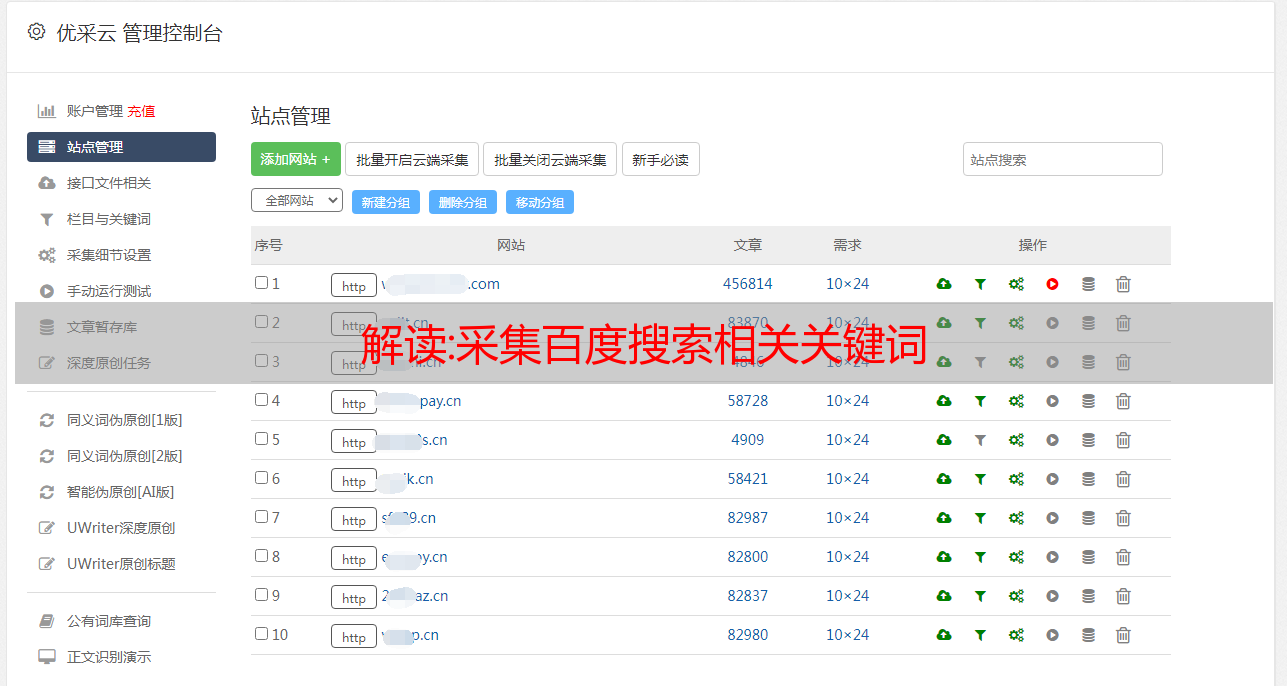
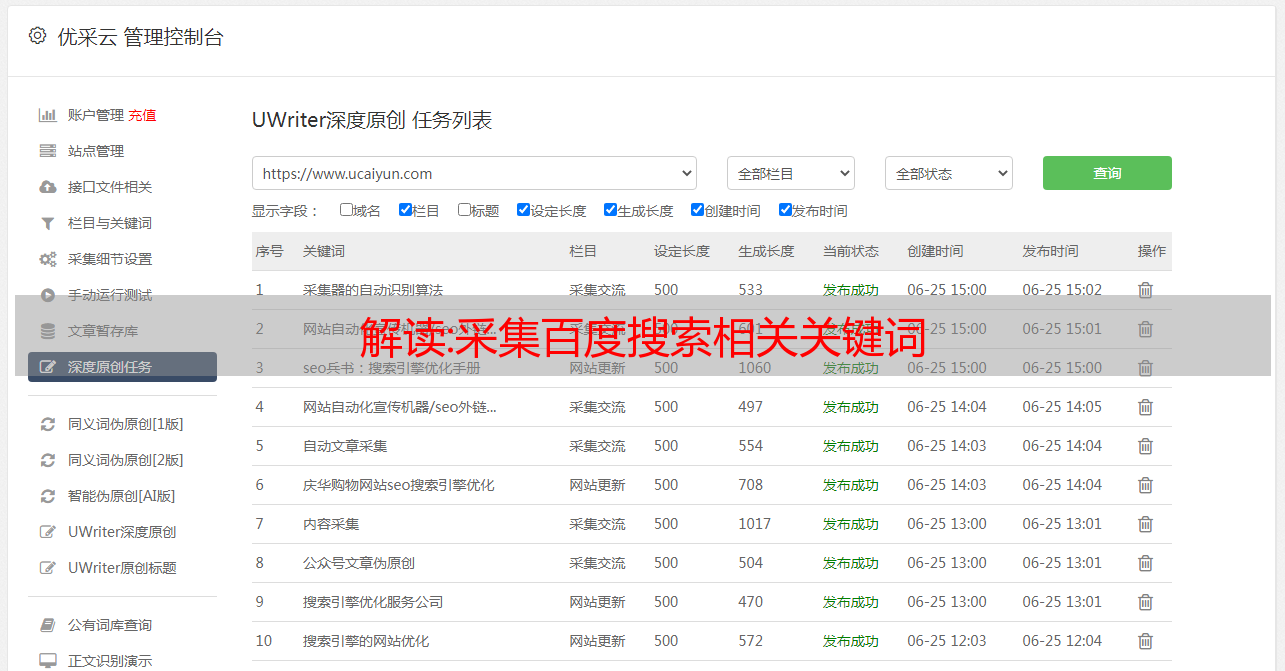
解读:采集百度搜索相关关键词
优采云 发布时间: 2022-10-21 16:17首先,让我们看看我们想要采集的是百度搜索时自动推荐功能显示的关键词。
代码如下:
import requests
import json
def get_sug(word):
url = 'https://sp0.baidu.com/5a1Fazu8AA54nxGko9WTAnF6hhy/su?wd=%s&sugmode=2&json=1&p=3&sid=1427_21091_21673_22581&req=2&pbs=%%E5%%BF%%AB%%E6%%89%%8B&csor=2&pwd=%%E5%%BF%%AB%%E6%%89%%8B&cb=jQuery11020924966752020363_1498055470768&_=1498055470781' % word
r = requests.get(url)
content = r.text.replace('jQuery11020924966752020363_1498055470768(', '')
content = content.replace(');', '')
res_json = json.loads(content)
return (res_json['s'])
"""
把a~z遍历一遍,会出现更多关键词
"""
def get_more_sug(word):
all_words = []
for i in 'abcdefghijklmnopqrstuvwxyz':
all_words += get_sug(word+i)
return list(set(all_words)) # 去重
"""
再次遍历,获得更多关键词
"""
def get_most_sug(word):
all_words = []
for i in 'abcdefghijklmnopqrstuvwxyz':
for j in 'abcdefghijklmnopqrstuvwxyz':
all_words += get_sug(word+i+j)
return list(set(all_words)) # 去重
# print('\n'.join(get_more_sug('黄山')))
print(get_sug('水蜜桃'))
效果图如下:
添加换行符后的效果:
于2020-10-18更新
二、采集百度搜索底部的相关关键词
1. 安装必要的库
pip install install fake-useragent
但是,发现有时在运行时会报告错误:
加载数据期间出错。尝试使用缓存服务器
/浏览器/0.1.11
因此,如果您不需要它,可以将其注释掉。
2. 相关代码
import requests,time,random
from lxml import etree
from fake_useragent import UserAgent
<p>
def get_keyword(keyword):
data=[]
ua=UserAgent()
headers={
'Cookie': 'PSTM=1558408522; BIDUPSID=BFDF2424811E5E531D933DC854B78C67; BAIDUID=BFDF2424811E5E531D933DC854B78C67:SL=0:NR=10:FG=1; MSA_WH=375_812; BD_UPN=12314353; H_WISE_SIDS=144367_142699_144157_142019_144883_141875_141744_143161_144989_144420_144134_142919_144483_136861_131246_137745_144743_138883_140259_141942_127969_144171_140065_144338_140593_143057_141808_140350_144608_144727_143923_131423_144289_142206_144220_144501_107312_143949_144105_144306_143478_144966_142911_140312_143549_143647_144239_142113_143855_136751_140842_110085; BDUSS_BFESS=1vQzN4d0pPNzB2MUQyUUQtV3d6OEZzYldhN2FWUm1RZEZ3UUVyb1Y1Mmtqc0JlSVFBQUFBJCQAAAAAAAAAAAEAAACgwJmS08W4xcTuAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAKQBmV6kAZleVW; MCITY=-%3A; sug=3; sugstore=0; ORIGIN=0; bdime=0; BDORZ=B490B5EBF6F3CD402E515D22BCDA1598; BDSFRCVID=LuuOJexroG3_dMRrBfK9UG9zgmKK0gOTDYLEUamaI2AU2V4VN4vPEG0Pt_U-mEt-J8jwogKK0gOTH6KF_2uxOjjg8UtVJeC6EG0Ptf8g0M5; H_BDCLCKID_SF=tbkD_C-MfIvhDRTvhCcjh-FSMgTBKI62aKDs2P5aBhcqJ-ovQTbrbMuwK45hB5cP3b5E0b6cWKJJ8UbeWfvp3t_D-tuH3lLHQJnp2DbKLp5nhMJmBp_VhfL3qtCOaJby523ion3vQpP-OpQ3DRoWXPIqbN7P-p5Z5mAqKl0MLPbtbb0xXj_0-nDSHH-tt6De3j; delPer=0; BD_CK_SAM=1; PSINO=7; H_PS_PSSID=1457_31670_32141_32139_32046_32230_32092_32298_26350_32261; COOKIE_SESSION=7_0_4_5_9_5_0_3_2_3_0_0_1608_0_0_0_1594720087_0_1594723266%7C9%23328033_18_1594447339%7C9; H_PS_645EC=8046hkQMotVPI51%2B5I0oGWsgl5ams9mPpS71Aw1L%2FgLPGzpf4I2A6FpO8U4',
#'User-Agent': random.choice(ua_list)
'User-Agent': ua.random,
}
url=f"https://www.baidu.com/s?wd={keyword}&ie=UTF-8"
html=requests.get(url,headers = headers,timeout=5).content.decode('utf-8')
time.sleep(2)
try:
req=etree.HTML(html)
tt=req.xpath('//div[@id="rs"]//text()')
tt.remove('相关搜索')
print(tt)
data=tt
except Exception as e:
print(e.args)
time.sleep(5)
print(f">> 等待5s,正在尝试重新采集 {keyword} 相关关键词")
get_ua_keyword(keyword)
return data
def get_ua_keyword(keyword):
data = []
print(f'>> 正在采集 {keyword} 相关关键词..')
ua_list = [
'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.108 Safari/537.36',
'Mozilla/5.0 (Windows; U; Windows NT 6.1; en-us) AppleWebKit/534.50 (KHTML, like Gecko) Version/5.1 Safari/534.50',
'Mozilla/5.0 (Windows NT 6.1; WOW64; rv:6.0) Gecko/20100101 Firefox/6.0Firefox 4.0.1',
'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_7_0) AppleWebKit/535.11 (KHTML, like Gecko) Chrome/17.0.963.56 Safari/535.11',
'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.103 Safari/537.36Chrome 17.0',
'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/535.1 (KHTML, like Gecko) Chrome/14.0.835.163 Safari/535.1',
]
headers = {
'Cookie': 'PSTM=1558408522; BIDUPSID=BFDF2424811E5E531D933DC854B78C67; BAIDUID=BFDF2424811E5E531D933DC854B78C67:SL=0:NR=10:FG=1; MSA_WH=375_812; BD_UPN=12314353; H_WISE_SIDS=144367_142699_144157_142019_144883_141875_141744_143161_144989_144420_144134_142919_144483_136861_131246_137745_144743_138883_140259_141942_127969_144171_140065_144338_140593_143057_141808_140350_144608_144727_143923_131423_144289_142206_144220_144501_107312_143949_144105_144306_143478_144966_142911_140312_143549_143647_144239_142113_143855_136751_140842_110085; BDUSS_BFESS=1vQzN4d0pPNzB2MUQyUUQtV3d6OEZzYldhN2FWUm1RZEZ3UUVyb1Y1Mmtqc0JlSVFBQUFBJCQAAAAAAAAAAAEAAACgwJmS08W4xcTuAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAKQBmV6kAZleVW; MCITY=-%3A; sug=3; sugstore=0; ORIGIN=0; bdime=0; BDORZ=B490B5EBF6F3CD402E515D22BCDA1598; BDSFRCVID=LuuOJexroG3_dMRrBfK9UG9zgmKK0gOTDYLEUamaI2AU2V4VN4vPEG0Pt_U-mEt-J8jwogKK0gOTH6KF_2uxOjjg8UtVJeC6EG0Ptf8g0M5; H_BDCLCKID_SF=tbkD_C-MfIvhDRTvhCcjh-FSMgTBKI62aKDs2P5aBhcqJ-ovQTbrbMuwK45hB5cP3b5E0b6cWKJJ8UbeWfvp3t_D-tuH3lLHQJnp2DbKLp5nhMJmBp_VhfL3qtCOaJby523ion3vQpP-OpQ3DRoWXPIqbN7P-p5Z5mAqKl0MLPbtbb0xXj_0-nDSHH-tt6De3j; delPer=0; BD_CK_SAM=1; PSINO=7; H_PS_PSSID=1457_31670_32141_32139_32046_32230_32092_32298_26350_32261; COOKIE_SESSION=7_0_4_5_9_5_0_3_2_3_0_0_1608_0_0_0_1594720087_0_1594723266%7C9%23328033_18_1594447339%7C9; H_PS_645EC=8046hkQMotVPI51%2B5I0oGWsgl5ams9mPpS71Aw1L%2FgLPGzpf4I2A6FpO8U4',
'User-Agent': random.choice(ua_list)
}
url = f"https://www.baidu.com/s?wd={keyword}&ie=UTF-8"
html = requests.get(url, headers=headers, timeout=5).content.decode('utf-8')
time.sleep(2)
try:
if '相关搜索' in html:
req = etree.HTML(html)
tt = req.xpath('//div[@id="rs"]//text()')
tt.remove('相关搜索')
print(tt)
data = tt
else:
print(f">> {keyword} 无相关关键词!! ")
data=[]
except Exception as e:
print(e.args)
print(f">> 采集 {keyword} 相关关键词失败!! ")
print('>> 正在保存失败关键词..')
with open('fail_keywords.txt', 'a+', encoding='utf-8') as f:
f.write(f'{keyword}\n')
return data
def lead_keywords():
print('>> 正在导入关键词列表..')
try:
with open('keyss.txt','r',encoding='gbk') as f:
keywords=f.readlines()
except:
with open('keyss.txt','r',encoding='utf-8') as f:
keywords=f.readlines()
print(keywords)
print('>> 正在导入关键词列表成功!')
return keywords
def save(datas):
print('>> 正在保存相关关键词列表..')
with open('keywords.txt', 'w', encoding='utf-8') as f:
f.write('\n'.join(datas))
print('>> 正在保存相关关键词列表成功!')
def main():
datas=[]
keywords=lead_keywords()
for keyword in keywords:
keyword.strip()
data=get_keyword(keyword)
datas.extend(data)
save(datas)
if __name__ == '__main__':
main()
</p>
网站数据采集,最近许多网站数据采集网站站长问我,我应该网站数据采集文章采集做些什么?插件采集文章采集有很好的网站数据吗?采集文章批量发布和一键式自动百度、搜狗、360、神马推送,采集文章自动伪原创网站数据,关键词整个文章网络和网站数据的泛采集,并通过推送主动将采集伪原创发布的文章链接提交到各大搜索引擎进行批量收录。
关键词挖矿文章采集插件采集关键词应如何设置?长尾关键词的定位应该是一个完整的句子。标题应反映长尾关键词的需求。没有必要做太多。每个标题只需要反映一个长尾关键词,而不需要反映多个长尾关键词。长尾关键词是必需的。因为这里涉及搜索引擎算法,即单核长尾关键词标题比多核长尾关键词标题具有更大的优势。
使用关键词计划向内容添加具有强烈搜索意图的相关关键词,以提高内容的相关性,并关键词以获得更好的排名。当消费者搜索长尾关键词时,他们会找到您的网站。可以为您的网站带来可观的流量。
关键词挖矿文章采集插件可以支持伪原创。关键词挖掘文章采集插件以制作高质量的伪原创文章时,请务必先通读文章。这有两个优点:一是保证文章内容能被用户理解,二是解决用户的需求。二是删除这些文章中出现的广告网站,或者用自己的广告替换。然后自然地将文章段落和内容与要优化的长尾关键词穿插在一起。这时,搜索引擎会认为这个文章与一个长尾关键词有关,从而起到了提高关键词排名的作用。
关键词挖掘文章采集插件如何产生高质量的文章内容。高质量的伪原创文章不仅仅是为二次加工寻找文章的问题。高质量的伪原创文章通常由几个文章放在一起组成。例如,如果你想写一篇关于如何提高关键词排名文章,你首先需要找到三个关于如何在网上提高关键词排名文章,然后拿出这三个文章的重要部分并重新排列它们。句子清晰,符合用户文章阅读习惯,这样的文章更容易被百度收录。
这
关键词挖文章采集插件的原理是你的网站是帝国cms、奕优cms、ZBLOG、织梦cms、网站数据采集、苹果cms、人人cms、米拓cms、云游cms、小旋风蜘蛛池、THINKCMF、PHPcmsV9、PBoot cms、德通、海洋cms、极限cms、EMLOG、TYPECHO、WXYcms、TWcms网站数据采集子版主题、迅瑞cms等主要cms,可以同时管理和发布。
网站数据采集网站建设中,使用关键词挖掘文章采集插件进行现场优化,我们需要挖掘行业关键词,合理设置网站标题和创建的速度、质量、标题标签、锚点分布、内部链接网站文章更新。合理设置关键词密度,使网站的内容与关键词匹配得更好,从而获得更高的排名。
网站数据采集网站优化包括代码优化、内容优化、URL优化、关键词优化、网站结构优化、内部链接优化、内容优化、图像优化、视频优化、TDK优化、标签优化、网站图优化、机器人优化、
伪静态优化等,使用可用于提高网站排名的所有内容。今天对WP关键词挖掘文章采集插件的解释将在下一期中分享更多与SEO相关的知识和技能。

