(续)如何获取互联网知识以形成自己的知识库/资料库
优采云 发布时间: 2020-08-08 19:23
X
tagLyst最初旨在标记文档. 现在,您还可以在“剪贴板”中标记图片/文本,并将其另存为“数据库”中的文档. 特别适合提取网页内容的一部分并将其存储为“卡”.
从那时起,采集互联网知识的宝藏就更加方便了!
采集和管理文本: 以“ 知乎”为例
我们仍然以“ 知乎”为例. “芝湖”是一种高质量的矿山.
\ 1. 首先打开tagLyst并切换到“浮动窗口模式”.
\ 2. 在“ 知乎”上搜索您感兴趣的问题时,如果找到喜欢的内容,请使用传统的Ctrl + C复制.
\ 3. tagLyst浮动窗口可以自动显示我们刚刚复制的内容. 我们需要做的就是更改文件标题或为其添加标签,然后单击“存档”. 如果发现麻烦,也可以直接单击存档,然后在tagLyst界面中对其进行缓慢组织.
(默认保存文件类型为TXT,也可以选择Markdown格式)
以Unsplash为例,采集和管理图片
\ 1. 首先打开tagLyst并切换到“浮动窗口模式”.
\ 2. 如果您在Unsplash网页上看到自己喜欢的图片,请右键单击“复制图片”.
\ 3. tagLyst浮动窗口可以自动显示我们刚刚复制的图片. 就像采集文本一样,直接选择标题,标签或文件.
管理下载文件,以Office模板为例
许多网站都提供高质量的Office模板下载. 我们下载的文件可能会散布在整个桌面或下载目录中,但是我们不知道何时需要特定文件.
类似地,使用tagLyst对其进行组织
\ 1. 首先打开tagLyst并切换到“浮动窗口模式”.
\ 2. 假设该Office模板文件在桌面上,则将其下载到网页上.
\ 3. 将文件拖到“浮动窗口”,选择数据库,然后直接归档.
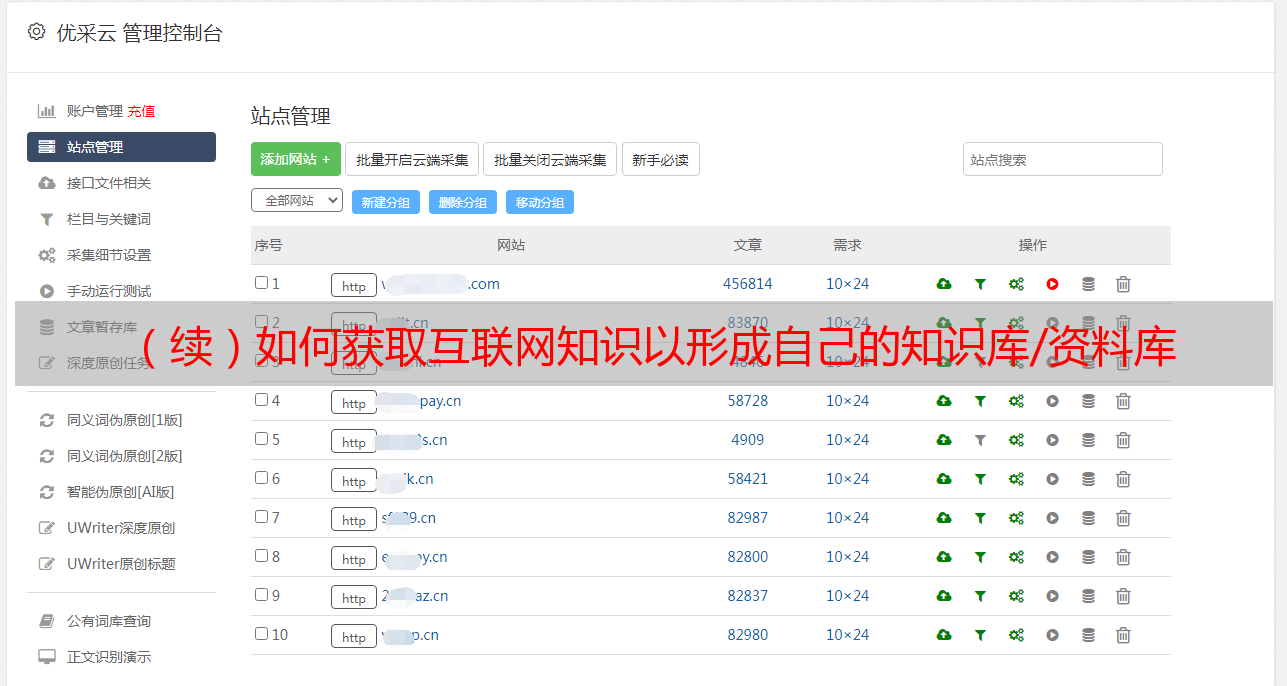
一个更具体的例子,以棒球知识库为例
我们的一个小朋友非常喜欢棒球. 我一直在Wiki上采集一些棒球明星和经典比赛. 他将使用tagLyst构建“棒球明星数据库”. 有关具体操作,请参见以下GIF*敏*感*词*:
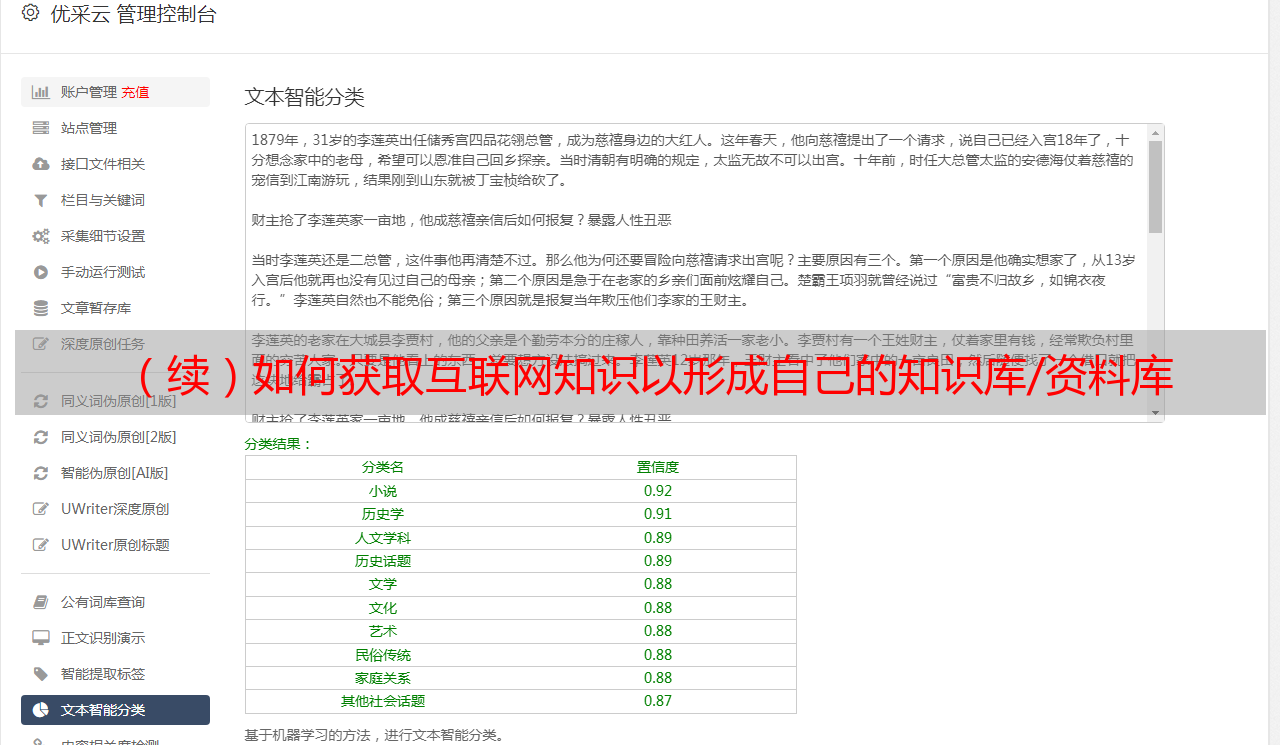
最后
所有采集的知识都存储在tagLyst的每个“数据库”中,您可以在需要时基于标签进行搜索.
即使如此,您通常也可以在“卡片模式”中浏览结果并添加“标签尺寸”,以使存档的数据真正成为我们的专有知识.
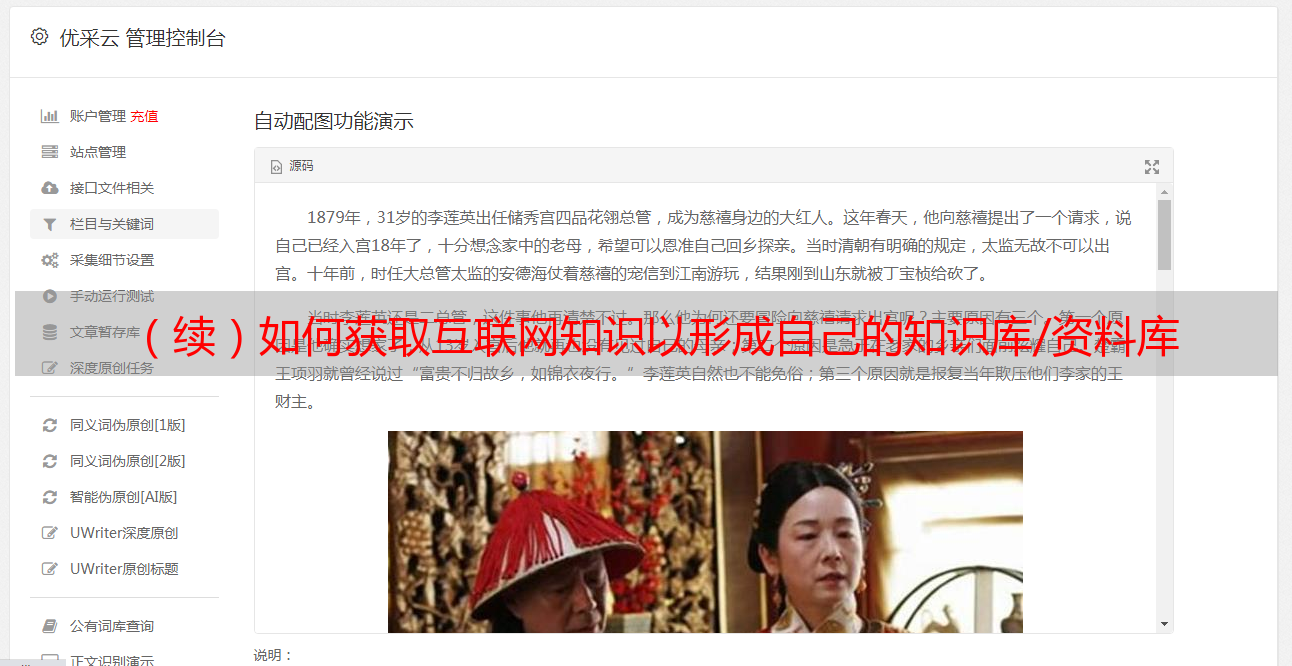
此外,对于保存在“数据库”中的文本文件/ Word / PDF / XLSX,tagLyst还支持全文搜索,这使获取知识变得更加容易!
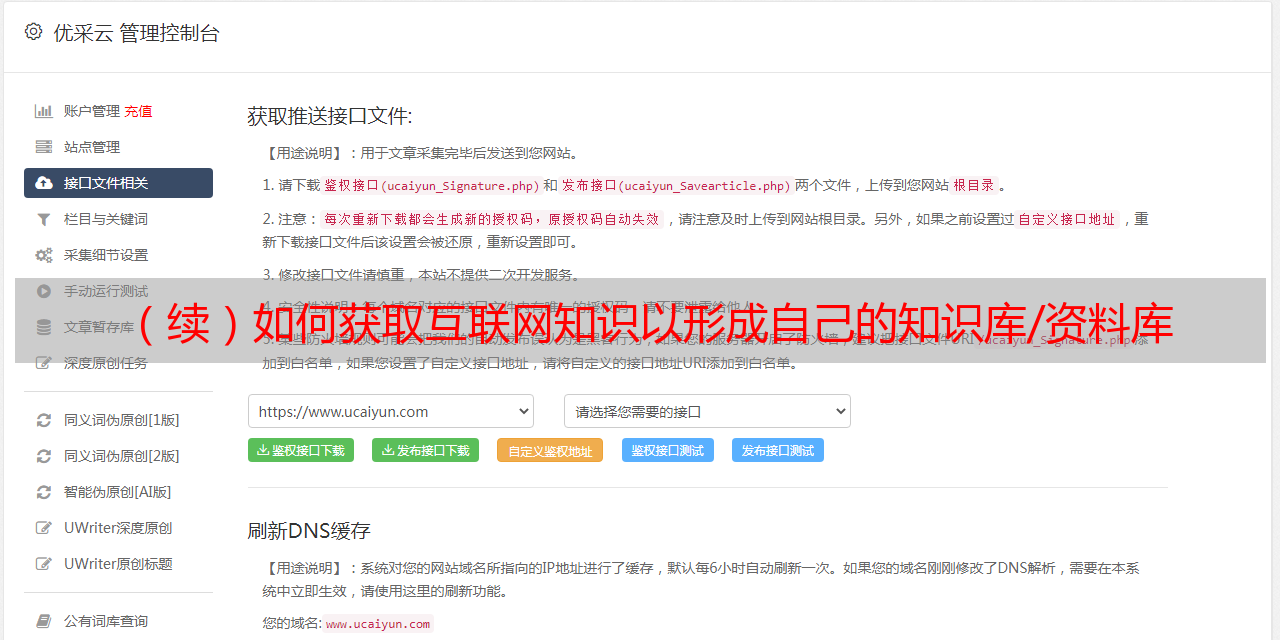
您如何使自己领先于“知识增长”?最好尽快开始使用“ Internet”并建立自己的专有知识库!
tagLyst官方网站地址

