新闻检索系统思路与框架本系统的实现思路和框架
优采云 发布时间: 2021-08-02 02:26新闻检索系统思路与框架本系统的实现思路和框架
1 系统介绍
1.1 系统要求
新闻检索系统:针对采集不少于4个中文社交news网站或频道,实现对这些网站news信息和评论信息的自动抓取、提取、索引和检索。本项目未使用Lucene、Goose等成熟的开源框架。
1.2 系统思路和框架
本系统整体实现思路如图1所示:
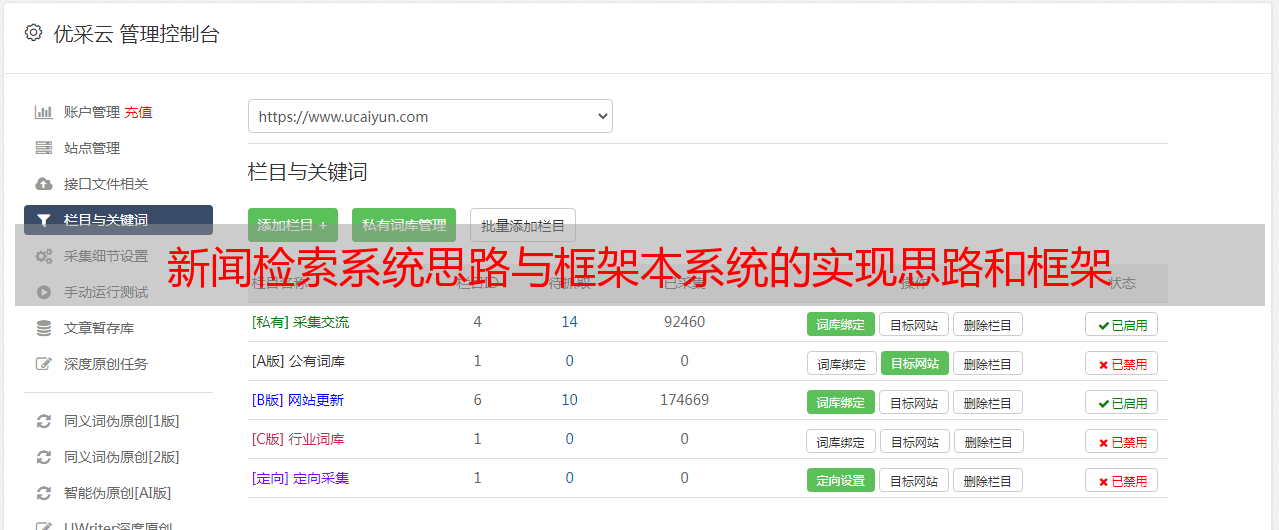
一个完整的搜索系统的主要步骤是:
爬取新闻网页获取语料库
提取新闻主要内容得到结构化xml数据
内存型单遍扫描索引构造方法构造倒排索引供检索模块使用
用户输入查询,相关文档返回给用户
2 设计方案
2.1 新闻爬取
2.1.1 算法简述
本模块抓取搜狐、网易、腾讯三大主流新闻网站的新闻,以及官方参考新闻网站。并基于其网站结构设计了不同的爬取模式。由于网站架构彼此相似,因此选取以下两类典型代表进行介绍:
(1)搜狐新闻
搜狐新闻除了普通首页之外,还有隐藏的列表式新闻页面,比如。
(2)网易新闻
网易新闻和腾讯新闻可归于一般新闻首页。我们从新闻主页开始采用广度优先的递归爬取策略。请注意,新闻的正文页面通常是静态网页 .html。因此,我们记录所有出现在网页中的以.html结尾的网页的网址,并在达到一定的抓取量后进行去重。
对于一些误分类的非新闻网页,通过检查新闻正文标签进行容错处理
将被删除。
在主新闻页面,我们专注于内容、时间和评论获取。
2.1.2 创新点
实现了新闻网页动态加载评论的爬取,如搜狐新闻评论爬取
在没有借助开源新闻爬虫工具的情况下,实现了对新闻标题、文本、时间、评论内容、评论数的高效爬取。
2.2 索引构建
分词,我们使用开源的jieba中文分词组件来完成,jieba分词可以将一个中文句子切割成单独的词条,这样tf,df就可以统计了
要停用词,在jieba分词后完成停用词步骤
倒排记录表存储,字典采用B-tree或hash存储,倒排记录表采用相邻链表存储方式,可以大大减少存储空间
倒排索引构建算法采用基于内存的单遍扫描索引构建方法(SPIMI),即依次对每条新闻进行切分。如果出现新的词条,则将其插入到词典中,否则将文档的信息附加到词条对应的倒排记录表中。
2.3 搜索模块
2.3.1 搜索模式
(1)关键词search
查询是根据用户输入的关键字返回相应的新闻。首先根据用户的查询进行jieba分词,记录分词后的词条数并以字典的形式存储。
完整源代码和详细文档上传至WRITE-BUG技术分享平台。有需要的请自取:

