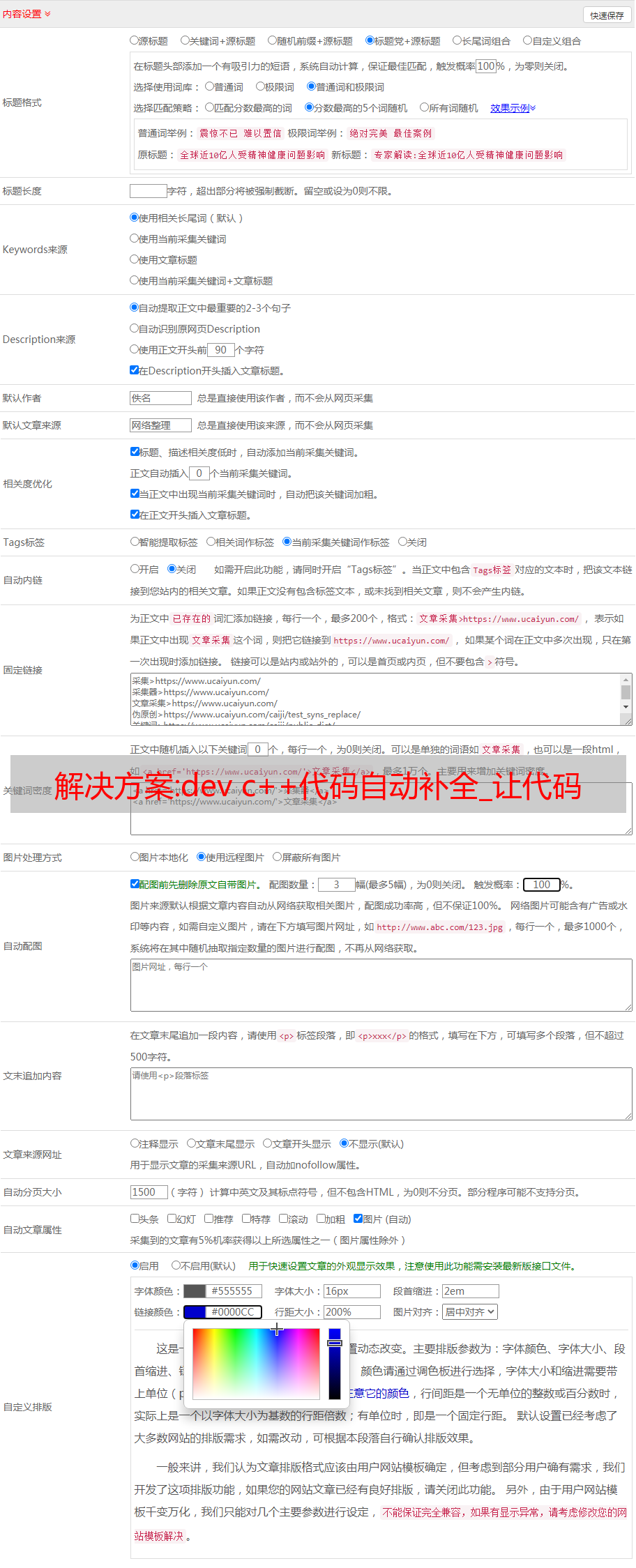
解决方案:dev c++代码自动补全_让代码自动补全的全套流程
优采云 发布时间: 2022-12-25 08:45解决方案:dev c++代码自动补全_让代码自动补全的全套流程
作者:熊伟,黄飞,腾讯PCG/QQ研发中心/CV应用研究组
如果AI真的能写代码,程序员将何去何从? 近年来,NLP 领域的生成任务有了显着改善。 能否通过AI让代码自动完成后续补全? 本文主要介绍如何使用GPT2框架实现代码自动补全功能。
如果AI真的可以自己编写代码,程序员将何去何从?
去年做了一个代码补全的小功能,打包成androidStudio插件。 效果如下:
有时候代码补全模型预测出来的结果真的吓到我了,可以借鉴一下~? 那么如果它看到了世界上优秀的代码,然后给它足够量级的参数和优秀的模型框架,真的可以实现作为输入,直接输出代码的需求吗?
“我的需求完成了,你的代码呢?” 我希望看到这一天。
代码补全功能已经被其他优秀的插件实现,比如tabnine、Kite和国产的aixcoder。 本文主要介绍代码补全功能需要实现的整个过程。 主要包括数据、算法和工程。
数据
我们都知道算法工程师大部分时间都在处理数据。
深度学习是利用大数据训练模型的过程,数据是非常重要的一个模块。 人很累,休息不好会导致记忆力变差。 人工智能意味着它可以存储和接收你提供给它的尽可能多的数据。 如果它不能学习信息,那是人类的错。 给的数据不好或者算法设计不好。 所以我们首先准备尽可能多的训练数据。
1. 数据采集
本文的目的是代码补全,训练数据是代码段。 鉴于每种语言的风格和语法不一致,单个模型仅针对一种代码语言。
我使用的训练数据主要来自GitHub,写了一个简单的爬虫代码,指定语言后,按照stars顺序下载项目。
Github的搜索API官方地址:
2. 数据清洗
直接下载的数据一定不能直接使用,我们还需要清理数据。
首先,我们的训练数据只需要项目中的代码文件。 以java项目为例,我们只保留.java结尾的文件,其他文件可以剔除。
其次,我的代码补全目标是代码段,而不是注释函数。 而对于代码补全训练,我们会给出一定范围的上面,如果有评论区,会占用有效代码信息。 另*敏*感*词*内,所以需要清理代码中的注释和日志。
1.删除代码行中除符号和英文以外的字符
2.删除日志行
3.删除注释行,主要针对以下几种格式
/* 注释文本*/
/**
注释段落
*/
// 注释文本
code //注释
经过以上数据清洗,得到纯代码数据。
3.数据编码
得到训练数据后,需要对代码文本进行编码。 本文采用bpe(byte pair encoder)字节对编码,主要是数据压缩。 BPE简单理解就是把一个词拆分成多个字母组合,比如把tencent拆分成ten-cent,这些组合是根据大量数据和统计频率得到的。 由于我们期望的代码补全功能是在行首输入几个字母,所以该行的内容按照上面的期望。
假设tensorflow的token编码对应一个id,我不可能输入十就输出tensorflow。 所以在训练过程中,我会随机打断token,比如打断tensorflow进入t-en-sor-flow进行编码。 打断的原则是被切分的部分必须在词汇表中。 数据编码后,code的每个token被编码成1~N个id。 模型预测的id可以反向编码成token。 回车被认为是预测终止符。 经过上面的处理,我们已经准备好了训练数据,下面就可以进行算法部分了。
模型算法
众所周知,算法工程师大部分时间都花在算法上。
在腾讯文档错别字的纠错要求中,我们使用了facebook提出的基于LSTM的seq2seq和基于CNN的seq2seq,可以得到很好的纠错效果。 直到出现了NLP领域的“网红”——BERT,采用后准确率直接提升了8个点左右,这对google来说已经不错了。 下面简单介绍一下bert和gpt2。
BERT 和 GPT2
2017年年中,谷歌提出了Transformer结构。 没有rnn,没有cnn,提出关注就是你所需要的。 2018年,openAI采用了transformers结构,2018年发布了GPT。同年,google AI Language发布了bert paper,提出的BERT模型在11个NLP任务上刷新记录。 2019年,openAI推出了GPT-2模型。 .
BERT(Bidirectional Encoder Representation from Transformers)是基于transformers框架的编码器部分,自编码语言模型,适用于N-1(如句子分类)、NN(如词性标注)任务, 但它不适合生成任务。
GPT(Generative Pre-Training)是基于transformers的decoder部分,一种自回归语言模型,适用于生成任务。
代码补全功能基于GPT2框架。 OPenAI官方提供多套GPT2预训练模型:
作为一个经常将模型部署到移动端的CVer,看到这个参数水平,我选择最小的模型进行finetune。
对于GPT算法,这篇文章很不错,有兴趣的同学可以看看。
本文在训练中使用了512个上下文,预测回车符终止。 模型网络使用超参数:12层,768个隐藏节点,12个头,使用uber的Horovod分布式框架进行训练。
在infer阶段使用beam-search会导致整个预测过程特别耗时。 所以参考论文,采用top-k采样。 top3每次预测的结果经过概率阈值过滤后作为最终的候选输出。
最终推断效果:
输入一段代码,预测后续代码,回车结束。
项目
我们都知道,算法工程师大部分时间都在做工程。
模型训练好后,需要对模型进行应用,所以需要实现一些工程化工作。 代码补全功能最适合的应用场景就是IDE。 nlp模型不适合本地部署,最终选择将模型部署在GPU机器上,然后终端通过http请求获取预测文本显示方案。
后台部署
Flask 是一个灵活、轻量级且易于使用的 Web 应用程序框架。 本文简单介绍一下如何使用flask启动一个web服务,以及如何访问和调用我们的功能接口。 首先我们创建一个conda环境:
conda create -n flask python=3.6
source activate flask
pip install flask
在代码中添加一个接口函数:
from flask import Flask
from flask import request
app = Flask()
# route把一个函数绑定到对应的 url 上
@app.route("/plugin",methods=['GET',])
def send():
data = request.args.get('data')
# 模型预测逻辑
out = model_infer(data)
return out
if __name__ == '__main__':
app.run(host='0.0.0.0',port=8080, debug=False)
执行run.py代码,后台服务开始运行:
客户要求:
url = http://ip:8080/plugin?data="输入"
其中model_infer函数需要实现模型的infer前向计算逻辑,从请求中获取data字段作为输入,将infer预测的结果列表作为输出返回给调用者。
经过上面的工作,我们已经提供了一个服务接口来返回我们代码补全的预测结果。
插件编写
最后一步是如何在 IDE 上使用该功能。 我们要开发AS插件,需要用到IntelliJ,首先我们需要在本地安装配置IntelliJ IDEA
下载链接:
社区版源代码:
一个有用的插件可以为程序员节省很多时间。 在实现插件的时候,我还加入了一个git-blame的小功能,可以实时查看指定行的git committer。 对于手Q等多人协作工作比较实用。 你也可以通过IntelliJ自己开发一些常用的功能。
gitBlame的主要代码:
public class GitBlame extends AnAction {
private void showPopupBalloon(final Editor editor, final String result) {
ApplicationManager.getApplication().invokeLater(new Runnable() {
public void run() {
JBPopupFactory factory = JBPopupFactory.getInstance();
factory.createHtmlTextBalloonBuilder(result, null, new JBColor(new Color(186, 238, 186), new Color(73, 117, 73)), null)
.setFadeoutTime(5000)
.createBalloon()
.show(factory.guessBestPopupLocation(editor), Balloon.Position.below);
}
});
}
@Override
public void actionPerformed(AnActionEvent e) {
// TODO: insert action logic here
<p>
//获得当前本地代码根目录
String base_path = e.getProject().getBasePath();
String file_path = e.getProject().getProjectFilePath();
//获取编辑mEditor
final Editor mEditor = e.getData(PlatformDataKeys.EDITOR);
if (null == mEditor) {
return;
}
SelectionModel model = mEditor.getSelectionModel();
final String selectedText = model.getSelectedText();
if (TextUtils.isEmpty(selectedText)) {
return;
}
//获取当前编辑文档的目录
PsiFile mPsifile = e.getData(PlatformDataKeys.PSI_FILE);
VirtualFile file = mPsifile.getContainingFile().getOriginalFile().getVirtualFile();
if (file != null && file.isInLocalFileSystem()) {
file_path = file.getCanonicalPath();
}
//gitkit工具
JGitUtil gitKit = new JGitUtil();
String filename = file_path.replace(base_path+"/","");
//得到blame信息
int line_index = mEditor.getSelectionModel().getSelectionStartPosition().getLine();
String blame_log = gitKit.git_blame(base_path,filename,line_index);
//展示
if (!blame_log.isEmpty()){
showPopupBalloon(mEditor, blame_log);
}
}
}
</p>
本文代码补全插件的主要代码逻辑是调用上一步后台部署的请求。
// 请求url格式(和flask接口一致)
String baseUrl = "http://ip:8080/plugin?data=";
// 获取当前编辑位置文本
PsiFile str = position.getContainingFile();
// 根据模型上文限制获取代码端
String data = getContentCode();
String url = baseUrl+data;
// 发送请求
String result = HttpUtils.doGet(url);
// 后处理逻辑,在提示框显示预测结果
show()
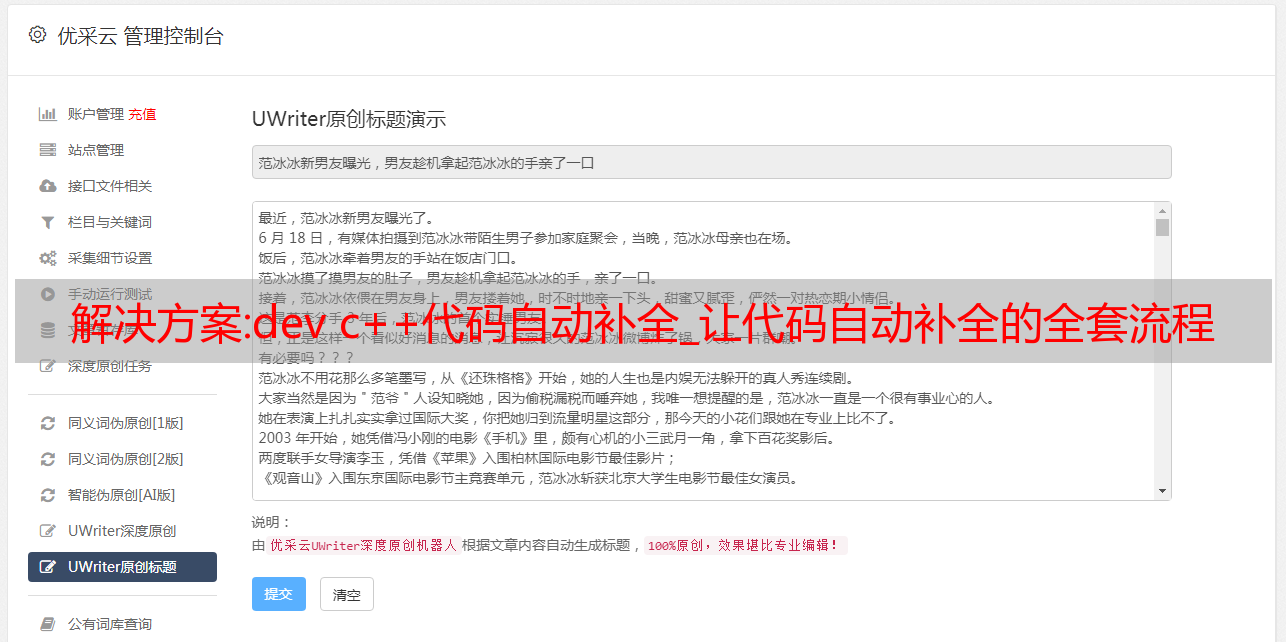
最终渲染形式:
可以看出模型的预测结果还是不错的~
以上就是代码补全功能的实现与应用,是AI自动编写代码的一小步。
AI能否自己编写代码在嫌疑人追踪上达到TM的水平? 我不敢说不可能,但以我现在的知识,是无法实现的。 毕竟,编写代码的是程序员,将数据提供给算法的是程序。 算法设计还是程序员,AI还没出现帮人类解决bug!
参考:
[1]
[2]
[3]
[4]
技巧:易语言程序防修改源码
立即注册,结交更多易友,享受更*敏*感*词*,让您轻松享受米蜂论坛。
您需要登录才能下载或查看,还没有帐号?立即注册
X
易语言程序防修改源代码例程程序采用插入汇编代码的方法检测程序是否被修改。
易语言源码例程属于易语言进阶教程。
点评: 易语言程序防止源代码被修改时的易语言汇编应用例程。
游客,如需查看本帖隐藏内容,请回复
游客,如需查看本帖隐藏内容,请回复
游客,如需查看本帖隐藏内容,请回复
游客,如需查看本帖隐藏内容,请回复
无币种下载方法:百度搜索“易语言程序防修改源码”!
游客,如需查看本帖隐藏内容,请回复

