解决方案:安全小课堂第四十九期【网站安全检测之信息收集类工具】
优采云 发布时间: 2022-10-21 15:20解决方案:安全小课堂第四十九期【网站安全检测之信息收集类工具】
网站安全检测的第一步是尽可能地采集目标系统的信息,这也是网站安全检测的关键一步。网站安全检查的每一步都伴随着信息采集和分析。作为一名拥有多年网络安全经验的资深白帽,在做渗透测试的时候通常会使用哪些信息采集工具呢?在JSRC安全课第49期,我们邀请了华华若祥大师简单介绍一下他们常用的信息采集工具。和 JSRC 白帽强迫 Sima、DragonEgg、wadcl、iDer、PX1624 讨论。
主讲人:花如相惜
讲师简介:
Hard Earth Security CTO,Pax.MacTeam创始人之一,多年渗透测试和安全培训经验。专注于安全开发、渗透测试、代码审计等领域。
讲师:秋天
讲师简介:
安全白帽,甲方安全研究员,网络尖刀团队核心成员,具有渗透测试、漏洞挖掘等相关经验和技能。
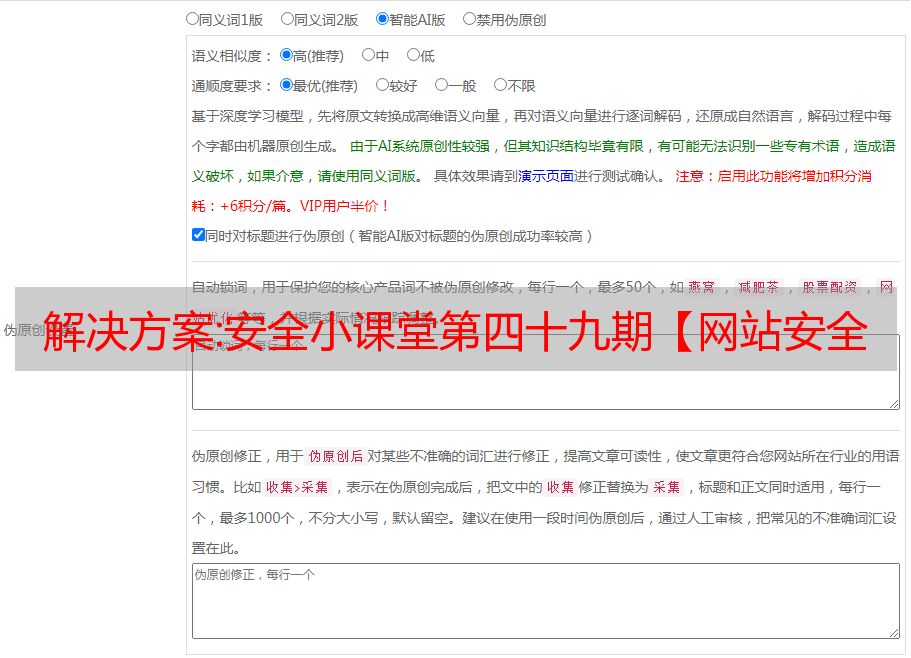
用于信息采集的工具有哪些?静安小美
subDomainsBrute, Layer subdomain miner, WebRobot, nmap, wyportma,
Python 和一双勤劳的手会自动使用 python 来自动化常用的东西。
主讲人:落下,花开似相惜
白帽视角:matego
白帽观点:和Sublist3r类似,自动从各种搜索引擎中搜索一个域名的子域
白帽视图:theharverser
白帽观点:指纹识别也有各种工具
白帽观点:在人员安全方面,在QQ群搜索,搜索公司名称等,如果你尝试进群,可能会有意想不到的发现。
如果只能推荐三种工具,您会推荐哪三种?为什么?静安小妹
seay写的Layer子域挖掘机字典在速度和速度方面都相当不错。唯一的缺点是每次都必须打开虚拟机。
chrome插件shodan ip、端口信息mysql redis等各种信息一目了然。
谷歌,你知道的。
subDomainsBrute、WebRobot、nmap,尝试了几个域名后,我还是觉得subDomainsBrute采集域名更准确,没有太多重复的业务。查询、域名暴力破解等),nmap扫描端口指纹识别效果更好。
主讲人:落下,花开似相惜
请分别描述这三个工具的常用用法。静安小妹
图层子域挖掘机输入好域名,点击开始,喝杯咖啡等结果。
shodan 单击图标 view-hoste-detail 查看详细信息。
谷歌:每个人都知道要搜索什么,搜索什么,以及谷歌黑客域名采集什么。subDomainsBrute 的使用非常简单。从github下载后,直接写入subDomainsBrute的执行文件有相关使用说明,如:
- 满的。
WebRobot 比较容易理解。
.
Nmap是必备的,我相信它会被使用。
主讲人:落下,花开似相惜
这三个工具在使用中存在哪些问题?怎么解决?
静安小妹
使用过程中确实存在一些不足。比如用 subDomainsBrute 扫描只采集 IP 和域名,但有些指纹是无法识别的。例如 网站 的标题、服务和端口可以在 subDomainsBrute 的前提下使用。编写和添加这些函数更方便。
主讲人:落下,花开似相惜
企业有没有办法防御这三种工具?我需要使用什么方法?静安小美
如果使用了端口,可以通过添加防火墙规则来处理。
那么,如果域名一般对外公开,迟早会被采集。最好的方法是在上线前进行全面的安全测试,通过后上线。
主讲人:落下,花开似相惜
本次 JSRC 安全类到此结束。更多内容,敬请期待下一期安全课。如果有什么内容你想在安全类中出现还没有出现,请留言告诉我们。
解决方案:3人团队,如何管理10万采集网站?(最全、最细解读)
人类的发展经历了猿到人的发展。工业发展经历了石器时代、工业时代和智能工业的发展。
采集 也经历了从单点到多点,再到分布式的发展。采集源的数量也从 10、100、1000 增加到 1W、50,000 和 100,000。这么多网站,怎么保证一直有效(网站可以正常打开)?
时代在进步,公司在不断发展壮大,网站的内容不断丰富。每年和每个月,都会有新的柱子上架,旧的柱子会下架。我们如何确保我们的 采集 列始终有效?
今天跟大家分享一下我这几年做采集的心得。
第一:搭建信息源系统
由于我们是做舆情监测服务的,所以我们的采集覆盖面比较广,包括我们经营所在行业的所有网站(尽可能的),以及各大媒体发布的一、二级各大媒体。国家、各类党媒、纸媒、APP等,以及微博、微信、论坛等社交媒体网站。
网站,栏目管理
现在我们采集覆盖网站大约6W个家庭,而且每天还在增加。我们应该如何管理这么大量的网站?这就是源系统的价值!
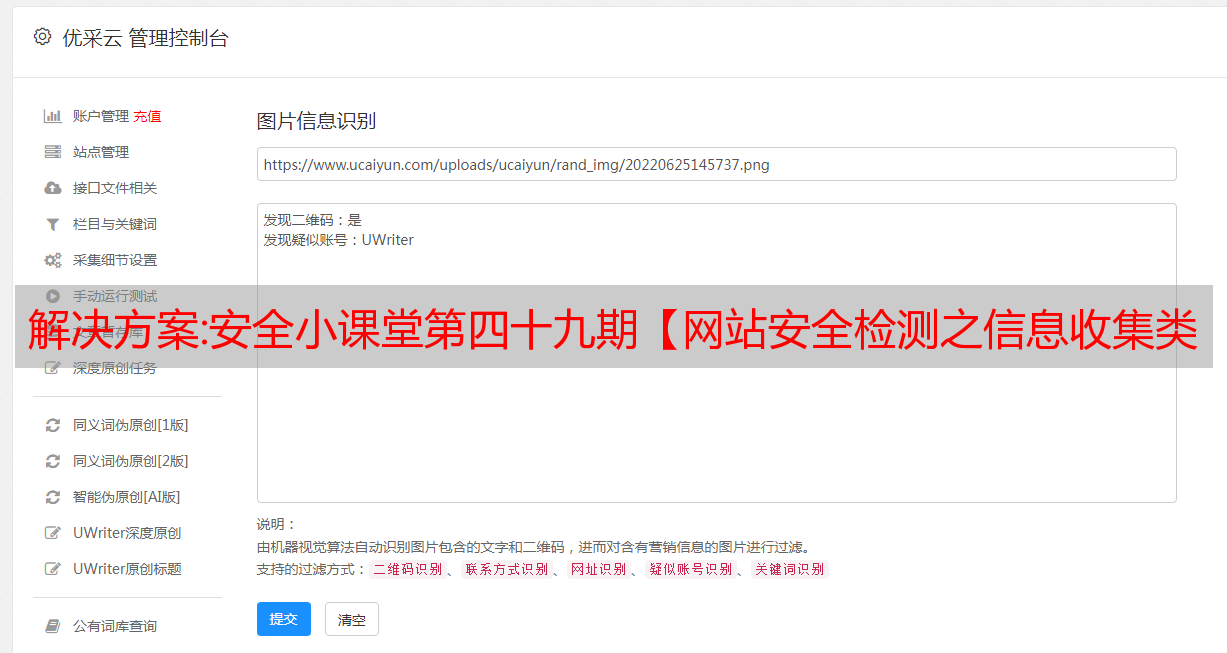
我们管理源系统中需要采集的网站以及这些网站下需要采集的通道或列。同时,部分网站媒体分类、行业分类、网站类型等均在系统中进行管理。
同时为了提高网站、栏目等的配置效率,我们支持直接将栏目的HTML源码复制到系统中,然后自动分析栏目名称、栏目网址、列下数据和其他数据的正则表达式。通过这样的优化,过去每人每天的网站数量已经增加到100多个。
关键词搜索
数据采集,除了直接采集发布信息网站,另一种快速获取数据的方式是通过关键词采集在各大搜索引擎中搜索,如:百度、搜狗、360等搜索引擎。
在源系统中,除了管理上述两类采集源外,还可以管理服务器,部署采集器等。因为在大批量的采集中,有上百个的服务器,每台服务器上部署三五个甚至十个或二十个爬虫。这些爬虫的上传、部署、启动、关闭也是耗时耗力的。能源的事。通过对系统的统一管理,可以大大减少部署、运维时间,降低很多成本。
二:搭建网站监控系统
这部分主要包括两部分:一是网站或者列状态的监控(可以正常访问);二是定期信息的监测;
网站,列状态监控
1:自动化
通常,所有 网站 都会以自动方式每两周或一个月检查一次。
然后,如果返回状态码不是 200,则再次进行第二次和第三次检查。主要目的是防止网络问题或网站响应问题导致的监控失败,增加人工二次处理。时间;
根据验证码,删除404、403等类型,502,域名未备案,过一段时间再验证其他类型。但记得要同步关闭这些网站的采集,否则会大大降低采集的效率。
2:传递结果数据
如果你有10W的网站,每次进行自动验证也是很费时间的。为了提高效率,我们可以结合采集的结果进行处理。从采集的结果数据,我们先分析一下上周哪些列没有收到采集数据,然后自动校验这些网站,效率会大大提高。
3:爬虫监控
当然,我们也可以在解析HTML源码的时候标记爬虫数据。如果网站没有响应,直接保存任务的ID,然后在源系统中标记,运维人员可以实时看到网站的状态>,及时处理,提高数据效率采集。
同时,如果网站正常返回数据,但没有解析出任何信息,则该任务可能是常规异常,也可能是网站异常。需要进行第二次测试。
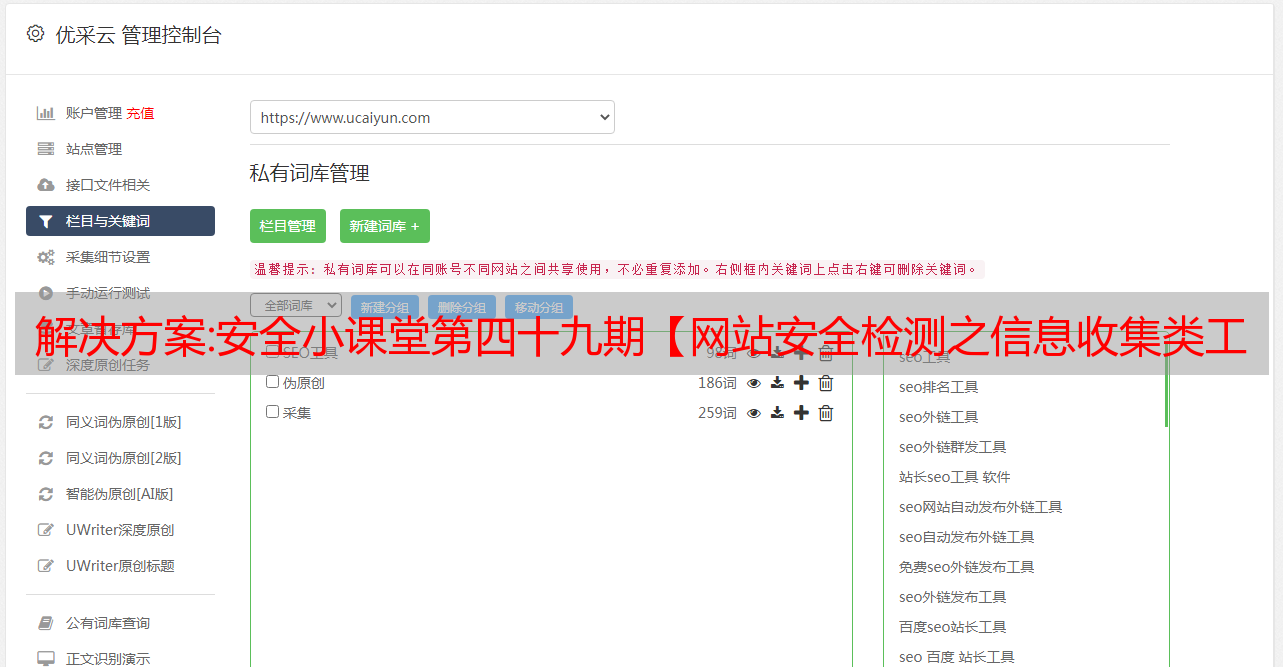
正则表达式的验证
如前所述,在采集的时候,我们可以通过当前列或者网站记录数据是否按照已有的正则表达式解析,如果不是,则标记源系统中的对应数据列上。
同时需要建立一个自动识别列正则表达式的服务,每隔一段时间(比如30分钟)读取一次识别的记录,自动识别其正则表达式,并同步到采集 队列。
为了保证正确获取正则表达式,自动识别后同步到采集队列,如果信息仍然不匹配。此时系统需要提示运维人员进行人工分析。
三:数据补充记录
在舆情监测中,无论你对采集的覆盖范围有多大,角落里总会有数据。如果你没有 采集,你可以看到。这时候,为了提升客户体验,我们需要密切关注人工对系统的补充录音,然后呢?
那么首先要分析一下我们的网站是否配置,列是否配置正确,正则表达式是否正确。通过检查这些步骤,我们就能找到错过挖矿的原因。根据原因优化源或改进采集器。
数据补充记录可以及时减少客户的不满,同时可以改善信息来源和采集,使采集实现闭环。
第四:自动化
第一:智能识别采集的频率
目前我们的网站和列采集的频率还是固定频率,所以一些更新信息比较少的网站,或者无效的列采集,会大大减少采集的效率>。这导致网站或列采集信息更新频繁,数据的价值降低。
我们现在根据每个网站或采集列的数据分布情况,对采集的频率进行更合适的统计分析,尽量减少服务器资源的浪费,提高采集 效率和最大化数据价值。
二:智能识别网站栏目
我们现在的采集的网站有6W左右,列有70W左右。这6W的网站中,每天都有很多网站的升级和改版,大量新柱上架,旧柱下架。一个 3 人的运维团队不可能完成这些工作量。
因此,我们根据 6W 网站 中配置的列进行训练,然后每周分析一次 网站 以自动识别列。然后,过滤掉与我的业务无关的列,最后进行人工抽检,最后发布到采集队列中供采集使用。就这样,我们的运维团队从9人减少到了现在的3人。并且还可以保证采集的稳定性和效率。
在大数据盛行的今天,一切分析的基础都是数据。
随着人工智能时代的到来,人类能做的一切,或多或少都可以被机器取代。
那么,30、50 年后,机器人能战胜人类吗?哈哈.....

