天甘慕理:如何通过元数据中心提升开发效率
优采云 发布时间: 2021-06-08 07:18
天甘慕理:如何通过元数据中心提升开发效率
作者 |阿里娱乐高级开发工程师田干木力责任编辑|涂敏头像| CSDN从东方IC下载
背景
你一定也有同样的感觉。在开发业务需求时,1/3的时间花在了准备工作上。比如研究数据从哪里来,检查几条真实数据及其结构,然后开始编写代码过滤出需要的数据,将数据组装成需要的结构……经过漫长的过程,你可以进入主题。今天我将介绍如何使用元数据中心来帮助您直接提高开发效率。
什么是元数据中心?主要有两个功能:数据源方的沉淀和自定义界面。
1)数据源广场:通过关键词搜索基础平台服务相关接口,手动快速调用查看接口;
2)自定义接口:根据业务定制的必填字段(字段名、类型),元数据中心SDK还抽象出接口调用的一系列逻辑,积累“接口调用引擎”,业务开发只需要将平台下发的接口标签传递给引擎即可完成接口访问,由硬编码变为配置。
除了以上两点,元数据中心还建立了统一的监控和融合能力,并采用了多线程池来保证接口调用的效率和稳定性。
架构

元数据中心有两个核心模块:1)data source,对基础平台服务的接口(如需求中的ABCD系统)进行标准化调用; 2)custom interface,为业务开发组织接口,包括输入输出参数的定义。
1、数据源
数据源模块对基本平台服务接口进行标准化调用。与其他平台标准化不同,基础平台服务不需要实现java接口,减少了基础服务的访问。目前元数据中心暂时支持 HTTP 和 RPC 接口,后续会逐步支持分布式数据库数据源、分布式缓存数据源和模拟数据源。数据源模块使用以下技术来保证调用的稳定性:
数据源模块采用多线程池技术,不仅可以并发调用保证接口调用的稳定性,还可以根据接口调用情况动态调整使用的线程池,保证性能不佳一个接口不会影响其他接口调用;
采用广义调用技术,广义调用技术避免了引入两方包导致的包冲突问题;
数据源模块也支持批量调用。对于queryByIdList等很多查询,查询ID必须有count限制,但有时业务需要的单次查询数量超过限制,则需要批量并发。多次调用,然后合并结果;
使用ThreadLocal技术,元数据中心还支持接口调用超时时间的动态调整。有的业务为了获取数据可以容忍长时间的RT,有的业务对RT比较敏感,所以可以根据不同的业务调整超时时间。进行个性化设置。
2、Business 自定义界面
1)Schema 的定义
通常在业务开发的时候,接口主要解决两件事:1)连接底层数据源,2)结合几个数据源的结果形成一个业务接口,暴露给上层业务。所以在设计Schema的时候就考虑了以上两点,Schema分为call和return,根据不同的需求调用了哪些数据源,配置了这些数据源的依赖关系,接口需要的方式要返回的配置。可以直接显示数据源的返回结果,并对结果进行简单的维护。您也可以自己定义结果,指定值的来源,控制和干预结果的类型和结构。
2)Schema 执行引擎
先解决依赖,再进行数据源调用,调用后根据返回配置进行处理。这里,如果返回值配置为表达式,则引擎直接将该表达式作为中间结果执行,并根据特殊配置对中间结果进行处理。如果不指定配置表达式,而是指定需要哪些字段,引擎会根据这些字段值的表达式进行设置。如果该字段是嵌套的,则引擎将递归处理嵌套的 Schema。
有很多使用场景,一个业务接口需要两个数据源的支持。对于依赖,抽象出依赖解析器,遍历所有数据源调用,分析调用关系,生成依赖树。调用时,对树进行分层和预排序,确保先执行非依赖调用,再处理依赖调用。比如总共需要调用8个数据源,分别是A、B、C、D、E、F、G、H,其中C依赖A,D依赖A和B,E依赖B,G依赖C,F依赖C和D,H依赖E。下图是生成的依赖树:
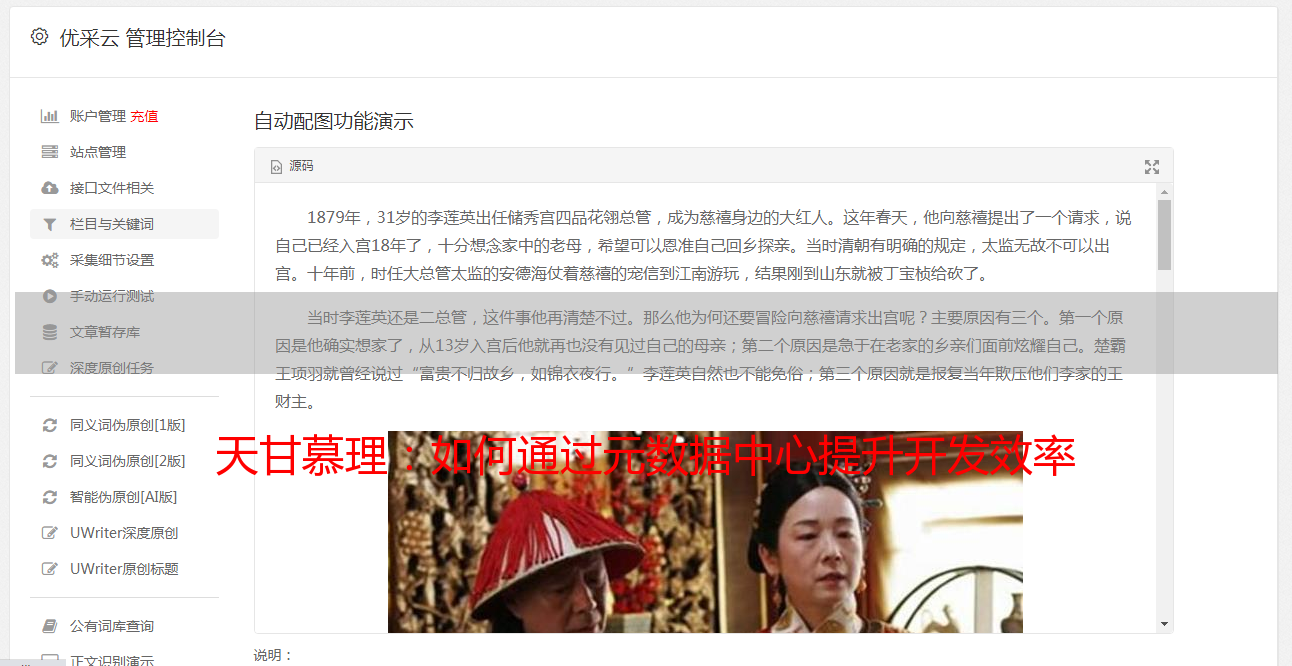
如图,ROOT是先逐级遍历的,不过这是一个没有处理的虚拟节点,然后处理A和B。这里可以并发调用,也可以顺序调用,交给数据源调用层处理。 . A和B的处理完成后,处理A的子节点和B的子节点C、D、F。直到处理完所有节点。
引擎调用数据源后,需要根据表达式映射结果。如果需要自定义每个返回的key,比如调用视频查询,默认返回的key是id,需要返回给业务端的是vid,可以配置key的value表达式。在设计中,我们希望表达式尽可能简单,所以我们设计了这样一个表达式,比如vid,可以配置为datasource.video.response.id。
3)动态脚本执行与优化
因为整体技术栈是Java,首选脚本语言基于JVM,选择Groovy是因为成熟,语法比Java简单,二是因为访问简单(只有一个jar包)需要),第三是因为它兼容Java的大部分语法,学习成本低。
主要是安全问题和性能问题。安全问题非常严重,因为脚本是交给用户输入的,所以很容易出现有风险的代码。系统对Groovy编译器进行了一系列的定制,同时使用沙箱来拦截代码,过滤敏感操作,最大限度的避免有风险的代码执行。
在性能方面,Groovy 的性能比 Java 慢很多,所以做了一些优化,比如预编译和缓存 Groovy 代码,以确保在执行过程中不会发生编译动作,以及确保不会执行单个 Groovy 脚本。性能问题太大了。
经过测试,发现Groovy本身的执行效率还是很低的,因为一个请求可能需要执行成百上千个脚本。一次执行的性能问题不明显,但多次执行的问题很容易暴露。原生 Java 执行仍有百倍差距。
既然是Groovy的问题,也没有解决办法,就想着能不能用其他方式代替Groovy,于是研究了各种表达式引擎,包括Aviator、FEL、MVEL、JSONPath、Java动态编译。并且为了测试这些代码,使用两个语义相同的代码,分别编写不同的脚本版本,并与原生Java代码进行比较。长时间运行后的结果如下:
上图展示了两个脚本执行耗时1000次。发现使用Java动态编译和JSON-Path的性能比Groovy高150倍左右。但是缺点也很明显:JSON-Path可以写单行值语句,而Java语法复杂,不方便写内部类和方法。考虑到使用场景,Java和JSON-Path满足95%以上的场景,可以使用Groovy编写更复杂的脚本。
稳定性
稳定性比一切都重要。接口调用稳定性是重要的一环。如何保证稳定性? 1)遇到问题一定能及时报警。 2)为了整个应用的稳定性需要自动熔断。
1、监控报警
由于元数据中心SDK是去中心化的,接口调用逻辑发生在业务应用本地。 SDK使用logback的appender扩展将日志异步发送到日志服务,然后使用监控平台采集日志服务的日志,在监控平台完成监控和告警构建。元数据中心 SDK 还集成了调用链监控平台。不仅可以在业务应用对应的调用链监控平台上看到接口调用状态,还可以通过logback的ClassicConverter扩展,在日志中统一添加调用链的唯一ID,方便访问这个ID查看完整链接日志,快速定位问题。
2、fuse 降级
如果你的应用有外部依赖,那么熔断是保证系统稳定性必不可少的手段。想象一下,一个依赖的 RT 突然变高了。如果不及时进行fuse,那么你的应用的线程池资源会很快被依赖消耗掉,整个应用都不会响应,造成雪崩,所以fuse的重要性不言而喻。元数据中心目前支持三种融合策略:RT、二级异常率、分钟异常数。
提高效率的实践
说了这么多,能不能提高业务开发的效率?实践是检验真理的唯一标准。接下来我们来看看元数据中心如何与业务融合,提高业务开发效率。
1、与内容分发开发框架集成
目前优酷的主打APP业务基本采用统一的内容分发开发框架进行开发,因此与内容分发开发框架的整合是提升业务开发效率的最佳切入点。内容分发开发框架虽然拥有强大的配置能力,但其数据源开发仍然面临着到处找接口、学习调用、然后引入两方包、硬编码、测试的问题。 Aone 发布了一系列冗长且重复的操作。另外,一旦有接口需要切换或者业务需要添加字段等变更操作,也需要通过硬代码进行变更,不仅开发效率低下,而且频繁的发布也会增加系统的不稳定性。结合元数据中心的目标,与元数据中心集成的内容分发开发框架可以完美解决其痛点:
我们来看看开发者的反馈。最近跟业务开发同学了解到,目前开发新组件的需求涉及到需要读取一定的数据,通过元数据中心配置相关接口和必填字段,并结合开发框架的配置能力,有从开发到上线基本没有硬编码,通过配置快速上线验证。
2.与 Faas 集成
众所周知,互联网产品强调快速迭代和试错,企业需要具备快速上线与竞争对手竞争的能力。这意味着其背后的技术研发过程需要更加高效,元数据中心与Faas的结合才能达到快速上线的效果。因为业务开发可以通过元数据中心快速接入接口,结合Faas开箱即用的特性,直接编写业务逻辑,保存后自动完成构建和部署。整个过程简单而高效。足以达到快速在线验证的目的。原优酷小程序业务已经在元数据中心+Faas下开展了多项业务。
总结与展望
元数据中心平台已初步上线,通过与内容分发开发框架的整合,服务了优酷APP的部分业务场景,并与Faas整合服务了部分小程序的业务场景。从业务开发反馈的角度,实现了业务在数据源访问层面从硬编码模式向配置模式的转变,大大提高了开发效率。
虽然平台的基础能力已经搭建完成,提升开发效率的目标已经初步实现,但是平台建设还有很长的路要走,还有很多工作要做,比如提高配置效率,支持更多协议数据源,最大化平台价值。
更多精彩推荐
☞急缺芯片,高通是华为的唯一选择吗?☞征战云时代,为什么安全是关键命题?☞人均月薪 7.5 万,腾讯 Q2 成绩单来了,网友酸了?☞为什么气象站和 AI 都测不准天气?☞2019年中国IaaS公有云市场排名及份额出炉☞马小峰:金融科技界的区块链博士