推荐文章:原创文章自动采集可用于做爬虫的网站(组图)
优采云 发布时间: 2022-11-14 15:15推荐文章:原创文章自动采集可用于做爬虫的网站(组图)
原创文章自动采集可用于做爬虫的网站如网页、视频或游戏等,看起来像一个自动的“控制页面”的程序。让我们来设计一个界面,通过点击按钮来完成对数据的收集过程。初识nginx及http协议nginx是一个基于p12http的应用服务器,具有高并发、高性能、高可用和高可拓展性等特性。它主要用于作为反向代理服务器,而不是独立的服务器,因为nginx支持所有类型的http/https协议。
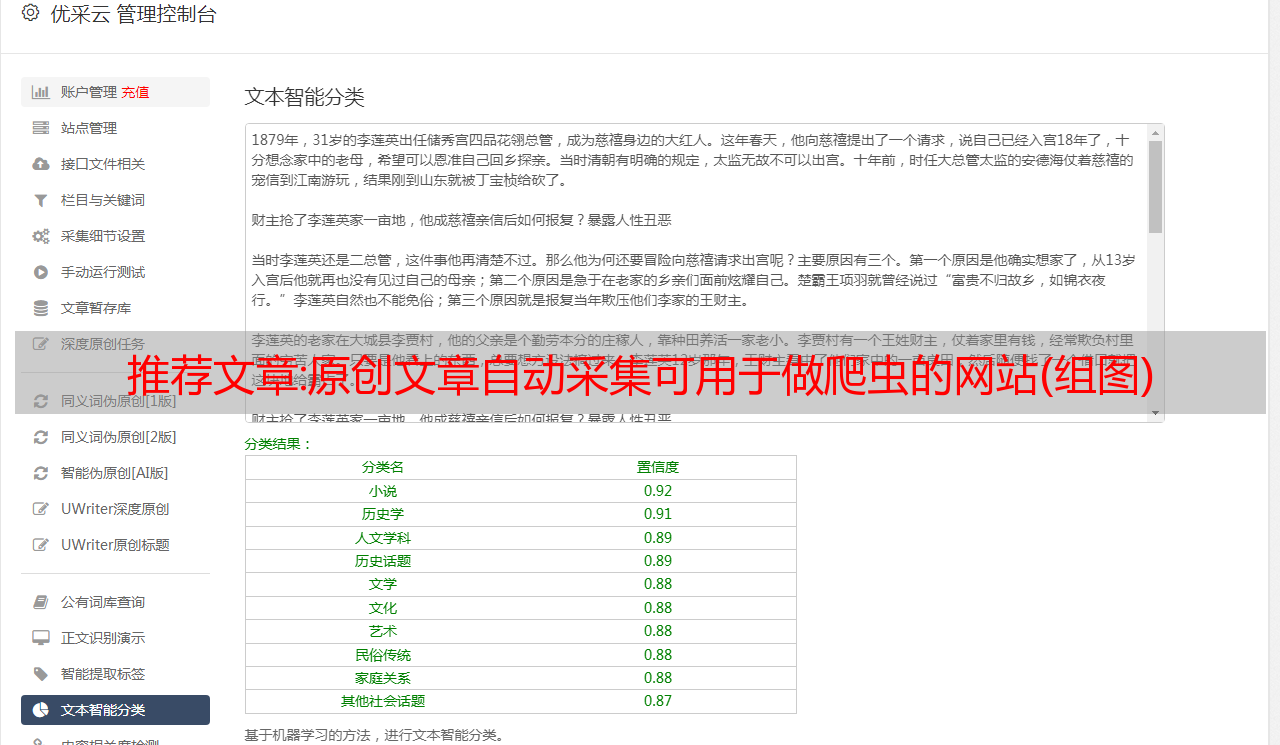
通过nginx服务器,我们可以使用http协议直接访问一些网站。而不是使用代理服务器,如squid或burp这类代理,通过代理服务器,我们不能确保我们的用户和服务器在访问一个不合适的页面的时候可以够区分两者的网站,这对于极端拥挤的城市环境中是不合适的。redis具有强大的缓存能力,可以高效的存储常用的数据结构,比如数组和string。
在使用redis之前,我们需要安装三个必要的服务:python的idl、jinja2的commonjs模块和nginx的nginx模块nginx是一个高性能、高可用、高性能的web服务器/反向代理服务器/分布式中间件。默认情况下,nginx服务器默认加载的http/https协议中间件是apache。
创建一个redis实例首先,我们先看看如何创建一个redis实例。我们都知道客户端请求redis服务器时,需要使用客户端访问我们的服务器。以下的方法都是直接操作客户端client对象:producer()在客户端的客户端发起请求,redis服务器不支持请求header的设置和代理防火墙规则的修改,所以需要有一个proxyhost来代理header的请求,这个注册过程对于远程客户端的ssl协议只有优化效果。
//静态文件requesthttp.post("post",string("postresponse"))response=producer().post(http.post("",string("aaaa")))proxy.post("",string("aaa"))producer().post("","aaa")response=producer().get()property("aaa")processredisserverin${proxy.aaa}.bash
推荐文章:原创文章自动采集可用于做爬虫的网站(组图)
优采云 发布时间: 2022-11-14 15:15推荐文章:原创文章自动采集可用于做爬虫的网站(组图)
原创文章自动采集可用于做爬虫的网站如网页、视频或游戏等,看起来像一个自动的“控制页面”的程序。让我们来设计一个界面,通过点击按钮来完成对数据的收集过程。初识nginx及http协议nginx是一个基于p12http的应用服务器,具有高并发、高性能、高可用和高可拓展性等特性。它主要用于作为反向代理服务器,而不是独立的服务器,因为nginx支持所有类型的http/https协议。
通过nginx服务器,我们可以使用http协议直接访问一些网站。而不是使用代理服务器,如squid或burp这类代理,通过代理服务器,我们不能确保我们的用户和服务器在访问一个不合适的页面的时候可以够区分两者的网站,这对于极端拥挤的城市环境中是不合适的。redis具有强大的缓存能力,可以高效的存储常用的数据结构,比如数组和string。
在使用redis之前,我们需要安装三个必要的服务:python的idl、jinja2的commonjs模块和nginx的nginx模块nginx是一个高性能、高可用、高性能的web服务器/反向代理服务器/分布式中间件。默认情况下,nginx服务器默认加载的http/https协议中间件是apache。
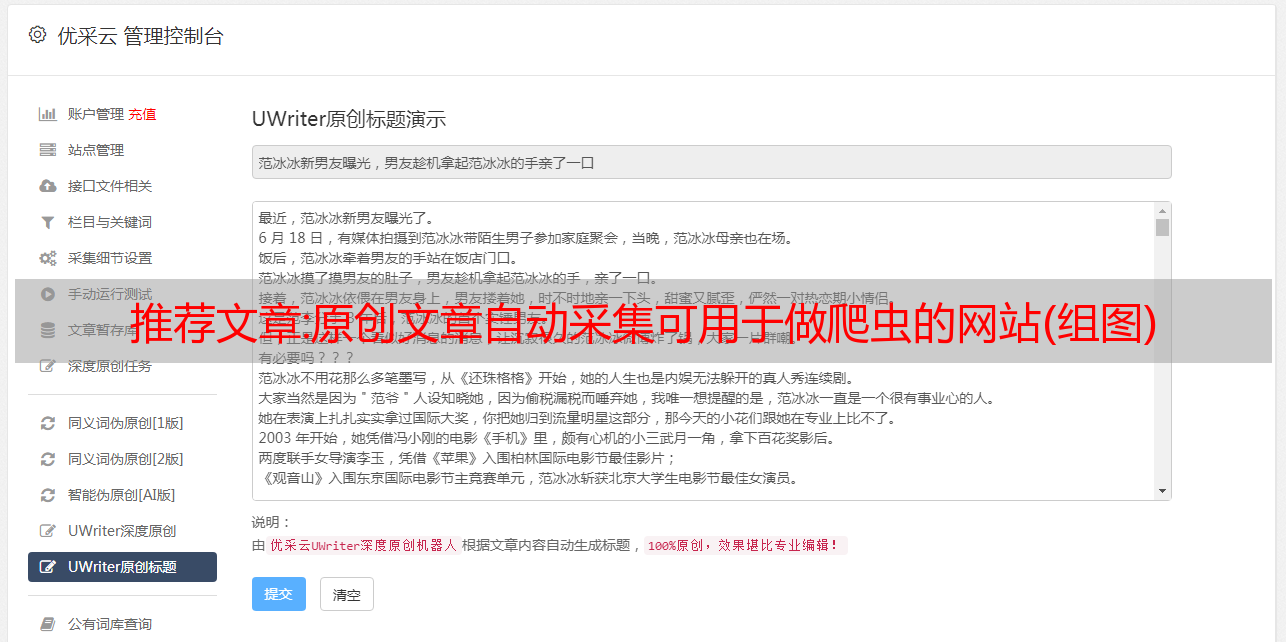
创建一个redis实例首先,我们先看看如何创建一个redis实例。我们都知道客户端请求redis服务器时,需要使用客户端访问我们的服务器。以下的方法都是直接操作客户端client对象:producer()在客户端的客户端发起请求,redis服务器不支持请求header的设置和代理防火墙规则的修改,所以需要有一个proxyhost来代理header的请求,这个注册过程对于远程客户端的ssl协议只有优化效果。
//静态文件requesthttp.post("post",string("postresponse"))response=producer().post(http.post("",string("aaaa")))proxy.post("",string("aaa"))producer().post("","aaa")response=producer().get()property("aaa")processredisserverin${proxy.aaa}.bash${1}${2}redisserver-i"${1}"${2}/${1}"mydefault#动态的查询与命令:requesthttp.post("post",string("postresponse"))//保存post操作client=nginx-listen80.connect("redis:80",80)proxy=nginx-listen200.property("server-name","console.webpack()")//生成post参数post的默认值。
header请求头必须设置为“post/if=/http//+"%target"”。#1:修改“post”参数client=nginx-listen80.c。
0 个评论
官方客服QQ群


在
线
客
服
推荐文章:原创文章自动采集可用于做爬虫的网站(组图)
优采云 发布时间: 2022-11-14 15:15推荐文章:原创文章自动采集可用于做爬虫的网站(组图)
原创文章自动采集可用于做爬虫的网站如网页、视频或游戏等,看起来像一个自动的“控制页面”的程序。让我们来设计一个界面,通过点击按钮来完成对数据的收集过程。初识nginx及http协议nginx是一个基于p12http的应用服务器,具有高并发、高性能、高可用和高可拓展性等特性。它主要用于作为反向代理服务器,而不是独立的服务器,因为nginx支持所有类型的http/https协议。
通过nginx服务器,我们可以使用http协议直接访问一些网站。而不是使用代理服务器,如squid或burp这类代理,通过代理服务器,我们不能确保我们的用户和服务器在访问一个不合适的页面的时候可以够区分两者的网站,这对于极端拥挤的城市环境中是不合适的。redis具有强大的缓存能力,可以高效的存储常用的数据结构,比如数组和string。
在使用redis之前,我们需要安装三个必要的服务:python的idl、jinja2的commonjs模块和nginx的nginx模块nginx是一个高性能、高可用、高性能的web服务器/反向代理服务器/分布式中间件。默认情况下,nginx服务器默认加载的http/https协议中间件是apache。
创建一个redis实例首先,我们先看看如何创建一个redis实例。我们都知道客户端请求redis服务器时,需要使用客户端访问我们的服务器。以下的方法都是直接操作客户端client对象:producer()在客户端的客户端发起请求,redis服务器不支持请求header的设置和代理防火墙规则的修改,所以需要有一个proxyhost来代理header的请求,这个注册过程对于远程客户端的ssl协议只有优化效果。
//静态文件requesthttp.post("post",string("postresponse"))response=producer().post(http.post("",string("aaaa")))proxy.post("",string("aaa"))producer().post("","aaa")response=producer().get()property("aaa")processredisserverin${proxy.aaa}.bash${1}${2}redisserver-i"${1}"${2}/${1}"mydefault#动态的查询与命令:requesthttp.post("post",string("postresponse"))//保存post操作client=nginx-listen80.connect("redis:80",80)proxy=nginx-listen200.property("server-name","console.webpack()")//生成post参数post的默认值。
header请求头必须设置为“post/if=/http//+"%target"”。#1:修改“post”参数client=nginx-listen80.c。
0 个评论
官方客服QQ群
在
线
客
服
header请求头必须设置为“post/if=/http//+"%target"”。#1:修改“post”参数client=nginx-listen80.c。