干货教程:帝国CMS源码《花生小说》源码 花生日记公众号引流导航站模板 带wap手机站+采
优采云 发布时间: 2022-10-13 17:33干货教程:帝国CMS源码《花生小说》源码 花生日记公众号引流导航站模板 带wap手机站+采
放开眼睛,戴上耳机,听~!
帝国cms源码《花生小说》源码花生日记公众号引流导航站模板带wap手机站+采集【纯版】
帝国cms源码《花生小说》源码花生日记公众号引流导航站模板带wap手机站+采集【纯版】
开发环境:
帝国cms 7.5
安装环境:
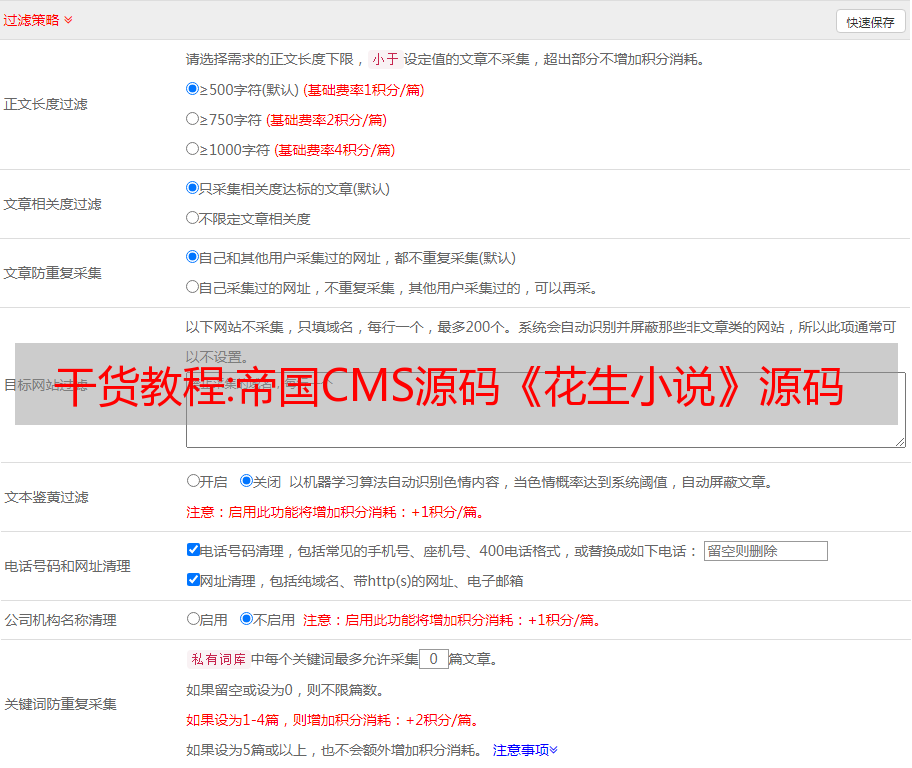
php+mysql
源代码说明:
一个专注于小说阅读细化分类的网站。我们会根据不同的用户喜好,将海量的小说分类为详细的主题类别。
让你找到自己喜欢的小说阅读速度更快。此外,我们每天通过用户阅读量、付费率等大数据指标,为小说爱好者推荐几本好看的小说。
关键词:好小说,推荐好小说,小说分类导航
说明:小说公众号模板,小说网站导航引流网站源码,网站结构清晰易优化收录。
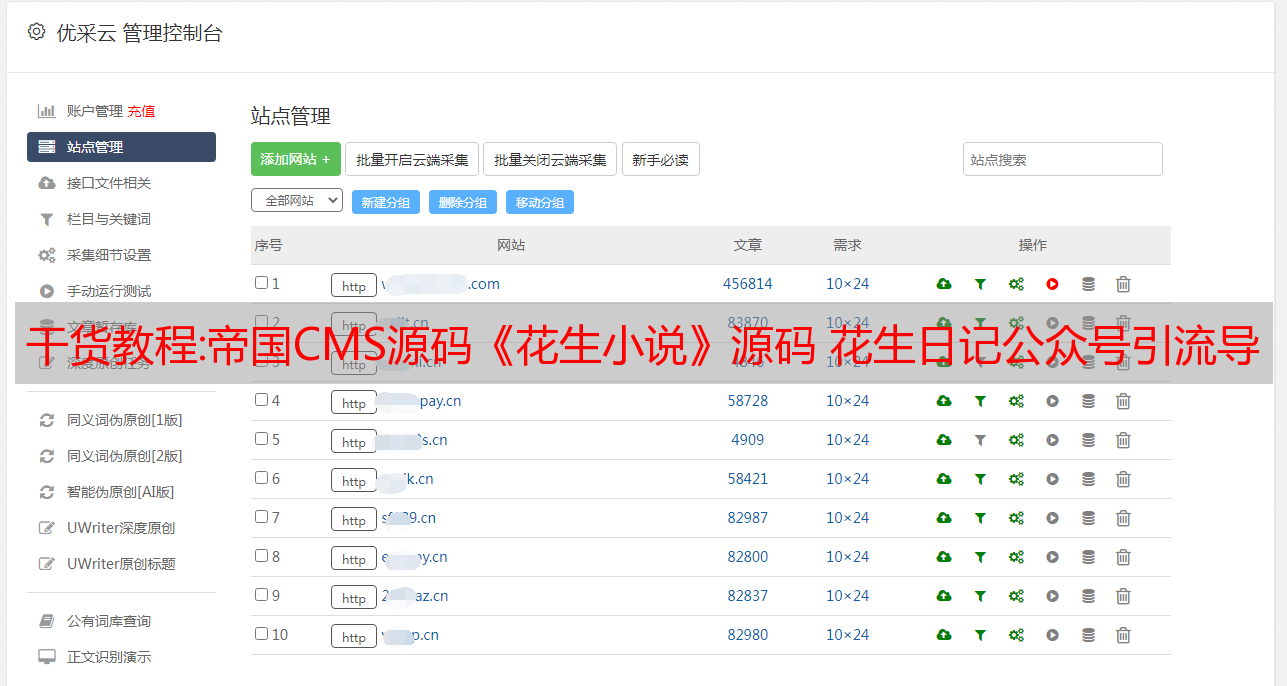
本站配备优采云自动采集、手机端、同步生成插件。模仿Empirecms7.5内核,更安全、更高效。
APP流、下载站、游戏公会人群引流等都是不错的选择。模板易于更改和维护。
采集可以使用这种导航方式的网站很多,也可以购买版权直接在线阅读。
注:此版本为纯版本,无任何数据。如果您需要数据,请使用提供的 优采云 for 采集
分享文章:python自动获取微信公众号最新文章的实现代码
目录
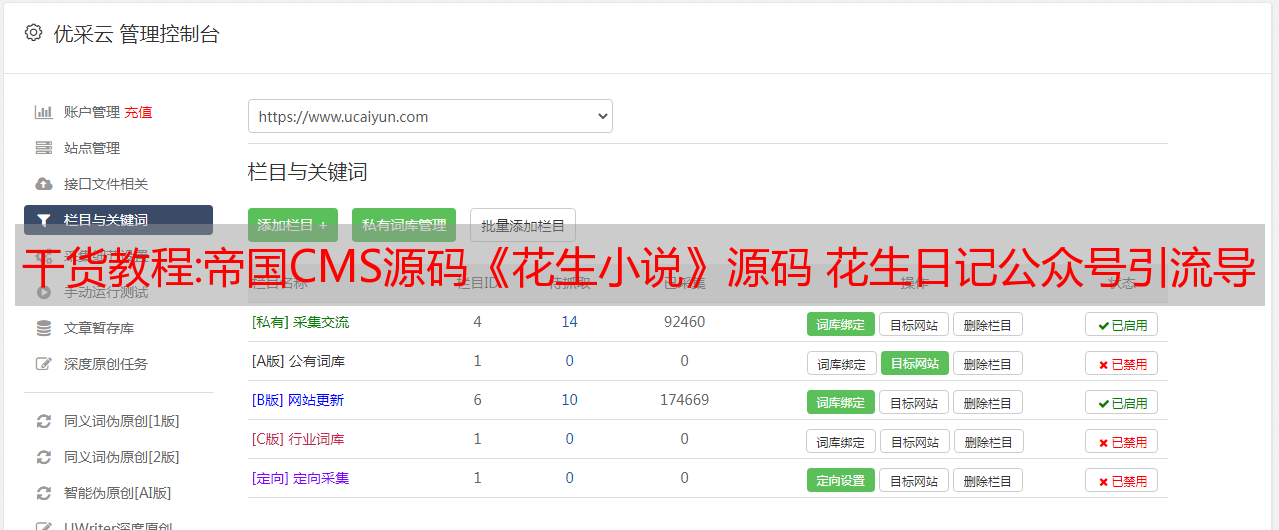
微信公众号获取思路
获取微信公众号文章常用的方法有搜狐、微信公众号首页和api接口。
听说最近搜狐不太好用,而且之前使用的API接口也经常维护,所以使用微信公众平台进行数据爬取。
首先,登录你的微信公众平台。如果您没有帐户,您可以注册一个。进来后找“图文资料”,就是写公众号的地方
点击后会出现写公众号的界面文章。在界面中,您会找到“超链接”字段,您可以在其中搜索其他公众号。
以“python”为例,输入要检索的公众号名称,从显示的公众号中选择公众号为采集
点击浏览器查看,在网络中找到链接,下图中的链接,右边的Request URL是存储公众号数据的真实链接。表示这是一个 json 网页。
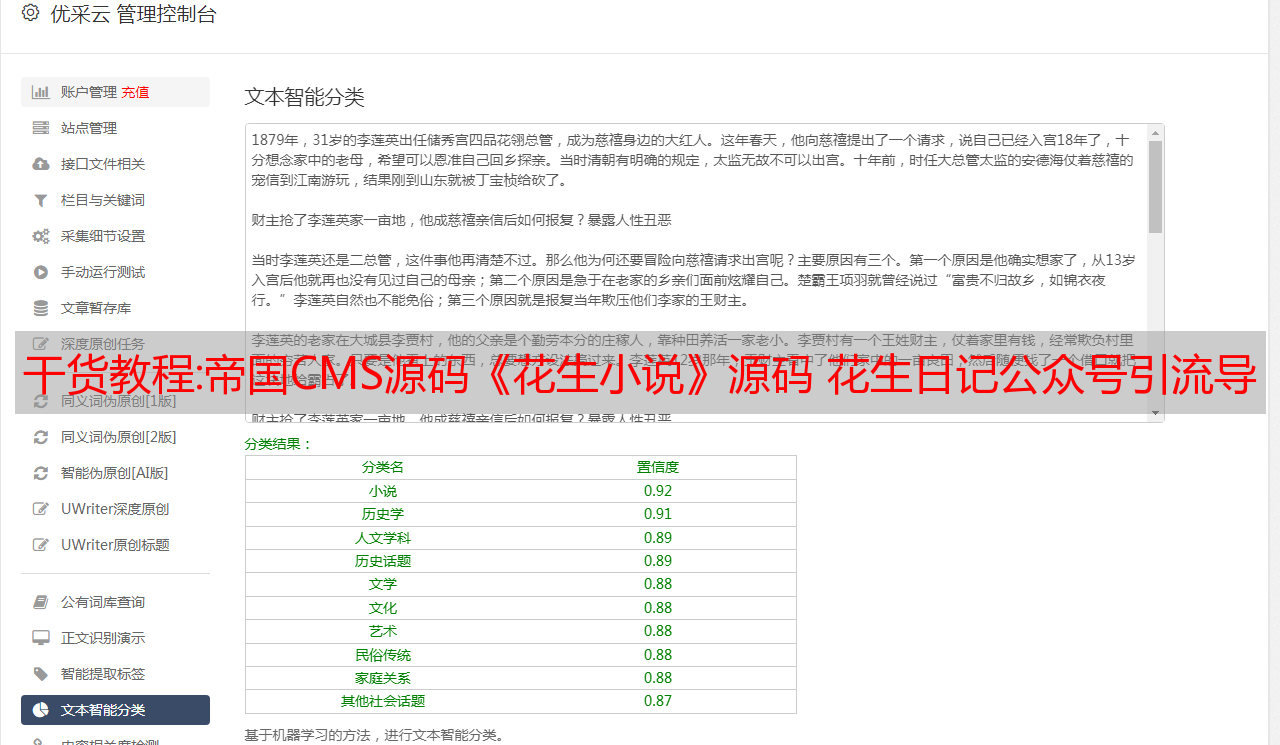
采集实例
以公众号“python”的链接为例,分析URL。
https://mp.weixin.qq.com/cgi-bin/appmsg:微信公众平台的链接
"token": "163455614", #需要定期修改的token
"lang": "zh_CN", #语言
"f": "json",
"ajax": "1", #显示几天的文章
"action": "list_ex"
"begin": "0", #起始页面
"count": "1", #计数
"query": "",
"fakeid": 'MzIwNDA1OTM4NQ==', #公众号唯一编码
"type": "9",
由于我发现fakeid是唯一代表公众号的代码,那么我只需要找到所需公众号的fakeid即可。我随机找了三个公众号进行测试。
fakeid=[ 'MzIwNDA1OTM4NQ==','MzkxNzAwMDkwNQ==','MjM5NzI0NTY3Mg==']
<p>
#若增加公众号需要增加fakeid</p>
然后下一步就是请求URL
首先导入需要的库
import time
import requests
from lxml import etree
import pandas as pd
import json
import numpy as np
import datetime
import urllib3
from urllib3.exceptions import InsecureRequestWarning
urllib3.disable_warnings(InsecureRequestWarning)
由于不想重复登录公众号平台,可以使用cookies来避免登录。在请求文章之前,需要先找到网页的cookie和User-Agent。由于微信公众号是定期刷新的,所以这个cookie和上面的token都要定期刷新。代替。
为了避免反扒,最好找个代理ip
headers = {
"Cookie": "appmsglist_action_3567997841=card;wxuin=49763073568536;pgv_pvid=6311844914;ua_id=x6Ri8bc9LeaWnjNNAAAAADI-VXURALRxlSurJyxNNvg=;mm_lang=zh_CN;pac_uid=0_3cf43daf28071;eas_sid=11Q6v5b0x484W9i7W0Z7l7m3I8;rewardsn=;wxtokenkey=777;wwapp.vid=;wwapp.cst=;wwapp.deviceid=;uuid=fd43d0b369e634ab667a99eade075932;rand_info=CAESIHgWwDfp3W4M9F3/TGnzHp4kKkrkMiCEvN/tSNhHtNBm;slave_bizuin=3567997841;data_bizuin=3567997841;bizuin=3567997841;data_ticket=IfMEEajZ8UvywUZ1NiIv9eKZkq0cgeS0oP6tTzEwNSjwK6q+u5vLw0XYeFvLL/JA;slave_sid=aVBzSlpYOGt4eTdmbzFRWDc1OUhzR1A1UkwzdUdBaklDaGh2dWY2MUZKTEw1Um1aalZRUXg5aVBMeEJVNklCcGlVN0s5Z3VEMmRtVENHS1ZxNTBDOWRCR0p2V2FyY2daU0hxT09Remd5YmlhRWExZkMwblpweVc3SndUbnJIQk55MGhUeExJa1NJcWZ0QmJS;slave_user=gh_e0f449d4f2b6;xid=7d5dc56bb7bb526c70cfef3f6bdfa18a",
"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_0) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/100.0.4896.75 Safari/537.36",
}
proxies = {'http': '112.80.248.73'}
接下来可以爬取页面,获取页面中的文章标题和文章链接,以及文章的时间,分析网页的信息,发现所有的信息网页保存在“app_msg_list”字段中,因此提取该字段中的数据。
代码显示如下:
得到的数据包存放在df中。这里的数据不是微信公众号最新的文章数据,而是微信公众号最近一天发送的文章数据。因此,还需要过滤发布时间。注意这里的时间格式是时间戳,所以需要转换时间数据
转换代码如下:
def time_s(df):
def transfer_time(s): #时间处理
aa = time.ctime(s)
<p>
bb = aa.split(' ')
cc = (bb[-1]+"-"+bb[1]+"-"+bb[-3]).replace('Jan','1').replace('Feb','2').replace('Mar','3'). \
replace('Apr','4').replace('May','5').replace('Jun','6').replace('Jul','7').replace('Aug','8') \
.replace('Sep','9').replace('Oct','10').replace('Nov','11').replace('Dec','12')
dd = datetime.datetime.strptime(cc,'%Y-%m-%d').date()
return dd
ti=[]
hd=[]
for i in range(0,len(df['time'])):
timestap= transfer_time(df['time'][i])
ti.append(timestap)
#print(ti)
d= ti[i] + datetime.timedelta(weeks=0, days=0, hours=0, minutes=0, seconds=0, milliseconds=0, microseconds=0, )
#dc = d.strftime("%Y-%m-%d")
hd.append(d)
df['time']=hd</p>
这样就可以将微信公众号的时间戳数据转换为时间数据,然后根据当天的日期提取数据集中的内容并存储。
dat=df[df['time'] == datetime.date.today() + datetime.timedelta(days= -1)] #自动获取昨天日期,将-1改为-2,则为前天的日期,以此类推
##改自动化
path = 'C:/Users/gpower/Desktop/work/行业信息/' #根据自己电脑位置更改
import re
filename=path+"微信公众号采集" + re.sub(r'[^0-9]','',datetime.datetime.now().strftime("%Y-%m-%d")) + '.csv'
# 对文件进行命名,以“微信公众号采集+当前日期”命名
dat.to_csv(filename,encoding='utf_8_sig')
print("保存成功")
这样就可以下载最新的微信公众号文章采集。如果需要多个微信公众号,可以在fakeid中添加公众号的识别码。
这是文章关于python自动获取微信公众号最新文章的介绍。更多关于python自动获取微信公众号文章的信息,请搜索三水点胶木的往期文章或继续浏览以下相关文章希望大家在木头支持三水点未来!

