :lastmod => Time.now, :host => default_host
#
# Examples:
#
# Add '/articles'
#
# add articles_path, :priority => 0.7, :changefreq => 'daily'
#
# Add all articles:
#
# Article.find_each do |article|
# add article_path(article), :lastmod => article.updated_at
# end
Blog.where("fqdn is NULL").find_in_batches do |blogs|
blogs.each do |blog|
add "/", :host => "#{blog.domain}", :priority => 0.7, :changefreq => "daily", :lastmod => blog.updated_at
blog.posts.published.find_in_batches do |posts|
posts.each do |post|
add post.relative_url, :host => "#{blog.domain}", :lastmod => blog.updated_at
end
end
end
end
end
Blog.find_in_batches do |blogs|
blogs.each do |blog|
SitemapGenerator::Sitemap.default_host = "#{blog.domain}"
SitemapGenerator::Sitemap.filename = "#{blog.subdomain}"
SitemapGenerator::Sitemap.public_path = 'tmp/'
SitemapGenerator::Sitemap.adapter = SitemapGenerator::WaveAdapter.new
SitemapGenerator::Sitemap.sitemaps_host = "http://#{Setting.aws.bucket}.s3.amazonaws.com/"
SitemapGenerator::Sitemap.sitemaps_path = 'sitemap/'
SitemapGenerator::Sitemap.create do
blog.posts.published.find_in_batches do |posts|
posts.each do |post|
add post.relative_url, :host => "#{blog.domain}", :lastmod => blog.updated_at
end
end
end
end
end

