教程:湖南云秀seo教你:如何批量提取百度site:网址的链接
优采云 发布时间: 2022-11-10 18:14教程:湖南云秀seo教你:如何批量提取百度site:网址的链接
今天用之前的域名重新做SEO优化的时候,用百度网站:网址查询收录,发现收录就是之前所有的信息(17000多条)如图在下图中。由于已经被删除,所以点击都是死链接(页面找不到)。所以需要在百度站长平台上提取链接并提交死链接。因为有50多页,点进去一个一个复制链接很麻烦。今天给大家推荐一个我们平时使用的时间利用工具,爱站SEO工具提取链接(下图红框内的链接)。
爱站工具包站点:URL 提取教程
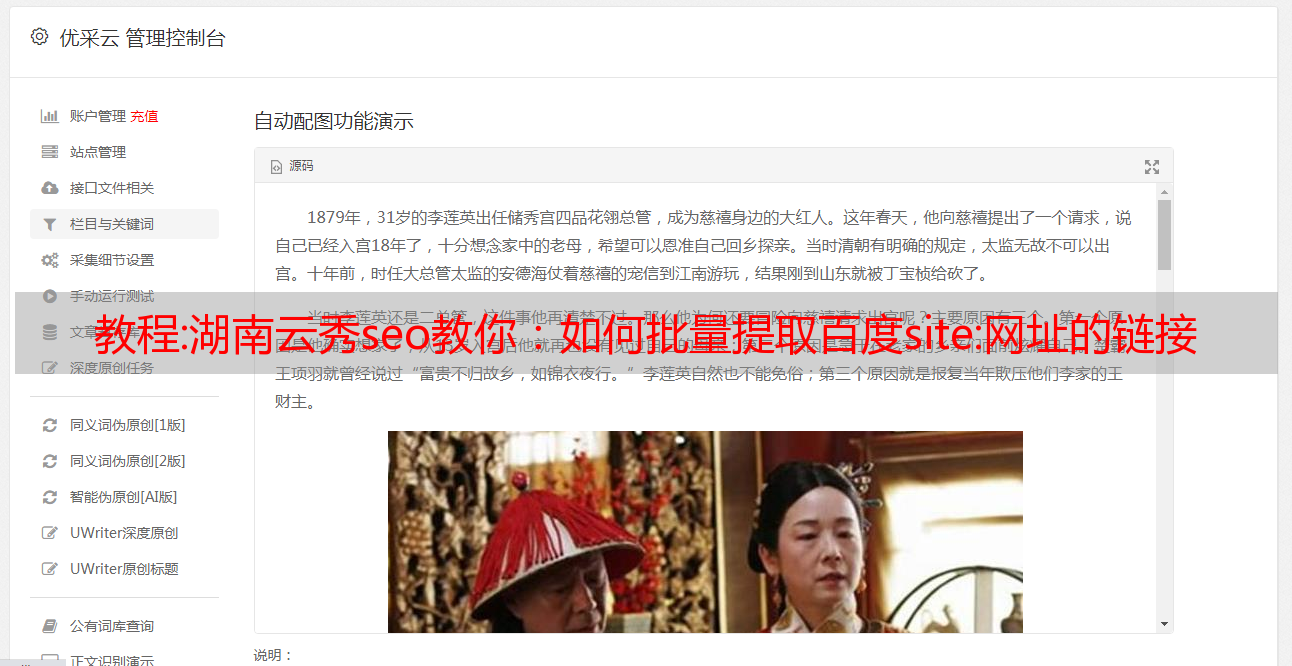
1.下载爱站SEO工具安装包进行安装,SEO,注册登录,点击实用工具下的“查询实效”,如下图
2、继续后,在关键词框内填写site:URL(勾选Unlimited,SEO网站优化,让所有站点链接都可以爬取)。然后点击右边的查询。如下所示
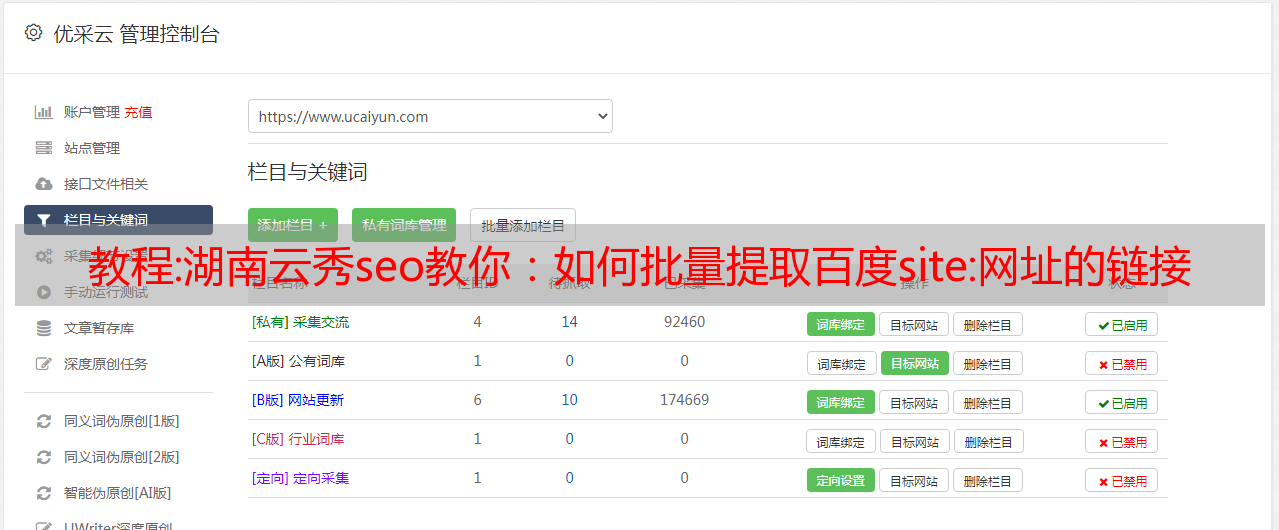
3、导出整理后,上传到你的网站根目录,提交到百度站长平台。爱站SEO Toolkit (v1.7.0.3) 下载 /s/1slnz8Up 可以从爱站官网下载
,百度SEO优化
教程:Python编程-利用爬虫配合dedecms全自动采集发布
作者:“文章作者”#文章作者
类型标识:“主列 ID2” #主栏目ID
正文:“文章内容
“ #文章内容
点击:“文章点击
“ #文章点击次数
发布日期:“提交时间”#提交时间
然后开始嘲笑dedecms发布文章测试,python代码如下:
6223242526272829336373839446474849556575859
#
!/usr/bin/python#coding:utf8import requests,random,time# 访问登录界面保持 cookiesid = requests. session()login_url = ”。0。0。2/dede/index。php?username=admin&password=admin“header = { ”User-Agent“:”Mozilla/5。0 (Windows NT 6。1;哇64;房车:44。0) 壁虎/20100101火狐/44。0“,”引用“ :”。0。0。2“}#登陆接口获取Cookiesloadcookies = sid。get(url=login_url,headers=header)#进入增加文章page#get_html=sid. get('。0。0。2/dede/article_add。php?channelid=1',headers = header)#print get_html。content# 定义固定字段 article = {'channelid':1, #普通文章提交 'dopost':'save', #提交方式'shorttitle':'', #短标题'autokey':1, #自动获取关键词'remote':1, #不指定缩略图,远程自动获取缩略图 'autolitpic':1, #提取第一个图片为缩略图'sptype':'auto', #自动分页'spsize':5, #5k大小自动分页'notpost':1, #禁止评论'sortup':0, #文章sort, 默认 'arcrank':0, #阅读权限为开放浏览money': 0,#消费金币0'ishtml':1, #生成html'click':random.
randint(10, 300), #随机生成文章命中 'pubdate':time. strftime(“%Y-%m-%d %H:%M:%S”, time。localtime()), #s生成当前提交时间}#定义可变字段article['source'] = “文章source” #文章sourcearticle['writer'] = “文章author” #文章author'['typeid'] = “2” #Main列 ID#定义提交文章请求URLarticle_request = ”。0。0。2/dede/article_add。php“”“”“#测试提交数据article['title'] = ”test_文章title“ #文章titlearticle['body'] = ”test_文章 content“ #文章content# 提交后将自动重定向 生成 HTML,HTTP 返回状态 200 成功! res = sid。post(url = article_request,data = article,headers = header)print res“”“for i in range(50): article['title'] = str(i) + ”_文章 title“ #文章 title article['body'] = str(i) + ”_文章 content“ #文章 内容 #print 文章 res = sid. post(url = article_request,data = article, headers = header) print res
二是分析爬虫需求的阶段,具体如下:
采集采集页面:
每个采集页面和要更改的规则不同,文章的列也可能更改,要编写多个爬虫,一个爬虫无法实现此功能,必须有爬虫、处理器、配置文件、函数文件(避免代码重复)、数据库文件。
数据库主要保存文章URL和标题,主要是判断这个文章是否更新,如果是
已经采集发布,不要重复发布,如果不存在文章是最新的文章,则需要写入数据库并发布文章。数据库适用于收录几个字段的表,使用 sqlite3、数据库文件 db.dll 创建表,如下所示:
123456
创建表历史记录(ID 整数主键 ASC 自动增量,URL VARCHAR( 100),标题文本,日期日期时间默认值 ( ( 日期时间( '现在', '本地时间' ) ) ));
该体系结构设计如下:
│ 分贝.dll #sqlite数据库
│ dede.py #测试dede登陆接口
│ function.py #公共函数
│ run.py #爬虫集开始函数
│ settings.py #爬虫配置设置
│ spiders.py #爬虫示例
│ SQLitestudio-2.1.5.exe #sqlite数据库编辑工具
│ __init__.py #前置方法供模块用
dede.py 如下:
6223242526272829336373839446474849556575859666
#
!/usr/bin/python#coding:utf8import requests,random,timeimport lxml#define domain domain = ”。0。0。2/“admin_dir = ”dede/“houtai = 域 + admin_dirusername = ”admin“密码 = ”admin“#访问登陆接口保持cookiessid = 请求。session()login_url = 后台 + “索引”。php?username=“ + username + ”&password=“ + passwordheader = { ”User-Agent“:”Mozilla/5。0 (Windows NT 6。1;哇64;房车:44。0) 壁虎/20100101火狐/44。0“,”引用“ : 域}#登陆接口获取Cookiesloadcookies = sid.get(url = login_url,headers = header)#定义固定字段article = {'channelid':1, #普通文章 commit 'dopost':'save', #提交方式'shorttitle':'', #短标题'autokey':1, #自动获取关键词'remote':1, #不指定缩略图, Remote Automatic fetch thumbnail 'autolitpic':1, #提取第一个图片为缩略图'sptype':'auto', #自动分页'spsize':5, #5k大小自动分页'notpost':1, #禁止评论'sortup':0, #文章sort, default 'arcrank':0, #阅读权限为开放浏览'money': 0,#消费金币0'ishtml':1, #生成html 'click':random.
randint(10, 300), #随机生成文章命中 'pubdate':time. strftime(“%Y-%m-%d %H:%M:%S”, time。localtime()), #s生成当前提交时间}#定义可变字段article['source'] = “文章source” #文章sourcearticle['writer'] = “文章author” #文章author article['typeid'] = “2” #Main列 ID#定义提交文章请求URLarticle_request = houtai + “article_add。php“”“”“#测试提交数据article['title'] = ”11 tests_文章标题“ #文章 标题文章['正文'] = ”11 tests_文章内容“ #文章 内容# 提交后会自动重定向 生成 HTML,http 返回状态 200 成功! res = sid。post(url = article_request,data = article, headers = header)print res“”“”for i in range(50): article['title'] = str(i) + “_文章 title” #文章 title article['body'] = str(i) + “_文章 content” #文章 内容 #print 文章 res = sid. post(url = article_request,data = article, headers = header) print res“””
function.py 如下:
62232425262728293363738394464748495
# 编码:utf-8 从设置导入 *#检查数据库中是否存在文章,0 表示不存在,1 表示 def res_check(文章): exec_select = “从历史记录中选择计数(*),其中 url = '%s' 和标题 = '%s' ” res_check = cur。执行(exec_select % (article[0],article[1]))) for res in res_check: result = res[0] 返回结果# 写入数据库 def res_insert(article): exec_insert = “插入历史记录 (url,title) 值 ( '%s','%s')” cur。执行(exec_insert % (文章[0],文章[1])) 连接。commit()#模拟登陆发布文章def send_article(title,body,typeid = “2”): article['title'] = title #文章title article['body'] = body #文章 content article['typeid'] = “2” #print文章#提交后会自动重定向 生成 HTML,HTTP 返回状态为 200 成功! res = sid。
post(url = article_request,data = article, headers = header) #print res if res。status_code == 200 : #print u“发送邮件!” send_mail(标题=标题,正文=正文)打印U“成功文章发送!” 否则:#发布文章失败处理通过#电子邮件通知send_mail(收据,标题,内容)def send_mail(标题,正文):寿建=“admin@0535code。com“ # 设置服务器、用户名、密码和电子邮件后缀 mail_user = ”610358898“ mail_pass=”您的邮箱密码“ mail_postfix=”qq.“ com” me=mail_user+“” msg = MIMEText(body, 'html', 'utf-8') msg['Subject'] = title #msg['to'] = shoujian try: mail = smtplib。
SMTP() 邮件。连接(“SMTP。QQ。com“)#配置SMTP服务器邮件。登录(mail_user,mail_pass)邮件。发送邮件(我,寿健,味精。as_string()) 邮件。close() print u“Send Mail success!” 除了 Exception, e: print str(e) print u“send mail exit!”
run.py 如下:
1234年
# -*-
编码:UTF-8 -*-import spiders #开始第一个爬虫 spiders.start()。
settings.py 如下:
62232425262728293363738394464748495565758596666768697767778
# 编码:utf-8import re,sys,os,requests,lxml,string,time,random,loggingfrom bs4 import BeautifulSoupfrom lxml import etreeimport smtplibfrom email。哑剧。text import MIMETextimport sqlite3import HTMLParser#Refresh system reload(sys)sys.setdefaultencoding( “utf-8” )# 定义当前时间 #now = 时间。strftime( '%Y-%m-%d %X',time。localtime())#设置头信息headers={ “User-Agent”: “Mozilla/5.0 (Windows NT 5。1) AppleWebKit/537。36 (KHTML, like Gecko) Chrome/42。0。2311。152 野生动物园/537。36“,”接受“:”*/*“,”接受语言“:”zh-CN,zh;q=0。8,en-US;q=0。
5,en; q=0。3“,”接受编码“:”gzip, deflate“,”Content-Type“:”application/x-www-form-urlencoded;charset=UTF-8“,”Connection“:”keep-alive“,”X-Request-with“:”XMLHttpRequest“,}domain = u”Beijing Software Outsourcing“.decode(“string_escape”) #要替换的超链接html_parser = HTMLParser.HTMLParser() #Generate escaper###dede 参数配置#定义域域域 = ”。0。0。2/“admin_dir = ”dede/“houtai = 域 + admin_dirusername = ”admin“密码 = ”admin“#访问登陆接口保持cookiessid = 请求。session()login_url = 后台 + “索引”。
php?username=“ + username + ”&password=“ + passwordheader = { ”User-Agent“:”Mozilla/5。0 (Windows NT 6。1;哇64;房车:44。0) 壁虎/20100101火狐/44。0“,”引用“ : 域}#登陆接口获取Cookiesloadcookies = sid.get(url = login_url,headers = header)#定义固定字段article = {'channelid':1, #普通文章 commit 'dopost':'save', #提交方式'shorttitle':'', #短标题'autokey':1, #自动获取关键词'remote':1, #不指定缩略图, Remote Automatic fetch thumbnail 'autolitpic':1, #提取第一个图片为缩略图'sptype':'auto', #自动分页'spsize':5, #5k大小自动分页'notpost':1, #禁止评论'sortup':0, #文章sort, default 'arcrank':0, #阅读权限为开放浏览'money': 0,#消费金币0'ishtml':1, #生成html 'click':random.
randint(10, 300), #随机生成文章命中 'pubdate':time. strftime(“%Y-%m-%d %H:%M:%S”, time。localtime()), #s生成当前提交时间}#定义可变字段article['source'] = “文章source” #文章sourcearticle['writer'] = “文章author” #文章author#definition 提交文章请求URLarticle_request = 后台 + “article_add.php”###Establish 数据库连接Conn = sqlite3 connect(“db。dll“)#创建游标cur = conn。游标()
spiders.py 如下:
622324252627282933637383944647484955657585966667686970
# 编码:utf-8 从设置导入 *从函数导入 *#获取内容、文章url,文章 内容 xpath 表达式 def get_content(url = “.中克德。com/news/content-1389。html“ , xpath_rule = ”//html/body/div[3]/div/div[2]/div/div[2]/div/div[1]/div/div/dl/dd“ ): html = requests。get(url,headers = headers)。内容树 = etree。HTML(html) res = 树 。xpath(xpath_rule)[0] res_content = etree。tostring(res) #转为字符串 res_content = html_parser。取消转义(res_content) #转为html编码输出res_content = res_content。替换('\t','')。替换(“\n”,“”) #去除空格 。
replace(' ',''), 换行符, 制表符返回 res_content# 获取结果, URL 列表 def get_article_list(URL = “.中克德。com/news。html“ ): body_html = 请求。get(url,headers = headers)。含量 #print body_html 汤 = 美丽汤(body_html,'lxml') page_div = 汤。find_all(name = “a”,href = re。compile(“content”),class_=“w-bloglist-entry-link”) #print page_div list_url = [] for a in page_div: #print a #print a。get('href') #print a。字符串list_url。追加((a.get('href'),a。字符串)) #print get_content(a。get('href')) else: #print list_url返回 list_url# 句柄采集页面定义 res_content(URL): 内容 = get_content(URL) #print内容信息 = re. findall(r'
(.*?
',内容,再。S)[0] #去掉dd标签 re_zhushi = pile(r'') #HTML注释 re_href = pile(r']*>[^[^

