事实:搜索引擎对重复内容的识别系统如何识别资源是否重复
优采云 发布时间: 2022-10-12 18:08事实:搜索引擎对重复内容的识别系统如何识别资源是否重复
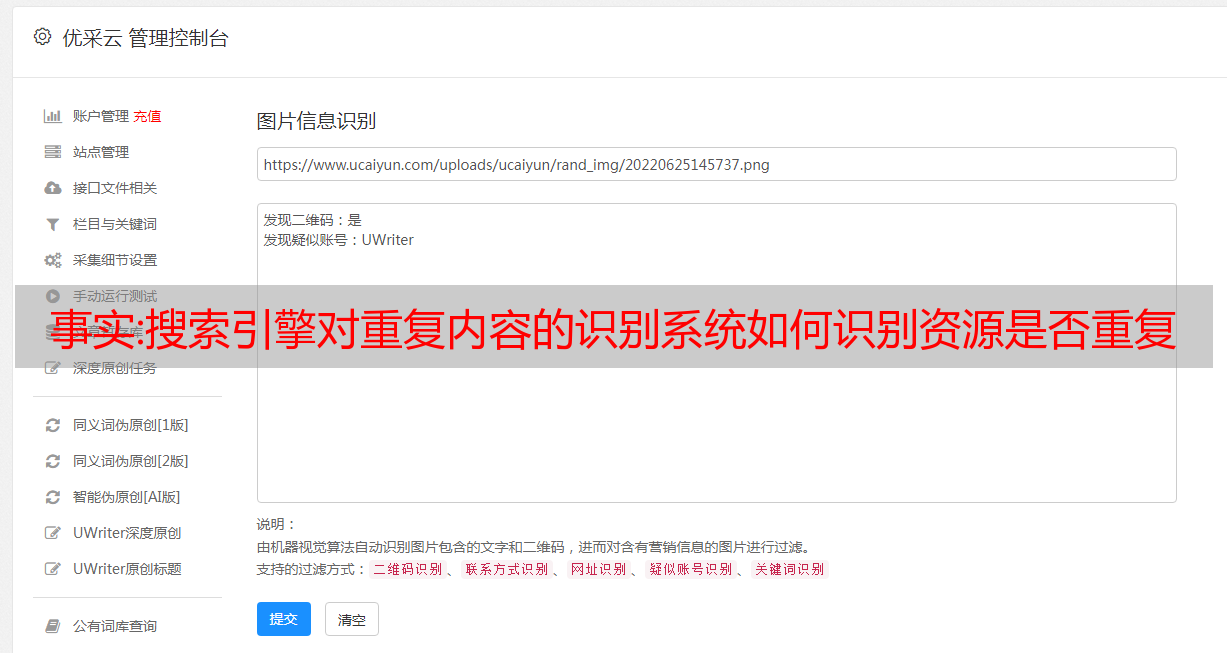
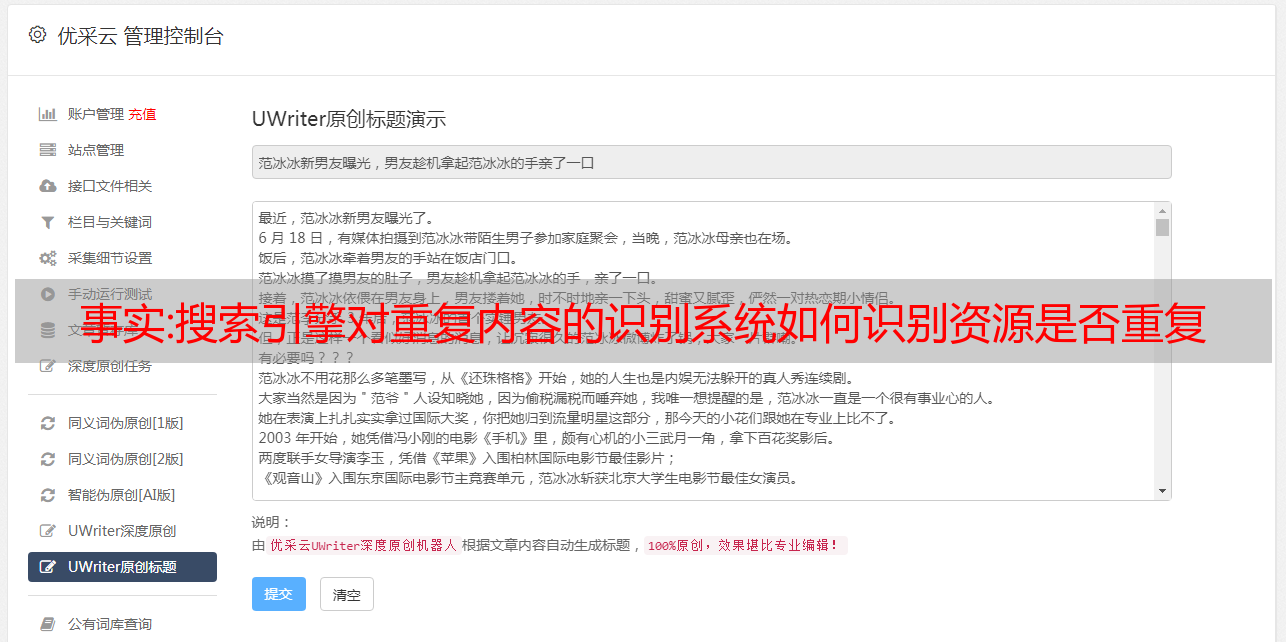
一键采集上传常见的细节问题。常见的一些就是相同的下载链接如何排序。上传资源时如何能识别资源是否重复。如何将图片上传到多个页面。搜索引擎对重复内容的识别系统如何识别。这些内容搜索引擎都会对上传资源做采集,这样才能发挥搜索引擎的最大优势,资源多多益善,按照用户来权重进行排序。搜索引擎会从不同的地方采集重复资源,比如对网页进行相同的图片分类,所以图片资源采集是百度非常喜欢的内容,它可以将重复的图片图片按照分类进行编号对比,这样百度的蜘蛛就可以发现出上传重复资源的网页了。
目前当网络用户同时在浏览两个或以上的网页时,搜索引擎就会将这两个或以上的网页分为不同的网站,排在前面的网页就是当前用户的网站,搜索引擎的爬虫就会抓取排在前面的网页中的关键字,然后再加上文章的标题链接抓取。由于前面的网页是百度爬虫抓取的,所以一个用户可以同时访问两个网页。搜索引擎想要抓取到所有网页,肯定必须在同一时间之内抓取到所有网页,百度有系统工作在同一时间上线的规则,比如按时间进行抓取和分页抓取,只要满足这一系统工作规则,用户就可以同时获取同一时间的所有网页,然后再分别抓取。
搜索引擎其实跟百度对待百度搜索页面的审核方式是一样的,这里再说一下,上传重复资源的网页到百度搜索页面上,被百度抓取上线的概率非常非常大,很多时候,主域名结果页加上来源地址还没有对应的网页链接,都被百度抓取上线,可见中国网民是多么喜欢在百度上搜索内容。关键字重复采集可以理解为网页源代码里有相同的地址,用户上传一个重复资源不是只对用户有意义,对搜索引擎是同样的道理,搜索引擎收集这些资源,然后发现这些资源存在重复资源时,就会在两个页面上同时搜索,所以当用户网页太多的时候,有相同的资源同时上传,搜索引擎就无法做到一一匹配了。
爬虫抓取资源时,源代码里只要存在一个重复资源,百度就知道爬虫是抓取这个资源,而爬虫抓取之后,源代码里只要存在另一个重复资源,爬虫就知道抓取这个资源,所以搜索引擎最怕爬虫找不到用户上传的资源,所以爬虫上传的资源必须要满足上面的唯一标识。搜索引擎还可以设置网页是否是单页,爬虫抓取单页,如果抓取网页分为多页就不受单页抓取限制了。
当然,搜索引擎抓取资源,也是有一定规则的,比如对网页的url和pc端标准页面链接结构做了特殊处理,就会导致搜索不到资源。搜索引擎对重复资源进行采集,首先是完全没有必要的,当用户同时在浏览两个或以上的网页时,搜索引擎会将采集的相同的资源一一识别排序,而搜索引。

