专业知识:seo查询工具有哪些(网站SEO优化必备软件)
优采云 发布时间: 2022-12-17 01:45专业知识:seo查询工具有哪些(网站SEO优化必备软件)
SEO人员在做SEO优化时,会使用很多SEO工具来智能诊断网站 SEO问题。SEO工具主要是为了方便SEOer做日常工作,如采集、发布、收录查询、主动推送、SEO诊断等,提高效率,简化操作,解放双手,查询一些网站问题,监控关键词排名收录等。
1. 免费 采集
免费 采集 功能:
1.只需导入关键词到采集相关的关键词文章,即可同时创建几十个或上百个采集任务(一个任务可以支持上传1000 关键词), 支持过滤关键词
2.支持多新闻来源:各平台资讯、知识经验、重大新闻等(可同时设置多个采集来源采集)
3.可以设置关键词采集文章数,在软件上可以直接查看多个任务的采集状态-支持本地预览-支持采集链接预习
4、自动批量挂机采集,与各大cms发布者无缝对接,采集自动挂机——实现采集释放自动挂机。
2.全平台发布
cms 发布者对所有平台的特点:
1. cms发布:目前市面上唯一同时支持Empire、易友、ZBLOG、织梦、WP、PB、Apple、搜外的主流cms等,以及一个可以同时管理和发布批次的工具
2.对应栏目:对应的文章可以发布对应的栏目
3、定时发布:可控发布间隔/每天发布总数
4、监控数据:软件直接监控已发布、待发布、是否伪原创、发布状态、URL、程序、发布时间等。
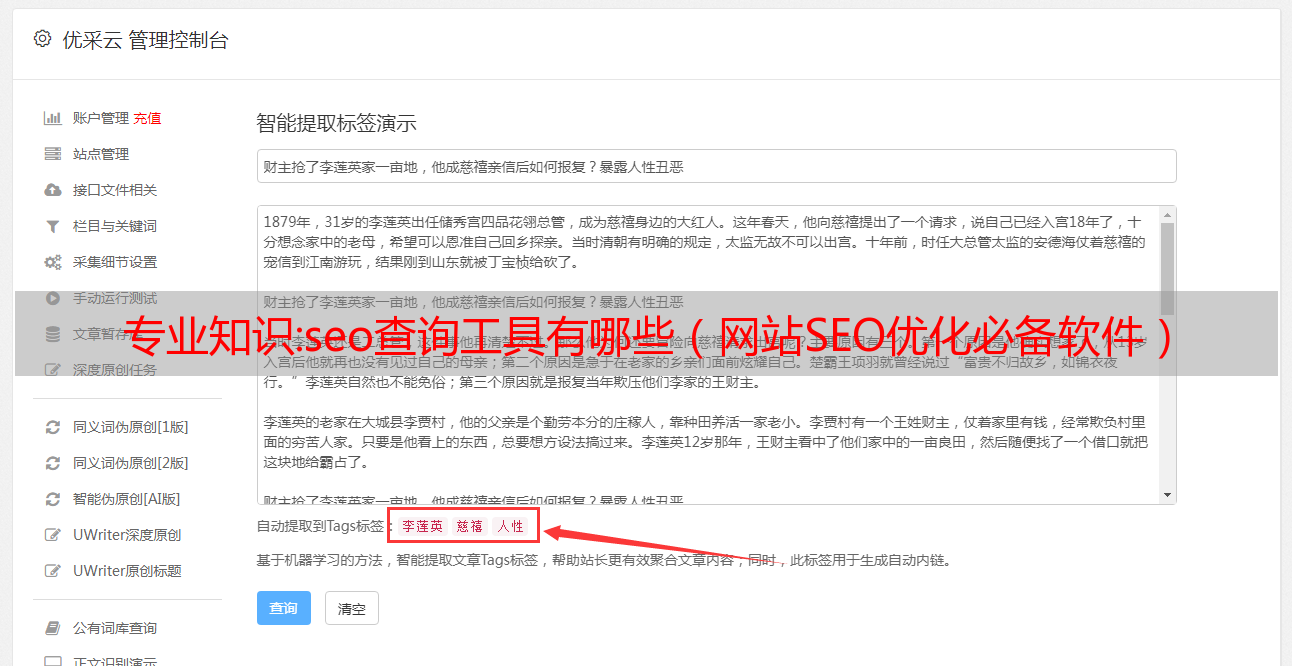
3.收录详细数据查询
收录链接查询功能:
1. 收录排名,收录标题,收录链接,收录时间,真实标题,真实链接,真实关键词,一次性查询统计
2、输入关键词或site命令查看优秀同行网页收录的数量和排名。可以直观的看到同行在百度/搜狗/今日头条的收录中的网站排名,通过大量的关键词布局经验确定自己的网站布局优秀的同行。以及优化方向!您也可以通过关键词查询,详细了解您的网站关键词排名和收录情况!
3、查询工具可以做的其他事情:防止网站被黑客攻击(通过观察收录的情况,检查收录是否有不良信息)-网站修改(通过工具提取收录链接到百度资源搜索平台提交新链接(URL路径更改)-关键词排名(通过关键词查询网站的排名,重点在 关键词 排名上)- 网站 推送(通过查询 收录 链接 - 只推送而不是 收录网站)
4、通过site:域名,查询收录有多少篇网站,收录中有多少篇关键词?可以直接在软件上导出Excel表格做进一步分析,进行整体分析!(SEO站长必备的收录链接数据分析工具)
4. 全平台推送工具
全平台推送功能特点:
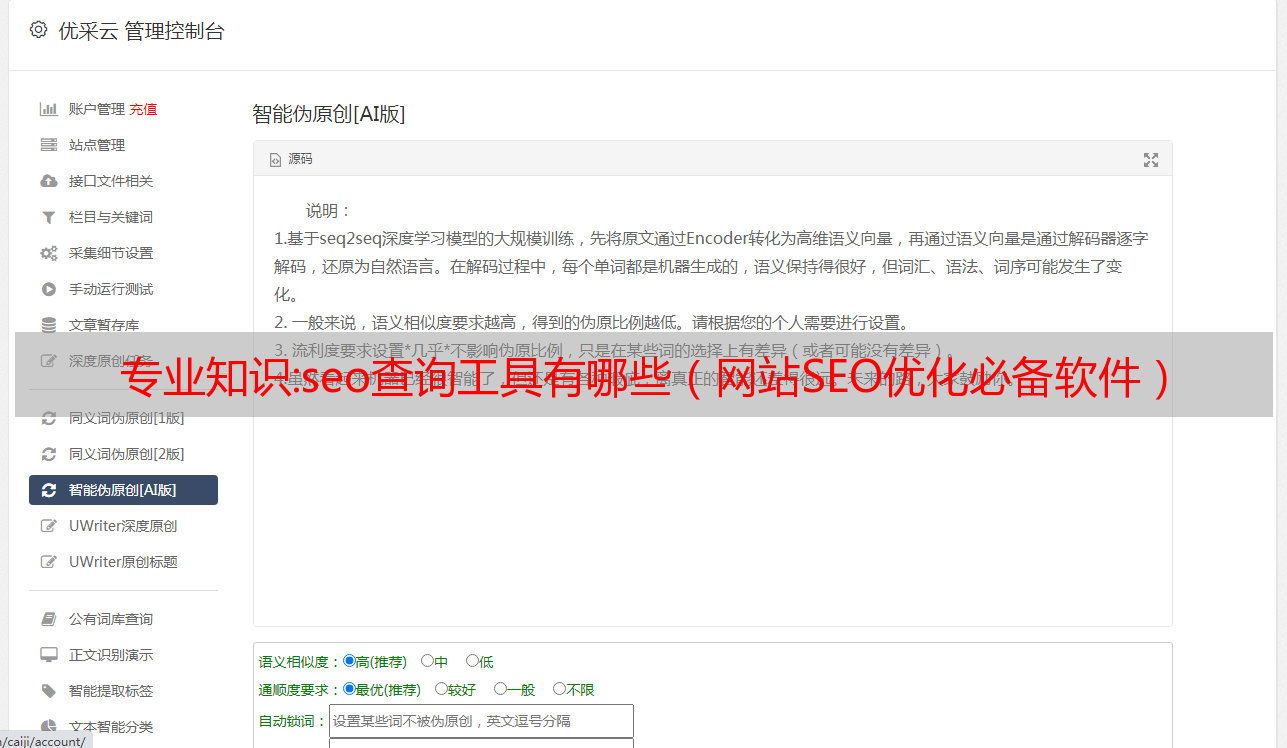
工具替代手动主动推送,效率提升数倍,收录提升数倍,解放双手!
批量搜狗推送:
1、验证站点提交(官方规定单站每天推送200条,软件可以突破限制,单站每天推送几十万条)
2.非验证站点提交(软件可天天推送)
批量百度推送:
采用百度最快的API推送方式,可一次性大量推送至百度
批量360推送:
通过软件自动完成360主动批量推送,每天可提交上万个链接
批量神马推送:
采用Whatsmart最快的MIP推送方式,可一次性大量推送至Whatsmart
以上功能全部集成到一个SEO工具中,SEO工具还配备:批量搜狗快照更新/批量搜狗投诉/批量搜狗绑定站/链接生成/链接抓取/在线伪原创等功能!
技巧:简单做一个seo关键词排名查询工具
点击蓝字关注pyseo
简单做一个seo关键词排名查询工具
技能要求:多线程,pyquery
网上seo排名查询工具很多,基本上都是非常好用的,比如爱站软件包、斗牛软件等,可以轻松查询关键词的排名。这次主要分享如何用python做一个简单的排名查询工具,比SEO软件打开起来更方便。您只需一键运行程序,无需打开软件导入等繁琐步骤。下面直接上源码:
获取百度响应源码01
获取百度查询地址关键词&pn=页码,只需要这个地址,两个参数就可以获取百度响应页面的源代码
BASE_URL = 'https://www.baidu.com/s?{}'
@retry(stop_max_attempt_number=3,retry_on_result=lambda x: x is None,wait_fixed=2000)
def scrape_html(url):
# logger.info(f'开始爬取{url}')
try:
headers = Headers(headers=True).generate()
response = requests.get(url,headers=headers)
if response.status_code == requests.codes.ok:
# logger.info(f'抓取成功{url}')
response.encoding = 'utf-8'
return response.text
except:
logger.error(f'抓取失败,请重新抓取')
return None
伪查询解析 02
使用pyquery分析页面获取指定网站地址或品牌名称的位置。如果页面源代码中没有网站地址和品牌名称,则直接返回None,无需继续下面的循环。如果收录地址和姓名,则执行如下循环,确定收录姓名和地址的索引号,根据索引号可以计算排名。排序后直接返回True
def parse_html(html,page,name,keyword):
doc = pq(html)
items = doc('#content_left')
rank_list = items.children('.result')
if name not in str(rank_list):
return None
for index,info in enumerate(rank_list.items()):
webname = lambda x :name.replace('.','\.') if '.' in name else name
if info(rf'a:contains({webname(name)})'):
ranking = index + page
if ranking == 0:
ranking += 1
logger.info(f'{keyword}--排名在第{page//10 + 1}页,第{ranking}名')
return True
导入 关键词03
在关键词文本中,我们导入需要查询的关键词,例如留学行业的关键词
def read_keyword():
with open(r'keywords.txt','r',encoding='utf-8') as f:
keywords = f.read().splitlines()
return keywords
接下来输入要查询的网站地址或品牌名称,我们通过python自带的多线程threading包进行查询,提高查询效率;
webname = input('请输入网址名称或品牌名称')
if webname == 'q':
exit()
# main(keyword,webname)
keywords = read_keyword()
task_join = []
for keyword in keywords:
task_start = threading.Thread(target=main,args=(keyword,webname))
task_start.start()
task_join.append(task_start)
for j in task_join:
j.join()
多线程04
最后我们将程序打包成exe,打开cmd进入exe所在路径执行程序。执行效果如下:
通过运行程序,可以方便的查询关键词在百度上的排名信息。注意:由于多线程查询速度快,关键词可以查询太多布料,否则百度会有反屏蔽措施,所以我这里不使用代理ip进行操作。总体来说,查询关键词排名在小范围内,效果还是不错的。最后,如果想要获取打包好的关键词查询工具exe,可以关注并私信我,我会把程序打包发给大家!
结尾
只做干货分享,勿喷巨魔,喜欢冷漠的请关注,勿迷路!

