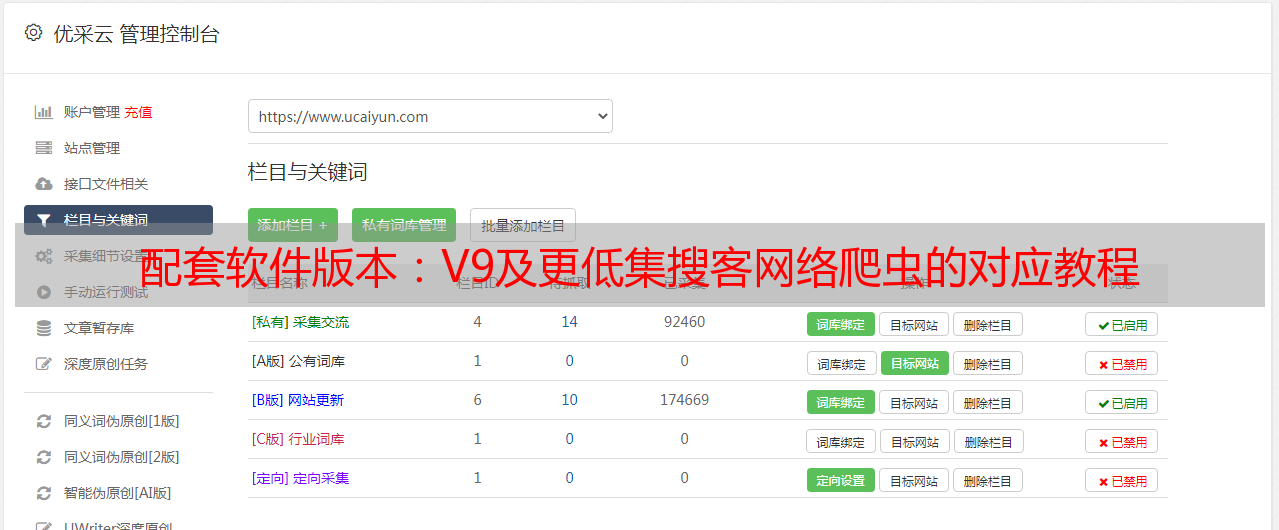
配套软件版本:V9及更低集搜客网络爬虫的对应教程
优采云 发布时间: 2021-08-09 23:16配套软件版本:V9及更低集搜客网络爬虫的对应教程
支持软件版本:V9及以下吉首网络爬虫软件
新版本对应教程:V10及更高版本Data Manager-Enhanced Web Crawler对应教程为《定义爬虫规则采集网站数据》
注:Jisouke的GooSeeker爬虫从V9.0.2版本开始,爬虫术语“主题”改为“任务”。在爬虫浏览器中,先给任务命名然后创建规则,然后登录吉首可以查看任务的采集执行状态,管理线程URL,在“任务管理”中进行调度设置可客官网会员中心。
一、操作步骤(看视频)
下面以京东网站为例,向大家展示如何使用可视化标注的功能采集网页数据。操作步骤如下:
二、Case规则+操作步骤
第一步:打开网页
1.1,打开GS爬虫浏览器,输入网址回车,网页加载完成后,点击“定义规则”按钮,会看到一个浮动窗口,称为工作台,可以定义规则;
1.2,在工作台输入主题名称,然后点击“检查重复”,提示“这个名字可以使用”或者“名字已经被占用,可编辑:是”,可以使用这个主题名称,否则请重命名。
温馨提示:为了准确定位网页信息,点击“定义规则”会冻结整个网页,无法跳转到网页链接。点击“正常浏览”返回正常网页浏览模式。
第2步:标记需要采集的信息
2.1,注解是对网页的文字信息进行操作,双击目标信息选中,在弹出的窗口中输入标签名称,打勾确认或回车。对于第一个标签,输入整理框的名称,即存储数据的表的名称。这也是建立标签和网页信息映射关系的过程。
2.2,重复上一步,标记地址和电话信息。
第 3 步:保存规则并捕获数据
3.1,点击“测试”检查信息的完整性。如果不完整,请右键删除整理框的标签,然后备注。
3.2,点击“保存规则”。
3.3,点击“抓取数据”,会弹出DS点票机启动采集data,测试采集规则是否有效。除了通过“抓取数据”按钮启动采集任务外,还有其他操作方法,详见“DS编号机采集数据”。
第 4 步:查看数据
4.1,采集 成功的数据会以xml文件的形式保存在DataScraperWorks文件夹中。详情请参考文章“查看数据结果”
提醒:本教程只有采集有第一个产品的数据。如果想要采集本页所有产品信息,直接进入下一篇文章第三部分“采集表数据”的步骤,制作样例。

