自动采集编写 技巧:假如你已经开始学Python,对爬虫没有头绪,不妨看看这几个案例!
优采云 发布时间: 2022-12-25 08:53自动采集编写 技巧:假如你已经开始学Python,对爬虫没有头绪,不妨看看这几个案例!
这些案例是为一些想进入Python行业的朋友写的。 我看大家都满意,就又拿出来了。 如果你已经开始学习python,对爬虫一窍不通,不妨看看这些案例!
2、环境准备
蟒蛇3
请求库、lxml 库、beautifulsoup4 库
一起安装pip install XX XX XX。
三、Python爬虫小案例
1.获取本机公网IP地址
使用python的requests库+接口查公网IP自动获取IP地址
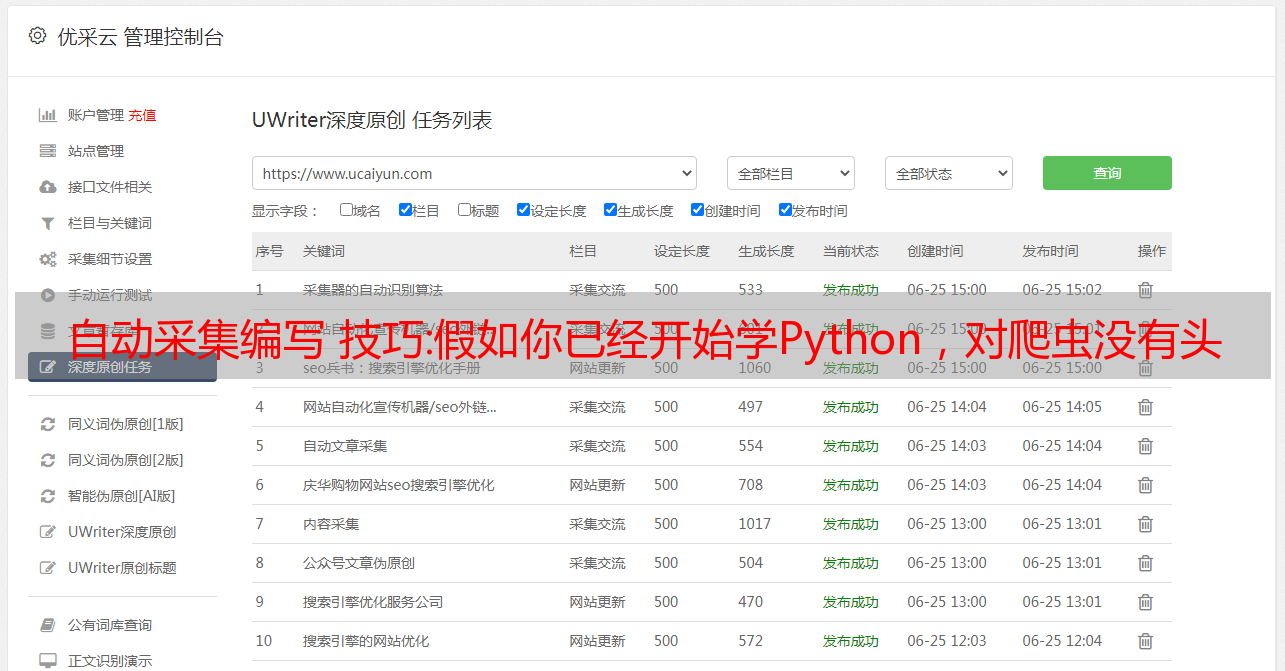
2.使用百度的搜索接口和Python编写url采集工具
需要使用requests库和BeautifulSoup库来观察百度搜索结构的URL链接规则。 绕过百度搜索引擎反爬虫机制的方法是在程序中设置User-Agent请求头。
蟒蛇源代码:
用Python语言写好程序后,使用关键词inurl:/dede/login.php批量提取某网cms后台地址:
3.使用Python创建自动下载搜狗壁纸的爬虫
搜狗壁纸的地址是json格式的,所以用json库解析这组数据,把爬虫程序存放图片的磁盘路径改成要存放图片的路径。
效果图:
4.Python自动填写问卷
与一般网页一样,如果多次提交数据,则需要输入验证码。 这就是反爬虫机制。
如图所示:
那么如何绕过验证码的反爬措施呢? 使用X-Forwarded-For伪造IP地址访问,Python代码如下:
影响:
5、获取Xithorn代理上的IP,验证这些代理被封禁的可能性和延迟时间
可以将Python爬取的代理IP添加到proxychain中,即可进行一般的渗透任务。 这里linux系统命令ping -c 1 " + ip.string + " | awk 'NR==2{print}' - 被直接调用。 要在 Windows 中运行此程序,需要修改倒数第二行 os.popen 中的命令,将其修改为 Windows 可执行。
爬取到的数据如图:
演示:
综上所述
解决方法:关于网站链接使用相对路径还是绝对路径的问题
今天在网上看到一些文章网站链接是使用相对路径还是绝对路径的文章。 我总结整理了一下。 如果我错了,我希望你能纠正我:
1.使用绝对路径的好处
1、当有人采集或抄袭你的网站内容时,他们也可能会采集文章中的链接,为你添加外链
2.当不能使用301重定向时
比如域名不能实现301重定向,那么这个网站的链接就会被硬编码修改链接到,这样即使用户在这个网站点击了这个链接,也会链接到另一个网站, 蜘蛛也可以跟随它。 此链接收录到您要收录的网站
3、使用绝对链接,即使移动了网页的位置,仍然可以链接到想要的URL位置(例如:A页面使用绝对路径链接到B页面,A--》B,那么无论a页如何移动,只要b页的位置保持不变就可以链接到)
弱点是:
1、本地测试不方便,因为都是指向网络的绝对地址
(如果本地测试用的是相对地址,上传完再修改成绝对地址,好像很费时间,麻烦~)
2、优势3中提到,如果要移动B页,A页不能链接到B页的原地址
3、更改域名时,需要更改链接
二、相对路径的优缺点与绝对路径正好相反
优点是: 1. 更改域名时,无需更改链接
2.方便本地测试
复制
缺点是:1.容易被别人采集或复制,或者直接镜像网站

