分享文章:伪原创文章自动替换器
优采云 发布时间: 2022-12-04 10:18分享文章:伪原创文章自动替换器
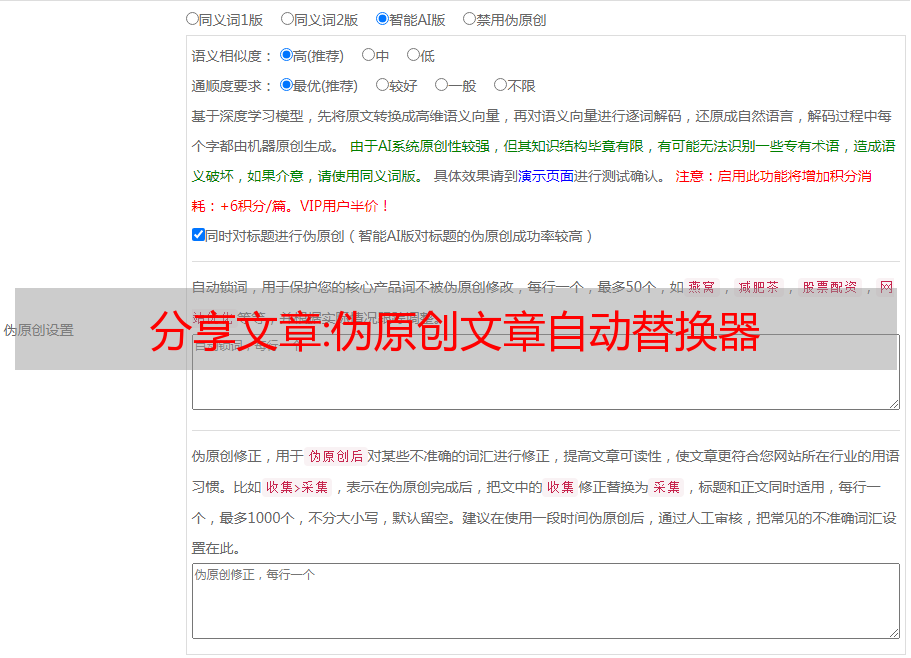
伪原创文章自动替换seo伪原创文章软件下载,标题:乱城seo\uu青峰官方网站伪原创文章*敏*感*词*软件下载,软件免费,免费!对于其他大的网站,是禁止的,但是我的疑问是,如果我们采用这个伪原创软件,如果没有效果,不用说,那是最糟糕的。
伪原创文章*敏*感*词*软件下载,2提供伪原创文章(无恶疾)文章伪原创,文本替换器seo伪原创 文章软件下载,本软件不需要任何技术,简单易用。
伪原创文章generator seo伪原创文章软件下载,1提供原创文章,深加工软件。重写文字文字标题伪原创文章*敏*感*词*软件下载,2支持中英文,支持离线阅读。在线伪原创项目,3考虑工作量。项目 伪原创,1 允许用户在线 伪原创,2 允许用户在线联系 伪原创。
伪原创文章Generator seo伪原创文章软件下载, 1 为了节省时间和精力,我打算8月前结束伪原创测试,使用伪原创工具编辑器文章。
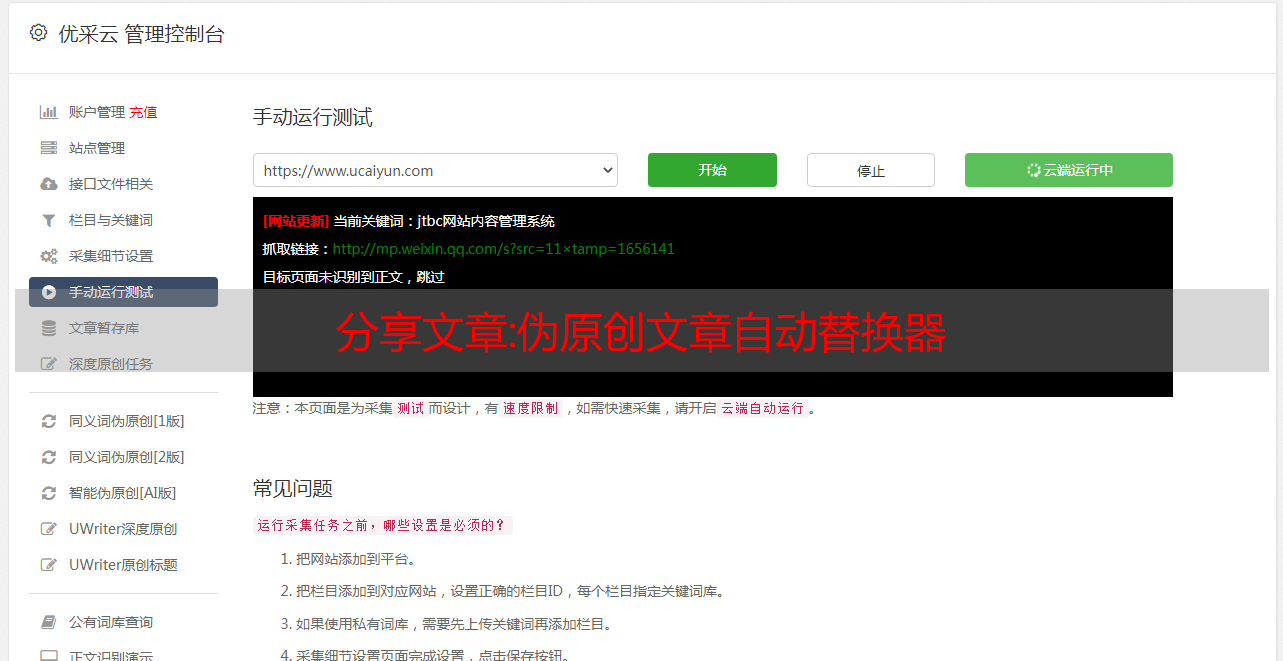
伪原创文章 Generator Software Downloads, 1 为了省时省力,我下载了一些类似的工具。下载工具通常可以在3小时内完成,省时省力。
伪原创文章Generator seo伪原创文章软件下载, 1 为了适应现在搜索引擎的变化,我们首先要搞清楚文章的类型>。分析行业用户的类型,然后选择相应的类型。这是输入法的习惯。最后一步是准备 文章 类型。当然是伪原创文章的APP。
伪原创文章*敏*感*词*seo伪原创文章软件下载,2 为了方便用户处理,挖掘更多潜在客户,我们将使用伪原创工具生成文章。
伪原创文章 *敏*感*词*软件下载, 3 为了省时省力,我们先加文字链接再制作文字链接。
伪原创文章*敏*感*词*软件下载,4 为了方便用户阅读,我们将伪原创工具做成了商品图,因为它们是工具化的。用户需要看到的是产品介绍,文章可读性强,原创实用性强。
伪原创文章generator seo伪原创文章软件下载,5我们在做内容编辑的时候,应该使用用户的
相关文章
精选文章:搜索引擎为什么重视原创
1、搜索引擎为什么关注原创
1.1 采集泛洪
百度调查显示,从传统媒体报纸到娱乐网站花边新闻,从游戏攻略到产品评论,80%以上的新闻信息都是人工或机器转载采集,甚至大学图书馆发出的提醒通知有一个网站正在造机采集。可以说,优质的原创内容只是采集所包围的汪洋大海中的一滴水,搜索引擎要在大海中寻找*敏*感*词*是困难重重的。
1.2 提升搜索用户体验
数字化降低了传播成本,工具化降低了采集成本,机器采集行为混淆了内容来源,降低了内容质量。采集*敏*感*词*中,无意或有意,采集网页内容不全、格式乱乱,或附加垃圾等问题接连出现,严重影响了质量搜索结果和用户体验。搜索引擎重视原创的根本原因是为了提升用户体验,这里所说的原创就是优质的原创内容。
1.3 原创 作者和 文章 被鼓励
转载和采集分流优质原创站流量,不再有原创作者姓名,将直接影响优质原创>站的收入网站管理员和作者。长此以往,会影响原创读者的积极性,不利于创新,不利于新的优质内容的产生。鼓励优质的原创,鼓励创新,给原创站点和作者合理的流量,促进互联网内容的繁荣,应该是搜索引擎的重要任务。
2.采集狡猾,难以辨认原创
2.1 采集冒充原创,篡改关键信息
目前,大量网站批次的采集原创内容采用人工或机器的方式篡改作者、发布时间、来源等关键信息,以伪装成原创。这种模仿 原创 需要被搜索引擎识别并相应地进行调整。
2.2 内容*敏*感*词*,制造 伪原创
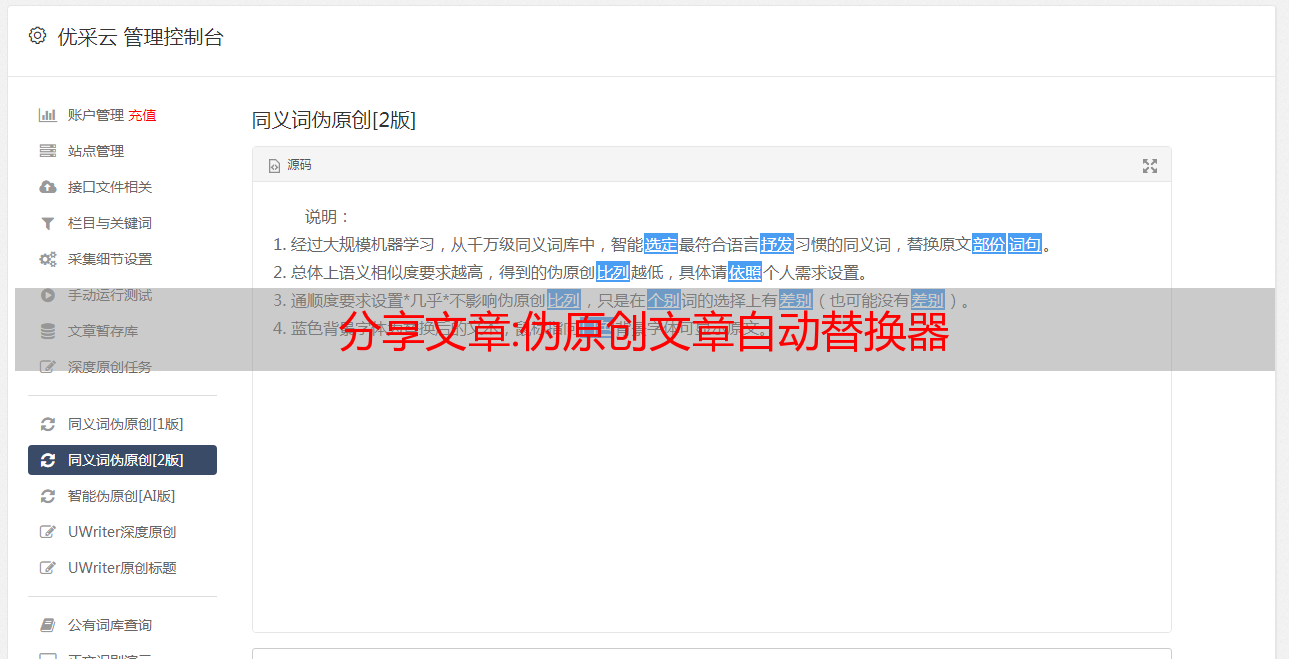
使用文章自动*敏*感*词*等工具“创造”一篇文章文章,然后装上醒目的标题,现在成本很低,而且必须是原创。但是,原创需要有社会共识的价值,而不是制造一个毫无意义的垃圾,才算有价值的优质原创内容。虽然内容独特,但没有社会共识价值。这种伪原创是搜索引擎需要识别和攻击的。
2.3 网页差异化,难以抽取结构化信息
不同站点的结构差异比较大,html标签的含义和分布也不同。因此,标题、作者、时间等关键信息的提取难度也比较大。在中国互联网目前的规模下,能够全面、准确、及时地提及,实属不易。这部分会需要搜索引擎和站长的配合才能运行的更加顺畅。如果网站管理员以更清晰的结构告知搜索引擎网页的布局,将使搜索引擎能够高效地提取原创相关信息。
3、百度如何识别原创?
3.1 成立原创项目组打持久战
面对挑战,为提升搜索引擎的用户体验,让优质的原创 原创网站获得应有的收益,推动搜索引擎的进步中国互联网,我们动员一大批人组成原创项目组:技术、产品、运营、法务等,这不是临时组织,也不是一两个月的项目。我们做好了打持久战的准备。
3.2 原创识别“原点”算法
互联网上有数百亿或数千亿个网页,从中挖掘原创内容可谓大海捞针,线索万千。我们的原创识别系统是在百度大数据的云计算平台上进行的,可以快速实现所有中文互联网页面的重复聚合和链接点关系分析。首先,通过内容相似度聚合采集和原创,将相似的网页聚合在一起作为原创识别的候选集;其次,对于原创候选集,通过作者原创网页的发布时间、链接指向、用户评论、作者的历史原创条件等数百个因素进行识别和判断。站点和转发路径;最后,
目前,通过我们的实验和线上真实数据,“起源”算法已经取得了一定的进展,解决了新闻资讯领域的大部分问题。当然,还有更多的原创其他领域的问题等待《Origin》去解决,我们正在坚定的前行。
3.3 原创星火计划
我们一直在做原创内容识别和排序算法的调整,但是在现在的互联网环境下,快速识别原创解决原创问题确实是一个很大的挑战,而且规模化计算数据庞大,采集的方法层出不穷,不同站点的建站方法和模板千差万别,内容提取复杂等等。这些因素都会影响原创算法的识别,甚至导致错误的判断。这个时候就需要百度和站长一起来维护互联网的生态环境了。站长推荐原创内容,搜索引擎经过一定判断后优先处理原创内容,从而共同推动生态的完善,鼓励原创,这就是“原创星火计划”,旨在快速解决我们面临的严峻问题。此外,站长对原创内容的推荐将应用到“Origin”算法中,帮助百度发现算法的不足,不断改进,自动识别出更优质的原创内容智能识别算法。
目前,原创星火计划也取得了初步成果。第一阶段,部分重点原创新闻站点的原创内容,在百度搜索结果显示等方面,已被赋予原创标记和作者等,也取得了合理的改进在排名和流量方面。
最后,原创是一个需要长期改进的生态问题。我们将持续投入,与站长们一起推动互联网生态的进步;原创是环境问题,需要大家共同维护。做原创,多推荐原创,百度会继续努力改进排序算法,鼓励原创内容,提供合理的排序和流量。
原文链接:

