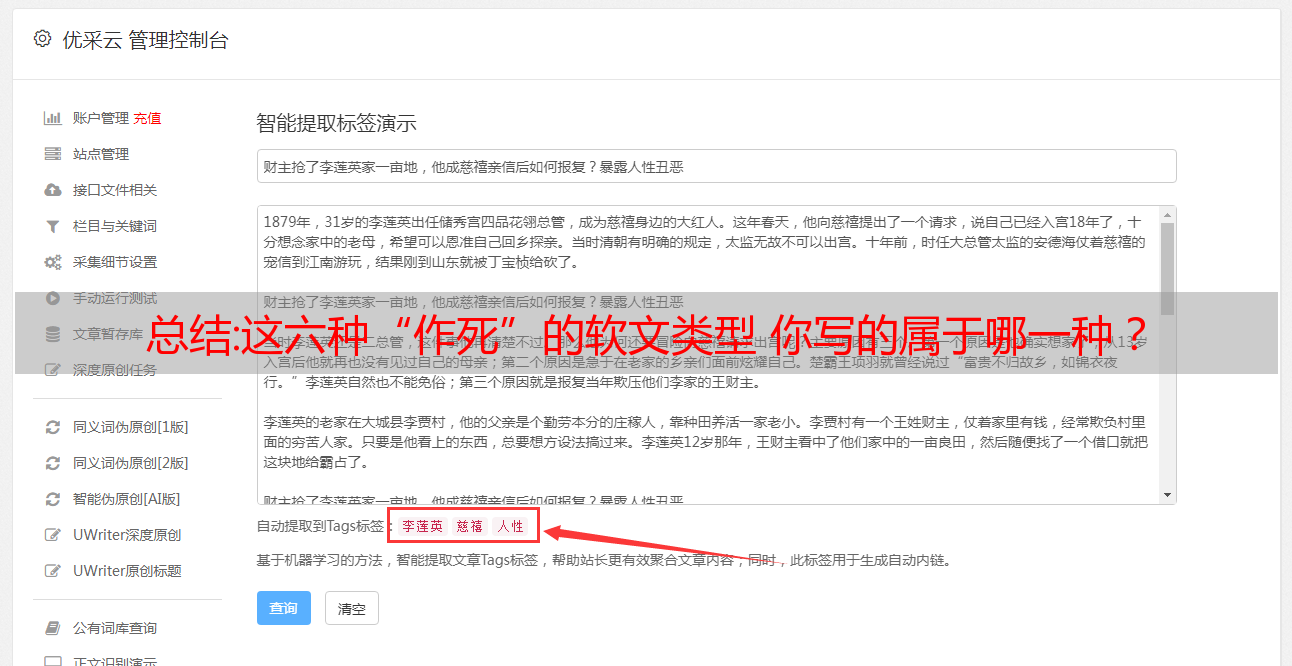
总结:这六种“作死”的软文类型 你写的属于哪一种?
优采云 发布时间: 2022-10-16 19:11总结:这六种“作死”的软文类型 你写的属于哪一种?
软文,英文是Advertorial,是指由公司营销策划人员或广告公司文案撰写的“文字广告”,与刚性广告相对。与硬广告相比,软文之所以叫软文,其微妙之处在于“软”二字,让用户避免了强制广告的推广,文章内容和广告完美结合,达到广告效果。
以上是百度百科给出的软文的定义。至于作者对软文的理解,我认为软文最基本也是最核心的元素,就是以你想推广的内容为契机,明确你想传达什么,用户需要什么,从而提供发散*敏*感*词*绕品牌、产品、用户讲故事,立案例,讲理想,讲经验,用理性去理解,用情感去感动。
也就是说,营销成分其实并不是软文的重点,关键在于你如何用软文打动和说服读者,让它自然融入“软”部分。
优秀的软文,读后让人如沐春风,你的产品和服务很容易被用户接受,同时默默润物。一篇不合格的软文 文章会让人们觉得自己被卡在喉咙里,难以下咽,甚至厌恶你的产品。
公司和文案都希望写出好的软文,看到最直接的效果。但往往事与愿违。投入大量精力后,发现效果还没有出来,甚至对产品和品牌都有不良影响。每个人都想写100,000+,但是软文的大部分读数可能不到几百!
网上关于如何写好软文的教程数不胜数。其实他们都是实话实说,听完就明白了,但实际操作起来就没那么容易了。与其说软文怎么写好,不如来分析一下我们日常软文营销中经常犯的“杀”行为,看看我们的软文是如何一步步为“写死”,如何解决这些问题。
1. 自杀软文
植入过多、质量差伪原创、纯抄袭是这类软文的特点。这种软文可以说是最粗心,也是最坏的类型。甚至连 软文 都没有。
这是一个过度植入的例子。这篇软文的全文是关于公司介绍、企业文化、模型理念的。基本上可以看成是广告。软文的精髓就在于一篇软文,这样的“硬文”,没有任何铺垫,也没有任何分析和案例,用户看了标题后不会点击标题,即使他们打开软文@文章链接也有可能“一秒消失”,将该企业拉入“黑名单”。
大量“自杀型软文”存在的原因,与多年来网络上“投机取巧”行为的盛行直接相关,网上也充斥着教你如何伪原创即使抄袭也能达到效果。文章 的。诚然,互联网经历了野蛮生长,低质量的软文也发挥了一定的价值。但是,随着国内互联网发展这么多年,搜索引擎越来越智能化,用户识别能力不断提升。我还在写这篇文章。种文章,说明你和软文营销走得更远了!
2.自愈型软文
一个人可能会写出好的文章,但不一定是好的软文。
文章是思想文化的载体,可以表达情感,发表意见,发表科研成果。这就要求作者在特定领域具有较高的文化素养,而对于文学作品,则需要扎实的文笔功底和优秀的文采。
但是,软文与普通的文章不同,它需要在内容中融入营销元素。“自愈型软文”也被取消资格。
这是图片广告文案的示例。这是奥克斯空调的产品图片。虽然“再见还是一见钟情”这句话充满了文采,但具体的惊喜却让用户难以理解。而“在家邂逅奥克斯之美”并没有表达出这款空调的美。可以说,这篇文字真的是“一见钟情”。
3. 泛泛而谈软文
熊折断了棍子,折断了一根,扔掉了另一根。很多公司在写软文的时候,都希望把所有的卖点罗列出来,从头到尾介绍产品。这种类型的 文章 经常会错过重点,缺乏骨干。大而不全,太多而不精确,都写不出一个活生生的卖点,整个内容也缺乏深度。
软文如果要告别笼统,其实两点就够了:
1、内容有针对性,不相关的内容尽量不要出现。
澄清这个 文章 的意图,然后开始写作。比如我想强调一个返利APP可以通过返利和佣金赚钱,那么我可以通过实际使用案例,某款产品返利多少,赚取佣金的真实截图,用图文强调这一点通过回扣。如果我写了很多关于如何下载APP,APP有多少用户,与多少商家合作,用户很难得到你想要表达的东西。
2.关注1-2点。
软文篇幅有限,不要越长越好。写的点越多,篇幅就会越长,而且你经常会专注于一件事或另一件事,甚至头重脚轻。所以软文在写的时候,抓1-2个关键点写一篇文章就够了。
4.过多的SEO类型软文
软文营销的价值之一是帮助SEO优化,提高品牌产品关键词在搜索引擎中的排名和外观。运用SEO思维,在文章中正确设置关键词确实很有效。但是有的公司在文章中堆积了大量的关键词进行优化,可以说是偷了。
看完上面的截图,你有什么想法吗?首先,这是一个质量比较低的软文,其次,内容与关键词叠加过多,极大地影响了用户体验。
百度和其他搜索引擎有特定的算法来判断过度的 SEO。堆叠关键词很可能导致用户体验不佳,文章没有收录甚至网站被降级惩罚。
运气好的话,一个软文和关键词叠加起来可能排名靠前,但是这些文章大部分都不会出现在百度搜索结果的顶部,不仅仅是因为搜索引擎会惩罚,也是因为这样做的人太多,而你出现 文章 的机会很低。
5. 金屋藏美女软文
俗话说,酒香也怕巷子深。都说品牌和产品做的再好,缺少宣传也很难出名。而在宣传中,如果力度不够或者方法不对,很有可能是没用的。就好像你娶了一个漂亮的老婆,整天说老婆有多好看,你却不想说出来,大家只会觉得你在吹牛。
许多公司可能软文 写得很好,但交付并不理想。可以总结为四个原因:
1、不愿意花钱:
我一直想通过免费渠道获得软文效果。事实上,软文营销需要一定的投入才能有效。
2、仅限自建渠道:
私域流量现在比较流行。一些企业沉浸在自建微信公众号、自媒体矩阵和一些平台免费投稿,忽略了外部渠道的作用。
3、过度依赖外部渠道:
单纯靠外部渠道推广软文也是错误的方式,因为外部渠道变数很多,免费投稿会被拒,付费软文可能会被删,外部资源质量差混杂,带有大量数据的造假行为,内外结合可以产生更好的效果。
4.频道投放不准确,频道选择错误:
渠道的选择是根据自己的需要而定的。
如果您更关心覆盖搜索 关键词 的品牌和口碑,那么您可以放置更多 收录 好的门户网站。例如,通过A5创业网推出的企业会员服务,我们为企业软文定制专属套餐,与数千家企业合作。开设企业专栏、独家发布渠道、快速收录、直接接触潜在用户,一直是中小型创业公司的首选。
如果您的需求更多是提高产品转化率,请直接或间接吸引读者下单。那你不妨考虑一下与你的产品领域相关的微信公众号和自媒体平台。这些账户拥有大量潜在用户,可以提高转化率。
六、棒读式软文
邦度,网上的流行语,指的是没有感情的阅读,也指没有距离感。我们通常会抱怨一些演员和主持人台词生硬,缺乏情感。事实上,这是一种很好的阅读方式。
没人愿意写自己的文案作为小学生流水账作文
如果一篇文章软文写成流水账,内容直白,文字生硬,缺乏比喻修辞,排版混乱,那就是“棒读式软文”。这种文章不仅难以打动读者,甚至会让人发笑。
以上就是对上述六种“杀”的软文形式的简单解决方法,希望对大家有用。由于篇幅有限,作者会更新一些有针对性的文章来回答具体怎么做,这里就不过多赘述了。
经典:这可能是你看过最“硬核”的小红书算法
这是哈佛医学院的 HMS 学者 文章。一位名叫 Nsoesie 的男子和他的朋友们分析了医院停车场的车辆数量和网络搜索趋势,得出的结论是,疫情首先发生在 2019 年 8 月的武汉。当然,这一说法被哈佛医学院自己驳斥了,理由是数据不适当和不充分,对统计方法的误用和误解,以及互联网搜索词的选择。事情并没有随着问题的发现而结束,Nsoesie 的说法被媒体广泛报道。
让我们简单总结一下整个时间,大致如下:大量数据表明医院的汽车更多;车多,看病的人就多;看病的人多,肯定有新冠肺炎;南京中华门风景区旁边是市第一医院,直线距离1.1公里。除了一个小停车场,一条胡同,还有医院地下停车场,没有其他停车位,小停车场和胡同总是满满的。国庆假期到了,医院停车场已经满了。结论是南京爆发了疫情。
如果从现象中推断原因,事实会有多大的不同?一个不能摆上台面的科研骗局,但用脚投票的人选择相信,不相信的人则别有用心地传播。
对应运营行业,是不是和一些人在方法论、刀法、套路、核心、SOP上很像?方法从结果中拆分出来,总结方法再用告诉100个人。只要一个人做的好,你就可以说:“你做的不好,别人能做好,都是你的错。” 哲学中有一个简单的观点,即“实践是检验真理的唯一标准”,而实践之所以是检验真理的标准,是由真理的性质和实践的特点所决定的。
开过一两个账号/连个账号都没开过,总结出来的运营经验报表不流畅,前后经不起推敲,大家都已经掏钱了。如下图,其实所有需要分发内容的APP都有这个逻辑。
因此,我不会写这个内容。如果你在网上搜索,你会发现10个和9个相同的小红书算法内容。也和前面的内容一样。不容易理解,甚至无聊。. 但是相信我,读完之后你会收获很多。或许业务上的一些小问题终于得到了确认,或许小红书的经营视角更加多元化,又或许学到了更具体的思路。
想听剑法、方法论、胡说八道,可以点击右上角的×。如果您想从较低的层次了解您正在开发的平台,如果此内容对您有所帮助,那就太好了。捡了很多论文、论坛,找到了很多小红书公开演讲的PPT总结,结合实际业务,欢迎关注、点赞、留言。
01
很多人常说小红书算法,大部分人从产品角度出发,少数人从运营角度出发,几乎没有人从技术角度出发。
算法是解决问题的一系列明确指令,算法代表了描述解决问题的策略机制的系统方法。方向 A ➡ 方向 B,可能是男性和女性,也可能是国王和王后。与其讨论如何从 A➡B 得到,不如先解释 A 和 B。
从产品上看没有什么大问题,但主要有两点,就是产品的背景和用途。产品的背景包括它解决了什么需求,具体使用场景是什么,目标用户是什么。产品的使用包括体验、UI、美术和交互。我看过大部分人从UI的角度分析小红书算法,也就是用户界面,其实还是挺不准确或者说肤浅的。
从 UI 的角度来看,抖音 与小红书非常相似。抖音-recommend、follow、same-city的首页和小红书的首页-discover、follow、same-city基本一致,新闻页面和我的页面基本一致,算法和逻辑一样吗?
太糟糕了,反映在结果上,我们抖音和小红书的粉丝都在200万左右。一个基本没有*敏*感*词*,另一个利润很高。后来,我们反复回顾,平台就像那些年我们追逐的女孩一样,没有人永远年轻,但总有人年轻。即使经营了很多年,我们也常常对当时的女孩感到陌生。而平台总会孕育出新的机遇,给后来者的遐想空间。
废话不多说,简单梳理一下小红书算法。很多段落摘自ArchSummit深圳演讲——赵小萌(小红书算法架构师,负责机器学习应用),2019阿里云峰会上海开发者开源大数据专场小红书实时推荐团队负责人郭毅,以及秦波(推荐引擎北京项目负责人)和Marko(小红书大数据组工程师)的帖子/PPT。如有侵权,请联系修改或删除。
小红书社区是一个分享社区+电商APP。共享社区通常由女性主导,并由一些主题引导。如何每天将平台产生的内容转发和分发给用户,让用户看到自己想看的,是算法需要解决的问题。
对于小红书来说,社区提供用户粘性,为电商吸引流量。电商将这部分流量变现,在APP内形成闭环。对于算法团队来说,社区有用户数据,电商板块有用户行为数据。如何连接双方的用户行为,更好地理解用户,是算法的根本出发点。
现在大家普遍认可的流量分配模型如下,根据用户交互效果打分的系统是CES。其实太笼统了,不知道CES分数是出现在整个推荐过程的第一、二、三步,还是重复计算。接下来,我将通过一些具体的案例,从技术的角度来解释。
如果你看过我上一篇关于搜索流量的文章,你应该会有一个印象,一个note的搜索流量是比较稳定的,推荐流量是note成为hit的核心。小红书在线推荐流程主要分为三个步骤:
候选集从小红书用户每天上传的笔记库中选出,通过各种策略从千万条笔记中选出数千个候选集进行初步排名。在模型排序阶段,对每条笔记进行评分,根据小红书用户的点赞和采集行为给平台带来的价值,设计一套加权评价体系。通过估计用户的点击率,对点击后的点赞、采集和评论等进行评估。在向用户展示笔记之前,选择得分高的笔记,并通过各种策略调整多样性。
02
那么小红书是如何从每日笔记池中选择候选集进行初步排名的呢?
小红书内容图文并茂,用户生成的内容质量上乘。使用CNN(卷积神经网络)提取图像特征,使用Doc2Vec(Text to Vector Model)提取文本特征,并使用简单的分类器将用户分类为主题,主题是手动校准数十万个主题。这是第一行。
03
CNN 和 Doc2Vec 如何提取注释进行分类?
关于图像识别,小红书是一个非常视觉化的社区。有很多图像。小红书通过从图像中提取特征已经可以取得不错的效果。当准确率在85%左右时,覆盖率可以达到73%左右。添加文字后效果更好,准确率达到90%,覆盖率达到84%。
图片 这是内容创作中首先要注意的地方。图像的夸张程度能被识别到什么程度?
我们曾经发过一个幼儿、中小学的教育案例,在角落里翻开的一本书中拍到两行母婴胎教的字眼,肉眼看不清楚。违规发出警告,称涉及婴儿遗传学等敏感内容。帐号 3天不推荐。反复寻找原因后,我发现了这个问题。
这是另一个更常见的例子,涉及 GBTD 模型中的机器深度学习。在小红书上分享痘痘治疗很流行。关于如何治疗脸上的痤疮有很多注意事项。如何将这些不舒服的内容推荐给想看的人是个问题。
小红书尝试用CNN模型做这件事时发现,无论照片是全脸、半脸、1/4脸甚至是少数人脸部位,都能识别甚至识别出里面的文字。图片很好。对防作弊很有帮助。所以,图片上不要携带任何私人物品,图片识别+图文识别,基本准确率90%。
我们来谈谈文本的向量表示。文本的向量表示有很多种。一种比较著名的向量表示称为 Word2Vec,它是由 Google 提出的。它的原理很简单。事实上,它是一个非常浅的浅层神经网络。它根据前后词预测中间词出现的概率。当预测被优化时,模型得到单词的向量表示。
同一个词的向量表示在空间上也是有意义的,相似的词也在相似的空间中。这个模型的有趣之处在于,你可以随时通过取出向量来进行向量操作。
从女人指向男人的向量与从皇后指向国王的向量相同,所以我们知道其中三个,我们可以计算另一个。如果我们的笔记重点是“自驾”和“露营”,Word2Vec会根据前后两个词预测中间词出现的概率,可能是设备、路线、西藏、过夜、海边、周边、策略,并将其推送到相应的用户页面。
04 什么是用户画像和笔记画像?它在算法中起什么作用?
1、小红书的推荐预测模型已经进化为GBDT+Sparse D&W的模型
预测任务主要有9个,包括点击、隐藏、点赞、采集、评论、分享、关注等。点击、保持、点赞、评论、分享、关注。Click是小红书最大的模型,每天产生约5亿个样本用于模型训练。GBDT 模型中的笔记分布有大量的用户行为统计,并生成一些静态信息和动态特征来描述用户或笔记。
通过用户档案和人口统计信息来描述用户,例如性别和年龄等静态信息。笔记分为作者和内容两个维度,如作者分数、笔记质量、标签和主题。动态功能很少,但非常重要。
动态特征包括用户是否点击浏览搜索、是否有深度行为等用户反馈。这些交互数据有一条从线下直接进入线上模型的实时管道,线上会利用这些数据来预测点击率等交互质量指标,然后根据用户和笔记的无形分类进行推荐。
2.关于动态特征的提取,小红书使用的是Doc2Vec模型,也称为相关说明
相关备注有什么要求?推荐的笔记和用户正在查看的笔记最好是关于同一件事。比如,同样的口红,同样的酒店,同样的旅游城市,同样的衣服,可能不是一家酒店,而是一家类似的酒店。
可能不是同一个旅游城市,但可能是相似的旅游城市,是不是很难理解?那么让我们更具体一点。如果我看亚特兰蒂斯同级别的酒店,那么小红书不会向我推荐格林豪泰,而是同级别的酒店。如果我经常搜索雪山/草原/沙漠,我不会推荐上海/北京/广州这些人文和城市景观优秀的地方。
需要注意的一点是,虽然 TFIDF 模型的基本要求是一样的,但是它可以找到一类笔记,即描述用户心理和描述用户心情的笔记。因为用户用来描述自己心情的词汇非常接近,所以这个方法也会找出扩展的内容。“jejuezi”是一个非常明显的情态助词或形容词,小红书有461万+个音符。

核心实时归因场景业务如何创建用户行为标签?
用户画像比较简单,不会有太多的状态,而实时归因是整个实时流处理中最关键的场景。实时归因会在向用户推荐笔记后产生曝光,生成积分信息,用户的每一次曝光、点击、查看、回滚都会被记录下来。
看下图,用户行为的四次曝光导致四次笔记曝光。如果用户点击第二条笔记,则会生成第二条笔记的点击信息,点赞会生成点赞的点击信息。如果用户倒带,它将显示用户在第二个音符上停留了 20 秒。实时归因会生成两条数据。第一个是点击模型的数据标签。下图中第一个和第三个音符没有咔嗒声,第二个和第四个音符有咔嗒声。这种数据对于训练点击很有用。模型很重要。类似的模型也与上面几乎完全相同。
05 CES评分在什么阶段参与算法?
在整个在线推荐过程中,每个note只在模型排序阶段进行评分。笔记在笔记展示给用户之前,小红书会通过各种策略选择得分高的笔记进行多样性调整。
分数=pCTR*(plike*Like weight+pCmt*Cmt weight...)
如果涉及到CES,那只是很小的一部分。我通过爬虫爬下爆文笔记,以CES的形式做了一个Excel表格分析。无论是散点图还是曲线图都显示出各种数据之间的关系,没有规律的图表,所以用的最多的是CES。在冷启动时,少总比没有好。
06
综上所述,最后我们还是用比较通俗的话来解释一下这个内容想要展示或体现的观点:
小红书算法是解决问题的一系列清晰指令,算法代表了描述解决问题的策略机制的系统方法。方法论不应该从用户界面或成熟账户中进行梳理和总结,因为总结只是一系列机制中的一个琐碎点,不应该形成所谓的通用方法论。
大家的工作和业务也在进行。许多操作文章一下子解释了整个操作过程。我建议从算法开始。工作也是从你的实际理论和认知中进行的,而不是像葫芦一样。钢包。我给你一架飞机,让你画葫芦画瓢。好的,你可以构建它。
不要做公司要宣传的内容/自己喜欢的内容,而是做算法认为用户想看的内容。毕竟算法需要解决的问题就是将平台产生的内容转发给用户,让用户看到用户。想看。
对于小红书来说,算法的出发点是如何将社区的用户数据与用户在电商板块的行为数据联系起来。目前,小红书的盈利模式主要集中在专家种草。其实算法团队还不够好,中台也没办法提供足够优秀的支持。不管是电商还是广告,其实大家都在抱怨。
前台主要面向客户和终端卖家,实现营销推广和交易转化。中台主要面向运营商,完成运营支持。后端主要面向后端管理人员,实现流程审核、内部管理和后勤支持,如采购、人力资源、财务、OA等系统。
算法职位在各大公司的招聘线上也有着最高的OFFER。目前,想要做视频内容电商的算法人才倾向于去抖音和快手。想做传统电商的人,往往会去阿里或拼多多。至于电商或者图文形式的广告,其实他们已经做了很多年了,也不是特别好。小红书的图文能够做得很好,得益于70%的用户群是女性,社区氛围营造的生活氛围非常细腻。
选择正确的内容非常重要。如果内容是小众、刚需,那么小红书通过策略选择的候选集相对容易选择我们的笔记。在大量用户中出现的整个笔记中,我倾向于不涉及 CES 分数,而预测模型实际上起着很大的作用。反映在实际操作中,一张图一句的笔记乱七八糟,老账因为预测模型而流行。
小红书算法对图片的优先级很高,准确率至少在85%以上。如果加上文字,准确率可以达到90%。所以,无论是正常的图文,还是进水不报的便签,还是被非法排水的便签,算法一直都能查的清清楚楚,不会出错,但只关系到封口的松紧度。运营中心的账务处理。比如哪个月关账,哪个月查资质,哪个月抓引流,算法有数据,人为干预就好。
关于文本的动态特征提取,可以重点关注上面提到的估计词和相关注释。这是一个非常有趣但非常实用的模型算法。站在普通用户的角度,感觉抖音和小红这本书做的不错。
小红书算法对笔记内容的好坏取决于用户画像和笔记画像。用户画像一般是静态信息,大部分是在注册账号时完成的,比如性别、年龄等。笔记画像包括评分、笔记质量、标签和主题(主题是我上面提到的用于手动分类的数百种算法中的主题,而不是下面的标签或内容主题)。
我们在浏览推荐页面的时候,可以看一下一屏的内容(四条笔记),尤其是用其他账号刷到自己账号的时候,如果一屏还有其他和你同类别的笔记,关键是Research,算法认为你在各方面都相似,并展示给用户。
本文由@laozhaoshuo 原创 发布,大家都是产品经理,未经允许禁止转载
题图来自Unsplash,基于CC0协议

