总结归纳:企查查SEO亮点分析、采集+精准词库=高权重
优采云 发布时间: 2022-11-04 16:16总结归纳:企查查SEO亮点分析、采集+精准词库=高权重
最近又有朋友让我分析一下七叉叉。本着知识共享的原则,结合自己浅薄的认知和知识,给大家讲讲七叉叉的SEO亮点,希望能帮助更多的兄弟了解SEO。自然!
我之前也分析过顺奇网和58网。如果你喜欢它,你可以看看。58同城的词库比较笼统一点,七叉搜索比较准确。与以上两者相比,顺奇网的词更加复杂,不同的业务,不同的词库,不分级别。
(内容,模板)稀缺
现在很多人实现了SEO,仍然认为原创是SEO的核心。七叉叉就是对这种观点的最大否定。因为上面的信息基本都是采集。
不过目测采集的内容应该是调用国家数据库吧,因为国内每个企业的信息应该不会那么好采集,就算是采集,也有仍然是不准确的情况,因为非权威网站上的企业信息的信任度比较低。只有国家信息才能准确。
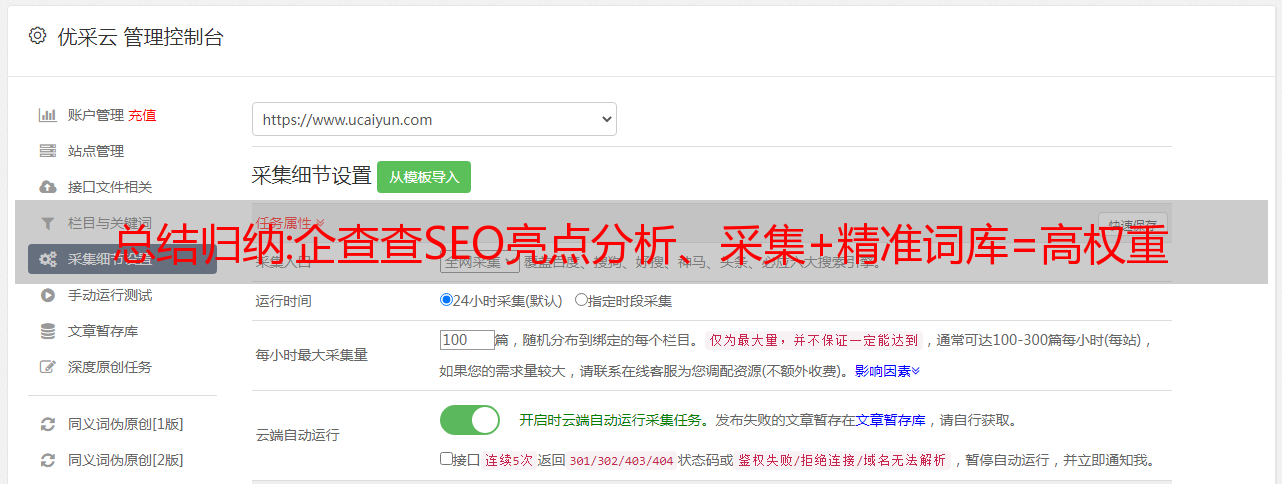
内容解决了,七叉叉在用户体验和模板上都做得很好。我们在之前的课程中也谈到了影响网站排名和收录的因素,模板也是其中之一。.
*敏*感*词*的网站到最后,绝对是一场量级的较量。词库决定权重,收录 决定词库。收录 这么大的规模,绝对不是几十上百人能做到的。
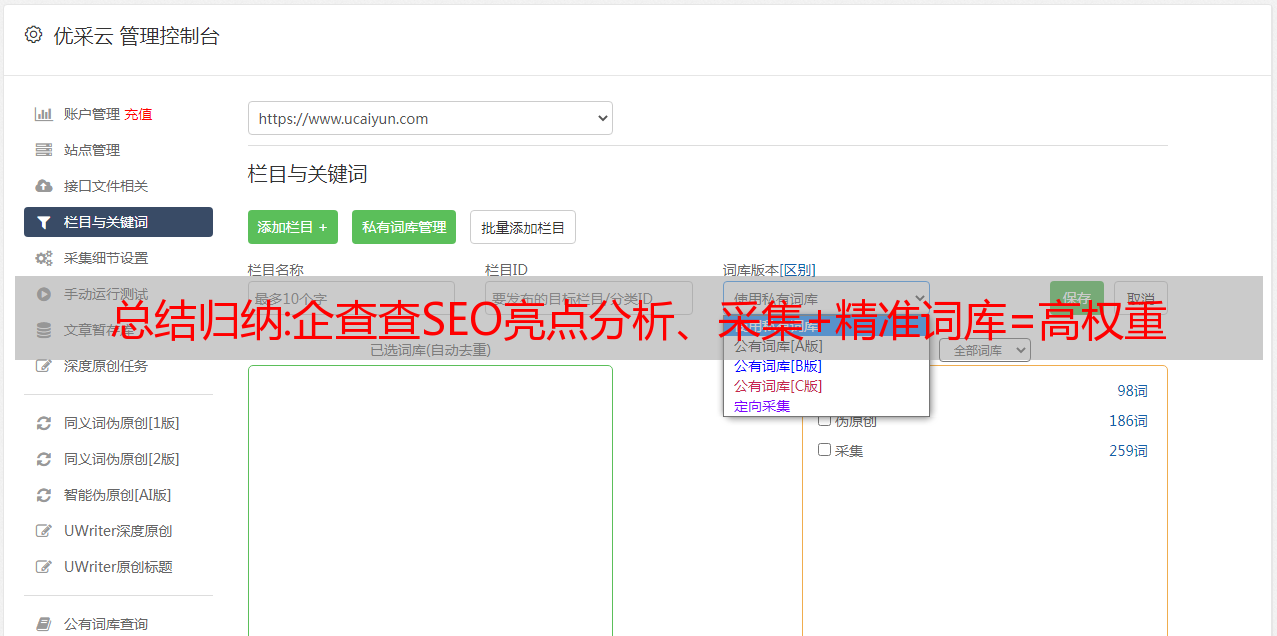
准确的词库定位
词库的定位与业务直接相关,但就竞争而言,七叉戟的词库远小于58同城的词库。七叉叉的词库一般以【企业名称】【法人名称、股东名称】为主,而58则主要以本地服务为主,比如XXX搬家、XXXX租车,大家自然明白很难关键词 轻松。
但是,词库的准确定位意味着客户将更加准确。当你的规模达到几千万、几亿的时候,长尾带来的流量是相当恐怖的,而这些恐怖流量的日访问量网站,增加的信任度绝不是普通小站点可比的.
就像之前和58聊天一样,以品牌流量为源头,带动网站的整体信任度。信任度高后,长尾流量来了,回馈给网站,一次又一次,良性循环!
学习和应用
其实为什么要分析七叉叉呢?因为七叉叉的词库难度比较低。我们可以将他的词库导出为权重站!
比如我之前做过人名站,可以做公司名站,或者其他站,毕竟有词库,而且内容是聚合的,即使是随机生成的,还是分分钟的分钟。
案例研究:用Python挖掘Twitter数据:数据采集
这是 7 部分系列的第 1 部分,专注于为各种用例挖掘 Twitter 数据。这是第一个文章,它专注于数据采集并作为基础。
Twitter 是一种流行的社交网络,用户可以在其中分享称为推文的短短信类消息。用户在 Twitter 上分享想法、链接和图片,记者评论现场活动,企业改进产品并吸引客户等等。使用 Twitter 的不同方式的列表可能很长,每天有 5 亿条推文,有大量数据等待分析。
这是一系列 文章 中的第一篇,专门用于使用 Python 进行 Twitter 数据挖掘。在第一部分,我们将了解 Twitter 数据采集的不同方式。一旦我们建立了一个数据集,我们将在接下来的会议中讨论一些有趣的数据应用程序。
注册应用程序
为了能够以编程方式访问 Twitter 数据,我们需要创建一个与 Twitter 的 API 交互的应用程序。
第一步是注册您的一个应用程序。值得注意的是,您需要转到浏览器,登录 Twitter(如果您尚未登录),然后注册一个新应用程序。您现在可以为您的应用程序选择名称和描述(例如“Mining Demo”或类似名称)。您将收到消费者密钥和消费者密码:这些是应用程序设置,应始终保密。在应用程序的配置页面上,您还可以要求获取访问令牌和访问令牌的密码。与消费者密钥类似,这些字符串也必须保密:它们为应用程序提供代表您的帐户访问 Twitter 的权限。默认权限是只读的,这在我们的案例中是我们需要的,但是如果您决定更改您的权限以在应用程序中提供更改功能,
重要提示:使用 Twitter 的 API 时存在速率限制,或者如果您想提供可下载的数据集,请参阅:>
您可以使用 Twitter 提供的 REST API 与他们的服务进行交互。还有一堆基于 Python 的客户端,我们可以一遍又一遍地回收。尤其是 Tweepy 是最有趣和最直接的一种,所以让我们一起安装它:
更新:Tweepy 发布的 3.4.0 版本 Python3 存在一些问题,目前绑定 GitHub 无法使用,所以在新版本出来之前我们会使用 3.3.0 版本。
更多更新:Tweepy 的 3.5.0 版本已经可用,并且似乎修复了 Python 3 上的上述问题。
为了授权我们的应用程序代表我们访问 Twitter,我们需要使用 OAuth 接口:
API 变量现在是我们可以在 Twitter 上执行的大多数操作的入口点。
例如,我们可以看到我们自己的时间线(或我们的 Twitter 主页):
Tweepy 提供了一个方便的光标接口来迭代不同类型的对象。在上面的示例中,我们使用 10 来限制我们正在阅读的推文数量,但当然我们可以访问更多。状态变量是 Status() 类的一个实例,是访问数据的一个很好的包装器。来自 Twitter API 的 JSON 响应在 _json 属性(带有前导下划线)上可用,它不是一个普通的 JSON 字符串,而是一个字典。
所以上面的代码可以重写来处理/存储JSON:
如果我们想要一个所有用户的列表怎么办?这里是:
那么我们所有推文的列表呢?也很简单:
通过这种方式,我们可以轻松地采集推文(以及更多)并将它们存储为原创 JSON 格式,可以根据我们的存储格式轻松地将其转换为不同的数据模型(许多 NoSQL 技术提供了一些批量导入功能)。
process_or_store() 函数是您的自定义实现的占位符。最简单的方法是您可以打印出 JSON,每行一条推文:
流动
如果我们想“保持联系”并采集有关将要出现的特定事件的所有推文,我们需要 Streaming API。我们需要扩展 StreamListener() 来定义我们如何处理输入数据。一个使用 #python 标签采集所有新推文的示例:
根据不同的搜索词,我们可以在几分钟内采集到数千条推文。对于覆盖全球的现场赛事(世界杯、超级碗、奥斯卡等)尤其如此,因此请密切关注 JSON 文件以了解其增长速度,并考虑您的测试可能需要多少推文。上面的脚本会将每条推文保存在一个新行上,因此您可以使用 Unix shell 中的 wc -l python.json 命令来找出您采集了多少条推文。
您可以在下面的要点中看到 Twitter API 流的最小工作示例:
twitter_stream_downloader.py
总结
我们已经介绍了 tweepy 作为通过 Python 访问 Twitter 数据的相当简单的工具。根据明确的“推文”项目目标,我们可以采集几种不同类型的数据。
一旦我们采集了一些数据,我们就可以继续分析应用程序。在下文中,我们将讨论其中的一些问题。
简历:Marco Bonzanini 是英国伦敦的一名数据科学家。他活跃于 PyData 社区,喜欢研究文本分析和数据挖掘应用程序。他是《用 Python 掌握社交媒体挖掘》(2016 年 7 月出版)的作者。
原创>>
文章来源36大数据,微信大数聚36,36大数据是一家专注于大数据创业、大数据技术与分析、大数据业务与应用的网站。分享大数据的干货教程和大数据应用案例,提供大数据分析工具和数据下载,解决大数据产业链创业、技术、分析、商业、应用等问题,提供企业和数据在大数据产业链。行业从业者提供支持和服务。
来自:舒梦
结尾。

