汇总:批量挖洞从收集信息到数据存储
优采云 发布时间: 2022-11-09 18:56汇总:批量挖洞从收集信息到数据存储
单个 网站 的信息采集可能并不困难。有大量的一键式信息采集工具,比如oneforall,但是如果你面对11000个目标,如何采集信息?数据应该如何使用?
现在很多同学都在挖坑,依赖一些网络空间的搜索引擎,比如zoomeye、fofa等。这些平台采集了很多网络空间的信息,包括IP、域名、端口、网站头部、正文和即使是指纹信息,在节省时间的同时,也让我们对自己产生了依赖,所以我们放弃了自己采集信息,因为自己做需要时间和精力,效果不一定好,技术能力也不一定能满足我们愿望。
我们是否有必要从零开始采集大量的目标数据,并将数据存储起来随时使用?我觉得有必要,毕竟网络空间搜索引擎是面向整个网络空间的,我们只关注必要的目标。另外,赛博搜索引擎的数据也不是100%覆盖的,你要的数据还有很多,他却没有。
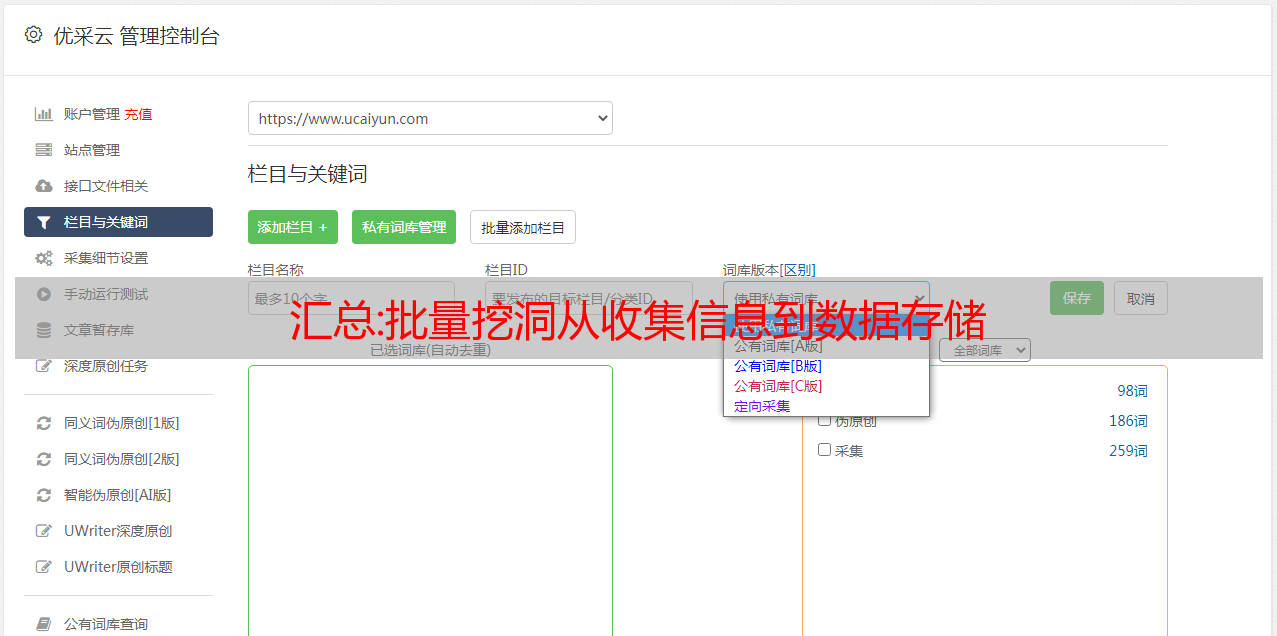
信息采集的几个步骤并没有太多新东西,无非就是子域采集(暴力枚举、爬虫、赛博引擎)、端口扫描(nmap、masscan、自研脚本)、网站指纹几个步骤。说起来容易,但实际操作起来就没那么容易了。当您的目标是数千时,许多工具无法满足您的需求,或者需要花费大量时间。你该怎么办?需要具备一定的编码能力,使用成熟工具得到的结果,对不同的数据结果进行数据归一化处理,适配不同的工具,或者自己实现各种功能,设计开发自动化的信息采集工具。
信息采集后,数据量非常惊人。如果把所有的数据都保存成文本格式,当你想在body中搜索某个关键词的时候,你会发现很慢,甚至会消耗系统。性能,这个时候,对数据进行处理并将其存储在数据库中是非常重要的。需要的时候可以直接搜索得到想要的结果,比如:
光看上面的图片,你可能看不到任何东西。事实上,对于采集到的数据,关键是子域名、IP、端口、服务、指纹、waf的存在、网站头、网页内容等信息。所有网页内容都存储在数据库中,数据库会非常大。没有必要。可以存储网页内容的关键部分,如jquery等,可以根据自己的经验提取关键内容,方便后续提取相关目标进行批量漏洞测试。.
最后分享一下我目前针对信息采集的数据设计的表结构:
至于以后如何使用这些数据,可以关注校长路和知识星球的公众号。我将记录和分享这些数据的使用过程和功能。如果你也想拥有自己的信息库,一个网络空间的小数据库,可以参加校长之路最后一期的公益src实战训练营,自己采集你想要的数据,并将所有数据格式化,然后入库,备用。
训练营相关内容:
更多精彩内容,您可以扫描下方二维码,加入知识星球,注册成长平台,参与实战训练营:
最新版:Python爬虫源码:微信公众号单页多音频MP3 批量采集提取保存音频文件
目前,几种有效的微信公众号采集方式:
1.通过网页端物料管理界面
2. 从手机到Appium
3. 通过逆向工程暴力获得
4. 通过第三方服务接口
5.搜狗微信公众号界面(降温)。
个人和小团体一般在公众号内容数量较少的情况下,采用前两种相对简单、方便、低成本的方式来获取内容,不差钱的团队肯定会购买第三方服务,通过提供微信公众号采集界面来盈利的服务绝对是逆向工程。我介绍第一个,比较简单,适合小规模采集
1.首先,我们需要注册一个我们自己的公众号平台微信公众号的注册地址
2.注册成功后,进入物料管理,如图所示
3. 单击“材料管理”,然后单击“新建图形消息”,如图所示
4. 单击新的图形消息,然后单击超链接,如图所示
5.点击解决超链接,点击选择其他公众账号如图所示
6.此时,您可以输入我们要获取的公众号内容名称进行搜索和查询
7. 我们通过捕获数据包进行查看和分析
通过抓包来分析请求参数并不难,这就像我的截图,后面会在代码中呈现,然后你也可以通过请求响应内容看到标题、链接、摘要、更新时间等内容 这里我们主要拿标题和URL,我想说明一下,我们这样得到的链接是临时链接,不是永久链接链接在手机上打开,但是我们只需要通过访问临时链接来下载内容也无妨,这个临时链接的有效持续时间其实是很长的,如果我们想转换成永久链接我们可以打开手机获取永久链接地址
获取代码流的一般概述
1.调用登录功能login_wechat通过网盘扫码登录微信公众号,这里不使用账号密码自动登录,因为即使输入了账号密码,还是需要扫码确认
2. 登录获取饼干信息,保存本地饼干.txt文件
3. 调用 采集 函数get_content获取 cookie .txt的 cookie 值并提取令牌
4、拼接好我们需要的请求参数后,在物料管理界面中请求我们等待采集的信息
5、通过请求界面获取文章的标题和链接,实现翻页功能
6.获取我们正在等待采集文章的链接,并请求链接地址以下载文章内容
7. 将标题、链接和内容保存到 CSV 文件
# -*- coding: utf-8 -*-
import re
import csv
import json
import time
import random
import requests
from selenium import webdriver
def login_wechat():
browser = webdriver.Chrome()
browser.get("https://mp.weixin.qq.com/")
time.sleep(2)
print("请拿手机扫码二维码登录公众号")
time.sleep(30)
print("登录成功")
# 获取cookies
cookie_items = browser.get_cookies()
post = {}
# 获取到的cookies是列表形式,将cookies转成json形式并存入本地名为cookie的文本中
for cookie_item in cookie_items:
post[cookie_item['name']] = cookie_item['value']
cookie_str = json.dumps(post)
with open('cookie.txt', 'w+', encoding='utf-8') as f:
f.write(cookie_str)
print("cookies信息已保存到本地")
browser.quit()
def get_content(ky):
<p>
# ky为要爬取的公众号名称
url = 'https://mp.weixin.qq.com' # 公众号主页
header = {
"HOST": "mp.weixin.qq.com",
"User-Agent": "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36"
}
# 读取上一步获取到的cookies
with open('cookie.txt', 'r', encoding='utf-8') as f:
cookie = f.read()
cookies = json.loads(cookie)
# 增加重试连接次数
session = requests.Session()
session.keep_alive = False
# 增加重试连接次数
session.adapters.DEFAULT_RETRIES = 10
time.sleep(5)
# 登录之后的微信公众号首页url变化为:https://mp.weixin.qq.com/cgi-bin/home?t=home/index&lang=zh_CN&token=657944522,从这里获取token信息
response = session.get(url=url, cookies=cookies)
token = re.findall(r'token=(\d+)', str(response.url))[0]
time.sleep(2)
# 搜索微信公众号的接口地址
search_url = 'https://mp.weixin.qq.com/cgi-bin/searchbiz?'
# 搜索微信公众号接口需要传入的参数,有三个变量:微信公众号token、随机数random、搜索的微信公众号名字
query_id = {
'action': 'search_biz',
'token': token,
'lang': 'zh_CN',
'f': 'json',
'ajax': '1',
'random': random.random(),
'query': ky,
'begin': '0',
'count': '5'
}
# 打开搜索微信公众号接口地址,需要传入相关参数信息如:cookies、params、headers
search_response = session.get(search_url,cookies=cookies,headers=header,params=query_id)
# 取搜索结果中的第一个公众号
lists = search_response.json().get('list')[0]
print(lists)
# 获取这个公众号的fakeid,后面爬取公众号文章需要此字段
fakeid = lists.get('fakeid')
# 微信公众号文章接口地址
appmsg_url = 'https://mp.weixin.qq.com/cgi-bin/appmsg?'
# 搜索文章需要传入几个参数:登录的公众号token、要爬取文章的公众号fakeid、随机数random
query_id_data = {
'token': token,
'lang': 'zh_CN',
'f': 'json',
'ajax': '1',
'random': random.random(),
'action': 'list_ex',
'begin': '0', # 不同页,此参数变化,变化规则为每页加5
'count': '5',
'query': '',
'fakeid': fakeid,
'type': '9'
}
# 打开搜索的微信公众号文章列表页
appmsg_response = session.get(appmsg_url,cookies=cookies,headers=header,params=query_id_data)
# 获取文章总数
max_num = appmsg_response.json().get('app_msg_cnt')
# 每页至少有5条,获取文章总的页数,爬取时需要分页爬
num = int(int(max_num) / 5)
print(num)
# 起始页begin参数,往后每页加5
begin = 0
seq = 0
while num + 1 > 0:
query_id_data = {
'token': token,
'lang': 'zh_CN',
'f': 'json',
'ajax': '1',
'random': random.random(),
'action': 'list_ex',
'begin': '{}'.format(str(begin)),
'count': '5',
'query': '',
'fakeid': fakeid,
'type': '9'
}
print('正在翻页:--------------', begin/5)
time.sleep(8)
# 获取每一页文章的标题和链接地址,并写入本地文本中
query_fakeid_response = session.get(appmsg_url,cookies=cookies,headers=header,params=query_id_data)
fakeid_list = query_fakeid_response.json().get('app_msg_list')
if fakeid_list:
for item in fakeid_list:
content_link = item.get('link')
content_title = item.get('title')
fileName = ky + '.txt'
seq += 1
content_body = session.get(content_link).text
info = [content_title, content_link, content_body]
save(ky,info)
begin = int(begin)
begin += 5
# csv head
def csv_head(ky):
ky = ky
head = ['content_title', 'content_link', 'content_body',]
csvFile = open(fr'{ky}.csv', 'w', newline='', encoding='utf-8-sig') # 设置newline,否则两行之间会空一行
writer = csv.writer(csvFile)
writer.writerow(head)
csvFile.close()
# 存储csv
def save(ky,info):
ky = ky
csvFile = open(fr'{ky}.csv', 'a+', newline='', encoding='utf-8-sig') # 设置newline,否则两行之间会空一行
writer = csv.writer(csvFile)
writer.writerow(info)
csvFile.close()
if __name__ == '__main__':
ky = '肯德基'
login_wechat()
csv_head(ky)
get_content(ky)
</p>

