归纳总结:收集写作素材,必须知道的一大原则和3个方法
优采云 发布时间: 2022-10-14 13:22归纳总结:收集写作素材,必须知道的一大原则和3个方法
很多人都佩服米萌写文章的能力。其实我更佩服的是米萌的搜集材料的能力。
我们看米萌的文章,精彩的短句、搞笑的段子、生活的短篇小说一目了然。除了米萌对写作的超强驾驭能力文章之外,相信米萌也很努力的做到了。材料库也做出了贡献。
对于这一点,咪蒙也多次公开分享和强调。
可见“聪明女子无米难煮”。
再厉害的作家,如果没有适合文章主题的素材,又在文章中丰富了生动的案例,又怎能写出生动丰富的文章。
材料对于写作非常重要。除了在日常生活中多关注、多思考、多看,我们还可以从网上采集写作所需的素材,建立自己的写作素材库,丰富写作主题。
通过自己的实践和总结,总结出一个大原则和3个实用的方法和技巧,在采集资料时必须遵循。
无论是开始写作还是采集资料,都必须遵循先确定主题的原则,然后根据主题采集相关的写作材料,建立相应的素材库。
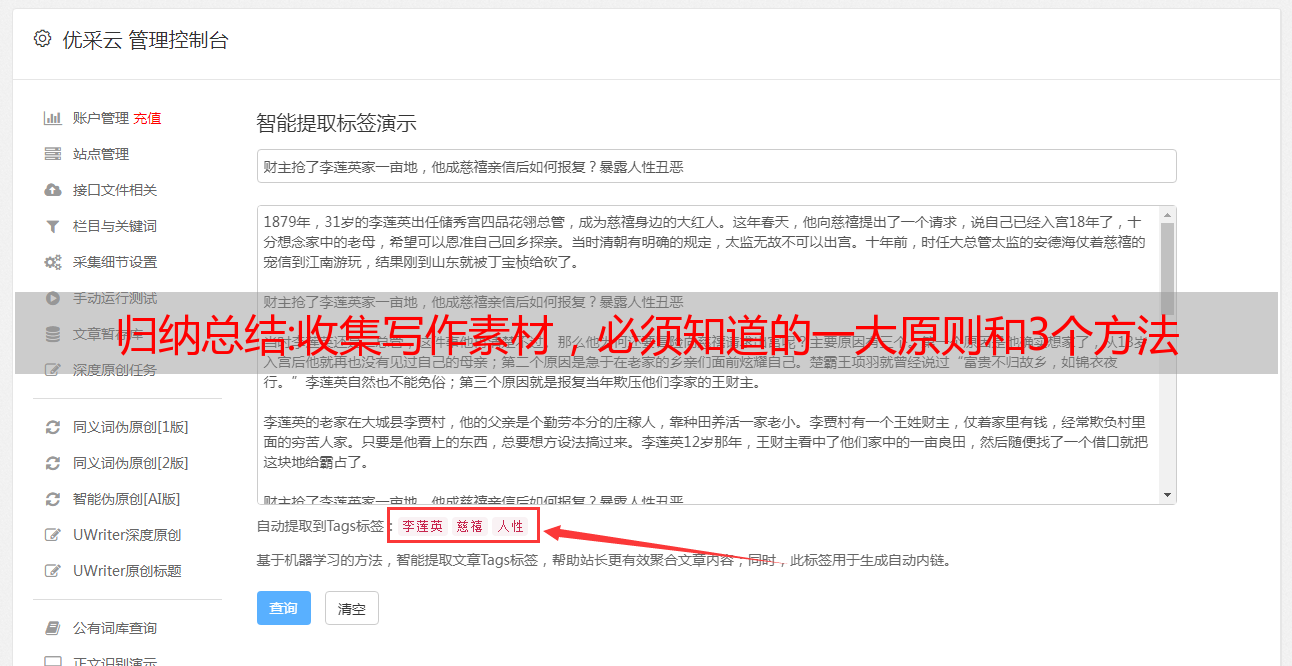
3种简单实用的材料采集方法和技巧:
1、创建对应的素材文件夹。
文章的标题、内容(包括短句、短篇故事、论据、示范案例等)、图片等,单独创建一个文件夹,方便提取。
2. 借助关键词定向搜索,可以快速找到你需要的素材。
A. 使用搜索引擎搜索
可以使用百度、搜狗、360、微信搜索入口、微博、知乎等搜索入口,基本能找到足够的所需材料。
B. 3个可以借助热点内容进行搜索的工具
对于热点内容相关的素材,我们可以使用搜狗微信搜索、新榜和百度搜索风云榜这三种搜索工具。
3. 组织材料库的 2 个最佳工具。
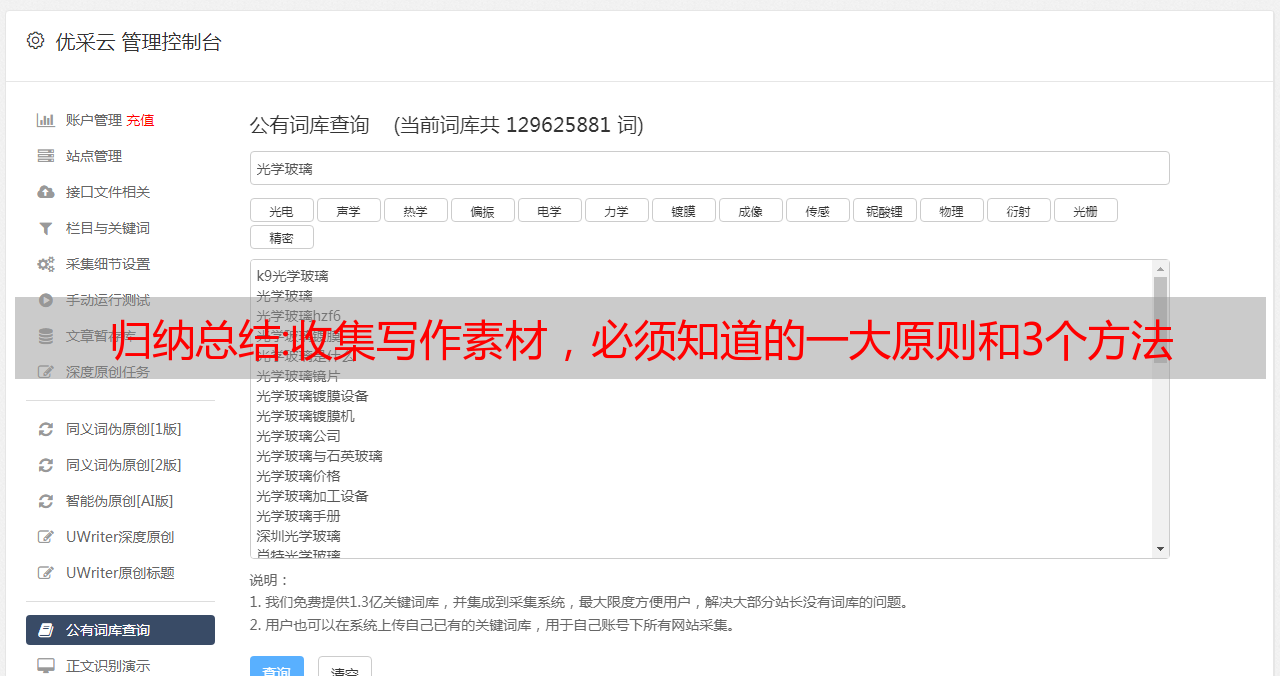
第一个推荐的是印象笔记,它在采集资料时具有其他软件不具备的便捷优势:
随时随地记录
浏览器剪辑功能
保存网页图片类文件和资料的合集(可识别图片的关键词信息,省去打字和编码的功夫,很强大的功能)
支持微信、微博、知乎、kindle、xmind等众多优质平台的内容分享和导入。
二是“Graphite Document”,手写也是不错的选择。
采集和整理材料既费时又费力。据调查,75%的自媒体作者表示,采集素材是整个写作过程中最耗能的部分。
在采集资料的时候,只要遵循我提出的其中一项大原则,熟练运用这三种实用方法,一定会对你有很大帮助!
我是江傲风。欢迎大家留言,和我一起讨论采集资料的话题。
干货教程:收藏 | 机器学习数据集汇总收集
转载于:机器学习算法和实践中的Python
大学发布数据集
(斯坦福大学)
69G大型无人机(校园)图像数据集[斯坦福].
人脸素描数据集[香港中文大学].
自然语言推理(文本含义标记)数据集 [NYU].。
伯克利
图像分割数据集 BSDS500 [伯克利].
宠物图像(分割)数据集[牛津]。
~视频/数据/宠物/
发布ADE20K场景感知/解析/分割/多目标识别数据集[麻省理工学院]。
多模态二元行为数据集 [GaTech
]。
计算机视觉/图像/视频数据集
时尚-MNIST风格服装形象数据集[小寒].
大型 (500,000) LOGO 徽标数据集
4D扫描(60fps移动非刚性物体3D扫描)数据集[D-浮士德]。
基于 MNIST 的可视化计数综合数据集 计数 MNIST
优酷MV视频数据集[崔坤宇]。
计算机视觉综合数据集/工具的大量列表[不现实]。
动物属性标记数据集 [克里斯托夫H.兰伯特/丹尼尔·普彻/约翰内斯·多斯塔尔】
日本*敏*感*词*数据集*敏*感*词*109
架空舞视频数据集
皮克斯夫图像数据集[李杰里].
电子视频数据集
#download
快速,绘制! 简笔画涂鸦数据集
简笔画涂鸦数据集 [硬丸
]。
服装肖像生成模型(>奇克托邦10K [人类解析]时尚肖像分析数据集)[克里斯托夫·拉斯纳/杰拉德·庞斯-莫尔/彼得·盖勒
]。
COCO 像素级标注数据集
大型街道图像(分割)数据集 [彼得·康奇德
]。
大型日本图像描述数据集
城市景观街景语义分割数据集(50个城市30个类别5k精细标签20k粗体标签图片和标记视频)。
(街头)时尚服装数据集(2000多张注释图片)。
PyTorch实现了VOC2012数据集像素级目标分割[波多凯撒]。
200亿神经元对象复杂运动和交互式视频数据集[尼基塔·约翰逊
]。
文本/评论/问答/自然语言数据集
(200,000)英语笑话数据集[塔伊沃蓬加斯]。
机器学习保险业问答开放数据集[海恩旺
]。
保险业问答(QA)数据集[冯敏伟].
斯坦福NLP发布了新的多轮,跨域,面向任务的对话数据集[Mihail Eric]。
实体/名词关系标签的大卫·巴蒂斯塔数据集
NLVR:自然语言基础数据集(对象分组、数量、比较和空间关系推断)
)。
28,000文章/100,000个问题*敏*感*词*(英语测试)阅读理解数据集
数据集拼写错误
~ROGER/corpora.html
文本可简化数据集
~德考查克/简化/
英语单词/句子/语义框架框架注释数据集框架网
(另一个)自然语言处理(NLP)数据集列表[尼古拉斯·伊德霍夫
]。
跨语言/多样式/多粒度文本相似性检测数据集
Quora 数据集:400,000 行潜在的重复问题
文本分类数据集
帧:马鲁巴对话框数据集
跨域(亚马逊产品评论)情绪数据集
~mdredze/datasets/sentiment/
语义 Web 机器学习系统评估/基线数据集采集
其他数据集
数据科学/机器学习数据集摘要
CORe50: 连续目标识别数据集 [文森佐·洛莫纳科 & 迪维德·马尔托尼
]。
(Matlab)数据集统计分布自动发现[伊莎贝尔·瓦莱拉
]。
(建筑)损失评估数据集[海啸].
独立网络社交地图集数据集
深度思维开源环境/数据集/代码集合 [深度思维]。
鸟叫数据集[异种-康托
]。
沃尔夫勒姆数据集存储库
大型音乐分析数据集 FMA
(300万)因斯塔卡特在线杂货店*敏*感*词*集[杰里米斯坦利]。
用于欺诈检测的合成金融数据集[见证]
NSynth:海量高质量笔记标记音频数据集
LIBSVM 格式分类/回归/多标签/字符串数据集
~cjlin/libsvmtools/datasets/binary.html
笔记本电脑适合具有逻辑回归的100G数据集[德米特里·谢利瓦诺夫
]。
堆栈交换近似/重复问题数据集
2010-2017年最全面的KDD CUP主题回顾和数据集
食谱数据集:超过20,000个食谱,*敏*感*词*和类别信息[雨果达伍德]。
美国电影艺术与科学学院
计算医学图书馆:(张量流)大型医学数据集分析和机器学习建模 [AkshayBhat
]。
聚类分析数据集
官方开放气候数据集
START联盟全球恐怖袭击数据集
七个机器学习时间序列数据集
大型众包关系数据库自然语言查询语义解析数据集(80000+查询样本)
)。
赛马赔率数据集
新的YELP数据集:470万条评论和156,000个商家
杰米尔数据
日本木版印刷文本识别数据集
多模态二进制行为数据集
机器学习论文/数据集/工具集(日语)。
机器学习公司的十大数据采集策略
NLP 数据集加载工具集
日语相似词数据集
海量人形格式塔填空(多项选择阅读理解)数据集
高质量的免费数据集列表
数据自然语言数据集/代码的美妙之处
微软数据集 MS MARCO,阅读理解领域的“图像网络”
AI2 科学问答数据集(多选)。
常用影像数据集的完整集合
(分类、跟踪、分割、检测等)。
搜狗实验室数据集:
互联网图片库来自搜狗图片搜索索引的一些数据。它采集了包括人物,动物,建筑,机械,风景,体育等类别,共有2,836,535张图片。对于每个图像,数据集都会提供图像的原创图像、缩略图、您所在的页面以及页面中的相关文本。超过 200 克
IMAGECLEF致力于在位图像相关领域和跨语言评估论坛(CLEF)领域提供基准(搜索,分类,注释等)。该竞赛自2003年以来每年举行一次
~西荣/索引.php?n=主要数据集

