事实:以自动化的方式采集网页中一段从未被访问过的数据
优采云 发布时间: 2022-11-14 13:17事实:以自动化的方式采集网页中一段从未被访问过的数据
自动采集数据是数据采集器的核心功能,如果直接采集数据还需要采集器本身的水印,有的水印可能无法识别。直接采集数据也有一些弊端,比如说下载时间需要等待,比如说采集过多数据难以识别等等。于是有了分页加载数据。说白了就是自动抓取不同长度的文本。比如:今天是6月13日。然后点击“下一页”,把数据抓取到excel文件。
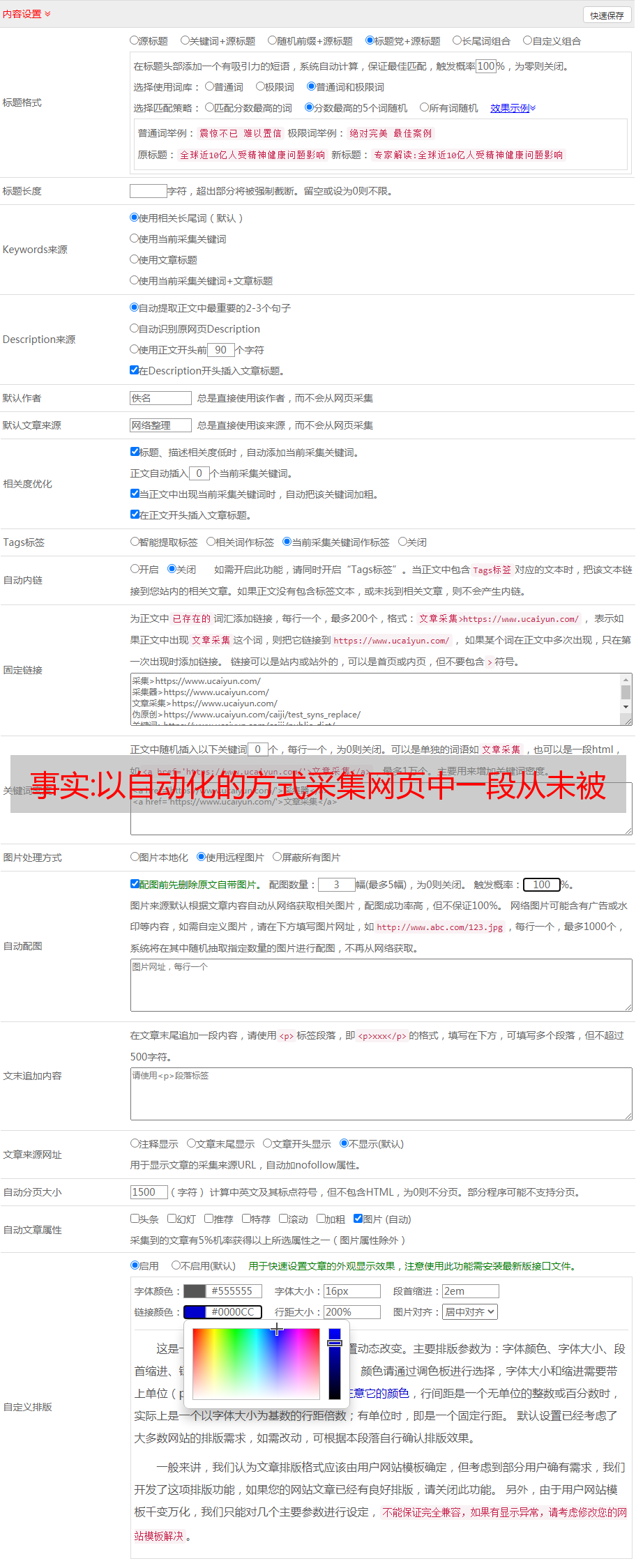
下一页是“下一页”。数据内容也没有水印。但是也不是所有都适用。那么“以自动化的方式采集网页中一段从未被访问过的页面的数据”是怎么做到的呢?一种是手动点选所有页面,然后抓取;一种是在这个页面内部抓取所有文本,然后用ui设计的分页标签来获取;一种是用数据抓取器抓取。数据抓取器不是为了抓取数据而生的,是为了分页设计的。
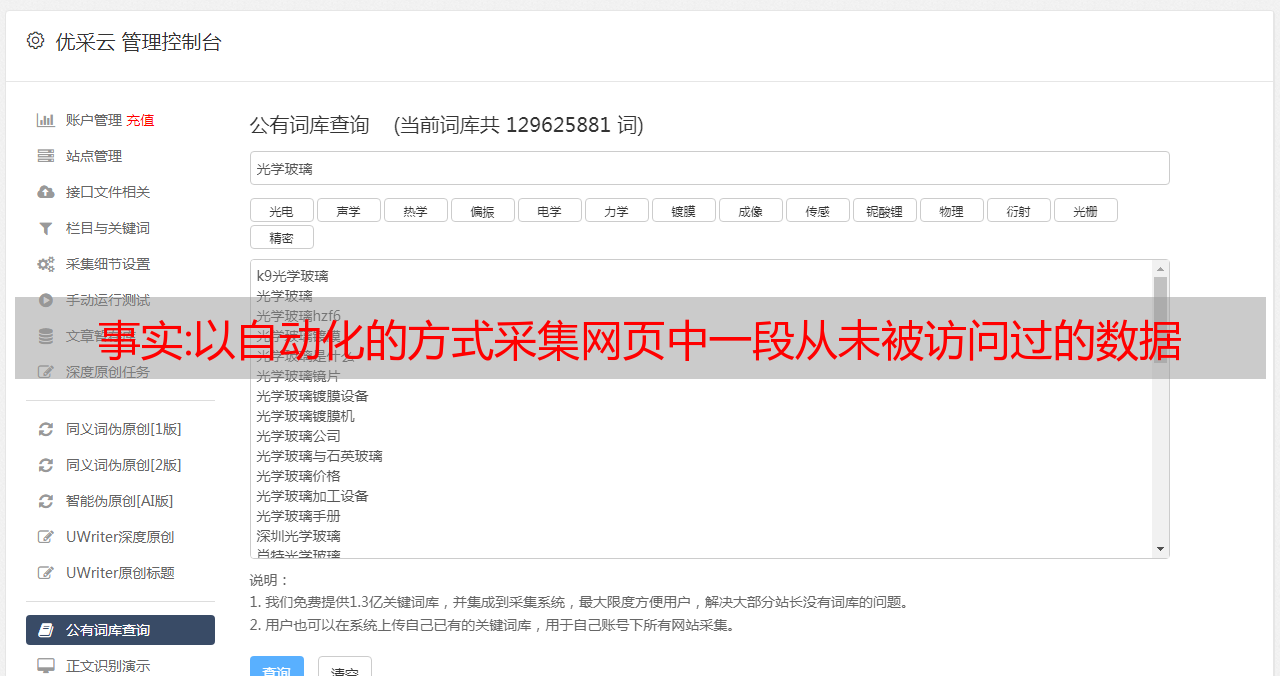
手动点选页面,抓取下一页,下一页再点,就不能再抓取了,必须用ui设计的分页标签,才能抓取到下一页数据。这是ui设计决定的。假设抓取图中“图2”中的第2页,那么就得用下一页抓取器去抓取,因为没有水印,设计的分页标签不好看,用不了分页标签。如果用html5通用模块,js和css就可以做到动态设置分页抓取器。
虽然可以显示不同的水印,但是不影响抓取。分页加载可以在抓取的文本内容中加入水印。比如说:图3中第二个文本中加入了文字,看上去也不丑。是不是很神奇,这就是github的一个分页加载加载器的介绍视频,建议大家好好看看,如果被别人不小心安利了,你就会很尴尬了。如果对视频很感兴趣,可以点赞、评论、关注我哦!我是采集中央宝宝,有什么技术问题欢迎评论讨论哦!。

