解决方案:集微社采集软件详细说明
优采云 发布时间: 2022-11-05 13:58解决方案:集微社采集软件详细说明
软件介绍:集微摄是一款智能微信群采集软件,结合了大数据爬虫技术和图像分析技术,是专门用于互联网上采集微信群二维码图片的工具。群分享“网站”、“微博”、“贴吧”、“公众号”等微信群二维码等大流量平台发布陌生人分享的大数据内容采集 软件可智能识别二维码,检测二维码真伪,智能过滤重复二维码,记忆查询功能,可帮助您大大提高找群效率,提高进群成功率,提高群质量。(学会简单使用集微摄采集
目前软件中内置了 5 个固定 采集 频道和 1 个自定义 采集 频道。五个固定的采集分别是:豆瓣、贴吧、微博、公众号、二维码分享网站。自定义采集通道允许用户根据自己的需要为某个网站添加采集监控任务,更加灵活通用,满足不同的采集需求用户。2.自动过滤重复数据——(新增)软件会自动过滤已经采集的二维码图片,已经采集的图片不会重复采集,保证即每天采集换一个不同的新二维码。3. 多重检测过滤——(安全)软件在使用过程中会对二维码进行安全检测,保障用户的安全。4.数据共享——(方便)
除了实时的采集二维码供用户使用,软件官方还将当天收到的二维码数据采集分享给大家使用。5.数据修复
当发现采集收到的二维码图片无法正常显示时,很有可能这条记录已被相应平台删除或屏蔽。用户可以尝试使用软件修复功能尝试修正二维码。图片已修复。6.数据批量导出支持采集接收到的数据批量导出。7、模拟操作自动加入组内,采用自动模拟人工操作,自动循环操作,无需人工值守。8、软件持续免费升级,提供优质的售后服务。使用说明1:微信群采集软件主要功能是群二维码采集、采集,自动加群操作符合腾讯规则,安全且不被阻塞。2:与QQ不同,微信群不提供精准分类和搜索功能。软件采集的二维码是第三方平台上他人共享的群组二维码数据。网上的采集群 二维码的内容和数量是软件无法控制的。同时,微信群本身并没有标注地区和行业的属性,标注的地区和行业群的内容是个人行为。3:微信群是用户的另一个私人空间。它只有两种加入方式:一种是被好浩邀请进群,另一种是扫描他人分享的群的二维码进群。软件主要是通过采集
2.微信群二维码分享者已离开微信群
3. 100人以上的群无法扫码进群,只能被其他群员邀请入群
4、二维码发布时间超过7天有效期
以上几点属于腾讯自己的规则,会导致二维码失效,无法入群。
目前还没有办法从技术上过滤这些情况,只有扫码才能知道二维码是什么。
为避免采集获取过多过期二维码,软件内部设置为仅采集各平台1-2天内更新的内容,使用此方法尽量减少采集 二维码过期的可能性。但是没有办法完全避免它。(数据内容更新不代表他人分享的二维码是同一天生成的)
如何提高组率:
每天采集,尽量保证采集的数据都是新的,每天采集数据可以让软件本地数据库更加完善,当有更多采集 记录,软件还会对之前的采集 接收到的数据进行比较和过滤。如果是每三五次采集,软件很可能采集1-2天前的数据。这将大大降低Crowd rate的成本。
优化的解决方案:网页抽取技术和算法
(在程序中,双引号和\必须在它们之前用\进行转义。
3.基于CSS选择器的网页提取
浏览器收到服务器返回的html源代码后,将网页解析成DOM树。CSS 选择器(CSS Selector)是一种基于 DOM 树的特性,广泛用于网页提取。目前最流行的网页提取组件 Jsoup (Java) 和 BeautifulSoup (Python) 都是基于 CSS 选择器的。
对于上面的例子:
(标题)此内容不要被抽取
(正文)此内容要被抽取
(页脚)此内容不要被抽取
使用 CSS 选择器将大大提高代码的可读性:
public static void cssExtract() {
String html="" +
"(标题)此内容不要被抽取" +
"(正文)此内容要被抽取" +
"(页脚)此内容不要被抽取" +
"";
//Jsoup中的Document类表示网页的DOM树
Document doc= Jsoup.parse(html);
//利用select方法获取所有满足css选择器的Element集合
// (实际是一个Elements类型的对象)
//由于在本网页的结构中,只会有一个Element满足条件
// 因此只要返回集合中的第一个Element即可
Element main=doc.select("div[class=main]").first();
//main是一个Element对象,这里main对应了网页中
//的(正文)此内容要被抽取
//我们调用Element的text()方法即可提取中间的文字
if(main!=null){
<p>
System.out.println("抽取结果:"+main.text());
}else{
System.out.println("无抽取结果");
}
}</p>
CSS 选择器有一个标准规范,但是 Jsoup (Java) 和 BeautifulSoup (Python) 等组件并没有完全按照规范实现 CSS 选择器。因此,在使用每个组件之前,最好阅读组件文档中对 CSS 选择器的描述。
Jsoup 是 CSS 选择器的一个很好的实现。如果想了解 CSS 选择器的使用,推荐阅读 Jsoup 的 CSS 选择器规范文档。
浏览器中的 javascript 直接支持 CSS 选择器。如果计算机上安装了 firefox 或 chrome,请打开浏览器,按 F12(调出开发人员界面),打开任意网页,然后选择 Console 选项卡。页面,在控制台输入
document.querySelectorAll("a")
回车后发现页面中的所有超链接都输出了,document.querySelectorAll(CSS选择器)获取页面中所有满足CSS选择器的元素,并以数组的形式返回。
如果只想获取第一个满足 CSS 选择器的元素,可以使用 document.querySelector(CSS selector) 方法。
浏览器 js 中的 CSS 选择器与 Jsoup (Java) 和 BeautifulSoup (Python) 中实现的 CSS 选择器略有不同,但大体相同。
4.基于机器学习的网页提取
基于常规或 CSS 选择器(或 xpath)的网页提取是基于基于包装器的网页提取。这种提取算法的共同问题是必须针对不同结构的网页制定不同的提取规则。如果一个舆情系统需要监控10000个异构网站s,它需要编写和维护10000组抽取规则。大约从 2000 年开始,人们一直在研究如何使用机器学习来让程序从网页中提取所需的信息,而无需手动规则。
从目前的科研成果来看,基于机器学习的网页提取重点偏向于新闻网页内容的自动提取,即当输入一个新闻网页时,程序可以自动输出新闻标题,文字、时间等信息。新闻、博客、百科网站收录比较简单的结构化数据,基本满足{title,time,text}的结构,提取目标很明确,机器学习算法设计的很好。但是,电子商务、求职等各类网页所收录的结构化数据非常复杂,有的存在嵌套,没有统一的提取目标。很难为此类页面设计机器学习提取算法。
本节主要介绍如何设计一种机器学习算法,从新闻、博客、百科全书等中提取文本信息。网站,以下简称网页内容提取(Content Extraction)。
基于机器学习的网页提取算法大致可以分为以下几类:
三类算法中,第一类算法实现最好,效果最好。
下面简单介绍一下这三种算法。如果你只是想在你的工程中使用这些算法,你只需要了解第一类算法。
下面会提到一些论文,但是请不要根据论文中自己的实验数据来判断算法的好坏。很多算法都是面向早期网页设计的(即以表格为框架的网页),有些算法有实验数据集,覆盖范围更广。狭窄。有条件的话最好自己评估一下这些算法。
4.1 基于启发式规则和无监督学习的网页提取算法
基于启发式规则和无监督学习的网页提取算法(第一类算法)是目前最简单、最有效的方法。并且通用性高,即该算法往往对不同语言、不同结构的网页有效。
这些早期的算法大多没有将网页解析成DOM树,而是将网页解析成一系列token,例如下面的html源码:
广告...(8字)
正文...(500字)
页脚...(6字)
该程序将其转换为一系列标记:
标签(body),标签(div),文本,文本....(8次),标签(/div),标签(div),文本,文本...(500次),标签(/div),标签(div),文本,文本...(6次),标签(/div),标签(/body)
早期有基于token序列的MSS算法(Maximum Subsequence Segmentation)。该算法有多个版本。一个版本为令牌序列中的每个令牌分配了一个分数。评分规则如下:
根据评分规则和上面的token序列,我们可以得到一个评分序列:
-3.25,-3.25,1,1,1...(8次),-3.25,-3.25,1,1,1...(500次),-3.25,-3.25,1,1,1...(6次),-3.25,-3.25
MSS算法认为,如果在token序列中找到一个子序列,使得该子序列中token对应的score之和达到最大值,那么这个子序列就是网页的文本。换个角度理解这个规则,就是从html源字符串中找一个子序列。这个子序列应该收录尽可能多的文本和尽可能少的标签,因为该算法会为标签分配更大的绝对值。负分 (-3.25),给文本一个小的正分 (1)。
如何从分数序列中找到和最大的子序列可以通过动态规划很好地解决。详细的算法这里就不给出了。有兴趣的可以参考论文《Extracting Article Text from the Web with Maximum Subsequence Segmentation》,MSS 算法效果不好,但是这篇论文认为它是很多早期算法的代表。
还有其他版本的 MSS,我们上面说过算法分别给标签和文本分配 -3.25 和 1 点,它们是固定值,并且有一个版本的 MSS(也在论文中)使用朴素贝叶斯作为标签和文本。文本计算分数。虽然这个版本的MSS效果有了一定程度的提升,但还是不够理想。
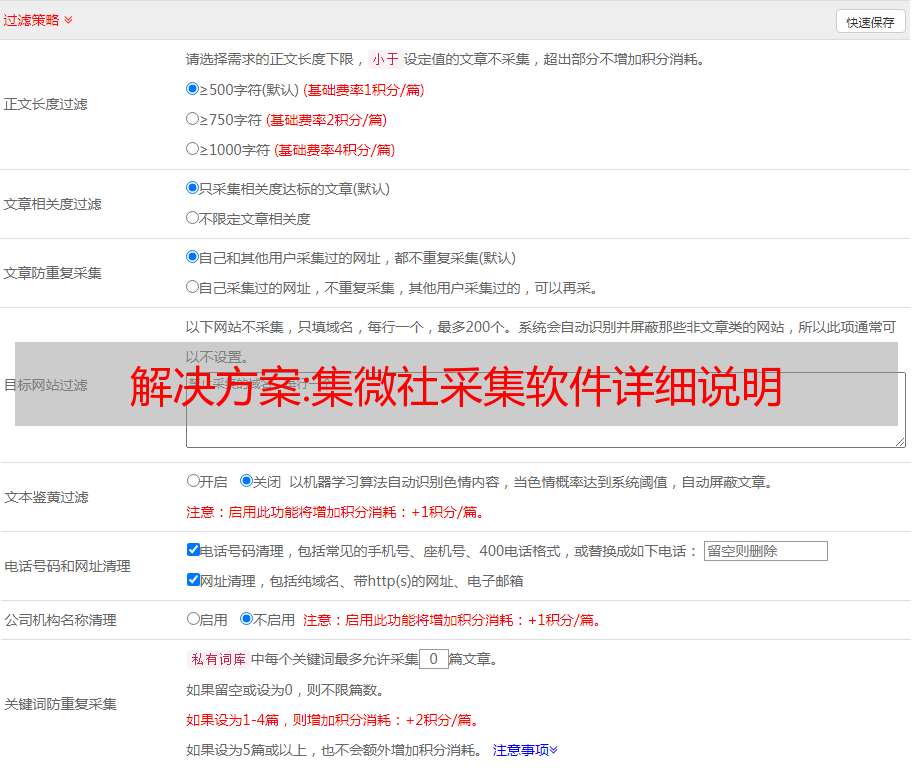
无监督学习在第一类算法中也扮演着重要的角色。许多算法使用聚类方法将网页的文本和非文本自动分为两类。例如,在“CETR - Content Extraction via Tag Ratios”算法中,网页被分成多行文本,算法为每行文本计算2个特征,分别是下图中的横轴和纵轴,以及红色椭圆中的单元格。(行),其中大部分是网页,绿色椭圆中收录的大部分单元(行)是非文本。使用 k-means 等聚类方法,可以很好地将文本和非文本分为两类。然后设计一些启发式算法来区分这两种类型中哪些是文本,哪些是非文本。
早期的算法经常使用记号序列和字符序列作为计算特征的单位。从某种意义上说,这破坏了网页的结构,没有充分利用网页的特性。在后来的算法中,很多使用 DOM 树节点作为特征计算的基本单元,例如“通过路径比率提取 Web 新闻”、“通过文本密度提取基于 Dom 的内容”,这些算法仍然使用启发式规则和无监督学习,因为DOM树的节点作为特征计算的基本单元,算法可以获得更好更多的特征,因此可以设计出更好的启发式规则和无监督学习算法。通常比前面描述的算法要高得多。由于提取时以DOM树的Node为单位,
我们在WebCollector(1.12版本开始)中实现了一流的算法,可以直接从官网下载源代码使用。
4.2 基于分类器的网页抽取算法(第二类机器学习抽取算法)
实现基于分类器的网页提取算法(第二种算法),一般流程如下:
对于网页提取来说,特征设计是第一要务,使用什么分类器有时并不那么重要。在使用相同特征的情况下,使用决策树、SVM、神经网络等不同的分类器,不一定对提取效果有太大影响。
从工程的角度来看,该过程的第一步和第二步都比较困难。训练集的选择也很讲究,保证所选数据集中网页结构的多样性。比如现在比较流行的文本结构是:
xxxx
xxxxxxxx
xxx
xxxxx
xxxx
如果训练集中只有五六个网站页面,很有可能这些网站的文本都是上面的结构,而仅仅在特征设计上,有两个特征:
假设使用决策树作为分类器,最终训练出来的模型很可能是:
如果一个节点的标签类型为div,且其孩子节点中标签为p的节点超过3个,则这个节点对应网页的正文。
虽然这个模型可以在训练数据集上取得更好的提取效果,但是很明显有很多网站不符合这个规则。因此,训练集的选择对提取算法的效果影响很大。
网页设计的风格在不断变化。早期的网页经常使用表格来构建整个网页的框架。现在的网页都喜欢用div来搭建网页的框架。如果希望提取算法覆盖较长的时间,那么在设计特征时应该尽量使用那些不易改变的特征。标签类型是一个很容易改变的特征,并且随着网页设计风格的变化而变化,所以如前所述,强烈不建议使用标签类型作为训练特征。
上面提到的基于分类器的网页提取算法属于急切学习,即算法通过训练集生成模型(如决策树模型、神经网络模型等)。对应的惰性学习,也就是不预先使用训练集就生成模型的算法,比较有名的KNN属于惰性学习。
有些提取算法使用KNN来选择提取算法,听上去可能有点混乱,这里解释一下。假设有2个提取算法A和B,有3个网站site1,site2,site3。2种算法对3个网站的提取效果(这里使用0%到100%之间的数字表示,越大越好)如下:
网站A算法提取效果B算法提取效果
站点1
90%
70%
站点2
80%
85%
站点3
60%
87%
可以看出,在site1上,算法A的提取效果优于B,在site2和site3上,算法B的提取效果更好。在实践中,这种情况非常普遍。所以有人想设计一个分类器,这个分类器不是用来对文本和非文本进行分类,而是帮助选择提取算法。例如,在这个例子中,当我们提取site1中的网页时,分类器应该告诉我们使用A算法以获得更好的结果。
举个直观的例子,算法A对政府网站的提取效果更好,算法B对网络新闻网站的提取效果更好。那么当我提取政府类网站时,分类器应该会帮我选择A算法。
这个分类器的实现可以使用KNN算法。需要提前准备一个数据集。数据集中有多个站点的网页,需要同时维护一个表。哪种算法提取最好的结果)。当遇到要提取的网页时,我们将该网页与数据集中的所有网页进行比较(效率低下),找到最相似的K个网页,然后查看K个网页中哪个站点的网页最多(例如k= 7,其中6个来自CSDN News),那么我们选择本站最好的算法来提取这个未知网页。
4.3 基于网页模板自动生成的网页提取算法
基于网页模板自动生成的网页提取算法(第三类算法)有很多种。这是一个例子。在“URL Tree: Efficient Unsupervised Content Extraction from Streams of Web Documents”中,比较相同结构的多个页面(以URL判断),找出异同。页面之间的共同部分是非文本的,页面之间的差异很大。部分可能是文本。这很容易理解。例如,在某些网站 页面中,所有页脚都相同,即归档信息或版权声明。这是页面之间的共性,所以算法认为这部分是非文本的。不同网页的文本往往是不同的,因此算法更容易识别文本页面。该算法往往不会从单个网页中提取文本,而是在采集大量同构网页后同时提取多个网页。也就是说,不需要实时输入网页并提取。

