不会玩爬虫写代码,小白是怎样爬天猫店抓数据的
优采云 发布时间: 2020-05-07 08:00
爬淘宝商铺?就那么简单
在数据营销中,有效、及时地把握第一手数据常常是基本中的基本。在电子商务中更是这样天猫爬虫,了解竞争对手的动态可以使你更好地对自身产品、定价和表现形式进行优化。本篇我们将奔向主题提供一种简单的抓取天猫店数据的方式。
这或许是最简单的爬虫方式
我们将用到的是谷歌Chrome浏览器的桌面版,还有Chrome的浏览器插件Web Scraper。该插件可以在webscraper.io下载到,完全免费。
安装完Web Scraper可以在Chrome右上角找到图标
我们假定在Windows平台上,按F12。Chrome开发者工具会弹出。我们在菜单中选择最左边的Web Scraper先放到一边。至此打算工作已完成。
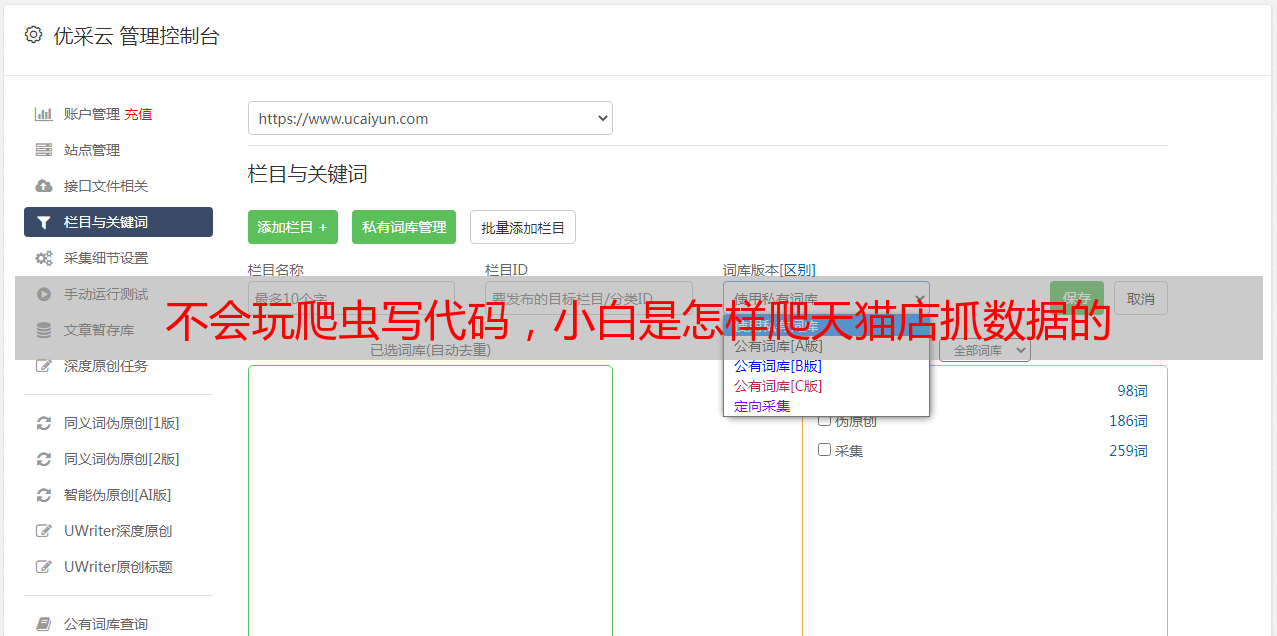
我们打开天猫店铺总能见到全部商品分类的选项。我们选中后会带我们去和下边URL相像的地址。
spm=a1z10.5-b-s.w17695525-15102841353.2.1be86b1ednN0aS&search=y
上面URL中标红的参数spm并没有用,有用的是search还有未在里面出现的pageNo。前者永远为y,后者为页数。那么索尼官方旗舰店的第二页商品列表的URL就是
y&pageNo=2
而索尼官方旗舰店产品只有5页。所以我们先把这个URL规律和总商品页数记出来。
我们回到Web Scraper。点击Create new sitemap。依次填入Sitemap name:sony-tmall和Start URL:;pageNo=2。点击Create Sitemap按键。
我们先尝试抓取第二页上的所有商品
新建后我们会在有一个Add new selector黑色按键的界面。此处我们的位置为_root。
这里的selector的意思是CSS Selector即CSS选择器。我们在之前文章中详尽介绍过。
CSS选择器的作用是在HTML中定位。我们如今浏览器的地址栏中打开我们要爬的页面。然后点击刚刚提及的白色按键Add new selector。
我们首先要选的是页面元素天猫爬虫,每个元素就是一个商品的长方形表示区域。在Id中填入item,在Type中选择Element后,我们点击Selector中的Select按键。
鼠标渐渐联通,直到整个元素不多不少高亮
当你的键盘此时放在商品区域边沿时,该区域会高亮,点击后再按下边的白色按键Done selecting!你会发觉Data preview门口早已手动输入了选择器。
如果此时你跟随马老师的节奏,你的选择器看上去会是这个样子:div.item5line1:nth-of-type(1) dl.item:nth-of-type(2)
启用Element preview按键时,该块区域会再度高亮,先关掉它。接下去我们点上Multiple这个选框,没哪些变化,这是因为我们的选择器只选择了一件商品。因此我们要自动进行更改,去掉一些过滤条件把它简化为divdl.item。
当我们再度启用Element preview时,就能看见所有商品区域都高亮了。
Checkpoint,看下是不是做对了
点击红色按键Save selector保存。我们的第一个选择器就完成了。
上面我们只是对一个个商品单元做了定位,它们相当于你的数据表中的每一行。接下来每一列就是我们要在商品单元中真正抓取的数据了。我们大约须要抓取商品名称(title)、价格(price)、销量(sale)、评价(comment)这些数据。于是我们点入刚才我们新建的选择器开始新建那些列。此时我们的位置在_root / item。
上述4个数据元素的选择器构建方式和我们里面的方式基本一致,为了节约篇幅我们只说一些区别。
类型(Type)不再选择Element而是Text。由于每位单元中只有一个惟一数据源,因此不勾选Multiple。Parent Selectors记得选择item而不是_root。评论的选择器中添加Regex:[0-9]+这是为了去除“评价: ”而只保留纯数字。
最后我们要建一个产品ID栏——product_id。选择器为_parent_
注意Type和Attribute name:data-id
保存完最后这个属性后,我们可以看见界面中有这种选择器,上面略过的所有选择器都在右图中列举,可直接使用:
这就是我们要抓取的每位商品的5个属性
点击_root回到上一层,然后点击红色按键Data preview,我们就可以预览这个页面上我们要抓取的内容。
检视是否数据已被正确抓取辨识
是不是觉得渐入佳境了?你会发觉有几个商品的评论数为null,这是因为这些是页面顶部的促销款式,我们可以在导入后在Excel中过滤掉。现在先不用处理。
你是否注意到我们只抓了第二页?别急,我们如今就来补完。你应当注意到页脚2/5了。没错一共有5页。我们可以点击菜单中的Edit metadata来修改Sitemap的设定。
更改抓取页面范围
我们只要将Start URL改为;pageNo=[1-5]就可以连续抓5个页面了,请放心食用。改完保存后就可以点选上图菜单中的Scrape,然后开始一街抓取。这里请注意,由于防爬虫机制假如你未登入淘宝,那么过不了多久马爷爷会请你输入验证码。因此建议你保持登入状态。(至于登陆后是不是会封号,请后果自负……)
爬完了点击refresh就可以看见抓取完的数据了。是不是满意呢?再次点击上图菜单中的Export data as CSV即可导入数据到Excel进行后续的剖析处理,这里不再赘言。