内容分享:利用 fidder + 微信pc端 全自动抓取微信公众号文章
优采云 发布时间: 2022-11-19 17:36内容分享:利用 fidder + 微信pc端 全自动抓取微信公众号文章
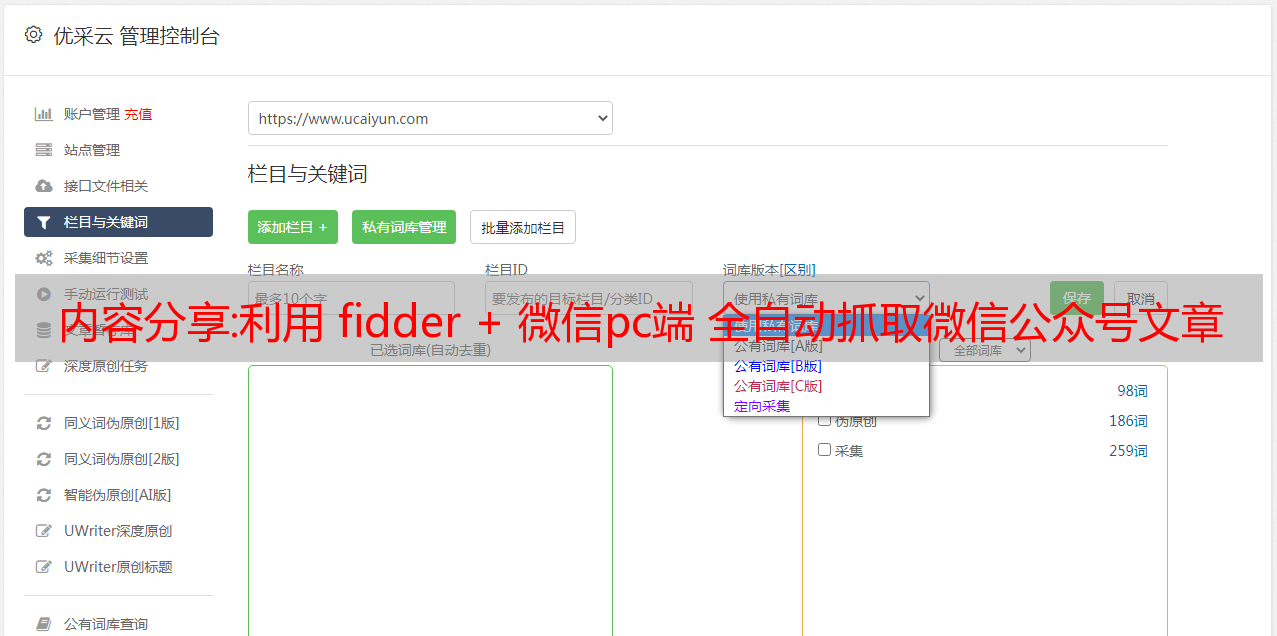
一、基本流程
1.
" rel="nofollow" target="_blank">采集
现有公众号文章:
一、使用任意微信登录微信PC端(下载安装微信PC端)
将您制作的采集
条目(如:)发送至微信
点击直接在微信PC端打开
2.如果公众号不存在:
做一个注册对应的公众号文章,一篇就够了
做一个自动客户端。当有新文章时,它会自动导航并访问它。fidder检测到后会自动推送到后台生成“公众号记录”
2. 准备
1、Fidder开启抓取https支持:工具-》选项
2.自动解码
3.配置过滤
3.编写爬虫脚本
1.在Fidder中编写抓取脚本:Rules-》Customize Rules
static var tagUrl = "&abc=";
static var begincollectHost = "web.test.com";//替换成你的服务器
static var begincollectUrl = "/api/proxy/begincollect"; //替换成你的等待页面入口地址
static var host = "localhost:33386";//你的api服务主机地址
static var apiUrl = "/api/proxy/weixin";//你的api服务地址
static var debug = false;
static function httpPost(url: String,host: String,contentStr: String): String{
var content: byte[] = System.Text.Encoding.UTF8.GetBytes(contentStr);
var oRQH: HTTPRequestHeaders = new HTTPRequestHeaders(url, ['Host: '+host,
'Content-Length: '+content.length.ToString(), 'Content-Type: application/x-www-url-encoded']);
oRQH.HTTPMethod = "POST";
var oSD = new System.Collections.Specialized.StringDictionary();
var newSession = FiddlerApplication.oProxy.SendRequestAndWait(oRQH, content, oSD, null);
var jsonString = newSession.GetResponseBodyAsString();
return jsonString;
}
static function sendMsg(contentStr: String,type: String) : Object {
var jsonString = httpPost(apiUrl+"?type="+type,host,contentStr);
FiddlerApplication.Log.LogString("result:"+jsonString);
return Fiddler.WebFormats.JSON.JsonDecode(jsonString);
}
static function getFullUrl(url:String){
if(debug){
var end = "";
if (url.IndexOf('#') > 0)
{
end = url.Substring(url.IndexOf('#'));
url = url.Substring(0, url.IndexOf('#'));
}
url = url + (url.IndexOf('?') > 0 ? "" : "?a=") + tagUrl + end;
}
return "https://mp.weixin.qq.com/"+url;
}
static function getRndInternal(){
return new System.Random().Next(3, 11) * 1000;
}
static function getReloadScript(url:String){
return getReloadScript(url,0);
}
static function getReloadScript(url:String,time:int){
if(time==0)
time = getRndInternal();
var script = " setTimeout(function(){window.location.href='"+url+"'},"+time+");";
FiddlerApplication.Log.LogString("reloadscript:"+script);
return script;
}
static function getMPHisUrl(biz:String){ //获取公众号历史记录url
return getFullUrl("mp/profile_ext?action=home&__biz="+biz+"&scene=124#wechat_redirect");
}
static function getMPhisReloadScript(biz:String){
var url = getMPHisUrl(biz);
return getReloadScript(url);
}
static function getMsgHisUrl(biz:String,pass_ticket:String,offset:String){ //获取公众号历史记录api url
return getFullUrl("/mp/profile_ext?action=getmsg&__biz="+biz+"&f=json&offset="+
offset+"&count=10&is_ok=1&scene=124&pass_ticket="+pass_ticket
+"&x5=0&f=json");
}
static function OnBeforeResponse(oSession: Session) {
if (m_Hide304s && oSession.responseCode == 304) {
oSession["ui-hide"] = "true";
}
if(debug && !oSession.uriContains(tagUrl))
return;
if(oSession.HostnameIs(begincollectHost) && oSession.uriContains(begincollectUrl)){ //开始采集入口,地址要通过微信pc端浏览器打开
var reloadScript="";
var responses = oSession.GetResponseBodyAsString();
var url="";
var collect_url = "http://"+begincollectHost+begincollectUrl+"?key="+tagUrl;
var time = 0;
if(System.DateTime.Now.Hour=21)
{ //21点之后,9点之前不采集
url = collect_url;
time = 3600 * 13 * 1000;
}
else
{
//获取公众号biz
var jsonObj = sendMsg("","4");
var biz = jsonObj.JSONObject["biz"];
if(biz!=undefined){
//跳转到公众号历史文章地址
url = getMPHisUrl(biz);
}
else{ //没有可采集的公众号,继续空页面轮询
time = 3600 * 1000 + getRndInternal();
url = collect_url;
}
}
reloadScript = getReloadScript(url, time);
//我的入口页面返回是json,如果是html,则不用下面这句
oSession.oResponse["Content-Type"]="text/html; charset=UTF-8";
oSession.utilSetResponseBody(responses+reloadScript);
return;
}
if(oSession.HostnameIs("mp.weixin.qq.com")){
var reloadScript="";
var responses = oSession.GetResponseBodyAsString();
oSession.utilDecodeResponse(); //解码
if(oSession.uriContains("profile_ext?action=home")){ //公众号历史消息页
sendMsg(responses,"1");//记录公众号信息
//获取公众号历史第1页记录
<p>

" />
var url = oSession.fullUrl.Replace("action=home","action=getmsg")+"&x5=0&f=json&f=json&offset=0&count=10&is_ok=1";
reloadScript = getReloadScript(url);
}
else if(oSession.uriContains("profile_ext?action=getmsg")){ //获取历史消息
var reload = oSession.uriContains("&offset=0");
var content = (reload?"":oSession.url)+responses;
//保存文章记录
sendMsg(content,"2");
if(reload){ //再次获取文章记录,总共获取20条
//获取第2页10条记录
var url = oSession.fullUrl.Replace("&offset=0&","&offset=10&");
reloadScript = getReloadScript(url);
}
else
{ //返回轮询等待页面
var url = "http://"+begincollectHost+begincollectUrl+"?key="+tagUrl;
reloadScript = getReloadScript(url);
}
oSession.oResponse["Content-Type"]="text/html; charset=UTF-8";
}
else if(oSession.uriContains("/s/") || oSession.uriContains("s?__biz=")){//文章
//保存文章内容
var jsonObj = sendMsg(responses,"3");
return;
}
oSession.utilSetResponseBody(responses+reloadScript);
}
}</p>
2、服务端脚本(这里以c#.net为例)
public class ProxyController : ApiController
{
[System.Web.Http.HttpGet]
[System.Web.Http.HttpPost]
public JsonResult BeginCollect()
{
return Json("Collect,现在时间:" + DateTime.Now.ToString());
}
// GET: Proxy
public async Task weixin(int type)
{
//获取从Fidder推送过来的内容
string content = await Request.Content.ReadAsStringAsync();
object obj = string.Empty;
string biz = "";
if (type == 1)
{ //从公众号历史页面获取并保存公众号信息
Func getValue = (pattern) => {
return GetValue(content, pattern);
};
AddMsg(() => {
//获取biz
biz = getValue("var\s*__biz\s*=\s*\".+\"");
//获取昵称
string nickName = getValue("var\s*nickname\s*=\s*\".+\"");
//获取headimage
string headImg = getValue("var\s*headimg\s*=\s*\".+\"");
//appid
string appid = getValue("appid\s*:\s*\".+\"");
string errMsg;
if (nickName.Length > 0 && biz.Length > 0)
{ //todo:保存数据到数据库
}
});
}
else if (type == 2)
{
if (!content.StartsWith("{"))
{ //url和response组合
int index = content.IndexOf('{');
string url = content.Substring(0, index);
string[] paramList = url.Split('&');
Func getValue = (name) => paramList.First(item => item.StartsWith(name + "=")).Replace(name + "=", "");
biz = getValue("__biz");
content = content.Substring(index);
//obj = new { biz, uin, pass_ticket, key };
DataService.SetData("princess_updateflag", new { biz }, out string errMsg);
}
AddMsg(() => RecorData(content, biz));
}
else if (type==4)
{
string errMsg;
dynamic data = DataService.GetData("princess_getbiz", out errMsg);
if (data != null)
{
biz = data.biz;
if (biz?.Length > 0)
obj = new { biz };
}
}
else if(type==3)
{
AddMsg(() => {
BuildPrincess(content);
});
}
return Json(obj);
}
private void AddMsg(Action action)
{
MessageQueue.Add(new MessageQueueItem(() => {
try
{
action();
}
catch (Exception ex)
{
}
}));
}
private void BuildPrincess(string content)
{ //从文章信息里获取公众号信息
//string url = content.Substring(0, 3000);
string biz = GetValue(content, "var\s*msg_link\s*=\s*\".+\"");
if (biz.Length == 0) return;
biz = biz.Substring(0, biz.IndexOf('&')).Substring(6);
biz = biz.Substring(biz.IndexOf("__biz=") + 6);
//content = content.Substring(1000);
//公众号名称
string source_name = GetValue(content, "var\s*nickname\s*=\s*\".+\"");
string source_img_url = GetValue(content, "var\s*ori_head_img_url\s*=\s*\".+\"");
string wechat_num = GetValue(content,
<p>
" />
"\(?.+)\");
DataService.SetData("Princess_insert", new
{
org_id = biz,
source_name = source_name,
source_url = "",
source_img_url = source_img_url,
img_url = source_img_url,
biz = biz
}, out string errMsg);
}
private string GetValue(string value, string pattern)
{
if (Regex.IsMatch(value, pattern))
{
Match match = Regex.Match(value, pattern);
if (match.Groups.Count > 1)
return match.Groups[1].Value;
string result = match.Value;
if (result.IndexOf('\"') > 0)
{
result = result.Substring(result.IndexOf('\"') + 1);
result = result.Substring(0, result.IndexOf('\"'));
}
return result;
}
return "";
}
private void RecorData(string jsonData,string biz)
{
dynamic result = jsonData.ToObjectFromJson();
if (result.ret == 0)
{
string general_msg_list = result.general_msg_list;
string errMsg;
dynamic data = general_msg_list.ToObjectFromJson();
IEnumerable docs = (data.list as List).Where(item => {
if (!(item as IDictionary).ContainsKey("app_msg_ext_info"))
return false;
return DataService.GetDataValue("doc_exists",
out errMsg, new { articleid =
#34;{item.comm_msg_info.id}-{item.app_msg_ext_info.fileid}" }) == 0;
}).Select(item =>
{
item.app_msg_ext_info.create_date =
DateTimeHelper.GetDateTimeFromXml(item.comm_msg_info.datetime);
item.app_msg_ext_info.pid = item.comm_msg_info.id.ToString();
return item.app_msg_ext_info;
});
if (docs.Count() == 0) return;
string org_id = docs.First().content_url;
org_id = org_id.Substring(org_id.IndexOf("__biz=") + 6).Split('&')[0];
var paras = GetDatas(org_id, docs);
var subDocs = docs.Where(item => item.is_multi == 1)
.Select(item =>
{
IEnumerable multiDocs =
item.multi_app_msg_item_list as IEnumerable;
return GetDatas(org_id, multiDocs, item.create_date, #34;{item.pid}");
}
);
if (subDocs.Count() > 0)
{
List list = paras.ToList();
foreach (var item in subDocs)
{
list.AddRange(item);
}
paras = list;
}
if (!DataService.SetData("doc_insert", paras, out errMsg))
{
}
}
}
///
/// 上传图片到文件服务器
///
///
///
private string UploadFile(string picUrl)
{
dynamic picResult = DataService.Execute("fileservice", new
{
keyword = "file",
content = new
{
ext = "jpg",
data = picUrl
}
});
return picResult.picurl;
}
///
/// 获取要存储的数据对象
///
///
///
///
///
///
private IEnumerable GetDatas(string org_id, IEnumerable docs
, DateTime? create_date = null, string pid = null)
{
var paras = docs.Select(item => {
string imageUrl = item.cover;
imageUrl = UploadFile(imageUrl);
return new
{
articleid = #34;{pid ?? item.pid}-{item.fileid}",
title = item.title,
digest = item.digest,
ori_url = item.content_url,
url = item.content_url,
image_url = imageUrl,
ori_image_url = imageUrl,
doc_type = "图文",
create_date = create_date ?? item.create_date,
org_id = org_id
};
});
return paras;
}
}</p>
推荐文章:网站文章内容怎么写?
写作文章其实是一种向他人传递的信息,而这种信息传递是否有价值,重点在于内容的逻辑性和深度能否表达一种观点。接下来,通过四个技术分析,深入解读网站 文章的内容怎么写。
1.明确内容主题。
澄清内容主题的最好方法是在写一些内容文章时先把主题抛出来,然后再慢慢介绍。
2.概述细化的内容。
一般来说,在第一段中,我们可以直接明确内容主题,也可以理解底层就像我们家一样是基础。如何构建高质量的内容大纲?
1.总结。
2.由浅到深。
3.文本接地气。
4.文章想法。
5.分发段落。
6.寓言图片搭配。
7. 一致的内容生成。
8.强大的层次结构逻辑。
9.深度内容发布。
10.有一定的观点。
11.细化内容。
3.强化内容逻辑。
内容的逻辑也可以用相应的方式进行,很多人说话没有逻辑和组织。其实每个文章都有一个主题,所有的内容输出都是从题词中填充出来的。
4.输出内容值。
即写出带有一定营养量的内容信息。互联网时代最好的营销方法是什么?内容营销无疑是最好的营销方法。
那么应该如何找到文章内容呢?现在很多SEO都因此头疼,写不出高质量的原创文章,想着用伪原创工具工具或者直接复制转载。但我想说的是,现在互联网上的这伪原创工具除了一个5118都比较好,其余的我都不想多说。 伪说,连文章的意思都变了。
首先,去书里找内容
利用书籍寻找原创文章创作资源,这一点对于很多SEO来说,应该并不陌生,但根据目前互联网信息爆炸的今天,仍然很难找到一本没有采集的书,但还是有一些,或者刚出炉,刚刚出版的。其实我这里说的书采集其实是采集书上的内容,找一本相关的书,采集上面的内容,不过建议大家去百度看看文章有没有采集过采集,如果没有,可以放心采集,如果有的话,需要仔细考虑。
二、根据自己的工作经验写作
虽然原创文章能给SEO带来很多帮助,但要真正写出一篇非常有价值的原创文章并不容易,最好也是最直接有效的方法就是根据自己的经验写作,发现问题,解决问题。SEO可以写自己在工作中遇到的问题,写解决问题的方式方法,经验和经验总结等等,这类文章不仅被用户喜欢,也被百度搜索引擎喜欢,而且这个文章不仅仅是写给读者看的,让读者避免跳坑, 也是为自己写的,是对自己本行业工作的总结,有助于提高自己的工作能力。
3. 通过视频录制进行创作
在当今的互联网上,网站有很多非常有价值的视频,而这会给SEO爱好者在创作中增加很多灵感,我们可以利用互联网搜索文章的相关词汇,然后打开搜索引擎的视频栏目,记录在视频讲座中非常重要和精彩的内容, 并列出相关表格,然后用自己的话总结变更语句,尽量简单明了,这样用户就不会觉得浏览起来太难,这样大大提高了网站的可读性,给网站操作带来了意想不到的好处。

