解决方案:2019在线智能AI文章伪原创网站源码提供网站收录网站权重快速SEO机器人AI文
优采云 发布时间: 2022-12-13 16:24解决方案:2019在线智能AI文章伪原创网站源码提供网站收录网站权重快速SEO机器人AI文
系统说明:
所有站长朋友一定对网站内容原创的问题感到头疼,作为一个草根站长,如果你想自己写原创文章,那是不可能的,当然,我不是说你不能写文章。就个别站长的人手而言,写原创文章是不现实的,只有时间才是问题。
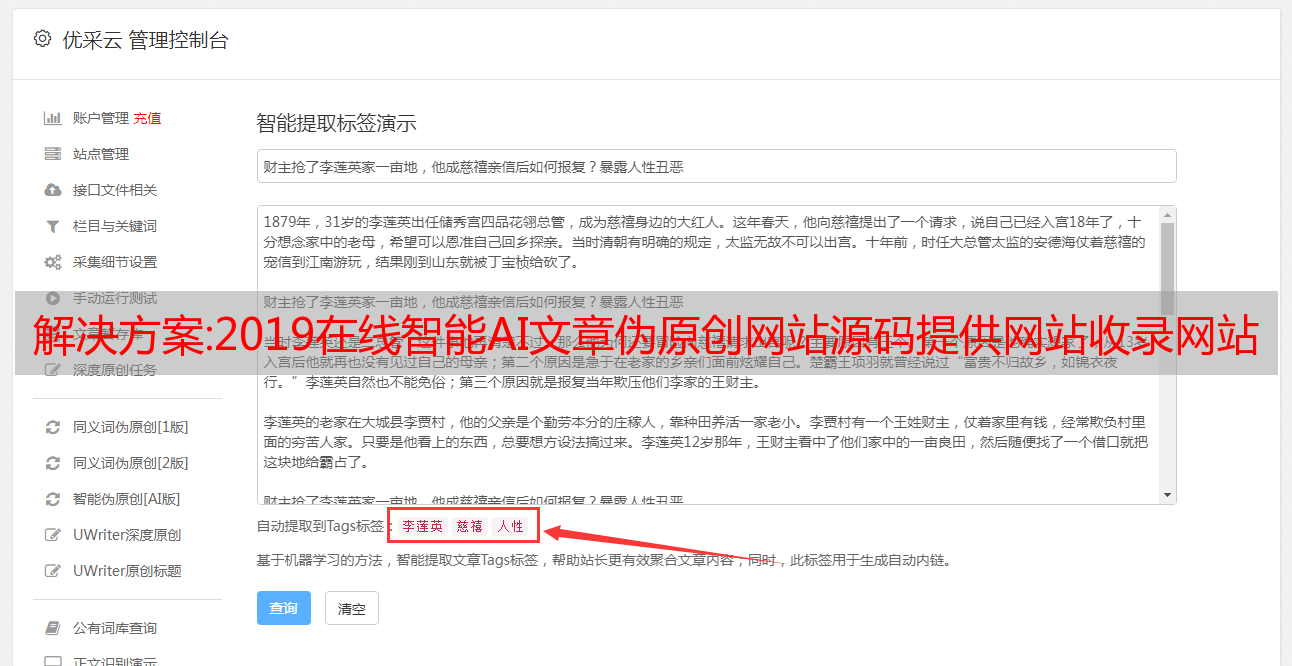
也许有些站长朋友应该问:不写原创文章怎么能得到好网站?
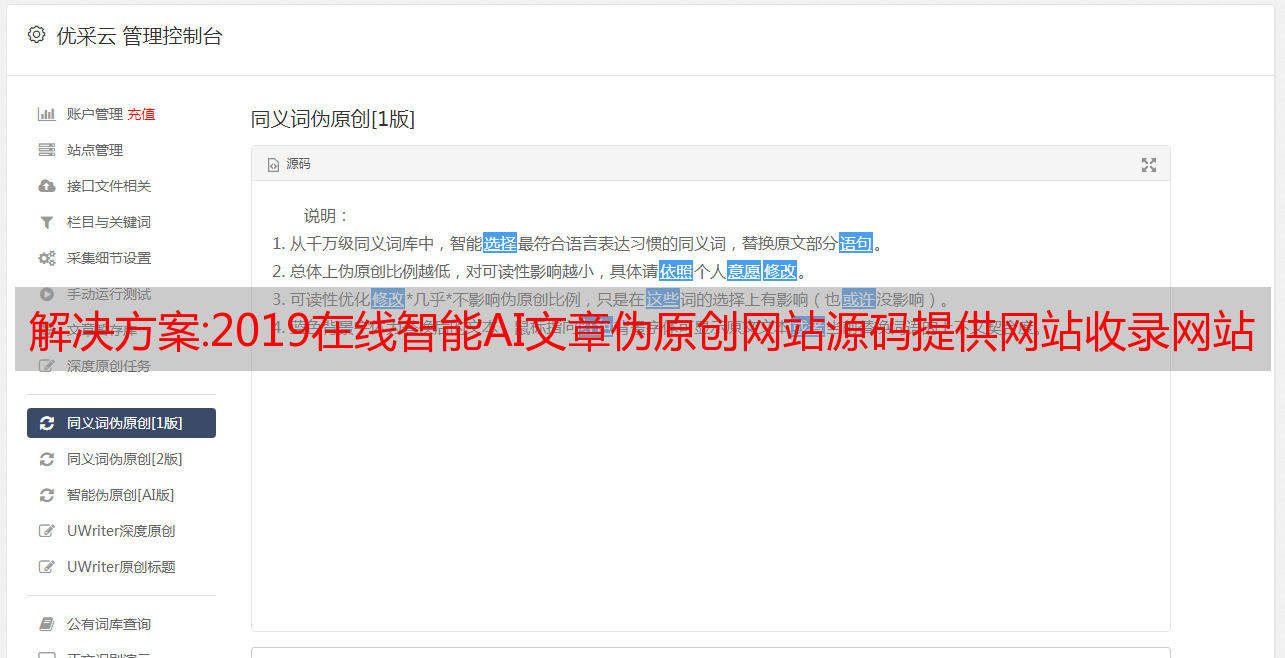
其实不光是我们,国内的几家大型门户网站也不全原创文章,他们也利用对方的内容进行修改,然后改了标题,就成了自己的“新闻”。现在是时候谈谈我的伪原创工具了。该程序是一个免费的在线伪原创工具,原理是同义词替换。
安装环境:PHP可以直接上传到其中,不需要数据库。
下载地址:
访问者,如果您想查看此帖子的隐藏内容,请回复
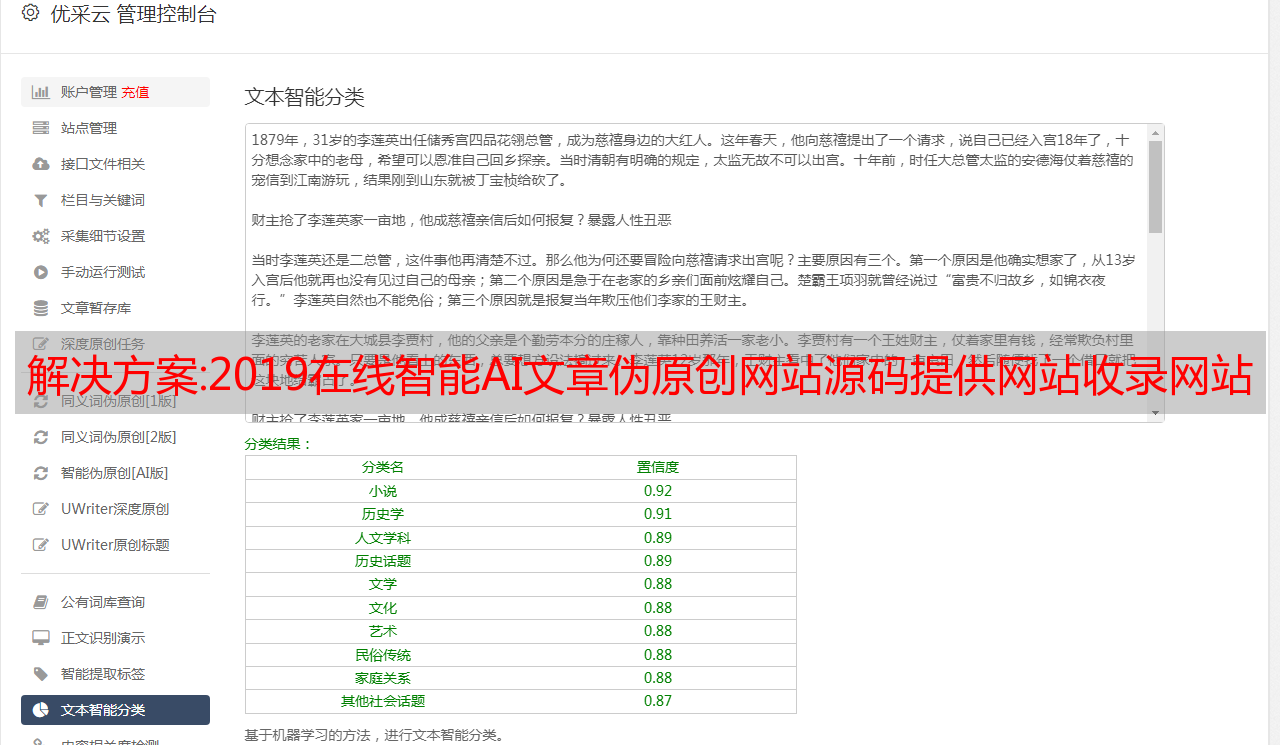
核心方法:Python与SEO,三大SEO网站查询工具关键词查询采集源码!
网站关键词查询挖掘,包括三个常用网站SEO查询工具网站,爱站,站长和5118,
其中,爱站和站长最多可以查询50个页面,5118最多可以查询100个页面,如果要查询完整的网站关键词排名数据,需要充值才能购买会员,当然免费查询也需要注册会员,否则没有查询权限!
5118
您必须自行完成网站地址和cookie协议标头,并且需要登录权限才能查询!
# 5118网站关键词采集
# -*- coding: utf-8 -*-
import requests
from lxml import etree
import time
import logging
logging.basicConfig(filename='s5118.log', level=logging.DEBUG,format='%(asctime)s - %(levelname)s - %(message)s')
#获取关键词
def get_keywords(site,page):
url="https://www.5118.com/seo/baidupc"
headers={
"Cookie":Cookie,
"User-Agent": "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.198 Safari/537.36",
}
data={
"isPager": "true",
"viewtype": 2,
"days": 90,
"url": site,
"orderField": "Rank",
"orderDirection" : "sc",
"pageIndex": page,
"catalogName": "",
"referKeyword": "",
}
response=requests.post(url=url,data=data,headers=headers,timeout=10)
print(response.status_code)
html=response.content.decode('utf-8')
tree=etree.HTML(html)
keywords=tree.xpath('//td[@class="list-col justify-content "]/a[@class="w100 all_array"]/text()')
print(keywords)
save_txt(keywords, site)
return keywords
#存储为csv文件
def save_csv(keywords,site):
filename=site.replace("www.",'').replace(".com",'').replace(".cn",'').replace('https://','').replace('http://','')
for keyword in keywords:
with open(f'5118_{filename}.csv','a+',encoding='utf-8-sig') as f:
f.write(f'{keyword}\n')
print("保存关键词列表成功!")
#存储为txt文件
def save_txt(keywords,site):
filename=site.replace("www.",'').replace(".com",'').replace(".cn",'').replace('https://','').replace('http://','')
for keyword in keywords:
with open(f'5118_{filename}.txt','a+',encoding='utf-8') as f:
f.write(f'{keyword}\n')
print("保存关键词列表成功!")
def main(site):
logging.info(f"开始爬取网站{site}关键词数据..")
num = 100
keys=[]
for page in range(1,num+1):
print(f"正在爬取第{page}页数据..")
logging.info(f"正在爬取第{page}页数据..")
try:
keywords = get_keywords(site, page)
keys.extend(keywords)
time.sleep(8)
except Exception as e:
print(f"爬取第{page}页数据失败--错误代码:{e}")
logging.error(f"爬取第{page}页数据失败--错误代码:{e}")
time.sleep(10)
keys = set(keys) #去重
<p>
save_csv(keys, site)
if __name__ == '__main__':
site=""
main(site)
</p>
复制
爱站
您必须自行完成网站地址和cookie协议标头,并且需要登录权限才能查询!
# 爱站网站关键词采集
# -*- coding: utf-8 -*-
import requests
from lxml import etree
import time
import logging
logging.basicConfig(filename='aizhan.log', level=logging.DEBUG,format='%(asctime)s - %(levelname)s - %(message)s')
#获取关键词
def get_keywords(site,page):
url=f"https://baidurank.aizhan.com/baidu/{site}/-1/0/{page}/position/1/"
headers = {
"Cookie":Cookie ,
}
response = requests.get(url=url,headers=headers, timeout=10)
print(response.status_code)
html = response.content.decode('utf-8')
tree = etree.HTML(html)
keywords = tree.xpath('//td[@class="title"]/a[@class="gray"]/@title')
print(keywords)
save_txt(keywords, site)
return keywords
#存储为csv文件
def save_csv(keywords,site):
filename=site.replace("www.",'').replace(".com",'').replace(".cn",'').replace('https://','').replace('http://','')
for keyword in keywords:
with open(f'aizhan_{filename}.csv','a+',encoding='utf-8-sig') as f:
f.write(f'{keyword}\n')
print("保存关键词列表成功!")
#存储为txt文件
def save_txt(keywords,site):
filename=site.replace("www.",'').replace(".com",'').replace(".cn",'').replace('https://','').replace('http://','')
for keyword in keywords:
with open(f'aizhan_{filename}.txt','a+',encoding='utf-8') as f:
f.write(f'{keyword}\n')
print("保存关键词列表成功!")
def main(site):
logging.info(f"开始爬取网站{site}关键词数据..")
num = 50
keys=[]
for page in range(1,num+1):
print(f"正在爬取第{page}页数据..")
logging.info(f"正在爬取第{page}页数据..")
try:
keywords = get_keywords(site, page)
keys.extend(keywords)
time.sleep(8)
except Exception as e:
print(f"爬取第{page}页数据失败--错误代码:{e}")
logging.error(f"爬取第{page}页数据失败--错误代码:{e}")
time.sleep(10)
keys = set(keys) #去重
save_csv(keys, site)
if __name__ == '__main__':
site=""
<p>
main(site)
</p>
复制
网站站长
您必须自行完成网站地址和cookie协议标头,并且需要登录权限才能查询!
# 站长之家网站关键词采集
# -*- coding: utf-8 -*-
import requests
from lxml import etree
import time
import logging
logging.basicConfig(filename='chinaz.log', level=logging.DEBUG,format='%(asctime)s - %(levelname)s - %(message)s')
#获取关键词
def get_keywords(site,page):
headers={
"Cookie":Cookie,
"User-Agent": "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.198 Safari/537.36",
}
url=f"https://rank.chinaz.com/{site}-0---0-{page}"
response=requests.get(url=url,headers=headers,timeout=8)
print(response)
html=response.content.decode('utf-8')
tree=etree.HTML(html)
keywords=tree.xpath('//ul[@class="_chinaz-rank-new5b"]/li[@class="w230 "]/a/text()')
print(keywords)
save_txt(keywords, site)
return keywords
#存储为csv文件
def save_csv(keywords,site):
filename=site.replace("www.",'').replace(".com",'').replace(".cn",'').replace('https://','').replace('http://','')
for keyword in keywords:
with open(f'chinaz_{filename}.csv','a+',encoding='utf-8-sig') as f:
f.write(f'{keyword}\n')
print("保存关键词列表成功!")
#存储为txt文件
def save_txt(keywords,site):
filename=site.replace("www.",'').replace(".com",'').replace(".cn",'').replace('https://','').replace('http://','')
for keyword in keywords:
with open(f'chinaz_{filename}.txt','a+',encoding='utf-8') as f:
f.write(f'{keyword}\n')
print("保存关键词列表成功!")
def main(site):
logging.info(f"开始爬取网站{site}关键词数据..")
num = 50
keys=[]
for page in range(1,num+1):
print(f"正在爬取第{page}页数据..")
logging.info(f"正在爬取第{page}页数据..")
try:
keywords = get_keywords(site, page)
keys.extend(keywords)
time.sleep(8)
except Exception as e:
print(f"爬取第{page}页数据失败--错误代码:{e}")
logging.error(f"爬取第{page}页数据失败--错误代码:{e}")
time.sleep(10)
keys = set(keys) #去重
save_csv(keys, site)
if __name__ == '__main__':
site=""
main(site)
复制·
···完···

