汇总:笨办法学采集-网站数据采集常用库(组图)
优采云 发布时间: 2022-11-17 13:23汇总:笨办法学采集-网站数据采集常用库(组图)
免费的文章采集器太多了,像hao123,csdn,pp助手,太多太多了,这里不一一列举了,采集主要还是看你的需求是什么,每个平台的设计也都不一样的。
excel都不会用,还来做采集。
oracleebsemcm最好的
最好的就是w3cschool了,
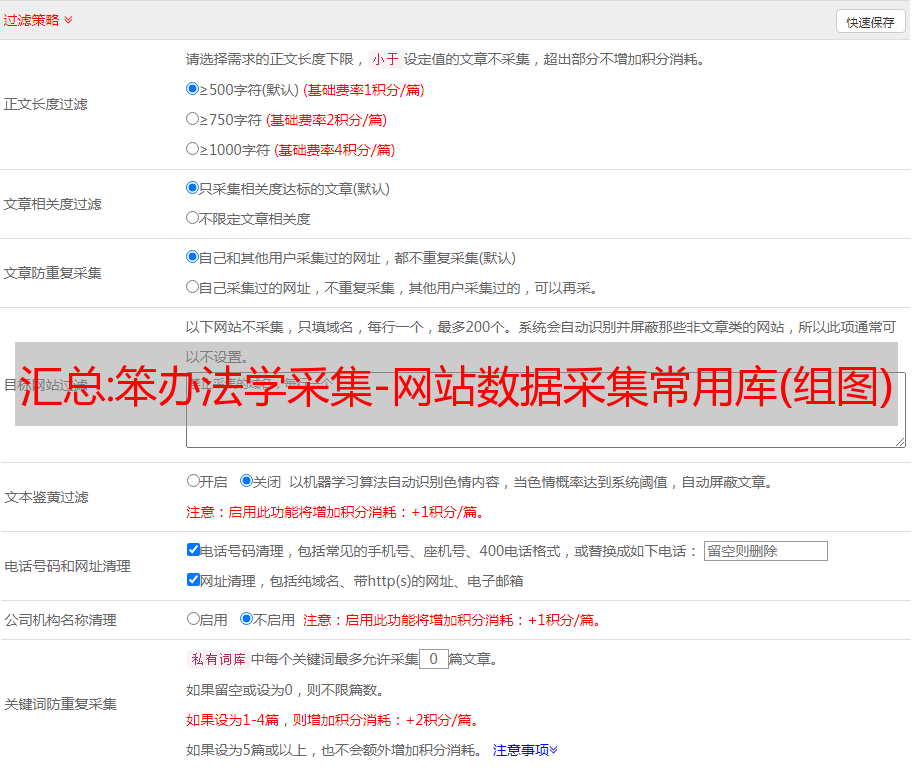
笨办法学采集-网站数据采集常用库
按照你提供的信息来看我觉得如果你自己操作能力足够强的话你可以试一下采集-excel导入必须会正则表达式能有效的去掉这部分内容采集-w3cschool可以全站去除无效页面和采集敏感词加密的东西可以拿网站举例~采集-excel这个好像是我用过最好用的导入网站的方法了比导入word方便多了多了多了~
u2k
推荐免费的采集网站:/
建议用爬虫工具,
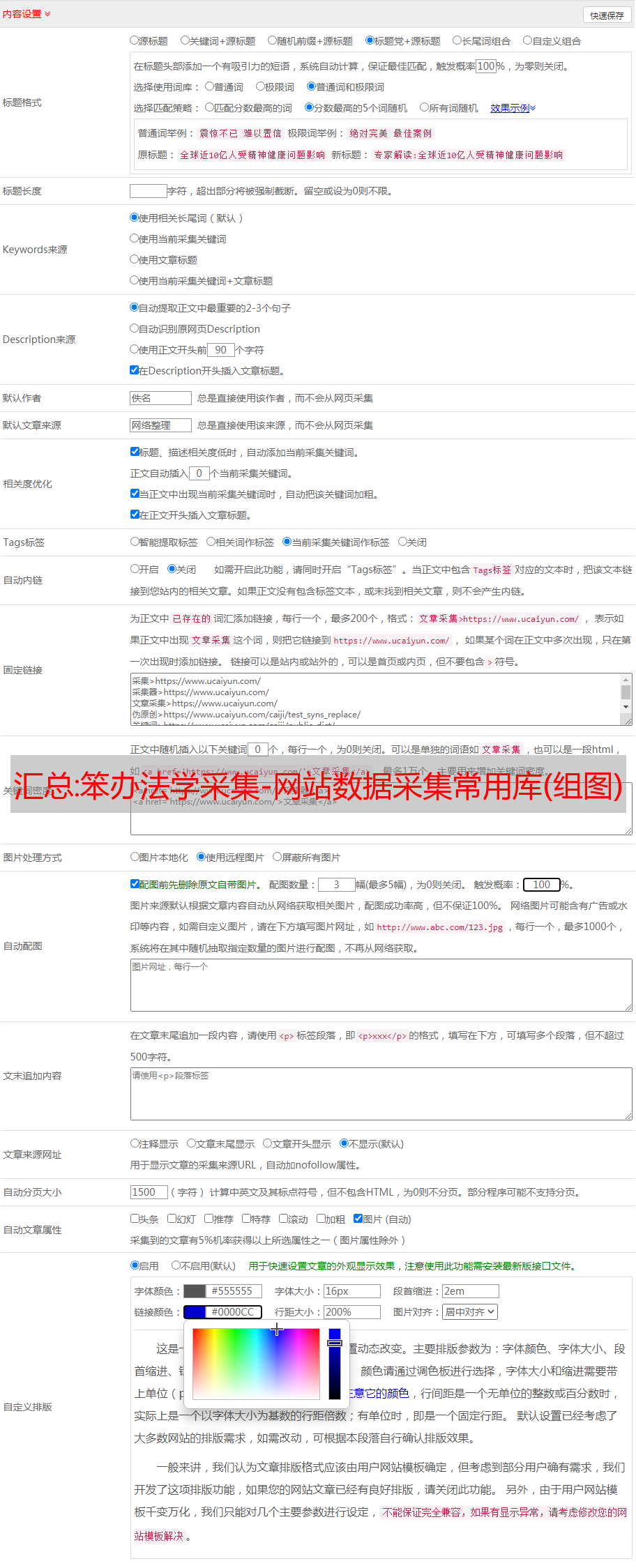
没推荐,搜之不得,我等更新,没优化过去,
傻瓜式采集直接查找采集
每一行简单代码(4个表或行数字类型数据)即可
excelhome的需要怎么说就没有了吧
最好用的采集器?个人认为,采集软件就是一个术的问题,需要技术,采集网站就是一个道的问题,需要深度。而哪些免费的采集软件,虽然也是免费的,但是对于新手来说,往往比较吃力,新手往往不会设置谷歌或者百度的那些反爬条件,所以往往有些繁琐。所以大多数的采集软件无法深入下去,往往无法精准抓取。对于刚学习爬虫的人来说,不是好选择。
目前国内比较成熟的就是requests、selenium、phantomjs了吧。python基本上集成了上述的这些东西,对于刚入门的人来说,基本上没什么难度。除了以上几个软件,还有像lxml、xpathtoolkit,beautifulsoup等等,各有所长。推荐lxml。===。

