干货教程:文章自动*敏*感*词*-采集
优采云 发布时间: 2022-11-03 15:38干货教程:文章自动*敏*感*词*-采集
文章自动发电机
文章自动*敏*感*词*,最近很多站长问我有没有网站批量更新,如何做不同的cms采集伪原创发布?如何将大量的文章批量采集发布和一键自动推送到搜索引擎,结合标题构成、翻转配置、关键词设置、图片配置、文章属性设置、SEO属性设置、翻译设置、推送设置、伪原创设置、HTML设置等相应的SEO优化设置。
文章 关键词自动发电机采集的来源。这应该基于你网站关键词文章核心词概括关键词采集然后文章伪原创组合起来,发布到你的网站。长尾关键词可以通过关键词通过整个网络进行挖掘。
文章发电机中使用的长尾关键词通常是指网站上的非目标关键词。关键词分为长尾关键词和目标关键词。长尾关键词主要是一个围绕关键词目标延伸的词。长尾关键词的搜索量不大,但相当广泛,而且很多。面对网站,除了选择几个目标关键词外,你还要面对每一页。从字面上看,它是一个记录长尾关键词的列表文档。做SEO不仅仅是几个关键词,一个网站优化的程度取决于它的长尾。
文章,文章自动*敏*感*词*的内容会发生什么变化?文章发布后,将由AI智能伪原创自动处理。虽然伪原创内容不如原创,但如果内容伪原创有价值,那么搜索引擎也会收录。文章自动*敏*感*词*如何生成伪原创内容?
我们知道搜索引擎越来越关注文章的原创。自动*敏*感*词*文章 采集 文章由搜索引擎发布在搜索引擎无法捕获的平台上,例如标题。如果其他人没有发布它,您的文章将受到搜索引擎的青睐。所以搜索引擎伪原创避免这些问题,这样你的文章就会被推荐,这对以后申请原创标签非常有利。
文章自动*敏*感*词*文章采集伪原创发布后,我们还能做什么SEO优化?我们可以分析和改进所有页面网站的TDK(标题,描述关键词),然后链接进行分析和改进。链接网站所有页面,检查反向链接、单个链接、死链接、空链接等。
文章自动*敏*感*词*不会限制您网站cms的类型。您的网站有帝国cms,易cms,帝国cms,织梦cms,环球网站采集器,苹果cms,人人cms,水户cms,云友cms,小旋风蜘蛛池,THINKCMF,PHPcmsV9,PBoot cms,Destoon,Ocean cms,极限cms,EMLOG,TYPECHO,WXYcms,TWcms,Zibi主题,迅瑞cms等主要cms。
使网站链接之间的访问更加友好,更好地传递网站页面的权限。 并包括推送的网页和内容。搜索爬虫爬行和快照更新。网页代码。在结构级别网站网址规范和代码优化。关键词匹配、内容相关性、内部链接优化。优化页面加载。发布规范和内容优化。优化快照左侧的缩略图。网站搜索结果标题和摘要的优化。
文章自动*敏*感*词*自动提交给搜索引擎,人们知道推送是SEO的重要组成部分。通过推送主动向搜索引擎公开链接,提高蜘蛛爬行频率,从而促进网站收录。建议您立即以这种方式将站点的新输出链接推送到搜索引擎,以确保搜索引擎能够及时收录新链接。今天对文章自动*敏*感*词*的解释,将在下一期中分享更多与SEO相关的知识和技能。
技巧干货:搜外SEO:网站日志的分析是每个SEO人员的必备技能之一
每个做SEO的站长都应该具备分析网站日志的基本能力。因为网站的日志可以分析搜索引擎蜘蛛的动态,用户访问的动态,发现网站的哪些链接异常。
网站日志的分析和诊断就像为网站看病一样。通过对网站日志的分析,我们可以更清楚地了解网站的健康状况,这可以有益于这些数据让我们更好地进行网站SEO优化。这里有一些关于日志分析的事情要告诉你:
常见的蜘蛛名称:
百度蜘蛛;
百度蜘蛛-图片;
谷歌机器人;
谷歌机器人图像;
360蜘蛛;
搜狗蜘蛛。
1、网站日志的重要作用?
1、通过网站日志可以了解网站上蜘蛛的基本爬行情况,可以知道蜘蛛的爬行轨迹和爬行量。通过我们的网站日志,有很多外部链接。何少河网站蜘蛛爬行的数量有直接的影响。我们所说的链接诱饵就是如果你创建了一个外部链接,当蜘蛛抓取到外部链接页面并释放页面时,蜘蛛就会通过你留下的链接抓取你的网站,而网站 log 会记录蜘蛛的爬行动作。
2、网站的更新频率也和网站的日志中蜘蛛爬行的频率有关。一般来说,更新频率越高,蜘蛛的爬行频率就越高。更新不仅是添加新内容,还包括我们的调整。
3、我们可以根据网站日志的响应,对我们空间中的某些事件和问题进行预警,因为如果服务器出现问题,会反映在网站日志中尽快知道服务器的恒定速度和打开速度都会直接影响我们的网站。
4、通过网站日志可以知道网站的页面很受蜘蛛的欢迎,哪些页面甚至没有被蜘蛛触及。同时我们也可以发现,有些蜘蛛是过度爬取,消耗了我们服务器的大量资源,需要我们进行屏蔽工作。
2、如何下载日志以及设置日志的注意事项?
1.首先我们的空间应该支持网站日志下载,这个很重要。购买空间前一定要问好是否支持网站日志下载,因为有些服务商不提供这个服务,如果支持的话,空间后台一般都有log WebLog日志下载功能. 下载到根目录,使用FTP传输到本地。如果使用服务器,可以设置要下载的日志文件到指定路径。
2. 这里有一个很重要的问题。网站强烈建议每小时生成一次日志。小型企业网站和页面内容较少的 网站 可以设置为一天。默认为一天。如果内容很多,或者设置的网站很大,一天生成一次,那么一天只会生成一个文件,这个文件会很大。有时,当我们的计算机打开时,它会导致崩溃。如果你设置它,你可以找到一个空间商来协调设置。
3.网站日志分析
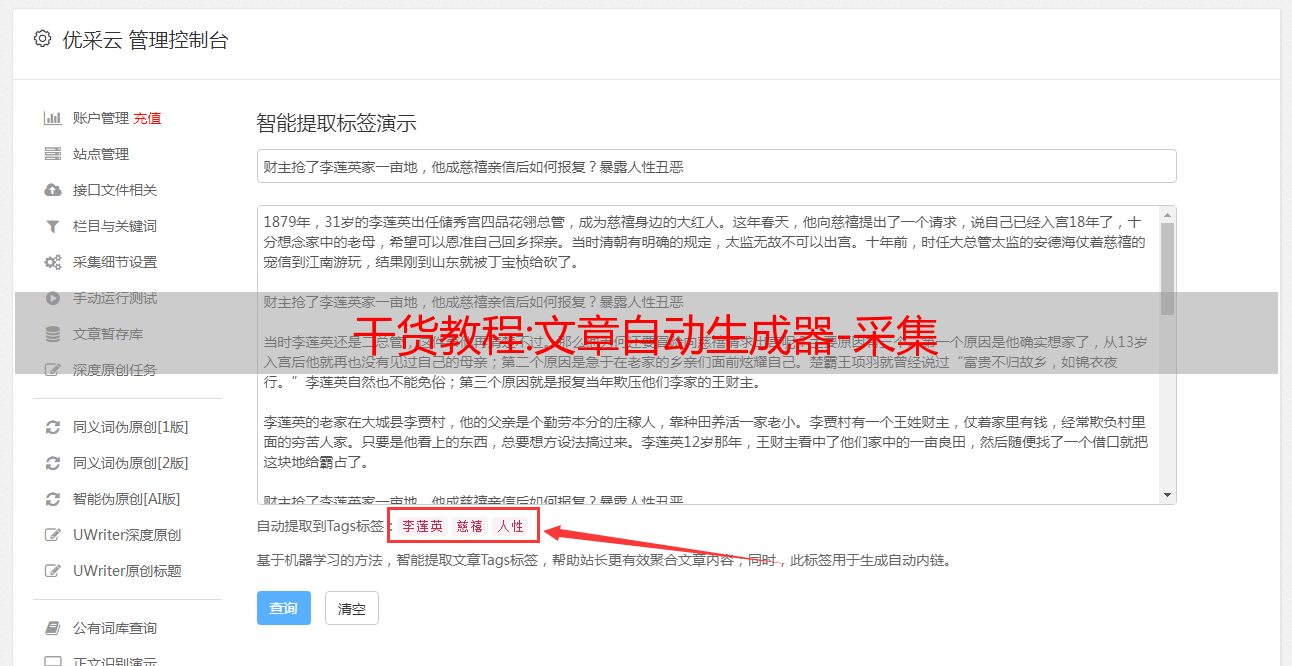
1、日志的后缀名为log。我们用记事本打开它,在格式中选择自动换行,看起来很方便,用搜索功能搜索了BaiduSpider和Googlebot这两个蜘蛛。
例如:
百度蜘蛛 2012-03-13 00:47:10 W3SVC177 116.255.169.37 GET / – 80 – 220.181.51.144 Baiduspider-favo+ (+baidu /search/spider) 200 0 0 15256 197 265
谷歌机器人 2012-03-13 08:18:48 W3SVC177 116.255.169.37 GET /robots.txt – 80 – 222.186.24.26 Googlebot/2.1+ (+google/bot) 200 0 0 985 200 31
我们分章节解释
2012-03-13 00:47:10 蜘蛛爬行的日期和时间;W3SVC177 这是机器码,就这一个,我们不管;116.255.169.37 这个IP地址就是服务器的IP地址;GET代表事件,GET后面是蜘蛛爬取的网站页面,斜杠代表主页,80表示端口,IP 220.181.51.144是蜘蛛的IP。假百度蜘蛛的方法,我们点击电脑开始运行,输入cmd打开命令提示符,进入nslookup空间添加蜘蛛IP回车。一般来说,真正的百度蜘蛛有自己的服务器IP,而假的蜘蛛没有。
如果网站中出现大量假蜘蛛,说明有人冒充百度蜘蛛来采集你的内容,需要注意,如果太霸道,会占用一个很多你的服务器资源,我们需要阻止他们的IP。200 0 0 这里是状态码的意思 状态码可以百度搜索;最后两个数字 197 265 表示访问和下载的数据字节数。
2、我们分析的时候先看状态码200表示下载成功,304表示页面没有被修改,500表示服务器超时。这些是可以在百度中找到的通用其他代码。我们必须处理不同的问题。
3.我们需要看看蜘蛛经常抓取哪些页面。我们需要把它们记录下来,分析它们为什么经常被蜘蛛爬取,从而分析出蜘蛛喜欢的内容。
4. 有时我们的路径并不统一,有斜线和没有斜线。蜘蛛会自动识别为 301 并跳转到带有斜杠的页面。在这里我们发现搜索引擎可以判断我们的目录。,所以我们需要统一我们的目录。

