解决方案:批量采集自动提取保存网页内容.docx
优采云 发布时间: 2022-10-31 23:26解决方案:批量采集自动提取保存网页内容.docx
《批量采集自动提取并保存网页内容.docx》会员共享,可在线阅读。关于“批量采集自动提取并保存网页内容.docx(8页采集版)”的更多信息,请参考图书馆在线搜索。
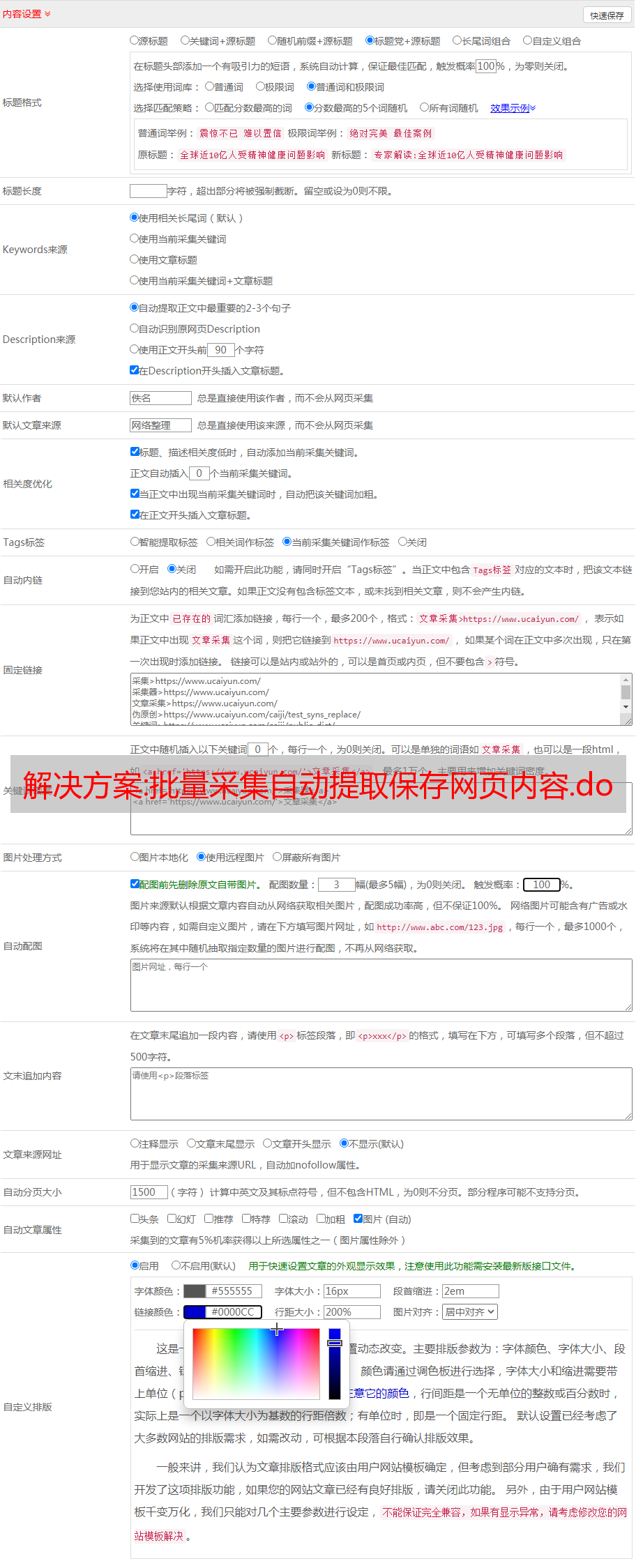
1.批量采集自动提取并保存网页内容这是本教程使用的网页:本教程是教大家使用网页自动化通用工具中的刷新工具来刷新并提取内容的网页。从(网页)批量获取姓名、电话、职业等信息,并将结果保存到文件中。以下是教程的开始。首先我们看一下软件的大体界面: 然后需要先添加一个URL,点击“添加”按钮,输入需要刷新提取信息的URL,然后点击“自动获取”按钮。如下图所示: 接下来,我们设置刷新间隔时间。刷新间隔时间可以在自动网页刷新监控操作中设置。这里我设置了每 10 秒刷新一次。如果取消对刷新次数的检查限制,则没有限制。在本教程中,每次刷新都需要保存更改的网页信息,所以在“其他监控”中,需要设置“无条件启动监控和报警”。
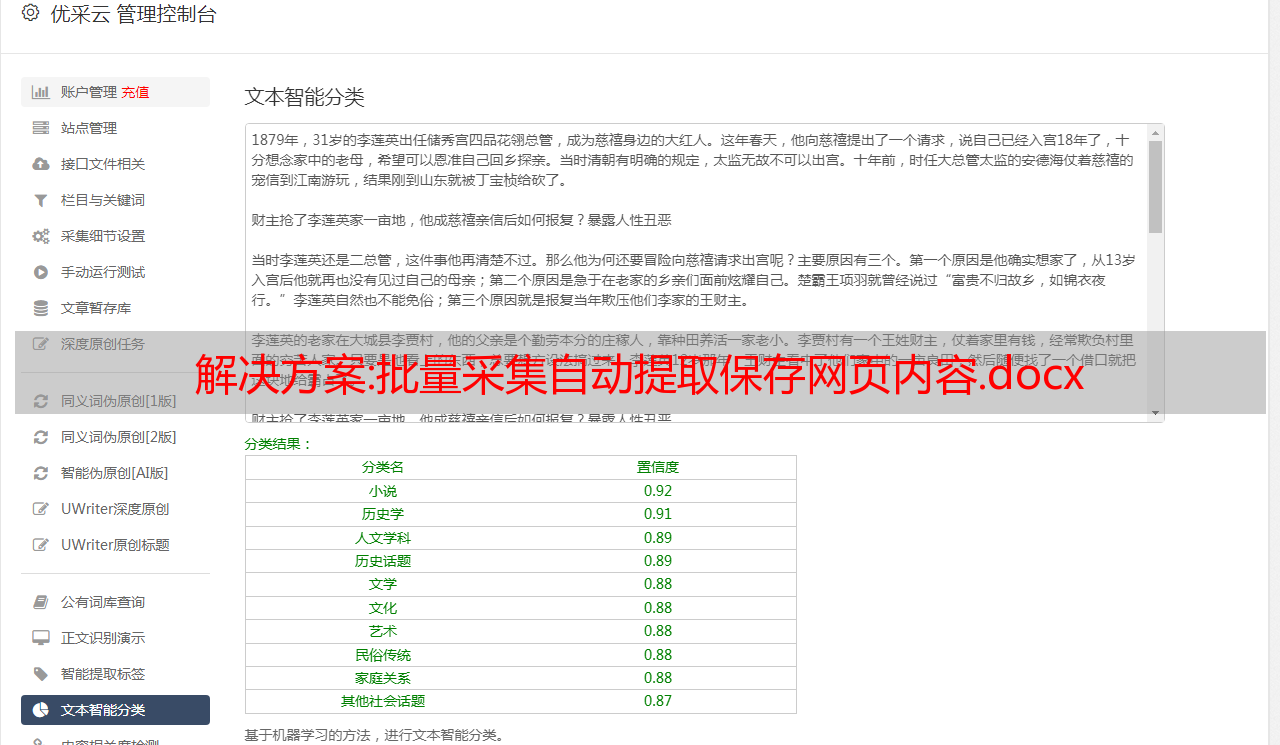
2.(看各自需要的设置)然后就是设置需要保存的网页信息。在“监控设置”中,添加“报警提示动态内容”——然后自动获取。如下图: 点击自动获取后,会打开之前添加的URL。页面加载完成后,选择要获取的信息-右键-获取元素自动提取元素标识-添加元素。如下图操作: 元素属性名这里使用value值。这里要特别说明一下,有些网页可以开始监控是因为需要延迟打开,否则会失效。因此,此处设置了“监控前的延迟等待时间设置为 3 秒”。(同时监控多个网页的内容) 网页自动操作通用工具在这个版本中可以保存为三种格式,即csv文件,txt文件,每个动态元素保存为单独的文件。"可以设置类型。以下是监控网页后保存的各种文件格式。第一种是将每个元素保存在一个单独的txt文件中;第二种是将所有元素组合在一起保存在一个txt文件中;第三种是将所有元素保存为csv文件:本教程结束,欢迎搜索:木头软件。以下是监控网页后保存的各种文件格式。第一种是将每个元素保存在单独的txt文件中;第二种是将所有元素组合起来保存在一个txt文件中;第三个是将所有元素保存为 csv 文件:本教程结束。欢迎搜索:木工软件。以下是监控网页后保存的各种文件格式。第一种是将每个元素保存在单独的txt文件中;第二种是将所有元素组合起来保存在一个txt文件中;第三个是将所有元素保存为 csv 文件:本教程结束。欢迎搜索:木工软件。
整套解决方案:一、入Binlog实时采集 + 离线还原的解决方案
文章目录
前言
关系模型构建了整个数据分析的基石,而关系数据库作为具体实现,采集MySQL数据访问Hive是很多企业进行数据分析的前提。如何及时准确地将MySQL数据同步到Hive?
1.进入Binlog实时采集+离线恢复解决方案
基于Binlog日志的数据恢复,与线上业务解耦
采集通过分布式队列实时投递,还原操作在集群上实现,时效性和扩展性强
Binlog日志收录增删改查等详细动作,支持自定义ETL
二、使用步骤1.Binlog
binlog 是二进制格式的日志文件,用于记录数据库的数据更新或潜在更新(例如,DELETE 语句执行删除但实际上没有符合条件的数据)。主要用于数据库的主从复制和增量恢复。
二进制记录方法有两种:
语句模式:每条修改数据的sql都会被记录在binlog中,例如inserts、updates、delete。
行模式:每一行的具体变化事件都会记录在binlog中。
混合模式是上述两个层次的混合。默认使用Statement模式,根据具体场景自动切换到Row模式。MySQL 5.1 提供行(混合)模式。
滴滴的 MySQL Binlog 采用 Row 模式,记录每次数据增删改改前后一行数据的值。同时,无论单列是否发生变化,都会记录一行数据的完整信息。
2.Canal纯Java开发。基于数据库增量日志分析,提供增量数据订阅&消费。目前主要支持MySQL(也支持mariaDB)。滴滴内部版本在开源的基础上增加了MQ同步、消息上报、容灾机制。
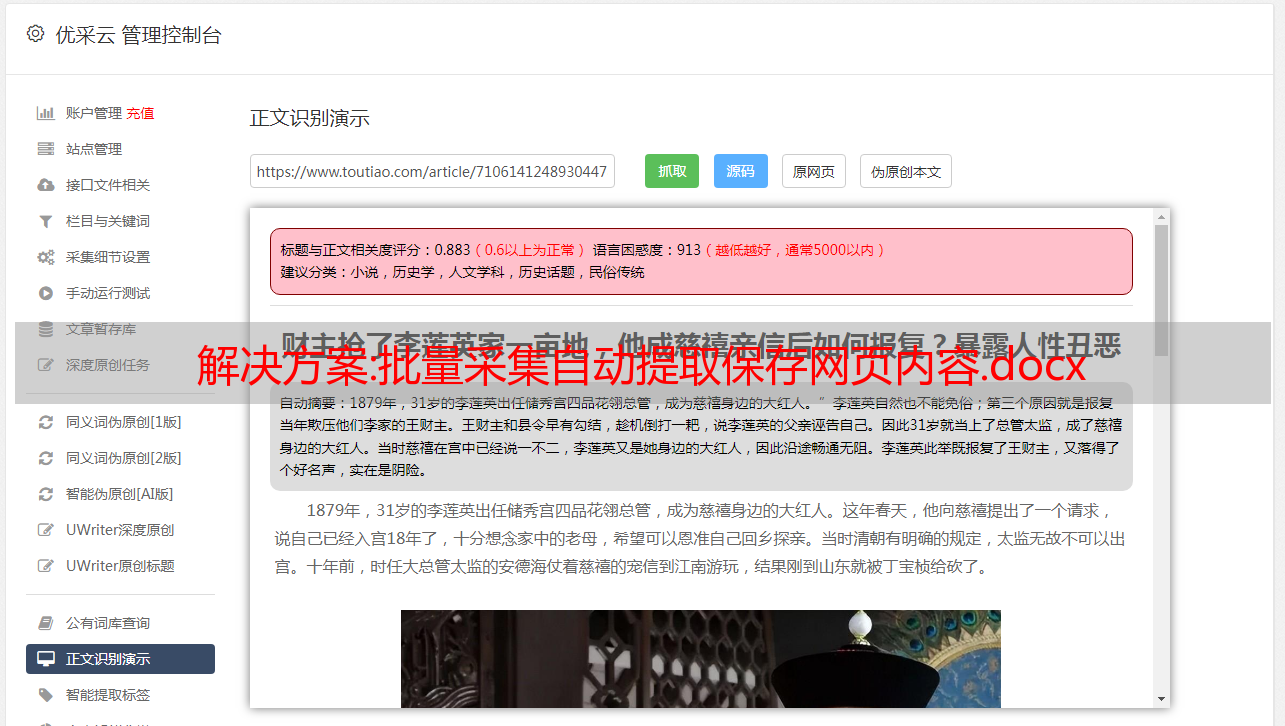
运河的主要运营如下:
canal模拟mysql slave的交互协议,伪装成mysql slave,向master发送dump协议
mysql master收到dump请求,开始push二进制日志到canal
canal 解析二进制日志对象,并将解析结果编码为 JSON 格式的文本字符串
将解析后的文本字符串发送到消息队列并上报发送状态(如Kafka、DDMQ)
此处使用的 url 网络请求数据。
总结
每日1.9w+同步任务,近50T数据同步量,实时级别毫秒级延迟,实现及时、准确、定制化的同步需求

