汇总:网站数据采集器
优采云 发布时间: 2022-12-23 23:41汇总:网站数据采集器
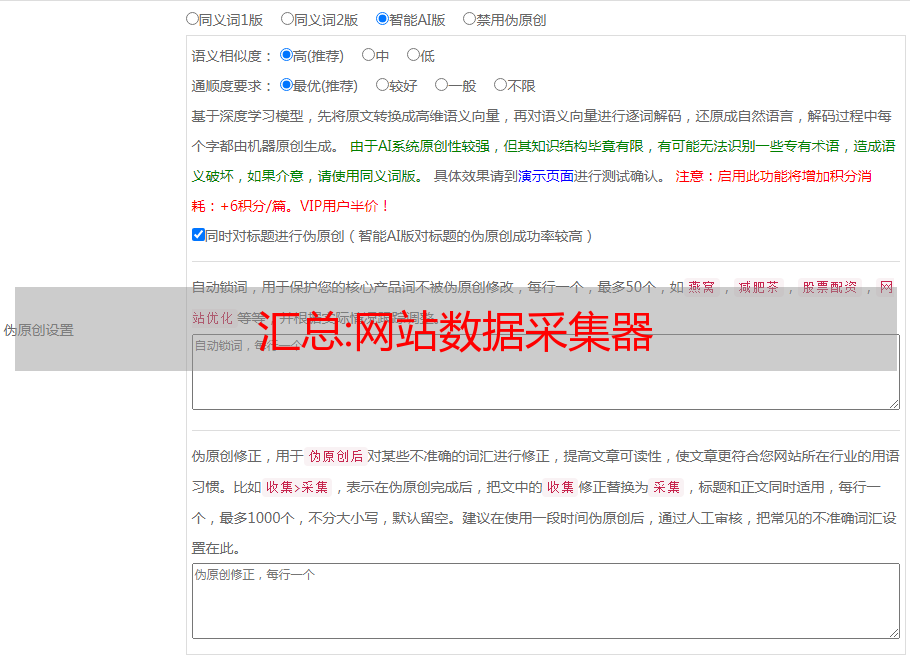
Telegraf 是一个用 Go 编写的代理程序,用于采集系统和服务统计信息并写入各种数据库。 官方文档介绍地址:Telegraf具有内存占用小的特点,开发者可以通过插件系统轻松添加扩展支持其他服务。 目前可用的插件包括: 系统(内存、CPU、网络等)——裸机、虚拟机监控 Docker——容器监控指标 MySQL——软件监控指标 tomcat、Apache——应用软件指标 Redis、kafka、ELK——中级软件指标 http-json—http自定义监控指标等软件监控指标。 【注:本文配置仅为生产演示配置,不一定是生产环节的最终标准配置】 1.安装部署 a. 手动安装步骤: linux操作系统:#wget(官网下载较慢,不推荐)#yum localinstall -y telegraf-1.1.1.x86_64.rpm#service telegraf restart(或systemctl start telegraf)#chkconfig(检查是否有已添加自动启动)Windows操作系统: 1、下载采集器安装文件并将安装文件上传到被监控服务器并解压; 2. 创建目录 C:\ProgramFiles\Telegraf3。 将解压后的两个文件放在Telegraf文件夹中; 4.Powershell以管理员身份执行:C:\”ProgramFiles”\Telegraf\telegraf.exe--serviceinstall5。 运行采集器:netstarttelegraf6。 按照流程修改采集器配置文件中的全局标签配置,修改为项目名称和所属机房名称; b. 自动化一键安装:linux脚本:(注:需要使用自动化脚本安装修改脚本中全局标签“机架”、“部门”、“公司”,使其自动分类显示自动安装后)#wget #仅机房自动安装脚本#sh telegraf.shWindows脚本:自动安装脚本已经完成 从所有工作中下载软件包到配置项,所以直接执行即可,但是需要确定对应的自动安装脚本,因为每个机房或者有些项目自动安装的数据库是不同的数据库,使用的采集器的配置根据项目不同或者子公司名称不同,所以这个需要付费业务运维人员关注,生产环境安装前确认; C。 采集器软件目录列表配置文件:/etc/telegraf/telegraf.conf(全局配置文件)和/etc/telegraf/telegraf.d/(自定义配置文件) pid:/var/run/telegraf.pid log:/var/ logs/telegraf/ 或 /var/logs/messags 程序:/usr/bin/telegraf2。 配置文件configuration 该文件一共分为3部分: a. 全局设置:全局配置文件默认为:/etc/telegraf/telegraf.conf,主要配置telegraf采集器的全局标签、采集频率、机器上报机制、日志格式等全局设置; [global_tags] #fullBureau tags set rack = "aliyun" #设置属于哪个公司的机房 = "xxx" #设置属于哪个公司的部门 = "sql" #设置属于哪个项目或部门#telegraf的配置agent[agent] 采集采集器interval = "60s" 采集采集器,默认10次,可以根据自己的项目修改为任意值 round_interval = true 采集器是否轮询上述间隔 metric_batch_size = 1000 #采集器每次产生的指标数量有限制 metric_buffer_limit = 10000 #采集器缓存指标的总数量限制 采集_jitter = "0s" #采集器的频率抖动时间差,可用于随机采集flush_interval = " 61s" #刷新数据写入输出时间间隔 flush_jitter = "0s" #刷新数据写入随机 Jitter time precision = "" #采集器的最小时间单位,默认 is ns debug = false #是否运行debug,默认不允许 quiet = false #是否以安静模式运行,不输出日志等 hostname="" #采集器的主机名,如果不是指定,就是主机名 omit_hostname = falseb.output设置:主要设置采集器需要发送到数据库的数据源类型。 比如后端数据库是influxDB,那么配置数据输出到influx: #Configuration for influxdb server to send metrics to[[ outputs.influxdb]] urls = [“:8086”] #influxdb address database = “telegraf_ali” #required #influxdb database retention_policy = “” #数据保留策略 write_consistency = “any” #数据写入策略,仅适用于集群模式 timeout = "5s" #写入超时策略 username = "telegraf_ali" #数据库用户名密码= "gPHhbeh" #database password #user_agent = "telegraf" 采集器 agent name 比如后端数据库是elasticsearch数据库,因为telegraf不能直接写入es,所以会写入kafka集群[[ outputs.kafka]] brokers = [“10.23.32.22:9092”] #kafka集群地址,多个实例用逗号分隔 topic = “telegraf-prd” #kafka的主题设置 routing_tag = “host” #是否路由标签,同一主机写入同一片段 compression_codec = 1 #W 数据传输是否压缩 required_acks = 1 #数据同步是否确认,0为否,1为leader确认,-1为全部同步确认 max_retry = 3 #数据写入尝试 data_format = "json" #数据发送格式 c.input setting:主要设置采集器采集,配置服务器的基本监控采用标准的telegraf.conf统一标准,配置软件工程,将新建的conf文件放在/etc/telegraf/telegraf.conf中。 d/文件夹,重启生效; 3.自定义INPUT插件示例自定义配置文件路径:/etc/telegraf/telegraf.d/INUPT一共分为三种,分别是container-level 采集 ,server-level 采集 ,software-level 采集 。 每个采集级别所需的配置可以在配置文件中找到。
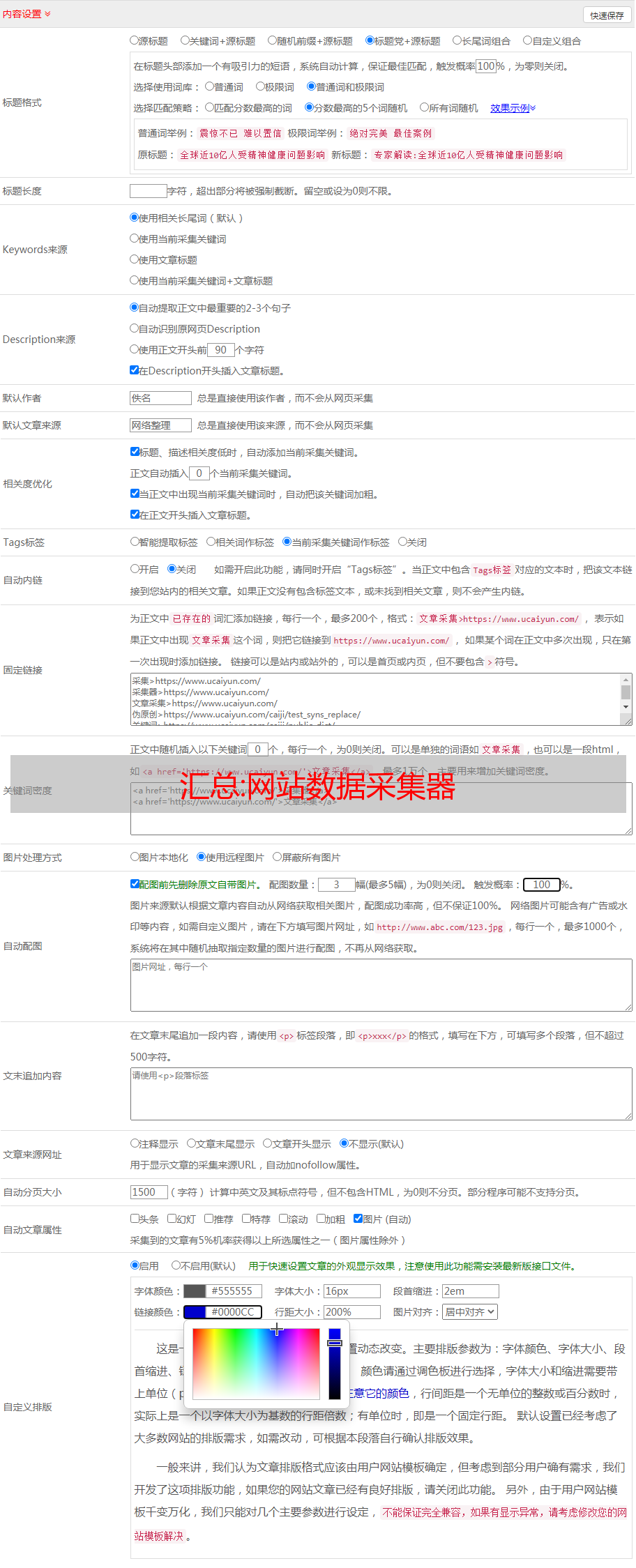
一种。 容器级采集标准示例(注:可直接上传对应标准配置文件覆盖默认配置文件,改用配置文件模板)修改配置文件/etc/telegraf/telegraf.conf 添加docker监控项因为容器采集是通过本地docker API接口调用的。 需要修改telegraf启动用户才能正确采集。 修改文件/usr/lib/systemd/system/telegraf.service 一行User=telegraf 为User=root 然后重新加载到配置中 重启服务生效#systemctl daemon-reload#systemctl restart telegraf#ps - ef|grep telegraf 手动测试容器接口是否输出数据: #telegraf -config /etc/telegraf/telegraf.conf -input-filter docker -test 如果是输出数据正确说明采集器的安装配置错误-自由。 b. 服务器级采集标准示例 打开配置文件/etc/telegraf/telegraf.conf。 在上面的配置行中,可以根据项目或子监控修改采集器的数据过滤、采集频率等选项。 如果没有特殊情况,可以使用默认的标准配置文件; 附demo配置代码: [[inputs.cpu]] #指标名称 percpu = true #指标详细项 totalcpu = true fielddrop = ["usage_guest*"] #指标键值过滤 [[inputs.disk]] # mount_points = [" /"] ignore_fs = ["tmpfs", "devtmpfs"][[inputs.diskio]] # 无配置[[inputs.kernel]] # 无配置[[inputs.mem]] # 无配置[[inputs.processes] ] # 不配置 fielddrop = ["wait","idle","unknown"][[inputs.swap]] fieldpass = ["used_percent"] #只允许索引键值[[inputs.system]] # no配置[[]]# interfaces = ["eth0"] fieldpass = ["packets_*", "bytes_*", "drop_*", "err_*"][[stat]] fielddrop = ["tcp_none", " tcp_closing" , "tcp_close*"] c. 软件配置标准示例 比如需要添加zk监控,修改配置文件/etc/telegraf/telegraf.d/zk.conf[[inputs.zookeeper]]servers = [“172.16.7.12:2181”]来测试zk监控是否成功,使用如下命令 #telegraf -config /etc/telegraf/telegraf.conf -input-filter zookeeper -test
汇总:网站流量查询工具都有哪些(网站流量统计分析工具)
关键词分析,我们在网站前需要选择关键词来优化网站。 哪些关键词可以带来更多流量和更高转化率? 这些转化率高的好关键词自然需要我们更多的关注。 最直接的方法就是分析同行网站,通过同行网站的域名链接抓取同行网站的所有关键词布局!
目录:
同行网站TDK标签
同行网站的收录和外部链接分析
同行网站打开速度
网站更新频率和文章质量
1. 同行网站上的TDK标签
TDK是网站的标题(title)、描述(description)和关键词(keyword)。 TDK是网站的一个非常重要的元素。 这是蜘蛛抓取您的网站后首先看到的内容,因此设置 TDK 对于网站优化至关重要。
标题(title):标题要有吸引力,同时要收录用户的需求,长度要合理。 标题中的关键词不要太多,最好在3个以内,太多的关键词容易导致权重分散。 有利于排名。
描述:描述突出公司或主要服务,是对整个网页的简单概括。 描述标签的字符数一般控制在200以内。如果是网站,可以写公司的主要业务范围或公司介绍。 如果是内页,可以填写本页的内容摘要。 比如你是产品页面,那就写产品的简单介绍。 如果是文章页面,就写文章的主要内容是什么,这样蜘蛛就可以爬出来,让用户更清楚你在写什么。 如果不想每次发文章都写描述,可以设置自动抓取文章前面的部分作为描述。
关键词 (关键词):关键词要简洁明了。 使用“,”分隔多个关键词。 关键词最好设置在3个以内,网站发展到比较高的权重后,可以增加到5个左右。 关键词对网站的排名也有很大的影响。 蜘蛛在抓取你的网页的时候,也会对你的关键词进行判断。 如果你不设置关键词,他们会集中在你的标题上。
2. 参赛者外链及收录
外链情况:分析对手的外链数量。 一般排名比较靠前的网站,外链数据比较多。 要保证外链的数量,还要保证外链的质量。 高质量的外部链接决定了网站在搜索引擎中的权重。 发布外链时,一定要在权重高的网站上发布有效的外链。
收录情况:先列出关键词和长尾关键词,用工具查看收录情况,收录文章使用了哪些关键词,关键词网站排名的前提收录收录。 更好的排名等于更大的机会
3 网站打开速度
网站的打开速度直接影响到网站的收录和用户体验,所以网站的打开速度太重要了!
1、网站服务器配置低。 当网站大量访问/爬虫或服务器内存快满等情况时,这些都会影响网站的打开速度。
2、当网站服务器支持的地区少或机房带宽差时,会增加本地访问者本地访问网站的延迟,导致网站打开速度变慢。
3、网站服务器是否使用gzip压缩功能。 压缩网站可以大大压缩网站网站和打开的速度。
4.网站更新频率和文章质量
大家都知道蜘蛛喜欢新鲜事物,所以我们每天都要给网站添加一些新的内容。 只有我们把这些蜘蛛喂饱了,搜索引擎才能对我们的网站进行很好的排名,那么更新文章应该注意哪些方面呢?
1.文章质量
首先,我们在更新网站的时候,一定要保证我们更新的内容是高质量的,也就是说,内容是和我们网站相关的。 我在做SEO优化。 如果我更新的内容都是卖靴子或者买衣服的内容,我的内容质量再好也只是浮云,对我网站的关键词排名没有多大用处,所以我们更新的文章一定要质量高,可读性强,这样用户才会喜欢我们的文章。 搜索引擎是根据用户体验来判断的,好的用户体验才是王道。
2、文章是否原创?
现在很多人觉得写文章太难了,就直接把网上的内容拿过来简单修改一下就发出去。 结果这篇文章的重复率达到了80%,这样的文章效果并不大。 搜索引擎很可能不会收录。 我们伪原创最好的办法就是看别人的文章,然后按照自己的理解说一二三。 这样的文章不再是伪原创,是绝对的原创,当然前提是你熟悉这个行业,能写出好文章。

