解决方案:采集器数据导出方法
优采云 发布时间: 2022-10-12 09:26解决方案:采集器数据导出方法
在之前的文章中,我提到过优采云采集器数据导出成table格式是收费的,其实采集器是以sqlite数据库格式保存的采集器@ 采集数据。当然,我们可以通过复制来复制数据,但是当有几万条数据时,我们只能将其导出。
首先要做的是下载一个Sqlite数据库操作软件。在这种数据库网络上有很多搜索。运行规则时,会出现一个任务 ID。我们会通过任务ID找到数据库文件。比如一个任务的ID是1611
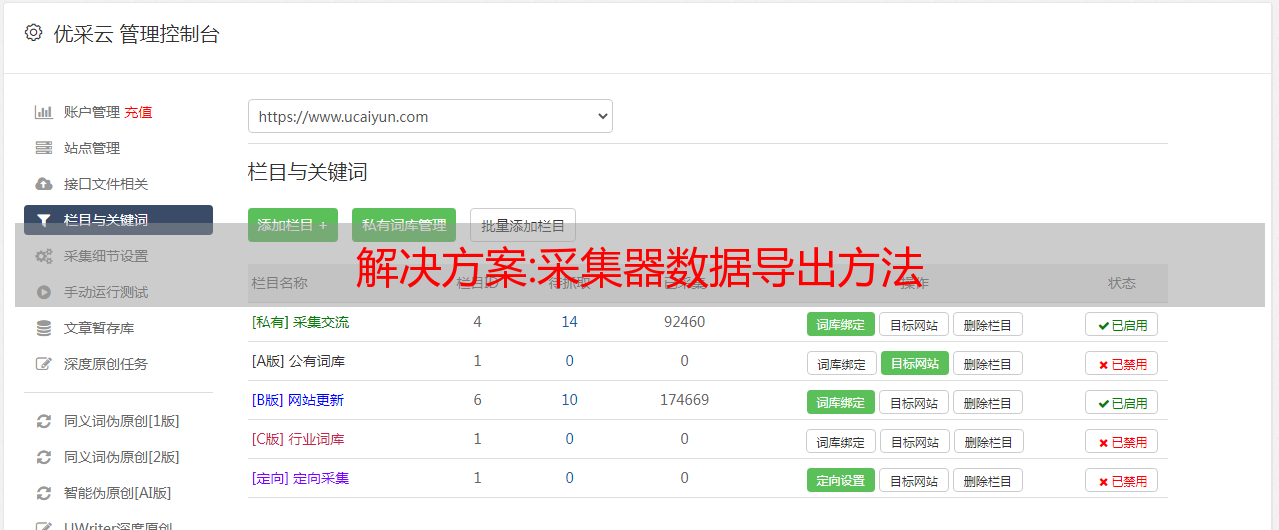
在优采云采集器的Data文件下找到1611,那么最后一个db3文件就是存放数据的地方。
我这里推荐一个免费的软件叫DB.Browser.for.SQLite,中文界面用起来很方便。
file-export-csv,我们可以导出我们很熟悉的表格格式,如果有坐标的话,可以直接在arcgis中使用。
采集器使用起来很方便,而且免费,虽然有更简单的web采集工具,但是要么收费,要么数量有限。但是还是有很多人觉得太麻烦,想直接求数据而不是方法。其实,当我们掌握了获取数据的方法,就不怕没有数据了。
但是采集器我也不好用。比如我需要自己判断页数,而不是通过设置自动判断页数。当数据为采集 时,Xpath 和 json 仍然不会被设置。常规和其他提取方法。希望有大神可以和我交流使用经验,希望能有更多的进步。
完整解决方案:教程:黑科技之云蛛系统大数据解决方案-数据采集/传输/处理/展现全套流程
黑科技云蜘蛛系统一经问世,便赢得了一片掌声。虽然主要关注的是数据可视化,但很多用户都在问你是否会生产大数据处理产品,就像很多用户眼中的黑科技——感知数据。如果你出来,就可以解决我们整个数据流程的问题。
大数据处理,云蜘蛛系统肯定是必须的,但具体的开发日期还没有敲定。但鉴于用户的强烈需求,蜘蛛网时代最终将大数据处理工具的开发提上了日程,并将其命名为DataCenter。为什么叫数据中心?这意味着云蜘蛛系统可以为您处理数据中心中的所有处理。
DataCenter+AutoBI+DataView,你的整个数据分析系统就可以搭建完成,而且非常简单。DataCenter为你做数据采集、传输、处理工作,AutoBI为你做数据报表工作,DataView为你做大屏显示工作。合作不是很好吗?
DataCenter使用自己的agent采集相关数据,然后返回Kafka集群进行数据清洗处理。Kafka集群作为高可靠传输,还需要进行高性能算法的去重计算,然后数据通过转换层进入。在数据仓库或者hadoop集群中,这是整个ETL过程,也是天鹿系统的工作。之后就是调度-北斗系统的工作了。它将根据依赖关系计算数据指标。如果没有完成当日指数的计算,则不能完成月指数的计算。如果指标计算错误,手动触发任务计算,是否会触发下游任务一起计算…… 整个核心将体现在调度-北斗系统中。尽我所能。HDFS数据通过调度计算吐入Hbase,数据仓库通过ODS层计算进入表现层,分布式查询ES……这些都是市面上最好的技术,或者说你能想到的查询方式,DataCenter都能搞定为你。
之后就是DataView和AutoBI大显身手的时候了。这两条产品线既可以支持传统的关系型数据库,也可以不支持sql数据库,比如redis、mongodb等,包括ES、rest等服务接口。因为是定制模型,只要现有技术可以实现,这两条产品线都会为你实现,你不需要为了适配这两条产品线而传输数据,所有云蜘蛛系统都适配对你来说很好。因为是同族产品,兼容性好!
这个怎么样?DataCenter可以说是大数据处理行业的一项黑科技。整个过程都是黑盒的。您只需要在网页中配置您的业务,系统的其余部分会自动为您处理。AutoBI和DataView作为它的老大哥,全面贯彻黑科技的概念,无缝集成、完美展示、多维分析……你能想到的所有需求,这两个帮你呈现。这就是黑科技-云蜘蛛系统,为您提供一整套大数据解决方案!

