总结:周振兴:如何从SEO角度分析一个网站(3)
优采云 发布时间: 2022-10-22 22:51总结:周振兴:如何从SEO角度分析一个网站(3)
每个页面是否有推荐与内容相关的内部链接是非常重要的。这对用户和蜘蛛非常有帮助。
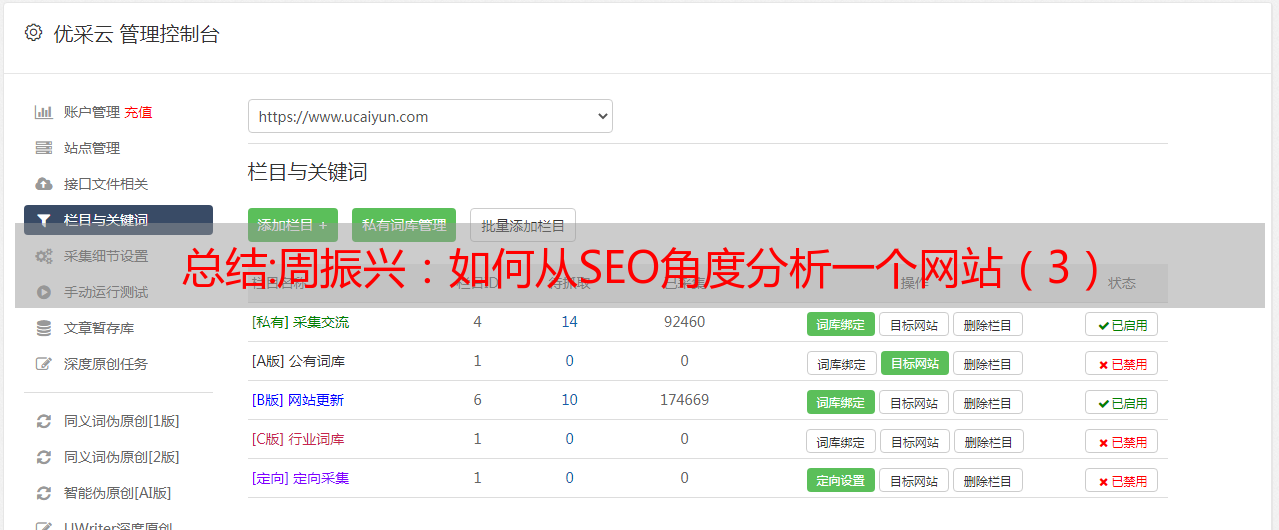
3.每个页面是否可以链接到其他相关页面
推荐内页,还有栏目页、专题页、首页,都是一样的,只是定位角度不同。
10.检查外链
那么如何查看外部链接呢?常用两种方法
1.通过域命令
您可以找出您是哪些 网站 链接,并检查它们是否与错误的 网站 一起出现。如有,应尽快处理,否则会产生影响。
2.通过友好的链接
检查友情链接是否正常。比如你链接到了别人,但是别人撤销了你的链接,或者别人的网站打不开等等,你需要及时处理。
11. 优化技能监控
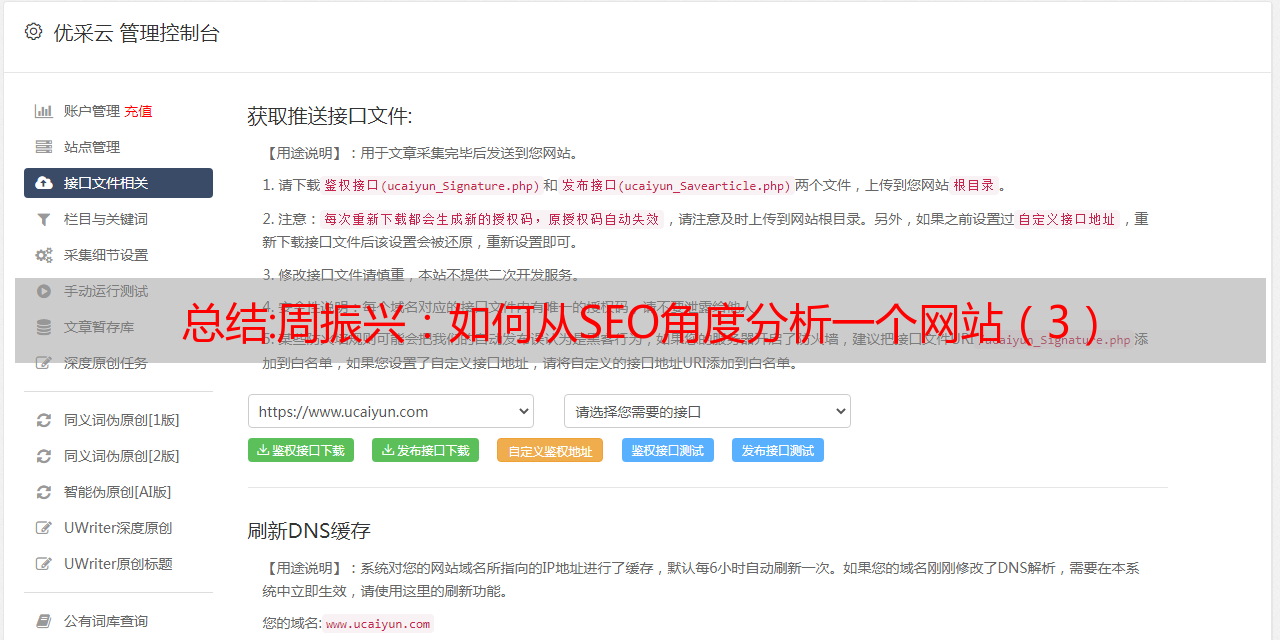
1.内容多久更新一次
每日内容更新可以让蜘蛛养成每天爬行的习惯。在这里,一定要注意每天定时定量更新,不要突然*敏*感*词*更新,或者几天不更新。
大网站的权重很高,主要是因为每天都能产生大量的新内容,而且随着时间的推移,权重越来越高。
2.推动技能
如果想让内容被蜘蛛快速发送,就必须使用百度站长平台的主动提交工具。具体操作可以参考百度站长平台中的技术文章。清楚,可以加我微信:58589584,我可以亲自指导你完成。
只要你把这个推技能做好,就再也不用担心蜘蛛不来爬了。当然,这也是一把双刃剑。加给你的所有内容都是来自采集,所以使用这种主动推送的方式其实会降低权限。
3. 网站地图制作
现在开源的cms都自带了网站的地图功能,是SEO必备的,一定要有,提交给搜索引擎。
4. 关键词的自然外观
看看有没有栈可以关键词,尽量自然合理,不要强求。
12、交通状况分析
通过诊断工具和站长工具平台检查是否有与网站主题不匹配的流量。如果有,请检查该页面的流量以确定它是否被黑客入侵。被挂了。
13.网站日志数据分析
很多人不太明白为什么要分析 网站 日志数据。这个非常重要。通过日志分析,我们可以分析蜘蛛每天爬什么,什么时候来的,爬的过程中是否有404频道等不利情况。
包括用户访问每个页面的所有记录详情,可以从日志中进行分析。基本上如果是新站点,上半月不需要分析,后期可以适当查看爬虫情况。
14. 网站安全备份
这算不上什么技能,但星哥觉得应该是作为必要的操作手段。星哥自己的习惯是每周日说网站备份一次,虽然安保工作已经做好了。,但 网站 仍需备份。
至此,从seo的角度诊断网站的14个要点已经讲完了。大家可以根据这里的理解用思维导图组织一个大纲,根据自己的理解在平时的诊断中使用。.
我是周振兴,每天写文章,我的微信是:58589584
个人博客:
完整解决方案:网络采集软件核心技术剖析系列(1)
一系列论文及其背景概述
自主研发的豆瓣博客备份专家软件工具自问世3年多以来,深受广大博客作者和读者的喜爱。同时也有一些技术爱好者问我如何在这个软件中实现各种实用功能。
该软件是使用 .NET 技术开发的。为了回馈社会,我们现开辟专栏,针对软件所使用的核心技术编写一系列文章,以娱乐广大技术爱好者。
本系列文章不仅讲解了网络编辑分发中用到的各种重要技术,还提供了界面开发中诸多问题的解决方案和编程经验。非常适合.NET开发的初学者和中级读者。希望大家多多支持。
很多初学者经常会有这样的困惑,“为什么我读了这本书,了解了C#的方方面面,却就是写不出一个像样的应用程序?”,
其实我还没有学会全面应用所学,锻炼编程思维,建立学习兴趣。我认为这个系列 文章 可以帮助你,我希望如此。
开发环境:VS2008
来源地点:
×××方法:安装SVN客户端(文末提供下载地址),然后签出如下地址:
文章 系列的大纲如下:
1、如何使用C#语言获取博客园中博主的所有文章链接和标题;
2、如何使用C#语言获取博文内容;
3.如何使用C#语言(html2pdf)将html网页转换为pdf
4.如何使用C#语言将博文中的图片全部下载到本地并离线浏览
5.如何使用C#语言将多个单个pdf文件合成为一个pdf并生成目录
6、如何使用C#语言获取网易博客的链接,网易博客的特殊性;
7、如何使用C#语言下载微信公众号文章;
8、如何获取任意一个文章的所有图文
9.如何使用C#语言去除html中的所有标签得到纯文本(html2txt)
10.如何使用C#语言将多个html文件编译成chm(html2chm)
11.如何使用C#语言远程发布文章到新浪博客
12.如何使用C#语言开发静态站点*敏*感*词*
13.如何使用C#语言搭建程序框架(经典Winform界面,顶部菜单栏,工具栏,左侧树形列表,右侧多Tab界面)
14.如何使用C#语言实现网页编辑器(Winform)
……
2.第一节主要内容介绍(如何使用C#语言获取博客园中某博主的所有文章链接和标题)
获取博主所有博文链接和标题的解决方案,demo演示如下图: 可执行文件下载
三个基本原则
获取采集的博主的所有博文网页地址,需要分2步:
1、通过分页链接获取网页源代码;
2、从获取的网页源代码中解析文章地址和标题;
第一步,先找到分页链接,比如我的博客
第一页 ice-river/default.html?page=1
第二页 ice-river/default.html?page=2
我们可以编写一个函数将这些分页地址字符串保存到一个队列中,如下代码所示,
在下面的代码中,我们默认保存 500 页,500 页 * 20 = 10,000 篇博文,一般来说已经足够了,除了非常有生产力的博主。
还有一点,有兴趣的朋友可能会问,500页是不是太多了,有的博主只有2、3页,是不是需要到采集500页才能获取所有的博文链接?
在这里,因为我们不知道博主写了多少篇博文(分成几页),所以我们先默认取500页。
,我会讲一个方法来判断所有的文章链接都获取到了。事实上,我们不会为每个博主访问 500 个页面。
protected void GatherInitCnblogsFirstUrls()
{ string strPagePre = "http://www.cnblogs.com/"; string strPagePost = "/default.html?page={0}&OnlyTitle=1"; string strPage = strPagePre + this.txtBoxCnblogsBlogID.Text + strPagePost; for (int i = 500; i > 0; i--)
{ string strTemp = string.Format(strPage, i);
m_wd.AddUrlQueue(strTemp);
}
}
至于获取网页的源文件(即在你的浏览器中,右键点击网页---查看网页源代码功能)
C#语言为我们提供了一个现成的HttpWebRequest类,我把它封装成一个WebDownloader类。具体可以参考源码。主要功能实现如下:
public string GetPageByHttpWebRequest(string url, Encoding encoding, string strRefer)
{ string result = null;
WebResponse response = null;
StreamReader reader = null; try
{
HttpWebRequest request = (HttpWebRequest)WebRequest.Create(url);
request.UserAgent = "Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1; .NET CLR 2.0.50727)";
request.Accept = "p_w_picpath/gif, p_w_picpath/x-xbitmap, p_w_picpath/jpeg, p_w_picpath/pjpeg, application/x-shockwave-flash, application/vnd.ms-excel, application/vnd.ms-powerpoint, application/msword, */*"; if (!string.IsNullOrEmpty(strRefer))
{
Uri u = new Uri(strRefer);
request.Referer = u.Host;
<p>
} else
{
request.Referer = strRefer;
}
request.Method = "GET";
response = request.GetResponse();
reader = new StreamReader(response.GetResponseStream(), encoding);
result = reader.ReadToEnd();
} catch (Exception ex)
{
result = "";
} finally
{ if (reader != null)
reader.Close(); if (response != null)
response.Close();
} return result;
}</p>
传入的第一个参数就是我们上面形成的500个分页地址,函数的返回值就是网页的源代码(我们要的文章地址和标题都在里面,然后我们需要把它们解析)。
第二步:从获取的网页源码中解析文章的地址和标题
我们需要使用著名的 HtmlAgilityPack 类库。HtmlAgilityPack 是一个用于解析 HTML 文档的工具。通过它,我们可以很方便的获取网页的标题、正文、分类、日期等。理论上任何元素在网上都有很多相关文档,这里就不多说了。这里我们在HtmlAgilityPack中添加一个扩展方法来提取任意网页源文件的所有超链接GetReferences和该链接对应的GetReferencesText。
private void GetReferences()
{
HtmlNodeCollection hrefs = m_Doc.DocumentNode.SelectNodes("//a[@href]"); if (Equals(hrefs, null))
{
References = new string[0]; return;
}
References = hrefs.
Select(href => href.Attributes["href"].Value).
Distinct().
ToArray();
}
private void GetReferencesText()
{ try
{
m_dicLink2Text.Clear();
HtmlNodeCollection hrefs = m_Doc.DocumentNode.SelectNodes("//a[@href]"); if (Equals(hrefs, null))
{ return;
} foreach (HtmlNode node in hrefs)
{ if (!m_dicLink2Text.Keys.Contains(node.Attributes["href"].Value.ToString())) if(!HttpUtility.HtmlDecode(node.InnerHtml).Contains("img src") && !HttpUtility.HtmlDecode(node.InnerHtml).Contains("img ") && !HttpUtility.HtmlDecode(node.InnerHtml).Contains(" src"))
m_dicLink2Text.Add(node.Attributes["href"].Value.ToString(), HttpUtility.HtmlDecode(node.InnerHtml));
} int a = 0;
} catch (System.Exception e)
{
System.Console.WriteLine(e.ToString());
}
}
但是请注意,到目前为止,我们已经获得了一个网页中的所有链接地址,这实际上距离我们想要的并不远,因此我们需要在这些链接地址集中过滤掉我们真正想要的博客帖子地址。
这时候,我们就需要用到一个功能强大的正则表达式工具。C#也提供了现成的支持类,但是我们需要对正则表达式有一些了解。正则表达式的相关知识我们这里就不做讲解了。不明白的请自行百度。
首先我们需要观察博文链接地址的格式:
随便找几篇博文:
冰河/p/3475041.html
直间流塘/p/4042770.html
我们发现链接和博主ID有关,所以我们需要一个变量(this.txtBoxCnblogsBlogID.Text)来记录博主ID,
上述链接模式可以表示为正则表达式,如下所示:
"www\.cnblogs\.com/" + this.txtBoxCnblogsBlogID.Text + "/p/.*?\.html$";
简单说明一下:\代表转义,因为. 在正则表达式中具有重要意义;$代表结束,html$代表html的结束。.*? 它是什么,它很重要,但不是很好理解
正则有两种模式,一种为贪婪模式(默认),另外一种为懒惰模式,以下为例:
(abc)dfe(gh)
<p>
对上面这个字符串使用(.*)将会匹配整个字符串,因为正则默认是尽可能多的匹配。
虽然(abc)满足我们的表达式,但是(abc)dfe(gh)也同样满足,所以正则会匹配多的那个。
如果我们只想匹配(abc)和(gh)就需要用到以下的表达式
(.*?)
在重复元字符*或者+后面跟一个?,作用就是在满足的条件下尽可能少匹配。</p>
因此,上述正则表达式的意思是“收录博主ID,后跟/p/,然后是任意数量的字符,直到遇到html结尾”。
然后,我们可以通过 C# 代码过滤所有符合该模式的链接。主要代码如下:
MatchCollection matchs = Regex.Matches(normalizedLink, m_strCnblogsUrlFilterRule, RegexOptions.Singleline); if (matchs.Count > 0)
{ string strLinkText = ""; if (links.m_dicLink2Text.Keys.Contains(normalizedLink))
strLinkText = links.m_dicLink2Text[normalizedLink]; if (strLinkText == "")
{ if (links.m_dicLink2Text.Keys.Contains(link))
strLinkText = links.m_dicLink2Text[link].TrimEnd().TrimStart();
}
PrintLog(strLinkText + "\n");
PrintLog(normalizedLink + "\n");
lstThisTimesUrls.Add(normalizedLink);
}
判断所有文章链接已经获取:之前我们计划采集500个分页地址,但是有可能博主的博文全部只有几页,那么如何判断所有文章 都下载了吗?
解决办法其实很简单,就是我们用2套,一套是当前下载的所有文章套,另一套是本次下载的文章套,如果都是文章本次下载的集合为 文章 ,之前下载的集合全部可用,则 文章 全部下载完毕。
在程序中,我把这个判断封装成一个函数,代码如下:
private bool CheckArticles(List lstThisTimesUrls)
{ bool bRet = true; foreach (string strTemp in lstThisTimesUrls)
{ if (!m_lstUrls.Contains(strTemp))
{
bRet = false; break;
}
} foreach (string strTemp in lstThisTimesUrls)
{ if (!m_lstUrls.Contains(strTemp))
m_lstUrls.Add(strTemp);
}
return bRet;
}
其他四个更重要的知识
1.BackgroundWorker工作线程的使用,因为我们的采集任务是一个比较耗时的工作,所以不应该放在界面的主线程上,应该启动一个后台线程,最方便的在c#使用后台线程的方式是使用BackgroundWorker类。
2、由于我们需要在界面上打印出每个文章的地址和标题,并且由于不能在工作线程中修改界面控件,所以这里需要使用C#。代理委托技术,通过回调在接口上输出信息。
TaskDelegate deles = new TaskDelegate(new ccTaskDelegate(RefreshTask));
public void RefreshTask(DelegatePara dp)
{ //如果需要在安全的线程上下文中执行 if (this.InvokeRequired)
{ this.Invoke(new ccTaskDelegate(RefreshTask), dp); return;
}
//转换参数 string strLog = (string)dp.strLog;
WriteLog(strLog);
} protected void PrintLog(string strLog)
{
DelegatePara dp = new DelegatePara();
dp.strLog = strLog;
deles.Refresh(dp);
} public void WriteLog(string strLog)
{ try
{
strLog = System.DateTime.Now.ToLongTimeString() + " : " + strLog;
this.richTextBoxLog.AppendText(strLog); this.richTextBoxLog.SelectionStart = int.MaxValue; this.richTextBoxLog.ScrollToCaret();
} catch
{
}
}

