分享文章:优采云采集怎么批量生产原创文章
优采云 发布时间: 2022-11-02 05:09分享文章:优采云采集怎么批量生产原创文章
优采云 是一个非常有用的文章采集 工具,但它也是一个很多人不知道的文章 构建工具。优采云采集+伪原创 方法已经流行了这么多年,仍然被大量的人使用,构建 原创文章 将使网站 改变更好的质量。今天,bug 博客( )分享了“优采云采集如何量产原创文章”。我希望能有所帮助。
优采云构建原创文章
1. 优采云采集+伪原创
报错博客先讲优采云采集伪原创的操作方法。查找更好的信息网站采集一些较新的文章、采集有互联网热词,如百度搜索热点、抖音热点、微信博热搜和很快。
标题不要重复,不建议直接伪原创标题。最好手动编辑标题。内容 伪原创 应该是可读的。如果不可读,不建议使用那种工具,因为这个内容已经发了很久了,网站活不了多久了。
优采云采集+伪原创的形式确实可以创作很多内容,但是也应该考虑在网站中发布一些原创文章提高百度信心,让您事半功倍。
2. 优采云构建原创文章
与其 优采云 构造 原创文章 不如调用内容,然后使用 文章 正文内容格式调用那些单词和句子。如何将这些单词和句子很好地呈现给用户和搜索引擎,不仅具有一定的可读性,而且具有看似实用的功能。这是错误博客的示例。当 爱站 网络对 网站 进行数据查询时,该页面是一个类似于 原创文章 的新页面,通过调用各种数据形成。页面,这样的页面有很好的排名。当这样的页面出现在搜索引擎中时,很多人会选择点击,而且可能会停留很长时间。这是一个成功的案例。
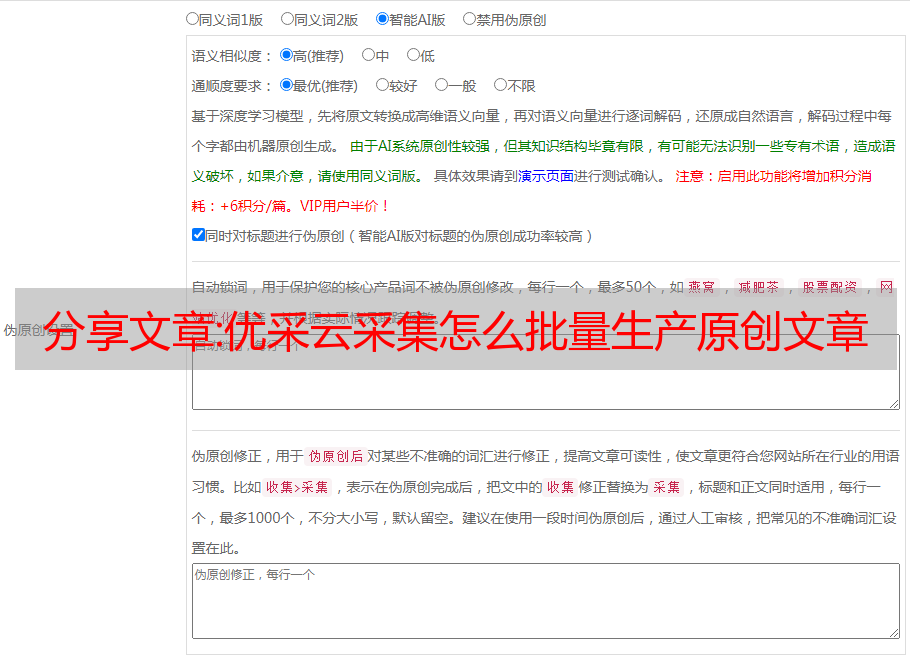
当然,错误博客并没有那么有能力做出这样一种形式的页面来调用各种数据,但是我们可以根据自己的能力来构建这样一个原创页面,从而生成大量的内容页面不会被使用。搜索引擎的罢工也可能会受到鼓励,毕竟这个页面非常实用。
那个bug博客用优采云搭建了一个原创文章的表格,主要是用大量的关键词来完成,一个词库是1000亿级是的,大数这样产生的页面基本不会重复。如果搜索引擎认为这种页面有价值,就会获得大量的收录和排名。
优采云建造文章排名
上面提到的关键词都是用一些竞争压力较小的词进行的测试。正常情况下,对于采集站来说,只要收录的文章可以正常>就不错了,如果有排名就更好了采集站.
那么文章到底是什么?错误博客向您展示了一些 文章:
优采云构建原创文章
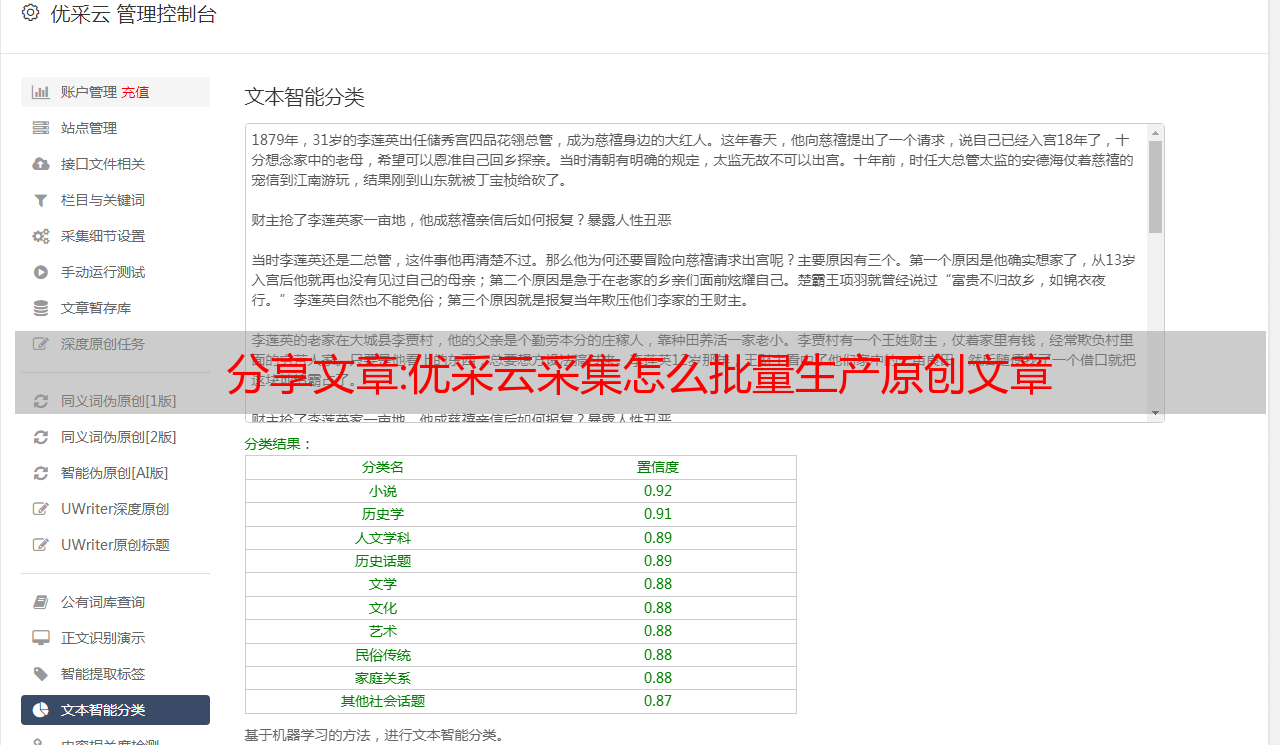
优采云构建原创文章
优采云构建原创文章
优采云构建原创文章
优采云构建原创文章
优采云构建原创文章
操作方法:用优采云采集器抓取文件并批量更改文件名
介绍
最近接触到一个图形爬虫,试了一下它相当好用,可以省去很多麻烦,但是笔者在网站抓取时发现一张图片,这个软件自己设置的文件名下载的文件其实是付费的!而且价格太高
于是作者决定一一更改图片文件的名称。
准备抓取
文件和分析提取数据
采集器可以将采集数据导出为excel文件,然后作者对表格进行了一些编辑,成品大约是这样的
可以看到文件的旧名称是一串数字,作者的要求是将这些数字替换为标题列中的数据。
代码实现
import pandas as pd
import os
dirpath = 'F:\spid\' #图片文件路径
namee = pd.read_excel('data2.xlsx',sheet_name='sheet1',header=0,usecols=['标题'])
adress = pd.read_excel('data2.xlsx',sheet_name='sheet1',header=0,usecols=['地址']) #分别获取标题和地址两列1的数据
for i in range(0, 784): #784为表格数据行数
ndata = namee.iloc[i,0]
adata = adress.iloc[i,0] #旧文件名
<p>
filetype = os.path.splitext(adata)[1] #获取文件扩展名
newname = ndata + filetype
newfilepath = os.path.join(dirpath, newname)
try:
os.rename(adata, newfilepath)
print(newfilepath)
except: #因为有的标题重复了,所以可能会发生文件已存在错误
ndata = ndata + 'A'
newname = ndata + filetype
newfilepath = os.path.join(dirpath, newname) #新文件名
os.rename(adata, newfilepath)
print(newfilepath)
print('ALL DONE')
</p>
未注释版本
import pandas as pd
import os
<p>
dirpath = 'F:\spid\'
namee = pd.read_excel('data2.xlsx',sheet_name='sheet1',header=0,usecols=['标题'])
adress = pd.read_excel('data2.xlsx',sheet_name='sheet1',header=0,usecols=['地址'])
for i in range(0, 784):
ndata = namee.iloc[i,0]
adata = adress.iloc[i,0]
filetype = os.path.splitext(adata)[1]
newname = ndata + filetype
newfilepath = os.path.join(dirpath, newname)
try:
os.rename(adata, newfilepath)
print(newfilepath)
except:
ndata = ndata + 'A'
newname = ndata + filetype
newfilepath = os.path.join(dirpath, newname)
os.rename(adata, newfilepath)
print(newfilepath)
print('ALL DONE')
</p>
最终结果

