事实:无监督构建词库:更快更好的新词发现算法
优采云 发布时间: 2022-10-11 17:37事实:无监督构建词库:更快更好的新词发现算法
作者:苏建林
单位丨吹一科技
研究方向丨NLP、神经网络
个人主页丨kexue.fm
新词发现是 NLP 的基本任务之一。主要是希望通过无监督挖掘一些语言特征(主要是统计特征),来判断一批语料库中哪些字符片段可能是一个新词。
“新词发现”是一个比较常见的名称,更准确的名称应该是“无监督构建词库”,因为原则上它可以构建一个完整的词库,而不仅仅是“新词”。当然,你可以将它与常用词汇进行对比,删除常用词,还可以获得新词。
分词的目的
作为文本挖掘的第一步,分词看起来很自然,但实际上应该问为什么:为什么需要分词?人类最初是根据文字来书写和理解的吗?
当模型的记忆和拟合能力足够强(或者简单地说,足够智能)时,我们可以直接用基于词的模型来做,而不用分词,比如研究中的基于词的文本分类、问答系统等. 然而,即使这些模型成功了,模型的复杂性导致效率低下,所以很多时候(尤其是在生产环境中),我们会寻找更简单、更高效的解决方案。
哪种解决方案最有效?以文本分类为例,估计最简单最有效的解决方案是“朴素贝叶斯分类器”。同样,更现代的是FastText,可以看作是“朴素贝叶斯”的“神经网络版”。请注意,朴素贝叶斯基于一个朴素的假设:特征彼此独立。这个假设越强,朴素贝叶斯的表现就越好。然而,对于文本来说,显然上下文是紧密相连的,这个假设是否成立?
注意,当特征明显不独立时,可以考虑组合特征来削弱特征之间的相关性,然后使用朴素贝叶斯。例如,对于文本,如果以词为特征,朴素假设显然不成立。例如,在“我喜欢数学”中,“Hi”和“Huan”、“Number”和“Learning”显然是相关的。这时候我们可以考虑将这些特征组合起来得到“I/Like/Math”,所以这三个段之间的相关性不是那么强,所以可以考虑上面的结果。
可以发现,这个过程与分词非常相似,或者反过来说,分词的主要目的之一就是将句子分成几个相关性相对较弱的部分进行进一步处理。从这个角度来看,点不一定是“词”,也可能是词组、常用搭配等。
说白了,分词就是弱化相关性,减少对词序的依赖,这在深度学习模型中也是非常重要的。有的模型不分词而是使用CNN,即用几个词组合作为特征,这也是通过词组合弱化特征之间相关性的表现。
算法效果
既然分词是弱化相关性,那么我们的分词就是在相关性弱的地方剪掉。文章《【中文分词系列】2.基于分词的新词发现》其实就是这个意思,但认为文本的相关性只取决于相邻的两个词(2grams),在很多案例都是不合理的。比如《林心如》中的“辛茹”和《共和国》中的“何国”,固化度(相关性)不是很强,很容易出错。
所以这篇文章是在上一篇的基础上进行的改进,这里只考虑了相邻字符的凝固度,这里也考虑了多个字符的内部凝固度(ngrams)。例如,一个三字串的内部凝固度定义为:
这个定义其实就是枚举所有可能的切分,因为一个词处处都应该是“强”,4个字符以上的字符串的凝聚度和定义差不多。一般我们只需要考虑 4 个词(4grams)(但注意我们仍然可以剪掉超过 4 个词的词)。
考虑到多个字符后,我们可以设置一个比较高的凝固阈值,同时防止“共和国”等单词被误切,因为考虑到三个字符的凝固度,“共和国”显得相当强,所以,这step是“最好放手,永不犯错”的原则。
但是,“items”和“items”这两个词的内部固化度很高,因为上一步是“最好放手,不要犯错”,所以这会导致“items”也变成单词,类似的例子包括“支持”、“团队合作”、“珠海港”等诸多例子。然而,在这些情况下,凝固程度非常低,以 3 克为单位。因此,我们必须有一个“回溯”过程。在前面的步骤中获得词汇后,再次过滤词汇。过滤规则是,如果n个单词,不在原来的高固化ngrams中,则必须“out”。
因此,考虑ngrams的好处是在互信息阈值大的情况下,可以很好地切分词,同时可以排除歧义词。比如“共和国”,三字互信息很强,二字很弱(主要是“和国”不够强),但可以保证“形势”之类的东西会不能被剪掉,因为门槛值越大,“情”和“情”都不稳固。
详细算法
完整的算法步骤如下:
第一步,统计:选择一个固定的n,统计2grams,3grams,...,ngrams,计算它们的内部凝固度,只保持碎片高于某个阈值,形成一个集合G;这一步可以为 2grams , 3grams, ..., ngrams 设置不同的阈值,也不必相同,因为字数越大,一般统计数据越不充分,越有可能高,所以词数越大,阈值越高;
第二步,切分:用上面的grams对语料进行切分(粗分词),统计频率。切分规则是,如果上一步得到的集合G中只有一个段出现,这个段就不会被切分,比如“每个item”,只要“item”和“item”都在G中,这个time 即使“如果“items”不在G中,那么“items”仍然是不可分割和保留的;
第三步,回溯:在第二步之后,“每一项”都会被剪掉(因为第二步保证了放手总比剪错好)。回溯就是检查,如果是小于等于n个单词的单词,则检查是否在G中,如果不在则出;如果是大于n个词的词,则检测它的每个n词段是否在G中,只要有一个词段不存在,就出局。我们以“每个项目”为例,回顾是看“每个项目”是否在3gram内,如果不是,则出局。
每个步骤的附加说明:
1. 凝固度较高,但综合考虑多个特性,更准确。比如二字“共和国”不会出现在高凝度集合中,所以会被剪掉(比如“我要和三个人一起玩。”,“共和国”被剪掉),但是高固化合集出现“共和国”三字,因此“中华人民共和国”的“共和国”不会被删减;
2、第二步,根据第一步筛选的集合对句子进行分词(可以理解为粗分词),然后统计“粗分词结果”。注意,现在是统计分词结果。一步凝固度集合筛选没有交叉点。我们认为这样的分词虽然比较粗糙,但是高频部分还是靠谱的,所以把高频部分筛选掉了;
3.比如第三步,因为“items”和“items”都出现在high-solidity剪辑中,所以在第二步,我们不会剪切“items”,但是我们不希望“items”变成词,因为“每个”和“项”的凝固度不高(“每个”和“项”的凝固度高并不意味着“每个”和“项”的凝固度高),所以通过回溯,“每个”和“项目”都有了高度的固化。项目”被删除(只要检查“每个项目”不在原创统计的高凝固度集合中,所以这一步的计算量很小)。
代码
开源地址位于:/bojone/word-discovery
请注意,此脚本只能在 Linux 系统上使用。如果你想在 Windows 下使用它,你应该需要做一些改变。我不知道要进行哪些更改。请自行解决。注意算法本身理论上可以适用于任何语言,但本文的实现只适用于基本单位为“单词”的语言。
Github 中的核心脚本是 word_discovery.py,其中收录完整的实现和使用示例。让我们简要回顾一下这个例子。
首先,编写一个语料库*敏*感*词*,逐句返回语料库:
import pymongo
<p>
import re
db = pymongo.MongoClient().baike.items
# 语料*敏*感*词*,并且初步预处理语料
# 这个*敏*感*词*例子的具体含义不重要,只需要知道它就是逐句地把文本yield出来就行了
def text_generator():
for d in db.find().limit(5000000):
yield re.sub(u'[^\u4e00-\u9fa50-9a-zA-Z ]+', '\n', d['text'])
</p>
读者不需要了解我的*敏*感*词*在做什么,只需要知道*敏*感*词*正在逐句生成原创语料库。如果您不知道如何编写*敏*感*词*,请自己学习。请不要在这个 文章 中讨论“语料库格式应该是什么”和“如何更改它以应用于我的语料库”之类的问题,谢谢。
顺便说一句,因为是无监督训练,所以语料越大越好。可以从几百M到几G,但其实如果只需要几M的语料(比如小说),也可以直接测试。可以看到基本效果(但下面的参数可能需要修改)。
有了*敏*感*词*之后,配置一些参数,然后就可以一步步执行了:
min_count = 32
order = 4
corpus_file = 'wx.corpus' # 语料保存的文件名
vocab_file = 'wx.chars' # 字符集
ngram_file = 'wx.ngrams' # ngram集
output_file = 'wx.vocab' # 最后导出的词表
write_corpus(text_generator(), corpus_file) # 将语料转存为文本
count_ngrams(corpus_file, order, vocab_file, ngram_file) # 用Kenlm统计ngram
ngrams = KenlmNgrams(vocab_file, ngram_file, order, min_count) # 加载ngram
ngrams = filter_ngrams(ngrams.ngrams, ngrams.total, [0, 1, 3, 5]) # 过滤ngram
注意,kenlm 需要一个空格分隔的纯文本语料库作为输入,而 write_corpus 函数为我们完成了这项工作,而 count_ngrams 是调用 kenlm 的 count_ngrams 程序对 ngram 进行计数。因此,您需要编译 kenlm 并将其 count_ngrams 放在与 word_discovery.py 相同的目录中。如果有Linux环境的话,编译kenlm还是挺简单的。作者这里[3]也讨论过kenlm,大家可以参考一下。
count_ngrams 执行后,结果会保存在一个二进制文件中,KenlmNgrams 就是读取这个文件。如果你输入的语料比较大,这一步需要比较大的内存。最后filter_ngrams就是过滤ngrams。[0, 1, 3, 5] 是互信息的阈值。第一个0无意义,仅用于填充,而1、3、5分别是2gram、3gram、4gram的互信息。阈值,基本单调递增为佳。
至此,我们已经完成了所有的“准备工作”,现在可以开始构建词库了。首先构建一个 ngram Trie 树,然后使用这个 Trie 树做一个基本的“预分割”:
ngtrie = SimpleTrie() # 构建ngram的Trie树
for w in Progress(ngrams, 100000, desc=u'build ngram trie'):
_ = ngtrie.add_word(w)
candidates = {} # 得到候选词
for t in Progress(text_generator(), 1000, desc='discovering words'):
<p>
for w in ngtrie.tokenize(t): # 预分词
candidates[w] = candidates.get(w, 0) + 1
</p>
上面已经介绍了这种预分割的过程。简而言之,有点像最大匹配,通过ngram片段连接成尽可能长的候选词。最后,再次过滤候选词,即可保存词库:
# 频数过滤
candidates = {i: j for i, j in candidates.items() if j >= min_count}
# 互信息过滤(回溯)
candidates = filter_vocab(candidates, ngrams, order)
# 输出结果文件
with open(output_file, 'w') as f:
for i, j in sorted(candidates.items(), key=lambda s: -s[1]):
s = '%s\t%s\n' % (i.encode('utf-8'), j)
f.write(s)
评估
这是我从500万微信公众号文章(另存为文本后超过20G)中提取的词库,供读者使用。
训练时间似乎是五六个小时。我记得不是很清楚。总之,它会比原来的实现更快,资源消耗也会更低。
读者常说我写的这些算法没有标准的评价。这次我做了一个简单的评价。评估脚本是评估.py。
具体来说,提取刚才词典wx.vocab.zip的前10万词作为词库,使用结巴分词加载10万词词库(不要使用自带词库,并关闭新词发现功能) ,它构成了一个基于无监督词库的分词工具,然后使用这个分词工具对 bakeoff 2005 提供的测试集进行分类,并使用其测试脚本进行评估,最终在 PKU 测试集上的得分为
也就是说,它可以达到0.746的F1。这是什么水平?ICLR 2019 有一篇文章文章 叫做 Unsupervised Word Discovery with Segmental Neural Language Models,里面提到它在同一个测试集上的结果是 F1=0.731,所以这个算法的结果并不比上面的最好结果。
注意:这是为了直观感受一下效果,比较可能不公平,因为我不确定本文的训练集使用的是什么语料库。但是我感觉这篇论文的算法会比同时论文的算法好,因为直觉论文的算法训练起来会很慢。作者没有开源,所以有很多不确定性。如果有任何错误,请纠正我。
总结
本文再现了作者之前提出的新词发现(词库构建)算法,主要是优化速度,然后做一个简单的效果评估。但具体效果读者还是要在使用中慢慢调试。
祝您使用愉快,使用愉快!
#投稿渠道#
如何让更多优质内容以更短的路径到达读者群,降低读者寻找优质内容的成本?答案是:你不认识的人。
总有一些你不认识的人知道你想知道什么。PaperWeekly或许是一座桥梁,让来自不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励大学实验室或个人在我们的平台上分享各种优质内容,可以是最新论文的解读、学习经验或技术干货。我们只有一个目的,让知识真正流动起来。
贡献标准:
• 稿件确实是个人原创的作品,稿件必须注明作者个人信息(姓名+学校/工作单位+*敏*感*词*/职位+研究方向)
• 如果文章 不是第一篇,请在提交时提醒并附上所有已发布的链接
• 默认情况下,PaperWeekly 上的每篇文章 文章都是第一次发表,并且会添加一个“原创”标记。
投稿方式:
• 方法一:在PaperWeekly知乎栏目页面点击“提交”提交文章
• 方法二:发邮件至:hr@paperweekly.site,文章的所有图片,请在附件中单独发送
解决方案:【VSRC唯科普】用自动化程序测试网站(13/14篇)
谢谢
VSRC 在此感谢我们的行业合作伙伴 Mils 对科普课程 文章 的贡献。VSRC欢迎优秀原创类别文章投稿,优秀文章一经录用及发表将有丰厚礼品赠送,我们为您准备了丰厚奖品!
(活动最终解释权归VSRC所有)
在开发技术栈较大的网络项目时,一些例行测试往往只在栈底进行,也就是项目后期用到的技术和功能。今天大部分的编程语言,包括Python,都有一些测试框架,但是网站的前端通常没有自动化测试工具,虽然前端通常是整个项目的一部分真正触动用户。. 每当添加新功能 网站 或元素位置发生变化时,测试团队通常会执行一组自动化测试来验证它。
在本期VIP中,我将介绍测试的基础知识以及如何使用Python网络爬虫测试各种简单或复杂的网站,大致可分为以下四个部分:
1. 使用 Python 进行单元测试
2.测试维基百科
3. 硒测试
4、Python单元测试和Selenium单元测试的选择
1. 使用 Python 进行单元测试
运行自动化测试方法可确保代码按预期运行,节省人力时间,并使版本升级更高效、更容易。为了理解什么是单元测试,我们引用网上对单元测试的一个更直观的描述来解释:“单元测试(module test)是开发者编写的一小段代码,使用的一小段代码来验证被测代码,函数是否正确。一般来说,单元测试是用来判断特定函数在特定条件(或场景)下的行为。例如,你可能会放一个很大的值进入有序列表,然后验证该值是否出现在列表的末尾。或者,您可以从字符串中删除与模式匹配的字符并验证该字符串不再收录这些字符。单元测试由程序员自己来完成,程序员自己最终受益。可以说,程序员负责编写功能代码,同时也负责为自己的代码编写单元测试。进行单元测试是为了证明这段代码的行为和我们的预期是一样的。在工厂组装电视之前,每个组件都经过测试,这称为单元测试。”
在 Python 中,您可以使用 unittest 模块进行单元测试。导入模块并继承unittest.TestCase类后,可以实现如下功能:
2.测试维基百科
将 Python 的 unittest 库与网络爬虫相结合,您可以在不使用 JavaScript 的情况下测试 网站 前端的功能:
#!/usr/bin/env python<br /># -*-coding:utf-8-*-<br /><br />from urllib.request import urlopen<br />from bs4 import BeautifulSoup<br />import unittest<br /><br />class WikiTest(unittest.TestCase):<br /> def setUpClass(self):<br /> global bsObj<br /> url = "https://wiki.mbalib.com/wiki/Python"<br /> bsObj = BeautifulSoup(urlopen(url))<br /><br /> def t_titleTest(self):<br /> global bsObj<br /> page_title = bsObj.find("h1").get_text()<br /> self.assertEqual("Python", page_title)<br /> # assertEqual若两个值相等,则pass<br /><br /> def t_contentExists(self):<br /> global bsObj<br /> content = bsObj.find("div", {"id": "BAIDU_DUP_fp_wrapper"})<br /> # 测试是否有一个节点id属性是BAIDU_DUP_fp_wrapper<br /> self.assertIsNotNone(content)<br /><br />if __name__ == '__main_':<br /> unittest.main()
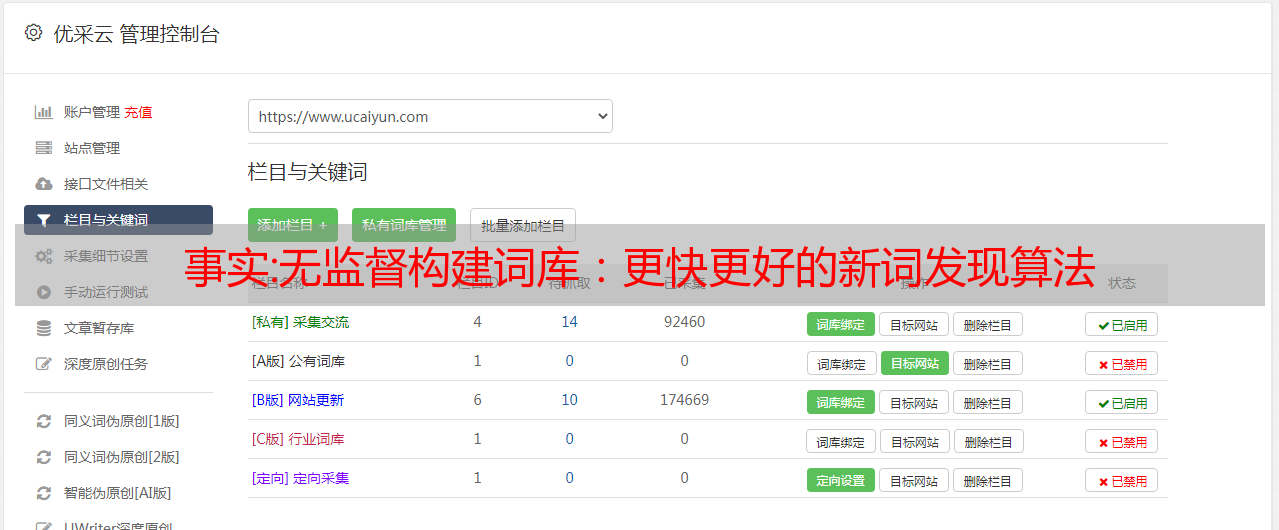
运行成功后会得到如下返回结果:
Ran 0 tests in 0.000s<br />OK<br />Process finished with exit code 0
这里需要注意的是,这个页面只加载了一次,全局对象bsObj被多个测试共享。这是通过 unittest 类的 setUpClass 函数实现的。该函数只在类的初始化阶段运行一次,一次性采集所有内容,用于多次测试。由于重复测试操作的方式有很多种,因此必须始终谨慎对待即将在页面上运行的所有测试,因为我们只加载页面一次,并且必须避免一次在内存中添加大量信息, 这可以通过以下设置来实现:
#!/usr/bin/env python<br /># -*-coding:utf-8-*-<br /><br />from urllib.request import urlopen<br />from urllib.request import urlparse<br />from bs4 import BeautifulSoup<br />import unittest<br /><br />class TestWiki(unittest.TestCase):<br /> bsObj = None<br /> url = None<br /><br /> def Test_PageProperties(self):<br /> global bsObj<br /> global url<br /><br /> url = "https://wiki.mbalib.com/wiki/Python"<br /> for i in range(1, 100):<br /> bsObj = BeautifulSoup(urlopen(url))<br /> titles = self.titleMatchesURL()<br /> self.asserEquals(titles[0], titles[1])<br /> self.asserTrue(self.contentExists())<br /> url = self.getNextLink()<br /> print("done")<br /><br /> def titleMatchesURL(self):<br /> global bsObj<br /> global url<br /> pageTitle = bsObj.find("h1").get_text()<br /> urlTitle = url[(url.index("/wiki/")+6):]<br /> urlTitle = urlTitle.replace("_", ' ')<br /> urlTitle = unquote(urlTitle)<br /> return [pageTitle.lower(), urlTitle.loser()]<br /><br /> def contentExists(self):<br /> global bsObj<br /> content = bsObj.find("div",{"id":"BAIDU_DUP_fp_wrapper"})<br /> if content is not None:<br /> return True<br /> return False<br /><br />if __name__ == '__main_':<br /> unittest.main()
3. 硒测试
虽然我们在之前的VIP中已经介绍了链接跳转、表单提交等网站交互行为,但本质是避开浏览器的图形界面,而不是直接使用浏览器。Selenium 可以在浏览器上实现文本输入、按钮点击等操作,从而可以发现异常表单、JavaScript 代码错误、HTML 排版错误等用户使用过程中可能出现的问题。下面例子中的测试代码使用了Selenium的elements对象,可以通过以下方式调用elements对象。
usernameFileld = driver.find_element_by_name('username')
正如用户可以在浏览器中对 网站 上的不同元素执行一系列操作一样,Selenium 也可以对任何给定元素执行许多操作:
myElement.Click()<br />myElement.Click_and_hold()<br />myElement.release()<br />myElement.double_click()<br />myElement.send_keys_to_element("content to enter")
为了一次完成对同一个元素的多个操作,可以使用动作链来存储多个操作,然后在一个程序中执行一次或多次。将多个操作存储在动作链中也很方便,它们的功能与在前面的示例中显式调用元素上的操作完全相同。
为了演示这两种方式的区别,以表格为例,按照如下方式填写并提交:
#!/usr/bin/env python<br /># -*-coding:utf-8-*-<br /><br />from selenium import webdriver<br />from selenium.webdriver.remote.webelement import WebElement<br />from selenium.webdriver.common.keys import Keys<br />from selenium.webdriver import ActionChains<br /><br />driver = webdriver.Chrome(executable_path='C:\chromedriver.exe')<br />driver.get("http://pythonscraping.com/pages/files/form.html")<br /><br />firstnameField = driver.find_elements_by_name('firstname')[0]<br />lastnameField = driver.find_elements_by_name('lastname')[0]<br />submitButton = driver.find_element_by_id('submit')<br /><br /># method 1<br />firstnameField.send_keys("VSRC")<br />lastnameField.send_keys('POP')<br />submitButton.click()<br /><br /># method 2<br />actions = ActionChains(driver).click(firstnameField).send_keys("VSRC").click(lastnameField).send_keys('POP').send_keys(Keys.RETURN)<br />actions.perform()<br /><br />print(driver.find_elements_by_tag_name('body')[0].text)<br />driver.close()
使用方法1在两个字段上调用send_keys,然后点击提交按钮;而方法2使用动作链点击每个字段并填写内容,最后确认这些动作只发生在perform调用之后。不管是第一种方法还是第二种方法,这个程序的执行结果都是一样的:
Hello there,VSRC POP!
除了处理命令的对象不同之外,第二种方法也有一点区别。注意第一种方法是提交点击操作,而第二种方法是使用回车键Keys.RETURN提交表单,因为网络事件可以有多个发生顺序来达到相同的效果,所以Selenium有很多方法可以达到相同的结果。
这是鼠标拖放操作的另一个演示。单击按钮和输入文本只是 Selenium 的一项功能,它真正的亮点是能够处理更复杂的 Web 表单交互。Selenium 可以轻松执行拖放操作。使用它的拖放功能,您需要指定要拖放的元素和拖放的距离,以及该元素将被拖放到的目标元素。. 这里使用一个页面来演示拖放操作:
from selenium import webdriver<br />from selenium.webdriver.remote.webelement import WebElement<br />from selenium.webdriver import ActionChains<br />import time<br /><br />exec_path = "C:\chromedriver.exe"<br />driver = webdriver.Chrome(executable_path=exec_path)<br />driver.get('http://pythonscraping.com/pages/javascript/draggableDemo.html')<br />print(driver.find_element_by_id('message').text)<br /><br />element = driver.find_element_by_id('draggable')<br />target = driver.find_element_by_id('div2')<br />actions = ActionChains(driver)<br />actions.drag_and_drop(element, target).perform()<br />time.sleep(1)<br />print(driver.find_element_by_id('message').text)<br />driver.close()
程序运行后会返回以下两条信息:
Prove you are not a bot, by dragging the square from the blue area to the red area!<br />You are definitely not a bot!
4、Python单元测试和Selenium单元测试的选择
通常Python的单元测试语法严谨冗长,比较适合大型项目编写测试,而Selenium的测试方式更加灵活强大,可以作为一些网站功能测试的首选。两者都有不同的特点。,而且综合效果也更有效。下面是一个测试拖拽功能的单元测试程序。如果一个元素没有正确拖放到另一个元素中,则推理条件为真,并显示“证明你不是机器人”:
#!/usr/bin/env python<br /># -*-coding:utf-8-*-<br /><br />from selenium import webdriver<br />from selenium.webdriver import ActionChains<br />import unittest<br /><br />class TestAddition(unittest.TestCase):<br /> driver = None<br /><br /> def setUp(self):<br /> global driver<br /> driver = webdriver.Chrome(executable_path="C:\chromedriver.exe")<br /> driver.get('http://pythonscraping.com/pages/javascript/draggableDemo.html')<br /><br /> def test_drag(self):<br /> global driver<br /> element = driver.find_element_by_id('draggable')<br /> target = driver.find_element_by_id('div2')<br /> actions = ActionChains(driver)<br /> actions.drag_and_drop(element, target).perform()<br /><br /> self.assertEqual("Prove you are not a bot, by dragging the square from the blue area to the red area!", driver.find_element_by_id("message").text)<br /><br />if __name__ == '__main_':<br /> unittest.main()
所以在网站上能看到的大部分内容,一般都可以通过Python单元测试和Selenium组合测试来完成。
参考
1、
2、
3. “使用 Python 进行网页抓取”
只有科学 | “数据采集”目录
又名“小白终结者”系列
第 13 章使用自动化程序进行测试网站
第 14 章,远程采集
.
.
精彩原创文章投稿有惊喜!
欢迎投稿!
VSRC欢迎提交精品原创类文章,优秀文章一经采纳并发表,将为您准备1000元税后*敏*感*词*或等值的丰厚奖金,不设上限!如果是安全的文章连载,奖金会更加丰厚,税后不会有10000元或等值的封顶!您还可以收到精美的礼物!点击“阅读原文”了解规则。(最终奖励以文章质量为准,活动最终解释权归VSRC所有)
我们倾听您的宝贵建议
不知道,你喜欢看什么类型的信息安全文章?
我不知道,您希望我们更新哪些主题?
即日起,只要您有任何想法或建议,请直接回复本公众号!
与精彩消息互动的热心用户将有机会获得VSRC的精美奖品!
同时,我们也会根据大家的反馈和建议,挑选热点话题并发布出来原创!

